
Как уже было сказано в прошлый раз, существует несколько видов преобразования слов в числа. Одним из таких NLP-методов является Word Embeddings. В этой статье рассмотрим наиболее популярную разновидность Word Embeddings – нейросеть Word2Vec.
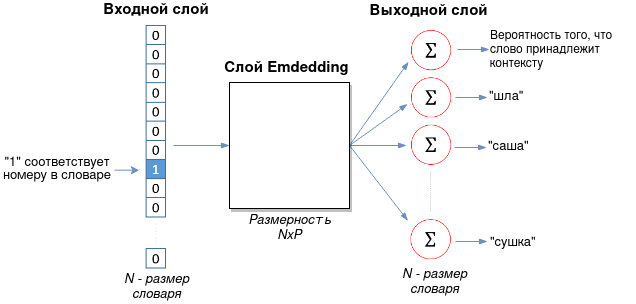
Архитектура Word2Vec состоит из 3 слоев
Нейронная сеть Word2Vec имеет две реализации: Skip-gram и CBOW (Сontinuous bag-of-words). Skip-gram состоит из следующих трех слоев:
- Входной слой, который принимает одно слово в формате one-hot, о котором говорилось тут. Суть one-hot encoding заключается в том, что слово кодируется бинарным вектором с одной единицей, которая представляет позицию слова в словаре:
{шла, саша, по, шоссе} # словарь [1, 0, 0, 0] # шла [0, 1, 0, 0] # саша [0, 0, 1, 0] # по [0, 0, 0, 1] # шоссеДлина one-hot вектора равняется размеру словаря.
- Слой Embedding, который представляет собой матрицу размером
 , где
, где  — размер словаря,
— размер словаря,  — гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1].
— гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1]. - Выходной слой с размером Nx1, где N — размер словаря. Это единственный слой, который имеет функцию активацию (softmax). Каждый из нейронов этого слоя выдает вероятность того, что входное слово принадлежит соответствующему контексту (другим словам).
 , где
, где  — гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1].
— гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1].Архитектура CBOW является зеркальным отражением Skip-gram, когда входной и выходной слой меняются местами: на вход подается контекст (множество слов), а модель предсказывает слово, подходящее этому контексту. Слой Embedding остается тем же.
Представление входного и выходного векторов через контекстное окно
После создания словаря необходимо выбрать входное слово и контекст к нему. Под контекстом подразумевается ближайшие слова, образованные в зависимости от размера контекстного окна. Например, есть предложение “Шла Саша по шоссе и сосала сушку”. Выбираем слово “шоссе” в качестве входного слова и окно с размером 2. Тогда имеем по два контекста слева и справа:
- (шоссе, и), (шоссе, сосала).
- (по, шоссе), (Саша, шоссе).
Число контекстных слов зависит от количества предложений и размера окна. Алгоритм word2vec ищет все предложения с входным словом и контекстом около него. Исходя из нашего предложения, можно составить входной и выходной векторы для одного слова:
{шла, саша, по, шоссе, и, сосала, сушку}
X_1 = [0, 0, 0, 1, 0, 0, 0] # входное слово “шоссе”
Y_1 = [0, 1, 1, 1, 1, 1, 0] # контекст (слова “шла” и “сушку” в него не входят)
Именно Y_1 является тем вектором, с которым сравниваются результаты выходного слоя.
Извлекаем из слоя Embedding только одну строку
Входной вектор (one-hot) умножается на матрицу Embedding, как это показано на рисунке ниже.
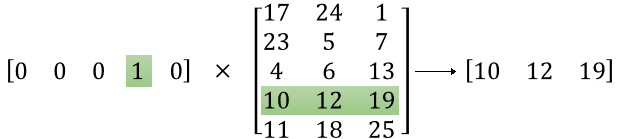
В итоге, из всей большой матрицы NxP выбирается только одна строка-вектор, которая и является векторным представлением слова (word embedding). Эта строка-вектор посылается на выходной слой, каждое соединение с нейроном которого имеет свои веса.
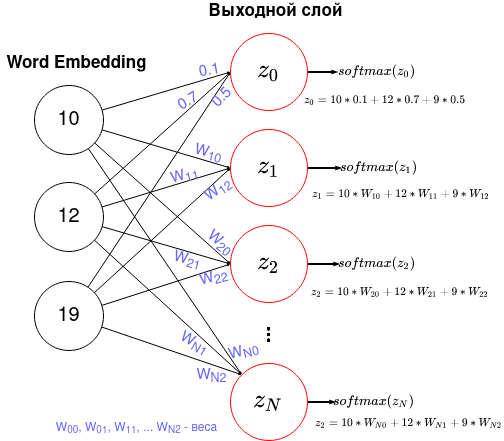
Выходной слой с функцией активацией softmax
Выходной слой содержит N нейронов с функцией активацией softmax, где N — размер словаря. Каждый нейрон соединен со слоем Emdedding. Рисунок ниже показывает эти соединения, где для нулевого нейрона показаны числовые значения весов.
Функция softmax вычисляется по следующей формуле:
![[ softmax(z_i)=frac{exp(z_i)}{sum_{k=0}^{N} exp(z_k)} ]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-cfa6d7d4d8d8519eed27cdc539d9adb4_l3.png "Rendered by QuickLaTeX.com")
Значение функции softmax – это вероятность того, что ответ правильный. Благодаря знаменателю, значения функции активации всех нейронов дадут в сумме 1.
Функция потерь считается вычисляется как
![[ L=-sum(Y*log{Y_{pred}}) ]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-05a58540ccd87043367ed3d8b9c17335_l3.png "Rendered by QuickLaTeX.com")
Минус стоит потому, что логарифм от чисел меньше 1 — отрицательный. На языке Python это может быть выражено следующим образом:
import np L = np.sum(Y*np.log(Y_pred))
Эту функцию и нужно минимизировать, изменяя значения весов и матрицу Emdedding через алгоритм обратного распространения ошибки.
Дополнительные улучшения: Phrase Learning, Subsampling, Negative Sampling
Также авторы Word2Vec добавили некоторые улучшения в модель, а именно Phrase Learning, Subsampling и Negative Sampling, вместо которого можно использовать Hierarchical softmax. Рассмотрим эти инструменты подробнее.
Phrase Learning, означает, что некоторые слова стоит рассматривать вместе, например, “New_York”. Слово “New” в некоторых случаях может обозначать “новый”, но если “New” и “York” стоят вместе, то, скорее всего, имеется в виду “Нью-Йорк”. Также это поможет различать людей: “Петр_Сидоров” от “Петр_Козлов”.
Subsampling подразумевает избавление от слишком повторяющихся слов.a Предлоги, союзы могут быть в каждом контексте, но не раскрывать его смысл. Для каждого слова вычисляется вероятность того, что оно должно учитываться в обучении. Такая вероятность вычисляется следующим образом:
![[ P(w_i)=frac{0.001}{f(w_i)}sqrt{frac{f(w_i)}{0.001}} ]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-56926a71dd65a6efce632e48f09ba094_l3.png "Rendered by QuickLaTeX.com")
где —  слово, а
слово, а  — частота встречаемости этого слова в корпусе. Таким образом, чем больше , тем выше вероятность того, что слово не имеет информативной ценности.
— частота встречаемости этого слова в корпусе. Таким образом, чем больше , тем выше вероятность того, что слово не имеет информативной ценности.
Negative Sampling необходим для уменьшения вычислительных затрат на обучение. Выходной слой имеет размерность N, равный размеру словаря. Если словарь содержит миллион слов, то и обновлять веса для каждого нейрона слишком затратно. Поэтому обновление весов можно осуществлять только для контекстных слов и 5-6 слов, которые не совпадают с контекстом (для большого датасета можно ограничиться 2-3). Кроме того, Negative sampling можно заменить на Hierarchical softmax, который разворачивает сеть в бинарное дерево, обновляя  весов вместо
весов вместо  весов.
весов.
В следующей статье расскажем о том, как обучить модель Word2Vec с примерами кода на Python. Еще больше подробностей о NLP-задачах в реальных проектах Data Science вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Источники
https://arxiv.org/abs/1310.4546
Статья рассказывает об алгоритмах word2vec, на выходе которых получаются векторные представления слов. Векторы слов лежат в основе многих систем обработки естественного языка (NLP), захлестнувших современный мир (Amazon Alexa, Google translate и т.д.).
Векторные представления слов: все дело в контексте
Давайте же погрузимся в тему. Слова-векторы (word vectors) — это численные представления слов, сохраняющие семантическую связь между ними. Например, для вектора cat (кошка) одним из наиболее близких будет слово dog (собака). Однако векторное представление слова pencil (карандаш) будет достаточно сильно отличаться от вектора cat. Эта схожесть обусловлена частотой встречаемости двух слов (т.е. [cat, dog] или [cat, pencil]) в одном контексте. Рассмотрим следующее предложение:
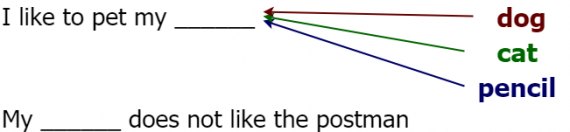
Думаю, не стоит объяснять, какое слово в этом предложении не подходит (очевидно, что это pencil). Как мы понимаем, что оно не подходит? С произношением все в порядке, с грамматикой все в порядке, тогда что же не так? Все дело в контексте, pencil не подходит по смыслу. Этот пример должен убедить вас в важности контекста. Алгоритмы word2vec используют контекст, чтобы сформировать численные представления слов, поэтому слова, используемые в одном и том же контексте, имеют похожие векторы.
Чтобы понять, как word2vec применяется в реальных проектах, попробуем следующее. Зайдем на google scholar и поищем там связанные с NLP задачи (например, вопросно-ответные системы, чат-боты, машинный перевод и прочее). Отфильтруем документы, опубликованные после 2013 года, когда появились методы word2vec. Если посчитать отношение количества статей, в которых рассказывается об использовании векторных представлений слов, к общему количеству статей, то получится довольно большое число.
Векторные представления слов используются во многих областях:
- Моделирование языков;
- Чат-боты;
- Машинный перевод;
- Вопросно-ответные системы;
- …и многое другое.
Вы можете заметить, что все современные приложения NLP основываются на алгоритмах word2vec. Давайте обсудим, как же можно улучшить существующие модели векторными представлениями слов. Они позволяют нам отобразить семантически сходные слова в близкие друг другу вектора в некоторой модели, в то время как далекие по смыслу слова будут выглядеть по-разному. Это желаемое свойство модели, которое приведет к лучшему результату.
Процесс создания векторов слов
Теперь, обладая интуитивным пониманием, мы первым делом обсудим общие принципы действия алгоритмов word2vec, а более детально рассмотрим их позднее. Чтобы обучить выборку слов без заранее размеченных данных, сначала нам нужно решить несколько задач:
- Создать кортежи данных в формате [входное слово, выходное слово], каждое слово представлено в виде двоичного вектора длины n, где i-ое значение кодируется единицей на i-ой позиции и нулями на всех остальных (one-hot кодировка);
- Создать модель, которая на вход и выход получает one-hot векторы;
- Определить функцию потерь, предсказывающую верное слово, чтобы оптимизировать модель;
- Определить качество модели, убедившись, что похожие слова имеют похожие векторные представления.
Как вы видите, процедура не очень сложная. В следующем разделе мы займемся каждым из шагов детально.
Создание структурированных данных из исходного текста
Возьмем такой пример:
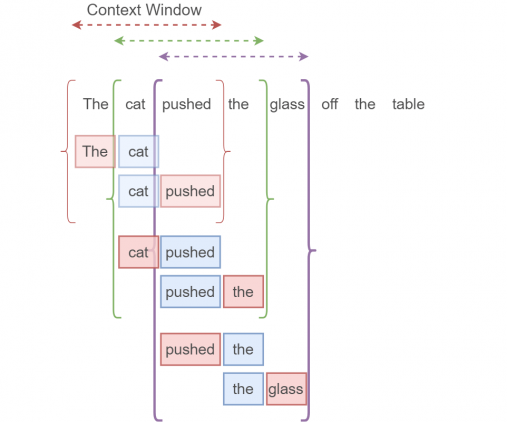
The cat pushed the glass off the table.
Нужные нам данные будут получаться так. Каждая скобка обозначает единичное контекстное окно. Синее поле обозначает входной one-hot вектор (целевое слово), красное поле — выходной one-hot вектор (любое слово в контекстном окне за исключением целевого слова, так называемое контекстное слово). Из одного контекстного окна получаются два элемента данных (на одно целевое слово приходится два соседних). Размер окна обычно определяется пользователем. Чем больше размер контекстного окна, тем лучше наша модель, но это влияет на время выполнения алгоритма. Не надо путать целевое слово с целевыми данными, это совершенно разные вещи.
Определение embedding layer и нейросети
Наша нейросеть будет обучаться на входных данных, которые мы задали выше. Нам потребуется следующее:
- набор входных one-hot векторов;
- набор выходных one-hot векторов (после обучения);
- embedding layer;
- нейросеть.
Не беспокойтесь, если вы пока не понимаете, как работают два последних компонента. Мы рассмотрим их подробнее.
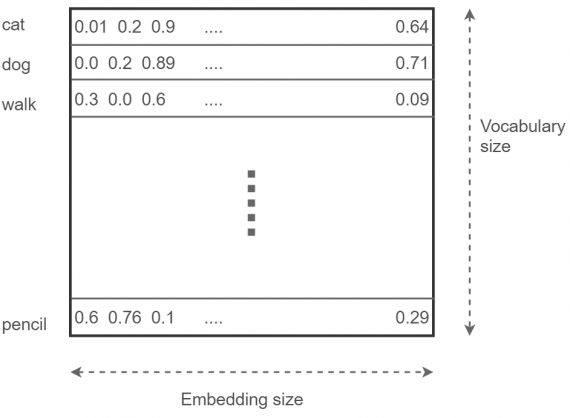
Embedding layer
Начнем с embedding layer. Он хранит вектора всех слов в словаре. Представьте себе огромную матрицу размера [число слов в словаре x размерность пространства сжатого векторного представления слов]). Эта размерность (embedding size) является настраиваемым параметром. Чем она больше, тем лучше модель (но по достижении определенного embedding size вы не получите большой прирост производительности). Эта гигантская матрица инициализируется случайным образом (как и нейросеть) и настраивается бит за битом в процессе оптимизации. Выглядит это так:
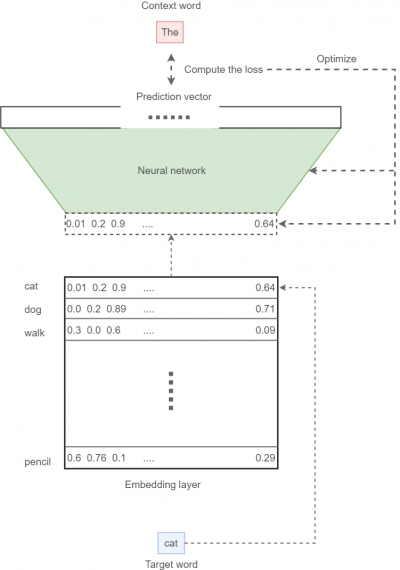
Нейронная сеть
Последний кирпичик нашей модели — нейронная сеть. В процессе обучения нейросеть получает входной вектор и пытается предсказать результат в виде распределения вероятностей слова быть в контексте входного слова на множестве всех слов (также его можно интерпретировать как линейную комбинацию one-hot кодировок этих слов). Затем с помощью функции потерь мы штрафуем модель за неправильную классификацию и награждаем за верную. Сейчас мы ограничимся обработкой одного входа и одного выхода за раз. В реальных проектах данные обрабатываются батчами (то есть группами; например, по 64 элемента). Опишем процесс обучения в общих чертах:
- Для данного введенного слова (целевого слова) найдем соответствующий вектор из embedding layer;
- Скормим этот вектор нашей нейросети, затем попытаемся предсказать правильное выходное (контекстное) слово;
- Сравнив предсказанное слово и то слово, которое на самом деле находится в контекстном окне, вычислим функцию потерь;
- Используя функцию потерь вместе со стохастическим градиентным спуском, оптимизируем нейросеть и embedding layer.
Нужно заметить, что при вычислении предсказания мы используем функцию softmax, чтобы нормализовать прогнозы до допустимого распределения вероятностей.
Собираем все вместе
Зная все детали алгоритма word2vec, мы можем собрать все воедино. После обучения модели нам остается только сохранить embedding layer на диске, после чего мы можем наслаждаться векторами с сохраненной семантикой в любое время. Вот так выглядит общая картина:
Эта модель известна как skip-gram алгоритм, это один из алгоритмов word2vec, на нем мы и сфокусируемся. Другой алгоритм известен как “непрерывный мешок со словами” (continuous bag-of-words model, CBOW).
Функция потерь: оптимизируем модель
Мы не обсудили одну из ключевых деталей — функцию потерь. Стандартная функция перекрестной энтропии (softmax cross entropy loss) является хорошим решением для задач классификации. Но для модели word2vec использование этой функции не является практичным, как например для более простой задачи вроде анализа тональности, где есть только два выходных варианта: положительный и отрицательный. В реальной задаче обработки слов, где их число может измеряться миллиардами, размер словаря запросто может вырасти до 100,000 значений или даже больше, что значительно усложняет вычисление softmax-нормализации. Это связано с тем, что для полного вычисления softmax требуется рассчитать потери в кросс-энтропии по всем выходным узлам.
Поэтому мы будем использовать более изящную альтернативу под названием sampled softmax loss функция. У нее есть ряд отличий от стандартной перекрестной энтропии.
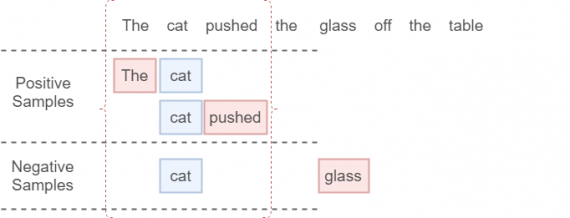
Сначала мы вычисляем функцию перекрестной энтропии между истинным значением контекстного слова для заданного целевого слова и значением предсказанного слова, соответствующего истинному значению контекстного слова. Затем мы добавим кросс-энтропийную потерю k негативных семплов (целевое слово + слово вне контекстного окна), которые мы отбирали в соответствии с некоторым распределением шума.
Функция потерь определяется следующим образом:
![]()
SigmoidCrossEntropy это ошибка, которую мы можем определить на одном выходном узле независимо от остальных. Это идеальное решение нашей проблемы, когда словарь становится слишком большим. Не будем вдаваться в детали этой функции. Вам необязательно понимать, как именно она реализована, поскольку в TensorFlow эта функция встроенная, но стоит понять, что такое k, что это за параметр. Самое важное — это что sampled softmax loss вычисляет ошибку, рассматривая два типа объектов:
- индекс правильного контекстного слова в предсказанном векторе (индекс слова в контекстном окне);
- k индексов шумовых слов.
Мы проиллюстрируем это примером. Тут k = 1 (cat + glass):
Реализация на TensorFlow: skip-gram алгоритм
В этом разделе мы соберем все части воедино и попробуем реализовать наш алгоритм. Код доступен тут. В этой секции мы займемся следующим:
- генератор данных;
- skip-gram модель (на TensorFlow);
- запуск skip-gram алгоритма.
Генерация данных
Мы не будем углубляться в код детально, так как уже обсудили внутренние механизмы генерации данных. Просто опишем наши действия на Python:
def generate_batch(batch_size, window_size):
global data_index
# two numpy arras to hold target words (batch)
# and context words (labels)
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
# span defines the total window size
span = 2 * window_size + 1
# The buffer holds the data contained within the span
queue = collections.deque(maxlen=span)
# Fill the buffer and update the data_index
for _ in range(span):
queue.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // (2*window_size)):
k=0
# Avoid the target word itself as a prediction
for j in list(range(window_size))+list(range(window_size+1,2*window_size+1)):
batch[i * (2*window_size) + k] = queue[window_size]
labels[i * (2*window_size) + k, 0] = queue[j]
k += 1
# Everytime we read num_samples data points, update the queue
queue.append(data[data_index])
# If end is reached, circle back to the beginning
data_index = (data_index + np.random.randint(window_size)) % len(data)
return batch, labels
Определим skip-gram модель
Сначала мы определим некоторые гиперпараметры:
batch_size = 128 embedding_size = 64 window_size = 4 num_sampled = 32 # Number of negative examples to sample.
batch_size устанавливает количество элементов данных, которые мы обрабатываем в данный момент времени. embedding_size это длина вектора. Гиперпараметр window_size определяет размер контекстного окна. Наконец, num_sampled — число негативных семплов в функции потерь (k). Теперь мы определим входные и выходные данные:
tf.reset_default_graph() # Training input data (target word IDs). train_dataset = tf.placeholder(tf.int32, shape=[batch_size])
# Training input label data (context word IDs) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
train_dataset принимает на вход список идентификаторов слов batch_size, который представляет выбранный набор целевых слов. train_labels представляет собой список batch_size
соответствующих контекстных слов для выбранных целевых слов.
Затем мы определяем параметры нейронной сети:
################################################
# Model variables #
################################################
# Embedding layer
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
# Neural network weights and biases
softmax_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=0.1 / math.sqrt(embedding_size))
)
softmax_biases = tf.Variable(tf.random_uniform([vocabulary_size],-0.01,0.01))
Embedding layer в TensorFlow определяется переменной embeddings, веса — переменной softmax_weights, параметры сдвига — softmax_biases.
Соединим embedding layer и нейросеть, чтобы оптимизировать результат:
# Look up embeddings for a batch of inputs. embed = tf.nn.embedding_lookup(embeddings, train_dataset)
Функция tf.nn.embedding_lookup принимает на вход embedding layer и набор идентификаторов слов (train_dataset), а на выходе выдает соответствующие вектора.
Теперь настало время функции sampled softmax loss:
################################################ # Computes loss # ################################################ loss = tf.reduce_mean(tf.nn.sampled_softmax_loss( weights=softmax_weights, biases=softmax_biases, inputs=embed, labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size) )
Здесь tf.nn.sampled_softmax_loss получает на вход набор весов (softmax_weights), сдвигов (softmax_biases), полученный в предыдущей функции набор векторов embed, идентификаторы верных контекстных слов (train_labels), количество шумовых семплов (num_sampled) и размер словаря (vocabulary_size).
Оптимизируем функцию потерь по параметрам embedding layer и нейросети:
################################################ # Optimization # ################################################ optimizer = tf.train.AdamOptimizer(0.001).minimize(loss)
Нормируем embedding layer:
################################################ # For evaluation # ################################################ norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keepdims=True)) normalized_embeddings = embeddings / norm
Запускаем код
Как же мы запустим нашу TensorFlow модель? Для начала определим session и инициализируем все переменные случайным образом.
num_steps = 250001
session = tf.InteractiveSession()
# Initialize the variables in the graph
tf.global_variables_initializer().run()
print('Initialized')
average_loss = 0
Теперь в течение заранее определенного числа шагов мы формируем группы данных: целевые слова (batch_data) и контекстные слова (batch_labels):
for step in range(num_steps):
# Generate a single batch of data
batch_data, batch_labels = generate_batch( batch_size, window_size)
Затем для каждой сгенерированной группы мы оптимизируем embedding layer и нейронную сеть с помощью session.run([optimize, loss],…). Также мы вычислим ошибку, чтобы убедиться, что она уменьшается.
# Optimize the embedding layer and neural network
# compute loss
feed_dict = {train_dataset : batch_data, train_labels : batch_labels}
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
Каждые пять тысяч шагов мы печатаем на экране среднюю ошибку:
if (step+1) % 5000 == 0:
if step > 0:
average_loss = average_loss / 5000
print('Average loss at step %d: %f' % (step+1, average_loss))
average_loss = 0
И вот мы получаем вектора, которые позже используем для визуализации определенных слов:
sg_embeddings = normalized_embeddings.eval() session.close()
Если мы визуализируем результат с помощью какого-нибудь алгоритма вроде t-SNE, получим следующее:
Как можно заметить, слова, относящиеся к кошкам, находятся в определенной области (cat, kitten, cats, wildcat), а слова, относящиеся к собакам, находятся в другой области (dog, dogs, wolf). Слова между этими областями (например, animal или pet) по смыслу относятся и к кошкам, и к собакам, что нам и требовалось.
Заключение
Вот мы и подошли к концу. Векторные представления слов — это очень мощный инструмент, который помогает улучшать современные модели машинного обучения. Мы научились генерировать данные и разобрались в базовых принципах работы word2vec. Затем мы обсудили skip-gram алгоритм и реализовали его на TensorFlow. В довершение ко всему мы визуализировали наши векторные представления и убедились, что семантическая составляющая действительно сохраняется. Надеюсь, эта статья была для вас полезной.
Оригинал — Thushan Ganegedara, перевод — Станислава Рунова.
From Wikipedia, the free encyclopedia
Word2vec is a technique for natural language processing (NLP) published in 2013. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that they capture the semantic and syntactic qualities of words; as such, a simple mathematical function (cosine similarity) can indicate the level of semantic similarity between the words represented by those vectors.
Approach[edit]
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space.
Word2vec can utilize either of two model architectures to produce these distributed representations of words: continuous bag-of-words (CBOW) or continuous skip-gram. In both architectures, word2vec considers both individual words and a sliding window of context words surrounding individual words as it iterates over the entire corpus. In the continuous bag-of-words architecture, the model predicts the current word from the window of surrounding context words. The order of context words does not influence prediction (bag-of-words assumption). In the continuous skip-gram architecture, the model uses the current word to predict the surrounding window of context words.[1][2] The skip-gram architecture weighs nearby context words more heavily than more distant context words. According to the authors’ note,[3] CBOW is faster while skip-gram does a better job for infrequent words.
After the model has trained, the learned word embeddings are positioned in the vector space such that words that share common contexts in the corpus — that is, words that are semantically and syntactically similar — are located close to one another in the space.[1] More dissimilar words are located farther from one another in the space.[1]
This occurs because words which influence relative word probabilities in similar ways will have learned similar embeddings once the model has finished. For example, consider the CBOW framework, which can be thought of as a ‘fill in the blank’ task. The learned embedding for a word will represent the way in which, when that word appears in a context window, it influences the relative probabilities of other words appearing in the ‘blank,’ or the position at the center of the context window. Therefore, words which are semantically similar should influence these probabilities in similar ways, because semantically similar words should be used in similar contexts.
History[edit]
Word2vec was created, patented,[4] and published in 2013 by a team of researchers led by Tomas Mikolov at Google over two papers.[1][2] Other researchers helped analyse and explain the algorithm.[5] Embedding vectors created using the Word2vec algorithm have some advantages compared to earlier algorithms[1][further explanation needed] such as latent semantic analysis.
By 2022, the Word2vec approach was described as «dated», with transformer models being regarded as the state of the art in NLP.[6]
Parameterization[edit]
Results of word2vec training can be sensitive to parametrization. The following are some important parameters in word2vec training.
Training algorithm[edit]
A Word2vec model can be trained with hierarchical softmax and/or negative sampling. To approximate the conditional log-likelihood a model seeks to maximize, the hierarchical softmax method uses a Huffman tree to reduce calculation. The negative sampling method, on the other hand, approaches the maximization problem by minimizing the log-likelihood of sampled negative instances. According to the authors, hierarchical softmax works better for infrequent words while negative sampling works better for frequent words and better with low dimensional vectors.[3] As training epochs increase, hierarchical softmax stops being useful.[7]
Sub-sampling[edit]
High-frequency and low-frequency words often provide little information. Words with a frequency above a certain threshold, or below a certain threshold, may be subsampled or removed to speed up training.[8]
Dimensionality[edit]
Quality of word embedding increases with higher dimensionality. But after reaching some point, marginal gain diminishes.[1] Typically, the dimensionality of the vectors is set to be between 100 and 1,000.
Context window[edit]
The size of the context window determines how many words before and after a given word are included as context words of the given word. According to the authors’ note, the recommended value is 10 for skip-gram and 5 for CBOW.[3]
Extensions[edit]
There are a variety of extensions to word2vec.
doc2vec[edit]
doc2vec, generates distributed representations of variable-length pieces of texts, such as sentences, paragraphs, or entire documents.[9][10] doc2vec has been implemented in the C, Python and Java/Scala tools (see below), with the Java and Python versions also supporting inference of document embeddings on new, unseen documents.
doc2vec estimates the distributed representations of documents much like how word2vec estimates representations of words: doc2vec utilizes either of two model architectures, both of which are allegories to the architectures used in word2vec. The first, Distributed Memory Model of Paragraph Vectors (PV-DM), is identical to CBOW other than it also provides a unique document identifier as a piece of additional context. The second architecture, Distributed Bag of Words version of Paragraph Vector (PV-DBOW), is identical to the skip-gram model except that it attempts to predict the window of surrounding context words from the paragraph identifier instead of the current word.[9]
doc2vec also has the ability to capture the semantic ‘meanings’ for additional pieces of ‘context’ around words; doc2vec can estimate the semantic embeddings for speakers or speaker attributes, groups, and periods of time. For example, doc2vec has been used to estimate the political positions of political parties in various Congresses and Parliaments in the U.S. and U.K.,[11] respectively, and various governmental institutions.[12]
top2vec[edit]
Another extension of word2vec is top2vec, which leverages both document and word embeddings to estimate distributed representations of topics.[13][14] top2vec takes document embeddings learned from a doc2vec model and reduces them into a lower dimension (typically using UMAP). The space of documents is then scanned using HDBSCAN,[15] and clusters of similar documents are found. Next, the centroid of documents identified in a cluster is considered to be that cluster’s topic vector. Finally, top2vec searches the semantic space for word embeddings located near to the topic vector to ascertain the ‘meaning’ of the topic.[13] The word with embeddings most similar to the topic vector might be assigned as the topic’s title, whereas far away word embeddings may be considered unrelated.
As opposed to other topic models such as LDA, top2vec provides canonical ‘distance’ metrics between two topics, or between a topic and another embeddings (word, document, or otherwise). Together with results from HDBSCAN, users can generate topic hierarchies, or groups of related topics and subtopics.
Furthermore, a user can use the results of top2vec to infer the topics of out-of-sample documents. After inferring the embedding for a new document, must only search the space of topics for the closest topic vector.
BioVectors[edit]
An extension of word vectors for n-grams in biological sequences (e.g. DNA, RNA, and proteins) for bioinformatics applications has been proposed by Asgari and Mofrad.[16] Named bio-vectors (BioVec) to refer to biological sequences in general with protein-vectors (ProtVec) for proteins (amino-acid sequences) and gene-vectors (GeneVec) for gene sequences, this representation can be widely used in applications of machine learning in proteomics and genomics. The results suggest that BioVectors can characterize biological sequences in terms of biochemical and biophysical interpretations of the underlying patterns.[16] A similar variant, dna2vec, has shown that there is correlation between Needleman–Wunsch similarity score and cosine similarity of dna2vec word vectors.[17]
Radiology and intelligent word embeddings (IWE)[edit]
An extension of word vectors for creating a dense vector representation of unstructured radiology reports has been proposed by Banerjee et al.[18] One of the biggest challenges with Word2vec is how to handle unknown or out-of-vocabulary (OOV) words and morphologically similar words. If the Word2vec model has not encountered a particular word before, it will be forced to use a random vector, which is generally far from its ideal representation. This can particularly be an issue in domains like medicine where synonyms and related words can be used depending on the preferred style of radiologist, and words may have been used infrequently in a large corpus.
IWE combines Word2vec with a semantic dictionary mapping technique to tackle the major challenges of information extraction from clinical texts, which include ambiguity of free text narrative style, lexical variations, use of ungrammatical and telegraphic phases, arbitrary ordering of words, and frequent appearance of abbreviations and acronyms. Of particular interest, the IWE model (trained on the one institutional dataset) successfully translated to a different institutional dataset which demonstrates good generalizability of the approach across institutions.
Analysis[edit]
The reasons for successful word embedding learning in the word2vec framework are poorly understood. Goldberg and Levy point out that the word2vec objective function causes words that occur in similar contexts to have similar embeddings (as measured by cosine similarity) and note that this is in line with J. R. Firth’s distributional hypothesis. However, they note that this explanation is «very hand-wavy» and argue that a more formal explanation would be preferable.[5]
Levy et al. (2015)[19] show that much of the superior performance of word2vec or similar embeddings in downstream tasks is not a result of the models per se, but of the choice of specific hyperparameters. Transferring these hyperparameters to more ‘traditional’ approaches yields similar performances in downstream tasks. Arora et al. (2016)[20] explain word2vec and related algorithms as performing inference for a simple generative model for text, which involves a random walk generation process based upon loglinear topic model. They use this to explain some properties of word embeddings, including their use to solve analogies.
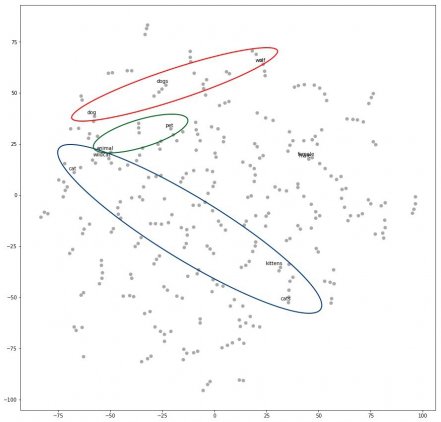
Preservation of semantic and syntactic relationships[edit]

Visual illustration of word embeddings
The word embedding approach is able to capture multiple different degrees of similarity between words. Mikolov et al. (2013)[21] found that semantic and syntactic patterns can be reproduced using vector arithmetic. Patterns such as «Man is to Woman as Brother is to Sister» can be generated through algebraic operations on the vector representations of these words such that the vector representation of «Brother» — «Man» + «Woman» produces a result which is closest to the vector representation of «Sister» in the model. Such relationships can be generated for a range of semantic relations (such as Country–Capital) as well as syntactic relations (e.g. present tense–past tense).
This facet of word2vec has been exploited in a variety of other contexts. For example, word2vec has been used to map a vector space of words in one language to a vector space constructed from another language. Relationships between translated words in both spaces can be used to assist with machine translation of new words.[22]
Assessing the quality of a model[edit]
Mikolov et al. (2013)[1] develop an approach to assessing the quality of a word2vec model which draws on the semantic and syntactic patterns discussed above. They developed a set of 8,869 semantic relations and 10,675 syntactic relations which they use as a benchmark to test the accuracy of a model. When assessing the quality of a vector model, a user may draw on this accuracy test which is implemented in word2vec,[23] or develop their own test set which is meaningful to the corpora which make up the model. This approach offers a more challenging test than simply arguing that the words most similar to a given test word are intuitively plausible.[1]
Parameters and model quality[edit]
The use of different model parameters and different corpus sizes can greatly affect the quality of a word2vec model. Accuracy can be improved in a number of ways, including the choice of model architecture (CBOW or Skip-Gram), increasing the training data set, increasing the number of vector dimensions, and increasing the window size of words considered by the algorithm. Each of these improvements comes with the cost of increased computational complexity and therefore increased model generation time.[1]
In models using large corpora and a high number of dimensions, the skip-gram model yields the highest overall accuracy, and consistently produces the highest accuracy on semantic relationships, as well as yielding the highest syntactic accuracy in most cases. However, the CBOW is less computationally expensive and yields similar accuracy results.[1]
Overall, accuracy increases with the number of words used and the number of dimensions. Mikolov et al.[1] report that doubling the amount of training data results in an increase in computational complexity equivalent to doubling the number of vector dimensions.
Altszyler and coauthors (2017) studied Word2vec performance in two semantic tests for different corpus size.[24] They found that Word2vec has a steep learning curve, outperforming another word-embedding technique, latent semantic analysis (LSA), when it is trained with medium to large corpus size (more than 10 million words). However, with a small training corpus, LSA showed better performance. Additionally they show that the best parameter setting depends on the task and the training corpus. Nevertheless, for skip-gram models trained in medium size corpora, with 50 dimensions, a window size of 15 and 10 negative samples seems to be a good parameter setting.
See also[edit]
- Semantle
- Autoencoder
- Document-term matrix
- Feature extraction
- Feature learning
- Neural network language models
- Vector space model
- Thought vector
- fastText
- GloVe
- Normalized compression distance
References[edit]
- ^ a b c d e f g h i j k Mikolov, Tomas; et al. (2013). «Efficient Estimation of Word Representations in Vector Space». arXiv:1301.3781 [cs.CL].
- ^ a b Mikolov, Tomas; Sutskever, Ilya; Chen, Kai; Corrado, Greg S.; Dean, Jeff (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems. arXiv:1310.4546. Bibcode:2013arXiv1310.4546M.
- ^ a b c «Google Code Archive — Long-term storage for Google Code Project Hosting». code.google.com. Retrieved 13 June 2016.
- ^ US 9037464, Mikolov, Tomas; Chen, Kai & Corrado, Gregory S. et al., «Computing numeric representations of words in a high-dimensional space», published 2015-05-19, assigned to Google Inc.
- ^ a b Goldberg, Yoav; Levy, Omer (2014). «word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method». arXiv:1402.3722 [cs.CL].
- ^ Von der Mosel, Julian; Trautsch, Alexander; Herbold, Steffen (2022). «On the validity of pre-trained transformers for natural language processing in the software engineering domain». IEEE Transactions on Software Engineering: 1. arXiv:2109.04738. doi:10.1109/TSE.2022.3178469. ISSN 1939-3520. S2CID 237485425.
- ^ «Parameter (hs & negative)». Google Groups. Retrieved 13 June 2016.
- ^ «Visualizing Data using t-SNE» (PDF). Journal of Machine Learning Research, 2008. Vol. 9, pg. 2595. Retrieved 18 March 2017.
- ^ a b Le, Quoc; Mikolov, Tomas (May 2014). «Distributed Representations of Sentences and Documents». Proceedings of the 31st International Conference on Machine Learning. arXiv:1405.4053.
- ^ Rehurek, Radim. «Gensim».
- ^ Rheault, Ludovic; Cochrane, Christopher (3 July 2019). «Word Embeddings for the Analysis of Ideological Placement in Parliamentary Corpora». Political Analysis. 28 (1).
- ^ Nay, John (21 December 2017). «Gov2Vec: Learning Distributed Representations of Institutions and Their Legal Text». SSRN. SSRN 3087278.
- ^ a b Angelov, Dimo (August 2020). «Top2Vec: Distributed Representations of Topics». arXiv:2008.09470 [cs.CL].
- ^ Angelov, Dimo (11 November 2022). «Top2Vec». GitHub.
- ^ Campello, Ricardo; Moulavi, Davoud; Sander, Joerg (2013). «Density-Based Clustering Based on Hierarchical Density Estimates». Advances in Knowledge Discovery and Data Mining. Lecture Notes in Computer Science. 7819: 160–172. doi:10.1007/978-3-642-37456-2_14. ISBN 978-3-642-37455-5.
- ^ a b Asgari, Ehsaneddin; Mofrad, Mohammad R.K. (2015). «Continuous Distributed Representation of Biological Sequences for Deep Proteomics and Genomics». PLOS ONE. 10 (11): e0141287. arXiv:1503.05140. Bibcode:2015PLoSO..1041287A. doi:10.1371/journal.pone.0141287. PMC 4640716. PMID 26555596.
- ^ Ng, Patrick (2017). «dna2vec: Consistent vector representations of variable-length k-mers». arXiv:1701.06279 [q-bio.QM].
- ^ Banerjee, Imon; Chen, Matthew C.; Lungren, Matthew P.; Rubin, Daniel L. (2018). «Radiology report annotation using intelligent word embeddings: Applied to multi-institutional chest CT cohort». Journal of Biomedical Informatics. 77: 11–20. doi:10.1016/j.jbi.2017.11.012. PMC 5771955. PMID 29175548.
- ^ Levy, Omer; Goldberg, Yoav; Dagan, Ido (2015). «Improving Distributional Similarity with Lessons Learned from Word Embeddings». Transactions of the Association for Computational Linguistics. Transactions of the Association for Computational Linguistics. 3: 211–225. doi:10.1162/tacl_a_00134.
- ^ Arora, S; et al. (Summer 2016). «A Latent Variable Model Approach to PMI-based Word Embeddings». Transactions of the Association for Computational Linguistics. 4: 385–399. doi:10.1162/tacl_a_00106 – via ACLWEB.
- ^ Mikolov, Tomas; Yih, Wen-tau; Zweig, Geoffrey (2013). «Linguistic Regularities in Continuous Space Word Representations». HLT-Naacl: 746–751.
- ^ Jansen, Stefan (9 May 2017). «Word and Phrase Translation with word2vec». arXiv:1705.03127.
- ^ «Gensim — Deep learning with word2vec». Retrieved 10 June 2016.
- ^ Altszyler, E.; Ribeiro, S.; Sigman, M.; Fernández Slezak, D. (2017). «The interpretation of dream meaning: Resolving ambiguity using Latent Semantic Analysis in a small corpus of text». Consciousness and Cognition. 56: 178–187. arXiv:1610.01520. doi:10.1016/j.concog.2017.09.004. PMID 28943127. S2CID 195347873.
External links[edit]
- Wikipedia2Vec[1] (introduction)
Implementations[edit]
- C
- C#
- Python (Spark)
- Python (TensorFlow)
- Python (Gensim)
- Java/Scala
- R
Векторное представление слов (англ. word embedding) — общее название для различных подходов к моделированию языка и обучению представлений в обработке естественного языка, направленных на сопоставление словам из некоторого словаря векторов небольшой размерности.
Содержание
- 1 One-hot encoding
- 2 word2vec
- 3 fastText
- 4 Примеры кода с использованием библиотеки Gensim
- 4.1 Загрузка предобученной модели русского корпуса
- 4.2 Обучение модели word2vec и fastText на текстовом корпусе
- 5 ELMO
- 6 BERT
- 7 См. также
- 8 Источники информации
One-hot encoding
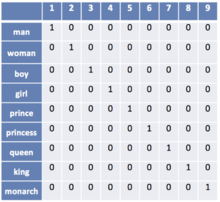
Рисунок 1. Пример one-hot encoding для словаря из 9 слов. Источник
Пусть число различных слов равно . Сопоставим слову с номером вектор длины , в котором -тая координата равна единице, а все остальные — нулям (рис. 1). Недостатком one-hot encoding является то, что по векторным представлениям нельзя судить о схожести смысла слов. Также вектора имеют очень большой размер, из-за чего их неэффективно хранить в памяти.
word2vec
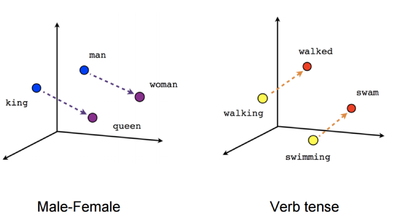
Рисунок 2. Полученные векторы-слова отражают различные грамматические и семантические концепции.
word2vec — способ построения сжатого пространства векторов слов, использующий нейронные сети. Принимает на вход большой текстовый корпус и сопоставляет каждому слову вектор. Сначала он создает словарь, а затем вычисляет векторное представление слов. Векторное представление основывается на контекстной близости: слова, встречающиеся в тексте рядом с одинаковыми словами (а следовательно, имеющие схожий смысл) (рис. 2), в векторном представлении имеют высокое косинусное сходство (англ. cosine similarity):
В word2vec существуют две основных модели обучения: Skip-gram (рис. 3) и CBOW (англ. Continuous Bag of Words) (рис. 4). В модели Skip-gram по слову предсказываются слова из его контекста, а в модели CBOW по контексту подбирается наиболее вероятное слово. На выходном слое используется функция или его вариация, чтобы получить на выходе распределение вероятности каждого слова. В обеих моделях входные и выходные слова подаются в one-hot encoding, благодаря чему при умножении на матрицу , соединяющую входной и скрытый слои, происходит выбор одной строки . Размерность является гиперпараметром алгоритма, а обученная матрица — выходом, так как ее строки содержат векторные представления слов.
Для ускорения обучения моделей Skip-gram и CBOW используются модификации , такие как иерархический и negative sampling, позволяющие вычислять распределение вероятностей быстрее, чем за линейное время от размера словаря.
fastText
Недостатком word2vec является то, что с его помощью не могут быть представлены слова, не встречающиеся в обучающей выборке. fastText решает эту проблему с помощью -грамм символов. Например, -граммами для слова яблоко являются ябл, бло, лок, око. Модель fastText строит векторные представления -грамм, а векторным представлением слова является сумма векторных представлений всех его -грамм. Части слов с большой вероятностью встречаются и в других словах, что позволяет выдавать векторные представления и для редких слов.
Примеры кода с использованием библиотеки Gensim
Загрузка предобученной модели русского корпуса
import gensim import gensim.downloader as download_api russian_model = download_api.load('word2vec-ruscorpora-300')
# Выведем первые 10 слов корпуса.
# В модели "word2vec-ruscorpora-300" после слова указывается часть речи: NOUN (существительное), ADJ (прилагательное) и так далее.
# Но существуют также предоубученные модели без разделения слов по частям речи, смотри репозиторий list(russian_model.vocab.keys())[:10] # ['весь_DET', 'человек_NOUN', 'мочь_VERB', 'год_NOUN', 'сказать_VERB', 'время_NOUN', 'говорить_VERB', 'становиться_VERB', 'знать_VERB', 'самый_DET']
# Поиск наиболее близких по смыслу слов. russian_model.most_similar('кошка_NOUN') # [('кот_NOUN', 0.7570087909698486), ('котенок_NOUN', 0.7261239290237427), ('собака_NOUN', 0.6963180303573608), # ('мяукать_VERB', 0.6411399841308594), ('крыса_NOUN', 0.6355636119842529), ('собачка_NOUN', 0.6092042922973633), # ('щенок_NOUN', 0.6028496026992798), ('мышь_NOUN', 0.5975362062454224), ('пес_NOUN', 0.5956044793128967), # ('кошечка_NOUN', 0.5920293927192688)]
# Вычисление сходства слов russian_model.similarity('мужчина_NOUN', 'женщина_NOUN') # 0.85228276
# Поиск лишнего слова russian_model.doesnt_match('завтрак_NOUN хлопья_NOUN обед_NOUN ужин_NOUN'.split()) # хлопья_NOUN
# Аналогия: Женщина + (Король - Мужчина) = Королева russian_model.most_similar(positive=['король_NOUN','женщина_NOUN'], negative=['мужчина_NOUN'], topn=1) # [('королева_NOUN', 0.7313904762268066)]
# Аналогия: Франция = Париж + (Германия - Берлин) russian_model.most_similar(positive=['париж_NOUN','германия_NOUN'], negative=['берлин_NOUN'], topn=1) # [('франция_NOUN', 0.8673800230026245)]
Обучение модели word2vec и fastText на текстовом корпусе
from gensim.models.word2vec import Word2Vec from gensim.models.fasttext import FastText import gensim.downloader as download_api
# Скачаем небольшой текстовый корпус (32 Мб) и откроем его как итерируемый набор предложений: iterable(list(string)) # В этом текстовом корпусе часть речи для слов не указывается corpus = download_api.load('text8')
# Обучим модели word2vec и fastText word2vec_model = Word2Vec(corpus, size=100, workers=4) fastText_model = FastText(corpus, size=100, workers=4)
word2vec_model.most_similar('car')[:3] # [('driver', 0.8033335208892822), ('motorcycle', 0.7368553876876831), ('cars', 0.7001584768295288)]
fastText_model.most_similar('car')[:3] # [('lcar', 0.8733218908309937), ('boxcar', 0.8559106588363647), ('ccar', 0.8268736004829407)]
ELMO
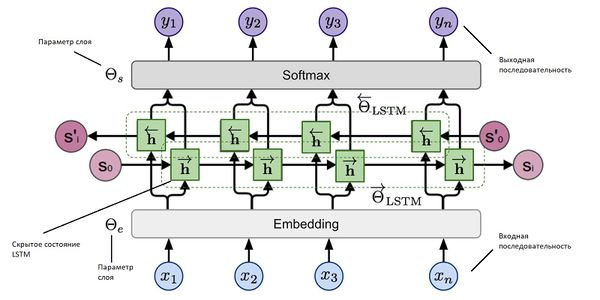
ELMO — это многослойная двунаправленная рекуррентная нейронная сеть c LSTM (рис. 5).
При использовании word2vec или fastText не учитывается семантическая неоднозначность слов.
Так, word2vec назначает слову один вектор независимо от контекста.
ELMO решает эту проблему. В основе стоит идея использовать скрытые состояния языковой модели многослойной LSTM.
Было замечено, что нижние слои сети отвечают за синтаксис и грамматику, а верхние — за смысл слов.
Пусть даны токены , на которые поделено предложение. Будем считать логарифм правдоподобия метки слова в обоих направлениях, учитывая контекст слева и контекст справа, то есть на основании данных от начала строки до текущего символа и данных от текущего символа и до конца строки.
Таким образом, модель предсказывает вероятность следующего токена с учетом истории.
Пусть есть слоев сети. Входные и выходные данные будем представлять в виде векторов, кодируя слова. Тогда каждый результирующий вектор будем считать на основании множества:
.
Здесь — входящий токен, а и — скрытые слои в одном и в другом направлении.
Тогда результат работы ELMO будет представлять из себя выражение:
.
Обучаемый общий масштабирующий коэффициент регулирует то, как могут отличаться друг от друга по норме векторные представления слов.
Коэффициенты — это обучаемые параметры, нормализованные функцией .
Модель применяют дообучая ее: изначально берут предобученную ELMO, а затем корректируют и под конкретную задачу. Тогда вектор, который подается в используемую модель для обучения, будет представлять собой взвешенную сумму значений этого векторах на всех скрытых слоях ELMO.
На данный момент предобученную модель ELMO можно загрузить и использовать в языке программирования Python.
BERT
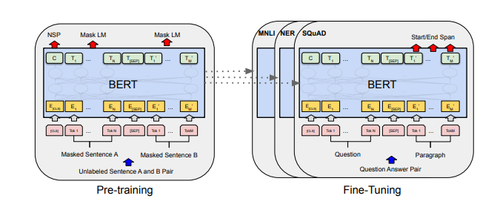
BERT — это многослойный двунаправленный кодировщик Transformer. В данной архитектуре (рис. 6) используется двунаправленное самовнимание (англ. self-attention).
Модель используется в совокупности с некоторым классификатором, на вход которого подается результат работы BERT — векторное представление входных данных.
В основе обучения модели лежат две идеи.
Первая заключается в том, чтобы заменить слов масками и обучить сеть предсказывать эти слова.
Второй трюк состоит в том, чтобы дополнительно научить BERT определять, может ли одно предложение идти после другого.
Точно так же, как и в обычном трансформере, BERT принимает на вход последовательность слов, которая затем продвигается вверх по стеку энкодеров.
Каждый слой энкодера применяет самовнимание и передает результаты в сеть прямого распространения, после чего направляет его следующему энкодеру.
Для каждой позиции на выход подается вектор размерностью ( в базовой модели).
Этот вектор может быть использован как входной вектор для классификатора.
Bert поддерживается в качестве модели в языке Python, которую можно загрузить.
См. также
- Обработка естественного языка
Источники информации
- Word embedding — статья о векторных представлениях в английской Википедии
- (YouTube) Обработка естественного языка — лекция на русском Даниила Полыковского в курсе Техносферы
- (YouTube) Word Vector Representations: word2vec — лекция на английском в Стэнфордском Университете
- word2vec article — оригинальная статья по word2vec от Томаса Миколова
- word2vec code — исходный код word2vec на Google Code
- Gensim tutorial on word2vec — небольшое руководство по работе с word2vec в библиотеке Gensim
- Gensim documentation on fastText — документация по fastText в библиотеке Gensim
- Gensim Datasets — репозиторий предобученных моделей для библиотеки Gensim
- fastText — NLP библиотека от Facebook
- fastText article — оригинальная статья по fastText от Piotr Bojanowski
- RusVectōrēs — онлайн сервис для работы с семантическими отношениями русского языка
- Cornell univerity arxiv — оригинальная статья про Bert
- Cornell univerity arxiv — оригинальная статья с описанием ELMO
У людей есть естественная способность понимать, что говорят другие люди и что им отвечать. Эта способность развивается благодаря постоянному взаимодействию с другими людьми и обществом на протяжении многих лет. Язык играет очень важную роль в том, как люди взаимодействуют. Языки, которые люди используют для взаимодействия, называются естественными языками.
Правила разных естественных языков различны. Однако у естественных языков есть одна общая черта: гибкость и эволюция.
Естественные языки очень гибкие. Предположим, вы ведете машину, и ваш друг произносит одно из этих трех высказываний: «Остановить», «Остановить машину», «Остановиться». Сразу понимаешь, что он просит тебя остановить машину. Это потому, что естественные языки чрезвычайно гибки.
Еще один важный аспект естественных языков – это то, что они постоянно развиваются. Например, несколько лет назад не было такого термина, как «Google it», который относился бы к поиску чего-либо в поисковой системе Google. Естественные языки всегда эволюционируют.
Напротив, компьютерные языки следуют строгому синтаксису. Если вы хотите, чтобы компьютер напечатал что-то на экране, для этого есть специальная команда. Задача обработки естественного языка – заставить компьютеры понимать и генерировать человеческий язык аналогично человеческому.
Это огромная задача, в которой есть много препятствий. Эта видеолекция из Мичиганского университета содержит очень хорошее объяснение того, почему НЛП так сложно.
В этой статье мы реализуем технику встраивания слов Word2Vec, используемую для создания векторов слов с помощью библиотеки Gensim. Однако, прежде чем сразу перейти к разделу кодирования, мы сначала кратко рассмотрим некоторые из наиболее часто используемых техник встраивания слов, а также их плюсы и минусы.
Подходы к встраиванию слов
Одна из причин, по которой обработка естественного языка является сложной задачей, заключается в том, что, в отличие от людей, компьютеры могут понимать только числа. Мы должны представлять слова в числовом формате, понятном для компьютеров. Встраивание слов относится к числовым представлениям слов.
В настоящее время существует несколько подходов к встраиванию слов, и все они имеют свои плюсы и минусы. Мы обсудим здесь три из них:
- Bag of Words;
- Схема TF-IDF;
- Word2Vec.
Bag of Words
Подход «Bag of Words» – один из простейших подходов к встраиванию слов. Ниже приведены шаги для создания вложений слов с использованием подхода «Bag of Words».
Мы увидим вложения слов, сгенерированные подходом «Bag of Words», на примере. Предположим, у вас есть корпус из трех предложений:
- S1 = я люблю дождь;
- S2 = идет дождь;
- S3 = я далеко.
Чтобы преобразовать приведенные выше предложения в соответствующие им представления встраивания слов с использованием подхода «Bag of Words», нам необходимо выполнить следующие шаги:
- Создайте словарь уникальных слов из корпуса. В приведенном выше корпусе у нас есть следующие уникальные слова.
- Разберите предложение. Для каждого слова в предложении добавьте 1 вместо слова в словаре и добавьте ноль для всех других слов, которых нет в словаре. Например, набор слов для предложения S1 (Я люблю дождь) выглядит так: [1, 1, 1, 0, 0, 0]. Аналогичным образом для S2 и S3 набором представлений слов являются [0, 0, 2, 1, 1, 0] и [1, 0, 0, 0, 1, 1] соответственно.
Обратите внимание, что для S2 мы добавили 2 вместо слова «дождь» в словаре, это потому, что S2 дважды содержит слово «дождь».
Плюсы и минусы
У подхода «Bag of Words» есть как плюсы, так и минусы. Основным преимуществом подхода с использованием набора слов является то, что вам не нужен очень большой набор слов для получения хороших результатов. Как видите, мы строим очень простую модель набора слов из трех предложений. В вычислительном отношении модель набора слов не очень сложна.
Основным недостатком подхода «Bag of Words» является тот факт, что нам нужно создавать огромные векторы с пустыми пробелами, чтобы представить число (разреженную матрицу), которое потребляет память и пространство. В предыдущем примере у нас было всего 3 предложения. Тем не менее, вы можете видеть по три нуля в каждом векторе.
Представьте себе корпус с тысячами статей. В таком случае количество уникальных слов в словаре может достигать тысячи. Если один документ содержит 10% уникальных слов, соответствующий вектор внедрения все равно будет содержать 90% нулей.
Еще одна серьезная проблема, связанная с подходом с использованием набора слов, заключается в том, что он не поддерживает никакой контекстной информации. Его не волнует порядок, в котором слова появляются в предложении. Например, он одинаково обрабатывает предложения «Бутылка в машине» и «Машина в бутылке», которые являются совершенно разными предложениями.
Метод набора слов, известный как n-граммы, может помочь поддерживать взаимосвязь между словами. N-грамма относится к непрерывной последовательности из n слов. Например, 2 грамма для предложения «Вы не счастливы», это «Вы», «не счастливы» и «несчастлив». Хотя подход n-граммов позволяет фиксировать отношения между словами, размер набора функций растет экспоненциально при слишком большом количестве n-граммов.
Схема TF-IDF
Схема TF-IDF – это тип подхода с использованием слов-пакетов, при котором вместо добавления нулей и единиц в вектор внедрения вы добавляете плавающие числа, которые содержат больше полезной информации по сравнению с нулями и единицами. Идея схемы TF-IDF заключается в том, что слова, часто встречающиеся в одном документе и реже встречающиеся во всех других документах, более важны для классификации.
TF-IDF – это продукт двух значений: Term Frequency (TF) и Inverse Document Frequency (IDF).
Частота термина – это количество раз, когда слово появляется в документе, и может быть рассчитана как:
Term frequence = (Number of Occurences of a word)/(Total words in the document)
Например, если мы посмотрим на предложение S1 из предыдущего раздела, то есть «Я люблю дождь», каждое слово в предложении встречается один раз и, следовательно, имеет частоту 1. Напротив, для S2, т.е. частота «дождя» равна двум, а для остальных слов – 1.
IDF относится к журналу общего количества документов, разделенному на количество документов, в которых существует это слово, и может быть рассчитано как:
IDF(word) = Log((Total number of documents)/(Number of documents containing the word))
Например, значение IDF для слова «дождь» составляет 0,1760, поскольку общее количество документов равно 3, а дождь присутствует в 2 из них, поэтому log (3/2) составляет 0,1760. С другой стороны, если вы посмотрите на слово «любовь» в первом предложении, оно появляется в одном из трех документов, и поэтому его значение IDF равно log (3), что составляет 0,4771.
Плюсы и минусы
Хотя TF-IDF является усовершенствованием по сравнению с простым набором слов и дает лучшие результаты для общих задач НЛП, общие плюсы и минусы остаются теми же. Нам все еще нужно создать огромную разреженную матрицу, которая также требует гораздо больше вычислений, чем подход простого набора слов.
Метод встраивания <a target=”_blank rel=”nofollow”” href=”https://en.wikipedia.org/wiki/Word2vec”> Word2Vec, разработанный Томасом Миколовым, считается современным. Подход Word2Vec использует методы глубокого обучения и нейронных сетей для преобразования слов в соответствующие векторы таким образом, чтобы семантически похожие векторы были близки друг к другу в N-мерном пространстве, где N относится к размерам вектора.
Word2Vec возвращает удивительные результаты. Способность Word2Vec поддерживать семантическую связь отражена в классическом примере, где, если у вас есть вектор для слова «Король», и вы удалите вектор, представленный словом «Мужчина» из «Короля», и добавите к нему «Женщины», вы получить вектор, близкий к вектору “Королевы”. Это отношение обычно представлено как:
King - Man + Women = Queen
Модель Word2Vec бывает двух видов: модель Skip Gram и модель Continuous Bag of Words (CBOW).
В модели Skip Gram контекстные слова предсказываются с использованием базового слова. Например, для предложения «Я люблю танцевать под дождем» модель предсказывает «любовь» и «танец».
Напротив, модель CBOW будет предсказывать «до», если контекстные слова «любовь» и «танец» вводятся в модель в качестве входных данных. Модель изучает эти отношения с помощью глубоких нейронных сетей.
Плюсы и минусы
Word2Vec имеет несколько преимуществ перед пакетом слов и схемой IF-IDF. Word2Vec сохраняет семантическое значение различных слов в документе. Контекстная информация не теряется. Еще одним большим преимуществом подхода Word2Vec является то, что размер вектора внедрения очень мал. Каждое измерение в векторе внедрения содержит информацию об одном аспекте слова. Нам не нужны огромные разреженные векторы, в отличие от мешка слов и подходов TF-IDF.
Примечание. Математические детали того, как работает Word2Vec, включают объяснение нейронных сетей и вероятности softmax, что выходит за рамки данной статьи.
Библиотека Gensim
В этом разделе мы реализуем модель Word2Vec с помощью библиотеки Gensim в Python. Следуй этим шагам.
Создание корпуса
Ранее мы обсуждали, что для создания модели Word2Vec нам нужен корпус. В реальных приложениях модели Word2Vec создаются с использованием миллиардов документов. Например, модель Google Word2Vec обучается с использованием 3 миллионов слов и фраз. Однако для простоты мы создадим модель Word2Vec, используя отдельную статью в Википедии. Наша модель будет хуже, чем у Google. Хотя этого достаточно, чтобы объяснить, как модель может быть реализована с использованием библиотеки Gensim.
Прежде чем мы сможем обобщить статьи Википедии, нам нужно получить их. Для этого мы воспользуемся парочкой библиотек. Первая библиотека, которую нам нужно загрузить, – это библиотека Beautiful Soup, очень полезная утилита для парсинга веб-страниц. Выполните следующую команду в командной строке, чтобы загрузить служебную программу.
$ pip install beautifulsoup4
Еще одна важная библиотека, которая нам нужна для синтаксического анализа XML и HTML, – это библиотека lxml. Выполните следующую команду в командной строке, чтобы загрузить lxml:
$ pip install lxml
Статья, которую мы собираемся очистить, – это статья в Википедии об искусственном интеллекте. Напишем скрипт Python для очистки статьи из Википедии:
import bs4 as bs
import urllib.request
import re
import nltk
scrapped_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Artificial_intelligence')
article = scrapped_data .read()
parsed_article = bs.BeautifulSoup(article,'lxml')
paragraphs = parsed_article.find_all('p')
article_text = ""
for p in paragraphs:
article_text += p.text
В приведенном выше скрипте мы сначала загружаем статью из Википедии, используя метод urlopen класса запроса библиотеки urllib. Затем мы читаем содержание статьи и анализируем его с помощью объекта класса BeautifulSoup. Википедия хранит текстовое содержимое статьи внутри тегов p. Мы используем функцию find_all объекта BeautifulSoup для извлечения всего содержимого из тегов абзацев статьи.
Наконец, мы объединяем все абзацы вместе и сохраняем извлеченную статью в переменной article_text для дальнейшего использования.
Предварительная обработка
На этом этапе мы импортировали статью. Следующим шагом является предварительная обработка содержимого для модели Word2Vec. Следующий скрипт предварительно обрабатывает текст:
# Cleaing the text
processed_article = article_text.lower()
processed_article = re.sub('[^a-zA-Z]', ' ', processed_article )
processed_article = re.sub(r's+', ' ', processed_article)
# Preparing the dataset
all_sentences = nltk.sent_tokenize(processed_article)
all_words = [nltk.word_tokenize(sent) for sent in all_sentences]
# Removing Stop Words
from nltk.corpus import stopwords
for i in range(len(all_words)):
all_words[i] = [w for w in all_words[i] if w not in stopwords.words('english')]
В приведенном выше скрипте мы преобразовываем весь текст в нижний регистр, а затем удаляем из текста все цифры, специальные символы и лишние пробелы. После предварительной обработки нам остались только слова.
Модель Word2Vec обучается на наборе слов. Во-первых, нам нужно преобразовать нашу статью в предложения. Мы используем утилиту nltk.sent_tokenize для преобразования нашей статьи в предложения. Для преобразования предложений в слова мы используем утилиту nltk.word_tokenize. На последнем этапе предварительной обработки мы удаляем из текста все стоп-слова.
После того, как скрипт завершит свое выполнение, объект all_words содержит список всех слов в статье. Мы будем использовать этот список для создания нашей модели Word2Vec с библиотекой Gensim.
Создание модели
С Gensim очень просто создать модель Word2Vec. Список слов передается в класс Word2Vec пакета gensim.models. Нам нужно указать значение параметра min_count. Значение 2 для min_count указывает на включение в модель Word2Vec только тех слов, которые встречаются в корпусе как минимум дважды. Следующий скрипт создает модель Word2Vec с использованием статьи в Википедии, которую мы скопировали.
from gensim.models import Word2Vec word2vec = Word2Vec(all_words, min_count=2)
Чтобы увидеть словарь уникальных слов, которые существуют как минимум дважды в корпусе, выполните следующий скрипт:
vocabulary = word2vec.wv.vocab print(vocabulary)
Когда приведенный выше скрипт будет выполнен, вы увидите список всех уникальных слов, встречающихся как минимум дважды.
Анализ модели
Мы успешно создали нашу модель Word2Vec в последнем разделе. Пришло время изучить то, что мы создали.
Поиск векторов для слова
Мы знаем, что модель Word2Vec преобразует слова в соответствующие им векторы. Давайте посмотрим, как мы можем просматривать векторное представление любого конкретного слова.
v1 = word2vec.wv['artificial']
Вектор v1 содержит векторное представление слова «искусственный». По умолчанию, Gensim Word2Vec создает стомерный вектор. Это намного меньший вектор по сравнению с тем, что можно было бы создать из пакета слов. Если для встраивания статьи мы воспользуемся подходом «Bag of Words», длина вектора для каждого будет равна 1206, поскольку имеется 1206 уникальных слов с минимальной частотой 2. Если минимальная частота появления установлена на 1, размер Bag of Words будет и дальше увеличиваться. С другой стороны, векторы, созданные с помощью Word2Vec, не зависят от размера словаря.
Поиск похожих слов
Ранее мы говорили, что контекстная информация слов не теряется при использовании подхода Word2Vec. В этом можно убедиться, найдя все слова, похожие на слово «интеллект».
Взгляните на следующий скрипт:
sim_words = word2vec.wv.most_similar('intelligence')
Если вы напечатаете в консоли переменную sim_words, вы увидите слова, наиболее похожие на «интеллект», как показано ниже:
('ai', 0.7124934196472168)
('human', 0.6869025826454163)
('artificial', 0.6208730936050415)
('would', 0.583903431892395)
('many', 0.5610555410385132)
('also', 0.5557990670204163)
('learning', 0.554862380027771)
('search', 0.5522681474685669)
('language', 0.5408136248588562)
('include', 0.5248900055885315)
На выходе вы можете увидеть слова, похожие на «интеллект», а также их индекс сходства. Слово «ai» наиболее похоже на слово «интеллект» согласно модели, что действительно имеет смысл. Точно так же такие слова, как «человек» и «искусственный», часто сосуществуют со словом «интеллект». Наша модель успешно зафиксировала эти отношения, используя всего одну статью в Википедии.
Заключение
В этой статье мы реализовали модель встраивания слов Word2Vec с помощью библиотеки Gensim в Python. Мы сделали это, скопировав статью из Википедии, и построили нашу модель, используя статью в качестве корпуса. Мы также кратко рассмотрели наиболее часто используемые подходы к встраиванию слов, а также их плюсы и минусы.