
![]()
I’ve been playing this game for a while and every time I’m asked to pick up 15 words tokens I end up buying the missions as I have no idea what they are. I’ll pick up everything on the subway but none qualifies as word tokens. It’s now my mission again and I think it’a time I ask what they are. Please help.
![]()
level 1
It is the letters you pick up for the Word Hunt or Wordy Weekend
level 2
I swear I’ve collected those and it still did not show like I’ve completed any of it but I’ll try tomorrow as it’s weekend. Thank you
level 2
· 1 yr. ago · edited 1 yr. agoBoombot
Unfortunately the Wordy Weekend ones don’t count. I’ve suggested to Sybo to change this some time ago, but apparently they don’t want it that way.
Привет, дорогие друзья-серферы! Многие из вас столкнулись с проблемой перевода миссий любимой нами игры Сабвей Серферс на русский язык. Множество вопросов и комментариев в нашей группе ВКонтакте вынудили нас сделать перевод всех миссий игры Subway Surfers (Subway Surf) на русский язык.
Магазин:
Hoverboard – вид доски, который дает возможность один раз столкнуться с каким-нибудь предметом и при этом не умереть. ( Включается двойным щелчком мыши)
Mystery Box — мистическая коробка (кому-то везет получить джекпот, кому-то нет))
Super Mystery Box — тоже мистическая коробка, только призы ценнее в несколько раз
Score Booster — увеличивает очки ( прибавляет +5 к рейтам очков за один забег)
Mega Headstart — Мега Старт (позволяет полностью пропустить первый километр в забеге)
Всего в игре Subway Serfers 48 миссий, которые необходимо выполнить
I группа задач — 1-29 миссии
II группа задач — 30-49 миссии
[Начиная с 30-й миссии вы будет получать в награду Super Mystery Box]
Потом задания из этих двух групп повторяются, только идут в другом порядке.
MISSION SET 1 (Миссия 1)
1) Collect 500 coins. — Собрать 500 монет
2) Score 1000 points in one run. — За один забег набрать 1000 очков.
3) Pickup 2 Powerups. — Собрать два любых бонуса ( из списка бонусов, приведенного выше)
MISSION SET 2
1) Collect 200 coins in one run. — За один забег собрать 200 монет.
2) Jump 20 times. — Прыгнуть 20 раз. (Проводя вниз по экрану вы ускорите прыжки)
3) Pick up 2 Super Sneakers. — Найдите и соберите 2 супер — ботинка
MISSION SET 3
1) Get 2 character tokens from Mystery Box. — Достаньте из мистической коробки 2 предмета для открытия новых персонажей. (магнитофон,гитара, летающая тарелка)
2) Roll 30 times in total. — Кувыркнуться 30 раз (свайп вниз 30 раз)
3) Spend 2000 coins. — Потратить на что-нибудь 2000 монет (можете например купить mystery box)
MISSION SET 4
1) Complete 1 Daily Challenge. — Выполнить 1 ежедневное задание (например, собрать буквы)
2) Dodge 20 barriers. — Увернуться от 20 препятствий кувыркнувшись или перепрыгнув над барьером (просто обойти сбоку их нельзя!)
3) Score 6000 points in one run. — За один забег набрать 6000 очков.
MISSION SET 5
1) Collect 2500 coins. — Собрать 2500 монет
2) Jump 30 times in one run. — За один забег попрыгать 30 раз.
3) Buy 1 Mystery Box. — Приобрести одну мистическую коробку.
MISSION SET 6
1) Use 1 hoverboard — Использовать hoverboard-доску (двойным нажатием по экрану во время забега)
2) Pick up 5 Coin Magnets — Собрать 5 магнитных монеток
3) Stumble into 2 barriers — Столкнуться с барьером 2 раза (для этого нужно очень осторожно рассчитать время, чтобы прыгнуть сверху на барьер и при этом не умереть)
4) Beat High Score — Побить свой рекорд
MISSION SET 7
1) Pick up 2 Jetpacks — Собрать 2 джетпака
2) Beat 1 friend. — Побить рекорд одного твоего друга
3) Use 1 Headstart — Использовать один Мега-Старт (ег можно купить в магагзине, а можно получить из мистической коробки)
MISSION SET 8
1) Bump into 3 trains in one run — Врезаться в поезд за один забег 3 раза (сбоку, в тот момент, когда пробегаете рядом с ним)
2) Pickup 40 coins with a Magnet — Соберать с помощью магнита 40 монет
3) Get caught in first 10 seconds of run — Вас должен поймать инспектор в первые 10 секунд забега
MISSION SET 9
1) Use 1 Hoverboard without crashing — Использовать одну доску без столкновений с барьерами, поездами
2) Pick up 2 Mystery boxes — Собрать 2 мистических коробки
3) Roll 30 times in a single run — Кувыркнуться за один забег 30 раз
MISSION SET 10
1) Score 20000 points in one run — Собрать за один забег 20000 очков
2) Pick up 12 Powerups — Собрать 12 бонусов (магниты, ботинки, джетпаки и т.д.)
3) Jump over 2 trains — Перепрыгнуть через два поезда (при помощи супер-ботинок)
MISSION SET 11
1) Score 4000 points without collecting coins — Набрать 4000 очков при этом не подбирая монет (это проще всего сделать с помощью Headstart)
2) Roll 50 times in the center lane — Кувыркнуться 50 раз, находясь на центральной линии
3) Collect 5000 coins — Соберать 5000 штук монет
MISSION SET 12
1) Complete 2 Daily Challenges. — Выполнить 2 ежедневных задачи
2) Dodge 40 barriers. — Увернуться от 40 препятствий
3) Pick up 5 Super Sneakers. — Собраь 5 пар супер-ботинок
MISSION SET 13
1) Use 4 Score Booster — использовать увеличитель очков 4 раза (сначала купить в магазине, даёт +5х)
2) Bump 2 bushes. — Врезаться в 2 зеленых куста (просто пробегите сквозь них)
3) Pick up 160 coins with a Magnet. — Собрать 160 монет с помощью магнита
4) Pick up 2 Magnets in one run. — Собрать за один забег 2 магнита
MISSION SET 14
1) Pick up 4 Mystery Boxes. — Собрать 4 мистических коробки
2) Roll 40 times in one run. — Кувыркнуться за 1 забег 40 раз
3) Collect 400 coins in one run. — Собрать за 1 забег 400 монет.
MISSION SET 15
1) Collect 100,000 points. — Набрать 100.000 очков
2) Pick up 5 Jetpacks. — Поднять 5 Джетпаков
3) Bump into 12 light signals. — Столкнуться с 12-ю светофорами
MISSION SET 16
1) Complete 3 Daily Challenges. — Выполнить три любых ежедневных задачи
2) Pick up 3 Super Sneakers in one run. — Поднять за один забег 3 супер-ботинка
3) Jump over 4 trains. — Перепрыгнуть через 4 поезда (используя супер-ботинки)
MISSION SET 17
1) Score 50,000 points in one run. — Набрать 50.000 очков (за один забег)
2) Spend 4000 coins. — Потратить на что-нибудь 4000 монет
3) Pick up 15 Coin Magnets. — Собрать 15 штук магнитов
MISSION SET 18
1) Pick up 2 Jetpacks in one run. — Собрать 2 Джетпака (за один забег)
2) Bump into 6 trains in one run. — Столкнуться 6 поездами (за один забег)
3) Use 3 Hoverboards without crashing. — Используовать 3 доски-hoverboard (без столкновений)
MISSION SET 19
1) Pick up 2 Keys — Подобрать 2 ключа
2) Use 5 Hoverboards. — Использовать 5 любых досок
3) Pick up 3 Magnets in one run. — Собрать 3 магнита (за 1 забег)
4) Get 5 character tokens from Mystery Box. — Достаньте из мистических коробок 5 предметов, открывающих новых персонажей (магнитофон, гитара,летающая тарелка и т.д)
MISSION SET 20
1) Collect 250,000 points. — Собрать 250.000 очков (уже не за забег, всего)
2) Jump 40 times in one run. — Прыгать 40 раз (за один забег)
3) Pickup 25 Powerups. — Собрать 25 разных бонусов (магниты, джетпаки, ботинки, х2)
MISSION SET 21
1) Stumble into 15 barriers. — Дотронуться до 15 барьеров (прыгнуть на них сверху)
2) Buy 3 Mystery boxes. — Купить 3 мистические коробки
3) Pickup 240 coins with a Magnet. — Собрать 250 монет с помощью магнита
MISSION SET 22
1) Dodge 80 barriers. — Увернуться от 80 препятствий
2) Spend 8000 coins. — Потратить на что-нибудь 8000 монет
3) Pick up 4 Super Sneakers in one run. — Собрать 4 пары супер-ботинок (за один забег)
MISSION SET 23
1) Poke 1 frend — Нажать кнопку нажать Poke (заходим на фейсбука, выбираем любого друга и рядом с ним кнопка Poke)
2) Use 8 Headstarts. — Использовать 8 раз Мега Старт
3) Jump over 10 trains. — Перепрыгнуть через 10 поездов
4) Pick up 15 Jetpacks. — Поднять15 джетпаков
MISSION SET 24
1) Pick up 8 Mystery Boxes. — Найти и собрать 8 мистических коробок
2) Roll 200 times in the center lane. — Кувыркнуться 200 раз (на центральной линии)
3) Complete 4 Daily Challenges. — Выполнить 4 ежедневных задачи
MISSION SET 25
1) Collect 15000 coins. — Собрать 15.000 монет
2) Score 120,000 points in one run. — Собрать 120.000 очков (за один забег)
3) Jump over 3 trains in one run. — Перепрыгнуть 3 поезда (за один забег)
MISSION SET 26
1) Roll 50 times in one run. — кувыркнуться 50 раз (за один забег)
2) Collect 500,000 points. — Набрать 500.000 очков (всего)
3) Score 12,000 points without collecting coins. — Набрать 12.000 очков, при этом не собирая монет (можно использовать Мега Старт)
MISSION SET 27
1) Get 10 character tokens from Mystery Box. — Достать из мистических коробок 10 различных предметов для открытия новых персонажей (гитара, летающая тарелка, магнитофон)
2) Buy 6 Mystery Boxes. — Приобрести 6 мистических коробок (купить в магазине)
3) Bump into 20 light signals. — Столкнуться с 20-ю светофорами
MISSION SET 28
1) Jump 50 times in one run. — Прыгнуть 50 раз (за один забег)
2) Use 12 Hoverboards. — Использовать 12 досок
3) Use 4 Hoverboards without crashing. — Использовать 4 доски (без столкновений!)
MISSION SET 29
1) Collect 750 coins in one run. — Собрать 750 монет (за один забег)
2) Stumble into 25 barriers. — Столкнуться с 25-ю барьерами (прыгнуть на них сверху)
3) Score 250000 points in one run. — Набрать 250.000 очков (за один забег)
Дальше задания повторяются, просто в другом порядке и меняются числа.
И еще несколько миссий:
Pick up 4 Double Multipliers in one run. — Найти и собрать 4 множителя очков (за один забег)
Stay in same lane for 20 seconds. — Оставаться 20 секунд на одной и той же линии
Score 25000 points without jumping. — Набрать 25.000 очков (без прыжков!)
Pick up 12 Daily Letters — Собрать 12 букв (из ежедневных задач)
Я описал инструменты и методы для новичков, имеющих только общее представление в данной теме. Если вы более опытный практик, вам нужны вторая часть о представлении вектора и третья — тематическое моделирование и конвейеры. Конечно, в этой области есть свой жаргон. Он может немного напугать, но я сведу технические термины к минимуму.
Вам понадобится базовое понимание Python и какой-то опыт в машинном обучении желателен, но не обязателен. Как всегда, я даю ссылки на документацию там, где в объяснениях или приёмах не останавливаюсь на деталях.
Токенизация
Токен — это последовательность символов в документе, имеющая значение для анализа. Обычно это отдельные слова, но не всегда. Документ — это коллекция текста. Им может быть твит, книга или что-то еще. Признаки хороших токенов:
- Хранятся в перечисляемых структурах (список, генератор) для упрощения анализа в будущем.
- Имеют единый регистр для одной цели.
- Содержат только буквы и цифры.
Пример: токенизация
import re
def tokenize(text):
text = text.lower()
text = re.sub(r'[^a-zA-Z ^0-9]', '', str(text))
return text.split()
# Используем оригинал текста выше
tokens = tokenize(sample_text)
tokens[:10]
____________________________________________________________________
['a', 'token', 'is', 'a', 'sequence', 'of', 'characters', 'in', 'a', 'document']Подсчёт слов
Теперь, когда у нас есть токены, мы можем приступить к самому простому анализу. Подсчитаем количество слов через Counter.
from collections import Counter
def word_counter(tokens):
word_counts = Counter()
word_counts.update(tokens)
return word_countsword_count =
word_counter(tokens)
word_count.most_common(5)
____________________________________________________________________
[('a', 7), ('of', 4), ('in', 4), ('be', 4), ('an', 3)]И отобразим на гистограмме:
import matplotlib.pyplot as plt
x = list(word_count.keys())[:10]
y = list(word_count.values())[:10]
plt.bar(x, y)
plt.show();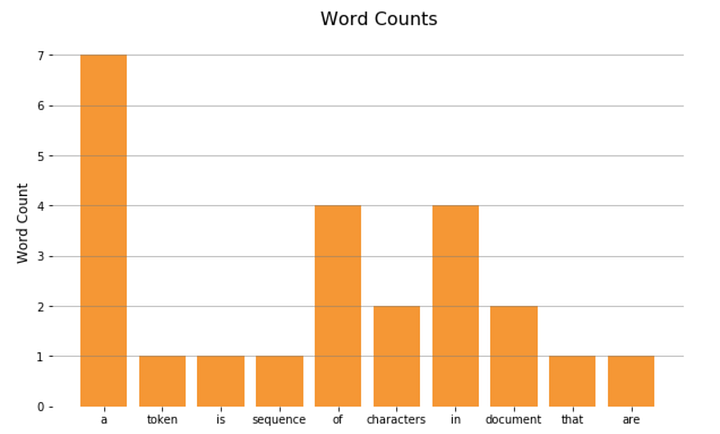
3. Состав документа
Количество слов может быть полезно, но обычно требуется более глубокий анализ, отвечающий на вопросы бизнеса, особенно когда данные состоят не из одного документа. Мы можем настроить себя на успех, создав Pandas DataFrame, содержащий функции, возвращающие:
- Количество и процент документов с токеном.
- Количество токенов.
- Их ранг по частотности употребления по отношению к другим токенам.
- Процент токенов от общего состава документа.
- Текущую сумму этих процентов.
Пример: анализ состава документов с DataFrame
import pandas as pddef count(docs):
word_counts = Counter()
appears_in = Counter()
total_docs = len(docs)
for doc in docs:
word_counts.update(doc)
appears_in.update(set(doc))
temp = list(zip(word_counts.keys(), word_counts.values()))
# Колонки слов и количества
wc = pd.DataFrame(temp, columns = ['word', 'count'])
# Колонка ранга
wc['rank'] = wc['count'].rank(method='first', ascending=False)
# Колонка с общим процентом
total = wc['count'].sum()
wc['pct_total'] = wc['count'].apply(lambda x: x / total)
# Колонка с кумулятивным общим процентом
wc = wc.sort_values(by='rank')
wc['cul_pct_total'] = wc['pct_total'].cumsum()
# Появляется в колонке
t2 = list(zip(appears_in.keys(), appears_in.values()))
ac = pd.DataFrame(t2, columns=['word', 'appears_in'])
wc = ac.merge(wc, on='word')
# Появляется в колонке процентов
wc['appears_in_pct'] = wc['appears_in'].apply(lambda x: x / total_docs)
return wc.sort_values(by='rank')
wc = count([tokens])wc.head()
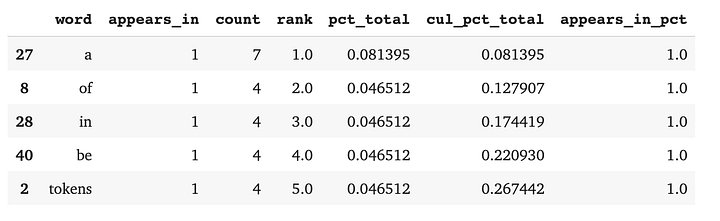
С помощью DataFrame мы видим график функции распределения вероятностей, показывающий, как ранг токена связан с совокупным составом наших документов:
import seaborn as sns
sns.lineplot(x = 'rank', y = 'cul_pct_total', data = wc)
plt.show();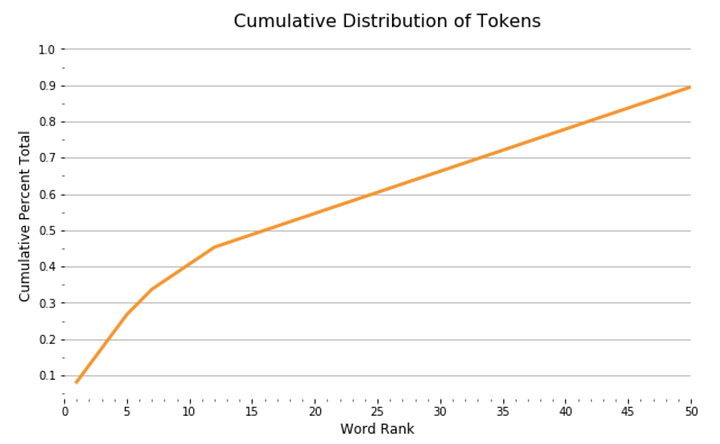
Из графика видно, что 13 наиболее употребимых токенов составляют 45% документа, а после распределение выглядит довольно равномерным. Мы можем увидеть относительный процент этих токенов в составе документа в виде сплошных занимаемых ими участков документа:
import squarify
wc_top13 = wc[wc['rank'] <= 13]
squarify.plot(sizes=wc_top13['pct_total'], label=wc_top13['word'], alpha=.8 )
plt.axis('off')
plt.show();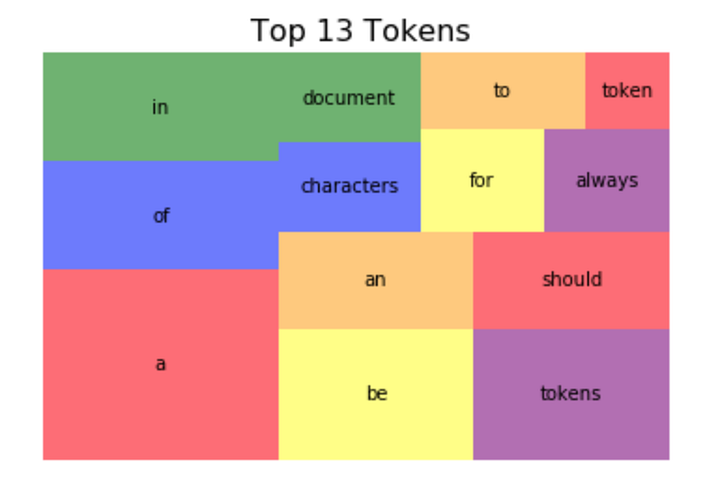
Эти примеры демонстрируют принципы, необходимые для более глубокого понимания мира обработки естественного языка. Токенизация, подсчёт слов и анализ состава документов — основополагающие концепции. Мы могли бы написать целую библиотеку с нуля, но обычно это не самый эффективный способ решения проблем. Существует зоопарк библиотек с открытым кодом, но только одна из них — лидер в области.
4. Введение в SpaCy
SpaСy — свободная, открытая библиотека Python для решения передовых задач NLP, разработанная Explosion. Она не хранит повторяющиеся компоненты документов в разных структурах данных. Вместо этого SpaСy индексирует компоненты и хранит уточняющую информацию. Поэтому её считают эффективнее в проектах производственного класса, чем библиотеки вроде NLTK. Токены в SpaCy:
import spacy
nlp = spacy.load("en_core_web_lg")
def spacy_tokenize(text):
doc = nlp.tokenizer(text)
return [token.text for token in doc]
spacy_tokens = spacy_tokenize(sample_text)
spacy_tokens[:10]
____________________________________________________________________
['a', 'token', 'is', 'a', 'sequence', 'of', 'characters', 'in', 'a', 'document']5. Стоп-слова
Слова “I”, “and”, “of” и тому подобные почти не имеют смысловой нагрузки. Мы называем их стоп-словами и в анализ не включаем. Большинство библиотек имеют встроенный список часто используемых английских слов. Союзов, артиклей, наречий, предлогов и общеупотребимых глаголов. Однако лучшая практика — настройка списка под задачу.
Пример удаления стоп-слов:
spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS
def remove_stopwords(tokens):
cleaned_tokens = []
for token in tokens:
if token not in spacy_stopwords:
cleaned_tokens.append(token)
return cleaned_tokens
cleaned_tokens = remove_stopwords(spacy_tokens)
cleaned_tokens[:10]
____________________________________________________________________
['A', 'token', 'sequence', 'characters', 'document', 'useful', 'analytical', 'purpose', '.', 'Often']
6. Леммы
Лемматизация — поиск леммы слова или корневого слова. Говоря простым языком, лемма — это то слово, которое можно найти в словаре. Например, бег, бежит, бегущий, бежал — формы одной и той же лексемы (слова) с леммой “бег”. Пример лемматизации:
def spacy_lemmatize(text):
doc = nlp.tokenizer(text)
return [token.lemma_ for token in doc]
spacy_lemmas = spacy_lemmatize(sample_text)
spacy_lemmas[:10]
____________________________________________________________________
['A', 'token', 'be', 'a', 'sequence', 'of', 'character', 'in', 'a', 'document']Заключение
Токены, состав документа, стоп-слова, леммы — все они играют свою роль в обработке естественного языка, хотя они довольно просты сами по себе. Мой следующий пост NLP в Python: представления вектора погрузит нас глубже в тему NLP.
Jupyter Notebook на Github
Как выполняется обработка и очистка текстовых данных для создания модели? Чтобы ответить на этот вопрос, давайте исследуем некоторые интересные концепции, лежащие в основе Natural Language Processing (NLP).
Решение проблемы НЛП – это процесс, разделенный на несколько этапов. Прежде всего, мы должны очистить неструктурированные текстовые данные перед переходом к этапу моделирования. Очистка данных включает несколько ключевых шагов. Эти шаги заключаются в следующем:
- Токенизация слов
- Части предсказания речи для каждого токена
- Лемматизация текста
- Определение и удаление стоп-слов и многое другое.
В данном уроке мы узнаем намного больше о самом основном шаге, известном как токенизация. Мы изучим, что такое токенизация и почему она необходима для обработки естественного языка (NLP). Более того, мы также откроем для себя некоторые уникальные методы для выполнения токенизации в Python.
Понятие токенизации
Токенизация разделяет большое количество текста на более мелкие фрагменты, известные как токены. Эти фрагменты или токены очень полезны для поиска закономерностей и рассматриваются в качестве основного шага для стемминга и лемматизации. Токенизация также поддерживает замену конфиденциальных элементов данных на нечувствительные.
Обработка естественного языка(NLP) используется для создания таких приложений, как классификация текста, сентиментальный анализ, интеллектуальный чат-бот, языковой перевод и многие другие. Таким образом, становится важным понимать текстовый шаблон для достижения указанной выше цели.
Но пока рассмотрим стемминг и лемматизацию как основные шаги для очистки текстовых данных с помощью обработки естественного языка (NLP). Такие задачи, как классификация текста или фильтрация спама, используют NLP вместе с библиотеками глубокого обучения, такими как Keras и Tensorflow.
Значение токенизации в НЛП
Чтобы понять значение токенизации, давайте рассмотрим английский язык в качестве примера. Возьмем любое предложение и запомним его при понимании следующего раздела.
Перед обработкой естественного языка мы должны идентифицировать слова, составляющие строку символов. Таким образом, токенизация представляется наиболее важным шагом для продолжения обработки естественного языка (NLP).
Этот шаг необходим, поскольку фактическое значение текста можно интерпретировать путем анализа каждого слова, присутствующего в тексте.
Теперь давайте рассмотрим следующую строку в качестве примера:
My name is Jamie Clark.
После выполнения токенизации в указанной выше строке мы получим результат, как показано ниже:
[‘My’, ‘name’, ‘is’, ‘Jamie’, ‘Clark’]
Существуют различные варианты использования операции. Мы можем использовать токенизированную форму, чтобы:
- подсчитать общее количество слов в тексте;
- подсчитать частоту слова, то есть общее количество раз, когда конкретное слово присутствует, и многое другое.
Теперь давайте разберемся с несколькими способами выполнения токенизации в обработке естественного языка (NLP) в Python.
Методы
Существуют различные уникальные методы токенизации текстовых данных. Некоторые из этих уникальных способов описаны ниже.
Токенизация с использованием функции split()
Функция split() – один из основных доступных методов разделения строк. Эта функция возвращает список строк после разделения предоставленной строки определенным разделителем. Функция split() по умолчанию разбивает строку в каждом пробеле. Однако при необходимости мы можем указать разделитель.
Рассмотрим следующие примеры:
Пример 1.1: Токенизация Word с использованием функции split()
my_text = """Let's play a game, Would You Rather! It's simple, you have to pick one or the other. Let's get started. Would you rather try Vanilla Ice Cream or Chocolate one? Would you rather be a bird or a bat? Would you rather explore space or the ocean? Would you rather live on Mars or on the Moon? Would you rather have many good friends or one very best friend? Isn't it easy though? When we have less choices, it's easier to decide. But what if the options would be complicated? I guess, you pretty much not understand my point, neither did I, at first place and that led me to a Bad Decision.""" print(my_text.split())
Выход:
['Let's', 'play', 'a', 'game,', 'Would', 'You', 'Rather!', 'It's', 'simple,', 'you', 'have', 'to', 'pick', 'one', 'or', 'the', 'other.', 'Let's', 'get', 'started.', 'Would', 'you', 'rather', 'try', 'Vanilla', 'Ice', 'Cream', 'or', 'Chocolate', 'one?', 'Would', 'you', 'rather', 'be', 'a', 'bird', 'or', 'a', 'bat?', 'Would', 'you', 'rather', 'explore', 'space', 'or', 'the', 'ocean?', 'Would', 'you', 'rather', 'live', 'on', 'Mars', 'or', 'on', 'the', 'Moon?', 'Would', 'you', 'rather', 'have', 'many', 'good', 'friends', 'or', 'one', 'very', 'best', 'friend?', 'Isn't', 'it', 'easy', 'though?', 'When', 'we', 'have', 'less', 'choices,', 'it's', 'easier', 'to', 'decide.', 'But', 'what', 'if', 'the', 'options', 'would', 'be', 'complicated?', 'I', 'guess,', 'you', 'pretty', 'much', 'not', 'understand', 'my', 'point,', 'neither', 'did', 'I,', 'at', 'first', 'place', 'and', 'that', 'led', 'me', 'to', 'a', 'Bad', 'Decision.']
Объяснение:
В приведенном выше примере мы использовали метод split(), чтобы разбить абзац на более мелкие фрагменты или слова. Точно так же мы также можем разбить абзац на предложения, указав разделитель в качестве параметра для функции split(). Как мы знаем, предложение обычно заканчивается точкой “.”; что означает, что мы можем использовать “.” как разделитель для разделения строки.
Давайте рассмотрим то же самое в следующем примере:
Пример 1.2: Токенизация предложения с использованием функции split()
my_text = """Dreams. Desires. Reality. There is a fine line between dream to become a desire and a desire to become a reality but expectations are way far then the reality. Nevertheless, we live in a world of mirrors, where we always want to reflect the best of us. We all see a dream, a dream of no wonder what; a dream that we want to be accomplished no matter how much efforts it needed but we try."""
print(my_text.split('. '))
Выход:
['Dreams', 'Desires', 'Reality', 'There is a fine line between dream to become a desire and a desire to become a reality but expectations are way far then the reality', 'Nevertheless, we live in a world of mirrors, where we always want to reflect the best of us', 'We all see a dream, a dream of no wonder what; a dream that we want to be accomplished no matter how much efforts it needed but we try.']
Объяснение:
В приведенном выше примере мы использовали функцию split() с точкой(.) в качестве параметра, чтобы разбить абзац до точки. Основным недостатком использования функции split() является то, что функция принимает по одному параметру за раз. Следовательно, мы можем использовать только разделитель для разделения строки. Более того, функция split() не рассматривает знаки препинания как отдельный фрагмент.
Токенизация с использованием RegEx(регулярных выражений) в Python
Прежде чем перейти к следующему методу, давайте вкратце разберемся с регулярным выражением. Регулярное выражение, также известное как RegEx, представляет собой особую последовательность символов, которая позволяет пользователям находить или сопоставлять другие строки или наборы строк с помощью этой последовательности в качестве шаблона.
Чтобы начать работу с RegEx в Python предоставляет библиотеку, известную как re. Библиотека re – одна из предустановленных библиотек в Python.
Пример 2.1: Токенизация Word с использованием метода RegEx в Python
import re my_text = """Joseph Arthur was a young businessman. He was one of the shareholders at Ryan Cloud's Start-Up with James Foster and George Wilson. The Start-Up took its flight in the mid-90s and became one of the biggest firms in the United States of America. The business was expanded in all major sectors of livelihood, starting from Personal Care to Transportation by the end of 2000. Joseph was used to be a good friend of Ryan.""" my_tokens = re.findall
Выход:
['Joseph', 'Arthur', 'was', 'a', 'young', 'businessman', 'He', 'was', 'one', 'of', 'the', 'shareholders', 'at', 'Ryan', 'Cloud', 's', 'Start', 'Up', 'with', 'James', 'Foster', 'and', 'George', 'Wilson', 'The', 'Start', 'Up', 'took', 'its', 'flight', 'in', 'the', 'mid', '90s', 'and', 'became', 'one', 'of', 'the', 'biggest', 'firms', 'in', 'the', 'United', 'States', 'of', 'America', 'The', 'business', 'was', 'expanded', 'in', 'all', 'major', 'sectors', 'of', 'livelihood', 'starting', 'from', 'Personal', 'Care', 'to', 'Transportation', 'by', 'the', 'end', 'of', '2000', 'Joseph', 'was', 'used', 'to', 'be', 'a', 'good', 'friend', 'of', 'Ryan']
Объяснение:
В приведенном выше примере мы импортировали библиотеку re, чтобы использовать ее функции. Затем мы использовали функцию findall() библиотеки re. Эта функция помогает пользователям найти все слова, соответствующие шаблону, представленному в параметре, и сохранить их в списке.
Кроме того, “ w” используется для обозначения любого символа слова, относится к буквенно-цифровому (включая буквы, числа) и подчеркиванию(_). «+» обозначает любую частоту. Таким образом, мы следовали шаблону [ w ‘] +, так что программа должна искать и находить все буквенно-цифровые символы, пока не встретит какой-либо другой.
Теперь давайте посмотрим на токенизацию предложения с помощью метода RegEx.
Пример 2.2: Токенизация предложения с использованием метода RegEx в Python
import re
my_text = """The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America. The product became so successful among the people that the production was increased. Two new plant sites were finalized, and the construction was started. Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care. Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories. Many popular magazines were started publishing Critiques about him."""
my_sentences = re.compile('[.!?] ').split(my_text)
print(my_sentences)
Выход:
['The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America', 'The product became so successful among the people that the production was increased', 'Two new plant sites were finalized, and the construction was started', "Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care", 'Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories', 'Many popular magazines were started publishing Critiques about him.']
Объяснение:
В приведенном выше примере мы использовали функцию compile() библиотеки re с параметром ‘[.?!]’ И использовали метод split() для отделения строки от указанного разделителя. В результате программа разбивает предложения, как только встречает любой из этих символов.
Токенизация с набором инструментов естественного языка
Набор инструментов для естественного языка, также известный как NLTK, – это библиотека, написанная на Python. Библиотека NLTK обычно используется для символьной и статистической обработки естественного языка и хорошо работает с текстовыми данными.
Набор инструментов для естественного языка(NLTK) – это сторонняя библиотека, которую можно установить с помощью следующего синтаксиса в командной оболочке или терминале:
$ pip install --user -U nltk

Чтобы проверить установку, можно импортировать библиотеку nltk в программу и выполнить ее, как показано ниже:
import nltk
Если программа не выдает ошибку, значит, библиотека установлена успешно. В противном случае рекомендуется повторить описанную выше процедуру установки еще раз и прочитать официальную документацию для получения более подробной информации.
В наборе средств естественного языка(NLTK) есть модуль с именем tokenize(). Этот модуль далее подразделяется на две подкатегории: токенизация слов и токенизация предложений.
- Word Tokenize: метод word_tokenize() используется для разделения строки на токены или слова.
- Sentence Tokenize: метод sent_tokenize() используется для разделения строки или абзаца на предложения.
Давайте рассмотрим пример, основанный на этих двух методах:
Пример 3.1: Токенизация Word с использованием библиотеки NLTK в Python
from nltk.tokenize import word_tokenize my_text = """The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America. The product became so successful among the people that the production was increased. Two new plant sites were finalized, and the construction was started. Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care. Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories. Many popular magazines were started publishing Critiques about him.""" print(word_tokenize(my_text))
Выход:
['The', 'Advertisement', 'was', 'telecasted', 'nationwide', ',', 'and', 'the', 'product', 'was', 'sold', 'in', 'around', '30', 'states', 'of', 'America', '.', 'The', 'product', 'became', 'so', 'successful', 'among', 'the', 'people', 'that', 'the', 'production', 'was', 'increased', '.', 'Two', 'new', 'plant', 'sites', 'were', 'finalized', ',', 'and', 'the', 'construction', 'was', 'started', '.', 'Now', ',', 'The', 'Cloud', 'Enterprise', 'became', 'one', 'of', 'America', "'s", 'biggest', 'firms', 'and', 'the', 'mass', 'producer', 'in', 'all', 'major', 'sectors', ',', 'from', 'transportation', 'to', 'personal', 'care', '.', 'Director', 'of', 'The', 'Cloud', 'Enterprise', ',', 'Ryan', 'Cloud', ',', 'was', 'now', 'started', 'getting', 'interviewed', 'over', 'his', 'success', 'stories', '.', 'Many', 'popular', 'magazines', 'were', 'started', 'publishing', 'Critiques', 'about', 'him', '.']
Объяснение:
В приведенной выше программе мы импортировали метод word_tokenize() из модуля tokenize библиотеки NLTK. Таким образом, в результате метод разбил строку на разные токены и сохранил ее в списке. И, наконец, мы распечатали список. Более того, этот метод включает точки и другие знаки препинания как отдельный токен.
Пример 3.1: Токенизация предложения с использованием библиотеки NLTK в Python
from nltk.tokenize import sent_tokenize my_text = """The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America. The product became so successful among the people that the production was increased. Two new plant sites were finalized, and the construction was started. Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care. Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories. Many popular magazines were started publishing Critiques about him.""" print(sent_tokenize(my_text))
Выход:
['The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America.', 'The product became so successful among the people that the production was increased.', 'Two new plant sites were finalized, and the construction was started.', "Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care.", 'Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories.', 'Many popular magazines were started publishing Critiques about him.']
Объяснение:
В приведенной выше программе мы импортировали метод sent_tokenize() из модуля tokenize библиотеки NLTK. Таким образом, в результате метод разбил абзац на разные предложения и сохранил его в списке. Затем мы распечатали список.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
В предыдущий раз мы говорили о векторизации текстовых данных в NLP. Однако прежде чем преобразовать слова в числа, их следует обработать. Читайте в нашей статье о методах предобработки текста: токенизации, удалении стоп-слов, стемминге и лемматизации с Python-библиотеками pymorphy2 и NLTK.
Разбиваем текст на токены
Токенизация – процесс разбиения текста на текстовые единицы, например, слова или предложения. В случае разбиений на предложения задача кажется тривиальной, нужно просто найти точку, вопросительный или восклицательный знак. Но в русском языке существует сокращения, в которых есть точка, например, к.т.н. — кандидат технических наук или т.е. — то есть. Поэтому такой путь может привести к ошибкам. К счастью, Python-библиотека NLTK позволяет избежать этой проблемы. Рассмотрим пример:
>>> from nltk.tokenize import sent_tokenize >>> text = "Я - к.т.н, т.е. проучился долгое время. Имею образование." >>> sent_tokenize(text, language="russian") ['Я - к.т.н, т.е. проучился долгое время.', 'Имею образование.']
Как видим, функция sent_tokenize разбила исходное предложения на два, несмотря на присутствие слов к.т.н. и т.е.
Помимо разбиения на предложения в NLTK можно в качестве токенов использовать слова:
>>> from nltk.tokenize import sent_tokenize, word_tokenize >>> text = "Я - к.т.н. Сижу на диван-кровати." >>> word_tokenize(text, language="russian") ['Я', '-', 'к.т.н.', 'Сижу', 'на', 'диван-кровати', '.']
Здесь к.т.н. и диван-кровать были определены как отдельные слова.
Исключаем стоп-слова из исходного текста
Иногда одних слов в тексте больше, чем других, к тому же они встречаются почти в каждом предложении и не несут большой информативной нагрузки. Такие слова являются шумом для последующего глубокого обучения (Deep Learning) и называются стоп-словами. Библиотека NLTK также имеет список стоп-слов, который предварительно необходимо скачать. Это можно сделать следующим образом:
>>> import nltk
>>> nltk.download('stopwords')
После этого доступен список стоп-слов для русского языка:
>>> from nltk.corpus import stopwords
>>> stopwords.words("russian")
Всего их насчитывается в этом списке 151. Вот некоторые из них:
и, в, во, не, что, он, на, я, с, со, как, а, то, все, чтоб, без, будто, впрочем, хорошо, свою, этой, перед, иногда, лучше, чуть, том, нельзя, такой, им, более, всегда, конечно, всю, между
Поскольку это список, то к нему можно добавить дополнительные слова или, наоборот, удалить из него те, которые будут информативными для вашего случая. Для последующего исключения слов из токенизированного текста можно написать следующее:
for token in tokens:
if token not in stop_words:
filtered_tokens.append(token)
Стемминг: удаляем окончания
Русский язык обладает богатой морфологической структурой. Слово хороший и хорошая имеют тот же смысл, но разную форму, например, хорошая мебель и хороший стул. Поэтому для машинного обучения (Machine Learning) лучше привести их к одной форме для уменьшения размерности. Одним из таких методов является стемминг (stemming). В частности, он опускает окончания слова. В Python-библиотеке NLTK для этого есть Snowball Stemmer, который поддерживает русский язык:
>>> from nltk.stem import SnowballStemmer
...
>>> snowball = SnowballStemmer(language="russian")
>>> snowball.stem("Хороший")
хорош
>>> snowball.stem("Хорошая")
хорош
Проблемы могут возникнуть со словами, которые значительно изменяются в других формах:
>>> snowball.stem("Хочу")
хоч
>>> snowball.stem("Хотеть")
хотет
Хотеть и хочу — грамматические формы одного и то же слова, но стемминг обрубает окончания согласно своему алгоритму. Поэтому возможно следует применить другой метод — лемматизацию.
Приведение к начальной форме с лемматизацией
Над словом можно провести морфологический анализ и выявить его начальную форму. Например, хочу, хотят, хотели имеют начальную форму хотеть. Тогда можем воспользоваться pymorphy2 — инструмент для морфологического анализа русского и украинского языков.
Рассмотрим пример для слова “хочу”:
>>> import pymorphy2
>>> morph = pymorphy2.MorphAnalyzer()
>>> morph.parse("хочу")
[Parse(word='хочу', tag=OpencorporaTag('VERB,impf,tran sing,1per,pres,indc'), normal_form='хотеть', score=1.0, methods_stack=((<DictionaryAnalyzer>, 'хочу', 2999, 1),))]
Метод parse возвращает список объектов Parse, которые обозначают виды грамматических форм анализируемого слова. Такой объект обладает следующими атрибутами:
tagобозначает набор граммем. В данном случае слово хочу — это глагол (VERB) несовершенного вида (impf), переходный (tran), единственного числа (sing), 1 лица (1per), настоящего времени (pres), изъявительного наклонения (indc);normal_form— нормального форма слова;score— оценка вероятности того, что данный разбор правильный;methods_stack— тип словаря распарсенного слова с его индексом.
Нас больше всего интересует нормальная форма слова. По умолчанию объекты Parse сортированы в порядке убывания значения score. Поэтому из списка лучше всего брать 1-й элемент:
>>> morph.parse("хотеть")[0].normal_form
хотеть
>>> morph.parse("хочу")[0].normal_form
хотеть
>>> morph.parse("хотят")[0].normal_form
хотеть
Таким образом, мы получили одно слово из разных его форм.
Как обрабатывать текстовые данные и применять их в реальных проектах Data Science для моделей Machine Learning с помощью Python, вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
На основании Вашего запроса эти примеры могут содержать грубую лексику.
На основании Вашего запроса эти примеры могут содержать разговорную лексику.
After this procedure, the funds turned up on a new smart contract that allowed owners to pick up their tokens.
После этого денежные средства перевели на новый умный контракт, откуда владельцы могли забрать свои деньги.
After this system, cash were on the brand new wise contract that allows the proprietor to pick up their tokens.
После этой процедуры средства оказались на новом умном контракте, который позволял владельцам забрать свои токены.
Given the hassle and hazards involved, it’s no wonder many investors prefer to wait and pick up tokens on IDEX, where there’s no verification and coins can often be bought at half the price.
Однако учитывая возможные проблемы в случае утечки данных, многие пользователи предпочитают подождать и приобрести токены на IDEX, где нет никакой проверки, и монеты часто можно купить за половину цены.
Pick up HOURGLASS TOKEN 1/4 (L).
Результатов: 44375. Точных совпадений: 2. Затраченное время: 198 мс
Documents
Корпоративные решения
Спряжение
Синонимы
Корректор
Справка и о нас
Индекс слова: 1-300, 301-600, 601-900
Индекс выражения: 1-400, 401-800, 801-1200
Индекс фразы: 1-400, 401-800, 801-1200
RegEx 1
If we’d be looking for any word with compared in it, maybe this expression might work:
bw*(?:compared)w*b
Demo
Test with re.finditer
import re
regex = r"bw*(?:compared)w*b"
test_str = "some text you wish before then compared or anythingcompared or any_thing_01_compared_anything_after_that "
matches = re.finditer(regex, test_str)
for matchNum, match in enumerate(matches, start=1):
print ("Match {matchNum} was found at {start}-{end}: {match}".format(matchNum = matchNum, start = match.start(), end = match.end(), match = match.group()))
for groupNum in range(0, len(match.groups())):
groupNum = groupNum + 1
print ("Group {groupNum} found at {start}-{end}: {group}".format(groupNum = groupNum, start = match.start(groupNum), end = match.end(groupNum), group = match.group(groupNum)))
RegEx 2
If we might want to find strings with compared in it, my guess is that this expression in s mode,
^(?=.*bacomparedb|bthiscomparedb|bnotcomparedb).*$
DEMO 2
or this one in m mode
^(?=[sS]*bacomparedb|bthiscomparedb|bnotcomparedb)[sS]*$
might be a start to solve this problem.
DEMO 3
Test 1 with re.findall
import re
regex = r"^(?=.*bacomparedb|bthiscomparedb|bnotcomparedb).*$"
test_str = ("Net income was $9.4 million acompared to the prior year of $2.7 million.,nn"
"some other words with new lines")
print(re.findall(regex, test_str, re.DOTALL))
Test 2 with re.findall
import re
regex = r"^(?=[sS]*bacomparedb|bthiscomparedb|bnotcomparedb)[sS]*$"
test_str = ("Net income was $9.4 million acompared to the prior year of $2.7 million.,nn"
"some other words with new lines")
print(re.findall(regex, test_str, re.MULTILINE))