
Время на прочтение
5 мин
Количество просмотров 1.1M
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM CustomersВыбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM CustomersWHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers
WHERE City = 'London'Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers
GROUP BY CityГруппировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers
GROUP BY Country, CityГруппировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails
GROUP BY ProductIDГруппировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers
WHERE Country = 'Germany'
GROUP BY CityПереименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers
group by CityHAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers
group by City
HAVING count(CustomerID) >= 5 В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers
group by City
HAVING number_of_clients >= 5Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers
ORDER BY CityОсуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers
ORDER BY Country, CityПо умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers
order by CustomerID DESCОбратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers
order by Country DESC, CityJOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders
JOIN Customers ON Orders.CustomerID = Customers.CustomerIDНередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders
join Customers on Orders.CustomerID = Customers.CustomerID
where Customers.CustomerID >10Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:
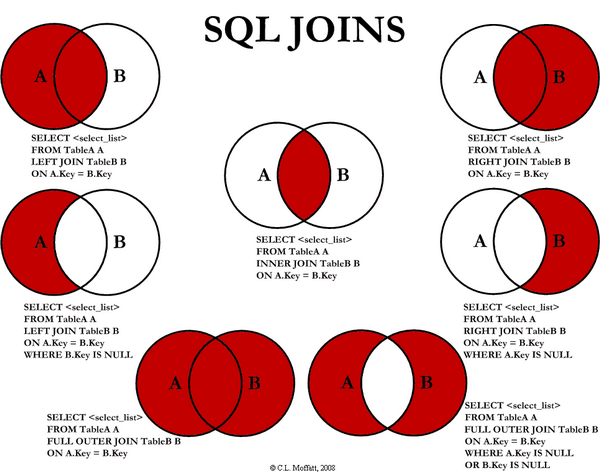
В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
This should ideally be done with the help of SQL Server full text search if using that.
However, if you can’t get that working on your DB for some reason, here is a performance-intensive solution:
-- table to search in
CREATE TABLE dbo.myTable
(
myTableId int NOT NULL IDENTITY (1, 1),
code varchar(200) NOT NULL,
description varchar(200) NOT NULL -- this column contains the values we are going to search in
) ON [PRIMARY]
GO
-- function to split space separated search string into individual words
CREATE FUNCTION [dbo].[fnSplit] (@StringInput nvarchar(max),
@Delimiter nvarchar(1))
RETURNS @OutputTable TABLE (
id nvarchar(1000)
)
AS
BEGIN
DECLARE @String nvarchar(100);
WHILE LEN(@StringInput) > 0
BEGIN
SET @String = LEFT(@StringInput, ISNULL(NULLIF(CHARINDEX(@Delimiter, @StringInput) - 1, -1),
LEN(@StringInput)));
SET @StringInput = SUBSTRING(@StringInput, ISNULL(NULLIF(CHARINDEX
(
@Delimiter, @StringInput
),
0
), LEN
(
@StringInput)
)
+ 1, LEN(@StringInput));
INSERT INTO @OutputTable (id)
VALUES (@String);
END;
RETURN;
END;
GO
-- this is the search script which can be optionally converted to a stored procedure /function
declare @search varchar(max) = 'infection upper acute genito'; -- enter your search string here
-- the searched string above should give rows containing the following
-- infection in upper side with acute genitointestinal tract
-- acute infection in upper teeth
-- acute genitointestinal pain
if (len(trim(@search)) = 0) -- if search string is empty, just return records ordered alphabetically
begin
select 1 as Priority ,myTableid, code, Description from myTable order by Description
return;
end
declare @splitTable Table(
wordRank int Identity(1,1), -- individual words are assinged priority order (in order of occurence/position)
word varchar(200)
)
declare @nonWordTable Table( -- table to trim out auxiliary verbs, prepositions etc. from the search
id varchar(200)
)
insert into @nonWordTable values
('of'),
('with'),
('at'),
('in'),
('for'),
('on'),
('by'),
('like'),
('up'),
('off'),
('near'),
('is'),
('are'),
(','),
(':'),
(';')
insert into @splitTable
select id from dbo.fnSplit(@search,' '); -- this function gives you a table with rows containing all the space separated words of the search like in this e.g., the output will be -
-- id
-------------
-- infection
-- upper
-- acute
-- genito
delete s from @splitTable s join @nonWordTable n on s.word = n.id; -- trimming out non-words here
declare @countOfSearchStrings int = (select count(word) from @splitTable); -- count of space separated words for search
declare @highestPriority int = POWER(@countOfSearchStrings,3);
with plainMatches as
(
select myTableid, @highestPriority as Priority from myTable where Description like @search -- exact matches have highest priority
union
select myTableid, @highestPriority-1 as Priority from myTable where Description like @search + '%' -- then with something at the end
union
select myTableid, @highestPriority-2 as Priority from myTable where Description like '%' + @search -- then with something at the beginning
union
select myTableid, @highestPriority-3 as Priority from myTable where Description like '%' + @search + '%' -- then if the word falls somewhere in between
),
splitWordMatches as( -- give each searched word a rank based on its position in the searched string
-- and calculate its char index in the field to search
select myTable.myTableid, (@countOfSearchStrings - s.wordRank) as Priority, s.word,
wordIndex = CHARINDEX(s.word, myTable.Description) from myTable join @splitTable s on myTable.Description like '%'+ s.word + '%'
-- and not exists(select myTableid from plainMatches p where p.myTableId = myTable.myTableId) -- need not look into myTables that have already been found in plainmatches as they are highest ranked
-- this one takes a long time though, so commenting it, will have no impact on the result
),
matchingRowsWithAllWords as (
select myTableid, count(myTableid) as myTableCount from splitWordMatches group by(myTableid) having count(myTableid) = @countOfSearchStrings
)
, -- trim off the CTE here if you don't care about the ordering of words to be considered for priority
wordIndexRatings as( -- reverse the char indexes retrived above so that words occuring earlier have higher weightage
-- and then normalize them to sequential values
select s.myTableid, Priority, word, ROW_NUMBER() over (partition by s.myTableid order by wordindex desc) as comparativeWordIndex
from splitWordMatches s join matchingRowsWithAllWords m on s.myTableId = m.myTableId
)
,
wordIndexSequenceRatings as ( -- need to do this to ensure that if the same set of words from search string is found in two rows,
-- their sequence in the field value is taken into account for higher priority
select w.myTableid, w.word, (w.Priority + w.comparativeWordIndex + coalesce(sequncedPriority ,0)) as Priority
from wordIndexRatings w left join
(
select w1.myTableid, w1.priority, w1.word, w1.comparativeWordIndex, count(w1.myTableid) as sequncedPriority
from wordIndexRatings w1 join wordIndexRatings w2 on w1.myTableId = w2.myTableId and w1.Priority > w2.Priority and w1.comparativeWordIndex>w2.comparativeWordIndex
group by w1.myTableid, w1.priority,w1.word, w1.comparativeWordIndex
)
sequencedPriority on w.myTableId = sequencedPriority.myTableId and w.Priority = sequencedPriority.Priority
),
prioritizedSplitWordMatches as ( -- this calculates the cumulative priority for a field value
select w1.myTableId, sum(w1.Priority) as OverallPriority from wordIndexSequenceRatings w1 join wordIndexSequenceRatings w2 on w1.myTableId = w2.myTableId
where w1.word <> w2.word group by w1.myTableid
),
completeSet as (
select myTableid, priority from plainMatches -- get plain matches which should be highest ranked
union
select myTableid, OverallPriority as priority from prioritizedSplitWordMatches -- get ranked split word matches (which are ordered based on word rank in search string and sequence)
),
maximizedCompleteSet as( -- set the priority of a field value = maximum priority for that field value
select myTableid, max(priority) as Priority from completeSet group by myTableId
)
select priority, myTable.myTableid , code, Description from maximizedCompleteSet m join myTable on m.myTableId = myTable.myTableId
order by Priority desc, Description -- order by priority desc to get highest rated items on top
--offset 0 rows fetch next 50 rows only -- optional paging
Результатом выполнения оператора SELECT является таблица. К этой таблице может быть снова применен оператор SELECT и т.д., то есть такие операторы могут быть вложены друг в друга. Вложенные операторы SELECT называют подзапросами.
Синтаксис оператора SELECT использует следующие основные предложения:
SELECT <список столбцов>
FROM <список таблиц>
[WHERE <условие выбора строк>]
[GROUP BY <условие группировки>]
[HAVING <условие выбора групп>]
[ORDER BY <условие сортировки>]Кратко пояснить смысл предложений оператора SELECT можно следующим образом:
SELECT— выбрать данные из указанных столбцов и (если необходимо) выполнить перед выводом их преобразование в соответствии с указанными выражениями и (или) функциямиFROM— из перечисленных таблиц, в которых расположены эти столбцыWHERE— где строки из указанных таблиц должны удовлетворять указанному перечню условий отбора строкGROUP BY— группируя по указанному перечню столбцов с тем, чтобы получить для каждой группы единственное значениеHAVING— имея в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора группORDER BY— сортируя по указанному перечню столбцов
Как видно из синтаксиса рассматриваемого оператора, обязательными являются только два первых предложения: SELECT и FROM.
Рассмотрим каждое предложение оператора SELECT.
Спонсор поста
База данных для примеров
Дальше будет много примеров и логично постоянно использовать одну и ту же БД. Так что на основании базы данных ниже будут продемонстрированы все примеры, не только в этой статье, но и в других.
Постановка задачи: пусть требуется разработать БД для предметной области «Поставка деталей»!
Требуется хранить следующую информацию:
- О поставщиках (P) pnum, pname
- О деталях (D) pnum, dname, dprice
- О поставках (PD) volume
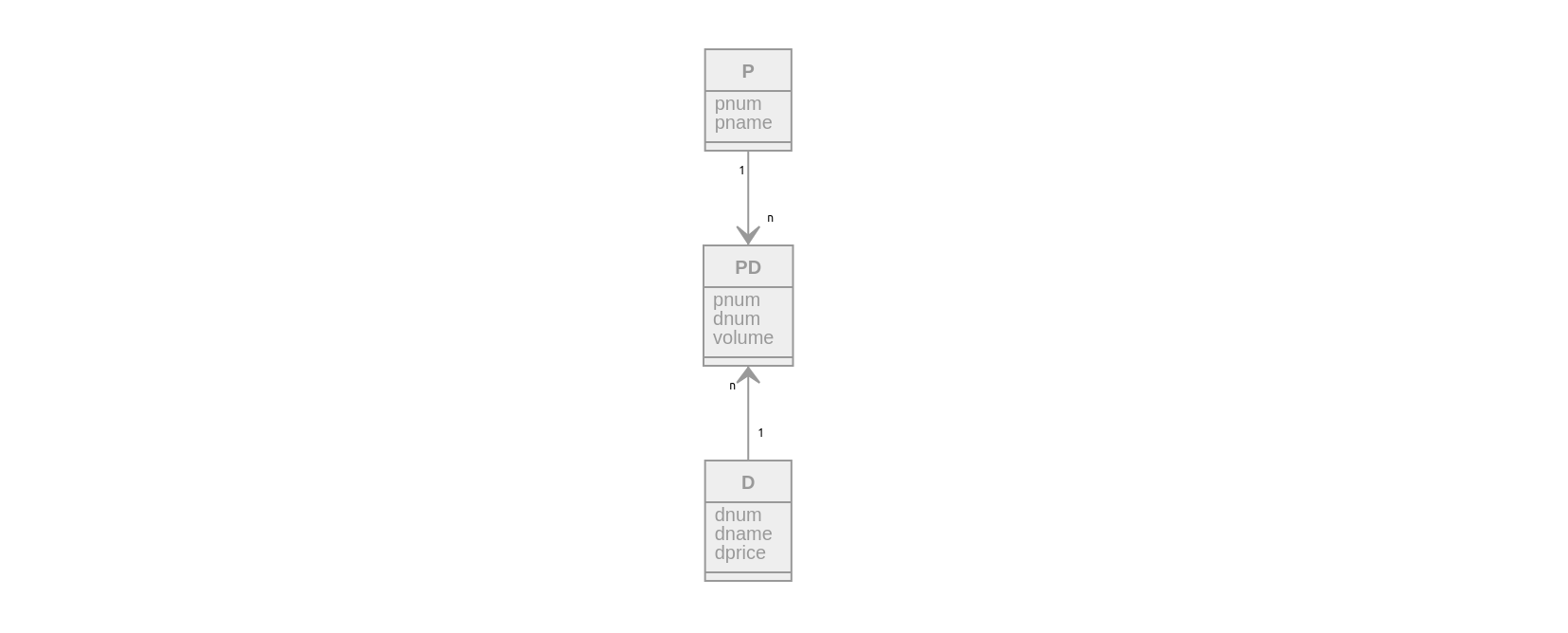
Значения таблицы P
| pnum | pname |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| 3 | Сидоров |
| 4 | Кузнецов |
Значения таблицы D
| pnum | dname | dprice |
|---|---|---|
| 1 | Болт | 10 |
| 2 | Гайка | 20 |
| 3 | Винт | 30 |
Значения таблицы PD
| pnum | dnum | volume |
|---|---|---|
| 1 | 1 | 100 |
| 1 | 2 | 100 |
| 1 | 3 | 300 |
| 2 | 1 | 150 |
| 1 | 2 | 250 |
| 3 | 1 | 1000 |
После служебного слова SELECT перечисляются имена столбцов, значения которых будут входить в результат выполнения запроса.
Столбцы в результирующей таблице размещаются в том порядке, в котором они были указаны в предложении SELECT. Имена столбцов указываются через запятую.
Если имя столбца содержит пробелы или разделители, то его необходимо заключить в квадратные скобки.
При обработке данных из разных таблиц может возникнуть ситуация, когда столбцы разных таблиц имеют одинаковые имена. В этом случае имя столбца необходимо записывать как составное, указывая перед ним имя соответствующей таблицы: <Имя таблицы>.<Имя столбца>
Предложение FROM
В предложении FROM перечисляются имена таблиц, которые содержат столбцы, указанные после слова SELECT.
Пример 1.
Вывести список наименований деталей из таблицы D (“Детали”).
SELECT dname
FROM DПример 2.
Получить всю информацию из таблицы D (“Детали”).
Получить результат можно двумя способами:
-
Явным указанием всех столбцов таблицы.
SELECT dnum, dname, dprice FROM D -
Полный список столбцов таблицы заменяет символ
*.SELECT * FROM D
В результате и первого и второго запроса получаем новую таблицу, представляющую собой полную копию таблицы D (“Детали”).
Можно осуществить выбор отдельных столбцов и их перестановку.
Пример 3.
Получить информацию о наименовании и номере поставщика.
SELECT pname, pnum
FROM PПример 4.
Определить номера поставщиков, которые поставляют детали в настоящее время (то есть номера тех поставщиков, которые присутствуют в таблице PD (“Поставки”)).
SELECT pnum
FROM PDРезультат:
| pnum |
|---|
| 1 |
| 1 |
| 1 |
| 2 |
| 2 |
| 3 |
Дополнительно о SELECT
Теперь, когда мы научились делать простые запросы с SELECT и FROM, можно ненадолго снова вернуться к SELECT.
Агрегатные функции
В операторе SELECT можно использовать агрегатные функции, которые дают единственное значение для целой группы строк в таблице.
Агрегатная функция записывается в следующем виде: <имя функции>(<имя столбца>)
Пользователю доступны следующие агрегатные функции:
SUM‑ вычисляет сумму множества значений указанного столбца;COUNT‑ вычисляет количество значений указанного столбца;MIN/MAX‑ определяет минимальное/максимальное значение в указанном столбце;AVG‑ вычисляет среднее арифметическое значение множества значений столбца;FIRST/LAST‑ определяет первое/последнее значение в указанном столбце.
Пример 5.
Определить общий объем поставляемых деталей.
SELECT SUM(volume)
FROM PD| Expr1000 |
|---|
| 2000 |
Вычисляемые столбцы
Столбцы результирующей таблицы, которых не существовало в исходных таблицах, называются вычисляемыми. Таким столбцам СУБД присваивает системные имена, что не всегда является удобным.
При вычислении результатов любой агрегатной функции СУБД сначала исключает все NULL-значения, после чего требуемая операция применяется к оставшимся значениям.
Для функции COUNT возможен особый вариант использования — COUNT(*). Его назначение состоит в подсчете всех строк в результирующей таблице, включая NULL-значения.
Следует запомнить, что агрегатные функции нельзя вкладывать друг в друга. Такая конструкция работать не будет: MAX(SUM(VOLUME))
Переименование столбца
Язык SQL позволяет задавать новые имена столбцам результирующей таблицы, для чего используется операция AS. Переименование также используют для изменения сложных имен столбцов таблицы.
Например, присвоить новое имя вычисляемому столбцу в предыдущем примере позволит выполнение следующего запроса.
SELECT SUM(volume) AS SUM
FROM PD| Sum |
|---|
| 2000 |
Пример 6.
Определить количество поставщиков, которые поставляют детали в настоящее время.
SELECT COUNT(pnum) AS COUNT
FROM PD| Count |
|---|
| 6 |
Несмотря на то, что реальное число поставщиков деталей в таблице PD равно 3, СУБД возвращает число 6. Такой результат объясняется тем, что СУБД подсчитывает все строки в таблице PD, не обращая внимание на то, что в строках есть одинаковые значения.
Операция DISTINCT
Если до применения агрегатной функции необходимо исключить дублирующиеся значения, следует перед именем столбца указать ключевое слово DISTINCT.
SELECT COUNT(DISTINCT pnum) AS COUNT
FROM PD| Count |
|---|
| 3 |
DISTINCT можно задать только один раз для одного предложения SELECT.
Противоположностью DISTINCT является операция ALL. Она имеет противоположное действие «показать все строки таблицы» и предполагается по умолчанию.
Операция TOP
Итоговый набор записей, получаемых после выполнения запроса можно ограничить первыми N строками или первыми N процентами от общего количества строк результата.
Для этого используется операция TOP, которая записывается в предложении SELECT следующим образом: SELECT TOP N [PERCENT] <список столбцов>
Пример 7.
Определить номера первых двух деталей таблицы D.
SELECT TOP 2 dnum
FROM DСтандарт SQL требует, чтобы при сортировке NULL-значения трактовались либо как превосходящие, либо как уступающие по сравнению со всеми остальными значениями. Так как конкретный вариант стандартом не оговаривается, то в зависимости от используемой СУБД при сортировке NULL-значения следуют до или после остальных значений. В MS SQL Server NULL-значения считаются уступающими по сравнению с остальными значениями.
Предложение WHERE
После служебного слова WHERE указываются условия выбора строк, помещаемых в результирующую таблицу. Существуют различные типы условий выбора:
Типы условий выбора:
- Сравнение значений атрибутов со скалярными выражениями, другими атрибутами или результатами вычисления выражений.
- Проверка значения на принадлежность множеству.
- Проверка значения на принадлежность диапазону.
- Проверка строкового значения на соответствие шаблону.
- Проверка на наличие
null-значения.
Сравнение
В языке SQL используются традиционные операции сравнения =,<>,<,<=,>,>=.
В качестве условия в предложении WHERE можно использовать сложные логические выражения, использующие атрибуты таблиц, константы, скобки, операции AND, OR, отрицание NOT.
Пример 8.
Определить номера деталей, поставляемых поставщиком с номером 2.
SELECT dnum
FROM PD
WHERE pnum = 2Пример 9.
Получить информацию о поставщиках Иванов и Петров.
SELECT *
FROM P
WHERE pname='Иванов' OR pname='Петров'Строковые значения атрибутов заключаются в апострофы.
Проверка на принадлежность множеству
Операция IN проверяет, принадлежит ли значение атрибута заданному множеству.
Пример 10.
Получить информацию о поставщиках ‘Иванов’ и ‘Петров’.
SELECT *
FROM P
WHERE pname IN ('Иванов','Петров')Пример 11.
Получить информацию о деталях с номерами 1 и 2.
SELECT *
FROM D
WHERE dnum IN (1, 2)Проверка на принадлежность диапазону
Операция BETWEEN определяет минимальную и максимальную границу диапазона, в которое должно попадать значение атрибута. Обе границы считаются принадлежащими диапазону.
Пример 12.
Определить номера деталей, с ценой от 10 до 20 рублей.
SELECT dnum
FROM D
WHERE dprice BETWEEN 10 AND 20Пример 13.
Вывести наименования поставщиков, начинающихся с букв от ‘К’ по ‘П’.
SELECT pname
FROM P
WHERE pname BETWEEN 'К' AND 'Р'Сравнение символов
Буква Р в условии запроса объясняется тем, что строки сравниваются посимвольно. Для каждого символа при этом определяется код. Для нашего случая справедливо условие: П < Петров < Р
Проверка строкового значения на соответствие шаблону
Операция LIKE используется для поиска подстрок. Значения столбца, указываемого перед служебным словом LIKE сравниваются с задаваемым после него шаблоном. Форматы шаблонов различаются в конкретных СУБД.
Для СУБД MS SQL Server:
- Символ
%заменяет любое количество любых символов. - Символ
_заменяет один любой символ. [<множество символов>]‑ вместо символа строки может быть подставлен один любой символ из множества возможных, указанных в ограничителях.[^<множество символов>]‑ вместо символа строки может быть подставлен любой из символов кроме символов из множества, указанного в ограничителях.
Множество символов в квадратных скобках можно указывать через запятую, либо в виде диапазона.
Пример 14.
Вывести фамилии поставщиков, начинающихся с буквы И.
SELECT pname
FROM P
WHERE pname LIKE 'И%'Пример 15.
Вывести фамилии поставщиков, начинающихся с букв от К по П.
SELECT pname
FROM P
WHERE dname LIKE '[К-П]%'Проверка на наличие null-значения
Операции IS NULL и IS NOT NULL используются для сравнения значения атрибута со значением NULL.
Пример 16.
Определить наименования деталей, для которых не указана цена.
SELECT dname
FROM D
WHERE dprice IS NULLПример 17.
Определить номера поставщиков, для которых указано наименование.
SELECT pnum
FROM P
WHERE pname IS NOT NULLПредложение GROUP BY
Использование GROUP BY позволяет разбивать таблицу на логические группы и применять агрегатные функции к каждой из этих групп. В результате получим единственное значение для каждой группы.
Обычно предложение GROUP BY применяют, если формулировка задачи содержит фразу «для каждого…», «каждому..» и т.п.
Пример 18.
Определить суммарный объем деталей, поставляемых каждым поставщиком.
SELECT pnum, SUM(VOLUME) AS SUM
FROM PD
GROUP BY pnum| pnum | sum |
|---|---|
| 1 | 600 |
| 2 | 400 |
| 3 | 1000 |
Выполнение запроса можно описать следующим образом: СУБД разбивает таблицу PD на три группы, в каждую из групп помещаются строки с одинаковым значением номера поставщика. Затем к каждой из полученных групп применяется агрегатная функция SUM, что дает единственное итоговое значение для каждой группы.
Рассмотрим два похожих примера. В примере 19 определяется минимальный объем поставки каждого поставщика. В примере 20 определяется объем минимальной поставки среди всех поставщиков.
Пример 19:
SELECT pnum, MIN(VOLUME) AS MIN
FROM PD
GROUP BY pnumПример 20:
SELECT MIN(VOLUME) AS MIN
FROM PРезультаты запросов представлены в следующей таблице:
| pnum | min | max |
|---|---|---|
| 1 | 100 | 100 |
| 2 | 150 | |
| 3 | 1000 |
Следует обратить внимание, что в первом примере мы можем вывести номера поставщиков, соответствующие объемам поставок, а во втором примере – не можем.
Все имена столбцов, перечисленные после ключевого слова SELECT должны присутствовать и в предложении GROUP BY, за исключением случая, когда имя столбца является аргументом агрегатной функции.
Однако в предложении GROUP BY могут быть указаны имена столбцов, не перечисленные в списке вывода после ключевого слова SELECT.
Если предложение GROUP BY расположено после предложения WHERE, то группы создаются из строк, выбранных после применения WHERE.
Пример 21.
Для каждой из деталей с номерами 1 и 2 определить количество поставщиков, которые их поставляют, а также суммарный объем поставок деталей.
SELECT dnum, COUNT(pnum) AS COUNT, SUM(volume) AS SUM
FROM PD
WHERE dnum=1 OR dnum=2
GROUP BY dnumРезультат запроса:
| dnum | COUNT | SUM |
|---|---|---|
| 1 | 3 | 1250 |
| 2 | 2 | 450 |
Чтобы организовать вложенные группировки, после GROUP BY следует указать несколько группирующих столбцов через запятую. В этом случае реальный подсчет данных будет происходить по той группе, которая указана последней.
Предложение HAVING
Предложение HAVING определяет критерий, согласно которому, определенные группы, сформированные с помощью предложения GROUP BY, исключаются из результирующей таблицы.
Выполнение предложения HAVING сходно с выполнением предложения WHERE. Но предложение WHERE исключает строки до того, как выполняется группировка, а предложение HAVING — после. Поэтому предложение HAVING может содержать агрегатные функции, а предложение WHERE — не может.
Пример 22.
Определить номера поставщиков, поставляющих в сумме более 500 деталей.
SELECT pnum, SUM(volume) AS SUM
FROM PD
GROUP BY pnum
HAVING SUM(volume) > 500| pnum | SUM |
|---|---|
| 1 | 600 |
| 3 | 1000 |
Пример 23.
Определить номера поставщиков, которые поставляют только одну деталь.
SELECT pnum, COUNT(dnum) AS COUNT
FROM PD
GROUP BY pnum
HAVING COUNT(dnum) = 1| pnum | SUM |
|---|---|
| 3 | 1 |
Предложение ORDER BY
При выполнении запроса СУБД возвращает строки в случайном порядке. Предложение ORDER BY позволяет упорядочить выходные данные запроса в соответствии со значениями одного или нескольких выбранных столбцов.
Можно задать возрастающий — ASC (от слова Ascend) или убывающий — DESC (от слова Descend) порядок сортировки. По умолчанию принят возрастающий порядок сортировки.
Пример 24.
Отсортировать таблицу PD в порядке возрастания номеров поставщиков, а строки с одинаковыми значениями pnum отсортировать в порядке убывания объема поставок.
SELECT pnum, volume, dnum
FROM PD
ORDER BY pnum ASC, volume DESC| pnum | volume | dnum |
|---|---|---|
| 1 | 300 | 3 |
| 1 | 200 | 2 |
| 1 | 100 | 1 |
| 2 | 250 | 2 |
| 2 | 150 | 1 |
| 3 | 1000 | 1 |
Операцию TOP удобно применять после сортировки результирующего набора с помощью предложения ORDER BY.
Пример 25.
Определить номера первых двух деталей с наименьшей стоимостью.
SELECT TOP 2 dnum
FROM D
ORDER BY dprice ASCСледует отметить, что если в таблице D будут две детали без указания цены, то именно их и отобразит предыдущий запрос. Поэтому при наличии NULL-значений их необходимо исключать с помощью предложения WHERE.
SELECT TOP 2 dnum
FROM D
WHERE dprice IS NOT NULL
ORDER BY dprice ASCЗаключение
В статье было рассмотрен оператор выборки SELECT. Знание оператора SELECT является ключевым при написании любых SQL-запросов. Он позволяет производить выборку данных из таблиц и преобразовывать результаты в соответствии с нужными выражениями и функциями.
Результатом выполнения оператора SELECT является таблица, которую можно вложить в другой оператор SELECT в качестве подзапроса.
Синтаксис оператора SELECT содержит несколько предложений, из которых обязательными являются только SELECT и FROM. Остальные предложения, такие как WHERE, GROUP BY, HAVING и ORDER BY, могут использоваться по желанию для уточнения выборки данных.
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
-
Что такое SQL?
-
Основные предложения SQL: SELECT, FROM и WHERE
-
Сортировка результатов: предложение ORDER BY
-
Работа со сводными данными: предложения GROUP BY и HAVING
-
Объединение результатов запроса: оператор UNION
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'Mary';
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Инструкции SELECT
Чтобы описать набор данных с помощью SQL, нужно написать заявление SELECT. Инструкция SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных. К ним относятся файлы со следующими элементами:
-
таблицы, в которых содержатся данные;
-
связи между данными из разных источников;
-
поля или вычисления, на основе которых отбираются данные;
-
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
-
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
|
Предложение SQL |
Описание |
Обязательное |
|
SELECT |
Определяет поля, которые содержат нужные данные. |
Да |
|
FROM |
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
Да |
|
WHERE |
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
Нет |
|
ORDER BY |
Определяет порядок сортировки результатов. |
Нет |
|
GROUP BY |
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
HAVING |
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Нет |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
|
Термин SQL |
Сопоставимая часть речи |
Определение |
Пример |
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
AS |
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
42 |
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |
К началу страницы
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
-
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
-
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
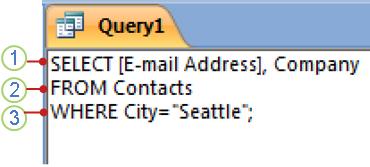
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City=»Seattle»
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
-
Access SQL. Предложение SELECT
-
Access SQL. Предложение FROM
-
Access SQL. Предложение WHERE
К началу страницы
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY.
К началу страницы
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
К началу страницы
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
К началу страницы
Приветствую Вас на сайте Info-Comp.ru! Сегодня мы приступим к рассмотрению полнотекстовых запросов в СУБД Microsoft SQL Server, с помощью которых осуществляется полнотекстовый поиск.

Напомню, ранее мы с Вами рассмотрели компонент Full-Text Search, на основе которого реализуется полнотекстовый поиск в SQL сервере и даже в качестве примера написали пару простых запросов. В этом материале мы будем более подробно рассматривать полнотекстовые запросы.
Примечание! В качестве исходных данных у нас будет выступать таблица, которую мы создавали в предыдущем материале (TestTable), она содержит список определений технологий (столбец TextData). В качестве СУБД выступает Microsoft SQL Server 2019.
Содержание
- CONTAINS
- Логические операторы
- Поиск по префиксным выражениям
- Поиск слова по словоформам
- Поиск слов или фраз с учетом расположения
- Функция CONTAINSTABLE
- Поиск с использованием взвешенных значений
- FREETEXT
- Функция FREETEXTTABLE
- Запросы на получение полнотекстовых свойств индексирования
- Функция FULLTEXTCATALOGPROPERTY
- Функция OBJECTPROPERTYEX
CONTAINS
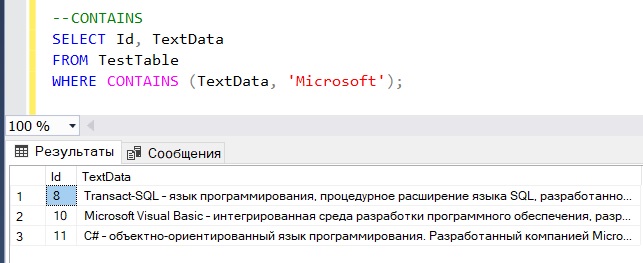
CONTAINS – это ключевое слово, которое используется в конструкции WHERE для поиска слов или фраз в столбце, который участвует в полнотекстовом поиске.
В следующем примере мы просто ищем строки, которые содержат слово Microsoft
--CONTAINS SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, 'Microsoft');
Логические операторы
При составлении критерия поиска можно использовать логические операторы AND, OR, AND NOT, т.е., например, можно построить запрос так, чтобы искались строки со словами и Microsoft и SQL
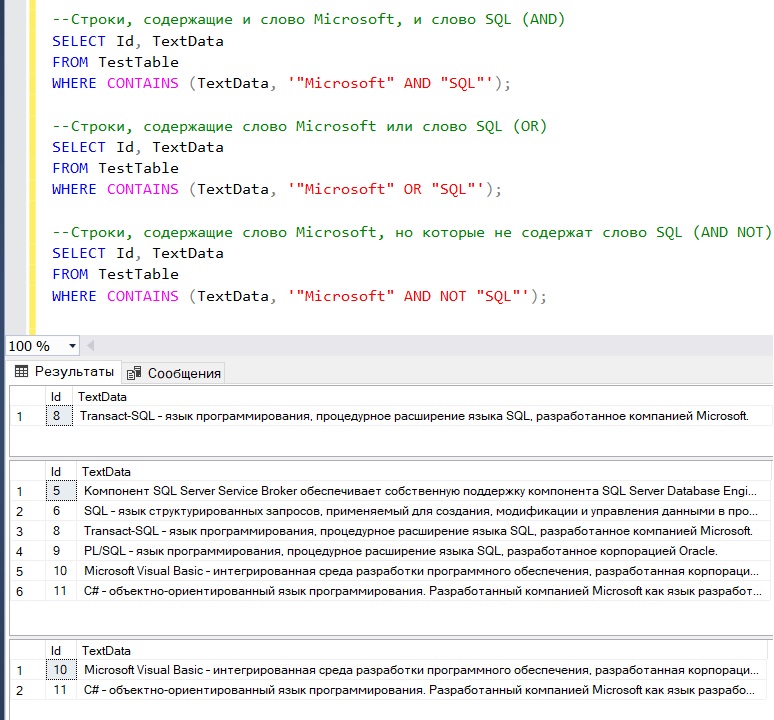
--Строки, содержащие и слово Microsoft, и слово SQL (AND) SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"Microsoft" AND "SQL"'); --Строки, содержащие слово Microsoft или слово SQL (OR) SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"Microsoft" OR "SQL"'); --Строки, содержащие слово Microsoft, но которые не содержат слово SQL (AND NOT) SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"Microsoft" AND NOT "SQL"');
Поиск по префиксным выражениям
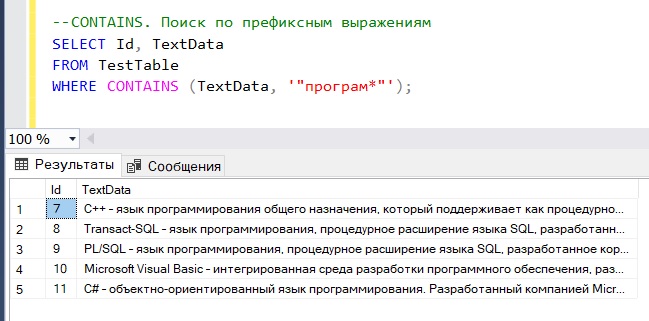
Префиксные выражения означают, что мы можем искать слова, не указывая их полностью, например, указав только начало, это делается с помощью знака *
Допустим, нам необходимо найти строки, где есть упоминания о программах или программировании, для этого мы напишем следующее:
--CONTAINS. Поиск по префиксным выражениям SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"програм*"');
Поиск слова по словоформам
Полнотекстовый поиск SQL сервера позволяет искать различные формы глаголов или существительные в единственном и во множественном числе, например, давайте найдем записи, в которых есть слово «запрос» и его производные выражения.
--CONTAINS. Поиск слова по словоформам SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, 'FORMSOF(INFLECTIONAL, "запрос")');
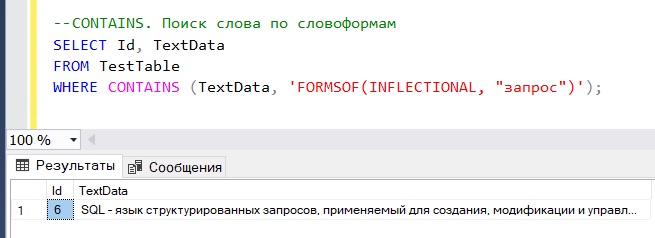
Как видим слова «запрос» у нас нет, но есть слово «запросов» поэтому эта строка и вывелась. Для поиска по словоформам мы использовали функцию FORMSOF().
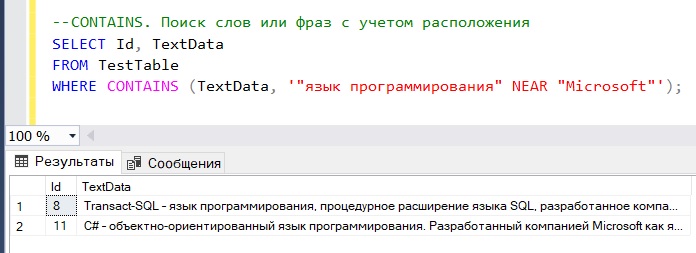
Поиск слов или фраз с учетом расположения
Если Вам нужно найти слова или фразы, которые располагаются недалеко друг от друга, то можно использовать ключевое слово NEAR. Допустим, мы хотим получить все строки, в которых есть упоминание о любом языке программирования, но при условии, что компания Microsoft должна иметь к нему какое-то отношение, другими словами, фраза «язык программирования» должна располагаться неподалеку от слова «Microsoft».
--CONTAINS. Поиск слов или фраз с учетом расположения SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"язык программирования" NEAR "Microsoft"');
Заметка! Если Вас интересует язык SQL, то рекомендую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных.
Функция CONTAINSTABLE
Это табличная функция, которая возвращает результирующий набор данных с проставленным рангом. RANK — это значение от 0 до 1000, показывающее степень соответствия каждой строки условию поиска. Другими словами, мы можем написать запрос и получить отсортированный результат по релевантности. При использовании функции CONTAINSTABLE можно использовать такие же условия поиска, как и в CONTAINS. Эта функция помимо RANK возвращает еще столбец KEY — это уникальный ключ базовой таблицы, по которому можно произвести объединение.
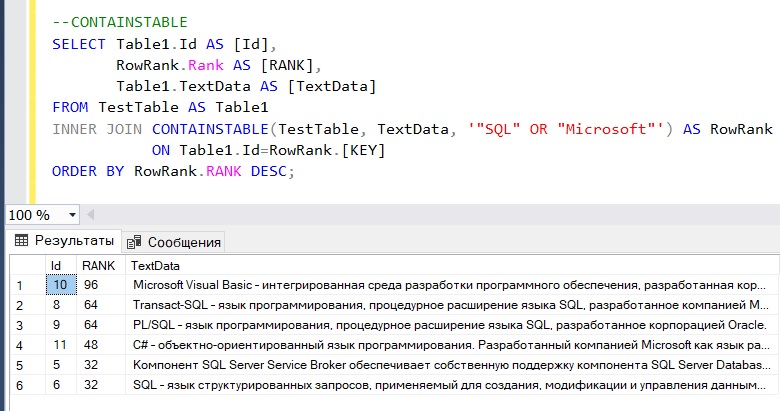
Давайте напишем полнотекстовый запрос, который вернет записи, в которых есть слово «SQL» или «Microsoft», при этом отсортируем результат по релевантности, т.е. сначала будут идти те строки, которые максимально подходят под наш критерий.
--CONTAINSTABLE
SELECT Table1.Id AS [Id],
RowRank.Rank AS [RANK],
Table1.TextData AS [TextData]
FROM TestTable AS Table1
INNER JOIN CONTAINSTABLE(TestTable, TextData, '"SQL" OR "Microsoft"') AS RowRank
ON Table1.Id=RowRank.[KEY]
ORDER BY RowRank.RANK DESC;
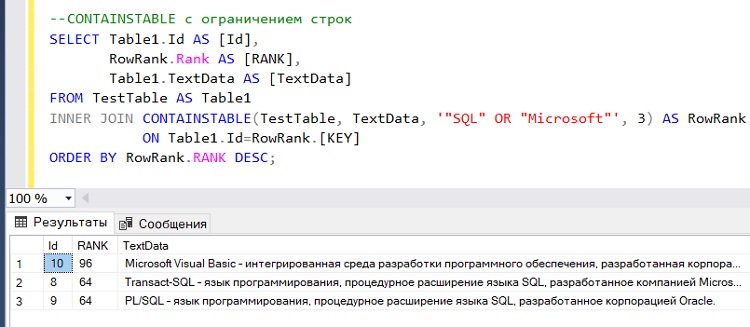
В случае необходимости в функцию CONTAINSTABLE четвертым параметром можно передать язык, ресурсы которого будут использоваться для разбиения слов, но он не обязателен. Также пятым или четвертым параметром (если не указан параметр LANGUAGE) можно передать число, которое ограничит результирующий набор. Например, для получения только первых 3 строк мы бы написали вот такой запрос:
--CONTAINSTABLE с ограничением строк
SELECT Table1.Id AS [Id],
RowRank.Rank AS [RANK],
Table1.TextData AS [TextData]
FROM TestTable AS Table1
INNER JOIN CONTAINSTABLE(TestTable, TextData, '"SQL" OR "Microsoft"', 3) AS RowRank
ON Table1.Id=RowRank.[KEY]
ORDER BY RowRank.RANK DESC;

Поиск с использованием взвешенных значений
В условии поиска можно указать важность того или иного слова или фразы от 0.0 до 1.0, т.е. осуществлять поиск со взвешенными значениями. Значение 0.0 является самым низким, а значение 1.0 самым высоким (в качестве десятичного разделителя всегда используется точка). Чтобы в запросе использовать взвешенные значения, необходимо использовать такие функции, как ISABOUT и WEIGHT. Их также можно использовать и в запросах CONTAINS.
А теперь допустим, что нас результаты ранжирования, из предыдущего примера, не устроили, мы хотим видеть сначала только самые релевантные строки, содержащие слово SQL, а только потом строки со словом Microsoft. Для этого мы назначим более высокий приоритет слову SQL, допустим 0.9, а Microsoft 0.1.
--CONTAINSTABLE. Поиск с использованием взвешенных значений
SELECT Table1.Id AS [Id],
RowRank.Rank AS [RANK],
Table1.TextData AS [TextData]
FROM TestTable Table1
INNER JOIN CONTAINSTABLE(TestTable, TextData,
'ISABOUT("SQL" WEIGHT(.9), "Microsoft" WEIGHT(.1))') AS RowRank
ON Table1.id=RowRank.[KEY]
ORDER BY RowRank.RANK DESC;
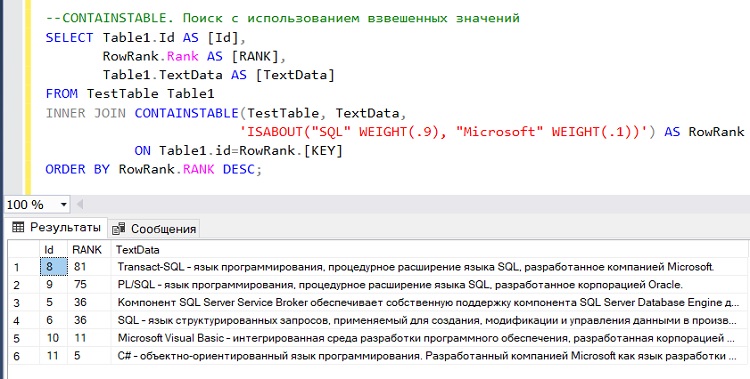
Как видим, результат у нас изменился и теперь строки, которые содержат слово SQL, имеют более высокий ранг.
FREETEXT
FREETEXT – это ключевое слово, с помощью которого осуществляется поиск по произвольной текстовой строке. Другими словами, мы можем написать любую фразу или предложение, а FREETEXT сам выделит все слова и определит все словоформы этих слов и только потом выполнит запрос. Полнотекстовые запросы с использованием FREETEXT являются менее точными по сравнению с CONTAINS. Как Вы понимаете, использование ключевых слов WEIGHT, FORMSOF, NEAR и прочего синтаксиса запрещено.
Для примера давайте представим, что мы не знаем, что конкретно мы ищем, например, мы хотим узнать, есть ли в нашей базе языки, которые используются для разработки программ, и для этого пишем следующий запрос:
--FREETEXT SELECT Id, TextData FROM TestTable WHERE FREETEXT (TextData, 'Языки для разработки программ');
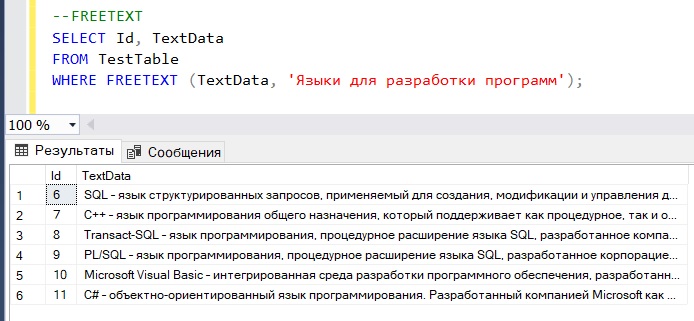
В итоге мы получаем список, который примерно соответствует нашему запросу, т.е. в этих строках есть слова, похожие на слова из строки нашего условия.
Заметка! Новичкам рекомендую посмотреть мой видеокурс по T-SQL для начинающих, в нем подробно рассмотрены все базовые конструкции языка T-SQL.
Функция FREETEXTTABLE
Для определения, какая строка самая релевантная, т.е. подходящая под строку запроса, можно использовать табличную функцию FREETEXTTABLE, которая так же, как и CONTAINSTABLE, проставляет ранжирующее значение от 0 до 1000 и возвращает два столбца KEY и RANK. Количество возвращаемых строк можно также ограничить, передав дополнительный параметр. В условии запроса использовать ключевые слова WEIGHT, FORMSOF, NEAR и другие, как и во FREETEXT, нельзя.
В примере выше мы получили результирующий набор, но мы не знаем, какие строки действительно релевантные нашему запросу, поэтому имеет смысл использовать функцию FREETEXTTABLE, для того чтобы увидеть ранжирующее значение каждой строки и, допустим, отсортировать по нему.
--FREETEXTTABLE
SELECT Table1.Id AS [Id],
RowRank.Rank AS [RANK],
Table1.TextData AS [TextData]
FROM TestTable Table1
INNER JOIN FREETEXTTABLE(TestTable, TextData,
'Языки для разработки программ') AS RowRank
ON Table1.id=RowRank.[KEY]
ORDER BY RowRank.RANK DESC;
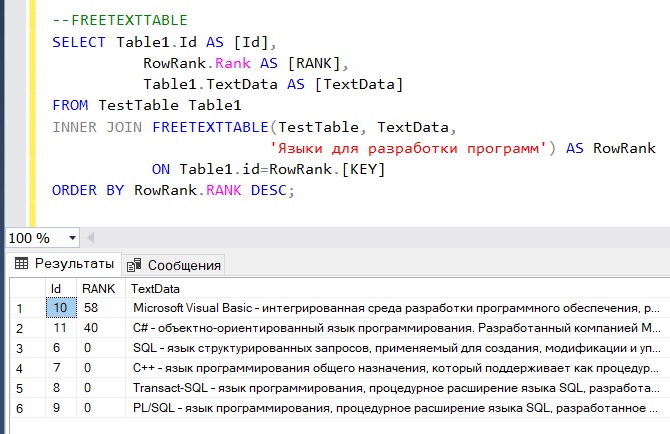
Результат этого запроса уже более понятен, исключение составляет строка с C++, в которой кроме слова «язык» ничего похожего на слова из нашей фразы нет.
Запросы на получение полнотекстовых свойств индексирования
Дополнительно хотелось бы еще отметить пару функций, с помощью которых нельзя выполнить поиск, но можно узнать параметры, которые влияют на результаты поиска.
Функция FULLTEXTCATALOGPROPERTY
С помощью этой функции можно узнать свойства полнотекстового каталога. Она имеет два параметра: первый — это название полнотекстового каталога и второй — это имя свойства, значение которого мы хотим узнать.
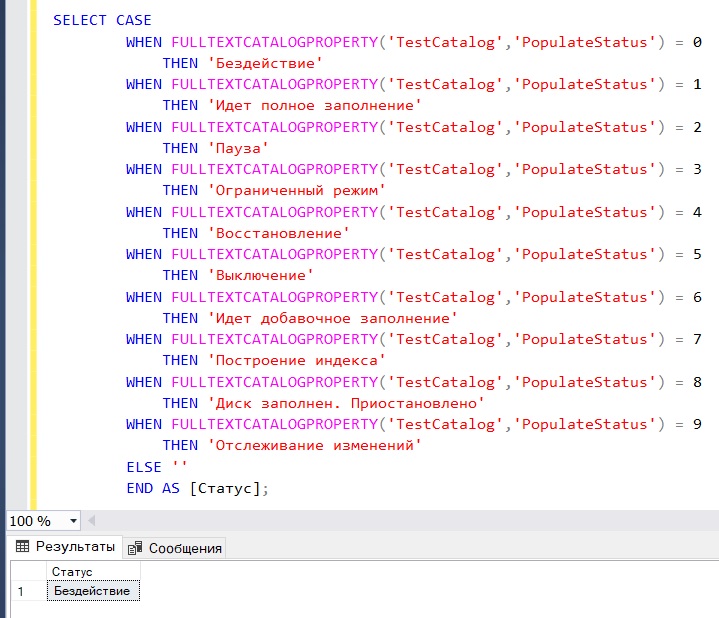
Например, следующий запрос показывает статус полнотекстового каталога, т.е. какая операция в данный момент выполняется:
SELECT CASE
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 0
THEN 'Бездействие'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 1
THEN 'Идет полное заполнение'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 2
THEN 'Пауза'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 3
THEN 'Ограниченный режим'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 4
THEN 'Восстановление'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 5
THEN 'Выключение'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 6
THEN 'Идет добавочное заполнение'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 7
THEN 'Построение индекса'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 8
THEN 'Диск заполнен. Приостановлено'
WHEN FULLTEXTCATALOGPROPERTY('TestCatalog','PopulateStatus') = 9
THEN 'Отслеживание изменений'
ELSE ''
END AS [Статус];
Также доступны и другие свойства, например:
- AccentSensitivity – учет диакритических знаков, 0 без учета, 1 с учетом;
- IndexSize – логический размер полнотекстового каталога в мегабайтах (МБ);
- ItemCount – количество элементов в полнотекстовом каталоге;
- MergeStatus – выполняется ли слияние в единый файл, 0 слияние не выполняется, 1 слияние выполняется;
- PopulateCompletionAge – разница в секундах между последним заполнением полнотекстового индекса и 01/01/1990 00:00:00;
- UniqueKeyCount – количество уникальных ключей в полнотекстовом каталоге;
- ImportStatus – выполняется ли в настоящее время импорт полнотекстового каталога, 0 не выполняется, 1 выполняется.
Функция OBJECTPROPERTYEX
Это функция используется для получения данных об объектах области схемы в текущей базе данных. Другими словами, с помощью нее можно узнать свойства объектов, не только относящихся к полнотекстовому индексированию. В качестве параметров она принимает: первый параметр — идентификатор объекта и второй — это название свойства, значение которого мы хотим узнать.
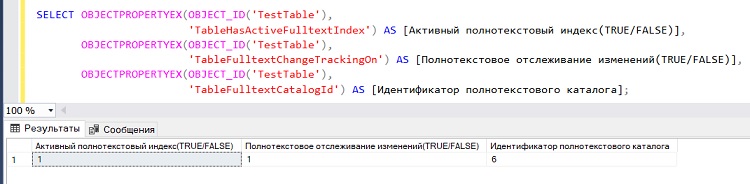
В случае с полнотекстовым поиском она нам может помочь, например, тогда, когда мы хотим узнать, есть ли у таблицы полнотекстовый индекс или включено ли полнотекстовое отслеживание изменений.
SELECT OBJECTPROPERTYEX(OBJECT_ID('TestTable'),
'TableHasActiveFulltextIndex') AS [Активный полнотекстовый индекс(TRUE/FALSE)],
OBJECTPROPERTYEX(OBJECT_ID('TestTable'),
'TableFulltextChangeTrackingOn') AS [Полнотекстовое отслеживание изменений(TRUE/FALSE)],
OBJECTPROPERTYEX(OBJECT_ID('TestTable'),
'TableFulltextCatalogId') AS [Идентификатор полнотекстового каталога];
Заметка! Еще больше статей по Microsoft SQL Server и языку T—SQL Вы можете найти в специальном сборнике статей – Сборник статей для изучения Microsoft SQL Server.
На этом у меня все, пока!