
Дадим определение терминам уровень надежности и уровень значимости. Покажем, как и где они используется в
MS
EXCEL
.
Уровень значимости
(Level of significance) используется в
процедуре проверки гипотез
и при
построении доверительных интервалов
.
СОВЕТ
: Для понимания терминов
Уровень значимости и
Уровень надежности
потребуется знание следующих понятий:
-
выборочное распределение среднего
;
-
стандартное отклонение
;
-
проверка гипотез
;
-
нормальное распределение
.
Уровень значимости
статистического теста – это вероятность отклонить
нулевую гипотезу
, когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность
ошибки первого рода
(type I error).
Уровень значимости
обычно обозначают греческой буквой α (
альфа
). Чаще всего для
уровня значимости
используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении
доверительного интервала для оценки среднего значения распределения
, его ширину рассчитывают таким образом, чтобы вероятность события «
выборочное среднее (Х
ср
) находится за пределами доверительного интервала
» было равно
уровню значимости
. Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о
равенстве среднего заданному значению
.
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение
уровня значимости α
(т.е. вероятности
ошибки первого рода
) может привести к увеличению вероятности
ошибки второго рода
, то есть вероятности принять
нулевую гипотезу
, когда на самом деле она не верна. Подробнее об
ошибке второго рода
см. статью
Ошибка второго рода и Кривая оперативной характеристики
.
Уровень значимости
обычно указывается в аргументах
обратных функций MS EXCEL
для вычисления
квантилей
соответствующего распределения:
НОРМ.СТ.ОБР()
,
ХИ2.ОБР()
,
СТЬЮДЕНТ.ОБР()
и др. Примеры использования этих функций приведены в статьях про
проверку гипотез
и про построение
доверительных интервалов
.
Уровень надежности
Уровень
доверия
(этот термин более распространен в отечественной литературе, чем
Уровень надежности
) — означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Уровень
доверия
равен
1-α,
где α –
уровень значимости
.
Термин
Уровень надежности
имеет синонимы:
уровень доверия, коэффициент доверия, доверительный уровень
и
доверительная вероятность (англ.
Confidence
Level
,
Confidence
Coefficient
).
В математической статистике обычно используют значения
уровня доверия
90%; 95%; 99%, реже 99,9% и т.д.
Например,
Уровень
доверия
95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор
уровня доверия
полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание
: Стоит отметить, что математически не корректно говорить, что
Уровень
доверия
является вероятностью, того что оцениваемый параметр распределения принадлежит
доверительному интервалу
, вычисленному на основе
выборки
. Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что
доверительный интервал
, с вероятностью равной
Уровню
доверия,
накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL
Уровень надежности
упоминается в
надстройке Пакет анализа
. После вызова надстройки, в диалоговом окне необходимо выбрать инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно.
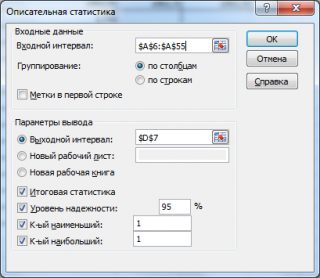
В этом окне задается
Уровень надежности,
т.е.значениевероятности в процентах. После нажатия кнопки
ОК
в
выходном интервале
выводится значение равное
половине ширины
доверительного интервала
. Этот
доверительный интервал
используется для оценки
среднего значения распределения, когда дисперсия не известна
(подробнее см.
статью про доверительный интервал
).
Необходимо учитывать, что данный
доверительный интервал
рассчитывается при условии, что
выборка
берется из
нормального распределения
. Но, на практике обычно принимается, что при достаточно большой
выборке
(n>30),
доверительный интервал
будет построен приблизительно правильно и для распределения, не являющегося
нормальным
(если при этом это распределение не будет иметь
сильной асимметрии
).
Примечание
: Понять, что в диалоговом окне речь идет именно об оценке
среднего значения распределения
, достаточно сложно. Хотя в английской версии диалогового окна это указано прямо:
Confidence
Level
for
Mean
.
Если
Уровень надежности
задан 95%, то
надстройка Пакет анализа
использует следующую формулу (выводится не сама формула, а лишь ее результат):
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) *СТЬЮДЕНТ.ОБР.2Х(1-0,95;СЧЁТ(Выборка)-1)
или эквивалентную ей
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) *СТЬЮДЕНТ.ОБР((1+0,95)/2;СЧЁТ(Выборка)-1)
где
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка))
– является
стандартной ошибкой среднего
(формулы приведены в
файле примера
).
или
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Подробнее см. в
статьях про доверительный интервал
.
Сводка
В этой статье описана функция ДОВЕРИТ в Microsoft Office Excel 2003 и Microsoft Office Excel 2007, а также сравнивает результаты функции для Excel 2003 и Excel 2007 с результатами функции ДОВЕРИТ в более ранних версиях Excel.
Значение доверительных интервалов часто неправильно интерпретировано, и мы стараемся предоставить объяснение допустимой и недопустимой выписки, которые могут быть сделаны после определения доверительного значения на основе данных.
Дополнительные сведения
Функция ДОВЕРИТ(альфа; сигма, n) возвращает значение, которое можно использовать для построения доверительный интервал для многая населения. Доверительный интервал — это диапазон значений, вы центр на основе известного значения выборки. Предполагается, что результаты наблюдений в выборке взяты из нормального распределения с известным стандартным отклонением, сигмой, а количество наблюдений в выборке — n.
Синтаксис
CONFIDENCE(alpha,sigma,n)
Параметры: альфа — вероятность и 0 < альфа < 1. Сигма — это положительное число, а n — положительное integer, соответствующее размеру выборки.
Обычно альфа — это небольшая вероятность, например 0,05.
Пример использования
Предположим, что оценки коэффициента аналитики следуют за обычным распределением со стандартным отклонением 15. Вы тестировали IQ-тест для 50 учащихся в вашем учебном замещаемом учебном замещаке и получили пример средней 105. Необходимо вычислить доверительный интервал в 95 % для математических вычислений. Доверительный интервал 95 % или 0,95 соответствует альфа = 1 – 0,95 = 0,05.
Чтобы проиллюстрировать функцию ДОВЕРИТ, создайте пустой Excel, скопируйте таблицу ниже и выберите ячейку A1 на Excel листе. В меню Правка выберите команду Вставить.
Примечание: В Excel 2007 нажмите кнопку Вировать в группе Буфер обмена на вкладке Главная.
Элементы в таблице ниже заполняют ячейки A1:B7 на вашем компьютере.
|
Альфа |
0,05 |
|
Stdev |
15 |
|
м |
50 |
|
выборка «вехи» |
105 |
|
=ДОВЕРИТ(B1;B2;B3) |
|
|
=НОРМСИНВ(1 — B1/2)*B2/SQRT(B3) |
После вжатия этой таблицы на новый Excel нажмите кнопку Параметры вжатия и выберите пункт Найти формат назначения.
Вы можете выбрать в меню Формат пункт Столбец, а затем выбрать пункт Авто подбор по столбцу.
Примечание: В Excel 2007 г. с выбранным диапазоном ячеек нажмите кнопку Формат в группе Ячейки на вкладке Главная, а затем выберите Авто ширина столбца.
Ячейка A6 отображает значение ДОВЕРИТ. Ячейка A7 имеет то же значение, так как звонок на значение ДОВЕРИТ(альфа; сигма, n) возвращает результат вычисления:
NORMSINV(1 – alpha/2) * sigma / SQRT(n)
Непосредственно в доверии не внося изменений, но в Microsoft Excel 2002 г. была улучшена норм.В.ВОСЬМ, а затем в Excel 2002 и Excel 2007 г. были внесены дополнительные улучшения. Поэтому в этих более поздних версиях стандарта ДОВЕРИТ могут возвращаться другие (и улучшенные Excel) результаты, так как доверит их на основе нормСИНВ.
Это не означает, что в более ранних версиях Excel доверие к доверию. Неточности в нормОЛИНВ обычно связаны со значениями аргумента, близкими к 0 или очень близко к 1. На практике альфа обычно имеет 0,05, 0,01 или, возможно, 0,001. Значения альфа-значения должны быть намного меньше, чем это, например 0,0000001, прежде чем ошибки округления в НОРМСИНВ, скорее всего, будут заметили.
Примечание: В этой статье на сайте НОРМ.В.ВН можно узнать о различиях в вычислениях в нормСИНХНОВ.
Для получения дополнительных сведений щелкните номер следующей статьи, чтобы просмотреть статью в базе знаний Майкрософт:
826772 Excel статистические функции: НОРМСИНВ
Интерпретация результатов проверки доверия
Файл Excel справки для confidence был перезаписан в Excel 2003 и Excel 2007, так как все более ранние версии файла справки вводили в заблуждение при интерпретации результатов. В примере говорится: «Предположим, что в нашем примере из 50 сотрудников в пути средняя продолжительность поездки на работу составляет 30 минут со стандартным отклонением в 2,5. Мы можем быть уверены в том, что значение «0,692951» находится в интервале 30 +/- 0,692951″, где значение 0,692951 — это значение, возвращаемого значением ДОВЕРИТ(0,05, 2,5, 50).
В этом же примере в заключение говорится, что средняя продолжительность поездки на работу равна 30 ± 0,692951 минуты или от 29,3 до 30,7 минуты. Это также утверждение о том, что численность населения находится в интервале [30 –0,692951, 30 + 0,692951] с вероятностью 0,95.
Перед проведением эксперимента, который дает данные в данном примере, статистический статистик (в отличие от байеса) не может делать никаких заявлений о распределении вероятности распределения по численности населения. Вместо этого статистический статистик в классической версии имеет дело с проверкой гипотез.
Например, классическому статистику может потребоваться провести двухбоговую проверку гипотезы на основе гипотезы на основе гипотезы о нормальном распределении с известным стандартным отклонением (например, 2,5), заранее выбранным значением μ0 и предопределенным уровнем значимости (например, 0,05). Результат проверки будет основан на значении наблюдаемого значения выборки (например, 30), а гипотеза null о том, что это μ0, будет отклонена на уровне значимости 0,05, если наблюдаемое значение имеет значение слишком далеко от μ0 в любом направлении. Если гипотеза NULL отклонена, то интерпретация состоит в том, что выборка означает, что выборка означает, что гораздо больше μ0 может возникнуть менее 5 % времени при позиции, что μ0 — это истинное подмногление численности населения. После проведения этого теста статистический статистик по-прежнему не может сделать никаких заявлений о распределении вероятностей для распределения по численности населения.
С другой стороны, байесский статистический статистик начинается с предполагается распределение вероятности для распределения по численности населения (априори), собирает экспериментальные признаки так же, как и статистический статистик, и использует его для изменения его распределения вероятности для многубного распределения по численности населения и тем самым получения задняя часть распределения. Excel не предусмотрены статистические функции, которые помогли бы байесам в этом случае. Excel статистические функции классической статистики.
Доверительный интервал связан с проверкой гипотез. Учитывая экспериментальные признаки, доверительный интервал делает краткое утверждение о значениях среднего среднего гипотезы μ0, которое позволит принять нулевую гипотезу о том, что это μ0, и значения μ0, которые подавят отклонение гипотезы null о том, что это значение имеет значение μ0. Статистический статистик не может сделать ни одного заявления о вероятности того, что оно попадает в определенный интервал, так как он никогда не делает предопределенные предположения относительно этого распределения вероятности, и такие предположения потребуются, если они будут использовать экспериментальные признаки для их изменения.
Изучение связи между проверками гипотез и доверитными интервалами с помощью примера в начале этого раздела. Связь между доверим и НОРМСИНХОV, которая была заверяема в последнем разделе, имеется:
CONFIDENCE(0.05, 2.5, 50) = NORMSINV(1 – 0.05/2) * 2.5 / SQRT(50) = 0.692951
Так как выборка имеет 30-е, доверительный интервал составляет 30 +/- 0,692951.
Теперь рассмотрим двухбудную проверку гипотезы с уровнем значимости 0,05, как описано выше, в котором предполагается нормальное распределение со стандартным отклонением 2,5, выборку размером 50 и определенным гипотезой о среднего распределения ( μ0). Если это истинное решение по численности населения, то выборка будет взята из нормального распределения со стандартным отклонением μ0 и стандартным отклонением 2,5/SQRT(50). Это распределение симметрично о μ0, и вы хотите отклонить гипотезу null, если abS(выборка μ0) > некого конечного значения. Конечное значение будет таким, что если μ0 — это истинное значение по численности населения, значение выборки — μ0 больше, чем это обрезка, или значение μ0 — выборочная величина выше, чем это обрезка будет возникать с вероятностью 0,05/2. Это вырезание
NORMSINV(1 – 0.05/2) * 2.5/SQRT(50) = CONFIDENCE(0.05, 2.5, 50) = 0. 692951
Отклонить нулевую гипотезу (о численности населения = μ0), если одно из следующих заявлений истинно:
выборка «mean» — μ0 > 0. 692951
0 — пример > 0. 692951
Так как в нашем примере примере выборка » = 30″, эти две выписки становятся следующими:
30 — μ0 > 0. 692951
μ0 –30 > 0. 692951
При переописи слева отображается только μ0, что приводит к следующим утверждениям:
μ0 < 30-0. 692951
μ0 > 30 + 0. 692951
Это точно те значения μ0, которые не находятся в доверительный интервал [30 – 0,692951, 30 + 0,692951]. Поэтому доверительный интервал [30 –0,692951, 30 + 0,692951] содержит значения μ0, где null-гипотеза о том, что это μ0, не будет отклонена с учетом примеров признаков. Для значений μ0 вне этого интервала гипотеза null о том, что это μ0, будет отклонена с учетом примеров признаков.
Выводы
Неточности в более ранних версиях Excel обычно возникают при очень небольших или очень больших значениях p в нормУРОВН(p). Доверит оценивается с помощью вызовов НОРМ.СТ.ВВ(p), поэтому точность НОРМСИНВ является потенциальной проблемой для пользователей ДОВЕРИТ. Однако значения p, которые используются на практике, вряд ли являются достаточно крайними, чтобы вызывать существенные ошибки округленного округления в нормУРОВН, и производительность доверит пользователям любой версии Excel.
В большинстве статей основное внимание уделялось анализу результатов проверки доверить. Другими словами, мы спросили: «В чем смысл доверительный интервал?» Доверительный интервал часто неправильно понимается. К сожалению, Excel этой теме были Excel справки во всех версиях Excel 2003. Улучшен Excel 2003.
A T-test is a way of deciding if there are statistically significant differences between datasets, using a Student’s t-distribution. The T-Test in Excel is a two-sample T-test comparing the means of two samples. This article explains what statistical significance means and shows how to do a T-Test in Excel.
Instructions in this article apply to Excel 2019, 2016, 2013, 2010, 2007; Excel for Microsoft 365 and Excel Online.
What is Statistical Significance?
Imagine you want to know which of two dice will give a better score. You roll the first die and get a 2; you roll the second die and get a 6. Does this tell you the second die usually gives higher scores? If you answered, “Of course not,” then you already have some understanding of statistical significance. You understand the difference was due to the random change in the score, each time a die is rolled. Because the sample was very small (only one roll) it didn’t show anything significant.
Now imagine you roll each die 6 times:
- The first die rolls 3, 6, 6, 4, 3, 3; Mean = 4.17
- The second die rolls 5, 6, 2, 5, 2, 4; Mean = 4.00
Does this now prove the first die gives higher scores than the second? Probably not. A small sample with a relatively small difference between the means makes it likely the difference is still due to random variations. As we increase the number of dice rolls it becomes difficult to give a common sense answer to the question — is the difference between the scores the result of random variation or is one actually more likely to give higher scores than the other?
Significance is the probability that an observed difference between samples is due to random variations. Significance is often called the alpha level or simply ‘α.’ The confidence level, or simply ‘c,’ is the probability that the difference between the samples is not due to random variation; in other words, that there’s a difference between the underlying populations. Therefore: c = 1 – α
We can set ‘α’ at whatever level we want, to feel confident we’ve proven significance. Very often α=5% is used (95% confidence), but if we want to be really sure that any differences are not caused by random variation, we might apply a higher confidence level, using α=1% or even α=0.1%.
Various statistical tests are used to calculate significance in different situations. T-tests are used to determine whether the means of two populations are different and F-tests are used to determine whether the variances are different.
Why Test for Statistical Significance?
When comparing different things, we need to use significance testing to determine if one is better than the other. This applies to many fields, for example:
- In business, people need to compare different products and marketing methods.
- In sports, people need to compare different equipment, techniques, and competitors.
- In engineering, people need to compare different designs and parameter settings.
If you want to test whether something performs better than something else, in any field, you need to test for statistical significance.
What is a Student’s T-Distribution?
A Student’s t-distribution is similar to a normal (or Gaussian) distribution. These are both bell-shaped distributions with most results close to the mean, but some rare events are quite far from the mean in both directions, referred to as the tails of the distribution.
The exact shape of the Student’s t-distribution depends on the sample size. For samples of more than 30 it’s very similar to the normal distribution. As the sample size is reduced, the tails get larger, representing the increased uncertainty that comes from making inferences based on a small sample.
How to Do a T-Test in Excel
Before you can apply a T-Test to determine whether there’s a statistically significant difference between the means of two samples, you must first perform an F-Test. This is because different calculations are performed for the T-Test depending on whether there’s a significant difference between the variances.
You will need the Analysis Toolpak add-in enabled to perform this analysis.
Checking and Loading the Analysis Toolpak Add-In
To check and activate the Analysis Toolpak follow these steps:
-
Select the FILE tab >select Options.
-
In the Options dialogue box, select Add-Ins from the tabs on the left-hand side.
-
At the bottom of the window, select the Manage drop-down menu, then select Excel Add-ins. Select Go.
-
Ensure the check-box next to Analysis Toolpak is checked, then select OK.
-
The Analysis Toolpak is now active and you are ready to apply F-Tests and T-Tests.
Performing an F-Test and a T-Test in Excel
-
Enter two datasets into a spreadsheet. In this case, we’re considering the sales of two products during a week. The mean daily sales value for each product is also calculated, together with its standard deviation.
-
Select the Data tab > Data Analysis
-
Select F-Test Two-Sample for Variances from the list, then select OK.
The F-Test is highly sensitive to non-normality. It may therefore be safer to use a Welch test, but this is more difficult in Excel.
-
Select the Variable 1 Range and Variable 2 Range; set the Alpha (0.05 gives 95% confidence); select a cell for the top left corner of the output, considering that this will fill 3 columns and 10 rows. Select OK.
For the for Variable 1 Range, the sample with the largest standard deviation (or variance) must be selected.
-
View the F-Test results to determine whether there is a significant difference between the variances. The results give three important values:
- F: The ratio between the variances.
- P(F<=f) one-tail: The probability that variable 1 doesn’t actually have a larger variance than variable 2. If this is larger than alpha, which is generally 0.05, then there’s no significant difference between the variances.
- F Critical one-tail: The value of F that would be required to give P(F<=f)=α. If this value is greater than F, this also indicates there’s no significant difference between the variances.
P(F<=f) can also be calculated using the FDIST function with F and the degrees of freedom for each sample as its inputs. Degrees of freedom is simply the number of observations in a sample minus one.
-
Now that you know whether there is a difference between the variances you can select the appropriate T-Test. Select the Data tab > Data Analysis, then select either t-Test: Two-Sample Assuming Equal Variances or t-Test: Two-Sample Assuming Unequal Variances.
-
Regardless of which option you chose in the previous step, you will be presented with the same dialogue box to enter the details of the analysis. To start, select the ranges containing the samples for Variable 1 Range and Variable 2 Range.
-
Assuming you want to test for no difference between the means, set the Hypothesized Mean Difference to zero.
-
Set the significance level Alpha (0.05 gives 95% confidence), and select a cell for the top left corner of the output, considering that this will fill 3 columns and 14 rows. Select OK.
-
Review the results to decide if there’s a significant difference between the means.
Just as with the F-Test, if the p-value, in this case P(T<=t), is greater than alpha, then there’s no significant difference. However, in this case there are two p-values given, one for a one-tail test and the other for a two-tail test. In this case, use the two-tail value since either variable having a greater mean would be a significant difference.
Thanks for letting us know!
Get the Latest Tech News Delivered Every Day
Subscribe
Содержание
- FРАСПОБР для проверки значимости модели регрессии в Excel
- Функция FРАСПОБР для оценки значимости параметров модели регрессии
- Определение верхнего квартиля F-распределения Фишера в Excel
- Оценка в Excel эффективности использования технологий на производстве
- Особенности использования функции FРАСПОБР в Excel
- Как найти критическое значение F в Excel
- Как найти критическое значение F в Excel
- Предостережения по поиску критического значения F в Excel
- РЕГРЕССИЯ И EXCEL
FРАСПОБР для проверки значимости модели регрессии в Excel
Функция FПАСПОБР в Excel используется для проверки значимости модели регрессии с применением F-критерия (критерий Фишера), и возвращает числовое значение, соответствующее обратному значению для F-распределения вероятностей (верхнему квантилю). Например, если в качестве вероятности (первый аргумент функции) было введено значение уровня значимости, к примеру, 0,08, то FПАСПОБР вычислит значение случайной величины x, для которой выполняется следующее условие – P(X>x) = 0,08.
Функция FРАСПОБР для оценки значимости параметров модели регрессии
Критическое значения F может быть определено в случае, если в качестве первого аргумента рассматриваемой функции будет введено значение уровня значимости.
Для расчета F используется следующая формула:
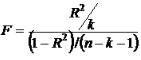
Функция оперирует двумя дополнительными критериями:
- Числитель степеней свободы: n1 = k.
- Знаменатель степеней свободы: n2 = (n – k – 1).
Через переменную k обозначают число факторов, которые были включены в исследуемую модель регрессии.
В Excel предусмотрена функция для расчета вероятности для распределения Фишера – FРАСП. Между данной и рассматриваемой функциями существует следующая взаимосвязь: =FРАСПОБР(FРАСП(x;n1;n2);n1;n2)=x.
В MS Office 2007 и более поздних версиях была введена функция F.ОБР.ПХ, которая заменила рассматриваемую функцию. FПАСПОБР была оставлена для обеспечения совместимости с документами, созданными в более старых версиях Excel.
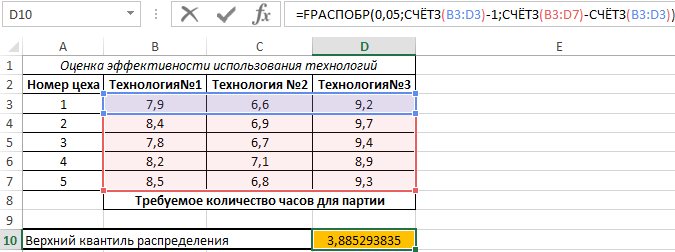
Определение верхнего квартиля F-распределения Фишера в Excel
Пример 1. В таблице указаны вероятность, связанная с распределением Фишера, а также числитель и знаменатель степеней свободы соответственно. Определить верхний квантиль данного F-распределения.
Вид таблицы данных:
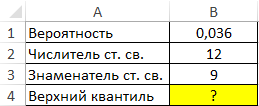
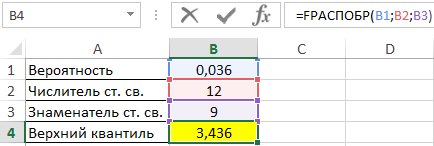
Вычислим искомое значение с помощью функции:
Оценка в Excel эффективности использования технологий на производстве
Пример 2. На заводе есть несколько цехов по производству одного типа продукции. Существует 3 различные технологии изготовления данной продукции. Для оценки были записаны данные о количестве часов, необходимых для производства одной партии продукции каждым цехом с использованием каждой из трех технологий. Оценить эффективность использования технологий, проанализировать полученные значения.
Вид таблицы данных:
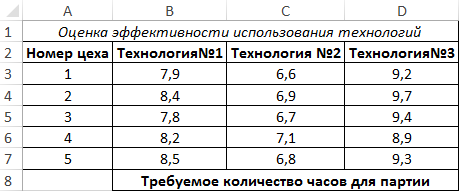
Проведем однофакторный дисперсионный анализ для данных, находящихся в диапазоне ячеек B3:D7, используя соответствующую надстройку Excel. Полученная таблица результатов:
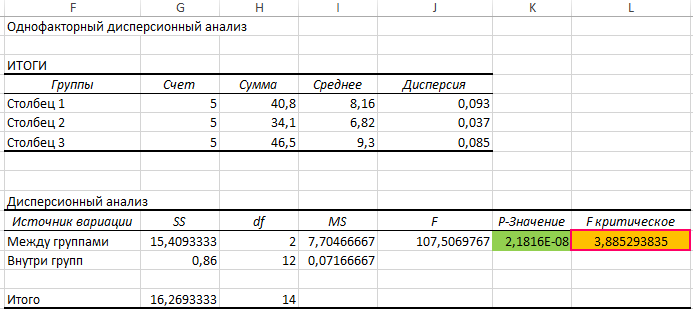
По условия поставленной задачи нас интересует выделенное значение. Поскольку оно
Здесь СЧЁТЗ(B3:D3) определяет число полей данных, а СЧЁТЗ(B3:D7) – количество исследуемых числовых значений.
Особенности использования функции FРАСПОБР в Excel
Функция имеет следующую синтаксическую запись:
- вероятность – обязательный, принимает числовое значение, характеризующее вероятность, которая связана с распределением Фишера;
- степени_свободы1 – обязательный, принимает числовое значение, соответствующее числителю степеней свободы (равно числу факторов исследуемой регрессии);
- степени_свободы2 – обязательный, принимает числовое значение, соответствующее знаменателю степеней свободы.
- Рассматриваемая функция принимает в качестве любого из аргументов только числовые значения и данные, которые могут быть преобразованы к числам. Если любой из аргументов принимает данные недопустимого типа, будет сгенерирован код ошибки #ЗНАЧ!
- Первый аргумент должен быть задан числом из диапазона от 0 до 1. В противном случае функция FПАСПОБР вернет код ошибки #ЧИСЛО!
- Второй и третий аргумент функции должны быть заданы числами из диапазона от 1 до 10^10. При вводе значений, находящихся вне допустимого диапазона, будет сгенерирован код ошибки #ЧИСЛО!
- Рассматриваемая функция использует итеративный подход к вычислениям (последовательный подбор приближенного значения в циклах). Если спустя 100 итераций решение не было найдено, результатом выполнения функции FПАСПОБР будет код ошибки #Н/Д.
Источник
Как найти критическое значение F в Excel
Когда вы проводите F-тест, в результате вы получаете F-статистику. Чтобы определить, являются ли результаты теста F статистически значимыми, можно сравнить статистику F с критическим значением F. Если статистика F больше критического значения F, то результаты теста статистически значимы.
Критическое значение F можно найти с помощью таблицы распределения F или с помощью статистического программного обеспечения.
Чтобы найти критическое значение F, вам нужно:
- Уровень значимости (обычно выбирают 0,01, 0,05 и 0,10).
- Числитель степеней свободы
- Знаменатель степеней свободы
Используя эти три значения, вы можете определить критическое значение F для сравнения со статистикой F.
Как найти критическое значение F в Excel
Чтобы найти критическое значение F в Excel, вы можете использовать функцию F.ОБР.ПВ() , которая использует следующий синтаксис:
F.INV.RT (вероятность, степень_свободы1, степень_свободы2)
- вероятность: уровень значимости для использования
- deg_freedom1 : Степени свободы в числителе
- deg_freedom2 : Степени свободы в знаменателе
Эта функция возвращает критическое значение из F-распределения на основе предоставленного уровня значимости, степеней свободы числителя и степеней свободы знаменателя.
Например, предположим, что мы хотим найти критическое значение F для уровня значимости 0,05, степени свободы числителя = 4 и степени свободы знаменателя = 6.
В Excel мы можем ввести следующую формулу: F.ОБР.ВУ(0,05, 4, 6)

Это возвращает значение 4,5337.Это критическое значение для уровня значимости 0,05, степени свободы числителя = 4 и степени свободы знаменателя = 6.
Обратите внимание, что это также соответствует числу, которое мы нашли бы в таблице распределения F с α = 0,05, DF1 (степени свободы в числителе) = 4 и DF2 (степени свободы в знаменателе) = 6.

Предостережения по поиску критического значения F в Excel
Обратите внимание, что функция F.ОБР.ПВ() в Excel выдаст ошибку, если произойдет одно из следующих событий:
- Если какой-либо аргумент не является числовым.
- Если значение вероятности меньше нуля или больше 1.
- Если значение для deg_freedom 1 или deg_freedom2 меньше 1.
Источник
РЕГРЕССИЯ И EXCEL




![]()
![]()
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты.
Для работы необходима надстройка Пакет анализа, которую необходимо включить в пункте меню СервисНадстройки
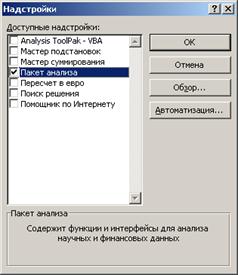
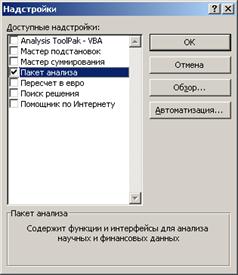
В Excel 2007 для включения пакета анализа надо нажать перейти в блок Параметры Excel, нажав кнопку в левом верхнем углу, а затем кнопку «Параметры Excel» внизу окна:



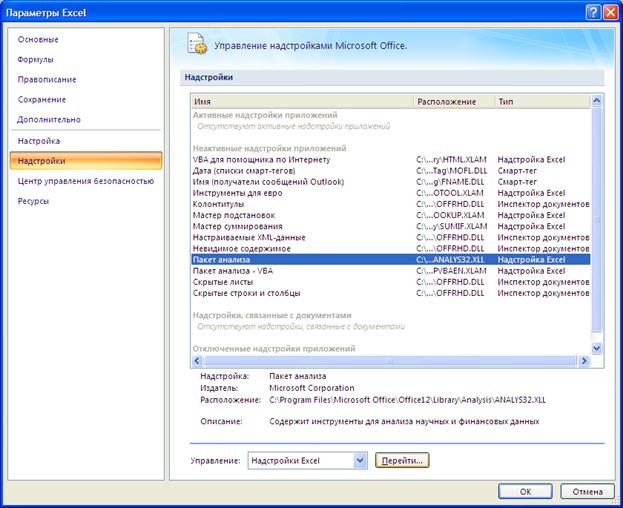
Далее в открывшемся списке нужно выбрать Надстройки, затем установить курсор на пункт Пакет анализа, нажать кнопку Перейти и в следующем окне включить пакет анализа.
Для построения модели регрессии необходимо выбрать пункт СервисАнализ данныхРегрессия. (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/ Регрессия). Появится диалоговое окно, которое нужно заполнить:
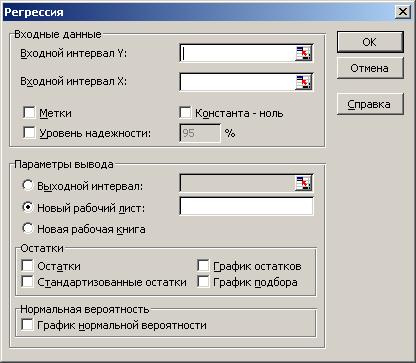
1) Входной интервал Y ¾ содержит ссылку на ячейки, которые содержат значения результативного признака y. Значения должны быть расположены в столбце;
2) Входной интервал X ¾ содержит ссылку на ячейки, которые содержат значения факторов 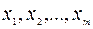
 . Значения должны быть расположены в столбцах;
. Значения должны быть расположены в столбцах;
3) Признак Метки ставится, если первые ячейки содержат пояснительный текст (подписи данных);
4) Уровень надежности ¾ это доверительная вероятность, которая по умолчанию считается равной 95%. Если это значение не устраивает, то нужно включить этот признак и ввести требуемое значение;
5) Признак Константа-ноль включается, если необходимо построить уравнение, в котором свободная переменная 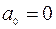 ;
;
6) Параметры вывода определяют, куда должны быть помещены результаты. По умолчанию строит режим Новый рабочий лист;
7) Блок Остатки позволяет включать вывод остатков и построение их графиков.
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой 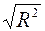 (коэффициент корреляции Пирсона);
(коэффициент корреляции Пирсона);
R -квадрат вычисляется по формуле 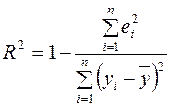 (коэффициент детерминации);
(коэффициент детерминации);
Нормированный R -квадрат вычисляется по формуле 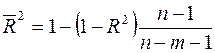 (используется для множественной регрессии);
(используется для множественной регрессии);
Стандартная ошибка S вычисляется по формуле 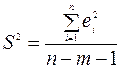 ;
;
Наблюдения ¾ это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой 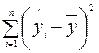 ;
;
Параметр MS определяется формулой 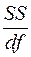 ;
;
Статистика F определяется формулой 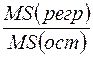 ;
;
Значимость F. Если полученное число превышает 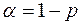 , то принимается гипотеза
, то принимается гипотеза 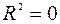 (нет линейной взаимосвязи), иначе принимается гипотеза
(нет линейной взаимосвязи), иначе принимается гипотеза 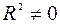 (есть линейная взаимосвязь).
(есть линейная взаимосвязь).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен 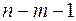 ;
;
Параметр SS определяется формулой 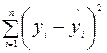 ;
;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента 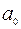 , стандартной ошибки
, стандартной ошибки 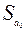 и t -статистики
и t -статистики 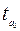 .
.
P -значение ¾ это значение уровней значимости, соответствующее вычисленным t -статистикам. Определяется функцией СТЬЮДРАСП(t -статистика; ). Если P -значение превышает , то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% ¾ это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки содержат значения коэффициентов, стандартных ошибок, t -статистик, P -значений и доверительных интервалов для соответствующих 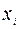 .
.
7. Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это 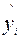 ) и остатки
) и остатки 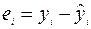 .
.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник

С помощью t-критерия Стьюдента можно определить, имеются ли статистически значимые различия между наборами данных. T-тест в Excel — это T-тест с двумя образцами, сравнивающий средние значения двух образцов. В этой статье объясняется, что означает статистическая значимость, и показано, как выполнить T-тест в Excel.
Инструкции в этой статье относятся к Excel 2019, 2016, 2013, 2010, 2007; Excel для Office 365 и Excel Online.
Что такое статистическая значимость?
Представьте, что вы хотите знать, какая из двух костей даст лучший результат. Вы бросаете первый кубик и получаете 2; вы бросаете второй кубик и получаете 6. Это говорит вам, что второй кубик обычно дает более высокие оценки? Если вы ответили «Конечно, нет», то у вас уже есть некоторое понимание статистической значимости. Вы понимаете, что разница была связана со случайным изменением счета, каждый раз, когда бросали кубик. Поскольку образец был очень маленьким (только один рулон), он не показал ничего существенного.
Теперь представьте, что вы бросаете каждый кубик 6 раз:
- Первые кубики бросают 3, 6, 6, 4, 3, 3; Среднее = 4,17
- Второй бросает кубики 5, 6, 2, 5, 2, 4; Среднее = 4,00
Означает ли это, что первый кубик дает больше очков, чем второй? Возможно нет. Небольшая выборка с относительно небольшой разницей между средними значениями делает вероятным, что разница все же обусловлена случайными отклонениями. По мере того как мы увеличиваем количество бросков костей, становится трудно дать здравый смысл ответить на вопрос — является ли разница между оценками результатом случайного отклонения или один из них на самом деле с большей вероятностью дает более высокие оценки, чем другой?
Значимость — это вероятность того, что наблюдаемая разница между образцами обусловлена случайными колебаниями. Значение часто называют альфа-уровнем или просто «α». Уровень достоверности, или просто «с», — это вероятность того, что разница между выборками не обусловлена случайным изменением; другими словами, есть разница между основными группами населения. Следовательно: c = 1 — α
Мы можем установить «α» на любом желаемом уровне, чтобы чувствовать себя уверенно, что доказали свою значимость. Очень часто используется α = 5% (95% достоверности), но если мы хотим быть действительно уверенными в том, что какие-либо различия не вызваны случайными колебаниями, мы можем применить более высокий уровень достоверности, используя α = 1% или даже α = 0,1 %.
Зачем проверять статистическую значимость?
Сравнивая разные вещи, мы должны использовать тестирование значимости, чтобы определить, лучше ли одно, чем другое. Это относится ко многим полям, например:
- В бизнесе люди должны сравнивать разные продукты и методы маркетинга.
- В спорте люди должны сравнивать различное оборудование, техники и конкурентов.
- В разработке люди должны сравнивать различные проекты и настройки параметров.
Если вы хотите проверить, работает ли что-то лучше, чем что-либо, в любой области вам необходимо проверить статистическую значимость.
Что такое T-распределение студента?
T-распределение Стьюдента аналогично нормальному (или гауссовскому) распределению. Это оба распределения в форме колокола, большинство результатов которых близко к среднему, но некоторые редкие события довольно далеки от среднего значения в обоих направлениях, которые называются хвостами распределения.
Точная форма распределения Стьюдента зависит от размера выборки. Для образцов более 30 это очень похоже на нормальное распределение. По мере того как размер выборки уменьшается, хвосты становятся больше, что отражает возросшую неопределенность, возникающую в результате заключения на основе небольшой выборки.
Как сделать T-тест в Excel
Прежде чем вы сможете применить T-тест, чтобы определить, есть ли статистически значимая разница между средними значениями двух образцов, вы должны сначала выполнить F-тест. Это связано с тем, что для T-теста выполняются разные вычисления в зависимости от того, есть ли существенная разница между отклонениями.
Для выполнения этого анализа вам понадобится надстройка Пакет инструментов анализа.
Проверка и загрузка надстройки Toolpak для анализа
Чтобы проверить и активировать пакет инструментов анализа, выполните следующие действия.
-
Выберите вкладку ФАЙЛ > выберите Параметры .
-
В диалоговом окне «Параметры» выберите « Надстройки» на вкладках с левой стороны.
-
В нижней части окна выберите раскрывающееся меню «Управление» , затем выберите « Надстройки Excel» . Выберите Go .
-
Убедитесь, что установлен флажок рядом с Пакетом инструментов анализа , затем выберите ОК .
-
Пакет инструментов анализа теперь активен, и вы готовы применить F-тесты и T-тесты.
Выполнение F-теста и T-теста в Excel
-
Выберите вкладку « Данные »> « Анализ данных».
-
Выберите F-Test Two-Sample для отклонений из списка, затем нажмите OK .
F-тест очень чувствителен к ненормальности. Поэтому может быть безопаснее использовать тест Уэлча, но это сложнее в Excel.
-
Выберите диапазон переменной 1 и диапазон переменной 2; установить альфа (0,05 дает 95% уверенности); выберите ячейку для верхнего левого угла вывода, учитывая, что это заполнит 3 столбца и 10 строк. Выберите ОК .
Для диапазона переменной 1 необходимо выбрать выборку с наибольшим стандартным отклонением (или дисперсией).
-
Просмотрите результаты F-теста, чтобы определить, есть ли существенная разница между отклонениями. Результаты дают три важных значения:
- F : соотношение между дисперсиями.
- P (F <= f) one-tail : вероятность того, что переменная 1 на самом деле не имеет большей дисперсии, чем переменная 2. Если она больше, чем альфа, которая обычно равна 0,05, то нет существенной разницы между дисперсиями.
- F Критический односторонний : значение F, которое требуется, чтобы P (F <= f) = α. Если это значение больше, чем F, это также означает, что между отклонениями нет существенной разницы
P (F <= f) также можно рассчитать, используя функцию FDIST с F и степенями свободы для каждого сэмпла в качестве входных данных. Степени свободы — это просто число наблюдений в выборке минус один.
-
Теперь, когда вы знаете, есть ли разница между отклонениями, вы можете выбрать соответствующий T-критерий. Перейдите на вкладку « Данные »> « Анализ данных» , затем выберите « t-критерий: две выборки в предположении равных отклонений» или « t-критерий: две выборки в предположении неравных отклонений» .
-
Независимо от того, какой вариант вы выбрали на предыдущем шаге, вам будет предложено одно и то же диалоговое окно для ввода подробностей анализа. Чтобы начать, выберите диапазоны , содержащие образцы для переменных 1 Диапазона и переменных 2 Диапазона .
-
Предполагая, что вы хотите проверить отсутствие разницы между средними, установите гипотетическую среднюю разницу на ноль.
-
Установите уровень значимости Альфа (0,05 дает 95% достоверности) и выберите ячейку для верхнего левого угла выходных данных, учитывая, что это заполнит 3 столбца и 14 строк. Выберите ОК .
-
Просмотрите результаты, чтобы решить, есть ли существенная разница между средствами.
Как и в F-тесте, если значение p, в данном случае P (T <= t), больше, чем альфа, то существенной разницы нет. Однако в этом случае даются два значения p: одно для теста с одним хвостом, а другое для теста с двумя хвостами. В этом случае используйте значение с двумя хвостами, поскольку любая переменная, имеющая большее среднее значение, будет существенной разницей.
history 23 ноября 2016 г.
- Группы статей
- Статистический вывод
Дадим определение терминам уровень надежности и уровень значимости. Покажем, как и где они используется в MS EXCEL .
СОВЕТ : Для понимания терминов Уровень значимости и Уровень надежности потребуется знание следующих понятий:
Уровень значимости статистического теста – это вероятность отклонить нулевую гипотезу , когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность ошибки первого рода (type I error).
Уровень значимости обычно обозначают греческой буквой α ( альфа ). Чаще всего для уровня значимости используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении доверительного интервала для оценки среднего значения распределения , его ширину рассчитывают таким образом, чтобы вероятность события « выборочное среднее (Х ср ) находится за пределами доверительного интервала » было равно уровню значимости . Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о равенстве среднего заданному значению .
Ошибка первого рода часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина ошибки первого рода задается перед проверкой гипотезы , таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение уровня значимости α (т.е. вероятности ошибки первого рода ) может привести к увеличению вероятности ошибки второго рода , то есть вероятности принять нулевую гипотезу , когда на самом деле она не верна. Подробнее об ошибке второго рода см. статью Ошибка второго рода и Кривая оперативной характеристики .
Уровень значимости обычно указывается в аргументах обратных функций MS EXCEL для вычисления квантилей соответствующего распределения: НОРМ.СТ.ОБР() , ХИ2.ОБР() , СТЬЮДЕНТ.ОБР() и др. Примеры использования этих функций приведены в статьях про проверку гипотез и про построение доверительных интервалов .
Уровень надежности
Уровень доверия (этот термин более распространен в отечественной литературе, чем Уровень надежности ) — означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Уровень доверия равен 1-α, где α – уровень значимости .
Термин Уровень надежности имеет синонимы: уровень доверия, коэффициент доверия, доверительный уровень и доверительная вероятность (англ. Confidence Level , Confidence Coefficient ).
В математической статистике обычно используют значения уровня доверия 90%; 95%; 99%, реже 99,9% и т.д.
Например, Уровень доверия 95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор уровня доверия полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание : Стоит отметить, что математически не корректно говорить, что Уровень доверия является вероятностью, того что оцениваемый параметр распределения принадлежит доверительному интервалу , вычисленному на основе выборки . Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что доверительный интервал , с вероятностью равной Уровню доверия, накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL Уровень надежности упоминается в надстройке Пакет анализа . После вызова надстройки, в диалоговом окне необходимо выбрать инструмент Описательная статистика . 
После нажатия кнопки ОК будет выведено другое диалоговое окно. 
В этом окне задается Уровень надежности, т.е.значениевероятности в процентах. После нажатия кнопки ОК в выходном интервале выводится значение равное половине ширины доверительного интервала . Этот доверительный интервал используется для оценки среднего значения распределения, когда дисперсия не известна (подробнее см. статью про доверительный интервал ).
Необходимо учитывать, что данный доверительный интервал рассчитывается при условии, что выборка берется из нормального распределения . Но, на практике обычно принимается, что при достаточно большой выборке (n>30), доверительный интервал будет построен приблизительно правильно и для распределения, не являющегося нормальным (если при этом это распределение не будет иметь сильной асимметрии ).
Примечание : Понять, что в диалоговом окне речь идет именно об оценке среднего значения распределения , достаточно сложно. Хотя в английской версии диалогового окна это указано прямо: Confidence Level for Mean .
Если Уровень надежности задан 95%, то надстройка Пакет анализа использует следующую формулу (выводится не сама формула, а лишь ее результат):
или эквивалентную ей
где =СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) – является стандартной ошибкой среднего (формулы приведены в файле примера ).
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Решение задач описательной статистики средствами пакета анализа Microsoft Excel Текст научной статьи по специальности « Компьютерные и информационные науки»
CC BY
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Трущелёв Сергей Андреевич
Представлено определение описательной статистики , изложены методика вычисления основных ее показателей, а также пошаговая процедура статистического анализа. Сообщение содержит обучающий компонент.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Трущелёв Сергей Андреевич
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics , and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with.
Текст научной работы на тему «Решение задач описательной статистики средствами пакета анализа Microsoft Excel»
МЕТОДОЛОГИЯ НАУЧНО-ИССЛЕДОВАТЕЛЬСКОЙ ДЕЯТЕЛЬНОСТИ
Уважаемые читатели, коллеги!
В связи с возрастающими требованиями к качеству публикаций результатов научно-исследовательских работ в «Российском психиатрическом журнале» открыта новая рубрика «Методология научно-исследовательской деятельности». Планируется публикация обучающих и информационно-разъяснительных материалов по разным разделам науковедения, организации научной работы, биоинформатике, биостатистике, биоэтике и т.д. Приглашаем ученых и исследователей поделиться опытом в этой области. Надеемся, что наша инициатива будет поддержана не только в научном сообществе, но и воспринята в среде практикующих специалистов.
© С.А. Трущелёв, 2013 Для корреспонденции
УДК 311:004 Трущелёв Сергей Андреевич — кандидат медицинских наук,
доцент, ведущий научный сотрудник ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Адрес: 107076, г. Москва, ул. Потешная, д. 3 Телефон: (495) 963-25-31 E-mail: sat-geo@mail.ru
Решение задач описательной статистики средствами пакета анализа Microsoft Excel
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics, and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with. Key words: science of science, biostatistics, descriptive statistics, data analysis toolpak, Excel
ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Moscow Research Institute of Psychiatry
Представлено определение описательной статистики, изложены методика вычисления основных ее показателей, а также пошаговая процедура статистического анализа. Сообщение содержит обучающий компонент.
Ключевые слова: науковедение, биостатистика, описательная статистика, пакет анализа, Excel
Каждое явление (предмет исследования) определяется многими факторами. В научном исследовании полностью учесть все факторы и обеспечить их стабильность удается редко. Следовательно, явление, определяемое этими факторами, не поддается точному предсказанию — оно приобретает вероятностные черты, т.е. ведет себя случайным образом. Этому подвержены многие явления, поэтому они определяются случайной величиной, которая принимает в результате опыта или наблюдения одно из множества значений. Случайные величины могут быть дискретными (прерывными) и непрерывными. Немаловажно их распределение — правило, которое устанавливает связь между значениями случайной величины и вероятностями (частотами) их появления.
Наглядное представление о распределении случайных величин дает разброс песчинок, образующих кучу при высыпании (рассеивании) из некоторого точечного источника. Его проекция является параметром положения и соответствует математическому ожиданию распределения, если куча симметрична. Разброс песчинок (параметр рассеяния) характеризуется радиусом кучи на высоте примерно 2/3. Такой параметр рассеяния соответствует так называемому стандартному (среднеквадратичному) отклонению случайных величин в распределении. Горизонтальные расстояния песчинок от проекции источника (математического ожидания) моделируют рассеяние случайной величины. Поверхность кучи (ее высоты) соответствует частоте случайных величин на разных расстояниях от центра. Вершина кучи, расположенная под источником, отвечает максимуму частоты. На периферии высота кучи уменьшается до нуля, что соответствует уменьшению частот больших отклонений от центра рассеяния. Статистическая обработка совокупности данных состоит в некоторых осредняющих вычислительных процедурах, погашающих сугубо индивидуальные особенности — отклонения от общей закономерности и подчеркивающих типичные (популяцион-ные) свойства явления в целом. Начальный раздел математической статистики — описательная статистика — занимается характеристикой (описанием) картины случайного рассеяния по совокупности данных. В соответствии с законом распределения данных решаются вопросы выбора и вычислений надлежащих показателей. Описательная статистика включает методы организации, суммирования и описания данных. Дескриптивные (от англ. descriptive — описательный) показатели позволяют быстро обобщать данные. К описательным методам относят частотные распределения, меры централь-
ной тенденции и меры относительного положения [4, с. 95].
К основным показателям описательной статистики относятся среднее значение (среднее арифметическое, медиана, мода), усредненное значение, разброс (диапазон разброса данных), дисперсия, стандартное среднеквадратное отклонение (СКО), квартили, доверительный интервал [2, с. 28].
Статистическая обработка результатов исследований и получение показателей описательной статистики в недалеком прошлом обычно занимали много времени, однако с внедрением средств компьютерной техники многое изменилось — вычислительные процессы стали происходить очень быстро. Для проведения статистических расчетов в электронной таблице Microsoft Excel имеется пакет анализа. Надстройка «Анализ данных» располагается во вкладке «Данные», в крайне правом блоке ленты (рис. 1).
Для демонстрации вычислений будем использовать гипотетический набор данных. Далее приведем пошаговую инструкцию по созданию описательной статистики признака (показателя систолического давления), измеренного до лечения и после него, в группе наблюдения (n=60).
Для проведения вычисления обратитесь к ленте: Данные ^ Анализ данных ^ Описательная статистика ^ ОК. Затем, перейдя в окно инструмента, выберите входной интервал, группирование (по столбцам), поставьте галочку, если в первой строке выделены метки; в параметрах вывода на поле электронной страницы выберите ячейку вывода результатов, установите галочку рядом с итоговой статистикой. Потом нажмите кнопку ОК. После этого вы получите результаты описательной статистики выбранных признаков (рис. 2 и 3).
[й1 A «ï- V m И^ЭгшИ Главная Ш I» 1 Описательная статистика — Microsoft Excel □ 0 й Вставка Разметка страницы Формулы Данные Рецензирование Вид Разработчик Надстройки MetaXL Л □ S3
П внец m 1олучение jних данныхт ч [^Подключения ^Свойства Обновить все т && Изменить связи Подключения A I AIЯ I Я + Я 1А1 Я| Сортировка Со pi ч Ш ^ Очистить ^ Повторить Фильтр ™ № Дополнительно ировка и фильтр S Ii ы» вш а в Текст по Удалить ,—, столбцам дубликаты » Работа сданными Ф Фор» орма Jbi ssprfa ф ^ ^Анализданных Поиск решения Стр^И^ра Анализ
А в с D Е F G У 1 J К 1 L _
1 Номер_исс Признак_1 Признак_2 у
3 2 178 143 Анализ данным lia
Инструменты анализа У _ 1 о, 1
4 3 320 188 Двухфакторный дисперсионный^нализ без повторений Корреляция Л* 3 J d Отмена |
6 5 159 161 Экспоненциальное сглаживание Двухвыборочный Р-тест для дисперсии Анализ Фурье Гистограмма Скользящее среднее 1 Генерация случайных чисел_| Справка
Рис. 1. Пошаговый выбор инструмента анализа данных
Рис. 2. Окно инструмента описательной статистики
Среднее (арифметическое; М; х ) — одна из наиболее распространенных мер центральной тенденции, представляющая собой сумму всех значений, деленную на их количество. Если значения интересующего нас признака у большинства объектов близки к их среднему и с равной вероятностью отклоняются от него в большую или меньшую сторону, лучшими характеристиками совокупности будут само среднее значение и стандартное отклонение. Напротив, когда значения признака распределены несимметрично относительно среднего, совокупность лучше описать с помощью медианы и процен-тилей [1, с. 27].
Стандартная ошибка (т) — показатель надежности расчетного параметра; стандартное отклонение оценок, которые будут получены при многократной случайной выборке данного размера из одной и той же совокупности. Стандартная ошибка — это убывающая функция объема выборки: чем меньше стандартная ошибка, тем более достоверной является оценка параметра. Весьма часто для описания непрерывных количественных данных используют стандартную ошибку, которая (в отличие от СКО) является не характеристикой, описывающей распределение наблюдений исследуемой выборки по области значений, а только мерой точности оценки популяционного среднего и, следовательно, не характеризует дисперсию (разброс) в анализируемой выборке. Однако часто именно стандартную ошибку среднего приводят в качестве параметра описательной статистики, пытаясь продемонстрировать тем самым малую вариабельность своих данных, так как всегда (по определению) т Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
60 Среднее 161,77 Среднее 134,03
61 Стандартная ошибка 12,46 Стандартная ошибка 6.59
62 Медиана 167 Медиана 121,5
63 Мода 72 Мода 141
64 Стандартное отклонение 96.54 Стандартное отклонение 51,03
65 Дисперсия выборки 9320.59 Дисперсия выборки 2604.34
66 Эксцесс 0.89 Эксцесс 2.75
67 Асимметричность 0.96 Асимметричность 1,43
68 Интервал 420 Интервал 254
69 Минимум 50 Минимум 55
70 Максимум 470 Максимум 309
71 Сумма 9706 Сумма 8042
72 Счет 60 Счет 60
73 74 Уровень надежности(95.0%) 24.94 Уровень надежности(95.0%) 13,18
Коэффициент вариации 60% Коэффициент вариации 38%
Рис. 3. Результаты описательной статистики двух признаков
Медиану и интерквартильный размах рекомендуется применять для описания распределения, не являющегося нормальным (а это большинство распределений медико-биологических параметров) [1, с. 34]. Интерквартильный размах указывают в виде процентилей. Рекомендуется указывать уровни 25 и 75%, которые соответствуют верхней границе 1-го и нижней границе 4-го квартилей. Пример описания: Me (25%; 75%) = 60 (23; 78).
Мода (Мо) — значение, которое встречается наиболее часто во множестве. Иногда в совокупности встречается более одной моды. Тогда говорят, что совокупность мультимодальна — свидетельство того, что набор данных не подчиняется нормальному распределению. Мода как средняя величина употребляется чаще для данных, имеющих нечисловую природу. Например, в группе пациентов наибольшая частота тяжести болезни будет равна моде. При экспертной оценке с помощью этого показателя определяют предпочтения участников исследования. Недостаток — показатель не учитывает поведение распределения в других точках.
Стандартное отклонение (синонимы: среднеквадратичное отклонение, квадратичное отклонение; стандартный разброс; СКО; в; о) — в теории вероятностей и статистике наиболее распространенный показатель рассеивания значений случайной величины относительно ее математического ожидания. Измеряется в единицах случайной величины. Равно корню квадратному из дисперсии случайной величины. Стандартное отклонение используют при расчете стандартной ошибки среднего арифметического, построении доверительных интервалов, статистической проверке гипотез, измерении линейной взаимосвязи между случайными величинами. Большое значение СО показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения во множестве сгруппированы вокруг среднего. Если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратичного отклонения), то полученные значения или метод их получения следует перепроверить.
Дисперсия (D; о2) — мера разброса случайной величины, т.е. ее отклонения от математического ожидания. Квадратный корень из дисперсии называется стандартным отклонением. Дисперсия измеряется в квадратах единицы измерения. Однако в самостоятельном виде (как, например, средняя арифметическая) дисперсия используется редко. Это скорее вспомогательный и промежуточный показатель, который применяют в других методах статистического анализа.
Эксцесс — скалярная характеристика островершинности графика плотности вероятности унимо-
дального распределения, которую используют в качестве некоторой меры отклонения рассматриваемого распределения от нормального. Если коэффициент эксцесса равен нулю или близок к нему, то плотность вероятности распределения имеет нормальный эксцесс. Если коэффициент эксцесса сильно больше нуля, то плотность вероятности имеет положительный эксцесс. Это, как правило, соответствует тому, что график плотности рассматриваемого распределения в окрестности моды имеет более острую и более высокую вершину, чем нормальная кривая. Когда коэффициент эксцесса сильно больше нуля, говорят об отрицательном эксцессе плотности, при этом плотность вероятности имеет в окрестности моды более низкую и плоскую вершину, чем плотность нормального закона. Для генеральных совокупностей больших объемов его малыми значениями можно пренебречь.
Асимметричность (коэффициент асимметрии или скоса) — величина, характеризующая асимметрию распределения данной случайной величины. Коэффициент асимметрии положителен, если правый хвост распределения длиннее левого, и отрицателен в альтернативном случае. Если распределение симметрично относительно математического ожидания, то его коэффициент асимметрии равен нулю.
Интервал — размах показателей, т.е. разность между максимумом и минимумом значений вариант.
Максимум — наибольшее значение вариант.
Минимум — наименьшее значение вариант.
Сумма — сумма значений вариант.
Счет — количество вариант.
Уровень надежности — свойство объекта сохранять в установленных пределах значения всех параметров. Показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%.
Коэффициент вариации случайной величины -мера относительного разброса случайной величины. Показывает, какую долю среднего значения этой величины составляет ее средний разброс. Исчисляется в процентах. Вычисляется только для количественных данных. В отличие от стандартного отклонения, он измеряет не абсолютную, а относительную меру разброса значений признака в статистической совокупности. В Excel нет готовой функции для расчета коэффициента вариации. Расчет можно провести простым делением стандартного отклонения на среднее значение. Эти значения имеются в таблице описательной статистики. Для вычисления этого важного показателя в ячейке ниже надписи Уровень надежности пишем Коэффициент вариации, затем в ячейке справа делаем запись: =G64/G60. То же необходимо по-
вторить для вычисления коэффициента вариации для другого измерения.
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на панели инструментов в закладке «Главная». Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что совокупность данных является однородной, если коэффициент вариации менее 33%, неоднородной — если более 33%. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений.
Анализ показателей описательной статистики
При сравнении значений среднего, медианы, моды в каждом измерении следует отметить, что эти показатели сильно отличаются друг от друга.
Коэффициенты эксцесса и асимметрии значимо отличаются от установленных границ, коэффициенты вариации больше критического (предельного) значения. Следовательно, распределение данных в обеих группах измерений отлично от нормального. В последующем необходимо применять непараметрические методы статистического анализа. Для быстрой сравнительной оценки можно использовать показатели доверительных интервалов.
Для представления результатов сравнения обычно используют формат в виде М (95% ДИ) — значение среднего и указание 95% доверительного интервала. В тексте публикации запись может выглядеть следующим образом: Средний уровень систолического давления в группе пациентов до лечения составил 161,77 мм рт. ст. (95% ДИ от 136,83 до 186,71 мм рт. ст.), после лечения -134,03 мм рт. ст. (95% ДИ от 120,85 до 147,21 мм рт. ст.). Указанные доверительные интервалы имеют зону совмещения, следовательно, существенного различия в изменении признака нет. Исходя из этого с большой долей вероятности можно утверждать, что для данной группы пациентов лекарственный препарат, примененный для снижения уровня систолического артериального давления, был не эффективен.
1. Гланц С. Медико-биологическая статистика / Пер. с англ. -М., Практика, 1998. — 459 с.
2. Ланг Т.А., Сесик М. Как описывать статистику в медицине. Аннотированное руководство для авторов, редакторов и рецензентов / Пер. с англ. под ред. В.П. Леонова. -М.: Практическая медицина, 2011. — 480 с.
3. Леонов В.П. Ошибки статистического анализа биомедицинских данных // Междунар. журн. мед. практики. — 2007. -№ 2. — С. 19-35.
4. Трущелев С.А. Медицинская диссертация: руководство: 3-е изд. / Под ред. проф. И.Н. Денисова. — М.: ГЭОТАР-Медиа, 2009. — 416 с.
Теория “p-values” и нулевая гипотеза может показаться сложной на первый взгляд, но понимание концепций поможет вам ориентироваться в мире статистики. К сожалению, эти термины часто неправильно используются в популярной науке, поэтому всем необходимо понимать основы.
< p>Вычисление “p-значения” модели и доказательство/опровержение нулевой гипотезы на удивление просто с MS Excel. Есть два способа сделать это. Давайте углубимся.
Нулевая гипотеза — это утверждение, также называемое позицией по умолчанию, утверждающее, что взаимосвязь между наблюдаемыми явлениями не существует. Нулевая гипотеза может также применяться к ассоциациям между двумя экспериментальными группами. В ходе исследования вы проверяете эту гипотезу и пытаетесь ее опровергнуть.
Например, вы хотите посмотреть, дает ли конкретная причудливая диета значительные результаты. Нулевая гипотеза в данном случае состоит в том, что между испытуемыми нет существенной разницы». вес до и после диеты. Альтернативная гипотеза состоит в том, что диета действительно имела значение. Альтернатива — это то, что попытаются доказать исследователи.
“p-значение” представляет вероятность того, что статистическая сводка будет равна или больше наблюдаемого значения, когда нулевая гипотеза верна для конкретной статистической модели. Хотя “p-значение” часто выражается в виде десятичного числа, обычно лучше описывать его в процентах. Например, значение “p-value” 0,1 должно быть представлено как 10%.
Низкое значение “p-значение” означает, что доказательства против нулевой гипотезы сильны. Это также означает, что ваши данные важны. С другой стороны, высокое “значение p” означает, что нет убедительных доказательств против гипотезы. Чтобы доказать, что причудливая диета работает, исследователям необходимо найти низкое “p-значение”
Статистически значимый результат — это такой результат, который маловероятен, если нулевая гипотеза верна. Уровень значимости обозначается греческой буквой “альфа” и оно должно быть больше “p-value” чтобы результат был статистически значимым.
Многие исследователи используют “p-значение” для лучшего и более глубокого понимания данных эксперимента. Некоторые известные научные области, в которых используется значение “p-value” включают социологию, уголовное правосудие, психологию, финансы и экономику.
Поиск значения p в Excel 2010
Вы можете найти “р-значение” набора данных в MS Excel с помощью теста “T-Test” или с помощью функции “Анализ данных” инструмент. Во-первых, мы рассмотрим “T-Test” функция. Вы увидите пять студентов колледжа, которые соблюдали 30-дневную диету, и сопоставимые данные об их весе до и после диеты.
ПРИМЕЧАНИЕ. В этой статье рассматриваются функции p-value для MS Excel 2010 и 2016, но шаги должны применяться ко всем версиям. Однако макет графического пользовательского интерфейса (GUI) меню и многого другого будет отличаться.
Функция T-теста
Выполните следующие действия, чтобы вычислить “p-значение” с помощью функции T-Test.
- Создайте и заполните таблицу. Наша таблица выглядит следующим образом:

- Нажмите на любую ячейку за пределами таблицы.
< img src=»/wp-content/uploads/2022/06/1ef3347516be459ba15580224cbc478d.png» /> - Тип”=T.Test(“(включите открывающую скобку) в ячейку.
- После открывающей скобки введите в первом аргументе. В этом примере это “Перед диетой” столбец. Диапазон должен быть ”B2:B6.” Пока функция выглядит так: T.Test(B2:B6.
- Далее введите второй аргумент. Программа «После диеты» столбец вместе с его результатами является вторым аргументом, и вам нужен следующий диапазон: “C2:C6.” Давайте добавим его в формулу: T.Test(B2:B6,C2:C6.
- Введите запятую после второго аргумента. Параметры одностороннего распределения и двустороннего распределения автоматически появятся в раскрывающемся меню. Продолжайте и выберите “одностороннее распределение”, дважды щелкнув по нему.< бр>
- Введите еще одну запятую. Для простоты использования полный код приведен ниже.
- Дважды щелкните значок Параметр «Пара» в следующем раскрывающемся меню.
- Теперь, когда у вас есть все необходимые элементы, вам нужно вставить закрывающую скобку. Формула для этого примера выглядит следующим образом: =T.Test(B2:B6,C2:C6,1,1)
- Нажмите “Ввод”. Теперь в ячейке отображается значение “p-value” немедленно. В нашем случае значение равно “0,133905569” или “13.3905569%.”









Более 5%, это “p-значение” не дает убедительных доказательств против нулевой гипотезы. В нашем примере исследование не доказало, что диета помогла испытуемым значительно похудеть. Результаты не обязательно означают, что нулевая гипотеза верна, а только то, что она еще не была опровергнута.
Маршрут анализа данных
«Анализ данных»; позволяет делать много интересных вещей, в том числе “p-значение” расчеты. Мы будем использовать ту же таблицу, что и в предыдущем методе, чтобы упростить процесс.
Вот как использовать “Анализ данных” инструмент.
- Поскольку у нас уже есть “вес” различия в “D” столбец, мы пропустим вычисление разницы. Для будущих таблиц используйте следующую формулу: =”Ячейка 1”-“Ячейка 2”.
- Далее нажмите “Данные” в главном меню.
- Выберите инструмент “Анализ данных”.
- Прокрутите список вниз и выберите “t-Test: два образца в паре для средних значений”
< img src=»/wp-content/uploads/2022/06/b3c8545a8ccf465a320b19b78794cf5f.png» /> - Нажмите “ОК”< br>
- Появится всплывающее окно. Это выглядит так:
- Введите первый диапазон/аргумент. В нашем примере это “$B$2:$B$6“как “B2:B6.”
- Введите второй диапазон/аргумент. В данном случае это “$C$2:$C$6“как в “C2:C6”
- Оставьте значение по умолчанию в “Alpha” текстовое поле (0,05).
- Нажмите “Вывод Диапазон” и выберите желаемый результат. Если это “A8″ введите следующее:”$A$8.”
- Нажмите <эм>“ОК”
- Excel рассчитает “p-значение” и ряд других параметров. Итоговая таблица может выглядеть так:










Как видите, односторонний “p-значение” такое же, как и в первом случае (0,133905569). Поскольку оно выше 0,05, к этой таблице применима нулевая гипотеза, а доказательства против нее слабые.
Поиск значения p в Excel 2016
Как и в предыдущих шагах, давайте рассмотрим расчет “p-Value” в Excel 2016.
- Мы будем использовать тот же пример, что и выше, поэтому создайте таблицу, если хотите продолжить.
- Теперь в ячейке “A8&rdquo ; введите следующее: =T.Test(B2:B6, C2:C6.
- Затем в ячейке A8 введите “запятую” после “C6” и выберите “Одностороннее распределение”
- Затем введите еще одну “запятую” и выберите “В паре”
- Теперь уравнение должно выглядеть следующим образом: =T.Тест(B2:B6, C2:C6,1,1).
- Наконец нажмите “Enter”, чтобы показать результат.




Результаты могут отличаться на несколько знаков после запятой в зависимости от ваших настроек и доступного места на экране. .
Что нужно знать о значении p
Вот несколько ценных советов относительно “p-value” расчеты в Excel.
- Если значение “p-value” равно 0,05 (5%), данные в вашей таблице “значительны” Если он меньше 0,05 (5%), данные являются “высокозначимыми”
- В случае “p-значения” больше 0,1 (10%), данные в вашей таблице “несущественны” Если он находится в диапазоне 0,05–0,10, у вас есть “минимально значимый” данные.
- Вы можете изменить “альфа” значение, хотя наиболее распространенными вариантами являются 0,05 (5%) и 0,10 (10%).
- В зависимости от вашей гипотезы выбор “двухстороннего тестирования” может быть лучшим выбором. В приведенном выше примере “одностороннее тестирование” означает, что мы исследуем, потеряли ли испытуемые вес после диеты, что нам и нужно было выяснить точно. Но «двухвостый» тест также будет проверять, значительно ли они прибавили в весе.
- “p-значение” не может идентифицировать переменные. Другими словами, если он находит корреляцию, он не может распознать причины, лежащие в ее основе.
p– Демистификация ценности
Каждый статистик должен знать все тонкости проверки нулевой гипотезы и знать значение “p-value” означает. Эти знания также пригодятся исследователям во многих других областях.

Простая линейная регрессия в EXCEL
history 26 января 2019 г.
-
Группы статей
- Статистический анализ
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В MS EXCEL имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Примечание : Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место множественная регрессия .
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части — оценке неизвестных параметров линейной модели .
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем прочность этого волокна (Y) зависит только от рабочей температуры процесса в реакторе (Х), которая задается оператором.
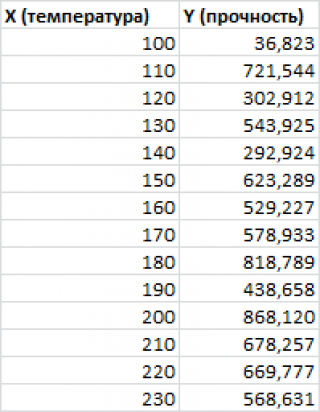
Построим диаграмму рассеяния (см. файл примера лист Линейный ), созданию которой посвящена отдельная статья . Вообще, построение диаграммы рассеяния для целей регрессионного анализа де-факто является стандартом.
СОВЕТ : Подробнее о построении различных типов диаграмм см. статьи Основы построения диаграмм и Основные типы диаграмм .
Приведенная выше диаграмма рассеяния свидетельствует о возможной линейной взаимосвязи между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание : Наличие даже такой очевидной линейной взаимосвязи не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие причинной взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание : Как известно, уравнение прямой линии имеет вид Y = m * X + k , где коэффициент m отвечает за наклон линии ( slope ), k – за сдвиг линии по вертикали ( intercept ), k равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х ( рабочую температуру процесса ) при некотором значении Х i и произвести несколько наблюдений переменной Y ( прочность нити ). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого значения . При увеличении количества измерений, среднее этих измерений, будет стремиться к математическому ожиданию случайной величины Y (при Х i ) равному μy(i)=Е(Y i ).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела Проверка статистических гипотез . В статье о проверке гипотезы о среднем значении генеральной совокупности в качестве нулевой гипотезы предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае простой линейной регрессии в качестве нулевой гипотезы предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ y(i) =α* Х i +β. Уравнение μ y(i) =α* Х i +β можно переписать в обобщенном виде (для всех Х и μ y ) как μ y =α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
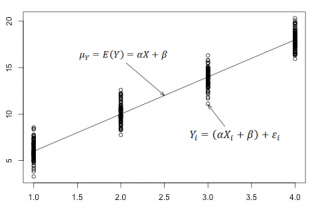
Данная линия называется регрессионной линией генеральной совокупности (population regression line), параметры которой ( наклон a и сдвиг β ) нам не известны (по аналогии с гипотезой о среднем значении генеральной совокупности , где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х + β , к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют линейной регрессионной моделью . Часто Х еще называют независимой переменной (еще предиктором и регрессором , английский термин predictor , regressor ), а Y – зависимой (или объясняемой , response variable ). Так как регрессор у нас один, то такая модель называется простой линейной регрессионной моделью ( simple linear regression model ). α часто называют коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε i была адекватной — требуется:
- Ошибки ε i должны быть независимыми переменными;
- При каждом значении Xi ошибки ε i должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε i ]=0);
- При каждом значении Xi ошибки ε i должны иметь равные дисперсии (обозначим ее σ 2 ).
Примечание : Последнее условие называется гомоскедастичность — стабильность, гомогенность дисперсии случайной ошибки e. Т.е. дисперсия ошибки σ 2 не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε i ]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε i ]= Е[a*Xi+β]+ Е[ε i ]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия случайной переменной Y равна дисперсии ошибки ε, т.е. VAR(Y)= VAR(ε)=σ 2 . Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε i ).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует регрессионная линия генеральной совокупности , т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений .
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно a и b . Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Первая задача регрессионного анализа – оценка неизвестных параметров ( estimation of the unknown parameters ). Подробнее см. раздел Оценки неизвестных параметров модели .
Вторая задача регрессионного анализа – Проверка адекватности модели ( model adequacy checking ).
Примечание : Оценки параметров модели обычно вычисляются методом наименьших квадратов (МНК), которому посвящена отдельная статья .
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры простой линейной регрессионной модели Y=a*X+β+ε оценим с помощью метода наименьших квадратов (в статье про МНК подробно описано этот метод ).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
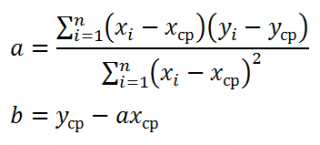
Таким образом, мы получим уравнение прямой линии Y= a *X+ b , которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание : В статье про метод наименьших квадратов рассмотрены случаи аппроксимации линейной и квадратичной функцией , а также степенной , логарифмической и экспоненциальной функцией .
Оценку параметров в MS EXCEL можно выполнить различными способами:
Сначала рассмотрим функции НАКЛОН() , ОТРЕЗОК() и ЛИНЕЙН() .
Пусть значения Х и Y находятся соответственно в диапазонах C 23: C 83 и B 23: B 83 (см. файл примера внизу статьи).
Примечание : Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью Генерация данных для линейной регрессии в MS EXCEL ).
В MS EXCEL наклон прямой линии а ( оценку коэффициента регрессии ), можно найти по методу МНК с помощью функции НАКЛОН() , а сдвиг b ( оценку постоянного члена или константы регрессии ), с помощью функции ОТРЕЗОК() . В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции ЛИНЕЙН() , английская версия LINEST (см. статью об этой функции ).
Формула =ЛИНЕЙН(C23:C83;B23:B83) вернет наклон а . А формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) — сдвиг b . Здесь требуются пояснения.
Функция ЛИНЕЙН() имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент статистика имеет значение ЛОЖЬ или опущен, то функция ЛИНЕЙН() возвращает только оценки параметров модели: a и b .
Примечание : Остальные значения, возвращаемые функцией ЛИНЕЙН() , нам потребуются при вычислении стандартных ошибок и для проверки значимости регрессии . В этом случае аргумент статистика должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
- ввести формулу в Строке формул
- нажать CTRL+SHIFT+ENTER (см. статью про формулы массива ).
Если в Строке формул выделить формулу = ЛИНЕЙН(C23:C83;B23:B83) и нажать клавишу F9 , то мы увидим что-то типа <3,01279389265416;154,240057900613>. Это как раз значения a и b . Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу = ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83)) . При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция ТРАНСП() транспонировала строку в столбец ).
Чтобы разобраться в этом подробнее необходимо ознакомиться с формулами массива .
Чтобы не связываться с вводом формул массива , можно использовать функцию ИНДЕКС() . Формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1) или просто ЛИНЕЙН(C23:C83;B23:B83) вернет параметр, отвечающий за наклон линии, т.е. а . Формула =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) вернет параметр b .
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент а , можно также вычислить через коэффициент корреляции и стандартные отклонения выборок :
= КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению ковариации выборок Х и Y и дисперсии выборки Х:
И, наконец, запишем еще одну формулу для нахождения сдвига b . Воспользуемся тем фактом, что линия регрессии проходит через точку средних значений переменных Х и Y.
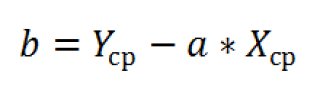
Вычислив средние значения и подставив в формулу ранее найденный наклон а , получим сдвиг b .
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры линии регрессии можно найти в матричной форме (см. файл примера лист Матричная форма ).
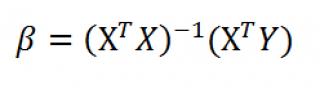
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг b ), β1 (наклон a ).
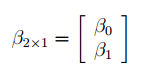
Матрица Х равна:
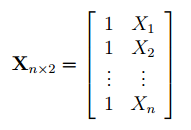
Матрица Х называется регрессионной матрицей или матрицей плана . Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица Х T – это транспонированная матрица Х . Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом Y обозначен столбец значений переменной Y.
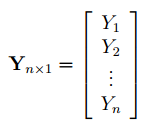
Чтобы перемножить матрицы используйте функцию МУМНОЖ() . Чтобы найти обратную матрицу используйте функцию МОБР() .
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
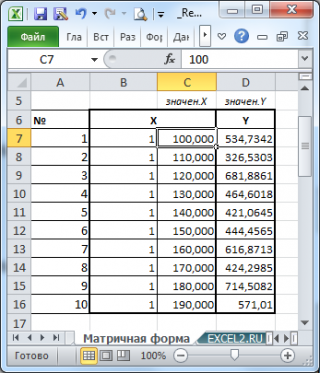
Слева от него достроим столбец с 1 для матрицы Х.
и введя ее как формулу массива в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае множественной регрессии .
Построение линии регрессии
Для отображения линии регрессии построим сначала диаграмму рассеяния , на которой отобразим все точки (см. начало статьи ).
Для построения прямой линии используйте вычисленные выше оценки параметров модели a и b (т.е. вычислите у по формуле y = a * x + b ) или функцию ТЕНДЕНЦИЯ() .
Формула = ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23) возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца В2 .
Примечание : Линию регрессии можно также построить с помощью функции ПРЕДСКАЗ() . Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции ТЕНДЕНЦИЯ() работает только в случае одного регрессора. Функция ТЕНДЕНЦИЯ() может быть использована и в случае множественной регрессии (в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
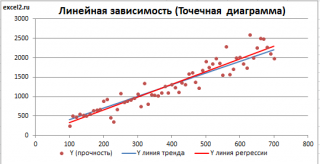
Как видно из диаграммы выше линия тренда и линия регрессии не обязательно совпадают: отклонения точек от линии тренда случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента Линия тренда. Для этого выделите диаграмму, в меню выберите вкладку Макет , в группе Анализ нажмите Линия тренда , затем Линейное приближение. В диалоговом окне установите галочку Показывать уравнение на диаграмме (подробнее см. в статье про МНК ).
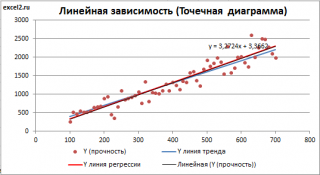
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами линией регрессии, а параметры уравнения a и b должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание: Для того, чтобы вычисленные параметры уравнения a и b совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был Точечная, а не График , т.к. тип диаграммы График не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; . Именно эти значения и берутся при расчете параметров линии тренда . Убедиться в этом можно если построить диаграмму График (см. файл примера ), а значения Хнач и Хшаг установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с a и b .
Коэффициент детерминации R 2
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения регрессионной модели ). Очевидно, что лучшей оценкой для yi будет среднее значение ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание : Далее будет использована терминология и обозначения дисперсионного анализа .
После построения регрессионной модели для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
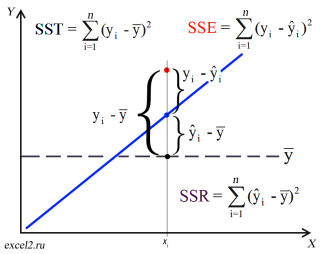
Очевидно, что используя регрессионную модель мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
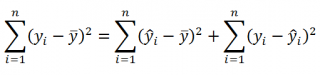
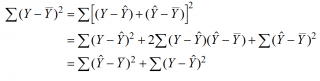
или в других, общепринятых в зарубежной литературе, обозначениях:
Total Sum of Squares = Regression Sum of Squares + Error Sum of Squares
Примечание : SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность дисперсии (вариации) и соответственно описывают разброс (изменчивость): Общую изменчивость (Total variation), Изменчивость объясненную моделью (Explained variation) и Необъясненную изменчивость (Unexplained variation).
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью / Общая изменчивость.
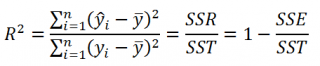
Этот показатель равен квадрату коэффициента корреляции и в MS EXCEL его можно вычислить с помощью функции КВПИРСОН() или ЛИНЕЙН() :
R 2 принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии ( Standard Error of a regression ) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение линейной регрессионной модели Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со средним значением μ и дисперсией σ 2 .
Оценив значение дисперсии σ 2 и вычислив из нее квадратный корень – получим Стандартную ошибку регрессии. Чем точки наблюдений на диаграмме рассеяния ближе находятся к прямой линии, тем меньше Стандартная ошибка.
Примечание : Вспомним , что при построении модели предполагается, что среднее значение ошибки ε равно 0, т.е. E[ε]=0.
Оценим дисперсию σ 2 . Помимо вычисления Стандартной ошибки регрессии эта оценка нам потребуется в дальнейшем еще и при построении доверительных интервалов для оценки параметров регрессии a и b .
Для оценки дисперсии ошибки ε используем остатки регрессии — разности между имеющимися значениями yi и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки дисперсии σ 2 используют следующую формулу:
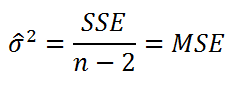
где SSE – сумма квадратов значений ошибок модели ε i =yi — ŷi ( Sum of Squared Errors ).
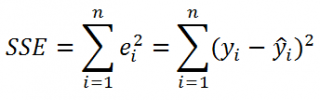
SSE часто обозначают и как SSres – сумма квадратов остатков ( Sum of Squared residuals ).
Оценка дисперсии s 2 также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов ошибок или MSRES (Mean Square of Residuals), т.е. среднее квадратов остатков . Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание : Напомним, что когда мы использовали МНК для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на линии регрессии.
Математическое ожидание случайной величины MSE равно дисперсии ошибки ε, т.е. σ 2 .
Чтобы понять почему SSE выбрана в качестве основы для оценки дисперсии ошибки ε, вспомним, что σ 2 является также дисперсией случайной величины Y (относительно среднего значения μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi = a * Хi + b (значение уравнения регрессии при Х= Хi), то логично использовать именно SSE в качестве основы для оценки дисперсии σ 2 . Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае простой линейной регрессии число степеней свободы равно n-2, т.к. при построении линии регрессии было оценено 2 параметра модели (на это было «потрачено» 2 степени свободы ).
Итак, как сказано было выше, квадратный корень из s 2 имеет специальное название Стандартная ошибка регрессии ( Standard Error of a regression ) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см. этот раздел ). Если ошибки предсказания ε имеют нормальное распределение , то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от линии регрессии . SEy имеет размерность переменной Y и откладывается по вертикали. Часто на диаграмме рассеяния строят границы предсказания соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
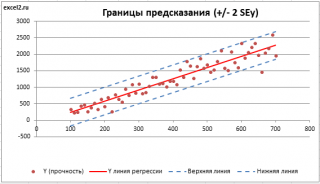
В MS EXCEL стандартную ошибку SEy можно вычислить непосредственно по формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе Оценка неизвестных параметров линейной модели мы получили точечные оценки наклона а и сдвига b . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ).
Стандартная ошибка коэффициента регрессии a вычисляется на основании стандартной ошибки регрессии по следующей формуле:
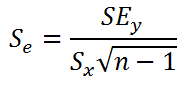
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
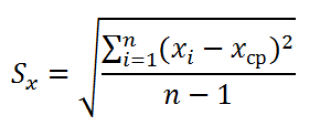
где Sey – стандартная ошибка регрессии, т.е. ошибка предсказания значения переменой Y ( см. выше ).
В MS EXCEL стандартную ошибку коэффициента регрессии Se можно вычислить впрямую по вышеуказанной формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции ЛИНЕЙН() :
Формулы приведены в файле примера на листе Линейный в разделе Регрессионная статистика .
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
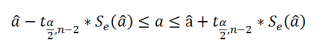
где — квантиль распределения Стьюдента с n-2 степенями свободы. Величина а с «крышкой» является другим обозначением наклона а .
Например для уровня значимости альфа=0,05, можно вычислить с помощью формулы =СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
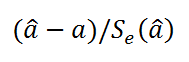
является t-распределением Стьюдента с n-2 степенью свободы (то же справедливо и для наклона b ).
Примечание : Подробнее о построении доверительных интервалов в MS EXCEL можно прочитать в этой статье Доверительные интервалы в MS EXCEL .
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии. Здесь мы считаем, что коэффициент регрессии a имеет распределение Стьюдента с n-2 степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
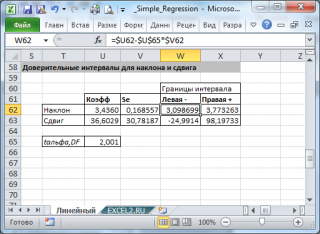
Примечание : Подробнее о построении доверительных интервалов с использованием t-распределения см. статью про построение доверительных интервалов для среднего .
Стандартная ошибка сдвига b вычисляется по следующей формуле:
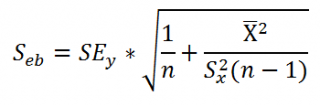
В MS EXCEL стандартную ошибку сдвига Seb можно вычислить с помощью функции ЛИНЕЙН() :
При построении двухстороннего доверительного интервала для сдвига его границы определяются аналогичным образом как для наклона : b +/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда коэффициент регрессии a равен 0.
Чтобы убедиться, что вычисленная нами оценка наклона прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда нулевую гипотезу Н 0 не удается отвергнуть.
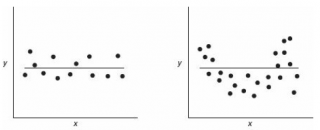
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом коэффициент линейной корреляции равен 0.
Ниже — 2 ситуации, когда нулевая гипотеза Н 0 отвергается.
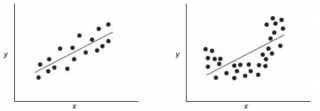
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
- Установить уровень значимости , пусть альфа=0,05;
- Рассчитать с помощью функции ЛИНЕЙН() стандартное отклонение Se для коэффициента регрессии (см. предыдущий раздел );
- Рассчитать число степеней свободы: DF=n-2 или по формуле = ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
- Вычислить значение тестовой статистики t 0 =a/S e , которая имеет распределение Стьюдента с числом степеней свободы DF=n-2;
- Сравнить значение тестовой статистики |t0| с пороговым значением t альфа ,n-2. Если значение тестовой статистики больше порогового значения, то нулевая гипотеза отвергается ( наклон не может быть объяснен лишь случайностью при заданном уровне альфа) либо
- вычислить p-значение и сравнить его с уровнем значимости .
В файле примера приведен пример проверки гипотезы:
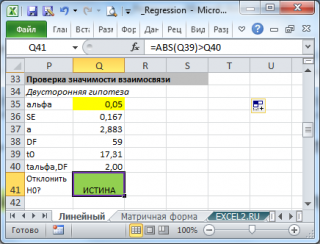
Изменяя наклон тренда k (ячейка В8 ) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание : Проверка значимости взаимосвязи эквивалентна проверке статистической значимости коэффициента корреляции . В файле примера показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью процедуры F-тест .
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры простой линейной регрессионной модели Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ= a * Хi + b
Ŷ также является точечной оценкой для среднего значения Yi при заданном Хi. Но, при построении доверительных интервалов используются различные стандартные ошибки .
Стандартная ошибка нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
- неопределенность связанную со случайностью оценок параметров модели a и b ;
- случайность ошибки модели ε.
Учет этих неопределенностей приводит к стандартной ошибке S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
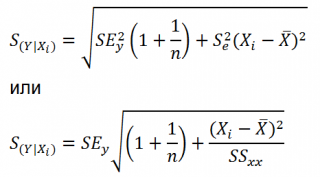
где SS xx – сумма квадратов отклонений от среднего значений переменной Х:
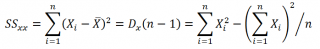
В MS EXCEL 2010 нет функции, которая бы рассчитывала эту стандартную ошибку , поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал или Интервал предсказания для нового наблюдения (Prediction Interval for a New Observation) построим по схеме показанной в разделе Проверка значимости взаимосвязи переменных (см. файл примера лист Интервалы ). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х ср ), то интервал будет постепенно расширяться при удалении от Х ср .
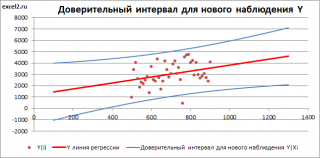
Границы доверительного интервала для нового наблюдения рассчитываются по формуле:
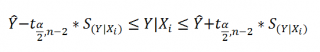
Аналогичным образом построим доверительный интервал для среднего значения Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае доверительный интервал будет уже, т.к. средние значения имеют меньшую изменчивость по сравнению с отдельными наблюдениями ( средние значения, в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
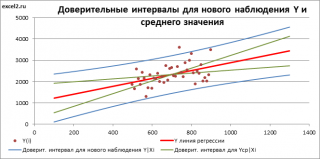
Стандартная ошибка S(Yср|Xi) вычисляется по практически аналогичным формулам как и стандартная ошибка для нового наблюдения:
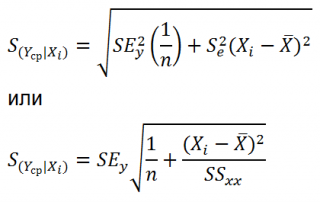
Как видно из формул, стандартная ошибка S(Yср|Xi) меньше стандартной ошибки S(Y|Xi) для индивидуального значения .
Границы доверительного интервала для среднего значения рассчитываются по формуле:
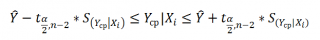
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел Предположения линейной регрессионной модели ).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках простой линейной модели n остатков имеют только n-2 связанных с ними степеней свободы . Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о нормальности распределения ошибок строят график проверки на нормальность (Normal probability Plot).
В файле примера на листе Адекватность построен график проверки на нормальность . В случае нормального распределения значения остатков должны быть близки к прямой линии.
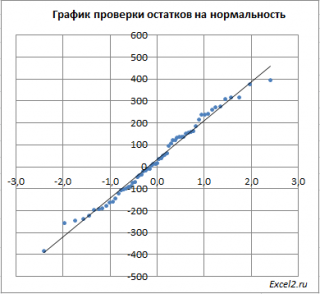
Так как значения переменной Y мы генерировали с помощью тренда , вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор о нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе Стандартная ошибка регрессии оценкой стандартного отклонения ошибок является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
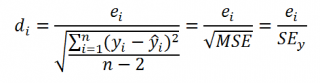
SEy можно вычислить с помощью функции ЛИНЕЙН() :
Иногда нормирование остатков производится на величину стандартного отклонения остатков (это мы увидим в статье об инструменте Регрессия , доступного в надстройке MS EXCEL Пакет анализа ), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
Регрессионный анализ в Microsoft Excel

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
-
Перемещаемся во вкладку «Файл».

Переходим в раздел «Параметры».


В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.

- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».

Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Помимо этой статьи, на сайте еще 12771 полезных инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
источники:
http://lumpics.ru/regression-analysis-in-excel/
http://exceltable.com/otchety/korrelyacionno-regressionnyy-analiz
Содержание
- Определение термина
- Расчет показателя в Excel
- Способ 1: Мастер функций
- Способ 2: работа со вкладкой «Формулы»
- Способ 3: ручной ввод
- Вопросы и ответы

Одним из наиболее известных статистических инструментов является критерий Стьюдента. Он используется для измерения статистической значимости различных парных величин. Microsoft Excel обладает специальной функцией для расчета данного показателя. Давайте узнаем, как рассчитать критерий Стьюдента в Экселе.
Определение термина
Но, для начала давайте все-таки выясним, что представляет собой критерий Стьюдента в общем. Данный показатель применяется для проверки равенства средних значений двух выборок. То есть, он определяет достоверность различий между двумя группами данных. При этом, для определения этого критерия используется целый набор методов. Показатель можно рассчитывать с учетом одностороннего или двухстороннего распределения.
Теперь перейдем непосредственно к вопросу, как рассчитать данный показатель в Экселе. Его можно произвести через функцию СТЬЮДЕНТ.ТЕСТ. В версиях Excel 2007 года и ранее она называлась ТТЕСТ. Впрочем, она была оставлена и в позднейших версиях в целях совместимости, но в них все-таки рекомендуется использовать более современную — СТЬЮДЕНТ.ТЕСТ. Данную функцию можно использовать тремя способами, о которых подробно пойдет речь ниже.
Способ 1: Мастер функций
Проще всего производить вычисления данного показателя через Мастер функций.
- Строим таблицу с двумя рядами переменных.
- Кликаем по любой пустой ячейке. Жмем на кнопку «Вставить функцию» для вызова Мастера функций.
- После того, как Мастер функций открылся. Ищем в списке значение ТТЕСТ или СТЬЮДЕНТ.ТЕСТ. Выделяем его и жмем на кнопку «OK».
- Открывается окно аргументов. В полях «Массив1» и «Массив2» вводим координаты соответствующих двух рядов переменных. Это можно сделать, просто выделив курсором нужные ячейки.
В поле «Хвосты» вписываем значение «1», если будет производиться расчет методом одностороннего распределения, и «2» в случае двухстороннего распределения.
В поле «Тип» вводятся следующие значения:
- 1 – выборка состоит из зависимых величин;
- 2 – выборка состоит из независимых величин;
- 3 – выборка состоит из независимых величин с неравным отклонением.
Когда все данные заполнены, жмем на кнопку «OK».



Выполняется расчет, а результат выводится на экран в заранее выделенную ячейку.

Способ 2: работа со вкладкой «Формулы»
Функцию СТЬЮДЕНТ.ТЕСТ можно вызвать также путем перехода во вкладку «Формулы» с помощью специальной кнопки на ленте.
- Выделяем ячейку для вывода результата на лист. Выполняем переход во вкладку «Формулы».
- Делаем клик по кнопке «Другие функции», расположенной на ленте в блоке инструментов «Библиотека функций». В раскрывшемся списке переходим в раздел «Статистические». Из представленных вариантов выбираем «СТЬЮДЕНТ.ТЕСТ».
- Открывается окно аргументов, которые мы подробно изучили при описании предыдущего способа. Все дальнейшие действия точно такие же, как и в нём.

Способ 3: ручной ввод
Формулу СТЬЮДЕНТ.ТЕСТ также можно ввести вручную в любую ячейку на листе или в строку функций. Её синтаксический вид выглядит следующим образом:
= СТЬЮДЕНТ.ТЕСТ(Массив1;Массив2;Хвосты;Тип)
Что означает каждый из аргументов, было рассмотрено при разборе первого способа. Эти значения и следует подставлять в данную функцию.
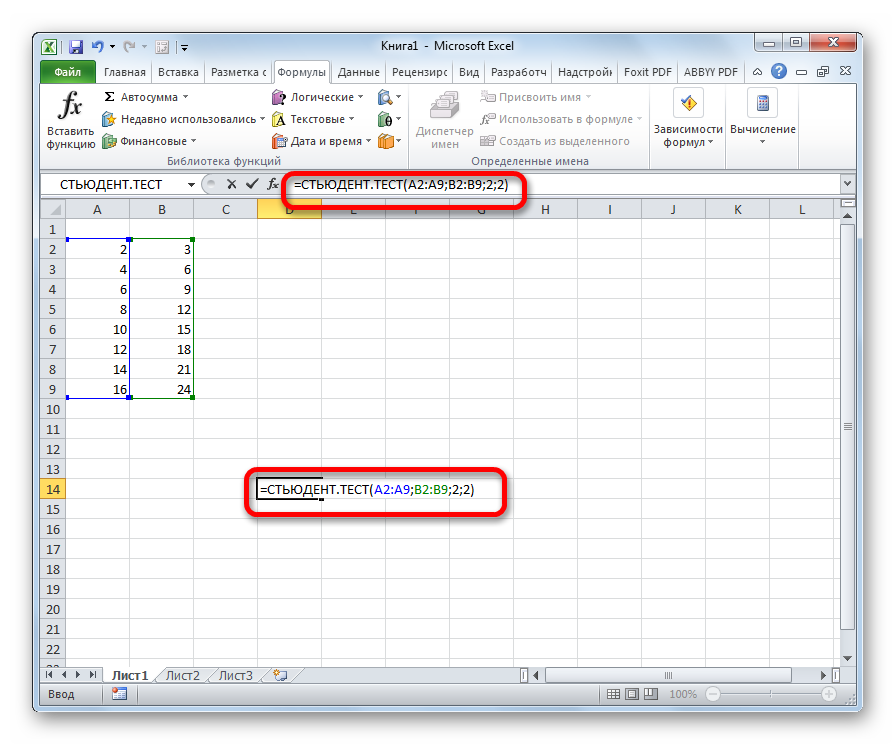
После того, как данные введены, жмем кнопку Enter для вывода результата на экран.
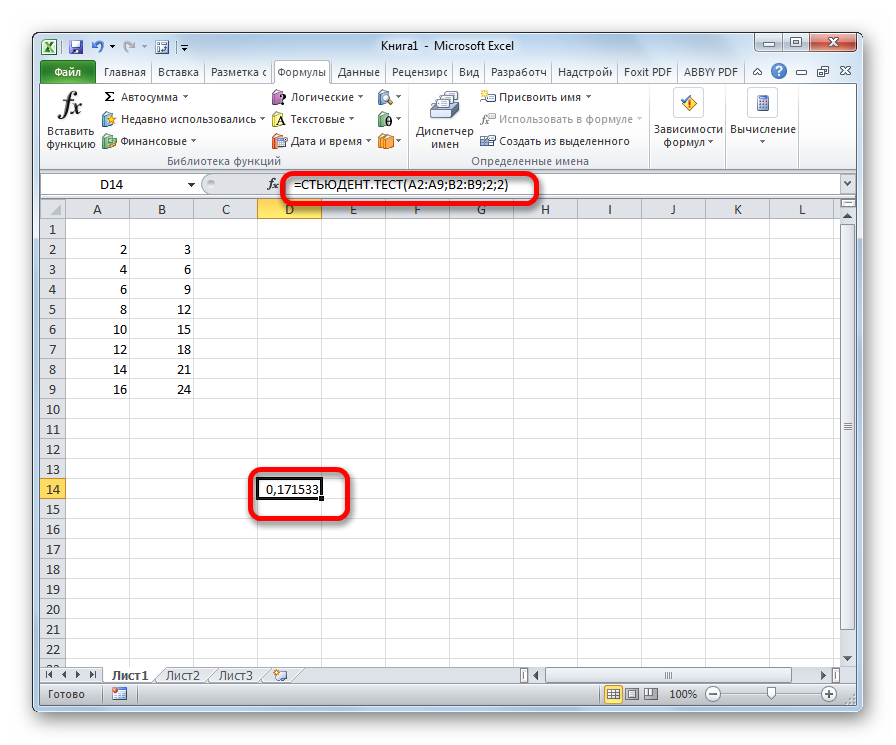
Как видим, вычисляется критерий Стьюдента в Excel очень просто и быстро. Главное, пользователь, который проводит вычисления, должен понимать, что он собой представляет и какие вводимые данные за что отвечают. Непосредственный расчет программа выполняет сама.
Еще статьи по данной теме: