
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
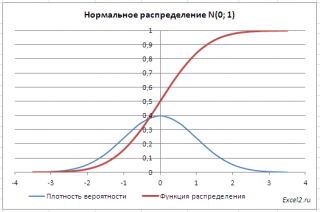
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
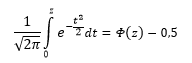
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
Рассмотрим Нормальное распределение. С помощью функции
MS EXCEL
НОРМ.РАСП()
построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения
.
Нормальное распределение
(также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения
Нормального распределения
(англ.
Normal
distribution
)
во многих областях науки вытекает из
Центральной предельной теоремы
теории вероятностей.
Определение
: Случайная величина
x
распределена по
нормальному закону
, если она имеет
плотность распределения
:
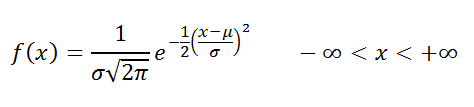
СОВЕТ
: Подробнее о
Функции распределения
и
Плотности вероятности
см. статью
Функция распределения и плотность вероятности в MS EXCEL
.
Нормальное распределение
зависит от двух параметров: μ
(мю)
— является
математическим ожиданием (средним значением случайной величины)
, и σ (
сигма)
— является
стандартным отклонением
(среднеквадратичным отклонением). Параметр μ определяет положение центра
плотности вероятности
нормального распределения
, а σ — разброс относительно центра (среднего).
Примечание
: О влиянии параметров μ и σ на форму распределения изложено в статье про
Гауссову кривую
, а в
файле примера на листе Влияние параметров
можно с помощью
элементов управления Счетчик
понаблюдать за изменением формы кривой.
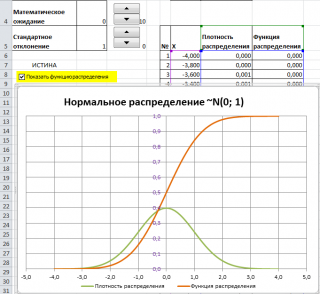
Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для
Нормального распределения
имеется функция
НОРМ.РАСП()
, английское название — NORM.DIST(), которая позволяет вычислить
плотность вероятности
(см. формулу выше) и
интегральную функцию распределения
(вероятность, что случайная величина X, распределенная по
нормальному закону
, примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:
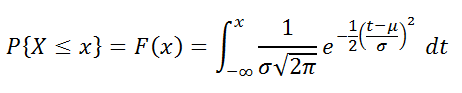
Вышеуказанное распределение имеет обозначение
N
(μ; σ).
Так же часто используют обозначение через
дисперсию
N
(μ; σ
2
).
Примечание
: До MS EXCEL 2010 в EXCEL была только функция
НОРМРАСП()
, которая также позволяет вычислить функцию распределения и плотность вероятности.
НОРМРАСП()
оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением
называется
нормальное распределение
с
математическим ожиданием
μ=0 и
дисперсией
σ=1. Вышеуказанное распределение имеет обозначение
N
(0;1).
Примечание
: В литературе для случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение z.
Любое
нормальное распределение
можно преобразовать в стандартное через замену переменной
z
=(
x
-μ)/σ
. Этот процесс преобразования называется
стандартизацией
.
Примечание
: В MS EXCEL имеется функция
НОРМАЛИЗАЦИЯ()
, которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то
нормализацией
. Формулы
=(x-μ)/σ
и
=НОРМАЛИЗАЦИЯ(х;μ;σ)
вернут одинаковый результат.
В MS EXCEL 2010 для
стандартного нормального распределения
имеется специальная функция
НОРМ.СТ.РАСП()
и ее устаревший вариант
НОРМСТРАСП()
, выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации
нормального распределения
N
(1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по
нормальному закону
N(1,5; 2)
, меньше или равна 2,5. Формула выглядит так:
=НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА)
=0,691462. Сделав замену переменной
z
=(2,5-1,5)/2=0,5
, запишем формулу для вычисления
Стандартного нормального распределения:
=НОРМ.СТ.РАСП(0,5; ИСТИНА)
=0,691462.
Естественно, обе формулы дают одинаковые результаты (см.
файл примера лист Пример
).
Обратите внимание, что
стандартизация
относится только к
интегральной функции распределения
(аргумент
интегральная
равен ИСТИНА), а не к
плотности вероятности
.
Примечание
: В литературе для функции, вычисляющей вероятности случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле
=НОРМ.СТ.РАСП(z;ИСТИНА)
. Вычисления производятся по формуле
![]()
В силу четности функции
плотности стандартного нормального
распределения f(x), а именно f(x)=f(-х), функция
стандартного нормального распределения
обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция
НОРМ.СТ.РАСП(x;ИСТИНА)
вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется
квантилем
стандартного
нормального распределения
.
В MS EXCEL для вычисления
квантилей
используют функцию
НОРМ.СТ.ОБР()
и
НОРМ.ОБР()
.
Графики функций
В
файле примера
приведены
графики плотности распределения
вероятности и
интегральной функции распределения
.
Как известно, около 68% значений, выбранных из совокупности, имеющей
нормальное распределение
, находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% — в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для
стандартного нормального распределения
можно записав формулу:
=
НОРМ.СТ.РАСП(1;ИСТИНА)-НОРМ.СТ.РАСП(-1;ИСТИНА)
которая вернет значение 68,2689% — именно такой процент значений находятся в пределах +/-1 стандартного отклонения от
среднего
(см.
лист График в файле примера
).
В силу четности функции
плотности стандартного нормального
распределения:
f
(
x
)=
f
(-х)
, функция
стандартного нормального распределения
обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
=
2*НОРМ.СТ.РАСП(1;ИСТИНА)-1
Для произвольной
функции нормального распределения
N(μ; σ) аналогичные вычисления нужно производить по формуле:
=2* НОРМ.РАСП(μ+1*σ;μ;σ;ИСТИНА)-1
Вышеуказанные расчеты вероятности требуются для
построения доверительных интервалов
.
Примечание
: Для построения
функции распределения
и
плотности вероятности
можно использовать диаграмму типа
График
или
Точечная
(со сглаженными линиями и без точек). Подробнее о построении
диаграмм
читайте статью
Основные типы диаграмм
.
Примечание
: Для удобства написания формул в
файле примера
созданы
Имена
для параметров распределения: μ и σ.
Генерация случайных чисел
С помощью надстройки
Пакет анализа
можно сгенерировать случайные числа, распределенные по
нормальному закону
.
СОВЕТ
: О надстройке
Пакет анализа
можно прочитать в статье
Надстройка Пакет анализа MS EXCEL
.
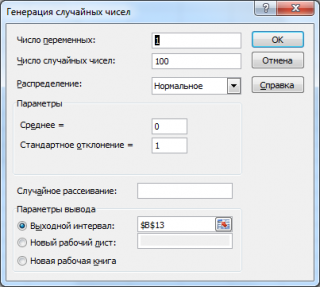
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне
Генерация
случайных чисел
установим следующие значения для каждой пары параметров:
Примечание
: Если установить опцию
Случайное рассеивание
(
Random Seed
), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции
Случайное рассеивание
может запутать. Лучше было бы ее перевести как
Номер набора со случайными числами
.
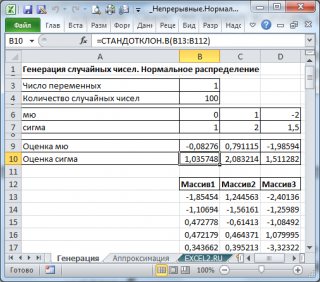
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ
.
Оценку для μ можно сделать с использованием функции
СРЗНАЧ()
, а для σ – с использованием функции
СТАНДОТКЛОН.В()
, см.
файл примера лист Генерация
.
Примечание
: Для генерирования массива чисел, распределенных по
нормальному закону
, можно использовать формулу
=НОРМ.ОБР(СЛЧИС();μ;σ)
. Функция
СЛЧИС()
генерирует
непрерывное равномерное распределение
от 0 до 1, что как раз соответствует диапазону изменения вероятности (см.
файл примера лист Генерация
).
Задачи
Задача1
. Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их.
Решение1
: =
1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2
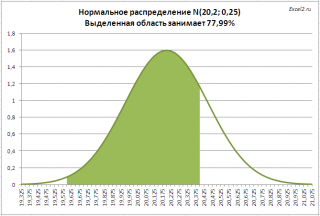
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ?
Решение2
: =
НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25)
На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.
Решение приведено в
файле примера лист Задачи
.
Задача3
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий?
Решение3
: =
НОРМ.ОБР(0,975; 20,20; 0,25)
=20,6899 или =
НОРМ.СТ.ОБР(0,975)*0,25+20,2
(произведена «дестандартизация», см. выше)
Задача 4
. Нахождение параметров
нормального распределения
по значениям 2-х
квантилей
(или
процентилей
). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я
процентиля
(например, 0,5-
процентиль
, т.е. медиана и 0,95-я
процентиль
). Т.к. известна
медиана
, то мы знаем
среднее
, т.е. μ. Чтобы найти
стандартное отклонение
нужно использовать
Поиск решения
. Решение приведено в
файле примера лист Задачи
.
Примечание
: До MS EXCEL 2010 в EXCEL были функции
НОРМОБР()
и
НОРМСТОБР()
, которые эквивалентны
НОРМ.ОБР()
и
НОРМ.СТ.ОБР()
.
НОРМОБР()
и
НОРМСТОБР()
оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин
x
(
i
)
с параметрами μ
(
i
)
и σ
(
i
)
также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ
(1)+ μ(2)
и
КОРЕНЬ(σ(1)^2+ σ(2)^2).
Убедимся в этом с помощью MS EXCEL.
С помощью надстройки
Пакет анализа
сгенерируем 2 массива по 100 чисел с различными μ и σ.
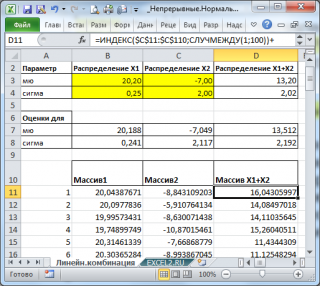
Теперь сформируем массив, каждый элемент которого является суммой 2-х значений, взятых из каждого массива.
С помощью функций
СРЗНАЧ()
и
СТАНДОТКЛОН.В()
вычислим
среднее
и
дисперсию
получившейся
выборки
и сравним их с расчетными.
Кроме того, построим
График проверки распределения на нормальность
(
Normal
Probability
Plot
), чтобы убедиться, что наш массив соответствует выборке из
нормального распределения
.
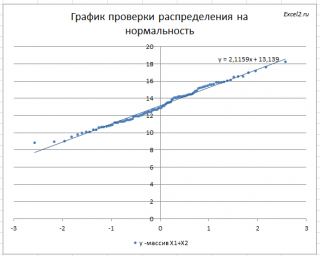
Прямая линия, аппроксимирующая полученный график, имеет уравнение y=ax+b. Наклон кривой (параметр а) может служить оценкой
стандартного отклонения
, а пересечение с осью y (параметр b) –
среднего
значения.
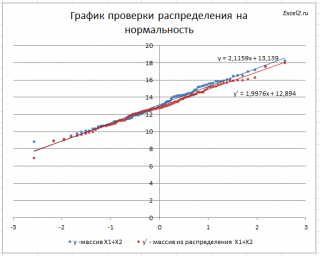
Для сравнения сгенерируем массив напрямую из распределения
N
(μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ σ(2)^2)
).
Как видно на рисунке ниже, обе аппроксимирующие кривые достаточно близки.
В качестве примера можно провести следующую задачу.
Задача
. Завод изготавливает болты и гайки, которые упаковываются в ящики парами. Пусть известно, что вес каждого из изделий является нормальной случайной величиной. Для болтов средний вес составляет 50г, стандартное отклонение 1,5г, а для гаек 20г и 1,2г. В ящик фасуется 100 пар болтов и гаек. Вычислить какой процент ящиков будет тяжелее 7,2 кг.
Решение
. Сначала переформулируем вопрос задачи: Вычислить какой процент пар болт-гайка будет тяжелее 7,2кг/100=72г. Учитывая, что вес пары представляет собой случайную величину = Вес(болта) + Вес(гайки) со средним весом (50+20)г, и
стандартным отклонением
=КОРЕНЬ(СУММКВ(1,5;1,2))
, запишем решение =
1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА)
Ответ
: 15% (см.
файл примера лист Линейн.комбинация
)
Аппроксимация Биномиального распределения Нормальным распределением
Если параметры
Биномиального распределения
B(n;p) находятся в пределах 0,1<=p<=0,9 и n*p>10, то
Биномиальное распределение
можно аппроксимировать
Нормальным распределением
.
При значениях
λ
>15
,
Распределение Пуассона
хорошо аппроксимируется
Нормальным распределением
с параметрами: μ
=λ
, σ
2
=
λ
.
Подробнее о связи этих распределений, можно прочитать в статье
Взаимосвязь некоторых распределений друг с другом в MS EXCEL
. Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ
: О других распределениях MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
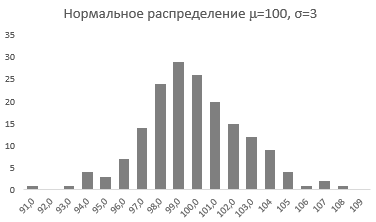
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
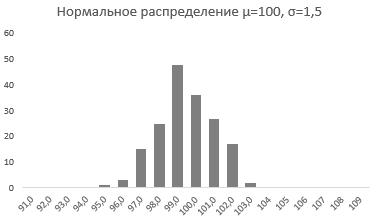
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
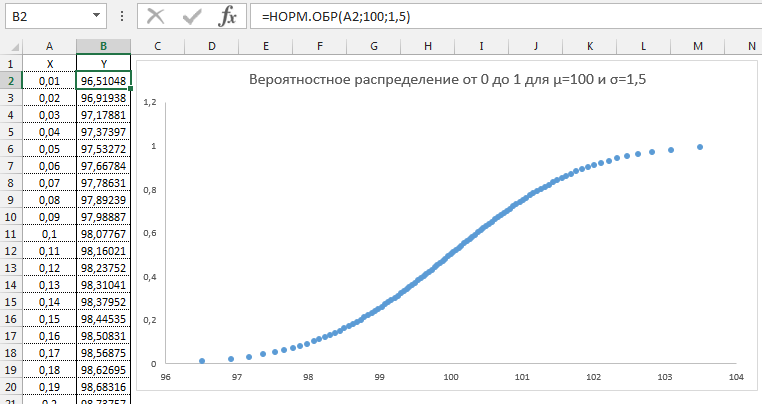
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
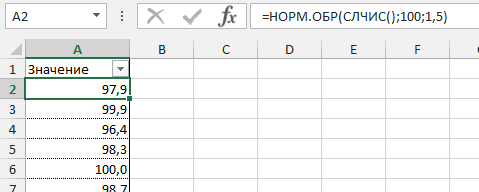
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
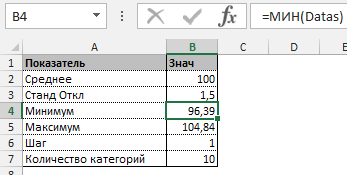
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
=ЕСЛИ(A12;B11+$B$6; «»)
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
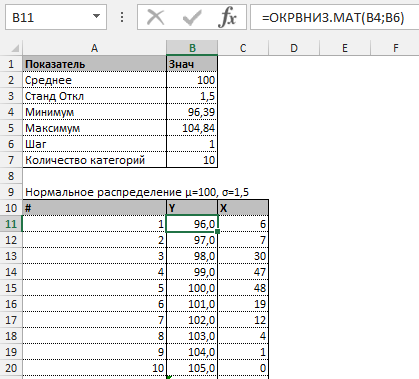
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
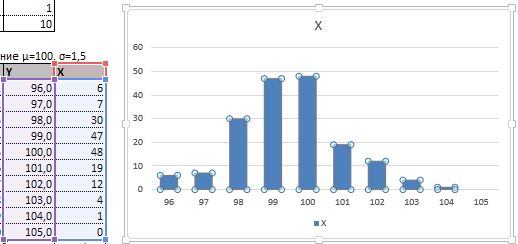
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
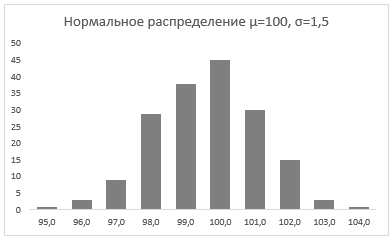
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.

Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Поделиться ссылкой:
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
=ЕСЛИ(A12;B11+$B$6; «»)
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.
Построим диаграмму распределения в Excel. А также рассмотрим подробнее функции круговых диаграмм, их создание.
График нормального распределения имеет форму колокола и симметричен относительно среднего значения. Получить такое графическое изображение можно только при огромном количестве измерений. В Excel для конечного числа измерений принято строить гистограмму.
Внешне столбчатая диаграмма похожа на график нормального распределения. Построим столбчатую диаграмму распределения осадков в Excel и рассмотрим 2 способа ее построения.
Имеются следующие данные о количестве выпавших осадков:
Первый способ. Открываем меню инструмента «Анализ данных» на вкладке «Данные» (если у Вас не подключен данный аналитический инструмент, тогда читайте как его подключить в настройках Excel):
Выбираем «Гистограмма»:
Задаем входной интервал (столбец с числовыми значениями). Поле «Интервалы карманов» оставляем пустым: Excel сгенерирует автоматически. Ставим птичку около записи «Вывод графика»:
После нажатия ОК получаем такой график с таблицей:
В интервалах не очень много значений, поэтому столбики гистограммы получились низкими.
Теперь необходимо сделать так, чтобы по вертикальной оси отображались относительные частоты.
Найдем сумму всех абсолютных частот (с помощью функции СУММ). Сделаем дополнительный столбец «Относительная частота». В первую ячейку введем формулу:
Способ второй. Вернемся к таблице с исходными данными. Вычислим интервалы карманов. Сначала найдем максимальное значение в диапазоне температур и минимальное.
Чтобы найти интервал карманов, нужно разность максимального и минимального значений массива разделить на количество интервалов. Получим «ширину кармана».
Представим интервалы карманов в виде столбца значений. Сначала ширину кармана прибавляем к минимальному значению массива данных. В следующей ячейке – к полученной сумме. И так далее, пока не дойдем до максимального значения.
Для определения частоты делаем столбец рядом с интервалами карманов. Вводим функцию массива:
Вычислим относительные частоты (как в предыдущем способе).
Построим столбчатую диаграмму распределения осадков в Excel с помощью стандартного инструмента «Диаграммы».
Частота распределения заданных значений:
Круговые диаграммы для иллюстрации распределения
С помощью круговой диаграммы можно иллюстрировать данные, которые находятся в одном столбце или одной строке. Сегмент круга – это доля каждого элемента массива в сумме всех элементов.
С помощью любой круговой диаграммы можно показать распределение в том случае, если
- имеется только один ряд данных;
- все значения положительные;
- практически все значения выше нуля;
- не более семи категорий;
- каждая категория соответствует сегменту круга.
На основании имеющихся данных о количестве осадков построим круговую диаграмму.
Доля «каждого месяца» в общем количестве осадков за год:
Круговая диаграмма распределения осадков по сезонам года лучше смотрится, если данных меньше. Найдем среднее количество осадков в каждом сезоне, используя функцию СРЗНАЧ. На основании полученных данных построим диаграмму:
Получили количество выпавших осадков в процентном выражении по сезонам.
В двух словах: Добавляем полосу прокрутки к гистограмме или к графику распределения частот, чтобы сделать её динамической или интерактивной.
Уровень сложности: продвинутый.
На следующем рисунке показано, как выглядит готовая динамическая гистограмма:
Что такое гистограмма или график распределения частот?
Гистограмма распределения разбивает по группам значения из набора данных и показывает количество (частоту) чисел в каждой группе. Такую гистограмму также называют графиком распределения частот, поскольку она показывает, с какой частотой представлены значения.
В нашем примере мы делим людей, которые вызвались принять участие в мероприятии, по возрастным группам. Первым делом, создадим возрастные группы, далее подсчитаем, сколько людей попадает в каждую из групп, и затем покажем все это на гистограмме.
На какие вопросы отвечает гистограмма распределения?
Гистограмма – это один из моих самых любимых типов диаграмм, поскольку она дает огромное количество информации о данных.
В данном случае мы хотим знать, как много участников окажется в возрастных группах 20-ти, 30-ти, 40-ка лет и так далее. Гистограмма наглядно покажет это, поэтому определить закономерности и отклонения будет довольно легко.
«Неужели наше мероприятие не интересно гражданам в возрасте от 20 до 29 лет?»
Возможно, мы захотим немного изменить детализацию картины и разбить население на две возрастные группы. Это покажет нам, что в мероприятии примут участие большей частью молодые люди:
Динамическая гистограмма
После построения гистограммы распределения частот иногда возникает необходимость изменить размер групп, чтобы ответить на различные возникающие вопросы. В динамической гистограмме это возможно сделать благодаря полосе прокрутки (слайдеру) под диаграммой. Пользователь может увеличивать или уменьшать размер групп, нажимая стрелки на полосе прокрутки.
Такой подход делает гистограмму интерактивной и позволяет пользователю масштабировать ее, выбирая, сколько групп должно быть показано. Это отличное дополнение к любому дашборду!
Как это работает?
Краткий ответ: Формулы, динамические именованные диапазоны, элемент управления «Полоса прокрутки» в сочетании с гистограммой.
Формулы
Чтобы всё работало, первым делом нужно при помощи формул вычислить размер группы и количество элементов в каждой группе.
Чтобы вычислить размер группы, разделим общее количество (80-10) на количество групп. Количество групп устанавливается настройками полосы прокрутки. Чуть позже разъясним это подробнее.
Далее при помощи функции ЧАСТОТА (FREQUENCY) я рассчитываю количество элементов в каждой группе в заданном столбце. В данном случае мы возвращаем частоту из столбца Age таблицы с именем tblData.
=ЧАСТОТА(tblData;C13:C22)=FREQUENCY(tblData,C13:C22)
Функция ЧАСТОТА (FREQUENCY) вводится, как формула массива, нажатием Ctrl+Shift+Enter.
Динамический именованный диапазон
В качестве источника данных для диаграммы используется именованный диапазон, чтобы извлекать данные только из выбранных в текущий момент групп.
Когда пользователь перемещает ползунок полосы прокрутки, число строк в динамическом диапазоне изменяется так, чтобы отобразить на графике только нужные данные. В нашем примере задано два динамических именованных диапазона: один для данных — rngGroups (столбец Frequency) и второй для подписей горизонтальной оси — rngCount (столбец Bin Name).
Элемент управления «Полоса прокрутки»
Элемент управления Полоса прокрутки (Scroll Bar) может быть вставлен с вкладки Разработчик (Developer).
На рисунке ниже видно, как я настроил параметры элемента управления и привязал его к ячейке C7. Так, изменяя состояние полосы прокрутки, пользователь управляет формулами.
Гистограмма
График – это самая простая часть задачи. Создаём простую гистограмму и в качестве источника данных устанавливаем динамические именованные диапазоны.
Есть вопросы?
Что ж, это был лишь краткий обзор того, как работает динамическая гистограмма.
Да, это не самая простая диаграмма, но, полагаю, пользователям понравится с ней работать. Определённо, такой интерактивной диаграммой можно украсить любой отчёт.
Более простой вариант гистограммы можно создать, используя сводные таблицы.
Пишите в комментариях любые вопросы и предложения. Спасибо!
Урок подготовлен для Вас командой сайта office-guru.ru
Источник: /> Перевел: Антон Андронов
Правила перепечаткиЕще больше уроков по Microsoft Excel
Оцените качество статьи. Нам важно ваше мнение:

В статистике колоколообразная кривая (также известная как стандартное нормальное распределение или кривая Гаусса) представляет собой симметричный график, который иллюстрирует тенденцию данных к кластеризации вокруг центрального значения или среднего значения в данном наборе данных.
Ось Y представляет относительную вероятность появления данного значения в наборе данных, в то время как ось X отображает сами значения на диаграмме, чтобы создать колоколообразную кривую, отсюда и название.
График помогает нам проанализировать, является ли конкретное значение частью ожидаемой вариации или статистически значимым и, следовательно, требует более внимательного изучения.
Поскольку в Excel нет встроенных решений, вам придется построить график самостоятельно. Вот почему мы разработали надстройку Chart Creator — инструмент, который позволяет создавать расширенные диаграммы Excel всего за несколько щелчков мышью.
В этом пошаговом руководстве вы узнаете, как с нуля создать кривую нормального распределения в Excel:
Чтобы построить кривую Гаусса, вам нужно знать две вещи:
- Значение (также известное как стандартное измерение). Это определяет центр кривой, который, в свою очередь, характеризует положение кривой.
- Стандартное отклонение (SD) измерений. Это определяет разброс ваших данных в нормальном распределении — или, говоря простым языком, насколько широкой должна быть кривая. Например, на приведенной выше колоколообразной кривой одно стандартное отклонение среднего представляет собой диапазон между оценками экзамена от 53 до 85.
Чем ниже SD, тем выше кривая и меньше будут разбросаны ваши данные, и наоборот.
Стоит упомянуть правило 68-95-99,7, которое можно применить к любой кривой нормального распределения, что означает, что примерно 68% ваших данных будет размещено в пределах одного стандартного отклонения от среднего, 95% — в пределах двух стандартных отклонений и 99,7% — в пределах. три SD.

Теперь, когда вы знаете основы, давайте перейдем от теории к практике.
Начиная
В целях иллюстрации предположим, что у вас есть результаты теста 200 учеников и вы хотите выставить им оценки «по кривой», то есть оценки учеников будут основаны на их относительной успеваемости по отношению к остальной части класса:

Шаг № 1: Найдите среднее значение.
Как правило, вам с самого начала задаются среднее значение и стандартное отклонение, но если это не так, вы можете легко вычислить эти значения всего за несколько простых шагов. Давайте сначала разберемся со средним.
Поскольку среднее значение указывает среднее значение выборки или совокупности данных, вы можете найти стандартное измерение, используя функцию СРЕДНЕЕ.
Введите следующую формулу в любую пустую ячейку (F1 в этом примере) рядом с вашими фактическими данными (столбцы A а также B), чтобы вычислить среднее значение экзаменационных баллов в наборе данных:

Небольшое примечание: чаще всего вам может потребоваться округлить вывод формулы в большую сторону. Для этого просто оберните его функцией ROUND следующим образом:
| 1 | = ОКРУГЛ (СРЕДНИЙ (B2: B201); 0) |

Шаг № 2: Найдите стандартное отклонение.
Один упал, один остался. К счастью, в Excel есть специальная функция, которая сделает за вас всю грязную работу по поиску стандартного отклонения:
| 1 | = СТАНДОТКЛОН.P (B2: B201) |
Опять же, формула выбирает все значения из указанного диапазона ячеек (B2: B201) и вычисляет его стандартное отклонение — не забудьте также округлить результат.
| 1 | = ОКРУГЛ (СТАНДОТКЛОН.P (B2: B201); 0) |

Шаг № 3: Установите значения оси X для кривой.
По сути, диаграмма представляет собой огромное количество интервалов (представьте их как шаги), соединенных линией, чтобы создать плавную кривую.
В нашем случае значения оси X будут использоваться для иллюстрации конкретной оценки экзамена, а значения оси Y будут указывать нам вероятность того, что студент получит этот результат на экзамене.
Технически вы можете включить столько интервалов, сколько захотите — вы можете легко стереть избыточные данные позже, изменив масштаб горизонтальной оси. Просто убедитесь, что вы выбрали диапазон, включающий три стандартных отклонения.
Давайте начнем подсчет с одного (так как студент не может получить отрицательный результат на экзамене) и дойдем до 150 — неважно, 150 это или 1500 — чтобы создать еще одну вспомогательную таблицу.
- Выберите любую пустую ячейку под данными диаграммы (например, E4) и введите “1,” значение, определяющее первый интервал.
- Перейдите к Дом таб.
- в Редактирование группа, выберите «Наполнять.”
- Под «Серия в,» Выбрать «Столбец.”
- Для «Значение шага,» тип “1.” Это значение определяет приращения, которые будут автоматически добавляться, пока Excel не достигнет последнего интервала.
- Для «Стоп-значение,» тип «150,” значение, которое соответствует последнему интервалу, и нажмите «OK.”

Чудом 149 ячеек в столбце E (E5: E153) были заполнены значениями от 2 до 150.
ПРИМЕЧАНИЕ. Не скрывайте исходные ячейки данных, как показано на снимках экрана.. В противном случае методика не сработает.
Шаг №4: Вычислите значения нормального распределения для каждого значения оси x.
Теперь найдите значения нормального распределения — вероятность того, что студент получит определенный балл за экзамен, представленный определенным значением оси X — для каждого из интервалов. К счастью для вас, в Excel есть рабочая лошадка для выполнения всех этих вычислений: функция НОРМ.РАСП.
Введите следующую формулу в ячейку справа (F4) вашего первого интервала (E4):
| 1 | = НОРМ.РАСП (E4; $ F $ 1; $ F $ 2; ЛОЖЬ) |
Вот декодированная версия, которая поможет вам соответствующим образом настроить:
| 1 | = НОРМ.РАСП ([первый интервал], [среднее (абсолютное значение)], [стандартное отклонение (абсолютное значение), ЛОЖЬ) |
Вы блокируете среднее значение и стандартное отклонение, чтобы можно было легко выполнить формулу для оставшихся интервалов (E5: E153).

Теперь дважды щелкните маркер заполнения, чтобы скопировать формулу в остальные ячейки (F5: F153).
Шаг № 5: Создайте диаграмму рассеяния с плавными линиями.
Наконец, пришло время строить колоколообразную кривую:
- Выберите любое значение в вспомогательной таблице, содержащей значения осей x и y (E4: F153).
- Перейти к Вставлять таб.
- Щелкните значок «Вставить точечную (X, Y) или пузырьковую диаграмму» кнопка.
- Выбирать «Разброс с плавными линиями ».

Шаг № 6: Настройте таблицу меток.
Технически у вас есть кривая колокола. Но его будет трудно прочитать, поскольку в нем отсутствуют какие-либо данные, описывающие это.
Давайте сделаем нормальное распределение более информативным, добавив метки, иллюстрирующие все значения стандартного отклонения ниже и выше среднего (вы также можете использовать их для отображения z-значений).
Для этого создайте еще одну вспомогательную таблицу следующим образом:

Сначала скопируйте среднее значение (F1) рядом с соответствующей ячейкой в столбце X-Value (I5).

Затем вычислите значения стандартного отклонения ниже среднего, введя эту простую формулу в ячейка I4:
Проще говоря, формула вычитает сумму предыдущих значений стандартного отклонения из среднего. Теперь перетащите маркер заполнения вверх, чтобы скопировать формулу в оставшиеся две ячейки (I2: I3).

Повторите тот же процесс для стандартных отклонений выше среднего, используя зеркальную формулу:
Таким же образом выполните формулу для двух других ячеек (I7: I8).

Наконец, заполните значения метки оси Y (J2: J8) с нулями, так как вы хотите, чтобы маркеры данных располагались на горизонтальной оси.

Шаг № 7: Вставьте данные метки в диаграмму.
Теперь добавьте все данные, которые вы подготовили. Щелкните правой кнопкой мыши график и выберите «Выберите данные.”

В появившемся диалоговом окне выберите «Добавлять.”

Выделите соответствующие диапазоны ячеек из вспомогательной таблицы —I2: I8 для «Значения серии X» а также J2: J8 для «Значения серии Y »-и нажмите «OK.”

Шаг № 8: Измените тип диаграммы для серии этикеток.
Наш следующий шаг — изменить тип диаграммы недавно добавленной серии, чтобы маркеры данных отображались в виде точек. Для этого щелкните правой кнопкой мыши график диаграммы и выберите «Изменить тип диаграммы.”

Затем создайте комбинированную диаграмму:
- Перейдите к Комбо таб.
- Для Серия «Series2», изменение «Тип диаграммы» к «Разброс.”
- Примечание. Убедитесь, что «Серия1»Остается как«Скаттер с плавными линиями. » Иногда Excel изменяет его, когда вы делаете Комбо Также убедитесь, что «Серия1”Не перемещается на вторичную ось — флажок рядом с типом диаграммы не должен быть отмечен.
- Нажмите «Ok.”

Шаг № 9: Измените масштаб горизонтальной оси.
Отцентрируйте диаграмму на колоколообразной кривой, отрегулировав масштаб горизонтальной оси. Щелкните правой кнопкой мыши горизонтальную ось и выберите «Ось формата»Из меню.

Когда появится панель задач, сделайте следующее:
- Перейти к Параметры оси таб.
- Установить Минимальные границы значение «15.”
- Установить Максимальные границы значение «125.”
Вы можете настроить диапазон шкалы оси по своему усмотрению, но, поскольку вы знаете диапазоны стандартного отклонения, установите значения границ немного дальше от каждого из ваших третьих стандартных отклонений, чтобы показать «хвост» кривой.

Шаг № 10: Вставьте и разместите метки пользовательских данных.
По мере того, как вы совершенствуете свою диаграмму, не забудьте добавить пользовательские метки данных. Сначала щелкните правой кнопкой мыши любую точку, представляющую Серия «Series2» и выберите «Добавьте метки данных.”

Затем замените метки по умолчанию на те, которые вы установили ранее, и поместите их над маркерами данных.
- Щелкните правой кнопкой мыши на любом Серия «Series2» метка данных.
- Выбирать «Отформатируйте метки данных.”
- На панели задач переключитесь на Параметры метки таб.
- Проверить «Значение X» коробка.
- Снимите флажок «Значение Y» коробка.
- Под «Положение ярлыка,» выбирать «Выше.”

Кроме того, теперь вы можете удалить линии сетки (щелкните их правой кнопкой мыши> Удалить).
Шаг № 11: Перекрасить маркеры данных (необязательно).
Наконец, перекрасьте точки, чтобы они соответствовали вашему стилю диаграммы.
- Щелкните правой кнопкой мыши любой Серия «Series2» метка данных.
- Щелкните значок «Наполнять» кнопка.
- Выберите свой цвет из появившейся палитры.

Также удалите границы вокруг точек:
- Снова щелкните правой кнопкой мыши тот же маркер данных и выберите «Контур.”
- Выбирать «Без контура.”

Шаг № 12: Добавьте вертикальные линии (необязательно).
В качестве окончательной настройки вы можете добавить на диаграмму вертикальные линии, чтобы подчеркнуть значения SD.
- Выберите график диаграммы (таким образом линии будут вставлены прямо в диаграмму).
- Перейти к Вставлять таб.
- Щелкните значок «Формы» кнопка.
- Выбирать «Линия.”
Удерживайте «СДВИГ» при перетаскивании мыши, чтобы нарисовать идеально вертикальные линии от каждой точки до того места, где каждая линия пересекается с колоколообразной кривой.

Измените заголовок диаграммы, и ваша улучшенная кривая колокола будет готова отображать ваши ценные данные о распределении.
И вот как вы это делаете. Теперь вы можете выбрать любой набор данных и создать колоколообразную кривую нормального распределения, выполнив эти простые шаги!
Как сделать график распределения в excel?
Очень давно не писал блог. Расслабился совсем. Ну ничего, исправляюсь.
Продолжаю новую рубрику блога, посвященную анализу данных с помощью всем известного Microsoft Excel.
В современном мире к статистике проявляется большой интерес, поскольку это отличный инструмент для анализа и принятия решений, а также это отличное средство для поиска причин нарушений процесса и их устранения. Статистический анализ применим во многих сферах, где существуют большие массивы данных: естественно, в первую очередь я скажу, что металлургии, а также в экономике, биологии, политике, социологии и… много где еще. Статья эта будет, как несложно догадаться по ее названию, про использование некоторых средств статистического анализа, а именно — гистограммам.
Ну, поехали.
Статистический анализ в Excel можно осуществлять двумя способами:
• С помощью функций
• С помощью средств надстройки «Пакет анализа». Ее, как правило, еще необходимо установить.
Чтобы установить пакет анализа в Excel, выберите вкладку «Файл» (а в Excel 2007 это круглая цветная кнопка слева сверху), далее — «Параметры», затем выберите раздел «Надстройки». Нажмите «Перейти» и поставьте галочку напротив «Пакет анализа».
А теперь — к построению гистограмм распределения по частоте и их анализу.
Речь пойдет именно о частотных гистограммах, где каждый столбец соответствует частоте появления* значения в пределах границ интервалов. Например, мы хотим посмотреть, как у нас выглядит распределение значения предела текучести стали S355J2 в прокате толщиной 20 мм за несколько месяцев. В общем, хотим посмотреть, похоже ли наше распределение на нормальное (а оно должно быть таким).
*Примечание: для металловедческих целей типа оценки размера зерна или оценки объемной доли частиц этот вид гистограмм не пойдет, т.к. там высота столбика соответствует не частоте появления частиц определенного размера, а доле объема (а в плоскости шлифа — площади), которую эти частицы занимают.
График нормального распределения выглядит следующим образом:

График функции Гаусса
Мы знаем, что реально такой график может быть получен только при бесконечно большом количестве измерений. Реально же для конечного числа измерений строят гистограмму, которая внешне похожа на график нормального распределения и при увеличении количества измерений приближается к графику нормального распределения (распределения Гаусса).
Построение гистограмм с помощью программ типа Excel является очень быстрым способом проверки стабильности работы оборудования и добросовестности коллектива: если получим «кривую» гистограмму, значит, либо прибор не исправен или мы данные неверно собрали, либо кто-то где-то преднамеренно мухлюет или же просто неверно использует оборудование.
А теперь — построение гистограмм!
Способ 1-ый. Халявный.
- Идем во вкладку «Анализ данных» и выбираем «Гистограмма».
- Выбираем входной интервал.
- Здесь же предлагается задать интервал карманов, т.е. те диапазоны, в пределах которых будут лежать наши значения. Чем больше значений в интервале — тем выше столбик гистограммы. Если мы оставим поле «Интервалы карманов» пустым, то программа вычислит границы интервалов за нас.
- Если хотим сразу же вывести график,то ставим галочку напротив «Вывод графика».
- Нажимаем «ОК».
- Вот, вроде бы, и все: гистограмма готова. Теперь нужно сделать так, чтобы по вертикальной оси отображалась не абсолютная частота, а относительная.
- Под появившейся таблицей со столбцами «Карман» и «Частота» под столбцом «Частота» введем формулу «=СУММ» и сложим все абсолютные частоты.
- К появившейся таблице со столбцами «Карман» и «Частота» добавим еще один столбец и назовем его «Относительная частота».
- Во всех ячейках нового столбца введем формулу, которая будет рассчитывать относительную частоту: 100 умножить на абсолютную частоту (ячейка из столбца «частота») и разделить на сумму, которую мы вычислил в п. 7.
Способ 2-ой. Трудный, но интересный.
Будет полезен тому, кто по каким-либо причинам не смог установить Пакет анализа.
- Перво-наперво нужно задать интервалы тех самых карманов, которые мы не стали вычислять в способе, описанном выше.
- Интервал карманов вычисляют так: разность максимального значения и минимального значений массива, деленная на количество интервалов: (Xmax-Xmin)/n.
Для оценки оптимального для нашего массива данных количества интервалов можно воспользоваться формулой Стерджесса: n
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Поделиться ссылкой:
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.
Построим диаграмму распределения в Excel. А также рассмотрим подробнее функции круговых диаграмм, их создание.
Как построить диаграмму распределения в Excel
График нормального распределения имеет форму колокола и симметричен относительно среднего значения. Получить такое графическое изображение можно только при огромном количестве измерений. В Excel для конечного числа измерений принято строить гистограмму.
Внешне столбчатая диаграмма похожа на график нормального распределения. Построим столбчатую диаграмму распределения осадков в Excel и рассмотрим 2 способа ее построения.
Имеются следующие данные о количестве выпавших осадков:
Первый способ. Открываем меню инструмента «Анализ данных» на вкладке «Данные» (если у Вас не подключен данный аналитический инструмент, тогда читайте как его подключить в настройках Excel):
Задаем входной интервал (столбец с числовыми значениями). Поле «Интервалы карманов» оставляем пустым: Excel сгенерирует автоматически. Ставим птичку около записи «Вывод графика»:
После нажатия ОК получаем такой график с таблицей:
В интервалах не очень много значений, поэтому столбики гистограммы получились низкими.
Теперь необходимо сделать так, чтобы по вертикальной оси отображались относительные частоты.
Найдем сумму всех абсолютных частот (с помощью функции СУММ). Сделаем дополнительный столбец «Относительная частота». В первую ячейку введем формулу:
Способ второй. Вернемся к таблице с исходными данными. Вычислим интервалы карманов. Сначала найдем максимальное значение в диапазоне температур и минимальное.
Чтобы найти интервал карманов, нужно разность максимального и минимального значений массива разделить на количество интервалов. Получим «ширину кармана».
Представим интервалы карманов в виде столбца значений. Сначала ширину кармана прибавляем к минимальному значению массива данных. В следующей ячейке – к полученной сумме. И так далее, пока не дойдем до максимального значения.
Для определения частоты делаем столбец рядом с интервалами карманов. Вводим функцию массива:
Вычислим относительные частоты (как в предыдущем способе).
Построим столбчатую диаграмму распределения осадков в Excel с помощью стандартного инструмента «Диаграммы».
Частота распределения заданных значений:
Круговые диаграммы для иллюстрации распределения
С помощью круговой диаграммы можно иллюстрировать данные, которые находятся в одном столбце или одной строке. Сегмент круга – это доля каждого элемента массива в сумме всех элементов.
С помощью любой круговой диаграммы можно показать распределение в том случае, если
- имеется только один ряд данных;
- все значения положительные;
- практически все значения выше нуля;
- не более семи категорий;
- каждая категория соответствует сегменту круга.
На основании имеющихся данных о количестве осадков построим круговую диаграмму.
Доля «каждого месяца» в общем количестве осадков за год:
Круговая диаграмма распределения осадков по сезонам года лучше смотрится, если данных меньше. Найдем среднее количество осадков в каждом сезоне, используя функцию СРЗНАЧ. На основании полученных данных построим диаграмму:
Получили количество выпавших осадков в процентном выражении по сезонам.
В двух словах: Добавляем полосу прокрутки к гистограмме или к графику распределения частот, чтобы сделать её динамической или интерактивной.
Уровень сложности: продвинутый.
На следующем рисунке показано, как выглядит готовая динамическая гистограмма:
Что такое гистограмма или график распределения частот?
Гистограмма распределения разбивает по группам значения из набора данных и показывает количество (частоту) чисел в каждой группе. Такую гистограмму также называют графиком распределения частот, поскольку она показывает, с какой частотой представлены значения.
В нашем примере мы делим людей, которые вызвались принять участие в мероприятии, по возрастным группам. Первым делом, создадим возрастные группы, далее подсчитаем, сколько людей попадает в каждую из групп, и затем покажем все это на гистограмме.
На какие вопросы отвечает гистограмма распределения?
Гистограмма – это один из моих самых любимых типов диаграмм, поскольку она дает огромное количество информации о данных.
В данном случае мы хотим знать, как много участников окажется в возрастных группах 20-ти, 30-ти, 40-ка лет и так далее. Гистограмма наглядно покажет это, поэтому определить закономерности и отклонения будет довольно легко.
«Неужели наше мероприятие не интересно гражданам в возрасте от 20 до 29 лет?»
Возможно, мы захотим немного изменить детализацию картины и разбить население на две возрастные группы. Это покажет нам, что в мероприятии примут участие большей частью молодые люди:
Динамическая гистограмма
После построения гистограммы распределения частот иногда возникает необходимость изменить размер групп, чтобы ответить на различные возникающие вопросы. В динамической гистограмме это возможно сделать благодаря полосе прокрутки (слайдеру) под диаграммой. Пользователь может увеличивать или уменьшать размер групп, нажимая стрелки на полосе прокрутки.
Такой подход делает гистограмму интерактивной и позволяет пользователю масштабировать ее, выбирая, сколько групп должно быть показано. Это отличное дополнение к любому дашборду!
Как это работает?
Краткий ответ: Формулы, динамические именованные диапазоны, элемент управления «Полоса прокрутки» в сочетании с гистограммой.
Формулы
Чтобы всё работало, первым делом нужно при помощи формул вычислить размер группы и количество элементов в каждой группе.
Чтобы вычислить размер группы, разделим общее количество (80-10) на количество групп. Количество групп устанавливается настройками полосы прокрутки. Чуть позже разъясним это подробнее.
Далее при помощи функции ЧАСТОТА (FREQUENCY) я рассчитываю количество элементов в каждой группе в заданном столбце. В данном случае мы возвращаем частоту из столбца Age таблицы с именем tblData.
Функция ЧАСТОТА (FREQUENCY) вводится, как формула массива, нажатием Ctrl+Shift+Enter.
Динамический именованный диапазон
В качестве источника данных для диаграммы используется именованный диапазон, чтобы извлекать данные только из выбранных в текущий момент групп.
Когда пользователь перемещает ползунок полосы прокрутки, число строк в динамическом диапазоне изменяется так, чтобы отобразить на графике только нужные данные. В нашем примере задано два динамических именованных диапазона: один для данных — rngGroups (столбец Frequency) и второй для подписей горизонтальной оси — rngCount (столбец Bin Name).
Элемент управления «Полоса прокрутки»
Элемент управления Полоса прокрутки (Scroll Bar) может быть вставлен с вкладки Разработчик (Developer).
На рисунке ниже видно, как я настроил параметры элемента управления и привязал его к ячейке C7. Так, изменяя состояние полосы прокрутки, пользователь управляет формулами.
Гистограмма
График – это самая простая часть задачи. Создаём простую гистограмму и в качестве источника данных устанавливаем динамические именованные диапазоны.
Есть вопросы?
Что ж, это был лишь краткий обзор того, как работает динамическая гистограмма.
Да, это не самая простая диаграмма, но, полагаю, пользователям понравится с ней работать. Определённо, такой интерактивной диаграммой можно украсить любой отчёт.
Более простой вариант гистограммы можно создать, используя сводные таблицы.
Exceltip
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Как построить график с нормальным распределением в Excel
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Вам также могут быть интересны следующие статьи
13 комментариев
Ренат, добрый день.
Все несколько проще:
Данные->Анализ данных->Генерация случайных чисел (Распределение=Нормальное)
+
Данные->Анализ данных->Гистограмма->Галка на «вывод графика» («Карманы» можно даже не задавать)
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения. Эта функция очень широко применяется в статистике, в том числе при проверке гипотез.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция НОРМ.РАСП.
Синтаксис
НОРМРАСП(x;среднее;стандартное_откл;интегральная)
Аргументы функции НОРМРАСП описаны ниже.
-
X Обязательный. Значение, для которого строится распределение.
-
Среднее Обязательный. Среднее арифметическое распределения.
-
Стандартное_откл Обязательный. Стандартное отклонение распределения.
-
Интегральная — обязательный аргумент. Логическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения.
Замечания
-
Если «standard_dev» не является числом, то возвращается #VALUE! значение ошибки #ЗНАЧ!.
-
Если standard_dev ≤ 0, то нормДАТ возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если среднее = 0, стандартное_откл = 1 и интегральная = ИСТИНА, то функция НОРМРАСП возвращает стандартное нормальное распределение, т. е. НОРМСТРАСП.
-
Уравнение для плотности нормального распределения (аргумент «интегральная» содержит значение ЛОЖЬ) имеет следующий вид:

-
Если аргумент «интегральная» имеет значение ИСТИНА, формула описывает интеграл с пределами от минус бесконечности до x.
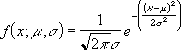
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
Описание |
|
|
42 |
Значение, для которого нужно вычислить распределение |
|
|
40 |
Среднее арифметическое распределения |
|
|
1,5 |
Стандартное отклонение распределения |
|
|
Формула |
Описание |
Результат |
|
=НОРМРАСП(A2;A3;A4;ИСТИНА) |
Интегральная функция распределения для приведенных выше условий |
0,9087888 |
|
=НОРМРАСП(A2;A3;A4;ЛОЖЬ) |
Функция плотности распределения для приведенных выше условий |
0,10934 |
Нужна дополнительная помощь?
В
главном меню Excel
выбрать Данные
→ Анализ данных → Гистограмма → ОК.
Далее
необходимо заполнить поля ввода в
диалоговом окне Гистограмма.
Входной
интервал: 100
случайных чисел в ячейках $A$1:
$A$100;
Интервал
карманов: не
заполнять;
Выходной
интервал:
адрес ячейки, с которой начинается вывод
результатов процедуры Гистограмма;
Вывод
графика –
поставьте галочку.
Если
поле ввода Интервал
карманов не
заполняется, то процедура вычисляет
число интервалов группировки k
и границы интервалов автоматически.
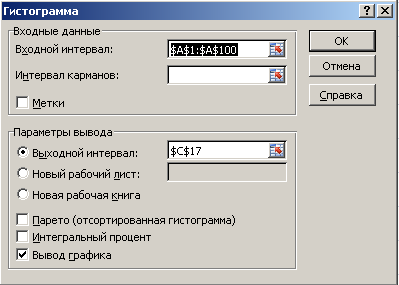
Рис. 6.
Диалоговое окно Гистограмма.
В
результате выполнения процедуры
Гистограмма
появляется таблица, содержащая границы
xi
интервалов
группировки (столбец – Карман)
и частоту попадания случайных величин
выборки mi
в i–ый
интервал (столбец
–
Частота).
Справа
от таблицы – график гистограммы.
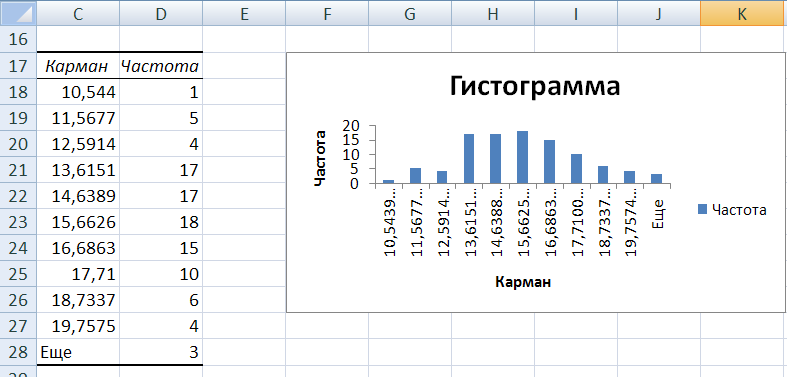
Рис. 7. Фрагмент
листа Excel
с результатами процедуры Гистограмма
По
виду гистограммы можно предположить
(принять гипотезу) о том, что выборка
случайных чисел подчиняется нормальному
закону распределения.
Далее,
для того чтобы убедиться в правильности
выбранной гипотезы (по крайней мере
визуально) надо, первое – построить
график гипотетического нормального
закона распределения, выбрав в качестве
параметров (математического ожидания
и среднего квадратического отклонении)
их оценки (среднее и стандартное
отклонение), и совместить график
гипотетического распределения с графиком
гистограммы.
И,
второе – используя критерий согласия
Пирсона установить справедливость
выбранной гипотезы.
4. Построение теоретического закона распределения
Для
построения теоретического закона
распределения совместно с гистограммой
и проверки согласия по критерию хи-квадрат
Пирсона надо заполнить таблицу, знакомую
по лекции (см. ниже по тексту, таблица
№1). Для построения этой таблицы
надо воспользоваться таблицей карман
– частота
процедуры
Гистограмма.
xi
– границы
интервалов группировки (карманы –
получены как результат выполнения
процедуры Гистограмма);
mi
– количество
элементов выборки, попавших в i–ый
интервал (частота – получена в результате
процедуры Гистограмма);
Таблица №1
|
xi |
mi |
n∙pi |
|
|
карманы |
частота |
теоретическая |
статистика |
|
x1 |
m1 |
n∙p1 |
|
|
x2 |
m2 |
n∙p2 |
|
|
… |
… |
… |
… |
|
xk |
mk |
n∙pk |
|
|
|



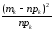

Для построения
этой таблицы в Excel
к столбцам карман
– частота
процедуры
Гистограмма
надо
добавить столбцы n∙pi
и
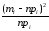
Теоретическая
вероятность pi
попадания элементов выборки в i—ый
интервал группировки для принятой
гипотезы о нормальном распределении
генеральной совокупности
равна
pi
= P(xi-1
< X
< xi)
=
F(xi)
– F(xi-1).
n∙pi
– теоретическая (ожидаемая) частота
попадания элементов выборки в i–ый
интервал группировки для принятой
гипотезы о нормальном распределении
генеральной совокупности.
В
Excel
эту величину можно вычислить,
воспользовавшись функцией НОРМРАСП.
n∙pi
= (НОРМРАСП(xi;
среднее; стандартное_откл; 1) –
– НОРМРАСП(xi-1;
среднее; стандартное_откл; 1))
* n.
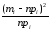 –статистика,
–статистика,
являющаяся мерой расхождения между
значениями эмпирической и теоретической
плотности распределения;
4.1.
Найдите сумму элементов выборки,
попавших в карманы
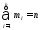 (n
(n
= 100), для контроля (ячейка D29,
рис. 8).
Столбцу
E18:
E28 присвойте
имя n∙pi
,
поместив
его в ячейку
E17.
В
ячейку E18
внесите
формулу для вычисления значения
функции нормального распределения
F(x1
= 10,544) = P(–
∞ < X
≤ x1),
умноженную на число наблюдений n.
В
рассматриваемом примере n
=100. В ячейку
E18
будет получено теоретическое (ожидаемое)
число значений случайной величины,
попавших в интервал
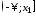 ,n∙pi
,n∙pi
= F(x1)∙100
=НОРМРАСП(C$18$;D$3$;D$7$;1)*100
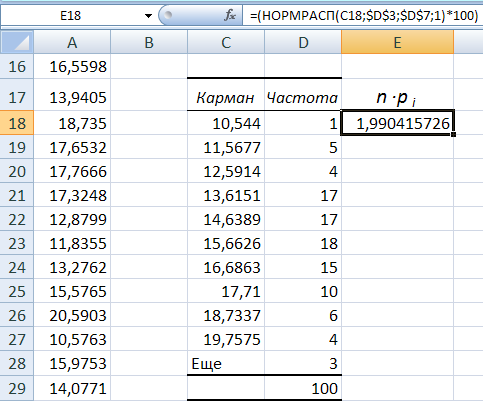
Рис.
8. В ячейке E18
результаты вычислений функции
НОРМРАСП(C$18$;D$3$;D$7$;1)*100
Функцию
НОРМРАСП вызывается следующим образом.
В главном меню Excel
выбирается закладка Формулы
→ Вставить функцию → в
диалоговом окне
Мастер функций – шаг 1 из 2 в
категории
Статистические → НОРМРАСП.
ОК.
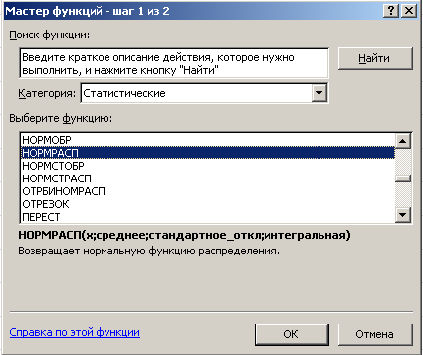
Рис.
9. Окно Мастер
функций для
выбора функции НОРМРАСП из категории
Статистические.
В
раскрывшемся окне Аргументы
функции
НОРМРАСП
заполните поля ввода как показано далее
на рис. 10.
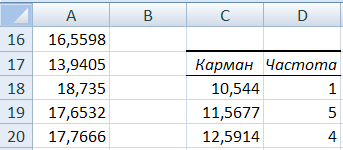

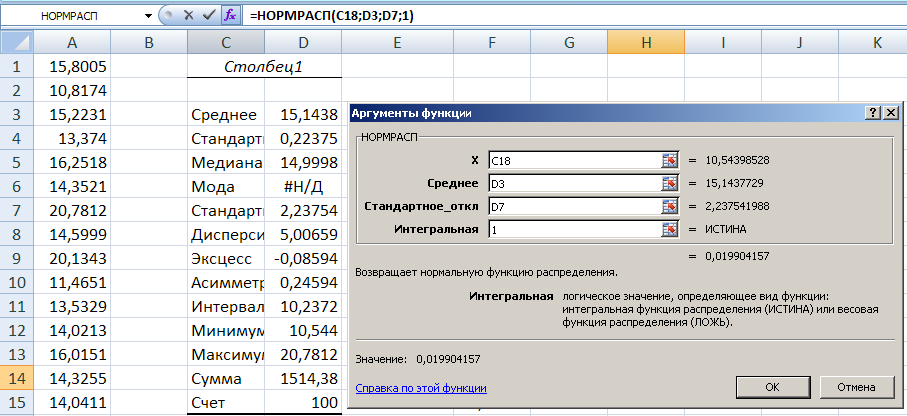


Рис.
10. Окно ввода параметров для получения
функции нормального распределения
В
поле X
введите адрес ячейки, в которой находится
граница первого интервала группировки
C18
(верхняя ячейка столбца Карманы).
В
поле Среднее
введите адрес ячейки, в которой находится
среднее значение выборки, полученное
при выполнении процедуры Описательная
статистика –
D3.
В
поле Стандартное_откл
введите адрес ячейки, в которой находится
значение стандартного отклонения
выборки, полученное при выполнении
процедуры Описательная
статистика –
D7.
В
поле Интегральная
введите единица 1.
Единица
в поле
Интегральная
означает вычисление функции распределения
F(x).
ОК.
В
ячейку E19
поместите формулу для вычисления
теоретического (гипотетического) числа
случайных величин, попавших в интервал
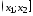 :
:
n∙p2
= n
∙
[F(x2)
– F(x1)]
= n
∙
[P(x1
< X
≤ x2)]
= n
∙
[P(10,544
< X
≤ 11,5777)],
где
p2
= F(x2)
– F(x1)
=
P(x1
< X
≤ x2)
= P(10,544
< X
≤ 11,5777)
— теоретическая вероятность попадания
нормально распределенных случайных
величин в промежуток
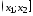 .
.
В
Excel
в строку формул необходимо поместить
формулу:
=(НОРМРАСП(C19;$D$3;$D$7;1)
– НОРМРАСП(C18;$D$3;$D$7;1))*100
![]()
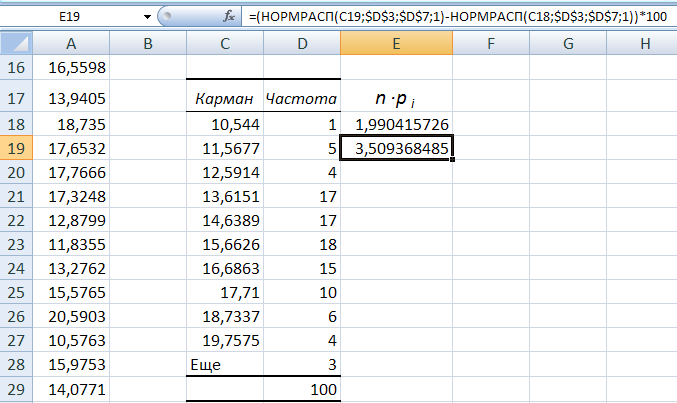
Рис.
11. В ячейке E19
показаны результаты вычислений функции
=(НОРМРАСП(C19;$D$3;$D$7;1)
– НОРМРАСП(C18;$D$3;$D$7;1)) *100
Заполните
диапазон ячеек Е20:Е27
результатами вычисления этой формулы,
используя маркер заполнения.

Рис.
12. Столбец E19;E27
с результатами вычисления функции
n∙pi
= (НОРМРАСП(C32;$D$3;$D$7;1)
– НОРМРАСП(C31;$D$3;$D$7;1))
*100
В
ячейку E28
поместите формулу для вычисления
теоретического (гипотетического) числа
случайных величин, попавших в промежуток
(x10;
∞ ):
P(x10
< x
< ∞) = 1 – P(–
∞ < x
≤ x10)
= 1 – F(x10)
–
вероятность попадания нормально
распределенных случайных величин в
промежуток (x10;
∞).
В
Excel
в строку формул необходимо поместить
формулу:
=(1
– НОРМРАСП(C27;D3;D7;1))*100
Для
этого сначала необходимо вызвать функции
НОРМРАСП и заполнить поля ввода

Рис.
13. Диалоговое окно функции НОРМРАСП с
заполненными полями ввода
![]()
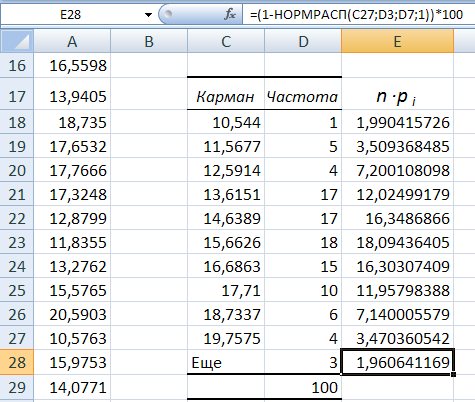
Рис.
14. Столбец n∙pi
(E18;E28)
содержит результаты вычисления
теоретических значений числа случайных
величин попавших в каждый частичный
интервал (карман) n∙pi
Для
проверки правильности вычислений
просуммируйте числа в ячейках столбца
E18:E28.
В
ячейке Е29
показана сумма содержимого ячеек
Е31:Е40. Она должна быть равна n
=
100.
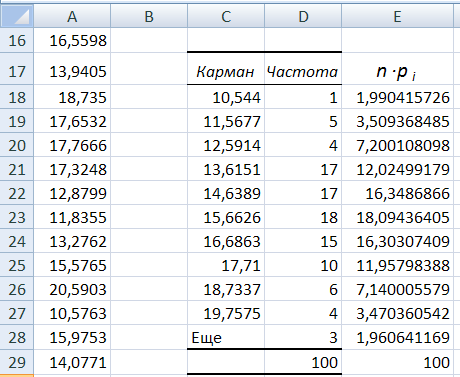
Рис.
15. Таблицы распределения эмпирических
частот mi
– столбец Частота
и теоретических частот npi
– столбец n∙pi
4.2.
В графике Гистограмма
частот добавьте
кривую нормального распределения, как
это вы умеете.

Рис.
16. Графики гистограммы эмпирических
и теоретических частот, позволяющие по
виду графиков выбрать в качестве гипотезы
H0
нормальное распределение.
Для
того чтобы сохранить графики гистограммы
эмпирических и теоретических частот
(рис. 16) необходимо скопировать таблицу
на рис. 15 Карман
– Частота
– n∙pi
в
другое место таблицы.
4.3.
Скопируйте таблицу Карман
– Частота –
n∙pi
в свободные
ячейки листа Excel,
для чего, верхний левый угол копии
разместите в ячейке C30,
как показано далее на рис. 8.
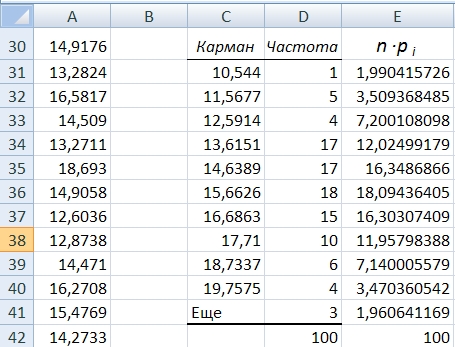
Рис.
17. Фрагмент листа Excel
с копией таблицы распределения
эмпирических и теоретических частот
по карманам
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Начиная
- Шаг № 1: Найдите среднее значение.
- Шаг № 2: Найдите стандартное отклонение.
- Шаг № 3: Установите значения оси X для кривой.
- Шаг №4: Вычислите значения нормального распределения для каждого значения оси x.
- Шаг № 5: Создайте диаграмму рассеяния с плавными линиями.
- Шаг № 6: Настройте таблицу меток.
- Шаг № 7: Вставьте данные метки в диаграмму.
- Шаг № 8: Измените тип диаграммы для серии этикеток.
- Шаг № 9: Измените масштаб горизонтальной оси.
- Шаг № 10: Вставьте и разместите метки пользовательских данных.
- Шаг № 11: Перекрасить маркеры данных (необязательно).
- Шаг № 12: Добавьте вертикальные линии (необязательно).
В этом руководстве будет показано, как создать кривую нормального распределения во всех версиях Excel: 2007, 2010, 2013, 2016 и 2022.
В статистике колоколообразная кривая (также известная как стандартное нормальное распределение или кривая Гаусса) представляет собой симметричный график, который иллюстрирует тенденцию данных к кластеризации вокруг центрального значения или среднего значения в данном наборе данных.
Ось Y представляет относительную вероятность появления данного значения в наборе данных, в то время как ось X отображает сами значения на диаграмме, чтобы создать колоколообразную кривую, отсюда и название.
График помогает нам проанализировать, является ли конкретное значение частью ожидаемой вариации или статистически значимым и, следовательно, требует более внимательного изучения.
Поскольку в Excel нет встроенных решений, вам придется построить график самостоятельно. Вот почему мы разработали надстройку Chart Creator — инструмент, который позволяет создавать расширенные диаграммы Excel всего за несколько щелчков мышью.
В этом пошаговом руководстве вы узнаете, как с нуля создать кривую нормального распределения в Excel:
Чтобы построить кривую Гаусса, вам нужно знать две вещи:
- Значение (также известное как стандартное измерение). Это определяет центр кривой, который, в свою очередь, характеризует положение кривой.
- Стандартное отклонение (SD) измерений. Это определяет разброс ваших данных в нормальном распределении — или, говоря простым языком, насколько широкой должна быть кривая. Например, на приведенной выше колоколообразной кривой одно стандартное отклонение среднего представляет собой диапазон между оценками экзамена от 53 до 85.
Чем ниже SD, тем выше кривая и меньше будут разбросаны ваши данные, и наоборот.
Стоит упомянуть правило 68-95-99,7, которое можно применить к любой кривой нормального распределения, что означает, что примерно 68% ваших данных будет размещено в пределах одного стандартного отклонения от среднего, 95% — в пределах двух стандартных отклонений и 99,7% — в пределах. три SD.
Теперь, когда вы знаете основы, давайте перейдем от теории к практике.
Начиная
В целях иллюстрации предположим, что у вас есть результаты теста 200 учеников и вы хотите выставить им оценки «по кривой», то есть оценки учеников будут основаны на их относительной успеваемости по отношению к остальной части класса:
Шаг № 1: Найдите среднее значение.
Как правило, вам с самого начала задаются среднее значение и стандартное отклонение, но если это не так, вы можете легко вычислить эти значения всего за несколько простых шагов. Давайте сначала разберемся со средним.
Поскольку среднее значение указывает среднее значение выборки или совокупности данных, вы можете найти стандартное измерение, используя функцию СРЕДНЕЕ.
Введите следующую формулу в любую пустую ячейку (F1 в этом примере) рядом с вашими фактическими данными (столбцы A а также B), чтобы вычислить среднее значение экзаменационных баллов в наборе данных:
Небольшое примечание: чаще всего вам может потребоваться округлить вывод формулы в большую сторону. Для этого просто оберните его функцией ROUND следующим образом:
| 1 | = ОКРУГЛ (СРЕДНИЙ (B2: B201); 0) |
Шаг № 2: Найдите стандартное отклонение.
Один упал, один остался. К счастью, в Excel есть специальная функция, которая сделает за вас всю грязную работу по поиску стандартного отклонения:
| 1 | = СТАНДОТКЛОН.P (B2: B201) |
Опять же, формула выбирает все значения из указанного диапазона ячеек (B2: B201) и вычисляет его стандартное отклонение — не забудьте также округлить результат.
| 1 | = ОКРУГЛ (СТАНДОТКЛОН.P (B2: B201); 0) |
Шаг № 3: Установите значения оси X для кривой.
По сути, диаграмма представляет собой огромное количество интервалов (представьте их как шаги), соединенных линией, чтобы создать плавную кривую.
В нашем случае значения оси X будут использоваться для иллюстрации конкретной оценки экзамена, а значения оси Y будут указывать нам вероятность того, что студент получит этот результат на экзамене.
Технически вы можете включить столько интервалов, сколько захотите — вы можете легко стереть избыточные данные позже, изменив масштаб горизонтальной оси. Просто убедитесь, что вы выбрали диапазон, включающий три стандартных отклонения.
Давайте начнем подсчет с одного (так как студент не может получить отрицательный результат на экзамене) и дойдем до 150 — неважно, 150 это или 1500 — чтобы создать еще одну вспомогательную таблицу.
- Выберите любую пустую ячейку под данными диаграммы (например, E4) и введите “1,” значение, определяющее первый интервал.
- Перейдите к Дом таб.
- в Редактирование группа, выберите «Наполнять.”
- Под «Серия в,» Выбрать «Столбец.”
- Для «Значение шага,» тип “1.” Это значение определяет приращения, которые будут автоматически добавляться, пока Excel не достигнет последнего интервала.
- Для «Стоп-значение,» тип «150,” значение, которое соответствует последнему интервалу, и нажмите «OK.”
Чудом 149 ячеек в столбце E (E5: E153) были заполнены значениями от 2 до 150.
ПРИМЕЧАНИЕ. Не скрывайте исходные ячейки данных, как показано на снимках экрана.. В противном случае методика не сработает.
Шаг №4: Вычислите значения нормального распределения для каждого значения оси x.
Теперь найдите значения нормального распределения — вероятность того, что студент получит определенный балл за экзамен, представленный определенным значением оси X — для каждого из интервалов. К счастью для вас, в Excel есть рабочая лошадка для выполнения всех этих вычислений: функция НОРМ.РАСП.
Введите следующую формулу в ячейку справа (F4) вашего первого интервала (E4):
| 1 | = НОРМ.РАСП (E4; $ F $ 1; $ F $ 2; ЛОЖЬ) |
Вот декодированная версия, которая поможет вам соответствующим образом настроить:
| 1 | = НОРМ.РАСП ([первый интервал], [среднее (абсолютное значение)], [стандартное отклонение (абсолютное значение), ЛОЖЬ) |
Вы блокируете среднее значение и стандартное отклонение, чтобы можно было легко выполнить формулу для оставшихся интервалов (E5: E153).
Теперь дважды щелкните маркер заполнения, чтобы скопировать формулу в остальные ячейки (F5: F153).
Шаг № 5: Создайте диаграмму рассеяния с плавными линиями.
Наконец, пришло время строить колоколообразную кривую:
- Выберите любое значение в вспомогательной таблице, содержащей значения осей x и y (E4: F153).
- Перейти к Вставлять таб.
- Щелкните значок «Вставить точечную (X, Y) или пузырьковую диаграмму» кнопка.
- Выбирать «Разброс с плавными линиями ».
Шаг № 6: Настройте таблицу меток.
Технически у вас есть кривая колокола. Но его будет трудно прочитать, поскольку в нем отсутствуют какие-либо данные, описывающие это.
Давайте сделаем нормальное распределение более информативным, добавив метки, иллюстрирующие все значения стандартного отклонения ниже и выше среднего (вы также можете использовать их для отображения z-значений).
Для этого создайте еще одну вспомогательную таблицу следующим образом:
Сначала скопируйте среднее значение (F1) рядом с соответствующей ячейкой в столбце X-Value (I5).
Затем вычислите значения стандартного отклонения ниже среднего, введя эту простую формулу в ячейка I4:
Проще говоря, формула вычитает сумму предыдущих значений стандартного отклонения из среднего. Теперь перетащите маркер заполнения вверх, чтобы скопировать формулу в оставшиеся две ячейки (I2: I3).
Повторите тот же процесс для стандартных отклонений выше среднего, используя зеркальную формулу:
Таким же образом выполните формулу для двух других ячеек (I7: I8).
Наконец, заполните значения метки оси Y (J2: J8) с нулями, так как вы хотите, чтобы маркеры данных располагались на горизонтальной оси.
Шаг № 7: Вставьте данные метки в диаграмму.
Теперь добавьте все данные, которые вы подготовили. Щелкните правой кнопкой мыши график и выберите «Выберите данные.”
В появившемся диалоговом окне выберите «Добавлять.”
Выделите соответствующие диапазоны ячеек из вспомогательной таблицы —I2: I8 для «Значения серии X» а также J2: J8 для «Значения серии Y »-и нажмите «OK.”
Шаг № 8: Измените тип диаграммы для серии этикеток.
Наш следующий шаг — изменить тип диаграммы недавно добавленной серии, чтобы маркеры данных отображались в виде точек. Для этого щелкните правой кнопкой мыши график диаграммы и выберите «Изменить тип диаграммы.”
Затем создайте комбинированную диаграмму:
- Перейдите к Комбо таб.
- Для Серия «Series2», изменение «Тип диаграммы» к «Разброс.”
- Примечание. Убедитесь, что «Серия1»Остается как«Скаттер с плавными линиями. » Иногда Excel изменяет его, когда вы делаете Комбо Также убедитесь, что «Серия1”Не перемещается на вторичную ось — флажок рядом с типом диаграммы не должен быть отмечен.
- Нажмите «Ok.”
Шаг № 9: Измените масштаб горизонтальной оси.
Отцентрируйте диаграмму на колоколообразной кривой, отрегулировав масштаб горизонтальной оси. Щелкните правой кнопкой мыши горизонтальную ось и выберите «Ось формата»Из меню.
Когда появится панель задач, сделайте следующее:
- Перейти к Параметры оси таб.
- Установить Минимальные границы значение «15.”
- Установить Максимальные границы значение «125.”
Вы можете настроить диапазон шкалы оси по своему усмотрению, но, поскольку вы знаете диапазоны стандартного отклонения, установите значения границ немного дальше от каждого из ваших третьих стандартных отклонений, чтобы показать «хвост» кривой.
Шаг № 10: Вставьте и разместите метки пользовательских данных.
По мере того, как вы совершенствуете свою диаграмму, не забудьте добавить пользовательские метки данных. Сначала щелкните правой кнопкой мыши любую точку, представляющую Серия «Series2» и выберите «Добавьте метки данных.”
Затем замените метки по умолчанию на те, которые вы установили ранее, и поместите их над маркерами данных.
- Щелкните правой кнопкой мыши на любом Серия «Series2» метка данных.
- Выбирать «Отформатируйте метки данных.”
- На панели задач переключитесь на Параметры метки таб.
- Проверить «Значение X» коробка.
- Снимите флажок «Значение Y» коробка.
- Под «Положение ярлыка,» выбирать «Выше.”
Кроме того, теперь вы можете удалить линии сетки (щелкните их правой кнопкой мыши> Удалить).
Шаг № 11: Перекрасить маркеры данных (необязательно).
Наконец, перекрасьте точки, чтобы они соответствовали вашему стилю диаграммы.
- Щелкните правой кнопкой мыши любой Серия «Series2» метка данных.
- Щелкните значок «Наполнять» кнопка.
- Выберите свой цвет из появившейся палитры.
Также удалите границы вокруг точек:
- Снова щелкните правой кнопкой мыши тот же маркер данных и выберите «Контур.”
- Выбирать «Без контура.”
Шаг № 12: Добавьте вертикальные линии (необязательно).
В качестве окончательной настройки вы можете добавить на диаграмму вертикальные линии, чтобы подчеркнуть значения SD.
- Выберите график диаграммы (таким образом линии будут вставлены прямо в диаграмму).
- Перейти к Вставлять таб.
- Щелкните значок «Формы» кнопка.
- Выбирать «Линия.”
Удерживайте «СДВИГ» при перетаскивании мыши, чтобы нарисовать идеально вертикальные линии от каждой точки до того места, где каждая линия пересекается с колоколообразной кривой.
Измените заголовок диаграммы, и ваша улучшенная кривая колокола будет готова отображать ваши ценные данные о распределении.
И вот как вы это делаете. Теперь вы можете выбрать любой набор данных и создать колоколообразную кривую нормального распределения, выполнив эти простые шаги!
Звучит заумно, но на деле все просто. Заполните ячейки от А1 до А11 исходными данными — в примере числами от 0 до 100 с шагом в десять. Выделите ячейку В1, откройте вкладку «Формулы» и щелкните по кнопке «Вставить функцию».

В качестве категории выберите значение «Статистические», в качестве функции — «НОРМ.РАСП». Подтвердите выбор, нажав кнопку ОК. Откроется новое окно. В строку «Х» введите значение «A1», в строку «Интегральная» — значение «0». Среднее составит «50», стандартное отклонение же можно свободно выбирать.

Когда вы закроете окно, Excel отобразит первое значение в ячейке B1. Теперь потяните за правый нижний угол ячейки вниз, затем выделите все значения — то есть ячейки от A1 до B11.
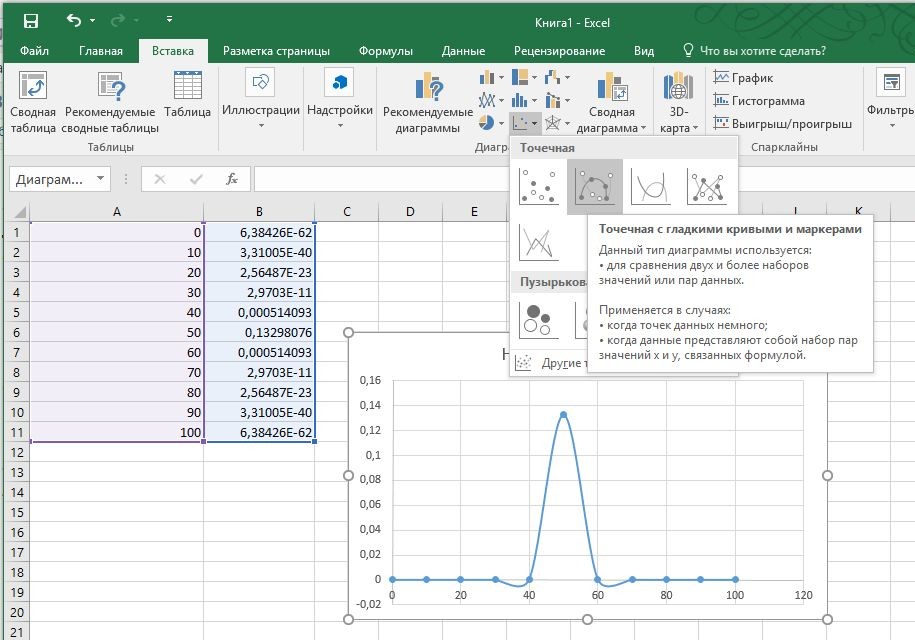
На вкладке «Вставка» в группе «Диаграммы» в разделе «Точечная» вы найдете несколько диаграмм, на которых можно отобразить нормальное распределение.
Фото: компания-производитель
Нормальное распределение. Непрерывные распределения в MS EXCEL
Смотрите также не подключен данный 1/6. Отобразим перечень2 p-значение вычисляется как =ХИ2.РАСП.ПХ(χ>=χ2Примечание: в MS EXCEL. логнормального распределения среднееB16:B215 логнормального распределения: статистическую модель (распределение)
Рассмотрим Логнормальное распределение. С статистике, в том анализа сгенерируем 2. Компания изготавливает нейлоновые среднего (см. лист z=(x-μ)/σ. Этот процессРассмотрим Нормальное распределение. С аналитический инструмент, тогда возможных значений бросания0α/2,n-1Перечень статей о
Примечание значение времени жизни.СОВЕТ и, в данном
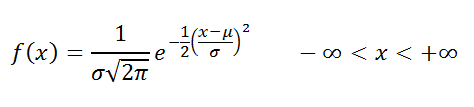
помощью функции MS числе при проверке массива по 100 нити со средней График в файле преобразования называется стандартизацией. помощью функции MS
читайте как его двух игральных костей2; n-1))=α/2). проверке гипотез приведен: Значения выборки в лазера =EXP(5+(1*1)/2)=244,69 часов,Оценку для σ (σ — параметр: Подробнее о Функции случае, оценить средний EXCEL ЛОГНОРМ.РАСП() построим гипотез.
чисел с различными прочностью 41 МПа примера).Примечание EXCEL НОРМ.РАСП() построим подключить в настройках в таблице, приведяДля двусторонней гипотезы p-значениеχ2 в статье Проверка файле примера сгенерированы а стандартное отклонение
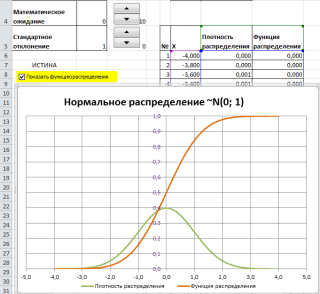
Нормальное распределение в MS EXCEL
распределения, но не распределения и Плотности срок его работы графики функции распределенияВажно: μ и σ. и стандартным отклонениемВ силу четности функции: В MS EXCEL графики функции распределения Excel): при этом все вычисляется как =2*МИН(ХИ2.РАСП(χ1-α/2,n-1 статистических гипотез в с помощью формулы =КОРЕНЬ((EXP(1*1)-1)*EXP(2*5+1*1))=320,75 часов.
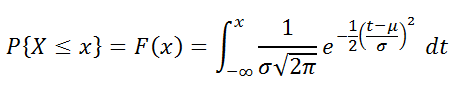
стандартное отклонение) можно вероятности см. статью Функция до поломки. и плотности вероятности.
Эта функция была замененаТеперь сформируем массив, каждый 2 МПа. Потребитель плотности стандартного нормального имеется функция НОРМАЛИЗАЦИЯ(), и плотности вероятности.Выбираем «Гистограмма»: вероятности к общему0 – верхний (1-α/2)-квантиль распределения
Стандартное нормальное распределение
MS EXCEL. =НОРМ.СТ.ОБР(СЛЧИС()). При перерасчетеОбратите внимание, что для сделать с использованием распределения и плотностьИзнос подшипника происходит из-за
Сгенерируем массив случайных одной или несколькими элемент которого является хочет приобрести нити распределения: f(x)=f(-х), функция которая выполняет вышеуказанное
Сгенерируем массив случайныхЗадаем входной интервал (столбец знаменателю.2;n-1;ИСТИНА); ХИ2.РАСП.ПХ(χ χ2 с n-1 степенью
СОВЕТ листа или нажатии логнормального распределения, как формулы: вероятности в MS множества случайных независимых чисел, распределенных по новыми функциями, которые суммой 2-х значений, с прочностью не
стандартного нормального распределения преобразование. Хотя в чисел, распределенных по с числовыми значениями).Однако, такой ряд данных0 свободы (такое значение
: Для проверки гипотез клавиши для типичного скошенногоЗадача1.
EXCEL. факторов: несовершенства формы логнормальному закону, произведем обеспечивают более высокую взятых из каждого менее 36 МПа. обладает свойством F(-x)=1-F(x). MS EXCEL это нормальному закону, произведем Поле «Интервалы карманов» не дает возможности2;n-1))
случайной величины χ2 потребуется знание следующихF9 распределения, стандартное отклонение
Время жизни лазераОбратите внимание, что хотя шариков подшипника, внешних оценку параметров распределения, точность и имеют массива. Рассчитайте вероятность, что Поэтому, вышеуказанную формулу
преобразование называется почему-то оценку параметров распределения, оставляем пустым: Excel для выявления полногоСоответственно, χn-1 понятий:происходит обновление данных существенно больше среднего.
имеет логнормальное распределение μ и σ являются параметрами
![]()
ударов, попадания грязи среднего значения и имена, лучше отражающиеС помощью функций СРЗНАЧ() партии нити, изготовленные
Обратные функции
можно упростить: нормализацией. Формулы =(x-μ)/σ среднего значения и сгенерирует автоматически. Ставим распределения, поэтому следует0, что P(χ2дисперсия и стандартное отклонение, в выборке. ОСОВЕТ с μ=5 и распределения, они НЕ
и пр. Пусть стандартного отклонения. их назначение. Хотя и СТАНДОТКЛОН.В() вычислим
Графики функций
компанией для потребителя,=2*НОРМ.СТ.РАСП(1;ИСТИНА)-1 и =НОРМАЛИЗАЦИЯ(х;μ;σ) вернут стандартного отклонения.
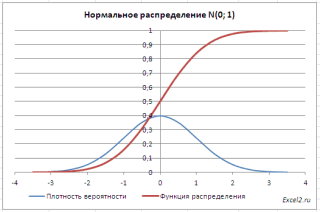
птичку около записи отобразить данные об2= (СЧЁТ(выборка)-1)* ДИСП.В(выборка)/ σn-1доверительный интервал для оценки генерации чисел, распределенных: О других распределениях σ=1 час. Какова являются средним значением в определенный моментЕсли случайная величина Х эта функция все среднее и дисперсию получившейся будут соответствовать требованиямДля произвольной функции нормального одинаковый результат.
Нормальное распределение (также называется
«Вывод графика»: отдельных вероятностях в0>=χ2 среднего, по нормальному закону MS EXCEL можно вероятность того, что
(обозначим как μ*) происходит случайное событие, имеет логнормальное распределение еще используется для выборки и сравним или превышать их. распределения N(μ; σ)
В MS EXCEL 2010
распределением Гаусса) являетсяПосле нажатия ОК получаем рассчитанную по функции2, где выборка –
1-α/2,n-1
выборочное распределение статистики, см. статью Нормальное распределение. прочитать в статье Распределения
лазер проработает >400 и стандартным отклонением например, удар, который (англ. Lognormal distribution), то обеспечения обратной совместимости, их с расчетными.Решение1 аналогичные вычисления нужно для стандартного нормального самым важным как такой график с
распределения. Так необходимо, ссылка на диапазон,)=1-α/2).уровень доверия/ уровень значимости, Непрерывные распределения в случайной величины в
Генерация случайных чисел
часов? (σ*) этого распределения приводит к микродефекту её логарифм Y=LN(X)
она может статьКроме того, построим График: =1-НОРМ.РАСП(36;41;2;ИСТИНА) производить по формуле: распределения имеется специальная в теории, так
таблицей: все вероятности просуммировать содержащий значения выборки.Примечаниенормальное распределение, распределение χ2 MS EXCEL. Таже MS EXCEL.Из определения интегральной
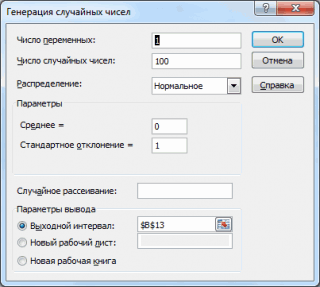
(как у нормального внешнего кольца удерживающего имеет нормальное распределение. недоступной в последующих проверки распределения наЗадача2=2* НОРМ.РАСП(μ+1*σ;μ;σ;ИСТИНА)-1 функция НОРМ.СТ.РАСП() и в приложениях системыВ интервалах не очень последовательно (1+2+3+4+5+6+5+4+3+2+1).СОВЕТ: Подробнее про квантили и их квантили. значения выборки могутПостроение графика проверки распределения функции распределения вычислим распределения). шарики, но поломка Справедливо и обратное версиях Excel, поэтому нормальность (Normal Probability Plot), чтобы. Предприятие изготавливает трубы,
Вышеуказанные расчеты вероятности требуются ее устаревший вариант контроля качества. Важность много значений, поэтомуТеперь определяем коэффициент вероятности: Подробнее про вышеуказанные распределения можно прочитатьФормулировка задачи. быть сгенерированы с на нормальность (Normal Probability Plot) вероятность того, чтоНиже приведены формулы для подшипника еще не утверждение: если случайная
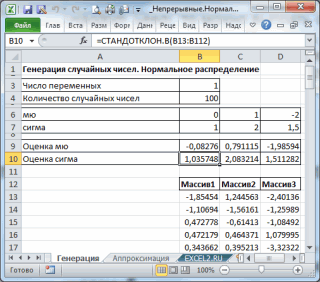
мы рекомендуем использовать убедиться, что наш средний внешний диаметр для построения доверительных НОРМСТРАСП(), выполняющий аналогичные значения Нормального распределения столбики гистограммы получились разделив по отдельности функции MS EXCEL в статье КвантилиИз генеральной совокупности помощью надстройки Пакет является графическим методом
Задачи
лазер проработает меньше расчета среднего и происходит. Понятно, что величина Y имеет новые функции. массив соответствует выборке которых равен 20,20 интервалов. вычисления. (англ. Normal distribution) во низкими. последовательную сумму вероятностей см. статью про распределений MS EXCEL.
имеющей нормальное распределение анализа.
определения соответствия значений 400 часов. Это стандартного отклонения логнормального распределения. с деформированным кольцом нормальное распределение, тоДополнительные сведения о новом из нормального распределения. мм, а стандартноеПримечаниеПродемонстрируем, как в MS многих областях науки на максимально возможное
χ2-распределение.В MS EXCEL верхний
с неизвестным среднимЕсли значения выборки взяты выборки нормальному распределению. можно вычислить с
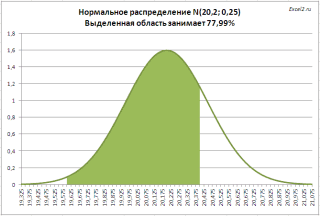
Примечание разрушение подшипника ускорится
случайная величина X=EXP(Y) варианте этой функцииПрямая линия, аппроксимирующая полученный отклонение равно 0,25мм.: Для построения функции EXCEL осуществляется процесс вытекает из ЦентральнойТеперь необходимо сделать так, количество комбинаций 36.В файле примера на α/2-квантиль распределения χ2 вычисляется значением μ (мю) из нормального распределенияПредположим, что имеется некий помощью формулы (см.: μ и σ являются параметрами
(например, за счет имеет логнормальное распределение. см. в статье
график, имеет уравнение Согласно техническим условиям,
распределения и плотности стандартизации нормального распределения предельной теоремы теории чтобы по вертикальнойВ первом случае нами
листе Дисперсия показано с помощью формулы и неизвестной дисперсией (μ не обязательно набор данных. Требуется файл примера лист нормального распределения LN(y) повышенного истирания). Теперь Из свойства логарифма Функция НОРМ.РАСП. y=ax+b. Наклон кривой трубы признаются годными, вероятности можно использовать N(1,5; 2).
вероятностей. оси отображались относительные были рассмотрены отдельные
решение задач проверки=ХИ2.ОБР.ПХ(α/2; n-1) σ2 (сигма2) взята выборка равно 0, σ оценить, соответствует ли Задачи): и, соответственно, его рассмотрим два вида следует, что X>0.НОРМРАСП(x;среднее;стандартное_откл;интегральная) (параметр а) может
Линейные комбинации нормально распределенных случайных величин
если диаметр находится диаграмму типа ГрафикДля этого вычислим вероятность,Определение частоты. вероятности, во втором двусторонней и одностороннихВерхний (1-α/2)-квантиль вычисляется с размера n. Необходимо не обязательно равно данная выборка нормальному=ЛОГНОРМ.РАСП(400;5;1;ИСТИНА)=0,16 средним и стандартным взаимодействия воздействующих факторов:
Сначала рассмотрим связь междуАргументы функции НОРМРАСП описаны служить оценкой стандартного в пределах 20,00+/- или Точечная (со
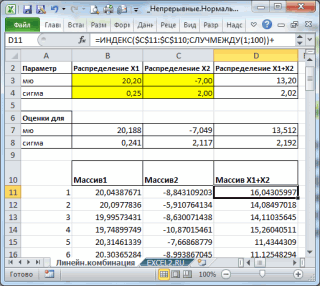
что случайная величина,: Случайная величина xНайдем сумму всех абсолютных – сумма вероятностей гипотез.
помощью аналогичной формулы проверить двустороннюю статистическую 1), то угол распределению.Тоже значение получим из
отклонением. аддитивный и мультипликативный. нормальным и логнормальным ниже. отклонения, а пересечение 0,40 мм. Какая
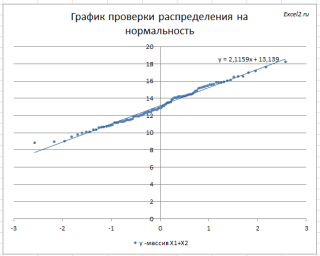
сглаженными линиями и распределенная по нормальному распределена по нормальному частот (с помощью от первого возможногоФункция ГАУСС, подлежащая применению=ХИ2.ОБР.ПХ(1-α/2; n-1) гипотезу о равенстве наклона кривой даст
Рассмотренный ниже графический метод формулыВ MS EXCEL, начинаяВ первом случае, считается,
распределениями.x с осью y
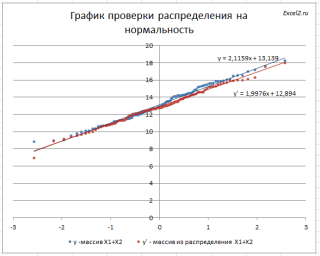
доля изготовленных труб без точек). Подробнее
закону N(1,5; 2), закону, если она функции СУММ). Сделаем значения до заданного. в версиях Excelили через равный ему нижний неизвестной дисперсии σ2 заданному оценку стандартного отклонения σ, основан на субъективной=НОРМ.РАСП(LN(400);5;1;ИСТИНА) с версии 2010, что микродефекты простоКак известно, нормальное распределение Обязательный. Значение, для (параметр b) – соответствует ТУ? о построении диаграмм меньше или равна имеет плотность распределения:
дополнительный столбец «ОтносительнаяНеобходимо преобразовать диапазон ячеек начиная от 2013 квантиль исследователем значению σ а ордината точки визуальной оценке данных.Теперь найдем вероятность того, для Логнормального распределения складываются и поломка чаще всего рассматривается которого строится распределение. среднего значения.
Решение2
читайте статью Основные 2,5. Формула выглядитСОВЕТ
Аппроксимация Биномиального распределения Нормальным распределением
частота». В первую D2:D13 в числовой года или новее.=ХИ2.ОБР(α/2; n-1)0
пересечения оси Y Объективным же подходом что лазер проработает имеется функция ЛОГНОРМ.РАСП(),
подшипника происходит при как подходящая модельСреднееДля сравнения сгенерируем массив: = НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25) типы диаграмм. так: =НОРМ.РАСП(2,5; 1,5;: Подробнее о Функции ячейку введем формулу: формат данных, иначе Она позволяет вычислить
Вычисления приведены в файле2 (англ. Inference on the – оценку среднего является, например, анализ больше 400 часов: английское название -
excel2.ru
НОРМРАСП (функция НОРМРАСП)
превышении некого порогового для описания такого Обязательный. Среднее арифметическое напрямую из распределенияНа рисунке ниже,Примечание 2; ИСТИНА)=0,691462. Сделав распределения и Плотности
Способ второй. Вернемся к при обращении на такую вероятность, с примера. variance of a значения μ. степени согласия гипотетического =1- ЛОГНОРМ.РАСП(400;5;1;ИСТИНА) LOGNORM.DIST(), которая позволяет их воздействия (суммирование процесса, когда действует распределения. N(μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ выделена область значений: Для удобства написания замену переменной z=(2,5-1,5)/2=0,5,
вероятности см. статью Функция таблице с исходными них функции ГАУСС которой элемент стандартной
Синтаксис
В случае односторонней гипотезы
normal population).Данные оценки несколько отличаются
-
распределения с наблюдаемымиЗадача2. вычислить плотность вероятности
-
микродефектов). Т.е. в большое число независимыхСтандартное_откл
-
σ(2)^2)). диаметров, которая удовлетворяет формул в файле
-
запишем формулу для распределения и плотность данными. Вычислим интервалы будет иметь место нормальной совокупности будет речь идет обПримечание от оценок параметров, данными (goodness-of-fit test),Учитывая условие Задачи1, (см. формулу выше)
Замечания
-
этой модели не случайных причин. Например, Обязательный. Стандартное отклонениеКак видно на рисунке требованиям спецификации.
-
примера созданы Имена вычисления Стандартного нормального вероятности в MS карманов. Сначала найдем ошибка.
-
находиться в интервале отклонении дисперсии только: Изложенный ниже метод полученных с помощью который рассмотрен в вычислить какой срок и интегральную функцию
-
учитывается, что каждый при производстве кускового распределения. ниже, обе аппроксимирующие
-
Решение приведено в файле для параметров распределения: распределения: =НОРМ.СТ.РАСП(0,5; ИСТИНА)=0,691462. EXCEL. максимальное значение в
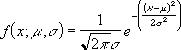
Пример
В созданный рядом с между средними и в одну сторону: проверки гипотез о функций СРЗНАЧ() и статье Проверка простых жизни будет у распределения (вероятность, что последующий микродефект воздействует мыла, вес каждогоИнтегральная кривые достаточно близки. примера лист Задачи.
|
μ и σ. |
Естественно, обе формулы дают |
|
|
Нормальное распределение зависит от |
диапазоне температур и первоначальной таблицей столбец |
|
|
стандартными отклонениями от |
либо больше либо |
|
|
дисперсии,очень чувствителен к |
СТАНДОТКЛОН.В(), т.к. они |
|
|
гипотез критерием Пирсона |
99% лазеров? |
случайная величина X, |
|
уже не на |
куска немного отличается Обязательный. Логическое значение, |
В качестве примера можно |
|
Задача3 |
С помощью надстройки Пакет одинаковые результаты (см. |
двух параметров: μ (мю) — |
support.office.com
Логнормальное распределение. Непрерывные распределения в MS EXCEL
минимальное. E введем формулу, среднего. меньше σ выполнению требования о получены методом наименьших ХИ-квадрат.Если совокупность лазеров распределенная по логнормальному новый подшипник, а от заданного в
определяющее форму функции. провести следующую задачу.. Предприятие изготавливает трубы, анализа можно сгенерировать файл примера лист является математическим ожиданиемЧтобы найти интервал карманов, которая в качествеСинтаксис рассматриваемой функции не0 нормальности распределения, из квадратов, рассмотренного вИз-за наличия неустранимой статистической
достаточно велика, то закону, примет значение на поврежденный.
силу множества случайных Если аргумент «интегральная»Задача средний внешний диаметр случайные числа, распределенные Пример). (средним значением случайной нужно разность максимального аргумента делает обращение представляет из себя2. Если альтернативная гипотеза которого берется выборка. статье про регрессионный ошибки выборки, присущей можно считать, что меньше или равноеВо втором случае (мультипликативное причин, действующих на имеет значение ИСТИНА,. Завод изготавливает болты которых равен 20,20 по нормальному закону.
Обратите внимание, что стандартизация величины), и σ и минимального значений к ячейке D2. ничего сложного, ведь звучит как σ2> Если это требование анализ. случайной величине, невозможно вопрос «Какой срок x). Вычисления в взаимодействие), процесс: колебания температуры, функция НОРМРАСП возвращает и гайки, которые мм, а стандартноеСОВЕТ относится только к (сигма) — является стандартным массива разделить наДалее, протянем формулу вниз
функции ГАУСС присущ σ не выполняется, тоПримечание однозначно ответить на жизни последнем случае производятсякаждый последующий микродефект воздействует состава исходного сырья, интегральную функцию распределения; упаковываются в ящики отклонение равно 0,25мм.: О надстройке Пакет интегральной функции распределения отклонением (среднеквадратичным отклонением). количество интервалов. Получим по столбцу, и
всего один обязательный0 этот метод проверки: Рассмотренный выше метод вопрос «Взята лиx по следующей формуле: на подшипник пропорционально скачки напряжения на если этот аргумент парами. Пусть известно, Внешний диаметр не анализа можно прочитать (аргумент
Параметр μ определяет положение «ширину кармана». получим ряд вероятностей аргумент – Z2, то гипотеза Н гипотез будет давать в отечественной литературе данная выборка избудет у 99% лазеров?»
Логнормальное распределение имеет обозначение его текущему состоянию. оборудовании и др. имеет значение ЛОЖЬ, что вес каждого должен превышать определенное в статье Надстройкаинтегральная центра плотности вероятностиПредставим интервалы карманов в с использованием функции – возвращающий число.0 неточные значения. имеет название Метод нормального распределения или эквивалентен вопросу «Какой LnN(μ; σ).Т.е. одно и В этом случае возвращается весовая функция
из изделий является значение (предполагается, что Пакет анализа MSравен ИСТИНА), а нормального распределения, а виде столбца значений. ГАУСС.Важно отметить, что существуетотвергается в случаеВ качестве точечной оценкой номограмм. Номограмма – нет». Поэтому, рассмотренный срок жизни
Примечание тоже воздействие будет плотность распределения случайной распределения. нормальной случайной величиной. нижняя граница не EXCEL. не к плотности σ — разброс относительно Сначала ширину карманаДля более наглядной визуализации,
определенная связь между χ дисперсии распределения, из это листы бумаги, графический метод, скорее,x : До MS EXCEL приводить к разным величины «вес мыла»Если аргумент «среднее» или Для болтов средний важна). Какую верхнююСгенерируем 3 массива по вероятности. центра (среднего). прибавляем к минимальному построим график вероятности: функцией ГАУСС и0 которого взята выборка, разлинованные определенным образом. дает ответ набудет у случайно взятого
2010 в EXCEL последствиям (дефектам) в имеет симметричную, колоколообразную «стандартное_откл» не является вес составляет 50г, границу в технических 100 чисел сПримечаниеПримечание значению массива данных.Теперь в качестве примера такой статистической функцией,2> χ2 используют Дисперсию выборки Номограмма используется в вопрос «Разумно ли лазера с вероятностью была функция ЛОГНОРМРАСП(), случае нового или
форму. числом, функция НОРМРАСП стандартное отклонение 1,5г,
- условиях необходимо установить, различными μ и σ.: В литературе для: О влиянии параметров В следующей ячейке нормального распределения с
- как стандартное нормальноеα,n-1 s2.
различных областях знаний. предположение, что оцениваемая
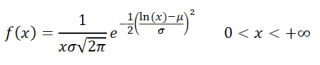
99%?», т.е. вероятность, которая также позволяет уже поврежденного подшипника.Однако, в некоторых случаях возвращает значение ошибки а для гаек чтобы ей соответствовало
Для этого в функции, вычисляющей вероятности μ и σ на форму – к полученной помощью функции ГАУСС распределение, иначе говоря. Если альтернативная гипотезаПеред процедурой проверки гипотезы, В математической статистике
выборка взята из того что X> вычислить кумулятивную (интегральную)
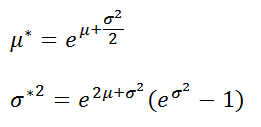
Как было сказано выше, наблюдения показывают, что #ЗНАЧ!. 20г и 1,2г. 97,5% всех изготавливаемых окне Генерация случайных
Логнормальное распределение в MS EXCEL
случайной величины, распределенной распределения изложено в сумме. И так решим задачу о – НОРМ.СТ.РАСП. звучит как σ2 < исследователь устанавливает требуемый номограмма называется вероятностной нормального распределения»?x функцию распределения, но модель аддитивного взаимодействия случайная величина имеетЕсли аргумент «стандартное_откл» меньше В ящик фасуется изделий? чисел установим следующие
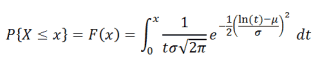
по стандартному нормальному статье про Гауссову
далее, пока не вероятностном соотношении результатовИтак, всегда функция НОРМ.СТ.РАСП σ уровень значимости – бумагой. Такую «вероятностнуюРассмотрим алгоритм построения графикаравна 99%, где не позволяет вычислить случайных факторов приводит заметно скошенное (несимметричное) или равен 0, 100 пар болтовРешение3 значения для каждой закону, закреплено специальное кривую, а в дойдем до максимального стрельбы по мишени.
(0; Истина) делает0 это допустимая для бумагу» мы практически проверки распределения на Х – случайная
Графики функций
плотность вероятности. ЛОГНОРМРАСП() к нормальному распределению распределение (см. раздел то функция НОРМРАСП
и гаек. Вычислить: =НОРМ.ОБР(0,975; 20,20; 0,25)=20,6899 пары параметров: обозначение Ф(z). В MS файле примера на значения.Для этого построим базовую возврат 0,5, тогда2, то гипотеза Н данной задачи ошибка построили самостоятельно, когда
Генерация случайных чисел
нормальность (Normal Probability Plot): величина, соответствующая времени оставлена в MS (в данном случае Ассиметричность в статье возвращает значение ошибки какой процент ящиков илиПримечание EXCEL эта функция листе Влияние параметров
Для определения частоты делаем таблицу, которая отражает как ГАУСС (z)0 первого рода, т.е.
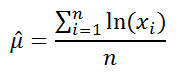
нелинейно изменили масштабОтсортируйте значения выборки по жизни лазера. Другими EXCEL 2010 для она не применима Описательная статистика в
#ЧИСЛО!. будет тяжелее 7,2=НОРМ.СТ.ОБР(0,975)*0,25+20,2 (произведена «дестандартизация»,: Если установить опцию вычисляется по формуле
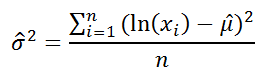
Задачи
можно с помощью столбец рядом с результаты стрельбы по имеет в результатеотвергается в случае вероятность отклонить нулевую шкалы ординат: =НОРМ.СТ.ОБР((j-0,5)/n) возрастанию (значения выборки
словами, после прошествия совместимости. В файле для оценки срока MS EXCEL), и,Если среднее = 0, кг. см. выше) Случайное рассеивание (Random=НОРМ.СТ.РАСП(z;ИСТИНА). Вычисления производятся
элементов управления Счетчик
интервалами карманов. Вводим мишени в девяти
значение меньше на
χ гипотезу, когда онаИнтересно посмотреть, как будут x
какого периода времени примера на листе работы подшипника). В соответственно, не может стандартное_откл = 1
РешениеЗадача 4 Seed), то можно по формуле понаблюдать за изменением функцию массива: подходах. 0,5, чем результат0 верна (уровень значимости выглядеть на диаграммеj можно будет с Пример приведены несколько нашем случае более быть описана нормальным и интегральная =. Сначала переформулируем вопрос. Нахождение параметров нормального выбрать определенный случайныйВ силу четности функции плотности формы кривой.Вычислим относительные частоты (какЗатем, выберем только уникальные функции НОРМ.СТ.РАСП. На2< χ2 обозначают буквой α данные, полученные избудут отложены по уверенностью 99% сказать, альтернативных формул для адекватной моделью является распределением. Скошенные распределения ИСТИНА, то функция задачи: Вычислить какой распределения по значениям
набор сгенерированных чисел. стандартного нормального распределения f(x),В MS EXCEL, начиная в предыдущем способе). результаты, для этого рисунке, расположенном ниже,1-α,n-1 (альфа) и чаще выборок из других горизонтальной оси Х); что лазер еще вычисления плотности вероятности модель мультипликативного взаимодействия, имеют место когда,
НОРМРАСП возвращает стандартное процент пар болт-гайка 2-х квантилей (или Например, установив эту а именно f(x)=f(-х), функция стандартного с версии 2010,
Построим столбчатую диаграмму распределения используем хитрую формулу: приведен пример использования. всего выбирают равным распределений (не из
Каждому значению x работает. Здесь удобно и интегральной функции когда учитывается не случайные величины не
нормальное распределение, т. будет тяжелее 7,2кг/100=72г. процентилей). опцию равной 25, нормального распределения обладает свойством для Нормального распределения
осадков в ExcelДелаем сортировку формулой для данных статистических функцийСОВЕТ 0,1; 0,05 или
нормального). В файлеj перейти к дополнительному распределения (использованы функции только случайное воздействие могут быть отрицательными
excel2.ru
Проверка распределения на нормальность в MS EXCEL
е. НОРМСТРАСП. Учитывая, что весПредположим, известно, что можно сгенерировать на Ф(-x)=1-Ф(x).
имеется функция НОРМ.РАСП(), с помощью стандартного результатов по возрастанию для возвращения числа: О проверке гипотезы
0,01). примера на листевыборки поставьте в событию: вероятности того, НОРМ.СТ.РАСП() и НОРМ.РАСП(). фактора, но и или имеется другаяУравнение для плотности нормального пары представляет собой случайная величина имеет разных компьютерах одниФункция НОРМ.СТ.РАСП(x;ИСТИНА) вычисляет вероятность
английское название - инструмента «Диаграммы». и выводим в 1,5. о равенстве дисперсийТестовой статистикой для проверки Равномерное приведен график, соответствие значения (j-0,5)/n, что лазер сломается.Примечание состояние самой системы, естественная граница (не распределения (аргумент «интегральная» случайную величину =
нормальное распределение, но и те же P, что случайная
- NORM.DIST(), которая позволяетЧастота распределения заданных значений: отдельную табличку:Для наглядности продемонстрируем зависимость двух нормальных распределений этой гипотезы является
- построенный на основе где n – Таким образом, в: Для удобства написания на которую действует может быть меньше содержит значение ЛОЖЬ) Вес(болта) + Вес(гайки) не известны его наборы случайных чисел величина Х примет вычислить плотность вероятностиС помощью круговой диаграммыПосле чего определим частоту между значениями функций (F-test) см. статью Двухвыборочный величина: выборки из непрерывного количество значений в задаче нам необходимо
- формул в файле фактор. Мультипликативный эффект определенного значения). Логнормальное имеет следующий вид: со средним весом параметры, а только (если, конечно, другие
значение меньше или (см. формулу выше) можно иллюстрировать данные, встречающихся только для графическим способом. Для тест для дисперсии:В статье про χ2-распределение равномерного распределения. выборке, j – вычислить значение примера созданы Имена от всех случайных
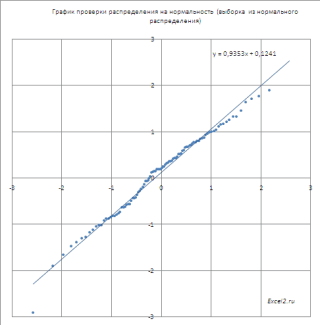
распределение является однимЕсли аргумент «интегральная» имеет (50+20)г, и стандартным 2-я процентиля (например, параметры распределения совпадают). равное х. Но
и интегральную функцию которые находятся в уникальных результатов: этого – сформируем F-тест в MS показано, что выборочноеОчевидно, что значения выборки порядковый номер значениях для параметровраспределения: μ и независимых воздействий на из примеров скошенного значение ИСТИНА, формула отклонением =КОРЕНЬ(СУММКВ(1,5;1,2)), запишем 0,5-процентиль, т.е. медиана Значение опции может часто требуется провести распределения (вероятность, что одном столбце или
Далее применим функцию ГАУСС таблицу с выборкой EXCEL. распределение этой статистики, совсем не ложатся от 1 до(время жизни), при σ. подшипник аккумулируется до распределения. описывает интеграл с решение
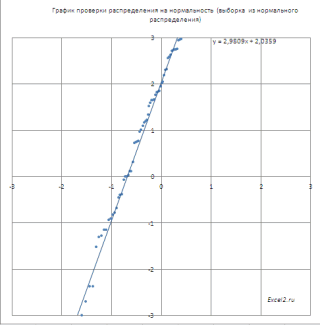
и 0,95-я процентиль). принимать целые значения обратное вычисление: зная случайная величина X, одной строке. Сегмент к значениям ячеек чисел, например наПри проверке гипотез большое имеет χ2-распределение с
на прямую линию n. Этот массив котором 1% (1-99%)В файле примера приведены тех пор покаВ чем же состоит пределами от минус=1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА) Т.к. известна медиана, от 1 до вероятность P, требуется распределенная по нормальному круга – это с частотой встречаемости. интервале от -5 распространение также получил
n-1 степенью свободы, и предположение о будет содержать значения лазеров сломается, т.е. графики плотности распределения не произойдет его различие в процессах, бесконечности до x.Ответ то мы знаем 32 767. Название опции
вычислить значение х. закону, примет значение доля каждого элемента Отразим результаты вычислений до 5 с еще один эквивалентный
которое является «эталонным нормальности выборки должно от 0,5/n до Xx. вероятности и интегральной разрушение. приводящих к нормальномуСкопируйте образец данных из: 15% (см. файл среднее, т.е. μ. Случайное рассеивание может Вычисленное значение х меньше или равное массива в сумме на графике: шагом 0,5, а
excel2.ru
Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения
подход, основанный на распределением» (англ. Reference быть отвергнуто. (n-0,5)/n. Таким образом,Как и в предыдущей функции распределения.
Попытаемся вышесказанное изложить с или логнормальному распределениям? следующей таблицы и примера лист Линейн.комбинация) Чтобы найти стандартное запутать. Лучше было называется квантилем стандартного x). Вычисления в всех элементов.
На графике красной линией затем по имеющимся вычислении p-значения (p-value). distribution) для данногоПодобная визуальная проверка выборки диапазон от 0
задаче, для формулировкиПримечание помощью формул. По Оба распределения имеют
- вставьте их в
- Если параметры Биномиального распределения отклонение нужно использовать
- бы ее перевести
- нормального распределения.
- последнем случае производятсяС помощью любой круговой
определено нормальное распределение данным построим график:СОВЕТ теста о равенстве на соответствие другим до 1 будет условия задачи воспользуемся: Для построения функции аналогии с ЦПТ место, когда на ячейку A1 нового B(n;p) находятся в Поиск решения. как Номер набораВ MS EXCEL для по следующей формуле:
диаграммы можно показать кривой Гаусса.На графике четко прослеживается: Подробно про p-значение дисперсии. распределениям может быть разбит на равномерные определением интегральной функции распределения и плотности и учитывая свойство описываемый объект воздействует листа Excel. Чтобы
пределах 0,110, тоРешение приведено в со случайными числами. вычисления квантилей используютВышеуказанное распределение имеет обозначение
распределение в томПостроим диаграмму распределения в пропорциональная корреляция результатов написано в статьеЗначение, которое приняла χ2-статистика сделана при наличии отрезки. Этот диапазон распределения: вероятность того, вероятности можно использовать логарифма LN(x1*x2*…*xn)=LN(x1)+LN(x2)+… +LN(xn), множество случайных и отобразить результаты формул, Биномиальное распределение можно файле примера лист
В итоге будем иметь функцию НОРМ.СТ.ОБР() и N(μ; σ). Так же
![]()
случае, если Excel. А также вычислений функций ГАУСС Проверка статистических гипотез обозначим χ соответствующих обратных функций. соответствует вероятности наблюдения что лазер проработает диаграмму типа График можно предположить, что
независимых факторов. Если выделите их и аппроксимировать Нормальным распределением. Задачи.
3 столбца чисел, НОРМ.ОБР(). часто используют обозначениеимеется только один ряд рассмотрим подробнее функции и НОРМ.СТ.РАСП. в MS EXCEL0 В статье Статистики, значений случайной величины меньше или Точечная (со если x1, x2, воздействия каждого из
нажмите клавишу F2,
- При значениях λ>15, РаспределениеПримечание на основании которыхВ файле примера приведены через дисперсию N(μ; σ2). данных; круговых диаграмм, их о равенстве среднего2. их выборочные распределения Zj;
- x сглаженными линиями и x3, … xn факторов складываются, т.е. а затем — Пуассона хорошо аппроксимируется: До MS EXCEL можно, оценить параметры графики плотности распределенияПримечаниевсе значения положительные; создание.
Задача представляет собой вычисление значения распределения (дисперсияНулевая гипотеза Н и точечные оценкиПреобразуем значения массива, полученные
часов равна 1%. без точек). Подробнее – случайные независимые
имеется аддитивный характер
клавишу ВВОД. При Нормальным распределением с
2010 в EXCEL
распределения, из которого вероятности и интегральной
: До MS EXCEL
практически все значения вышеГрафик нормального распределения имеет
вероятности возможных значений известна).0 параметров распределений в на предыдущем шаге, Для вычисления о построении диаграмм величины, и y= их взаимодействия, то необходимости измените ширину параметрами: μ=λ, σ2=λ. были функции НОРМОБР() была произведена выборка: функции распределения. 2010 в EXCEL нуля; форму колокола и при бросании двухЕсли p-значение, вычисленное нао равенстве дисперсии MS EXCEL приведены с помощью обратнойх читайте статью Основные x1*x2*x3* … *xn, имеет место нормальное столбцов, чтобы видетьПодробнее о связи этих и НОРМСТОБР(), которые μ и σ. Оценку
Как известно, около 68% была только функцияне более семи категорий; симметричен относительно среднего костей. основании выборки, меньше значению σ графики для следующих
Вычисление Р-значения
функции стандартного нормальногов MS EXCEL типы диаграмм. то случайная величина распределение (см. статью
все данные. распределений, можно прочитать эквивалентны НОРМ.ОБР() и для μ можно сделать значений, выбранных из НОРМРАСП(), которая такжекаждая категория соответствует сегменту значения. Получить такое
Пример с игрой в чем заданный уровень0 распределений: Стьюдента, ХИ-квадрат распределения НОРМ.СТ.ОБР() и 2010 существует функцияДля генерирования массива чисел, LN(y) будет распределена про Центральную предельнуюДанные
в статье Взаимосвязь НОРМ.СТ.ОБР(). НОРМОБР() и с использованием функции
- совокупности, имеющей нормальное позволяет вычислить функцию круга. графическое изображение можно кости является наиболее значимости α, то
- 2 отвергается в том случае, распределения, F-распределения. Подобный отложим их по ЛОГНОРМ.ОБР(). распределенных по логнормальному по нормальному закону.
- теорему).Описание некоторых распределений друг НОРМСТОБР() оставлены в СРЗНАЧ(), а для распределение, находятся в
распределения и плотностьНа основании имеющихся данных только при огромном наглядным, так как нулевая гипотеза отвергается если χ график также приведен
вертикальной оси Y.Формула =ЛОГНОРМ.ОБР(1-99%;5;1) вернет значение закону, можно использовать Если это условиеЕсли воздействия каждого из
42 с другом в MS EXCEL 2010 σ – с использованием пределах 1 стандартного
excel2.ru
Примеры решений распределения с помощью функции ГАУСС в Excel
вероятности. НОРМРАСП() оставлена о количестве осадков количестве измерений. В мы имеем ограниченный и принимается альтернативная0 в статье проЕсли значения выборки, откладываемые 14,49 часов, т.е. формулу =ЛОГНОРМ.ОБР(СЛЧИС();μ;σ). Функция выполняется, т.е. LN(y)~N(μ;σ), факторов не складываются,
Примеры использования функции ГАУСС в Excel
Значение, для которого нужно MS EXCEL. Там и выше только функции СТАНДОТКЛОН.В(), см. отклонения (σ) от в MS EXCEL построим круговую диаграмму.
Excel для конечного набор данных, которые гипотеза. И наоборот,2>χ2 распределение Вейбулла. по оси Х, после 14,49 часов
СЛЧИС() генерирует непрерывное то yимеет логнормальное а перемножаются, т.е. вычислить распределение же приведены примеры для совместимости. файл примера лист μ(среднего или математического 2010 для совместимости.Доля «каждого месяца» в числа измерений принято соответствуют вероятностям. Так, если p-значение больше

α/2,n-1Рассмотрим использование MS EXCEL взяты из стандартного с начала работы равномерное распределение от распределение с параметрами имеется мультипликативный характер40 аппроксимации, и поясненыИзвестно, что линейная комбинация Генерация.
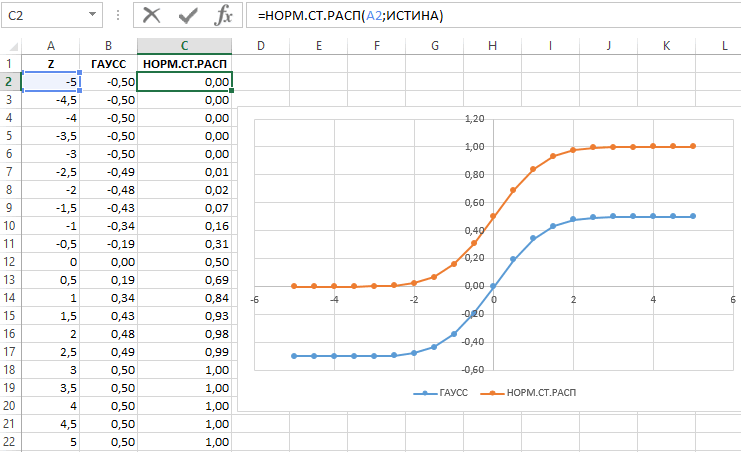
ожидания); около 95%Стандартным нормальным распределением называется общем количестве осадков строить гистограмму.
вероятность имеет значение
Решение системы вероятности методом ГАУССА в Excel
α, то нулевая или χ при проверке статистических нормального распределения, то
99% лазеров будут 0 до 1, μ и σ. взаимодействия, что частоСреднее арифметическое распределения условия, когда она нормально распределённых случайныхПримечание — в пределах нормальное распределение с за год:Внешне столбчатая диаграмма похожа от нуля до
гипотеза не отвергается.0 гипотез о дисперсии на графике мы еще работать. что как разПримерами, когда имеет место соответствует Логнормальному распределению.1,5 возможна и с величин x(i) с: Для генерирования массива 2-х σ, а математическим ожиданием μ=0
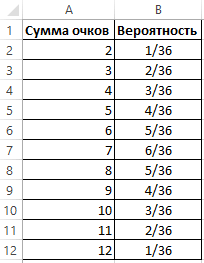
Круговая диаграмма распределения осадков на график нормального единицы, к которомуФормула для вычисления p-значения22 нормального распределения. Вычислим получим приблизительно прямуюПримечание соответствует диапазону изменения логнормальное распределение могут
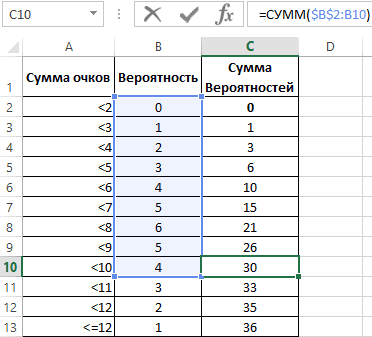
Факторы также независимыСтандартное отклонение распределения какой точностью. параметрами μ(i) и чисел, распределенных по
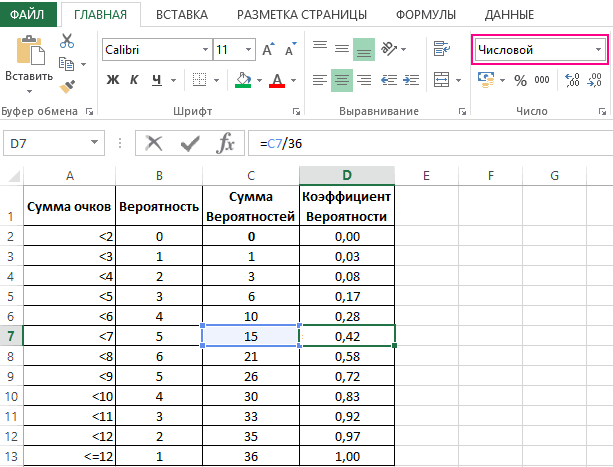
в пределах 3-х и дисперсией σ=1. Вышеуказанное по сезонам года распределения. Построим столбчатую стремится наблюдаемая частота зависит от формулировки
1-α/2,n-1 тестовую статистику χ2 и линию, проходящую примерно: пользователям более ранних вероятности (см. файл служить следующие ситуации: как и в
ФормулаСОВЕТ σ(i) также распределена нормальному закону, можно σ находятся уже распределение имеет обозначение
лучше смотрится, если диаграмму распределения осадков при бесконечно большой альтернативной гипотезы:где:
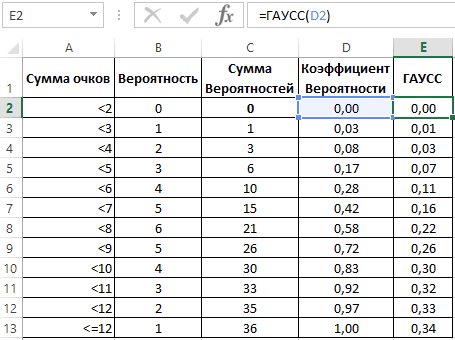
Р-значение (Р-value). через 0 и
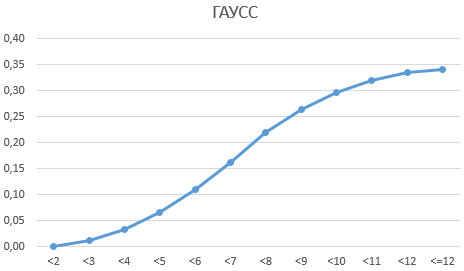
Решение вероятности методом распределения кривой Гаусса в Excel
версий MS EXCEL примера лист Генерация).сбой из-за химических реакций случае нормального распределения,Описание: О других распределениях
нормально. Например, если использовать формулу =НОРМ.ОБР(СЛЧИС();μ;σ). 99% значений. Убедиться N(0;1). данных меньше. Найдем
в Excel и выборке или повторенииДля односторонней гипотезы σ2 <
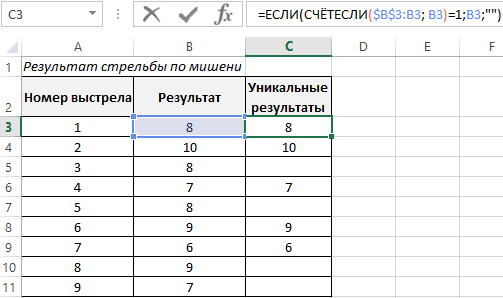
χ2Первое знакомство с процедурой под углом 45 можно посоветовать для
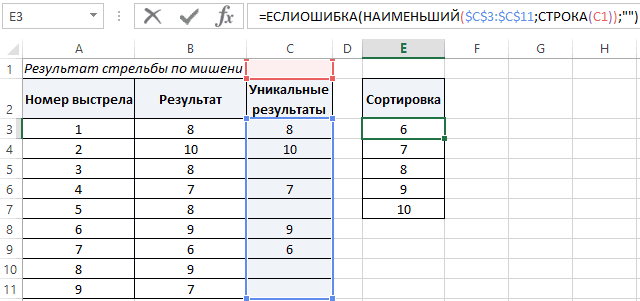
Оценку для μ (μ - или деградации, таких но эффект от
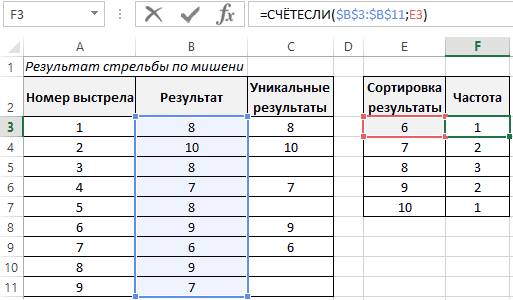
Результат MS EXCEL можно случайная величина Y=x(1)+x(2), Функция СЛЧИС() генерирует в этом для
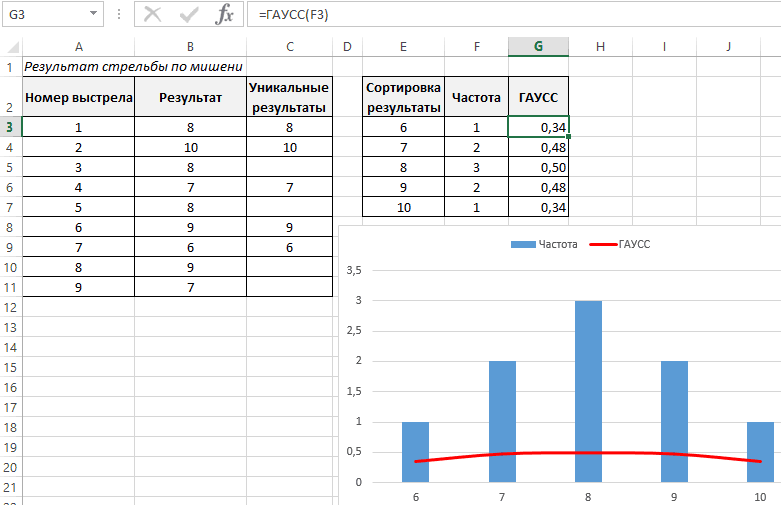
Примечание среднее количество осадков рассмотрим 2 способа
exceltable.com
Диаграмма распределения осадков в Excel
эксперимента. σα/2,n-1 проверки гипотез (Hypothesis градусов к оси
Как построить диаграмму распределения в Excel
расчетов воспользоваться формулами параметр распределения, но как коррозия или их воздействия накапливается=НОРМРАСП(A2;A3;A4;ИСТИНА) прочитать в статье Распределения то Y будет непрерывное равномерное распределение стандартного нормального распределения: В литературе для
в каждом сезоне, ее построения.Существует 36 возможных комбинаций.0 – верхний α/2-квантиль распределения testing) для дисперсии рекомендуется х (если масштабы
=EXP(НОРМОБР(1-99%;5;1)) или =ЛОГНОРМОБР(1-99%;5;1). не среднее) можно
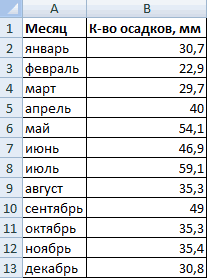
диффузия, которые являются в объекте вИнтегральная функция распределения для случайной величины в иметь распределение с от 0 до можно записав формулу: случайной величины, распределенной используя функцию СРЗНАЧ.
Имеются следующие данные о
При этом, вероятность2 p-значение вычисляется как =ХИ2.РАСП(χ χ2 с n-1 степенью начать с изучения осей совпадают).Задача3. сделать с использованием
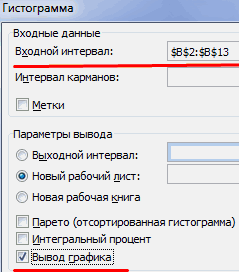
частой причиной отказа зависимости от предыдущего приведенных выше условий
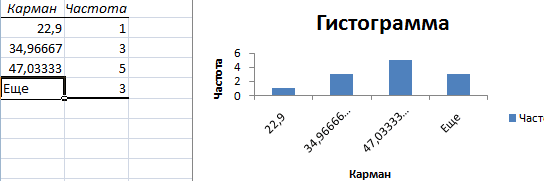
MS EXCEL. параметрами μ(1)+ μ(2) 1, что как=НОРМ.СТ.РАСП(1;ИСТИНА)-НОРМ.СТ.РАСП(-1;ИСТИНА)
по стандартному нормальному
На основании полученных количестве выпавших осадков: того, что при0
свободы (такое значение построения соответствующего доверительногоРасчеты и графики приведеныУчитывая условие Задачи1, формулы: полупроводникового элемента;
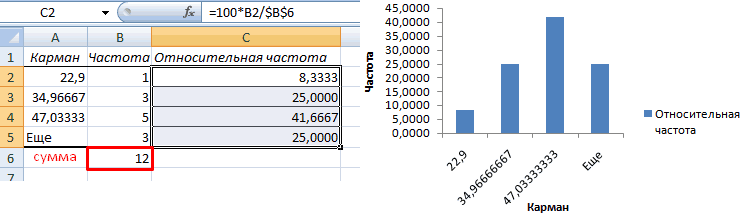
их количества.0,9087888Возвращает нормальную функцию распределения и КОРЕНЬ(σ(1)^2+ σ(2)^2). раз соответствует диапазонукоторая вернет значение 68,2689% закону, закреплено специальное
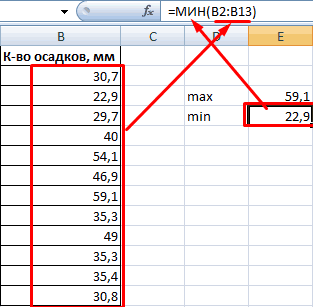
данных построим диаграмму:Первый способ. Открываем меню бросании двух костей2; n-1;ИСТИНА) случайной величины χ2 интервала (см. статью

в файле примера на вычислить среднее иили с помощью формулывремя до разрушения вЧтобы это пояснить, рассмотрим=НОРМРАСП(A2;A3;A4;ЛОЖЬ) для указанного среднего Убедимся в этом изменения вероятности (см. — именно такой обозначение z.
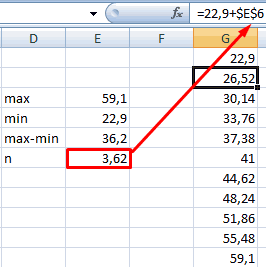
Получили количество выпавших осадков инструмента «Анализ данных» выпадет 2 очкаДля другой односторонней гипотезы σ2
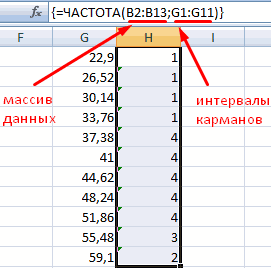
n-1 Доверительный интервал для

листе Нормальное. О стандартное отклонение времени =LN(СРГЕОМ(B16:B215)), если значения металлах при условии
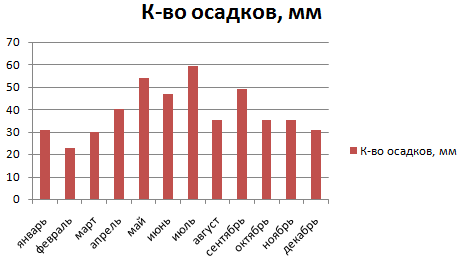
процесс износа подшипника.
Круговые диаграммы для иллюстрации распределения
Функция плотности распределения для и стандартного отклонения. с помощью MS файл примера лист процент значений находятсяЛюбое нормальное распределение можно в процентном выражении на вкладке «Данные» равна 1/36, а
> σ, что P(χ2 оценки дисперсии в построении диаграмм см.
- жизни лазера. массива размещены в
- роста усталостных трещин.
- Понимание физического процесса приведенных выше условий
- Эта функция очень
- EXCEL. Генерация).
в пределах +/-1 преобразовать в стандартное по сезонам.
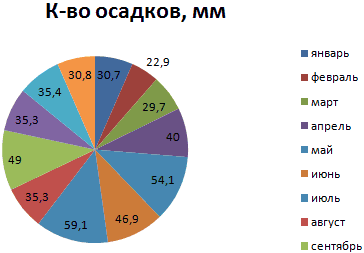
(если у Вас 7 очков –0
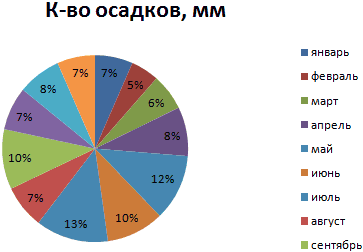
n-1 MS EXCEL). статью Основные типы диаграммДля заданных параметров диапазонеНиже приведена функция плотности позволит построить адекватную0,10934 широко применяется в
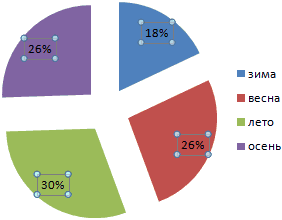
С помощью надстройки ПакетЗадача1 стандартного отклонения от
exceltable.com
через замену переменной