
Время на прочтение
16 мин
Количество просмотров 54K
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
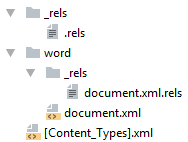
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>word/document.xml
Основное содержимое документа.
word/document.xml
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math"
xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"
xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing"
xmlns:w10="urn:schemas-microsoft-com:office:word"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml"
xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup"
xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk"
xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml"
xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape"
mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"
w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
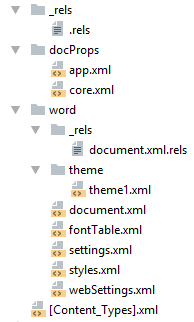
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.sh.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
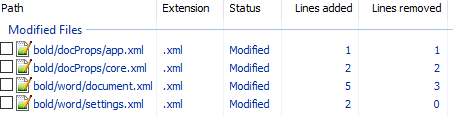
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@
- <TotalTime>0</TotalTime>
+ <TotalTime>1</TotalTime>Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@
- <cp:revision>1</cp:revision>
+ <cp:revision>2</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created>
- <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified>
+ <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
diff
@@ -1,24 +1,26 @@
<w:body>
- <w:p w:rsidR="0076695C" w:rsidRPr="00290C70" w:rsidRDefault="00290C70">
+ <w:p w:rsidR="0076695C" w:rsidRPr="00F752CF" w:rsidRDefault="00290C70">
<w:pPr>
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
</w:pPr>
- <w:r>
+ <w:r w:rsidRPr="00F752CF">
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
- <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:sectPr w:rsidR="0076695C" w:rsidRPr="00F752CF">Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
<w:rPr>
+ <w:b/>в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@
+ <w:proofState w:spelling="clean"/>
@@ -17,10 +18,11 @@
+ <w:rsid w:val="00F752CF"/>Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
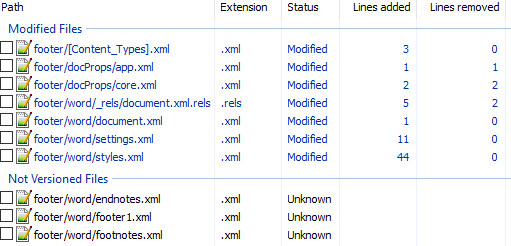
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
+ <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/>
+ <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/>
+ <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
diff
@@ -1,8 +1,11 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
+ <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/>
+ <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/>
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>
- <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
- <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>
</Relationships>Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
@@ -3,6 +3,9 @@
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:footerReference w:type="default" r:id="rId6"/>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/>
<w:cols w:space="708"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
diff
@@ -1,19 +1,30 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15">
<w:zoom w:percent="100"/>
+ <w:proofState w:spelling="clean"/>
<w:defaultTabStop w:val="708"/>
<w:characterSpacingControl w:val="doNotCompress"/>
+ <w:footnotePr>
+ <w:footnote w:id="-1"/>
+ <w:footnote w:id="0"/>
+ </w:footnotePr>
+ <w:endnotePr>
+ <w:endnote w:id="-1"/>
+ <w:endnote w:id="0"/>
+ </w:endnotePr>
<w:compat>
<w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/>
<w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
</w:compat>
<w:rsids>
<w:rsidRoot w:val="00290C70"/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:rsid w:val="001B0DE6"/>А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
diff
@@ -480,6 +480,50 @@
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman"/>
<w:b/>
<w:sz w:val="28"/>
</w:rPr>
</w:style>
+ <w:style w:type="paragraph" w:styleId="a4">
+ <w:name w:val="header"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a5"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a5">
+ <w:name w:val="Верхний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a4"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
+ <w:style w:type="paragraph" w:styleId="a6">
+ <w:name w:val="footer"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a7"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a7">
+ <w:name w:val="Нижний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a6"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
</w:styles>Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B">
<w:pPr>
<w:pStyle w:val="a6"/>
</w:pPr>
<w:r>
<w:t>123</w:t>
</w:r>
</w:p>
</w:ftr>Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels. - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ.
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
<xml>TEST</xml>В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/>
<xsl:template match="/">
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>
<xsl:value-of select="//xml/text()"/>
</w:t>
</w:r>
</w:p>
</w:ftr>
</xsl:template>
</xsl:stylesheet>Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml") В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>TEST</w:t>
</w:r>
</w:p>
</w:ftr>Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Relationship
Id="rId0"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer"
Target="footer0.xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/content-types" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Override
PartName="/word/footer0.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>В результате
Весь код опубликован. Работает он так:
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т… к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула
With approximately one billion people using Microsoft Office, the DOCX format is the most popular de facto standard for exchanging document files between offices. Its closest competitor — the ODT format — is only supported by Open/LibreOffice and some open source products, making it far from standard. The PDF format is not a competitor because PDFs can’t be edited and they don’t contain a full document structure, so they can only take limited local changes like watermarks, signatures, and the like. This is why most business documents are created in the DOCX format; there’s no good alternative to replace it.
While DOCX is a complex format, you may want to parse it manually for simpler tasks such as indexing, converting to TXT and making other small modifications. I’d like to give you enough information on DOCX internals so you don’t have to reference the ECMA specifications, a massive 5,000 page manual.
The best way to understand the format is to create a simple one-word document with MSWord and observe how editing the document changes the underlying XML. You’ll face some cases where the DOCX doesn’t format properly in MS Word and you don’t know why, or come across instances when it’s not evident how to generate the desired formatting. Seeing and understanding exactly what’s going on in the XML will help that.
I worked for about a year on a collaborative DOCX editor, CollabOffice, and I want to share some of that knowledge with the developer community. In this article I will explain the DOCX file structure, summarising information that is scattered over the internet. This article is an intermediary between the huge, complex ECMA specification and the simple internet tutorials currently available. You can find the files that accompany this article in the toptal-docx project on my github account.
A Simple DOCX file
A DOCX file is a ZIP archive of XML files. If you create a new, empty Microsoft Word document, write a single word ‘Test’ inside and unzip it contents, you will see the following file structure:
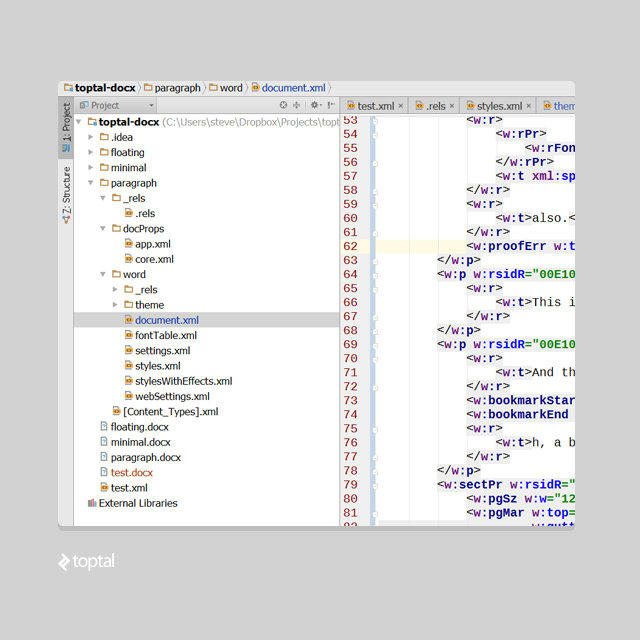
Even though we’ve created a simple document, the save process in Microsoft Word has generated default themes, document properties, font tables, and so on, in XML format.
All the files inside a DOCX are XML files, even those with the «.rels» extension.
To start, let us remove the unused stuff and focus on document.xml, which contains the main text elements. When you delete a file, make sure you have deleted all the relationship references to it from other the xml files. Here is a code-diff example on how I’ve cleared dependencies to app.xml and core.xml. If you have any unresolved/missing references, MSWord will consider the file broken.
Here’s the structure of our simplified, minimal DOCX document (and here’s the project on github):
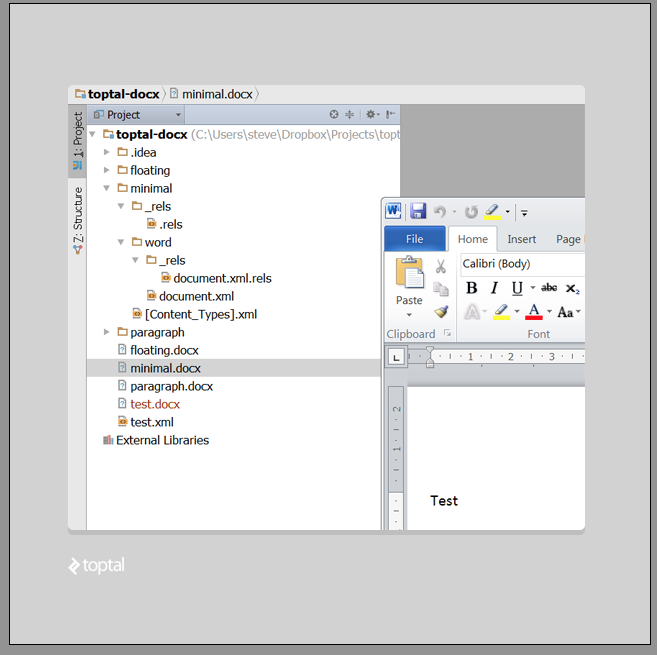
Let’s break it down by file from here, from the top:
_rels/.rels
This defines the reference that tells MS Word where to look for the document contents. In this case, it references word/document.xml:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>
_rels/document.xml.rels
This file defines references to resources, such as images, embedded in the document content. Our simple document has no embedded resources, so the relationship tag is empty:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>
[Content_Types].xml
[Content_Types].xml contains information about the types of media inside the document. Since we only have text content, it’s pretty simple:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>
document.xml
Finally, here is the main XML with the document’s text content. I have removed some of namespace declarations for clarity, but you can find the full version of the file in the github project. In that file you’ll find that some of the namespace references in the document are unused, but you shouldn’t delete them because MS Word needs them.
Here’s our simplified example:
<w:document>
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r><w:t>Test</w:t></w:r>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720"
w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>
The main node <w:document> represents the document itself, <w:body> contains paragraphs, and nested within <w:body> are page dimensions defined by <w:sectPr>.
<w:rsidR> is an attribute that you can ignore; it’s used by MS Word internals.
Let’s take a look at a more complex document with three paragraphs. I have highlighted the XML with the same colors on the screenshot from Microsoft Word, so you can see the correlation:

<w:p w:rsidR="0081206C" w:rsidRDefault="00E10CAE"> <w:r> <w:t xml:space="preserve">This is our example first paragraph. It's default is left aligned, and now I'd like to introduce</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/> <w:color w:val="000000"/> </w:rPr> <w:t>some bold</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/> <w:b/> <w:color w:val="000000"/> </w:rPr> <w:t xml:space="preserve"> text</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/> <w:color w:val="000000"/> </w:rPr> <w:t xml:space="preserve">, </w:t> </w:r> <w:proofErr w:type="gramStart"/> <w:r> <w:t xml:space="preserve">and also change the</w:t> </w:r> <w:r w:rsidRPr="00E10CAE"> <w:rPr><w:rFonts w:ascii="Impact" w:hAnsi="Impact"/> </w:rPr> <w:t>font style</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Impact" w:hAnsi="Impact"/> </w:rPr> <w:t xml:space="preserve"> </w:t> </w:r> <w:r> <w:t>to 'Impact'.</w:t></w:r> </w:p> <w:p w:rsidR="00E10CAE" w:rsidRDefault="00E10CAE"> <w:r> <w:t>This is new paragraph.</w:t> </w:r></w:p> <w:p w:rsidR="00E10CAE" w:rsidRPr="00E10CAE" w:rsidRDefault="00E10CAE"> <w:r> <w:t>This is one more paragraph, a bit longer.</w:t> </w:r> </w:p>
Paragraph Structure
A simple document consists of paragraphs, a paragraph consists of runs (a series of text with the same font, color, etc), and runs consist of characters (such as <w:t>).<w:t> tags may have several characters inside, and there might be a few in the same run.
Again, we can ignore <w:rsidR>.
Text properties
Basic text properties are font, size, color, style, and so on. There are about 40 tags that specify text appearance. As you can see in our three paragraph example, each run has its own properties inside <w:rPr>, specifying <w:color>, <w:rFonts> and boldness <w:b>.
An important thing to note is that properties make a distinction between the two groups of characters, normal and complex script (Arabic, for instance), and that the properties have a different tag depending on which type of character it’s affecting.
Most normal script property tags have a matching complex script tag with an added “C” specifying the property is for complex scripts. For example: <w:i> (italic) becomes <w:iCs>, and the bold tag for normal script, <w:b>, becomes <w:bCs> for complex script.
Styles
There’s an entire toolbar in Microsoft Word dedicated to styles: normal, no spacing, heading 1, heading 2, title, and so on. These styles are stored in /word/styles.xml (note: in the first step in our simple example, we removed this XML from DOCX. Make a new DOCX to see this).
Once you have text defined as a style, you will find reference to this style inside the paragraph properties tag, <w:pPr>. Here’s an example where I’ve defined my text with the style Heading 1:
<w:p>
<w:pPr>
<w:pStyle w:val="Heading1"/>
</w:pPr>
<w:r>
<w:t>My heading 1</w:t>
</w:r>
</w:p>
and here is the style itself from styles.xml:
<w:style w:type="paragraph" w:styleId="Heading1">
<w:name w:val="heading 1"/>
<w:basedOn w:val="Normal"/>
<w:next w:val="Normal"/>
<w:link w:val="Heading1Char"/>
<w:uiPriority w:val="9"/>
<w:qFormat/>
<w:rsid w:val="002F7F18"/>
<w:pPr>
<w:keepNext/>
<w:keepLines/>
<w:spacing w:before="480" w:after="0"/>
<w:outlineLvl w:val="0"/>
</w:pPr>
<w:rPr>
<w:rFonts w:asciiTheme="majorHAnsi" w:eastAsiaTheme="majorEastAsia" w:hAnsiTheme="majorHAnsi"
w:cstheme="majorBidi"/>
<w:b/>
<w:bCs/>
<w:color w:val="365F91" w:themeColor="accent1" w:themeShade="BF"/>
<w:sz w:val="28"/>
<w:szCs w:val="28"/>
</w:rPr>
</w:style>
The <w:style/w:rPr/w:b> xpath specifies that the font is bold, and <w:style/w:rPr/w:color> indicates the font color. <w:basedOn> instructs MSWord to use “Normal” style for any missing properties.
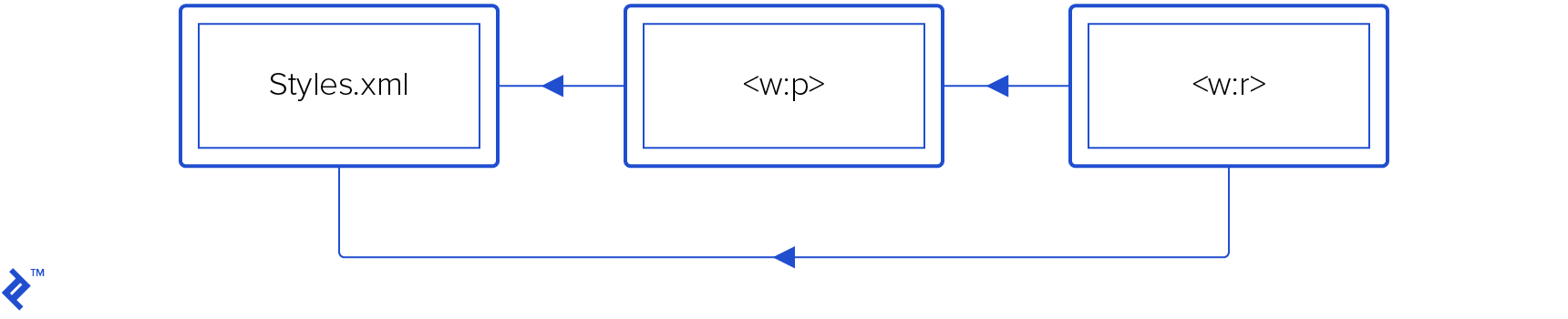
Property Inheritance
Text properties are inherited. A run has its own properties (w:p/w:r/w:rPr/*), but it also inherits properties from paragraph (w:r/w:pPr/*), and both can reference style properties from the /word/styles.xml.
<w:r>
<w:rPr>
<w:rStyle w:val="DefaultParagraphFont"/>
<w:sz w:val="16"/>
</w:rPr>
<w:tab/>
</w:r>
Paragraphs and runs start with default properties: w:styles/w:docDefaults/w:rPrDefault/*
and w:styles/w:docDefaults/w:pPrDefault/*. To get the end result of a character’s properties you should:
- Use default run/paragraph properties
- Append run/paragraph style properties
- Append local run/paragraph properties
- Append result run properties over paragraph properties
When I say “append” B to A, I mean to iterate through all B properties and override all A’s properties, leaving all non-intersecting properties as-is.
One more place where default properties may be located is in the <w:style> tag with w:type="paragraph" and w:default="1". Note, that characters themselves inside a run never have a default style, so <w:style w:type="character" w:default="1"> doesn’t actually affect any text.
1554402290400-dbb29eef3ba6035df7ad726dfc99b2af.png)
Characters in a run can inherit from its paragraph and both can inherit from styles.xml.
Toggle properties
Some of the properties are “toggle” properties, such as <w:b> (bold) or <w:i> (italic); these attributes behave like an XOR operator.
This means if the parent style is bold and a child run is bold, the result will be regular, non-bold text.
You have to do lots of testing and reverse-engineering to handle toggle attributes correctly. Take a look at paragraph 17.7.3 of ECMA-376 Open XML specification to get the formal, detailed rules for toggle properties/
Toggle properties are the most complex for a layouter to handle correctly.
Fonts
Fonts follow the same common rules as other text attributes, but font property default values are specified in a separate theme file, referenced under word/_rels/document.xml.rels like this:
<Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
Based on the above reference, the default font name will be found in word/theme/themes1.xml, inside a <a:theme> tag, a:themeElements/a:fontScheme/a:majorFont or a:minorFont tag.
The default font size is 10 unless the w:docDefaults/w:rPrDefault tag is missing, then it is size 11.
Text alignment
Text alignment is specified by a <w:jc> tag with four w:val modes available: "left", "center", "right" and "both".
"left" is the default mode; text is started at the left of paragraph rectangle (usually the page width). (This paragraph is aligned to the left, which is standard.)
"center" mode, predictably, centers all characters inside the page width. (Again, this paragraph exemplifies centered alignment.)
In "right" mode, paragraph text is aligned to the right margin. (Notice how this text is aligned to the right side.)
"both" mode puts extra spacing between words so that lines get wider and occupy the full paragraph width, with the exception of the last line which is left aligned. (This paragraph is a demonstration of that.)
Images
DOCX supports two sorts of images: inline and floating.
Inline images appear inside a paragraph along with the other characters, <w:drawing> is used instead of using <w:t> (text). You can find image ID with the following xpath syntax:
w:drawing/wp:inline/a:graphic/a:graphicData/pic:pic/pic:blipFill/a:blip/@r:embed
The image ID is used to look up the filename in the word/_rels/document.xml.rels file, and it should point to gif/jpeg file inside word/media subfolder. (See the github project’s word/_rels/document.xml.rels file, where you can see the image ID.)
Floating images are placed relative to paragraphs with text flowing around them. (Here’s th github project sample document with a floating image.)
Floating images use <wp:anchor> instead of <w:drawing>, so if you delete any text inside <w:p>, be careful with the anchors if you don’t want the images removed.

MS Word’s image options refer to image alignment as «text wrapping mode».
Tables
XML tags for tables are similar to HTML table markup– is the same as <table>, matches with <tr>, etc.
<w:tbl>, the table itself, has table properties <w:tblPr>, and each column property is presented by <w:gridCol> inside <w:tblGrid>. Rows follow one by one as <w:tr> tags and each row should have same number of columns as specified in <w:tblGrid>:
<w:tbl>
<w:tblPr>
<w:tblW w:w="5000" w:type="pct" />
</w:tblPr>
<w:tblGrid><w:gridCol/><w:gridCol/></w:tblGrid>
<w:tr>
<w:tc><w:p><w:r><w:t>left</w:t></w:r></w:p></w:tc>
<w:tc><w:p><w:r><w:t>right</w:t></w:r></w:p></w:tc>
</w:tr>
</w:tbl>
Width for table columns can be specified in the <w:tblW> tag, but if you don’t define it MS Word will use its internal algorithms to find the optimal width of columns for the smallest effective table size.
Units
Many XML attributes inside DOCX specify sizes or distances. While they’re integers inside the XML, they all have different units so some conversion is necessary. The topic is a complicated one, so I’d recommend this article by Lars Corneliussen on units in DOCX files. The table he presents is useful, though with a small misprint: inches should be pt/72, not pt*72.
Here’s a cheat sheet:
| COMMON DOCX XML UNIT CONVERSIONS | ||||||
| 20th of a point | Points dxa/20 |
Inches pt/72 |
Centimeters in*2,54 |
Font half size pt/144 |
EMU in*914400 |
|
| Example | 11906 | 595.3 | 8,27… | 21.00086… | 4,135 | 7562088 |
| Tags using this | pgSz/pgMar/w:spacing | w:sz | wp:extent, a:ext |
Tips for Implementing a Layouter
If you want to convert a DOCX file (to PDF, for instance), draw it on canvas, or count number of pages, you’ll have to implement a layouter. A layouter is an algorithm for calculating character positions from a DOCX file.
This is a complex task if you need 100 percent fidelity rendering. The amount of time needed to implement a good layouter is measured in man-years, but if you only need a simple, limited one, it can be done relatively quickly.
A layouter fills a parent rectangle, which is usually a rectangle of the page. It add words from a run one by one. When the current line overflows, it starts a new one. If the paragraph is too high for the parent rectangle, it’s wrapped to the next page.
Here are some important things to keep in mind if you decide to implement a layouter:
- The layouter should take care about text alignment and text floating over images
- It should be capable of handling nested objects, such as nested tables
- If you want to provide full support for such images, you’ll have to implement a layouter with at least two passes, the first step collects floating images’ positions and the second fills empty space with text characters.
- Be aware of indentations and spacings. Each paragraph has spacing before and after, and these numbers are specified by the
w:spacingtag. Vertical spacing is specified byw:afterandw:beforetags. Note that line spacing is specified byw:line, but this is not the size of the line as one may expect. To get the size of the line, take the current font height, multiply byw:lineand divide by 12. - DOCX files contain no information about pagination. You won’t find the number of pages in the document unless you calculate how much space you need for each line to ascertain the number of pages. If you need to find exact coordinates of each character on the page, be sure to take into account all spacings, indentations and sizes.
- If you implement a full-featured DOCX layouter that handles tables, note the special cases when tables span multiple pages. A cell which causes a page overflow also affects other cells.
- Creating an optimal algorithm for calculating a table columns’ width is a challenging math problem and word processors and layouters usually use some suboptimal implementations. I propose using the algorithm from W3C HTML table documentation as a first approximation. I haven’t found a description of the algorithm used by MS Word, and Microsoft has fine-tuned the algorithm over time so different versions of Word may lay out tables slightly differently.
If something is unclear: reverse-engineer the XML!
When it’s not obvious how this or that XML tag works inside MS Word, there are two main approaches to figuring it out:
-
Create the desired content step-by-step. Start with a simple docx file. Save each step to its own file, as in
1.docx,2.docx, for example. Unzip each of them and use a visual diff tool for folder comparison to see which tags appear after your changes. (For a commercial option, try Araxis Merge, or for a free option, WinMerge.) -
If you generate a DOCX file that MS Word doesn’t like, work backwards. Simplify your XML step by step. At some point you will learn which change MS Word found incorrect.
DOCX is quite complex, isn’t it?
It is complex, and Microsoft’s license forbids using MS Word on the server side for processing DOCX– this is pretty standard for commercial products. Microsoft has, however, provided the XSLT file to handle most DOCX tags, but it won’t give you 100 percent or even 99 percent fidelity. Processes such as text wrapping over images are not supported, but you will be able to support the majority of documents. (If you don’t need complexity, consider using Markdown as an alternative.)
If you have a sufficient budget (there is no free DOCX rendering engine), you may want to use commercial products such as Aspose or docx4j. The most popular free solution is LibreOffice for converting between DOCX and other formats, including PDF. Unfortunately, LibreOffice contains many small bugs during conversion, and since it’s a sophisticated, open-source C++ product, it’s slow and difficult to fix fidelity issues.
Alternatively, if you find DOCX layouting too complicated to implement yourself, you can also convert it to HTML and use a browser to render it. You can also consider one of Toptal’s freelance XML developers.
DOCX Resources for further reading
- ECMA DOCX specification
- OpenXML library for DOCX manipulation from C#. It doesn’t contain information on layouting or rendering code, but offers a class hierarchy matching each possible XML node in DOCX.
- You can always search or ask on stackoverflow with keywords like docx4j, OpenXML and docx; there are people in the community who are knowledgeable.
I’m trying to create a parser to find the tracked changes and author of a Word .docx file…
I found the document.xml but there are so many tags! Is there a glossary somewhere to what all those tags stand for?
I’d like to avoid brute forcing my way through this if possible.
![]()
Pac0
20.9k8 gold badges65 silver badges74 bronze badges
asked Oct 12, 2017 at 16:06
![]()
fifamaniac04fifamaniac04
2,30312 gold badges49 silver badges72 bronze badges
The «Office Open XML» format and its XML vocabularies are described in detail in http://www.ecma-international.org/publications/standards/Ecma-376.htm .
To give you an idea, the following piece of XSLT should extract just the effective result text without tracked deletions of a wordprocessingML document, like would be stored under word/document.xml in a .docx file (a ZIP archive).
<!-- Match and output text spans except when
appearing in w:delText child content -->
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<xsl:output method="text"/>
<xsl:template match="w:t">
<xsl:value-of select="."/>
</xsl:template>
<xsl:template match="w:delText"/>
<xsl:template match="*">
<xsl:apply-templates/>
</xsl:template>
</xsl:stylesheet>
For your application to extract changes instead, you’d also have to take care of w:ins elements.
answered Oct 12, 2017 at 17:22
![]()
imhotapimhotap
2,1951 gold badge8 silver badges15 bronze badges
"w:ins" denotes what was inserted when trackedchanges are enabled.
"w:del" denotes what was deleted when trackedchanges are enabled.
"w:commentRangeStart" denotes the start of a comment
"w:commentRangeEnd" denotes the end of the comment.
All text are found inside
"w:t" tags.
answered Oct 26, 2017 at 22:30
![]()
fifamaniac04fifamaniac04
2,30312 gold badges49 silver badges72 bronze badges
Как я разбирал docx с помощью XSLT
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом

Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types"> <Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/> <Default Extension="xml" ContentType="application/xml"/> <Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/> </Types>
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument" Target="word/document.xml"/> </Relationships>
word/document.xml
Основное содержимое документа.
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" mc:Ignorable="w14 wp14"> <w:body> <w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5"> <w:r> <w:t>Test</w:t> </w:r> <w:bookmarkStart w:id="0" w:name="_GoBack"/> <w:bookmarkEnd w:id="0"/> </w:p> <w:sectPr w:rsidR="005F670F"> <w:pgSz w:w="12240" w:h="15840"/> <w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/> <w:cols w:space="720"/> <w:docGrid w:linePitch="360"/> </w:sectPr> </w:body> </w:document>
Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> </Relationships>
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@ - <TotalTime>0</TotalTime> + <TotalTime>1</TotalTime>
Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@ - <cp:revision>1</cp:revision> + <cp:revision>2</cp:revision> <dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created> - <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified> + <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
«`diff
@@ -1,24 +1,26 @@
—
+
+
—
+
+
Test
—
+
«`
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@ + <w:proofState w:spelling="clean"/> @@ -17,10 +18,11 @@ + <w:rsid w:val="00F752CF"/>
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@ <Default Extension="xml" ContentType="application/xml"/> <Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/> + <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/> + <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/> + <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:
Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
«`diff
@@ -1,8 +1,11 @@
+
+
—
—
+
+
+
«`
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
«`diff
@@ -3,6 +3,9 @@
+
+
+
«`
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@ </w:r> <w:bookmarkStart w:id="0" w:name="_GoBack"/> <w:bookmarkEnd w:id="0"/> </w:p> <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70"> + <w:footerReference w:type="default" r:id="rId6"/> <w:pgSz w:w="11906" w:h="16838"/> <w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/> <w:cols w:space="708"/> <w:docGrid w:linePitch="360"/> </w:sectPr>
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
@@ -1,19 +1,30 @@ <?xml version="1.0" encoding="UTF-8" standalone="yes"?> <w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15"> <w:zoom w:percent="100"/> + <w:proofState w:spelling="clean"/> <w:defaultTabStop w:val="708"/> <w:characterSpacingControl w:val="doNotCompress"/> + <w:footnotePr> + <w:footnote w:id="-1"/> + <w:footnote w:id="0"/> + </w:footnotePr> + <w:endnotePr> + <w:endnote w:id="-1"/> + <w:endnote w:id="0"/> + </w:endnotePr> <w:compat> <w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/> <w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> <w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> <w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> <w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> </w:compat> <w:rsids> <w:rsidRoot w:val="00290C70"/> + <w:rsid w:val="000A7B7B"/> + <w:rsid w:val="001B0DE6"/>
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
«`diff
@@ -480,6 +480,50 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
«`
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B"> <w:pPr> <w:pStyle w:val="a6"/> </w:pPr> <w:r> <w:t>123</w:t> </w:r> </w:p> </w:ftr>
Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:
Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ
- Добавляем наш нижний колонтитул
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0"> <xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/> <xsl:template match="/"> <w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:p> <w:r> <w:rPr> <w:lang w:val="en-US"/> </w:rPr> <w:t> <xsl:value-of select="//xml/text()"/> </w:t> </w:r> </w:p> </w:ftr> </xsl:template> </xsl:stylesheet>
Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml")
В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:p> <w:r> <w:rPr> <w:lang w:val="en-US"/> </w:rPr> <w:t>TEST</w:t> </w:r> </w:p> </w:ftr>
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
«`xml
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
</spoiler>
#### Прописываем ссылки в документе
Далее надо в каждый тег `<w:sectPr>` добавить тег `<w:footerReference>` или заменить в нём ссылку на наш нижний колонтитул. [Оказалось](https://msdn.microsoft.com/en-us/library/documentformat.openxml.wordprocessing.footerreference(v=office.14).aspx), что у каждого тега `<w:sectPr>` может быть 3 тега `<w:footerReference>` - для первой страницы, четных страниц и всего остального:
<spoiler title="XSLT">
```xml
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
«`xml
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
</spoiler>
#### В результате
Весь код [опубликован](https://github.com/intersystems-ru/Converter/blob/master/Converter/Footer.cls.xml). Работает он так:
```cos
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")
Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т..к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула
From Wikipedia, the free encyclopedia
| Filename extension | .XML (XML document) |
|---|---|
| Developed by | Microsoft |
| Type of format | Document file format |
| Extended from | XML, DOC |
| Filename extension | .VDX (XML Drawing),.VSX (XML Stencil),.VTX (XML Template) |
|---|---|
| Developed by | Microsoft |
| Type of format | Diagramming vector graphics |
| Extended from | XML, VSD, VSS, VST |
| Filename extension | .XML (XML Spreadsheet) |
|---|---|
| Developed by | Microsoft |
| Type of format | Spreadsheet |
| Extended from | XML, XLS |
The Microsoft Office XML formats are XML-based document formats (or XML schemas) introduced in versions of Microsoft Office prior to Office 2007. Microsoft Office XP introduced a new XML format for storing Excel spreadsheets and Office 2003 added an XML-based format for Word documents.
These formats were succeeded by Office Open XML (ECMA-376) in Microsoft Office 2007.
File formats[edit]
- Microsoft Office Word 2003 XML Format — WordProcessingML or WordML (.XML)
- Microsoft Office Excel 2002 and Excel 2003 XML Format — SpreadsheetML (.XML)
- Microsoft Office Visio 2003 XML Format — DataDiagramingML (.VDX, .VSX, .VTX)
- Microsoft Office InfoPath 2003 XML Format — XML FormTemplate (.XSN) (Compressed XML templates in a Cabinet file)
- Microsoft Office InfoPath 2003 XML Format — XMLS FormTemplate (.XSN) (Compressed XML templates in a Cabinet file)
Limitations and differences with Office Open XML[edit]
Besides differences in the schema, there are several other differences between the earlier Office XML schema formats and Office Open XML.
- Whereas the data in Office Open XML documents is stored in multiple parts and compressed in a ZIP file conforming to the Open Packaging Conventions, Microsoft Office XML formats are stored as plain single monolithic XML files (making them quite large, compared to OOXML and the Microsoft Office legacy binary formats). Also, embedded items like pictures are stored as binary encoded blocks within the XML. In case of Office Open XML, the header, footer, comments of a document etc. are all stored separately.
- XML Spreadsheet documents cannot store Visual Basic for Applications macros, auditing tracer arrows, chart and other graphic objects, custom views, drawing object layers, outlining, scenarios, shared workbook information and user-defined function categories.[1] In contrast, the newer Office Open XML formats support full document fidelity.
- Poor backward compatibility with the version of Word/Excel prior to the one in which they were introduced. For example, Word 2002 cannot open Word 2003 XML files unless a third-party converter add-in is installed.[2] Microsoft has released a Word 2003 XML Viewer which allows WordProcessingML files saved by Word 2003 to be viewed as HTML from within Internet Explorer.[3] For Office Open XML, Microsoft provides converters for Office 2003, Office XP and Office 2000.
- Office Open XML formats are also defined for PowerPoint 2007, equation editing (Office MathML), vector drawing, charts and text art (DrawingML).
Word XML format example[edit]
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <?mso-application progid="Word.Document"?> <w:wordDocument xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml" xmlns:wx="http://schemas.microsoft.com/office/word/2003/auxHint" xmlns:o="urn:schemas-microsoft-com:office:office" w:macrosPresent="no" w:embeddedObjPresent="no" w:ocxPresent="no" xml:space="preserve"> <o:DocumentProperties> <o:Title>This is the title</o:Title> <o:Author>Darl McBride</o:Author> <o:LastAuthor>Bill Gates</o:LastAuthor> <o:Revision>1</o:Revision> <o:TotalTime>0</o:TotalTime> <o:Created>2007-03-15T23:05:00Z</o:Created> <o:LastSaved>2007-03-15T23:05:00Z</o:LastSaved> <o:Pages>1</o:Pages> <o:Words>6</o:Words> <o:Characters>40</o:Characters> <o:Company>SCO Group, Inc.</o:Company> <o:Lines>1</o:Lines> <o:Paragraphs>1</o:Paragraphs> <o:CharactersWithSpaces>45</o:CharactersWithSpaces> <o:Version>11.6359</o:Version> </o:DocumentProperties> <w:fonts> <w:defaultFonts w:ascii="Times New Roman" w:fareast="Times New Roman" w:h-ansi="Times New Roman" w:cs="Times New Roman" /> </w:fonts> <w:styles> <w:versionOfBuiltInStylenames w:val="4" /> <w:latentStyles w:defLockedState="off" w:latentStyleCount="156" /> <w:style w:type="paragraph" w:default="on" w:styleId="Normal"> <w:name w:val="Normal" /> <w:rPr> <wx:font wx:val="Times New Roman" /> <w:sz w:val="24" /> <w:sz-cs w:val="24" /> <w:lang w:val="EN-US" w:fareast="EN-US" w:bidi="AR-SA" /> </w:rPr> </w:style> <w:style w:type="paragraph" w:styleId="Heading1"> <w:name w:val="heading 1" /> <wx:uiName wx:val="Heading 1" /> <w:basedOn w:val="Normal" /> <w:next w:val="Normal" /> <w:rsid w:val="00D93B94" /> <w:pPr> <w:pStyle w:val="Heading1" /> <w:keepNext /> <w:spacing w:before="240" w:after="60" /> <w:outlineLvl w:val="0" /> </w:pPr> <w:rPr> <w:rFonts w:ascii="Arial" w:h-ansi="Arial" w:cs="Arial" /> <wx:font wx:val="Arial" /> <w:b /> <w:b-cs /> <w:kern w:val="32" /> <w:sz w:val="32" /> <w:sz-cs w:val="32" /> </w:rPr> </w:style> <w:style w:type="character" w:default="on" w:styleId="DefaultParagraphFont"> <w:name w:val="Default Paragraph Font" /> <w:semiHidden /> </w:style> <w:style w:type="table" w:default="on" w:styleId="TableNormal"> <w:name w:val="Normal Table" /> <wx:uiName wx:val="Table Normal" /> <w:semiHidden /> <w:rPr> <wx:font wx:val="Times New Roman" /> </w:rPr> <w:tblPr> <w:tblInd w:w="0" w:type="dxa" /> <w:tblCellMar> <w:top w:w="0" w:type="dxa" /> <w:left w:w="108" w:type="dxa" /> <w:bottom w:w="0" w:type="dxa" /> <w:right w:w="108" w:type="dxa" /> </w:tblCellMar> </w:tblPr> </w:style> <w:style w:type="list" w:default="on" w:styleId="NoList"> <w:name w:val="No List" /> <w:semiHidden /> </w:style> </w:styles> <w:docPr> <w:view w:val="print" /> <w:zoom w:percent="100" /> <w:doNotEmbedSystemFonts /> <w:proofState w:spelling="clean" w:grammar="clean" /> <w:attachedTemplate w:val="" /> <w:defaultTabStop w:val="720" /> <w:punctuationKerning /> <w:characterSpacingControl w:val="DontCompress" /> <w:optimizeForBrowser /> <w:validateAgainstSchema /> <w:saveInvalidXML w:val="off" /> <w:ignoreMixedContent w:val="off" /> <w:alwaysShowPlaceholderText w:val="off" /> <w:compat> <w:breakWrappedTables /> <w:snapToGridInCell /> <w:wrapTextWithPunct /> <w:useAsianBreakRules /> <w:dontGrowAutofit /> </w:compat> </w:docPr> <w:body> <wx:sect> <w:p> <w:r> <w:t>This is the first paragraph</w:t> </w:r> </w:p> <wx:sub-section> <w:p> <w:pPr> <w:pStyle w:val="Heading1" /> </w:pPr> <w:r> <w:t>This is a heading</w:t> </w:r> </w:p> <w:sectPr> <w:pgSz w:w="12240" w:h="15840" /> <w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="720" w:footer="720" w:gutter="0" /> <w:cols w:space="720" /> <w:docGrid w:line-pitch="360" /> </w:sectPr> </wx:sub-section> </wx:sect> </w:body> </w:wordDocument>
Excel XML spreadsheet example[edit]
<?xml version="1.0" encoding="UTF-8"?> <?mso-application progid="Excel.Sheet"?> <Workbook xmlns="urn:schemas-microsoft-com:office:spreadsheet" xmlns:x="urn:schemas-microsoft-com:office:excel" xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet" xmlns:html="https://www.w3.org/TR/html401/"> <Worksheet ss:Name="CognaLearn+Intedashboard"> <Table> <Column ss:Index="1" ss:AutoFitWidth="0" ss:Width="110"/> <Row> <Cell><Data ss:Type="String">ID</Data></Cell> <Cell><Data ss:Type="String">Project</Data></Cell> <Cell><Data ss:Type="String">Reporter</Data></Cell> <Cell><Data ss:Type="String">Assigned To</Data></Cell> <Cell><Data ss:Type="String">Priority</Data></Cell> <Cell><Data ss:Type="String">Severity</Data></Cell> <Cell><Data ss:Type="String">Reproducibility</Data></Cell> <Cell><Data ss:Type="String">Product Version</Data></Cell> <Cell><Data ss:Type="String">Category</Data></Cell> <Cell><Data ss:Type="String">Date Submitted</Data></Cell> <Cell><Data ss:Type="String">OS</Data></Cell> <Cell><Data ss:Type="String">OS Version</Data></Cell> <Cell><Data ss:Type="String">Platform</Data></Cell> <Cell><Data ss:Type="String">View Status</Data></Cell> <Cell><Data ss:Type="String">Updated</Data></Cell> <Cell><Data ss:Type="String">Summary</Data></Cell> <Cell><Data ss:Type="String">Status</Data></Cell> <Cell><Data ss:Type="String">Resolution</Data></Cell> <Cell><Data ss:Type="String">Fixed in Version</Data></Cell> </Row> <Row> <Cell><Data ss:Type="Number">0000033</Data></Cell> <Cell><Data ss:Type="String">CognaLearn Intedashboard</Data></Cell> <Cell><Data ss:Type="String">janardhana.l</Data></Cell> <Cell><Data ss:Type="String"></Data></Cell> <Cell><Data ss:Type="String">normal</Data></Cell> <Cell><Data ss:Type="String">text</Data></Cell> <Cell><Data ss:Type="String">always</Data></Cell> <Cell><Data ss:Type="String"></Data></Cell> <Cell><Data ss:Type="String">GUI</Data></Cell> <Cell><Data ss:Type="String">2016-10-14</Data></Cell> <Cell><Data ss:Type="String"></Data></Cell> <Cell><Data ss:Type="String"></Data></Cell> <Cell><Data ss:Type="String"></Data></Cell> <Cell><Data ss:Type="String">public</Data></Cell> <Cell><Data ss:Type="String">2016-10-14</Data></Cell> <Cell><Data ss:Type="String">IE8 browser_Modules screen tool tip text is shown twice</Data></Cell> <Cell><Data ss:Type="String">new</Data></Cell> <Cell><Data ss:Type="String">open</Data></Cell> <Cell><Data ss:Type="String"></Data></Cell> </Row> </Table> </Worksheet> </Workbook>
See also[edit]
- List of document markup languages
- Comparison of document markup languages
References[edit]
- ^ «Features and limitations of XML Spreadsheet format (broken)». Archived from the original on 2007-10-09. Retrieved 2007-11-01.
- ^ «Polar WordML add-in (broken)». Archived from the original on 2009-04-11. Retrieved 2007-11-01.
- ^ Word 2003 XML Viewer
- Overview of Office 2003 Developer Technologies
- Office 2003 XML. ISBN 0-596-00538-5
External links[edit]
- MSDN: XML Spreadsheet Reference
- MSDN: Word 2003 XML Reference
- Lawsuit about XML patent