

Формат XML предназначен для хранения данных, которые могут быть полезны в работе некоторых программ, сайтов и поддержке определенных языков разметки. Создать и открыть файл в этом формате несложно. Это можно сделать, даже если на вашем компьютере не установлено специализированное программное обеспечение.
XML сам по себе является языком разметки, чем-то похожим на HTML, который используется на веб-страницах. Но если последний используется только для отображения информации и ее правильной разметки, XML позволяет структурировать ее определенным образом, что делает этот язык похожим на аналог базы данных, не требующий СУБД.
Вы можете создавать файлы XML, используя как специализированные программы, так и встроенный текстовый редактор Windows. Удобство написания кода и уровень его функциональности зависят от типа используемого программного обеспечения.
Способ 1: Visual Studio
Вместо этого редактора кода Microsoft вы можете использовать любые его аналоги от других разработчиков. Фактически, Visual Studio — это более продвинутая версия обычного Блокнота. Код теперь имеет специальную подсветку, ошибки автоматически выделяются или исправляются, а специальные шаблоны уже загружены в программу, что упрощает создание больших файлов XML.
Для начала вам необходимо создать файл. Щелкните элемент «Файл» на верхней панели и выберите «Создать…» в раскрывающемся меню. Откроется список, в котором указана запись «Файл».
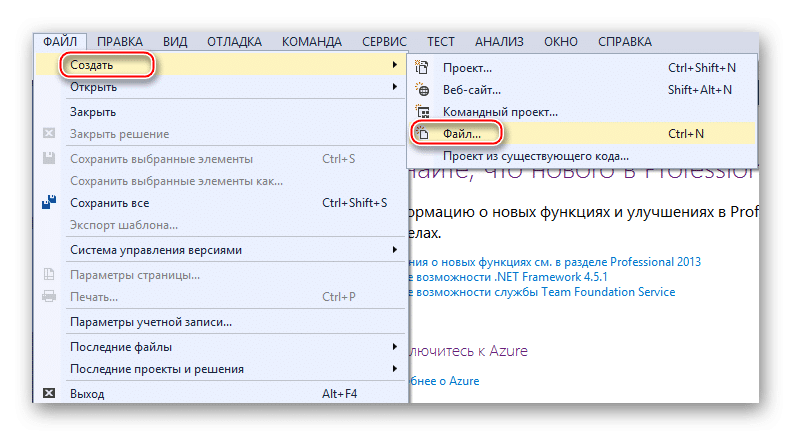
Вам будет перенесено окно с выбором расширения файла, соответственно выберите пункт «XML файл».
Во вновь созданном файле уже будет первая строка с кодировкой и версией. По умолчанию записывается первая версия и кодировка UTF-8, которую вы можете изменить в любой момент. Затем, чтобы создать полный XML-файл, вам нужно записать все, что было в предыдущем операторе.
По окончании работы снова выберите в верхней панели «Файл», затем из выпадающего меню пункт «Сохранить все».
Способ 2: Microsoft Excel
Вы можете создать XML-файл без написания кода, например, используя современные версии Microsoft Excel, что позволяет сохранять таблицы с этим расширением. Однако нужно понимать, что в этом случае у вас не получится создать что-то более функциональное, чем обычный стол.
Этот метод лучше всего подходит для тех, кто не хочет или не умеет работать с кодом. Однако в этом случае пользователь может столкнуться с некоторыми проблемами при перезаписи файла в формате XML. К сожалению, преобразование обычной таблицы в XML возможно только в более новых версиях MS Excel. Для этого воспользуйтесь следующими пошаговыми инструкциями:
- Дополните таблицу некоторым содержанием.
- Нажмите кнопку «Файл» в верхнем меню.
- Откроется специальное окно, в котором нужно нажать «Сохранить как…». Этот пункт находится в левом меню.
- Укажите папку, в которой вы хотите сохранить файл. Папка указана в центре экрана.
- Теперь вам нужно указать имя файла и в разделе «Тип файла» из выпадающего меню выбрать
Данные XML». - Нажмите кнопку «Сохранить».
Способ 3: Блокнот
Даже обычный Блокнот вполне подходит для работы с XML, но у пользователя, незнакомого с синтаксисом языка, возникнут трудности, так как в нем придется писать различные команды и теги. Несколько проще и продуктивнее процесс будет в специализированных программах для редактирования кода, например, в Microsoft Visual Studio. В них есть специальные метки и подсказки, которые значительно упрощают работу человеку, не знающему синтаксиса этого языка.
Для этого метода ничего скачивать не нужно, так как в операционной системе уже есть встроенный «Блокнот». Попробуем создать простую XML-таблицу по приведенным инструкциям:
- Создайте простой текстовый документ с расширением TXT. Вы можете разместить его где угодно. Открой это.
- Начните набирать в нем первые команды. Во-первых, вам нужно установить кодировку для всего файла и указать версию XML, это делается с помощью следующей команды:
Первое значение — это версия, менять ее не нужно, а второе значение — это кодировка. Рекомендуется использовать кодировку UTF-8, так как с ней прекрасно работает большинство программ и обработчиков. Однако его можно изменить на любое другое, просто набрав желаемое имя.
- Создайте первый каталог в вашем файле, написав тег и закрыв его вот так .
- Теперь вы можете написать какой-то контент внутри этого тега. Создаем тег и даем ему любое имя, например «Иван Иванов». Готовая конструкция должна выглядеть так:
- Внутри тега теперь можно писать более подробные параметры, в данном случае это информация об определенном Иване Иванове. Мы пропишем ваш возраст и местонахождение.
- Если вы следовали инструкциям, вы должны получить тот же код, что и ниже. Когда закончите, найдите «Файл» в верхнем меню и выберите «Сохранить как…» в раскрывающемся меню. При сохранении в поле «Имя файла» после точки должно стоять расширение не TXT, а XML.
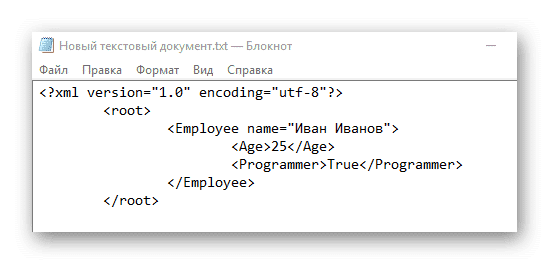
Компиляторам XML необходимо обработать этот код в виде таблицы с одним столбцом, содержащей данные о некоем Иване Иванове.
В «Блокноте» вполне можно создавать такие простые таблицы, но при создании массивов более объемных данных могут возникнуть трудности, так как в обычном «Блокноте» нет функций для исправления ошибок в коде или их выделения.
Как видите, в создании XML-файла нет ничего сложного. При желании его может создать любой пользователь, более-менее умеющий работать на компьютере. Однако для создания полного XML-файла рекомендуется изучить этот язык разметки, по крайней мере, на примитивном уровне.
Документы в формате XML запускаются в любых текстовых редакторах, браузерах, а также в специальных онлайн-сервисах. Расскажем, как открыть файл XML: с тегами и без них, только для просмотра или для редактирования.
Содержание
- XML: что за формат и где часто используется
- Программы для просмотра и редактирования файлов XML
- Word
- Excel
- Стандартный «Блокнот»
- Через Google Chrome и другие браузеры
- NotePad++
- Онлайн-сервисы для редактирования файлов XML
- XmlGrid
- TutorialsPoint
XML – язык разметки. С помощью него пользователи группируют, структурируют данные, которые представлены в виде обычного текста или таблицы. Для создания структуры (иерархии) используют самописный синтаксис – теги. Их придумывает сам автор документа. На рисунке ниже показан текст, обернутый в произвольные теги: <to> (от кого послание), <from> (кому), <heading> (заголовок послания), <body> (само послание).

Язык XML используют для передачи данных между разными видами приложений без потери их структуры. Формат отличается надежностью. Повредить информацию в таких файлах сложнее, поэтому документы, которые публикуют в интернете, часто идут именно с этим расширением. Файлы xml встречаются на ГосУслугах, в Росреестре и на других государственных сайтах.
Документ xml можно открыть разными способами. Выбор программы или веб-сервиса зависит от того, в каком виде должен быть представлен текст: с тегами или без них, с возможностью редактирования или просто чтение.
Только просмотр текста/таблицы доступен в любом браузере, в Microsoft Word и Excel. Редактировать файл можно в онлайн-сервисах и в стандартном «Блокноте» в Windows.

Программы для просмотра и редактирования файлов XML
Программы Microsoft Office есть практически на каждом компьютере с Windows, поэтому часто для запуска xml не нужно ничего дополнительно устанавливать.
Если Офиса у вас нет, и вы не хотите скачивать целый пакет, чтобы открыть один единственный файл, воспользуйтесь «Блокнотом» или сторонним приложением NotePad++.
Word
Чтобы установить Word на ПК, нужно скачать целый пакет Microsoft Office, где будет сам текстовый редактор, Excel (для работы с таблицами) и Power Point (для создания презентаций).
Не все версии Microsoft Word умеют открывать документы xml без тегов. Подойдут варианты Word 2007 и выше. Версии ниже показывают информацию только с тегами.
В Word вы сможете просматривать текст, отправлять его на печать в принтер. Редактирование документа здесь недоступно.
Как открыть файл XML в Word:
- Нажмите правой кнопкой мыши на файл xml – при этом не важно, где он находится: на рабочем столе или в папке на жестком диске.

- Наведите стрелку на пункт «Открыть с помощью». Выберите программу Word. Если ее нет в списке, нажмите «Выбрать другое приложение».

- В появившемся меню нажмите на «Microsoft Word». При желании поставьте галочку под списком приложений, чтобы система открывала xml-файлы с помощью Word. Щелкните по «ОК».

- Подождите, пока запустится файл с текстом.





Excel
Если данные документа представлены в виде таблицы, используйте другую программу из пакета Microsoft Office – инструмент Excel.
Открыть документ в Excel можно таким же образом, как и в Word. Кликнуть по файлу правой клавишей, а затем в списке «Открыть с помощью» выбрать Excel.
Если Excel в списке не оказалось, используйте другой метод запуска:
- Если у вас Windows 10, нажмите на иконку в виде лупы справа от кнопки «Пуск». Вбейте в поисковую строку слово «excel».

- В верхней области панели появятся результаты поиска – нажмите на «Microsoft Excel», чтобы запустить программу.

- В интерфейсе приложения нажмите на «Файл». Выберите пункт «Открыть».

- В «Проводнике Windows» найдите документ xml. Выделите его левой кнопкой мыши и нажмите «Открыть».

- Выберите способ открытия файла, например, XML-таблица. Нажмите на «ОК».

- Подождите, пока загрузится таблица. Если она большая, процесс займет некоторое время.







Стандартный «Блокнот»
В «Блокноте» откроется текст, обернутый в теги. При необходимости вы сможете его отредактировать в окне.
Запустить файл можно через то же контекстное меню документа. Выбираете «Открыть с помощью», нажимаете на «Блокнот».

Если «Блокнота» в списке приложений не оказалось, используйте другой способ:
- Откройте пустое окно «Блокнота». Для этого найдите программу через поиск Windows 10. Введите название приложения в строке поиска – выберите «Блокнот» в результатах запроса.

- Теперь зажмите мышкой файл xml (на рабочем столе либо в папке в «Проводнике») и перетащите его на пустое окно «Блокнота».

- Подождите, пока документ откроется.




Через Google Chrome и другие браузеры
Для Google Chrome и любого другого браузера действует тот же способ запуска: через пункт «Открыть с помощью» в контекстном меню файла. Можно выбрать «Гугл Хром» или любой другой веб-обозреватель: Internet Explorer, Yandex, Opera и т. д.

Еще один способ – перетаскивание файла на окно браузера. Откройте новую пустую вкладку обозревателя (обычно это иконка в виде плюса на панели с вкладками). Перетащите файл xml мышкой на любую область пустой вкладки.

Подождите, пока браузер загрузит документ в свое окно.

NotePad++
В NotePad++ можно читать и редактировать готовые xml-документы, а также создавать новые. Приложение также работает с другими форматами веб-файлов, например, с YML.
При установке программы можно выбрать русский язык интерфейса. Плюс NotePad++ в том, что она выделяет корневую структуру кода, что упрощает работу с документом. В «Блокноте», к примеру, теги идут чуть ли не сплошным текстом.
Как открыть XML-файл в NotePad++:
- Запустите приложение и нажмите на раздел «File» («Файл»). В меню выберите «Open» («Открыть»).

- Либо сразу после запуска программы зажмите комбинации клавиш Ctrl + O. Также можно нажать на вторую иконку «Open» на панели инструментов, которая находится чуть ниже.

- В «Проводнике Windows» найдите документ xml. Выберите его левой кнопкой мыши и нажмите на «Открыть».
- Подождите, пока загрузится файл со структурой кода.




Онлайн-сервисы для редактирования файлов XML
Для работы онлайн-сервисов понадобится стабильный скоростной интернет. Рассмотрим два инструмента: XML Grid и TutorialsPoint.
XmlGrid
Сервис простой и функциональный. Здесь можно создавать свои файлы xml, редактировать готовые документы. Документ можно загрузить двумя способами: вставить ссылку на файл в интернете либо загрузить физический документ с жесткого диска ПК.
Интерфейс у сервиса на английском языке, но разобраться в нем сможет каждый:
- Откройте веб-сервис. Нажмите на «Open File», если документ находится на жестком диске вашего ПК. В «Проводнике Windows» найдите файл, выделите его левой кнопкой мыши – нажмите «Открыть».

- Кликните «Submit», чтобы система начала загрузку файла. Подождите некоторое время, пока она завершится.
- Если у вас есть ссылка на файл в интернете, кликните по «By URL». Вставьте скопированную ссылку в поле и нажмите «Submit».

- Подождите, пока откроется структура файла (список главных веток).

- Чтобы изменить название ветки, просто нажмите на ее название. Включится режим редактирования: удалите старую надпись и введите новую.

- Чтобы отредактировать текст, откройте ветку, в которой он находится. Для этого нажмите на стрелку слева от ее названия. Теперь выберите левой кнопкой синее поле для редактирования.

- Выберите пункт «Edit» в контекстном меню.

- Введите нужный текст в синее поле.

- Чтобы увидеть результат редактирования (структуру текста в целом), нажмите на стрелку над таблицей.

- В меню выберите «Show XML Source Code».

- Подождите, пока откроется дополнительное окно с текстом и тегами. Чтобы закрыть окно, нажмите на крестик в правом верхнем углу.

- Когда закончите редактирование, нажмите на иконку «Save» справа от кнопок «Validate» и «Textview». Выберите папку на жестком диске для сохранения файла.










TutorialsPoint
Сервис работает с множеством файлов: XML-документы, изображения, программные коды. Интерфейс тоже на английском языке.
Как работать в сервисе:
- Перейдите на сайт инструмента. Выберите кнопку «XML Editor».

- Нажмите на «Upload File». Выберите способ загрузки с помощью URL (ссылка на файл в интернете) либо загрузка документа с ПК («Upload from Computer»). В первом случае вставьте скопированную ранее ссылку и нажмите «Go». Во втором случае выберите файл в окне «Проводник Windows» и нажмите «Открыть».

- В разделе «Editable XML Code» появится содержимое файла xml. В нем можно менять текст и теги как в обычном редакторе.

- По мере редактирования в правой части окна «XML Tree» данные тоже меняются: вместо старого текста и тегов появляются новые. Этот режим удобно использовать для визуальной оценки файла.

- Когда закончите редактирование, нажмите на «Download» справа вверху, чтобы скачать измененный документ обратно на ПК.






Если вам нужно лишь прочитать содержимое файла xml, выбирайте браузер, Word или Excel (если документ представлен в виде таблицы, а не обычным текстом). Для редактирования можно использовать стандартный «Блокнот», стороннюю программу NotePad++ либо онлайн-сервисы: XML Grid или TutorialsPoint.
This post describes how you can create a Microsoft Office Word (2007/2010/2013) document by merging a Word template and a custom xml document.
Note: This post uses Microsoft Office Word 2013, but the same applies to Microsoft Office Word 2007 and 2010.
Open Microsoft Office Word 2013 open the developer tab on the ribbon
![]()
If the developer tab is not visible, go to File > Options

Go to Customize Ribbon > Enable «Developer» tab

First insert some text, a table and an image to give the template some body.
Now insert a Plain Text Content Control

Click on Properties and enter as:
Title: «CustomerName»
Tag: «CustomerName»

Save the document to «C:TempCustomerInfo.docx» and close Microsoft Office Word

Rename the file to «C:TempCustomerInfo.zip»

Extract the file to «C:TempCustomerInfo»

Add the folder «C:TempCustomerInfocustomXml»

Create the files item1.xml and itemProps1.xml and the folder _rels in the folder «C:TempCustomerInfocustomXml»

item1.xml
<root>
<customer>
<name>Customer 1</name>
</customer>
</root>
itemProps1.xml
<?xml version=»1.0″ encoding=»UTF-8″ standalone=»no»?>
<ds:datastoreItem ds:itemID=»{8f93798d-1506-45f2-811e-70f72165a32d}» xmlns:ds=»http://schemas.openxmlformats.org/officeDocument/2006/customXml» />
The itemID is just a GUID.
You can create a new GUID with Microsoft Visual Studio:


Create a file item1.xml.rels in the folder «C:TempCustomerInfocustomXml_rels»
<?xml version=»1.0″ encoding=»utf-8″?>
<Relationships xmlns=»http://schemas.openxmlformats.org/package/2006/relationships»>
<Relationship Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/customXmlProps» Target=»/customXml/itemProps1.xml» Id=»Rb8d5386a2f8640f88dad1eff30868bcf» />
</Relationships>
The Id is just a GUID without «-«.
Edit the file «C:TempCustomerInfoword_relsdocument.xml.rels»
<?xml version=»1.0″ encoding=»UTF-8″ standalone=»yes»?>
<Relationships xmlns=»http://schemas.openxmlformats.org/package/2006/relationships»>
<Relationship Id=»rId3″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings» Target=»webSettings.xml»/>
<Relationship Id=»rId7″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme» Target=»theme/theme1.xml»/>
<Relationship Id=»rId2″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings» Target=»settings.xml»/>
<Relationship Id=»rId1″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles» Target=»styles.xml»/>
<Relationship Id=»rId6″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/glossaryDocument» Target=»glossary/document.xml»/>
<Relationship Id=»rId5″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable» Target=»fontTable.xml»/><Relationship Id=»rId4″ Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/image» Target=»media/image1.jpeg»/>
<Relationship Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/customXml» Target=»../customXml/item1.xml» Id=»Rdfc14bfb0c244ab3″ />
</Relationships>
The ID is a GUID without «-«.
Edit the file «C:TempCustomerInfoworddocument.xml»
Search for «CustomerName» in the file.

Add <w:dataBinding w:xpath=»/root/customer[1]/name[1]» w:storeItemID=»{8f93798d-1506-45f2-811e-70f72165a32d}» />
just after the <w:sdtPr> containing the CustomerName content control.
![]()
Edit the file «C:TempCustomerInfo[Content_Types].xml»
![]()
Now when you zip the contents of the folder «C:TempCustomerInfo» and rename the zip to CustomerInfo2.docx, the CustomerName content control should be automatically filled with the text «Customer 1» from the item1.xml file.
When zipping make sure, you zip the contents of the folder en not the folder itself:

These manual steps can be automated by using the tool: http://dbe.codeplex.com/ (Word Content Control Toolkit)
This tool was created for Office 2007, but can be used for Office 2010 and Office 2013.
Tags: Word
There are alternative approaches and which I covered in my blog Windward Wrocks (links and better formatting at my blog):
Custom XML for Word and the i4i patent case Windward Reports never
used Custom XML (or bookmarks) for tagging. (We looked at both but
each approach has issues that make them problematic at times.) But we
do use tagging in Word, Excel, & PowerPoint as our report designer. We
do have a very powerful Office AddIn to support this tagging. So I
think I have as good an understanding of the issues around this as one
can have and yet still be a disinterested party.I’m not going to give an opinion on the case except to say I wish they
could have reached an agreement. The big losers on this are everyone
who made use of Custom XML for tagging as this is now removed. (And to
say a pox on all software patents.)First for the programmers who have to adjust, there is a product from
i4i that hacks around this called x4w. However, I don’t think that is
your best solution (explained below). My suggestion is to switch to
using content controls, fields, bitmaps, and/or plain old text. The
first three of these approaches are more robust than custom XML and
are still supported by Word. We use all four approaches (user
selected) and they are rock solid.So what do you do if you have custom XML in your Word documents? If
you don’t use the custom XML, then there’s no problem, just open the
files and Word will strip it out, leaving you the rest of the
document. Same if your use can be switched to using another feature.
You will lose your existing markers but otherwise can continue.If you need to find any files that have custom XML in them, this
program for Microsoft will do the job (DOCX/DOCM only). Also, this
restriction only comes in to play for Word 2007 sold on or after 11
January this year – and all copies of Word 2010. Microsoft has a good
summation here.If you must have the custom XML, your only option at present is x4w.
However, I strongly recommend that you only use this as a stop-gap
measure as you find an alternative to custom XML. Because you could
find that the next service pack of Word will render x4w unable to save
your custom XML. As there is no love lost between Microsoft and i4i, I
would not be surprised to see in the next service pack:1.Word drops support for custom XML. At present it strips the custom
XML out but when it is inserted back in, Word still has the
functionality to display and use it. But if custom XML support is not
allowed, they can then remove that functionality from Word. 2.Word
strips custom XML on saving as well as on loading a document. If this
occurs i4i can try to hack around this too, but this is a much more
difficult problem. And for cases that the hack fails, you won’t know
until the next time you open the file – and all your work is lost.
3.Word changes at what point during the load process that it strips
out the custom XML. It presently occurs before the open document event
(which I assume is when x4w inserts the custom XML back in). But Word
could strip it out right after that event – and it is then a much
harder hack to get the custom XML back in.
Время на прочтение
16 мин
Количество просмотров 54K
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
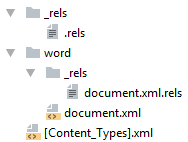
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>word/document.xml
Основное содержимое документа.
word/document.xml
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math"
xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"
xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing"
xmlns:w10="urn:schemas-microsoft-com:office:word"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml"
xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup"
xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk"
xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml"
xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape"
mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"
w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
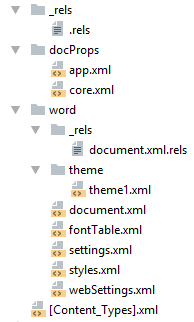
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.sh.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
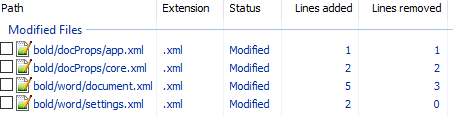
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@
- <TotalTime>0</TotalTime>
+ <TotalTime>1</TotalTime>Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@
- <cp:revision>1</cp:revision>
+ <cp:revision>2</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created>
- <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified>
+ <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
diff
@@ -1,24 +1,26 @@
<w:body>
- <w:p w:rsidR="0076695C" w:rsidRPr="00290C70" w:rsidRDefault="00290C70">
+ <w:p w:rsidR="0076695C" w:rsidRPr="00F752CF" w:rsidRDefault="00290C70">
<w:pPr>
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
</w:pPr>
- <w:r>
+ <w:r w:rsidRPr="00F752CF">
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
- <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:sectPr w:rsidR="0076695C" w:rsidRPr="00F752CF">Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
<w:rPr>
+ <w:b/>в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@
+ <w:proofState w:spelling="clean"/>
@@ -17,10 +18,11 @@
+ <w:rsid w:val="00F752CF"/>Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
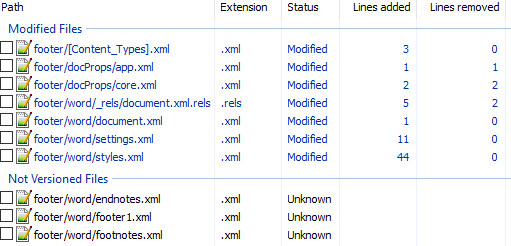
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
+ <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/>
+ <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/>
+ <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
diff
@@ -1,8 +1,11 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
+ <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/>
+ <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/>
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>
- <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
- <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>
</Relationships>Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
@@ -3,6 +3,9 @@
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:footerReference w:type="default" r:id="rId6"/>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/>
<w:cols w:space="708"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
diff
@@ -1,19 +1,30 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15">
<w:zoom w:percent="100"/>
+ <w:proofState w:spelling="clean"/>
<w:defaultTabStop w:val="708"/>
<w:characterSpacingControl w:val="doNotCompress"/>
+ <w:footnotePr>
+ <w:footnote w:id="-1"/>
+ <w:footnote w:id="0"/>
+ </w:footnotePr>
+ <w:endnotePr>
+ <w:endnote w:id="-1"/>
+ <w:endnote w:id="0"/>
+ </w:endnotePr>
<w:compat>
<w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/>
<w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
</w:compat>
<w:rsids>
<w:rsidRoot w:val="00290C70"/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:rsid w:val="001B0DE6"/>А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
diff
@@ -480,6 +480,50 @@
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman"/>
<w:b/>
<w:sz w:val="28"/>
</w:rPr>
</w:style>
+ <w:style w:type="paragraph" w:styleId="a4">
+ <w:name w:val="header"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a5"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a5">
+ <w:name w:val="Верхний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a4"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
+ <w:style w:type="paragraph" w:styleId="a6">
+ <w:name w:val="footer"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a7"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a7">
+ <w:name w:val="Нижний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a6"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
</w:styles>Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B">
<w:pPr>
<w:pStyle w:val="a6"/>
</w:pPr>
<w:r>
<w:t>123</w:t>
</w:r>
</w:p>
</w:ftr>Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels. - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ.
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
<xml>TEST</xml>В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/>
<xsl:template match="/">
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>
<xsl:value-of select="//xml/text()"/>
</w:t>
</w:r>
</w:p>
</w:ftr>
</xsl:template>
</xsl:stylesheet>Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml") В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>TEST</w:t>
</w:r>
</w:p>
</w:ftr>Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Relationship
Id="rId0"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer"
Target="footer0.xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/content-types" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Override
PartName="/word/footer0.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>В результате
Весь код опубликован. Работает он так:
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т… к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула