
С помощью модуля python-docx можно создавать и изменять документы MS Word с расширением .docx. Чтобы установить этот модуль, выполняем команду
> pip install python-docx
При установке модуля надо вводить python-docx, а не docx (это другой модуль). В то же время при импортировании модуля python-docx следует использовать import docx, а не import python-docx.
Чтение документов MS Word
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx эта структура представлена тремя различными типами данных. На самом верхнем уровне объект Document представляет собой весь документ. Объект Document содержит список объектов Paragraph, которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов Run, представляющих собой фрагменты текста с различными стилями форматирования.

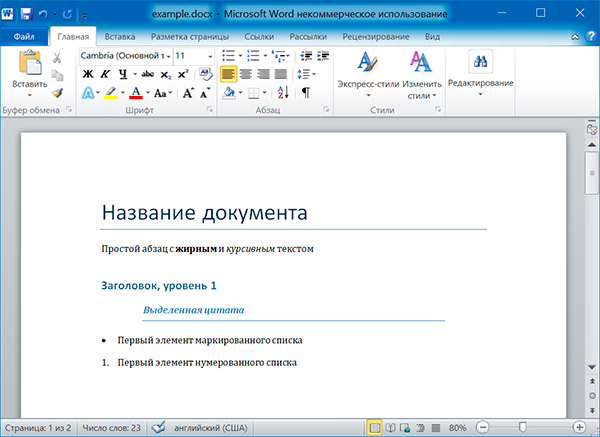
import docx doc = docx.Document('example.docx') # количество абзацев в документе print(len(doc.paragraphs)) # текст первого абзаца в документе print(doc.paragraphs[0].text) # текст второго абзаца в документе print(doc.paragraphs[1].text) # текст первого Run второго абзаца print(doc.paragraphs[1].runs[0].text)
6 Название документа Простой абзац с жирным и курсивным текстом Простой абзац с
Получаем весь текст из документа:
text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) print('n'.join(text))
Название документа Простой абзац с жирным и курсивным текстом Заголовок, уровень 1 Выделенная цитата Первый элемент маркированного списка Первый элемент нумерованного списка
Стилевое оформление
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к объектам Paragraph, стили символов, которые могут применяться к объектам Run. Как объектам Paragraph, так и объектам Run можно назначать стили, присваивая их атрибутам style значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля задано значение None, то у объекта Paragraph или Run не будет связанного с ним стиля.
Стили абзацев
NormalBody TextBody Text 2Body Text 3CaptionHeading 1Heading 2Heading 3Heading 4Heading 5Heading 6Heading 7Heading 8Heading 9Intense QuoteListList 2List 3List BulletList Bullet 2List Bullet 3List ContinueList Continue 2List Continue 3List NumberList Number 2List Number 3List ParagraphMacro TextNo SpacingQuoteSubtitleTOCHeadingTitle
Стили символов
EmphasisStrongBook TitleDefault Paragraph FontIntense EmphasisSubtle EmphasisIntense ReferenceSubtle Reference
paragraph.style = 'Quote' run.style = 'Book Title'
Атрибуты объекта Run
Отдельные фрагменты текста, представленные объектами Run, могут подвергаться дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может быть задано одно из трех значений: True (атрибут активизирован), False (атрибут отключен) и None (применяется стиль, установленный для данного объекта Run).
bold— Полужирное начертаниеunderline— Подчеркнутый текстitalic— Курсивное начертаниеstrike— Зачеркнутый текст
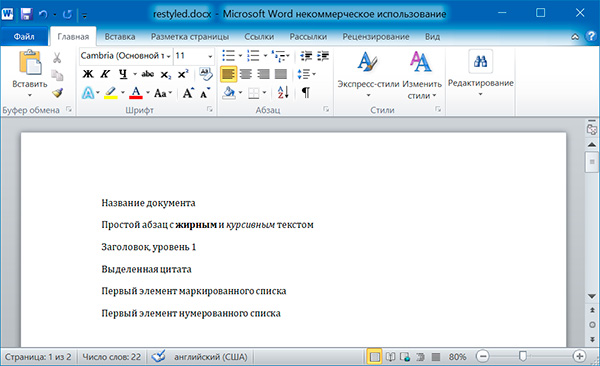
Изменим стили для всех параграфов нашего документа:
import docx doc = docx.Document('example.docx') # изменяем стили для всех параграфов for paragraph in doc.paragraphs: paragraph.style = 'Normal' doc.save('restyled.docx')
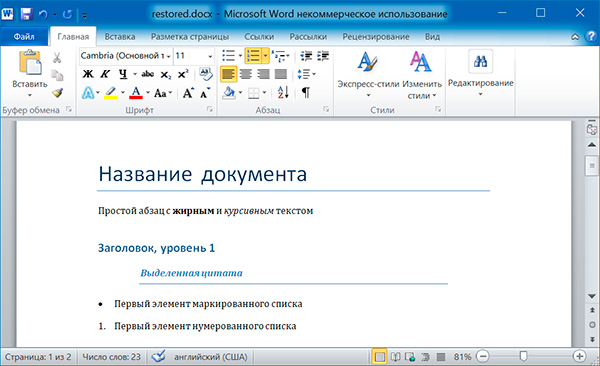
А теперь восстановим все как было:
import docx os.chdir('C:\example') doc1 = docx.Document('example.docx') doc2 = docx.Document('restyled.docx') # получаем из первого документа стили всех абзацев styles = [] for paragraph in doc1.paragraphs: styles.append(paragraph.style) # применяем стили ко всем абзацам второго документа for i in range(len(doc2.paragraphs)): doc2.paragraphs[i].style = styles[i] doc2.save('restored.docx')
Изменим форматирвание объектов Run второго абзаца:
import docx doc = docx.Document('example.docx') # добавляем стиль символов для runs[0] doc.paragraphs[1].runs[0].style = 'Intense Emphasis' # добавляем подчеркивание для runs[4] doc.paragraphs[1].runs[4].underline = True doc.save('restyled2.docx')
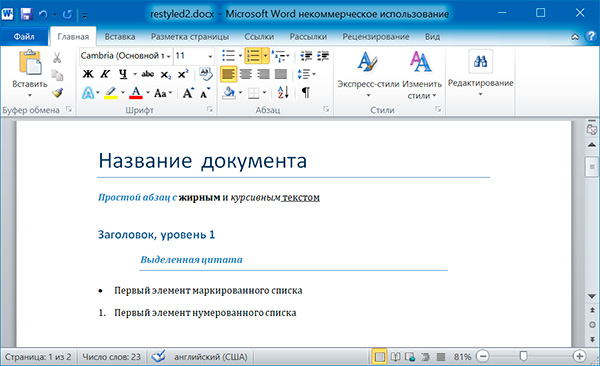
Запись докуменов MS Word
Добавление абзацев осуществляется вызовом метода add_paragraph() объекта Document. Для добавления текста в конец существующего абзаца, надо вызвать метод add_run() объекта Paragraph:
import docx doc = docx.Document() # добавляем первый параграф doc.add_paragraph('Здравствуй, мир!') # добавляем еще два параграфа par1 = doc.add_paragraph('Это второй абзац.') par2 = doc.add_paragraph('Это третий абзац.') # добавляем текст во второй параграф par1.add_run(' Этот текст был добавлен во второй абзац.') # добавляем текст в третий параграф par2.add_run(' Добавляем текст в третий абзац.').bold = True doc.save('helloworld.docx')
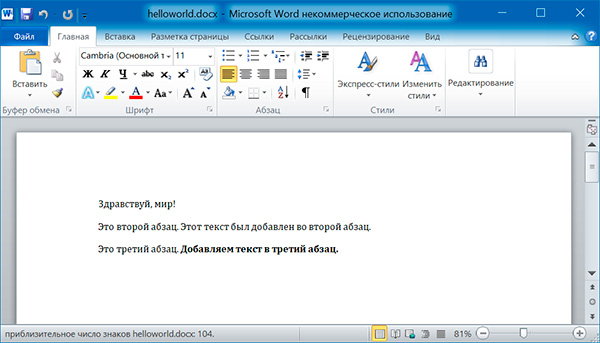
Оба метода, add_paragraph() и add_run() принимают необязательный второй аргумент, содержащий строку стиля, например:
doc.add_paragraph('Здравствуй, мир!', 'Title')
Добавление заголовков
Вызов метода add_heading() приводит к добавлению абзаца, отформатированного в соответствии с одним из возможных стилей заголовков:
doc.add_heading('Заголовок 0', 0) doc.add_heading('Заголовок 1', 1) doc.add_heading('Заголовок 2', 2) doc.add_heading('Заголовок 3', 3) doc.add_heading('Заголовок 4', 4)
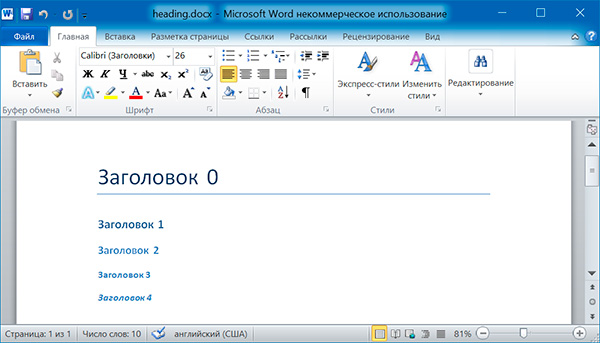
Аргументами метода add_heading() являются строка текста и целое число от 0 до 4. Значению 0 соответствует стиль заголовка Title.
Добавление разрывов строк и страниц
Чтобы добавить разрыв строки (а не добавлять новый абзац), нужно вызвать метод add_break() объекта Run. Если же требуется добавить разрыв страницы, то методу add_break() надо передать значение docx.enum.text.WD_BREAK.PAGE в качестве единственного аргумента:
import docx doc = docx.Document() doc.add_paragraph('Это первая страница') doc.paragraphs[0].runs[0].add_break(docx.enum.text.WD_BREAK.PAGE) doc.add_paragraph('Это вторая страница') doc.save('pages.docx')
Добавление изображений
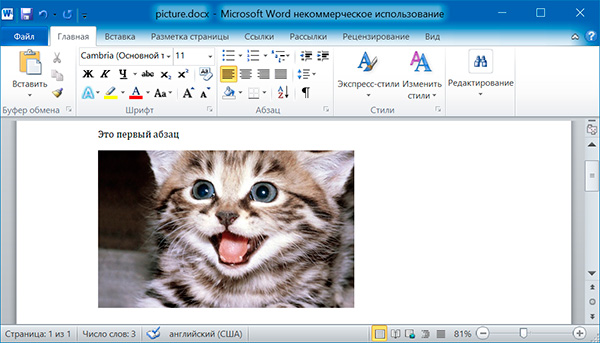
Метод add_picture() объекта Document позволяет добавлять изображения в конце документа. Например, добавим в конец документа изображение kitten.jpg шириной 10 сантиметров:
import docx doc = docx.Document() doc.add_paragraph('Это первый абзац') doc.add_picture('kitten.jpg', width = docx.shared.Cm(10)) doc.save('picture.docx')
Именованные аргументы width и height задают ширину и высоту изображения. Если их опустить, то значения этих аргументов будут определяться размерами самого изображения.
Добавление таблицы
import docx doc = docx.Document() # добавляем таблицу 3x3 table = doc.add_table(rows = 3, cols = 3) # применяем стиль для таблицы table.style = 'Table Grid' # заполняем таблицу данными for row in range(3): for col in range(3): # получаем ячейку таблицы cell = table.cell(row, col) # записываем в ячейку данные cell.text = str(row + 1) + str(col + 1) doc.save('table.docx')
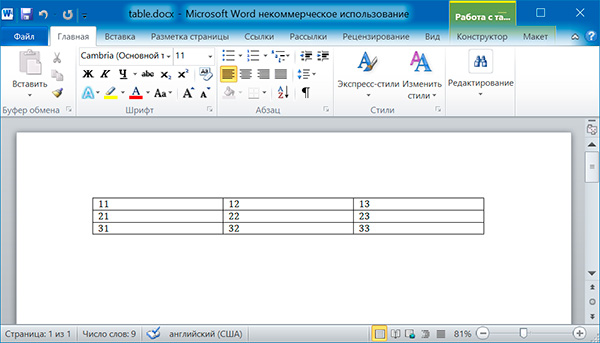
import docx doc = docx.Document('table.docx') # получаем первую таблицу в документе table = doc.tables[0] # читаем данные из таблицы for row in table.rows: string = '' for cell in row.cells: string = string + cell.text + ' ' print(string)
11 12 13 21 22 23 31 32 33
Дополнительно
- Документация python-docx
Поиск:
MS • Python • Web-разработка • Word • Модуль
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Модуль python-docx предназначен для создания и обновления файлов с расширением .docx — Microsoft Word. Этот модуль имеет одну зависимость: сторонний модуль lxml.
Модуль python-docx размещен на PyPI, поэтому установка относительно проста.
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль python-docx (VirtualEnv):~$ python3 -m pip install -U python-docx
Основы работы с файлами Microsoft Word на Python.
- Открытие/создание документа;
- Добавление заголовка документа;
- Добавление абзаца;
- Применение встроенного стиля в Microsoft Word к абзацу;
- Жирный, курсив и подчеркнутый текст в абзаце;
- Применение стилей Microsoft Word к символам текста (к прогону);
- Пользовательский стиль символов текста;
- Добавление разрыва страницы;
- Добавление картинки в документ;
- Чтение документов MS Word.
Открытие/создание документа.
Первое, что вам понадобится, это документ, над которым вы будете работать. Самый простой способ:
from docx import Document # создание документа document = Document() # открытие документа document = Document('/path/to/document.docx')
При этом создается пустой документ, основанный на «шаблоне» по умолчанию. Другими словами, происходит примерно то же самое, когда пользователь нажимает на иконку в Microsoft Word «Новый документ» с использованием встроенных значений по умолчанию.
При этом шрифт документа и его размер по умолчанию для всего документа можно задать следующим образом:
from docx import Document from docx.shared import Pt doc = Document() # задаем стиль текста по умолчанию style = doc.styles['Normal'] # название шрифта style.font.name = 'Arial' # размер шрифта style.font.size = Pt(14) document.add_paragraph('Текст документа')
Так же, можно открывать существующий документ Word и работать с ним при помощи модуля python-docx. Для этого, в конструктор класса Document() необходимо передать путь к существующему документу Microsoft Word.
Добавление заголовка документа.
В любом документе, основной текст делится на разделы, каждый из которых начинается с заголовка. Название таких разделов можно добавить методом Document.add_heading():
# без указания аргумента `level` # добавляется заголовок "Heading 1" head = document.add_heading('Основы работы с файлами Microsoft Word на Python.') from docx.enum.text import WD_ALIGN_PARAGRAPH # выравнивание посередине head.alignment = WD_ALIGN_PARAGRAPH.CENTER
По умолчанию, добавляется заголовок верхнего уровня, который отображается в Word как «Heading 1». Если нужен заголовок для подраздела, то просто указываем желаемый уровень в виде целого числа от 1 до 9:
document.add_heading('Добавление заголовка документа', level=2)
Если указать level=0, то будет добавлен текст с встроенным стилем титульной страницы. Такой стиль может быть полезен для заголовка относительно короткого документа без отдельной титульной страницы.
Так же, заголовки разделов можно добавлять методом document.add_paragraph().add_run(), с указанным размером шрифта.
Например:
from docx import Document from docx.shared import Pt doc = Document() # добавляем текст прогоном run = doc.add_paragraph().add_run('Заголовок, размером 24 pt.') # размер шрифта run.font.size = Pt(24) run.bold = True doc.save('test.docx')
Добавление абзаца.
Абзацы в Word имеют основополагающее значение. Они используются для добавления колонтитулов, основного текста, заголовков, элементов списков, картинок и т.д.
Смотрим самый простой способ добавить абзац/параграф:
p = document.add_paragraph('Абзацы в Word имеют основополагающее значение.')
Метод Document.add_paragraph() возвращает ссылку на только что добавленный абзац (объект Paragraph). Абзац добавляется в конец документа. Эту ссылку можно использовать в качестве своеобразного «курсора» и например, вставить новый абзац прямо над ним:
prior_p = p.insert_paragraph_before( 'Объект `paragraph` - это ссылка на только что добавленный абзац.')
Такое поведение позволяет вставить абзац в середину документа, это важно при изменении существующего документа, а не при его создании с нуля.
Ссылка на абзац, так же используется для его форматирования встроенными в MS Word стилями или для кастомного/пользовательского форматирования.
Пользовательское форматирование абзаца.
Форматирование абзацев происходит при помощи объекта ParagraphFormat.
Простой способ форматировать абзац/параграф:
from docx import Document from docx.shared import Mm from docx.enum.text import WD_ALIGN_PARAGRAPH doc = Document() # Добавляем абзац p = doc.add_paragraph('Новый абзац с отступами и красной строкой.') # выравниваем текст абзаца p.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # получаем объект форматирования fmt = p.paragraph_format # Форматируем: # добавляем отступ слева fmt.first_line_indent = Mm(15) # добавляем отступ до fmt.space_before = Mm(20) # добавляем отступ слева fmt.space_after = Mm(10) doc.add_paragraph('Новый абзац.') doc.add_paragraph('Еще новый абзац.') doc.save('test.docx')
Чтобы узнать, какие параметры абзаца еще можно настроить/изменить, смотрите материал «Объект ParagraphFormat»
Очень часто в коде, с возвращенной ссылкой (в данном случае p) ничего делать не надо, следовательно нет смысла ее присваивать переменной.
Применение встроенного стиля в Microsoft Word к абзацу.
Стиль абзаца — это набор правил форматирования, который заранее определен в Microsoft Word, и храниться в редакторе в качестве переменной. По сути, стиль позволяет сразу применить к абзацу целый набор параметров форматирования.
Можно применить стиль абзаца, прямо при его создании:
document.add_paragraph('Стиль абзаца как цитата', style='Intense Quote') document.add_paragraph('Стиль абзаца как список.', style='List Bullet')
В конкретном стиле 'List Bullet', абзац отображается в виде маркера. Также можно применить стиль позже. Две строки, в коде ниже, эквивалентны примеру выше:
document.add_paragraph('Другой стиль абзаца.').style = 'List Number' # Эквивалентно paragraph = document.add_paragraph('Другой стиль абзаца.') # применяем стиль позже paragraph.style = 'List Number'
Стиль указывается с использованием его имени, в этом примере имя стиля — 'List'. Как правило, имя стиля точно такое, как оно отображается в пользовательском интерфейсе Word.
Обратите внимание, что можно установить встроенный стиль прямо на результат document.add_paragraph(), без использования возвращаемого объекта paragraph
Жирный, курсив и подчеркнутый текст в абзаце.
Разберемся, что происходит внутри абзаца:
- Абзац содержит все форматирование на уровне блока, такое как — отступ, высота строки, табуляции и так далее.
- Форматирование на уровне символов, например полужирный и курсив, применяется на уровне прогона
paragraph.add_run(). Все содержимое абзаца должно находиться в пределах цикла, но их может быть больше одного. Таким образом, для абзаца с полужирным словом посередине требуется три прогона: обычный, полужирный — содержащий слово, и еще один нормальный для текста после него.
Когда создается абзац методом Document.add_paragraph(), то передаваемый текст добавляется за один прогон Run. Пустой абзац/параграф можно создать, вызвав этот метод без аргументов. В этом случае, наполнить абзац текстом можно с помощью метода Paragraph.add_run(). Метод абзаца .add_run() можно вызывать несколько раз, тем самым добавляя информацию в конец данного абзаца:
paragraph = document.add_paragraph('Абзац содержит форматирование ') paragraph.add_run('на уровне блока.')
В результате получается абзац, который выглядит так же, как абзац, созданный из одной строки. Если не смотреть на полученный XML, то не очевидно, где текст абзаца разбивается на части. Обратите внимание на конечный пробел в конце первой строки. Необходимо четко указывать, где появляются пробелы в начале и в конце прогона, иначе текст будет слитный (без пробелов). Они (пробелы) автоматически не вставляются между прогонами paragraph.add_run(). Метод paragraph.add_run() возвращает ссылку на объект прогона Run, которую можно использовать, если она нужна.
Объекты прогонов имеют следующие свойства, которые позволяют установить соответствующий стиль:
.bold: полужирный текст;.underline: подчеркнутый текст;.italic: курсивный (наклонный) текст;.strike: зачеркнутый текст.
paragraph = document.add_paragraph('Абзац содержит ') paragraph.add_run('форматирование').bold = True paragraph.add_run(' на уровне блока.')
Получится текст, что то вроде этого: «Абзац содержит форматирование на уровне блока».
Обратите внимание, что можно установить полужирный или курсив прямо на результат paragraph.add_run(), без использования возвращаемого объекта прогона:
paragraph.add_run('форматирование').bold = True # или run = paragraph.add_run('форматирование') run.bold = True
Передавать текст в метод Document.add_paragraph() не обязательно. Это может упростить код, если строить абзац из прогонов:
paragraph = document.add_paragraph() paragraph.add_run('Абзац содержит ') paragraph.add_run('форматирование').bold = True paragraph.add_run(' на уровне блока.')
Пользовательское задание шрифта прогона.
from docx import Document from docx.shared import Pt, RGBColor # создание документа doc = Document() # добавляем текст прогоном run = doc.add_paragraph().add_run('Заголовок, размером 24 pt.') # название шрифта run.font.name = 'Arial' # размер шрифта run.font.size = Pt(24) # цвет текста run.font.color.rgb = RGBColor(0, 0, 255) # + жирный и подчеркнутый run.font.bold = True run.font.underline = True doc.save('test.docx')
Применение стилей Microsoft Word к символам текста (к прогону).
В дополнение к встроенным стилям абзаца, которые определяют группу параметров уровня абзаца, Microsoft Word имеет стили символов, которые определяют группу параметров уровня прогона paragraph.add_run(). Другими словами, можно думать о стиле текста как об указании шрифта, включая его имя, размер, цвет, полужирный, курсив и т. д.
Подобно стилям абзацев, стиль символов текста будет определен в документе, который открывается с помощью вызова Document() (см. Общие сведения о стилях).
Стиль символов можно указать при добавлении нового прогона:
paragraph = document.add_paragraph('Обычный текст, ') paragraph.add_run('текст с акцентом.', 'Emphasis')
Также можете применить стиль к прогону после его добавления. Этот код дает тот же результат, что и строки выше:
paragraph = document.add_paragraph() paragraph.add_run('Обычный текст, ') paragraph.add_run('текст с акцентом.').style = 'Emphasis'
Как и в случае со стилем абзаца, имя стиля текста такое, как оно отображается в пользовательском интерфейсе Word.
Пользовательский стиль символов текста.
from docx import Document from docx.shared import Pt, RGBColor # создание документа doc = Document() # задаем стиль текста по умолчанию style = doc.styles['Normal'] # название шрифта style.font.name = 'Calibri' # размер шрифта style.font.size = Pt(14) p = doc.add_paragraph('Пользовательское ') # добавляем текст прогоном run = p.add_run('форматирование ') # размер шрифта run.font.size = Pt(16) # курсив run.font.italic = True # добавляем еще текст прогоном run = p.add_run('символов текста.') # Форматируем: # название шрифта run.font.name = 'Arial' # размер шрифта run.font.size = Pt(18) # цвет текста run.font.color.rgb = RGBColor(255, 0, 0) # + жирный и подчеркнутый run.font.bold = True run.font.underline = True doc.save('test.docx')
Добавление разрыва страницы.
При создании документа, время от времени нужно, чтобы следующий текст выводился на отдельной странице, даже если последняя не заполнена. Жесткий разрыв страницы можно сделать следующим образом:
document.add_page_break()
Если вы обнаружите, что используете это очень часто, это, вероятно, знак того, что вы могли бы извлечь выгоду, лучше разбираясь в стилях абзацев. Одно свойство стиля абзаца, которое вы можете установить, — это разрыв страницы непосредственно перед каждым абзацем, имеющим этот стиль. Таким образом, вы можете установить заголовки определенного уровня, чтобы всегда начинать новую страницу. Подробнее о стилях позже. Они оказываются критически важными для получения максимальной отдачи от Word.
Жесткий разрыв страницы можно привязать к стилю абзаца, и затем применять его для определенных абзацев, которые должны начинаться с новой страницы. Так же можно установить жесткий разрыв на стиль заголовка определенного уровня, чтобы с него всегда начинать новую страницу. В общем, стили, оказываются критически важными для того, чтобы получить максимальную отдачу от модуля python-docx.
Добавление картинки в документ.
Microsoft Word позволяет разместить изображение в документе с помощью пункта меню «Вставить изображение«. Вот как это сделать при помощи модуля python-docx:
document.add_picture('/path/to/image-filename.png')
В этом примере используется путь, по которому файл изображения загружается из локальной файловой системы. В качестве пути можно использовать файловый объект, по сути, любой объект, который действует как открытый файл. Такое поведение может быть полезно, если изображение извлекается из базы данных или передается по сети.
Размер изображения.
По умолчанию, изображение добавляется с исходными размерами, что часто не устраивает пользователя. Собственный размер рассчитывается как px/dpi. Таким образом, изображение размером 300×300 пикселей с разрешением 300 точек на дюйм появляется в квадрате размером один дюйм. Проблема в том, что большинство изображений не содержат свойства dpi, и по умолчанию оно равно 72 dpi. Следовательно, то же изображение будет иметь одну сторону, размером 4,167 дюйма, что означает половину страницы.
Чтобы получить изображение нужного размера, необходимо указывать его ширину или высоту в удобных единицах измерения, например, в миллиметрах или сантиметрах:
from docx.shared import Mm document.add_picture('/path/to/image-filename.png', width=Mm(35))
Если указать только одну из сторон, то модуль python-docx использует его для вычисления правильно масштабированного значения другой стороны изображения. Таким образом сохраняется соотношение сторон и изображение не выглядит растянутым.
Классы Mm() и Cm() предназначены для того, чтобы можно было указывать размеры в удобных единицах. Внутри python-docx используются английские метрические единицы, 914400 дюймов. Так что, если просто указать размер, что-то вроде width=2, то получится очень маленькое изображение. Классы Mm() и Cm() импортируются из подпакета docx.shared. Эти классы можно использовать в арифметике, как если бы они были целыми числами. Так что выражение, width=Mm(38)/thing_count, работает нормально.
Чтение документов Microsoft Word.
В модуле python-docx, структура документа Microsoft Word представлена тремя различными типами данных. На самом верхнем уровне объект Document() представляет собой весь документ. Объект Document() содержит список объектов Paragraph(), которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов Run(), представляющих собой фрагменты текста с различными стилями форматирования.
Например:
>>> from docx import Document >>> doc = Document('/path/to/example.docx') # количество абзацев в документе >>> len(doc.paragraphs) # текст первого абзаца в документе >>> doc.paragraphs[0].text # текст второго абзаца в документе >>> doc.paragraphs[1].text # текст первого прогона второго абзаца >>> doc.paragraphs[1].runs[0].text
Используя следующий код, можно получить весь текст документа:
text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) print('nn'.join(text))
А так можно получить стили всех параграфов:
styles = [] for paragraph in doc.paragraphs: styles.append(paragraph.style)
Использовать полученные стили можно следующим образом:
# изменим стиль 1 параграфа на # стиль взятый из 3 параграфа doc.paragraphs[0].style = styles[2]
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Prerequisite: Working with .docx module
Word documents contain formatted text wrapped within three object levels. The lowest level- run objects, middle level- paragraph objects, and highest level- document object. So, we cannot work with these documents using normal text editors. But, we can manipulate these word documents in python using the python-docx module. Pip command to install this module is:
pip install python-docx
Python docx module allows users to manipulate docs by either manipulating the existing one or creating a new empty document and manipulating it. It is a powerful tool as it helps you to manipulate the document to a very large extend.
Now, to use the python-docx module you have to import it as docx.
# Import docx NOT python-docx import docx
Then to create an instance of the word document. We will use the Document() method of the docx module.
Syntax: docx.Document(String path)
Parameter:
- String path: It is an optional parameter. It specifies the path of the file to be open. If it is left empty then a new empty document file is created.
And to save the document we will use save() method of the docx module.
Syntax: doc.save(String path_to_document)
Parameter:
- String path_to_document: It is the file name by which document will be saved. You can even put the path to where you want to save it.
Example 1: Opening a new document.
Python3
import docx
doc = docx.Document()
doc.save('gfg.docx')
Output:
Example 2: Opening a previously created document and again saving it with a different name.
Python3
import docx
doc = docx.Document('gfg.docx')
doc.save('gfg-copy.docx')
Output:
Like Article
Save Article
В своей работе мы часто анализируем большой объем данных. Давайте рассмотрим, как можно автоматизировать процесс анализа документов на примере библиотеки docx (способной обрабатывать документы в формате. docx).
А также расскажем другие возможности, которые предлагает Python: как отделить текст с нужным стилем форматирования? Как извлечь все изображения из документа?
Для установки библиотеки в командной строке необходимо ввести:
> pip install python-docx
После успешной установки библиотеки, её нужно импортировать в Python. Обратите внимание, что несмотря на то, что для установки использовалось название python-docx, при импорте следует называть библиотеку docx:
import docx
Как правило, мы обращаемся к автоматизации, когда нам нужно извлечь нужную информацию не из одного, а сразу из многих документов. Чтобы иметь возможность обработать все документы, для начала нужно собрать список таких документов. Здесь сможет помочь библиотека os, с помощью которой можно рекурсивно обойти директории, в которых хранятся документы. Предположим, что все они находятся внутри директории, где расположен скрипт:
import os
paths = []
folder = os.getcwd()
for root, dirs, files in os.walk(folder):
for file in files:
if file.endswith(‘docx’) and not file.startswith(‘~’):
paths.append(os.path.join(root, file))
Мы прошли по всем директориям и занесли в список paths все файлы с расширением. docx. Файлы, начинавшиеся с тильды, игнорировались (эти временные файлы возникают лишь тогда, когда в Windows открыт какой-либо из документов). Теперь, когда у нас уже есть список всех документов, можно начинать с ними работать:
for path in paths:
doc = docx.Document(path)
В блоке выше на каждом шаге цикла в переменную doc записывается экземпляр, представляющий собой весь документ. Мы можем посмотреть основные свойства такого документа:
properties = doc.core_properties
print(‘Автор документа:’, properties.author)
print(‘Автор последней правки:’, properties.last_modified_by)
print(‘Дата создания документа:’, properties.created)
print(‘Дата последней правки:’, properties.modified)
print(‘Дата последней печати:’, properties.last_printed)
print(‘Количество сохранений:’, properties.revision)
Из основных свойств можно получить автора документа, основные даты, количество сохранений документа и пр. Обратите внимание, что даты и время будут указаны в часовом поясе UTC+0.
Теперь поговорим о том, как можно проанализировать содержимое документа. Файлы с расширением docx обладают развитой внутренней структурой, которая в библиотеке docx представлена следующими объектами:
Объект Document, представляющий собой весь документ
- Список объектов Paragraph – абзацы документа
* Список объектов Run – фрагменты текста с различными стилями форматирования (курсив, цвет шрифта и т.п.)
- Список объектов Table – таблицы документа
* Список объектов Row – строки таблицы
* Список объектов Cell – ячейки в строке
* Список объектов Column – столбцы таблицы
* Список объектов Cell – ячейки в столбце
- Список объектов InlineShape – иллюстрации документа
Работа с текстом документа
Для начала давайте разберёмся, как работать с текстом документа. В библиотеке docx это возможно через обращение к абзацам документа. Можно получить как сам текст абзаца, так и его характеристики: тип выравнивания, величину отступов и интервалов, положение на странице.
Очень часто стоит задача получить весь текст из документа для дальнейшей обработки. Чтобы это сделать, достаточно лишь перебрать все абзацы документа:
text = []
for paragraph in doc.paragraphs:
text.append(paragraph.text)
print(‘n’.join(text))
Как мы видим, для получения текста абзаца нужно просто обратиться к объекту paragraph.text. Но что же делать, если нужно извлечь только абзацы с определёнными характеристиками и далее работать именно с ними? Рассмотрим основные характеристики абзацев, которые можно проанализировать.
В первую очередь, можно получить стиль выравнивания абзацев в документе:
for paragraph in doc.paragraphs:
print(‘Выравнивание абзаца:’, paragraph.alignment)
Значения alignment будут соответствовать одному из основных стилей выравнивания: LEFT (0), center (1), RIGHT (2) или justify (3). Однако если пользователь не установил стиль выравнивания, значение параметра alignment будет None.
Кроме того, можно получить и значения отступов у абзацев документа:
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
print(‘Отступ перед абзацем:’, formatting.space_before)
print(‘Отступ после абзаца:’, formatting.space_after)
print(‘Отступ слева:’, formatting.left_indent)
print(‘Отступ справа:’, formatting.right_indent)
print(‘Отступ первой строки абзаца:’, formatting.first_line_indent)
Как и в предыдущем примере, если отступы не были установлены, значения параметров будут None. В остальных случаях они будут представлены в виде целого числа в формате EMU (английские метрические единицы). Этот формат позволяет конвертировать число как в метрическую, так и в английскую систему мер. Привести полученные числа в привычный формат довольно просто, достаточно просто добавить нужные единицы исчисления после параметра (например, formatting.space_before.cm или formatting.space_before.pt). Главное помнить, что такое преобразование нельзя применять к значениям None.
Наконец, можно посмотреть на положение абзаца на странице. В меню Абзац… на вкладке Положение на странице находятся четыре параметра, значения которых также можно посмотреть при помощи библиотеки docx:
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
print(‘Не отрывать от следующего абзаца:’, formatting.keep_with_next)
print(‘Не разрывать абзац:’, formatting.keep_together)
print(‘Абзац с новой страницы:’, formatting.page_break_before)
print(‘Запрет висячих строк:’, formatting.widow_control)
Параметры будут иметь значение None для случаев, когда пользователь не устанавливал на них галочки, и True, если устанавливал.
Мы рассмотрели основные способы, которыми можно проанализировать абзац в документе. Но бывают ситуации, когда мы точно знаем, что информация, которую нужно извлечь, написана курсивом или выделена определённым цветом. Как быть в таком случае?
Можно получить список фрагментов с различными стилями форматирования (список объектов Run). Попробуем, к примеру, извлечь все фрагменты, написанные курсивом:
for paragraph in doc.paragraphs:
for run in paragraph.runs:
if run.italic:
print(run.text)
Очень просто, не так ли? Посмотрим, какие ещё стили форматирования можно извлечь:
for paragraph in doc.paragraphs:
for run in paragraph.runs:
print(‘Полужирный текст:’, run.bold)
print(‘Подчёркнутый текст:’, run.underline)
print(‘Зачёркнутый текст:’, run.strike)
print(‘Название шрифта:’, run.font.name)
print(‘Цвет текста, RGB:’, run.font.color.rgb)
print(‘Цвет заливки текста:’, run.font.highlight_color)
Если пользователь не менял стиль форматирования (отсутствует подчёркивание, используется стандартный шрифт и т.п.), параметры будут иметь значение None. Но если стиль определённого параметра изменялся, то:
- параметры italic, bold, underline, strike будут иметь значение True;
- параметр font.name – наименование шрифта;
- параметр font.color.rgb – код цвета текста в RGB;
- параметр font.highlight_color – наименование цвета заливки текста.
Делая цикл по фрагментам стоит иметь ввиду, что фрагменты с одинаковым форматированием могут быть разбиты на несколько, если в них встречаются символы разных типов (буквенные символы и цифры, кириллица и латиница).
Абзацы и их фрагменты могут быть оформлены в определённом стиле, соответствующем стилям Word (например, Normal, Heading 1, Intense Quote). Чем это может быть полезно? К примеру, обращение к стилям абзаца может пригодиться при выделении нумерованных или маркированных списков. Каждый элемент таких списков считается отдельным абзацев, однако каждому из них приписан особый стиль – List Paragraph. С помощью кода ниже можно извлечь только элементы списков:
for paragraph in doc.paragraphs:
if paragraph.style.name == ‘List Paragraph’:
print(paragraph.text)
Чтобы закрепить полученные знания, давайте разберём менее тривиальный случай. Предположим, что у нас есть множество документов с похожей структурой, из которых нужно извлечь названия продуктов. Проанализировав документы, мы установили, что продукты встречаются только в абзацах, начинающихся с новой страницы и выровненных по ширине. Притом сами названия написаны с использованием полужирного начертания, шрифт Arial Narrow. Посмотрим, как можно проанализировать документы:
for path in paths:
doc = docx.Document(path)
product_names = []
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
if formatting.page_break_before and paragraph.alignment == 3:
product_name, is_sequential = », False
for run in paragraph.runs:
if run.bold and run.font.name == ‘Arial Narrow’:
is_sequential = True
product_name += run.text
elif is_sequential == True:
product_names.append(product_name)
product_name, is_sequential = », False
В блоке кода выше последовательно обрабатываются все файлы из списка paths, преобразовываемые в ходе обработки в объект Document. В каждом документе происходит перебор абзацев и выполняются проверки: абзац должен начинаться с новой страницы и быть выровненным по ширине. Если проверки прошли успешно, внутри абзаца происходит уже перебор фрагментов с различными типами форматированием и проверки на начертание и шрифт.
Обратим внимание на переменную is_sequential, которая помогает определить, идут ли фрагменты, прошедшие проверку, друг за другом. Фрагменты с символами разных типов (буквы и числа, кириллица и латиница) разбиваются на несколько, но поскольку в названии продукта одновременно могут встретиться символы всех типов, все последовательно идущие фрагменты соединяются в один. Он и заносится в результирующий список product_names.
Работа с таблицами
Мы рассмотрели способы, которыми можно обрабатывать текст в документах, а теперь давайте перейдём к обработке таблиц. Любую таблицу можно перебирать как по строкам, так и по столбцам. Посмотрим, как можно построчно получить текст каждой ячейки в таблице:
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
Если же во второй строке заменить rows на columns, то можно будет аналогичным образом прочитать таблицу по столбцам. Текст в ячейках таблицы тоже состоит из абзацев. Если мы захотим проанализировать абзацы или фрагменты внутри ячейки, то можно будет воспользоваться всеми методами объектов Paragraph и Run.
Часто может понадобиться проанализировать только таблицы, содержащие определённые заголовки. Попробуем, например, выделить из документа только таблицы, у которых в строке заголовка присутствуют названия Продукт и Стоимость. Для таких таблиц построчно распечатаем все значения из ячеек:
for table in doc.tables:
for index, row in enumerate(table.rows):
if index == 0:
row_text = list(cell.text for cell in row.cells)
if ‘Продукт’ not in row_text or ‘Стоимость’ not in row_text:
break
for cell in row.cells:
print(cell.text)
Также нам может понадобиться определить, какие из ячеек в таблице являются объединёнными. Стандартной функции для этого нет, однако мы можем воспользоваться тем, что нам доступно положение ячейки от каждого из краев таблицы:
for table in doc.tables:
unique, merged = set(), set()
for row in table.rows:
for cell in row.cells:
tc = cell._tc
cell_loc = (tc.top, tc.bottom, tc.left, tc.right)
if cell_loc in unique:
merged.add(cell_loc)
else:
unique.add(cell_loc)
print(merged)
Воспользовавшись этим кодом, можно получить все координаты объединённых ячеек для каждой из таблиц документа. Кроме того, разница координат tc.top и tc.bottom показывает, сколько строк в объединённой ячейке, а разница tc.left и tc.right – сколько столбцов.
Наконец, рассмотрим возможность выделения из таблиц ячеек, в которых фон окрашен в определённый цвет. Для этого понадобится с помощью регулярных выражений посмотреть на xml-код ячейки:
import re
pattern = re.compile(‘w:fill=»(S*)»‘)
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
match = pattern.search(cell._tc.xml)
if match:
if match.group(1) == ‘FFFF00’:
print(cell.text)
В этом блоке кода мы выделили только те ячейки, фон которых был окрашен в жёлтый цвет ( #FFFF00 в формате RGB).
Работа с иллюстрациями
В библиотеке docx также реализована возможность работы с иллюстрациями документа. Стандартными способами можно посмотреть только на размеры изображений:
for shape in doc.inline_shapes:
print(shape.width, shape.height)
Однако при помощи сторонней библиотеки docx2txt и анализа xml-кода абзацев становится возможным не только выгрузить все иллюстрации документов, но и определить, в каком именно абзаце они встречались:
import os
import docx
import docx2txt
for path in paths:
splitted = os.path.split(path)
folders = [os.path.splitext(splitted[1])[0]]
while splitted[0]:
splitted = os.path.split(splitted[0])
folders.insert(0, splitted[1])
images_path = os.path.join(‘images’, *folders)
os.makedirs(images_path, exist_ok=True)
doc = docx.Document(path)
docx2txt.process(path, images_path)
rels = {}
for rel in doc.part.rels.values():
if isinstance(rel._target, docx.parts.image.ImagePart):
rels[rel.rId] = os.path.basename(rel._target.partname)
for paragraph in doc.paragraphs:
if ‘Graphic’ in paragraph._p.xml:
for rId in rels:
if rId in paragraph._p.xml:
print(os.path.join(images_path, rels[rId]))
print(paragraph.text)
В этом блоке мы выводим путь к изображению, которое сохранено на диске, и текст параграфа, в котором встретилось изображение. Все изображения находятся внутри директории images, а именно — в поддиректориях, соответствующих расположению исходного файла Word.
В этой статье вы узнаете, как в Python считывать и записывать файлы MS Word.
- Установка библиотеки Python-Docx
- Чтение файлов MS Word с помощью модуля Python-Docx
- Чтение параграфов
- Чтение прогонов
- Написание файлов MS Word с помощью модуля Python-Docx
- Запись абзацев
- Запись прогонов
- Запись заголовков
- Добавление изображений
- Заключение
Существует несколько библиотек, которые можно использовать для чтения и записи в Python файлов MS Word. Мы будем использовать модуль python-docx .
Выполните приведенную ниже pip команду в терминале, чтобы загрузить модуль python-docx:
$ pip install python-docx
Создайте новый файл MS Word и переименуйте его в my_word_file.docx. Я сохранил файл в корне диска E. Файл my_word_file.docx должен иметь следующее содержимое

Чтобы считать указанный файл, импортируйте модуль docx, а затем создайте объект класса Document из модуля docx. Затем передайте путь к файлу my_word_file.docx в конструктор класса Document:
import docx
doc = docx.Document("E:/my_word_file.docx")
Объект doc класса Document теперь можно использовать для чтения содержимого файла my_word_file.docx.
С помощью объекта класса Document и пути к файлу можно получить доступ ко всем абзацам документа с помощью атрибута paragraphs. Пустая строка также читается как абзац.
Извлечем все абзацы из файла my_word_file.docx и затем отобразим общее количество абзацев документа:
all_paras = doc.paragraphs len(all_paras)
Вывод:
Теперь поочередно выведем все абзацы, присутствующие в файле my_word_file.docx:
for para in all_paras:
print(para.text)
print("-------")
Вывод:
------- Introduction ------- ------- Welcome to stackabuse.com ------- The best site for learning Python and Other Programming Languages ------- Learn to program and write code in the most efficient manner ------- ------- Details ------- ------- This website contains useful programming articles for Java, Python, Spring etc. -------
Вывод демонстрирует все абзацы, присутствующие в файле my_word_file.docx.
Также можно получить доступ к определенному абзацу, индексируя свойство paragraphs как массив. Давайте выведем пятый абзац в файле:
single_para = doc.paragraphs[4] print(single_para.text)
Вывод:
The best site for learning Python and Other Programming Languages
Прогон в текстовом документе представляет собой непрерывную последовательность слов, имеющих схожие свойства. Например, одинаковые размеры шрифта, формы шрифта и стили шрифта.
Вторая строка файла my_word_file.docx содержит текст «Welcome to stackabuse.com». Слова «Welcome to» написаны простым шрифтом, а текст «stackabuse.com» — жирным. Следовательно, текст «Welcome to» считается одним прогоном, а текст, выделенный жирным шрифтом «stackabuse.com», считается другим прогоном.
Чтобы получить все прогоны в абзаце, можно использовать свойство run атрибута paragraphобъекта doc.
Считаем все прогоны из абзаца №5 (четвертый указатель) в тексте:
single_para = doc.paragraphs[4]
for run in single_para.runs:
print(run.text)
Вывод:
The best site for learning Python and Other Programming Languages
Аналогичным образом приведенный ниже скрипт выводит все прогоны из 6-го абзаца файла my_word_file.docx:
second_para = doc.paragraphs[5]
for run in second_para.runs:
print(run.text)
Вывод:
Learn to program and write code in the most efficient manner
Чтобы записать файлы MS Word, создайте объект класса Document с пустым конструктором.
Для записи абзацев используйте метод add_paragraph() объекта класса Document. После добавления абзаца нужно вызвать метод save(). Путь к файлу, в который нужно записать абзац, передается в качестве параметра методу save(). Если файл не существует, то будет создан новый файл. Иначе абзац будет добавлен в конец существующего файла MS Word.
Приведенный ниже скрипт записывает простой абзац во вновь созданный файл my_written_file.docx.
mydoc.add_paragraph("This is first paragraph of a MS Word file.")
mydoc.save("E:/my_written_file.docx")
После выполнения этого скрипта вы должны увидеть новый файл my_written_file.docx в каталоге, который указали в методе save(). Внутри файла должен быть один абзац, который гласит: «This is first paragraph of a MS Word file.».
Добавим в файл my_written_file.docx еще один абзац:
mydoc.add_paragraph("This is the second paragraph of a MS Word file.")
mydoc.save("E:/my_written_file.docx")
Этот абзац будет добавлен в конец файла my_written_file.docx.
Вы также можете записать прогоны с помощью модуля python-docx. Для этого нужно создать дескриптор абзаца, к которому хотите добавить прогон:
third_para = mydoc.add_paragraph("This is the third paragraph.")
third_para.add_run(" this is a section at the end of third paragraph")
mydoc.save("E:/my_written_file.docx")
В приведенном выше скрипте записывается абзац с помощью метода add_paragraph()объекта mydoc класса Document. Метод add_paragraph() возвращает дескриптор для вновь добавленного пункта.
Чтобы добавить прогон к новому абзацу, необходимо вызвать метод add_run() для дескриптора абзаца. Текст прогона передается в виде строки в метод add_run(). Затем необходимо вызвать метод save() для создания фактического файла.
В файлы MS Word также можно добавлять заголовки. Для этого нужно вызвать метод add_heading(). Первым параметром метода add_heading() является текстовая строка для заголовка, а вторым – размер заголовка.
Приведенный ниже скрипт добавляет в файл my_written_file.docx три заголовка уровня 0, 1 и 2:
mydoc.add_heading("This is level 1 heading", 0)
mydoc.add_heading("This is level 2 heading", 1)
mydoc.add_heading("This is level 3 heading", 2)
mydoc.save("E:/my_written_file.docx")
Чтобы добавить в файлы MS Word изображения, используется метод add_picture(). Путь к изображению передается как параметр метода add_picture(). Также можно указать ширину и высоту изображения с помощью атрибута docx.shared.Inches().
Приведенный ниже скрипт добавляет изображение из локальной файловой системы в файл my_written_file.docx. Ширина и высота изображения будут 5 и 7 дюймов:
mydoc.add_picture("E:/eiffel-tower.jpg", width=docx.shared.Inches(5), height=docx.shared.Inches(7))
mydoc.save("E:/my_written_file.docx")
После выполнения всех скриптов, рассмотренных в этой статье, окончательный файл my_written_file.docx должен выглядеть следующим образом:

Он должен содержать три абзаца, три заголовка и одно изображение.
И этой статьи вы узнали, как читать и записывать файлы MS Word с помощью модуля python-docx.
Дайте знать, что вы думаете по этой теме материала в комментариях. Мы очень благодарим вас за ваши комментарии, лайки, отклики, дизлайки, подписки!
The MS Word utility from Microsoft Office suite is one of the most commonly used tools for writing text documents, both simple and complex. Though humans can easily read and write MS Word documents, assuming you have the Office software installed, often times you need to read text from Word documents within another application.
For instance, if you are developing a natural language processing application in Python that takes MS Word files as input, you will need to read MS Word files in Python before you can process the text. Similarly, often times you need to write text to MS Word documents as output, which could be a dynamically generated report to download, for example.
In this article, article you will see how to read and write MS Word files in Python.
Installing Python-Docx Library
Several libraries exist that can be used to read and write MS Word files in Python. However, we will be using the python-docx module owing to its ease-of-use. Execute the following pip command in your terminal to download the python-docx module as shown below:
$ pip install python-docx
Reading MS Word Files with Python-Docx Module
In this section, you will see how to read text from MS Word files via the python-docx module.
Create a new MS Word file and rename it as «my_word_file.docx». I saved the file in the root of my «E» directory, although you can save the file anywhere you want. The my_word_file.docx file should have the following content:
To read the above file, first import the docx module and then create an object of the Document class from the docx module. Pass the path of the my_word_file.docx to the constructor of the Document class, as shown in the following script:
import docx
doc = docx.Document("E:/my_word_file.docx")
The Document class object doc can now be used to read the content of the my_word_file.docx.
Reading Paragraphs
Once you create an object of the Document class using the file path, you can access all the paragraphs in the document via the paragraphs attribute. An empty line is also read as a paragraph by the Document. Let’s fetch all the paragraphs from the my_word_file.docx and then display the total number of paragraphs in the document:
all_paras = doc.paragraphs
len(all_paras)
Output:
10
Now we’ll iteratively print all the paragraphs in the my_word_file.docx file:
for para in all_paras:
print(para.text)
print("-------")
Output:
-------
Introduction
-------
-------
Welcome to stackabuse.com
-------
The best site for learning Python and Other Programming Languages
-------
Learn to program and write code in the most efficient manner
-------
-------
Details
-------
-------
This website contains useful programming articles for Java, Python, Spring etc.
-------
The output shows all of the paragraphs in the Word file.
We can even access a specific paragraph by indexing the paragraphs property like an array. Let’s print the 5th paragraph in the file:
single_para = doc.paragraphs[4]
print(single_para.text)
Output:
The best site for learning Python and Other Programming Languages
Reading Runs
A run in a word document is a continuous sequence of words having similar properties, such as similar font sizes, font shapes, and font styles. For example, if you look at the second line of the my_word_file.docx, it contains the text «Welcome to stackabuse.com», here the text «Welcome to» is in plain font, while the text «stackabuse.com» is in bold face. Hence, the text «Welcome to» is considered as one run, while the bold faced text «stackabuse.com» is considered as another run.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Similarly, «Learn to program and write code in the» and «most efficient manner» are treated as two different runs in the paragraph «Learn to program and write code in the most efficient manner».
To get all the runs in a paragraph, you can use the run property of the paragraph attribute of the doc object.
Let’s read all the runs from paragraph number 5 (4th index) in our text:
single_para = doc.paragraphs[4]
for run in single_para.runs:
print(run.text)
Output:
The best site for
learning Python
and Other
Programming Languages
In the same way, the following script prints all the runs from the 6th paragraph of the my_word_file.docx file:
second_para = doc.paragraphs[5]
for run in second_para.runs:
print(run.text)
Output:
Learn to program and write code in the
most efficient manner
Writing MS Word Files with Python-Docx Module
In the previous section, you saw how to read MS Word files in Python using the python-docx module. In this section, you will see how to write MS Word files via the python-docx module.
To write MS Word files, you have to create an object of the Document class with an empty constructor, or without passing a file name.
mydoc = docx.Document()
Writing Paragraphs
To write paragraphs, you can use the add_paragraph() method of the Document class object. Once you have added a paragraph, you will need to call the save() method on the Document class object. The path of the file to which you want to write your paragraph is passed as a parameter to the save() method. If the file doesn’t already exist, a new file will be created, otherwise the paragraph will be appended at the end of the existing MS Word file.
The following script writes a simple paragraph to a newly created MS Word file named «my_written_file.docx».
mydoc.add_paragraph("This is first paragraph of a MS Word file.")
mydoc.save("E:/my_written_file.docx")
Once you execute the above script, you should see a new file «my_written_file.docx» in the directory that you specified in the save() method. Inside the file, you should see one paragraph which reads «This is first paragraph of a MS Word file.»
Let’s add another paragraph to the my_written_file.docx:
mydoc.add_paragraph("This is the second paragraph of a MS Word file.")
mydoc.save("E:/my_written_file.docx")
This second paragraph will be appended at the end of the existing content in my_written_file.docx.
Writing Runs
You can also write runs using the python-docx module. To write runs, you first have to create a handle for the paragraph to which you want to add your run. Take a look at the following example to see how it’s done:
third_para = mydoc.add_paragraph("This is the third paragraph.")
third_para.add_run(" this is a section at the end of third paragraph")
mydoc.save("E:/my_written_file.docx")
In the script above we write a paragraph using the add_paragraph() method of the Document class object mydoc. The add_paragraph() method returns a handle for the newly added paragraph. To add a run to the new paragraph, you need to call the add_run() method on the paragraph handle. The text for the run is passed in the form of a string to the add_run() method. Finally, you need to call the save() method to create the actual file.
You can also add headers to MS Word files. To do so, you need to call the add_heading() method. The first parameter to the add_heading() method is the text string for header, and the second parameter is the header size. The header sizes start from 0, with 0 being the top level header.
The following script adds three headers of level 0, 1, and 2 to the file my_written_file.docx:
mydoc.add_heading("This is level 1 heading", 0)
mydoc.add_heading("This is level 2 heading", 1)
mydoc.add_heading("This is level 3 heading", 2)
mydoc.save("E:/my_written_file.docx")
Adding Images
To add images to MS Word files, you can use the add_picture() method. The path to the image is passed as a parameter to the add_picture() method. You can also specify the width and height of the image using the docx.shared.Inches() attribute. The following script adds an image from the local file system to the my_written_file.docx Word file. The width and height of the image will be 5 and 7 inches, respectively:
mydoc.add_picture("E:/eiffel-tower.jpg", width=docx.shared.Inches(5), height=docx.shared.Inches(7))
mydoc.save("E:/my_written_file.docx")
After executing all the scripts in the Writing MS Word Files with Python-Docx Module section of this article, your final my_written_file.docx file should look like this:
In the output, you can see the three paragraphs that you added to the MS word file, along with the three headers and one image.
Conclusion
The article gave a brief overview of how to read and write MS Word files using the python-docx module. The article covers how to read paragraphs and runs from within a MS Word file. Finally, the process of writing MS Word files, adding a paragraph, runs, headers, and images to MS Word files have been explained in this article.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Word documents contain formatted text wrapped within three object levels. Lowest level- Run objects, Middle level- Paragraph objects and Highest level- Document object.
So, we cannot work with these documents using normal text editors. But, we can manipulate these word documents in python using the python-docx module.
1. The first step is to install this third-party module python-docx. You can use pip “pip install python-docx” or download the tarball from here. Here’s the Github repository.
2. After installation import “docx” NOT “python-docx”.
3. Use “docx.Document” class to start working with the word document.
Code #1:
import docx
doc = docx.Document()
doc.add_heading('Heading for the document', 0)
doc_para = doc.add_paragraph('Your paragraph goes here, ')
doc_para.add_run('hey there, bold here').bold = True
doc_para.add_run(', and ')
doc_para.add_run('these words are italic').italic = True
doc.add_page_break()
doc.add_heading('Heading level 2', 2)
doc.add_picture('path_to_picture')
doc.save('path_to_document')
Output:


Notice the page break in the second page.
Code #2: Now, to open a word document, create an instance along with passing the path to the document.
from docx import Document
doc = Document('path_to_the_document')
print('List of paragraph objects:->>>')
print(doc.paragraphs)
print('nList of runs objects in 1st paragraph:->>>')
print(doc.paragraphs[0].runs)
print('nText in the 1st paragraph:->>>')
print(doc.paragraphs[0].text)
print('nThe whole content of the document:->>>n')
for para in doc.paragraphs:
print(para.text)
Output:
List of paragraph objects:->>> [<docx.text.paragraph.Paragraph object at 0x7f45b22dc128>, <docx.text.paragraph.Paragraph object at 0x7f45b22dc5c0>, <docx.text.paragraph.Paragraph object at 0x7f45b22dc0b8>, <docx.text.paragraph.Paragraph object at 0x7f45b22dc198>, <docx.text.paragraph.Paragraph object at 0x7f45b22dc0f0>] List of runs objects in 1st paragraph:->>> [<docx.text.run.Run object at 0x7f45b22dc198>] Text in the 1st paragraph:->>> Heading for the document The whole content of the document:->>> Heading for the document Your paragraph goes here, hey there, bold here, and these words are italic Heading level 2
Reference: https://python-docx.readthedocs.io/en/latest/#user-guide.
Like Article
Save Article