
Практическая работа
Тема: «Создание БД в MS Excel»
Цель: познакомиться с правилами оформления БД в MS Excel
Оборудование: АРМ.
Задание: В центральный банк г.NNN от филиалов по локально-вычислительной сети (ЛВС) поступают счета оплаты населением города коммунальных услуг. Поступающая информация фиксируется в ЭТ таблице Excel, состоящей из следующих столбцов (полей).
|
Характеристика списка (БД) |
Имена полей |
|
1-Наименование районов г.NNN; |
Район |
|
2-Дата поступления счета; |
Дата |
|
3-Категория коммунальных услуг (газ,свет,кв.м); |
Услуги |
|
4-Стоимость(тыс.руб) |
Сумма |
|
5-Пеня за задолженность (% от стоимости); |
Пеня (%) |
|
6-Пеня в рублях |
Пеня (руб) |
|
7- Всего оплачено(тыс.руб)=сумма+пеня(%)*Сумма/100 |
Всего |
Сформировать в Excel таблицу поступлений счетов за коммунальные услуги от населения за 1 месяц
Учесть следующее:
- Даты поступления счетов от районов фиксируются в произвольном порядке, т.е. поздние даты могут быть впереди начальных дат месяца;
- Наименование районов формируются в произвольном порядке;
- Категория услуг формируется последовательно (газ, свет, кв.м);
- Сумма-случайно распределенные числа в диапазоне,соответственно:
|
За газ |
-[1;10]; |
|
За свет |
-[10;25]; |
|
За кв.м |
-[50;500]; |
|
Пеня (%) |
-[1;12] – случайные целые числа |
Требования:
- Для выполнения задания потребуется 5 рабочих листов Excel.
На 1-ом листе оформляется в виде списка все сведения о поступивших счетах оплаты коммунальных услуг по районам города(рис.1).
На 2-ом листе сформировать таблицу отфильтрованную по категории оплаты за газ(рис.2)
На 3-м листе сформировать таблицу отфильтрованную по оплте за свет в первую десятидневку месяца с построением диаграммы(рис.3).
На 4-ом листе сформировать таблицу в соответствии с условием фильтрации списка по варианту самостоятельной работы.
- Оглавление таблицы должно содержать: название города, месяца;
- Указаны реквизиты банка (наименование банка, адрес, расчетный счет);
Порядок выполнения задания.
- Создать новую книгу в Excel, дополнить ее необходимым количеством
рабочих листов для выполнения задания.
Рис. 1 База данных «Коммунальные платежи»
|
|
коммунальные платежи |
|||||
|
Адрес: |
14125 г NNN, ул Мира,3 |
|||||
|
Корр.Счет: |
700161399 в ГРКЦ ГУ РФ |
|||||
|
Телефон,Факс |
(095)175-7989,175-2154 |
|||||
|
Е-mail |
NN@rrrcom.ru |
|||||
|
за май 2000г. |
||||||
|
Район |
Дата |
Услуги |
Сумма |
Пеня(%) |
Пеня (руб) |
Всего |
|
центральный |
03.05.2000 |
газ |
1 |
1 |
0,01 |
1,01 |
|
центральный |
03.05.2000 |
свет |
15 |
2 |
0,3 |
15,3 |
|
центральный |
03.05.2000 |
кв.м |
257 |
5 |
12,85 |
269,85 |
|
индустриальный |
14.05.2000 |
газ |
9 |
7 |
0,63 |
9,63 |
|
индустриальный |
14.05.2000 |
свет |
19 |
2 |
0,38 |
19,38 |
|
индустриальный |
14.05.2000 |
кв.м |
58 |
10 |
5,8 |
63,8 |
|
индустриальный |
24.05.2000 |
газ |
2 |
7 |
0,14 |
2,14 |
|
первомайский |
24.05.2000 |
свет |
22 |
6 |
1,32 |
23,32 |
|
первомайский |
24.05.2000 |
кв.м |
65 |
2 |
1,3 |
66,3 |
|
индустриальный |
27.05.2000 |
газ |
7 |
11 |
0,77 |
7,77 |
|
торговый |
27.05.2000 |
свет |
16 |
8 |
1,28 |
17,28 |
|
торговый |
27.05.2000 |
кв.м |
348 |
10 |
34,8 |
382,8 |
|
первомайский |
06.05.2000 |
газ |
6 |
8 |
0,48 |
6,48 |
|
центральный |
06.05.2000 |
свет |
17 |
11 |
1,87 |
18,87 |
|
центральный |
06.05.2000 |
кв.м |
459 |
1 |
4,59 |
463,59 |
|
первомайский |
13.05.2000 |
газ |
8 |
5 |
0,4 |
8,4 |
|
индустриальный |
13.05.2000 |
свет |
12 |
11 |
1,32 |
13,32 |
|
индустриальный |
13.05.2000 |
кв.м |
341 |
11 |
37,51 |
378,51 |
|
первомайский |
20.05.2000 |
газ |
5 |
7 |
0,35 |
5,35 |
|
первомайский |
20.05.2000 |
свет |
20 |
12 |
2,4 |
22,4 |
|
первомайский |
20.05.2000 |
кв.м |
425 |
12 |
51 |
476 |
|
первомайский |
28.05.2000 |
газ |
5 |
2 |
0,1 |
5,1 |
|
торговый |
28.05.2000 |
свет |
16 |
1 |
0,16 |
16,16 |
|
торговый |
28.05.2000 |
кв.м |
330 |
5 |
16,5 |
346,5 |
|
торговый |
05.05.2000 |
газ |
3 |
8 |
0,24 |
3,24 |
|
центральный |
05.05.2000 |
свет |
20 |
10 |
2 |
22 |
|
центральный |
05.05.2000 |
кв.м |
51 |
10 |
5,1 |
56,1 |
|
торговый |
18.05.2000 |
газ |
7 |
11 |
0,77 |
7,77 |
|
индустриальный |
18.05.2000 |
свет |
13 |
1 |
0,13 |
13,13 |
|
индустриальный |
18.05.2000 |
кв.м |
304 |
8 |
24,32 |
328,32 |
|
торговый |
19.05.2000 |
газ |
3 |
6 |
0,18 |
3,18 |
|
первомайский |
19.05.2000 |
свет |
15 |
9 |
1,35 |
16,35 |
|
первомайский |
19.05.2000 |
кв.м |
305 |
10 |
30,5 |
335,5 |
|
торговый |
26.05.2000 |
газ |
10 |
1 |
0,1 |
10,1 |
|
торговый |
26.05.2000 |
свет |
18 |
8 |
1,44 |
19,44 |
|
торговый |
26.05.2000 |
кв.м |
300 |
4 |
12 |
312 |
|
центральный |
04.05.2000 |
газ |
9 |
5 |
0,45 |
9,45 |
|
центральный |
26.05.2000 |
свет |
18 |
3 |
0,54 |
18,54 |
|
центральный |
26.05.2000 |
кв.м |
329 |
5 |
16,45 |
345,45 |
|
центральный |
09.05.2000 |
газ |
1 |
11 |
0,11 |
1,11 |
|
индустриальный |
09.05.2000 |
свет |
11 |
1 |
0,11 |
11,11 |
|
индустриальный |
09.05.2000 |
кв.м |
83 |
1 |
0,83 |
83,83 |
|
центральный |
21.05.2000 |
газ |
4 |
12 |
0,48 |
4,48 |
|
первомайский |
21.05.2000 |
свет |
20 |
5 |
1 |
21 |
|
первомайский |
21.05.1900 |
кв.м |
75 |
5 |
3,75 |
78,75 |
|
центральный |
26.05.2000 |
газ |
6 |
7 |
0,42 |
6,42 |

Выделить пять листов и заполнить оглавление, шапку таблицы Рис1.
Рис.2 Заполнение базы данных

3.в ячейки С10,С11,С12 ввести текст соответственно газ, свет, кв.м, выделить диапазон ячеек С10:С12, установить указатели мыши на квадратик в нмжнем правом углу (маркер заполнения) ячейки С12, пока не появится черный крестик и протянуть обрамляющую рамку вниз до ячейки С55.
4. В ячейку D10 ввести формулу =ОКРУГЛ(СЛУЧМЕЖДУ(1;10);2) и нажать клавишу; [Enter].
5. В ячейку D11 ввести формулу =ОКРУГЛ(СЛУЧМЕЖДУ(10;25);2) и нажать клавишу; [Enter].
6. В ячейку D12 ввести формулу =ОКРУГЛ(СЛУЧМЕЖДУ(50;500);2) и нажать клавишу; [Enter].
7.Выделить диапазон ячеек D10: D12 и установить указатель мыши на маркер заполнения, скопировать формулы до ячейки D55.
8. В ячейку E10 ввести формулу ОКРУГЛ(СЛУЧМЕЖДУ(1;12);2) и нажать клавишу [Enter].
9. заполнить формулами диапазон ячеек Е11:Е55 методом АВТОЗАПОЛНЕНИЯ. В результате выполнения вычислений по формулам, значения результатов не будут совпадать с результатами на образце, т.к для расчетов применилась функция датчика случайных чисел.
10. В ячейку F10 ввести формулу =D10*E1/100 и нажать клавишу [Enter]. Заполнить этой формулой диапазон ячеек F11:F55.
11. В ячейку G10 ввести формулу =D10+F10 и нажать клавишу [Enter]. заполнить этой формулой диапазон ячеек G11:G55.
12. Выделить числовые значения таблицы (диапазон D10:G55). Установить указатель мыши на выделенной области и нажать правую клавишу мыши. в появившемся контекстном меня выбрать команду Копировать. Выделить ячейку D10 и выбрать команду Правка=>Специальная вставка. В появившемся диалоговом окне Специальная вставка установить переключатель Значения, нажать кнопку ОК.
Этими действиями в скопированном блоке ячеек зафиксированы только числовые значения.
13. Выделить только первый лист.
14.переименовать лист 1, присвоить ему имя ПЛАТЕЖИ.
15. на втором листе произвести фильтрацию по полю Услуги. Для этого выделить ячейку С9 и выбрать команду данные=>фильтр=>Автофильтр. Установить указатель мыши на появившемся квадратике с черным треугольником (список) и выбрать из появившегося списка-газ. В итоге, будет получен результат фильтра См рис2.

Рис 3
16.перейти на Лист 3 и произвести фильтрацию таблицы по полю Дата (условие…<11.05.00) и Услуги (Условие…=свет).
17. построить диаграмму для данных столбцов Дата и Всего отфильтрованной таблицы (Рис4)
Рис 4 Задание на Лист 3

18.Перейти на четвертый лист, отфильтровать данные с помощью Расширенного фильтра и скопировать результат в другое место рабочего листа Excel. Расширенный фильтр распознает три специальные имени диапазонов: «База данных», «Критерии», «Извлечь» (рис.4.). Оформить область критериев по образцу (рис.4). критерий отбора записей формируется так:
Критерий 1-й строки –Извлечь из базы данных платежи за кв.м в 1-ю половину месяца, непревосходящие сумму (столбец всего )350
ИЛИ
Критерий 2-й строки— Извлечь платежи по центральному району за свет.
Несколько критериев одной строки связаны логической функцией –И
Критерии на разных строках связаны логической функцией-ИЛИ
- Активизировать расширенный фильтр по схеме данные=>фильтр=>расширенные фильтр
- Заполнить поля окна расширенного фильтра по образцу:
|
Исходный диапазон |
$A$9:$G$55 |
|
Диапазон условий |
$A$58:$G$60 |
|
Поместить результат в диапазон |
$A$63:$G$77 |
Заполнять диапазоны базы данных критериев и извлеченных данных можно выделением. Для этого следует предварительно щелкнуть на красной стрелке поля, которая находится справа в полях ввода, а затем выделить мышью соответствующие диапазоны для Базы данных, критериев, извлечь. В группе переключателей Обработка следует установить переключатель Скопировать результат в другое место.
20. На пятом листе выполнить самостоятельную работу .
Сформировать таблицу-результат фильтрации данных из исходной таблицы ПЛАТЕЖИ по условию варианта(1-15)и построить диаграмму типа обычная гистограмма результата для столбцов :
- Района и Всего( если фильтр по полю Всего, или по – Дата ,или по— Услуге ).
- Услуги и Всего (если фильтр по полю Всего, или по – Дата ,или по— Район).
Варианты фильтров для поля Всего :
1. Счета для газа во 2-ю десятидневку месяца
- Счета для света в 3-ю десятидневку месяца
- Счета для света в 1-ю десятидневку месяца
- Счета для кв м в 1-ю неделю месяца
- Счета для кв м в 3-ю неделю месяца
- Счета в диапазоне 50/100 тыс.руб.
- Счета в диапазоне 15/50 тыс.руб.
- Счета в диапазоне 250/350тыс.руб.
- Счета в диапазоне 100/200 тыс.руб.
- Счета в диапазоне 350/500 тыс.руб.
- Счета Центрального района за свет
- Счета Центрального района за газ
- Счета Центрального района за кв.м
- Счета Индустриального района в 1-ю половину месяца
- Счета Торгового района во 2-ю половину месяца.
После выполнения практической работы, сделать самостоятельную работу по вариантам (номер варианта соответствует номеру ученика в списке электронного журнала).
По практической работе сделать отчёт, написать вывод.
Практическая работа «Создание базы
данных в Excel»
Цель работы: создание базы данных в Excel, которая будет содержать сведения о продажах в продуктовом магазине.
Для этого нам надо будет создать три таблицы: Прайс (в ней будут
храниться наименования товаров, их цена), Клиенты (в ней будут храниться
данные о клиентах), Продажи (в эту таблицу будут заноситься данные о
продажах с учетом сведений из первых двух таблиц). Так же будет создан лист Форма
ввода, с помощью которой можно будет заполнять таблицу Продажи, используя
уже введенные ранее данные в таблицы Прайс и Клиенты.
Методические
рекомендации по выполнению практической работы
Шаг 1. Исходные данные в виде таблиц.
Создаем таблицу Прайс:
1)
Создаем в Excel новый лист с
названием Прайс.
2)
Создаем три столбца: Наименование, Категория,
Цена. Заполняем 20 строк в созданной таблице по следующему образцу:
3)

4)
Превращаем созданную таблицу в «умную таблицу». Для
этого выделяем все заполненные ячейки, нажимаем Главная – Форматировать как
таблицу. Из выпавшего списка выбираем тот стиль оформления, который нам
понравился.
5)
Далее идем на вкладку Работа с таблицами — Конструктор.
В окошке Имя таблицы меняем наименование на Прайс.
6)
Создаем в Excel новый лист с
названием Клиенты.
7)
Создаем два столбца: Клиент, Город.
Заполняем 20 строк в созданной таблице по следующему образцу:


Аналогично предыдущем листу превращаем созданную
таблицу в «умную таблицу». Для этого выделяем все заполненные ячейки, нажимаем Главная
– Форматировать как таблицу. Из выпавшего списка выбираем тот стиль
оформления, который нам понравился.
9)
Далее идем на вкладку Работа с таблицами — Конструктор.
В окошке Имя таблицы меняем наименование на Клиенты.
10) Создаем в Excel новый лист с названием Продажи.
11)
Создаем пять столбцов: Дата, Товар, Кол-во,
Стоимость, Клиент. Не заполняем!!!

12)
Аналогично предыдущем листу превращаем созданную
таблицу в «умную таблицу». Для этого выделяем все заполненные ячейки, нажимаем Главная
– Форматировать как таблицу. Из выпавшего списка выбираем тот стиль
оформления, который нам понравился.
Шаг 2. Создаем форму для ввода данных
Можно вводить данные о продажах непосредственно в таблицу Продажи,
но это не всегда удобно и влечет за собой появление ошибок и опечаток из-за
«человеческого фактора». Поэтому лучше будет на отдельном листе
сделать специальную форму для ввода данных.
Создаем Форму ввода:
1) Создаем в Excel новый лист с названием Форма
ввода.
2) Оформляем лист следующим образом:

3) В ячейке Клиент найдем нужное значение из созданной ранее «умной
таблицы». Для этого выделяем ячейку, используем команду Данные – Проверка
данных:

4) Откроется диалоговое окно:

5) В поле Тип данных выбираем Список.
6)
Поставить курсор в появившееся поле Источник
данных, перейти на лист Клиенты, выделить диапазон ячеек с фамилиями,
нажать ОК. После этого, в появившемся выпадающем списке выбираем любую
фамилию.

7)
Аналогичным образом поступаем с ячейкой Товар.
В результате произведенных действий Форма ввода должна иметь следующий вид
(дата, количество заполняются вручную):

Для того, чтобы подставить цену товара в форму ввода, необходимо
воспользоваться функцией ВПР, для этого в ячейке Цена введем
следующую формулу:
![]()
В
скобках первым в кавычках указывается наименование позиции, которая была
выбрана в поле Товар. После точки с запятой указывается наименование
таблицы, откуда будут подставляться значения (наименование Прайс мы задали в
Шаге 1, п. 5). Далее через точку с запятой идет номер столбца в таблице Прайс,
где содержится нужный нам параметр.
После
нажатия кнопки Enter нужная цена появится автоматически.
9) В поле Стоимость вводим формулу, для вычисления стоимости
данного товара при выбранных цене и количестве.
Шаг 3. Добавляем макрос ввода продаж
1)
После заполнения формы нужно введенные в нее данные
добавить в конец таблицы Продажи. Сформируем при помощи простых ссылок
строку для добавления прямо под формой (обратите внимание, ячейки формируются в
той последовательности, в какой они идут в таблице Продажи, т.е. в
ячейке A20 будет ссылка =B3, в ячейке B20 ссылка на =B7 и т.д.):


2)
Теперь создадим макрос, который копирует созданную
строку и добавляет его в таблицу Продажи. Для этого нажимаем Разработчик
— Visual Basic. Если вкладку Разработчик
не видно, то включите ее сначала в настройках Файл — Параметры — Настройка
ленты. Поставить галочку напротив меню Разработчик:

3)
После этого откроется окно Microsoft Visual Basic for Applications:

4)
В открывшемся окне редактора Visual Basic вставляем
новый пустой модуль через меню Insert — Module и вводим туда код нашего
макроса (обратите внимание, названия листов должны полностью совпадать с
вашими):
Sub Add_Sell()
Worksheets("Форма ввода").Range("A20:E20").Copy
n
= Worksheets("Продажи").Range("A100000").End(xlUp).Row
Worksheets("Продажи").Cells(n + 1, 1).PasteSpecial Paste:=xlPasteValues
Worksheets("Форма ввода").Range("B5,B7,B9").ClearContents
End Sub
5)
Закрываем окно редактора Visual Basic (никаких
сохранений это действие не потребует).
6)
Теперь можно добавить к нашей форме кнопку для
запуска созданного макроса используя выпадающий список Вставить на
вкладке Разработчик:

7)
После того, как вы ее нарисуете, удерживая нажатой
левую кнопку мыши, Excel сам спросит вас — какой именно макрос нужно на нее
назначить — выбираем наш макрос Add_Sell. Текст на кнопке можно поменять,
щелкнув по ней правой кнопкой мыши и выбрав команду Изменить текст.
Теперь после заполнения формы можно просто жать на
нашу кнопку, и введенные данные будут автоматически добавляться к таблице
Продажи, а затем форма очищается для ввода новой сделки.
9)
Сохранять созданный файл нужно следующим образом: Файл
– Сохранить как – Тип файла: Книга Excel с
поддержкой макросов.
Цель
работы:
Научиться создавать базы данных в MS
Excel.
Изучить возможности работы с базами
данных.
Задание:
-
Оформление
базы данных. -
Создание
формы. -
Сортировка
элементов базы данных. -
Фильтрация
данных. -
Суммирование
чисел в базе данных.
Пример
выполнения задания:
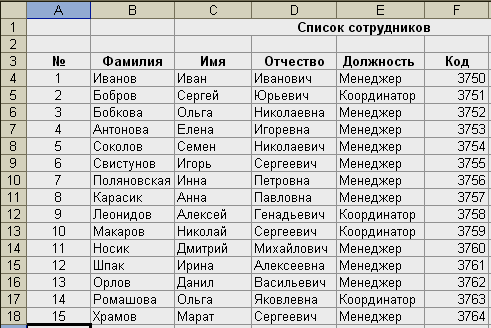
Создать
базу данных сотрудников предприятия,
заголовок которой имеет вид:
|
№ |
Фамилия |
Имя |
Отчество |
Должность |
Код |
|
1 |
Иванов |
Иван |
Иванович |
Менеджер |
3750 |
Заполнить базу
данных на 15 сотрудников.
-
Оформление
базы данных производится так же, как и
оформление любой таблицы в MS
Excel.
Только следует помнить, что таблица
для базы данных не должна иметь пустых
строк и пустых столбцов, а также не
допускается объединение ячеек для
данной таблицы.
В нашем случае
заголовок имеет вид:

Теперь
в ячейку A4
запишем:
=СТРОКА(А4)-3
и
растянем эту формулу до ячейки А18.
Далее
заполняем ячейки B4:F18
данными,
получим:
-
Рассмотрим
работу с формой базы данных, для этого
добавим при помощи формы еще двух
сотрудников. Выполним: ДанныеФорма…
получим
диалоговое окно вида:
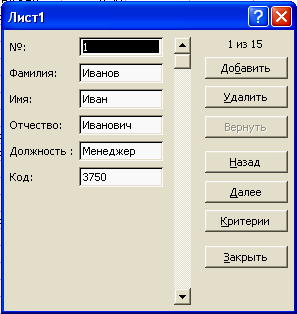
Теперь если мы
хотим добавить запись в базу данных, то
нажмем кнопку «Добавить» и получим:
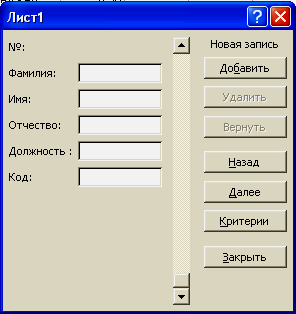
Заметим,
что поле ввода номера не доступно, так
как там заложена формула. Мы заполняем
только доступные нам поля и получаем:
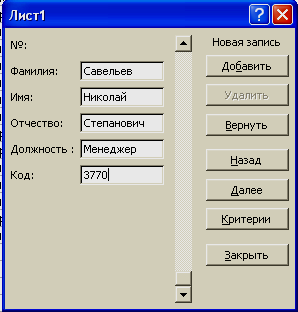
Заметим,
что для перехода из одного поля ввода
в другое необходимо нажимать клавишу
TAB.
Теперь для того,
чтобы добавить еще одного сотрудника,
снова нажмите кнопку «Добавить» и
введите данные этого сотрудника.
Для завершения
добавлений в базу данных необходимо
нажать клавишу «Закрыть». Произойдет
выход из режима «Форма», а также добавление
сотрудников в базу данных.
Обращаем
ваше внимание на то, что сотрудники
добавляются не по алфавиту, а в конце
списка.
В результате наша
база данных приобретет вид:
-
Теперь рассмотрим
сортировку базы данных.
Сортировать
базу данных в MS
Excel
можно по столбцу любого типа в порядке
возрастания или убывания. Допускается
задание от одного до трех критериев
сортировки.
Установите курсор
в любую ячейку базы данных.
В меню
«Данные» выберите пункт «Сортировка…»:
Получим диалоговое
окно вида:
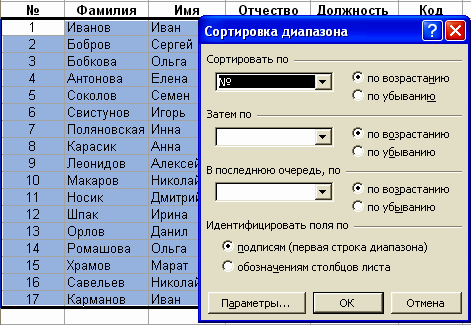
Теперь заполним
поле «Сортировать по». Для начала
отсортируем нашу базу данных по «Фамилиям»
в порядке возрастания, получим:
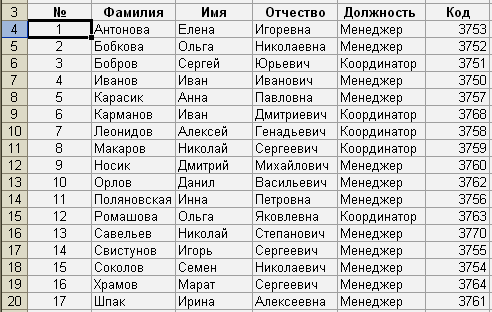
Обратите
внимание, что заданная нами формула для
«№» позволяет сохранять правильную
нумерацию независимо от сортировки.
Теперь
отсортируем нашу базу данных по двум
столбцам. Сначала отсортируем по
«Должности», а потом по «Коду». Для этого
в диалоговом окне сортировки наберем:
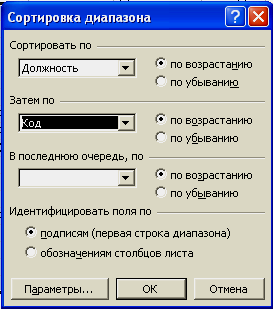
В результате
получим:
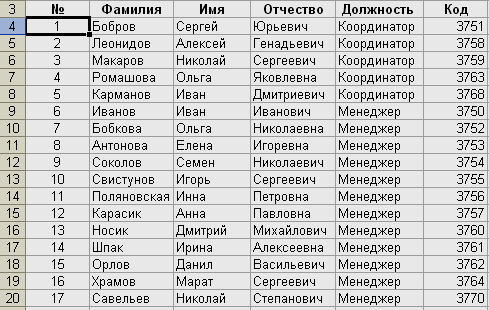
В
результате такой сортировки на первые
позиции встали все «Координаторы»,
причем между собой они отсортированы
по «Коду». В конце у нас «Менеджеры»,
которые тоже отсортированы между собой
по «Коду».
-
Фильтрация
базы данных предусмотрена для того,
чтобы быстро извлекать из документа
записи, которые соответствуют указанным
критериям, а затем переносить эту
информацию в другие части листа или
применять в отчетах.
Для
извлечения информации из базы данных
по заданному критерию установите курсор
в любую ячейку базы данных и выполните:
ДанныеФильтрАвтофильтр
В результате вы
получите:

Обратите внимание,
что в строке заголовка появились кнопки
со стрелками.
Теперь
с помощью фильтра оставим всех «Менеджеров»
с «Кодом» из диапазона от 3755 до 3760. Для
этого нажмем кнопку со стрелочкой в
столбце «Должность» и выберем «Менеджер»:

Далее нажмем кнопку
со стрелочкой в столбце «Код» и выберем
«Условие», в результате получим диалоговое
окно вида:
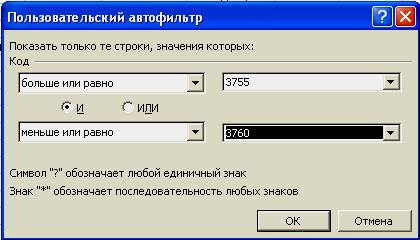
Заполнив
это окно так, как показано на рисунке,
получим:

Обратите
внимание на то, что вы не удаляли ничего,
а просто выбрали лишь те элементы,
которые вам необходимы. Стрелочки в
столбцах, по которым задавались критерии
для фильтрации, выделены цветом, так
что если вам необходимо отменить данную
фильтрацию, достаточно у выделенных
стрелочек выбрать раздел «Все».
Если вы хотите
снять фильтр, то выберите:
ДанныеФильтрАвтофильтр
Примечание.
Для того
чтобы не только извлечь, но и переместить
данные, выполните команду: Данные
ФильтрРасширенный фильтр…
В открывшемся диалоговом окне включите
опцию «Скопировать результат в другое
место» и укажите, куда копировать
результат.
-
Вы
можете подводить промежуточный и
окончательный итоги, анализируя любой
список базы данных, содержащий числовую
информацию. Для получения промежуточных
итогов весь список должен быть разбит
на отдельные группы записей. Чтобы
программа Excel
распознала эти группы, список следует
отсортировать.
Для
того чтобы изучить эту возможность,
добавим в нашу базу данных еще один
столбец «Зарплата» и отсортируем ее по
«Фамилиям», получим:
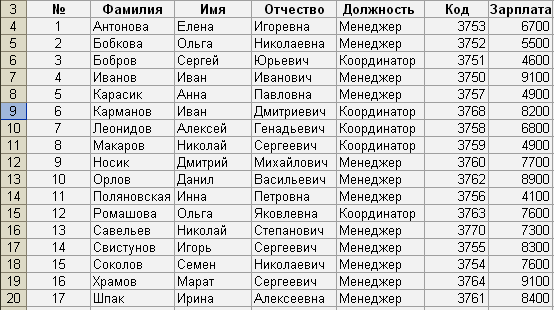
Установим
курсор в любую ячейку базы данных и
выполним:
ДанныеИтоги…
получим
диалоговое окно вида:
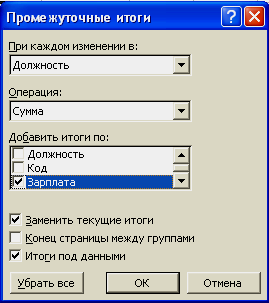
Укажем
подводить промежуточные итоги при
каждом изменении «Должности», операция
«Сумма», а итоги подводить только по
«Зарплате» и нажмем кнопку «ОК», получим:
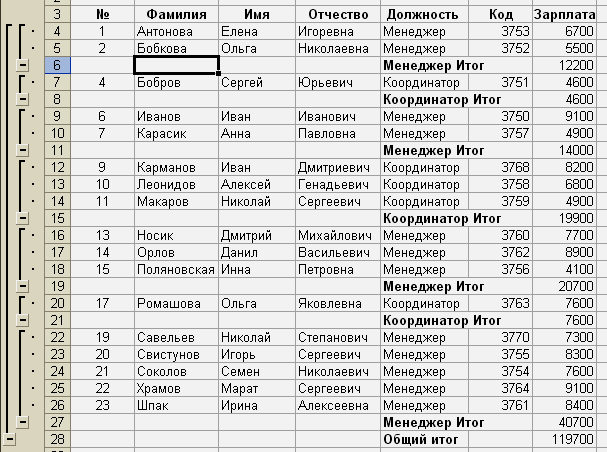
Теперь
отменим итоги, для чего выполним
ДанныеИтоги…
и в появившемся диалоговом окне нажмем
кнопку «Убрать все». Отсортируем базу
данных по «Должности» и вновь установим
итоги по тому же принципу, что и ранее,
получим:
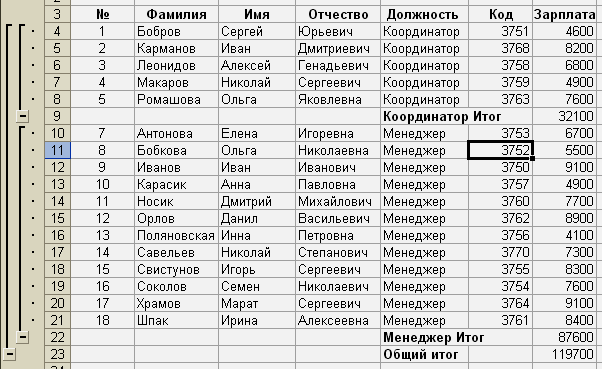
Для
того чтобы вывести только промежуточные
итоги, необходимо щелкнуть по кнопке
со знаком «-» (![]() ),
),
которая расположена в левой части окна.
В результате получим:
![]()
Оставшийся
минус в левой части окна позволяет вам
увидеть только итоговый результат.
Зачетное
задание:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Выполнение поиска по огромным таблицам с тысячами позиций информации о товарах или объемах продаж – это непростой вызов для большинства пользователей Excel. Для эффективного решения данной задачи, пользователи вынуждены комбинировать многоэтажные формулы из поисковых функций, которым нужно еще вычислить соответствующие адреса и значения для их аргументов. Чтобы сократить путь решения и не нагружать вычислительные ресурсы Excel в первую очередь следует обратить внимание на функции Excel для работы с базами данных.
Примеры работы функции базы данных БИЗВЛЕЧЬ в Excel
Допустим мы располагаем базой данных, которая экспортированная в Excel так как показано ниже на рисунке:
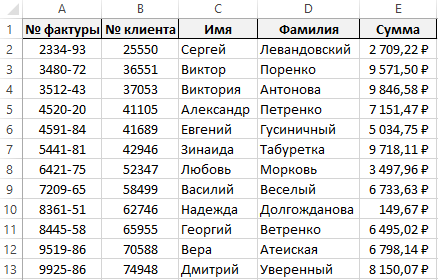
Наша задача найти всю информацию (номер фактуры, номер клиента, сумма и т.д.), которая относится к одной конкретной фамилии определенного клиента. Для этой цели рекомендуем воспользоваться функцией Excel для работы с базами данных – БИЗВЛЕЧЬ. Данная функция на основе критериев поискового запроса, введенных в ее аргументы, по отдельности выберите все соответствующие строки из базы данных.
Функция БИЗВЛЕЧЬ примеры в Excel
Все функции Excel, которые предназначены для работы с базами данных обладают одним общим свойством. Все они требуют заранее сформатировать диапазон запросов к базе, который необходимо заполнить для поиска и дальнейшей работы. Поэтому в первую очередь мы должны предварительно сформатировать все критерии наших запросов к базе. Для этого:
- Выше базы данных добавим 4 пустых строки. Для этого достаточно выделить 4 заголовка строк листа Excel и щелкнуть правой кнопкой мышки. Из контекстного меню выбрать вставить. Или после выделения строк по заголовкам нажать комбинацию горячих клавиш CTRL+SHIFT+=.
- Далее скопируйте все заголовки столбцов базы данных и вставьте их в первую строку листа для вспомогательной таблицы критериев.
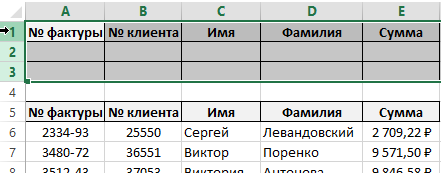
Пространство для заполнения критериев запросов выше данных базы.
Сначала попытаемся получить номер фактуры по фамилии клиента:
- В ячейке D2 введите фамилию Антонова.
- В ячейке A3 введите следующую формулу:
Сразу же получаем готовый результат как показано ниже на рисунке:
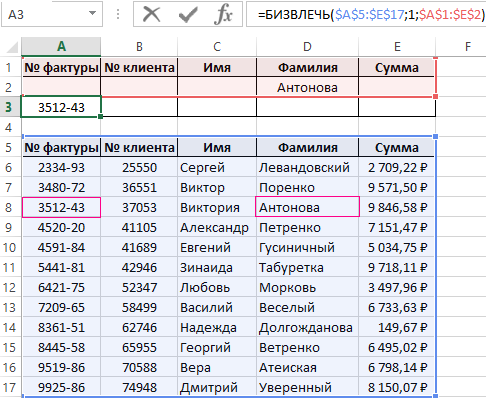
Формула нашла соответствующий номер фактуры для клиента с фамилией Антонова.
Разбор принципа действия функции БИЗВЛЕЧЬ для работы с базами данных в Excel:
БИЗВЛЕЧЬ – главная функция базы данных в Excel. В первом аргументе функции вводим диапазон просматриваемой базы данных вместе с заголовками. Во втором аргументе функции указываем адрес ячейки где будет возвращено значение соответствующие критериям поискового запроса. Третьим аргументом является диапазон ячеек, содержащий следующие условия: заголовок столбца БД и диапазон для поиска под этим заголовком. Вспомогательная табличка критериев поискового запроса к базе данных, должна быть так сформулирована, чтобы критерии однозначно и точно определяли данные, которые нужно найти в БД. Если же функция БИЗВЕЧЬ возвращает ошибку #ЗНАЧ! – значит в базе данных нет записей, соответствующих критериям поискового запроса. Если же возвращена ошибка #ЧИСЛО! – значит в базе данных более 1 одинаковой записи по данному критерию.
В нашем случаи функция БИЗВЕЧЬ вернула одно значение – без ошибок. Эту функцию можно так же использовать для вывода целой строки за одну операцию без копирования функции в другие ячейки с другими аргументами. Чтобы избежать необходимости указывать новый критерий для каждой ее копии составим простую формулу, в которую добавим функцию СТОЛБЕЦ. Для этого:
- В ячейке A3 введите следующую формулу:
- Скопируйте ее во все ячейки диапазона A3:E3.
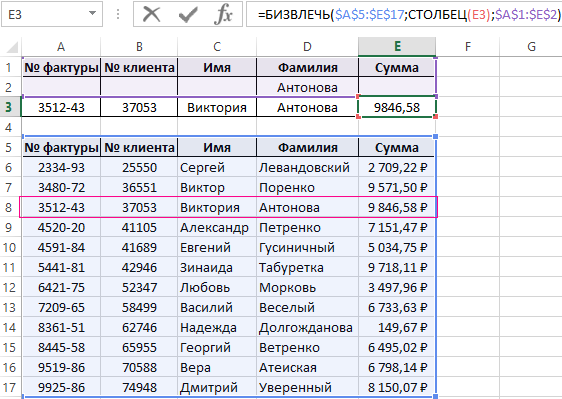
Выбрана целая строка информации по конкретной фамилии определенного клиента.
Принцип действия формулы для вывода целой строки из базы данных:
В конструкции функции БИЗВЕЧЬ изменили мы только второй аргумент, значение которого вычисляется функцией СТОЛБЕЦ в место числа 1. Данная функция возвращает номер текущего столбца для текущей ячейки.
Бесспорное преимущество использования функции БИЗВЛЕЧЬ заключается в автоматизации. Достаточно лишь изменить критерий и в результате мы получаем уже новую строку информации из базы данных клиентов фирмы. Например, найдем данные теперь по номеру клиента 58499. Удаляем старый критерий вводим новый и сразу же получаем результат.
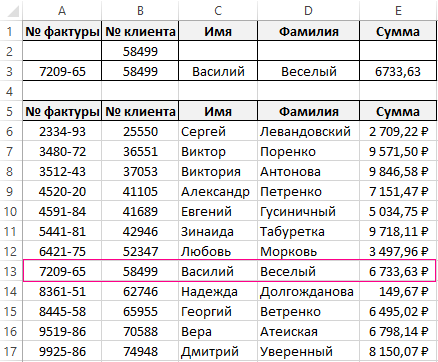
Данную задачу можно было бы решить и с помощью сложных формул с комбинациями функций ИНДЕКС, ПОИСКПОЗ, ВПР, ПРОСМОТР, но зачем изобретать велосипед? Функция БИЗВЛЕЧЬ прекрасно справляется с поставленной задачей и при этом весьма лаконична.
Обработка баз данных в Excel по нескольким критериям
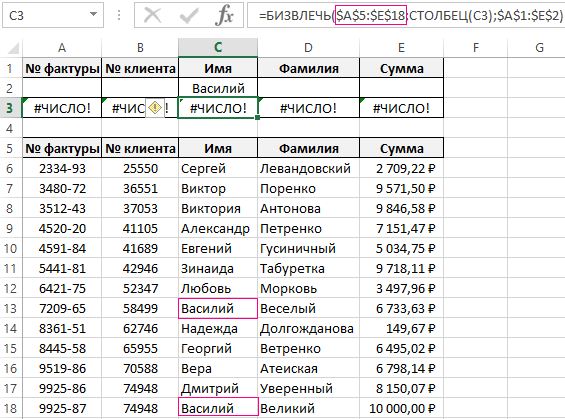
Допустим нашу базу пополнил новый прибыльный клиент с таким же именем «Василий». Нам известно о нем только имя и фамилия «Василий Великий». На именины в день Василия нам нужно выслать только 1 подарок для более прибыльного клиента фирмы. Мы должны выбрать кому отдать предпочтение: Василию Веселому или Василию Великому. Для этого сравниваем их суммы транзакций:
- Расширьте диапазон для просматриваемой таблицы $A$5:$E$18 в параметрах формул, так как у нас добавился новый клиент и на одну запись стало больше:

Теперь функция возвращает ошибку #ЧИСЛО! так как в базе более чем 1 запись по данному критерию. - В поле критериев «Имя» вводим значение «Василий», а потом в поле «Фамилия» вводим значение «Великий».
Скачать пример работы функции БИЗВЛЕЧЬ с базой данных
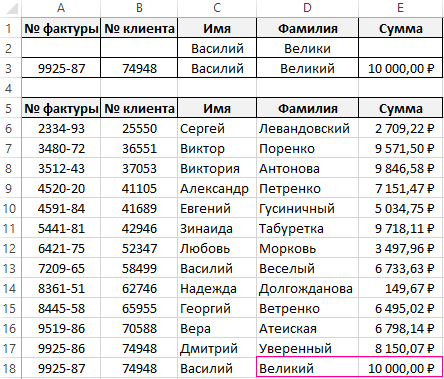
В результате мы видим, что подарок получит более активный клиент Василий Великий.
Время на прочтение
11 мин
Количество просмотров 14K
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
Итак представим, что у нас есть онлайн чат с высокой активностью, и заказчик хочет выгружать все сообщения, обогащенные данными о пользователе, за определенную дату в Excel. В день может копиться более 1 миллиона сообщений.
У нас есть 3 таблицы:
-
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
-
Message. Хранит данные о сообщении – Имя пользователя, ДатуВремя, Текст сообщения.
-
Task. Задача на формирование отчета, которую создает заказчик. Хранит ID, Статус задачи (выполнено или нет), и два параметра: Дату сообщения начало, Дату сообщения конец.
Состав колонок будет следующим:
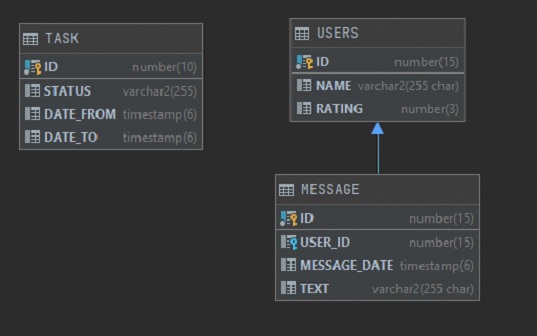
В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.4.5</version>
</dependency>Для тестирования добавим spring-boot-starter-test
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>И еще нам нужен сам драйвер для подключения к БД
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc10</artifactId>
<version>19.10.0.0</version>
</dependency>Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
package com.report.generator.demo.config;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.TaskScheduler;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
@Configuration
@EnableScheduling
@EnableAsync
@EnableJpaRepositories(basePackages = "com.report.generator.demo.repository")
@PropertySource({"classpath:application.properties"})
@ConditionalOnProperty(
value = "app.scheduling.enable", havingValue = "true", matchIfMissing = true
)
public class DemoConfig {
private static final int CORE_POOL_SIZE = 2;
@Bean(name = "taskScheduler")
public TaskScheduler getTaskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(CORE_POOL_SIZE);
scheduler.initialize();
return scheduler;
}
}
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
@Async("taskScheduler")
@Scheduled(fixedDelay = 60000)
public void scheduledTask() {
log.info("scheduledTask is started");
Task task = getTask();
if (Objects.isNull(task)) {
log.info("task not found");
return;
}
log.info("task found");
generate(task);
}Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
List<Message> findAllByMessageDateBetween(Instant dateFrom, Instant dateTo);А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
create function message_ref(
date_from timestamp,
date_to timestamp
) return sys_refcursor as
ret_cursor sys_refcursor;
begin
open ret_cursor for
select m.id,
u.name,
u.rating,
m.message_date,
m.text
from message m
left join users u on m.user_id = u.id
where m.message_date between date_from and date_to;
return ret_cursor;
end message_ref;Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: «{ ? = call message_ref(?, ?) }», callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
package com.report.generator.demo.repository.entity;
import lombok.Data;
import org.hibernate.annotations.CacheModeType;
import org.hibernate.annotations.NamedNativeQuery;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import java.io.Serializable;
import java.time.Instant;
import static com.report.generator.demo.repository.entity.MessageData.MESSAGE_REF_QUERY_NAME;
@Data
@Entity
@NamedNativeQuery(
name = MESSAGE_REF_QUERY_NAME,
query = "{ ? = call message_ref(?, ?) }",
callable = true,
cacheMode = CacheModeType.IGNORE,
resultClass = MessageData.class
)
public class MessageData implements Serializable {
public static final String MESSAGE_REF_QUERY_NAME = "MessageData.callMessageRef";
private static final long serialVersionUID = -6780765638993961105L;
@Id
private long id;
@Column
private String name;
@Column
private int rating;
@Column(name = "MESSAGE_DATE")
private Instant messageDate;
@Column
private String text;
}Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);В итоге наш метод генерации имеет следующий вид:
@Transactional
void generate(Task task) {
log.info("generating report is started");
try (
StatelessSession statelessSession = sessionFactory.openStatelessSession()
) {
ReportExcelStreamWriter writer = new ReportExcelStreamWriter();
Query<MessageData> query = statelessSession.createNamedQuery(MESSAGE_REF_QUERY_NAME, MessageData.class);
query.setParameter(1, task.getDateFrom());
query.setParameter(2, task.getDateTo());
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);
ScrollableResults results = query.scroll(ScrollMode.FORWARD_ONLY);
int index = 0;
while (results.next()) {
index++;
writer.createRow(index, (MessageData) results.get(0));
if (index % 100000 == 0) {
log.info("progress {} rows", index);
}
}
writer.writeWorkbook();
task.setStatus(DONE.toString());
log.info("task {} complete", task);
} catch (Exception e) {
task.setStatus(FAIL.toString());
e.printStackTrace();
log.error("an error occurred with message {}. While executing the task {}", e.getMessage(), task);
} finally {
taskRepository.save(task);
}
}4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.0.0</version>
</dependency>Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelWriter {
private final XSSFWorkbook wb;
private final XSSFSheet sheet;
public ReportExcelWriter() {
this.wb = new XSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
XSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
XSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(XSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:

А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.streaming.SXSSFCell;
import org.apache.poi.xssf.streaming.SXSSFRow;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelStreamWriter {
private final SXSSFWorkbook wb;
private final SXSSFSheet sheet;
public ReportExcelStreamWriter() {
this.wb = new SXSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
SXSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
SXSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(SXSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
5. Итог
В результате удалось добиться максимальной производительности за счет использования хранимой функции, StatelessSession, ScrollableResults и использования библиотеки org.apache.poi из пакета streaming. При большом желании можно улучшить производительность еще, если написать все на чистом jdbc, может быть есть еще варианты, как, что и где можно улучшить. Буду рад услышать комментарии от более опытных в этом экспертов. В данном примере не учтено ограничение на 1 млн. строк, т. к. это простая формальность и для примера не очень важна. Для наполнения БД тестовыми данными был добавлен тестовый класс DemoApplicationTests. Весь код можно посмотреть в репозитории на GitHub.
Урок посвящен тому, как решать 3 задание ЕГЭ по информатике про базы данных
Содержание:
- Объяснение заданий 3 ЕГЭ по информатике
- Базы данных
- Файловая система
- Сравнение строковых данных
- Решение заданий 3 ЕГЭ по информатике
- Задания с базами данных
- Задания прошлых лет для тренировки
- Задания для тренировки
- Задания со сравнением строковых данных
- Задания с файлами и масками файлов
3-е задание: «Реляционные базы данных»
Уровень сложности
— базовый,
Требуется использование специализированного программного обеспечения
— нет,
Максимальный балл
— 1,
Примерное время выполнения
— 3 минуты.
Проверяемые элементы содержания: Знание о технологии хранения, поиска и сортировки информации в реляционных базах данных
До ЕГЭ 2021 года — это было задание № 4 ЕГЭ
* Некоторые изображения страницы взяты из материалов презентации К. Полякова
Для решения задания 3 ЕГЭ необходимо рассмотреть тему предыдущего урока — структуризация данных (деревья).
Иногда также попадаются задания, которые требуют знаний основ алгебры логики.
Базы данных
База данных – это хранилище больших объемов данных некоторой предметной области, организованное в определенную структуру, т.е. хранящихся в упорядоченном виде.
Задания ЕГЭ в основном связаны с табличными базами данных, поэтому мы их кратко и рассмотрим.
Данные в табличных БД представлены, соответственно, в виде таблицы.
Строки таблицы носят название записи, а столбцы — поля:

- Абсолютно все поля должны быть снабжены уникальными именами. В примере: Фамилия, Имя, Адрес, Телефон.
- Поля имеют различные типы данных, в зависимости от их содержимого (например, символьный, целочисленный, денежный и т.п.).
- Поля могут быть обязательными для заполнения или нет.
- Таблица может иметь безграничное количество записей.
Ключевое поле – это поле, которое однозначно определяет запись.
В таблице не может быть двух и более записей с одинаковым значением ключевого поля (ключа).
- Для выбора ключевого поля берутся какие-либо уникальные данные об объекте: например, номер паспорта человека (второго такого номера ни у кого нет).
- Если в таблице не предусмотрены такие уникальные поля, то создается так называемый суррогатный ключ — поле (обычно ID или Код) с уникальными номерами — счетчик — для каждой записи в таблице.
Реляционная база данных – это совокупность таблиц, которые связываются между собой (между которыми устанавливаются отношения). Связь создается с помощью числовых кодов (ключевых полей).

Реляционная БД «Магазин»
Положительное в реляционных БД:
- исключено дублирование информации;
- если изменяются какие-либо данные, к примеру, адрес фирмы, то достаточно изменить его только в одной таблице — Продавцы;
- защита от неправильного ввода (или ввода с ошибками): можно выбрать (как бы ввести) только фирму, которая есть в таблице Продавцы;
- Для удобства осуществления поиска в базе данных часто создается специальная таблица Индексы.
- Индекс – это специальная таблица, предназначенная для осуществления быстрого поиска в основной таблице по выбранному столбцу.
Последовательность выполнения логических операций в сложных запросах:
- сначала выполняются отношения, затем – «И», потом – «ИЛИ». Чтобы изменить порядок выполнения используются скобки.

Индексы
Файловая система
* тема с масками скорее всего не будет представлена на ЕГЭ 2021 года
- файлы на диске хранятся в так называемых каталогах или папках;
- каталоги организованы в иерархическую структуру — дерево каталогов;
- главный каталог диска называется корневым каталогом и обозначается буквой логического диска, за которой следует двоеточие и знак «» (обратный слэш); например, A: – это обозначение корневого каталога диска А.
- каждый каталог (кроме корневого) имеет один единственный «родительский» каталог – это тот каталог, внутри которого и располагается данный каталог
- полный адрес каталога – это перечисление всех каталогов, в которые нужно войти, чтобы попасть в данный каталог (начиная с корневого каталога диска); например
- полный адрес файла состоит из адреса каталога, в котором он находится, символа
и имени файла, например - маска — выделение группы файлов по их именам; имена этих файлов имеют общие свойства, например, одинаковое расширение
- в масках, кроме стандартных символов используются два специальных символа: звездочка «*» и знак вопроса «?»;
- звездочка «*» обозначает любое количество любых символов, в том числе, может обозначать 0 символов;
- знак вопроса «?» обозначает ровно один любой символ.

Дерево каталогов
С:USERBINSCHOOL — полный путь каталога SCHOOL

Полный путь файла

Примеры масок файлов
Сравнение строковых данных
В задачах 3-го типа часто приходится сравнивать строковые значения. Посмотрим, как правильно это делать:

Любой символ всегда больше пустого:

Егифка ©:

Решение заданий 3 ЕГЭ по информатике
Плейлист видеоразборов задания на YouTube: 
Задание демонстрационного варианта 2022 года ФИПИ
Задания с базами данных
3_1 new:
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 3-2.xls приведён фрагмент базы данных «Рейсы» о рейсах самолетов. База данных состоит из одной таблицы. Таблица «Рейсы» содержит записи о городах отправления и прибытия, и также номер борта, совершающего рейс. На рисунке приведена схема данных.

Используя информацию из приведённой базы данных, определите сколько рейсов совершил борт 128 таких, что Москва была одним из концов маршрута — городом отправления или городом прибытия. В ответе запишите только число.
✍ Решение:
- Задание можно выполнить использую опцию Фильтр в Excel.
- Выделим полностью первую строку и применим к ней фильтр (меню Данные — Фильтр).
- В фильтре для столбца
Dвыбираем сначала Выделить всё (чтобы отменить все выделения), а затем — только значение128: - Для столбца
Bаналогичным образом выбираемМосква: - Получаем в результате 3 записи:
- Отменяем фильтр для столбца
Bи применяем его для столбцаС(Москва): - Получаем также 3 записи:





3 + 3 = 6
Ответ: 6
3_2 new:
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 3-1.xls приведён фрагмент базы данных «Рейсы» о движении грузов на базе. База данных состоит из одной таблицы. Таблица «Рейсы» содержит записи о водителе, объеме перевезенного груза в килограммах и характере перевозки («привоз» на базу или «вывоз» с базы). На рисунке приведена схема данных.

Используя информацию из приведённой базы данных, определите на сколько килограммов отличается суммарное количество вывезенных и привезенных Ивановым грузов. В ответе запишите только число.
✍ Решение:
- Задание можно выполнить использую опцию Фильтр в Excel.
- Выделим полностью первую строку и применим к ней фильтр (меню Данные — Фильтр).
- В фильтре для столбца
Bвыбираем сначала Выделить всё (чтобы отменить все выделения), а затем — значениеИванов. - Для столбца
Dаналогичным образом выбираемПривоз. - Полностью выделяем весь столбец
С(Объем груза) отфильтрованной таблицы. В нижней части окна Excel смотрим сведения по выделенным ячейкам: - Запоминаем сумму (то же самое можно сделать, выполнив действие автосумма, к примеру).
- Теперь для столбца
Dаналогичным образом выбираемВывоз. - Полностью выделяем весь столбец
Сотфильтрованной таблицы. В нижней части окна Excel смотрим сведения по выделенным ячейкам. Получаем значение 680096. - Вычитаем полученные значения с помощью калькулятора или формулы в Excel. В результате имеем:

680096 - 668372 = 11724
Ответ: 11724
3_3 new:
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 3-1.xls приведён фрагмент базы данных «Рейсы» о движении грузов на базе. База данных состоит из одной таблицы. Таблица «Рейсы» содержит записи о водителе, объеме перевезенного груза в килограммах и характере перевозки («привоз» на базу или «вывоз» с базы). На рисунке приведена схема данных.
Используя информацию из приведённой базы данных, определите сколько раз Уточкин и Сидоров вывезли с базы грузы объемом не менее 1500 кг и не более 2000 кг. В ответе запишите только число.
✍ Решение:
- Задание можно выполнить использую опцию Фильтр в Excel.
- Выделим полностью первую строку и применим к ней фильтр (меню Данные — Фильтр).
- В фильтре для столбца
Bвыбираем сначала Выделить всё (чтобы отменить все выделения), а затем — значенияСидоровиУточкин. - Для столбца
Свыбираем в Фильтре Числовые фильтры — Между …. В открывшемся окне настраиваем диапазон: - Теперь для столбца
Dаналогичным образом выбираемВывоз. - Полностью выделяем весь столбец
С(Объем груза) отфильтрованной таблицы. В нижней части окна Excel смотрим сведения по выделенным ячейкам: - Результат 107.


Ответ: 107
3_4 new:
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 3-4.xls приведён фрагмент базы данных «Родственники» о родственных отношениях между людьми. База данных состоит из двух таблиц. Таблица «Люди» содержит записи о людях — Фамилия ИО, пол («м» или «ж») и город рождения. Таблица «Родственные связи» содержит информацию о родительских связях — ID родителя из таблицы «Люди» и ID ребенка и той же таблицы. На рисунке приведена схема базы данных.

Используя информацию из приведённой базы данных, укажите количество людей, у которых в базе данных указан только один родитель. В ответе запишите только число.
✍ Решение:
-
✎ Решение в Excel с помощью фильтров:
- Если у ребенка только один родитель, то в таблице Родственные связи в столбце ID ребенка для него будет только одно значение (дважды не может быть).
- Таким образом, необходимо отфильтровать значения этого столбца, выделив только уникальные ячейки (не повторяющиеся). Для этого выделите полностью столбец
B, затем в меню Главная — Условное форматирование — выберите Правила выделения ячеек — Повторяющиеся значения. В открывшемся окошке в выпадающем списке выберите Уникальные. Щелкните Ок. Уникальные ячейки должны подсветиться указанным цветом. - Затем выберите Фильтр для этого же столбца (меню Данные — Фильтр). В окошке фильтра выберите Фильтр по цвету — указанный цвет. Остались только выделенные цветом ячейки.
- Выделите все ячейки столбца и в нижней части окна Excel смотрим сведения по выделенным ячейкам:


✎ Решение в Excel с помощью формул:
Ответ: 112
3_5 new:
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 3-4.xls приведён фрагмент базы данных «Родственники» о родственных отношениях между людьми. База данных состоит из двух таблиц. Таблица «Люди» содержит записи о людях — Фамилия ИО, пол («м» или «ж») и город рождения. Таблица «Родственные связи» содержит информацию о родительских связях — ID родителя из таблицы «Люди» и ID ребенка и той же таблицы. На рисунке приведена схема базы данных.
Используя информацию из приведённой базы данных, укажите количество людей, родители которых родились в одном городе. В ответе запишите только число. В ответе запишите только число.
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
✍ Решение:
- Задача усложняется тем, что сведения по детям и их родителям мы имеем в одной таблице — Родственные связи, а города — в другой — Люди. То есть для вычисления необходимо
город рожденияродителя добавить в таблицуРодственные связи. - Для этого необходимо у каждого родителя смотреть ID_родителя в таблице Родственные связи и, затем, искать этот ID и соответствующий ему город в таблице Люди.
- Для поиска нам необходима функция
ИНДЕКС: - В нашем случае мы будем искать в массиве данных таблицы Люди ячейку Город рождения: по строке со значением
ID родителя(т.к. номер строки совпадает сID) и столбцу №4 в нашем массиве данных. Установите курсор в ячейкуD2таблицыРодственные связи:
ИНДЕКС — возвращает значение ячейки на пересечении конкретных строки и столбца.
=ИНДЕКС (Люди!A$2:D$1001;A2;4)
$, чтобы при копировании формулы значение не менялось.D.B, выделив только повторяющиеся ячейки (так как нам необходимо оставить только тех детей, у которых указаны оба родителя, а не один). Для этого выделите полностью столбец B, затем в меню Главная — Условное форматирование — выберите Правила выделения ячеек — Повторяющиеся значения. В открывшемся окошке в выпадающем списке выберите Повторяющиеся. Щелкните Ок. Повторяющиеся ячейки должны подсветиться указанным цветом.D будем выводить значение 1, если для родителей одного и того же ребенка совпадают, и 0 если не совпадают:Ячейка D3:
=ЕСЛИ(И(B3=B2;C3=C2);1;0)
Сумма: 16Ответ: 16
3_6 new: :
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 3-4.xls приведён фрагмент базы данных «Родственники» о родственных отношениях между людьми. База данных состоит из двух таблиц. Таблица «Люди» содержит записи о людях — Фамилия ИО, пол («м» или «ж») и город рождения. Таблица «Родственные связи» содержит информацию о родительских связях — ID родителя из таблицы «Люди» и ID ребенка и той же таблицы. На рисунке приведена схема базы данных.
Используя информацию из приведённой базы данных, укажите максимальное количество детей у одного родителя. В ответе запишите только число.
✍ Решение:
-
Логика решения такова: сколько раз один и тот же родитель встречается в таблице
- В таблице
Родственные связииз диапазона ячеекID родителясчитаем количество повторов каждого родителя:
Родственные связи, соответственно, столько у него и детей. Таким образом, необходимо посчитать, сколько раз встречается каждый родитель; затем найти максимальное из этих значений.✎ Способ 1:
Ячейка D2:
=СЧЁТЕСЛИ(A:A;A2)
D.D:= МАКС(D:D)
✎ Способ 2:
Ячейка D2:
=МОДА(A:A)
ID родителя ищем значение 165 и считаем количество отфильтрованных строк.Ответ: 4
Задания прошлых лет для тренировки
3_6:
Ниже представлены две таблицы из базы данных. Каждая строка таблицы 2 содержит информацию о ребёнке и об одном из его родителей. Информация представлена значением поля ID в соответствующей строке таблицы 1.
Определите на основании приведённых данных фамилию и инициалы племянника Геладзе П.П.

Варианты ответа:
1) Вильямс С.П.
2) Геладзе П.И.
3) Леоненко М.С.
4) Леоненко С.С.
Подобные задания для тренировки
✍ Решение:
Подробное решение задания ГВЭ смотрите в видеоуроке:
📹 Видеорешение на RuTube здесь
3_1:
Ниже представлены две таблицы из базы данных. Каждая строка Таблицы 2 содержит информацию о ребенке и об одном из его родителей. Информация представлена значением поля ID в соответствующей строке Таблицы 1.
Определите на основании приведенных данных суммарное количество прямых потомков (т.е. детей, внуков, правнуков) Иоли А.Б.

Подобные задания для тренировки
✍ Решение:
- В первой таблице находим Иоли А.Б, ей соответствует ID 84
- Все остальное решение будет связано со второй таблицей: будем в ней искать ID родителя и соответствующего ему ID ребенка.
- Выполним задание при помощи дерева, подробно рассматривая каждый уровень иерархии: сначала детей родителя 84, затем по полученным ID — найдем внуков Иоли А.Б, затем правнуков и т.д.
- Посчитаем количество потомков: их 7

Результат: 7
Также можно посмотреть видео решения 3 задания ЕГЭ по информатике:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
3_2:
Ниже представлены две таблицы из базы данных, в которых собраны сведения о сотрудниках некоторой организации. Каждая строка Таблицы 2 содержит информацию о сотруднике структурного подразделения и о его непосредственном руководителе, который, в свою очередь, является непосредственным подчиненным руководителя более высокого уровня. Информация представлена значением поля ID в соответствующей строке Таблицы 1.
Определите на основании приведенных данных суммарное количество подчиненных (непосредственных и через руководителей более низкого уровня) Сидорова Т.И.

✍ Решение:
- В первой таблице находим Сидорова Т.И., ему соответствует ID 17
- Все остальное решение будет связано со второй таблицей: будем в ней искать ID руководителя и соответствующих ему ID подчиненных.
- Выполним задание при помощи дерева, подробно рассматривая каждый уровень иерархии: сначала непосредственных подчиненных руководителя 17, затем по полученным ID — найдем подчиненных подчиненных и т.д.
- Посчитаем количество подчиненных: 9

Результат: 9
Можете ознакомиться с решением данного 3 задания ЕГЭ по информатике из видеоурока:
📹 YouTube здесь
3_4: Демоверсия ЕГЭ 2018 информатика (ФИПИ):
Ниже представлены два фрагмента таблиц из базы данных о жителях микрорайона. Каждая строка таблицы 2 содержит информацию о ребёнке и об одном из его родителей. Информация представлена значением поля ID в соответствующей строке таблицы 1.
Определите на основании приведённых данных, у скольких детей на момент их рождения матерям было больше 22 полных лет. При вычислении ответа учитывайте только информацию из приведённых фрагментов таблиц.

Подобные задания для тренировки
✍ Решение:
- Из второй таблицы выпишем ID всех детей и соответствующих им ID родителей. Найдем выбранные ID родителей и детей в первой таблице и оставим только те ID родителей, которые соответствуют женскому полу. Выпишем также год рождения:
ID 23: 1968 - 1941 = 27 ! 24: 1993 - 1967 = 26 ! 32: 1960 - 1941 = 19 33: 1987 - 1960 = 27 ! 35: 1965 - 1944 = 21 44: 1990 - 1960 = 30 ! 52: 1995 - 1967 = 28 !
>22).Результат: 5
Подробное решение данного 3 (раньше № 4) задания из демоверсии ЕГЭ 2018 года смотрите на видео:
Задания для тренировки
Задания со сравнением строковых данных
Рассмотрим одно на первый взгляд простое, но с «ловушкой», задание ЕГЭ:
3_3:
В таблице представлены несколько записей из базы данных «Расписание»:
| № | Учитель | День недели | Номер урока | Класс |
|---|---|---|---|---|
| 1 | Айвазян Г.С. | понедельник | 3 | 8А |
| 2 | Айвазян Г.С. | понедельник | 4 | 9Б |
| 3 | Айвазян Г.С. | вторник | 2 | 10Б |
| 4 | Михальчук М.С. | вторник | 2 | 9А |
| 5 | Пай С.В. | вторник | 3 | 10Б |
| 6 | Пай С.В. | среда | 5 | 8Б |
Укажите номера записей, которые удовлетворяют условию
Номер_урока > 2 И Класс > ‘8А’
1) 1, 6
2) 2, 6
3) 2, 5, 6
4) 1, 2, 5, 6
С примером решения данного 3 задания ознакомьтесь из видеоурока:
📹 YouTube здесь
Задания с файлами и масками файлов
* тема с масками скорее всего не будет внесена в ЕГЭ 2021 года
3_5:
Для групповых операций с файлами используются маски имён файлов.
Символ «?» (вопросительный знак) означает ровно один произвольный символ.
Символ «*» (звёздочка) означает любую последовательность символов произвольной длины, в том числе «*» может задавать и пустую последовательность.
В каталоге находится 8 файлов:
declaration.mpeg delaware.mov delete.mix demo.mp4 distrib.mp2 otdel.mx prodel.mpeg sdelka.mp3
Определите, по какой из перечисленных масок из этих 8 файлов будет отобрана указанная группа файлов:
otdel.mx prodel.mpeg
Варианты ответа:
1) *de?.m*
2) ?de*.m?
3) *de*.mp*
4) de*.mp?
Подобные задания для тренировки
✍ Решение:
Решение задания 3 ГВЭ по информатике можно посмотреть на видео:
Содержание
- Excel задания с решениями. Скачать примеры
- Задание 1
- Решение задания
- Задание 2
- Задачи по Excel
- Решение задач по Excel. Выпуск 4
- Решение задач по Excel. Выпуск 3
- Решение задач по Excel. Выпуск 2
- Решение задач по Excel. Выпуск 1
- Решение простых задач с помощью Excel
Excel задания с решениями. Скачать примеры
В этом уроке мы постараемся закрепить то, что прошли на предыдущих. Рассмотрим несколько заданий с примерами решения.
Задание 1
Ниже на рисунке изображена таблица автоматически вычисляющая объем прямоугольной канистры. Даны ее размеры. Это самое простое задание, с которого мы начнем. Для начала постарайтесь добиться решения самостоятельно.
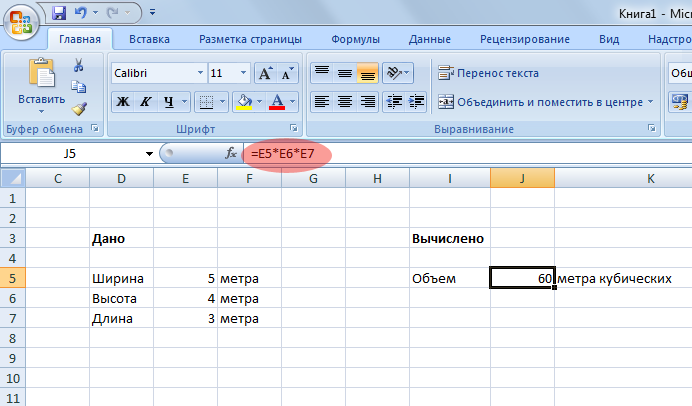
Решение задания
Первое, что необходимо сделать это заполнить ячейки словами «дано», «ширина», «высота» и так далее. Обратите внимание на то, что слово «метра» я вписал один раз, а потом автозаполнением заполнил оставшиеся 2 ячейки. Для того, чтобы отформатировать текст (сделать жирным слова «дано» и «Вычислено» выберите ячейку и воспользуйтесь инструментом Ж (полужирный) на панели вверху в закладке Главная.
После того как вы создали внешний вид таблицы (т.е. вписали в ячейки все кроме цифр) переходим к решению самой задачи. У меня в примере ячейка J5 содержит формулу для вычисления объема. Сама по себе формула просто, чтобы вычислить объем прямоугольного параллелипипеда надо перемножить длины всех его 3 сторон.
В нашем примере значение ширины, высоты и длины содержится в ячейках E5, E6, E7. Как раз их нам надо и перемножить и результат записать в ячейку J5, для этого в ячейке J5 пишем формулу =E5*E6*E7. и жмем Enter.
Внимание! если вы не вписали значение ширины, высоты и длины, то там где будет ответ высветиться предупреждение об ошибки, чтобы оно исчезло просто введите значение сторон, чтобы компьютеру было, что ему перемножать.
Задание 2
Это задание не чуть не сложнее, просто больше надо заполнять и больше ввести формул, если Вы все верно поняли в первом задании и разобрались, то решение этого задание в не составит особого труда
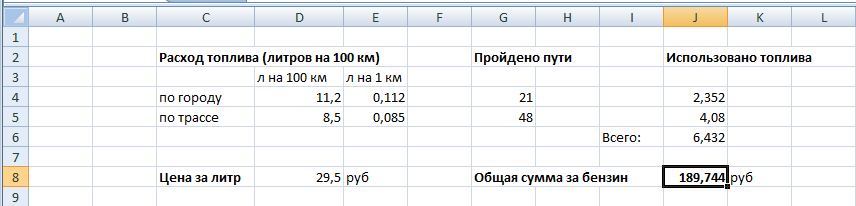
В этом задании все, что нам дано это количество расхода бензина на 100 км, пройденный путь и цена на топливо. Все остальное значения в ячейках программа Excel считает автоматически после того как будут введены формулы.
Скачать файл Еxcel с примером решения этой задачи.
Для тех кому понравился стиль объяснения и подробного описания рекомендую статью про выпадающие списки в экселе все так же подробно и понятно
Жми Привет! Если статья полезна, поддержи меня и сайт, поделись ей
Источник
Задачи по Excel
Решение задач по Excel. Выпуск 4

Задание 1.
- Ввести исходные данные, оформить таблицу с помощью обрамления, добавить заголовок, расположив его по центру таблицы, шапку таблицы оформить заливкой. Для форматирования текста используйте Формат Ячейки/ Выравнивание.
- Добавить в таблицу дополнительные ячейки для внесения формул и получения результата.
- Функции, используемые при выполнении работы:
Математические:
- СУММ — сумма аргументов;
- ПРОИЗВЕД — произведение аргументов;
- СУММПРОИЗВ — сумма произведений соответствующих массивов.
Статистические:
- СРЗНАЧ — среднее арифметическое аргументов;
- МАКС — максимальное значение из списка аргументов;
- МИН — минимальное значение из списка аргументов;
- СЧЕТЕСЛИ — подсчитывает количество непустых ячеек в диапазоне, удовлетворяющих заданному условию.
- Заполнить таблицу (5-7 строк). Имеющиеся в шапке таблицы данные (года, месяцы, дни недели) заносить с помощью автозаполнения.
- Оформить таблицу с помощью обрамления, добавить заголовок, расположив его по центру таблицы. Шапку таблицы выполнить в цвете (шрифт и фон), полужирным шрифтом.
- Переименовать лист книги по смыслу введенной информации.
- Добавить в начало таблицы столбец «№ пп» и заполнить его автоматически.
- Выполнить соответствующие вычисления.
Решение задач по Excel. Выпуск 3

1. Спланируйте расходы на бензин для ежедневных поездок из п. Половинка в г. Урай на автомобиле. Если известно:
- расстояние м/д населёнными пунктами в км. (30 км. в одну сторону)
- расход бензина (8 литров на 100 км.)
- количество поездок в месяц разное (т.к. разное количество рабочих дней.)
- цена 1 литра бензина ( n рублей за литр.)
- ежемесячный прогнозируемый рост цены на бензин — k% в месяц
Рассчитайте ежемесячный и годовой расход на бензин. Постройте график изменения цены бензина и график ежемесячных расходов.
2. Представьте, что вы директор ресторана. Общий месячный фонд заработной платы — 10000$. На совете акционеров было установлено, что:
- официант получает в 1,5 раза больше мойщика посуды;
- повар — в 3 раза больше мойщика посуды;
- шеф-повар — на 30$ больше.
Решение задач по Excel. Выпуск 2

1. Рассчитайте еженедельную выручку зоопарка, если известно:
- количество проданных билетов каждый день,
- цена взрослого билета — 15 руб,
- цена детского на 30% дешевле чем взрослого.
Постройте диаграмму (график) ежедневной выручки зоопарка.
2. Подготовьте бланк заказа для магазина, если известно:
- продукты (хлеб, мука, макаронные изделия и т.д., не менее 10 наименований)
- цена каждого продукта
- количество заказанного каждого продукта
Рассчитайте на какую сумму заказано продуктов. Усовершенствуйте бланк заказа, добавив скидку (например 10%), если стоимость купленных продуктов будет более 5000 руб. Постройте диаграмму (гистограмму) стоимости.
Решение задач по Excel. Выпуск 1

1. Найти решение уравнения вида kx + b = 0, где k, b — произвольные постоянные.
2. Сахарный тростник содержит 9% сахара. Сколько сахара будет получено из 20 тонн сахарного тростника?
3. Школьники должны были посадить 200 деревьев. Они перевыполнили план посадки на 23%. Сколько деревьев они посадили?
4. Из 50 кг. семян, собранных учениками, 17% составили семена клена, 15% — семена липы, 25% — семена акации, а стальное — семена дуба. Сколько килограмм.
Источник
Решение простых задач с помощью Excel
Классы: 6 , 7
Ключевые слова: Excel , функции в Excel , ячейка , адрес ячейки , таблица
Цель урока: продолжить формирование навыков работы с электронными таблицами.
Задачи:
- обучающие: формировать умения создания, редактирования, форматирования и выполнения простейших вычислений в электронных таблицах.
- развивающие: расширить представления учащихся о возможных сферах применения электронных таблиц; развивать навыки аналитического мышления, речи и внимания.
- воспитательные: формировать и воспитывать познавательный интерес; прививать навыки самостоятельности в работе.
План урока.
- Организационный момент.
- Актуализация знаний учащихся.
- Проверка домашнего задания.
- Решение задач.
- Самостоятельное решение задачи.
- Подведение итогов. Оценки.
- Домашнее задание.
1. Организационный момент.
Сообщить тему урока, сформулировать цели и задачи урока.
Сегодня мы вновь окажемся в гостях у маленького великана Васи в Сказочной стране. Ему, как всегда, требуется ваша помощь, ребята.
Сможете ли вы помочь Васе? Сейчас проверим!
2. Актуализация знаний учащихся.
1) Устно ответить на вопросы.
| A | B | C | D | |
| 1 | 2 | 1 | =A1+3*B1 | =A1^2+B1 |
| 2 | 4 | 6 | =A2+3*B2 | =A2^2+B2 |
- Что такое электронная таблица?
- Какие основные элементы электронной таблицы вам известны?
- Как задается имя ячейки (строки, столбца) в электронной таблице?
- Что может быть содержимым ячейки?
- Число 1 находится в столбце . в строке . в ячейке с адресом .
- Число 4 находится в ячейке с адресом .
- Каковы правила записи формул в ячейках?
- Чему равно значение, вычисляемое по формуле, в ячейке С1?
- Чему равно значение, вычисляемое по формуле, в ячейке D2?
2) Какой результат будет получен в ячейках с формулами?
| A | B | C | D |
| 1 | 5 | 2 | 1 |
| 2 | 6 | 8 | 3 |
| 3 | 8 | 3 | 4 |
| 4 | =СУММ(B1:D3) |
- Что означает запись =СУММ(В1:D3)?
- Сколько элементов содержит блок В1:D3? Ответ: 9.
- Содержимое ячейки D3? Ответ: 5+2+1+6+8+3+8+3+4= 40
3) Проверка домашнего задания
Результаты соревнований по плаванию
Один ученик рассказывает, как он выполнил домашнее задание (через проектор).
| № | Ф.И.О. | 1 | 2 | 3 | Лучшее время | Среднее время | Отклонение |
| 1 | Лягушкин | 3.23 | 3.44 | 3.30 | |||
| 2 | Моржов | 3.21 | 3.22 | 3.24 | |||
| 3 | Акулов | 3.17 | 3.16 | 3.18 | |||
| 4 | Рыбин | 3.24 | 3.20 | 3.18 | |||
| 5 | Черепахин | 3.56 | 3.44 | 3.52 | |||
| Лучший результат соревнований | |||||||
| Среднее время участников соревнований | |||||||
| Максимальное отклонение |
- Среднее время для каждого спортсмена находится как среднее арифметическое трех его заплывов.
- В ячейку «Лучшее время» записывается минимальный результат из 3 заплывов.
- В ячейку «Лучший результат соревнований» записывается минимальное время из столбца.
- В столбец «Отклонение» записывается разность между лучшим временем спортсмена и лучшим результатом соревнований.
- В ячейку «Максимальное отклонение» записывается максимальное значение столбца.
| Результаты соревнований по плаванию | |||||||
| № | Ф.И.О. | 1 | 2 | 3 | Лучшее время | Среднее время | Отклонение |
| 1 | Лягушкин | 3,23 | 3,44 | 3,30 | 3,23 | 3,32 | 0,07 |
| 2 | Моржов | 3,21 | 3,22 | 3,24 | 3,21 | 3,22 | 0,05 |
| 3 | Акулов | 3,17 | 3,16 | 3,18 | 3,16 | 3,17 | 0,00 |
| 4 | Рыбин | 3,24 | 3,20 | 3,18 | 3,18 | 3,21 | 0,02 |
| 5 | Черепахин | 3,56 | 3,44 | 3,52 | 3,44 | 3,51 | 0,28 |
| Лучший результат соревнований | 3,16 | ||||||
| Среднее время участников соревнований | 3,29 | ||||||
| Максимальное отклонение | 0,28 |
4) Решение простых задач.
Маленький великан Вася решил отремонтировать забор вокруг своего огорода и вскопать его под посадку овощей (наступила очередная весна), разметить грядки прямоугольной формы. Для работы ему потребовалось найти длину забора и площадь участка. Но ведь в школе он никогда не учился. Поможем Васе.
№ 1. Вычислить периметр и площадь прямоугольника со сторонами:
а) 3 и 5; б) 6 и 8; в) 10 и 7.
Эту задачу обсуждаем совместно с детьми:
- Как оформить таблицу?
- Какие формулы использовать?
- Как использовать уже записанные формулы для следующего прямоугольника?
Оформление таблицы – на доске и в тетрадях.
В то же время другой ученик самостоятельно решает следующую задачу и представляет свое решение учащимся (через проектор).
№ 2. Маленький великан Вася решил подсчитать, через сколько дней в его копилке будет 100 руб., если ежедневно он стал класть туда на 5 руб. больше, чем в предыдущий день. Помогите Васе. Сейчас в его копилке 2,02 руб.
Обсудив решение задачи № 2, переходим к решению следующей.
Один ученик показывает, как работать с формулами, другой – как использовать функцию суммирования, числовой формат (общий, денежный) и т.д. (Таблица уже готова, ученикам предстоит ввести формулы, использовать суммирование и получить ответ).
№ 3. Посчитайте, используя ЭТ, хватит ли Васе 150 рублей, чтобы купить все продукты, которые ему заказала мама, и хватит ли на чипсы за 10 рублей? Сдачу мама разрешила положить в копилку. Сколько рублей попадет в копилку?
Итого:
| № | Наименование | Цена в рублях | Количество | Стоимость |
| 1 | Хлеб | 9,6 | 2 | =C2*D2 |
| 2 | Кофе | 2,5 | 5 | =C3*D3 |
| 3 | Молоко | 13,8 | 2 | =C4*D4 |
| 4 | Пельмени | 51,3 | 1 | =C5*D5 |
| =СУММ(E2:E5) | ||||
| После покупок останется | =150-E6 | |||
| После покупки чипсов останется | =D7-10 |
5) Самостоятельное решение задачи.
Маленький великан Вася часто бывал в гостях у жителей Цветочного города.
Собираясь на пляж, веселые человечки решили запастись прохладительными напитками. Незнайка взял с собой 2 литра кваса, 1 литр газировки и 1 литр малинового сиропа, Пончик – 3 литра газировки и 2 литра малинового сиропа, Торопыжка – 2 литра газировки, доктор Пилюлькин – 1 литр кваса и 1 литр касторки.
- Сколько литров напитков каждого вида взяли все человечки вместе?
- Сколько всего литров напитков взял с собой каждый из человечков?
- Сколько всего литров напитков взяли все человечки вместе?
Оформите таблицу произвольно и сохраните в своей личной папке.
| Веселые человечки. Напитки. | |||||
| Напиток | Незнайка | Пончик | Торопыжка | Пилюлькин | Всего |
| Квас, л | 2 | 0 | 0 | 1 | 3 |
| Газировка, л | 1 | 3 | 2 | 0 | 6 |
| Сироп, л | 1 | 2 | 0 | 0 | 9 |
| Касторка, л | 0 | 0 | 0 | 1 | 1 |
| ИТОГО: | 4 | 5 | 2 | 2 | 13 |
7) Подведение итогов. Оценки.
Домашнее задание.
Подумайте и решите эту задачу, если известны еще следующие величины.
Как изменится таблица? Какие формулы появятся?
Известно, что 1 литр кваса в Цветочном городе стоит 1 монету, 1 литр газировки – 3 монеты, 1 литр малинового сиропа – 6 монет, 1 литр касторки – 2 монеты.
- Сколько монет истратил на покупку напитков каждый человечек?
- Сколько монет затрачено на покупку напитков каждого вида?
- Сколько потрачено денег всеми человечками вместе?
Источник