
Project description
Copyright (c) 2016 Akshay Nagpal (https://github.com/akshaynagpal)
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the “Software”), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Download-URL: https://github.com/Oknolaz/Russian_w2n/tarball/1.1
Description: Convert russian number words to numbers.
Keywords: numbers,convert,words
Platform: UNKNOWN
Classifier: Intended Audience :: Developers
Classifier: Programming Language :: Python
Download files
Download the file for your platform. If you’re not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Эта задача решается не так тривиально, как формулируется. Мне приходилось заниматься подобной задачей и в нашей команде её решали с помощью парсеров (анализаторов).
Лексический и синтаксический анализатор широко используются при создании интерпретаторов и компиляторов. Сейчас популярны так называемые PEG-анализаторы.
Я писал парсеры для C#, и мы использовали библиотеку IronMeta. Вам для Python надо будет выбрать свою библиотеку. В частности, в Google я нашёл Parsimonious, но вы лучше повыбирайте сами.
Грамматика будет выглядеть приблизительно так:
zero = "ноль"
one = "один"
two = "два"
three = "три"
...
nine = "девять"
ones = one | two | three | ... | nine
eleven = "одинадцать"
twelve = "двенадцать"
...
nineteen = "девятнадцать"
teens = elevent | ... | twelve | ... | nineteen
ten = "десять"
twenty = "двадцать"
ninety = "девяности"
tens = ten | twenty | ... | ninety
number = zero | ones | teens | tens | tens ones
В визиторе, который описан в документации на Parsimonious, надо завести аккумулятор, в который надо прибавлять значения. visit_twenty добавит 20, visit_nine добавит 9, итого «двадцать девять» превратится в 29.
Word-to-Number (Russian)
Проект для перевода чисел, записанных в текстовом виде на русском языке.
Необходимые библиотеки
- yargy;
- natasha.
Установка библиотек:
$ pip install -r requirements.txt
Структура проекта
- number.py — грамматики для текстового представления чисел;
- extractor.py — класс для извлечения чисел;
- test.py — модуль тестирования.
Пример использования
Код:
text = "Выплаты за второго-третьего ребенка выросли на пятьсот двадцать пять тысячных процента и составили 90 тысяч рублей" extractor = NumberExtractor() for match in extractor(text): print(match.fact) print(extractor.replace(text)) print(extractor.replace_groups(text))
Результат:
Number(int=2, multiplier=None) Number(int=3, multiplier=None) Number(int=500, multiplier=None) Number(int=20, multiplier=None) Number(int=5, multiplier=0.001) Number(int=90, multiplier=1000) Выплаты за 2-3 ребенка выросли на 500 20 0.005 процента и составили 90000 рублей Выплаты за 2-3 ребенка выросли на 0.525 процента и составили 90000 рублей
Время прочтения: 6 мин.
Проект Natasha хорошо зарекомендовал себя в решении задач NER для работы с русским языком. Он предоставляет возможности для базовой обработки текстов: сегментация на токены и предложения, морфологический и синтаксический анализы, лемматизация и, наконец, распознавание именованных сущностей – аспект, который мы подробно рассмотрим сегодня. Также будет представлено составление своих правил с помощью Yargy-парсера, что необходимо в тех случаях, когда готовые решения показывают низкое качество.
Распространенный метод извлечения именованных сущностей из текста – готовые библиотеки. Они дают неплохой результат, но, в случае с переводом русскоязычных слов в числа возникают проблемы. Одна из них – склеивание цифр. Например, такое происходит, когда во фрагменте проговариваются только числа, без уточнения, что из них является номером документа, а что – его датой. Библиотека Word-to-Number (Russia), которая реализована на основе Yargy и Natasha в такой ситуации работает недостаточно корректно, выдавая в качестве результата неупорядоченный набор цифр.
Однако, данную задачу можно решить посредством доработки правил, используя Yargy-парсер . Он представляет собой библиотеку для извлечения структурированной информации из текстов на русском языке. Правила описываются контекстно-свободными грамматиками и словарями ключевых слов. Парсер реализует алгоритм Earley parser. Библиотека написана на чистом Python, поддерживает Python 3.5+ и Pypy 3, использует Pymorphy2 для работы с морфологией.
Перейдем к конкретному решению поставленной задачи по извлечению параметров сделки из аудиозаписи на русском языке.
Тестовый образец аудиозаписи сделки выглядит следующим образом:
добрый день представьтесь пожалуйста меня зовут иван иванов я представляю компанию ооо триал согласно соглашению номер восемьсот пятьдесят семь пятого марта две тысячи двадцатого года дата сделки сегодня первое января две тысячи двадцать второго года начала действия сделки сегодня окончание действия сделки первого марта две тысячи двадцать пятого года на сумму один миллион рублей
Устанавливаем библиотеку Yargy:
pip install yargyИмпортируем только те модули, которые необходимы для составления правил:
from yargy.interpretation import fact
from yargy import (
Parser,
rule
)
from yargy.predicates import (
normalized,
dictionary
)
from yargy.pipelines import morph_pipeline
import re
Составляем функции для предобработки и поиска необходимого фрагмента, чтобы исключить ненужные параметры и увеличить скорость работы Yargy-парсера, так как он достаточно медленный, а тексты в аудиозаписях отличаются большим объемом.
def preprocess(text):
text = text.replace('n', ' ')
text = find_section(text)
return text
def find_section(text):
res = []
result = re.finditer('соглашени[еяю]s', text)
for el in result:
res.append(text[el.start()-10:el.end()+45])
return res
line = preprocess(text)
В функции find_section строка res.append(text[el.start()-10:el.end()+45]) устанавливает диапазон знаков, который был определен методом подбора, чтобы необходимый фрагмент параметра точно попал в него с небольшим запасом.
Получившийся фрагмент:
[‘ согласно соглашению номер восемьсот пятьдесят семь пятого марта д’]
Примечание: номер может быть только трехзначный.
Прописываем правила для парсера. Метод fact является интерпретатором, он работает в связке с конструкцией intepretation(…), чтобы извлекать числа в нужную вершину дерева разбора. Конструкция, выполняющая интерпретацию извлекаемых параметров для дальнейшей обработки:
Number = fact(
'number',
['num1', 'num2', 'num3', ‘flag’]
)
Заводим словари, чтобы извлекать в поля fact значения num1, num2, num3, flag:
DIGIT_NUM1 = {
'один': 1,
'два': 2,
'три': 3,
'четыре': 4,
'пять': 5,
'шесть': 6,
'семь': 7,
'восемь': 8,
'девять': 9,
'сто': 100,
'двести': 200,
'триста': 300,
'четыреста': 400,
'пятьсот': 500,
'шестьсот': 600,
'семьсот': 700,
'восемьсот': 800,
'девятьсот': 900
}
DIGIT_NAME_NUM1 = dictionary(
DIGIT_NUM1
)
DIGIT_NUM2 = {
'один': 1,
'два': 2,
'три': 3,
'четыре': 4,
'пять': 5,
'шесть': 6,
'семь': 7,
'восемь': 8,
'девять': 9,
'десять': 10,
'одиннадцать': 11,
'двенадцать': 12,
'тринадцать': 13,
'четырнадцать': 14,
'пятнадцать': 15,
'шестнадцать': 16,
'семнадцать': 17,
'восемнадцать': 18,
'девятнадцать': 19,
'двадцать': 20,
'тридцать': 30,
'сорок': 40,
'пятьдесят': 50,
'шестьдесят': 60,
'семьдесят': 70,
'восемьдесят': 80,
'девяносто': 90
}
DIGIT_NAME_NUM2 = dictionary(
DIGIT_NUM2
)
DIGIT_NUM3 = {
'один': 1,
'два': 2,
'три': 3,
'четыре': 4,
'пять': 5,
'шесть': 6,
'семь': 7,
'восемь': 8,
'девять': 9
}
DIGIT_NAME_NUM3 = dictionary(
DIGIT_NUM3
)
MONTH_NAME = morph_pipeline([
'январь',
'февраль',
'март',
'апрель',
'май',
'июнь',
'июль',
'август',
'сентябрь',
'октябрь',
'ноябрь',
'декабрь'
]).interpretation(Number.flag)
Дополняем правила:
RULE = rule(
normalized('соглашение'),
normalized('номер').optional(),
DIGIT_NAME_NUM1.interpretation(Number.num1.normalized().custom(DIGIT_NUM1.get)),
DIGIT_NAME_NUM2.interpretation(Number.num2.normalized().custom(DIGIT_NUM2.get)).optional(),
DIGIT_NAME_NUM3.interpretation(Number.num3.normalized().custom(DIGIT_NUM3.get)).optional(),
MONTH_NAME.optional()
).interpretation(
Number
)
Пояснение:
Извлекаем элементы в нужной нам форме в определенное поле факта для дальнейшей обработки. Указываем имя переменной факта – Number и добавляем в нужное поле – num1. Уточнение: normalized()— это предикат, он позволит искать в словаре все формы слова, что избавляет нас от необходимости прописывания всех вариантов (в парсер встроено много готовых предикатов, есть возможность добавить свои). custom создает предикат из произвольной функции и может применяться вместе сnormalized(), тогда слово сначала ставится в нормальную форму, а затем к нему применяется функция DIGIT_NUM1.get для извлечение из словаря значения по ключу «один»: 1 à извлечь «1».
DIGIT_NAME_NUM1.interpretation(Number.num1.normalized().custom(DIGIT_NUM1.get)Добавление optional() во второй и последующих позициях делает этот параметр не обязательным. Это сделано для того чтобы номера из одного слова наподобие “восемьсот” тоже извлекались.
DIGIT_NAME_NUM2.interpretation(Number.num2.normalized().custom(DIGIT_NUM2.get)).optional()MONTH_NAME.optional() добавлен в правило для извлечения названия месяца и представляет собой словарь, созданный газеттиром morph_pipeline (перед работой приводит слова к нормальной форме). Для его интерпретации создано поле факта flag. Позже напишем функцию extractor, в которой реализуем возможность не учитывать числа, если они относятся к дате. Этот прием позволит убрать часть ошибок при извлечении номера соглашения.
MONTH_NAME.optional()Создаем объект парсера:
parser = Parser(RULE)У парсера есть метод findall, он ищет все строки, удовлетворяющие правилам. Собираем результат работы в список:
matches = list(parser.findall(text))Результат разбора на токены:
matches
[Match(
tokens=[MorphToken(
value='соглашению',
span=[102, 112),
type='RU',
forms=[Form('соглашение', Grams(NOUN,datv,inan,neut,sing))]
),
MorphToken(
value='номер',
span=[113, 118),
type='RU',
forms=[Form('номер', Grams(NOUN,inan,masc,nomn,sing)),
Form('номер', Grams(NOUN,accs,inan,masc,sing))]
),
MorphToken(
value='восемьсот',
span=[119, 128),
type='RU',
forms=[Form('восемьсот', Grams(NUMR,nomn)),
Form('восемьсот', Grams(NUMR,accs))]
),
MorphToken(
value='пятьдесят',
span=[129, 138),
type='RU',
forms=[Form('пятьдесят', Grams(NUMR,nomn)),
Form('пятьдесят', Grams(NUMR,accs))]
),
MorphToken(
value='семь',
span=[139, 143),
type='RU',
forms=[Form('семь', Grams(NUMR,nomn)),
Form('семь', Grams(NUMR,accs))]
)],
span=[102, 143)
)]
Посмотрим на факты:
facts = [_.fact for _ in matches]
facts
[number(
num1=800,
num2=50,
num3=7,
flag=None
)]
Создаем функцию для извлечения параметров сделок:
def extractor(text):
fraction = preprocess(text)
for el in fraction:
matches = parser.findall(el)
if matches:
result = []
res = []
facts = [_.fact for _ in matches]
for f in facts:
res += [f.num1, f.num2, f.num3]
res = [int(i) for i in res if i]
if len(res) == 1:
result.append(f.num1)
elif len(res) == 2:
if f.flag:
result.append(res[0])
else:
result.append(f"{res[0]+res[1]}")
elif len(res)==3 and res[0]<10 and res[1]<10 and res[2]<10 and not f.flag:
digit = f"{res[0]}{res[1]}{res[2]}"
result.append(int(digit))
elif len(res)==3:
if f.flag:
result.append(f"{res[0]+res[1]}")
else:
result.append(f"{res[0]+res[1]+res[2]}")
return result
else:
return ''
extractor(text)
Результат: [‘857’].
Yargy-парсер предоставляет достаточно широкий функционал, чтобы справиться с нестандартными задачами. Он позволяет создавать расширенные правила, чтобы более эффективно извлекать необходимую информацию, минимизировав неточности получения данных из русскоязычных аудиозаписей.
Data Science развивается очень быстро, поэтому появляются все больше и больше библиотек Python. Одну задачу можно выполнить с помощью более чем одной библиотеки и более чем одним способом. Среди всего этого множества новых библиотек некоторые выделяются своей простотой использования и готовыми реализациями. В этой статье мы расскажем о 5 библиотеках, которые могут ускорить процесс машинного обучения (machine learning): Dabl, Emot, FlashText, Numerizer и Word-to-Number-Russian.
1. Dabl (Data Analysis Baseline Library)
Библиотека Dabl была создана Андреасом Мюллером, одним из основных разработчиков Python-библиотеки машинного обучения scikit-learn, поэтому многое оттуда взято [1]. Идея Dabl состоит в том, чтобы сделать контролируемое машинное обучение (supervised machine learning) более доступным для новичков и уменьшить количество шаблонов для решения общих задач.
Dabl можно использовать для предварительной обработки набора данных, а также для построения модели в рамках конвейера машинного обучения (machine learning pipeline). Библиотека очень хорошо работает в паре с Pandas. Основные особенности:
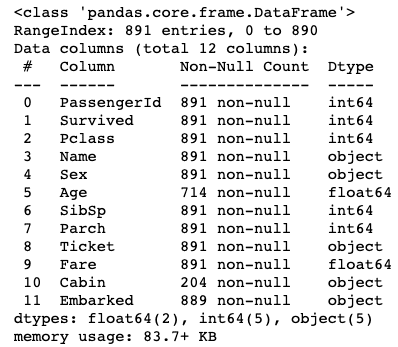
- Анализ данных. Dabl пытается определить отсутствующие значения, типы данных и ошибочные данные. Если не получается узнать семантический тип (непрерывный, категориальный, порядковый, текстовый и т. д.), то метод
type_hintsпоможет изучить этот вопрос.

Отображение типов данных в Dabl - Dabl поможет визуализировать данные за одну строчу кода. Обычно ML-специалисты используют matplotlib для визуализации, строя нужны графики один за другим. В Dabl вызов одного метода построит целый набор диаграмм.
- Построение моделей машинного обучения также осуществляется за одну строчку кода, причем используется множество семейство алгоритмов. Например, вот так в Python выглядит решение задачи классификации:
2. Emot
Emot — это Python-библиотека для обнаружения эмотиконов и эмодзи. Она может очень пригодиться, когда нам нужно предварительно обработать текстовые данные, чтобы удалить эмотиконы и эмодзи или изучить их влияние на семантику [2]. Функции библиотеки принимают на вход строку и возвращает список словарей. Вот так это выглядит в Python:
Emot особенно подойдет тем, кто собирает данные с социальных сетей, например, Twitter.
3. FlashText
Flastext — это библиотека Python, который позволяет извлекать и/или заменять ключевые слова из предложения [3]. Она использует собственный алгоритм и значительно быстрее регулярных выражений в рамках задач NLP.
В примере ниже метод extract_keywords находит указанные в аргументе ключевые слова. Поэтому, можно посчитать сколько раз эти слова встречаются в тексте. А метод replace_keywords поможет вам заменить одно ключевое слово на другое.
4. Numerizer
Numerizer предназначен для перевода чисел, записанных в текстовом виде на английском языке, в обычный набор арабских цифр [4]. Numerizer может быть полезным для задач NLP, когда требуется извлечь числа, которые записаны словами. Вот так в Python выглядят некоторые примеры:
>>> from numerizer import numerize
>>> numerize('forty two')
'42'
>>> numerize('forty-two')
'42'
>>> numerize('one billion and one')
'1000000001'
>>> numerize('nine and three quarters')
'9.75'
>>> numerize('platform nine and three quarters')
'platform 9.75'
5. Word-to-Number-Russian
Numerizer работает с текстом на английском языке. Если же у вас тексты на русском, то для перевода числительных в обычные числа подойдет библиотека Word-to-Number-Russian [5]. В Python процесс перевода выглядит следующим образом:
О том, как использовать библиотеки Python для решения реальных задач Data Science, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://amueller.github.io/dabl/dev/
- https://github.com/NeelShah18/emot
- https://github.com/vi3k6i5/flashtext
- https://github.com/jaidevd/numerizer
- https://github.com/SergeyShk/Word-to-Number-Russian