
I had a long list (57 pages!) of Latin species names, sorted into alphabetical order. I’d separated the words so that there was only one word on each line. My next task was to go through and remove all the duplicates (i.e. a word immediately followed by the same word) so I could add the final list to my custom dictionary for species in Microsoft Word. I started doing it manually—it’s easy enough to find duplicates when the words are familiar, but for Latin words, my brain just wasn’t coping well and I was missing subtle differences like a single or double ‘i’ at the end of a word. There had to be a better way…
And there is! Good old Dr Google came to the rescue, and with a bit of fiddling to suit my circumstances (one word on each line), I got a wildcard find and replace routine to find the duplicates.
NOTE: DO NOT do a ‘replace all’ with this, in case Word makes unwanted changes. In my case it didn’t treat the second word as a whole word for matching purposes (e.g. it thought banksi, banksia, and banksii were duplicates). Even though I had to skip some of these, it was still worth it to automate much of the process. Another caveat—if you have several lines of the same word, each pair will be found, but you’ll have to run the find several times to get them all. Much better to move your cursor into Word and delete the excess multiple duplicates when you find them. You may still have to do a couple of passes over the document, but the heavy lifting will have been done for you.
Here’s what I did to get it work:
- Press Ctrl+H to open the Find and Replace window.
- Click More, then select the Use Wildcards checkbox.
- In the Find What field, type (<*>)^0131 (there are no spaces in this string).
- In the Replace With field, type 1 (there are no spaces in this string either).
- Click Find Next.
- When a pair of matching whole words is found, click Replace. NOTE: If the second word is only a partial match for the first word, click Find Next.
- Repeat steps 5 and 6 until you’re satisfied you’ve found them all.
How this works:
- (<*>) is the first element (later represented by 1) of the find. The angle brackets specify the start and end of a word, and the ‘word’ is anything (represented by the *). In other words, you’re looking for a whole ‘word’ of any length and made up of any characters (including numbers).
- ^013 is the paragraph marker at the end of the line. In my situation, each word was on its own line with a paragraph mark at the end of the line. If you don’t have this situation, leave this out and replace it with a space (two repeated words in the same line are separated by a space). NOTE: Normally you can find a paragraph mark in a Find with ^p, but not with a wildcard Find—you have to use ^013.
- 1 is the first element. In the Find, it means the duplicate of whatever was found by (<*>); in the Replace, it means replace the duplicated word with the first word found.
The word that comes closest to describing this sort of behavior(repetition of the same word in a sentence) is: Epizeuxis
According to Wikipedia:
In rhetoric, an epizeuxis is the repetition of a word or phrase
in immediate succession, for vehemence or emphasis.
Some examples provided(among others):
«Never give in — never, never, never, never, in nothing great or small, large or petty, never give in except to convictions of honour
and good sense. Never yield to force; never yield to the apparently
overwhelming might of the enemy.» —Winston Churchill«O horror, horror, horror.» —Macbeth
«Words, words, words.» —Hamlet
«Rain, rain, rain, rain, rain.» —Guy Gavriel Kay
«Developers, developers, developers, developers, developers, developers. Developers, developers, developers, developers,
developers, developers, developers, developers!» —Steve Ballmer«Never, never, never, never, never!» —King Lear
«But you never know now do you now do you now do you.» —David Foster Wallace, Brief Interviews with Hideous Men
However, do note this in the definition of Epizeuxis:
for vehemence or emphasis
It appears this sort of repetition is usually done to emphasize some meaning. Accordingly, I’m not sure if a sentence like:
That that exists exists in that that that that exists exists in.
would classify, without any further context.
But then again, upon reading the answers in your cited EL&U questions, it looks like these sentences do make sense. In that case, I would say «Epizeuxis» is indeed the word you’re looking for.
Also take a look at Repetition as defined on Wikipedia. There seem to be some other types of repetitions which you might be interested in:
Conduplicatio is the repetition of a word in various places throughout a paragraph.
«And the world said, ‘Disarm, disclose, or face serious
consequences’—and therefore, we worked with the world, we worked to
make sure that Saddam Hussein heard the message of the world.»(George
W. Bush)Mesodiplosis is the repetition of a word or phrase at the middle of every clause.
«We are troubled on every side, yet not distressed; we are perplexed, but not in despair; persecuted, but not forsaken; cast
down, but not destroyed…» (Second Epistle to the Corinthians)Diacope is a rhetorical term meaning uninterrupted repetition of a word, or repetition with only one or two words between each repeated
phrase.
The article is an abstract of my book [1] based on previously presented publications [2], [3], [4], [5].
1. Coordinating texts
1.1. Rules
1.1.1. Texts and algebra
Numbers and letters are two kinds of ideal objects-signs for studying relations of real objects. Understanding (interpretation) of texts is personified — it depends on a person’s genotype and phenotype. Also, the meaning of words can change over time. All words of contextual language are homonyms. A word has as many properties (relationships between words) as there are contexts in the entire corpus of natural language.
People understand numbers in roughly the same way and regardless of where and when they are used. The language of numbers is universal, universal, and eternal.
Algebra (a symbolic generalization of arithmetic) and text (a sequence of symbols) are so far two very different tools of cognition.
1.1.2. Coordination
Application of mathematical methods in any subject area is preceded by coordinatization, which begins with digitization. Coordinatization is the replacement, modeling of the object of research by its digital copy. This is followed by the correct replacement of the model numbers themselves with symbols and the determination of the properties and regularities of combinations of these symbols.
If correct coordinatization is applied to the text, the text can be reduced to algebra.
For successful algebraization, it is extremely important to describe the coordinatization rules and the properties of the coordinating objects in such a way as to reduce the variability of their choices.
1.1.3. Purpose of Algebraization
The goal of text algebraization is to be able to compute from solutions of systems of algebraic equations the meaning of text, variants of structuring, vocabularies, summaries and versions of text by the target function.
Texts are understood as sequences of signs (letters, words, notes, etc.). There are five types of sign systems: natural, figurative, linguistic, records, and codes.
1.1.3. Purpose of Algebraization
The carrier of a character sequence is all its characters without repetition. A carrier may be called an alphabet or a dictionary of a sign sequence.
Words are sequences of letters or elementary phonemes. The meaning of a letter is only in its form or sound. There is no contextual dependence of the letters of the alphabet.
Ultimate context dependence is present in the words of homonyms of the natural language. For example, the Russian word «kosa» has four different meanings. It is believed that a fifth of the vocabulary of the English language is occupied by homonymy.
1.1.5. Repetition
Text is a character sequence with at least one repetition. Vocabulary is an iconic sequence without repetition. The presence of repetitions allows one to reduce the number of used sign-words (reduce the vocabulary). But then the repeated signs can differ in meaning. The meaning of a word depends on the words around it. Problems of understanding words and text have as their cause that this some part of meaning (meaning) is determined or guessed subjectively and ambiguously. Different readers and listeners understand different meanings for the same word.
When words are repeated in a text, there are preferable, in the opinion of the author of the text, connections-relationships of the repeated word with other words. These relationships are recorded as the new meaning of the repeated word.
1.1.6. Semantic markup
If a particular text does not have explicit repetitions, it does not mean that they are not hidden in semantic (contextual) form. The meaning can be repeated, not only the character-sign (word) denoting it. The context here is a fragment of text between repeating words. If the contexts of different words are similar, then different words are similar in the sense of their common contexts, the word-signs of those contexts. Contexts are similar if they have at least one common sign-word.
The context is not only for two words repeated in a row. The meaning or context of a word can be pointed to by referring to any suitable fragment of text, not necessarily located in the immediate vicinity of the repeated word. In this case, the text loses its linear order, like making words out of letters. If there are no such fragments, the meaning of the word is borrowed by reference to a suitable context from another corpus text (library).
Common words in contexts, in turn, also have their contexts — the notion of a refined word context arises.
1.1.7. Coordination rules
In a finite character sequence, each character has a unique number that determines the place of the character in the sequence. No two characters can be in the same place. But the text requires another index to indicate the repetition of a sign in the text. This second index creates equivalence relations on a finite set of words. It is reasonable to match the sign with some two-index object (for example, some matrix). The first index of the matrix indicates the number of the sign in the sequence. The second index indicates the number of this sign, first encountered in the sequence. The carrier (dictionary) of a character sequence (text) is its part of characters with the same indices. Missing word numbers in the dictionary can be eliminated by continuous numbering.
Text coordinating rules:
The first index of the coordinating text (matrix) is the ordinal number of the word in the text, the second index is the ordinal number of the same word first encountered in the text. If the word has not been previously encountered, the second index is equal to the first index.
The dictionary is the original text with deleted repetitions. It is possible to order the dictionary with exclusion of gaps in word numbering.
For two or more texts that are not a single text, the word order in each text is independent. In two texts, the initial words are equally first. Just as in two books, the beginning pages begin with one.
The common dictionary of a set of texts is the dictionary of all texts after their concatenation. It is possible to order the dictionary with deletion of gaps in the numbering of words.
1.2. Examples
1.2.1. Similarity and sameness
According to G. Frege any object having relations with other objects and their combinations has as many properties (meanings) as these relations of similarity and sameness (tolerance and equivalence). The part of the values taken into account is called the sense by which the object is represented in a given situation. The naming of an object by a number, a symbol, a word, a picture, a sound, a gesture to describe it briefly is called the sign of the object (this is one of the meanings).
Each of the all possible parts (boolean set) of an object’s meanings (meaning) corresponds to one sign. This is the main problem of meaning recognition, but it is also the basis for making do with minimal sets of signs. It is impossible to assign a unique sign to each subset of values. The objects of information exchange are minimal sets of signs (notes, alphabet, language dictionary). The meaning of signs is usually not calculated, but is determined by the contexts (neighborhoods) of the sign so far intuitively.
1.2.2. Example on the abacus
A solution to the problem of sign ambiguity is the semantic markup of text. The semantic markup can be explained on the example of marginal unambiguity. On Russian abacus the text is a sequence of identical signs (knuckles). The vocabulary of such a text consists of a single word. This is even stronger than in Morse code, where the dictionary consists of two words. Without semantic markup, it is impossible to use such texts. Therefore, the vocabulary changes and the characters are divided into groups — ones, tens, hundreds, etc. These group names (numbers) become unique word numbers. The vocabulary are numbers from zero to nine. Each knuckle, too, can be represented so far by an undefined matrix on such a Cartesian abacus.
The transformation of identical objects into similar ones has taken place. The measure of similarity is the coordinate values of the words. In addition to positional, repetitions of dictionary digits occur when arithmetic operations are performed. Equivalence relations are established: if after an arithmetic operation the number 9+1 is obtained, then 0 appears in that position and 1 is added to the next digit. On the abacus, all the knuckles are shifted to the original (zero) position, and one is added in the next digit (wire). Some matrix transformation is performed on the matrix abacus.
If one sets a measure of the sameness of signs, then the ratio of tolerance (similarity) can be transformed again into the ratio of equivalence (sameness) by this measure. For example, by rounding numbers. One can recognize the difference between tolerance and equivalence by the violation of transitivity. For tolerance relations it can be violated. For example, let an element A be similar to B in one sense. If the sense of B does not coincide with the sense of element C, then A can be similar to C only in the part of intersection of their senses (part of properties). The transitivity of relations is restored (closed), but only for this common part of sense. After the sameness is achieved, A will be equivalent to C. For example, the above transformation (closure) on some coordinates provides arithmetic operations on a matrix abacus.
1.2.3. Chess example
For chess, the vocabulary of their matrix text of the game is the numbers of one of the pieces of each color and the move separator (from 1 to 11). The word of the chess text is also a kind of matrix. The first coordinate i is unique and is the cell number on the chessboard (from 1 to 64). The second coordinate j is a number from the dictionary. The chess matrix text at any moment of the game is the sum of matrices, each showing a piece on the corresponding place on the chessboard. The repetitions in the text appear both because of duplication of pieces and because of constant transitions during the game from similarity to sameness and vice versa for all pieces except the king. The game consists in implementing the most effective such transitions and the actual classification of the pieces. Pawns that are identical in the beginning then become similar only by the move rule, and sometimes a pawn becomes identical with a queen.
The tool of matrix text analysis is a transitivity control to check the difference between similarity and sameness. Lack of transitivity control is an algebraic explication of misunderstanding for language texts, loss in chess, or errors in numerical calculations.
Relational transitivity is a condition for transforming a set of objects into a mathematical category. The semantic markup of a text can become the computation of its categories by means of transitive closure. The category objects are the contexts of matrix words, the morphisms are the transformation matrices of these contexts.
1.2.4. Example of a language text
Example text:
A set is an object that is a set of objects. A polynomial is a set of monomial objects which are a set of objects-somnomials.
Text in normal form is coordinated according to the above rules. The vocabulary of a text is the text itself, but without repetitions. Text coordination is its indexing and matching of indexed matrix words.
1.2.5. Example of a mathematical text
As an example of a mathematical text selected formulas for the volume of the cone, cylinder and torus. The formulas are treated as texts. This means that signs included in texts are not mathematical objects and there are no algebraic operations for them.
For the semiotic analysis of formulas as texts, the repetition of signs is important. The repetitions determine the patterns.
Formulas are presented according to the rules of coordinating in index form in a single numbering, as if they were not three texts, but one. The coordinated text is written through matrices in tabular form.
1.2.6. Example of a Morse-Weil-Herke code
This example is chosen because of the extreme brevity of the dictionary. In Morse code, the character sequences of 26 Latin letters can be considered as texts consisting of words — dots and dashes. The order of words (dots and dashes) is extremely important in each individual text (alphabet letter). In linguistic texts, the order is also important («mom’s dad» is not «dad’s mom», but there are exceptions («languid evening» and «languid evening»).
The dictionary and carrier of Morse code is a sequence of two character-characters — («dot» and «dash») that coincides with the letter A. The order of the characters in the dictionary or the carrier is no longer important. Therefore, the carrier may also be the letter N. One letter is the carrier (dictionary), the remaining 25 letters are code texts. Defining the 26 letters of Morse code as texts of words is unusual for linguistic texts. In linguistic texts, words are composed of letters. But for codes, as relations of signs, the composition of letters (cipher) from words is natural.
Each code word (of dots and dashes), as some object, has two coordinates. The first coordinate is the number of the word in this letter (from one to four). The second coordinate is the number in the dictionary (1 or 2). The dictionary is the same for all 26 texts.
All the 26 texts (Latin letters) are independent of each other: the presence of dots or dashes in one text (as letters) and their order have no effect on the composition of the other text (another letter). Therefore the numbering of the first character in Morse code in all letters begins with one according to the third coordinate rule.
Each point or dash, of which a letter consists, taking into account their order, according to the coordinating rule, is assigned a coordinating object — a matrix, the choice of which must satisfy certain requirements.
1.3. Requirements for coordinate objects
Coordination for texts consists in matching the words of the text with some «number-like objects» that satisfy three general requirements:
-
The objects must be individual like numbers;
-
The objects must be abstract (the volume of the concept is maximal, the content of the concept is minimal);
-
Algebraic operations (addition, multiplication, comparison) can be performed over the objects.
The text-appropriate objects in algebra are two-index matrix units:
-
They are individual-all matrix units are different as matrices.
-
An arbitrary n-order matrix can be represented through a decomposition by matrix units. Matrix units are the basis of a complete matrix algebra and a matrix ring. This means that the maximum concept volume requirement is satisfied. Matrix units contain only one unit — the content is minimal.
-
All algebraic operations necessary for the coordinate object can be performed with matrices.
2. Matrix units
In the section on the basis of matrix units (hyperbinary numbers) the necessary algebraic systems for transformation of coordinated texts into matrix ones are constructed and investigated. The matrix representation of texts allows to recognize and create the meaning of texts by means of mathematical methods.
2.1. Definition
Matrix units are matrices in which the unit is at the intersection of the row number (first index) and the column number (second index). In the following, only square matrix units are considered.
The number of all square matrix units (full set) is equal to the total number of elements of a square matrix.
Hereinafter matrix units are considered as a matrix generalization of integers 0 and 1. The main difference between such hyperbinary numbers and integers is the noncommutativity of their product.
2.2. Product
2.2.1. Определяющее соотношение
The product of matrix units is different from zero (zero matrix) only if the internal indices of the product matrices are equal. Then the product is a matrix unit with the first index of the first factor and the second index of the second factor.
Some matrix units can be called simple matrix units by analogy with simple integers, and others can be called composite matrix units because they are products of simple ones.
A complete set of matrix units can be obtained from simple matrix units, which are called the formants of the complete set.
Matrix units are treated precisely as a matrix generalization of integers. Left and right noncommutative divisors of hyperbinary numbers can be different, and there are divisors of zero when each multiplier (the divisor of the product) is different from zero, but their product is equal to a zero matrix. This property of matrices essentially distinguishes them from integers, for which there are no divisors of zero. But many concepts of modular arithmetic (comparisons of integers modulo) remain valid for hyperbinary numbers, but only because of their matrix form. The elements of such matrices (zero and one) have no such properties.
Simple matrix units (analog of simple integers) in the full set are recognized by the ratio of indices.
2.2.2. Indexes
The indices of simple matrix units are of two kinds: the units in such binary matrices are immediately above or below the main diagonal of the square matrix. The elements with the same indices (diagonal matrix units) are located on the main diagonal, and they are not simple.
In composite matrix units, the difference of the first and second indices is either zero (diagonal matrix units), or the difference of the indices is greater than one in absolute value. In composite matrix units their units are outside the two diagonals where the units of simple matrix units are located.
The indices of composite matrix units are all pairs of indices of elements of a square matrix of dimension n except for pairs of indices of simple matrix units.
The ratio of indices determines the value of the product of two identical matrix units. Unlike integers, the square of any hyperbinary number is either zero (nilpotent numbers) or the same number (idempotent hyperbinary numbers).
2.2.3. Idempotent and nilpotent
Idempotency is a property of an algebraic operation and an object, when repeatedly applied to an object, to produce the same result as the first application of the operation. For example, it is the addition of a number to zero, multiplication by one, or raising to the power of one.
Diagonal matrix units are idempotent. Squares of diagonal matrix units are matrices themselves due to equality of internal indices. The product of diagonal matrix units with different indices is zero. Such algebraic objects are known as orthogonal projectors.
A nilpotent element is an element of algebraic structure, some degree of which turns to zero. All matrix units (hyperbinary numbers) except for idempotent ones are nilpotent matrix units. Their second degree is converted to zero. A pair of identical nilpotent matrix units (hyperbinary numbers) are divisors of zero.
The ratio (distribution) of prime and composite hyperbinary numbers in the full set is determined by their dimension n (the corresponding dimension of matrix units).
2.2.4. Distribution
The distribution of prime and composite matrix units is as follows. The number of matrix units with elements above and below the main diagonal is simple out of the total number of complete matrix units. The remaining matrix units are composite matrix units (products of simple ones).
The peculiarity of the system of hyperbinary numbers is that they have left and right multipliers (phantom), multiplication by which does not lead to their change.
2.2.5. Phantomness
Phantom units are such multipliers of matrix units that when multiplied do not lead to a change in the matrix units. Phantom is a generalization of unipotency. Matrix units have a countable set (an infinite set that can be numbered by a natural number series) of phantom left and right factors. The phantom multipliers do not lead to a change in the matrix unit and are analogous to the unit for integers
In contrast to the case of integers and their dull multiplication by one, the phantom multipliers of matrix units are countably manifold. If the occurrence of a particular phantom multiplier has signs of a pattern, then matrix units can be compared by their phantom multipliers. Phantom multipliers are some free index (coordinate) parameters of hyperbinary numbers.
The motivation for using phantom multipliers is that the relations between matrix units can be extended by corresponding equivalence and similarity relations between their phantom multipliers. Different matrix units with the same or similar phantom multipliers can be compared modulo this phantom multiplier. Conversely, identical matrix units may differ by their phantom multipliers.
If a one-to-one correspondence between a matrix unit and its phantom multiplier is defined, then this multiplier can be the module of comparison of matrix units.
The presence of such phantom multipliers will further be used to compare words by their contexts and to compose systems of matrix text equations. Contexts for words will be their corresponding phantom multipliers.
One-valuedness of decomposition of integers into prime factors (factoriality) for matrix units is generalized taking into account their noncommutativity and the need to restrict the ambiguity of decompositions.
2.2.6. Hyperbinary factoriality
Matrix units have a countable set of decompositions into factorizers. This means that there is no single-valuedness of factorization for matrix units. This property will prove useful for comparisons of text fragments at any distance from each other.
Among the decompositions of matrix units it is possible to define some canonical decompositions generalizing the decompositions of integers into prime factors. Such decompositions are algebraically richer than decompositions of integers due to noncommutativity of hyperbinary numbers.
There is the following classification of canonical expansions.
2.2.7. Classification
There are three classes of canonical decompositions of matrix units. A decomposition is called canonical if the co-multipliers are simple matrix units. The property determining the canonical decompositions is the maximal closeness in coordinates of the multipliers of the decomposition of composite hyperbinary numbers into prime numbers.
In general case there are three classes of canonical expansions of arbitrary matrix units depending on the ratio of indices:
2.2.7.1. The first index is greater than the second.
This is the first class of decomposition into prime matrix units — here the first index is greater than the second one strictly by one in each factor. It is impossible to be less than that.
2.2.7.2. The first index is less than the second.
This is the second class of decomposition into prime matrix units — the first index is less than the second in each factor. The first index is strictly less than the second index by one in each factor.
2.2.7.3. The indices are equal
This is the third class of decomposition into simple matrix units — the first index in the first factor is less than the second one strictly by one, and in the second factor the first index is greater than the second one by one and equal to the second index of the first factor.
The decomposition is singular and therefore it is canonical.
All simple matrix units are the complete system of formants of the complete set of matrix units.
2.2.8. Formators
A comparatively small number of simple matrix units will allow to write any texts only with the help of such formants which are formants for all matrix units (complete set). The formants are the alphabet of matrix texts, and monomials, as products of formants, are the words.
A complete system of formants consists of simple matrix units. Compound matrix units (monomials) are called basis units of a complete set in systems of hypercomplex numbers, e.g. alternions.
These formants, like basis elements, are linearly independent. There is no set of any numbers other than zero such that any partial sum or sum of all elements and basis elements equals the zero matrix. This follows from the fact that the units in all matrix units of any formant and basis element are in different places in the matrix and it is impossible to achieve a zero matrix sum by using numbers (integers or real numbers) as coefficients before the summands.
The multiplicity of integers for hyperbinary numbers is inherited in terms of similarity.
2.2.9 Similarity on the left
Matrix units having the same second indexes are multiples (similar) from the left.
2.2.10. Similarity on the right
Matrix units having the same first indexes are multiples from the right.
The transitivity of multiplicity for triples of integers is inherited for triples of hyperbinary numbers.
2.2.11. Left similarity transitivity
The similarity relations of matrix units are transitive: if the first matrix unit is similar to the second matrix unit on the left and the second matrix unit is similar to the third matrix unit, then the first matrix unit is similar to the third matrix unit on the left.
2.2.12. Transitivity of similarity to the right
If the first matrix unit is similar to the right of the second matrix unit and the second matrix unit is similar to the third matrix unit, then the first matrix unit is similar to the right of the third matrix unit. The similarity relations on the right are transitive.
The transitivity property of similarity of matrix units will be used further in the construction of the category of context.
2.3. Addition
2.3.1. Problem
The result of matrix unit multiplication is a matrix unit. Matrix units are closed with respect to the multiplication operation. Therefore the algebraic system of matrix units by multiplication is a monoid of matrix units or a semigroup with a unit matrix (a common neutral element).
The result of adding matrix units will no longer be a matrix unit in the general case.
Matrix units are matrix monomials (monomials). They are either simple matrix units or their products. A matrix polynomial (polynomial) is the sum of matrix monomials.
Any n×n binary matrix (basis element) can be represented as a polynomial with respect to simple matrix units (formants). Matrices over the ring of integers and the field of real numbers are not considered here. But the binary matrices (consisting of 0 and 1) needed to create matrix texts should also have appropriate constraints.
Text binary matrices should not have more than one unit in a row in accordance with the rules of text coordinating. The first coordinate of words is unique — it is the first index of matrix units and the number of the row where the unit is located. When adding identical matrix units, for example, the result ceases to be a binary matrix at all. Therefore, the addition of textual matrix units must be defined in a special way.
There are different rules for adding binary numbers.
2.3.2. Known Binary Additions
When multiplying square binary matrices of the same dimensionality, the result will always be binary matrices. The analogue of the binary multiplication operation in the language of logical functions is logical multiplication. The truth table for this operation coincides with the usual 0 and 1 multiplication.
Logical addition can be considered as a pretender to the rule of addition of text binary matrices. In this case the result of their element-by-element addition and multiplication will again be a binary matrix.
In its turn, logical addition (disjunction) is of two kinds: strict disjunction (addition modulo 2); unstrict (weak) disjunction.
The table of truth for them differs by the addition of units. In set theory addition modulo 2 corresponds to the operation of symmetric difference of two sets. Strict disjunction has the meaning of «either this or that». Non-strict disjunction has the meaning «either this, or that, or both at once». In terms of set theory, a non-strict disjunction is analogous to a union of sets.
The operations of logical addition instead of usual addition when adding matrix units solve the problem of appearance of elements in absolute value greater than one, but as a result of matrix addition, units may appear in several places of the rows of the sum matrix. According to the text coordinate rule, this means that two or more words can be in the same place of the text (defined by the first coordinate).
An addition rule devoid of these disadvantages is required.
2.3.3. Addition by matching (concordance)
The three types of addition operations differ in the rules for matching the summand to the summand. If some rule is accepted (concordance), then the addition rule is uniquely defined.
The three types of addition can be combined into one concordance addition (concordant addition). On the basis of concordant addition it is possible to define matrix unit concordance addition. Such multiplication must be closed by such addition.
The sum by concordance of two text binary matrices is a text binary matrix. The result of concordance addition is the usual addition of matrices.
An algebraic system of matrix units by addition is a monoid of matrix units or a semigroup with zero matrix (a common neutral element).
Before investigating the division operation of hyperbinary numbers, it is necessary to determine the order relation for them. Division of hyperbinary numbers, as with integers, is generally possible, but only as a division with a remainder, which by definition must be less than the divisor. The property of hyperbinary numbers to be smaller or larger needs to be determined.
2.4. Order
On the set of hyperbinary numbers it is possible to define a relation of order through the relation of membership, like integers. Any integer is a sum of units. One number is greater than another if the latter is contained by a fraction of those units in the former and belongs to it. The same approach is used for hyperbinary numbers with phantom multipliers, which is an example of the usefulness of their use.
2.4.1. Magnitude
The value on the left-hand side of the hyperbinary numbers is the trace of their left-hand phantom multiplier matrices. The value to the right of the hyperbinary numbers is the trace of the matrices of their right phantom multipliers. Then, a hyperbinary number is larger (smaller) on the left or on the right if the advising traces of their phantom multiplier matrices are larger or smaller.
The scalar measure of the value µ is a necessary feature of ordering of hyperbinary numbers, but not sufficient.
2.4.2. Neter chains
The value µ does not distinguish the distribution of units on the diagonal of the matrix. As already mentioned, the hyperbinary number is similar on the left and right of its phantom multipliers. This means that the phantom multipliers generate sets of hyperbinary numbers, which differ from each other by corresponding similarity coefficients. These similarity coefficients are themselves hyperbinary numbers.
There arise sets generated on the left or on the right by the corresponding phantom hyperbinary numbers. The set of all such subsets (booleans) are arranged in chains with their generating diagonal elements — one, the sum of two, the sum of three, and so on. These are increasing chains by the number of generating elements. For textual hyperbinary chains are broken because their dictionaries (phantom multipliers) are finite.
Chains with such properties are neter chains.
There is a simple method for constructing such neuter chains for hyperbinary numbers:
-
The product of the generating phantom multipliers of neighboring links is different from the zero matrix.
-
The value µ of the link must be smaller than µ of the next link.
The increasing chains of the Nether booleans generated by the left and right phantom multipliers are a sufficient indication of ordering of hyperbinary numbers.
2.5. Subtraction and division
2.5.1. Subtraction
The operation of subtracting text hyperbinary numbers is not generally defined, as it is for positive integers. The result can be a negative number. But subtraction of identical positive integers is always defined.
The same is true for hyperbinary numbers. The difference matrix of different matrix units will generally contain negative numbers and then it is not a binary matrix. But the result of subtracting the same matrix units is a zero matrix. It is a binary matrix.
2.5.2. Division
The division operation for hyperbinary numbers, like for integers, is undefined. For integers, the division operation is replaced by the corresponding multiplication operation, which is called division with a remainder (division by multiplication and addition).
Square matrix units are singular (have no inverse matrices). For hyperbinary numbers, there is a matrix counterpart to division with a remainder of integers.
2.6. Phantom multiplier comparisons
Comparisons of integers are generalized to the case of hyperbinary numbers.
A diagonal hyperbinary number is called a module comparison of two hyperbinary numbers if the difference of the right (left) diagonal phantom multipliers of those two hyperbinary numbers is divided without remainder by that module.
The set of all hyperbinary numbers comparable modulo is called the modulo deduction class. Thus, the comparison is equivalent to the equality of deduction classes.
Any hyperbinary number of the class is called a modulo deduction. Let there be a residue from division of any member of the chosen class, then the deduction equal to the residue is called the smallest nonnegative deduction, and the deduction smallest in µ is called the absolutely smallest deduction.
Since comparability modulo is an equivalence relation on the set of integers, the classes of deductions modulo are equivalence classes; their number is equal to the measure µ of their phantom multipliers.
2.7. Transformations and equations
2.7.1. Transformations
There is always a quadruple of such hyperbinary numbers that the product of three numbers equals the fourth hyperbinary number. Such equality is a general formula for transforming any number from this quadruple.
2.7.2. Equations
The formula for converting hyperbinary numbers is an equality on the four numbers. It can be thought of as an equation where each set of hyperbinary numbers and their components can be an unknown matrix number and the remaining set can be a given number. A system of linear or nonlinear equations can be made on different words (matrix units), their place in the text, phantom multipliers and summands, if on the set of equations the equivalence relations of hyperbinary numbers on their phantom multipliers and summands are given or defined. In this case, different words are considered equal if their phantom elements (phantoms) are similar, and vice versa, if words are similar (repeated in different places in the text), then their phantoms may differ. The same applies not only to words, but also to text fragments. For example, a phantom (hyperbinary number) may be common to all fragments and words of a text, such as a text abstract as its invariant in transformations and the meaning of the text. In turn, this common phantom can be an unknown for the corresponding system of equations.
In the case of such equivalence classes of textual hyperbinary numbers, the equations become entangled on equivalent hyperbinary numbers.
Unlike polynomial systems of equations over a field of numbers, in systems of hyperbinary equations the given and unknown variables are noncommutative. A method for solving such systems of equations will be proposed in the following.
3. Matrix Texts
3.1. The hyperbinary coordinate formula
In accordance with the rules of coordinatization texts are transformed into matrix texts by the following formula. Each text word with some ordinal number corresponds to a square matrix unit with two indices, where the second index is a function of the first index, and this first index is the word number. The function takes two values: if the word has not occurred earlier in the text, the second index is assigned a value equal to the word number in the text; if the word has occurred earlier in the text under some number, the second index is equal to this number.
A matrix text is a special matrix polynomial — a special case of a hyperbinary number. The sum of monomials in this polynomial should be treated as a concordance summation. After matching, this hyperbinary number acquires the properties corresponding to the rules of coordinating texts.
A matrix text consists of the sum of matrix words (monomials), in part of which a second index (repetition of words in the text) may be repeated. This sum is a matrix polynomial and a hyperbinary number (after coordination), since each of its summands is a matrix monomial, which may be a simple matrix unit or their product (composite matrix unit). In this case the monomials must correspond to the coordinate formula.
The right matrix dictionary is a matrix text with excluded monomials with different indices and consists of matrix units with the same indices. The left matrix dictionary is the full sum of matrix units with the same indices, each of which is a word number in the text. The dimensionality of the square matrix units of the text and dictionaries is equal to the maximum dimensionality of any of them.
There is not more than one unit in each row of the text matrices and dictionaries, the remaining elements are equal to zero. This property is a consequence of the uniqueness of the first index in all matrix words of the text in accordance with the coordinate rules and formula. In which place of the matrix row one is located is determined by the corresponding second index.
In the matrix of dictionaries the corresponding words of the text the units are on the main diagonal. The remaining elements of the diagonal and matrix are zero. In the matrix of the left dictionary there are ones on each place of the main diagonal, the matrix is unitary. The right dictionary is not a unit matrix.
Separator (space) of words in ordinary texts turns into the matrix addition operation. Inversely, the original text is reconstructed of the matrix text by indexes «forgetting» the algebraic properties (by turning the addition operation into a divider-space).
The order of elements in matrix texts is no longer essential, unlike regular texts. The summands can be swapped, but without changing their indices. Consequently, algebraic transformations can be performed with matrix texts (e.g., similarity reduction) as in the case of numerical polynomials.
3.2. Properties
The product on the left of the full left dictionary by the whole matrix text is, of course, the whole matrix text, because the full left dictionary is a unit matrix (phantom multiplier). The part of the left dictionary is a projector. Multiplication of this projector by the text on the left will extract from the whole matrix text the part of the text corresponding to this projector.
The product on the right of the full right dictionary by the whole matrix text is the whole matrix text, since this dictionary contains all the second indices present in the text, and there are no other second indices in the text monomials that would not be present in the right dictionary. The right dictionary is the right phantom multiplier for the matrix text as a hyperbinary number. At that, the right dictionary, unlike the left dictionary, is not a unit matrix.
The squares of the matrix text and dictionaries are the text itself and the dictionaries. The product of the right dictionary on the left one is the right dictionary. The product of the left dictionary on the right one is the right dictionary.
3.3. Fragments.
Each word of a matrix text is its minimal fragment. The sum of all minimal fragments is the text itself. In general, the fragments of a matrix text are the polynomials resulting from the product of the left-hand part of the full left-hand dictionary by the whole matrix text. For the sum of any text fragments to be this text it is necessary to understand addition as a matching addition. After such a concordance the intersection of fragments will be excluded.
The algebraic goal of transformations of matrix texts is a reasonable (with the help of phantom multipliers) fragmentation of the original text with a significant reduction of the number of fragments used compared to the combinatorial evaluation.
3.4. Example of a linguistic text
3.5. Example of matrix mathematical text
3.6. Example of matrix Morse code
4. Algebra of text
4.1. Definitions of algebraic systems
A semigroup is a non-empty set in which any pair of elements taken in a certain order has a new element called their product, and for any three elements the product is associative. Matrix units by multiplication form a semigroup. For matrix units the condition of associativity is satisfied because they are square matrices of the same dimensionality. Matrix units have no inverse (singular). The presence of a neutral element (unit matrix) and an inverse element is not required for a semigroup (unlike a group). A semigroup with a neutral element is called a monoid. Any semigroup that does not contain a neutral element can be turned into a monoid by adding to it some element permutation with all elements of the semigroup, for example a unit matrix of the same dimension for a semigroup of matrix units.
A ring is an algebraic structure, a set in which a reversible addition operation and an multiplication operation, similar in properties to the corresponding operations on numbers, are defined for its elements. The result of these operations must belong to the same system. Integer numbers form a ring. Integer numbers can be multiplied and added, the result is an integer. For integers, there are opposite numbers on addition (negative integers) — addition is reversible. Integers are an infinite commutative ring with one, with no divisors of zero (integral ring). Two elements are elements of an integer ring or the first element (divisor) divides the second if and only if there exists a third element such that the product of the first number by the third is equal to the second number.
A ring of integers is a Euclidean ring. A Euclidean ring is a ring in which the elements are analogous to the Euclidean algorithm for division with a remainder. The Euclidean algorithm is an efficient algorithm for computing the greatest common divisor of two integers (or the common measure of two segments).
For a ring, an ideal is a subcolumn closed with respect to multiplication by the elements of the ring. An ideal is called left (respectively right) if it is closed with respect to multiplication from the left (respectively right) by the elements of the whole ring. A finitely generated ideal of an associative ring is an ideal that is generated by a finite number of its elements. The simplest example of an ideal is a subcollection of even numbers in a ring of integers.
Rings are distinguished by a characteristic — the smallest integer k, such that the product of each element by such k (the sum of k instances of this element) equals the zero element of the ring. If no such k exists, then the ring has characteristic zero. For example, a finite field (finite number of elements) of characteristic 2 is a field consisting of two elements 0 and 1. The sum of the two units here is zero.
A semi-ring is two semigroups (additive and multiplicative) connected by the law of distributivity of multiplication with respect to addition on both sides. For example, the natural numbers form a semicircle. The result of multiplication of natural numbers will be a natural number. But because there are no negative numbers, there are no elements opposite to natural numbers with respect to addition.
Algebra is a ring that has these same elements multiplied by the elements of some field. A field is also a ring, but such that its elements are permutable when multiplied by each other and the elements are inverse (the product of an element by its inverse is a unit element).
Module over a ring is one of the basic concepts in general algebra, which is a generalization of vector space (module over a field) and abelian group (module over a ring of integers). In vector space, a field is a set of numbers, such as real numbers, to which vectors can be multiplied. This operation satisfies the corresponding axioms, such as distributivity of multiplication. Modulus, on the other hand, only requires that the elements on which vectors are multiplied form a ring (associative with unity), such as a ring of matrices, not necessarily a field of real numbers.
An ideal (right or left) can be defined as a submodule of a ring considered as a right or left module over itself.
A half-module is similar to a module, but it is a module over a half-ring (no inverse elements).
A free module is a module over a ring if it has a generating set of linearly independent formants generating that module. The term free means that this set remains generating after linear transformations of the formants. Every vector space, for example, is a free modulus.
A free half-module is a free module over a half-ring.
Algebraic systems are an inverted hierarchical system of concepts (an inverted pyramid), where natural numbers are at the base and various number-like objects on top, with their properties defined by axioms and correspondences («forgetting» some part of properties) between them. For example, complex numbers turn into real numbers by forgetting the imaginary unit, hypercomplex numbers turn into complex numbers by forgetting their matrix nature. Free semi-modules turn into vector spaces when vector coordinates are real numbers, not hypercomplex matrix numbers, and they have no inverse in addition and multiplication (hyperbinary numbers).
4.2. Free semi-module
A text algebra is a free noncommutative semi-module (an associative algebra with a unit) whose elements (matrix units of the text) are commutative in addition and noncommutative in multiplication, and satisfy two relations. The first relation determines the multiplication of matrix units (semigroup by multiplication). The second relation determines the addition of matrix units by agreement. The result of such addition satisfies the rules and formula for text coordination (semigroup by addition). The sum of the text matrix units will be the text matrix unit.
A semigroup is two semigroups. The multiplicative semigroup and the additive semigroup are related by the law of distributivity of multiplication with respect to addition on both sides, since their elements are square binary matrices which are distributive with respect to their joint multiplication and addition.
4.3 Fragment Algebra
Matrix text fragments have the following algebraic properties:
1. The divisor, divisor and quotient are defined for any matrix text fragments almost the same way as for integers. The fragments are hyperbinary numbers. Each fragment has a corresponding left and right phantom multiplier.
The relation of divisibility (or multiplicity) of fragments is reflexive, like for integers (a fragment divides by itself). However, the matrix of a quotient is not always unambiguous. One-valuedness and diagonality of the quotient matrix are restored by using matching addition. The reason of multivaluedness is possible repetitions of indices in matrix units of text fragments.
The divisibility (multiplicity) relation is transitive,
4. — 7. Describe the properties of multiplication and addition of divisibility relations similar to integers.
7. Properties of right and left multiplication of multiples by combinations of matrix units (matrix polynomials) distinguish divisibility (multiplicity) of integers and divisibility (multiplicity) of number-like elements (hyperbinary numbers) as polynomials of matrix units. Integers always exist when multiples of numbers on the left or right are multiplied by integers. In the case of hyperbinary numbers they do not always exist.
8. и 9. The sign of divisibility of matrix text fragments is the divisibility (multiplicity) of their right and left dictionaries.
10.-18. Definitions and signs of common divisor, NOD, mutual simplicity, common multiple.
19, 20. The left ideal of a matrix text is the corpus of all texts (all possible first coordinates) which can be composed from the words of a given right dictionary (second coordinates). Indeed, the left ideal is the set of all matrix polynomials, which are multiplied from the left by the right dictionary. The multiplication results in polynomials that have second coordinates only such as are available in the dictionary. Also, when any polynomial on the left is multiplied by another polynomial, the result of the multiplication is such a matrix polynomial that all its second indices are a subset of the second indices of the polynomial to which the left is multiplied. Any matrix polynomial generates a left ideal of polynomials that have the same right dictionary or smaller. When textual matrix polynomials are added by agreement, the result is a textual polynomial: the polynomial matrix is binary and there is at most one unit on each row of the matrix.
If a textual hyperbinary number (after adding the monomials that make it up) is multiplied to the left or right by any element of a matrix semicircle, this hyperbinary number generates a left or right ideal — all matrix units multiple to the left or right of the given matrix unit. This means that multiplying an even number by any integer results in an even number.
The main left and right ideals are generated by each matrix unit of the dictionaries. The left and right ideals of a matrix semicircle are generated by the sum of the generating elements of the principal ideals.
21. Ideals of matrix texts, by analogy with ideals of integers, allow to investigate not only specific texts and fragments, but also their sets (classes). The theorems for ideals of texts are the same as for ideals of integers, but taking into account that matrix words are noncommutative and some of them are divisors of zero.
22. The notion of divisibility of matrix texts is generalized to the divisibility of ideals of matrix texts. The properties of divisibility of matrix fragments of the text take place in the division of ideals. The notions of NOD and NOC are also generalized to the case of ideals of matrix texts.
23. Comparisons of integers are also generalized to the case of matrix texts. Fragments of matrix texts are comparable modulo (measure) of some fragment if the residues from dividing these fragments by a given fragment are multiples. If the residues are multiples then they have the same dictionaries. Therefore fragments are comparable modulo a given fragment if the residues from division of the fragments on the given fragment have the same dictionaries. Comparability of texts modulo some text can be interpreted as follows. Let there be a corpus of English. Six books are chosen which most correspond to the six basic plots of Shakespeare. The matrix text of these six books is a common fragment. Then the six books that have multiples of the residuals from dividing their matrix texts by the common fragment are comparable. This means that it is possible to make a catalog of books for those who are interested not only in Shakespearean plots. And the multiplicity of residues is a classifying feature for this catalog. There are six classes of residues in this example. By taking only three books, for example, one can compare the entire corpus of English with only three stories out of six. If one has ten favorite books or authors, one can classify the corpus of language in terms of differences from this topthen.
24. For classes of deductions (residues) of matrix texts, operations of modular arithmetic are performed, taking into account that, as for ideals, matrix words and fragments are noncommutative and some of them can be divisors of zero.
25. The notion of solving comparisons also generalizes to matrix texts. To solve a system of comparisons modulo means to find all classes of deductions such that any combinations of matrix fragment units from these classes satisfy the comparison equation.
The unknowns in the comparison equation are the coordinates of the matrix units in the text fragments. The result of solving a system of comparisons is such a replacement of words and/or places of words in the text that the comparison equation is satisfied. For example, if a person has read ten books, then the remaining books are edited into the vocabulary and phrases of those ten books by the comparison solution. If there is a partial solution to the comparison, then the general solution is the class of deductions for which the partial solution (e.g., the working version of the text) is representative of that class. Then the current version of the matrix text corresponds to the set of possible matrix texts corresponding to the solutions of the comparison system. This property of matrix texts can be used in the creation of texts by predicting the variant continuation of a fragment of text (autauthor).
26. Euclid’s algorithm for polynomials of matrix units is simpler than for integers. The incomplete quotient is found in one step and depends on the number of common second coordinates. These common coordinates are defined as the incomplete quotient of the dictionaries of polynomials that are divisible. The incomplete quotient of the fragment dictionaries is uniquely found in contrast to the incomplete quotient of the fragment dictionaries because there are no repetitions in each of the fragment dictionaries.
The ring of integers is Euclidean. The free noncommutative semi-modulus of hyperbinarian numbers is Euclidean.
5. Algebraic structurization
5.1. Structurization
Structure — the totality and arrangement of the links between the parts of the whole. The signs of a structured text are: headings of different levels of fragments (paragraphs, chapters, volumes, the whole text); summaries (preface, introduction, conclusion, abstract, abstract — extended abstract); context and frequency dictionary; dictionaries of synonyms, antonyms and homonyms; marking of text-forming fragments with separators (commas, dots, signs of paragraphs, paragraphs, chapters).
The listed structural features are the corresponding parts (fragments) of the text. For polynomial representation of matrix text some such parts are corresponding noncommutative Gr¨obner-Shirschov bases of free noncommutative semi-modular hyperbinary numbers (text algebra).
5.2 Example of a linguistic text
Algebraic structuring of the example text is done by transforming, using properties of matrix units, the original matrix text in additive form into multiplicative form (similar to division of ordinary polynomials «in column»). The corresponding commutatives are the noncommutative analog of the Gr¨obner-Shirschov basis for commutative polynomials. The diamond lemma is satisfied — the summands have meshing to the right of the second index, but they are solvable.
During transformation (reduction) a transformation of the vocabulary of the text takes place. In the new vocabulary (the basis of the ideal) there are new words. The words as signs are the same, but the meaning of repeated words in the text changes. Words are defined by contexts. Words are close if their contexts contain at least one word in common. Contexts are the more close the more common words from the corresponding dictionary (common second indices) they contain.
In natural languages, the multiplicity of word contexts is the cause of ambiguity in understanding the meaning of words. The meaning according to Frege is the corresponding part of the meanings of the sign (word). The meanings of a word are all its contexts (properties).
The right dictionary in the beginning of structurization was a dictionary of signs-words. In the process of structurization it is converted into context-dependent matrix constructions of n-grams (combinations of word-signs, taking into account their mutual order and distance in the text). The semantic partitioning of the text is based on extending the original vocabulary of the text with homonyms (the signs are the same, the context meaning is different), and the text itself is already constructed using such an extended vocabulary from the noncommutative Gröbner-Shirshov basis.
The marked text, after the first separation of homonyms and their introduction into the extended dictionary, can be algebraically structured again for a finer semantic partitioning.
The extended dictionary (Gröbner-Shirschov basis) together with the contexts of repeated words is called the matrix context dictionary of the text.
The matrix synonym dictionary is a fragment of the context dictionary for words that have similar contexts in semantic distance, but different, like the signs in the right dictionary. Semantic distance measures a measure of synonymy.
The matrix dictionary of homonyms is a fragment of the context dictionary for words that are the same as signs, but with zero semantic distance.
A matrix dictionary of antonyms is a fragment of the context dictionary for words with opposite contexts. A sign of opposites in linguistic texts is the presence of negative words (particles, pronouns, and adverbs) in contexts.
The hierarchical headings of the matrix text are fragments of the Gröbner-Shirschov basis, which have the corresponding frequency of words of the synonymic dictionary. For example, for the example of a linguistic text, the highest heading is two bigrams «set object» «object set».
The preface, the introduction, the conclusion, the abstract, the abstract are the headings supplemented with the elements of the Gröbner-Shirschow basis of lower frequency. and the deductions included in the basis (as in the Buchberger algorithm).
The repetitive words are defined by the frequency matrix dictionary of the text, which is equal to the product of the transposed text by the matrix text itself.
The list of contexts is defined by the context matrix dictionary, which is equal to the product of the matrix text by the transposed text. The context matrix dictionary is a dictionary of intervals between repeating words of the text. The context of non-repeating words is the whole character sequence containing them. The context of the dictionary is the vocabulary.
The text can be restructured with a fragment of the baseline. For example, the novel War and Peace can be restructured into a medical theme by using a dictionary fragment related to the scene of field surgery, and laying out the entire text on the module of this fragment of the general Gröbner-Shirschov basis. In doing so, the supreme title may change. The existing title of the novel (the supreme title) is considered controversial. The word «peace» has two different meanings (an antonym of «war» and a synonym for «society»). In 1918, the dictionary of the Russian language was changed. The letters «ъ» and «і» disappeared. Two words «world» and «mir» became one word, possibly changing the author’s meaning of the novel’s title. Using algebraic structurization, it is possible to calculate the text title as a function of the text, using the two texts (and the two calculated context dictionaries of the novel) before and after the spelling reform.
Two texts under algebraic structurization turn into one text with a unique first coordinate of matrix words as follows. Let each unique first coordinate of a word turn into two indexes. The first is the number of the text, the second is the number of the word in this text. Then pairs of indexes of two texts are numbered with one index and turned into one character sequence with unique numbers (concatenation of texts).
The meaning of the text, its understanding is determined by the motivation and personal context vocabulary of the reader. If they are determined, it is possible to restructure the author’s text, presented in matrix form, into a text as understandable to the reader as possible (in his personal Gröbner-Shirshov basis), but with elements of the unknown, stated in the reader’s personal language, and with additions or clarifications of his personal context vocabulary.
Personal adaptation of texts on the basis of its restructuring is possible. To understand a text is to put it into one’s own words — the basic technique of semantic reading. For texts in matrix form, to understand it means to decompose and restructure the author’s text on its Gröbner-Shirshov basis.
Restructuring requires an algebraic structuring of the corpus of texts to compose the above vocabularies of the corpus of language. In this case the ideals and classes of deductions of the matrix ring of the corpus of matrix texts should be constructed and investigated beforehand. In the Bergman-Kohne structural theory, free (finitely generated) matrix rings are related (connected) with rings of noncommutative polynomials over corpora as commutative regions of principal ideals with rings of polynomials from one variable over the field.
In a free semicircle between the polynomials of a text, there are relations defined by interval and semantic extended vocabularies of the corpus of texts. A particular matrix text can be defined by a system of polynomial equations on text coordinates (the unknowns in the equations are monomials with unknown indices; the noncommutative coefficients given in the equations are monomials with known indices). Some of them will be given by extended dictionaries or inequalities to fragments, and some of them will be unknowns. In this case it is possible to set headings and summaries by equations, and to compute draft text from systems of polynomial equations (inverse problem of structurization — restructuring). It is possible to find the necessary redistribution of text-forming fragments, to replace some dictionaries with others, to change the significance of repeated words, and to define neologisms.
5.3. An example of a mathematical text
The method of algebraic structuring of texts allows us to find appropriate classifiers and dictionaries for texts of different nature. That is, to classify texts without a priori setting the features of classification and naming the classes. Such classification is called categorization or a posteriori classification. Using the example of a mathematical text, five classification attributes, their combinations and corresponding classes are calculated. The names of classes coincide with the names of features and their combinations.
5.4. Example of Morse code
Morse code is algebraically structured into three ideals (classes) by the corresponding noncommutative Grebner-Shirshov bases.
The title of those letters that have a dash sign on the first place of the 4-digit sequence pattern is:
_BCD__G___K_MNO_Q__T___XYZ (13 letters)
The title of those letters that have a «dot» sign on the second place of the 4-character sequence pattern:
_BCD_F_HI_K__N____S_UV_XY_ (13 letters)
The title of those letters that have a «dash» sign in the third place of the 4-character sequence pattern:
__C__F___J K ___OP____U_W_Y_ (9 letters)
6. Context category
6.1. Definitions.
A matrix text word’s context is its fragment — the sum of matrix units (words) between two matrix words-repeaters. Context is all words of a matrix text between repeating characters of the dictionary. For example, between repeating words, repeating dots, signs of paragraphs, chapters, volumes of language texts or phrases, periods and parts of musical works.
The signs of text fragments look the same, but they are also marks homonyms — their context is the corresponding fragments. The context of a linguistic fragment (explication or explanation) can be not only linguistic text, but also audio (for example, music), figurative (photo) or joint (video). The context of a musical text can be a linguistic text (e.g., a libretto).
Matrix words correspond to their matrix contexts, represented as algebraic objects. All possible relations between these objects are the subject of analysis in determining the meaning of words. Category theory is useful for the study of such constructions because it is based on the notion of transitivity.
The category of the text sign context is defined as follows:
-
Category objects are pairwise multiples of contexts.
-
For each pair of multiple objects there exists a set of morphisms (right and left parts), each morphism corresponds to a single context.
-
For a pair of morphisms there is a composition (the product of square matrices of two partials) such that if one partial of the first and second contexts and the second partial of the second and third contexts are given, then the partial of the first and third contexts equals the product of matrices of these two partials (taking into account the right and left products) — the condition of transitivity.
-
A unit matrix is defined for each object as an identical morphism. Categorical associativity follows from associativity of matrix multiplication.
The intersection (common words) of matrix dictionaries is their product. The proof follows from the defining property of matrix units and the definition of dictionaries. When the matrix units of dictionaries are multiplied (the lower indices are the same in each unit), the product of their matrix words (units) with different indices is equal to zero. In the product there remain only common words with matching indices of all the multipliers.
The union of any pair of dictionaries is their sum minus the intersection (deleted repetitions of matrix units).
The minimal right-hand dictionary of the matrix text fragment is such a dictionary of the text that the dictionary and the text are mutually multiples. For mutually multiples of the text and the right dictionary nonzero matrices of their privates exist. The privates exist if the matrix units of the text and the right dictionary contain the same number of second indices (coordinates) and do not contain any other second indices.
Minimal dictionaries do not contain matrix words (second indices of matrix units) that are absent in the corresponding text fragment.
The equivalence classes of contexts are defined by the common minimal right dictionaries. If a pair of contexts has a common minimum dictionary, then these contexts are mutually multiple. Hence, there are their mutual transformations (matrices).
If the sign-word contexts have a minimum common right vocabulary, then they are multiples of each other. Hereinafter, the dictionaries of text fragments mean their minimal dictionaries.
If the given contexts are multiplied by the right dictionary such that each resulting context has a right dictionary (minimum), they are called reduced contexts. During the reduction (multiplication by the dictionary on the right) the part of matrix units with second indices, which are not in the corresponding dictionary, is removed in each of the given fragments. If any of the obtained fragments lacks at least one of the dictionary indices, it should not get into the reduced set.
Contexts with shared vocabularies, for example, after reduction of some word-sign from the dictionary, are objects of the category of that sign.
A transitive closure can be defined for any set of fragments by specifying for them a common vocabulary that is less than or equal to any fragment by the order of the corresponding Neuter chain.
6.2. Example
The same example of a linguistic text is used, in which there are four identical as signs for the word «set. These four signs, in turn, have four contexts and their four vocabularies.
The problem is to calculate the sameness and difference of the four words «set» depending on the sameness and difference in some measure (modulo) of their contexts. The sameness of contexts is determined by the presence of common vocabularies, which are used as a module for comparing contexts. The difference is determined by the deductions of the contexts by the same module. Deductions will define their equivalence classes (classes of deductions) and categories of deductions, since transitivity closure can also occur for them.
The general vocabulary of the four contexts is constructed as their product. Transitive closure on the common vocabulary-module leads to the removal of «superfluous» words.
Thus, the reduced (reduced) contexts of the sign-word «set» are the four corresponding matrix words. These words have the same matrix unit of the sign-word «object» in the unified matrix dictionary (see Dictionary Unification). The category of this sign is computed: the four matrix morphisms and their composition. The composition is an expression in the language of category theory of the interval partitioning of the word «set» (chapter on algebraic structurization), and the reduction is an example of solving a system of comparisons modulo minimal dictionary. The usefulness of using category theory is that its approach is more general and allows the use of methods from different sections of algebra.
Thus, all four fragments of the text are the same (equivalent) in the sense of the matrix-word sign «set» (comparable modulo this word). There are four matrix-morphisms transforming these texts into each other. By analogy with a library catalog, all these four texts (objects of the matrix-word «set» category) are in the same catalog box with the name of the matrix-word «set». This is an example of a crude keyword classification of texts. The contextual meaning of words is not taken into account, all such words as signs are the same, and all cases of their occurrence in the text can be added up to calculate the significance of keywords by frequency of use.
The obtained result means that in the first approximation all four words «set» are contextually related to the word «object». The words «set» can be the same or different as long as their reduced (reduced) contexts are the same or different.
For matrix texts, modulo comparisons are performed. The residues of division of fragments of matrix texts into other fragments (modules) can have residues (subtractions), which, as well as modules, are classifying signs.
The sign of divisibility (multiplicity) of fragments of matrix texts is the divisibility (multiplicity) of their right dictionaries. The residues of division of the dictionaries (deductions of dictionaries) of fragments are the dictionaries of the residues of division of these fragments.
To calculate the similarities and differences of the words you need to compare the corresponding four contexts modulo matrix word «object». Four deductions of each context modulo matrix word «object» are calculated.
It follows from the result that all four contexts are incomparable modulo matrix word «object». The deductions are not pairwise multiples and do not form any class of deductions in pairs. This means that all «set» words are different in sense (context).
The similarity is found in the next step of calculations (for deductions) by calculating common vocabularies for pairs of deductions and performing the reduction. There is no common dictionary for all deductions. This is the reason why there is no common class of deductions and no corresponding category of the matrix word «object». But some three pairs of deductions have three corresponding common vocabularies. Then these pairs of deductions, after reduction, form classes and categories of deductions with the matrix word names «this», «being» and «point». The directory with the matrix name «this» contains the first and second fragments, the directory with the matrix name «to be» contains the first and third fragments, and the directory with the matrix name «dot» contains the second and fourth fragments.
The matrix word «polynomial» is the annulator (divisor of zero) of the first, third, and fourth fragments.
The matrix word «monom» is an annulator (divisor of zero) of the deductions of the first, second and fourth fragments.
The matrix word «coinvariant» is an annulator (divisor of zero) of the deductions of the first, second and third fragments.
These are context-free matrix words (the last three summands in the context dictionary of the chapter on algebraic structurization) — when multiplying a deduction by an annulator the product is different from zero if the deduction contains this annulator.
So the problem statement of the above example was to calculate the sameness and difference of the four matrix words «set» depending on the sameness and difference of their four contexts (fragments) by some measure (modulo).
The solution is obtained: the corresponding four matrix words (as their four contexts) are comparable in modulo of the matrix word «object» and are not comparable (different) in modulo of the matrix words «polynomial», «monomial» and «coinvariant».
It means that the reduction should not be done by the common dictionary consisting of one matrix word-sign «object». As it turns out, this word-sign has different meanings in different places of the text. We calculate the extension of the original vocabulary into the appropriate context vocabulary. In the chapter on algebraic structurization this was done using the Grebner Shirshov noncommutative basis.
The original dictionary is converted into a context dictionary. To the four matrix signs-words «object» additional matrix words «polynomial», «monomial» and «multiplier» were added with the help of category calculation. With these additional words the three non-diagonal matrix words «object» differ from each other.
The above categorization is a categorization of matrix texts by dictionaries. In categorization, classes and their names are calculated as algebraic functions of the text. The categorization was computed by dictionaries, since the categorizing features (category names) were determined by mutual intersection of dictionaries. This categorization does not take into account the order of words in the text, but can be further used in the construction of a more subtle categorization that takes into account the mutual order of words. Modules of comparison in this case will not be parts of dictionaries, but fragments of contexts. Repetition of words in contexts may appear when replacing fragments of dictionaries with fragments of texts. There is an ambiguity in the division (construction of category morphisms). That’s why at first a comparison is made modulo dictionaries, similarities and differences (divisors and remainders) on this measure are determined. Then, after establishing the similarities and differences of the word-repeats in the contexts, the dictionary comparison module is replaced by a text fragment, which already takes into account the order of words. The category names become the text fragments.
The general method for computing the classifying features gives an analogue of CRT for matrix texts. The Chinese remainder theorem (CRT) for matrix texts is formulated as follows. Let be given:
-
Pairwise non-multiple minimal dictionaries of matrix text fragments (already agreed).
-
Right dictionary of some set of similar texts as a sum of minimal dictionaries.
-
Right vocabulary of a set of other similar texts, smaller in measure (following vocabulary).
-
The set of second texts is a subset of the first texts in the sense that their right-hand dictionaries are part of the right-hand vocabulary of the first texts.
-
A tuple of subtractions, where its elements are comparisons of each text from the second set with the union of all the second texts by the moduli of the dictionaries of the first set of texts.
Then there exists a one-to-one correspondence between the texts of the second set of texts with this tuple of deductions. It is proved by induction using the definition of multiplicity of polynomials of matrix units and minimality of the dictionary.
The tuple of deductions is a classifying feature of all possible multiplicities of the texts having the vocabulary of the second set of texts or any part of it. It is by this correspondence that it is expedient to build classifiers of linguistic and other sign sequences.
7. Concordance of meaning
Earlier texts (sign sequences with repetitions) were transformed (coordinated) into algebraic systems with the help of matrix units as word images. Coordinatization is a necessary condition of algebraization of any subject area. A function (arrow) is a matrix coordinatization of a text. One can perform algebraic operations with words and fragments of matrix texts as with integers, but taking into account the noncommutativity of multiplication of words as matrices. Structurization of texts is reduced to calculation of ideals and categories of texts in matrix (hyperbinary) form.
Here the notion of a matrix word in context is defined. Words-signs in repetition may have different fragments of text between them (contexts), and words that are the same in spelling and sound — have different meanings (as homonyms). In a text, all repeated words can be homonyms if their contexts differ by an appropriate measure (modulo). Conversely, words different in spelling and sound can have similar contexts and different measures of synonymy. The frequency of keywords in semantic analysis is more appropriately defined as the frequency of contexts comparable by an appropriate measure than as the frequency of word-signs, like letters of the alphabet. When calculating the semantic frequency of words taking into account the context, different word-signs with the same contexts should be summed in the frequency calculation and, conversely, the same word-signs with different contexts should be excluded.
Matrix words are complemented by context multipliers. These multipliers, due to the properties of matrix units, do not lead to the change of words as signs, but contain signs affecting the meaning of the defined words. Phantom context multipliers are present in matrix words, but do not affect the signs. Multipliers contain relations (according to Frege) with other signs (part of the properties of these signs is their meaning in a given context). The semantic similarity and difference of words can then be calculated by comparing (matching) these phantom multipliers-contexts.
Algebraic operations with matrix words in context require concordance (concordance) — the semantic concordance of signs and text fragments, which depends on the measure (module) of concordance. Matrix words can add up to a text if their contexts have a common meaning (module). The invariants of matrix texts, which preserve their meaning when words and text fragments are replaced with consonant ones, are increasing Nether chains. Nöther chains allow one to make systems of algebraic equations for transformations of texts preserving their meaning.
7.1. Contextual concordance of words
Suppose there are two repeated words of text, whose first coordinate of the second word is greater than the first coordinate of the first word, and a matrix text fragment between these words (context). In this case according to the coordinate rules and formula all the second indices of the fragment are less than the first coordinate of the second word. Then the product to the left of this context fragment on the second word is zero.
The word in the context is the product on the left of the sum of the context fragment and the unit matrix by this matrix word.
The context fragment plus the unit matrix is the left phantom multiplier of the matrix word. The phantom multiplier does not result in a word change, but can be used to compare two (not necessarily repeated) words by comparing their matrix contexts. Such a semantic comparison of text words by context (meaning) will hereafter be referred to as concordance (concordance) by word meaning.
Two words can be concordant (coordinated) either by the intersection of word contexts or by their union. In what follows, only the intersection of contexts will be considered. Algebraically the descriptions for union and intersection are the same. For application, their purpose is different. A human, due to natural physical limitations, can hold only a few entities (about seven) at a time in the process of comprehension. Such an operation of thinking as abstraction is used to reduce the variety of the world to this number. Concordance by intersection is a mathematical explication of the process of abstraction in the form of reduction. The limiting case of abstract concepts of natural language are logical categories (Aristotle, Kant, Hegel). Hierarchical continuity of concepts (words) is necessary for the construction of part-whole relations (relations of understanding).
Concordance by association increases the essences. But their number matters only for humans. For machine languages, this limitation is insignificant. Therefore, concordance on association can be applied to machine interactions, and to the future collective intelligence of the human population, for which collective understanding technologies must be created. At present, acceptable understanding is achieved in collectives of programmers. For collectives of five or more, such as medics, there is no single term that they understand in the same way. In mathematics, seemingly the universal language of humanity, with ideal objects not changing over time, specialization has reached such a level that fully understood by territorially distributed teams of three or four people.
Concordance by intersection would be called simply concordance.
Two words are concordant (matched) by the intersection of the right dictionaries of their contexts, if the intersection (product) of the two dictionaries is different from zero. Words are concordant in the sense that their contexts have a common vocabulary. Contexts after reduction are congruent. Reduction (see «Context Category») is the product to the right of each context by this common intersectional vocabulary.
Each reduced context contains all words from the common dictionary. N words are concordant if each word pair is concordant.
The relation of concordance is an equivalence relation, because the conditions of reflexivity and symmetry for matrices are satisfied, and the transitivity of the relation follows from the definition of word concordance.
The measure (module) of concordance is the common vocabulary. It is this modulus that explains the emergence of the term «modulo concordance» by analogy with the term «modulo comparison» for integers. Just as different integers can be equal modulo, so different (as characters) words in a text can be equivalent (interchangeable) modulo concordance. This means that if words have concordant contexts, then the words have concordant meaning and can be considered equivalent (interchangeable in meaning in the text).
Words and their sums can be concordant modulo. On concordance relations, like equality and comparison modulo, it is possible to make systems of concordance equations. The unknowns can be definable and determinable words, concordance moduli, contexts, and text fragments. Concordance equations allow to calculate answers to such questions: in what sense (here the unknown is the module of concordance) are words and texts concordant? If the meaning (modulus) is given, what set of words do we replace with other words? In this way, it is possible to compute word definitions and sense versions of texts. Find interchangeable words, compute semantic markup and text structuring, annotation text drafts, and semantic text translation (even of the same language). New functions of text editors and readers, messengers and social networks can be based on these computational capabilities. In the latter case it is possible, by compiling a personal contextual dictionary of a user-participant according to his messages, to accompany the communication with semantic translation of text and sound through personal contextual languages of other participants.
Concordant addition of a pair of words is an expression in which in the common left phantom multiplier two fragments are added and multiplied to the right (reduced) by the common vocabulary. A unit matrix is then added to this expression of the sum of the fragment-contexts. This final expression is the phantom multiplier and the concordant context of the concordant sum of the two words. The module of concordance is the common vocabulary of the two contexts. The concordant sum of n words is defined similarly. The common dictionary is the product of their n right dictionaries of n contexts.
Two words are concordant if the right dictionaries of their contexts have a non-zero overlapping area. But each word of these contexts, in turn, is also a word in context. Therefore, the mutual concordance of the word being defined with the words being defined is necessary. Such reflexivity, is the reason for the ambiguity of natural language and interpretations of texts («I think that they think that I think, …»).
A mathematical explication of reflexion is the latent semantic nonlinearity of linearly ordered word-signs. Perhaps, in the future, linguistic texts will cease to be linear and one-dimensional. Note texts, for example, are 5-dimensional, although they can also be transposed into one-dimensional stan-«thread», but this will turn note texts into monstrously incomprehensible codes with dictionaries comparable to the dictionaries of language texts. Such one-dimensional music texts, like language texts, would require a semantic gestalt translation, not just a personal intonation translation, as for 5-dimensional music texts. Future multidimensional language texts will be able to point to meaning chains to reveal the meaning of words and text fragments, rather than recognizing them intuitively or with the help of meaningful (quick) reading tips.
A fragment in the definition of a word in context, in turn, can be seen as a concordant sum of matrix words, since each summation word in this fragment also has its own context. Then the word can be appropriately defined in such a refined context. The word in the refined context is a matrix bilinear form.
Two words are concordant in refined contexts if the intersection (product) of all vocabularies of all contexts of both words is different from zero. N words can be concordant in refined contexts if each pair is concordant. The modulus of concordance is the product of all vocabularies of all contexts of all forms.
There can be concordant sums of words (text fragments) over refined contexts if each pair of sums is concordant.
A pair of word summaries is concordant if the product of the vocabularies of all contexts of all words of the summation pair is non-zero.
If the modulus of concordance, as the product of the dictionaries of all refined contexts of all words as bilinear forms, is nonzero, then the text of these words is concordant.
All words and fragments of the matrix text can be decomposed into concordance classes.
Each word corresponds to its phantom multiplier on the left defined above. Each text fragment corresponds to its vocabulary (phantom multiplier on the right). These multipliers exist, but do not change the word or fragment. At the same time such multipliers are uniquely determined from the text by its fragments. The absence of multiplier influence on signs is a necessary condition, but not sufficient for concordance relations. A sufficient condition is that multipliers not affecting signs and fragments of signs are a one-valued function (property) of the text.
Each pair of words in the text corresponds to a concordance module (kappa) — the product of all vocabularies of all refined contexts of both words.
Each pair of text fragments corresponds to a kappa concordance module — the product of all the dictionaries of all the specified contexts of all the words of the pair of fragments.
Each pair of word and text fragment corresponds to a kappa concordance module — the product of all the dictionaries of all the refined contexts of the word and text fragment.
Conversely, each kappa module (class name) corresponds to a set of refined contexts, a set of words corresponding to these contexts and a set of text fragments with a vocabulary equal to kappa. All these three sets are mutually concordant and all their elements are elements of the same kappa concordance class.
The set of all concordance classes modulo kappa is the Boolean set of all n words of the vocabulary of the text or all its partial sums (fragment dictionaries). The number of all partial sums is two to the power of n.
The belonging of such elements to the same class means that there are matrices of transformation of elements into each other. Indeed, if the set of refined contexts, the set of words corresponding to these contexts by and the set of text fragments have a single dictionary equal to kappa, then all these elements are similar to each other. In this case, the common object of transformation in refined contexts and text fragments are matrix polynomials (hyperbinary numbers).
Mutual transformations of refined contexts, words corresponding to these contexts and text fragments having the vocabulary equal to kappa are as follows:
1. Conversion of a pair of refined contexts of the form.
Let there be two matrix texts. Because they belong to the same class, they have the same kappa modulus or, what is the same, they have the same right dictionaries. But matrix texts having the same dictionaries form ideals of the matrix semicircle (are multiples of the dictionary). There is always a matrix polynomial, whose multiplication of the left by one refined fragment results in the corresponding refined fragment. To the precision of the matrix multiplier (quotient) the two refined fragments are indistinguishable (interchangeable).
2. Conversion of words in a refined context.
Let there be two words in context. Since the words are concordant (have a common kappa dictionary as the product of all the dictionaries of all the refined contexts), the words are concordant by kappa. Like integer comparisons, matrix unit concordance can be written appropriately through equality.
3. Conversion of words and contexts.
Let there be a word and a context. A word and a context are concordant if they share a common kappa modulus. There is also a notation via equality as a formula for computing the naming of a text fragment by a word belonging to the kappa concordance class. And vice versa, the definition of a word by a text.
7.2. Meaningful Nether chains
The kappa concordance classes are distinguished by the words included in the kappa dictionary. Let a sequence of dictionaries be given such that neighboring dictionaries differ by one word.
The concordance class (title kappa) for each kappa is the set of all words in the refined context, all refined contexts and all text fragments sharing a common kappa dictionary. Elements (header kappa) are mutually substitutable by the formulas
Let there be concordance classes as chains of «includes in» and «includes itself». In such chains of dictionaries there is an increase of words in each dictionary from left to right or a decrease.
The sequence of such non-empty subsets of a corpus of texts based on a corpus dictionary of all texts is increasing, because each one is a subset of the next one.
Conversely, the sequence of subsets is decreasing, since each of them contains the next subset.
A sequence is said to stabilize after a finite number of steps if there exists such n that for all subsequent numbers of the subset chain they coincide. This holds for matrix texts — there is no greater dictionary than the dictionary of all texts. The set of subsets of a given set (capital kappa) satisfies the condition of cliffing of increasing chains, since any increasing sequence becomes constant after a finite number of steps.
Any decreasing sequence becomes constant after a finite number of steps, since the dictionary (header kappa) has a minimal set — one word, hence the corresponding set of subsets satisfies the condition of breaking of decreasing chains.
In general algebra, objects are called nether objects if they satisfy chain breaking conditions. Amalia Emmy Nöther made masterful use of the cliff chain technique in her many cases. Objects such as concordance classes are also Nether chains.
Nether chains can also be defined for word order in a text. Relative word order is essential for texts. For example, «incidental in the necessary» differs in meaning from «necessary in the necessary» or «mom’s dad» and «dad’s mom». For musical texts and codes, the order of characters is as significant as the characters themselves.
The concordance module is a fragment of the vocabulary of the text. For a dictionary, the word order is insignificant. Therefore, the concordance class contains elements without taking into account the order of words in text fragments. The word order is taken into account through the available subclasses of the concordance class. As a result of the calculations, the corresponding concordance class and the three features of its three subclasses that take into account word order are described. The order subclasses are defined by ascending or descending Neuter chains for the first coordinates of matrix monomials in the left word dictionaries. For the left-hand dictionaries there are also Neuther chains as for the right-hand dictionaries, and this is how the meaning of the word order in the matrix texts is taken into account.
Neuter chains for words and their order are semantic invariants of the text, preserved by appropriate concordant word substitutions in the text (retelling the text in one’s own words), substitutions of fragments with words (abstracting and annotating), substitutions of words with fragments (bot-authorship). The invariance comes from the fact that the neoteric chains are constructed by the left or right dictionaries of matrix polynomials. The invariance on the neoteric chains of the right dictionaries means that the places of words in the text are not important for the meaning of the text, what matters is the system of their context correspondence as a function of embedding (taking into account the order of words within n-grams). Invariant on the Nöther Chains of the Left Dictionaries means that for the structure of the text the words from the right dictionary are not important, the system of their structural correspondence as a function of embedding the left dictionaries of the text-forming fragments (the structural pattern of the text) is important.
The Neuter chains of the text are more preferable for semantic analysis than the frequent keywords, because they take into account the contexts of words, and also reveal the regularities of disclosure of the system of concepts in the text through the sequence of nesting of their content (context) — this is the above-mentioned hierarchical continuity of concepts (words). Logical, ethical and aesthetic categories of natural languages can be computed as Neuther chains of meaning.
If the Nöther chains of meaning are defined as target functions (sequences of embeddings), it is possible to compose systems of equations on variables of bilinear forms. Because the variables are pairwise meshed with each other (pairwise nested in Nether chains) a system of quadratic equations on words in refined context, their contexts and text-forming fragments as unknowns of such equations can be compiled.
7.3 Meaning Equalizers
In category theory the following model is called an equalizer (a generalization of the equation) as applied to matrix text fragments. Let four fragment objects and their dictionaries be given. The objects are connected by a pair of morphisms. The second dictionary is part or all of the vocabulary of the first dictionary. The third object-fragment and its morphism-transformation to the first object-fragment (inclusion function) is called an equalizer of the first pair of morphisms if the matrix products to the right of each morphism of this pair on this inclusion function are concordant. For any other fourth object, the right products of each morphism of the same pair on the inclusion function of the fourth object in the first one are also concordant and there exists a single morphism of the third object in the fourth such that the matrix product of the first object morphism in the third one by the morphism
The essential difference between the above definition for the equalizer of matrix fragments and the canonical definition of the equalizer for the Set category, for example, is the replacement of the equality relation by the concordance relation. But since equality and concordance relations are equivalence relations (they have properties of reflexivity, symmetry and transitivity), such replacement is admissible and satisfies the axioms of the category.
The reason for using concordance is as follows. For the first two objects-fragments of the category it is required to find the third fragment of the text and its corresponding matrix polynomial-transformation such that, when multiplied by it on the right, the ambiguity connected with the repetitions of the indices in the fragment monomials is eliminated. Since in the monomials of matrix polynomials both coordinates refer to the position of words in the text, multiplying the first pair of morphisms by the inclusion function is the consistent rule of choice for repeated words, which eliminates ambiguity.
If words are considered in a refined context, the semantic distinction of repeated words in the text and their concordance by refined contexts are used to achieve this unambiguity.
The system of equations for fragments in refined contexts (a word is a special case of a fragment) can be compiled in three ways:
-
By the correlation of the concordance of text fragments in specified contexts. For example, it is the concordance of the title of the text and the whole text or parts of the text (paragraphs, chapters, etc.), parts of the text (for example, the abstract and the whole text, the first paragraphs of paragraphs, etc.). The listed combinations of fragments are labeled and are the corresponding equation numbers in the equation systems of the text.
-
According to the Nöther chains of text fragments and their ordering. The equations in this case are recurrence and are defined by corresponding formulas. Recurrence on the first coordinates determines the sequence of text fragments (structural pattern of the text). Recurrence on the second coordinates determines the sequence of fragments by continuity of meaning (contextual table of contents of the whole text and its sections). Each Nether chain defines an equation in a system of equations.
-
The combination of the two points above.
Systems of matrix equations have the general form of a bilinear form and, depending on which fragments in the corresponding bilinear form are taken as unknowns, are either systems of linear or quadratic equations. The set and unknown quantities are matrices. For the linear case, there are matrix versions of the Gaussian method for solving systems of linear matrix equations. For systems of quadratic matrix equations, there is also a generalization of the Gaussian method of eliminating the unknowns and reductions in systems of equations with many unknowns to an equation with one unknown and formulas for the relationship between the unknowns.
It is possible to reduce a system of quadratic equations to a system of linear equations without loss of generality and accuracy by using alternions, which are hypercomplex numbers consisting of hyperbinary numbers.
An example of an exact linearization is given.
For accurate linearization and solution of systems of concordant equations, it is necessary that matrix words and texts commutate with the alternions and that the squares of the unknowns exist. The first requirement is satisfied by using the corresponding property of the Kronecker (direct) product of matrices, the second requirement for matrix texts is always satisfied since the square of a matrix text fragment is the same fragment.
Conclusion
The practical application of text algebra is illustrated by the description of the functions of the Frege semantic assistant. This application is an enhancer of human cognitive abilities. Cognition has three components: perception, awareness, and understanding. At the same time, everyone sees and hears only what he understands (J. W. Goethe).
Perception is sensual, direct cognition of surrounding objects. Equivalence relations (naming) of sense signals (audio and video, for example), their combinations (scenes) and words are established.
Awareness is the use of a person’s active vocabulary (operative vocabulary) in the everyday life of his or her community. Operative vocabulary (active structured vocabulary) is related to the vocabulary of a person’s actions. The main question to this vocabulary is «what?». Contains the person’s personal vocabulary of interests and motives.
Comprehension — using the full structured vocabulary of an individual person (persona). The questions to it are «how?» («why?», «why?»). Necessary for adaptation of the person and actualization of the operative vocabulary. It is a passive structured vocabulary, a part of the general vocabulary of natural language, its personal part. Partiality is determined by upbringing, education and experience — it is a person’s personal vocabulary of words and the connections between them on the basis of the formation of similarity relations. The aggregation of all personal vocabularies of all humans throughout the history of language is the universal contextual vocabulary of the language of the human population.
Frege’s mental digital assistant is a set of features to enhance cognition and thinking operations such as:
-
Analysis is the division of an object/phenomenon into its constituent components.
-
Synthesis is the unification of components divided by analysis and revealing essential connections (properties).
-
Analysis and synthesis are the main operations of thinking, on the basis of which ontological units (words, concepts and logical, ethical, aesthetic categories) are built.
-
Comparison (comparison of objects and phenomena, revealing their similarities and differences).
-
Classification (grouping of subjects according to attributes)
-
Generalization (association of objects according to general essential features)
-
Concretization (singling out the particular from the general)
-
Abstraction (emphasizing some aspect, aspect of an object or phenomenon while ignoring the others).
Machine representation of thinking operations is as follows:
-
Separation (analysis, classification, concretization, abstraction)
-
Unification (synthesis, generalization)
These are the basic operations of set theory. In the mathematical theory of categories they are replaced by one operation, ordering (arrow).
The main function of Frege’s application is adaptive structurization and increase of active and passive stores of language. The other functions are:
-
Improvement (training) of the perception vocabulary. Support for increasing the quantity and quality of image and scene recognition. Practical implementation — the client application provides the user with a signal system about the recognized images and scenes with the possibility of their demonstration with the names from personal dictionaries and classifiers.
-
Improvement (training) of the comprehension vocabulary. Actualization of the active vocabulary of words by frequency of use in various classes of activity. Frequency is determined by the number of calls to the activity vocabulary (vocabulary mapping) and references to the comprehension vocabulary.
-
Comprehension vocabulary improvement (training) — improvement of personal meaning recognition. Personal structuring, closing equivalence, similarity and order relations. Comprehension vocabulary development takes place on the server. All client dictionaries (mental clones) are projections, personalization of dictionaries on the basis of the client’s actions (references to dictionaries).
Mapping client vocabularies is a mapping of client vocabularies.
Client training — structuring and updating client dictionaries based on monitoring client activity and recognizing client interests (interest dictionary updating).
Server dictionary training — based on feedback from client applications, analysis of user activity and queries.
Frege’s semantic digital assistant — a cognition enhancer based on relationship closure and vocabulary mapping. Application Results:
The user clearly has (created and maintained) personal dictionaries (contextual, synonymic, antonymic, homonymic), personal ontologies as dictionaries with heterarchical relationships of used sign sequences (linguistic, figurative, musical). A set of such dictionaries is called a human model and represents logical (true-false), ethical (good-bad), and aesthetic (beautiful-horrible) assessments of the world. Personal dictionaries are projections (parts) of general corpus dictionaries of language, images and sounds.
The purpose of the application is to agree in real time on the meaning (common parts of meanings) of the signs (words, images, sounds) used in communication, the semantic translation of personal dictionaries. For example, in negotiations (meetings) it is an instant semantic translation of used concepts and terms for specialists from different subject areas and schools in the context of the goal of the negotiations.
The initial mental state of the client application is allowed in two forms:
— the user has no personal dictionaries, but is motivated to create them. Then the purpose of the application is to compute personal dictionaries on the basis of the provided access to personal character sequences (if there is a sufficient number and quality). If not, the creation of personal character sequences on the basis of providing support tools for personal consultant mentors. For example, creation of the necessary photo, audio and video archives, creation of a personal library by retelling the language texts «in their own words.
— The user has no personal dictionaries and no motivation to create them, but has an interest. In this case, access to the application cases is provided:
-
Happiness is when you are understood
-
In lieu of a resume (supports personal relevance)
-
Eternal life (digital existence after biological death)
-
Personal teacher (keeps personal vocabularies up to date and comfortably developed)
-
Work in place of self (model and person remotely indistinguishable)
-
Seek only for oneself (information, knowledge, music, images, close social groups) without additional selection
-
Interpreting meaningfully from a foreign language (word-for-word translation)
-
Fast semantic reading (personal adaptation of texts, retelling in their own words)
-
Fast career change (personal meshing of the unknown with the known)
-
Personal choice (auto-search of goods and services «for oneself»)
-
Question formulation (translation from «his» language to the universal one)
-
Creating drafts of character sequences by titles and annotations
-
Dementia cupping (support as actual dictionaries their necessary and possible parts)
Frege’s Meaning Assistant is based on the following principles of modern learning:
— The ability to ask questions is more important than memorizing answers. A well formulated question is guaranteed to be answered with the help of modern information technology. The role of the machine teacher (a personal digital mentor) is to teach you how to formulate questions or problem statements with examples, systematize the answers and the next stage of formulating questions.
— Not only are answers true or false, but so are questions. A question is called true if the answer is true or false (yes or no); otherwise the question is called false. In other words, you must formulate a question so that it can be answered affirmatively or negatively. Then the wording of the question is considered worked out (true). If it cannot be answered this way, then the question is not good enough (false). The student must demonstrate the ability to ask true questions when testing. The skill of decomposing a primary question into elementary questions must be mastered. Questions, not answers, should be evaluated. The relative number of true questions determines the overall grade.
— Grades should not be assigned subjectively but should be calculated. An elementary grade can take only two values (pass or fail). Final grades are calculated from elementary according to simple algorithms (synthesis). Learning is assessed continuously and continuously. The student must have an opportunity to change (correct) the elementary grades (failures) received earlier. The subject area must be decomposed into elementary blocks (topics). Knowledge of all blocks must be checked.
The systematized and structured contexts of words that are mastered in learning are called the logical, ethical, and aesthetic components of the human model — its phenotype. A person is his genotype and phenotype. In the past, they were biologically stored in a person’s personal genetic sequences and memory. Modern information technology makes it possible to store not only the genotype, but also the phenotype separately from the person. It is possible and necessary to preserve the phenotype cumulatively in learning over the course of a short biological life. The learning phenotype is used, tested and refined in processes of meaning understanding. The individual is objectively motivated to create his or her second self. The formalized phenotype created will allow human immortality by biological cloning of genotype and phenotype, or/and virtually in information space.
The purpose of meaningful digital assistants is technological support of universal understanding to create the collective mind of the human population and universal relevance.
References
-
Pshenichnikov S., Algebra of text. book // Researchgate, 2022.
-
Pshenichnikov S., Valkov A., Converting text into algebra
-
Pshenichnikov S., Concordance of sense
-
Pshenichnikov S.,Context category
-
Pshenichnikov S., Algebra of text. Examples
 Please Note:
Please Note:
This article is written for users of the following Microsoft Word versions: 97, 2000, 2002, and 2003. If you are using a later version (Word 2007 or later), this tip may not work for you. For a version of this tip written specifically for later versions of Word, click here: Correctly Repeated Words.
![]()
Written by Allen Wyatt (last updated February 20, 2019)
This tip applies to Word 97, 2000, 2002, and 2003
Word has a spell checker that tries to helpfully point out potential errors in your documents. For most people, the potential errors are marked with a red underline. As detailed in other issues of WordTips, you can modify how the spell checker does its work by adding words to a custom dictionary, or by creating an exclusion file. One of the spelling errors that Word always marks, however, is double words. Type in «the the,» and Word underlines the second «the» as being incorrect.
A problem crops up when words really should be duplicated. For instance, if you type in the name «Walla Walla,» a city in Washington State, the second «Walla» is marked as a spelling error because the word is repeated. There is no way to turn off this spelling check, and there is no way to add the double word (Walla Walla) to the dictionary as a correct word. Even if you open the custom dictionary and add «Walla Walla» to it, the word is still marked as incorrect by the spell checker.
The only solution is to trick Word into thinking that Walla Walla is a single word. You can do this by using a non-breaking space between the first «Walla» and the second. (A non-breaking space is created by pressing Ctrl+Shift+Space.) The word is not marked as incorrect by the spell checker once this is done. The drawback, of course, is that the phrase is now treated as a single word, which will affect how line breaks occur—if a line break would normally occur between the first «Walla» and the second, the entire phrase will now be shifted to the second line.
Another way to solve the problem is to mark the text so that there is no grammar or spell checking done on it. You can then create an AutoText entry for the phrase so that when you enter a short mnemonic, the full phrase—marked for no grammar or spell checking—is inserted in the document. Follow these steps:
- Type the phrase «Walla Walla», without the quote marks. The second word should be underlined as a spelling error.
- Select the phrase, making sure not to include any spaces or punctuation after the phrase.
- Choose Tools | Language | Set Language. Word displays the Language dialog box. (See Figure 1.)
- Make sure the Do Not Check Spelling or Grammar check box is selected.
- Click OK. The red line under the second instance of «Walla» should disappear.
- With the phrase still selected, press Alt+F3. Word displays the Create AutoText dialog box. (See Figure 2.)
- Click OK. Word creates an AutoText entry for the phrase.
- Delete the phrase you typed in step 1.
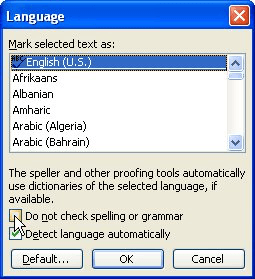
Figure 1. The Language dialog box.
Figure 2. The Create AutoText dialog box.
At this point, when you start to type «Walla Walla,» Word displays an AutoComplete prompt. This prompt appears after typing the fourth letter. Press Enter at that point, and Word completes the phrase, as if you had typed «Walla Walla». The difference is that the phrase, as completed by Word, has the spelling and grammar checking turned off, so you don’t see the incorrect spelling error noted.
WordTips is your source for cost-effective Microsoft Word training.
(Microsoft Word is the most popular word processing software in the world.)
This tip (225) applies to Microsoft Word 97, 2000, 2002, and 2003. You can find a version of this tip for the ribbon interface of Word (Word 2007 and later) here: Correctly Repeated Words.
Author Bio
With more than 50 non-fiction books and numerous magazine articles to his credit, Allen Wyatt is an internationally recognized author. He is president of Sharon Parq Associates, a computer and publishing services company. Learn more about Allen…
MORE FROM ALLEN
Protecting Hidden Text
Formatting some of your text as hidden can be a great help when you need to keep some things from being viewed or …
Discover More
Aligning Paragraphs in a Macro
Using a macro to format your document (or portions of your document) is not all that uncommon. If you want your macro to …
Discover More
Quickly Moving Text with the Mouse
Drag-and-drop editing is a handy feature when you love to use the mouse. There are two ways you can move text using the …
Discover More
I’m a regular expression newbie and I can’t quite figure out how to write a single regular expression that would «match» any duplicate consecutive words such as:
Paris in the the spring.
Not that that is related.
Why are you laughing? Are my my regular expressions THAT bad??
Is there a single regular expression that will match ALL of the bold strings above?
![]()
Mahozad
16.1k11 gold badges103 silver badges125 bronze badges
asked May 12, 2010 at 21:51
![]()
8
Try this regular expression:
b(w+)s+1b
Here b is a word boundary and 1 references the captured match of the first group.
Regex101 example here
![]()
answered May 12, 2010 at 21:55
![]()
GumboGumbo
638k108 gold badges773 silver badges841 bronze badges
12
The below expression should work correctly to find any number of duplicated words. The matching can be case insensitive.
String regex = "\b(\w+)(\s+\1\b)+";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(input);
// Check for subsequences of input that match the compiled pattern
while (m.find()) {
input = input.replaceAll(m.group(0), m.group(1));
}
Sample Input : Goodbye goodbye GooDbYe
Sample Output : Goodbye
Explanation:
The regex expression:
b : Start of a word boundary
w+ : Any number of word characters
(s+1b)* : Any number of space followed by word which matches the previous word and ends the word boundary. Whole thing wrapped in * helps to find more than one repetitions.
Grouping :
m.group(0) : Shall contain the matched group in above case Goodbye goodbye GooDbYe
m.group(1) : Shall contain the first word of the matched pattern in above case Goodbye
Replace method shall replace all consecutive matched words with the first instance of the word.
![]()
answered Mar 11, 2019 at 1:03
![]()
AkritiAkriti
2212 silver badges4 bronze badges
Try this with below RE
- b start of word word boundary
- W+ any word character
- 1 same word matched already
- b end of word
-
()* Repeating again
public static void main(String[] args) { String regex = "\b(\w+)(\b\W+\b\1\b)*";// "/* Write a RegEx matching repeated words here. */"; Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE/* Insert the correct Pattern flag here.*/); Scanner in = new Scanner(System.in); int numSentences = Integer.parseInt(in.nextLine()); while (numSentences-- > 0) { String input = in.nextLine(); Matcher m = p.matcher(input); // Check for subsequences of input that match the compiled pattern while (m.find()) { input = input.replaceAll(m.group(0),m.group(1)); } // Prints the modified sentence. System.out.println(input); } in.close(); }
![]()
YakovL
7,32012 gold badges59 silver badges94 bronze badges
answered Jun 5, 2017 at 6:49
![]()
FakharFakhar
3,86638 silver badges35 bronze badges
Regex to Strip 2+ duplicate words (consecutive/non-consecutive words)
Try this regex that can catch 2 or more duplicate words and only leave behind one single word. And the duplicate words need not even be consecutive.
/b(w+)b(?=.*?b1b)/ig
Here, b is used for Word Boundary, ?= is used for positive lookahead, and 1 is used for back-referencing.
Example
Source
answered Jul 5, 2018 at 11:46
![]()
Niket PathakNiket Pathak
6,0681 gold badge38 silver badges51 bronze badges
5
The widely-used PCRE library can handle such situations (you won’t achieve the the same with POSIX-compliant regex engines, though):
(bw+b)W+1
answered May 12, 2010 at 21:55
![]()
soulmergesoulmerge
73.1k19 gold badges118 silver badges153 bronze badges
3
Here is one that catches multiple words multiple times:
(bw+b)(s+1)+
answered Mar 24, 2018 at 0:08
![]()
synaptikonsynaptikon
6891 gold badge8 silver badges16 bronze badges
3
No. That is an irregular grammar. There may be engine-/language-specific regular expressions that you can use, but there is no universal regular expression that can do that.
answered May 12, 2010 at 21:53
![]()
1
This is the regex I use to remove duplicate phrases in my twitch bot:
(S+s*)1{2,}
(S+s*) looks for any string of characters that isn’t whitespace, followed whitespace.
1{2,} then looks for more than 2 instances of that phrase in the string to match. If there are 3 phrases that are identical, it matches.
answered Jul 18, 2015 at 1:17
![]()
NecerosNeceros
4434 silver badges6 bronze badges
2
Since some developers are coming to this page in search of a solution which not only eliminates duplicate consecutive non-whitespace substrings, but triplicates and beyond, I’ll show the adapted pattern.
Pattern: /(bS+)(?:s+1b)+/ (Pattern Demo)
Replace: $1 (replaces the fullstring match with capture group #1)
This pattern greedily matches a «whole» non-whitespace substring, then requires one or more copies of the matched substring which may be delimited by one or more whitespace characters (space, tab, newline, etc).
Specifically:
b(word boundary) characters are vital to ensure partial words are not matched.- The second parenthetical is a non-capturing group, because this variable width substring does not need to be captured — only matched/absorbed.
- the
+(one or more quantifier) on the non-capturing group is more appropriate than*because*will «bother» the regex engine to capture and replace singleton occurrences — this is wasteful pattern design.
*note if you are dealing with sentences or input strings with punctuation, then the pattern will need to be further refined.
answered Feb 1, 2018 at 4:41
![]()
mickmackusamickmackusa
42.8k12 gold badges83 silver badges130 bronze badges
0
The example in Javascript: The Good Parts can be adapted to do this:
var doubled_words = /([A-Za-zu00C0-u1FFFu2800-uFFFD]+)s+1(?:s|$)/gi;
b uses w for word boundaries, where w is equivalent to [0-9A-Z_a-z]. If you don’t mind that limitation, the accepted answer is fine.
answered Apr 24, 2013 at 21:04
![]()
DanielDaniel
9201 gold badge11 silver badges22 bronze badges
This expression (inspired from Mike, above) seems to catch all duplicates, triplicates, etc, including the ones at the end of the string, which most of the others don’t:
/(^|s+)(S+)(($|s+)2)+/g, "$1$2")
I know the question asked to match duplicates only, but a triplicate is just 2 duplicates next to each other 
First, I put (^|s+) to make sure it starts with a full word, otherwise «child’s steak» would go to «child’steak» (the «s»‘s would match). Then, it matches all full words ((bS+b)), followed by an end of string ($) or a number of spaces (s+), the whole repeated more than once.
I tried it like this and it worked well:
var s = "here here here here is ahi-ahi ahi-ahi ahi-ahi joe's joe's joe's joe's joe's the result result result";
print( s.replace( /(bS+b)(($|s+)1)+/g, "$1"))
--> here is ahi-ahi joe's the result
![]()
mickmackusa
42.8k12 gold badges83 silver badges130 bronze badges
answered Feb 18, 2016 at 20:08
![]()
NicoNico
4,0081 gold badge20 silver badges19 bronze badges
2
Try this regular expression it fits for all repeated words cases:
b(w+)s+1(?:s+1)*b
answered Nov 8, 2021 at 18:58
![]()
I think another solution would be to use named capture groups and backreferences like this:
.* (?<mytoken>w+)s+k<mytoken> .*/
OR
.*(?<mytoken>w{3,}).+k<mytoken>.*/
![]() Kotlin:
Kotlin:
val regex = Regex(""".* (?<myToken>w+)s+k<myToken> .*""")
val input = "This is a test test data"
val result = regex.find(input)
println(result!!.groups["myToken"]!!.value)
![]() Java:
Java:
var pattern = Pattern.compile(".* (?<myToken>\w+)\s+\k<myToken> .*");
var matcher = pattern.matcher("This is a test test data");
var isFound = matcher.find();
var result = matcher.group("myToken");
System.out.println(result);
![]() JavaScript:
JavaScript:
const regex = /.* (?<myToken>w+)s+k<myToken> .*/;
const input = "This is a test test data";
const result = regex.exec(input);
console.log(result.groups.myToken);
// OR
const regex = /.* (?<myToken>w+)s+k<myToken> .*/g;
const input = "This is a test test data";
const result = [...input.matchAll(regex)];
console.log(result[0].groups.myToken);
All the above detect the test as the duplicate word.
Tested with Kotlin 1.7.0-Beta, Java 11, Chrome and Firefox 100.
answered May 9, 2022 at 19:14
![]()
MahozadMahozad
16.1k11 gold badges103 silver badges125 bronze badges
You can use this pattern:
b(w+)(?:W+1b)+
This pattern can be used to match all duplicated word groups in sentences.
Here is a sample util function written in java 17, which replaces all duplications with the first occurrence:
public String removeDuplicates(String input) {
var regex = "\b(\w+)(?:\W+\1\b)+";
var pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
var matcher = pattern.matcher(input);
while (matcher.find()) {
input = input.replaceAll(matcher.group(), matcher.group(1));
}
return input;
}
answered Dec 30, 2022 at 5:53
![]()
Hadi RasouliHadi Rasouli
1,7913 gold badges26 silver badges43 bronze badges
As far as I can see, none of these would match:
London in the
the winter (with the winter on a new line )
Although matching duplicates on the same line is fairly straightforward,
I haven’t been able to come up with a solution for the situation in which they
stretch over two lines. ( with Perl )
answered Jan 8 at 14:54
![]()
1
To find duplicate words that have no leading or trailing non whitespace character(s) other than a word character(s), you can use whitespace boundaries on the left and on the right making use of lookarounds.
The pattern will have a match in:
-
Paris in
the thespring. -
Not
that thatis related.
The pattern will not have a match in:
- This is $word word
(?<!S)(w+)s+1(?!S)
Explanation
(?<!S)Negative lookbehind, assert not a non whitespace char to the left of the current location(w+)Capture group 1, match 1 or more word characterss+Match 1 or more whitespace characters (note that this can also match a newline)1Backreference to match the same as in group 1(?!S)Negative lookahead, assert not a non whitespace char to the right of the current location
See a regex101 demo.
To find 2 or more duplicate words:
(?<!S)(w+)(?:s+1)+(?!S)
- This part of the pattern
(?:s+1)+uses a non capture group to repeat 1 or more times matching 1 or more whitespace characters followed by the backreference to match the same as in group 1.
See a regex101 demo.
Alternatives without using lookarounds
You could also make use of a leading and trailing alternation matching either a whitespace char or assert the start/end of the string.
Then use a capture group 1 for the value that you want to get, and use a second capture group with a backreference 2 to match the repeated word.
Matching 2 duplicate words:
(?:s|^)((w+)s+2)(?:s|$)
See a regex101 demo.
Matching 2 or more duplicate words:
(?:s|^)((w+)(?:s+2)+)(?:s|$)
See a regex101 demo.
answered Jan 8 at 16:25
![]()
The fourth birdThe fourth bird
151k16 gold badges53 silver badges69 bronze badges
Use this in case you want case-insensitive checking for duplicate words.
(?i)\b(\w+)\s+\1\b
answered Aug 16, 2016 at 15:55
![]()
NeelamNeelam
3604 silver badges14 bronze badges
2
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Given a sequence of strings, the task is to find out the second most repeated (or frequent) string in the given sequence.(Considering no two words are the second most repeated, there will be always a single word).
Examples:
Input : {"aaa", "bbb", "ccc", "bbb",
"aaa", "aaa"}
Output : bbb
Input : {"geeks", "for", "geeks", "for",
"geeks", "aaa"}
Output : for
Asked in : Amazon
BRUTE FORCE METHOD:
Implementation:
Java
import java.io.*;
import java.util.*;
class GFG {
public static String secFrequent(String arr[], int N)
{
HashMap<String, Integer> hm = new HashMap<>();
for (int i = 0; i < N; i++) {
if (hm.containsKey(arr[i])) {
hm.put(arr[i], hm.get(arr[i]) + 1);
}
else {
hm.put(arr[i], 1);
}
}
int max = Collections.max(hm.values());
ArrayList<Integer> a = new ArrayList<>();
for (Map.Entry<String, Integer> j : hm.entrySet()) {
if (j.getValue() != max) {
a.add(j.getValue());
}
}
Collections.sort(a);
for (Map.Entry<String, Integer> x : hm.entrySet()) {
if (x.getValue() == a.get(a.size() - 1)) {
return x.getKey();
}
}
return "-1";
}
public static void main(String[] args)
{
String arr[] = { "ccc", "aaa", "ccc",
"ddd", "aaa", "aaa" };
int N = arr.length;
String ans = secFrequent(arr, N);
System.out.println(ans);
}
}
- Time Complexity: O(NLog(N)).
- Space Complexity: O(N).
Implementation:
C++
#include <bits/stdc++.h>
using namespace std;
string secMostRepeated(vector<string> seq)
{
unordered_map<string, int> occ;
for (int i = 0; i < seq.size(); i++)
occ[seq[i]]++;
int first_max = INT_MIN, sec_max = INT_MIN;
for (auto it = occ.begin(); it != occ.end(); it++) {
if (it->second > first_max) {
sec_max = first_max;
first_max = it->second;
}
else if (it->second > sec_max &&
it->second != first_max)
sec_max = it->second;
}
for (auto it = occ.begin(); it != occ.end(); it++)
if (it->second == sec_max)
return it->first;
}
int main()
{
vector<string> seq = { "ccc", "aaa", "ccc",
"ddd", "aaa", "aaa" };
cout << secMostRepeated(seq);
return 0;
}
Java
import java.util.*;
class GFG
{
static String secMostRepeated(Vector<String> seq)
{
HashMap<String, Integer> occ = new HashMap<String,Integer>(seq.size()){
@Override
public Integer get(Object key) {
return containsKey(key) ? super.get(key) : 0;
}
};
for (int i = 0; i < seq.size(); i++)
occ.put(seq.get(i), occ.get(seq.get(i))+1);
int first_max = Integer.MIN_VALUE, sec_max = Integer.MIN_VALUE;
Iterator<Map.Entry<String, Integer>> itr = occ.entrySet().iterator();
while (itr.hasNext())
{
Map.Entry<String, Integer> entry = itr.next();
int v = entry.getValue();
if( v > first_max) {
sec_max = first_max;
first_max = v;
}
else if (v > sec_max &&
v != first_max)
sec_max = v;
}
itr = occ.entrySet().iterator();
while (itr.hasNext())
{
Map.Entry<String, Integer> entry = itr.next();
int v = entry.getValue();
if (v == sec_max)
return entry.getKey();
}
return null;
}
public static void main(String[] args)
{
String arr[] = { "ccc", "aaa", "ccc",
"ddd", "aaa", "aaa" };
List<String> seq = Arrays.asList(arr);
System.out.println(secMostRepeated(new Vector<>(seq)));
}
}
Python3
def secMostRepeated(seq):
occ = {}
for i in range(len(seq)):
occ[seq[i]] = occ.get(seq[i], 0) + 1
first_max = -10**8
sec_max = -10**8
for it in occ:
if (occ[it] > first_max):
sec_max = first_max
first_max = occ[it]
elif (occ[it] > sec_max and
occ[it] != first_max):
sec_max = occ[it]
for it in occ:
if (occ[it] == sec_max):
return it
if __name__ == '__main__':
seq = [ "ccc", "aaa", "ccc",
"ddd", "aaa", "aaa" ]
print(secMostRepeated(seq))
C#
using System;
using System.Collections.Generic;
class GFG
{
static String secMostRepeated(List<String> seq)
{
Dictionary<String, int> occ =
new Dictionary<String, int>();
for (int i = 0; i < seq.Count; i++)
if(occ.ContainsKey(seq[i]))
occ[seq[i]] = occ[seq[i]] + 1;
else
occ.Add(seq[i], 1);
int first_max = int.MinValue,
sec_max = int.MinValue;
foreach(KeyValuePair<String, int> entry in occ)
{
int v = entry.Value;
if( v > first_max)
{
sec_max = first_max;
first_max = v;
}
else if (v > sec_max &&
v != first_max)
sec_max = v;
}
foreach(KeyValuePair<String, int> entry in occ)
{
int v = entry.Value;
if (v == sec_max)
return entry.Key;
}
return null;
}
public static void Main(String[] args)
{
String []arr = { "ccc", "aaa", "ccc",
"ddd", "aaa", "aaa" };
List<String> seq = new List<String>(arr);
Console.WriteLine(secMostRepeated(seq));
}
}
Javascript
<script>
function secMostRepeated(seq)
{
let occ = new Map();
for (let i = 0; i < seq.length; i++)
{
if(occ.has(seq[i])){
occ.set(seq[i], occ.get(seq[i])+1);
}
else occ.set(seq[i], 1);
}
let first_max = Number.MIN_VALUE, sec_max = Number.MIN_VALUE;
for (let [key,value] of occ) {
if (value > first_max) {
sec_max = first_max;
first_max = value;
}
else if (value > sec_max && value != first_max)
sec_max = value;
}
for (let [key,value] of occ)
if (value == sec_max)
return key;
}
let seq = [ "ccc", "aaa", "ccc", "ddd", "aaa", "aaa" ];
document.write(secMostRepeated(seq));
</script>
Time Complexity: O(N), where N represents the size of the given vector.
Auxiliary Space: O(N), where N represents the size of the given vector.
This article is contributed by Sahil Chhabra. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Like Article
Save Article
![]()
Download Article
![]()
Download Article
This wikiHow will teach you how to find and delete duplicate words in Word using a computer. Usually, the default grammar checker will underline any repeats, but you can always use the find and replace tool to locate specific words and delete them manually.
Steps
-

1
Open your project in Word. You can either click File > Open when you have Word open, or you can right-click your project file and select Open with > Word.
- If you’re using the mobile app, simply open your project in editing mode and tap the magnifying glass, then enter a word you’re looking for.
-
2
Click the Home tab (if needed). If you haven’t selected another tab, this should be selected when you open the project.
Advertisement
-
3
Click the arrow next to Find. It’s in the «Editing» group.
-
4
Click Advanced Find. This will pop up a «Find and Replace» window.
-
5
Type the word you want to search for. There should be a field for you to enter your word.
-
6
Click More. It’s at the bottom of the window.
-
7
Click to check the box next to «Find whole words only» and «Highlight All.« This sets the tool to find that word and highlight it.
- If you don’t see «Highlight All,» you may need to click Reading Highlight first.
-
8
Press ← Backspace or Delete until the word is deleted. You’ll manually need to delete the highlighted words if you want to remove duplicates.







Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
About This Article
Article SummaryX
1. Open your project in Word.
2. Click the Home tab (if needed).
3. Click the arrow next to Find.
4. Click Advanced Find.
5. Type the word you want to search for.
6. Click More.
7. Click to check the box next to «Find whole words only» and «Highlight All.»
Did this summary help you?
Thanks to all authors for creating a page that has been read 50,626 times.
Is this article up to date?
When writing, even the most expert makes mistakes. Both in writing and in style. On many occasions the same program corrects them, but sometimes you have to help it, as is the case of finding all the repeated words in a Word document .
When you review your document, no matter how many times you read it, you may not notice all the errors that are in it. Similarly, the automatic corrector is not always as effective as it is thought. Don’t worry, Word has the necessary tools to correct your text and leave it without a single error. You just have to learn how to use it to get the most out of it.
It is necessary to know how many versions of Windows 10 there are, to determine if you have the most recent and therefore the most current edition of Word.
One of the most common mistakes when writing a document is that sometimes repeated words can be written. Normally, Word’s auto-checker alerts you to this error by underlining repetition in red. But this is not infallible, if you have the correction tool disabled it is still possible to detect these errors very easily. Using the program’s wildcards.
Word wildcards
Wildcards in Word are quite useful tools when navigating and correcting a document. However, many users do not know how to use them and many more do not even know that they exist. To find all the repeated words in a Word document, you can make use of these wildcards and even lock the position of an image in Word.
Repeated words in a Word document and wildcards
To get a repeated word, the first thing to do is search for a word, right? For this we will use the Word tool ” Search “. This is in the ” Start ” section of the top menu. It should be noted that to use this type of search you must select the “Use wildcard characters” box in the Search and replace window.
If a word is a sequence of letters arranged in a specific way. So the first wildcard to use would be [a-zA-Z]. In this way the search engine will consider all the letters of the alphabet taking into account upper and lower case. Similarly, within this sequence will be the vowels with their accents and the letter “ñ”.
With that joker you can already get a letter. Now, how to find a word? Well, to do that you must use this wildcard [aaZ] {1;}. This is translated as a redundant letter one or more times, counting capital letters, accents, and the letter ñ.
The <> characters placed at the beginning and at the end of the wildcard will indicate the beginning and end of each word. But since you want to search for repeated words, you will modify the wildcard to the following <[a-zA-Z] {1;}). By replacing the “greater than” characters with a parenthesis, you are saying that you want to search for words followed by a space.
How to find all repeated words in a Word document using wildcards?
As an extra point, you should know that wildcards also apply to other cases, such as inserting a YouTube video in a Word document , a useful tool to finalize the file together with the elimination of repeated words.
Now, if the previous wildcard only searches for words followed by a space , how to find all the repeated words in a Word document? For that case, the wildcard explained above would be modified to the following (<[a-zA-Z] {1;}) 1>.
If you can tell, the previous wildcard is now inside parentheses. In wildcard theory it says that parentheses are used to create search references. Therefore adding parentheses created a reference.
This is followed by a space and then 1 follows. This refers to the word to search for. That is, to the first group of parentheses. If there were more sets of characters the reference would be 2, 3, or the amount of group of parentheses that are.
And finally this character> refers to the end of the word. So if you use this wildcard, it will find the redundancy “his his” but not “his dream” . Finally, after finding all the repeated words in a Word document, you will want to delete all the repeated words.
Thus, in the Word search and replace window you must put the following wildcard in the search bar (<[a-zA-Z] {1;}) 1> and in the replace window you must put 1. In this way, the repeated word will be deleted automatically.