
- Top Definitions
- Quiz
- Related Content
- Examples
- British
This shows grade level based on the word’s complexity.
[ rep-ri-zen-tey-shuhn, -zuhn- ]
/ ˌrɛp rɪ zɛnˈteɪ ʃən, -zən- /
This shows grade level based on the word’s complexity.
noun
the act of representing.
the state of being represented.
the expression or designation by some term, character, symbol, or the like.
action or speech on behalf of a person, group, business house, state, or the like by an agent, deputy, or representative.
the state or fact of being so represented: to demand representation on a board of directors.
Government. the state, fact, or right of being represented by delegates having a voice in legislation or government.
the body or number of representatives, as of a constituency.
Diplomacy.
- the act of speaking or negotiating on behalf of a state.
- an utterance on behalf of a state.
presentation to the mind, as of an idea or image.
a mental image or idea so presented; concept.
the act of portrayal, picturing, or other rendering in visible form.
a picture, figure, statue, etc.
the production or a performance of a play or the like, as on the stage.
Often representations. a description or statement, as of things true or alleged.
a statement of facts, reasons, etc., made in appealing or protesting; a protest or remonstrance.
Law. an implication or statement of fact to which legal liability may attach if material: a representation of authority.
QUIZ
CAN YOU ANSWER THESE COMMON GRAMMAR DEBATES?
There are grammar debates that never die; and the ones highlighted in the questions in this quiz are sure to rile everyone up once again. Do you know how to answer the questions that cause some of the greatest grammar debates?
Which sentence is correct?
Origin of representation
1375–1425; late Middle English representacion<Latin repraesentātiōn- (stem of repraesentātiō), equivalent to repraesentāt(us) (past participle of repraesentāre to represent) + -iōn--ion
OTHER WORDS FROM representation
non·rep·re·sen·ta·tion, nouno·ver·rep·re·sen·ta·tion, nounpre·rep·re·sen·ta·tion, nounself-rep·re·sen·ta·tion, noun
un·der·rep·re·sen·ta·tion, noun
Words nearby representation
repr., reprehend, reprehensible, reprehension, represent, representation, representational, representationalism, representative, representatives, repress
Dictionary.com Unabridged
Based on the Random House Unabridged Dictionary, © Random House, Inc. 2023
Words related to representation
depiction, image, portrayal, adumbration, copy, delegation, delineation, design, duplicate, enactment, exhibition, illustration, imitation, impersonation, impression, likeness, narration, personification, reproduction, account
How to use representation in a sentence
-
It was a metaphorical statement of giving and withdrawing consent for a show rooted in a literal representation of Coel being assaulted.
-
The mathematically manipulated results are passed on and augmented through the stages, finally producing an integrated representation of a face.
-
I hope this list—a representation of the most consequential changes taking places in our world—is similarly useful for you.
-
“Given the moment we are in, I can only hope our institutions really understand what this failure of representation means to our city,” he said.
-
The voters don’t want to have an elected city attorney on the, and representation said, that’s fine.
-
With all that said, representation of each of these respective communities has increased in the new Congress.
-
As this excellent piece in Mother Jones describes, however, Holsey had outrageously poor representation during his trial.
-
During that time days, Livvix went through court hearings without legal representation.
-
What do you think prompted the change in comic book representation of LGBTQ characters?
-
Barbie is an unrealistic, unhealthy, insulting representation of female appearance.
-
With less intelligent children traces of this tendency to take pictorial representation for reality may appear as late as four.
-
As observation widens and grows finer, the first bald representation becomes fuller and more life-like.
-
The child now aims at constructing a particular linear representation, that of a man, a horse, or what not.
-
He had heard it hinted that allowing the colonies representation in Parliament would be a simple plan for making taxes legal.
-
But sufficient can be discerned for the grasping of the idea, which seems to be a representation of the Nativity.
British Dictionary definitions for representation
noun
the act or an instance of representing or the state of being represented
anything that represents, such as a verbal or pictorial portrait
anything that is represented, such as an image brought clearly to mind
the principle by which delegates act for a constituency
a body of representatives
contract law a statement of fact made by one party to induce another to enter into a contract
an instance of acting for another, on his authority, in a particular capacity, such as executor or administrator
a dramatic production or performance
(often plural) a statement of facts, true or alleged, esp one set forth by way of remonstrance or expostulation
linguistics an analysis of a word, sentence, etc, into its constituentsphonetic representation
Collins English Dictionary — Complete & Unabridged 2012 Digital Edition
© William Collins Sons & Co. Ltd. 1979, 1986 © HarperCollins
Publishers 1998, 2000, 2003, 2005, 2006, 2007, 2009, 2012
1
a
: an artistic likeness or image
b(1)
: a statement or account made to influence opinion or action
(2)
: an incidental or collateral statement of fact on the faith of which a contract is entered into
c
: a dramatic production or performance
d(1)
: a usually formal statement made against something or to effect a change
(2)
: a usually formal protest
2
b(1)
: the action or fact of one person standing for another so as to have the rights and obligations of the person represented
(2)
: the substitution of an individual or class in place of a person (such as a child for a deceased parent)
c
: the action of representing or the fact of being represented especially in a legislative body
3
: the body of persons representing a constituency
representational
adjective
representationally
adverb

Example Sentences
Each state has equal representation in the Senate.
The letters of the alphabet are representations of sounds.
Recent Examples on the Web
With the expulsion of Pearson and Jones — who represent parts of Memphis and Nashville, respectively — two of Tennessee’s most diverse cities are stripped of representation temporarily.
— Liz Goodwin And Matthew Brown, Anchorage Daily News, 8 Apr. 2023
Liz Goodwin And Matthew Brown, Anchorage Daily News, 8 Apr. 2023
In Tennessee, the General Assembly has carved up the state’s more Democratic-leaning cities and all but guaranteed that the majority of political representation is determined in Republican primaries instead of in general elections, leaving lawmakers more responsive to a far-right base.
—Eliza Fawcett, New York Times, 7 Apr. 2023
With the expulsion of Pearson and Jones — who represent parts of Memphis and Nashville, respectively — two of the Tennessee’s most diverse cities are stripped of representation temporarily.
—María Luisa Paúl, Washington Post, 7 Apr. 2023
With no shortage of representation on the big stage, The Enquirer takes a look at some of high-profile athletes from the area making a name for themselves in the collegiate and professional ranks.
—Shelby Dermer, The Enquirer, 6 Apr. 2023
Since 2000, the company has achieved a 60% increase in African American and Black employees in entry-level through manager roles, and a 94% increase in representation at the director level.
—Megan Leonhardt, Fortune, 4 Apr. 2023
Hernandez eventually committed suicide in prison, but had publicly thanked Baez for his representation.
—Steve Helling, Peoplemag, 31 Mar. 2023
The prevailing theme of the press Alonso has done recently is her passionate belief in broadening representation at Marvel, which makes her acrimonious departure from Disney that much more notable.
—Angelique Jackson, Variety, 28 Mar. 2023
McCoughtry also named Carolyn Peck, the first African American woman to coach her team to an NCAA women’s basketball title in 1999 with Purdue, as another example of representation in the sport.
—Alanis Thames, oregonlive, 28 Mar. 2023
See More
These examples are programmatically compiled from various online sources to illustrate current usage of the word ‘representation.’ Any opinions expressed in the examples do not represent those of Merriam-Webster or its editors. Send us feedback about these examples.
Word History
First Known Use
15th century, in the meaning defined at sense 1
Time Traveler
The first known use of representation was
in the 15th century
Dictionary Entries Near representation
Cite this Entry
“Representation.” Merriam-Webster.com Dictionary, Merriam-Webster, https://www.merriam-webster.com/dictionary/representation. Accessed 14 Apr. 2023.
Share
More from Merriam-Webster on representation
Last Updated:
12 Apr 2023
— Updated example sentences
Subscribe to America’s largest dictionary and get thousands more definitions and advanced search—ad free!
Merriam-Webster unabridged
Word representations induced from models with discrete latent variables
(e.g. HMMs) have been shown to be beneficial in many NLP applications. In this
work, we exploit labeled syntactic dependency trees and formalize the induction
problem as unsupervised learning of tree-structured hidden Markov models.
Syntactic functions are used as additional observed variables in the model,
influencing both transition and emission components. Such syntactic information
can potentially lead to capturing more fine-grain and functional distinctions
between words, which, in turn, may be desirable in many NLP applications. We
evaluate the word representations on two tasks — named entity recognition and
semantic frame identification. We observe improvements from exploiting
syntactic function information in both cases, and the results rivaling those of
state-of-the-art representation learning methods. Additionally, we revisit the
relationship between sequential and unlabeled-tree models and find that the
advantage of the latter is not self-evident.
READ FULL TEXT
Table of Contents
- What is Transfer Learning
- Word2Vec
- Downloading Google’s word2Vec model
- Support Ticket Classification using Word2Vec
What is Transfer Learning?
Transfer learning is one of the most important breakthroughs in machine learning! It helps us to use the models created by others.
Since everyone doesn’t have access to billions of text snippets and GPU’s/TPU’s to extract patterns from it. If someone can do it and pass on the learnings then we can directly use it and solve business problems.
When someone else creates a model on a huge generic dataset and passes only the model to others for use. This is known as transfer learning because everyone doesn’t have to train the model on such a huge amount of data, hence, they “transfer” the learnings from others to their system.
Transfer learning is really helpful in NLP. Specially vectorization of text, because converting text to vectors for 50K records also is slow. So if we can use the pre-trained models from others, that helps to resolve the problem of converting the text data to numeric data, and we can continue with the other tasks, such as classification or sentiment analysis, etc.
Stanford’s GloVe and Google’s Word2Vec are two really popular choices in Text vectorization using transfer learning.
Word2Vec
Word2vec is not a single algorithm but a combination of two techniques – CBOW(Continuous bag of words) and Skip-gram model.
Both of these are shallow neural networks that map word(s) to the target variable which is also a word(s). Both of these techniques learn weights of the neural network which acts as word vector representations.
Basically each word is represented as a vector of numbers.

CBOW
CBOW(Continuous bag of words) predicts the probability of a word to occur given the words surrounding it. We can consider a single word or a group of words.
Skip-gram model
The Skip-gram model architecture usually tries to achieve the reverse of what the CBOW model does. It tries to predict the source context words (surrounding words) given a target word (the center word)
Which one should be used?
For a large corpus with higher dimensions, it is better to use skip-gram but it is slow to train. Whereas CBOW is better for small corpus and is faster to train too.

Word2Vec vectors are basically a form of word representation that bridges the human understanding of language to that of a machine.
They have learned representations of text in an n-dimensional space where words that have the same meaning have a similar representation. Meaning that two similar words are represented by almost similar vectors(set of numbers) that are very closely placed in a vector space.
For example, look at the below diagram, the words King and Queen appear closer to each other. Similarly, the words Man and Woman appear closer to each other due to the kind of numeric vectors assigned to these words by Word2Vec. If you compute the distance between two words using their numeric vectors, then those words which are related to each other with a context will have less distance between them.

Case Study: Support Ticket Classification using Word2Vec
In a previous case study, I showed you how can you convert Text data into numeric using TF-IDF. And then use it to create a classification model to predict the priority of support tickets.
In this case study, I will use the same dataset and show you how can you use the numeric representations of words from Word2Vec and create a classification model.
Problem Statement: Use the Microsoft support ticket text description to classify a new ticket into P1/P2/P3.
You can download the data required for this case study here.
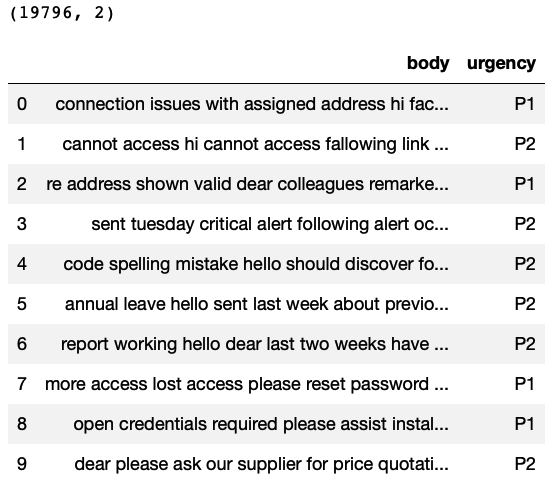
Reading the support ticket data
This data contains 19,796 rows and 2 columns. The column”body” represents the ticket description and the column “urgency” represents the Priority.
|
import pandas as pd import numpy as np import warnings warnings.filterwarnings(‘ignore’) # Reading the data TicketData=pd.read_csv(‘supportTicketData.csv’) # Printing number of rows and columns print(TicketData.shape) # Printing sample rows TicketData.head(10) |
Visualising the distribution of the Target variable
Now we try to see if the Target variable has a balanced distribution or not? Basically each priority type has enough rows to be learned.
If the data would have been imbalanced, for example very less number of rows for the P1 category, then you need to balance the data using any of the popular techniques like over-sampling, under-sampling, or SMOTE.
|
# Number of unique values for urgency column # You can see there are 3 ticket types print(TicketData.groupby(‘urgency’).size()) # Plotting the bar chart %matplotlib inline TicketData.groupby(‘urgency’).size().plot(kind=‘bar’); |

The above bar plot shows that there are enough rows for each ticket type. Hence, this is balanced data for classification.
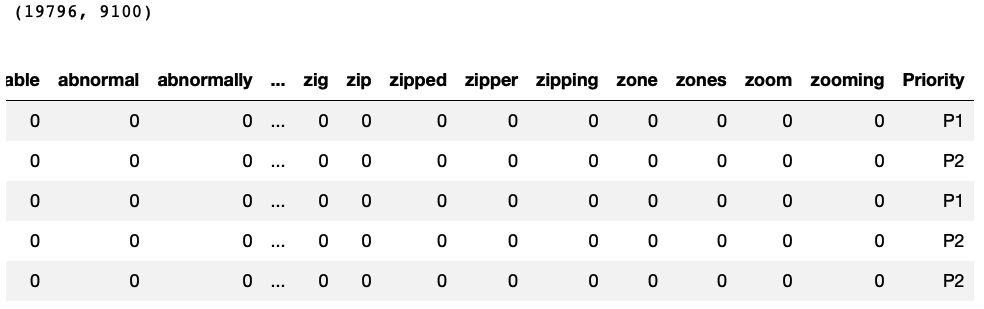
Count Vectorization: converting text data to numeric
This step will help to remove all the stopwords and create a document term matrix.
We will use this matrix to do further processing. For each word in the document term matrix, we will use the Word2Vec numeric vector representation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Count vectorization of text from sklearn.feature_extraction.text import CountVectorizer # Ticket Data corpus = TicketData[‘body’].values # Creating the vectorizer vectorizer = CountVectorizer(stop_words=‘english’) # Converting the text to numeric data X = vectorizer.fit_transform(corpus) #print(vectorizer.get_feature_names()) # Preparing Data frame For machine learning # Priority column acts as a target variable and other columns as predictors CountVectorizedData=pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names()) CountVectorizedData[‘Priority’]=TicketData[‘urgency’] print(CountVectorizedData.shape) CountVectorizedData.head() |
Word2Vec conversion:
Now we will use the Word2Vec representation of words to convert the above document term matrix to a smaller matrix, where the columns are the sum of the vectors for each word present in the document.
For example, look at the below diagram. The flow is shown for one sentence, the same happens for every sentence in the corpus.
- The numeric representation of each word is taken from Word2Vec.
- All the vectors are added, hence producing a single vector
- That single vector represents the information of the sentence, hence treated as one row.

Note: If you feel that your laptop is hanging due to the processing required for the below commands, you can use google colab notebooks!
Downloading Google’s word2Vec model
- We will Use the Pre-trained word2Vec model from google, It contains word vectors for a vocabulary of 3 million words.
- Trained on around 100 billion words from the google news dataset.
Download link: https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit?usp=sharing
This contains a binary file, that contains numeric representations for each word.
|
#Installing the gensim library required for word2Vec and Doc2Vec !pip install gensim |
|
import gensim #Loading the word vectors from Google trained word2Vec model GoogleModel = gensim.models.KeyedVectors.load_word2vec_format(‘/Users/farukh/Downloads/GoogleNews-vectors-negative300.bin’, binary=True,) |
|
# Each word is a vector of 300 numbers GoogleModel[‘hello’].shape |
![]()
|
# Looking at a sample vector for a word GoogleModel[‘hello’] |

Finding Similar words
This is one of the interesting features of Word2Vec. You can pass a word and find out the most similar words related to the given word.
In the below example, you can see the most relatable word to “king” is “kings” and “queen”. This was possible because of the context learned by the Word2Vec model. Since words like “queen” and “prince” are used in the context of “king”. the numeric word vectors for these words will have similar numbers, hence, the cosine similarity score is high.
|
# Finding similar words # The most_similar() function finds the cosine similarity of the given word with # other words using the word2Vec representations of each word GoogleModel.most_similar(‘king’, topn=5) |

|
# Checking if a word is present in the Model Vocabulary ‘Hello’ in GoogleModel.key_to_index.keys() |
![]()
|
# Creating the list of words which are present in the Document term matrix WordsVocab=CountVectorizedData.columns[:—1] # Printing sample words WordsVocab[0:10] |

Converting every sentence to a numeric vector
For each word in a sentence, we extract the numeric form of the word and then simply add all the numeric forms for that sentence to represent the sentence.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Defining a function which takes text input and returns one vector for each sentence def FunctionText2Vec(inpTextData): # Converting the text to numeric data X = vectorizer.transform(inpTextData) CountVecData=pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names()) # Creating empty dataframe to hold sentences W2Vec_Data=pd.DataFrame() # Looping through each row for the data for i in range(CountVecData.shape[0]): # initiating a sentence with all zeros Sentence = np.zeros(300) # Looping thru each word in the sentence and if its present in # the Word2Vec model then storing its vector for word in WordsVocab[CountVecData.iloc[i , :]>=1]: #print(word) if word in GoogleModel.key_to_index.keys(): Sentence=Sentence+GoogleModel[word] # Appending the sentence to the dataframe W2Vec_Data=W2Vec_Data.append(pd.DataFrame([Sentence])) return(W2Vec_Data) |
|
# Since there are so many words… This will take some time # Calling the function to convert all the text data to Word2Vec Vectors W2Vec_Data=FunctionText2Vec(TicketData[‘body’]) # Checking the new representation for sentences W2Vec_Data.shape |

![]()
|
# Comparing the above with the document term matrix CountVectorizedData.shape |
![]()
Preparing Data for ML
|
# Adding the target variable W2Vec_Data.reset_index(inplace=True, drop=True) W2Vec_Data[‘Priority’]=CountVectorizedData[‘Priority’] # Assigning to DataForML variable DataForML=W2Vec_Data DataForML.head() |

Splitting the data into training and testing
|
# Separate Target Variable and Predictor Variables TargetVariable=DataForML.columns[—1] Predictors=DataForML.columns[:—1] X=DataForML[Predictors].values y=DataForML[TargetVariable].values # Split the data into training and testing set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=428) # Sanity check for the sampled data print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) |

Standardization/Normalization
This is an optional step. It can speed up the processing of the model training.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from sklearn.preprocessing import StandardScaler, MinMaxScaler # Choose either standardization or Normalization # On this data Min Max Normalization is used because we need to fit Naive Bayes # Choose between standardization and MinMAx normalization #PredictorScaler=StandardScaler() PredictorScaler=MinMaxScaler() # Storing the fit object for later reference PredictorScalerFit=PredictorScaler.fit(X) # Generating the standardized values of X X=PredictorScalerFit.transform(X) # Split the data into training and testing set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=428) # Sanity check for the sampled data print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) |

Training ML classification models
Now the data is ready for machine learning. There are 300-predictors and one target variable. We will use the below algorithms and select the best one out of them based on the accuracy scores you can add more algorithms to this list as per your preferences.
- Naive Bayes
- KNN
- Logistic Regression
- Decision Trees
- AdaBoost
Naive Bayes
This algorithm trains very fast! The accuracy may not be very high always but the speed is guaranteed!
I have commented the cross-validation section just to save computing time. You can uncomment and execute those commands as well.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Naive Bayes from sklearn.naive_bayes import GaussianNB, MultinomialNB # GaussianNB is used in Binomial Classification # MultinomialNB is used in multi-class classification #clf = GaussianNB() clf = MultinomialNB() # Printing all the parameters of Naive Bayes print(clf) NB=clf.fit(X_train,y_train) prediction=NB.predict(X_test) # Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) # Printing the Overall Accuracy of the model F1_Score=metrics.f1_score(y_test, prediction, average=‘weighted’) print(‘Accuracy of the model on Testing Sample Data:’, round(F1_Score,2)) # Importing cross validation function from sklearn from sklearn.model_selection import cross_val_score # Running 10-Fold Cross validation on a given algorithm # Passing full data X and y because the K-fold will split the data and automatically choose train/test Accuracy_Values=cross_val_score(NB, X , y, cv=5, scoring=‘f1_weighted’) print(‘nAccuracy values for 5-fold Cross Validation:n’,Accuracy_Values) print(‘nFinal Average Accuracy of the model:’, round(Accuracy_Values.mean(),2)) |

KNN
This is a distance-based supervised ML algorithm. Make sure you standardize/normalize the data before using this algorithm, otherwise the accuracy will be low.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# K-Nearest Neighbor(KNN) from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=15) # Printing all the parameters of KNN print(clf) # Creating the model on Training Data KNN=clf.fit(X_train,y_train) prediction=KNN.predict(X_test) # Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) # Printing the Overall Accuracy of the model F1_Score=metrics.f1_score(y_test, prediction, average=‘weighted’) print(‘Accuracy of the model on Testing Sample Data:’, round(F1_Score,2)) # Importing cross validation function from sklearn from sklearn.model_selection import cross_val_score # Running 10-Fold Cross validation on a given algorithm # Passing full data X and y because the K-fold will split the data and automatically choose train/test #Accuracy_Values=cross_val_score(KNN, X , y, cv=10, scoring=’f1_weighted’) #print(‘nAccuracy values for 10-fold Cross Validation:n’,Accuracy_Values) #print(‘nFinal Average Accuracy of the model:’, round(Accuracy_Values.mean(),2)) # Plotting the feature importance for Top 10 most important columns # There is no built-in method to get feature importance in KNN |

Logistic Regression
This algorithm also trains very fast. Hence, whenever we are using high dimensional data, trying out Logistic regression is sensible. The accuracy may not be always the best.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# Logistic Regression from sklearn.linear_model import LogisticRegression # choose parameter Penalty=’l1′ or C=1 # choose different values for solver ‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’ clf = LogisticRegression(C=10,penalty=‘l2’, solver=‘newton-cg’) # Printing all the parameters of logistic regression # print(clf) # Creating the model on Training Data LOG=clf.fit(X_train,y_train) # Generating predictions on testing data prediction=LOG.predict(X_test) # Printing sample values of prediction in Testing data TestingData=pd.DataFrame(data=X_test, columns=Predictors) TestingData[‘Survived’]=y_test TestingData[‘Predicted_Survived’]=prediction print(TestingData.head()) # Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(prediction, y_test)) ## Printing the Overall Accuracy of the model F1_Score=metrics.f1_score(y_test, prediction, average=‘weighted’) print(‘Accuracy of the model on Testing Sample Data:’, round(F1_Score,2)) ## Importing cross validation function from sklearn #from sklearn.model_selection import cross_val_score ## Running 10-Fold Cross validation on a given algorithm ## Passing full data X and y because the K-fold will split the data and automatically choose train/test #Accuracy_Values=cross_val_score(LOG, X , y, cv=10, scoring=’f1_weighted’) #print(‘nAccuracy values for 10-fold Cross Validation:n’,Accuracy_Values) #print(‘nFinal Average Accuracy of the model:’, round(Accuracy_Values.mean(),2)) |


Decision Tree
This algorithm trains slower as compared to Naive Bayes or Logistic, but it can produce better results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# Decision Trees from sklearn import tree #choose from different tunable hyper parameters clf = tree.DecisionTreeClassifier(max_depth=20,criterion=‘gini’) # Printing all the parameters of Decision Trees print(clf) # Creating the model on Training Data DTree=clf.fit(X_train,y_train) prediction=DTree.predict(X_test) # Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) # Printing the Overall Accuracy of the model F1_Score=metrics.f1_score(y_test, prediction, average=‘weighted’) print(‘Accuracy of the model on Testing Sample Data:’, round(F1_Score,2)) # Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(DTree.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind=‘barh’) # Importing cross validation function from sklearn #from sklearn.model_selection import cross_val_score # Running 10-Fold Cross validation on a given algorithm # Passing full data X and y because the K-fold will split the data and automatically choose train/test #Accuracy_Values=cross_val_score(DTree, X , y, cv=10, scoring=’f1_weighted’) #print(‘nAccuracy values for 10-fold Cross Validation:n’,Accuracy_Values) #print(‘nFinal Average Accuracy of the model:’, round(Accuracy_Values.mean(),2)) |

Adaboost
This is a tree based boosting algorithm. If the data is not high dimensional, we can use this algorithm. otherwise it takes lot of time to train.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# Adaboost from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier # Choosing Decision Tree with 1 level as the weak learner DTC=DecisionTreeClassifier(max_depth=2) clf = AdaBoostClassifier(n_estimators=20, base_estimator=DTC ,learning_rate=0.01) # Printing all the parameters of Adaboost print(clf) # Creating the model on Training Data AB=clf.fit(X_train,y_train) prediction=AB.predict(X_test) # Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) # Printing the Overall Accuracy of the model F1_Score=metrics.f1_score(y_test, prediction, average=‘weighted’) print(‘Accuracy of the model on Testing Sample Data:’, round(F1_Score,2)) # Importing cross validation function from sklearn #from sklearn.model_selection import cross_val_score # Running 10-Fold Cross validation on a given algorithm # Passing full data X and y because the K-fold will split the data and automatically choose train/test #Accuracy_Values=cross_val_score(AB, X , y, cv=10, scoring=’f1_weighted’) #print(‘nAccuracy values for 10-fold Cross Validation:n’,Accuracy_Values) #print(‘nFinal Average Accuracy of the model:’, round(Accuracy_Values.mean(),2)) # Plotting the feature importance for Top 10 most important columns #%matplotlib inline #feature_importances = pd.Series(AB.feature_importances_, index=Predictors) #feature_importances.nlargest(10).plot(kind=’barh’) |

Training the best model on full data
Logistic regression algorithm is producing the highest accuracy on this data, hence, selecting it as final model for deployment.
|
# Generating the Logistic model on full data # This is the best performing model clf = LogisticRegression(C=10,penalty=‘l2’, solver=‘newton-cg’) FinalModel=clf.fit(X,y) |
Making predictions on new cases
To deploy this model, all we need to do is write a function which takes the new data as input, performs all the pre-processing required and passes the data to the Final model.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Defining a function which converts words into numeric vectors for prediction def FunctionPredictUrgency(inpText): # Generating the Glove word vector embeddings X=FunctionText2Vec(inpText) #print(X) # If standardization/normalization was done on training # then the above X must also be converted to same platform # Generating the normalized values of X X=PredictorScalerFit.transform(X) # Generating the prediction using Naive Bayes model and returning Prediction=FinalModel.predict(X) Result=pd.DataFrame(data=inpText, columns=[‘Text’]) Result[‘Prediction’]=Prediction return(Result) |
|
# Calling the function NewTicket=[«help to review the issue», «Please help to resolve system issue»] FunctionPredictUrgency(inpText=NewTicket) |

Conclusion
Transfer learning has made NLP research faster by providing an easy way to share the models produced by big companies and build on top of that. Similar to Word2Vec we have other algorithms like GloVe, Doc2Vec, and BERT which I have discussed in separate case studies.
I hope this post helped you to understand how Word2Vec vectors are created and how to use them to convert any text into numeric form.
Consider sharing this post with your friends to spread the knowledge and help me grow as well! 🙂

Lead Data Scientist
Farukh is an innovator in solving industry problems using Artificial intelligence. His expertise is backed with 10 years of industry experience. Being a senior data scientist he is responsible for designing the AI/ML solution to provide maximum gains for the clients. As a thought leader, his focus is on solving the key business problems of the CPG Industry. He has worked across different domains like Telecom, Insurance, and Logistics. He has worked with global tech leaders including Infosys, IBM, and Persistent systems. His passion to teach inspired him to create this website!