
Время на прочтение
2 мин
Количество просмотров 70K
Исполняем обязанности по получению сведений о своих бенефициарных владельцах
Небольшая вводная
Начиная с 21 декабря 2016 года вступили изменения в ФЗ РФ «О противодействии легализации (отмыванию) доходов, полученных преступным путем, и финансированию терроризма», касательно обязанности юридического лица по раскрытию информации о своих бенефициарных владельцах. В связи с этим, многие компании направляют запросы по цепочке владения с целью выяснения своих бенефициарных владельцев. Кто-то формирует запросы на бумаге, кто-то рассылает электронные письма.
На наш взгляд, надлежащим доказательством исполнения обязанности «знай своего бенефициарного владельца» является наличие письма на бумаге с отметкой об отправке/вручении. Данные письма в идеале должны готовиться не реже одного раза в год. Если в ведении юриста находится всего несколько компаний, то составление писем не составляет особого труда. Но, если компаний больше 3-х десятков, составление писем превращается в уничтожающую позитив рутину. Дело усугубляется тем, что реквизиты писем постоянно меняются: подписанты увольняются, компании перерегистрируются, меняя адреса. Все это надо учитывать. Как здесь могут помочь навыки программирования на python?
Очень просто — хорошо бы иметь программу, которая сама будет подставлять в письма необходимые реквизиты. В том числе формировать сами письма, не заставляя создавать документ за документом вручную. Попробуем.
Структура письма в word. Модуль python docxtpl
Перед написанием кода программы посмотрим как должен выглядеть шаблон письма, в который мы будем помещать наши данные.
Текст письма от общества своему участнику/акционеру будет примерно следующим:

Напишем простую программу, которая заполнит для начала одно поле в нашем шаблоне, чтобы понять принцип работы.
Для начала в самом шаблоне письма Word вместо одного из полей, например, подписанта поставим переменную. Данная переменная должна быть на либо на англ. языке, либо на русском, но в одно слово.Также переменная должна быть обязательно заключена в двойные фигурные скобки. Выглядеть это будет примерно так:

Сама программа будет иметь следующий вид:
from docxtpl import DocxTemplate
doc = DocxTemplate("шаблон.docx")
context = { 'director' : "И.И.Иванов"}
doc.render(context)
doc.save("шаблон-final.docx")
Вначале мы импортируем модуль для работы с документами формата Word. Далее мы открываем шаблон, и в поле директор, которое бы обозначили ранее в самом шаблоне, вносим ФИО директора. В конце документ сохраняется под новым именем.
Таким образом, чтобы заполнить все поля в файле-шаблоне Word нам для начала необходимо определить все поля ввода в самом шаблоне скобками {} вместе с переменными и потом написать программу. Код будет примерно следующим:
from docxtpl import DocxTemplate
doc = DocxTemplate("шаблон.docx")
context = { 'emitent' : 'ООО Ромашка', 'address1' : 'г. Москва, ул. Долгоруковская, д. 0', 'участник': 'ООО Участник', 'адрес_участника': 'г. Москва, ул. Полевая, д. 0', 'director': 'И.И. Иванов'}
doc.render(context)
doc.save("шаблон-final.docx")
На выходе при исполнении программы мы получим готовый заполненный документ.
Скачать готовый шаблон Word можно здесь.
Как часто вы заполняете документы по шаблону? Я не особо, но если вам приходиться заполнять одни и те же данные в шаблонный документ, то в этом рутинном деле может помочь Python. И в значительной мере, буквально несколькими строчками кода облегчить работу, которая выполниться в считанные секунды, вместо потраченного дня. Давайте сделаем небольшой скрипт, который поможет автоматизировать рутинный процесс.

В принципе, я могу представить, кому и когда требуется выполнять работу по заполнению шаблонных документов. Например, юристам. Различные уведомления, постановления и прочие документы, с которыми они работают. Или кадровикам. Если нужно, к примеру, сделать большое количество однотипных уведомлений, где меняется только Ф.И.О., должность и подразделение. Да мало ли где. Давайте приступим к написанию кода.
Что понадобиться?
В этот раз понадобиться не особо много, а точнее, нужно будет установить всего лишь одну библиотеку docxtpl, с помощью которой и будет заполняться документ. Пишем в терминале:
pip install docxtpl
Понадобиться шаблон документа, в котором будут указаны места, куда нужно вставлять переменные. Места для вставки указываются с помощью двойных парных скобок: {{date}}, где дата, это та переменная, что будет заменена на нужное значение. Я скачал какое-то уведомление об изменении условий трудового договора, и расставил в него переменные:

И еще вам понадобится база данных работников или файл Excel с заполненными данными. С ним тоже можно работать. Я для примера использовал json-файл, в который внес некоторые данные. Этот файл, может быть выгружен из реальной программы по учету персонала. Не суть, какой формат файла вы выберете. Главное, чтобы вы смогли прочитать из него данные.

Заполнение данных
Импортируем в скрипт все библиотеки, что нам необходимы:
Python:
import json
import locale
import os
from datetime import datetime as dt
from docxtpl import DocxTemplateЯ создал небольшую функцию filling_doc(). Здесь в нее ничего не передается и не возвращается. Просто обрабатываются и сохраняются файлы. Но, если у вас есть база и несколько шаблонов с похожими данными, то можно запрашивать у пользователя путь к шаблону и базе. И передавать их в функцию. Здесь же, для демонстрации работы это не требуется.
Для того, чтобы заполнение даты в документе не выглядело совсем уж печально, я решил, что надо переводить дату в формат вида: 12 января 1970. Но, у питона с русской локалью оказалась беда. И системную локаль он просто так не подхватывает. Потому вызываем функцию setlocale(locale.LC_ALL, ») модуля locale.
locale.setlocale(locale.LC_ALL, '')
Следующим шагом будет загрузить файл шаблона, загрузить файл БД или json, с которым вы работаете, а также создать папку для сохранения результатов заполнения. Ведь мы их все будем сохранять под разными именами.
Python:
doc = DocxTemplate("template.docx")
user = json.load(open(os.path.join(os.getcwd(), 'user_info.json'), encoding='utf-8'))
if not os.path.isdir(os.path.join(os.getcwd(), 'personal')):
os.mkdir(os.path.join(os.getcwd(), 'personal'))Затем запускаем цикл по файлу json. Выводим принт, чтобы не было скучно. Он тут больше для декорации.
Python:
for usr in user:
print(f'r[+] Заполняю: {usr["last_name"]}', end='')
data = {'manager': 'И. С. Иванов', 'reason': 'реструктуризацией и оптимизацией закваски',
'date': dt.strftime(dt.now(), '%d %B %Y'), 'fio': f'{usr["last_name"]} {usr["first_name"]} '
f'{usr["middle_name"]}', 'post': usr['post'],
'first_middle': f'{usr["first_name"]} {usr["middle_name"]}',
'contract_date': dt.strftime(dt.strptime(usr['contract_date'], "%d.%m.%Y"), '%d %B %Y'),
'contract_num': usr['contract_num'], 'day_x': '01.07.2021'}
doc.render(data)
doc.save(os.path.join(os.getcwd(), 'personal',
f'{usr["last_name"]} {usr["first_name"]} {usr["middle_name"]}.docx'))Заполняем словарь необходимыми значениями для подстановки. Значения должны иметь такие же названия, как и в шаблоне. С помощью render заполняем данные и сохраняем файл с Ф.И.О. человека, на которого заполнялся шаблон.
Python:
# pip install docxtpl
import json
import locale
import os
from datetime import datetime as dt
from docxtpl import DocxTemplate
def filling_doc():
locale.setlocale(locale.LC_ALL, '')
doc = DocxTemplate("template.docx")
user = json.load(open(os.path.join(os.getcwd(), 'user_info.json'), encoding='utf-8'))
if not os.path.isdir(os.path.join(os.getcwd(), 'personal')):
os.mkdir(os.path.join(os.getcwd(), 'personal'))
for usr in user:
print(f'r[+] Заполняю: {usr["last_name"]}', end='')
data = {'manager': 'И. С. Иванов', 'reason': 'реструктуризацией и оптимизацией закваски',
'date': dt.strftime(dt.now(), '%d %B %Y'), 'fio': f'{usr["last_name"]} {usr["first_name"]} '
f'{usr["middle_name"]}', 'post': usr['post'],
'first_middle': f'{usr["first_name"]} {usr["middle_name"]}',
'contract_date': dt.strftime(dt.strptime(usr['contract_date'], "%d.%m.%Y"), '%d %B %Y'),
'contract_num': usr['contract_num'], 'day_x': '01.07.2021'}
doc.render(data)
doc.save(os.path.join(os.getcwd(), 'personal',
f'{usr["last_name"]} {usr["first_name"]} {usr["middle_name"]}.docx'))
def main():
filling_doc()
print('n[+] Все записи обработаны')
if __name__ == "__main__":
main()Вот так вот, достаточно просто и быстро можно избавить себя от кучи рутинной работы. Единственное, на что здесь, именно в этом коде нужно обратить внимание, это на склонения названий месяцев. То есть, нужно или найти библиотеку, которая переводит данное название в нужное склонение, или написать функцию, которая это будет делать в коде. Я этого здесь делать не стал. Но, для использования на реальных датах, думаю, что может понадобиться.
В прикрепленных файлах, если понадобиться, шаблон документа и json с данными. Чтобы можно было попробовать сразу, как работает скрипт.
А на это, пожалуй, все.
Спасибо за внимание. Надеюсь, что данная информация будет полезна
Модуль python-docx предназначен для создания и обновления файлов с расширением .docx — Microsoft Word. Этот модуль имеет одну зависимость: сторонний модуль lxml.
Модуль python-docx размещен на PyPI, поэтому установка относительно проста.
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль python-docx (VirtualEnv):~$ python3 -m pip install -U python-docx
Основы работы с файлами Microsoft Word на Python.
- Открытие/создание документа;
- Добавление заголовка документа;
- Добавление абзаца;
- Применение встроенного стиля в Microsoft Word к абзацу;
- Жирный, курсив и подчеркнутый текст в абзаце;
- Применение стилей Microsoft Word к символам текста (к прогону);
- Пользовательский стиль символов текста;
- Добавление разрыва страницы;
- Добавление картинки в документ;
- Чтение документов MS Word.
Открытие/создание документа.
Первое, что вам понадобится, это документ, над которым вы будете работать. Самый простой способ:
from docx import Document # создание документа document = Document() # открытие документа document = Document('/path/to/document.docx')
При этом создается пустой документ, основанный на «шаблоне» по умолчанию. Другими словами, происходит примерно то же самое, когда пользователь нажимает на иконку в Microsoft Word «Новый документ» с использованием встроенных значений по умолчанию.
При этом шрифт документа и его размер по умолчанию для всего документа можно задать следующим образом:
from docx import Document from docx.shared import Pt doc = Document() # задаем стиль текста по умолчанию style = doc.styles['Normal'] # название шрифта style.font.name = 'Arial' # размер шрифта style.font.size = Pt(14) document.add_paragraph('Текст документа')
Так же, можно открывать существующий документ Word и работать с ним при помощи модуля python-docx. Для этого, в конструктор класса Document() необходимо передать путь к существующему документу Microsoft Word.
Добавление заголовка документа.
В любом документе, основной текст делится на разделы, каждый из которых начинается с заголовка. Название таких разделов можно добавить методом Document.add_heading():
# без указания аргумента `level` # добавляется заголовок "Heading 1" head = document.add_heading('Основы работы с файлами Microsoft Word на Python.') from docx.enum.text import WD_ALIGN_PARAGRAPH # выравнивание посередине head.alignment = WD_ALIGN_PARAGRAPH.CENTER
По умолчанию, добавляется заголовок верхнего уровня, который отображается в Word как «Heading 1». Если нужен заголовок для подраздела, то просто указываем желаемый уровень в виде целого числа от 1 до 9:
document.add_heading('Добавление заголовка документа', level=2)
Если указать level=0, то будет добавлен текст с встроенным стилем титульной страницы. Такой стиль может быть полезен для заголовка относительно короткого документа без отдельной титульной страницы.
Так же, заголовки разделов можно добавлять методом document.add_paragraph().add_run(), с указанным размером шрифта.
Например:
from docx import Document from docx.shared import Pt doc = Document() # добавляем текст прогоном run = doc.add_paragraph().add_run('Заголовок, размером 24 pt.') # размер шрифта run.font.size = Pt(24) run.bold = True doc.save('test.docx')
Добавление абзаца.
Абзацы в Word имеют основополагающее значение. Они используются для добавления колонтитулов, основного текста, заголовков, элементов списков, картинок и т.д.
Смотрим самый простой способ добавить абзац/параграф:
p = document.add_paragraph('Абзацы в Word имеют основополагающее значение.')
Метод Document.add_paragraph() возвращает ссылку на только что добавленный абзац (объект Paragraph). Абзац добавляется в конец документа. Эту ссылку можно использовать в качестве своеобразного «курсора» и например, вставить новый абзац прямо над ним:
prior_p = p.insert_paragraph_before( 'Объект `paragraph` - это ссылка на только что добавленный абзац.')
Такое поведение позволяет вставить абзац в середину документа, это важно при изменении существующего документа, а не при его создании с нуля.
Ссылка на абзац, так же используется для его форматирования встроенными в MS Word стилями или для кастомного/пользовательского форматирования.
Пользовательское форматирование абзаца.
Форматирование абзацев происходит при помощи объекта ParagraphFormat.
Простой способ форматировать абзац/параграф:
from docx import Document from docx.shared import Mm from docx.enum.text import WD_ALIGN_PARAGRAPH doc = Document() # Добавляем абзац p = doc.add_paragraph('Новый абзац с отступами и красной строкой.') # выравниваем текст абзаца p.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # получаем объект форматирования fmt = p.paragraph_format # Форматируем: # добавляем отступ слева fmt.first_line_indent = Mm(15) # добавляем отступ до fmt.space_before = Mm(20) # добавляем отступ слева fmt.space_after = Mm(10) doc.add_paragraph('Новый абзац.') doc.add_paragraph('Еще новый абзац.') doc.save('test.docx')
Чтобы узнать, какие параметры абзаца еще можно настроить/изменить, смотрите материал «Объект ParagraphFormat»
Очень часто в коде, с возвращенной ссылкой (в данном случае p) ничего делать не надо, следовательно нет смысла ее присваивать переменной.
Применение встроенного стиля в Microsoft Word к абзацу.
Стиль абзаца — это набор правил форматирования, который заранее определен в Microsoft Word, и храниться в редакторе в качестве переменной. По сути, стиль позволяет сразу применить к абзацу целый набор параметров форматирования.
Можно применить стиль абзаца, прямо при его создании:
document.add_paragraph('Стиль абзаца как цитата', style='Intense Quote') document.add_paragraph('Стиль абзаца как список.', style='List Bullet')
В конкретном стиле 'List Bullet', абзац отображается в виде маркера. Также можно применить стиль позже. Две строки, в коде ниже, эквивалентны примеру выше:
document.add_paragraph('Другой стиль абзаца.').style = 'List Number' # Эквивалентно paragraph = document.add_paragraph('Другой стиль абзаца.') # применяем стиль позже paragraph.style = 'List Number'
Стиль указывается с использованием его имени, в этом примере имя стиля — 'List'. Как правило, имя стиля точно такое, как оно отображается в пользовательском интерфейсе Word.
Обратите внимание, что можно установить встроенный стиль прямо на результат document.add_paragraph(), без использования возвращаемого объекта paragraph
Жирный, курсив и подчеркнутый текст в абзаце.
Разберемся, что происходит внутри абзаца:
- Абзац содержит все форматирование на уровне блока, такое как — отступ, высота строки, табуляции и так далее.
- Форматирование на уровне символов, например полужирный и курсив, применяется на уровне прогона
paragraph.add_run(). Все содержимое абзаца должно находиться в пределах цикла, но их может быть больше одного. Таким образом, для абзаца с полужирным словом посередине требуется три прогона: обычный, полужирный — содержащий слово, и еще один нормальный для текста после него.
Когда создается абзац методом Document.add_paragraph(), то передаваемый текст добавляется за один прогон Run. Пустой абзац/параграф можно создать, вызвав этот метод без аргументов. В этом случае, наполнить абзац текстом можно с помощью метода Paragraph.add_run(). Метод абзаца .add_run() можно вызывать несколько раз, тем самым добавляя информацию в конец данного абзаца:
paragraph = document.add_paragraph('Абзац содержит форматирование ') paragraph.add_run('на уровне блока.')
В результате получается абзац, который выглядит так же, как абзац, созданный из одной строки. Если не смотреть на полученный XML, то не очевидно, где текст абзаца разбивается на части. Обратите внимание на конечный пробел в конце первой строки. Необходимо четко указывать, где появляются пробелы в начале и в конце прогона, иначе текст будет слитный (без пробелов). Они (пробелы) автоматически не вставляются между прогонами paragraph.add_run(). Метод paragraph.add_run() возвращает ссылку на объект прогона Run, которую можно использовать, если она нужна.
Объекты прогонов имеют следующие свойства, которые позволяют установить соответствующий стиль:
.bold: полужирный текст;.underline: подчеркнутый текст;.italic: курсивный (наклонный) текст;.strike: зачеркнутый текст.
paragraph = document.add_paragraph('Абзац содержит ') paragraph.add_run('форматирование').bold = True paragraph.add_run(' на уровне блока.')
Получится текст, что то вроде этого: «Абзац содержит форматирование на уровне блока».
Обратите внимание, что можно установить полужирный или курсив прямо на результат paragraph.add_run(), без использования возвращаемого объекта прогона:
paragraph.add_run('форматирование').bold = True # или run = paragraph.add_run('форматирование') run.bold = True
Передавать текст в метод Document.add_paragraph() не обязательно. Это может упростить код, если строить абзац из прогонов:
paragraph = document.add_paragraph() paragraph.add_run('Абзац содержит ') paragraph.add_run('форматирование').bold = True paragraph.add_run(' на уровне блока.')
Пользовательское задание шрифта прогона.
from docx import Document from docx.shared import Pt, RGBColor # создание документа doc = Document() # добавляем текст прогоном run = doc.add_paragraph().add_run('Заголовок, размером 24 pt.') # название шрифта run.font.name = 'Arial' # размер шрифта run.font.size = Pt(24) # цвет текста run.font.color.rgb = RGBColor(0, 0, 255) # + жирный и подчеркнутый run.font.bold = True run.font.underline = True doc.save('test.docx')
Применение стилей Microsoft Word к символам текста (к прогону).
В дополнение к встроенным стилям абзаца, которые определяют группу параметров уровня абзаца, Microsoft Word имеет стили символов, которые определяют группу параметров уровня прогона paragraph.add_run(). Другими словами, можно думать о стиле текста как об указании шрифта, включая его имя, размер, цвет, полужирный, курсив и т. д.
Подобно стилям абзацев, стиль символов текста будет определен в документе, который открывается с помощью вызова Document() (см. Общие сведения о стилях).
Стиль символов можно указать при добавлении нового прогона:
paragraph = document.add_paragraph('Обычный текст, ') paragraph.add_run('текст с акцентом.', 'Emphasis')
Также можете применить стиль к прогону после его добавления. Этот код дает тот же результат, что и строки выше:
paragraph = document.add_paragraph() paragraph.add_run('Обычный текст, ') paragraph.add_run('текст с акцентом.').style = 'Emphasis'
Как и в случае со стилем абзаца, имя стиля текста такое, как оно отображается в пользовательском интерфейсе Word.
Пользовательский стиль символов текста.
from docx import Document from docx.shared import Pt, RGBColor # создание документа doc = Document() # задаем стиль текста по умолчанию style = doc.styles['Normal'] # название шрифта style.font.name = 'Calibri' # размер шрифта style.font.size = Pt(14) p = doc.add_paragraph('Пользовательское ') # добавляем текст прогоном run = p.add_run('форматирование ') # размер шрифта run.font.size = Pt(16) # курсив run.font.italic = True # добавляем еще текст прогоном run = p.add_run('символов текста.') # Форматируем: # название шрифта run.font.name = 'Arial' # размер шрифта run.font.size = Pt(18) # цвет текста run.font.color.rgb = RGBColor(255, 0, 0) # + жирный и подчеркнутый run.font.bold = True run.font.underline = True doc.save('test.docx')
Добавление разрыва страницы.
При создании документа, время от времени нужно, чтобы следующий текст выводился на отдельной странице, даже если последняя не заполнена. Жесткий разрыв страницы можно сделать следующим образом:
document.add_page_break()
Если вы обнаружите, что используете это очень часто, это, вероятно, знак того, что вы могли бы извлечь выгоду, лучше разбираясь в стилях абзацев. Одно свойство стиля абзаца, которое вы можете установить, — это разрыв страницы непосредственно перед каждым абзацем, имеющим этот стиль. Таким образом, вы можете установить заголовки определенного уровня, чтобы всегда начинать новую страницу. Подробнее о стилях позже. Они оказываются критически важными для получения максимальной отдачи от Word.
Жесткий разрыв страницы можно привязать к стилю абзаца, и затем применять его для определенных абзацев, которые должны начинаться с новой страницы. Так же можно установить жесткий разрыв на стиль заголовка определенного уровня, чтобы с него всегда начинать новую страницу. В общем, стили, оказываются критически важными для того, чтобы получить максимальную отдачу от модуля python-docx.
Добавление картинки в документ.
Microsoft Word позволяет разместить изображение в документе с помощью пункта меню «Вставить изображение«. Вот как это сделать при помощи модуля python-docx:
document.add_picture('/path/to/image-filename.png')
В этом примере используется путь, по которому файл изображения загружается из локальной файловой системы. В качестве пути можно использовать файловый объект, по сути, любой объект, который действует как открытый файл. Такое поведение может быть полезно, если изображение извлекается из базы данных или передается по сети.
Размер изображения.
По умолчанию, изображение добавляется с исходными размерами, что часто не устраивает пользователя. Собственный размер рассчитывается как px/dpi. Таким образом, изображение размером 300×300 пикселей с разрешением 300 точек на дюйм появляется в квадрате размером один дюйм. Проблема в том, что большинство изображений не содержат свойства dpi, и по умолчанию оно равно 72 dpi. Следовательно, то же изображение будет иметь одну сторону, размером 4,167 дюйма, что означает половину страницы.
Чтобы получить изображение нужного размера, необходимо указывать его ширину или высоту в удобных единицах измерения, например, в миллиметрах или сантиметрах:
from docx.shared import Mm document.add_picture('/path/to/image-filename.png', width=Mm(35))
Если указать только одну из сторон, то модуль python-docx использует его для вычисления правильно масштабированного значения другой стороны изображения. Таким образом сохраняется соотношение сторон и изображение не выглядит растянутым.
Классы Mm() и Cm() предназначены для того, чтобы можно было указывать размеры в удобных единицах. Внутри python-docx используются английские метрические единицы, 914400 дюймов. Так что, если просто указать размер, что-то вроде width=2, то получится очень маленькое изображение. Классы Mm() и Cm() импортируются из подпакета docx.shared. Эти классы можно использовать в арифметике, как если бы они были целыми числами. Так что выражение, width=Mm(38)/thing_count, работает нормально.
Чтение документов Microsoft Word.
В модуле python-docx, структура документа Microsoft Word представлена тремя различными типами данных. На самом верхнем уровне объект Document() представляет собой весь документ. Объект Document() содержит список объектов Paragraph(), которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов Run(), представляющих собой фрагменты текста с различными стилями форматирования.
Например:
>>> from docx import Document >>> doc = Document('/path/to/example.docx') # количество абзацев в документе >>> len(doc.paragraphs) # текст первого абзаца в документе >>> doc.paragraphs[0].text # текст второго абзаца в документе >>> doc.paragraphs[1].text # текст первого прогона второго абзаца >>> doc.paragraphs[1].runs[0].text
Используя следующий код, можно получить весь текст документа:
text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) print('nn'.join(text))
А так можно получить стили всех параграфов:
styles = [] for paragraph in doc.paragraphs: styles.append(paragraph.style)
Использовать полученные стили можно следующим образом:
# изменим стиль 1 параграфа на # стиль взятый из 3 параграфа doc.paragraphs[0].style = styles[2]
С помощью модуля python-docx можно создавать и изменять документы MS Word с расширением .docx. Чтобы установить этот модуль, выполняем команду
> pip install python-docx
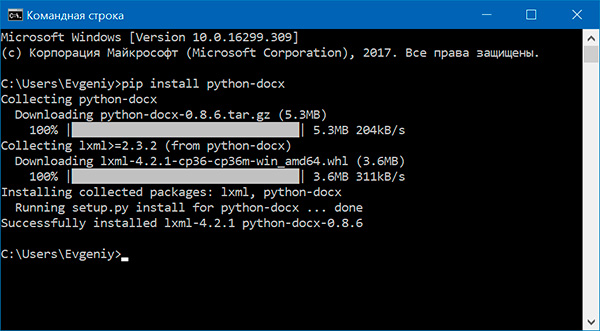
При установке модуля надо вводить python-docx, а не docx (это другой модуль). В то же время при импортировании модуля python-docx следует использовать import docx, а не import python-docx.
Чтение документов MS Word
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx эта структура представлена тремя различными типами данных. На самом верхнем уровне объект Document представляет собой весь документ. Объект Document содержит список объектов Paragraph, которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов Run, представляющих собой фрагменты текста с различными стилями форматирования.

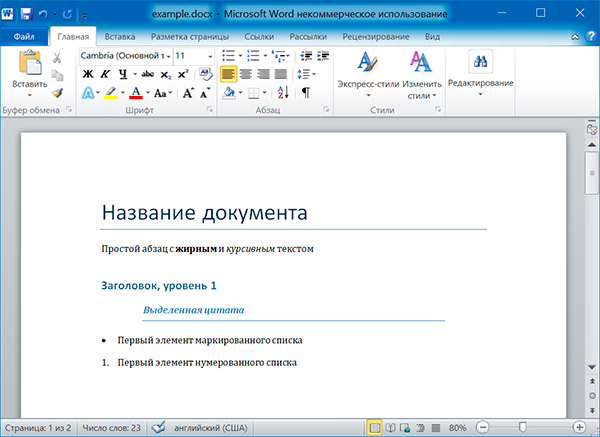
import docx doc = docx.Document('example.docx') # количество абзацев в документе print(len(doc.paragraphs)) # текст первого абзаца в документе print(doc.paragraphs[0].text) # текст второго абзаца в документе print(doc.paragraphs[1].text) # текст первого Run второго абзаца print(doc.paragraphs[1].runs[0].text)
6 Название документа Простой абзац с жирным и курсивным текстом Простой абзац с
Получаем весь текст из документа:
text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) print('n'.join(text))
Название документа Простой абзац с жирным и курсивным текстом Заголовок, уровень 1 Выделенная цитата Первый элемент маркированного списка Первый элемент нумерованного списка
Стилевое оформление
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к объектам Paragraph, стили символов, которые могут применяться к объектам Run. Как объектам Paragraph, так и объектам Run можно назначать стили, присваивая их атрибутам style значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля задано значение None, то у объекта Paragraph или Run не будет связанного с ним стиля.
Стили абзацев
NormalBody TextBody Text 2Body Text 3CaptionHeading 1Heading 2Heading 3Heading 4Heading 5Heading 6Heading 7Heading 8Heading 9Intense QuoteListList 2List 3List BulletList Bullet 2List Bullet 3List ContinueList Continue 2List Continue 3List NumberList Number 2List Number 3List ParagraphMacro TextNo SpacingQuoteSubtitleTOCHeadingTitle
Стили символов
EmphasisStrongBook TitleDefault Paragraph FontIntense EmphasisSubtle EmphasisIntense ReferenceSubtle Reference
paragraph.style = 'Quote' run.style = 'Book Title'
Атрибуты объекта Run
Отдельные фрагменты текста, представленные объектами Run, могут подвергаться дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может быть задано одно из трех значений: True (атрибут активизирован), False (атрибут отключен) и None (применяется стиль, установленный для данного объекта Run).
bold— Полужирное начертаниеunderline— Подчеркнутый текстitalic— Курсивное начертаниеstrike— Зачеркнутый текст
Изменим стили для всех параграфов нашего документа:
import docx doc = docx.Document('example.docx') # изменяем стили для всех параграфов for paragraph in doc.paragraphs: paragraph.style = 'Normal' doc.save('restyled.docx')
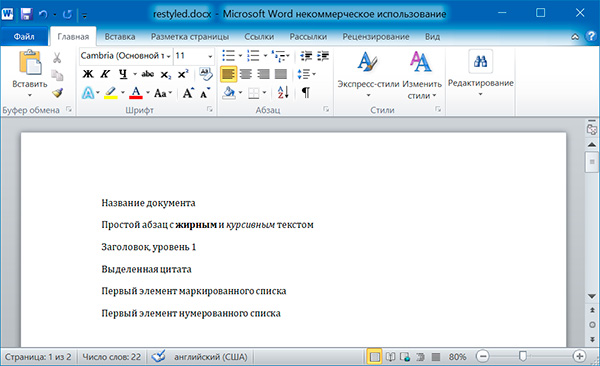
А теперь восстановим все как было:
import docx os.chdir('C:\example') doc1 = docx.Document('example.docx') doc2 = docx.Document('restyled.docx') # получаем из первого документа стили всех абзацев styles = [] for paragraph in doc1.paragraphs: styles.append(paragraph.style) # применяем стили ко всем абзацам второго документа for i in range(len(doc2.paragraphs)): doc2.paragraphs[i].style = styles[i] doc2.save('restored.docx')
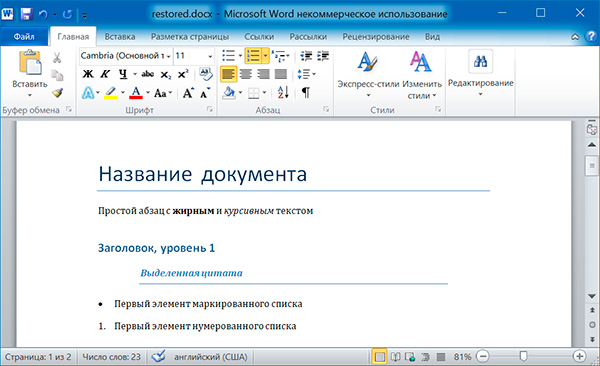
Изменим форматирвание объектов Run второго абзаца:
import docx doc = docx.Document('example.docx') # добавляем стиль символов для runs[0] doc.paragraphs[1].runs[0].style = 'Intense Emphasis' # добавляем подчеркивание для runs[4] doc.paragraphs[1].runs[4].underline = True doc.save('restyled2.docx')
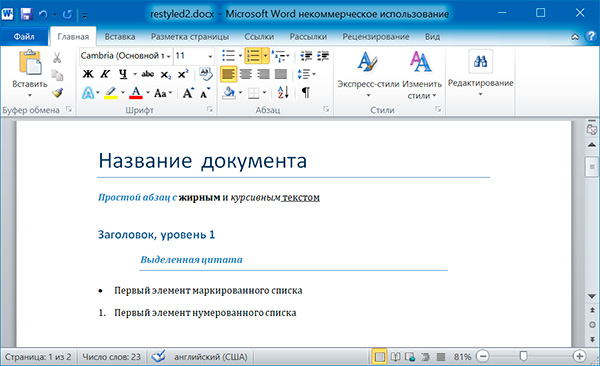
Запись докуменов MS Word
Добавление абзацев осуществляется вызовом метода add_paragraph() объекта Document. Для добавления текста в конец существующего абзаца, надо вызвать метод add_run() объекта Paragraph:
import docx doc = docx.Document() # добавляем первый параграф doc.add_paragraph('Здравствуй, мир!') # добавляем еще два параграфа par1 = doc.add_paragraph('Это второй абзац.') par2 = doc.add_paragraph('Это третий абзац.') # добавляем текст во второй параграф par1.add_run(' Этот текст был добавлен во второй абзац.') # добавляем текст в третий параграф par2.add_run(' Добавляем текст в третий абзац.').bold = True doc.save('helloworld.docx')
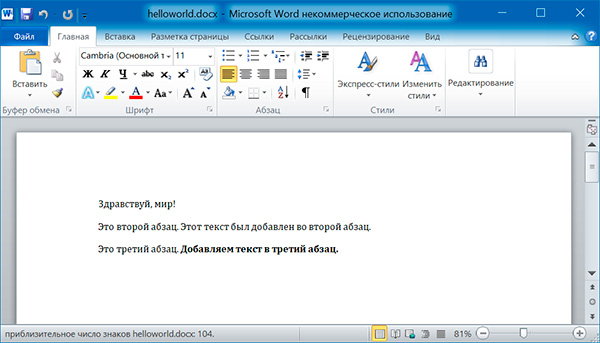
Оба метода, add_paragraph() и add_run() принимают необязательный второй аргумент, содержащий строку стиля, например:
doc.add_paragraph('Здравствуй, мир!', 'Title')
Добавление заголовков
Вызов метода add_heading() приводит к добавлению абзаца, отформатированного в соответствии с одним из возможных стилей заголовков:
doc.add_heading('Заголовок 0', 0) doc.add_heading('Заголовок 1', 1) doc.add_heading('Заголовок 2', 2) doc.add_heading('Заголовок 3', 3) doc.add_heading('Заголовок 4', 4)
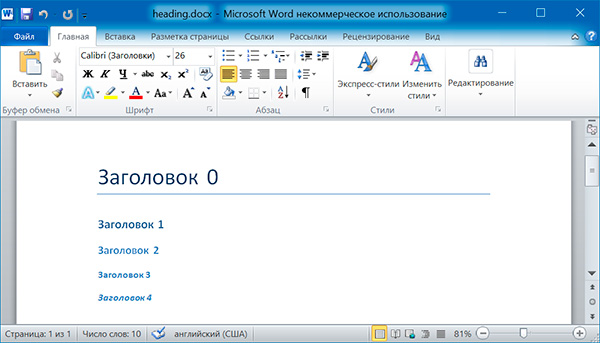
Аргументами метода add_heading() являются строка текста и целое число от 0 до 4. Значению 0 соответствует стиль заголовка Title.
Добавление разрывов строк и страниц
Чтобы добавить разрыв строки (а не добавлять новый абзац), нужно вызвать метод add_break() объекта Run. Если же требуется добавить разрыв страницы, то методу add_break() надо передать значение docx.enum.text.WD_BREAK.PAGE в качестве единственного аргумента:
import docx doc = docx.Document() doc.add_paragraph('Это первая страница') doc.paragraphs[0].runs[0].add_break(docx.enum.text.WD_BREAK.PAGE) doc.add_paragraph('Это вторая страница') doc.save('pages.docx')
Добавление изображений
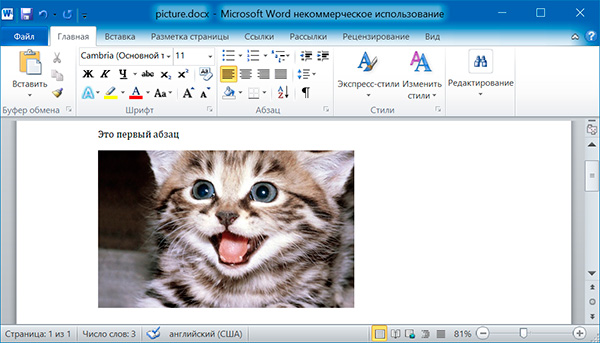
Метод add_picture() объекта Document позволяет добавлять изображения в конце документа. Например, добавим в конец документа изображение kitten.jpg шириной 10 сантиметров:
import docx doc = docx.Document() doc.add_paragraph('Это первый абзац') doc.add_picture('kitten.jpg', width = docx.shared.Cm(10)) doc.save('picture.docx')
Именованные аргументы width и height задают ширину и высоту изображения. Если их опустить, то значения этих аргументов будут определяться размерами самого изображения.
Добавление таблицы
import docx doc = docx.Document() # добавляем таблицу 3x3 table = doc.add_table(rows = 3, cols = 3) # применяем стиль для таблицы table.style = 'Table Grid' # заполняем таблицу данными for row in range(3): for col in range(3): # получаем ячейку таблицы cell = table.cell(row, col) # записываем в ячейку данные cell.text = str(row + 1) + str(col + 1) doc.save('table.docx')
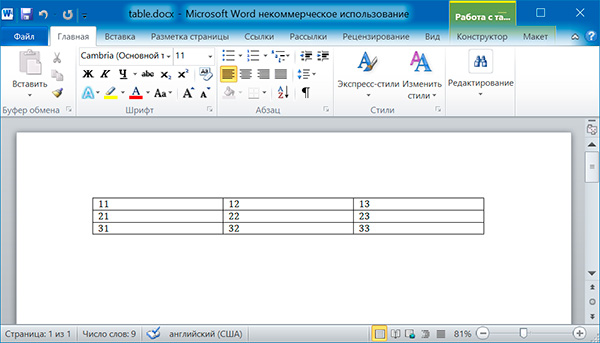
import docx doc = docx.Document('table.docx') # получаем первую таблицу в документе table = doc.tables[0] # читаем данные из таблицы for row in table.rows: string = '' for cell in row.cells: string = string + cell.text + ' ' print(string)
11 12 13 21 22 23 31 32 33
Дополнительно
- Документация python-docx
Поиск:
MS • Python • Web-разработка • Word • Модуль
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Рассмотрим пример простой программы на Python с помощью библотекы docx для автоматизации рабочего процесса, а именно автоматической вставки файлов (в данном случае изображений) и их подпись в документах Word (docx).
Данная статья будет интересна для начинающих изучающих Python, а также полезна для тех кто работает с большими объемами изображений, графиков, осциллограмм и тому подобное. В ней мы рассмотрим простой и удобный способ вставки изображений в Word и их подписью с помощью Python.
Я опишу свой
максимально дубовый и непрофессиональный но простой
код который Вы сможете повторить в своих проектах. (Полный код в низу статьи).
Цель
В жизни каждого инженера или аналитика или другого специалиста, наступает момент, когда нужно оформлять отчет. Часто это осциллограммы, графики, ВАХ или другие графические изображения. Отчет нужно оформить в вордовском файле, с приведением изображений и их подписью. Делать вручную это очень
увлекательно и интересно
долго, неэффективно, скучно и другие синонимы к етим словам.
Рассмотрим простой способ вставки изображений и их подписью в файл docx с помощью Python.
Начало написания программы
Сначала нам нужно добавить библиотеку docx для работы с файлами Word.
import docx
Давайте создадим блок в коде в котором укажем название docx файла и путь к нему, а также путь к папке с изображениями. Чтобы в дальнейшем для удобства было достаточно внести изменения путь к файлам только в верху кода.
folder_doc = r’D:PITONProject’ # Папка в которой docx файл
name_doc = ‘Report.docx’ # Название doc файла
folder_png = ‘D:PITONProjectPng’ # Папка в которой находятся графики
Далее добавим объект doc из библиотеки и укажем путь к файлу с названием документа.
doc = docx.Document(folder_doc + name_doc)
# Указываем параметры которые задавали в коде раньше (путь и имя)
Формируем последовательность вставки файлов
Исходя из названия файлов (изображений) нам нужно определить в какой последовательности мы будем вставлять изображения в Word.
В моем случае ето: Test_number1_Outside_humidity_10_Outside_temperature_25. Отличие в названии файлов есть в числах возле названия параметра (их мы и будем менять в коде для автоматического заполнения файла).
Создаем массивы с значениями этих чисел:
test_number = [1, 2, 3, 4, 5] # Указываем номер теста
outside_humidity = [10, 20, 30, 40, 50, 60, 70, 80, 90] # Указываем влажность
outside_temperature = [25, 50, 75, 100] # Указываем температуру
Основная часть программы
После того как мы разобрались с тем, как мы будем идентифицировать изображение для последующей вставки, нам необходимо определиться в порядке в котором будут идти изображения. У меня все картинки будут идти в таком порядке: test_number, outside_humidity, outside_temperature. Вы же можете сделать произвольный порядок.
Для этой реализации используем цикл for, который будет перебирать все значение из массива по очереди.
for r in range(len(test_number)):
for d in range(len(outside_humidity)):
for i in range(len(outside_temperature)):
Далее стандартными средствами библиотеки добавляем картинки в файл и создаем подписи.
doc.add_picture — добавляет изображения в файл Word
folder_png — это путь к папке которую мы указывали вверху кода
После этого мы указываем точное название файлов в папке, но вместо значений которые меняются вставляем в фигурные скобки.
В функции .format указываем те значения переменных которые меняются в каждом файле и которые мы внесли в цикле for. Эти значения будут применяться к каждому файлу, где мы указывали фигурные скобки (в той же последовательности).
Для подписи файла используем такой же алгоритм.
doc.add_paragraph — используем для записи параграфу
doc.add_paragraph(» «) — делаем отступ
doc.add_picture(folder_png + ‘/Test_number{}_Outside_humidity_{}_Outside_temperature_{}.png’
.format(test_number[r],outside_humidity[d], outside_temperature))
doc.add_paragraph(«Figure {}, Test number {}, Outside humidity = {} %, Outside temperature = {} C;»
.format(i + 1, test_number[r], outside_humidity[d], outside_temperature))
doc.add_paragraph(» «)
Сохраняем файл
doc.save(folder_doc + name_doc)
Меняем параметры изображения
Изображение будем вставлять размером 13.33 х 10 см, для этого воспользуемся дополнительными возможностями библиотеки docx.
Сначала напишем функцию которая будет конвертировать размер с inch в см.
def inch_to_cm(value):
return value / 2.54
Теперь добавим данные параметры к основному коду:
doc.add_picture(folder_png + ‘/Test_number{}_Outside_humidity_{}_Outside_temperature_{}.png’
.format(test_number[r],outside_humidity[d], outside_temperature),
width=docx.shared.Inches(inch_to_cm(13.330)),
height=docx.shared.Inches(inch_to_cm(9)))
Результат
В данной папке находится 180 изображений:

После запуска кода с помощью Python, в течение 5 секунд мы получаем следующий результат:
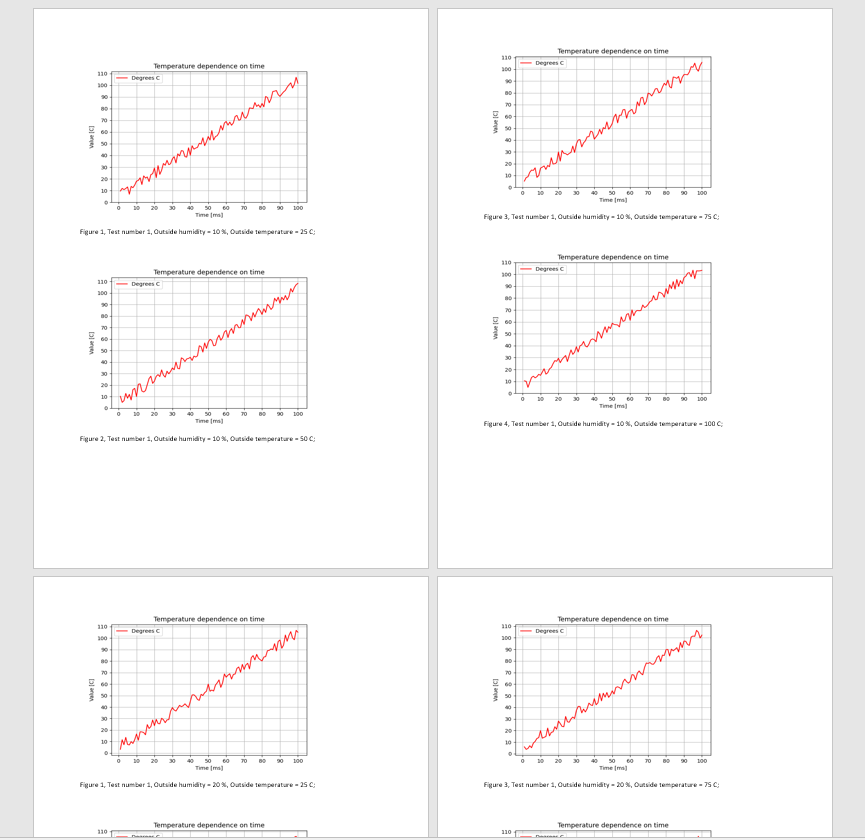
Вывод
Имея структурированные данные на базе данного кода с помощью Python и библиотеки docx можно в течение 10 минут написать свой код, который в течение нескольких секунд сделает всю грязную работу за Вас.
Разве не для этого придумывали компьютер?
Полный код программы
import docx
folder_doc = r’D:PITONProject’ # Папка в которой docx файл
name_doc = ‘Report.docx’ # Название doc файла
folder_png = ‘D:PITONProjectPng’ # Папка в которой находятся графики
doc = docx.Document(folder_doc + name_doc) # Указываем параметры которые задавали в коде раньше (путь и имя файла)
test_number = [1, 2, 3, 4, 5] # Указываем номер теста
outside_humidity = [10, 20, 30, 40, 50, 60, 70, 80, 90] # Указываем влажность
outside_temperature = [25, 50, 75, 100] # Указываем температуру
def inch_to_cm(value):
return value / 2.54 # Конвертируем в см
for r in range(len(test_number)):
for d in range(len(outside_humidity)):
for i in range(len(outside_temperature)):
# Test_number1_Outside_humidity_10_Outside_temperature_25
doc.add_picture(folder_png + ‘/Test_number{}_Outside_humidity_{}_Outside_temperature_{}.png’.format(test_number[r],outside_humidity[d], outside_temperature), width=docx.shared.Inches(inch_to_cm(13.330)), height=docx.shared.Inches(inch_to_cm(9)))
doc.add_paragraph(«Figure {}, Test number {}, Outside humidity = {} %, Outside temperature = {} C;» .format(i + 1, test_number[r], outside_humidity[d], outside_temperature))
doc.add_paragraph(» «)
doc.save(folder_doc + name_doc)