
Перевод
Ссылка на автора

Проведя почти десять лет с моей первой любовью к Excel, пришло время двигаться дальше и искать лучшую половину того, кто в своих повседневных делах со мной, гораздо лучше и быстрее, и кто может дать мне преимущество в сложные технологические времена, когда новые технологии очень быстро угнетаются чем-то новым. Идея состоит в том, чтобы воспроизвести почти все функциональные возможности Excel в Python, будь то простой фильтр или сложная задача создания массива данных из строк и обработки их для получения фантастических результатов.
Используемый здесь подход состоит в том, чтобы начать с простых задач и перейти к сложным вычислительным задачам. Я призываю вас повторить шаги самостоятельно для лучшего понимания.
Источником вдохновения для создания чего-то подобного послужило отсутствие бесплатного учебного пособия, которое буквально дает все. Я внимательно читаю и слежу за документацией по Python, и вы найдете много вдохновения на этом сайте.
Ссылка на репозиторий GitHub
https://github.com/ank0409/Ditching-Excel-for-Python
Импорт файлов Excel в DataFrame Pandas
Первым шагом является импорт файлов Excel в DataFrame, чтобы мы могли выполнять с ним все наши задачи. Я буду демонстрироватьread_excelметод панд, который поддерживаетXLSа такжеXLSXРасширения файлов.
read_csvтак же, как использованиеread_excelМы не будем углубляться, но я поделюсь примером.
Хотяread_excelМетод включает в себя миллион аргументов, но я ознакомлю вас с наиболее распространенными аргументами, которые очень пригодятся в повседневных операциях.
Хотя метод read_excel содержит миллион аргументов, я ознакомлю вас с наиболее распространенными из них, которые очень пригодятся в повседневных операциях.
Я буду использовать образец набора данных Iris, который свободно доступен в Интернете для образовательных целей.
Пожалуйста, перейдите по ссылке ниже, чтобы загрузить набор данных и сохранить его в той же папке, где вы сохраняете свой файл Python
https://archive.ics.uci.edu/ml/datasets/iris
Первый шаг — импортировать необходимые библиотеки в Python.

Мы можем импортировать данные электронной таблицы в Python, используя следующий код:
pandas.read_excel (io, sheet_name = 0, header = 0, names = None, index_col = None, parse_cols = None, usecols = None, squeeze = False, dtype = None, engine = None, конвертеры = None, true_values = None, false_values = нет, skiprows = нет, nrows = нет, na_values = нет, keep_default_na = True, многословно = False, parse_dates = False, date_parser = нет, тысячи = нет, комментарий = нет, skip_footer = 0, skipfooter = 0, convert_float = 0 True, mangle_dupe_cols = True, ** kwds)
Поскольку имеется множество доступных аргументов, давайте рассмотрим наиболее часто используемые аргументы.
Важные опции read_excel для Pandas

Если мы используем путь для нашего локального файла по умолчанию, он разделен знаком «», однако python принимает «/», поэтому сделайте так, чтобы изменить косую черту или просто добавить файл в ту же папку, где находится ваш файл python. Если вам требуется подробное объяснение выше, обратитесь к статье ниже среднего. https://medium.com/@ageitgey/python-3-quick-tip-the-easy-way-to-deal-with-file-paths-on-windows-mac-and-linux-11a072b58d5f
Мы можем использовать Python для сканирования файлов в каталоге и выбрать те, которые нам нужны.

Импортировать определенный лист
По умолчанию первый лист в файле импортируется в фрейм данных как есть.
Используя аргумент sheet_name, мы можем явно указать лист, который мы хотим импортировать. Значение по умолчанию 0, то есть первый лист в файле.
Мы можем либо упомянуть имя листа (ов), либо передать целочисленное значение для ссылки на индекс листа

Использование столбца из листа в качестве индекса
Если явно не указано иное, в DataFrame добавляется столбец индекса, который по умолчанию начинается с 0.
Используя аргумент index_col, мы можем манипулировать столбцом индекса в нашем фрейме данных, если мы установим значение 0 из none, он будет использовать первый столбец в качестве нашего индекса.

Пропустить строки и столбцы
Параметры read_excel по умолчанию предполагают, что первая строка представляет собой список имен столбцов, который автоматически включается как метки столбцов в DataFrame.
Используя такие аргументы, как skiprows и header, мы можем манипулировать поведением импортированного DataFrame.

Импортировать определенные столбцы
Используя аргумент usecols, мы можем указать, нужно ли импортировать определенный столбец в наш DataFrame.

Это не конец доступных функций, но это начало, и вы можете поиграть с ними в соответствии с вашими требованиями
Давайте посмотрим на данные с 10 000 футов
Поскольку теперь у нас есть наш DataFrame, давайте посмотрим на данные с разных точек зрения, просто чтобы освоить их /
У панд есть множество доступных функций, которые мы можем использовать. Мы используем некоторые из них, чтобы получить представление о нашем наборе данных.
«Голова» к «Хвосту»:
Для просмотра первого или последнего5строки
По умолчанию пять, однако аргумент позволяет нам использовать конкретное число

Просмотр данных конкретного столбца

Получение имени всех столбцов

Информационный метод
Предоставляет сводку DataFrame

Форма Метод
Возвращает размеры DataFrame

Посмотрите на типы данных в DataFrame

Срезы и кубики, т.е. фильтры Excel
Описательные отчеты — это все о подмножествах данных и агрегациях. В тот момент, когда мы должны немного понять наши данные, мы начинаем использовать фильтры для просмотра небольших наборов данных или просмотра определенного столбца, возможно, для лучшего понимания.
Python предлагает множество различных методов для нарезки и нарезки кубиков данных, поэтому мы поэкспериментируем с несколькими из них, чтобы понять, как это работает
Просмотр определенного столбца
Существует три основных метода выбора столбцов:
- Используйте точечную запись: например, data.column_name
- Используйте квадратные скобки и название столбца: например, данные [ «column_name»]
- Используйте числовую индексацию и селектор iloc data.loc [:, ‘column_number’]

Просмотр нескольких столбцов

Просмотр данных конкретной строки
Используемый здесь метод — это нарезка с использованием функции loc, где мы можем указать начальную и конечную строки, разделенные двоеточием.
Помнить,Индекс начинается с 0, а не 1

Срезать строки и столбцы вместе

Фильтровать данные в столбце

Фильтровать несколько значений

Фильтрация нескольких значений с использованием списка

Фильтровать значения НЕ в списке или не равно в Excel

Фильтрация с использованием нескольких условий в нескольких столбцах
На входе всегда должен быть список
Мы можем использовать этот метод для репликации расширенной функции фильтра в Excel

Фильтр с использованием числовых условий

Скопируйте пользовательский фильтр в Excel

Объедините два фильтра, чтобы получить результат

Содержит функцию в Excel

Получите уникальные значения из DataFrame

Если мы хотим просмотреть весь DataFrame с уникальными значениями, мы можем использовать метод drop_duplicates

Сортировать значения
Сортировать данные по определенному столбцу, по умолчанию сортировка по возрастанию

Статистическая сводка данных
DataFrame Опишите метод
Генерировать описательную статистику, которая суммирует центральную тенденцию, дисперсию и форму распределения набора данных, исключая значения NaN

Сводная статистика символьных столбцов

Агрегация данных
Подсчет уникальных значений определенного столбца
Итоговый результат — серия. Вы можете сослаться на него как сводную таблицу с одним столбцом

Подсчет клеток
Подсчет не-NA клеток для каждого столбца или строки

сумма
Суммирование данных для получения снимка по строкам или столбцам

Копирует метод добавления итогового столбца для каждой строки.

Добавить итоговый столбец в существующий набор данных

Сумма конкретных столбцов, используйте методы loc и передайте имена столбцов

Или мы можем использовать метод ниже

Не нравится новый столбец, удалите его методом drop

Добавление общей суммы под каждым столбцом

Многое было сделано выше, подход, который мы используем:
- Sum_Total: сделать сумму столбцов
- T_Sum: преобразовать выходные данные серии в DataFrame и транспонировать
- Переиндексировать, чтобы добавить отсутствующие столбцы
- Row_Total: добавить T_Sum к существующему DataFrame
Сумма на основе критериев, т. Е. Sumif в Excel

SUMIFS

СРЕСЛИ

Максимум

Min

Groupby, то есть промежуточные итоги в Excel

Сводные таблицы в фреймах данных, т. Е. Сводные таблицы в Excel
Кому не нравится сводная таблица в Excel, это один из лучших способов анализа ваших данных, быстрый обзор информации, помощь в нарезке и нарезке данных с помощью супер удобного интерфейса, помощь в построении графиков на основе данных добавить расчетные столбцы и т. д.
Нет, у нас не будет интерфейса для работы, нам придется явно писать код, чтобы получить вывод. Нет, он не будет генерировать диаграммы для вас, но я не думаю, что мы сможем завершить учебник, не изучив таблицы Pivot. ,

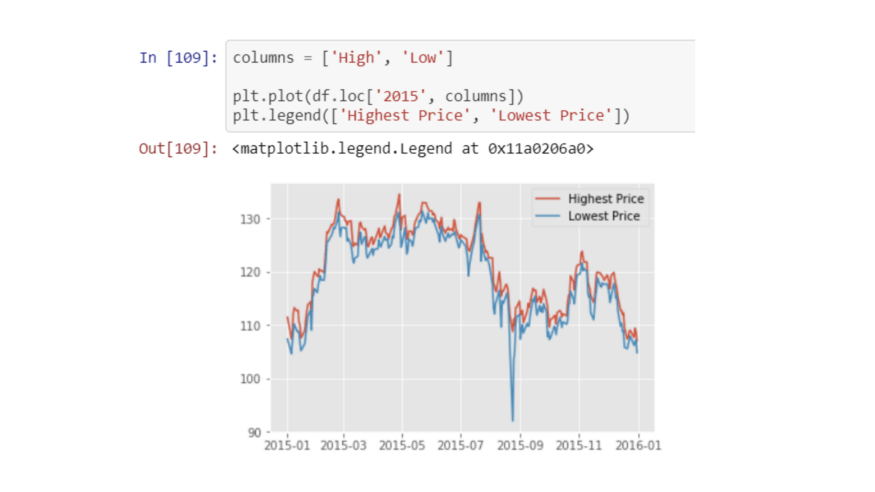
Простая сводная таблица, показывающая нам сумму значений SepalWidth в значениях, SepalLength в столбце строк и имени в метках столбцов
Давайте посмотрим, сможем ли мы немного усложнить это.

Пробелы теперь заменяются на 0 с помощью аргумента fill_value

У нас могут быть индивидуальные вычисления значений с использованием словарного метода, а также может быть несколько вычислений значений

Если мы используем аргумент поля, мы можем добавить общую строку
ВПР
Какая волшебная формула vlookup в Excel, я думаю, это первое, что каждый хочет изучить, прежде чем научиться даже добавлять. Выглядит увлекательно, когда кто-то применяет vlookup, выглядит как волшебство, когда мы получаем вывод. Облегчает жизнь Я могу с большой уверенностью сказать, что это основа каждого действия по сбору данных, выполняемого в электронной таблице.
к несчастьюу нас нет функции vlookup в Пандах!
Поскольку у нас нет функции «Vlookup» в Pandas, Merge используется как альтернатива, аналогичная SQL. Всего доступно четыре варианта слияния:
- «Слева» — используйте общий столбец в левом фрейме данных и сопоставьте правый фрейм данных. Заполните любой N / A как NaN
- «Вправо» — используйте общий столбец из правого фрейма данных и сопоставьте его с левым фреймом данных. Заполните любой N / A как NaN
- «Внутренний» — отображать данные только в тех случаях, когда два общих столбца перекрываются. Метод по умолчанию.
- «External» — возвращает все записи, когда в левом или правом кадре данных есть совпадение.

Вышесказанное может быть не лучшим примером для поддержки концепции, однако работа такая же.
Как говорится, «идеального учебника не существует», как и моего 
Многие пользуются Excel для анализа данных, но Python лучше подойдет для решения аналитических задач: в нем можно работать с неограниченным количеством данных и написать пару строк кода для сложной операции. Перевели статью Stop Using Excel for Data Analytics: Upgrade to Python Тайлера Фолкмана, руководителя направления ИИ в Branded Entertainment Network, в которой он объясняет, почему стоит перейти на Python.
Да, Excel — важный инструмент для компаний. До сих пор им пользуются аналитики и ученые. Но для большинства задач он не подходит. Вот пять причин, почему пора перестать использовать Excel и перейти на Python.
Причина 1. Масштабирование и автоматизация
Excel хорош, когда нужно за раз проанализировать небольшое количество данных. Но для масштабных вычислений он не подходит. Excel поддерживает данные размером до 1 048 576 строк и до 16 384 столбцов.
Python может масштабироваться до объема памяти. Кроме того, у него есть много инструментов, поддерживающих вычисления и вне памяти устройства. Например, с помощью библиотеки Dask можно масштабировать вычисления для работы на внешнем кластере, а не только на ноутбуке. Если вы уже работали с Pandas (библиотекой для анализа и обработки данных), то тут используется почти такой же код для чтения в формате CSV:

Всего одна строка кода, и вы можете прочесть данные, объем которых превышает размер памяти компьютера. В Excel это сделать невозможно.
Кроме того, Python можно использовать для работы с несколькими источниками данных. Если Excel — это одновременно и хранилище, и вычислительный механизм, то Python полностью независим. Если вы можете найти способ прочитать данные в Python, вы сможете их использовать. У Python много библиотек, поэтому можно анализировать данные из разных источников, будь то CSV, Excel, JSON или SQL.
Наконец, Python незаменим при автоматизации. Этот язык программирования позволяет напрямую подключаться к базе данных и выполнять обновления автоматически. С его помощью можно проводить расчеты, создавать отчеты или динамические дашборды, экономя массу времени. В Excel многое надо вводить вручную, а обновления нельзя автоматизировать.
Читайте также: Кому и для чего нужен Python?
Причина 2. Воспроизводимость
Воспроизводимость — это когда вашу аналитику или визуальный отчет легко может повторить другой человек. Он должен суметь не только перезапустить процессы и получить точно такой же результат, но и пройти те же самые шаги. Воспроизводимость важна при автоматизации, но настроить ее в Excel сложно.
Дело в том, что расчеты в ячейках Excel практически невозможно проверить по любой шкале измерений. Типы данных сбивают с толку — не всегда то, что вы видите, представлено в необработанных данных. Да, в Excel можно использовать VBA (Visual Basic for Applications) и он немного улучшает воспроизводимость.
VBA — это язык программирования, разработанный Microsoft и предназначенный для работы с пакетами Microsoft Office. Он позволяет писать программы прямо в файле и создавать макросы — набор команд для автоматического выполнения задач. При этом не нужно устанавливать среду для разработки — она уже есть в самом Excel.
Но лучше все же потратить время на изучение Python.
Посмотрите на этот документ в Excel:
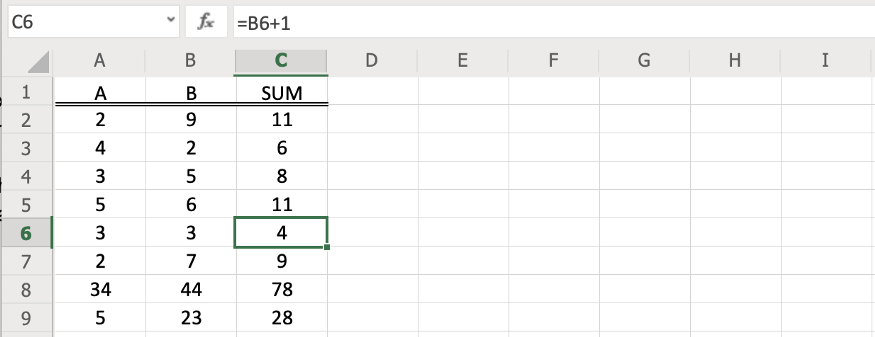
В столбце с sum должна отображаться сумма чисел из столбцов A и B, но как это проверить? Вы можете проверить одну из формул и увидеть, что это на самом деле сумма, но поскольку каждая ячейка тоже может быть формулой, то результат неверный. Если не проверять все вручную, то можно пропустить ошибки.
А в Python эти расчеты выглядели бы так:

Код простой и понятный, с его помощью можно легко проверить, что сумма рассчитана правильно.
C Python вы получаете все инструменты, предназначенные для того, чтобы улучшить воспроизводимость и совместную работу программистов.
Вдобавок ко всему, Python превосходит возможности подключения к данным. С его помощью можно анализировать данные в облаке и мгновенно повторять этот процесс. Git (распределенная система управления версиями), модульное тестирование, документация и стандарты форматирования кода широко распространены в сообществе Python.
В третьей версии Python можно добавить статическую типизацию, чтобы сделать ваш код более понятным. Все эти инструменты упрощают процесс создания кода и обеспечивают его правильное написание. В следующий раз, когда кто-то будет смотреть ваш код, он сможет легко его понять и воспроизвести.
Причина 3. Гибкость навыков
Если вы знаете Excel, это, безусловно, полезный навык, но больше его применить негде. Python же многофункционален. Это не только удобный инструмент для анализа и визуализации данных, но и язык программирования, который можно использовать для чего угодно. Хотите заниматься машинным или глубоким обучением? Создать сайт? Автоматизировать умный дом? Все это можно сделать с помощью Python.
Кроме того, Python намного ближе к другим языкам программирования, чем Excel. Поэтому, зная Python, гораздо легче изучить другие языки. Он открывает больше возможностей, чем Excel.
И, наконец, Python невероятно востребован. По данным Stack Overflow, в 2019 году он стал четвертым по популярности языком программирования в мире среди профессиональных разработчиков ПО, а также первым наиболее востребованным языком программирования. (По данным Stack Overflow на май 2021 года, Python — третий по популярности язык программирования после JavaScript и HTML/CSS.) По оценкам американского сервиса по поиску работы Indeed, средняя зарплата разработчика на Python в США в 2020 году составляла 120 тысяч долларов в год. Неплохо.
Причина 4. Продвинутые инструменты
В Excel есть множество встроенных формул, но они меркнут по сравнению с возможностями Python. У Python не только сотни библиотек, помогающих упростить расширенную статистику и аналитику, но и продвинутые инструменты для визуализации данных.
Это, например, библиотека Matplotlib, Plotly, фреймворк Streamlit и библиотека для статистических графиков Seaborn (все это — инструменты для визуализации данных). С их помощью вы можете прекрасно визуализировать данные, а также создавать интерактивные информационные панели и графики.
Библиотеки Numpy и SciPy поддерживают научные и векторизованные вычисления, линейную алгебру. Библиотека Scikit-learn позволяет применять различные алгоритмы машинного обучения: от дерева принятия решений до градиентного бустинга. Я думаю, xkcd сказал об этом лучше всего:

— Python. Я узнал его вчера вечером! Все так просто! Чтобы запустить программу Hello world, нужно просто напечатать фразу “Hello, world!”.
— Я не знаю… Динамический набор текста? Пробел?
— Присоединяйся к нам! Программирование — это весело! Это совершенно новый мир!
— Но как ты летаешь?
— Я только что набрал import antigravity (импортировать антигравитацию).
— И это все?
— Я также для сравнения попробовал все, что было в аптечке. Но, думаю, причина все же в Python.
Причина 5. Python легко выучить
Учитывая все преимущества Python над Excel, кажется, что он должен быть очень сложным. Но это не так. Посмотрите, как на Java выглядит самая простая программа Hello World:
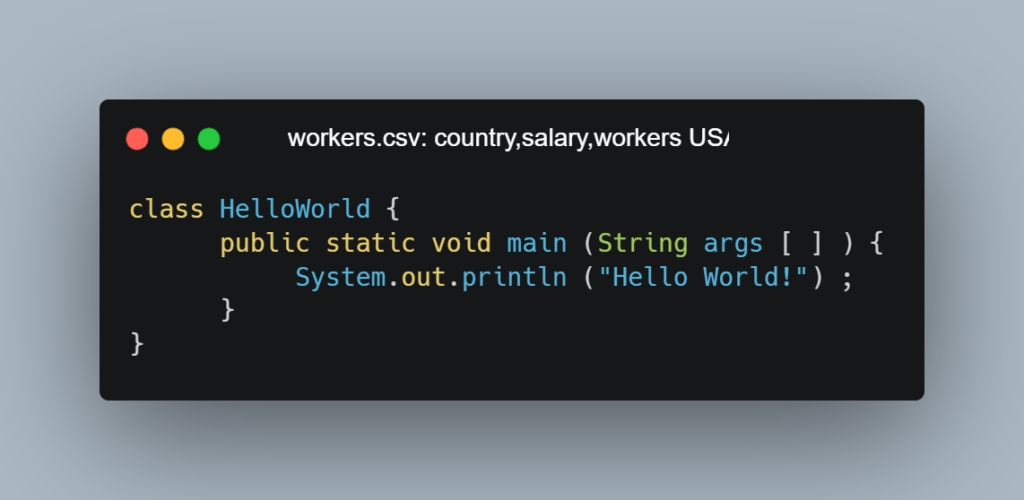
На Python она займет всего одну строку:

Python — один из самых интуитивно понятных языков программирования. Его могут освоить даже те, у кого нет опыта в написании кода. Хотя обучение Excel может оказаться предпочтительнее, выгоды от него гораздо меньше. Python стоит потраченного времени и усилий, и Excel никогда не сможет с ним сравниться из-за универсальности его дизайна. Расскажем немного про основы анализа и визуализации данных в Python.
Как начать использовать Python для анализа данных
Изучим основные команды и операции в Python, которые потребуются при анализе данных. Первый нюанс — Python использует пробелы и не использует точку с запятой, как и другие языки. Вот очень простой пример:

Импорт функций
Мы будем использовать множество библиотек. Некоторые из них предустановлены вместе с Python, а другие придется поставить самостоятельно. Чтобы загрузить библиотеку, используйте оператор импорта (import statement):

Эта команда импортирует класс Counter (счетчик) из библиотеки collections. Counter — полезный инструмент для дата-аналитиков. Он помогает подсчитать, сколько раз элементы появляются в коллекциях, например в списках. Ниже мы написали код, в котором создали список брачных возрастов. Используя Counter, мы можем быстро подсчитать, сколько раз появляется каждый возраст.
Списки на Python
Списки — это полезная структура данных, предназначенная для их хранения. Подробнее изучим их в следующем уроке. Например:
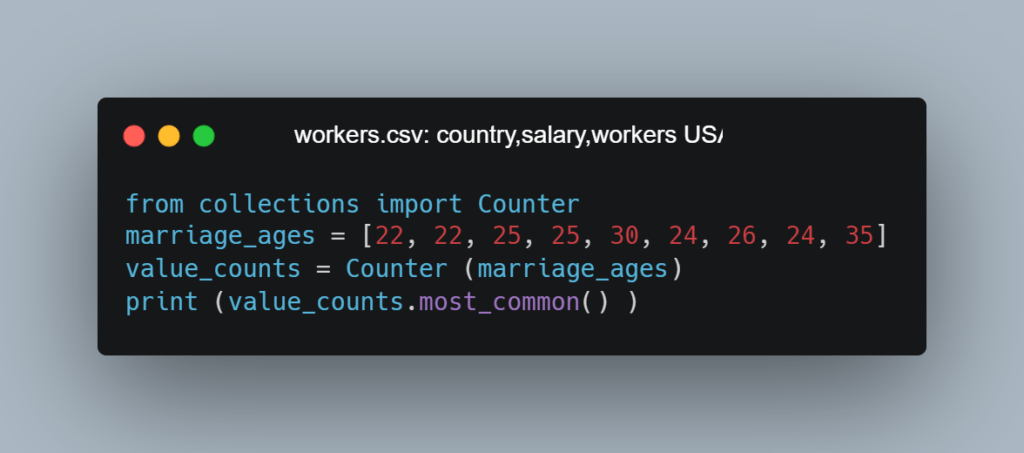
Видно, что мы создали список, содержащий возраст вступления в брак, используя [ ] во второй строке. Затем передали этот список в функцию Counter, чтобы вывести наиболее распространенные значения в виде списка кортежей (tuple).
Кортеж — это неизменяемый список внутри круглых скобок (). Кортежи содержат два элемента: значение и количество раз, когда это значение появлялось в вашем списке. Частота упорядочивает список кортежей. Первым отображается значение с наибольшим числом случаев.
Функции в Python
Функции в Python тоже полезны. Они начинаются с ключевого слова def и названия функции, затем добавляются аргументы в скобках. Вот функция, которая принимает 2 аргумента, x и y, и возвращает sum:
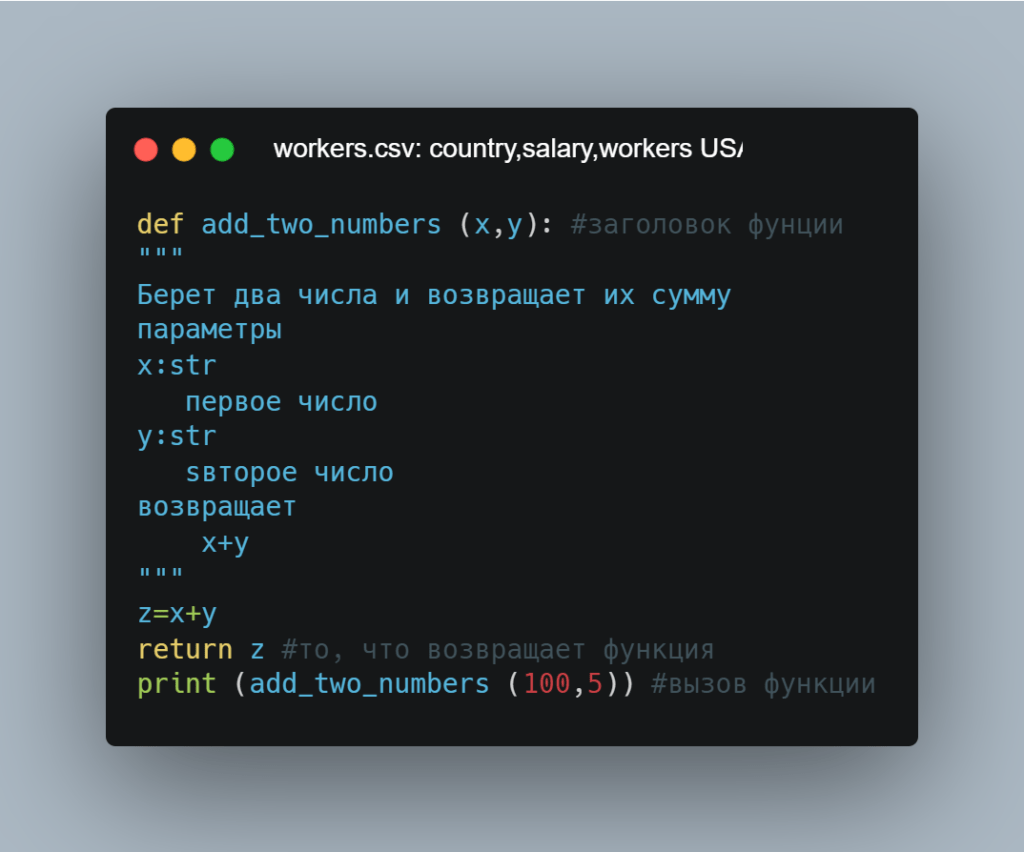
Функции также могут быть анонимными — в них не нужно расписывать всю структуру, указанную выше. Вместо этого можно использовать ключевое слово lambda. Вот та же функция, что и выше, но записанная как анонимная:

Итоги
Пришло время перейти на Python. Больше нет оправданий! Я надеюсь, что эта статья помогла увидеть все преимущества Python и развеять сомнения.
xlwings — Make Excel fly with Python!
xlwings (Open Source)
xlwings is a BSD-licensed Python library that makes it easy to call Python from Excel and vice versa:
- Scripting: Automate/interact with Excel from Python using a syntax that is close to VBA.
- Macros: Replace your messy VBA macros with clean and powerful Python code.
- UDFs: Write User Defined Functions (UDFs) in Python (Windows only).
Numpy arrays and Pandas Series/DataFrames are fully supported. xlwings-powered workbooks are easy to distribute and work
on Windows and macOS.
xlwings includes all files in the xlwings package except the pro folder, i.e., the xlwings.pro subpackage.
xlwings PRO
xlwings PRO offers additional functionality on top of xlwings (Open Source), including:
- xlwings Server: No local Python installation required, supports Excel on the web and Google Sheets in addition to Excel on Windows and macOS. Integrates with VBA, Office Scripts and Office.js and supports custom functions on all platforms.
- xlwings Reports: the flexible, template-based reporting system
- xlwings Reader: A faster and more feature-rich alternative for
pandas.read_excel()(no Excel installation required) - Easy deployment via 1-click installer and embedded code
- See the full list of PRO features
xlwings PRO is source available and dual-licensed under one of the following licenses:
- PolyForm Noncommercial License 1.0.0 (noncommercial use is free)
- xlwings PRO License (commercial use requires a paid plan)
License Key
To use xlwings PRO, you need to install a license key on a Terminal/Command Prompt like so (alternatively, set the env var XLWINGS_LICENSE_KEY:
xlwings license update -k YOUR_LICENSE_KEY
See the docs for more details.
License key for noncommercial purpose:
- To use xlwings PRO for free in a noncommercial context, use the following license key:
noncommercial.
License key for commercial purpose:
- To try xlwings PRO for free in a commercial context, request a trial license key: https://www.xlwings.org/trial
- To use xlwings PRO in a commercial context beyond the trial, you need to enroll in a paid plan (they include additional services like support and the ability to create one-click installers): https://www.xlwings.org/pricing
xlwings PRO licenses are developer licenses, are verified offline (i.e., no telemetry/license server involved) and allow royalty-free deployments to unlimited internal and external end-users and servers for a hassle-free management. Deployments use deploy keys that don’t expire but instead are bound to a specific version of xlwings.
Links
- Homepage: https://www.xlwings.org
- Quickstart: https://docs.xlwings.org/en/stable/quickstart.html
- Documentation: https://docs.xlwings.org
- Book (O’Reilly, 2021): https://www.xlwings.org/book
- Video Course: https://training.xlwings.org/p/xlwings
- Source Code: https://github.com/xlwings/xlwings
xltrail
The Excel files are also tracked with xltrail. You can see the diffs
here.
Добрый день, господа и дамы.
Так вышло, что изучать программирование я начал полтора года назад из-за необходимости автоматизации процессов на работе. Первым языком, с которым я познакомился, был Visual Basic for Applications (или VBA). Вы можете посмеяться, сказать, что VBA нельзя отнести к полноценным языкам программирования. Спорить не буду.
Я изучал VBA самостоятельно и добился, без преувеличения, неплохих успехов. Так как главной страстью моей жизни были и остаются видеоигры, то изучать язык я начал с их разработки. Знаю, это звучит странно, но игры в Excel — вполне реальная вещь. Я очень много раз рассказывал про человека, который сделал в Excel полноценный ретро-шутер, основанный на рейкастинге.
Ссылка на сайт проекта:
В свое время я написал несколько статей, которые были посвящены разработке игр в Excel с использованием VBA:
Все, что я создавал — это просто наработки. Я брал какую-нибудь идею и реализовывал ее в Excel, но никогда не доводил до конца.
В один прекрасный момент я решил разработать полноценную игру. Я создал паблик ВК для публикации отчетов и начал писать игровой движок. Преуспел ли я в этом? Не сильно. Базовыми функциями движок обладал, но дальше этого дело не продвинулось. Моя идея умерла, едва успев родиться.
Это случилось из-за того, что я перестал видеть перспективы. Сперва я двигался вперед, чтобы изучать язык, новые алгоритмы, основы игростроения, но в какой-то момент задумался о выходе в свет и монетизации своей работы. Понятное дело, что разработанная в Excel игра никому нужна не будет, кроме создателя.
Я забросил проект и стал размышлять о том, на какую платформу перейти. Параллельно с VBA я изучал C#, поэтому первым делом решил попробовать себя в Unity или использовать фреймворк MonoGame (на нем, к примеру, написана Stardew Valley). Достаточно быстро я отбросил эту мысль. Использовать готовые движки не хотелось по причине того, что это скучно, а C# я не знал настолько хорошо, чтобы писать на нем свой собственный движок.
Размышления затянулись на несколько месяцев. Я постоянно возвращался к идее закончить проект в Excel, метался между различными вариантами, но не мог определиться. Так продолжалось до тех пор, пока мой друг, который никогда в жизни не программировал, сказал, что изучает Python.
Я слышал много отзывов об этом языке, и не всегда они были положительные, но на следующий день я скачал IDE и приступил к разработке.
По поводу Python скажу немного:
- Это самый простой язык, с которым я имел дело. На усвоение базы у меня ушло три дня дня. Без шуток.
- Для Python есть очень много легко подключаемых библиотек. Из этого следует, что многие алгоритмы не надо писать с нуля.
- В языке немного странное объектно-ориентированное программирование. Например, инкапсуляция присутствует только номинально. Конечно, когда разрабатываешь в одиночку, можно обойтись и без этого, но факт есть факт.
Возможности текущей версии движка
Первым делом я подключил библиотеку PyGame. Она похожа на MonoGame для C#, но имеет меньше функций. Например, разработка 3D игры с этой библиотекой практически невозможна, что для, меня, однако, не является минусом.
Я прочитал несколько мануалов, нашел официальную документацию и за 15 дней написал скелет игрового движка. По состоянию на сегодня он умеет не очень много, а именно:
1. Отображать игровой уровень.
Все уровни состоят из подуровней. Такую разбивку я сделал «смотря сегодня в завтрашний день». На данный момент слабенький ноутбук может отображать в кадре около 400 объектов без задержек, а достаточно мощный компьютер около 750. В будущем этот показатель будет ухудшаться из-за новых вычислений. При этом, если все объекты находятся на пределами кадра, то задержки отсутствуют.
Каждый объект происходит от базового объекта, который имеет ряд параметров (обязательные: тип, ширина, высота, состояние анимации, путей и т.д.; необязательные: имя анимации, направление и т.д.). Базовые объекты прописаны в файле Obj.thconf. Они едины для всей игры.
Подчиненные объекты прописаны в файлах подуровней с расширением thmap. Могу же я придумать свои собственные расширения текстовых файлов, как настоящий разработчик=). Они тоже имеют собственные параметры (положение X, положение Y, слой, параметры анимации, параметры путей и т.д.). Все параметры базового объекта можно переопределить в подчиненном объекте.
Например, обычный объект пола представлен в следующем виде.
Базовый объект:
_START _DEFAULT_FLOOR
anim_name _F_GRASS_ANIM
type floor
width 64
height 64
solid 0
direction 0
anim_state 0
path_state 0
_END _DEFAULT_FLOOR
Подчиненный объект:
_START _DEFAULT_FLOOR
x 128
y 128
layer 1
anim_state 1
anim_speed 5
anim_cycle 1
anim_dir 1
path_state 1
path _PL_PATH
_END _DEFAULT_FLOOR
Не утверждаю, что все сделал правильно, но мне кажется, что такая система поможет ускорить разработку в будущем.
Все объекты отображаются на экране исходя из размера игровой камеры. Данные о камерах уровня хранятся в файлах CAM.thcam.
2. Анимировать объекты.
Анимация объекта зависит от прописанных в файле Anim.thconf последовательностей анимации, а также направления объекта на плоскости. Все последовательности представлены в следующем формате:
_START _ANIM_PL
1 P_DOWN_1
1 P_DOWN_2
1 P_DOWN_3
3 P_UP_1
3 P_UP_2
3 P_UP_3
_END _ANIM_PL
Цифры перед наименованиями отдельных кадров определяют последовательность анимации для конкретного направления объекта. Анимация может быть зацикленная (например, для движения персонажа), однонаправленная (к примеру, открытие двери), со стандартной отрисовкой кадров или реверсивная.
3. Двигать объекты.
Движение объекта реализовано с использованием полярной системы координат. Когда включается движение конкретного объекта, то нужная функция принимает радиус, направление и скорость (единицы в секунду).
4. Передвигать объекты в соответствии с установленным путем движения.
Все пути движения для объектов указанного уровня прописаны в файлах PATH.thpath в следующем формате.
_START _PL_PATH
1
64 90 32
64 45 32
64 225 32
64 270 32
64 314 64
64 134 64
_END _PL_PATH
Первое число определяет тип пути (циклический или однонаправленный), следующие последовательности определяют радиус, направление и скорость.
Пример
Для теста графического движка я беру (краду) бесплатные спрайты с различных сайтов. На следующем видео оба объекта используют почти все текущие возможности движка (анимация, движение, пути).
Планы
Так как это мой первый опыт разработки подобного движка, то сам процесс хаотичный. Несмотря на это, у меня есть несколько фич, которые я хочу добавить в ближайшее время:
1. Система коллизий (столкновение объектов).
2. Триггеры (например, переход между уровнями, открытие дверей).
3. Из предыдущего пункта следует создание скриптов для подобных действий.
4. Создание системы поиска объекта (например, для обнаружения игрока)
5. Создание системы контролируемых персонажей.
Самое важное — это создание редактора уровней в будущем. Без редактора прописывать объекты с десятками параметров будет сложно.
Следующий важный пункт — поиск людей для помощи в создании спрайтов и звукового сопровождения. На данном этапе это не так важно, потому что движок еще не готов. Возможно, я бы и сам справился с этой задачей, но иногда лучше довериться профессионалам.
Итого
На данный момент реализовано не так много, но предпосылки создания полноценного движка присутствуют. Движок я пишу для своих целей, поэтому он не будет универсальным.
В свое время, когда еще занимался изобретением велосипедов в Excel, я создал паблик ВК и наполнял его информацией о процессе разработки. Сейчас я перепрофилировал его под текущий проект.
Если кто заинтересовался, прошу, проходите по ссылке и вступайте в группу.
На этой ноте я покидаю вас на неопределенный срок. Спасибо за внимание!
Многие потенциальные пользователи pandas имеют некоторое представление о программах для работы с электронными таблицами, такими как Excel. На этой странице приведены примеры того, как выполняются различные операции с электронными таблицами с помощью pandas. На этой странице используется терминология Excel и ссылки на документацию Excel, но многое похожим образом делается в Google Таблицах, LibreOffice Calc, Apple Numbers и в другом программном обеспечении для работы с электронными таблицами, совместимом с Excel.
Если вы новичок в pandas, вы можете сначала прочитать 10 Minutes to pandas, чтобы ознакомиться с библиотекой.
Как обычно, импортируем pandas и NumPy следующим образом:
In [1]: import pandas as pd In [2]: import numpy as np
Структуры данных¶
Перевод общей терминологии¶
|
pandas |
Excel |
|---|---|
|
DataFrame |
лист |
|
Series |
столбец |
|
Index |
заголовки строк |
|
строка |
строка |
|
NaN |
пустая ячейка |
DataFrame¶
DataFrame в pandas аналогичен листу в Excel. В то время как книга Excel может содержать несколько листов, DataFrame в pandas существуют независимо друг от друга.
Series¶
Series — это структура данных, представляющая один столбец DataFrame. Работа с Series аналогична работе со столбцом электронной таблицы.
Index¶
У каждого DataFrame и Series есть Index, который является меткой для строк данных. В pandas, если индекс не указан, по умолчанию используется RangeIndex (первая строка = 0, вторая строка = 1 и так далее), аналогично заголовкам или номерам строк в электронных таблицах.
В pandas индекс можно установить на одно или несколько уникальных значений, что похоже на наличие столбца, который используется в качестве идентификатора строки на листе. В отличие от большинства электронных таблиц, эти значения Index могут фактически использоваться для ссылки на строки. (Обратите внимание, это можно сделать в Excel со структурированными ссылками.) Например, в электронных таблицах вы бы ссылались на первую строку как A1:Z1, а в pandas бы использовали populations.loc['Chicago'].
Значения индекса постоянны, поэтому, если вы измените порядок строк в DataFrame, метка для конкретной строки не изменится.
См. документацию по индексированию, чтобы узнать больше о том, как эффективно использовать Index.
Копии и операции на месте¶
Большинство операций pandas возвращают копии Series и DataFrame. Чтобы зафиксировать изменения, вам нужно либо назначить новую переменную:
sorted_df = df.sort_values("col1")
Либо перезаписать исходный объект:
df = df.sort_values("col1")
Примечание
Вы можете столкнуться с аргументом inplace=True, доступным для некоторых методов:
df.sort_values("col1", inplace=True)
Мы не рекомендуем его использовать.
Ввод и вывод данных¶
Построение DataFrame из значений¶
В электронной таблице значения можно вводить непосредственно в ячейки.
DataFrame в pandas можно создать разными способами, но для небольшого количества значений часто бывает удобно указать его как словарь Python, где ключи — это имена столбцов, а значения — это данные.
In [3]: df = pd.DataFrame({"x": [1, 3, 5], "y": [2, 4, 6]}) In [4]: df Out[4]: x y 0 1 2 1 3 4 2 5 6
Чтение данных из внешних источников¶
И Excel, и pandas могут импортировать данные из разных источников в разных форматах.
CSV¶
Давайте загрузим из тестов pandas и отобразим набор данных tips в формате CSV. В Excel вам нужно загрузить, а затем открыть файл CSV. В pandas вы передаете URL-адрес или локальный путь файла CSV в read_csv():
In [5]: url = ( ...: "https://raw.github.com/pandas-dev" ...: "/pandas/main/pandas/tests/io/data/csv/tips.csv" ...: ) ...: In [6]: tips = pd.read_csv(url) In [7]: tips Out[7]: total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 29.03 5.92 Male No Sat Dinner 3 240 27.18 2.00 Female Yes Sat Dinner 2 241 22.67 2.00 Male Yes Sat Dinner 2 242 17.82 1.75 Male No Sat Dinner 2 243 18.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Подобно Мастеру импорта текста Excel, read_csv в pandas принимает ряд параметров, которые позволяют указать, как нужно проанализировать данные. Например, если бы данные были разделены табуляцией и не имели имен столбцов, команда pandas была бы такой:
tips = pd.read_csv("tips.csv", sep="t", header=None) # alternatively, read_table is an alias to read_csv with tab delimiter tips = pd.read_table("tips.csv", header=None)
Файлы Excel¶
Excel открывает файлы различных форматов Excel двойным щелчком мыши или через меню Открыть. В pandas используются специальные методы для чтения и записи файлов Excel.
Давайте сначала создадим новый файл Excel на основе данных tips из приведенного выше примера:
tips.to_excel("./tips.xlsx")
Если вы хотите впоследствии получить доступ к данным в файле tips.xlsx, вы можете прочитать его так:
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
Вы только что прочитали файл Excel с помощью pandas!
Ограничение вывода¶
Программы для работы с электронными таблицами отображают данные, которые помещаются на экране, а затем позволяют прокручивать их, так что на самом деле нет необходимости ограничивать вывод. В pandas приходится подумать о том, как отображаются DataFrame.
По умолчанию pandas обрезает вывод больших DataFrame, чтобы показать первую и последнюю строки. Это можно переопределить, изменив параметры pandas или используя DataFrame.head() или DataFrame.tail().
In [8]: tips.head(5) Out[8]: total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
Экспорт данных¶
По умолчанию программное обеспечение для работы с электронными таблицами сохраняет файлы в соответствующем формате (.xlsx, .ods и т. д.). Однако вы можете сохранить файл в другом формате.
pandas может создавать файлы Excel, CSV и файлы других форматов.
Операции с данными¶
Операции над столбцами¶
В электронных таблицах формулы часто создаются в отдельных ячейках. а затем перетаскиваются в другие ячейки, чтобы применить аналогичные операции ко всем ячейкам в столбце. В pandas вы можете напрямую выполнять операции над целыми столбцами.
pandas обеспечивает векторизованные операции, указывая отдельные Series в DataFrame. Таким же образом можно назначить новые столбцы. Метод DataFrame.drop() удаляет столбец из DataFrame.
In [9]: tips["total_bill"] = tips["total_bill"] - 2 In [10]: tips["new_bill"] = tips["total_bill"] / 2 In [11]: tips Out[11]: total_bill tip sex smoker day time size new_bill 0 14.99 1.01 Female No Sun Dinner 2 7.495 1 8.34 1.66 Male No Sun Dinner 3 4.170 2 19.01 3.50 Male No Sun Dinner 3 9.505 3 21.68 3.31 Male No Sun Dinner 2 10.840 4 22.59 3.61 Female No Sun Dinner 4 11.295 .. ... ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 13.515 240 25.18 2.00 Female Yes Sat Dinner 2 12.590 241 20.67 2.00 Male Yes Sat Dinner 2 10.335 242 15.82 1.75 Male No Sat Dinner 2 7.910 243 16.78 3.00 Female No Thur Dinner 2 8.390 [244 rows x 8 columns] In [12]: tips = tips.drop("new_bill", axis=1)
Обратите внимание, что нам не пришлось выполнять вычитание по ячейкам — pandas сделал это за нас. См. как создать новые столбцы, производные от существующих столбцов.
Фильтрация¶
В Excel фильтрация осуществляется через графическое меню.
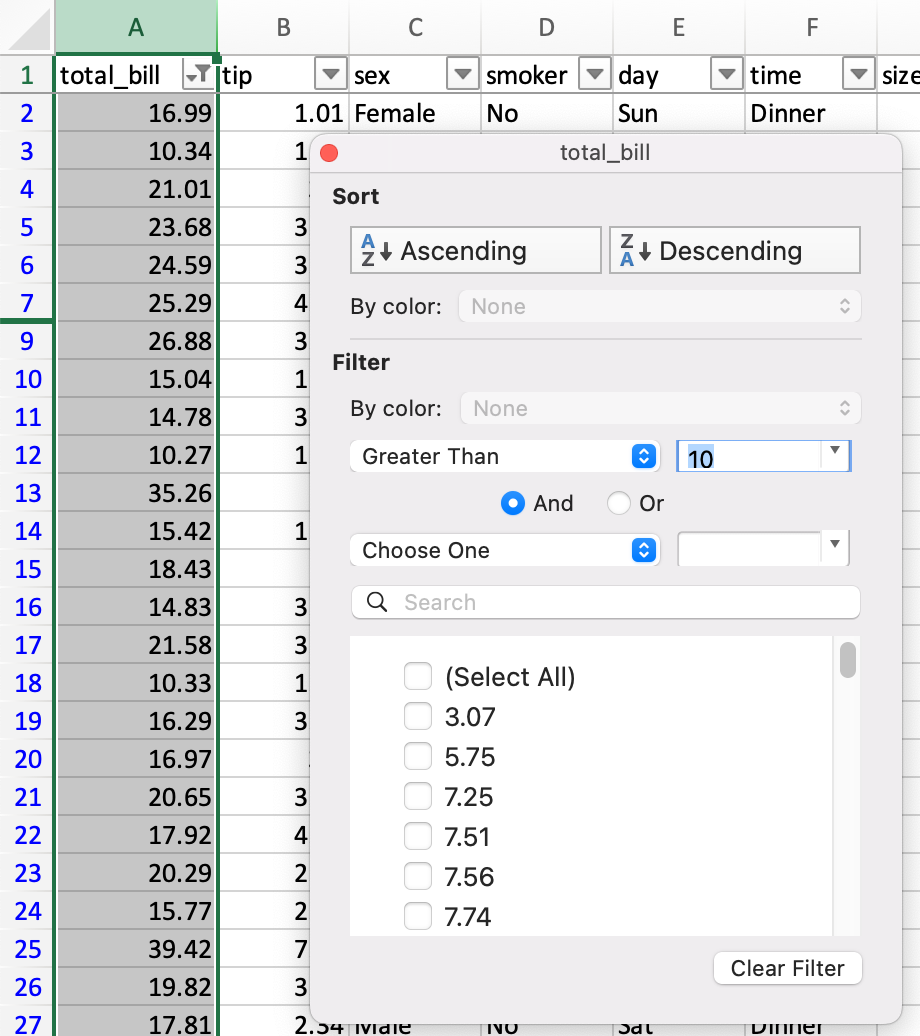
DataFrame можно фильтровать несколькими способами; наиболее интуитивным из них является использование логического индексирования.
In [13]: tips[tips["total_bill"] > 10] Out[13]: total_bill tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 5 23.29 4.71 Male No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [204 rows x 7 columns]
Вышеприведенный оператор просто передает Series объектов True и False в DataFrame, возвращая все строки с True.
In [14]: is_dinner = tips["time"] == "Dinner" In [15]: is_dinner Out[15]: 0 True 1 True 2 True 3 True 4 True ... 239 True 240 True 241 True 242 True 243 True Name: time, Length: 244, dtype: bool In [16]: is_dinner.value_counts() Out[16]: True 176 False 68 Name: time, dtype: int64 In [17]: tips[is_dinner] Out[17]: total_bill tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 1 8.34 1.66 Male No Sun Dinner 3 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [176 rows x 7 columns]
Логика if/then¶
Допустим, мы хотим создать столбец bucket со значениями low и high, в зависимости от того, меньше или больше 10 долларов значение в total_bill.
В электронных таблицах логическое сравнение можно выполнить с помощью условных формул. Мы бы использовали формулу =IF(A2 < 10, "low", "high"), перетащив ее во все ячейки в новом столбце bucket.
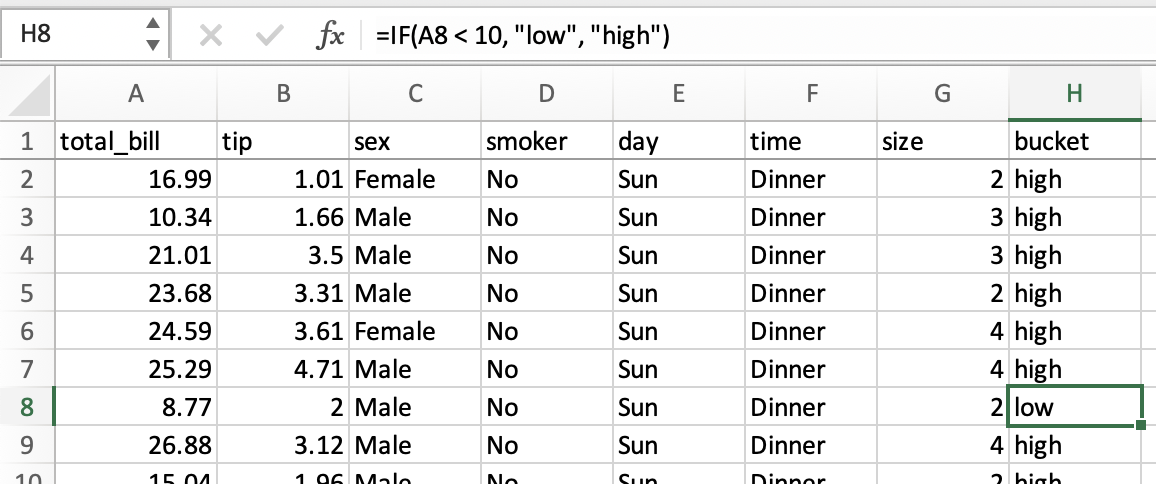
Ту же операцию в pandas можно выполнить с использованием метода where из numpy.
In [18]: tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high") In [19]: tips Out[19]: total_bill tip sex smoker day time size bucket 0 14.99 1.01 Female No Sun Dinner 2 high 1 8.34 1.66 Male No Sun Dinner 3 low 2 19.01 3.50 Male No Sun Dinner 3 high 3 21.68 3.31 Male No Sun Dinner 2 high 4 22.59 3.61 Female No Sun Dinner 4 high .. ... ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 high 240 25.18 2.00 Female Yes Sat Dinner 2 high 241 20.67 2.00 Male Yes Sat Dinner 2 high 242 15.82 1.75 Male No Sat Dinner 2 high 243 16.78 3.00 Female No Thur Dinner 2 high [244 rows x 8 columns]
Функциональность даты¶
В этом разделе будут упоминаться «даты», но метки времени обрабатываются аналогичным образом.
Функционал даты можно разделить на две части: синтаксический анализ и вывод. В электронных таблицах значения даты обычно анализируются автоматически, хотя существует функция DATEVALUE. В pandas вам нужно явно преобразовать обычный текст в объекты даты и времени, либо при чтении из CSV, либо в DataFrame.
После анализа электронные таблицы отображают даты в формате по умолчанию, хотя формат можно изменить. В pandas при вычислениях над датами их обычно хранят как объекты datetime. Вывод частей дат (например, года) осуществляется в электронных таблицах с помощью функций даты, а в pandas с помощью свойств datetime.
Учитывая date1 и date2 в столбцах A и B электронной таблицы, у вас могут быть следующие формулы:
|
столбец |
формула |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Эквивалентные операции pandas показаны ниже.
In [20]: tips["date1"] = pd.Timestamp("2013-01-15") In [21]: tips["date2"] = pd.Timestamp("2015-02-15") In [22]: tips["date1_year"] = tips["date1"].dt.year In [23]: tips["date2_month"] = tips["date2"].dt.month In [24]: tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin() In [25]: tips["months_between"] = tips["date2"].dt.to_period("M") - tips[ ....: "date1" ....: ].dt.to_period("M") ....: In [26]: tips[ ....: ["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"] ....: ] ....: Out[26]: date1 date2 date1_year date2_month date1_next months_between 0 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 1 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 2 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 3 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 4 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> .. ... ... ... ... ... ... 239 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 240 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 241 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 242 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 243 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> [244 rows x 6 columns]
См. более подробную информацию в разделе Time series / date functionality.
Выбор столбцов¶
В электронных таблицах вы можете выбрать нужные столбцы:
-
Скрытие столбцов
-
Удаление столбцов
-
Ссылка на диапазон с одного листа на другой
Поскольку столбцы электронной таблицы обычно именуются в строке заголовка, переименование столбца — это просто изменение текста в заголовочной ячейке.
Аналогичные операции в pandas продемонстрированы ниже.
Сохранить определенные столбцы¶
In [27]: tips[["sex", "total_bill", "tip"]] Out[27]: sex total_bill tip 0 Female 14.99 1.01 1 Male 8.34 1.66 2 Male 19.01 3.50 3 Male 21.68 3.31 4 Female 22.59 3.61 .. ... ... ... 239 Male 27.03 5.92 240 Female 25.18 2.00 241 Male 20.67 2.00 242 Male 15.82 1.75 243 Female 16.78 3.00 [244 rows x 3 columns]
Удалить столбец¶
In [28]: tips.drop("sex", axis=1) Out[28]: total_bill tip smoker day time size 0 14.99 1.01 No Sun Dinner 2 1 8.34 1.66 No Sun Dinner 3 2 19.01 3.50 No Sun Dinner 3 3 21.68 3.31 No Sun Dinner 2 4 22.59 3.61 No Sun Dinner 4 .. ... ... ... ... ... ... 239 27.03 5.92 No Sat Dinner 3 240 25.18 2.00 Yes Sat Dinner 2 241 20.67 2.00 Yes Sat Dinner 2 242 15.82 1.75 No Sat Dinner 2 243 16.78 3.00 No Thur Dinner 2 [244 rows x 6 columns]
Переименовать столбец¶
In [29]: tips.rename(columns={"total_bill": "total_bill_2"}) Out[29]: total_bill_2 tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 1 8.34 1.66 Male No Sun Dinner 3 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Сортировка по значениям¶
Сортировка в электронных таблицах осуществляется с помощью диалогового окна сортировки.
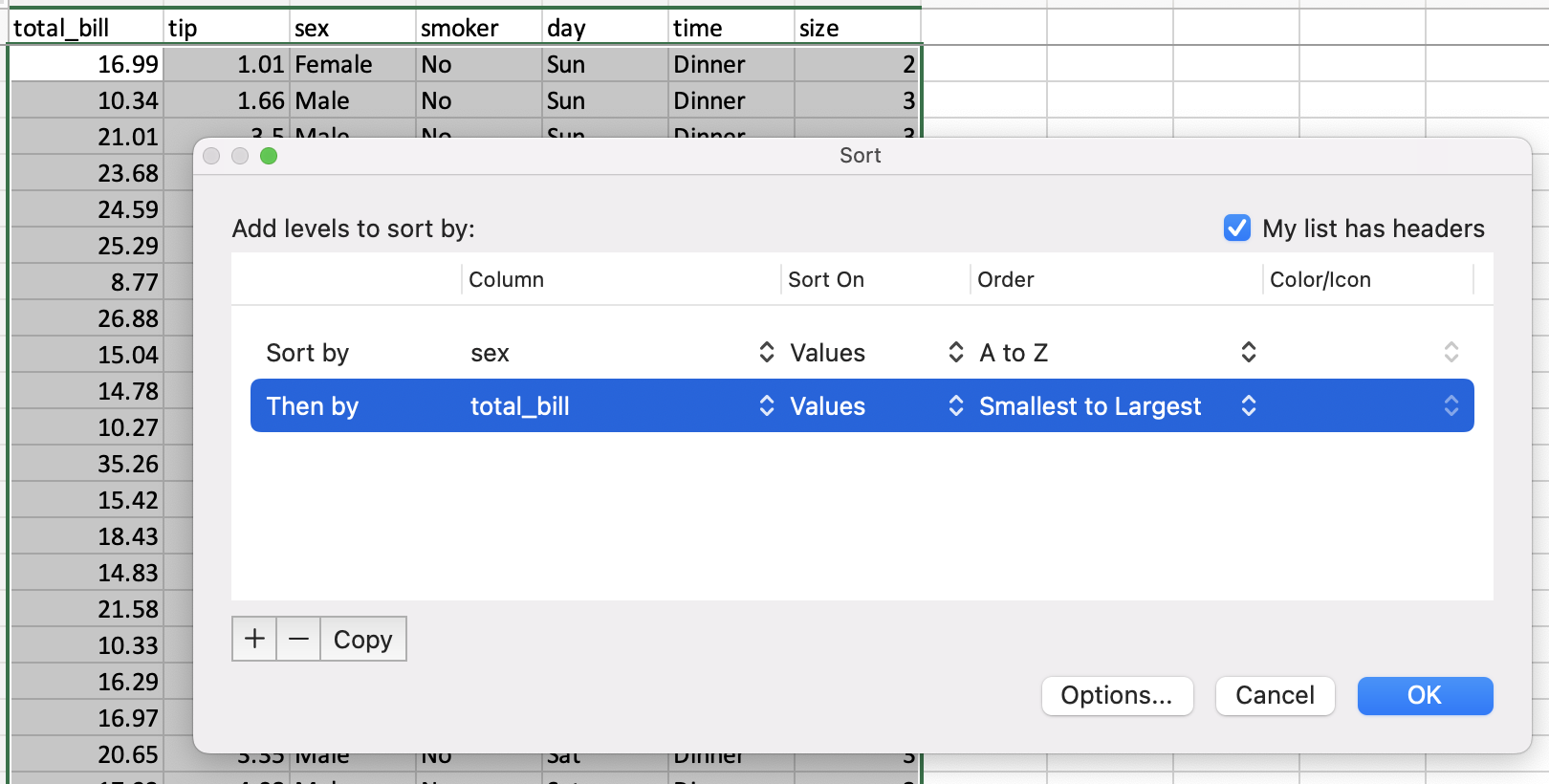
У pandas есть метод DataFrame.sort_values(), который принимает список столбцов для сортировки.
In [30]: tips = tips.sort_values(["sex", "total_bill"]) In [31]: tips Out[31]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns]
Обработка строк¶
Нахождение длины строки¶
В электронных таблицах количество символов в тексте можно узнать с помощью функции LEN. Ее можно использовать вместе с функцией TRIM, если нужно удалить лишние пробелы.
Вы можете узнать длину строки символов с помощью Series.str.len(). В Python 3 все строки являются строками Unicode. len включает конечные пробелы. Используйте len и rstrip, чтобы исключить пробелы в конце.
In [32]: tips["time"].str.len() Out[32]: 67 6 92 6 111 6 145 5 135 5 .. 182 6 156 6 59 6 212 6 170 6 Name: time, Length: 244, dtype: int64 In [33]: tips["time"].str.rstrip().str.len() Out[33]: 67 6 92 6 111 6 145 5 135 5 .. 182 6 156 6 59 6 212 6 170 6 Name: time, Length: 244, dtype: int64
Обратите внимание, что в этом случае множественные пробелы внутри строки останутся, так что функции эквивалентны не на 100%.
Поиск позиции подстроки¶
Функция электронной таблицы FIND возвращает позицию подстроки с первым символ 1.
В pandas вы можете найти положение символа в столбце строк с помощью метода Series.str.find(). find ищет первую позицию подстроки. Если подстрока найдена, метод возвращает ее позицию. Если не найдена, возвращается -1. Имейте в виду, что индексы Python отсчитываются от нуля.
In [34]: tips["sex"].str.find("ale") Out[34]: 67 3 92 3 111 3 145 3 135 3 .. 182 1 156 1 59 1 212 1 170 1 Name: sex, Length: 244, dtype: int64
Изменение регистра¶
В электронных таблицах есть функции UPPER, LOWER и PROPER для преобразование текста в верхний, нижний и заглавный регистр соответственно.
Эквивалентные методы pandas: Series.str.upper(), Series.str.lower() и Series.str.title().
In [40]: firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]}) In [41]: firstlast["upper"] = firstlast["string"].str.upper() In [42]: firstlast["lower"] = firstlast["string"].str.lower() In [43]: firstlast["title"] = firstlast["string"].str.title() In [44]: firstlast Out[44]: string upper lower title 0 John Smith JOHN SMITH john smith John Smith 1 Jane Cook JANE COOK jane cook Jane Cook
Объединение¶
В примерах объединения будут использоваться следующие таблицы:
In [45]: df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)}) In [46]: df1 Out[46]: key value 0 A 0.469112 1 B -0.282863 2 C -1.509059 3 D -1.135632 In [47]: df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)}) In [48]: df2 Out[48]: key value 0 B 1.212112 1 D -0.173215 2 D 0.119209 3 E -1.044236
В Excel объединение таблиц можно выполнить с помощью функции VLOOKUP.
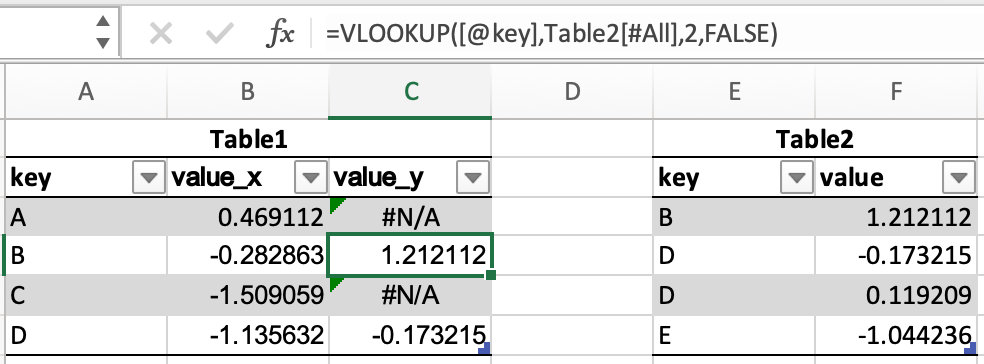
В pandas есть метод DataFrame.merge, который обеспечивает аналогичную функциональность. Данные не нужно сортировать заранее, а различные типы объединений выполняются с помощью ключевого слова how.
In [49]: inner_join = df1.merge(df2, on=["key"], how="inner") In [50]: inner_join Out[50]: key value_x value_y 0 B -0.282863 1.212112 1 D -1.135632 -0.173215 2 D -1.135632 0.119209 In [51]: left_join = df1.merge(df2, on=["key"], how="left") In [52]: left_join Out[52]: key value_x value_y 0 A 0.469112 NaN 1 B -0.282863 1.212112 2 C -1.509059 NaN 3 D -1.135632 -0.173215 4 D -1.135632 0.119209 In [53]: right_join = df1.merge(df2, on=["key"], how="right") In [54]: right_join Out[54]: key value_x value_y 0 B -0.282863 1.212112 1 D -1.135632 -0.173215 2 D -1.135632 0.119209 3 E NaN -1.044236 In [55]: outer_join = df1.merge(df2, on=["key"], how="outer") In [56]: outer_join Out[56]: key value_x value_y 0 A 0.469112 NaN 1 B -0.282863 1.212112 2 C -1.509059 NaN 3 D -1.135632 -0.173215 4 D -1.135632 0.119209 5 E NaN -1.044236
merge имеет ряд преимуществ перед VLOOKUP:
-
Искомое значение не обязательно должно быть в первом столбце таблицы поиска.
-
Если совпадают несколько строк, своя строка будет для каждого совпадения, а не только для первого.
-
Включаются все столбцы из таблицы поиска, а не только указанный столбец.
-
Поддерживаются более сложные операции объединения.
Другие соображения¶
Заполнение ячеек¶
Создайте ряд чисел по заданному шаблону в определенном наборе ячеек. В электронной таблице это можно сделать с помощью Shift + перетаскивания после ввода первого числа, или же путем ввода первых двух или трех значений с последующим перетаскиванием.
В pandas этого можно добиться, создав Series и назначив его нужным ячейкам.
In [57]: df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))}) In [58]: df Out[58]: AAA BBB 0 1 0 1 1 1 2 1 2 3 1 3 4 1 4 5 1 5 6 1 6 7 1 7 In [59]: series = list(range(1, 5)) In [60]: series Out[60]: [1, 2, 3, 4] In [61]: df.loc[2:5, "AAA"] = series In [62]: df Out[62]: AAA BBB 0 1 0 1 1 1 2 1 2 3 2 3 4 3 4 5 4 5 6 1 6 7 1 7
Удаление дубликатов¶
Excel имеет встроенную функцию удаления повторяющихся значений. Аналогичный функционал поддерживается в pandas с drop_duplicates().
In [63]: df = pd.DataFrame( ....: { ....: "class": ["A", "A", "A", "B", "C", "D"], ....: "student_count": [42, 35, 42, 50, 47, 45], ....: "all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"], ....: } ....: ) ....: In [64]: df.drop_duplicates() Out[64]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes In [65]: df.drop_duplicates(["class", "student_count"]) Out[65]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes
Сводные таблицы¶
Сводные таблицы из электронных таблиц могут быть реплицированы в pandas, см. изменение формы и сводные таблицы. Снова используя набор данных tips, давайте найдем среднее вознаграждение в зависимости от масштаба вечеринки и пола официанта.
В Excel мы используем следующую конфигурацию для сводной таблицы:
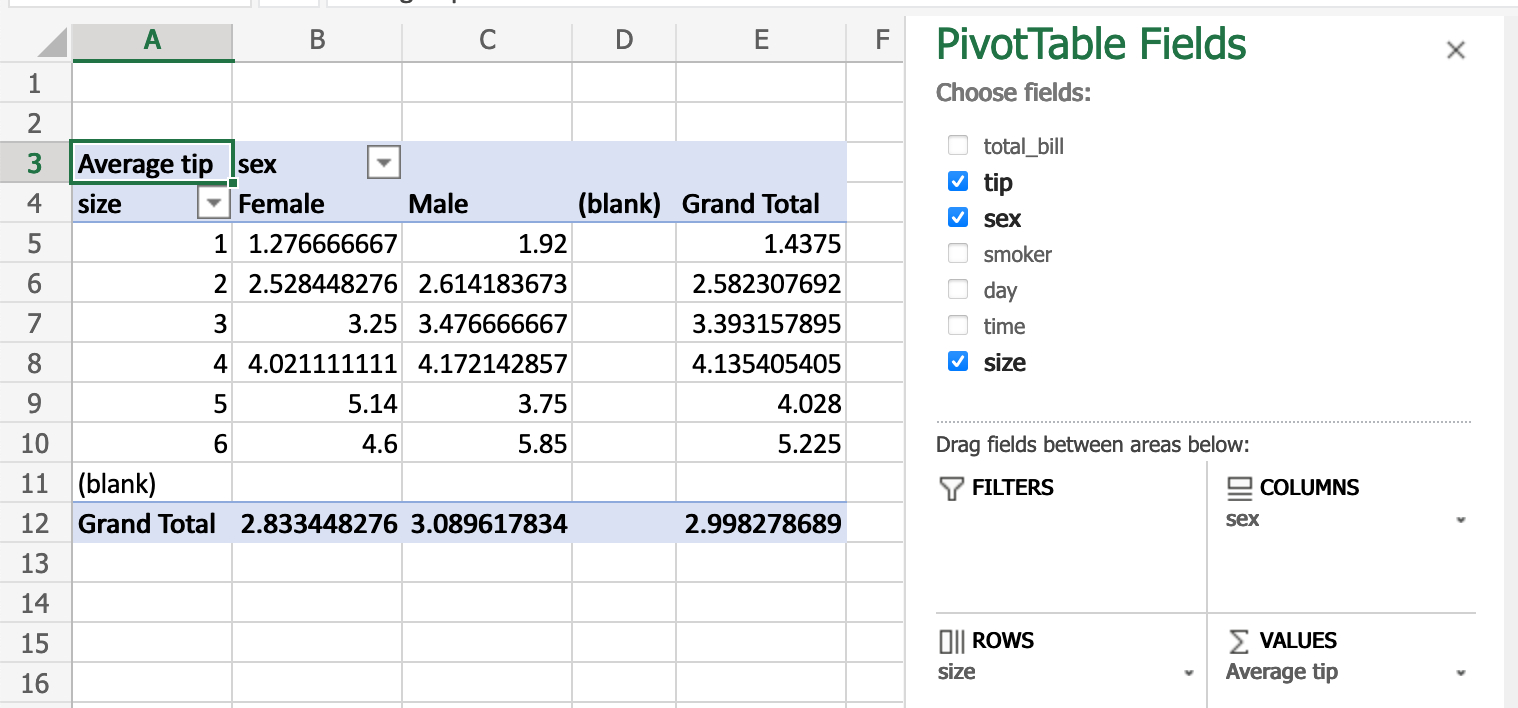
Эквивалент в pandas:
In [66]: pd.pivot_table( ....: tips, values="tip", index=["size"], columns=["sex"], aggfunc=np.average ....: ) ....: Out[66]: sex Female Male size 1 1.276667 1.920000 2 2.528448 2.614184 3 3.250000 3.476667 4 4.021111 4.172143 5 5.140000 3.750000 6 4.600000 5.850000
Добавление строки¶
Предполагая, что мы используем RangeIndex (с номером 0, 1 и т. д.), мы можем использовать concat(), чтобы добавить строку в конец DataFrame.
In [67]: df Out[67]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 2 A 42 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes In [68]: new_row = pd.DataFrame([["E", 51, True]], ....: columns=["class", "student_count", "all_pass"]) ....: In [69]: pd.concat([df, new_row]) Out[69]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 2 A 42 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes 0 E 51 True
Поиск и замена¶
Диалоговое окно поиска Excel показывает вам подходящие ячейки, одну за другой. В pandas эта операция обычно выполняется для всего столбца или DataFrame с помощью условных выражений.
In [70]: tips Out[70]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns] In [71]: tips == "Sun" Out[71]: total_bill tip sex smoker day time size 67 False False False False False False False 92 False False False False False False False 111 False False False False False False False 145 False False False False False False False 135 False False False False False False False .. ... ... ... ... ... ... ... 182 False False False False True False False 156 False False False False True False False 59 False False False False False False False 212 False False False False False False False 170 False False False False False False False [244 rows x 7 columns] In [72]: tips["day"].str.contains("S") Out[72]: 67 True 92 False 111 True 145 False 135 False ... 182 True 156 True 59 True 212 True 170 True Name: day, Length: 244, dtype: bool
Метод replace() в pandas сопоставим с Replace All в Excel.
In [73]: tips.replace("Thu", "Thursday") Out[73]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns]