

В этом уроке по подготовке к ЕГЭ по информатике 2022 разберём задание номер 10.
Это задание, как и предыдущее, решается с помощью компьютера. Нужно будет провести поиск в тексте по определённому критерию и ответить на поставленный вопрос.
Информационный поиск нужно сделать с помощью текстового редактора. Мы в наших задачах будем использовать текстовый редактор Word от компании Microsoft.
С помощью текстового редактора определите, сколько раз встречается слово «рад» или «Рад» в тексте А.С. Пушкина «Руслан и Людмила».Такие слова как «радостный», «радость» и т.д., учитывать не следует. В ответе укажите только число.
После открытия файла нужно открыть окно «Расширенный поиск«.
На вкладке «Главная» находится кнопка «Найти«. Кликаем по чёрному треугольнику возле этой кнопки и выбираем «Расширенный поиск«.

Далее, нажимаем кнопку «Больше>>«.
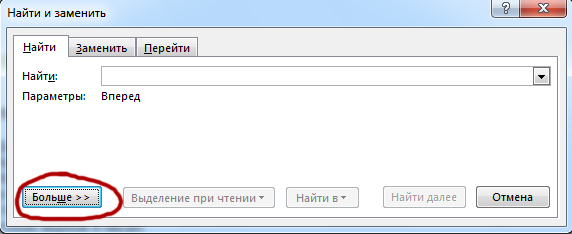
Теперь у нас есть все инструменты, чтобы решить 10 задание из ЕГЭ по информатике 2022.
В поле «Найти» пишем наше слово «рад».
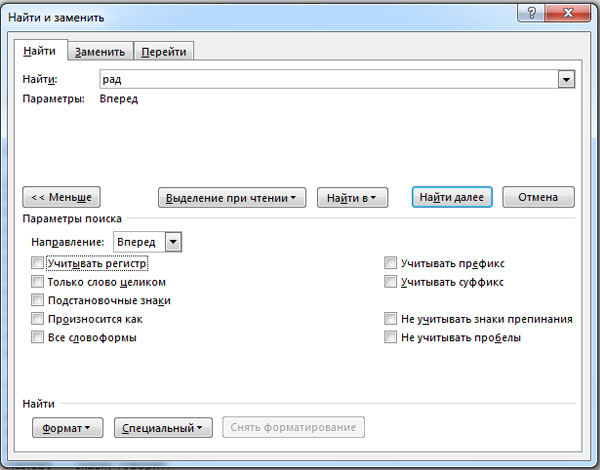
Рассмотрим некоторые параметры, которые присутствуют в этом окне.
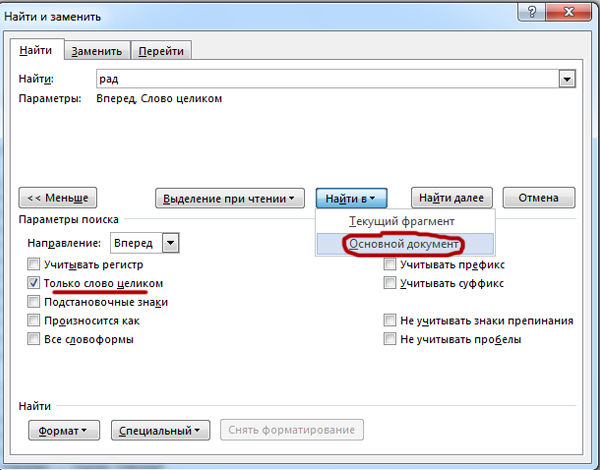
После того, как мы сделали нужные настройки нажимаем на кнопку «Найти в» (В некоторых версиях Word эта кнопка может называться «Область поиска» или как-то ещё.) и нажимаем «Основной документ«.
После того, как мы это сделаем, нам программа напишет ответ к нашей задаче.
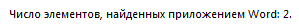
Ещё одна задача при подготовке к 10 заданию ЕГЭ по информатике 2022.
Определите, сколько раз в тексте произведения А. С. Пушкина «Капитанская дочка» встречается имя Емельян в любом падеже.
Вобьём в строку поиска слово Емельян. Будем нажимать на кнопку Найти далее и по очереди проверим каждый случай.
Первый случай не подходит, т.к. это слово находится в аннотации до основного произведения А.С. Пушкина. Нас просили найти именно слова, которые в тексте самого произведения.
Остальные случаи подходят. Всего получается два слова.
Ещё один пример из примерных задач ЕГЭ по информатике 2022, где мы составим маску для поиска.
С помощью текстового редактора определите, сколько раз, не считая сносок, встречается слово, которое начинается на букву «С» или на «с» в предложенном файле. Предлог «C» или «с» учитывать не нужно. В ответе укажите только число.
Эту задачу можно решить с помощью «Подстановочных знаков«, чтобы можно было использовать маску (шаблон).
Ставим галочку «Подстановочные знаки».
Основные правила для составления маски в программе Word:
| Спец. знаки | Что обозначают | Пример строки поиска | Что будет находить |
| ? | Один любой символ | р?к | рак, рок, рик, рык и т.д. |
| * | Любое число любых символов | р*к | риск, рок, ребёнок и т.д. |
| [] | Один из указанных символов | б[аоу]к | бак, бок, бук |
| [-] | Один символ из диапазона. Диапазон должен быть указан в порядке возрастания кодов символов. | [а-яё] | Любая строчная русская буква |
| [А-ЯЁ] | Любая прописная русская буква | ||
| 4 | Любая цифра буква | ||
| [!] | Один любой символ не указанный после восклицательного знака | б[!ы]к | бак, бок и т. п., но не бык |
| [!x-z] | Один любой символ, не входящий в диапазон указанный после восклицательного знака | [!а-яё]ок | Бок, Док и т. п., но не бок, док |
| [!0-9] | Любой символ кроме цифр | ||
| Строго n штук предыдущего символа или выражения. Выражением является все то, что заключено в круглые скобки. Выражение может состоять как из конкретных символов, так и содержать спец. знаки. | 10 | 1000, но не 100, 10000 | |
| 10(20) | 102020, но не 1020, 10202020 | ||
| n и более штук предыдущего символа или выражения | 10 | 1000, 10000, 100000 и т. д., но не 100 | |
| От n до m штук предыдущего символа или выражения | 10 | 1000, 10000, но не 100, 100000 | |
| @ | Один или более штук предыдущего символа или выражения | 10@ | 10, 100, 1000, 10000 и т. д. |
| Конец слова | бок> | колобок, но не боксер |
Сначала в поле «Найти» в нашей задаче нужно написать следующую маску:
Знак » » обозначает конец слова.
Источник
Содержание
- Как подсчитать слова в Word (Ворде)
- Подсчет числа слов во всем документе Word
- Подсчет количества слов во фрагменте текста
- Статьи из блога
- Как определить сколько раз встречается слово в тексте word
- Видео YouTube
Как подсчитать слова в Word (Ворде)
Подсчет числа слов во всем документе Word
Классический метод подсчета предполагает использования вкладки «Рецензирование» на панели инструментов.
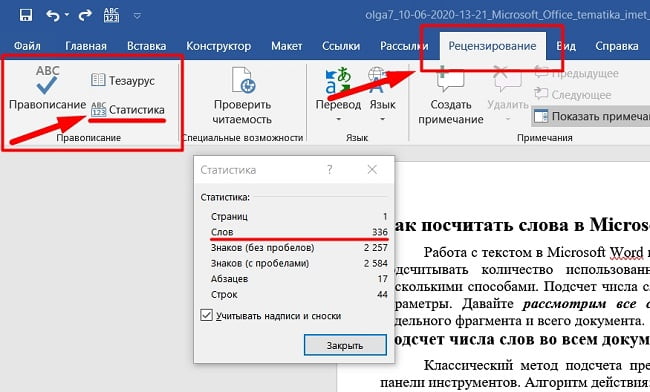
Чтобы продолжить работу с текстом, окно «Статистики» нужно закрыть. Иконка «АВС/123» может быть вынесена отдельным блоком на панель. Поэтому элемента «Правописания» может не быть. Классический метод дает развернутую статистику объектов по файлу. Если она пользователю не нужна, можно использовать данные нижней панели.
Пункт со статистическими данными находится снизу слева страницы. Называется «Число слов». В этом блоке их подсчет ведется автоматически. Цифра изменяется автоматически по мере набора данных.
Если в ходе работы с документом потребуется определить объем напечатанных букв (без пробелов или с пробелами), нажмите по «Число слов» в левом нижнем углу страницы. Появится окно «Статистика», где будет представлена развернутая информация об объектах файла.
Подсчет количества слов во фрагменте текста

Вкладку «Рецензирование» можно обойти, используя на нижней панели страницы блок «Число слов». При выделенном фрагменте текста информация в блоке будет подаваться иначе, чем для всего документа. Статистические данные будут представлены через дробь. Первое число (числитель) указывает, какое число слов было напечатано в выделенном фрагменте текста, второе (знаменатель) — во всем документе.
Выбор способа получения статистической информации по файлу не влияет на редактирование текста, поэтому можно использовать тот, который удобней в работе. Главное, после открытия окна «Статистика» не забывать его закрывать, иначе работать с объектами документа не получится.
Источник
Статьи из блога
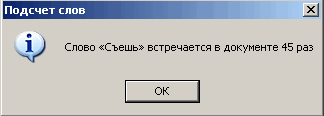
Если вам нужно определить количество вхождений в документ некоторого слова, то здесь может помочь следующий макрос (навеяно заметкой Грега Макси «Count Selected WordPhrase» ).
Вы выделяете некое слово и запускаете макрос, который после подсчета выдает сообщение о количестве найденных слов:
Если вы не знаете, как подключить к документу и применить этот макрос, изучите следующие заметки с сайта:






















Вы можете помочь в развитии сайта, сделав пожертвование:
—> Или помочь сайту популярной криптовалютой:
BTC Адрес: 1Pi3a4c6sJPbfF2sSYR2noy61DMBkncSTQ
ETH Адрес: 0x7d046a6eaa1bd712f7a6937b042e9eee4998f634
LTC Адрес: LUyT9HtGjtDyLDyEbLJZ8WZWGYUr537qbZ
USDT (ERC-20) Адрес: 0x7d046a6eaa1bd712f7a6937b042e9eee4998f634
Яндекс Деньги: 410013576807538
Источник
Как определить сколько раз встречается слово в тексте word
Это задание, как и предыдущее, решается с помощью компьютера.
Нужно будет провести поиск в тексте по определённому критерию и ответить
на поставленный вопрос.
Информационный поиск нужно сделать с помощью текстового редактора.
Мы в наших задачах будем использовать текстовый редактор Word
от компании Mircosoft.
С помощью текстового редактора определите, сколько раз встречается
слово «рад» или «Рад» в тексте А.С. Пушкина «Руслан и Людмила».
Такие слова как «радостный», «радость» и т.д., учитывать не следует.
В ответе укажите только число.
После открытия файла нужно открыть окно » Расширенный поиск«.
На вкладке » Главная» находится кнопка » Найти«. Кликаем по чёрному
треугольнику возле этой кнопки и выбираем » Расширенный поиск«.
Далее, нажимаем кнопку » Больше>>«.
Теперь у нас есть все инструменты, чтобы решить 10 задание из ЕГЭ по
В поле » Найти» пишем наше слово «рад».
Рассмотрим некоторые параметры, которые присутствуют в этом окне.
Учитывать регистр. Если не ставить эту галочку, то программа будет
игнорировать регистр. Т.е. не важно, как мы написали в строке поиске,
программа будет искать слова с большими буквами и с маленькими буквами.
Только слово целом. Если поставить эту галочку, то программа будет
игнорировать слова, куда наше искомое слово входит. Это то, что нам нужно в этой
После того, как мы сделали нужные настройки нажимаем на кнопку «Найти в»
(В некоторых версиях Word эта кнопка может называться «Область поиска»
или как-то ещё.) и нажимаем » Основной документ«.
После того, как мы это сделаем, нам программа напишет ответ к нашей задаче.
Ещё одна важная задача при подготовке к 10 заданию ЕГЭ по информатике 2021.
С помощью текстового редактора определите, сколько слов содержит
комбинацию букв «он» в отрывке текста Н.В.Гоголя «Мёртвые души».
При подсчёте не учитывать слово «он». В ответе укажите найденное количество.
Эту задачу нужно решать с помощью » Подстановочных знаков«, чтобы можно
было использовать маску (шаблон) для слова, которое содержит комбинацию «он».
Ставим галочку «Подстановочные знаки».
Основные правила для составления маски в программе Word: (Крупнее)
| Спец. знаки | Что обозначают | Пример строки поиска | Что будет находить |
| ? | Один любой символ | р?к | рак, рок, рик, рык и т.д. |
| * | Любое число любых символов | р*к | риск, рок, ребёнок и т.д. |
| [] | Один из указанных символов | б[аоу]к | бак, бок, бук |
| [-] | Один символ из диапазона. Диапазон должен быть указан в порядке возрастания кодов символов. | [а-яё] | Любая строчная русская буква |
| [А-ЯЁ] | Любая прописная русская буква | ||
| 7 | Любая цифра буква | ||
| [!] | Один любой символ не указанный после восклицательного знака | б[!ы]к | бак, бок и т. п., но не бык |
| [!x-z] | Один любой символ, не входящий в диапазон указанный после восклицательного знака | [!а-яё]ок | Бок, Док и т. п., но не бок, док |
| [!0-9] | Любой символ кроме цифр | ||
| Строго n штук предыдущего символа или выражения. Выражением является все то, что заключено в круглые скобки. Выражение может состоять как из конкретных символов, так и содержать спец. знаки. | 10 | 1000, но не 100, 10000 | |
| 10(20) | 102020, но не 1020, 10202020 | ||
| n и более штук предыдущего символа или выражения | 10 | 1000, 10000, 100000 и т. д., но не 100 | |
| От n до m штук предыдущего символа или выражения | 10 | 1000, 10000, но не 100, 100000 | |
| @ | Один или более штук предыдущего символа или выражения | 10@ | 10, 100, 1000, 10000 и т. д. |
| Начало слова | боксер, но не колобок | ||
| > | Конец слова | бок> | колобок, но н е боксер |
Сначала в поле » Найти» в нашей задаче нужно написать следующую маску:
Она нам даст все слова, где сочетание букв «он» находится внутри слова,
Эта маска говорит о том, что, если есть в слове хотя бы одна большая или
маленькая буква русского алфавита слева от «он» и хотя бы одна маленькая
буква справа, то программа должна засчитывать слово.
Символ @ («собака») обозначает как раз 1 или более повторений символа,
который указан слева от неё. Слева от @ («собаки») находится выражение в
квадратных скобках. В них находятся буквы русского алфавита через тире + буква «ё».
Это, значит, что можно применять на данном месте любую буквы из русского алфавита.
Символы » » показывают, что вышеописанный шаблон находится внутри слова.
В поле поиска введём вышеуказанную маску и нажмём
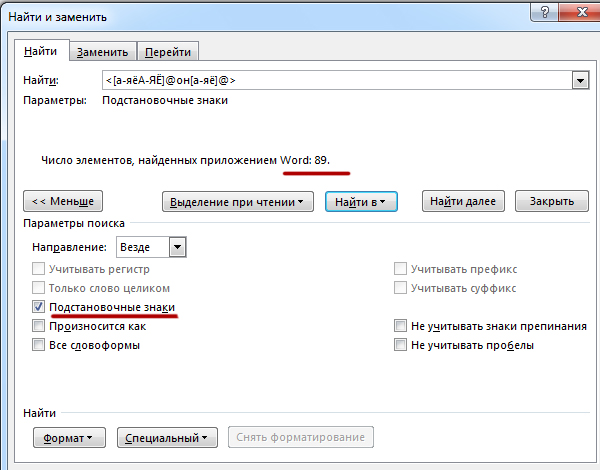
Программа нашла 89 слов. Ещё нужно прибавить к этому числу то количество,
когда комбинация «он» в начале слова и в конце.
Примечание 1: В вышеупомянутом шаблоне можно не писать знаки
» «. Всё равно конструкция [а-яёА-ЯЁ]@он[а-яё]@ будет означать одно слово,
ведь пробелов и других знаков, которые не входят в слово, здесь нет.
Составим шаблон, когда «он» находится в начале слова. Сочетание букв написано в
маленьких буквах, значит, и мы будем считать только в маленьких буквах. Шаблон:

Получилось 31 слово.
Примечание 2: Здесь уже обязательно нужно ставить знак «
Найдём, сколько слов будет, когда «он» стоит в конце слова. Шаблон:
В поле поиска введём комбинацию вышеуказанную маску и нажмём

Примечание 3: Здесь уже обязательно нужно ставить знак «>».
Примечание 4: В этой задаче нельзя было воспользоваться просто поиском
по сочетанию «он», потому что может быть слово, где два раза встретится данная
комбинация, и тогда это слово будет посчитано два раза.
Видео YouTube
 Ещё один важный пример из примерных задач ЕГЭ по информатике 2021.
Ещё один важный пример из примерных задач ЕГЭ по информатике 2021.
С помощью текстового редактора определите, сколько раз, не считая сносок,
встречается слово, которое начинается на букву «С» или на «с» в предложенном
файле. Предлог «C» или «с» учитывать не нужно. В ответе укажите только число.
В этой задаче нужно игнорировать сноски.
Выберем режим » Подстановочные знаки«. Напишем маску:
В начале слова может быть как большая буква «С», так и маленькая «с».
Поэтому эти две буквы написаны в квадратных скобках. Затем в слове должна
идти хотя бы одна буква русского алфавита.
Мы уже сделали поиск, игнорируя сноски, т.к. нажали поиск по основному документу.
С помощью текстового редактора определите, сколько раз,
не считая сносок, встречается слово «я» или «Я» в тексте романтической
поэмы М.Ю. Лермонтова «Мцыри». В ответе укажите только число.


Источник
Как в ворде найти повторы
Как найти повторяющиеся слова в Microsoft Word — Вокруг-Дом — 2021
Table of Contents:
Утилита Microsoft Word Find and Replace — это мощный инструмент, который позволяет пользователям быстро искать в своих документах определенные слова и фразы. Другое использование этого инструмента — найти повторяющиеся слова в тексте, используя опцию выделения, которая отображает повторяющиеся слова, так что вы можете легко просматривать и редактировать текст, чтобы исключить повторение слов.
Шаг 1
Откройте меню «Поиск» на вкладке «Главная» ленты и выберите «Расширенный поиск».
Шаг 2
Введите слово, в котором вы хотите найти дубликаты, в поле ввода «Найти что».
Шаг 3
При необходимости выберите другие параметры в разделе «Параметры поиска»; Использование параметров поиска, таких как «Поиск по регистру» и «Поиск только целых слов», делает ваш поиск более конкретным.
Шаг 4
Нажмите меню «Чтение выделения» и нажмите «Выделить все».
Как найти и выделить разные повторяющиеся слова
Есть текст, в котором объединено несколько списков фамилий.
В результате получилось, что в одном списке некоторые фамилии повторяются несколько раз.
Найти и выделить повторяющиеся слова в одном документе.
Нужно чтобы ворд сам выбрал те фамилии(слова), которые повторяются 2 и более раз и выделил их.
Например, повторяются фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН по нескольку раз.
Нужно выделить сразу всех галкиных, пугачевых и лениных и др. которые повторяются.
Т.к. список большой, то единичный поиск по фамилиям не пойдет.
Есть варианты?
Может макрос какой есть?
Помощь в написании контрольных, курсовых и дипломных работ здесь.
Как удалить повторяющиеся слова в Custom.DIC
Как удалить повторяющиеся слова в пользовательском словаре Custom.DIC? Может, конечно, они сами .
Как найти в списке повторяющиеся слова?
Здравствуйте! Подскажите пожалуйста, как найти в python повторяющиеся слова (в списке) и вывести.
Как найти повторяющиеся слова, записанные через дефис?
Доброго времени суток! Подскажите, возможно ли как-то с помощью регулярок(или чего-то другого).
Как удалить повторяющиеся слова и слова, которые меньше/больше 9 символов ?!
1) Надо удалить точно такие же повторяющиеся слова а их много! 2) Как из всего списка удалить.
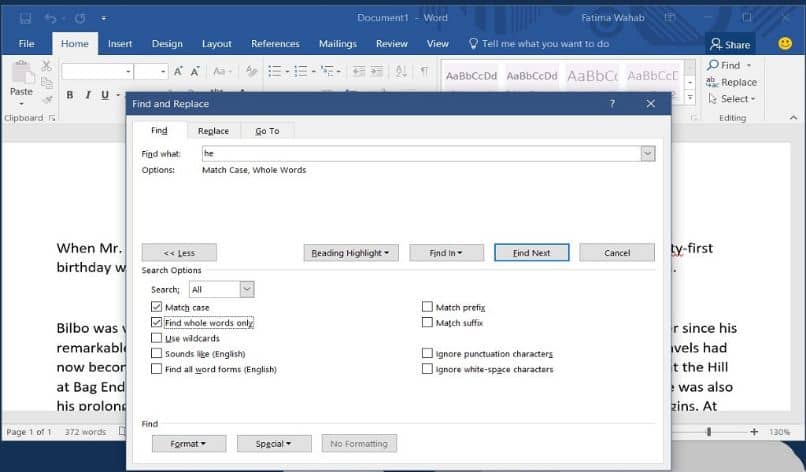
Как выделить одинаковые слова в Ворде?
Через Ctrl+F нашла все одинаковые слова. Теперь нужно выделить их ВСЕ и сразу одним цветом, например, красным. Как это сделать?
Чтобы выделить все необходимые слова необходимо после нажатия CTRL+F нажать кнопку и в открывшемся меню выбрать пункт .

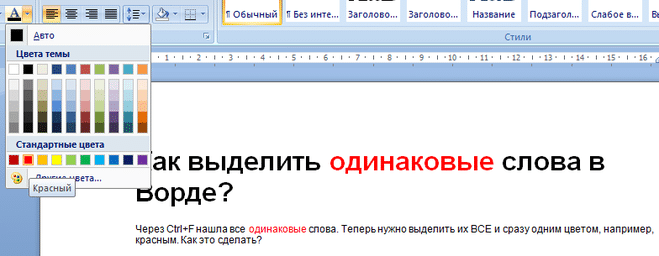
Выбираем команду изменение цвета текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:

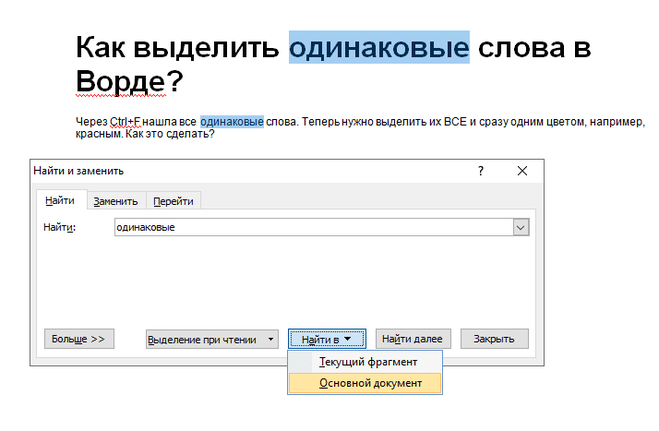
Объясню на примере. Допустим, у нас есть текст (я взяла отрывок из «12 стульев»), и нам нужно найти и выделить красным цветом все встречающиеся в нем местоимения ед.ч. ж.р. — «она».

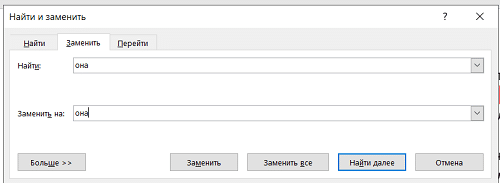
1) Заходим во вкладку «Главная», в верхней панели в крайнем правом окошке жмем «заменить»:
2) Во всплывающем окне в поле «найти» пишем она. И опять пишем она в поле «заменить на»

3) Нажимаем кнопку «больше» и выбираем: формат/выделение цветом.

4) Теперь ниже фразы «заменить на» должно появиться — выделение цветом:

5) Наконец жмем кнопку «заменить все».
Теперь все слова «она», имеющиеся в тексте выделены нужным нам цветом.
Кстати, можно выделять не только целые слова, но и части слов — например, только корень или только несколько цифр в длинных числах и т.д.
Выделение всех одинаковых слов в ворде происходит следующим методом. Нажмите Ctrl + f, после чего в выберите пункт «найти в» и в всплывающем меню выбрать основной документ. После чего ввести слово, которое вам нужно в графу поиска. Всё одинаковые слова выделяется, после чего можно делать с ними что угодно, изменить цвет, подчеркнуть, выделить жирным и тд.
Как в Ворде найти повторяющийся текст
Есть текст, в котором объединено несколько списков фамилий. В результате выяснилось, что в списке некоторые фамилии повторяются несколько раз. Найдите и выделите повторяющиеся слова в одном документе. необходимо, чтобы Слово само выбирало те фамилии (слова), которые повторяются 2 и более раз, и выделяло их.
Например, фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН повторяются несколько раз. необходимо сразу выделить всех повторяющихся Галкина, Пугачева, Ленина и т.д. Поскольку список большой, поиск по одной фамилии не сработает.
Как выделить одинаковые слова в Ворде?
Используя Ctrl + F, я нашел все те же слова. Теперь вам нужно выделить их ВСЕ и одновременно в один цвет, например красный. Как это сделать? Чтобы выделить все необходимые слова, после нажатия CTRL + F нажмите кнопку и выберите пункт в открывшемся меню .
Выбираем команду изменить цвет текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:
Позвольте мне объяснить на примере. Допустим, у нас есть текст (я взял отрывок из «12 стульев»), и нам нужно найти и выделить красным все местоимения в единственном числе в нем. Р. — «она».
1) Перейдите на вкладку «Главная», в верхней панели крайнего правого окна нажмите «заменить»:
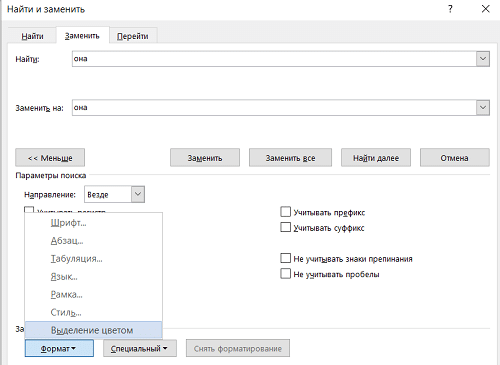
2) Во всплывающем окне в поле «найти» введите его. И снова пишем в поле «заменить на»
3) Нажмите кнопку «Другое» и выберите: выбор размера / цвета.
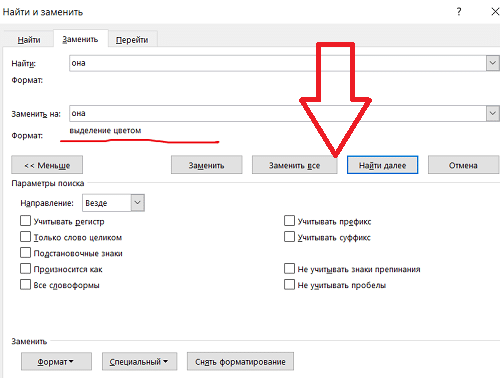
4) Теперь внизу должна появиться фраза «заменить на» — выделение цветом:
5) Наконец, нажмите кнопку «заменить все».
Теперь все слова «она» в тексте выделены нужным нам цветом.
Кстати, вы можете выделять не только слова целиком, но и части слов, например только корень или всего несколько цифр в длинных числах и т.д.
Подбор всех одинаковых слов в слове осуществляется следующим способом. Нажмите Ctrl + f, затем выберите запись «найти в» и выберите основной документ во всплывающем меню. Затем введите нужное слово в поле поиска. Выделяются все те же слова, после чего вы можете делать с ними все, что захотите, менять цвет, подчеркивание, выделение жирным шрифтом и т.д.
Как в ворде найти повторы текста?
 Компьютеры
Компьютеры
Чтобы заменить все одинаковые слова в тексте, не обязательно вручную просматривать весь документ. Это можно сделать с помощью инструмента «Заменить» в Microsoft Word, который присутствует даже в самых старых версиях программы.
Вне зависимости от установленной версии Microsoft Word для открытия инструмента воспользуйтесь сочетанием «Ctrl + H».
Для того чтобы открыть аналогичное окно в версии 2007 года или старше, перейдите на вкладку «Главная» и в разделе «Редактирование» нажмите на «Заменить». Откроется маленькое диалоговое окно с двумя полями для ввода текста: «Найти:» и «Заменить на:».

В первом необходимо ввести текст, который вы хотите заменить. Во втором — то, что должно оказаться на его месте.
Например, введя в первом поле слово «Microsoft » (с пробелом), а во втором — «Майкрософт » (тоже с пробелом), мы заменим все повторяющиеся слова в тексте, на затрагивая те, которые используются в адресе сайта. Если пробелы не использовать, то адрес сайта также поменяется.
Нажимая «Найти далее», вы видите, как в тексте подсвечивается нужный текст. Для одиночной замены нажмите «Заменить». Если уверены, что каждый случай проверять не нужно, жмите «Заменить все» и проверяйте работу.
Нажав на кнопку «Больше >>» вы получите список дополнительных инструментов:
- «Направление» — в каком направлении осуществлять замену относительно текущего положения курсора;
- «Учитывать регистр» — брать ли в расчет большие и маленькие буквы в тексте;
- «Только слово целиком» — с этим параметром вы можете не ставить пробел при замене;
- «Шрифт» — позволит выбрать текст с конкретными примененными изменениями, например, только полужирный, курсив и так далее;
- «Подстановочные знаки» — упростит процесс поиска. Введя «а*б», вы замените все фразы, начинающиеся на «а» и заканчивающиеся на «б». Используя символ « Поиск и замена текста в Word
Поиск и замена в Word 2003
Заходим в меню — Правка — Заменить.
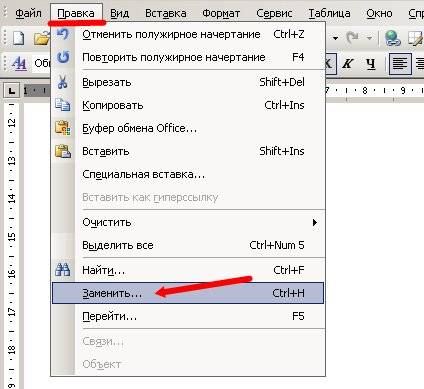
Откроется окно Найти и заменить. У этого маленького окошка очень большие возможности, но пока их все рассматривать не будем, а сразу перейдем на вкладку Заменить. В поле Найти напишем слово «статья», а в поле Заменить на, слово «книга».

Для более расширенных параметров поиска и замены, можно воспользоваться кнопкой Больше. Тогда это окошко примет такой вид.
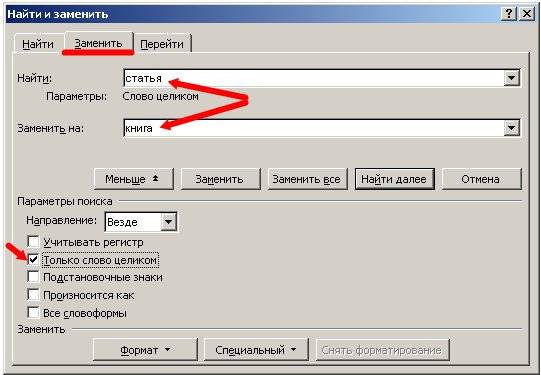
В параметрах поиска можно указать Направление поиска (Вперед, Назад, Везде). Все зависит от того, где у вас установлен курсор.
Если установить галочку Учитывать регистр, то поиск и замена будет производится строго с учетом регистра букв. Например, если в поле Найти указать слово «Статья» с большой буквы, то поиск будет ориентироваться только на слово «Статья» с большой буквы.
Так, что если указать в поле Заменить на — слово «книга» с маленькой буквы, то соответственно замена произойдет именно на слово «книга» с маленькой буквы.
Имейте в виду, что заменять можно не только одно слово в тексте, но и целые предложения и фразы. Подстановочные знаки применяются в том случае когда не так важно какая буква в слове. Например, если вы напишите слово «к*т», то поиск выдаст вам и «кот» и «кит» и «кат».
Если установить флажок на Все словоформы, то замена слова «статья» произойдет с любым окончанием этого слова (статьи, статьей, статью). Так, что думайте сразу, что на что менять, а то потом запутаетесь, и придется править весь текст вручную.
Кнопка Заменить, произведет замену первого найденного слова. Кнопка Заменить все, заменит все встречающиеся слова в тексте. Кнопка Найти далее, нужна только в том случае, если перед этим нажали кнопку Заменить. Ну а кнопка Отменить, естественно отменяет ваше предыдущее действие.
Если оставить поле Заменить на пустым, то программа просто удалит все слово, которые вы вписали в поле Найти.
Для того, чтобы найти и заменить слово или фразу в Word 2007/2010, необходимо перейти на вкладку Главная и открыть блок Редактирование, или нажать одновременно на клавиатуре клавиши Ctrl + H. Все остальное делается так, как описано выше.

Прежде, чем экспериментировать с текстом, создайте копию файла. Что бы потом не было мучительно больно за угробленный многодневный труд. Возьмите себе за правило — все эксперименты делать на копиях.
Как найти одинаковые строки с помощью программы Notepad++
Часто возникает необходимость удаления повторяющихся строк при обработке объемных текстовых документов.
Это простая, как может показаться, операция заставляет не один час искать специальные решения, отдельные программы или использовать функции MS Exel по сортировке и выборке уникальных значений. Что описано выше.
Есть более простой и удобный способ найти одинаковые строки используя бесплатный супер мега текстовый редактор Notepad++.
Найти одинаковые строки с помощью этой замечательной программы можно в два клика.
- Итак, открываем ваш текстовый документ в программе Notepad++.
- Выделяем весь текст (Ctrl+A)
- Идем в меню TextFX -> TextFX Tools -> Sort lines case insensitive
При этом должна стоять галочка возле пункта «Sort outputs only UNIQUE lines».
Результат, после нажатия «Sort lines case insensitive» — мы получаем отсортированные строки без повторов и дублей.
К примеру если у вас по тексту разбросано 10 одинаковых строк, то останется 1. Или если много строк имеют по несколько повторов то, останутся каждая по одной, без дублей.
Теперь при необходимости можно легко скопировать и вставить готовые строки в Exel или куда угодно.
Как и говорил в посте Как найти и заменить текст в Ms Office Word, Open Office Writer, Libre Office, сегодня попробуем поработать с большим количеством информации. Будем оставлять самое главное и удалять лишнее в очень большом тексте.
Текст, который мы будем «чистить»:

Итак, удаляем строки, которые выделены жирным и оставляем только нужный текст.
Обратите внимание, что длина удаляемого текста отличается. Для выделения строки независимо от количества символов нажимаем Ctrl+Shift+стрелка вниз. Под спойлером в конце поста вы увидите все команды выделения текста с помощью клавиатуры. А сейчас переводим курсор в начало текста, переходим в меню «Макросы» и включаем запись макроса.
Когда будете задавать имя макросу, не оставляйте пробелы — Word выдаст ошибку. Назначаем его для кнопки или клавиатуры. Я больше люблю работать с клавиатурой и выбрал поэтому клавиши.

Настраиваем макрос. Тут просто нажимаем любое сочетание клавиш. Если оно уже присвоено, то об этом появится информация.

Я присвоил макросу клавиатурную комбинацию Ctrl+G. Эта комбинация не используется в стандартном режиме редактирования и является свободной. Не переписывайте комбинации, которые часто используете .
- вырезать выделенный контент (текст, графика, вложения)
- скопировать выделенный контент
- выделить всё в документе
- отменить последнее действие
- повторить последнее действие (обратно сочетанию Ctrl+Z)
Начнём записывать макрос. На самом деле тут ничего сложного нет, просто делайте так, как редактируете обычно текст. Используйте чаще клавиши «Home» и «End», потому что они работают быстрее и не привязаны к количеству символов.
Таким образом, при записи вам нужно последовательно нажать после включения записи макроса следующие клавиши и комбинации клавиш. Стрелкой «вниз» сместить курсор на одну строку ниже, нажатием «Ctrl+Shift+стрелка вниз» выделить строку, клавишей « Delete » удалить строку.
- Включили запись макроса
- пропускаем строку и переходим к следующей
- выделяем 2 строку
- выделяем 3 строку
- выделяем 4 строку
- переносим строку 5 к строке 1
- переводим курсор в начало строки
- Переходим в начало следующего повторяющегося блока
- Выключаем запись макроса
Макрос записан, запись остановили. Кнопка остановки записи будет в том же месте, что и кнопка записи макроса.
Замечательно! Нажимаем Ctrl+G и лишний текст просто пропадает. Быстро, легко и удобно. А что делать, если записей… 1000 или больше?
Дадим команду обработать все вложения. А сколько этих вложений? Один из способов — найдите постоянное выражение через поиск. Я нажал Ctrl + F и ввёл в строку поиска выражение «Читайте блог Lassimarket.ru». Количество вхождений Word мне не показал, но я попросил его заменить это выражение на «*». Появилось окно с надписью «Произведено замен 24».

Запомнили число и нажали Ctrl+Z — отменили замену текста на звёздочку. Теперь я знаю, что в примере у меня 24 вхождения. Это я должен нажать 24 раза сочетание Ctrl+G для того, чтобы отформатировать текст. Будем упрощать это дело.
Нажимаем Alt+ F 11. Мы попали в редактор макросов. Это большая и сложная тема, тут самый настоящий язык программирования, но у нас всё будет просто, я вас уверяю.

Вписываем как на картинке две строки в начало и слово в конце.
Dim i As Integer
Что это значит? Мы обозначили i — числовой переменной и присвоили значения от 0 до 23, после окончания первого цикла замены число i увеличится на 1 и макрос будет снова повторяться (Next) до тех пор, пока не достигнет конца (23).
То есть эти строки дают команду после нажатия Ctrl+G повторить макрос «Удаляем3строки» 23 раза. Вот текст моего примера макроса.
Dim i As Integer
Selection.MoveDown Unit:=wdLine, Count:=1
Selection.MoveDown Unit:=wdParagraph, Count:=1, Extend:=wdExtend
Selection.Delete Unit:=wdCharacter, Count:=1
Selection.MoveDown Unit:=wdParagraph, Count:=1, Extend:=wdExtend
Selection.Delete Unit:=wdCharacter, Count:=1
Selection.MoveDown Unit:=wdParagraph, Count:=1, Extend:=wdExtend
Selection.Delete Unit:=wdCharacter, Count:=1
Selection.MoveDown Unit:=wdLine, Count:=1
Сохраняем макрос и закрываем редактор.
Обратите внимание, что после того, как мы перенесём пятую строку к первой, текст может вылезать на другую строку и макрос будет дальше работать неправильно.
Тогда можно временно заменить регулярное выражение на любой символ или уменьшить шрифт на этапе работы макроса и тому подобное.

Вернулись в редактор, нажали Ctrl+G, и текст мигом принял новый вид. Всё получилось. За пару минут обработали довольно большой текст в автоматическом режиме.
На уроке рассмотрен материал для подготовки к ЕГЭ по информатике, разбор 10 задания. Объясняется тема о выполнении информационного поиска средствами ОС или текстового редактора.
10-е задание: «Информационный поиск средствами ОС или текстового редактора»
Уровень сложности
— базовый,
Требуется использование специализированного программного обеспечения
— да,
Максимальный балл
— 1,
Примерное время выполнения
— 6 минут.
Проверяемые элементы содержания: Информационный поиск средствами операционной системы или текстового процессора
Выполнение 10 задания ЕГЭ
Плейлист видеоразборов задания на YouTube: 
Задание демонстрационного варианта 2022 года ФИПИ
10 задание. Демоверсия варианта ЕГЭ по информатике 2021, ФИПИ:
![]()
Задание выполняется с использованием прилагаемых файлов
С помощью текстового редактора определите, сколько раз, не считая сносок, встречается слово «долг» или «Долг» в тексте романа в стихах А.С. Пушкина «Евгений Онегин». Другие формы слова «долг», такие как «долги», «долгами» и т.д., учитывать не следует. В ответе укажите только число.
Ответ: 1
Видеоразбор 10 задания ЕГЭ
📹 Видеорешение на RuTube здесь
Задание 10_2: (эмулятор экзамена 2021)
![]()
Задание выполняется с использованием прилагаемых файлов
С помощью текстового редактора определите, сколько раз, не считая сносок, встречается слово «я» или «Я» в тексте романтической поэмы М.Ю. Лермонтова «Мцыри». В ответе укажите только число.
✍ Решение:
- Откройте файл в программе Microsoft Word. Щелкните горячие клавиши
[Ctrl+F]для открытия окна поиска; или выберите Расширенный поиск в меню Главная. - В расширенном поиске главное отметить пункт «Только слово целиком»:
- Стоит просмотреть несколько найденных слов, щелкая по кнопке Найти далее. Скопировав слово «я» из окна с расширенным поиском, вставьте его в окно поиска слева. Количество найденных слов будет равно 111.
- Возвратитесь в окно с расширенным поиском. Щелкая по кнопке Найти далее, вы заметите, что выделятся слово
1-я. Нас оно не устраивает. - Для исключения подобных слов необходимо ввести в поисковой строке
-я. Такое слово найдется одно. Соответственно необходимо вычесть 111 — 1 = 110
Ответ: 110
Задание 20_2:
![]()
Задание выполняется с использованием прилагаемых файлов
С помощью текстового редактора определите, сколько раз, не считая сносок, встречаются слова «ворон» и «ворона» в текстах басен И.А.Крылова (включая заголовки) в файле 10-J2. Слова могут начинаться как с заглавной, так и со строчной буквы. В ответе укажите только число.
✍ Решение:
- Откройте файл в программе Microsoft Word. Щелкните горячие клавиши
[Ctrl+F]для открытия окна поиска; или выберите Расширенный поиск в меню Главная. - В расширенном поиске главное отметить пункт «Только слово целиком»:
- Сначала посчитаем слово
ворон— их получается 7. Затем введем для поиска слововорона(также ищем только слово целиком) — их найдется 11. - Итого получаем 7 + 11 = 18
Ответ: 18
Задание 10_3:
![]()
Задание выполняется с использованием прилагаемых файлов
В файле 10-2.doc содержится учебное пособие по моделированию программных систем. Вам нет необходимости читать этот документ полностью. Используя поисковые средства текстового редактора, найдите пропущенное слово и запишите его в качестве ответа. Если вариант SADT-диаграммы одобрен экспертами, то ему присваивается статус ...
✍ Решение:
- Откройте файл в программе Microsoft Word. Щелкните горячие клавиши
[Ctrl+F]для открытия окна поиска; или выберите поиск в меню Главная. - В поисковой строке введем наиболее важное слово из указанной фразы, по которому можно найти ответ, — это слово
статус. - Начинаем щелкать Далее и просматриваем контекст встречаемого слова. Находим абзац:
Status – статус модели, характеризующий степень ее завершенности
(DRAFT-черновик, WORKING – рабочий вариант, RECOMMENDED – вариант,
прошедший экспертизу, PUBLICATION – окончательный вариант)
Ответ: RECOMMENDED
Помимо
функции поиска в Microsoft
Word
имеется
функция замены, при использовании
которой найденные совпадения с шаблоном
автоматически заменяются заданным
замещающим
текстом
(англ. replacement
text).
На
вкладке «Заменить» диалогового
окна «Найти и заменить» присутствуют
два поля: «Найти» и «Заменить на». В
поле «Найти», как и прежде, следует
вводить шаблон поиска, а в поле «Заменить
на» — замещающий
текст.
Для
поиска первого совпадения с шаблоном
следует нажать кнопку «Найти далее».
Найденное
совпадение будет выделено в тексте.
Далее можно нажать кнопку «Заменить»,
чтобы заменить это совпадение замещающим
текстом, или кнопку «Найти далее»,
чтобы оставить это совпадение без
изменения и перейти к следующему
совпадению
в тексте. Кроме того, имеется кнопка
«Заменить все», нажатие на которую
приведёт к замене всех оставшихся
совпадений.
Подстановочные
знаки, рассмотренные в §2, можно
использовать в поле «Найти», но
не в поле «Заменить на».
Если
в поле «Найти» введён шаблон с
подстановочными знаками, может возникнуть
необходимость некоторые части найденного
совпадения сохранить при замене, то
есть включить в замещающий текст. Для
этого нужно часть шаблона поиска,
соответствующую
сохраняемой части совпадения, заключить
в круглые скобки, а в поле «Заменить на»
использовать специальную конструкцию
п,
где п
—
номер пары круглых скобок
из поля «Найти». Пары круглых скобок
нумеруются слева направо, начиная с 1.
На место
данной специальной конструкции при
замене будет вставлена сохраняемая
часть найденного
совпадения.
7
Например,
поисковый шаблон <([а-я/@)-([а-я]@)>
и
замещающий
текст
2-l
приведут
к замене слова генерал-лейтенант
словом
лейтенант-генерал.
Поисковый
шаблон: <([а-я/@) — ([а-я]@)>
Номера
круглых скобок: 1 2
Совпадение:
генерал
лейтенант
Замещающий
текст: 2 1
Итоговый
замещающий текст:
лейтенант
генерал
Задачи
Текст:
names.doc
-
Изменить
фамилию всем женщинам на «Иванова». -
Привести
список к виду «И. О. Фамилия».
8
Решения
задач
(для
самопроверки)
§1
Задача
1. Встречается ли в тексте слово enormous«!
Если
да,
то
в
каких
контекстах оно
употребляется?
Решение.
Для
решения задачи необходимо воспользоваться
функцией поиска, встроенной
в Microsoft
Word.
В
меню «Правка» выберите пункт «Найти»,
в появившемся диалоговом
окне
введите enormous
в
поле «Найти» и нажмите «Найти далее».
Чтобы к
следующему употреблению слова enormous
в
тексте, снова нажмите «Найти I
Таким образом можно просмотреть все
контексты, в которых употребляется в
контексте
данное
слово.
Ответ.
Слово
enormous
встречается
в трёх контекстах:
-
I
regret
to state that I was not afraid of telling the enormous
lie comprehended in the
answer
«No.” -
Perhaps
I might have told Joe about the pale young gentleman, if I had not
previously
been
betrayed into those enormous
inventions to which I had confessed.
-
—
By degrees it became an enormous
injury to me that he stood before the fire.
Задача
2. Встречается ли в тексте словоформа
risk?
Решение.
Если
ввести
в
поле
«Найти» слово
risk
и
нажать «Найти далее», то Microsoft
Word
найдёт
не
совсем то, что было задумано: All
this
time
Mrs.
Joe
and
Joe
were
briskly
clearing
the
table
for
the
pie
and
pudding.
Для
того, чтобы находить
только целые слова, но не фрагменты
слов, необходимо жать
кнопку «Больше» и
установить галочку «Только слово
целиком».
Ответ.
Да, словоформа
risk
встречается
в тексте 1 раз.
Задача
3.
Сколько
всего раз
встречается
в тексте
слово beautiful?
Решение.
Слово
beautiful
встречается
в тексте достаточно много раз. Чтобы не
считать
количество употреблений вручную, можно
установить галочку «Выделить все
элементы,
найденные в:» и нажать «Найти все». Все
случаи употребления искомого слова
будут
выделены в тексте одновременно, а в окне
«Найти и заменить» будет отображено их
общее
количество (после слов «Найдено
элементов:»).
Ответ.
Слово
beautiful
встречается
в тексте 26 раз.
9
Задача
4. Определить, сколько раз встречаютсея
в тексте названия
цветов.
Решение.
Решение
задачи аналогично предыдущему. Необходимо
для
каждого
цвета
определить, сколько раз в тексте
встречается соответствующее
прилагательное.
Ответ.
См.
заполненную таблицу.
-
№п/п
Название
цветаЧастота
№ п/п
Название
цветаЧн(
кии1
black
82
6
magenta
0
2
blue
35
7
orange
5
3
brown
11
8
purple
2
4
pink
1
9
red
33
5
green
32
10
white
36
Задача
5. В какой орфографии (британской или
американской) представлен текст
Great
Expectations
в
файле?
Решение.
Можно
воспользоваться любым из отличительных
признаков британской или
американской орфографии. Например, в
британском варианте английского языка
употребляется написание colour,
а
в американском — color.
Решение
задачи сводится к поиску обоих слов в
тексте.
Ответ.
Текст
представлен в американской орфографии.
§2
Задача
1.
Найти
в тексте слова, состоящие из
трёх
букв.
Решение.
Сначала
нужно включить режим поиска с
подстановочными знаками. В меню «Правка»
следует выбрать пункт «Найти», в
появившемся диалоговом окне нажать
кнопку «Больше» и установить галочку
«Подстановочные знаки».
Для
решения задачи в поле «Найти» следует
ввести шаблон <???>
и
нажать кнопку
«Найти далее». Первым
найденным
трёхбуквенным
словом
будет
and:
My father’s family
name being Pirrip, and
my Christian name Philip… Для
поиска следующих трёхбуквенных
слов, как и прежде, можно нажимать кнопку
«Найти далее».
Разберём,
что означает шаблон <???>.
Выше
было сказано, что когда установлена
галочка
«Подстановочные знаки», определённые
символы в шаблоне приобретают специальное
значение. Так, символ < обозначает
начало слова, символ > — конец слова,
а вместо
символа ?
при
поиске может быть подставлен любой
символ из текста (отсюда название —
подстановочные
знаки).
Таким образом, шаблон <???>
в
целом означает, что в
тексте необходимо найти следующее:
начало слова, за которым символа,
за которыми идёт конец слова.
10
Ответ.
Первые
пять трёхбуквенных слов: and,
Pip,
Pip,
and,
Pip.
Все
эти
слова
находятся
в первом абзаце текста.
Задача
2. Найти в тексте трёхбуквенные слова,
начинающиеся на букву r
и заканчивающиеся
на букву t.
Решение.
Задача
аналогична предыдущей.
В тексте нужно
найти начало слова, за которым
идёт буква r,
за которой идет
одна любая буква, за
которой идёт буква t,
за
которой идёт
конец слова. Этому соответствуют
следующий шаблон:
<r?t>.
Ответ.
В
тексте встречаются слова
rat
и
rot.
Задача
3. Найти в тексте первые пять трёхбуквенных
слов, начинающихся на согласную
букву.
Решение.
Существенное
отличие этой задачи от двух предыдущих
состоит в том, что
первая буква слова — и не любая, как в
задаче 1 (следовательно, подстановочный
знак ? не
подходит),
и не конкретно заданная, как в задаче 2
(следовательно, её нельзя просто вписать
как
есть в шаблоне поиска).
Для
того, чтобы задать поиск любого символа
из некоторого перечня, нужно этот
перечень
взять
в квадратные скобки. В данном случае,
нужно перечислить в квадратных скобках
все согласные буквы
английского алфавита. Таким образом,
весь шаблон поиска будет
иметь вид: <(bcafghjklmnpqrstvwxzBCDFGHJKLMNPQRSTVWXZ]??>.
Этот
шаблон читается
следующим образом: необходимо найти
начало слова,
за которым следует один перечисленных
в квадратных скобках, за которым идут
два любых символа, за которыми
идёт конец
слова. Обратите внимание, что символы
в
квадратных скобках перечисляются
подряд, бет пробелов, запятых или
каких-либо иных
разделителей.
Первое
в
тексте
трехбуквенное
слово,
начинающееся
на
согласную,
— the:
I give Pirrip
as my
father’s
family
name, on the
authority
of his tombstone and my sister…
Шаблон,
использованный для решения этой задачи,
можно сократить. Вместо того, чтобы
перечислять в квадратных скобках буквы,
с одной из которых должно
начинаться
слово,
можно перечислить те буквы, с которых
слово не
должно начинаться
(то есть гласные),
а перед списком поставить признак
отрицания !:
<[!aeiouyAEIOUY]??>.
Полученная
конструкция читается следующим образом:
найти начало слова, после которого идёт
любой символ, кроме перечисленных в
скобках, за которым идут два
любых
символа, за которыми идет конец слова.
Ответ.
Первые пять трехбуквенных
слов
на согласную: Pip,
Pip,
Pip,
the,
his.
11
Задача
4. Сколько в тексте трёхбуквенных слов
следующей структуры: VCC,
где
V—любая
гласная буква, С—любая согласная буква?
Решение.
Аналогично задаче 3. Шаблон поиска:
<[aeiouyAEIOUY][!аeiouy]
[!aeiouy]>.
Ответ.
9057. ‘
Задача
5. Найти в тексте слова, состоящие из
пятнадцати букв.
Решение.
По аналогии с задачей 1, казалось бы,
можно выполнить поиск по тексту со
следующим шаблоном в поле «Найти»:
<???????????????>.
Однако
с таким шаблоном будут
совпадать не только слова, но и
словосочетания: GREAT
EXPECTATIONS
by
Charles
Dickens…,
My
father‘s
family
name
being
Pirrip…
и
т. д.
Это
не то, что требовалось, однако никакой
ошибки нет. Дело в том, что подстановочный
знак ?
означает
любой
символ
— не только букву, но и цифру, и знак
препинания,
и даже пробел или знак абзаца («красную
строку»). Таким образом, конструкция
<???????????????>
читается:
начало слова, за которым следует
пятнадцать любых символов (необязательно
букв), за которыми следует конец слова
(необязательно того
же самого слова). Легко видеть, что
найденные сочетания слов действительно
состоят
из пятнадцати символов, начинаются в
начале одного слова и заканчиваются в
конце
другого.
Как
исправить конструкцию, ясно из решения
задачи 3 — можно перечислить все буквы
латинского
алфавита
в квадратных
скобках
[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ]
и
повторить эти скобки
15 раз.
Разумеется,
вводить такую длинную строку в поле
«Найти» очень неудобно. Её можно
существенно сократить, воспользовавшись
двумя приёмами. Во-первых, подряд идущие
в алфавите буквы внутри квадратных
скобок можно заменять первой и последней
буквой
диапазона, записанными через дефис:
[a—zA—Z].
Во-вторых,
вместо многократного повторения
некоторого символа (обычного или
подстановочного) можно написать его
один
раз, и следом за ним указать в фигурных
скобках количество повторений:
[a—zA—Z]{15}.
Таким
образом, шаблон поиска примет вид:
<[a—zA—Z]{15}>.
13
Ответ.
broadshouldered,
characteristics, compassionating, congratulations (3 раза),
disappointments
(2 раза),
distinguishable,
extraordinarily, impossibilities (2
раза),
improbabilities,inaccessibility(2
раза),
incompatibility,notwithstanding
(5
раз),
plenipotentiary,
procrastinating, representations, retrospectively, sympathetically (2
раза),
12
transformations,
unacceptabobble, unceremoniously (2
раза),
unconsciousness (2
раза),
unintentionally.
Задача
6. Найти в тексте все слова с префиксом
ип-
и
суффиксом —ness
(существительные,
образованные от прилагательных с семой
отрицания).
Решение.
Если бы длина искомых слов была известна,
то задачу можно было бы решить
по аналогии с предыдущими. Пусть,
например, длина слова 10 букв. Префикс
ип-
состоит
из
двух букв, суффикс —ness
—
из четырёх, соответственно, на долю
корневой морфемы
остаётся 10 — (2 + 4) = 4 буквы, и в поле «Найти»
следует ввести шаблон поиска
<un[a—z){4}ness>.
Это
действительно
работает:
первое
найденное
слово
— uneasiness:
…in my
first uneasiness
and discontent I had turned to her for help, as a matter of course…
Но
длина искомого слова (а следовательно,
и корневой морфемы) нам неизвестна,
поэтому
какое число записать в фигурных скобках
— непонятно. В такой ситуации следует
вместо фигурных скобок использовать
знак @: <un[a—z]@ness>.
Вся
конструкция читается
так: искать начало слова, после которого
идут буквы и
и
n,
после которых идёт одна
или несколько строчных английских букв,
после которых идут буквы п,
е, s
и
s,
после которых
идёт конец слова.
Остаётся
учесть тот факт, что слово может начинаться
не только со строчной буквы но
и с заглавной буквы U.
Таким
образом, итоговый шаблон поиска будет
выглядеть следующим
образом: <luU]n[a—z]@ness>.
Ответ.
unconsciousness
(2
раза),
uneasiness
(5
раз),
unfitness,
unhappiness (2
раза),
unkindness,
untruthfulness, unworthiness.
Задача
7. Сколько в тексте слов с префиксами
in-, ir-, im-, ип- и суффиксом -1у (отрицательных
наречий)?
Решение.
Задача
отличается от предыдущей тем, что искомое
слово может начинаться
с одного из нескольких отрицательных
префиксов: in-,
ir-,
im—
или
ип-.
Перечислить
их в квадратных скобках (типа [inirimun])
нельзя,
потому что в тексте на месте
квадратных скобок должен быть только
один
из
перечисленных в скобках символов
[конструкция
[inirimun]
эквивалентна,
например, такой: [imrun]
—
ни повтор символов, ни
порядок их следования внутри квадратных
скобок роли не играют).
Выходом
может быть шаблон следующего вида:
<[iulU][mnr][a—z]@ly>.
Разумеется,
в этом случае будут найдены также слова
с «префиксами» иr—
и
um-,
если
гаковые
окажутся в тексте. Кроме того, будут
найдены слова типа imply
и
unexpectedly,
но
формально
они удовлетворяют заданным критериям
поиска, поэтому с ними ничего поделать
нельзя.
Ответ.
157, включая «лишние» слова, формально
похожие на отрицательные наречия.
Задача
8. Есть ли в тексте слова с кластером из
пяти согласных букв?
Решение.
Задача сводится к поиску пяти идущих
подряд согласных букв. В условии
не сказано, что кластер должен быть
строго в начале, в середине или в конце
слова,
поэтому «привязку» к границам слова
(с использованием подстановочных знаков
< и
>) делать не нужно.
Итоговый
шаблон поиска будет иметь следующий
вид: [bcdfghjklmnpqrstvwxzBCpFGHJKLMNPQRSTVWXZ]{5}.
Ответ.
Да, такое слово есть: hearthstone.
Задача
9. Сколько раз встречаются в тексте
наречия в сравнительной степени,
образованные
аналитическим способом?
Решение.
-
Лингвистический
анализ.
Аналитический способ образования
степеней сравнения
наречий заключается в использовании
служебных слов more
(для
сравнительной
степени) и most
(для
превосходной степени). Пример образования
степеней сравнения:
beautifully
~ more
beautifully
~
most
beautifully.
Формальным
признаком английского
наречия является суффикс -1у. -
Составление
шаблона.
Решение задачи сводится к составлению
шаблона для поиска
слова more,
вслед
за которым через пробел идёт слово,
оканчивающееся на -1у.
Это
может
быть шаблон вида: <[Mm]ore
[a—z]@ly>.
Ответ.
33.
Задача
10. Найти в тексте все сентенциональные
наречия на —ly
в
инициальной
позиции (в начале предложения) и оформить
их списком в отдельном файле.
Решение.
1.
Лингвистический анализ.
В английской грамматике сентенциональные
наречия (англ. sentence
adverbs)
—
это наречия, относящиеся ко всему
предложению в целом. Например:
Luckily,
it
did
not
rain
‘К
счастью, дождь не пошёл’. На русский
язык сентенциональные
наречия переводятся вводными словами,
описательными оборотами и
14
проч.
Сентенциональные
наречия, как правило, находятся в начале
предложения и всегда обособляются
запятой. Формальным признаком английского
наречия является суффикс -1у.
2.
Составление шаблона.
Для решения задачи нужно найти слова,
находящиеся в начале предложения,
оканчивающиеся на —1у,
после
которых идёт запятая. Начало предложения
характеризуется двумя особенностями.
Во-первых, первое слово в предложении
начинается с заглавной 6уквы. Во-вторых,
перед этим словом (через
пробел или
знак абзаца)
находится один из знаков
препинания,
завершающих предыдущее предложение:
точка, восклицательный знак или
вопросительный знак.
Шаблон
для поиска будет иметь следующий вид:
[.?!][^13[A—Z][a—z]@ly>.
Задача
11. В файле представлен список сотрудников
организации. Необходимо сохранить в
отдельном файле список всех женщин,
работающих в данной организации.
Решение.
1. Лингвистический
анализ.
Сначала нужно выбрать формальный
признак, на основании
которого можно определить пол человека
по его полному имени, состоящему из
фамилии, собственно имени и отчества.
Рассмотрим возможные варианты.
а)
Фамилия. Известно, что большинство
русских мужских фамилий заканчивается
на
-ин-ын или -ов/-ев, а женских — на -ина/-ына
или
–oea/-ева.
Однако
этот признак не универсален: так,
многие несклоняемые фамилии, не
относящиеся к исконно русским, олинаковы
как для мужчин, так и для женщин (ср.
Мацканюк,
Дудник).
б)
Имя. Большинство русских мужских имён
заканчивается на согласный, а женских
– на гласный. Этот признак также не
универсален (ср. Илья,
Любовь).
в)
Отчество. Отчества
в
русском языке образуются по регулярному
правилу, а именно
путем присоединения к имени отца
суффиксов —ич/
-вич для
мужчин и -на/-вна
для
женщин.
Таким образом, мужское отчество всегда
будет заканчиваться на -ч, а женское —
на
-а. Этот
формальный признак наиболее надежен
для разграничения мужских полных
имён.
2. Составление
шаблона.
Шаблон должен совпадать с тремя словами,
последнее из которых заканчивается на
-а.
Следует
учесть, что фамилия может быть двойной
(то есть
содержать дефисы и заглавные буквы в
середине слова).
Итоговый
шаблон поиска может иметь вид:
<[А-ЯЁа-яё-]@>
<[А-ЯЁа-яё]@> <[А-ЯЁа-яё]@а>.
15
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
|
ForzaLazio 0 / 0 / 0 Регистрация: 20.12.2020 Сообщений: 2 |
||||
|
1 |
||||
Посчитать, сколько раз встретится введенное с клавиатуры слово, начиная со второго абзаца20.12.2020, 15:30. Показов 1711. Ответов 4 Метки нет (Все метки)
Здравствуйте, требуется написать в среде Word макрос, который в выделенном фрагменте документа должен выполнять заданные действия и записывать результат после исходного текста:
0 |

|
Programming Эксперт 94731 / 64177 / 26122 Регистрация: 12.04.2006 Сообщений: 116,782 |
20.12.2020, 15:30 |
|
Ответы с готовыми решениями: WORD Подсчитать, сколько раз встречается введенное с клавиатуры слово, начиная со второго абзаца Подсчитать, сколько раз введенное с клавиатуры число N встретится среди 10 случайных чисел Посчитать, сколько раз в массиве встречается введенное слово Сколько раз встречалось введенное с клавиатуры слово. 4 |
|
66 / 59 / 14 Регистрация: 17.11.2013 Сообщений: 232 |
|
|
20.12.2020, 15:53 |
2 |
|
выделенном фрагменте документа
начиная со второго абзаца Так искать в выделенном фрагменте или во всем документе, начиная со второго абзаца, или в выделенном тексте, начиная со второго абзаца? Подсчитать сколько раз встречается слово
0 |

|
snipe 4038 / 1423 / 394 Регистрация: 07.08.2013 Сообщений: 3,541 |
||||
|
20.12.2020, 16:04 |
3 |
|||
|
алгоритмов решения задачи по определению количества вхождений образца текста в произвольный текст много
как видите все просто
0 |
|
0 / 0 / 0 Регистрация: 20.12.2020 Сообщений: 2 |
|
|
20.12.2020, 16:13 [ТС] |
4 |
|
Искать в выделенном тексте, начиная со второго абзаца Добавлено через 1 минуту
Так искать в выделенном фрагменте или во всем документе, начиная со второго абзаца, или в выделенном тексте, начиная со второго абзаца? искать в выделенном фрагменте, начиная со второго абзаца
0 |
|
aequit 223 / 134 / 45 Регистрация: 08.09.2012 Сообщений: 283 Записей в блоге: 1 |
||||
|
22.12.2020, 08:40 |
5 |
|||
|
Решение
искать в выделенном фрагменте, начиная со второго абзаца
1 |
 Сообщение было отмечено ForzaLazio как решение
Сообщение было отмечено ForzaLazio как решение
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
22.12.2020, 08:40 |
|
Помогаю со студенческими работами здесь Сколько раз встречалось введенное с клавиатуры слово.
Определить, сколько раз введенное с клавиатуры слово встретилось в файле Искать еще темы с ответами Или воспользуйтесь поиском по форуму: 5 |
В этом уроке по подготовке к ЕГЭ по информатике 2022 разберём задание номер 10.
Это задание, как и предыдущее, решается с помощью компьютера. Нужно будет провести поиск в тексте по определённому критерию и ответить на поставленный вопрос.
Информационный поиск нужно сделать с помощью текстового редактора. Мы в наших задачах будем использовать текстовый редактор Word от компании Microsoft.
Задача (Классическая)
С помощью текстового редактора определите, сколько раз встречается слово «рад» или «Рад» в тексте А.С. Пушкина «Руслан и Людмила».Такие слова как «радостный», «радость» и т.д., учитывать не следует. В ответе укажите только
число.
Решение:
После открытия файла нужно открыть окно «Расширенный поиск«.
На вкладке «Главная» находится кнопка «Найти«. Кликаем по чёрному треугольнику возле этой кнопки и выбираем «Расширенный поиск«.
")
Далее, нажимаем кнопку «Больше>>«.
")
Теперь у нас есть все инструменты, чтобы решить 10 задание из ЕГЭ по информатике 2022.
В поле «Найти» пишем наше слово «рад».
")
Рассмотрим некоторые параметры, которые присутствуют в этом окне.
Учитывать регистр. Если не ставить эту галочку, то программа будет игнорировать регистр. Т.е. не важно, как мы написали в строке поиске, программа будет искать слова с большими буквами и с маленькими буквами. Нам в этой задаче не нужно ставить эту галочку.
Только слово целом. Если поставить эту галочку, то программа будет игнорировать слова, куда наше искомое слово входит. Это то, что нам нужно в этой задаче. Поставим галочку в этой задаче.
После того, как мы сделали нужные настройки нажимаем на кнопку «Найти в» (В некоторых версиях Word эта кнопка может называться «Область поиска» или как-то ещё.) и нажимаем «Основной документ«.
")
После того, как мы это сделаем, нам программа напишет ответ к нашей задаче.
![]()
Ответ: 2.
Ещё одна задача при подготовке к 10 заданию ЕГЭ по информатике 2022.
Задача (Разные падежи)
Определите, сколько раз в тексте произведения А. С. Пушкина «Капитанская дочка» встречается имя Емельян в любом падеже.
Источник задачи: https://inf-ege.sdamgia.ru/
Решение:
Вобьём в строку поиска слово Емельян. Будем нажимать на кнопку Найти далее и по очереди проверим каждый случай.
Первый случай не подходит, т.к. это слово находится в аннотации до основного произведения А.С. Пушкина. Нас просили найти именно слова, которые в тексте самого произведения.
Остальные случаи подходят. Всего получается два слова.
Ответ: 2
Ещё один пример из примерных задач ЕГЭ по информатике 2022, где мы составим маску для поиска.
Задача (Маска поиска)
С помощью текстового редактора определите, сколько раз, не считая сносок, встречается слово, которое начинается на букву «С» или на «с» в предложенном файле. Предлог «C» или «с» учитывать не нужно. В ответе укажите только число.
Решение:
Эту задачу можно решить с помощью «Подстановочных знаков«, чтобы можно было использовать маску (шаблон).
Ставим галочку «Подстановочные знаки».
Основные правила для составления маски в программе Word:
| Спец. знаки | Что обозначают | Пример строки поиска | Что будет находить |
| ? | Один любой символ | р?к | рак, рок, рик, рык и т.д. |
| * | Любое число любых символов | р*к | риск, рок, ребёнок и т.д. |
| [] | Один из указанных символов | б[аоу]к | бак, бок, бук |
| [-] | Один символ из диапазона. Диапазон должен быть указан в порядке возрастания кодов символов. |
[а-яё] | Любая строчная русская буква |
| [А-ЯЁ] | Любая прописная русская буква |
||
| [0-9] | Любая цифра буква |
||
| [!] | Один любой символ не указанный после восклицательного знака |
б[!ы]к | бак, бок и т. п., но не бык |
| [!x-z] | Один любой символ, не входящий в диапазон указанный после восклицательного знака | [!а-яё]ок | Бок, Док и т. п., но не бок, док |
| [!0-9] | Любой символ кроме цифр | ||
| {n} | Строго n штук предыдущего символа или выражения. Выражением является все то, что заключено в круглые скобки. Выражение может состоять как из конкретных символов, так и содержать спец. знаки. |
10{3} | 1000, но не 100, 10000 |
| 10(20){2} | 102020, но не 1020, 10202020 |
||
| {n;} | n и более штук предыдущего символа или выражения |
10{3;} | 1000, 10000, 100000 и т. д., но не 100 |
| {n;m} | От n до m штук предыдущего символа или выражения |
10{3;4} | 1000, 10000, но не 100, 100000 |
| @ | Один или более штук предыдущего символа или выражения |
10@ | 10, 100, 1000, 10000 и т. д. |
| < | Начало слова | <бок | боксер, но не колобок |
| > | Конец слова | бок> | колобок, но не боксер |
Сначала в поле «Найти» в нашей задаче нужно написать следующую маску:
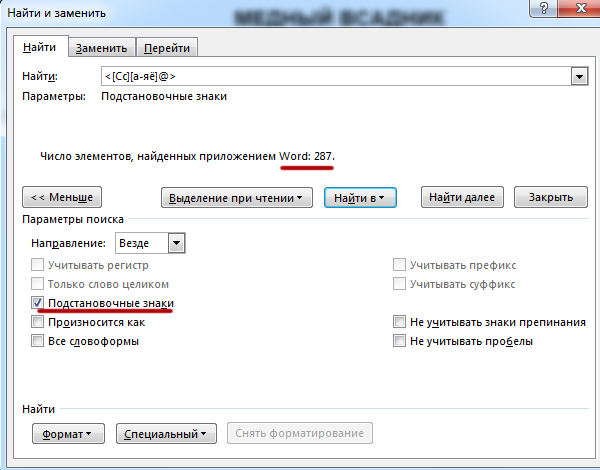
<[Сс][а-яё]@>
Знак «<» обозначает начало слова. Затем должна идти большая или маленькая буква «С», затем должна идти хотя бы одна маленькая буква русского алфавита. Знак «>» обозначает конец слова.
В этой задачке нужно игнорировать сноски, поэтому нажмём «Найти в» -> «Основной документ«. Это даст возможность не искать в сносках.
")
Нашлось 287 слов.
Ответ: 287
Счастливых экзаменов!
При написании ошибается даже самый знаток. И письменно, и по стилю. Во многих случаях их исправляет одна и та же программа, но иногда вам нужно помочь ей, как в случае, чтобы найти все повторяющиеся слова в документе. Word .
Когда вы просматриваете свой документ, сколько бы раз вы его ни читали, вы можете не заметить в нем всех ошибок. Точно так же автоматический корректор не всегда так эффективен, как вы думаете. Не волнуйтесь, в Word есть инструменты, чтобы исправить ваш текст и оставить его без единой ошибки. Вам просто нужно научиться использовать его, чтобы получить от него максимум пользы.
Необходимо знать количество версий Windows 10 чтобы определить, установлена ли у вас самая последняя и, следовательно, самая последняя версия Word.
Одна из самых распространенных ошибок при написании документа — это то, что иногда могут быть написаны повторяющиеся слова. как правило, le автоматическая проверка Word предупреждает вас об этой ошибке выделение повторения красным цветом. Но это не является надежным, если вы отключили инструмент исправления, все еще можно очень легко обнаружить эти ошибки. Использование подстановочных знаков программы.
Подстановочные знаки слов
Подстановочные знаки в Word — очень полезные инструменты при навигации и просмотре документа. Однако многие пользователи не знают, как их использовать, а многие даже не знают об их существовании. Чтобы найти все повторяющиеся слова в документе Word, вы можете использовать эти подстановочные знаки и даже зафиксировать положение рисунка в Word.
Повторяющиеся слова в документе Word и подстановочные знаки
Чтобы слово повторилось, первое, что нужно сделать, это поискать слово, верно? Для этого воспользуемся инструментом Word » поиск ». Это в разделе. » Démarrer Из верхнего меню. Обратите внимание, что для использования этого типа поиска необходимо установить флажок «Использовать подстановочные знаки» в окне «Найти и заменить».
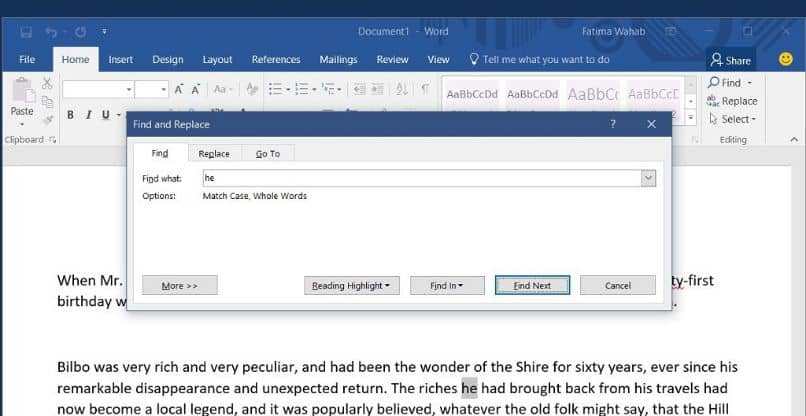
Если слово — это последовательность букв, расположенных определенным образом. Таким образом, первым используемым подстановочным знаком будет [а-я-я]. Таким образом, поисковая система будет рассматривать все буквы алфавита с учетом прописных и строчных букв. Точно так же в этой последовательности будут гласные с их ударением и буквой «ñ».
С этим джокером уже можно получить письмо. Как найти слово? Что ж, для этого вам нужно использовать этот подстановочный знак [ааЗ] {1;}. Это переводится как повторяющаяся буква один или несколько раз, включая все заглавные буквы, ударения и букву ñ.
Символы <>, помещенные в начале и в конце подстановочного знака, будут обозначать начало и конец каждого слова. Но поскольку вы хотите искать повторяющиеся слова, вы измените подстановочный знак на следующий <[a-zA-Z] {1;}). Заменяя символы «больше чем» круглыми скобками, вы указываете, что хотите искать слова, за которыми следует пробел.
Как найти все повторяющиеся слова в документе Word с помощью подстановочных знаков?
Кроме того, вы должны знать, что подстановочные знаки также применимы к другим случаям, таким как вставка видео YouTube в документ Word , полезный инструмент для финализации файла с удалением повторяющихся слов.
Теперь, если предыдущий подстановочный знак соответствует только словам, за которыми следует пробел , как найти все повторяющиеся слова в документе Word? В этом случае подстановочный знак, описанный выше, будет изменен следующим образом (<[a-zA-Z] {1;}) 1>.
Если вы понимаете, предыдущий подстановочный знак заключен в круглые скобки. В теории подстановочных знаков говорится, что скобки используются для создания поисковых ссылок. Таким образом, добавление круглых скобок создало ссылку.
После этого следует пробел, затем следует 1. Это слово для поиска. Другими словами, к первой группе скобок. Если бы было больше наборов символов, ссылка была бы 2, 3 или количество имеющихся групп скобок.
И, наконец, этот символ> указывает на конец слова. Поэтому, если вы используете этот подстановочный знак, он обнаружит избыточность «его звук» Маис Па «Его мечта» . Наконец, после того как вы найдете все повторяющиеся слова в документе Word, вы захотите удалить все повторяющиеся слова.
Итак, в окне поиска и замены Word вам нужно поместить следующий подстановочный знак в строку поиска (<[a-zA-Z] {1;}) 1> и в окно замена , вы должны поставить 1. Таким образом, повторяющееся слово будет автоматически удалено.
Если вам нужно определить количество вхождений в документ некоторого слова, то здесь может помочь следующий макрос (навеяно заметкой Грега Макси «Count Selected WordPhrase»).
Вы выделяете некое слово и запускаете макрос, который после подсчета выдает сообщение о количестве найденных слов:
Sub CountWords()
'макрос подсчета количества определенных слов в документе
'для подсчета количества вхождений конкретного слова, это слово должно быть выделено
Dim rng As Range
Dim sWord As String
Dim i As Long
Set rng = ActiveDocument.Range
Application.ScreenUpdating = False
If Selection.Type = wdSelectionIP Then
MsgBox "Слово не выделено", vbExclamation
Else
'удаляем знак абзаца справа от слова
If Right(Selection.Text, 1) = Chr(13) Then
Selection.MoveLeft wdCharacter, 1, wdExtend
End If
sWord = Trim(Selection.Text) 'Убираем прообелы вокруг слова и запоминаем
Selection.Collapse wdCollapseStart
With rng.Find
.ClearFormatting
.Replacement.ClearFormatting
.Text = sWord
.Forward = True
.MatchWholeWord = True
.MatchWildcards = False
.Wrap = wdFindStop
Do While .Execute
i = i + 1
Loop
End With
Select Case i
Case 2 To 4
MsgBox "Слово " & Chr(171) & sWord & Chr(187) & " встречается в документе " & i & " раза", _
vbInformation, "Подсчет слов"
Case 1
MsgBox "Слово " & Chr(171) & sWord & Chr(187) & " встречается в документе " & i & " раз", _
vbInformation, "Подсчет слов"
Case Else
MsgBox "Слово " & Chr(171) & sWord & Chr(187) & " встречается в документе " & i & " раз", _
vbInformation, "Подсчет слов"
End Select
rng.Find.Text = ""
End If
Application.ScreenUpdating = True
End Sub
Если вы не знаете, как подключить к документу и применить этот макрос, изучите следующие заметки с сайта:
Создание макроса из готового кода
Автоматическая запись макроса
Есть текст, в котором объединено несколько списков фамилий. В результате выяснилось, что в списке некоторые фамилии повторяются несколько раз. Найдите и выделите повторяющиеся слова в одном документе. необходимо, чтобы Слово само выбирало те фамилии (слова), которые повторяются 2 и более раз, и выделяло их.
Например, фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН повторяются несколько раз. необходимо сразу выделить всех повторяющихся Галкина, Пугачева, Ленина и т.д. Поскольку список большой, поиск по одной фамилии не сработает.
Как выделить одинаковые слова в Ворде?
Используя Ctrl + F, я нашел все те же слова. Теперь вам нужно выделить их ВСЕ и одновременно в один цвет, например красный. Как это сделать? Чтобы выделить все необходимые слова, после нажатия CTRL + F нажмите кнопку и выберите пункт в открывшемся меню .
Выбираем команду изменить цвет текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:
Позвольте мне объяснить на примере. Допустим, у нас есть текст (я взял отрывок из «12 стульев»), и нам нужно найти и выделить красным все местоимения в единственном числе в нем. Р. — «она».

1) Перейдите на вкладку «Главная», в верхней панели крайнего правого окна нажмите «заменить»:
2) Во всплывающем окне в поле «найти» введите его. И снова пишем в поле «заменить на»
3) Нажмите кнопку «Другое» и выберите: выбор размера / цвета.
4) Теперь внизу должна появиться фраза «заменить на» — выделение цветом:
5) Наконец, нажмите кнопку «заменить все».
Теперь все слова «она» в тексте выделены нужным нам цветом.
Кстати, вы можете выделять не только слова целиком, но и части слов, например только корень или всего несколько цифр в длинных числах и т.д.
Подбор всех одинаковых слов в слове осуществляется следующим способом. Нажмите Ctrl + f, затем выберите запись «найти в» и выберите основной документ во всплывающем меню. Затем введите нужное слово в поле поиска. Выделяются все те же слова, после чего вы можете делать с ними все, что захотите, менять цвет, подчеркивание, выделение жирным шрифтом и т.д.