
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip.
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame. А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas. Потом используем словарь для заполнения DataFrame:
import pandas as pd
df = pd.DataFrame({'Name': ['Manchester City', 'Real Madrid', 'Liverpool',
'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]})
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
df.to_excel('./teams.xlsx')
А вот и созданный файл Excel:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel():
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)
Также можно добавили параметр index со значением False, чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
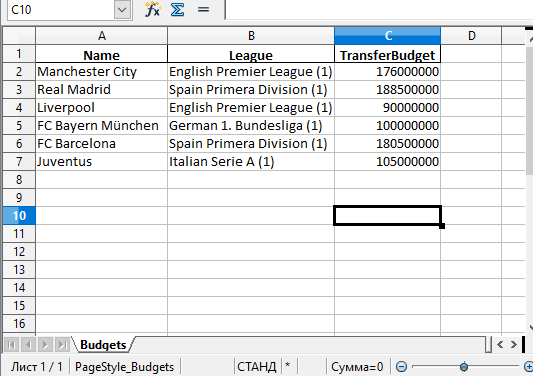
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame({'Name': ['L. Messi', 'Cristiano Ronaldo', 'J. Oblak'],
'Salary': [560000, 220000, 125000]})
salaries2 = pd.DataFrame({'Name': ['K. De Bruyne', 'Neymar Jr', 'R. Lewandowski'],
'Salary': [370000, 270000, 240000]})
salaries3 = pd.DataFrame({'Name': ['Alisson', 'M. ter Stegen', 'M. Salah'],
'Salary': [160000, 260000, 250000]})
salary_sheets = {'Group1': salaries1, 'Group2': salaries2, 'Group3': salaries3}
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets, где каждый ключ будет названием листа, а значение — объектом DataFrame.
Дальше используем движок xlsxwriter для создания объекта writer. Он и передается функции to_excel().
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
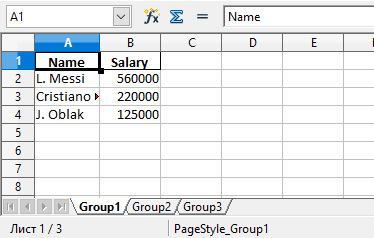
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter, который нужен для работы с классом ExcelWriter. Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save(), которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame. Для этого достаточно воспользоваться функцией read_excel():
top_players = pd.read_excel('./top_players.xlsx')
top_players.head()
Содержимое финального объекта можно посмотреть с помощью функции head().
Примечание:
Этот способ самый простой, но он и способен прочесть лишь содержимое первого листа.
Посмотрим на вывод функции head():
| Name | Age | Overall | Potential | Positions | Club | |
|---|---|---|---|---|---|---|
| 0 | L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| 1 | Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| 2 | J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| 3 | K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| 4 | Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
Pandas присваивает метку строки или числовой индекс объекту DataFrame по умолчанию при использовании функции read_excel().
Это поведение можно переписать, передав одну из колонок из файла в качестве параметра index_col:
top_players = pd.read_excel('./top_players.xlsx', index_col='Name')
top_players.head()
Результат будет следующим:
| Name | Age | Overall | Potential | Positions | Club |
|---|---|---|---|---|---|
| L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
В этом примере индекс по умолчанию был заменен на колонку «Name» из файла. Однако этот способ стоит использовать только при наличии колонки со значениями, которые могут стать заменой для индексов.
Чтение определенных колонок из файла Excel
Иногда удобно прочитать содержимое файла целиком, но бывают случаи, когда требуется получить доступ к определенному элементу. Например, нужно считать значение элемента и присвоить его полю объекта.
Это делается с помощью функции read_excel() и параметра usecols. Например, можно ограничить функцию, чтобы она читала только определенные колонки. Добавим параметр, чтобы он читал колонки, которые соответствуют значениям «Name», «Overall» и «Potential».
Для этого укажем числовой индекс каждой колонки:
cols = [0, 2, 3]
top_players = pd.read_excel('./top_players.xlsx', usecols=cols)
top_players.head()
Вот что выдаст этот код:
| Name | Overall | Potential | |
|---|---|---|---|
| 0 | L. Messi | 93 | 93 |
| 1 | Cristiano Ronaldo | 92 | 92 |
| 2 | J. Oblak | 91 | 93 |
| 3 | K. De Bruyne | 91 | 91 |
| 4 | Neymar Jr | 91 | 91 |
Таким образом возвращаются лишь колонки из списка cols.
В DataFrame много встроенных возможностей. Легко изменять, добавлять и агрегировать данные. Даже можно строить сводные таблицы. И все это сохраняется в Excel одной строкой кода.
Рекомендую изучить DataFrame в моих уроках по Pandas.
Выводы
В этом материале были рассмотрены функции read_excel() и to_excel() из библиотеки Pandas. С их помощью можно считывать данные из файлов Excel и выполнять запись в них. С помощью различных параметров есть возможность менять поведение функций, создавая нужные файлы, не просто копируя содержимое из объекта DataFrame.
In this tutorial, you’ll learn how to save your Pandas DataFrame or DataFrames to Excel files. Being able to save data to this ubiquitous data format is an important skill in many organizations. In this tutorial, you’ll learn how to save a simple DataFrame to Excel, but also how to customize your options to create the report you want!
By the end of this tutorial, you’ll have learned:
- How to save a Pandas DataFrame to Excel
- How to customize the sheet name of your DataFrame in Excel
- How to customize the index and column names when writing to Excel
- How to write multiple DataFrames to Excel in Pandas
- Whether to merge cells or freeze panes when writing to Excel in Pandas
- How to format missing values and infinity values when writing Pandas to Excel
Let’s get started!
The Quick Answer: Use Pandas to_excel
To write a Pandas DataFrame to an Excel file, you can apply the .to_excel() method to the DataFrame, as shown below:
# Saving a Pandas DataFrame to an Excel File
# Without a Sheet Name
df.to_excel(file_name)
# With a Sheet Name
df.to_excel(file_name, sheet_name='My Sheet')
# Without an Index
df.to_excel(file_name, index=False)Understanding the Pandas to_excel Function
Before diving into any specifics, let’s take a look at the different parameters that the method offers. The method provides a ton of different options, allowing you to customize the output of your DataFrame in many different ways. Let’s take a look:
# The many parameters of the .to_excel() function
df.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)Let’s break down what each of these parameters does:
| Parameter | Description | Available Options |
|---|---|---|
excel_writer= |
The path of the ExcelWriter to use | path-like, file-like, or ExcelWriter object |
sheet_name= |
The name of the sheet to use | String representing name, default ‘Sheet1’ |
na_rep= |
How to represent missing data | String, default '' |
float_format= |
Allows you to pass in a format string to format floating point values | String |
columns= |
The columns to use when writing to the file | List of strings. If blank, all will be written |
header= |
Accepts either a boolean or a list of values. If a boolean, will either include the header or not. If a list of values is provided, aliases will be used for the column names. | Boolean or list of values |
index= |
Whether to include an index column or not. | Boolean |
index_label= |
Column labels to use for the index. | String or list of strings. |
startrow= |
The upper left cell to start the DataFrame on. | Integer, default 0 |
startcol= |
The upper left column to start the DataFrame on | Integer, default 0 |
engine= |
The engine to use to write. | openpyxl or xlsxwriter |
merge_cells= |
Whether to write multi-index cells or hierarchical rows as merged cells | Boolean, default True |
encoding= |
The encoding of the resulting file. | String |
inf_rep= |
How to represent infinity values (as Excel doesn’t have a representation) | String, default 'inf' |
verbose= |
Whether to display more information in the error logs. | Boolean, default True |
freeze_panes= |
Allows you to pass in a tuple of the row, column to start freezing panes on | Tuple of integers with length 2 |
storage_options= |
Extra options that allow you to save to a particular storage connection | Dictionary |
.to_excel() methodHow to Save a Pandas DataFrame to Excel
The easiest way to save a Pandas DataFrame to an Excel file is by passing a path to the .to_excel() method. This will save the DataFrame to an Excel file at that path, overwriting an Excel file if it exists already.
Let’s take a look at how this works:
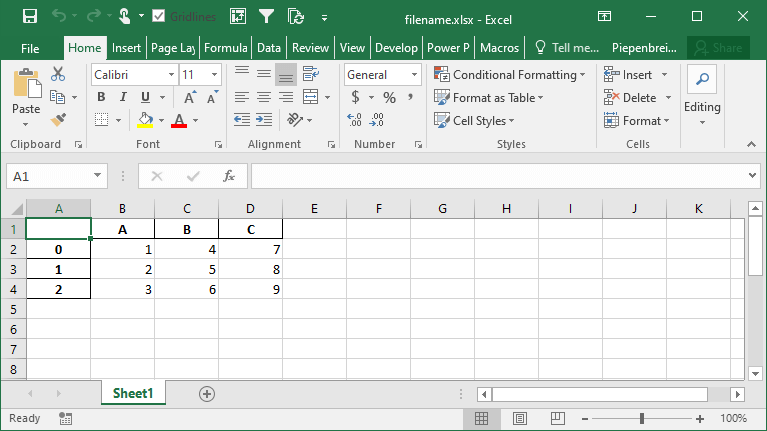
# Saving a Pandas DataFrame to an Excel File
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx')Running the code as shown above will save the file with all other default parameters. This returns the following image:
You can specify a sheetname by using the sheet_name= parameter. By default, Pandas will use 'sheet1'.
# Specifying a Sheet Name When Saving to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', sheet_name='Your Sheet')This returns the following workbook:
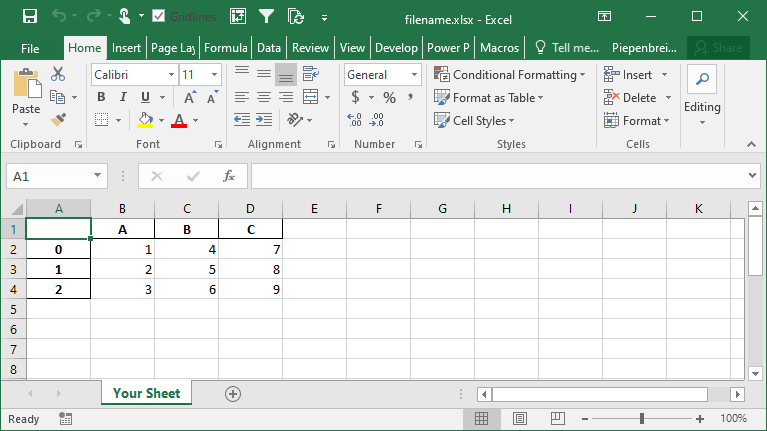
In the following section, you’ll learn how to customize whether to include an index column or not.
How to Include an Index when Saving a Pandas DataFrame to Excel
By default, Pandas will include the index when saving a Pandas Dataframe to an Excel file. This can be helpful when the index is a meaningful index (such as a date and time). However, in many cases, the index will simply represent the values from 0 through to the end of the records.
If you don’t want to include the index in your Excel file, you can use the index= parameter, as shown below:
# How to exclude the index when saving a DataFrame to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', index=False)This returns the following Excel file:
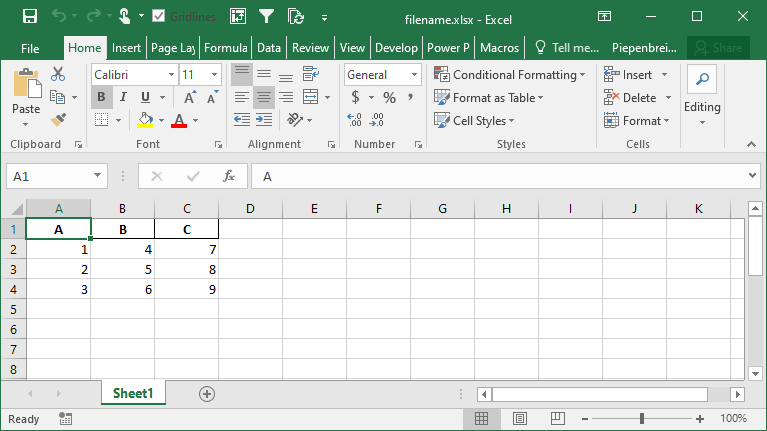
In the following section, you’ll learn how to rename an index when saving a Pandas DataFrame to an Excel file.
How to Rename an Index when Saving a Pandas DataFrame to Excel
By default, Pandas will not named the index of your DataFrame. This, however, can be confusing and can lead to poorer results when trying to manipulate the data in Excel, either by filtering or by pivoting the data. Because of this, it can be helpful to provide a name or names for your indices.
Pandas makes this easy by using the index_label= parameter. This parameter accepts either a single string (for a single index) or a list of strings (for a multi-index). Check out below how you can use this parameter:
# Providing a name for your Pandas index
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', index_label='Your Index')This returns the following sheet:
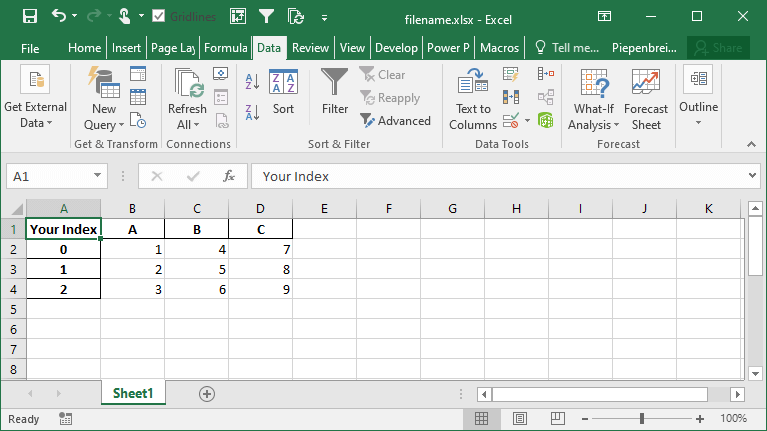
How to Save Multiple DataFrames to Different Sheets in Excel
One of the tasks you may encounter quite frequently is the need to save multi Pandas DataFrames to the same Excel file, but in different sheets. This is where Pandas makes it a less intuitive. If you were to simply write the following code, the second command would overwrite the first command:
# The wrong way to save multiple DataFrames to the same workbook
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', sheet_name='Sheet1')
df.to_excel('filename.xlsx', sheet_name='Sheet2')Instead, we need to use a Pandas Excel Writer to manage opening and saving our workbook. This can be done easily by using a context manager, as shown below:
# The Correct Way to Save Multiple DataFrames to the Same Workbook
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
with pd.ExcelWriter('filename.xlsx') as writer:
df.to_excel(writer, sheet_name='Sheet1')
df.to_excel(writer, sheet_name='Sheet2')This will create multiple sheets in the same workbook. The sheets will be created in the same order as you specify them in the command above.
This returns the following workbook:
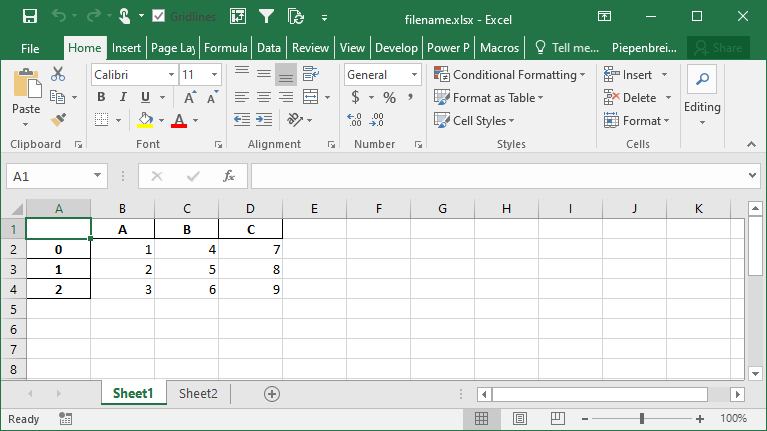
How to Save Only Some Columns when Exporting Pandas DataFrames to Excel
When saving a Pandas DataFrame to an Excel file, you may not always want to save every single column. In many cases, the Excel file will be used for reporting and it may be redundant to save every column. Because of this, you can use the columns= parameter to accomplish this.
Let’s see how we can save only a number of columns from our dataset:
# Saving Only a Subset of Columns to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', columns=['A', 'B'])This returns the following Excel file:
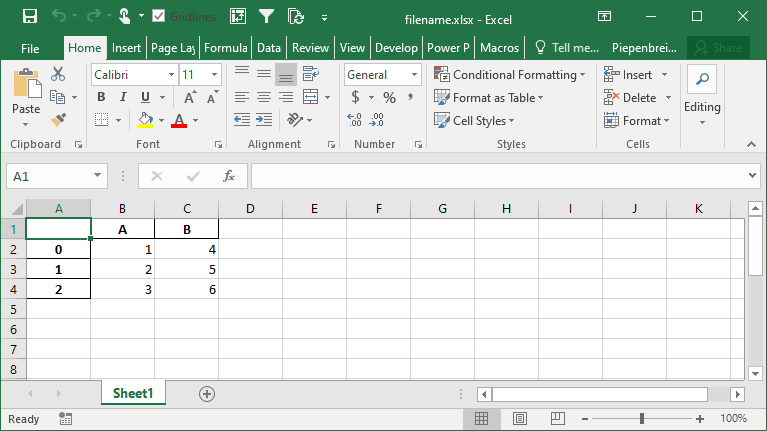
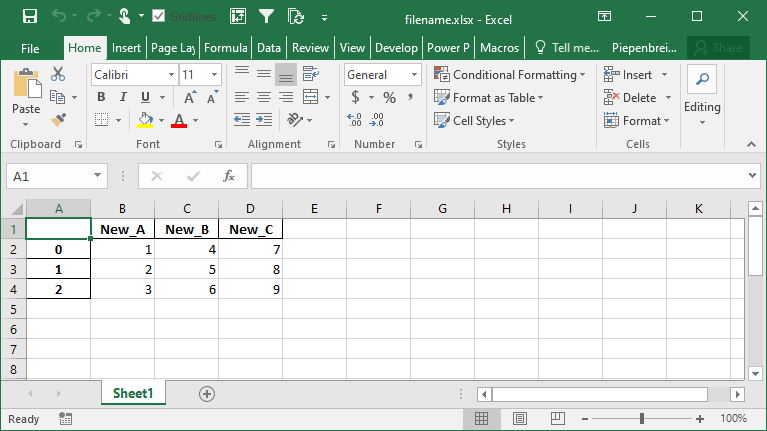
How to Rename Columns when Exporting Pandas DataFrames to Excel
Continuing our discussion about how to handle Pandas DataFrame columns when exporting to Excel, we can also rename our columns in the saved Excel file. The benefit of this is that we can work with aliases in Pandas, which may be easier to write, but then output presentation-ready column names when saving to Excel.
We can accomplish this using the header= parameter. The parameter accepts either a boolean value of a list of values. If a boolean value is passed, you can decide whether to include or a header or not. When a list of strings is provided, then you can modify the column names in the resulting Excel file, as shown below:
# Modifying Column Names when Exporting a Pandas DataFrame to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', header=['New_A', 'New_B', 'New_C'])This returns the following Excel sheet:
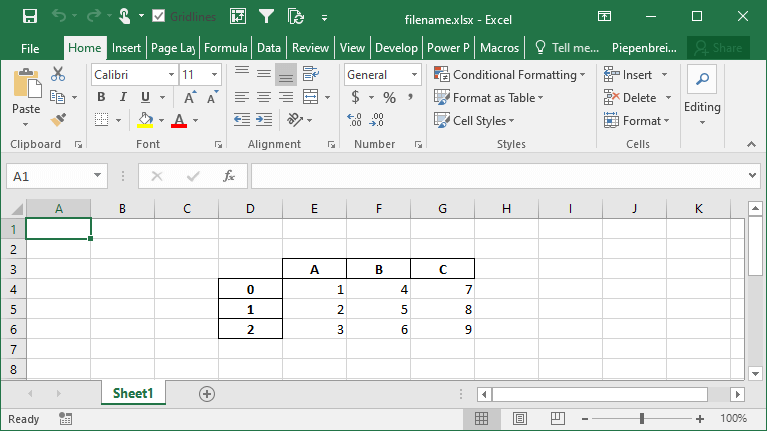
How to Specify Starting Positions when Exporting a Pandas DataFrame to Excel
One of the interesting features that Pandas provides is the ability to modify the starting position of where your DataFrame will be saved on the Excel sheet. This can be helpful if you know you’ll be including different rows above your data or a logo of your company.
Let’s see how we can use the startrow= and startcol= parameters to modify this:
# Changing the Start Row and Column When Saving a DataFrame to an Excel File
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', startcol=3, startrow=2)This returns the following worksheet:
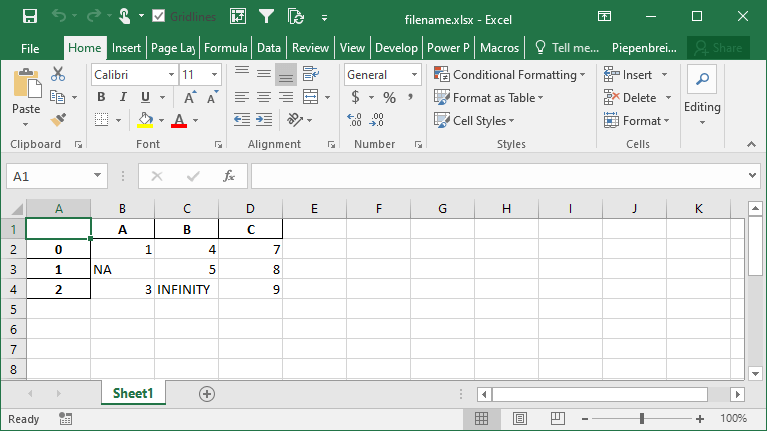
How to Represent Missing and Infinity Values When Saving Pandas DataFrame to Excel
In this section, you’ll learn how to represent missing data and infinity values when saving a Pandas DataFrame to Excel. Because Excel doesn’t have a way to represent infinity, Pandas will default to the string 'inf' to represent any values of infinity.
In order to modify these behaviors, we can use the na_rep= and inf_rep= parameters to modify the missing and infinity values respectively. Let’s see how we can do this by adding some of these values to our DataFrame:
# Customizing Output of Missing and Infinity Values When Saving to Excel
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{'A': [1, np.NaN, 3], 'B': [4, 5, np.inf], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', na_rep='NA', inf_rep='INFINITY')This returns the following worksheet:
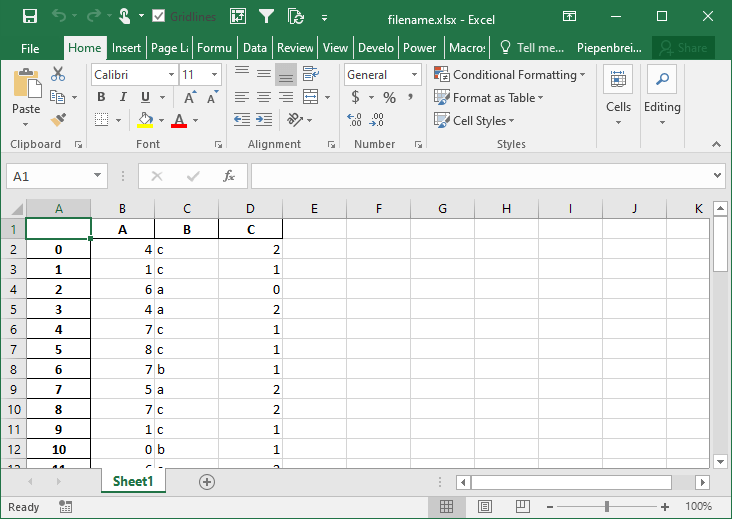
How to Merge Cells when Writing Multi-Index DataFrames to Excel
In this section, you’ll learn how to modify the behavior of multi-index DataFrames when saved to Excel. By default Pandas will set the merge_cells= parameter to True, meaning that the cells will be merged. Let’s see what happens when we set this behavior to False, indicating that the cells should not be merged:
# Modifying Merge Cell Behavior for Multi-Index DataFrames
import pandas as pd
import numpy as np
from random import choice
df = pd.DataFrame.from_dict({
'A': np.random.randint(0, 10, size=50),
'B': [choice(['a', 'b', 'c']) for i in range(50)],
'C': np.random.randint(0, 3, size=50)})
pivot = df.pivot_table(index=['B', 'C'], values='A')
pivot.to_excel('filename.xlsx', merge_cells=False)This returns the Excel worksheet below:
How to Freeze Panes when Saving a Pandas DataFrame to Excel
In this final section, you’ll learn how to freeze panes in your resulting Excel worksheet. This allows you to specify the row and column at which you want Excel to freeze the panes. This can be done using the freeze_panes= parameter. The parameter accepts a tuple of integers (of length 2). The tuple represents the bottommost row and the rightmost column that is to be frozen.
Let’s see how we can use the freeze_panes= parameter to freeze our panes in Excel:
# Freezing Panes in an Excel Workbook Using Pandas
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{'A': [1, np.NaN, 3], 'B': [4, 5, np.inf], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', freeze_panes=(3,4))This returns the following workbook:
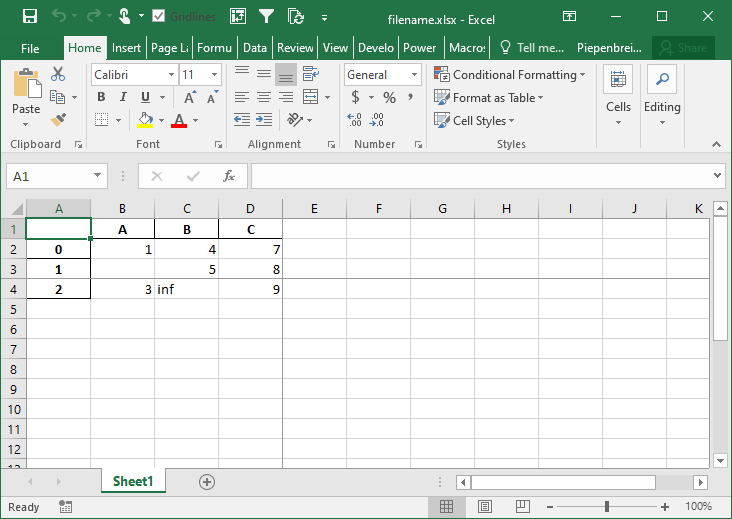
Conclusion
In this tutorial, you learned how to save a Pandas DataFrame to an Excel file using the to_excel method. You first explored all of the different parameters that the function had to offer at a high level. Following that, you learned how to use these parameters to gain control over how the resulting Excel file should be saved. For example, you learned how to specify sheet names, index names, and whether to include the index or not. Then you learned how to include only some columns in the resulting file and how to rename the columns of your DataFrame. You also learned how to modify the starting position of the data and how to freeze panes.
Additional Resources
To learn more about related topics, check out the tutorials below:
- How to Use Pandas to Read Excel Files in Python
- Pandas Dataframe to CSV File – Export Using .to_csv()
- Introduction to Pandas for Data Science
- Official Documentation: Pandas to_excel
17 авг. 2022 г.
читать 2 мин
Часто вас может заинтересовать экспорт фрейма данных pandas в Excel. К счастью, это легко сделать с помощью функции pandas to_excel() .
Чтобы использовать эту функцию, вам нужно сначала установить openpyxl , чтобы вы могли записывать файлы в Excel:
pip install openpyxl
В этом руководстве будет объяснено несколько примеров использования этой функции со следующим фреймом данных:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'points': [25, 12, 15, 14, 19],
'assists': [5, 7, 7, 9, 12],
'rebounds': [11, 8, 10, 6, 6]})
#view DataFrame
df
points assists rebounds
0 25 5 11
1 12 7 8
2 15 7 10
3 14 9 6
4 19 12 6
Пример 1: базовый экспорт
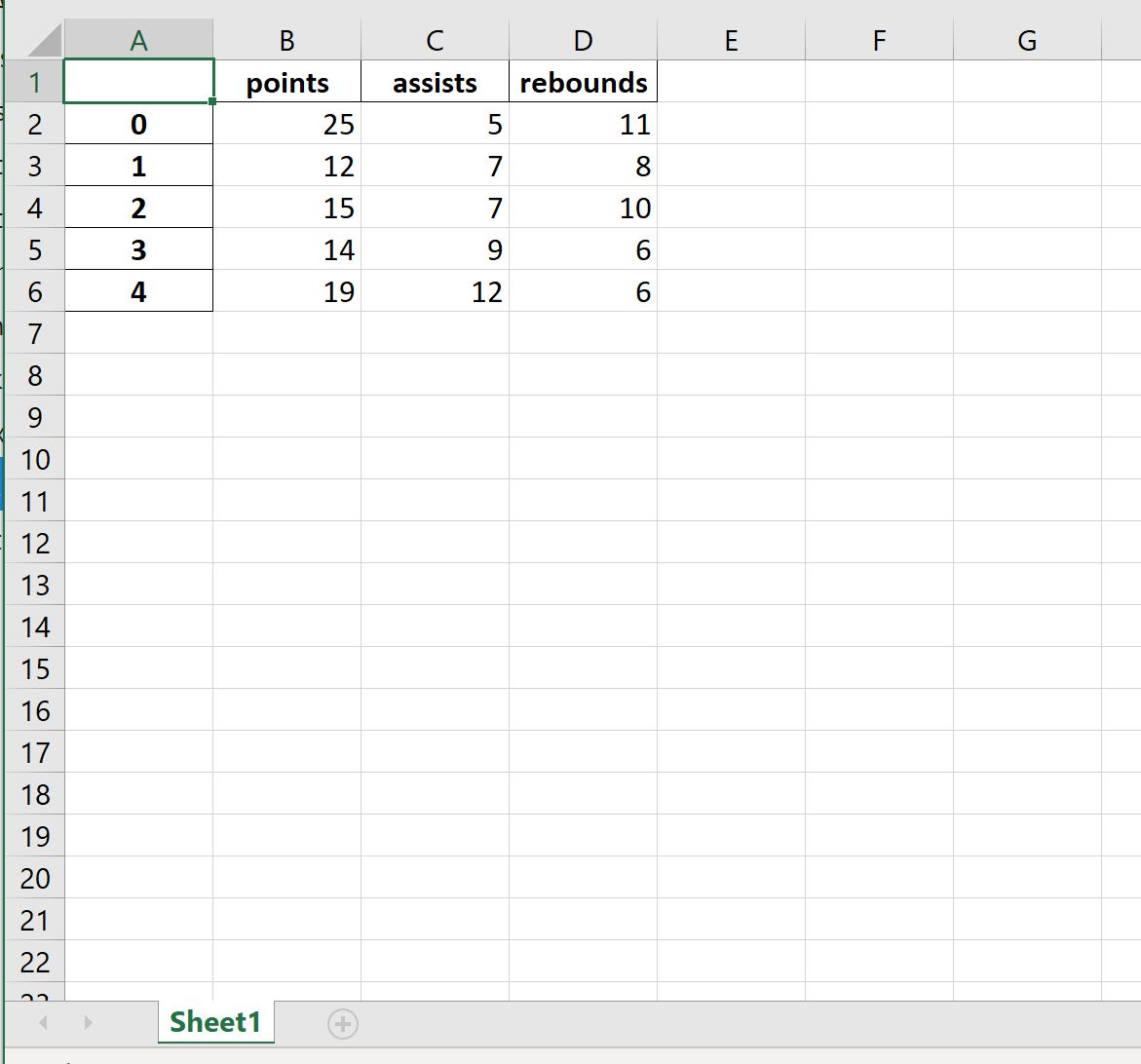
В следующем коде показано, как экспортировать DataFrame по определенному пути к файлу и сохранить его как mydata.xlsx :
df.to_excel (r'C:UsersZachDesktopmydata.xlsx')
Вот как выглядит фактический файл Excel:
Пример 2: Экспорт без индекса
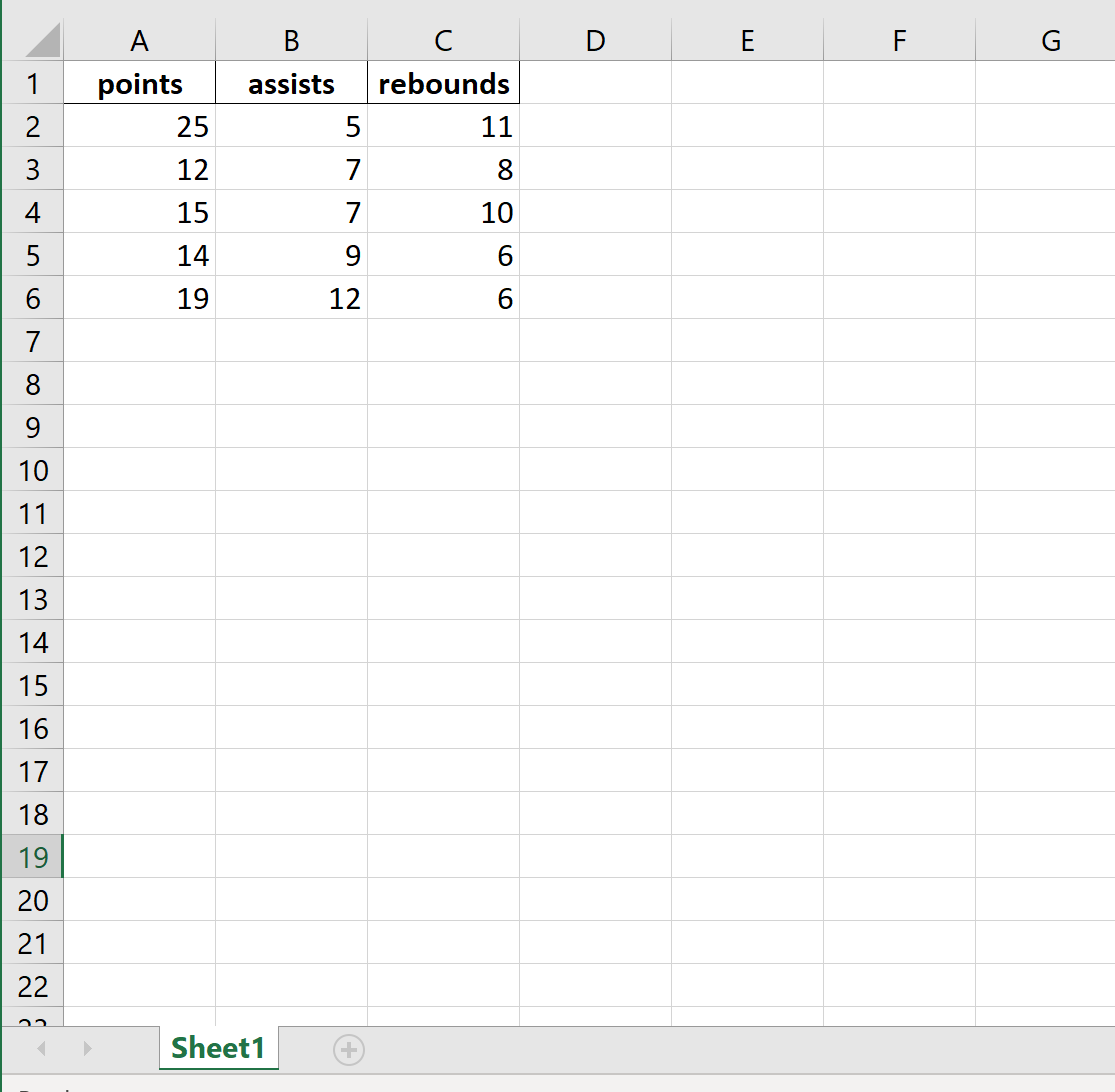
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', index= False )
Вот как выглядит фактический файл Excel:
Пример 3: Экспорт без индекса и заголовка
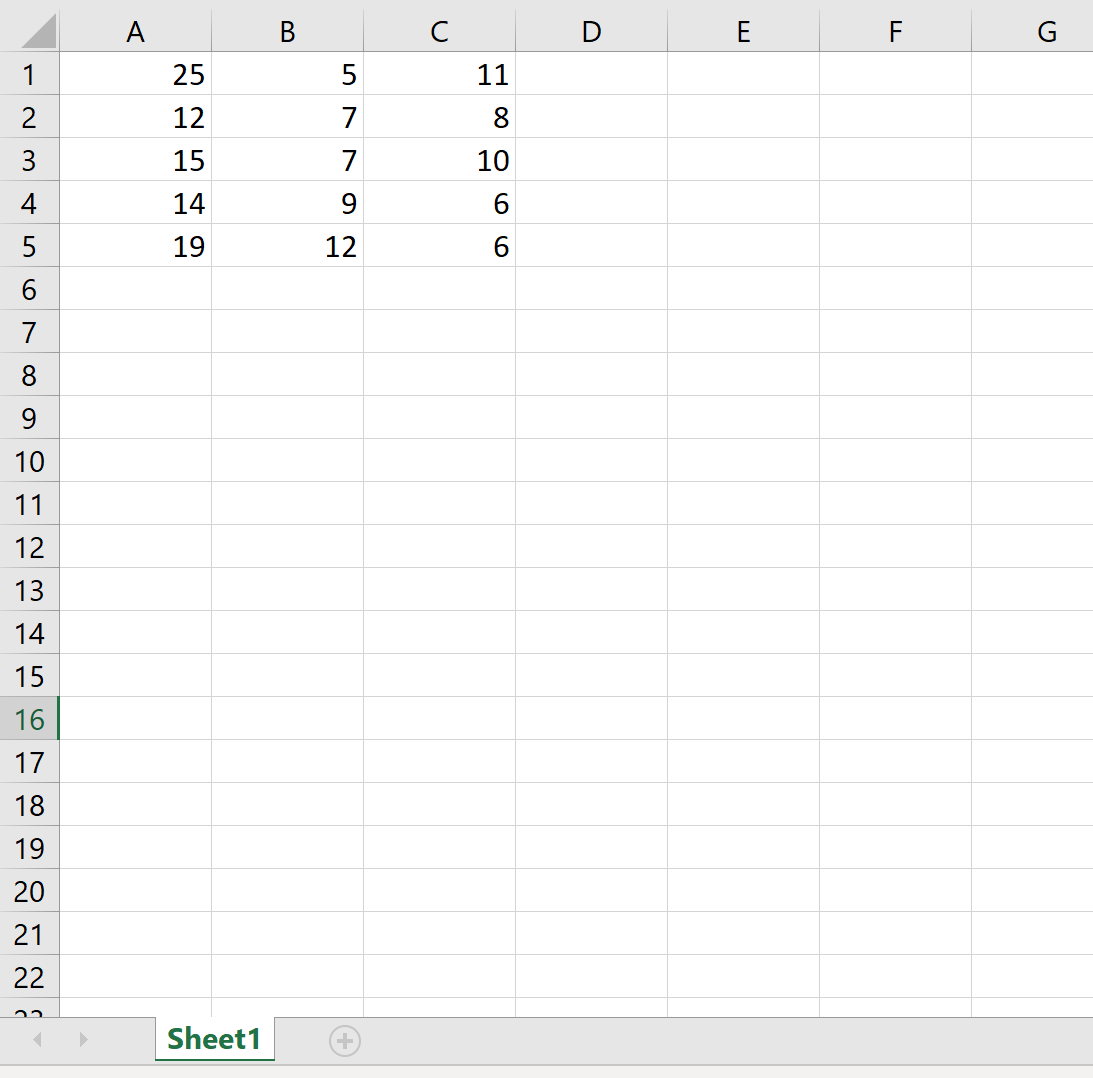
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса и строку заголовка:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', index= False, header= False )
Вот как выглядит фактический файл Excel:
Пример 4: Экспорт и имя листа
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и назвать рабочий лист Excel:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', sheet_name='this_data')
Вот как выглядит фактический файл Excel:
Полную документацию по функции to_excel() можно найти здесь .
Время чтения 4 мин.
Python Pandas — это библиотека для анализа данных. Она может читать, фильтровать и переупорядочивать небольшие и большие наборы данных и выводить их в различных форматах, включая Excel. ExcelWriter() определен в библиотеке Pandas.
Содержание
- Что такое функция Pandas.ExcelWriter() в Python?
- Синтаксис
- Параметры
- Возвращаемое значение
- Пример программы с Pandas ExcelWriter()
- Что такое функция Pandas DataFrame to_excel()?
- Запись нескольких DataFrames на несколько листов
- Заключение
Метод Pandas.ExcelWriter() — это класс для записи объектов DataFrame в файлы Excel в Python. ExcelWriter() можно использовать для записи текста, чисел, строк, формул. Он также может работать на нескольких листах.Для данного примера необходимо, чтоб вы установили на свой компьютер библиотеки Numpy и Pandas.
Синтаксис
|
pandas.ExcelWriter(path, engine= None, date_format=None, datetime_format=None, mode=’w’,**engine_krawgs) |
Параметры
Все параметры установлены на значения по умолчанию.
Функция Pandas.ExcelWriter() имеет пять параметров.
- path: имеет строковый тип, указывающий путь к файлу xls или xlsx.
- engine: он также имеет строковый тип и является необязательным. Это движок для написания.
- date_format: также имеет строковый тип и имеет значение по умолчанию None. Он форматирует строку для дат, записанных в файлы Excel.
- datetime_format: также имеет строковый тип и имеет значение по умолчанию None. Он форматирует строку для объектов даты и времени, записанных в файлы Excel.
- Mode: это режим файла для записи или добавления. Его значение по умолчанию — запись, то есть ‘w’.
Возвращаемое значение
Он экспортирует данные в файл Excel.
Пример программы с Pandas ExcelWriter()
Вам необходимо установить и импортировать модуль xlsxwriter. Если вы используете блокнот Jupyter, он вам не понадобится; в противном случае вы должны установить его.
Напишем программу, показывающую работу ExcelWriter() в Python.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import pandas as pd import numpy as np import xlsxwriter # Creating dataset using dictionary data_set = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} # Converting into dataframe df = pd.DataFrame(data_set) # Writing the data into the excel sheet writer_obj = pd.ExcelWriter(‘Write.xlsx’, engine=‘xlsxwriter’) df.to_excel(writer_obj, sheet_name=‘Sheet’) writer_obj.save() print(‘Please check out the Write.xlsx file.’) |
Выход:
|
Please check out the Write.xlsx file. |
Содержимое файла Excel следующее.

В приведенном выше коде мы создали DataFrame, в котором хранятся данные студентов. Затем мы создали объект для записи данных DataFrame на лист Excel, и после записи данных мы сохранили лист. Некоторые значения в приведенном выше листе Excel пусты, потому что в DataFrame эти значения — np.nan. Чтобы проверить данные DataFrame, проверьте лист Excel.
Что такое функция Pandas DataFrame to_excel()?
Функция Pandas DataFrame to_excel() записывает объект на лист Excel. Мы использовали функцию to_excel() в приведенном выше примере, потому что метод ExcelWriter() возвращает объект записи, а затем мы используем метод DataFrame.to_excel() для его экспорта в файл Excel.
Чтобы записать один объект в файл Excel .xlsx, необходимо только указать имя целевого файла. Для записи на несколько листов необходимо создать объект ExcelWriter с именем целевого файла и указать лист в файле для записи.
На несколько листов можно записать, указав уникальное имя листа. При записи всех данных в файл необходимо сохранить изменения. Обратите внимание, что создание объекта ExcelWriter с уже существующим именем файла приведет к удалению содержимого существующего файла.
Мы также можем написать приведенный выше пример, используя Python с оператором.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import pandas as pd import numpy as np import xlsxwriter # Creating dataset using dictionary data_set = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} # Converting into dataframe df = pd.DataFrame(data_set) with pd.ExcelWriter(‘WriteWith.xlsx’, engine=‘xlsxwriter’) as writer: df.to_excel(writer, sheet_name=‘Sheet’) print(‘Please check out the WriteWith.xlsx file.’) |
Выход:
|
Please check out the WriteWith.xlsx file. |
Вы можете проверить файл WriteWith.xlsx и просмотреть его содержимое. Это будет то же самое, что и файл Write.xlsx.
Запись нескольких DataFrames на несколько листов
В приведенном выше примере мы видели только один лист для одного фрейма данных. Мы можем написать несколько фреймов с несколькими листами, используя Pandas.ExcelWriter.
Давайте напишем пример, в котором мы создадим три DataFrames и сохраним эти DataFrames в файле multiplesheet.xlsx с тремя разными листами.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import pandas as pd import numpy as np import xlsxwriter # Creating dataset using dictionary data_set = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} data_set2 = { ‘Name’: [‘Ankit’, ‘Krunal’, ‘Rushabh’, ‘Dhaval’, ‘Nehal’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} data_set3 = { ‘Name’: [‘Millie’, ‘Jane’, ‘Michael’, ‘Bobby’, ‘Brown’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, np.nan], ‘maths’: [’93’, ’63’, np.nan, ’94’, ’83’], ‘science’: [’88’, np.nan, ’66’, ’94’, np.nan], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} # Converting into dataframe df = pd.DataFrame(data_set) df2 = pd.DataFrame(data_set2) df3 = pd.DataFrame(data_set3) with pd.ExcelWriter(‘multiplesheet.xlsx’, engine=‘xlsxwriter’) as writer: df.to_excel(writer, sheet_name=‘Sheet’) df2.to_excel(writer, sheet_name=‘Sheet2’) df3.to_excel(writer, sheet_name=‘Sheet3’) print(‘Please check out the multiplesheet.xlsx file.’) |
Выход:

Вы можете видеть, что есть три листа, и каждый лист имеет разные столбцы имени.
Функция to_excel() принимает имя листа в качестве параметра, и здесь мы можем передать три разных имени листа, и этот DataFrame сохраняется на соответствующих листах.
Заключение

Если вы хотите экспортировать Pandas DataFrame в файлы Excel, вам нужен только класс ExcelWriter(). Класс ExcelWrite() предоставляет объект записи, а затем мы можем использовать функцию to_excel() для экспорта DataFrame в файл Excel.
В Pandas есть встроенная функция для сохранения датафрейма в электронную таблицу Excel. Все очень просто:
|
df.to_excel( path ) # где path это путь до файла, куда будем сохранять |
Как записать в лист с заданным именем
В этом случае будет создан xls / xlsx файл, а данные сохранятся на лист с именем Sheet1. Если хочется сохранить на лист с заданным именем, то можно использовать конструкцию:
|
df.to_excel( path, sheet_name=«Лист 1») # где sheet_name название листа |
Как записать в один файл сразу два листа
Но что делать, если хочется записать в файл сразу два листа? Логично было бы использовать две команды
df.to_excel друг за другом, но с одним путем до файла и разными
sheet_name , однако в Pandas это так не работает. Для решения этой задачи придется использовать конструкцию посложнее:
|
from pandas.io.excel import ExcelWriter with ExcelWriter(path) as writer: df.sample(10).to_excel(writer, sheet_name=«Лист 1») df.sample(10).to_excel(writer, sheet_name=«Лист 2») |
В результате будет создан файл Excel, где будет два листа с именами Лист 1 и Лист 2.
Как добавить ещё один лист у уже существующему файлу
Если использовать предыдущий код, то текущий файл будет перезаписан и в него будет записан новый лист. Старые данные при этом, ожидаемо, будут утеряны. Выход есть, достаточно лишь добавить модификатор «a» (append):
|
with ExcelWriter(path, mode=«a») as writer: df.sample(10).to_excel(writer, sheet_name=«Лист 3») |
Но что, если оставить этот код, удалить существующий файл Excel и попробовать выполнить код? Получим ошибку Файл не найден. В Python существует модификатор «a+», который создает файл, если его нет, и открывает его на редактирование, если файл существует. Но в Pandas такого модификатора не существует, поэтому мы должны выбрать модификатор для ExcelWriter в зависимости от наличия или отсутствия файла. Но это не сложно:
|
with ExcelWriter(path, mode=«a» if os.path.exists(path) else «w») as writer: df.sample().to_excel(writer, sheet_name=«Лист 4») |
К сожалению в Pandas, на момент написания поста, такого функционала нет. Но это можно реализовать с помощью пакета openpyxl. Вот пример такой функции:
|
def update_spreadsheet(path : str, _df, starcol : int = 1, startrow : int = 1, sheet_name : str =«ToUpdate»): »’ :param path: Путь до файла Excel :param _df: Датафрейм Pandas для записи :param starcol: Стартовая колонка в таблице листа Excel, куда буду писать данные :param startrow: Стартовая строка в таблице листа Excel, куда буду писать данные :param sheet_name: Имя листа в таблице Excel, куда буду писать данные :return: »’ wb = ox.load_workbook(path) for ir in range(0, len(_df)): for ic in range(0, len(_df.iloc[ir])): wb[sheet_name].cell(startrow + ir, starcol + ic).value = _df.iloc[ir][ic] wb.save(path) |
Как работает код и пояснения смотри в видео
Если у тебя есть вопросы, что-то не получается или ты знаешь как решить задачи в посте лучше и эффективнее (такое вполне возможно) то смело пиши в комментариях к видео.