
Сегодня мы в качестве практики создадим пару документов для MS Word, не используя никаких специальных инструментов (за исключением XML-редактора и Zip-архиватора).
 В предыдущей статье я постарался “просто и доступно”
В предыдущей статье я постарался “просто и доступно” ![]() рассказать о том, что такое Open Package Convention (или иначе говоря, как устроены изнутри документы MS Office 2007+).
рассказать о том, что такое Open Package Convention (или иначе говоря, как устроены изнутри документы MS Office 2007+).
Сегодня мы в качестве практики создадим пару документов для MS Word, не используя никаких специальных инструментов (за исключением XML-редактора и Zip-архиватора).
Сразу же оговорюсь, что мы не будем сильно вдаваться в особенности разметки документов Word (хотя, конечно же, минимальные представления о ней все же понадобятся, но всё необходимое для понимания я постараюсь рассказать по мере развития статьи)! Наша задача: увидеть как строятся реальные пакеты на основе OPC – что такое компоненты, связи и как они хранятся.
Документ #1 – простой текст
Если попробовать заглянуть внутрь готового Word-документа, созданного в Office, можно легко прийти в ужас от обилия различных компонент непонятного формата назначения.
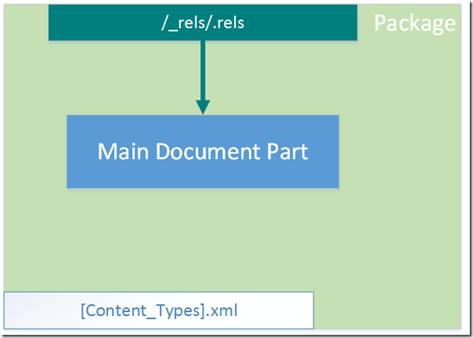
В реальности структура самого простого рабочего документа (такого, который сможет открыть и показать Word) включает всего 3 элемента:
- главный компонент, который содержит разметку всего документа
- 1 компонент связи (который содержит связь между пакетом и главным компонентом
- описание типов (файл [Content_Types].xml)
Примерно так:
Давайте теперь создадим пустую папку, которая будет представлять содержимое всего пакета, и будем последовательно её заполнять.
Главный компонент документа. Создадим в нашей папке файл main.xml (в стандарте OpenXML нет жесткого требования к именованию компонент, поэтому мы будем использовать свои имена, не такие как в Word).
Этот файл будет представлять содержимое главного компонента (Main Document ы терминологии стандарта). В лучших традициях книг по программированию зададим ему следующее содержимое:
<document xmlns=»http://schemas.openxmlformats.org/wordprocessingml/2006/main»>
<body>
<!—
Структра тела документа включает в себя:
параграф (тэг <p>)
элемент текста с форматированием (тэг <r>)
собственно отображаемый текст (тэг <t>)
—>
<p>
<r>
<t>Hello, World!</t>
</r>
</p>
</body>
</document>
Компонент связи. Теперь мы должны указать что именно компонент /main.xml содержит разметку документа. В OpenXML для этого используется механизм связей. В нашем документе будет только одна связь – от пакета к главному компоненту (главный компонент пока связей не имеет)
Как я писал в предыдущей статье у компонента, который хранит связи всего пакета имя будет /_rels/.rels. Для эмуляции такого имени (чтобы оно потом правильно создалось в конечном ZIP-архиве) мы создадим подпапку _rels, а в ней файл с именем .rels. Содержать этот файл будет всего одну связь:
<Relationships xmlns=»http://schemas.openxmlformats.org/package/2006/relationships»>
<Relationship
Id=»rId1″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument»
Target=»main.xml» />
</Relationships>
Описание типов. По большому счету, в нашем примере используется всего 2 типа контента: в компоненте с основным содержимым документа и в компоненте связи. Однако, хотя мы дали главному компоненту “расширение” .xml, его тип содержимого по стандарту OpenXML должен быть не просто application/xml, поэтому мы опишем 3 типа контента: для всех компонентов связей, для “некого произвольного xml” и явно для компонента /main.xml.
Итак, создадим в нашей папке файл [Content_Types].xml следующего содержания:
<Types xmlns=»http://schemas.openxmlformats.org/package/2006/content-types»>
<Default Extension=»rels»
ContentType=»application/vnd.openxmlformats-package.relationships+xml»/>
<Default Extension=»xml»
ContentType=»application/xml»/>
<Override PartName=»/main.xml»
ContentType=»application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml»/>
</Types>
Итак, содержимое нашей папки составляют 3 файла:
- _rels.rels
- [Content_Types].xml
- main.xml
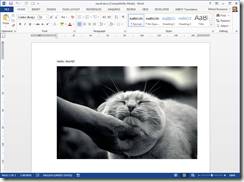
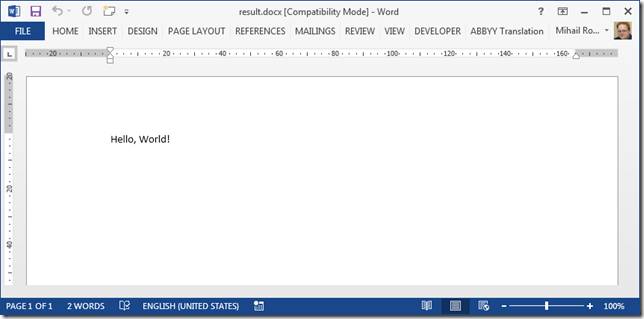
Осталось упаковать их в отдельный архив, переименовать архив в, например, result.docx, и открыть полученный файл в Word. Наш результат будет:
Давайте теперь усложним пример, добавив в документ изображение.
Какие изменения нам потребуется внести в предыдущий пример? Вот они:
- добавить компонент с изображением и дополнить описание типов содержимого
- создать связь от главного компонента к компоненту с изображением (а это значит, что добавить еще один компонент связей)
- дополнить разметку самого документа (указать место и параметры вставляемой картинки)
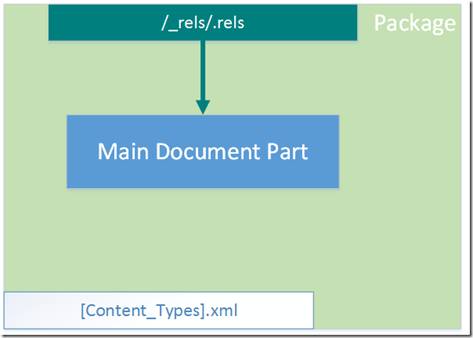
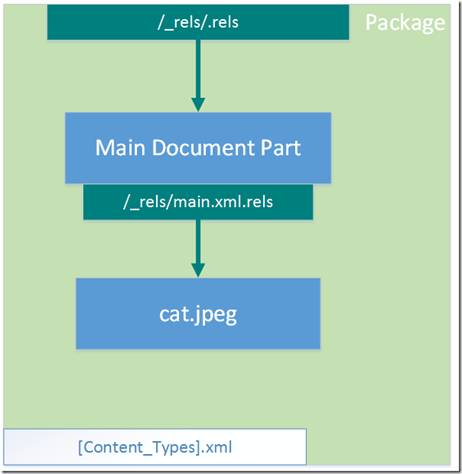
Структура нашего пакета приобретет во такой вид:
В принципе, ничего сверхъестественного, поэтому приступим.
Компонент картинки и тип содержимого для него. Для добавления компонента просто скопируем готовый файл с картинкой в папку, к остальным компонентам (пусть это будет файл cat.jpeg).
После этого обновим содержимое файла типов содержимого ([Content_Types].xml):
<Types xmlns=»http://schemas.openxmlformats.org/package/2006/content-types»>
<Default Extension=»jpeg»
ContentType=»image/jpeg»/>
<Default Extension=»rels»
ContentType=»application/vnd.openxmlformats-package.relationships+xml»/>
<Default Extension=»xml»
ContentType=»application/xml»/>
<Override PartName=»/main.xml»
ContentType=»application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml»/>
</Types>
Связь от /main.xml к /cat.jpeg. Так как мы создаем связь от компонента /main.xml, имя компонента связей для него будет /_rels/main.xml.rels, а значит создадим в папке _rels еще один файл с именем main.xml.rels и содержащем описание 1 связи:
<Relationships xmlns=»http://schemas.openxmlformats.org/package/2006/relationships»>
<Relationship
Id=»rId1″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/image»
Target=»cat.jpeg» />
</Relationships>
Осталось самое сложное – поправить разметку самого документа.
Разметка главного компонента. Вообще, надо признать, что разметка документов OpenXML местами весьма далека от “интуитивно понятной” и это справедливо, в том числе для описания изображений (в OpenXML используется единый подъязык для описания любых изображений – DrawingML, у которого есть еще несколько внутренних диалектов: для описания картинок, графиков, …).
Единственный предварительный комментарий нужно дать по поводу размерности единиц… В OpenXML используется специальная придуманная единица EMU (English Metric Unit) – единица, которая позволяет относительно удобно переводить размеры из метрической (метры/сантиметры) и американской (дюймы) систем единиц. Соотношения следующие:
|
1 см |
360000 EMU |
|
1 дюйм |
914400 EMU |
Все, можно оценивать (размеры областей вычислены на основе размеров картинки): Пример.
В нашей папке-пакете теперь содержатся такие файлы:
- _rels.rels
- _relsmain.xml.rels
- [Content_Types].xml
- cat.jpeg
- main.xml
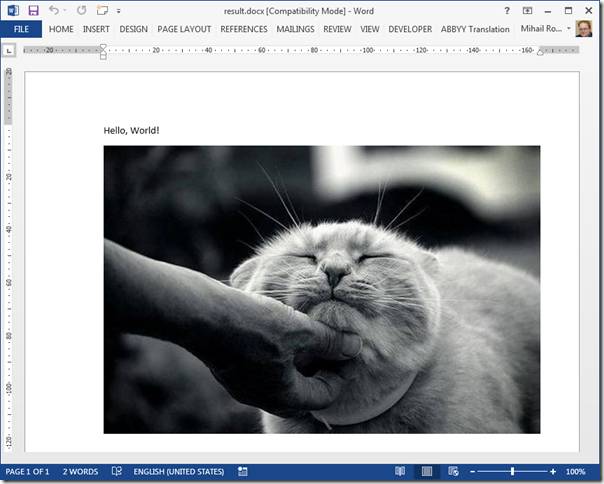
Вновь собираем все в один Zip-архив и открываем в Word:
Вот и все.
P.S. Для желающих продолжить эксперименты – все исходные файлы, а также результаты можно найти на Codeplex в проекте https://msosamples.codeplex.com (здесь и далее я планирую размещать все приводимые примеры). Прямая ссылка на нужную папку.
Источник: Блог Михаила Романова.

Формат XML предназначен для хранения данных, которые могут быть полезны в работе некоторых программ, сайтов и поддержке определенных языков разметки. Создать и открыть файл в этом формате несложно. Это можно сделать, даже если на вашем компьютере не установлено специализированное программное обеспечение.
XML сам по себе является языком разметки, чем-то похожим на HTML, который используется на веб-страницах. Но если последний используется только для отображения информации и ее правильной разметки, XML позволяет структурировать ее определенным образом, что делает этот язык похожим на аналог базы данных, не требующий СУБД.
Вы можете создавать файлы XML, используя как специализированные программы, так и встроенный текстовый редактор Windows. Удобство написания кода и уровень его функциональности зависят от типа используемого программного обеспечения.
Способ 1: Visual Studio
Вместо этого редактора кода Microsoft вы можете использовать любые его аналоги от других разработчиков. Фактически, Visual Studio — это более продвинутая версия обычного Блокнота. Код теперь имеет специальную подсветку, ошибки автоматически выделяются или исправляются, а специальные шаблоны уже загружены в программу, что упрощает создание больших файлов XML.
Для начала вам необходимо создать файл. Щелкните элемент «Файл» на верхней панели и выберите «Создать…» в раскрывающемся меню. Откроется список, в котором указана запись «Файл».
Вам будет перенесено окно с выбором расширения файла, соответственно выберите пункт «XML файл».
Во вновь созданном файле уже будет первая строка с кодировкой и версией. По умолчанию записывается первая версия и кодировка UTF-8, которую вы можете изменить в любой момент. Затем, чтобы создать полный XML-файл, вам нужно записать все, что было в предыдущем операторе.
По окончании работы снова выберите в верхней панели «Файл», затем из выпадающего меню пункт «Сохранить все».
Способ 2: Microsoft Excel
Вы можете создать XML-файл без написания кода, например, используя современные версии Microsoft Excel, что позволяет сохранять таблицы с этим расширением. Однако нужно понимать, что в этом случае у вас не получится создать что-то более функциональное, чем обычный стол.
Этот метод лучше всего подходит для тех, кто не хочет или не умеет работать с кодом. Однако в этом случае пользователь может столкнуться с некоторыми проблемами при перезаписи файла в формате XML. К сожалению, преобразование обычной таблицы в XML возможно только в более новых версиях MS Excel. Для этого воспользуйтесь следующими пошаговыми инструкциями:
- Дополните таблицу некоторым содержанием.
- Нажмите кнопку «Файл» в верхнем меню.
- Откроется специальное окно, в котором нужно нажать «Сохранить как…». Этот пункт находится в левом меню.
- Укажите папку, в которой вы хотите сохранить файл. Папка указана в центре экрана.
- Теперь вам нужно указать имя файла и в разделе «Тип файла» из выпадающего меню выбрать
Данные XML». - Нажмите кнопку «Сохранить».
Способ 3: Блокнот
Даже обычный Блокнот вполне подходит для работы с XML, но у пользователя, незнакомого с синтаксисом языка, возникнут трудности, так как в нем придется писать различные команды и теги. Несколько проще и продуктивнее процесс будет в специализированных программах для редактирования кода, например, в Microsoft Visual Studio. В них есть специальные метки и подсказки, которые значительно упрощают работу человеку, не знающему синтаксиса этого языка.
Для этого метода ничего скачивать не нужно, так как в операционной системе уже есть встроенный «Блокнот». Попробуем создать простую XML-таблицу по приведенным инструкциям:
- Создайте простой текстовый документ с расширением TXT. Вы можете разместить его где угодно. Открой это.
- Начните набирать в нем первые команды. Во-первых, вам нужно установить кодировку для всего файла и указать версию XML, это делается с помощью следующей команды:
Первое значение — это версия, менять ее не нужно, а второе значение — это кодировка. Рекомендуется использовать кодировку UTF-8, так как с ней прекрасно работает большинство программ и обработчиков. Однако его можно изменить на любое другое, просто набрав желаемое имя.
- Создайте первый каталог в вашем файле, написав тег и закрыв его вот так .
- Теперь вы можете написать какой-то контент внутри этого тега. Создаем тег и даем ему любое имя, например «Иван Иванов». Готовая конструкция должна выглядеть так:
- Внутри тега теперь можно писать более подробные параметры, в данном случае это информация об определенном Иване Иванове. Мы пропишем ваш возраст и местонахождение.
- Если вы следовали инструкциям, вы должны получить тот же код, что и ниже. Когда закончите, найдите «Файл» в верхнем меню и выберите «Сохранить как…» в раскрывающемся меню. При сохранении в поле «Имя файла» после точки должно стоять расширение не TXT, а XML.
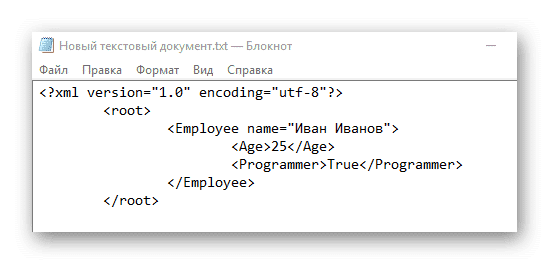
Компиляторам XML необходимо обработать этот код в виде таблицы с одним столбцом, содержащей данные о некоем Иване Иванове.
В «Блокноте» вполне можно создавать такие простые таблицы, но при создании массивов более объемных данных могут возникнуть трудности, так как в обычном «Блокноте» нет функций для исправления ошибок в коде или их выделения.
Как видите, в создании XML-файла нет ничего сложного. При желании его может создать любой пользователь, более-менее умеющий работать на компьютере. Однако для создания полного XML-файла рекомендуется изучить этот язык разметки, по крайней мере, на примитивном уровне.
Время на прочтение
16 мин
Количество просмотров 54K
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
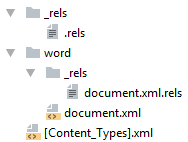
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>word/document.xml
Основное содержимое документа.
word/document.xml
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math"
xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"
xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing"
xmlns:w10="urn:schemas-microsoft-com:office:word"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml"
xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup"
xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk"
xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml"
xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape"
mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"
w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
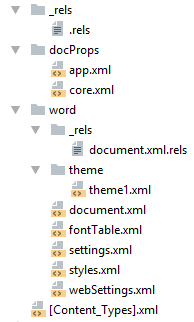
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.sh.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
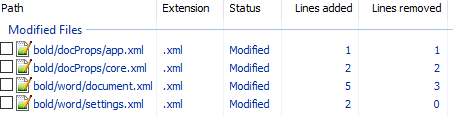
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@
- <TotalTime>0</TotalTime>
+ <TotalTime>1</TotalTime>Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@
- <cp:revision>1</cp:revision>
+ <cp:revision>2</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created>
- <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified>
+ <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
diff
@@ -1,24 +1,26 @@
<w:body>
- <w:p w:rsidR="0076695C" w:rsidRPr="00290C70" w:rsidRDefault="00290C70">
+ <w:p w:rsidR="0076695C" w:rsidRPr="00F752CF" w:rsidRDefault="00290C70">
<w:pPr>
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
</w:pPr>
- <w:r>
+ <w:r w:rsidRPr="00F752CF">
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
- <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:sectPr w:rsidR="0076695C" w:rsidRPr="00F752CF">Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
<w:rPr>
+ <w:b/>в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@
+ <w:proofState w:spelling="clean"/>
@@ -17,10 +18,11 @@
+ <w:rsid w:val="00F752CF"/>Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
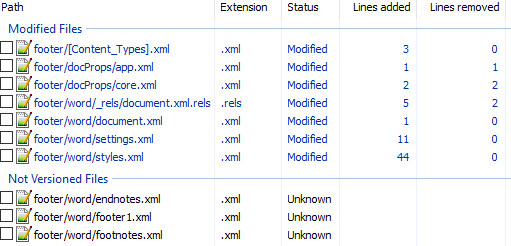
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
+ <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/>
+ <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/>
+ <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
diff
@@ -1,8 +1,11 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
+ <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/>
+ <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/>
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>
- <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
- <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>
</Relationships>Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
@@ -3,6 +3,9 @@
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:footerReference w:type="default" r:id="rId6"/>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/>
<w:cols w:space="708"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
diff
@@ -1,19 +1,30 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15">
<w:zoom w:percent="100"/>
+ <w:proofState w:spelling="clean"/>
<w:defaultTabStop w:val="708"/>
<w:characterSpacingControl w:val="doNotCompress"/>
+ <w:footnotePr>
+ <w:footnote w:id="-1"/>
+ <w:footnote w:id="0"/>
+ </w:footnotePr>
+ <w:endnotePr>
+ <w:endnote w:id="-1"/>
+ <w:endnote w:id="0"/>
+ </w:endnotePr>
<w:compat>
<w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/>
<w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
</w:compat>
<w:rsids>
<w:rsidRoot w:val="00290C70"/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:rsid w:val="001B0DE6"/>А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
diff
@@ -480,6 +480,50 @@
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman"/>
<w:b/>
<w:sz w:val="28"/>
</w:rPr>
</w:style>
+ <w:style w:type="paragraph" w:styleId="a4">
+ <w:name w:val="header"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a5"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a5">
+ <w:name w:val="Верхний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a4"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
+ <w:style w:type="paragraph" w:styleId="a6">
+ <w:name w:val="footer"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a7"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a7">
+ <w:name w:val="Нижний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a6"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
</w:styles>Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B">
<w:pPr>
<w:pStyle w:val="a6"/>
</w:pPr>
<w:r>
<w:t>123</w:t>
</w:r>
</w:p>
</w:ftr>Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels. - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ.
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
<xml>TEST</xml>В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/>
<xsl:template match="/">
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>
<xsl:value-of select="//xml/text()"/>
</w:t>
</w:r>
</w:p>
</w:ftr>
</xsl:template>
</xsl:stylesheet>Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml") В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>TEST</w:t>
</w:r>
</w:p>
</w:ftr>Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Relationship
Id="rId0"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer"
Target="footer0.xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/content-types" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Override
PartName="/word/footer0.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>В результате
Весь код опубликован. Работает он так:
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т… к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула

В предыдущей статье я постарался “просто и доступно”  рассказать о том, что такое Open Package Convention (или иначе говоря, как устроены изнутри документы MS Office 2007+).
рассказать о том, что такое Open Package Convention (или иначе говоря, как устроены изнутри документы MS Office 2007+).
Как водится статья писалась долго, вышла большой, съела много сил… в общем, я так и не показал реальный пример документа в формате OPC. В результате получилось несколько оторвано от практики и не очень наглядно, на что мне сразу указали коллеги.
Что ж, исправляюсь… Сегодня мы в качестве практики создадим пару документов для MS Word, не используя никаких специальных инструментов (за исключением XML-редактора и Zip-архиватора).
Сразу же оговорюсь, что мы не будем сильно вдаваться в особенности разметки документов Word (хотя, конечно же, минимальные представления о ней все же понадобятся, но всё необходимое для понимания я постараюсь рассказать по мере развития статьи)! Наша задача: увидеть как строятся реальные пакеты на основе OPC – что такое компоненты, связи и как они хранятся.
Документ #1 – простой текст
Если попробовать заглянуть внутрь готового Word-документа, созданного в Office, можно легко прийти в ужас от обилия различных компонент непонятного формата назначения.
В реальности структура самого простого рабочего документа (такого, который сможет открыть и показать Word) включает всего 3 элемента:
- главный компонент, который содержит разметку всего документа
- 1 компонент связи (который содержит связь между пакетом и главным компонентом
- описание типов (файл [Content_Types].xml)
Примерно так:

Давайте теперь создадим пустую папку, которая будет представлять содержимое всего пакета, и будем последовательно её заполнять.
Главный компонент документа. Создадим в нашей папке файл main.xml (в стандарте OpenXML нет жесткого требования к именованию компонент, поэтому мы будем использовать свои имена, не такие как в Word).
Этот файл будет представлять содержимое главного компонента (Main Document ы терминологии стандарта). В лучших традициях книг по программированию зададим ему следующее содержимое:
<document xmlns="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <body> <!-- Структра тела документа включает в себя: параграф (тэг <p>) элемент текста с форматированием (тэг <r>) собственно отображаемый текст (тэг <t>) --> <p> <r> <t>Hello, World!</t> </r> </p> </body> </document>
Компонент связи. Теперь мы должны указать что именно компонент /main.xml содержит разметку документа. В OpenXML для этого используется механизм связей. В нашем документе будет только одна связь – от пакета к главному компоненту (главный компонент пока связей не имеет)
Как я писал в предыдущей статье у компонента, который хранит связи всего пакета имя будет /_rels/.rels. Для эмуляции такого имени (чтобы оно потом правильно создалось в конечном ZIP-архиве) мы создадим подпапку _rels, а в ней файл с именем .rels. Содержать этот файл будет всего одну связь:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument" Target="main.xml" /> </Relationships>
Описание типов. По большому счету, в нашем примере используется всего 2 типа контента: в компоненте с основным содержимым документа и в компоненте связи. Однако, хотя мы дали главному компоненту “расширение” .xml, его тип содержимого по стандарту OpenXML должен быть не просто application/xml, поэтому мы опишем 3 типа контента: для всех компонентов связей, для “некого произвольного xml” и явно для компонента /main.xml.
Итак, создадим в нашей папке файл [Content_Types].xml следующего содержания:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types"> <Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/> <Default Extension="xml" ContentType="application/xml"/> <Override PartName="/main.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/> </Types>
Итак, содержимое нашей папки составляют 3 файла:
- _rels.rels
- [Content_Types].xml
- main.xml
Осталось упаковать их в отдельный архив, переименовать архив в, например, result.docx, и открыть полученный файл в Word. Наш результат будет:

Давайте теперь усложним пример, добавив в документ изображение.
Документ #2 – тот же текст и картинка
Какие изменения нам потребуется внести в предыдущий пример? Вот они:
- добавить компонент с изображением и дополнить описание типов содержимого
- создать связь от главного компонента к компоненту с изображением (а это значит, что добавить еще один компонент связей)
- дополнить разметку самого документа (указать место и параметры вставляемой картинки)
Структура нашего пакета приобретет во такой вид:

В принципе, ничего сверхъестественного, поэтому приступим.
Компонент картинки и тип содержимого для него. Для добавления компонента просто скопируем готовый файл с картинкой в папку, к остальным компонентам (пусть это будет файл cat.jpeg).
После этого обновим содержимое файла типов содержимого ([Content_Types].xml):
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types"> <Default Extension="jpeg" ContentType="image/jpeg"/> <Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/> <Default Extension="xml" ContentType="application/xml"/> <Override PartName="/main.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/> </Types>
Связь от /main.xml к /cat.jpeg. Так как мы создаем связь от компонента /main.xml, имя компонента связей для него будет /_rels/main.xml.rels, а значит создадим в папке _rels еще один файл с именем main.xml.rels и содержащем описание 1 связи:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image" Target="cat.jpeg" /> </Relationships>
Осталось самое сложное – поправить разметку самого документа.
Разметка главного компонента. Вообще, надо признать, что разметка документов OpenXML местами весьма далека от “интуитивно понятной” и это справедливо, в том числе для описания изображений (в OpenXML используется единый подъязык для описания любых изображений – DrawingML, у которого есть еще несколько внутренних диалектов: для описания картинок, графиков, …).
Единственный предварительный комментарий нужно дать по поводу размерности единиц… В OpenXML используется специальная придуманная единица EMU (English Metric Unit) – единица, которая позволяет относительно удобно переводить размеры из метрической (метры/сантиметры) и американской (дюймы) систем единиц. Соотношения следующие:
| 1 см | 360000 EMU |
| 1 дюйм | 914400 EMU |
Все, можно оценивать (размеры областей вычислены на основе размеров картинки):
<document xmlns="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:draw="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture" xmlns:rel="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:drawmain="http://schemas.openxmlformats.org/drawingml/2006/main"> <body> <p> <r> <t>Hello, World!</t> </r> </p> <p> <r> <!--Добавляем область рисования--> <drawing> <!-- Область будет внутритекстовой (есть также с жестким позиционированием) атрибуты - отступы по краям картинки от текста --> <draw:inline distT="0" distB="0" distL="0" distR="0"> <!-- Набор параметров <draw:extent> - размер области под изображение <draw:docPr> - метаданные изображения (ид, имя, ...) <draw:cNvGraphicFramePr> - некоторые параметры отображения --> <draw:extent cx="5940425" cy="3920490"/> <draw:docPr id="1" name="1"/> <draw:cNvGraphicFramePr> <drawmain:graphicFrameLocks noChangeAspect="true"/> </draw:cNvGraphicFramePr> <!-- Собственно само изображение --> <drawmain:graphic> <!-- Здесь определяется что именно будет вставляться - картинка, график, OLE, ... и в зависимости от этого выбирается диалект описания. У нас картинка --> <drawmain:graphicData uri="http://schemas.openxmlformats.org/drawingml/2006/picture"> <pic:pic> <!-- Вновь метаданные ... --> <pic:nvPicPr> <pic:cNvPr id="1" name="1"/> <pic:cNvPicPr> </pic:cNvPicPr> </pic:nvPicPr> <!-- Собственно вот здесь описывается как заполняется область изображения в нашем случае, это ссылка на связь с id: rId1--> <pic:blipFill> <drawmain:blip rel:embed="rId1"/> <drawmain:stretch> <drawmain:fillRect/> </drawmain:stretch> </pic:blipFill> <!-- Фигура, в которую вписывается изображение <drawmain:xfrm> - размеры фрейма для вписывание + его смещение относительно общей области рисования <drawmain:prstGeom> - указывает, что мы заполняем стандартную фигуру (у нас прямоугольник) --> <pic:spPr> <drawmain:xfrm> <drawmain:off x="0" y="0"/> <drawmain:ext cx="5940425" cy="3920490"/> </drawmain:xfrm> <drawmain:prstGeom prst="rect" /> </pic:spPr> </pic:pic> </drawmain:graphicData> </drawmain:graphic> </draw:inline> </drawing> </r> </p> </body> </document>
В нашей папке-пакете теперь содержатся такие файлы:
- _rels.rels
- _relsmain.xml.rels
- [Content_Types].xml
- cat.jpeg
- main.xml
Вновь собираем все в один Zip-архив и открываем в Word:

Вот и все.
P.S. Для желающих продолжить эксперименты – все исходные файлы, а также результаты можно найти на Codeplex в проекте https://github.com/MihailRomanov/msosamples (здесь и далее я планирую размещать все приводимые примеры). Прямая ссылка на нужную папку.

Здравствуйте. Интересует такой вопрос, как в xml формате ворда размечают разные стили списка?
Это разметка маркерованного списка:
| XML | ||
|
А это разметка нумировонного списка:
| XML | ||
|
По задданым id в файле тоже ничего нет, только один большой список:
| XML | ||
|
Я пробывал вставлять в документ шаблон списка ( бзе написания id, они сами вставляются в ворде), и у меня всегда получается нумерованный список без отступов, которые обычно бывают при созданий списка.
Шаблон:
| XML | ||
|