
В статье рассказывается:
- Понятие Всемирной паутины WWW
- Технологии и структура Всемирной паутины
- Стандарты Всемирной паутины
- ПО Всемирной паутины
- Отличия Всемирной паутины WWW от Интернета
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Всемирная паутина WWW часто ассоциируется с Интернетом, и эти термины употребляют как синонимы, хотя между ними есть разница. Именно благодаря World Wide Web мы можем пользоваться сайтами, обмениваться информацией и делать в Сети все, что привыкли за многие годы ее использования.
Чтобы лучше понять отличия WWW от Интернета, необходимо разобраться в устройстве Всемирной паутины. В нашей статье мы поговорим об этом, коснемся стандартов в данной сфере и разберем структуру и технологии WWW.
Всемирная паутина WWW – это система хранения и доступа к различной информации, которая построена в виде передачи данных между устройствами, находящимися внутри сети Интернет. Доступ к этой информации осуществляется через специальные идентификаторы, которые называются URL адреса.
Устройства в сети обмениваются данными с помощью протоколов HTTP или HTTPS стека TCP или IP. Все ресурсы внутри сети связаны между собой с помощью гиперссылок. Вся эта система выглядит как паутина или паучья сетка, от этой схожести она и получила своё известное сегодня всему миру название.

В обобщённом виде вся система включает в себя следующие компоненты:
- Все ресурсы внутри сети созданы в виде гипертекста. Документы, созданные в виде гипертекста, называются web-страницами. Несколько web-страниц объединяются в web-сайт.
- Доступ к ресурсам осуществляется по их адресам через протоколы HTTP или HTTPS.
- Все адреса ресурсов созданы на основе унифицированных адресов URL или URI.
- Получать доступ и просматривать ресурсы пользователи могут через web-браузеры на мобильных или десктопных устройствах.
Если говорить простым языком, то Всемирная паутина WWW – это такая система в сети Интернет, с помощью которой создаются HTML-страницы, реализованные в виде гипертекста и доступные внутри сети по определённой, принадлежащей только им гиперссылке. Все ресурсы внутри сети хранятся на специализированных серверах.
Всемирная паутина была создана для того, чтобы облегчить передачу и получение информации внутри сети Интернет в удобном графическом и текстовом виде. Это и повлияло на резкий скачок популярности Интернета во всём мире и развитие информационной эпохи в целом.
Теперь пользователи Интернета могли вместо посещения кинотеатра посмотреть желаемый фильм на сайте, не выходя из дома. Или прочитать свежие новости на специализированном новостном портале онлайн, а не ждать доставку печатной версии газеты.
Создателем Всемирной паутины является учёный из Великобритании Тим Бернес-Ли, начавший работать над её реализацией в 1989 году. И уже летом 1991 года с появлением первого браузера, который назывался WorldWideWeb, Всемирная паутина стала доступна для массового использования.

В 1993 году популярность WWW возросла до небес благодаря появлению Windows NCSA Mosaic – первого браузера, поддерживающего графический интерфейс.
В 1994 году создателем World Wide Web был организован консорциум, который был призван осуществлять контроль и содействие в развитии WWW. В это время разрабатывались и активно внедрялись технологические стандарты для веб-сайтов и спецификации для проверки соответствия сайтов введённым стандартам.
WWW лежит в основе стремительного развития сети Интернет и максимального роста её популярности. Миллиарды людей со всех уголков планеты сегодня являются активными пользователями этой системы.
Технологии и структура Всемирной паутины
WWW состоит из огромного количества web-серверов, сосредоточенных во всех уголках планеты. Web-сервер – это специальная программа, запускаемая на подсоединённом к сети локальном компьютере и передающая в сеть данные с помощью протокола HTTP.
Этой программе поступает запрос от пользователя на какой-либо ресурс, она находит подходящий файл на жёстком диске и передаёт его пользователю. Усложнённые версии этой программы могут в ответ на пользовательские запросы формировать в динамическом режиме документы, используя специальные шаблоны и сценарии.
Скачать файл
Чтобы просматривать запрашиваемую в сети информацию, используется специализированная программа, которая называется web-браузер. Её основная задача – отображение гипертекста, который лежит в основе всех ресурсов Всемирной паутины WWW (World Wide Web).
Внутри системы гипертекст создаётся, хранится и отображается с помощью HTML-языка (HyperText Markup language, что в переводе означает «язык разметки гипертекста»). Создание веб-документов на основе гипертекста называется вёрсткой. Такую работу выполняет web-мастер или верстальщик – специалист по гипертекстовой разметке. После создания HTML-разметки документ сохраняется в виде файла. Как только web-сервер получает доступ к этому файлу, он становится web-страницей.
Чтобы пользователи WWW могли быстро и просто перемещаться от одного ресурса к другому, на всех web-страницах содержатся гиперссылки. Для идентификации нахождения этих ресурсов внутри World Wide Web применяются унифицированные локаторы ресурсов URL (Uniform Resource Locator).

Чтобы упростить визуальное восприятие web-ресурсов применятся технология CSS, позволяющая закреплять за веб-страницами одинаковые стили графического и текстового оформления.
Чтобы сделать хранящиеся в сети Интернет данные более понятными и доступными для компьютеров, была создана специальная надстройка над World Wide Web, которую назвали семантической паутиной. С помощью неё компьютеры получают доступ к понятной и структурированной информации о любых ресурсах, независимо от того, на каком языке программирования и на какой платформе они были изначально созданы.
Благодаря семантической паутине программы имеют возможность самостоятельного искать необходимые ресурсы, выстраивать логические взаимосвязи и цепочки, классифицировать информацию, формировать выводы и принимать определённые решения на их основе. Всё это может привести к революционному развитию сети Интернет.
Для формирования понятных программам описаний web-ресурсов семантическая паутина применяет специальный формат RDF (Resource Description Framework), в основе которого лежит синтаксис XML. К новым форматам можно отнести RDFS (Resource Description Framework Schema) и SPARQL (Protocol and RDF Query language), позволяющие осуществлять оперативный доступ к данным RDF.
Стандарты Всемирной паутины
Веб-стандарты состоят из множества зависящих друг от друга технологических стандартов и спецификаций, часть из которых регулирует только WWW, а часть – весь Интернет в целом. Все эти стандарты оказывают влияние на создание и управление всеми сайтами и сервисами, находящимися внутри сети Интернет. Благодаря web-стандартам использование всех web-ресурсов принимает понятный, доступный и удобный характер.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 20405 ![]()
Веб-стандарты Всемирной паутины WWW включают в себя следующие компоненты:
- список рекомендаций, утверждённый Консорциумом Всемирной паутины (World Wide Web Consortium);
- документы запроса комментариев (Request for Comments), утверждённые Инженерной группой Интернета (Internet Engineering Task Force);
- официальные стандарты, утверждённые Международной организацией по стандартизации (International Organization for Standardization);
- официальные стандарты, утверждённые Организацией по стандартизации информационных и коммуникационных технологий (Ecma International);
- стандарты и технические отчёты Unicode, утверждённые консорциумом Unicode (Unicode –стандарт кодирования символов, который содержит знаки практически всех письменных языком мира);
- реестры имён и номеров, утверждённые Управлением по присвоению номеров Интернета (Internet Assigned Numbers Authority).
Важно отметить, что web-стандарты не являются фиксированным, неизменным набором правил, которому подчиняются абсолютно все ресурсы в сети Интернет. Они представляют собой постоянно меняющийся и усовершенствующийся набор технических стандартов и спецификаций, над разработкой которых работают специализированные и признанные по всём мире организации и консорциумы по стандартизации.

Эти объединения часто ведут конкурентную борьбу друг с другом, но имеют общую заинтересованность к приведению всех ресурсов к единым стандартам и правилам. Ещё один важный момент: необходимо чётко различать те стандарты и спецификации, которые ещё только находятся на этапе разработки и усовершенствования, от тех, которые уже признаны и получили статус финальной разработки.
ПО Всемирной паутины
В основе World Wide Web лежат web-серверы. Сегодня их функционал значительно расширен, поэтому достаточно часто они используются в виде шлюзов для серверов различных приложений либо сами способны поддерживать подобный функционал.
По всему миру существует огромное множество IT-инженеров, которые занимаются разработкой программного обеспечения для web-серверов. Наибольшую популярность завоевали такие программные продукты, как Apache Software Foundation, Internet International Services от Microsoft, Google Web Server от Google Incorporation.


Читайте также
Apache представляет собой бесплатное ПО, которое распространяется под совместимой с GPL лицензией. Несколько лет подряд это программное обеспечение держится в мировых лидерах по распространённости и применяемости в сети Интернет благодаря своей надёжности, безопасности, массовой масштабируемости.
Программное обеспечение Internet International Services, разработанное компанией Microsoft, представляет собой группу серверов, созданных для нескольких служб сети Интернет и применяемых совместно с операционными системами Windows, также являющимися ПО, созданным корпорацией Microsoft. В основе этого программного софта лежит web-сервер, который поддерживает такие протоколы, как POP3, NNTP, FTP, SMTP.
Компания Google является создателем ПО на базе Apache, которое называется Google Web Server. Оно было специально разработано для поддержки работы приложений сервиса Google Applications.
Nginx – это специализированный HTTP-сервер, который совмещён с кэширующим прокси-сервером. Первая версия этого программного обеспечения увидела свет в 2004 году, она была разработана программистом Игорем Сысоевым специально для компании Rambler. Сейчас это ПО поддерживается примерно на 9-12 % веб-серверах.
Только до 17.04
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
 Тест на определение компетенций
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:

Уже скачали 7503
Web-браузер, или web-обозреватель другими словами, – это специальное приложение, разработанное для пользователей для получения доступа к ресурсам сети Интернет. В большинстве случаев это программное обеспечение также поддерживает такие протоколы, как MMS, FTP, POP3, File.
Самые первые версии web-браузеров (такие, как lynx, w3m, links) относились к консольному типу и работали только в текстовом режиме, то есть позволяли только распознавать гипертекст и перемещаться по гиперссылкам.
Сейчас они уже практически не используются обычными пользователями сети Интернет. Однако они сохраняют свою популярность и обеспечивают расширенный функционал для профессиональных web-программистов и web-разработчиков, так как с помощью них можно смотреть на web-ресурсы с позиции поискового робота.

Первым web-браузером, поддерживающим графический интерфейс, и прародителем современного веб-браузера было программное обеспечение NCSA Mosaic, созданное М.Андерисоном и Э.Бином. По своему функционалу эта программа была достаточно упрощённой и ограниченной, но код, лежавший в её основе, стал базой для последующих экспериментов и разработок.
Отличия Всемирной паутины WWW от Интернета
Всемирная паутина World Wide Web и Интернет – разные понятия, хотя многие используют эти термины как синонимы. В реальности же Интернет – понятие, гораздо более обширное, чем WWW.
Разберёмся в значениях этих терминов:
- Всемирная паутина WWW (World Wide Web) включает в себя такие компоненты, как web-сайты, web-сервера, протоколы HTTP и HTTPS, web-браузер.
- Интернет помимо Всемирной паутины WWW включает в себя каналы связи и технические устройства, с помощью которых работает Всемирная паутина (спутники, ретрансляторы, передатчики, кабеля и пр.).
Если не брать во внимание технические устройства, с помощью которых работает Всемирная паутина, то среди основных компонентов Интернет можно выделить следующие:
- Сама Всемирная паутина WWW.
- Deep Web – так называемый глубокий Интернет, представляющий собой сеть, которая не подключена к WWW. Эта сеть не доступна рядовым пользователям. Её используют только организации и предприятия, которые хранят в ней конфиденциальную информацию, не распространяемую в широкие массы (например, организация финансовых операций банками).
- Dark Web – так называемый тёмный Интернет, не являющийся частью WWW. Он представляет собой альтернативу WWW и позиционируется как отдельная сеть, к которой можно присоединиться с помощью специализированных web-браузеров или программных технологий.
Распространено мнение о том, что рядовым пользователям доступно всего 17 % от всех ресурсов, имеющихся во Всемирной паутине WWW. Это то, к чему мы можем получить доступ с помощью web-браузера.
Всемирная паутина World Wide Web – самая значимая часть Интернета, позволяющая нам ежедневно выходить в сеть, находить нужную информацию, общаться в социальных сетях, читать книги онлайн, смотреть сериалы и прослушивать любимые треки.
This article is about the global system of pages accessed via URLs. For the worldwide computer network, see Internet. For the web browser, see WorldWideWeb.



A global map of the Web Index for countries in 2014
The World Wide Web (WWW), commonly known as the Web, is an information system enabling documents and other web resources to be accessed over the Internet.[1]
Documents and downloadable media are made available to the network through web servers and can be accessed by programs such as web browsers. Servers and resources on the World Wide Web are identified and located through character strings called uniform resource locators (URLs). The original and still very common document type is a web page formatted in Hypertext Markup Language (HTML). This markup language supports plain text, images, embedded video and audio contents, and scripts (short programs) that implement complex user interaction. The HTML language also supports hyperlinks (embedded URLs) which provide immediate access to other web resources. Web navigation, or web surfing, is the common practice of following such hyperlinks across multiple websites. Web applications are web pages that function as application software. The information in the Web is transferred across the Internet using the Hypertext Transfer Protocol (HTTP).
Multiple web resources with a common theme and usually a common domain name make up a website. A single web server may provide multiple websites, while some websites, especially the most popular ones, may be provided by multiple servers. Website content is provided by a myriad of companies, organizations, government agencies, and individual users; and comprises an enormous amount of educational, entertainment, commercial, and government information.
The World Wide Web has become the world’s dominant software platform.[2][3][4][5] It is the primary tool billions of people worldwide use to interact with the Internet.[6]
The Web was invented by Tim Berners-Lee at CERN in 1989 and opened to the public in 1991. It was conceived as a «universal linked information system».[7]
History

The Web was invented by English computer scientist Tim Berners-Lee while working at CERN. He conceived it as an information management system using several concepts and technologies, the most fundamental of which was the connections that existed between information.[8][9][10] The first proposal was written in 1989,[7] and a working system implemented by the end of 1990 including the WorldWideWeb browser and an HTTP server.[11] The technology was released outside CERN to other research institutions starting in January 1991, and then to the general public on 23 August 1991. The Web was a success at CERN, and began to spread to other scientific and academic institutions. Within the next two years, there were 50 websites created.[12][13]
CERN made the Web protocol and code available royalty free in 1993, enabling its widespread use.[14][15] After the NCSA released the Mosaic web browser later that year, the Web’s popularity grew rapidly as thousands of websites sprang up in less than a year.[16][17] Mosaic was a graphical browser that could display inline images and submit forms that were processed by the HTTPd server.[18][19] Marc Andreessen and Jim Clark founded Netscape the following year and released the Navigator browser, which introduced Java and JavaScript to the Web. It quickly became the dominant browser. Netscape became a public company in 1995 which triggered a frenzy for the Web and started the dot-com bubble.[20] Microsoft responded by developing its own browser, Internet Explorer, starting the browser wars. By bundling it with Windows, it became the dominant browser for 14 years.[21]
Tim Berners-Lee founded the World Wide Web Consortium (W3C) which created XML in 1996 and recommended replacing HTML with stricter XHTML.[22] In the meantime, developers began exploiting an IE feature called XMLHttpRequest to make Ajax applications and launched the Web 2.0 revolution. Mozilla, Opera, and Apple rejected XHTML and created the WHATWG which developed HTML5.[23] In 2009, the W3C conceded and abandoned XHTML[24] and in 2019, ceded control of the HTML specification to the WHATWG.[25]
The World Wide Web has been central to the development of the Information Age and is the primary tool billions of people use to interact on the Internet.[26][27][28][29][30]
Function

The World Wide Web functions as an application layer protocol that is run «on top of» (figuratively) the Internet, helping to make it more functional. The advent of the Mosaic web browser helped to make the web much more usable, to include the display of images and moving images (GIFs).
The terms Internet and World Wide Web are often used without much distinction. However, the two terms do not mean the same thing. The Internet is a global system of computer networks interconnected through telecommunications and optical networking. In contrast, the World Wide Web is a global collection of documents and other resources, linked by hyperlinks and URIs. Web resources are accessed using HTTP or HTTPS, which are application-level Internet protocols that use the Internet’s transport protocols.[31]
Viewing a web page on the World Wide Web normally begins either by typing the URL of the page into a web browser or by following a hyperlink to that page or resource. The web browser then initiates a series of background communication messages to fetch and display the requested page. In the 1990s, using a browser to view web pages—and to move from one web page to another through hyperlinks—came to be known as ‘browsing,’ ‘web surfing’ (after channel surfing), or ‘navigating the Web’. Early studies of this new behavior investigated user patterns in using web browsers. One study, for example, found five user patterns: exploratory surfing, window surfing, evolved surfing, bounded navigation and targeted navigation.[32]
The following example demonstrates the functioning of a web browser when accessing a page at the URL http://example.org/home.html. The browser resolves the server name of the URL (example.org) into an Internet Protocol address using the globally distributed Domain Name System (DNS). This lookup returns an IP address such as 203.0.113.4 or 2001:db8:2e::7334. The browser then requests the resource by sending an HTTP request across the Internet to the computer at that address. It requests service from a specific TCP port number that is well known for the HTTP service so that the receiving host can distinguish an HTTP request from other network protocols it may be servicing. HTTP normally uses port number 80 and for HTTPS it normally uses port number 443. The content of the HTTP request can be as simple as two lines of text:
GET /home.html HTTP/1.1 Host: example.org
The computer receiving the HTTP request delivers it to web server software listening for requests on port 80. If the webserver can fulfill the request it sends an HTTP response back to the browser indicating success:
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8
followed by the content of the requested page. Hypertext Markup Language (HTML) for a basic web page might look like this:
<html> <head> <title>Example.org – The World Wide Web</title> </head> <body> <p>The World Wide Web, abbreviated as WWW and commonly known ...</p> </body> </html>
The web browser parses the HTML and interprets the markup (<title>, <p> for paragraph, and such) that surrounds the words to format the text on the screen. Many web pages use HTML to reference the URLs of other resources such as images, other embedded media, scripts that affect page behaviour, and Cascading Style Sheets that affect page layout. The browser makes additional HTTP requests to the web server for these other Internet media types. As it receives their content from the web server, the browser progressively renders the page onto the screen as specified by its HTML and these additional resources.
HTML
Main article: HTML
Hypertext Markup Language (HTML) is the standard markup language for creating web pages and web applications. With Cascading Style Sheets (CSS) and JavaScript, it forms a triad of cornerstone technologies for the World Wide Web.[33]
Web browsers receive HTML documents from a web server or from local storage and render the documents into multimedia web pages. HTML describes the structure of a web page semantically and originally included cues for the appearance of the document.
HTML elements are the building blocks of HTML pages. With HTML constructs, images and other objects such as interactive forms may be embedded into the rendered page. HTML provides a means to create structured documents by denoting structural semantics for text such as headings, paragraphs, lists, links, quotes and other items. HTML elements are delineated by tags, written using angle brackets. Tags such as <img /> and <input /> directly introduce content into the page. Other tags such as <p> surround and provide information about document text and may include other tags as sub-elements. Browsers do not display the HTML tags, but use them to interpret the content of the page.
HTML can embed programs written in a scripting language such as JavaScript, which affects the behavior and content of web pages. Inclusion of CSS defines the look and layout of content. The World Wide Web Consortium (W3C), maintainer of both the HTML and the CSS standards, has encouraged the use of CSS over explicit presentational HTML since 1997.[34]
Linking
Most web pages contain hyperlinks to other related pages and perhaps to downloadable files, source documents, definitions and other web resources. In the underlying HTML, a hyperlink looks like this:
<a href="http://example.org/home.html">Example.org Homepage</a>.

Graphic representation of a minute fraction of the WWW, demonstrating hyperlinks
Such a collection of useful, related resources, interconnected via hypertext links is dubbed a web of information. Publication on the Internet created what Tim Berners-Lee first called the WorldWideWeb (in its original CamelCase, which was subsequently discarded) in November 1990.[35]
The hyperlink structure of the web is described by the webgraph: the nodes of the web graph correspond to the web pages (or URLs) the directed edges between them to the hyperlinks. Over time, many web resources pointed to by hyperlinks disappear, relocate, or are replaced with different content. This makes hyperlinks obsolete, a phenomenon referred to in some circles as link rot, and the hyperlinks affected by it are often called dead links. The ephemeral nature of the Web has prompted many efforts to archive websites. The Internet Archive, active since 1996, is the best known of such efforts.
WWW prefix
Many hostnames used for the World Wide Web begin with www because of the long-standing practice of naming Internet hosts according to the services they provide. The hostname of a web server is often www, in the same way that it may be ftp for an FTP server, and news or nntp for a Usenet news server. These hostnames appear as Domain Name System (DNS) or subdomain names, as in www.example.com. The use of www is not required by any technical or policy standard and many web sites do not use it; the first web server was nxoc01.cern.ch.[36] According to Paolo Palazzi, who worked at CERN along with Tim Berners-Lee, the popular use of www as subdomain was accidental; the World Wide Web project page was intended to be published at www.cern.ch while info.cern.ch was intended to be the CERN home page; however the DNS records were never switched, and the practice of prepending www to an institution’s website domain name was subsequently copied.[37][better source needed] Many established websites still use the prefix, or they employ other subdomain names such as www2, secure or en for special purposes. Many such web servers are set up so that both the main domain name (e.g., example.com) and the www subdomain (e.g., www.example.com) refer to the same site; others require one form or the other, or they may map to different web sites. The use of a subdomain name is useful for load balancing incoming web traffic by creating a CNAME record that points to a cluster of web servers. Since, currently, only a subdomain can be used in a CNAME, the same result cannot be achieved by using the bare domain root.[38][dubious – discuss]
When a user submits an incomplete domain name to a web browser in its address bar input field, some web browsers automatically try adding the prefix «www» to the beginning of it and possibly «.com», «.org» and «.net» at the end, depending on what might be missing. For example, entering «microsoft» may be transformed to http://www.microsoft.com/ and «openoffice» to http://www.openoffice.org. This feature started appearing in early versions of Firefox, when it still had the working title ‘Firebird’ in early 2003, from an earlier practice in browsers such as Lynx.[39][unreliable source?] It is reported that Microsoft was granted a US patent for the same idea in 2008, but only for mobile devices.[40]
In English, www is usually read as double-u double-u double-u.[41] Some users pronounce it dub-dub-dub, particularly in New Zealand.[42] Stephen Fry, in his «Podgrams» series of podcasts, pronounces it wuh wuh wuh.[43] The English writer Douglas Adams once quipped in The Independent on Sunday (1999): «The World Wide Web is the only thing I know of whose shortened form takes three times longer to say than what it’s short for».[44] In Mandarin Chinese, World Wide Web is commonly translated via a phono-semantic matching to wàn wéi wǎng (万维网), which satisfies www and literally means «10,000-dimensional net», a translation that reflects the design concept and proliferation of the World Wide Web. Tim Berners-Lee’s web-space states that World Wide Web is officially spelled as three separate words, each capitalised, with no intervening hyphens.[45] Nonetheless, it is often called simply the Web, and also often the web; see Capitalization of Internet for details. Use of the www prefix has been declining, especially when Web 2.0 web applications sought to brand their domain names and make them easily pronounceable.[46]
As the mobile Web grew in popularity, services like Gmail.com, Outlook.com, Myspace.com, Facebook.com and Twitter.com are most often mentioned without adding «www.» (or, indeed, «.com») to the domain.
Scheme specifiers
The scheme specifiers http:// and https:// at the start of a web URI refer to Hypertext Transfer Protocol or HTTP Secure, respectively. They specify the communication protocol to use for the request and response. The HTTP protocol is fundamental to the operation of the World Wide Web, and the added encryption layer in HTTPS is essential when browsers send or retrieve confidential data, such as passwords or banking information. Web browsers usually automatically prepend http:// to user-entered URIs, if omitted.
Pages
A screenshot of a web page on Wikimedia Commons
A web page (also written as webpage) is a document that is suitable for the World Wide Web and web browsers. A web browser displays a web page on a monitor or mobile device.
The term web page usually refers to what is visible, but may also refer to the contents of the computer file itself, which is usually a text file containing hypertext written in HTML or a comparable markup language. Typical web pages provide hypertext for browsing to other web pages via hyperlinks, often referred to as links. Web browsers will frequently have to access multiple web resource elements, such as reading style sheets, scripts, and images, while presenting each web page.
On a network, a web browser can retrieve a web page from a remote web server. The web server may restrict access to a private network such as a corporate intranet. The web browser uses the Hypertext Transfer Protocol (HTTP) to make such requests to the web server.
A static web page is delivered exactly as stored, as web content in the web server’s file system. In contrast, a dynamic web page is generated by a web application, usually driven by server-side software. Dynamic web pages are used when each user may require completely different information, for example, bank websites, web email etc.
Static page
A static web page (sometimes called a flat page/stationary page) is a web page that is delivered to the user exactly as stored, in contrast to dynamic web pages which are generated by a web application.
Consequently, a static web page displays the same information for all users, from all contexts, subject to modern capabilities of a web server to negotiate content-type or language of the document where such versions are available and the server is configured to do so.
Dynamic pages

Dynamic web page: example of server-side scripting (PHP and MySQL)
A server-side dynamic web page is a web page whose construction is controlled by an application server processing server-side scripts. In server-side scripting, parameters determine how the assembly of every new web page proceeds, including the setting up of more client-side processing.
A client-side dynamic web page processes the web page using JavaScript running in the browser. JavaScript programs can interact with the document via Document Object Model, or DOM, to query page state and alter it. The same client-side techniques can then dynamically update or change the DOM in the same way.
A dynamic web page is then reloaded by the user or by a computer program to change some variable content. The updating information could come from the server, or from changes made to that page’s DOM. This may or may not truncate the browsing history or create a saved version to go back to, but a dynamic web page update using Ajax technologies will neither create a page to go back to nor truncate the web browsing history forward of the displayed page. Using Ajax technologies the end user gets one dynamic page managed as a single page in the web browser while the actual web content rendered on that page can vary. The Ajax engine sits only on the browser requesting parts of its DOM, the DOM, for its client, from an application server.
Dynamic HTML, or DHTML, is the umbrella term for technologies and methods used to create web pages that are not static web pages, though it has fallen out of common use since the popularization of AJAX, a term which is now itself rarely used.[citation needed] Client-side-scripting, server-side scripting, or a combination of these make for the dynamic web experience in a browser.
JavaScript is a scripting language that was initially developed in 1995 by Brendan Eich, then of Netscape, for use within web pages.[47] The standardised version is ECMAScript.[47] To make web pages more interactive, some web applications also use JavaScript techniques such as Ajax (asynchronous JavaScript and XML). Client-side script is delivered with the page that can make additional HTTP requests to the server, either in response to user actions such as mouse movements or clicks, or based on elapsed time. The server’s responses are used to modify the current page rather than creating a new page with each response, so the server needs only to provide limited, incremental information. Multiple Ajax requests can be handled at the same time, and users can interact with the page while data is retrieved. Web pages may also regularly poll the server to check whether new information is available.[48]
Website
A website[49] is a collection of related web resources including web pages, multimedia content, typically identified with a common domain name, and published on at least one web server. Notable examples are wikipedia.org, google.com, and amazon.com.
A website may be accessible via a public Internet Protocol (IP) network, such as the Internet, or a private local area network (LAN), by referencing a uniform resource locator (URL) that identifies the site.
Websites can have many functions and can be used in various fashions; a website can be a personal website, a corporate website for a company, a government website, an organization website, etc. Websites are typically dedicated to a particular topic or purpose, ranging from entertainment and social networking to providing news and education. All publicly accessible websites collectively constitute the World Wide Web, while private websites, such as a company’s website for its employees, are typically a part of an intranet.
Web pages, which are the building blocks of websites, are documents, typically composed in plain text interspersed with formatting instructions of Hypertext Markup Language (HTML, XHTML). They may incorporate elements from other websites with suitable markup anchors. Web pages are accessed and transported with the Hypertext Transfer Protocol (HTTP), which may optionally employ encryption (HTTP Secure, HTTPS) to provide security and privacy for the user. The user’s application, often a web browser, renders the page content according to its HTML markup instructions onto a display terminal.
Hyperlinking between web pages conveys to the reader the site structure and guides the navigation of the site, which often starts with a home page containing a directory of the site web content. Some websites require user registration or subscription to access content. Examples of subscription websites include many business sites, news websites, academic journal websites, gaming websites, file-sharing websites, message boards, web-based email, social networking websites, websites providing real-time price quotations for different types of markets, as well as sites providing various other services. End users can access websites on a range of devices, including desktop and laptop computers, tablet computers, smartphones and smart TVs.
Browser
A web browser (commonly referred to as a browser) is a software user agent for accessing information on the World Wide Web. To connect to a website’s server and display its pages, a user needs to have a web browser program. This is the program that the user runs to download, format, and display a web page on the user’s computer.
In addition to allowing users to find, display, and move between web pages, a web browser will usually have features like keeping bookmarks, recording history, managing cookies (see below), and home pages and may have facilities for recording passwords for logging into web sites.
The most popular browsers are Chrome, Firefox, Safari, Internet Explorer, and Edge.
Server

A Web server is server software, or hardware dedicated to running said software, that can satisfy World Wide Web client requests. A web server can, in general, contain one or more websites. A web server processes incoming network requests over HTTP and several other related protocols.
The primary function of a web server is to store, process and deliver web pages to clients.[50] The communication between client and server takes place using the Hypertext Transfer Protocol (HTTP). Pages delivered are most frequently HTML documents, which may include images, style sheets and scripts in addition to the text content.

Multiple web servers may be used for a high traffic website; here, Dell servers are installed together to be used for the Wikimedia Foundation.
A user agent, commonly a web browser or web crawler, initiates communication by making a request for a specific resource using HTTP and the server responds with the content of that resource or an error message if unable to do so. The resource is typically a real file on the server’s secondary storage, but this is not necessarily the case and depends on how the webserver is implemented.
While the primary function is to serve content, full implementation of HTTP also includes ways of receiving content from clients. This feature is used for submitting web forms, including uploading of files.
Many generic web servers also support server-side scripting using Active Server Pages (ASP), PHP (Hypertext Preprocessor), or other scripting languages. This means that the behavior of the webserver can be scripted in separate files, while the actual server software remains unchanged. Usually, this function is used to generate HTML documents dynamically («on-the-fly») as opposed to returning static documents. The former is primarily used for retrieving or modifying information from databases. The latter is typically much faster and more easily cached but cannot deliver dynamic content.
Web servers can also frequently be found embedded in devices such as printers, routers, webcams and serving only a local network. The web server may then be used as a part of a system for monitoring or administering the device in question. This usually means that no additional software has to be installed on the client computer since only a web browser is required (which now is included with most operating systems).
Cookie
An HTTP cookie (also called web cookie, Internet cookie, browser cookie, or simply cookie) is a small piece of data sent from a website and stored on the user’s computer by the user’s web browser while the user is browsing. Cookies were designed to be a reliable mechanism for websites to remember stateful information (such as items added in the shopping cart in an online store) or to record the user’s browsing activity (including clicking particular buttons, logging in, or recording which pages were visited in the past). They can also be used to remember arbitrary pieces of information that the user previously entered into form fields such as names, addresses, passwords, and credit card numbers.
Cookies perform essential functions in the modern web. Perhaps most importantly, authentication cookies are the most common method used by web servers to know whether the user is logged in or not, and which account they are logged in with. Without such a mechanism, the site would not know whether to send a page containing sensitive information or require the user to authenticate themselves by logging in. The security of an authentication cookie generally depends on the security of the issuing website and the user’s web browser, and on whether the cookie data is encrypted. Security vulnerabilities may allow a cookie’s data to be read by a hacker, used to gain access to user data, or used to gain access (with the user’s credentials) to the website to which the cookie belongs (see cross-site scripting and cross-site request forgery for examples).[51]
Tracking cookies, and especially third-party tracking cookies, are commonly used as ways to compile long-term records of individuals’ browsing histories – a potential privacy concern that prompted European[52] and U.S. lawmakers to take action in 2011.[53][54] European law requires that all websites targeting European Union member states gain «informed consent» from users before storing non-essential cookies on their device.
Google Project Zero researcher Jann Horn describes ways cookies can be read by intermediaries, like Wi-Fi hotspot providers. He recommends using the browser in incognito mode in such circumstances.[55]
Search engine

The results of a search for the term «lunar eclipse» in a web-based image search engine
A web search engine or Internet search engine is a software system that is designed to carry out web search (Internet search), which means to search the World Wide Web in a systematic way for particular information specified in a web search query. The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). The information may be a mix of web pages, images, videos, infographics, articles, research papers, and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler.
Internet content that is not capable of being searched by a web search engine is generally described as the deep web.
Deep web
The deep web,[56] invisible web,[57] or hidden web[58] are parts of the World Wide Web whose contents are not indexed by standard web search engines. The opposite term to the deep web is the surface web, which is accessible to anyone using the Internet.[59] Computer scientist Michael K. Bergman is credited with coining the term deep web in 2001 as a search indexing term.[60]
The content of the deep web is hidden behind HTTP forms,[61][62] and includes many very common uses such as web mail, online banking, and services that users must pay for, and which is protected by a paywall, such as video on demand, some online magazines and newspapers, among others.
The content of the deep web can be located and accessed by a direct URL or IP address, and may require a password or other security access past the public website page.
Caching
A web cache is a server computer located either on the public Internet or within an enterprise that stores recently accessed web pages to improve response time for users when the same content is requested within a certain time after the original request. Most web browsers also implement a browser cache by writing recently obtained data to a local data storage device. HTTP requests by a browser may ask only for data that has changed since the last access. Web pages and resources may contain expiration information to control caching to secure sensitive data, such as in online banking, or to facilitate frequently updated sites, such as news media. Even sites with highly dynamic content may permit basic resources to be refreshed only occasionally. Web site designers find it worthwhile to collate resources such as CSS data and JavaScript into a few site-wide files so that they can be cached efficiently. Enterprise firewalls often cache Web resources requested by one user for the benefit of many users. Some search engines store cached content of frequently accessed websites.
Security
For criminals, the Web has become a venue to spread malware and engage in a range of cybercrimes, including (but not limited to) identity theft, fraud, espionage and intelligence gathering.[63] Web-based vulnerabilities now outnumber traditional computer security concerns,[64][65] and as measured by Google, about one in ten web pages may contain malicious code.[66] Most web-based attacks take place on legitimate websites, and most, as measured by Sophos, are hosted in the United States, China and Russia.[67] The most common of all malware threats is SQL injection attacks against websites.[68] Through HTML and URIs, the Web was vulnerable to attacks like cross-site scripting (XSS) that came with the introduction of JavaScript[69] and were exacerbated to some degree by Web 2.0 and Ajax web design that favours the use of scripts.[70] Today by one estimate, 70% of all websites are open to XSS attacks on their users.[71] Phishing is another common threat to the Web. In February 2013, RSA (the security division of EMC) estimated the global losses from phishing at $1.5 billion in 2012.[72] Two of the well-known phishing methods are Covert Redirect and Open Redirect.
Proposed solutions vary. Large security companies like McAfee already design governance and compliance suites to meet post-9/11 regulations,[73] and some, like Finjan have recommended active real-time inspection of programming code and all content regardless of its source.[63] Some have argued that for enterprises to see Web security as a business opportunity rather than a cost centre,[74] while others call for «ubiquitous, always-on digital rights management» enforced in the infrastructure to replace the hundreds of companies that secure data and networks.[75] Jonathan Zittrain has said users sharing responsibility for computing safety is far preferable to locking down the Internet.[76]
Privacy
Every time a client requests a web page, the server can identify the request’s IP address. Web servers usually log IP addresses in a log file. Also, unless set not to do so, most web browsers record requested web pages in a viewable history feature, and usually cache much of the content locally. Unless the server-browser communication uses HTTPS encryption, web requests and responses travel in plain text across the Internet and can be viewed, recorded, and cached by intermediate systems. Another way to hide personally identifiable information is by using a virtual private network. A VPN encrypts online traffic and masks the original IP address lowering the chance of user identification.
When a web page asks for, and the user supplies, personally identifiable information—such as their real name, address, e-mail address, etc. web-based entities can associate current web traffic with that individual. If the website uses HTTP cookies, username, and password authentication, or other tracking techniques, it can relate other web visits, before and after, to the identifiable information provided. In this way, a web-based organization can develop and build a profile of the individual people who use its site or sites. It may be able to build a record for an individual that includes information about their leisure activities, their shopping interests, their profession, and other aspects of their demographic profile. These profiles are of potential interest to marketers, advertisers, and others. Depending on the website’s terms and conditions and the local laws that apply information from these profiles may be sold, shared, or passed to other organizations without the user being informed. For many ordinary people, this means little more than some unexpected e-mails in their in-box or some uncannily relevant advertising on a future web page. For others, it can mean that time spent indulging an unusual interest can result in a deluge of further targeted marketing that may be unwelcome. Law enforcement, counter-terrorism, and espionage agencies can also identify, target, and track individuals based on their interests or proclivities on the Web.
Social networking sites usually try to get users to use their real names, interests, and locations, rather than pseudonyms, as their executives believe that this makes the social networking experience more engaging for users. On the other hand, uploaded photographs or unguarded statements can be identified to an individual, who may regret this exposure. Employers, schools, parents, and other relatives may be influenced by aspects of social networking profiles, such as text posts or digital photos, that the posting individual did not intend for these audiences. Online bullies may make use of personal information to harass or stalk users. Modern social networking websites allow fine-grained control of the privacy settings for each posting, but these can be complex and not easy to find or use, especially for beginners.[77] Photographs and videos posted onto websites have caused particular problems, as they can add a person’s face to an online profile. With modern and potential facial recognition technology, it may then be possible to relate that face with other, previously anonymous, images, events, and scenarios that have been imaged elsewhere. Due to image caching, mirroring, and copying, it is difficult to remove an image from the World Wide Web.
Standards
Web standards include many interdependent standards and specifications, some of which govern aspects of the Internet, not just the World Wide Web. Even when not web-focused, such standards directly or indirectly affect the development and administration of websites and web services. Considerations include the interoperability, accessibility and usability of web pages and web sites.
Web standards, in the broader sense, consist of the following:
- Recommendations published by the World Wide Web Consortium (W3C)[78]
- «Living Standard» made by the Web Hypertext Application Technology Working Group (WHATWG)
- Request for Comments (RFC) documents published by the Internet Engineering Task Force (IETF)[79]
- Standards published by the International Organization for Standardization (ISO)[80]
- Standards published by Ecma International (formerly ECMA)[81]
- The Unicode Standard and various Unicode Technical Reports (UTRs) published by the Unicode Consortium[82]
- Name and number registries maintained by the Internet Assigned Numbers Authority (IANA)[83]
Web standards are not fixed sets of rules but are constantly evolving sets of finalized technical specifications of web technologies.[84] Web standards are developed by standards organizations—groups of interested and often competing parties chartered with the task of standardization—not technologies developed and declared to be a standard by a single individual or company. It is crucial to distinguish those specifications that are under development from the ones that already reached the final development status (in the case of W3C specifications, the highest maturity level).
Accessibility
There are methods for accessing the Web in alternative mediums and formats to facilitate use by individuals with disabilities. These disabilities may be visual, auditory, physical, speech-related, cognitive, neurological, or some combination. Accessibility features also help people with temporary disabilities, like a broken arm, or ageing users as their abilities change.[85] The Web receives information as well as providing information and interacting with society. The World Wide Web Consortium claims that it is essential that the Web be accessible, so it can provide equal access and equal opportunity to people with disabilities.[86] Tim Berners-Lee once noted, «The power of the Web is in its universality. Access by everyone regardless of disability is an essential aspect.»[85] Many countries regulate web accessibility as a requirement for websites.[87] International co-operation in the W3C Web Accessibility Initiative led to simple guidelines that web content authors as well as software developers can use to make the Web accessible to persons who may or may not be using assistive technology.[85][88]
Internationalisation
The W3C Internationalisation Activity assures that web technology works in all languages, scripts, and cultures.[89] Beginning in 2004 or 2005, Unicode gained ground and eventually in December 2007 surpassed both ASCII and Western European as the Web’s most frequently used character encoding.[90] Originally RFC 3986 allowed resources to be identified by URI in a subset of US-ASCII. RFC 3987 allows more characters—any character in the Universal Character Set—and now a resource can be identified by IRI in any language.[91]
See also
- Electronic publishing
- Internet metaphors
- Internet security
- Lists of websites
- Streaming media
- Web development tools
- Web literacy
References
- ^ «What is the difference between the Web and the Internet?». W3C Help and FAQ. W3C. 2009. Retrieved 16 July 2015.
- ^ Bleigh, Michael (16 May 2014). «The Once And Future Web Platform». TechCrunch. Retrieved 9 March 2022.
- ^ «World Wide Web Timeline«. Pews Research Center. 11 March 2014. Retrieved 1 August 2015.
- ^ Dewey, Caitlin (12 March 2014). «36 Ways The Web Has Changed Us«. The Washington Post. Retrieved 1 August 2015.
- ^ «Website Analytics Tool«. Retrieved 1 August 2015.
- ^ «What is the difference between the Web and the Internet?». W3C Help and FAQ. W3C. 2009. Archived from the original on 9 July 2015. Retrieved 16 July 2015.
- ^ a b Berners-Lee, Tim. «Information Management: A Proposal». w3.org. The World Wide Web Consortium. Retrieved 12 February 2022.
- ^ Berners-Lee, T.; Cailliau, R.; Groff, J.-F.; Pollermann, B. (1992). «World-Wide Web: The Information Universe». Electron. Netw. Res. Appl. Policy. 2: 52–58. doi:10.1108/eb047254.
- ^ Quittner, Joshua (29 March 1999). «Network Designer Tim Berners-Lee». Time Magazine. Archived from the original on 15 August 2007. Retrieved 17 May 2010.
He wove the World Wide Web and created a mass medium for the 21st century. The World Wide Web is Berners-Lee’s alone. He designed it. He set it loose it on the world. And he more than anyone else has fought to keep it an open, non-proprietary and free.
[page needed] - ^ McPherson, Stephanie Sammartino (2009). Tim Berners-Lee: Inventor of the World Wide Web. Twenty-First Century Books. ISBN 978-0-8225-7273-2.
- ^ W3 (1991) Re: Qualifiers on Hypertext links
- ^ Hopgood, Bob. «History of the Web». w3.org. The World Wide Web Consortium. Retrieved 12 February 2022.
- ^ «A short history of the Web». CERN. Retrieved 15 April 2022.
- ^ «Software release of WWW into public domain». CERN Document Server. CERN. Retrieved 17 February 2022.
- ^ «Ten Years Public Domain for the Original Web Software». Tenyears-www.web.cern.ch. 30 April 2003. Archived from the original on 13 August 2009. Retrieved 27 July 2009.
- ^ Calore, Michael (22 April 2010). «April 22, 1993: Mosaic Browser Lights Up Web With Color, Creativity». Wired. Retrieved 12 February 2022.
- ^ Couldry, Nick (2012). Media, Society, World: Social Theory and Digital Media Practice. London: Polity Press. p. 2. ISBN 9780745639208.
- ^ Hoffman, Jay (21 April 1993). «The Origin of the IMG Tag». The History of the Web. Retrieved 13 February 2022.
- ^ Clarke, Roger. «The Birth of Web Commerce». Roger Clarke’s Web-Site. XAMAX. Retrieved 15 February 2022.
- ^ McCullough, Brian. «20 YEARS ON: WHY NETSCAPE’S IPO WAS THE «BIG BANG» OF THE INTERNET ERA». www.internethistorypodcast.com. INTERNET HISTORY PODCAST. Retrieved 12 February 2022.
- ^ Calore, Michael (28 September 2009). «Sept. 28, 1998: Internet Explorer Leaves Netscape in Its Wake». Wired. Retrieved 14 February 2022.
- ^ Daly, Janet (26 January 2000). «World Wide Web Consortium Issues XHTML 1.0 as a Recommendation». W3C. Retrieved 8 March 2022.
- ^ Hickson, Ian. «WHAT open mailing list announcement». whatwg.org. WHATWG. Retrieved 16 February 2022.
- ^ Shankland, Stephen (9 July 2009). «An epitaph for the Web standard, XHTML 2». CNet. Retrieved 17 February 2022.
- ^ «Memorandum of Understanding Between W3C and WHATWG». w3.org. W3C. Retrieved 16 February 2022.
- ^ In, Lee (30 June 2012). Electronic Commerce Management for Business Activities and Global Enterprises: Competitive Advantages: Competitive Advantages. IGI Global. ISBN 978-1-4666-1801-5.
- ^ Misiroglu, Gina (26 March 2015). American Countercultures: An Encyclopedia of Nonconformists, Alternative Lifestyles, and Radical Ideas in U.S. History: An Encyclopedia of Nonconformists, Alternative Lifestyles, and Radical Ideas in U.S. History. Routledge. ISBN 978-1-317-47729-7.
- ^ «World Wide Web Timeline». Pew Research Center. 11 March 2014. Archived from the original on 29 July 2015. Retrieved 1 August 2015.
- ^ Dewey, Caitlin (12 March 2014). «36 Ways the Web Has Changed Us». The Washington Post. Archived from the original on 9 September 2015. Retrieved 1 August 2015.
- ^ «Internet Live Stats». Archived from the original on 2 July 2015. Retrieved 1 August 2015.
- ^ «What is the difference between the Web and the Internet?». World Wide Web Consortium. Archived from the original on 22 April 2016. Retrieved 18 April 2016.
- ^ Muylle, Steve; Moenaert, Rudy; Despont, Marc (1999). «A grounded theory of World Wide Web search behaviour». Journal of Marketing Communications. 5 (3): 143. doi:10.1080/135272699345644.
- ^ Flanagan, David. JavaScript – The definitive guide (6 ed.). p. 1.
JavaScript is part of the triad of technologies that all Web developers must learn: HTML to specify the content of web pages, CSS to specify the presentation of web pages, and JavaScript to specify the behaviour of web pages.
- ^ «HTML 4.0 Specification – W3C Recommendation – Conformance: requirements and recommendations». World Wide Web Consortium. 18 December 1997. Retrieved 6 July 2015.
- ^ Berners-Lee, Tim; Cailliau, Robert (12 November 1990). «WorldWideWeb: Proposal for a HyperText Project». Archived from the original on 2 May 2015. Retrieved 12 May 2015.
- ^ Berners-Lee, Tim. «Frequently asked questions by the Press». W3C. Archived from the original on 2 August 2009. Retrieved 27 July 2009.
- ^ Palazzi, P (2011). «The Early Days of the WWW at CERN». Archived from the original on 23 July 2012.
- ^ Fraser, Dominic (13 May 2018). «Why a domain’s root can’t be a CNAME – and other tidbits about the DNS». FreeCodeCamp.
- ^ «automatically adding www.___.com». mozillaZine. 16 May 2003. Archived from the original on 27 June 2009. Retrieved 27 May 2009.
- ^ Masnick, Mike (7 July 2008). «Microsoft Patents Adding ‘www.’ And ‘.com’ To Text». Techdirt. Archived from the original on 27 June 2009. Retrieved 27 May 2009.
- ^ «Audible pronunciation of ‘WWW’«. Oxford University Press. Archived from the original on 25 May 2014. Retrieved 25 May 2014.
- ^ Harvey, Charlie. «How we pronounce WWW in English: a detailed but unscientific survey». charlieharvey.org.uk. Retrieved 19 May 2022.
- ^ «Stephen Fry’s pronunciation of ‘WWW’«. Podcasts.com. Archived from the original on 4 April 2017.
- ^ Simonite, Tom (22 July 2008). «Help us find a better way to pronounce www». newscientist.com. New Scientist, Technology. Archived from the original on 13 March 2016. Retrieved 7 February 2016.
- ^ «Frequently asked questions by the Press – Tim BL». W3.org. Archived from the original on 2 August 2009. Retrieved 27 July 2009.
- ^ Castelluccio, Michael (2010). «It’s not your grandfather’s Internet». thefreelibrary.com. Institute of Management Accountants. Retrieved 7 February 2016.
- ^ a b Hamilton, Naomi (31 July 2008). «The A-Z of Programming Languages: JavaScript». Computerworld. IDG. Archived from the original on 24 May 2009. Retrieved 12 May 2009.
- ^ Buntin, Seth (23 September 2008). «jQuery Polling plugin». Archived from the original on 13 August 2009. Retrieved 22 August 2009.
- ^ «website». TheFreeDictionary.com. Retrieved 2 July 2011.
- ^ Patrick, Killelea (2002). Web performance tuning (2nd ed.). Beijing: O’Reilly. p. 264. ISBN 978-0596001728. OCLC 49502686.
- ^ Vamosi, Robert (14 April 2008). «Gmail cookie stolen via Google Spreadsheets». News.cnet.com. Archived from the original on 9 December 2013. Retrieved 19 October 2017.
- ^ «What about the «EU Cookie Directive»?». WebCookies.org. 2013. Archived from the original on 11 October 2017. Retrieved 19 October 2017.
- ^ «New net rules set to make cookies crumble». BBC. 8 March 2011.
- ^ «Sen. Rockefeller: Get Ready for a Real Do-Not-Track Bill for Online Advertising». Adage.com. 6 May 2011.
- ^ Want to use my wifi?, Jann Horn accessed 5 January 2018.
- ^ Hamilton, Nigel. «The Mechanics of a Deep Net Metasearch Engine». CiteSeerX 10.1.1.90.5847.
- ^ Devine, Jane; Egger-Sider, Francine (July 2004). «Beyond google: the invisible web in the academic library». The Journal of Academic Librarianship. 30 (4): 265–269. doi:10.1016/j.acalib.2004.04.010.
- ^ Raghavan, Sriram; Garcia-Molina, Hector (11–14 September 2001). «Crawling the Hidden Web». 27th International Conference on Very Large Data Bases.
- ^ «Surface Web». Computer Hope. Retrieved 20 June 2018.
- ^ Wright, Alex (22 February 2009). «Exploring a ‘Deep Web’ That Google Can’t Grasp». The New York Times. Retrieved 23 February 2009.
- ^ Madhavan, J., Ko, D., Kot, Ł., Ganapathy, V., Rasmussen, A., & Halevy, A. (2008). Google’s deep web crawl. Proceedings of the VLDB Endowment, 1(2), 1241–52.
- ^ Shedden, Sam (8 June 2014). «How Do You Want Me to Do It? Does It Have to Look like an Accident? – an Assassin Selling a Hit on the Net; Revealed Inside the Deep Web». Sunday Mail. Archived from the original on 1 March 2020. Retrieved 5 May 2017.
- ^ a b Ben-Itzhak, Yuval (18 April 2008). «Infosecurity 2008 – New defence strategy in battle against e-crime». ComputerWeekly. Reed Business Information. Archived from the original on 4 June 2008. Retrieved 20 April 2008.
- ^ Christey, Steve & Martin, Robert A. (22 May 2007). «Vulnerability Type Distributions in CVE (version 1.1)». MITRE Corporation. Archived from the original on 17 March 2013. Retrieved 7 June 2008.
- ^ «Symantec Internet Security Threat Report: Trends for July–December 2007 (Executive Summary)» (PDF). XIII. Symantec Corp. April 2008: 1–2. Archived (PDF) from the original on 25 June 2008. Retrieved 11 May 2008.
- ^ «Google searches web’s dark side». BBC News. 11 May 2007. Archived from the original on 7 March 2008. Retrieved 26 April 2008.
- ^ «Security Threat Report (Q1 2008)» (PDF). Sophos. Archived (PDF) from the original on 31 December 2013. Retrieved 24 April 2008.
- ^ «Security threat report» (PDF). Sophos. July 2008. Archived (PDF) from the original on 31 December 2013. Retrieved 24 August 2008.
- ^ Fogie, Seth, Jeremiah Grossman, Robert Hansen, and Anton Rager (2007). Cross Site Scripting Attacks: XSS Exploits and Defense (PDF). Syngress, Elsevier Science & Technology. pp. 68–69, 127. ISBN 978-1-59749-154-9. Archived from the original (PDF) on 25 June 2008. Retrieved 6 June 2008.
{{cite book}}: CS1 maint: multiple names: authors list (link) - ^ O’Reilly, Tim (30 September 2005). «What Is Web 2.0». O’Reilly Media. pp. 4–5. Archived from the original on 15 April 2013. Retrieved 4 June 2008. and AJAX web applications can introduce security vulnerabilities like «client-side security controls, increased attack surfaces, and new possibilities for Cross-Site Scripting (XSS)», in Ritchie, Paul (March 2007). «The security risks of AJAX/web 2.0 applications» (PDF). Infosecurity. Archived from the original (PDF) on 25 June 2008. Retrieved 6 June 2008. which cites Hayre, Jaswinder S. & Kelath, Jayasankar (22 June 2006). «Ajax Security Basics». SecurityFocus. Archived from the original on 15 May 2008. Retrieved 6 June 2008.
- ^ Berinato, Scott (1 January 2007). «Software Vulnerability Disclosure: The Chilling Effect». CSO. CXO Media. p. 7. Archived from the original on 18 April 2008. Retrieved 7 June 2008.
- ^ «2012 Global Losses From phishing Estimated At $1.5 Bn». FirstPost. 20 February 2013. Archived from the original on 21 December 2014. Retrieved 25 January 2019.
- ^ Prince, Brian (9 April 2008). «McAfee Governance, Risk and Compliance Business Unit». eWEEK. Ziff Davis Enterprise Holdings. Retrieved 25 April 2008.
- ^ Preston, Rob (12 April 2008). «Down To Business: It’s Past Time To Elevate The Infosec Conversation». InformationWeek. United Business Media. Archived from the original on 14 April 2008. Retrieved 25 April 2008.
- ^ Claburn, Thomas (6 February 2007). «RSA’s Coviello Predicts Security Consolidation». InformationWeek. United Business Media. Archived from the original on 7 February 2009. Retrieved 25 April 2008.
- ^ Duffy Marsan, Carolyn (9 April 2008). «How the iPhone is killing the ‘Net». Network World. IDG. Archived from the original on 14 April 2008. Retrieved 17 April 2008.
- ^ boyd, danah; Hargittai, Eszter (July 2010). «Facebook privacy settings: Who cares?». First Monday. 15 (8). doi:10.5210/fm.v15i8.3086.
- ^ «W3C Technical Reports and Publications». W3C. Retrieved 19 January 2009.
- ^ «IETF RFC page». IETF. Archived from the original on 2 February 2009. Retrieved 19 January 2009.
- ^ «Search for World Wide Web in ISO standards». ISO. Retrieved 19 January 2009.
- ^ «Ecma formal publications». Ecma. Retrieved 19 January 2009.
- ^ «Unicode Technical Reports». Unicode Consortium. Retrieved 19 January 2009.
- ^ «IANA home page». IANA. Retrieved 19 January 2009.
- ^ Sikos, Leslie (2011). Web standards – Mastering HTML5, CSS3, and XML. Apress. ISBN 978-1-4302-4041-9. Archived from the original on 2 April 2015. Retrieved 12 March 2019.
- ^ a b c «Web Accessibility Initiative (WAI)». World Wide Web Consortium. Archived from the original on 2 April 2009. Retrieved 7 April 2009.
- ^ «Developing a Web Accessibility Business Case for Your Organization: Overview». World Wide Web Consortium. Archived from the original on 14 April 2009. Retrieved 7 April 2009.
- ^ «Legal and Policy Factors in Developing a Web Accessibility Business Case for Your Organization». World Wide Web Consortium. Archived from the original on 5 April 2009. Retrieved 7 April 2009.
- ^ «Web Content Accessibility Guidelines (WCAG) Overview». World Wide Web Consortium. Archived from the original on 1 April 2009. Retrieved 7 April 2009.
- ^ «Internationalization (I18n) Activity». World Wide Web Consortium. Archived from the original on 16 April 2009. Retrieved 10 April 2009.
- ^ Davis, Mark (5 April 2008). «Moving to Unicode 5.1». Archived from the original on 21 May 2009. Retrieved 10 April 2009.
- ^ «World Wide Web Consortium Supports the IETF URI Standard and IRI Proposed Standard» (Press release). World Wide Web Consortium. 26 January 2005. Archived from the original on 7 February 2009. Retrieved 10 April 2009.
Further reading
- Berners-Lee, Tim; Bray, Tim; Connolly, Dan; Cotton, Paul; Fielding, Roy; Jeckle, Mario; Lilley, Chris; Mendelsohn, Noah; Orchard, David; Walsh, Norman; Williams, Stuart (15 December 2004). «Architecture of the World Wide Web, Volume One». Version 20041215. W3C.
- Berners-Lee, Tim (August 1996). «The World Wide Web: Past, Present and Future».
- Brügger, Niels, ed, Web25: Histories from the first 25 years of the World Wide Web (Peter Lang, 2017).
- Fielding, R.; Gettys, J.; Mogul, J.; Frystyk, H.; Masinter, L.; Leach, P.; Berners-Lee, T. (June 1999). «Hypertext Transfer Protocol – HTTP/1.1». Request For Comments 2616. Information Sciences Institute.
- Niels Brügger, ed. Web History (2010) 362 pages; Historical perspective on the World Wide Web, including issues of culture, content, and preservation.
- Polo, Luciano (2003). «World Wide Web Technology Architecture: A Conceptual Analysis». New Devices.
- Skau, H.O. (March 1990). «The World Wide Web and Health Information». New Devices.
External links
![]()
- The first website
- Early archive of the first Web site
- Internet Statistics: Growth and Usage of the Web and the Internet
- Living Internet A comprehensive history of the Internet, including the World Wide Web
- Web Design and Development at Curlie
- World Wide Web Consortium (W3C)
- W3C Recommendations Reduce «World Wide Wait»
- World Wide Web Size Daily estimated size of the World Wide Web
- Antonio A. Casilli, Some Elements for a Sociology of Online Interactions
- The Erdős Webgraph Server Archived 1 March 2021 at the Wayback Machine offers weekly updated graph representation of a constantly increasing fraction of the WWW
- The 25th Anniversary of the World Wide Web Archived 11 July 2021 at the Wayback Machine is an animated video produced by USAID and TechChange which explores the role of the WWW in addressing extreme poverty
Шаталов Максим Русланович, студент 1-ого курса АВТФ НГТУ
Введение
Аннотация: В статье даётся определения поняти Web-паутине. Рассматривается история развития интернета, разделённая по поколениям, имеющим свои характерные черты.
Ключевые слова: WEB, интернет, поколения.
Цель: ознакомиться с историей создания WWW и современной веб паутиной.
Актуальность: WWW (World Wide Web) или всемирная паутина – это распределённая система, которая предоставляет доступ к различным документам, благодаря всемирной паутине мы можем общаться с родственниками по сети, узнавать любые сведения, накопленные человечеством за долго время и даже искать работу. Веб паутина с каждым годом становиться всё больше, в ней появляются новые возможности, новые сведения, поэтому надо понять, как зарождалась веб паутина и как она выглядит в современном мире.
Задачи:
1) Узнать первые шаги создания интернета
2) Что из себя представляла всемирная паутина в начале
3) Что из себя представляет всемирная паутина сейчас
4) Рассмотреть принцип и структуру работы всемирной паутины
Этапы развития интернета
Всемирная паутина делится на три этапа развития Web 1.0, Web 2.0, Web 3.0. Web 1.0 была эпохой, когда Netscape был единственным браузером долгое время. Web 2.0 — время, когда люди стали понимать, что данное программное обеспечение не позволяет использовать Интернет, который имеет большое значение. Новые технологии позволяют осуществлять интеллектуальный поиск и приводят к Web 3.0.
Web 1.0
В Web 1.0 небольшое количество сценаристов создавало веб-страницы для большого количества читателей. В результате, пользователи могли получить информацию, перейдя непосредственно к источнику. WWW или Web 1.0 представляет собой систему взаимосвязанных гипертекстовых документов, доступ к которым осуществляется через сеть Интернет. Первая реализация Web 1.0, согласно Бернерс-Ли, могла рассматриваться как «веб-сайт, доступный только для чтения». Другими словами, ранний веб позволял пользователям искать информацию и читать ее. Это был самый простой способ взаимодействия между пользователем и контентом. Однако, это именно то, что большинство владельцев сайтов хотели: веб-сайты должны были предоставлять необходимую информацию пользователям в любое время
Web 2.0
Web 2.0 — термин, введенный ДиНуччи в 1999 году и позднее в 2004 году он был изменен Тимом О’Рейли и Дейлом Дугерти, которые сообщили, что второе поколение WWW (World Wide Web) ориентировано на возможность пользователей вносить информацию в режиме онлайн с помощью веб-сообществ, социальных сетей и т.д. Web 2.0 является динамичным и более интерактивным веб-знанием и направленным на создание статических HTML-страниц . Это также означало более востребованное издание Web, где новые инструменты позволили практически любому человеку внести свой вклад, несмотря на их практические знания. В настоящее время Web 2.0 находится на начальном этапе, так называемая сеть «чтение-запись», по мнению Бернерса-Ли. Появившаяся возможность изменять контент и взаимодействовать с другими веб-пользователями за короткое время резко изменила ориентацию сети Интернет. Целью создания Web 2.0 была образование улучшенной формы WWW. Такие технологии, как блоги, вики, подкасты, социальные сети, веб-API и вебслужбы (eBay и Gmail) показывают значительные пре- имущества перед обычными сайтами Web 1.0, которые использовались только для чтения . Тим О’Рейли утверждал, что Web 2.0 — это, безусловно, перспективное направление в WWW, в котором используются новейшие технологии и концепции для того, чтобы сделать пользователя более интерактивным, полезным и вовлеченным. Это подразумевает еще один способ соединения мира путем сбора информации и обеспечения эффективного обмена данными. Это революция в области компьютеров и точно добьется большого успеха. В Википедии Web 2.0 — термин, суть которого заключается в переходе от набора веб-сайтов к полноценным вычислительным платформам, обслуживающим веб-приложения для конечных пользователей.
Web 3.0
Web 3.0 — это термин, который был разработан для описания эволюции использования Web и взаимодействия, которое включает преобразование Web в базу данных. Web 3.0 — это эпоха, в которую мы будем обновлять серверные приложения Web, после десяти лет сосредоточения на интерфейсной части приложений (Web 2.0 ориентирован на AJAX и другие инновация для работы с клиентами). Дополняя точку зрения Тима Бернерса Ли, Web 3.0 можно характеризовать как «чтение-запись-исполнение». Web 3.0 определяется как создание высококачественного контента и услуг, использующие технологии Web 2.0 в качестве базовой платформы. В эпоху Web 3.0 мы не будем пользоваться браузерами, будет технология искусственного интеллекта, использование семантической сети, геопространственной сети или 3D сети.
Структура и принципы Всемирной паутины
Всемирную паутину образуют миллионы веб-серверов сети Интернет, расположенных по всему миру. Веб-сервер — это компьютерная программа, запускаемая на подключённом к сети компьютере и использующая протокол HTTP для передачи данных. В простейшем виде такая программа получает по сети HTTP-запрос на определённый ресурс, находит соответствующий файл на локальном жёстком диске и отправляет его по сети запросившему компьютеру. Более сложные веб-серверы способны в ответ на HTTP-запрос динамически генерировать документы с помощью шаблонов и сценариев.
Для просмотра информации, полученной от веб-сервера, на клиентском компьютере применяется специальная программа — веб-браузер. Основная функция веб-браузера — отображение гипертекста. Всемирная паутина неразрывно связана с понятиями гипертекста и гиперссылки. Большая часть информации в Вебе представляет собой именно гипертекст.
Для создания, хранения и отображения гипертекста во Всемирной паутине традиционно используется язык HTML (англ. HyperText Markup Language «язык разметки гипертекста»). Работа по созданию (разметке) гипертекстовых документов называется вёрсткой, она делается веб-мастером либо отдельным специалистом по разметке — верстальщиком. После HTML-разметки получившийся документ сохраняется в файл, и такие HTML-файлы являются основным типом ресурсов Всемирной паутины. После того, как HTML-файл становится доступен веб-серверу, его начинают называть «веб-страницей». Набор веб-страниц образует веб-сайт.
Гипертекст веб-страниц содержит гиперссылки. Гиперссылки помогают пользователям Всемирной паутины легко перемещаться между ресурсами (файлами) вне зависимости от того, находятся ресурсы на локальном компьютере или на удалённом сервере. Для определения местонахождения ресурсов во Всемирной паутине используются единообразные локаторы ресурсов URL (англ. Uniform Resource Locator). Например, полный URL главной страницы русского раздела Википедии выглядит так: http://ru.wikipedia.org/wiki/Заглавная_страница. Подобные URL-локаторы сочетают в себе технологию идентификации URI (англ. Uniform Resource Identifier «единообразный идентификатор ресурса») и систему доменных имён DNS (англ. Domain Name System). Доменное имя (в данном случае ru.wikipedia.org) в составе URL обозначает компьютер (точнее — один из его сетевых интерфейсов), который исполняет код нужного веб-сервера. URL текущей страницы обычно можно увидеть в адресной строке браузера, хотя многие современные браузеры предпочитают по умолчанию показывать лишь доменное имя текущего сайта.
Заключение
В заключение хочу сказать, что изобретение World Wide Web изменило мир человечества, сначала это был обычный запрос – ответ, а теперь во всемирной паутине может пройти целая жизнь, мы можем там вести бизнес, купить дом, найти единомышленников по интересам. Всемирная паутина – это явно новый шаг в развитие человечества, и она будет всё больше развиваться, давая новые возможности.
Список литературы
Всеми́рная паути́на (англ. World Wide Web) — распределённая система, предоставляющая доступ к связанным между собой документам, расположенным на различных компьютерах, подключенных к Интернету. Для обозначения Всемирной паутины также используют слово веб (англ. web «паутина») и аббревиатуру WWW.
Всемирную паутину образуют сотни миллионов веб-серверов. Большинство ресурсов всемирной паутины основаны на технологии гипертекста. Гипертекстовые документы, размещаемые во Всемирной паутине, называются веб-страницами. Несколько веб-страниц, объединённых общей темой, дизайном, а также связанных между собой ссылками и обычно находящихся на одном и том же веб-сервере, называются веб-сайтом. Для загрузки и просмотра веб-страниц используются специальные программы — браузеры (англ. browser).
Всемирная паутина вызвала настоящую революцию в информационных технологиях и взрыв в развитии Интернета. Часто, говоря об Интернете, имеют в виду именно Всемирную паутину, однако важно понимать, что это не одно и то же.
Структура и принципы Всемирной паутины
Всемирная паутина вокруг Википедии
Всемирную паутину образуют миллионы веб-серверов сети Интернет, расположенных по всему миру. Веб-сервер является программой, запускаемой на подключённом к сети компьютере и использующей протокол HTTP для передачи данных. В простейшем виде такая программа получает по сети HTTP-запрос на определённый ресурс, находит соответствующий файл на локальном жёстком диске и отправляет его по сети запросившему компьютеру. Более сложные веб-серверы способны в ответ на HTTP-запрос динамически генерировать документы с помощью шаблонов и сценариев.
Для просмотра информации, полученной от веб-сервера, на клиентском компьютере применяется специальная программа — веб-браузер. Основная функция веб-браузера — отображение гипертекста. Всемирная паутина неразрывно связана с понятиями гипертекста и гиперссылки. Большая часть информации в Вебе представляет собой именно гипертекст.
Для облегчения создания, хранения и отображения гипертекста во Всемирной паутине традиционно используется язык HTML (англ. HyperText Markup Language «язык разметки гипертекста»). Работа по созданию (разметке) гипертекстовых документов называется вёрсткой, она делается веб-мастером либо отдельным специалистом по разметке — верстальщиком. После HTML-разметки получившийся документ сохраняется в файл, и такие HTML-файлы являются основным типом ресурсов Всемирной паутины. После того, как HTML-файл становится доступен веб-серверу, его начинают называть «веб-страницей». Набор веб-страниц образует веб-сайт.
Гипертекст веб-страниц содержит гиперссылки. Гиперссылки помогают пользователям Всемирной паутины легко перемещаться между ресурсами (файлами) вне зависимости от того, находятся ресурсы на локальном компьютере или на удалённом сервере. Для определения местонахождения ресурсов во Всемирной паутине используются единообразные локаторы ресурсов URL (англ. Uniform Resource Locator). Например, полный URL главной страницы русского раздела Википедии выглядит так: http://ru.wikipedia.org/wiki/Заглавная_страница. Подобные URL-локаторы сочетают в себе технологию идентификации URI (англ. Uniform Resource Identifier «единообразный идентификатор ресурса») и систему доменных имён DNS (англ. Domain Name System). Доменное имя (в данном случае ru.wikipedia.org) в составе URL обозначает компьютер (точнее — один из его сетевых интерфейсов), который исполняет код нужного веб-сервера. URL текущей страницы обычно можно увидеть в адресной строке браузера, хотя многие современные браузеры предпочитают по умолчанию показывать лишь доменное имя текущего сайта.
Технологии Всемирной паутины
Для улучшения визуального восприятия веба стала широко применяться технология CSS, которая позволяет задавать единые стили оформления для множества веб-страниц. Ещё одно нововведение, на которое стоит обратить внимание, — система обозначения ресурсов URN (англ. Uniform Resource Name).
Популярная концепция развития Всемирной паутины — создание семантической паутины. Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещённую в сети информацию более понятной для компьютеров. Семантическая паутина — это концепция сети, в которой каждый ресурс на человеческом языке был бы снабжён описанием, понятным компьютеру. Семантическая паутина открывает доступ к чётко структурированной информации для любых приложений, независимо от платформы и независимо от языков программирования. Программы смогут сами находить нужные ресурсы, обрабатывать информацию, классифицировать данные, выявлять логические связи, делать выводы и даже принимать решения на основе этих выводов. При широком распространении и грамотном внедрении семантическая паутина может вызвать революцию в Интернете. Для создания понятного компьютеру описания ресурса, в семантической паутине используется формат RDF (англ. Resource Description Framework), который основан на синтаксисе XML и использует идентификаторы URI для обозначения ресурсов. Новинки в этой области — это RDFS (англ.)русск. (англ. RDF Schema) и SPARQL (англ. Protocol And RDF Query Language) (произносится как «спа́ркл»), новый язык запросов для быстрого доступа к данным RDF.
История Всемирной паутины
Так выглядит самый первый веб-сервер, разработанный Тимом Бернерс-Ли
Изобретателями всемирной паутины считаются Тим Бернерс-Ли и в меньшей степени, Роберт Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он работал в Европейском совете по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) консультантом по программному обеспечению. Именно там, в Женеве (Швейцария), он для собственных нужд написал программу «Энквайр» (англ. Enquire, можно вольно перевести как «Дознаватель»), которая использовала случайные ассоциации для хранения данных и заложила концептуальную основу для Всемирной паутины.
В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как Всемирная паутина. Проект подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск и консолидацию информации для учёных CERN. Для осуществления проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал технические спецификации этих стандартов и опубликовал их. Но, всё же, официально годом рождения Всемирной паутины нужно считать 1989 год.
В рамках проекта Бернерс-Ли написал первый в мире веб-сервер httpd и первый в мире гипертекстовый веб-браузер, называвшийся WorldWideWeb. Этот браузер был одновременно и WYSIWYG-редактором (сокр. от англ. What You See Is What You Get — что видишь, то и получишь), его разработка была начата в октябре 1990 года, а закончена в декабре того же года. Программа работала в среде NeXTStep и начала распространяться по Интернету летом 1991 года.
Майк Сендал (Mike Sendall) покупает в это время компьютер NeXT cube для того, чтобы понять, в чём состоят особенности его архитектуры, и отдает его затем Тиму [Бернерс-Ли]. Благодаря совершенству программной системы NeXT cube Тим написал прототип, иллюстрирующий основные положения проекта, за несколько месяцев. Это был впечатляющий результат: прототип предлагал пользователям, кроме прочего, такие развитые возможности, как WYSIWYG browsing/authoring!… В течение одной из сессий совместных обсуждений проекта в кафетерии ЦЕРНа мы с Тимом попытались подобрать «цепляющее» название (catching name) для создаваемой системы. Единственное, на чём я настаивал, это чтобы название не было в очередной раз извлечено все из той же греческой мифологии. Тим предложил World Wide Web. Все в этом названии мне сразу очень понравилось, только трудно произносится по-французски.
— Robert Cailliau, 2 ноября 1995[1]
Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа 1991 года на первом веб-сервере доступном по адресу http://info.cern.ch/, (здесь архивная копия). Ресурс определял понятие Всемирной паутины, содержал инструкции по установке веб-сервера, использования браузера и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты.
Первая фотография во Всемирной паутине — группа Les Horribles Cernettes
На первой фотографии во Всемирной паутине была изображена пародийная филк-группа Les Horribles Cernettes.[2] Тим Бернес-Ли попросил их отсканированные снимки у лидера группы после CERN Hardronic Festival.
И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945 году Ванна́вер Буш разработал концепцию Memex — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году).
С 1994 года основную работу по развитию Всемирной паутины взял на себя консорциум Всемирной паутины (англ. World Wide Web Consortium, W3C), основанный и до сих пор возглавляемый Тимом Бернерсом-Ли. Данный консорциум — организация, разрабатывающая и внедряющая технологические стандарты для Интернета и Всемирной паутины. Миссия W3C: «Полностью раскрыть потенциал Всемирной паутины путём создания протоколов и принципов, гарантирующих долгосрочное развитие Сети». Две другие важнейшие задачи консорциума — обеспечить полную «интернационализа́цию Сети́» и сделать Сеть доступной для людей с ограниченными возможностями.
W3C разрабатывает для Интернета единые принципы и стандарты (называемые «рекомендациями», англ. W3C Recommendations), которые затем внедряются производителями программ и оборудования. Таким образом достигается совместимость между программными продуктами и аппаратурой различных компаний, что делает Всемирную сеть более совершенной, универсальной и удобной. Все рекомендации консорциума Всемирной паутины открыты, то есть не защищены патентами и могут внедряться любым человеком без всяких финансовых отчислений консорциуму.
Перспективы развития Всемирной паутины
В настоящее время наметились две тенденции в развитии Всемирной паутины: семантическая паутина и социальная паутина.
- Семантическая паутина предполагает улучшение связности и релевантности информации во Всемирной паутине через введение новых форматов метаданных.
- Социальная паутина полагается на работу по упорядочиванию имеющейся в Паутине информации, выполняемую самими пользователями Паутины. В рамках второго направления наработки, являющиеся частью семантической паутины, активно используются в качестве инструментов (RSS и другие форматы веб-каналов, OPML, микроформаты XHTML). Частично семантизированные участки Дерева категорий «Википедии» помогают пользователям осознанно перемещаться в информационном пространстве, однако, очень мягкие требования к подкатегориям не дают основания надеяться на расширение таких участков. В связи с этим интерес могут представлять попытки составления атласов Знания.
Существует также популярное понятие Web 2.0, обобщающее сразу несколько направлений развития Всемирной паутины.
Способы активного отображения информации во Всемирной паутине
Информация в вебе может отображаться как пассивно (то есть пользователь может только считывать её), так и активно — тогда пользователь может добавлять информацию и редактировать её. К способам активного отображения информации во Всемирной паутине относятся:
- гостевые книги,
- форумы,
- чаты,
- блоги,
- wiki-проекты,
- социальные сети,
- системы управления контентом.
Следует отметить, что это деление весьма условно. Так, скажем, блог или гостевую книгу можно рассматривать как частный случай форума, который, в свою очередь, является частным случаем системы управления контентом. Обычно разница проявляется в назначении, подходе и позиционировании того или иного продукта.
Отчасти информация с сайтов может также быть доступна через речь. В Индии уже началось[3] тестирование системы, делающей текстовое содержимое страниц доступным даже для людей, не умеющих читать и писать.
World Wide Web иногда иронично называют Wild Wild Web (дикий, дикий Web) — по аналогии с названием одноименного фильма Wild Wild West (Дикий, дикий Запад)[4].
Безопасность
Для киберпреступников Всемирная паутина стала ключевым способом распространения вредоносного программного обеспечения. Кроме того, под понятие сетевой преступности подпадают кража личных данных, мошенничество, шпионаж и незаконный сбор сведений о тех или иных субъектах или объектах[5]. Веб-уязвимости, по некоторым данным, в настоящее время превосходят по количеству любые традиционные проявления проблем компьютерной безопасности; по оценкам Google, примерно одна из десяти страниц во Всемирной паутине может содержать вредоносный код[6][7][8]. По данным компании Sophos, британского производителя антивирусных решений, большинство кибератак в веб-пространстве совершается со стороны легитимных ресурсов, размещённых по преимуществу в США, Китае и России[9]. Наиболее распространённым видом подобных нападений, по сведениям от той же компании, является SQL-инъекция — злонамеренный ввод прямых запросов к базе данных в текстовые поля на страницах ресурса, что при недостаточном уровне защищённости может привести к раскрытию содержимого БД[10]. Другой распространённой угрозой, использующей возможности HTML и уникальных идентификаторов ресурсов, для сайтов Всемирной паутины является межсайтовое выполнение сценариев (XSS), которое стало возможным с введением технологии JavaScript и набрало обороты в связи с развитием Web 2.0 и Ajax — новые стандарты веб-дизайна поощряли использование интерактивных сценариев[11][12][13]. По оценкам 2008 года, до 70 % всех веб-сайтов в мире были уязвимы для XSS-атак против их пользователей[14].
Предлагаемые решения соответствующих проблем существенно варьируются вплоть до полного противоречия друг другу. Крупные поставщики защитных решений вроде McAfee разрабатывают продукты для оценки информационных систем на предмет их соответствия определённым требованиям, другие игроки рынка (например, Finjan) рекомендуют проводить активное исследование программного кода и вообще всего содержимого в режиме реального времени, вне зависимости от источника данных[15][5]. Есть также мнения, согласно которым предприятия должны воспринимать безопасность как удачную возможность для развития бизнеса, а не как источник расходов; для этого на смену сотням компаний, обеспечивающих защиту информации сегодня, должна прийти немногочисленная группа организаций, которая приводила бы в исполнение инфраструктурную политику постоянного и повсеместного управления цифровыми правами[16][17].
Конфиденциальность
Каждый раз, когда пользовательский компьютер запрашивает у сервера веб-страницу, сервер определяет и, как правило, протоколирует IP-адрес, с которого поступил запрос. Аналогичным образом большинство обозревателей Интернета записывают сведения о посещённых страницах, которые затем можно просмотреть в журнале браузера, а также кэшируют загруженное содержимое для возможного повторного использования. Если при взаимодействии с сервером не используется зашифрованное HTTPS-соединение, запросы и ответы на них передаются через Интернет открытым текстом и могут быть считаны, записаны и просмотрены на промежуточных узлах сети.
Когда веб-страница запрашивает, а пользователь предоставляет определённый объём личных сведений, таких, к примеру, как имя и фамилия либо реальный или электронный адрес, поток данных может быть деанонимизирован и ассоциирован с конкретным человеком. Если веб-сайт использует файлы cookie, поддерживает аутентификацию пользователя или другие технологии отслеживания активности посетителей, то между предыдущими и последующими визитами также может быть установлена взаимосвязь. Таким образом, работающая во Всемирной паутине организация имеет возможность создавать и пополнять профиль конкретного клиента, пользующегося её сайтом (или сайтами). Такой профиль может включать, к примеру, информацию о предпочитаемом отдыхе и развлечениях, потребительских интересах, роде занятий и других демографических показателях. Такие профили представляют существенный интерес для маркетологов, сотрудников рекламных агентств и других специалистов подобного рода. В зависимости от условий обслуживания конкретных сервисов и местных законов такие профили могут продаваться или передаваться третьим сторонам без ведома пользователя.
Раскрытию сведений способствуют также социальные сети, предлагающие участникам самостоятельно изложить определённый объём личных данных о себе. Неосторожное обращение с возможностями таких ресурсов может приводить к попаданию в открытый доступ сведений, которые пользователь предпочел бы скрыть; помимо прочего, такая информация может становиться предметом внимания хулиганов или, более того, киберпреступников. Современные социальные сети предоставляют своим участникам довольно широкий спектр настроек конфиденциальности профиля, однако эти настройки могут быть излишне сложны — в особенности для неопытных пользователей[18].
Распространение
Шаблон:Чистить раздел
В период с 2005 по 2010 год количество веб-пользователей удвоилось и достигло отметки миллиарда[19]. Согласно ранним исследованиям 1998 и 1999 годах показало, что большинство существующих веб-сайтов не индексировались корректно поисковыми системами, а сама веб-сеть оказалась крупнее, чем ожидалось[20][21]. По данным на 2001 год было создано уже более 550 миллиардов
веб-документов, большинство из которых однако находились в пределах невидимой сети[22]. По данным на 2002 год было создано боле 2000 миллионов веб-страниц[23], 56.4% всего интернет-содержимого было на английском языке, после него шёл немецкий (7.7%), французский (5.6%) и японский (4.9%). Согласно исследованиям, проводимым в конце января 2005 года на 75 разных языках было определено более 11,5 миллиардов веб-страниц, которые были индексированы в открытой сети[24]. А по данным на март 2009 года, количество страниц увеличилось до 25.21 миллиардов[25]. 25 июля 2008 года инженеры программного обеспечения Google Джессе Альперт и Ниссан Хайай объявили, что поисковик Google Search засёк более миллиарда уникальных URL-ссылок[26].
Интересные факты
- В 2011 году в Санкт-Петербурге планировали установить памятник Всемирной паутине. Композиция должна была представлять собой уличную скамейку в виде аббревиатуры WWW с бесплатным доступом в Сеть[27].
См. также
- Семантическая паутина
- Глобальная вычислительная сеть
- Всемирная цифровая библиотека
Примечания
- ↑ Web как «следующий шаг» (NextStep) революции персональных компьютеров
- ↑ LHC: The First Band on the Web
- ↑ IBM разработала голосовой интернет
- ↑ Ховард М., Лебланк Д. Защищённый кодПер. с англ. — 2-е изд., испр. — М.: Издательско-торговый дом «Русская редакция», 2005, с. 3 (УДК 004.45, ББК 32Ю973Ю26-018.2, Х68, ISBN 5-7502-0238-0)
- ↑ 5,0 5,1 Ben-Itzhak, Yuval (18 April 2008). «Infosecurity 2008 – New defence strategy in battle against e-crime». ComputerWeekly (Reed Business Information). http://www.computerweekly.com/Articles/2008/04/18/230345/infosecurity-2008-new-defence-strategy-in-battle-against.htm. Retrieved 20 April 2008.
- ↑ Christey, Steve and Martin, Robert A. Vulnerability Type Distributions in CVE (version 1.1). MITRE Corporation (22 May 2007). Проверено 7 июня 2008. Архивировано из первоисточника 15 апреля 2013.
- ↑ «Symantec Internet Security Threat Report: Trends for July–December 2007 (Executive Summary)» (PDF) (April 2008) XIII: 1–2. Symantec Corp.. Retrieved on 11 May 2008.
- ↑ «Google searches web’s dark side». BBC News. 11 May 2007. http://news.bbc.co.uk/2/hi/technology/6645895.stm. Retrieved 26 April 2008.
- ↑ Security Threat Report (PDF). Sophos (Q1 2008). Проверено 24 апреля 2008. Архивировано из первоисточника 15 апреля 2013.
- ↑ Security threat report (PDF). Sophos (July 2008). Проверено 24 августа 2008. Архивировано из первоисточника 15 апреля 2013.
- ↑ Fogie, Seth, Jeremiah Grossman, Robert Hansen, and Anton Rager (2007) (PDF). Cross Site Scripting Attacks: XSS Exploits and Defense. Syngress, Elsevier Science & Technology. pp. 68–69, 127. ISBN 1-59749-154-3. http://www.syngress.com/book_catalog//SAMPLE_1597491543.pdf. Retrieved 6 June 2008.
- ↑ O’Reilly, Tim. What Is Web 2.0 4–5. O’Reilly Media (30 September 2005). Проверено 4 июня 2008. Архивировано из первоисточника 15 апреля 2013.
- ↑ Ritchie, Paul (March 2007). «The security risks of AJAX/web 2.0 applications» (PDF). Infosecurity. Elsevier. Retrieved on 6 June 2008.
- ↑ Berinato, Scott (1 January 2007). «Software Vulnerability Disclosure: The Chilling Effect». CSO (CXO Media): p. 7. Archived from the original on 18 April 2008. http://web.archive.org/web/20080418072230/http://www.csoonline.com/article/221113. Retrieved 7 June 2008.
- ↑ Prince, Brian (9 April 2008). «McAfee Governance, Risk and Compliance Business Unit». eWEEK (Ziff Davis Enterprise Holdings). http://www.eweek.com/c/a/Security/McAfee-Governance-Risk-and-Compliance-Business-Unit/. Retrieved 25 April 2008.
- ↑ Preston, Rob (12 April 2008). «Down To Business: It’s Past Time To Elevate The Infosec Conversation». InformationWeek (United Business Media). http://www.informationweek.com/news/security/client/showArticle.jhtml?articleID=207100989. Retrieved 25 April 2008.
- ↑ Claburn, Thomas (6 February 2007). «RSA’s Coviello Predicts Security Consolidation». InformationWeek (United Business Media). http://www.informationweek.com/news/security/showArticle.jhtml?articleID=197003826. Retrieved 25 April 2008.
- ↑ boyd, danah; Hargittai, Eszter (July 2010). «Facebook privacy settings: Who cares?». First Monday 15 (8). University of Illinois at Chicago.
- ↑ Lynn, Jonathan (19 October 2010). «Internet users to exceed 2 billion …». Reuters. http://www.reuters.com/article/2010/10/19/us-telecoms-internet-idUSTRE69I24720101019. Retrieved 9 February 2011.
- ↑ S. Lawrence, C.L. Giles, «Searching the World Wide Web,» Science, 280(5360), 98–100, 1998.
- ↑ S. Lawrence, C.L. Giles, «Accessibility of Information on the Web,» Nature, 400, 107–109, 1999.
- ↑ The ‘Deep’ Web: Surfacing Hidden Value. Brightplanet.com. Проверено 27 июля 2009. Архивировано из первоисточника 4 апреля 2008.
- ↑ Distribution of languages on the Internet. Netz-tipp.de. Проверено 27 июля 2009. Архивировано из первоисточника 24 мая 2013.
- ↑ Alessio Signorini. Indexable Web Size. Cs.uiowa.edu. Проверено 27 июля 2009. Архивировано из первоисточника 24 мая 2013.
- ↑ The size of the World Wide Web. Worldwidewebsize.com. Проверено 27 июля 2009. Архивировано из первоисточника 24 мая 2013.
- ↑ Alpert, Jesse; Hajaj, Nissan. We knew the web was big…. The Official Google Blog (25 июля 2008). Архивировано из первоисточника 24 мая 2013.
- ↑ Памятник Интернету установят в Санкт-Петербурге
Литература
- Филдинг, Р.; Геттис, Дж.; Могул, Дж.; Фристик, Г.; Мазинтер, Л.; Лич, П.; Бернерс-Ли, Т. (Июнь 1999).»Hypertext Transfer Protocol — http://1.1«. Request For Comments 2616. Information Sciences Institute.
- Бернерс-Ли, Тим; Брэй, Тим; Конноли, Дэн; Коттон, Пол; Филдинг, Рой; Джекл, Марио; Лилли, Крис; Мендельсон, Ной; Оркард, Дэвид; Уолш, Норман; Уиллиамс, Стюарт (Декабрь 15, 2004).»Architecture of the World Wide Web, Volume One«. Version 20041215. W3C.
- Поло, Лучано. World Wide Web Technology Architecture: A Conceptual Analysis. New Devices (2003). Проверено Июль 31 2005. Архивировано из первоисточника 24 августа 2011.
Ссылки
- Официальный сайт Консорциума Всемирной паутины (World Wide Web Consortium (W3C)) (англ.)
- Tim Berners-Lee, Mark Fischetti. Плетя паутину: истоки и будущее Всемирной паутины = Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web. — New York: HarperCollins Publishers (англ.)русск.. — 256 p. — ISBN 0-06-251587-X, ISBN 978-0-06-251587-2. (см. ISBN )
(англ.)
- Историческое предложение Тима Бернерса-Ли для CERN
- Первый в мире веб-сайт (архив)
- Эволюция Веба (интерактивное представление)
- Другие организации, занимающиеся развитием Всемирной паутины и Интернета в целом
- The Internet Engineering Task Force, IETF
- Internet Society, ISOC
- International Organization for Standardization, ISO
- Web Standards Group, WSG
- The Web Standards Project
- Unicode Organization
- The Semantic Web Community Portal
Веб и веб-сайты |
|
|---|---|
| Глобально |
Всемирная паутина |
| Локально |
Сайт • |
| Виды сайтов и сервисов |
Виртуальный атлас • |
| Создание и обслуживание |
Мастер • |
| Типы макетов, страниц, сайтов |
Статический • |
| Техническое |
Веб-сервер |
| Маркетинг |
Интернет-маркетинг • |
| Социум и культура |
Блогосфера • |
Шаблон:Семантическая паутина
Шаблон:Интернет
|
Выделить Всемирная паутина и найти в:
|
|
|
- Страница 0 — краткая статья
- Страница 1 — энциклопедическая статья
- Разное — на страницах: 2 , 3 , 4 , 5
- Прошу вносить вашу информацию в «Всемирная паутина 1», чтобы сохранить ее
Комментарии читателей:
Примечание
Интернет — это глобальная компьютерная сеть, объединяющая сотни миллионов компьютеров в общее информационное пространство. Интернет представляет свою инфраструктуру для прикладных сервисов различного назначения, самым популярным из которых является Всемирная Паутина – World Wide Web (www).
World Wide Web (www, web, рус.: веб, Всемирная Паутина) — распределенная информационная система, предоставляющая доступ к гипертекстовым документам по протоколу HTTP.
WWW — сетевая технология прикладного уровня стека TCP/IP, построенная на клиент-серверной архитектуре и использующая инфраструктуру Интернет для взаимодействия между сервером и клиентом (рис. 1).
Серверы www (веб-серверы) — это хранилища гипертекстовой (в общем случае) информации, управляемые специальным программным обеспечением.
Документы, представленные в виде гипертекста называются веб-страницами. Несколько веб-страниц, объединенных общей тематикой, оформлением, связанных гипертекстовыми ссылками и обычно находящихся на одном и том же веб-сервере, называются веб-сайтом.
Для загрузки и просмотра информации с веб-сайтов используются специальные программы — браузеры, способные обрабатывать гипертектовую разметку и отображать содержимое веб-страниц.
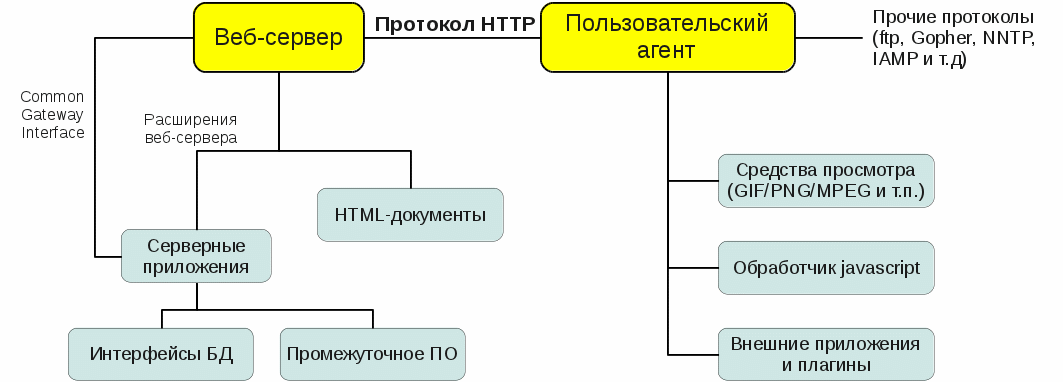
Рис. 1. Архитектура сервиса WWW
В основе www — взаимодействие между веб-сервером и браузерами по протоколу HTTP (HyperText Transfer Protocol). Веб-сервер — это программа, запущенная на сетевом компьютере и ожидающая клиентские запросы по протоколу HTTP. Браузер может обратиться к веб-серверу по доменному имени или по ip-адресу, передавая в запросе идентификатор требуемого ресурса. Получив запрос от клиента, сервер находит соответствующий ресурс на локальном устройстве хранения и отправляет его как ответ. Браузер принимает ответ и обрабатывает его соответствующим образом, в зависимости от типа ресурса (отображает гипертекст, показывает изображения, сохраняет полученные файлы и т.п.).
Основной тип ресурсов Всемирной паутины — гипертекстовые страницы. Гипертекст — это обычный текст, размеченный специальными управляющими конструкциями — тегами. Браузер считывает теги и интерпретирует их как команды форматирования при выводе информации. Теги описывают структуру документа, а специальные теги, якоря и гиперссылки, позволяют установить связи между веб-страницами и перемещаться как внутри веб-сайта, так и между сайтами.
Примечание
Т. Дж. Бернерс-Ли — «отец» Всемирной паутины

Сэр Тимоти Джон Бернерс-Ли — британский учёный-физик, изобретатель Всемирной паутины (совместно с Робертом Кайо), автор URI, HTTP и HTML. Действующий глава Консорциума Всемирной паутины (W3C). Автор концепции семантической паутины и множества других разработок в области информационных технологий. 16 июля 2004 года Королева Великобритании Елизавета II произвела Тима Бернерса-Ли в Рыцари-Командоры за «службу во благо глобального развития Интернета».
Компоненты WWW¶
Функционирование сервиса обеспечивается четырьмя составляющими:
- URL/URI — унифицированный способ адресации и идентификации сетевых ресурсов;
- HTML — язык гипертекстовой разметки веб-документов;
- HTTP — протокол передачи гипертекста;
- CGI — общий шлюзовый интерфейс, представляющий доступ к серверным приложениям.
Адресация веб-ресурсов. URL, URN, URI
Для доступа к любым сетевым ресурсам необходимо знать где они размещены и как к ним можно обратиться. Во Всемирной паутине для обращения к веб-документам изначально используется стандартизованная схема адресации и идентификации, учитывающую опыт адресации и идентификации таких сетевых сервисов, как e-mail, telnet, ftp и т.п. — URL, Uniform Resource Locator.
URL (RFC 1738) — унифицированный локатор (указатель) ресурсов, стандартизированный способ записи адреса ресурса в www и сети Интернет. Адрес URL имеет гибкую и расширяемую структуру для максимально естественного указания местонахождения ресурсов в сети. Для записи адреса используется ограниченный набор символов ASCII. Общий вид адреса можно представить так:
<схема>://<логин>:<пароль>@<хост>:<порт>/<полный-путь-к-ресурсу>
Где:
схема
схема обращения к ресурсу: http, ftp, gopher, mailto, news, telnet, file, man, info, whatis, ldap, wais и т.п.
логин:пароль
имя пользователя и его пароль, используемые для доступа к ресурсу
хост
доменное имя хоста или его IP-адрес.
порт
порт хоста для подключения
полный-путь-к-ресурсу
уточняющая информация о месте нахождения ресурса (зависит от протокола).
Примеры URL:
В августе 2002 года RFC 3305 анонсировал устаревание URL в пользу URI (Uniform Resource Identifier), еще более гибкого способа адресации, вобравшего возможности как URL, так и URN (Uniform Resource Name, унифицированное имя ресурса). URI позволяет не только указавать местонахождение ресурса (как URL), но и идентифицировать его в заданном пространстве имен (как URN). Если в URI не указывать местонахождение, то с его помощью можно описывать ресурсы, которые не могут быть получены непосредственно из Интернета (автомобили, персоны и т.п.). Текущая структура и синтаксис URI регулируется стандартом RFC 3986, вышедшим в январе 2005 года.
Язык гипертекстовой разметки HTML¶
HTML (`HyperText Markup Language <>`_) — стандартный язык разметки документов во Всемирной паутине. Большинство веб-страниц созданы при помощи языка HTML. Язык HTML интерпретируется браузером и отображается в виде документа, в удобной для человека форме. HTML является приложением SGML (стандартного обобщённого языка разметки) и соответствует международному стандарту ISO 8879.
HTML создавался как язык для обмена научной и технической документацией, пригодный для использования людьми, не являющимися специалистами в области вёрстки. Для этого он представляет небольшой (сравнительно) набор структурных и семантических элементов — тегов. С помощью HTML можно легко создать относительно простой, но красиво оформленный документ. Изначально язык HTML был задуман и создан как средство структурирования и форматирования документов без их привязки к средствам воспроизведения (отображения). В идеале, текст с разметкой HTML должен единообразно воспроизводиться на различном оборудовании (монитор ПК, экран органайзера, ограниченный по размерам экран мобильного телефона, медиа-проектор). Однако современное применение HTML очень далеко от его изначальной задачи. Со временем основная идея платформонезависимости языка HTML стала жертвой коммерциализации www и потребностей в мультимедийном и графическом оформлении.
Протокол HTTP¶
HTTP (`HyperText Transfer Protocol <>`_) — протокол передачи гипертекста, текущая версия HTTP/1.1 (RFC 2616). Этот протокол изначально был предназначен для обмена гипертекстовыми документами, сейчас его возможности существенно расширены в сторону передачи двоичной информации.
HTTP — типичный клиент-серверный протокол, обмен сообщениями идёт по схеме «запрос-ответ» в виде ASCII-команд. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя данный протокол является символьно-ориентированным.
HTTP — протокол прикладного уровня, но используется также в качестве «транспорта» для других прикладных протоколов, в первую очередь, основанных на языке XML (SOAP, XML-RPC, SiteMap, RSS и проч.).
Общий шлюзовый интерфейс CGI¶
CGI (`Common Gateway Interface <>`_) — механизм доступа к программам на стороне веб-сервера. Спецификация CGI была разработана для расширения возможностей сервиса www за счет подключения различного внешнего программного обеспечения. При использовании CGI веб-сервер представляет браузеру доступ к исполнимым программам, запускаемым на его (серверной) стороне через стандартные потоки ввода и вывода.
Интерфейс CGI применяется для создания динамических веб-сайтов, например, когда веб-страницы формируются из результатов запроса к базе данных. Сейчас популярность CGI снизилась, т.к. появились более совершенные альтернативные решения (например, модульные расширения веб-серверов).
Программное обеспечение сервиса WWW¶
Веб-серверы
Веб-сервер — это сетевое приложение, обслуживающее HTTP-запросы от клиентов, обычно веб-браузеров. Веб-сервер принимает запросы и возвращает ответы, обычно вместе с HTML-страницей, изображением, файлом, медиа-потоком или другими данными. Веб-серверы — основа Всемирной паутины. С расширением спектра сетевых сервисов веб-серверы все чаще используются в качестве шлюзов для серверов приложений или сами представляют такие функции (например, Apache Tomcat).
Созданием программного обеспечения веб-серверов занимаются многие разработчики, но наибольшую популярность (по статистике http://netcraft.com) имеют такие программные продукты, как Apache (Apache Software Foundation), IIS (Microsoft), Google Web Server (GWS, Google Inc.) и nginx.
Apache — свободное программное обеспечение, распространяется под совместимой с GPL лицензией. Apache уже многие годы является лидером по распространенности во Всемирной паутине в силу своей надежности, гибкости, масштабируемости и безопасности.
IIS (Internet Information Services) — проприетарный набор серверов для нескольких служб Интернета, разработанный Майкрософт и распространяемый с серверными операционными системами семейства Windows. Основным компонентом IIS является веб-сервер, также поддерживаются протоколы FTP, POP3, SMTP, NNTP.
Google Web Server (GWS) — разработка компании Google на основе веб-сервера Apache. GWS оптимизирован для выполнения приложений сервиса Google Applications.
nginx [engine x] — это HTTP-сервер, совмещенный с кэширующим прокси-сервером. Разработан И. Сысоевым для компании Рамблер. Осенью 2004 года вышел первый публично доступный релиз, сейчас nginx используется на 9-12% веб-серверов.
Браузеры
Браузер, веб-обозреватель (web-browser) — клиентское приложение для доступа к веб-серверам по протоколу HTTP и просмотра веб-страниц. Как правило браузеры дополнительно поддерживают и ряд других протоколов (например ftp, file, mms, pop3).
Первые HTTP-клиенты были консольными и работали в текстовом режиме, позволяя читать гипертекст и перемещаться по ссылкам. Сейчас консольные браузеры (такие, как lynx, w3m или links) практически не используются рядовыми посетителями веб-сайтов. Тем не менее такие браузеры весьма полезны для веб-разработчиков, так как позволяют «увидеть» веб-страницу «глазами» поискового робота.
Исторически первым браузером в современном понимании (т.е. с графическим интерфейсом и т.д.) была программа NCSA Mosaic, разработанная Марком Андерисеном и Эриком Бина. Mosaic имел довольно ограниченные возможности, но его открытый исходный код стал основой для многих последующих разработок.
Существует большое число программ-браузеров, но наибольшей популярностью пользуются следующие:
Source: StatCounter Global Stats — Browser Market Share
Internet Explorer (IE) — браузер, разработанный компанией Майкрософт и тесно интегрированный c ОС Windows. Платформозависим (поддержка сторонних ОС прекращена, начиная с версии 5). Единственный браузер, напрямую поддерживающий технологию ActiveX. Не полностью совместим со стандартами W3C, в связи с чем требует дополнительных затрат от веб-разработчиков.
Firefox — свободный кроссплатформенный браузер, разрабатываемый Mozilla Foundation и распространяемый под тройной лицензией GPL/LGPL/MPL. В основе браузера — движок Gekko, который изначально создавался для Netscape Communicator. Однако, вместо того, чтобы предоставить все возможности движка в стандартной поставке, Firefox реализует лишь основную его функциональность, предоставляя пользователям возможность модифицировать браузер в соответствии с их требованиями через поддержку расширений (add-ons), тем оформления и плагинов.
Safari — проприетарный браузер, разработаный корпорацией Apple и входящий в состав операционной системы Mac OS X. Бесплатно распространяется для операционных систем семейства Microsoft Windows. В браузере используется уникальный по производительности интерпретатор JavaScript и еще ряд интересных для пользователя решений, которые отсутствуют или не развиты в других браузерах.
Chrome — кроссплатформенный браузер с открытым исходным кодом, разрабатываемый компанией Google. Первая стабильная версия вышла 11 декабря 2008 года. В отличие от многих других браузеров, в Chrome каждая вкладка является отдельным процессом. В случае если процесс обработки содержимого вкладки зависнет, его можно будет завершить без риска потери данных других вкладок. Еще одна особенность — интеллектуальная адресная строка (Omnibox). К возможности автозаполнения она добавляет поисковые функции с учетом популярности сайта, релевантности и пользовательских предпочтений (истории переходов).
Opera — кроссплатформенный многофункциональный веб-браузер, впервые представленный в 1994 году группой исследователей из норвежской компании Telenor. Дальнейшая разработка ведется Opera Software ASA. Этот браузер обладает высокой скоростью работы и совместим с основными стандартами. Отличительными особенностями Opera долгое время являлись многостраничный интерфейс и возможность масштабирования веб-страниц целиком. На разных этапах развития в Opera были интегрированы возможности почтового/новостного клиента, адресной книги, клиента сети BitTorrent, агрегатора RSS, клиента IRC, менеджера закачек, WAP-браузера, а также поддержка виджетов — графические модулей, работающих вне окна браузера.
Роботы-«пауки»
Наряду с браузерами, ориентированными на пользователя, существуют и специализированные клиенты-роботы («пауки», «боты»), подключающиеся к веб-серверам и выполняющие различные задачи автоматической обработки гипертекстовой информации. Сюда относятся, в первую очередь, роботы поисковых систем, таких как google.com, yandex.ru, yahoo.com и т.п., выполняющие обход веб-сайтов для последующего построения поискового индекса.
Всеми́рная паути́на (англ. World Wide Web) — распределенная система, предоставляющая доступ к связанным между собой документам, расположенным на различных компьютерах, подключенных к Интернету. Всемирную паутину образуют миллионы web-серверов. Большинство ресурсов всемирной паутины представляет собой гипертекст. Гипертекстовые документы, размещаемые во всемирной паутине, называются web-страницами. Несколько web-страниц, объединенных общей темой, дизайном, а также связанных между собой ссылками и обычно находящихся на одном и том же web-сервере, называются web-сайтом. Для загрузки и просмотра web-страниц используются специальные программы – браузеры. Всемирная паутина вызвала настоящую революцию в информационных технологиях и бум в развитии Интернета. Часто, говоря об Интернете, имеют в виду именно Всемирную паутину, однако важно понимать, что это не одно и то же. Для обозначения Всемирной паутины также используют слово веб (англ. web) и «WWW».
Содержание
- 1 Структура и принципы Всемирной паутины
- 2 Технологии Всемирной паутины
- 3 История Всемирной паутины
- 4 Перспективы развития Всемирной паутины
- 5 Способы активного отображения информации во Всемирной паутине
- 6 Организации, занимающиеся развитием Всемирной паутины и Интернета в целом
- 7 Ссылки
- 8 Литература
- 9 Примечания
Структура и принципы Всемирной паутины
Графическое изображение информации во Всемирной паутине
Всемирную паутину образуют миллионы веб-серверов сети Интернет, расположенных по всему миру. Веб-сервер является программой, запускаемой на подключённом к сети компьютере и использующей протокол жёстком диске и отправляет его по сети запросившему компьютеру. Более сложные веб-серверы способны динамически распределять ресурсы в ответ на HTTP-запрос. Для идентификации ресурсов (зачастую файлов или их частей) во Всемирной паутине используются единообразные идентификаторы ресурсов англ. Uniform Resource Identifier). Для определения местонахождения ресурсов в сети используются единообразные локаторы ресурсов англ. Uniform Resource Locator). Такие URL-локаторы сочетают в себе технологию идентификации URI и систему доменных имён англ. Domain Name System) — доменное имя (или непосредственно
Для обзора информации, полученной от веб-сервера, на клиентском компьютере применяется специальная программа — веб-браузер. Основная функция веб-браузера — отображение гипертекста. Всемирная паутина неразрывно связана с понятиями гипертекста и гиперссы́лки. Большая часть информации в Вебе представляет собой именно гипертекст. Для облегчения создания, хранения и отображения гипертекста во Всемирной паутине традиционно используется язык англ. HyperText Markup Language), язык разметки гипертекста. Работа по разметке гипертекста называется вёрсткой, ма́стера по разметке называют веб-мастером или вебмастером (без дефиса). После HTML-разметки получившийся гипертекст помещается в файл, такой HTML-файл является самым распространённым ресурсом Всемирной паутины. После того, как HTML-файл становится доступен веб-серверу, его начинают называть «веб-страницей». Набор веб-страниц образует веб-сайт. В гипертекст веб-страниц добавляются гиперссылки. Гиперссылки помогают пользователям Всемирной паутины легко перемещаться между ресурсами (файлами) вне зависимости от того, находятся ресурсы на локальном компьютере или на удалённом сервере. Гиперссылки веба основаны на технологии URL.
Технологии Всемирной паутины
В целом можно заключить, что Всемирная паутина стоит на «трёх китах»: HTTP, HTML и URL. Хотя в последнее время HTML начал несколько сдавать свои позиции и уступать их более современным технологиям разметки: XML. XML (англ. eXtensible Markup Language) позиционируется как фундамент для других языков разметки. Для улучшения визуального восприятия веба стала широко применяться технология CSS, которая позволяет задавать единые стили оформления для множества веб-страниц. Ещё одно нововведение, на которое стоит обратить внимание, — система обозначения ресурсов англ. Uniform Resource Name).
Популярная концепция развития Всемирной паутины — создание семантической паутины. Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещённую в сети информацию более понятной для компьютеров. Семантическая паутина — это концепция сети, в которой каждый ресурс на человеческом языке был бы снабжён описанием, понятным компьютеру. Семантическая паутина открывает доступ к чётко структурированной информации для любых приложений, независимо от платформы и независимо от языков программирования. Программы смогут сами находить нужные ресурсы, обрабатывать информацию, классифицировать данные, выявлять логические связи, делать выводы и даже принимать решения на основе этих выводов. При широком распространении и грамотном внедрении семантическая паутина может вызвать революцию в Интернете. Для создания понятного компьютеру описания ресурса, в семантической паутине используется формат RDF (англ. Resource Description Framework), который основан на синтаксисе англ. RDF Schema) и англ. Protocol And RDF Query Language) (произносится как «спа́ркл»), новый язык запросов для быстрого доступа к данным RDF.
История Всемирной паутины
Изобретателями всемирной паутины считаются Тим Бернерс-Ли в меньшей степени, Роберт Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он работал в (фр. Conseil Européen pour la Recherche Nucléaire, Женеве (Швейцария), он для собственных нужд написал программу «Энквайр» (англ. «Enquire», можно вольно перевести как «Дознаватель»), которая использовала случайные ассоциации для хранения данных и заложила концептуальную основу для Всемирной паутины.
В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как Всемирная паутина. Проект подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск и консолидацию информации для учёных CERN. Для осуществления проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал технические спецификации этих стандартов и опубликовал их. Но, всё же, официально годом рождения Всемирной паутины нужно считать 1989 год.
В рамках проекта Бернерс-Ли написал первый в мире веб-сервер «httpd» и первый в мире гипертекстовый веб-браузер, называвшийся «WorldWideWeb». Этот браузер был одновременно и англ. What You See Is What You Get — что видишь, то и получишь), его разработка была начата в октябре 1990 года, а закончена в декабре того же года. Программа работала в среде «NeXTStep» и начала распространяться по Интернету летом 1991 года.
Первый в мире веб-сайт Бернерс-Ли создал по адресу http://info.cern.ch/, теперь сайт хранится в архиве. Этот сайт появился он-лайн в Интернете 6 августа 1991 года. На этом сайте описывалось, что такое Всемирная паутина, как установить веб-сервер, как использовать браузер и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты.

На первой фотографии во Всемирной паутине была изображена пародийная филк-группа Les Horribles Cernettes.[1] Тим Бернес-Ли попросил их отсканированные снимки и лидера группы после CERN Hardronic Festival.
И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945 году Ванна́вер Буш разработал концепцию «Memex» — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году).
С 1994 года основную работу по развитию Всемирной паутины взял на себя Консорциум Всемирной паутины (англ. World Wide Web Consortium, W3C), основанный и до сих пор возглавляемый Тимом Бернерсом-Ли. Данный Консорциум — организация, разрабатывающая и внедряющая технологические стандарты для Интернета и Всемирной паутины. Миссия W3C: «Полностью раскрыть потенциал Всемирной паутины путём создания протоколов и принципов, гарантирующих долгосрочное развитие Сети». Две другие важнейшие задачи Консорциума — обеспечить полную «интернационализа́цию Сети́» и сделать Сеть доступной для людей с ограниченными возможностями.
W3C разрабатывает для Интернета единые принципы и стандарты (называемые «Рекоменда́циями», англ. W3C Recommendations), которые затем внедряются производителями программ и оборудования. Таким образом достигается совместимость между программными продуктами и аппаратурой различных компаний, что делает Всемирную сеть более совершенной, универсальной и удобной. Все Рекомендации Консорциума Всемирной паутины открыты, то есть не защищены патентами и могут внедряться любым человеком без всяких финансовых отчислений консорциуму.
Перспективы развития Всемирной паутины
В настоящее время наметились две тенденции в развитии Всемирной паутины: семантическая паутина и социальная паутина. Семантическая паутина предполагает улучшение связности и релевантности информации во Всемирной паутине через введение новых форматов метаданных. Социальная паутина полагается на работу по упорядочиванию имеющейся в Паутине информации, выполняемую самими пользователями Паутины. В рамках второго направления наработки, являющиеся частью семантической паутины, активно используются в качестве инструментов (OPML, микроформаты XHTML).
Существует также популярное понятие Web 2.0, обобщающее сразу несколько направлений развития Всемирной паутины.
Способы активного отображения информации во Всемирной паутине
Информация в вебе может отображаться как пассивно (то есть пользователь может только считывать её), так и активно — тогда пользователь может добавлять информацию и редактировать её. К способам активного отображения информации во Всемирной паутине относятся:
- гостевые книги,
- форумы,
- чаты,
- блоги,
- wiki-проекты,
- системы управления контентом.
Следует отметить, что это деление весьма условно. Так, скажем, блог или гостевую книгу можно рассматривать как частный случай форума, который, в свою очередь, является частным случаем системы управления контентом. Обычно разница проявляется в назначении, подходе и позиционировании того или иного продукта.
Отчасти информация с сайтов может также быть доступна через речь. В Индии уже началось[2] тестирование системы, делающей текстовое содержимое страниц доступным даже для людей, не умеющих читать и писать.
Организации, занимающиеся развитием Всемирной паутины и Интернета в целом
- World Wide Web Consortium, W3C
- The Internet Engineering Task Force, IETF
- Internet Society, ISOC
- International Organization for Standardization, ISO
- Web Standards Group, WSG
- The Web Standards Project
- Unicode Organization
- The Semantic Web Community Portal
Ссылки
- Официальный сайт Консорциума Всемирной паутины
- Знаменитая книга Бернерса-Ли «Плетя паутину: истоки и будущее Всемирной паутины» он-лайн на английском языке
- Историческое предложение Тима Бернерса-Ли для CERN
- Первый в мире веб-сайт (архив)
Литература
- Филдинг, Р.; Геттис, Дж.; Могул, Дж.; Фристик, Г.; Мазинтер, Л.; Лич, П.; Бернерс-Ли, Т. (Июнь 1999). «Hypertext Transfer Protocol — http://1.1«. Request For Comments 2616. Information Sciences Institute.
- Бернерс-Ли, Тим; Брэй, Тим; Конноли, Дэн; Коттон, Пол; Филдинг, Рой; Джекл, Марио; Лилли, Крис; Мендельсон, Ной; Оркард, Дэвид; Уолш, Норман; Уиллиамс, Стюарт (Декабрь 15, 2004). «Architecture of the World Wide Web, Volume One«. Version 20041215. W3C.
- Поло, Лучано World Wide Web Technology Architecture: A Conceptual Analysis. New Devices (2003). Проверено Июль 31 2005.
Примечания
- ↑ http://musiclub.web.cern.ch/MusiClub/bands/cernettes/firstband.html
- ↑ IBM разработала голосовой интернет
Wikimedia Foundation.
2010.