
Word-sense disambiguation (WSD) is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious/automatic but can often come to conscious attention when ambiguity impairs clarity of communication, given the pervasive polysemy in natural language. In computational linguistics, it is an open problem that affects other computer-related writing, such as discourse, improving relevance of search engines, anaphora resolution, coherence, and inference.
Given that natural language requires reflection of neurological reality, as shaped by the abilities provided by the brain’s neural networks, computer science has had a long-term challenge in developing the ability in computers to do natural language processing and machine learning.
Many techniques have been researched, including dictionary-based methods that use the knowledge encoded in lexical resources, supervised machine learning methods in which a classifier is trained for each distinct word on a corpus of manually sense-annotated examples, and completely unsupervised methods that cluster occurrences of words, thereby inducing word senses. Among these, supervised learning approaches have been the most successful algorithms to date.
Accuracy of current algorithms is difficult to state without a host of caveats. In English, accuracy at the coarse-grained (homograph) level is routinely above 90% (as of 2009), with some methods on particular homographs achieving over 96%. On finer-grained sense distinctions, top accuracies from 59.1% to 69.0% have been reported in evaluation exercises (SemEval-2007, Senseval-2), where the baseline accuracy of the simplest possible algorithm of always choosing the most frequent sense was 51.4% and 57%, respectively.
Variants[edit]
Disambiguation requires two strict inputs: a dictionary to specify the senses which are to be disambiguated and a corpus of language data to be disambiguated (in some methods, a training corpus of language examples is also required). WSD task has two variants: «lexical sample» (disambiguating the occurrences of a small sample of target words which were previously selected) and «all words» task (disambiguation of all the words in a running text). «All words» task is generally considered a more realistic form of evaluation, but the corpus is more expensive to produce because human annotators have to read the definitions for each word in the sequence every time they need to make a tagging judgement, rather than once for a block of instances for the same target word.
History[edit]
WSD was first formulated as a distinct computational task during the early days of machine translation in the 1940s, making it one of the oldest problems in computational linguistics. Warren Weaver first introduced the problem in a computational context in his 1949 memorandum on translation.[1] Later, Bar-Hillel (1960) argued[2] that WSD could not be solved by «electronic computer» because of the need in general to model all world knowledge.
In the 1970s, WSD was a subtask of semantic interpretation systems developed within the field of artificial intelligence, starting with Wilks’ preference semantics. However, since WSD systems were at the time largely rule-based and hand-coded they were prone to a knowledge acquisition bottleneck.
By the 1980s large-scale lexical resources, such as the Oxford Advanced Learner’s Dictionary of Current English (OALD), became available: hand-coding was replaced with knowledge automatically extracted from these resources, but disambiguation was still knowledge-based or dictionary-based.
In the 1990s, the statistical revolution advanced computational linguistics, and WSD became a paradigm problem on which to apply supervised machine learning techniques.
The 2000s saw supervised techniques reach a plateau in accuracy, and so attention has shifted to coarser-grained senses, domain adaptation, semi-supervised and unsupervised corpus-based systems, combinations of different methods, and the return of knowledge-based systems via graph-based methods. Still, supervised systems continue to perform best.
Difficulties[edit]
Differences between dictionaries[edit]
One problem with word sense disambiguation is deciding what the senses are, as different dictionaries and thesauruses will provide different divisions of words into senses. Some researchers have suggested choosing a particular dictionary, and using its set of senses to deal with this issue. Generally, however, research results using broad distinctions in senses have been much better than those using narrow ones.[3][4] Most researchers continue to work on fine-grained WSD.
Most research in the field of WSD is performed by using WordNet as a reference sense inventory for English. WordNet is a computational lexicon that encodes concepts as synonym sets (e.g. the concept of car is encoded as { car, auto, automobile, machine, motorcar }). Other resources used for disambiguation purposes include Roget’s Thesaurus[5] and Wikipedia.[6] More recently, BabelNet, a multilingual encyclopedic dictionary, has been used for multilingual WSD.[7]
Part-of-speech tagging[edit]
In any real test, part-of-speech tagging and sense tagging have proven to be very closely related, with each potentially imposing constraints upon the other. The question whether these tasks should be kept together or decoupled is still not unanimously resolved, but recently scientists incline to test these things separately (e.g. in the Senseval/SemEval competitions parts of speech are provided as input for the text to disambiguate).
Both WSD and part-of-speech tagging involve disambiguating or tagging with words. However, algorithms used for one do not tend to work well for the other, mainly because the part of speech of a word is primarily determined by the immediately adjacent one to three words, whereas the sense of a word may be determined by words further away. The success rate for part-of-speech tagging algorithms is at present much higher than that for WSD, state-of-the art being around 96%[8] accuracy or better, as compared to less than 75%[citation needed] accuracy in word sense disambiguation with supervised learning. These figures are typical for English, and may be very different from those for other languages.
Inter-judge variance[edit]
Another problem is inter-judge variance. WSD systems are normally tested by having their results on a task compared against those of a human. However, while it is relatively easy to assign parts of speech to text, training people to tag senses has been proven to be far more difficult.[9] While users can memorize all of the possible parts of speech a word can take, it is often impossible for individuals to memorize all of the senses a word can take. Moreover, humans do not agree on the task at hand – give a list of senses and sentences, and humans will not always agree on which word belongs in which sense.[10]
As human performance serves as the standard, it is an upper bound for computer performance. Human performance, however, is much better on coarse-grained than fine-grained distinctions, so this again is why research on coarse-grained distinctions[11][12] has been put to test in recent WSD evaluation exercises.[3][4]
Pragmatics[edit]
Some AI researchers like Douglas Lenat argue that one cannot parse meanings from words without some form of common sense ontology. This linguistic issue is called pragmatics.
As agreed by researchers, to properly identify senses of words one must know common sense facts.[13] Moreover, sometimes the common sense is needed to disambiguate such words like pronouns in case of having anaphoras or cataphoras in the text.
Sense inventory and algorithms’ task-dependency[edit]
A task-independent sense inventory is not a coherent concept:[14] each task requires its own division of word meaning into senses relevant to the task. Additionally, completely different algorithms might be required by different applications. In machine translation, the problem takes the form of target word selection. The «senses» are words in the target language, which often correspond to significant meaning distinctions in the source language («bank» could translate to the French «banque»—that is, ‘financial bank’ or «rive»—that is, ‘edge of river’). In information retrieval, a sense inventory is not necessarily required, because it is enough to know that a word is used in the same sense in the query and a retrieved document; what sense that is, is unimportant.
Discreteness of senses[edit]
Finally, the very notion of «word sense» is slippery and controversial. Most people can agree in distinctions at the coarse-grained homograph level (e.g., pen as writing instrument or enclosure), but go down one level to fine-grained polysemy, and disagreements arise. For example, in Senseval-2, which used fine-grained sense distinctions, human annotators agreed in only 85% of word occurrences.[15] Word meaning is in principle infinitely variable and context-sensitive. It does not divide up easily into distinct or discrete sub-meanings.[16] Lexicographers frequently discover in corpora loose and overlapping word meanings, and standard or conventional meanings extended, modulated, and exploited in a bewildering variety of ways. The art of lexicography is to generalize from the corpus to definitions that evoke and explain the full range of meaning of a word, making it seem like words are well-behaved semantically. However, it is not at all clear if these same meaning distinctions are applicable in computational applications, as the decisions of lexicographers are usually driven by other considerations. In 2009, a task – named lexical substitution – was proposed as a possible solution to the sense discreteness problem.[17] The task consists of providing a substitute for a word in context that preserves the meaning of the original word (potentially, substitutes can be chosen from the full lexicon of the target language, thus overcoming discreteness).
Approaches and methods[edit]
There are two main approaches to WSD – deep approaches and shallow approaches.
Deep approaches presume access to a comprehensive body of world knowledge. These approaches are generally not considered to be very successful in practice, mainly because such a body of knowledge does not exist in a computer-readable format, outside very limited domains.[18] Additionally due to the long tradition in computational linguistics, of trying such approaches in terms of coded knowledge and in some cases, it can be hard to distinguish between knowledge involved in linguistic or world knowledge. The first attempt was that by Margaret Masterman and her colleagues, at the Cambridge Language Research Unit in England, in the 1950s. This attempt used as data a punched-card version of Roget’s Thesaurus and its numbered «heads», as an indicator of topics and looked for repetitions in text, using a set intersection algorithm. It was not very successful,[19] but had strong relationships to later work, especially Yarowsky’s machine learning optimisation of a thesaurus method in the 1990s.
Shallow approaches don’t try to understand the text, but instead consider the surrounding words. These rules can be automatically derived by the computer, using a training corpus of words tagged with their word senses. This approach, while theoretically not as powerful as deep approaches, gives superior results in practice, due to the computer’s limited world knowledge.
There are four conventional approaches to WSD:
- Dictionary- and knowledge-based methods: These rely primarily on dictionaries, thesauri, and lexical knowledge bases, without using any corpus evidence.
- Semi-supervised or minimally supervised methods: These make use of a secondary source of knowledge such as a small annotated corpus as seed data in a bootstrapping process, or a word-aligned bilingual corpus.
- Supervised methods: These make use of sense-annotated corpora to train from.
- Unsupervised methods: These eschew (almost) completely external information and work directly from raw unannotated corpora. These methods are also known under the name of word sense discrimination.
Almost all these approaches work by defining a window of n content words around each word to be disambiguated in the corpus, and statistically analyzing those n surrounding words. Two shallow approaches used to train and then disambiguate are Naïve Bayes classifiers and decision trees. In recent research, kernel-based methods such as support vector machines have shown superior performance in supervised learning. Graph-based approaches have also gained much attention from the research community, and currently achieve performance close to the state of the art.
Dictionary- and knowledge-based methods[edit]
The Lesk algorithm[20] is the seminal dictionary-based method. It is based on the hypothesis that words used together in text are related to each other and that the relation can be observed in the definitions of the words and their senses. Two (or more) words are disambiguated by finding the pair of dictionary senses with the greatest word overlap in their dictionary definitions. For example, when disambiguating the words in «pine cone», the definitions of the appropriate senses both include the words evergreen and tree (at least in one dictionary). A similar approach[21] searches for the shortest path between two words: the second word is iteratively searched among the definitions of every semantic variant of the first word, then among the definitions of every semantic variant of each word in the previous definitions and so on. Finally, the first word is disambiguated by selecting the semantic variant which minimizes the distance from the first to the second word.
An alternative to the use of the definitions is to consider general word-sense relatedness and to compute the semantic similarity of each pair of word senses based on a given lexical knowledge base such as WordNet. Graph-based methods reminiscent of spreading activation research of the early days of AI research have been applied with some success. More complex graph-based approaches have been shown to perform almost as well as supervised methods[22] or even outperforming them on specific domains.[3][23] Recently, it has been reported that simple graph connectivity measures, such as degree, perform state-of-the-art WSD in the presence of a sufficiently rich lexical knowledge base.[24] Also, automatically transferring knowledge in the form of semantic relations from Wikipedia to WordNet has been shown to boost simple knowledge-based methods, enabling them to rival the best supervised systems and even outperform them in a domain-specific setting.[25]
The use of selectional preferences (or selectional restrictions) is also useful, for example, knowing that one typically cooks food, one can disambiguate the word bass in «I am cooking basses» (i.e., it’s not a musical instrument).
Supervised methods[edit]
Supervised methods are based on the assumption that the context can provide enough evidence on its own to disambiguate words (hence, common sense and reasoning are deemed unnecessary). Probably every machine learning algorithm going has been applied to WSD, including associated techniques such as feature selection, parameter optimization, and ensemble learning. Support Vector Machines and memory-based learning have been shown to be the most successful approaches, to date, probably because they can cope with the high-dimensionality of the feature space. However, these supervised methods are subject to a new knowledge acquisition bottleneck since they rely on substantial amounts of manually sense-tagged corpora for training, which are laborious and expensive to create.
Semi-supervised methods[edit]
Because of the lack of training data, many word sense disambiguation algorithms use semi-supervised learning, which allows both labeled and unlabeled data. The Yarowsky algorithm was an early example of such an algorithm.[26] It uses the ‘One sense per collocation’ and the ‘One sense per discourse’ properties of human languages for word sense disambiguation. From observation, words tend to exhibit only one sense in most given discourse and in a given collocation.[27]
The bootstrapping approach starts from a small amount of seed data for each word: either manually tagged training examples or a small number of surefire decision rules (e.g., ‘play’ in the context of ‘bass’ almost always indicates the musical instrument). The seeds are used to train an initial classifier, using any supervised method. This classifier is then used on the untagged portion of the corpus to extract a larger training set, in which only the most confident classifications are included. The process repeats, each new classifier being trained on a successively larger training corpus, until the whole corpus is consumed, or until a given maximum number of iterations is reached.
Other semi-supervised techniques use large quantities of untagged corpora to provide co-occurrence information that supplements the tagged corpora. These techniques have the potential to help in the adaptation of supervised models to different domains.
Also, an ambiguous word in one language is often translated into different words in a second language depending on the sense of the word. Word-aligned bilingual corpora have been used to infer cross-lingual sense distinctions, a kind of semi-supervised system.[citation needed]
Unsupervised methods[edit]
Unsupervised learning is the greatest challenge for WSD researchers. The underlying assumption is that similar senses occur in similar contexts, and thus senses can be induced from text by clustering word occurrences using some measure of similarity of context,[28] a task referred to as word sense induction or discrimination. Then, new occurrences of the word can be classified into the closest induced clusters/senses. Performance has been lower than for the other methods described above, but comparisons are difficult since senses induced must be mapped to a known dictionary of word senses. If a mapping to a set of dictionary senses is not desired, cluster-based evaluations (including measures of entropy and purity) can be performed. Alternatively, word sense induction methods can be tested and compared within an application. For instance, it has been shown that word sense induction improves Web search result clustering by increasing the quality of result clusters and the degree diversification of result lists.[29][30] It is hoped that unsupervised learning will overcome the knowledge acquisition bottleneck because they are not dependent on manual effort.
Representing words considering their context through fixed size dense vectors (word embeddings) has become one of the most fundamental blocks in several NLP systems.[31][32][33] Even though most of traditional word embedding techniques conflate words with multiple meanings into a single vector representation, they still can be used to improve WSD.[34] A simple approach to employ pre-computed word embeddings to represent word senses is to compute the centroids of sense clusters.[35][36] In addition to word embeddings techniques, lexical databases (e.g., WordNet, ConceptNet, BabelNet) can also assist unsupervised systems in mapping words and their senses as dictionaries. Some techniques that combine lexical databases and word embeddings are presented in AutoExtend[37][38] and Most Suitable Sense Annotation (MSSA).[39] In AutoExtend,[38] they present a method that decouples an object input representation into its properties, such as words and their word senses. AutoExtend uses a graph structure to map words (e.g. text) and non-word (e.g. synsets in WordNet) objects as nodes and the relationship between nodes as edges. The relations (edges) in AutoExtend can either express the addition or similarity between its nodes. The former captures the intuition behind the offset calculus,[31] while the latter defines the similarity between two nodes. In MSSA,[39] an unsupervised disambiguation system uses the similarity between word senses in a fixed context window to select the most suitable word sense using a pre-trained word embedding model and WordNet. For each context window, MSSA calculates the centroid of each word sense definition by averaging the word vectors of its words in WordNet’s glosses (i.e., short defining gloss and one or more usage example) using a pre-trained word embeddings model. These centroids are later used to select the word sense with the highest similarity of a target word to its immediately adjacent neighbors (i.e., predecessor and successor words). After all words are annotated and disambiguated, they can be used as a training corpus in any standard word embedding technique. In its improved version, MSSA can make use of word sense embeddings to repeat its disambiguation process iteratively.
Other approaches[edit]
Other approaches may vary differently in their methods:
- Domain-driven disambiguation;[40][41]
- Identification of dominant word senses;[42][43][44]
- WSD using Cross-Lingual Evidence.[45][46]
- WSD solution in John Ball’s language independent NLU combining Patom Theory and RRG (Role and Reference Grammar)
- Type inference in constraint-based grammars[47]
Other languages[edit]
- Hindi : Lack of lexical resources in Hindi have hindered the performance of supervised models of WSD, while the unsupervised models suffer due to extensive morphology. A possible solution to this problem is the design of a WSD model by means of parallel corpora.[48][49] The creation of the Hindi WordNet has paved way for several Supervised methods which have been proven to produce a higher accuracy in disambiguating nouns.[50]
Local impediments and summary[edit]
The knowledge acquisition bottleneck is perhaps the major impediment to solving the WSD problem. Unsupervised methods rely on knowledge about word senses, which is only sparsely formulated in dictionaries and lexical databases. Supervised methods depend crucially on the existence of manually annotated examples for every word sense, a requisite that can so far[when?] be met only for a handful of words for testing purposes, as it is done in the Senseval exercises.
One of the most promising trends in WSD research is using the largest corpus ever accessible, the World Wide Web, to acquire lexical information automatically.[51] WSD has been traditionally understood as an intermediate language engineering technology which could improve applications such as information retrieval (IR). In this case, however, the reverse is also true: web search engines implement simple and robust IR techniques that can successfully mine the Web for information to use in WSD. The historic lack of training data has provoked the appearance of some new algorithms and techniques, as described in Automatic acquisition of sense-tagged corpora.
External knowledge sources[edit]
Knowledge is a fundamental component of WSD. Knowledge sources provide data which are essential to associate senses with words. They can vary from corpora of texts, either unlabeled or annotated with word senses, to machine-readable dictionaries, thesauri, glossaries, ontologies, etc. They can be[52][53] classified as follows:
Structured:
- Machine-readable dictionaries (MRDs)
- Ontologies
- Thesauri
Unstructured:
- Collocation resources
- Other resources (such as word frequency lists, stoplists, domain labels,[54] etc.)
- Corpora: raw corpora and sense-annotated corpora
Evaluation[edit]
Comparing and evaluating different WSD systems is extremely difficult, because of the different test sets, sense inventories, and knowledge resources adopted. Before the organization of specific evaluation campaigns most systems were assessed on in-house, often small-scale, data sets. In order to test one’s algorithm, developers should spend their time to annotate all word occurrences. And comparing methods even on the same corpus is not eligible if there is different sense inventories.
In order to define common evaluation datasets and procedures, public evaluation campaigns have been organized. Senseval (now renamed SemEval) is an international word sense disambiguation competition, held every three years since 1998: Senseval-1 (1998), Senseval-2 (2001), Senseval-3 (2004), and its successor, SemEval (2007). The objective of the competition is to organize different lectures, preparing and hand-annotating corpus for testing systems, perform a comparative evaluation of WSD systems in several kinds of tasks, including all-words and lexical sample WSD for different languages, and, more recently, new tasks such as semantic role labeling, gloss WSD, lexical substitution, etc. The systems submitted for evaluation to these competitions usually integrate different techniques and often combine supervised and knowledge-based methods (especially for avoiding bad performance in lack of training examples).
In recent years 2007-2012, the WSD evaluation task choices had grown and the criterion for evaluating WSD has changed drastically depending on the variant of the WSD evaluation task. Below enumerates the variety of WSD tasks:
Task design choices[edit]
As technology evolves, the Word Sense Disambiguation (WSD) tasks grows in different flavors towards various research directions and for more languages:
- Classic monolingual WSD evaluation tasks use WordNet as the sense inventory and are largely based on supervised/semi-supervised classification with the manually sense annotated corpora:[55]
- Classic English WSD uses the Princeton WordNet as it sense inventory and the primary classification input is normally based on the SemCor corpus.
- Classical WSD for other languages uses their respective WordNet as sense inventories and sense annotated corpora tagged in their respective languages. Often researchers will also tapped on the SemCor corpus and aligned bitexts with English as its source language
- Cross-lingual WSD evaluation task is also focused on WSD across 2 or more languages simultaneously. Unlike the Multilingual WSD tasks, instead of providing manually sense-annotated examples for each sense of a polysemous noun, the sense inventory is built up on the basis of parallel corpora, e.g. Europarl corpus.[56]
- Multilingual WSD evaluation tasks focused on WSD across 2 or more languages simultaneously, using their respective WordNets as its sense inventories or BabelNet as multilingual sense inventory.[57] It evolved from the Translation WSD evaluation tasks that took place in Senseval-2. A popular approach is to carry out monolingual WSD and then map the source language senses into the corresponding target word translations.[58]
- Word Sense Induction and Disambiguation task is a combined task evaluation where the sense inventory is first induced from a fixed training set data, consisting of polysemous words and the sentence that they occurred in, then WSD is performed on a different testing data set.[59]
Software[edit]
- Babelfy,[60] a unified state-of-the-art system for multilingual Word Sense Disambiguation and Entity Linking
- BabelNet API,[61] a Java API for knowledge-based multilingual Word Sense Disambiguation in 6 different languages using the BabelNet semantic network
- WordNet::SenseRelate,[62] a project that includes free, open source systems for word sense disambiguation and lexical sample sense disambiguation
- UKB: Graph Base WSD,[63] a collection of programs for performing graph-based Word Sense Disambiguation and lexical similarity/relatedness using a pre-existing Lexical Knowledge Base[64]
- pyWSD,[65] python implementations of Word Sense Disambiguation (WSD) technologies
See also[edit]
- Ambiguity
- Controlled natural language
- Entity linking
- Lesk algorithm
- Lexical substitution
- Part-of-speech tagging
- Polysemy
- Semeval
- Semantic unification
- Judicial interpretation
- Sentence boundary disambiguation
- Syntactic ambiguity
- Word sense
- Word sense induction
References[edit]
- ^ Weaver 1949.
- ^ Bar-Hillel 1964, pp. 174–179.
- ^ a b c Navigli, Litkowski & Hargraves 2007, pp. 30–35.
- ^ a b Pradhan et al. 2007, pp. 87–92.
- ^ Yarowsky 1992, pp. 454–460.
- ^ Mihalcea 2007.
- ^ A. Moro, A. Raganato, R. Navigli. Entity Linking meets Word Sense Disambiguation: a Unified Approach Archived 2014-08-08 at the Wayback Machine. Transactions of the Association for Computational Linguistics (TACL), 2, pp. 231-244, 2014.
- ^ Martinez, Angel R. (January 2012). «Part-of-speech tagging: Part-of-speech tagging». Wiley Interdisciplinary Reviews: Computational Statistics. 4 (1): 107–113. doi:10.1002/wics.195. S2CID 62672734.
- ^ Fellbaum 1997.
- ^ Snyder & Palmer 2004, pp. 41–43.
- ^ Navigli 2006, pp. 105–112.
- ^ Snow et al. 2007, pp. 1005–1014.
- ^ Lenat.
- ^ Palmer, Babko-Malaya & Dang 2004, pp. 49–56.
- ^ Edmonds 2000.
- ^ Kilgarrif 1997, pp. 91–113.
- ^ McCarthy & Navigli 2009, pp. 139–159.
- ^ Lenat & Guha 1989.
- ^ Wilks, Slator & Guthrie 1996.
- ^ Lesk 1986, pp. 24–26.
- ^ Diamantini, C.; Mircoli, A.; Potena, D.; Storti, E. (2015-06-01). «Semantic disambiguation in a social information discovery system». 2015 International Conference on Collaboration Technologies and Systems (CTS): 326–333. doi:10.1109/CTS.2015.7210442. ISBN 978-1-4673-7647-1. S2CID 13260353.
- ^ Navigli & Velardi 2005, pp. 1063–1074.
- ^ Agirre, Lopez de Lacalle & Soroa 2009, pp. 1501–1506.
- ^ Navigli & Lapata 2010, pp. 678–692.
- ^ Ponzetto & Navigli 2010, pp. 1522–1531.
- ^ Yarowsky 1995, pp. 189–196.
- ^ Mitkov, Ruslan (2004). «13.5.3 Two claims about senses». The Oxford Handbook of Computational Linguistics. OUP. p. 257. ISBN 978-0-19-927634-9.
- ^ Schütze 1998, pp. 97–123.
- ^ Navigli & Crisafulli 2010.
- ^ DiMarco & Navigli 2013.
- ^ a b Mikolov, Tomas; Chen, Kai; Corrado, Greg; Dean, Jeffrey (2013-01-16). «Efficient Estimation of Word Representations in Vector Space». arXiv:1301.3781 [cs.CL].
- ^ Pennington, Jeffrey; Socher, Richard; Manning, Christopher (2014). «Glove: Global Vectors for Word Representation». Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, PA, USA: Association for Computational Linguistics: 1532–1543. doi:10.3115/v1/d14-1162. S2CID 1957433.
- ^ Bojanowski, Piotr; Grave, Edouard; Joulin, Armand; Mikolov, Tomas (December 2017). «Enriching Word Vectors with Subword Information». Transactions of the Association for Computational Linguistics. 5: 135–146. doi:10.1162/tacl_a_00051. ISSN 2307-387X.
- ^ Iacobacci, Ignacio; Pilehvar, Mohammad Taher; Navigli, Roberto (2016). «Embeddings for Word Sense Disambiguation: An Evaluation Study». Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Berlin, Germany: Association for Computational Linguistics: 897–907. doi:10.18653/v1/P16-1085.
- ^ Bhingardive, Sudha; Singh, Dhirendra; V, Rudramurthy; Redkar, Hanumant; Bhattacharyya, Pushpak (2015). «Unsupervised Most Frequent Sense Detection using Word Embeddings». Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Denver, Colorado: Association for Computational Linguistics: 1238–1243. doi:10.3115/v1/N15-1132. S2CID 10778029.
- ^ Butnaru, Andrei; Ionescu, Radu Tudor; Hristea, Florentina (2017). «ShotgunWSD: An unsupervised algorithm for global word sense disambiguation inspired by DNA sequencing». Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: 916–926. arXiv:1707.08084.
- ^ Rothe, Sascha; Schütze, Hinrich (2015). «AutoExtend: Extending Word Embeddings to Embeddings for Synsets and Lexemes». Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics: 1793–1803. arXiv:1507.01127. Bibcode:2015arXiv150701127R. doi:10.3115/v1/p15-1173. S2CID 15687295.
- ^ a b Rothe, Sascha; Schütze, Hinrich (September 2017). «AutoExtend: Combining Word Embeddings with Semantic Resources». Computational Linguistics. 43 (3): 593–617. doi:10.1162/coli_a_00294. ISSN 0891-2017.
- ^ a b Ruas, Terry; Grosky, William; Aizawa, Akiko (December 2019). «Multi-sense embeddings through a word sense disambiguation process». Expert Systems with Applications. 136: 288–303. arXiv:2101.08700. doi:10.1016/j.eswa.2019.06.026. hdl:2027.42/145475. S2CID 52225306.
- ^ Gliozzo, Magnini & Strapparava 2004, pp. 380–387.
- ^ Buitelaar et al. 2006, pp. 275–298.
- ^ McCarthy et al. 2007, pp. 553–590.
- ^ Mohammad & Hirst 2006, pp. 121–128.
- ^ Lapata & Keller 2007, pp. 348–355.
- ^ Ide, Erjavec & Tufis 2002, pp. 54–60.
- ^ Chan & Ng 2005, pp. 1037–1042.
- ^ Stuart M. Shieber (1992). Constraint-based Grammar Formalisms: Parsing and Type Inference for Natural and Computer Languages. MIT Press. ISBN 978-0-262-19324-5.
- ^ Bhattacharya, Indrajit, Lise Getoor, and Yoshua Bengio. Unsupervised sense disambiguation using bilingual probabilistic models. Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004.
- ^ Diab, Mona, and Philip Resnik. An unsupervised method for word sense tagging using parallel corpora. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2002.
- ^ Manish Sinha, Mahesh Kumar, Prabhakar Pande, Laxmi Kashyap, and Pushpak Bhattacharyya. Hindi word sense disambiguation. In International Symposium on Machine Translation, Natural Language Processing and Translation Support Systems, Delhi, India, 2004.
- ^ Kilgarrif & Grefenstette 2003, pp. 333–347.
- ^ Litkowski 2005, pp. 753–761.
- ^ Agirre & Stevenson 2006, pp. 217–251.
- ^ Magnini & Cavaglià 2000, pp. 1413–1418.
- ^ Lucia Specia, Maria das Gracas Volpe Nunes, Gabriela Castelo Branco Ribeiro, and Mark Stevenson. Multilingual versus monolingual WSD Archived 2012-04-10 at the Wayback Machine. In EACL-2006 Workshop on Making Sense of Sense: Bringing Psycholinguistics and Computational Linguistics Together, pages 33–40, Trento, Italy, April 2006.
- ^ Els Lefever and Veronique Hoste. SemEval-2010 task 3: cross-lingual word sense disambiguation. Proceedings of the Workshop on Semantic Evaluations: Recent Achievements and Future Directions. June 04-04, 2009, Boulder, Colorado
- ^ R. Navigli, D. A. Jurgens, D. Vannella. SemEval-2013 Task 12: Multilingual Word Sense Disambiguation. Proc. of seventh International Workshop on Semantic Evaluation (SemEval), in the Second Joint Conference on Lexical and Computational Semantics (*SEM 2013), Atlanta, USA, June 14-15th, 2013, pp. 222-231.
- ^ Lucia Specia, Maria das Gracas Volpe Nunes, Gabriela Castelo Branco Ribeiro, and Mark Stevenson. Multilingual versus monolingual WSD Archived 2012-04-10 at the Wayback Machine. In EACL-2006 Workshop on Making Sense of Sense: Bringing Psycholinguistics and Computational Linguistics Together, pages 33–40, Trento, Italy, April 2006
- ^ Eneko Agirre and Aitor Soroa. Semeval-2007 task 02: evaluating word sense induction and discrimination systems. Proceedings of the 4th International Workshop on Semantic Evaluations, p.7-12, June 23–24, 2007, Prague, Czech Republic
- ^ «Babelfy». Babelfy. Retrieved 2018-03-22.
- ^ «BabelNet API». Babelnet.org. Retrieved 2018-03-22.
- ^ «WordNet::SenseRelate». Senserelate.sourceforge.net. Retrieved 2018-03-22.
- ^ «UKB: Graph Base WSD». Ixa2.si.ehu.es. Retrieved 2018-03-22.
- ^ «Lexical Knowledge Base (LKB)». Moin.delph-in.net. 2018-02-05. Retrieved 2018-03-22.
- ^ alvations. «pyWSD». Github.com. Retrieved 2018-03-22.
Works cited[edit]
- Agirre, E.; Lopez de Lacalle, A.; Soroa, A. (2009). «Knowledge-based WSD on Specific Domains: Performing better than Generic Supervised WSD» (PDF). Proc. of IJCAI.
- Agirre, E.; M. Stevenson. 2006. Knowledge sources for WSD. In Word Sense Disambiguation: Algorithms and Applications, E. Agirre and P. Edmonds, Eds. Springer, New York, NY.
- Bar-Hillel, Y. (1964). Language and information. Reading, MA: Addison-Wesley.
- Buitelaar, P.; B. Magnini, C. Strapparava and P. Vossen. 2006. Domain-specific WSD. In Word Sense Disambiguation: Algorithms and Applications, E. Agirre and P. Edmonds, Eds. Springer, New York, NY.
- Chan, Y. S.; H. T. Ng. 2005. Scaling up word sense disambiguation via parallel texts. In Proceedings of the 20th National Conference on Artificial Intelligence (AAAI, Pittsburgh, PA).
- Edmonds, P. 2000. Designing a task for SENSEVAL-2. Tech. note. University of Brighton, Brighton. U.K.
- Fellbaum, Christiane (1997). «Analysis of a handwriting task». Proc. of ANLP-97 Workshop on Tagging Text with Lexical Semantics: Why, What, and How? Washington D.C., USA.
- Gliozzo, A.; B. Magnini and C. Strapparava. 2004. Unsupervised domain relevance estimation for word sense disambiguation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP, Barcelona, Spain).
- Ide, N.; T. Erjavec, D. Tufis. 2002. Sense discrimination with parallel corpora. In Proceedings of ACL Workshop on Word Sense Disambiguation: Recent Successes and Future Directions (Philadelphia, PA).
- Kilgarriff, A. 1997. I don’t believe in word senses. Comput. Human. 31(2), pp. 91–113.
- Kilgarriff, A.; G. Grefenstette. 2003. Introduction to the special issue on the Web as corpus. Computational Linguistics 29(3), pp. 333–347
- Kilgarriff, Adam; Joseph Rosenzweig, English Senseval: Report and Results May–June, 2000, University of Brighton
- Lapata, M.; and F. Keller. 2007. An information retrieval approach to sense ranking. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (HLT-NAACL, Rochester, NY).
- Lenat, D. Archived at Ghostarchive and the Wayback Machine: «Computers versus Common Sense». YouTube. Retrieved 2008-12-10. (GoogleTachTalks on YouTube)
- Lenat, D.; R. V. Guha. 1989. Building Large Knowledge-Based Systems, Addison-Wesley
- Lesk; M. 1986. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. In Proc. of SIGDOC-86: 5th International Conference on Systems Documentation, Toronto, Canada.
- Litkowski, K. C. 2005. Computational lexicons and dictionaries. In Encyclopaedia of Language and Linguistics (2nd ed.), K. R. Brown, Ed. Elsevier Publishers, Oxford, U.K.
- Magnini, B; G. Cavaglià. 2000. Integrating subject field codes into WordNet. In Proceedings of the 2nd Conference on Language Resources and Evaluation (LREC, Athens, Greece).
- McCarthy, D.; R. Koeling, J. Weeds, J. Carroll. 2007. Unsupervised acquisition of predominant word senses. Computational Linguistics 33(4): 553–590.
- McCarthy, D.; R. Navigli. 2009. The English Lexical Substitution Task, Language Resources and Evaluation, 43(2), Springer.
- Mihalcea, R. 2007. Using Wikipedia for Automatic Word Sense Disambiguation. In Proc. of the North American Chapter of the Association for Computational Linguistics (NAACL 2007), Rochester, April 2007.
- Mohammad, S; G. Hirst. 2006. Determining word sense dominance using a thesaurus. In Proceedings of the 11th Conference on European chapter of the Association for Computational Linguistics (EACL, Trento, Italy).
- Navigli, R. 2006. Meaningful Clustering of Senses Helps Boost Word Sense Disambiguation Performance. Proc. of the 44th Annual Meeting of the Association for Computational Linguistics joint with the 21st International Conference on Computational Linguistics (COLING-ACL 2006), Sydney, Australia.
- Navigli, R.; A. Di Marco. Clustering and Diversifying Web Search Results with Graph-Based Word Sense Induction. Computational Linguistics, 39(3), MIT Press, 2013, pp. 709–754.
- Navigli, R.; G. Crisafulli. Inducing Word Senses to Improve Web Search Result Clustering. Proc. of the 2010 Conference on Empirical Methods in Natural Language Processing (EMNLP 2010), MIT Stata Center, Massachusetts, USA.
- Navigli, R.; M. Lapata. An Experimental Study of Graph Connectivity for Unsupervised Word Sense Disambiguation. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 32(4), IEEE Press, 2010.
- Navigli, R.; K. Litkowski, O. Hargraves. 2007. SemEval-2007 Task 07: Coarse-Grained English All-Words Task. Proc. of Semeval-2007 Workshop (SemEval), in the 45th Annual Meeting of the Association for Computational Linguistics (ACL 2007), Prague, Czech Republic.
- Navigli, R.;P. Velardi. 2005. Structural Semantic Interconnections: a Knowledge-Based Approach to Word Sense Disambiguation. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 27(7).
- Palmer, M.; O. Babko-Malaya and H. T. Dang. 2004. Different sense granularities for different applications. In Proceedings of the 2nd Workshop on Scalable Natural Language Understanding Systems in HLT/NAACL (Boston, MA).
- Ponzetto, S. P.; R. Navigli. Knowledge-rich Word Sense Disambiguation rivaling supervised systems. In Proc. of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), 2010.
- Pradhan, S.; E. Loper, D. Dligach, M. Palmer. 2007. SemEval-2007 Task 17: English lexical sample, SRL and all words. Proc. of Semeval-2007 Workshop (SEMEVAL), in the 45th Annual Meeting of the Association for Computational Linguistics (ACL 2007), Prague, Czech Republic.
- Schütze, H. 1998. Automatic word sense discrimination. Computational Linguistics, 24(1): 97–123.
- Snow, R.; S. Prakash, D. Jurafsky, A. Y. Ng. 2007. Learning to Merge Word Senses, Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL).
- Snyder, B.; M. Palmer. 2004. The English all-words task. In Proc. of the 3rd International Workshop on the Evaluation of Systems for the Semantic Analysis of Text (Senseval-3), Barcelona, Spain.
- Weaver, Warren (1949). «Translation» (PDF). In Locke, W.N.; Booth, A.D. (eds.). Machine Translation of Languages: Fourteen Essays. Cambridge, MA: MIT Press.
- Wilks, Y.; B. Slator, L. Guthrie. 1996. Electric Words: dictionaries, computers and meanings. Cambridge, MA: MIT Press.
- Yarowsky, D. Word-sense disambiguation using statistical models of Roget’s categories trained on large corpora. In Proc. of the 14th conference on Computational linguistics (COLING), 1992.
- Yarowsky, D. 1995. Unsupervised word sense disambiguation rivaling supervised methods. In Proc. of the 33rd Annual Meeting of the Association for Computational Linguistics.
External links and suggested reading[edit]
- Computational Linguistics Special Issue on Word Sense Disambiguation (1998)
- Evaluation Exercises for Word Sense Disambiguation The de facto standard benchmarks for WSD systems.
- Roberto Navigli. Word Sense Disambiguation: A Survey, ACM Computing Surveys, 41(2), 2009, pp. 1–69. An up-to-date state of the art of the field.
- Word Sense Disambiguation as defined in Scholarpedia
- Word Sense Disambiguation: The State of the Art (PDF) A comprehensive overview By Prof. Nancy Ide & Jean Véronis (1998).
- Word Sense Disambiguation Tutorial, by Rada Mihalcea and Ted Pedersen (2005).
- Well, well, well … Word Sense Disambiguation with Google n-Grams, by Craig Trim (2013).
- Word Sense Disambiguation: Algorithms and Applications, edited by Eneko Agirre and Philip Edmonds (2006), Springer. Covers the entire field with chapters contributed by leading researchers. www.wsdbook.org site of the book
- Bar-Hillel, Yehoshua. 1964. Language and Information. New York: Addison-Wesley.
- Edmonds, Philip & Adam Kilgarriff. 2002. Introduction to the special issue on evaluating word sense disambiguation systems. Journal of Natural Language Engineering, 8(4):279-291.
- Edmonds, Philip. 2005. Lexical disambiguation. The Elsevier Encyclopedia of Language and Linguistics, 2nd Ed., ed. by Keith Brown, 607–23. Oxford: Elsevier.
- Ide, Nancy & Jean Véronis. 1998. Word sense disambiguation: The state of the art. Computational Linguistics, 24(1):1-40.
- Jurafsky, Daniel & James H. Martin. 2000. Speech and Language Processing. New Jersey, USA: Prentice Hall.
- Litkowski, K. C. 2005. Computational lexicons and dictionaries. In Encyclopaedia of Language and Linguistics (2nd ed.), K. R. Brown, Ed. Elsevier Publishers, Oxford, U.K., 753–761.
- Manning, Christopher D. & Hinrich Schütze. 1999. Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press. Foundations of Statistical Natural Language Processing
- Mihalcea, Rada. 2007. Word sense disambiguation. Encyclopedia of Machine Learning. Springer-Verlag.
- Resnik, Philip and David Yarowsky. 2000. Distinguishing systems and distinguishing senses: New evaluation methods for word sense disambiguation, Natural Language Engineering, 5(2):113-133. [1]
- Yarowsky, David. 2001. Word sense disambiguation. Handbook of Natural Language Processing, ed. by Dale et al., 629–654. New York: Marcel Dekker.
-
Dr. Philip Edmonds, Sharp Laboratories of Europe, Edmund Halley Road, Oxford Science Park, Oxford OX4 4GB, U.K.
-
Dr. Eneko Agirre, University of the Basque Country, Donostia, Basque Country
In natural language processing, word sense disambiguation (WSD) is the
problem of determining which «sense» (meaning) of a word is activated by the use
of the word in a particular context, a process which appears to be
largely unconscious in people. WSD is a natural
classification problem: Given a word and its possible senses, as defined by a dictionary,
classify an occurrence of the word in context into one or more of its sense
classes. The features of the context (such as neighboring words)
provide the evidence for classification.
A famous example is to determine the sense of pen in the
following passage (Bar-Hillel 1960):
Little John was looking for his toy box. Finally he found it. The box was in the pen. John was very happy.
WordNet lists five senses for the word pen:
- pen — a writing implement with a point from which ink flows.
- pen — an enclosure for confining livestock.
- playpen, pen — a portable enclosure in which babies may be left to play.
- penitentiary, pen — a correctional institution for those convicted of major crimes.
- pen — female swan.
Research has progressed steadily to the point where WSD systems
achieve consistent levels of accuracy on a variety of word types and
ambiguities. A rich variety of
techniques have been researched, from dictionary-based methods that
use the knowledge encoded in lexical resources, to supervised
machine learning methods in which a classifier is trained for each distinct
word on a corpus of manually sense-annotated examples,
to completely unsupervised methods that cluster occurrences of words, thereby
inducing word senses.
Among these, supervised learning approaches have been the most successful algorithms to date.
Current accuracy is difficult to state without a host of caveats. On
English, accuracy at the coarse-grained (homograph) level is routinely above 90%, with
some methods on particular homographs achieving over 96%. On finer-grained sense distinctions, top accuracies from 59.1% to 69.0% have been
reported in recent evaluation exercises (SemEval-2007, Senseval-2), where the
baseline accuracy of the simplest possible algorithm of always choosing the
most frequent sense was 51.4% and 57%, respectively.
Contents
- 1 History
- 2 Applications
- 2.1 The utility of WSD
- 2.2 Machine translation
- 2.3 Information retrieval
- 2.4 Information extraction and knowledge acquisition
- 3 Methods
- 3.1 Dictionary- and knowledge-based methods
- 3.2 Supervised methods
- 3.3 Semi-supervised methods
- 3.4 Unsupervised methods
- 4 Evaluation
- 5 Why is WSD hard?
- 5.1 A sense inventory cannot be task-independent
- 5.2 Different algorithms for different applications
- 5.3 Word meaning does not divide up into discrete senses
- 6 References
- 7 External links
- 8 See also
History
WSD was first formulated as a distinct computational task during the
early days of machine translation in the 1940s, making it one of the
oldest problems in computational linguistics. Warren Weaver, in his famous 1949 memorandum on translation, first introduced the problem in a computational context. Early researchers
understood well the significance and difficulty of WSD. In fact,
Bar-Hillel (1960) used the above example to argue that WSD could not be solved by «electronic computer» because of
the need in general to model all world knowledge.
In the 1970s, WSD was a subtask of semantic
interpretation systems developed within the field of artificial
intelligence, but since WSD systems were largely rule-based and
hand-coded they were prone to a knowledge acquisition bottleneck.
By the 1980s large-scale lexical resources, such as the Oxford Advanced Learner’s Dictionary of Current English (OALD), became
available: hand-coding was replaced with knowledge automatically
extracted from these resources, but disambiguation was still
knowledge-based or dictionary-based.
In the 1990s, the statistical revolution swept through computational
linguistics, and WSD became a paradigm problem
on which to apply supervised machine learning techniques.
The 2000s saw supervised techniques reach a plateau in accuracy,
and so attention has shifted to coarser-grained senses, domain
adaptation, semi-supervised and unsupervised corpus-based systems,
combinations of different methods, and the return of knowledge-based
systems via graph-based methods. Still, supervised systems continue to
perform best.
Applications
Machine translation is the original and most obvious application for
WSD but WSD has actually been considered in almost every
application of language technology, including information retrieval,
lexicography, knowledge mining/acquisition and semantic interpretation, and
is becoming increasingly important in new research areas such as
bioinformatics and the Semantic Web.
The utility of WSD
There is no doubt that the above applications require and use word sense disambiguation
in one form or another. However, WSD as a separate module has not yet been shown to make
a decisive difference in any application. There are a few recent results
that show small positive effects in, for example, machine translation, but
WSD has also been shown to hurt performance, as is the case in well-known
experiments in information retrieval.
There are several possible reasons for this. First, the
domain of an application often constrains the number of senses a word
can have (e.g., one would not expect to see the ‘river side’ sense of
bank in a financial application), and so lexicons can and have
been constructed accordingly. Second, WSD might not be accurate enough
yet to show an effect and moreover the sense inventory used is
unlikely to match the specific sense distinctions required by the
application. Third, treating WSD as a separate component or module
may be misguided, as it might have to be more tightly integrated as an
implicit process (i.e., as mutual disambiguation, below).
Machine translation
WSD is required for lexical choice in MT for words that have different
translations for different senses. For example, in an English-French
financial news translator, the English noun change could translate
to either changement (‘transformation’) or monnaie (‘pocket
money’). However, most translation systems do not use a separate WSD
module. The lexicon is often pre-disambiguated for a given domain,
or hand-crafted rules are devised, or WSD is folded into a statistical
translation model, where words are
translated within phrases which thereby provide context.
Information retrieval
Ambiguity has to be resolved in some queries. For instance, given the
query «depression» should the system return documents about illness,
weather systems, or economics? Current IR systems (such as Web search
engines), like MT, do not use a WSD module; they rely on the user
typing enough context in the query to only retrieve documents relevant
to the intended sense (e.g., «tropical depression»). In a process
called mutual disambiguation, reminiscent of the Lesk method (below),
all the ambiguous words are disambiguated by virtue of the intended
senses co-occurring in the same document.
Information extraction and knowledge acquisition
In information extraction and text mining, WSD is required for the
accurate analysis of text in many applications. For instance, an
intelligence gathering system might need to flag up references to,
say, illegal drugs, rather than medical drugs. Bioinformatics
research requires the relationships between genes and gene products to
be catalogued from the vast scientific literature; however, genes and
their proteins often have the same name. More generally, the Semantic
Web requires automatic annotation of documents according to a
reference ontology. WSD is only beginning to be applied in these
areas.
Methods
There are four conventional approaches to WSD:
- Dictionary- and knowledge-based methods: These rely primarily on dictionaries, thesauri, and lexical knowledge bases, without using any corpus evidence.
- Supervised methods: These make use of sense-annotated corpora to train from.
- Semi-supervised or minimally-supervised methods: These make use of a secondary source of knowledge such as a small annotated corpus as seed data in a bootstrapping process, or a word-aligned bilingual corpus.
- Unsupervised methods: These eschew (almost) completely external information and work directly from raw unannotated corpora. These methods are also known under the name of word sense discrimination.
Dictionary- and knowledge-based methods
The Lesk method (Lesk 1986) is the seminal dictionary-based method. It
is based on the hypothesis that words used together in text are
related to each other and that the relation can be observed in the
definitions of the words and their senses. Two (or more) words are
disambiguated by finding the pair of dictionary senses with the
greatest word overlap in their dictionary definitions. For example, when disambiguating the words in
pine cone, the definitions of the appropriate senses both include the words
evergreen and tree (at least in one dictionary).
An alternative to the use of the definitions is to consider general
word-sense relatedness and to compute the semantic similarity of each
pair of word senses based on a given lexical knowledge-base such as
WordNet. Graph-based methods reminiscent of spreading-activation
research of the early days of AI research have been applied with
some success.
The use of selectional preferences (or selectional restrictions) are also useful. For example, knowing that one typically cooks food, one can disambiguate the word bass in
I am cooking bass (i.e., it’s not a musical instrument).
Supervised methods
Supervised methods are based on the assumption that the context can
provide enough evidence on its own to disambiguate words (hence, world
knowledge and reasoning are deemed unnecessary). Probably every
machine learning algorithm going has been applied to WSD, including
associated techniques such as feature selection, parameter
optimization, and ensemble learning. Support vector machines and
memory-based learning have been shown to be the most successful
approaches, to date, probably because they can cope with the
high-dimensionality of the feature space. However, these supervised
methods are subject to a new knowledge acquisition bottleneck since
they rely on substantial amounts of manually sense-tagged corpora for training, which are
laborious and expensive to create.
Semi-supervised methods
The bootstrapping approach starts from a small amount of seed data for
each word: either manually-tagged training examples or a small number
of surefire decision rules (e.g., play in the context of bass
almost always indicates the musical instrument). The seeds are used to
train an initial classifier, using any supervised method. This
classifier is then used on the untagged portion of the corpus to
extract a larger training set, in which only the most confident
classifications are included. The process repeats, each new classifier
being trained on a successively larger training corpus, until the
whole corpus is consumed, or until a given maximum number of iterations
is reached.
Other semi-supervised techniques use large quantities of untagged
corpora to provide co-occurrence information that supplements the
tagged corpora. These techniques have the potential to help in
the adaptation of supervised models to different domains.
Also, an ambiguous word in one language is often translated into
different words in a second language depending on the sense of the
word. Word-aligned bilingual corpora have been used to infer
cross-lingual sense distinctions, a kind of semi-supervised system.
Unsupervised methods
Unsupervised learning is the greatest challenge for WSD
researchers. The underlying assumption is that similar senses occur in
similar contexts, and thus senses can be induced from text by
clustering word occurrences using some measure of similarity of
context. Then, new occurrences of the word can be classified into the closest induced
clusters/senses. Performance has been lower than other methods, above,
but comparisons are difficult since senses induced must be mapped to a
known dictionary of word senses. Alternatively, if a mapping to a set
of dictionary senses is not desired, cluster-based evaluations (including
measures of entropy and purity) can be performed.
It is
hoped that unsupervised learning will overcome the knowledge
acquisition bottleneck because they are not dependent on manual
effort.
Evaluation
The evaluation of WSD systems requires a test corpus hand-annotated
with the target or correct senses, and assumes that such a corpus can
be constructed. Two main performance measures are used:
- Precision: the fraction of system assignments made that are correct
- Recall: the fraction of total word instances correctly assigned by a system
If a system makes an assignment for every word, then precision and
recall are the same, and can be called accuracy. This model has been
extended to take into account systems that return a set of senses with
weights for each occurrence.
There are two kinds of test corpora:
- Lexical sample: the occurrences of a small sample of target words need to be disambiguated, and
- All-words: all the words in a piece of running text need to be disambiguated.
The latter is deemed a more realistic form of evaluation, but the
corpus is more expensive to produce because human annotators
have to read the definitions for each word in the sequence every time
they need to make a tagging judgement, rather than once for a block of
instances for the same target word. In order to define common
evaluation datasets and procedures, public evaluation campaigns have
been organized. Senseval has been run three times: Senseval-1 (1998), Senseval-2 (2001), Senseval-3 (2004), and its successor, SemEval (2007), once.
Why is WSD hard?
This article discusses the common and traditional characterization of
WSD as an explicit and separate process of
disambiguation with respect to a fixed inventory of word senses. Words
are typically assumed to have a finite and discrete set of senses, a gross
simplification of the complexity of word meaning, as studied in lexical semantics.
While this characterization has been fruitful for research into WSD per se, it is somewhat at odds with what seems to
be needed in real applications, as discussed above.
WSD is hard for many reasons, three of which are discussed here.
A sense inventory cannot be task-independent
A task-independent sense inventory is not a coherent concept:
each task requires its own division of word meaning into senses
relevant to the task. For example, the ambiguity of mouse
(animal or device) is not relevant in English-French machine
translation, but is relevant in information retrieval. The opposite is
true of river, which requires a choice in French (fleuve
‘flows into the sea’, or rivière ‘flows into a river’).
Different algorithms for different applications
Completely different algorithms might be required by different
applications. In machine translation, the problem takes the form of
target word selection. Here the «senses» are words in the target
language, which often correspond to significant meaning distinctions
in the source language (bank could translate to French banque
‘financial bank’ or rive ‘edge of river’). In information
retrieval, a sense inventory is not necessarily required, because it
is enough to know that a word is used in the same sense in the query
and a retrieved document; what sense that is, is unimportant.
Word meaning does not divide up into discrete senses
Finally, the very notion of «word sense» is slippery and
controversial. Most people can agree in distinctions at the coarse-grained homograph level (e.g.,
pen as writing instrument or enclosure), but go down one level to
fine-grained polysemy, and disagreements arise. For example, in Senseval-2, which
used fine-grained sense distinctions, human
annotators agreed in only 85% of word occurrences. Word meaning is in
principle infinitely variable and context sensitive. It does not
divide up easily into distinct or discrete sub-meanings.
Lexicographers frequently discover in corpora loose and overlapping
word meanings, and standard or conventional meanings extended,
modulated, and exploited in a bewildering variety of ways. The art of
lexicography is to generalize from the corpus to definitions that
evoke and explain the full range of meaning of a word, making it seem like words are well-behaved semantically. However, it is
not at all clear if these same meaning distinctions are applicable in
computational applications, as the decisions of lexicographers are usually driven by other considerations.
References
Suggested reading
- Agirre, Eneko & Philip Edmonds (eds.). 2006. Word Sense Disambiguation: Algorithms and Applications. Dordrecht: Springer. www.wsdbook.org
- Bar-Hillel, Yehoshua. 1964. Language and Information. New York: Addison-Wesley.
- Edmonds, Philip & Adam Kilgarriff. 2002. Introduction to the special issue on evaluating word sense disambiguation systems. Journal of Natural Language Engineering, 8(4):279-291.
- Edmonds, Philip. 2005. Lexical disambiguation. The Elsevier Encyclopedia of Language and Linguistics, 2nd Ed., ed. by Keith Brown, 607-23. Oxford: Elsevier.
- Ide, Nancy & Jean Véronis. 1998. Word sense disambiguation: The state of the art. Computational Linguistics, 24(1):1-40.
- Jurafsky, Daniel & James H. Martin. 2000. Speech and Language Processing. New Jersey, USA: Prentice Hall.
- Lesk, Michael. 1986. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. Proceedings of SIGDOC-86: 5th International Conference on Systems Documentation, Toronto, Canada, 24-26.
- Manning, Christopher D. & Hinrich Schütze. 1999. Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press. http://nlp.stanford.edu/fsnlp/
- Mihalcea, Rada. 2007. Word sense disambiguation. Encyclopedia of Machine Learning. Springer-Verlag.
- Resnik, Philip and David Yarowsky. 2000. Distinguishing systems and distinguishing senses: New evaluation methods for word sense disambiguation, Natural Language Engineering, 5(2):113-133. http://www.cs.jhu.edu/~yarowsky/pubs/nle00.ps
- Schütze, Hinrich. 1998. Automatic word sense discrimination. Computational Linguistics, 24(1):97-123.
- Weaver, Warren. 1949. Translation. In Machine Translation of Languages: Fourteen Essays, ed. by Locke, W.N. and Booth, A.D. Cambridge, MA: MIT Press.
- Yarowsky, David. 1995. Unsupervised word sense disambiguation rivaling supervised methods. Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics, 189-196.http://www.cs.jhu.edu/~yarowsky/acl95.ps
- Yarowsky, David. 2000. Word sense disambiguation. Handbook of Natural Language Processing, ed. by Dale et al., 629-654. New York: Marcel Dekker.
Internal references
- Tomasz Downarowicz (2007) Entropy. Scholarpedia, 2(11):3901.
- Mark Aronoff (2007) Language. Scholarpedia, 2(5):3175.
External links
- Senseval website
- SemEval website
- WSD tutorial
See also
Linguistics,
Natural Language Processing
Challenges[]
Lack of labeled data: According to Resnik (1997)[1]:
«… not only the limited availability of such text at present, but skepticism that the situation will change any time soon. In marked contrast to annotated training material for part-of-speech tagging, (a) there is no coarse-level set of sense distinctions widely agreed upon (whereas part-of-speech tag sets tend to differ in the details);
(b) sense annotation has a comparatively high error rate (Miller, personal communication, reports an upper bound for human annotators of around 90%
for ambiguous cases, using a non-blind evaluation
method that may make even this estimate overly optimistic); and (c) no fully automatic method provides high enough quality output to support the «annotate automatically, correct manually» methodology used to provide high volume annotation by data
providers like the Penn Treebank project (Marcus et al., 1993)»
Features[]
- local features which represent the local context of a word usage, that is, features of a small number of words surrounding the target word, including part-of-speech tags, word forms, positions with respect to the target word, etc.;
- topical features which—in contrast to local features—define the general topic of a text or discourse, thus representing more general contexts (e.g., a window of words, a sentence, a phrase, a paragraph, etc.), usually as bags of words;
- syntactic features, representing syntactic cues and argument-head relations between the target word and other words within the same sentence (note that these words might be outside the local context);
- semantic features, representing semantic information, such as previously established senses of words in context, domain indicators, etc.
Approaches[]
A space of approaches to WSD according to the amount of supervision and knowledge used. (a) fully unsupervised methods, which do not use any amount of knowledge (not even sense inventories); (b) and (c) minimally supervised and semi-supervised approaches, requiring a minimal or partial amount of supervision, respectively; (d) supervised approaches (machine-learning classifiers); most knowledge-based approaches relying on structural properties (g), such as the graph structure of semantic networks, usually use more supervision and knowledge than those based on gloss overlap (e) or methods for determining word sense dominance (f). Finally, domain-driven approaches, which often exploit hand-coded domain labels, can be placed around point (h) if they include supervised components for estimating sense probabilities, or around point (i) otherwise. Taken from Navigli (2009).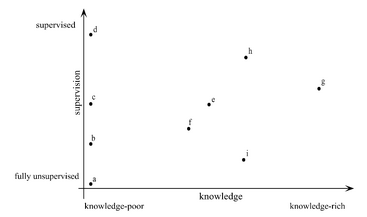
Supervised[]
Knowledge-rich[]
Algorithms[]
- Lesk[2]: performs WSD based on the overlap between the context surrounding the target word to be disambiguated and the definitions of its candidate senses (Kilgarriff and Rosenzweig, 2000). Given a target word w, this method assigns to w the sense whose gloss has the highest overlap (i.e. most words in common) with the context of w, namely the set of content words co-occurring with it in a pre-defined window.
- Simplified Lesk: the correct meaning of each word in a given context is determined individually by locating the sense that overlaps the most between its dictionary definition and the given context. Rather than simultaneously determining the meanings of all words in a given context, this approach tackles each word individually, independent of the meaning of the other words occurring in the same context.
- Extended Lesk: Due to the limited context provided by the WordNet glosses, Banerjee and Pedersen (2003) expand the gloss of each sense s to include words from the glosses of those synsets in a semantic relation with s.
- Degree Centrality: Starting from each sense s of the target word, it performs a depth-first search (DFS) of the WordNet graph and collects all the paths connecting s to senses of other words in context. As a result, a sentence graph is produced. A maximum search depth is established to limit the size of this graph. The sense of the target word with the highest vertex degree is selected.
Semi-supervised[]
Bootstrapping: From Niu et al. (2005)[3]: «bootstrapping algorithm works by iteratively classifying unlabeled examples and adding confidently classified examples into labeled dataset using a model learned from augmented labeled dataset in previous iteration.
Label propagation: Main ref: Niu et al. (2005)[3]. It’s not an algorithm to increase training data but to perform classification (i.e. it runs at test time only). It has been found to be more effective than bootstrapping and SVM (Niu et al. 2005).
Enriching WordNet[]
- WordNet++: Ponzetto & Navigli (2010)[4]
- Using random walk: Agirre et al. (2014)[5]
Datasets[]
- The SemEval-2013 task 12 dataset for multilingual WSD (Navigli et al., 2013), which consists of 13 documents in different domains, available in 5 languages. For each language, all noun occurrences were annotated using BabelNet, thereby providing Wikipedia and WordNet annotations wherever applicable. The number of mentions to be disambiguated roughly ranges from 1K to 2K per language in the different setups.
- The SemEval-2007 task 7 dataset for coarse-grained English all-words WSD (Navigli et al., 2007). We take into account only nominal mentions obtaining a dataset containing 1107 nouns to be disambiguated using WordNet.
- The SemEval-2007 task 17 dataset for fine-grained English all-words WSD (Pradhan et al., 2007). We considered only nominal mentions resulting in 158 nouns annotated with WordNet synsets.
- The Senseval-3 dataset for English all-words WSD (Snyder and Palmer, 2004), which contains 899 nouns to be disambiguated using WordNet.
- Babelfied English Wikipedia: from Flekova and Gurevych (2016)[6]: «Babelfied English Wikipedia (Scozzafava et al., 2015). To our knowledge, this is one of the largest published and evaluated sense-annotated corpora, containing over 500 million words, of which over 100 million are annotated with Babel synsets, with an estimated synset annotation accuracy of 77.8%.»
See also[]
- Word sense disambiguation examples
External links[]
- WSD on ACL wiki
- WSD state-of-the-art on ACL wiki (not populated yet)
References[]
- ↑ Resnik, P. (1997, April). Selectional preference and sense disambiguation. In Proceedings of the ACL SIGLEX Workshop on Tagging Text with Lexical Semantics: Why, What, and How (pp. 52-57).
- ↑ Lesk, M. (1986). Automatic sense disambiguation using machine readable dictionaries: how to tell a pine cone from an ice cream cone. In SIGDOC ’86: Proceedings of the 5th annual international conference on Systems documentation, pages 24-26, New York, NY, USA. ACM.
- ↑ 3.0 3.1 Zheng-Yu Niu, Dong-Hong Ji, and Chew Lim Tan. 2005. Word sense disambiguation using label propagation based semi-supervised learning. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pages 395–402. Association for Computational Linguistics.
- ↑ Ponzetto, S. P., & Navigli, R. (2010, July). Knowledge-rich word sense disambiguation rivaling supervised systems. In Proceedings of the 48th annual meeting of the association for computational linguistics (pp. 1522-1531). Association for Computational Linguistics.
- ↑ Agirre, E., de Lacalle, O. L., & Soroa, A. (2014). Random walks for knowledge-based word sense disambiguation. Computational Linguistics, 40(1), 57-84.
- ↑ Flekova, Lucie, and Iryna Gurevych. «Supersense Embeddings: A Unified Model for Supersense Interpretation, Prediction, and Utilization.» ACL 2016
Определение смысла слова, которое используется
В компьютерная лингвистика, определение смысловой неоднозначности (WSD ) — это открытая проблема, связанная с определением смысла из слова используется в предложении . Решение этой проблемы влияет на другие виды компьютерного письма, такие как дискурс, повышенная релевантность поисковых систем, разрешение анафоры, согласованность, и вывод.
человеческий мозг довольно хорошо разбирается в словесной неоднозначности. Этот естественный язык сформирован способом, который требует от него очень многого, и является отражением этой неврологической реальности. Другими словами, человеческий язык развивался таким образом, чтобы отражать (а также помогать формировать) врожденные способности, используемые нейронными сетями мозга. В компьютерных науках и информационные технологии, которые позволяют выполнять долгосрочным вызовом способности компьютеров выполнять обработка естественного языка и машинное обучение.
Было исследовано набор разнообразных методов, методов на основе словаря, использующих, закодированных в лексических ресурсах, до контролируемых методов машинного обучения, в которых классификатор обучается для каждого отдельного слова на корпусе примеров с ручной смысловой аннотацией, полностью неконтролируемым методам, которые группируют вхождения слов, тем самым вызывающим смысловое восприятие слов. Среди них подходы к обучению с учителем были наиболее успешными алгоритмами на сегодняшний день.
Точность текущих алгоритмов сложно констатировать без основок. На английском языке точность на уровне грубого помола (гомограф ) некоторых обычно превышает 90%, а методы на определенных омографах достигают более 96%. Что касается более тонких различий чувств, максимальная точность от 59,1% до 69,0% была зафиксирована в оценочных упражнениях (SemEval-2007, Senseval-2), где базовая точность простейшего возможного алгоритма выбора всегда наиболее частого смысла составила 51,4%. и 57% соответственно.
Содержание
- 1 О компании
- 2 История
- 3 Трудности
- 3.1 Различия между словарями
- 3.2 Тегирование части речи
- 3.3 Расхождения между судьями
- 3.4 Прагматика
- 3.5 Инвентаризация чувствительности и алгоритмов задач от задач
- 3.6 Дискретность смыслов
- 4 Подходы и методы
- 4.1 Методы, основанные на словарях и знаниях
- 4.2 Контролируемые методы
- 4.3 Полу-контролируемые методы
- 4.4 Неконтролируемые методы
- 4.5 Другие подходы
- 4.6 Другие языки
- 4.7 Местные препятствия и сводка
- 5 Внешние источники знаний
- 6 Оценка
- 6.1 Варианты разработки задачи
- 7 Программное обеспечение
- 8 См.
- 9 Примечания
- 10 Процитированные работы
- 11 Внешние ссылки и рекомендуемая литература
О
Устранение неоднозначности требует двух строгих входов: словарь для определения смыслов, которые должны быть устранены, и корпус данных языка для устранения неоднозначностей (в некоторых методах также требуется обучающий корпус языковых примеров). Задача WSD имеет два варианта: «» и «» задача. Первый включает неоднозначности в сопоставлении небольшой выборки целевых слов, которые были ранее выбраны, в то время как во втором фрагменте фрагмента текста должны быть устранены. Согласно одному и тому же целевому слову, каждый раз, когда им нужно сделать оценки для каждого в каждом раз, когда им нужно сделать оценку тегов, а не один раз для блока экземпляры для одного и того же целевого слова.
Чтобы прояснить, как все это работает, рассмотрим три примера различных смыслов, которые существуют для (письменного) слова «bass »:
- тип рыбы
- низкочастотные тона
- тип инструмента
и предложения:
- Я ловил морского окуня.
- Басовая линия песни слишком слабая.
Для людей, которые используют английский, в первом предложении, используется слово «bass (fish) », как в предыдущем смысле выше, так и во втором предложении., слово «бас (инструмент) » используется, как в последнем смысле, приведенном ниже. Разработка алгоритмов доказательств для воспроизведения этой способности человека часто может быть сложной сложной системой, о чем также неявная двусмысленность между «бас (звук) » и «бас (инструмент). «.
История
WSD была впервые сформулирована как отдельная вычислительная задача заре машинного перевода в 1940-х годах, что сделало ее одной из старейших проблем компьютерной лингвистики. Уоррен. Ранние исследователи хорошо понимали важность и сложность WSD. Фактически, Бар-Гиллель (1960) использовал приведенный выше пример, чтобы доказать, что Уивер в своем знаменитом меморандуме 1949 года впервые представил проблему в контексте вычислений. что WSD не может быть решена с помощью «электронного компьютера» из-за необходимости в целом моделировать все мировые знания.
В 1970-х годах WSD была подзадачей системной семантической интерпретации, разработанной в области искусственного интеллекта, начиная с семантики предпочтений Уилкса. Однако, поскольку системы WSD в основном основывались на правилах и кодировались вручную, они были склонны к узким местам в получении знаний.
К 1980-м годам стали доступн. ы крупномасштабные лексические ресурсы, такие как Oxford Advanced Learner’s Dictionary of Current English (OALD): ручное кодирование было заменено знаниями, автоматически извлеченными из этих ресурсов, но устранение неоднозначности по-прежнему основывалось на знаниях или словарях.
В 1990-х годах статистическая революция охватила вычислительную лингвистику, и WSD превратилась в парадигму проблемы, к которой можно было применить методы контролируемого машинного обучения.
В 2000-х годах контролируемые методы достижимости плато в точности, поэтому внимание переключилось на более грубые ощущения, адаптацию предметной области, полу-контролируемые и неконтролируемые системы на основе корпуса, комбинации различных методов и возвращение системы, основанные на знаниях, с помощью методов на основе графов. Тем не менее, контролируемые системы продолжают работать лучше всего.
Трудности
Различия между словарями
Одна проблема с устранением неоднозначности смысла слова — это определение, что такое чувства. По крайней мере, некоторые значения приведенному выше слову «бас». В других случаях, однако, различные смыслы через другое соединение (одно значение метафорическим или метонимическим расширением), и в таких случаях, слов на смыслы становится намного более сложным. трудно. Различные словари и тезаурусы обеспечат различное деление слов на значения. Одно из решений, которое использовали некоторые исследователи, — это выбрать конкретный словарь и просто использовать его набор смыслов. Однако в целом результаты исследований с использованием широких различий в чувствах были намного лучше, чем результаты исследований с использованием узких. Однако, учитывая отсутствие полноценной крупнозернистой системы чувств, большинство исследователей продолжают работать над мелкозернистой WSD.
Большинство исследований в области WSD выполняется с использованием WordNet в качестве справочного материала для английского языка. WordNet — это вычислительный лексикон, который кодирует понятия как наборы синонимов (например, понятие автомобиля кодируется как {автомобиль, авто, автомобиль, машина, автомобиль}). Другие ресурсы, использованные для устранения неоднозначности, включая Тезаурус Роджера и Википедию. Совсем недавно для многоязычного WSD использовался BabelNet, многоязычный энциклопедический словарь.
Теги части речи
В любом реальном тесте тегирование части-речи и смысловая маркировка очень связаны с другом, используемым созданием ограничения. И вопрос о том, должны ли эти задачи быть вместе или разделены, все еще не решены единогласно, но в последнее время ученые склонны проверять эти вещи по отдельности (например, в соревнованиях Senseval / SemEval части речи в качестве входных для текста для устранения неоднозначности).
Поучительно сравнить проблему неоднозначности смысла слова с проблемой тегирования части речи. Оба включают устранение неоднозначности или пометку слов, будь то чувства или части речи. Однако, используются для одного слова, не работают хорошо для другого, в основном потому, что часть речи слова в первую очередь определяется непосредственно соседними от одного до трех слов, как смысл слова может быть более удаленными словами.. Уровень для алгоритмов тегирования части речи в настоящее время намного выше, чем для WSD, при этом точность современного уровня техники составляет около 95% или лучше, по сравнению с точностью менее 75% в устранении неоднозначности слов с обучение с учителем. Эти цифры типичны для английского языка и могут сильно отличаться от данных для других языков.
Дисперсия между судьями
Другая проблема — Дисперсия между судьями дисперсия. Системы WSD обычно тестируются путем сравнения результатов выполнения задачи с результатами человека. Однако, в то время как связать части речи с текстом относительно легко, научить людей помечать чувства гораздо сложнее. Несмотря на то, что пользователи могут запоминать все случайные части речи, которые могут принимать, люди не могут запоминать все смыслы, которые может принимать слово. Более того, люди не согласны с поставленной задачей — приведите список смыслов и предложений, и люди не всегда соответствуются, какое слово принадлежит в каком смысле.
человеческая деятельность служит стандартом, это верхняя граница производительности компьютера. Однако эффективность человека намного лучше при крупнозернистых, чем мелкозернистых различий, так что это снова является причиной того, что исследования крупнозернистых различий были проверены в недавней оценке WSD.
Прагматика
Некоторые исследователи ИИ, такие как Дуглас Ленат, утверждают, что нельзя разбирать значения слов без здравого смысла. онтология. Этот лингвистический вопрос называется прагматикой. Например, сравнивая эти два предложения:
- «Джилл и Мэри — матери». — (каждый независимо друг от друга мать).
- «Джилл и Мэри — сестры». — (они сестры друг друга).
Чтобы правильно определить смысл слов, нужно знать факты здравого смысла. Более того, иногда требуется здравый смысл для устранения неоднозначности таких слов, как местоимения, в случае наличия в тексте анафор или катафор.
Смысловая инвентаризация и зависимость алгоритмов от задач
Смысловая инвентаризация, не зависящая от задачи, не является последовательной концепцией: каждая задача требует своего собственного разделения значений слова на смыслы, относящиеся к задаче. Например, двусмысленность «мышь » (животное или устройство) не актуальна для англо-французского машинного перевода, но актуальна в поиске информации. Обратное верно для слова «река», которое требует выбора во французском языке (fleuve «впадает в море» или rivière «впадает в реку»).
Кроме того, для разных приложений могут потребоваться совершенно разные алгоритмы. В машинном переводе проблема заключается в выборе целевого слова. Здесь «смыслы» — это слова на целевом языке, которые часто соответствуют различным значениям в исходном языке («банк» может переводиться с французского «банк», то есть «финансовый банк» или «рив»), то есть есть, «край реки »). При поиске информации инвентаризация смысла не обязательно требуется, потому что достаточно знать, что используется в одном и том же смысле в запросе и в извлеченном документе; какой это смысл, неважно.
Дискретность чувств
Наконец, само понятие «слово смысл » скользкий и неоднозначный. Большинство людей могут согласиться в различных на уровне крупнозернистого омографа (например, ручка как пишущий инструмент или корпус), но опускаются на один уровень до мелкозернистого многозначность, и возникает разногласия. Например, в Senseval-2, в котором использовались тонкие смысловые люди разные, аннотаторы-соглашались только в 85% случаев появления слов. Значение в принципе бесконечно вариативно и зависит от контекста. Его нелегко разделить на отдельные или отдельные подзначения. Лексикографы часто обнаруживают в корпусах нечеткие и частично совпадающие значения слов, а также стандартные или общепринятые значения, расширяемые, модулируемые и используемые пораз разнообразными способами. Искусство лексикографии состоит в том, чтобы делать обобщения от корпуса до определенных, которые создают и объясняют диапазон значений, создавая впечатление, что имеют слова хорошего семантического поведения. Совсем не ясно, применимы ли эти же различия значений в вычислительных приложениях, поскольку решения лексикографов обычно основываются на других соображениях. В 2009 году задача под названием лексическая замена была предложена как возможное решение проблемы дискретности смысла. Задача состоит в предоставлении замены для слова в контексте, сохраняющей значение исходного слова (раннее, могут быть выбраны из полного лексикона целевого языка, таким образом проходитьолевая дискретность).
Подходы и методы
Как и во всей обработки естественного языка, есть два основных подхода к WSD — и.
Глубинные подходы предполагают доступ к обширной совокупности мировых знаний. Такие знания, как «вы можете ловить рыбу, но не ловить низкочастотные звуки» и «песни содержат низкочастотные звуки как части, но не виды рыб», используемые для определения, в каком смысле «окунь». используется. Эти подходы не очень успешны на практике, как используется в машиночитаемом формате за пределами очень ограниченных областей. Однако, если бы такие знания действительно существовали, то глубокие подходы были намного точнее, чем поверхностные. В компьютерной лингвистике существует давняя традиция опробовать такие подходы с точки зрения закодированных знаний, а в некоторых случаях трудно четко сказать, является ли задействованное знание лингвистическим или мировым. Первая попытка была предпринята Маргарет Мастерман и ее коллегами в Англии в 1950-х годах. Эта попытка была использована в данных перфокарточной версии Тезауруса Роджера и его пронумерованные «главы» в индикаторе тем и искала повторы в тексте, используя в качестве заданного алгоритма пересечения. Он не был очень успешным, но имел прочные связи с более поздними работами, особенно с оптимизацией тезауруса методом машинного обучения Яровским в 1990-х годах.
Поверхностные подходы не пытаются понять текст. Они просто рассматривают окружающие слова, используя информацию, как «если у окуня есть слова море или рыбалка поблизости, это, вероятно, в смысле рыбы; если рядом с окунем есть слова музыка или песня, это, вероятно, в музыкальном смысле ». Эти правила могут быть автоматически выведены компьютером с использованием обучающего словаря, помеченных их смыслами. Этот подход, хотя теоретически не так эффективен, как глубокие подходы, на практике превосходные результаты из-за ограниченных знаний компьютера о мире. Однако его можно сбить с толку такими предложениями, как «Собаки лают на дерево», которые содержат слово «кора» рядом с деревом и собаками.
Существуют четыре стандартных подхода к WSD:
- Словарь — и методы, основанные на первых знаниях: они основаны в очереди на словарях, тезаурусах и лексических базах знаний, без использования каких-либо доказательства корпуса.
- Полу-контролируемые или минимально контролируемые методы : они используют вторичный источник знаний, такой как небольшой аннотированный корпус, в исходном процессе или выровненный по словам двуязычный корпус.
- Контролируемые методы : они используют аннотированные смысловые корпуса для обучения.
- Неконтролируемые методы : они избегают (почти) полностью внешней информации и работают непосредственно из необработанных неаннотированных корпусов. Эти методы также известны под названием . Смысла слов.
. Практически все эти подходы обычно работают, как они должны быть устранены в корпусе, и статистически анализируя эти n окружающих слов. Для обучения и устранения неоднозначности используются два неглубоких подхода: Наивные байесовские классификаторы и деревья решений. В недавнем исследовании методы на основе ядра, такие как вспомогательные векторные машины, показали превосходную производительность в контролируемом обучении. Подходы, основанные на графах, также привлекли большое внимание исследовательского сообщества и в настоящее время достигают показателей, близких к современным.
Словарные методы и методы, основанные на знаниях
Алгоритм Леска — это основанный на словарях метод. Он основан на гипотезе о том, что слова, используемые вместе в тексте, связаны друг с другом и что эту связь можно наблюдать в определениях слов и их значений. Два (или более) слова устраняются путем нахождения пары словарных смыслов с наибольшим перекрытием слов в их словарных определениях. Например, при устранении неоднозначности слов в слове «сосновая шишка» определения соответствующих смыслов включают слова вечнозеленое растение и дерево (по крайней мере, в одном словаре). Подобный подход ищет кратчайший путь между двумя словами: второе слово итеративно ищется среди определений каждого семантического варианта первого слова, затем среди определений каждого семантического варианта каждого слова в предыдущих определениях и так далее. Наконец, первое слово устраняется путем выбора семантического варианта, который минимизирует расстояние от первого до второго слова.
Альтернативой использованию определений является рассмотрение общего смысла родства и вычисление семантического сходства каждой пары значений слов на основе заданного лексическая база знаний, например WordNet. Графические методы, напоминающие исследования распространения активации первых дней исследований ИИ, применялись с некоторым успехом. Было показано, что более сложные подходы на основе графов работают почти так же хорошо, как контролируемые методы, или даже превосходят их в определенных областях. Недавно сообщалось, что простые меры связности графа, такие как степень, выполняют WSD на уровне современного уровня техники при наличии достаточно богатой лексической базы знаний. Кроме того, было показано, что автоматическая передача знаний в форме семантических отношений из Википедии в WordNet способствует развитию простых методов, основанных на знаниях, позволяя им конкурировать с лучшими контролируемыми системами и даже превосходить их. в настройках, зависящих от предметной области.
Использование предпочтений выбора (или) также полезно, например, зная, что обычно готовят еду, можно устранить неоднозначность слова «бас» в слове «Я готовлю басы» (т. е., это не музыкальный инструмент).
контролируемые методы
контролируемые методы основаны на предположении, что контекст сам по себе может предоставить достаточно свидетельств для устранения неоднозначности слов (отсюда здравыйсмысл и рассуждение считаются ненужными). Вероятно, каждый алгоритм машинного обучения был применен к WSD, включая связанные методы, такие как выбор функций и ансамблевое обучение. Машины опорных векторов и обучение на основе памяти оказались наиболее успешными подходами на сегодняшний день, вероятно, потому, что они могут справиться с высокой размерностью пространственных функций. Однако у этих контролируемых методов новое узкое место в получении знаний, созданных на основе огромного количества корпусов с ручными сенсорными метками, создается трудоемко и дорого.
Полу-контролируемые методы
Из-за отсутствия обучающих данных алгоритмы устранения неоднозначности словесного смысла использовать полу-контролируемое обучение, которое позволяет использовать как помеченные, так и немаркированные данные. Алгоритм Яровского был ранним примером такого алгоритма. Он использует свойства человеческих языков «Одно значение на словосочетание» и «Одно значение на словосочетание» для устранения неоднозначности слов. По наблюдениям, слова имеют тенденцию проявлять только один смысл в большей части данного дискурса и в данном словосочетании.
Подход начальной загрузки начинается с небольшого количества каждого слова: вручную помеченные обучающие примеры или небольшое количество верных правил принятия решений (например, «игра» в контексте «бас» почти всегда означает музыкальный инструмент). Начальные значения используются для обучения начального классификатора с использованием любого контролируемого метода. Затем этот классификатор используется в непомеченной части для извлечения большего обучающего набора, который включен только наиболее надежные классификации. Процесс повторяется, каждый новый классификатор обучается на последовательно увеличивающемся учебном корпусе, пока не будет израсходован весь корпус или пока не будет достигнуто заданное максимальное количество итераций.
Другие полу-контролируемые методы используют большие количества нетегированных корпусов для предоставления информации совместной работы, дополняющей помеченные корпуса. Эти методы могут помочь в адаптации контролируемых моделей к различным областям.
Кроме того, неоднозначное слово на одном языке часто переводится в разные слова на другом языке в зависимости от значения слова. Выровненные по словам двуязычные корпуса использовались для вывода частично межъязыковых смыслов различий, своего рода контролируемой системы.
Неконтролируемые методы
Неконтролируемое обучение — самая большая проблема для исследователей WSD. Основное предположение состоит в том, что существуют смыслы, которые могут быть вызваны из текста с помощью кластеризации в поисках слов с использованием некоторой меры сходства контекста, задача, называемая индукция смысла слова или различение. Затем новые вхождения слова можно классифицировать по ближайшим индуцированным группам / смыслам. Производительность ниже, чем у других методов, но сравнение способнены, индуцированные чувства, используемые в известном указанном слове значений. Если отображение на набор значений словаря нежелательно (включая энтропии и чистоты), может быть выполнено. В качестве альтернативы, методы индукции смысла слова могут быть протестированы и сравнены в приложении. Например, было показано, что индукция смысла улучшает кластеризацию результатов веб-поиска за счет повышения качества кластеров результатов и степени диверсификации списков результатов. Есть надежда, что обучение без учителя преодолеет узкое место приобретения знаний, потому что оно не зависит от ручных усилий.
Представление слов с учетом их контекста через плотные конструкции фиксированного размера (в словложения ) стало одним из самых фундаментальных блоков в нескольких системах НЛП. Несмотря на то, что большинство методов использует векторные изображения, которые можно использовать для улучшения WSD. В дополнение к методам встраивания слов лексические базы данных (например, WordNet, ConceptNet, BabelNet ) также могут помочь неконтролируемым системам отображать слова и их значения как словари. Некоторые методы, сочетающие лексические базы данных и наиболее подходящую для использования AutoExtend и подходящую смысловой аннотации (MSSA). В AutoExtend они предоставят метод, который разделяет входное представление объекта на его свойства, такие как слова и их значения слов. AutoExtend использует графа для сопоставления слов (например, текста) и объектов, не являющихся словами (например, synsets в WordNet ), как узлы, а отношения между узлами как ребер. Отношения (ребра) в AutoExtend могут выражать сложение или сходство между его узлами. Первый отражает интуицию, лежащую в основе расчета с ущербом, а второй определяет сходство между двумя узлами. В MSSA неконтролируемая система устранения неоднозначности использует контекстное контекстное меню для выбора наиболее подходящего смысла слова с помощью созданной модели встраивания слов и WordNet. Для каждого контекстного окна MSSA вычисляет центроид определения смысла каждого слова путем усреднения векторов его слов в Глоссы WordNet (т. Е. Краткий определяющий глянец и один или несколько примеров использования) с использованием использования обученного слова модель вложений. Эти центроиды позже используются для выбора смысла наиболее близкими соседями целевого слова с его ближайшими последователями (т. Е. Словами-предшественниками и последователями). После того, как все слова аннотированы и устранены неоднозначности, их можно использовать в обучающем корпусе в любой стандартной технике встраивания словосочетаний. В своей улучшенной версии MSSA может использовать вложения смысла слова для итеративного повторения процесса устранения неоднозначности.
Другие подходы
Другие подходы могут отличаться по своим методам:
- Устранение неоднозначности на основе операционной семантики логики по умолчанию.
- Устранение неоднозначности на основе предметной области;
- Идентификация доминирующих смыслов слов;
- WSD с использованием кросс- языковых свидетельств.
- Решение WSD в независимом от языка NLU Джона Болла, объединяющее теорию патома [1] и RRG (Role and Reference Grammar)
- Вывод типа в грамматиках на основе ограничений
Другие языки
- Хинди : Отсутствие лексические ресурсы на хинди препятствовали работе контролируемых моделей WSD, в то время как неконтролируемые модели страдают из-за обширной морфологии. Возможное решение этой проблемы — создание модели WSD с помощью параллельных корпусов. Создание хинди WordNet проложило путь для нескольких контролируемых методов, как было доказано, более высокой точности в устранении неоднозначности существительных.
Местные препятствия и краткое содержание
Узкое место получения знаний — возможно, главное препятствие на пути решения проблемы WSD. Неконтролируемые методы представлены на знания о смыслах слов, которые очень редко сформулированы в словарях и лексических базах данных. Контролируемые методы в решающей степени зависят от наличия вручную аннотированных примеров для каждого смысла, требование, которое может быть выполнено только для нескольких слов в тестировании, как это сделано в Senseval упражнений.
Одно из самых многообещающих тенденций в исследовании WSD — это использование самого большого корпуса, когда-либо доступного, World Wide Web, для автоматического получения лексической информации. WSD традиционно понимает как технология разработки промежуточного языка, которая может улучшить такие приложения, как поиск информации (IR). Однако в этом случае верно и обратное: поисковые системы реализуют простые и надежные методы IR, которые могут успешно добывать в Интернете информацию для использования в WSD. Историческая нехватка обучающих данных спровоцировала появление новых алгоритмов и методов, как описано в Автоматическое получение корпусов с тегами смысла.
Внешние источники <знания247>
Знания — фундаментальный компонент WSD. Источники предоставляют данные, которые необходимы для связи смыслов со словами. Они могут анализироваться от корпусов текстов, без надписей или аннотированных смыслами слов, до машиночитаемых словрей, тезаурусов, глоссариев, онтологий и т. Д. Можно классифицировать следующим образом:
Структурированные:
- Машинные- читаемые словари (MRD)
- Онтологии
- Тезаурусы
Неструктурированные:
- Ресурсы для совместного размещения
- Другие ресурсы (например, списки частотности слов, списки стоп-слов и т. Д.)
- Корпуса : необработанные корпуса и корпуса с сенсорными комментариями
Оценка
Сравнение и оценка различных систем WSD ужаснительны из-за различных наборов тестов, наборов чувств и т. д. и ресурсы знаний приняты. До организации оценочных систем оценивания на внутренних, часто небольших, наборах данных. Чтобы проверить свой алгоритм, разработчики должны тратить время на аннотирование всех в поисках слов. И сравнение методов даже в одном и том же корпусе недопустимо, если есть разные смысловые инвентаризации.
Для определения общих наборов данных и оценки были организованы общественные оценочные кампании. Senseval (теперь переименованный в SemEval ) — это международный конкурс по устранению неоднозначности, который проводится каждые три года с 1998 года: Senseval-1 (1998), Senseval-2 (2001), Senseval-3 (2004) и его преемник, SemEval (2007). Целью конкурса является организация различных лекций, подготовка и ручное аннотирование корпуса для тестовых систем, выполнение сравнительной оценки систем WSD в нескольких случаях, включая полнословный и лексический образец WSD для разных языков, а в последнее время, новые задачи, такие как обозначение семантических ролей, лексическая замена и т. д. Системы, представленные для оценки на эти соревнования, обычно объединяют различные методы и часто сочетаются контролируемые и основанные на знаниях методы (особенно для избегая плохой работы из-за отсутствия обучающих примеров).
В последние годы выбор задач оценки WSD увеличился, и критерий оценки WSD резко изменился в зависимости от варианта задачи оценки WSD. Ниже перечислено разнообразие задач WSD:
Выбор дизайна задачи
По мере развития технологий задачи устранения неоднозначности слов (WSD) становятся все более разнообразными в разных направлениях исследований и для большего количества языков:
- Классические одноязычные оценочные задачи WSD используют WordNet в инвентарного анализа и в степени основаны на контролируемой / полууправляемой классификации с аннотированными корпусами вручную:
- Классический английский WSD использует Princeton WordNet, поскольку он обеспечивает инвентаризацию, входные данные первичной классификации обычно основаны на корпусе SemCor.
- Классический WSD для других языков использует свои соответствующие WordNet в качестве реестров смысла и корпусов с комментариями, помеченными на соответствующих языках. Часто исследователи также обращаются к корпусу SemCor и выравнивают битексты с английским, поскольку его исходным языком
- Межъязыковая задача оценки WSD также сосредоточена на WSD на 2 или более языках одновременно. В отличие от многоязычных задач WSD, вместо предоставления вручную смысловых примеров для каждого смысла многозначного существительного, смысловой перечень строится на основе параллельных корпусов, например Europarl corpus.
- Многоязычные оценочные задания WSD были сосредоточены на WSD на 2 или более языках одновременно, с использованием соответствующих WordNets в качестве смысловой инвентаризации или BabelNet в качестве многоязычной смысловой инвентаризации. Он возник на основе оценочных задач Translation WSD, которые выполнялись в Senseval-2. Популярным подходом является выполнение одноязычного WSD с последующим отображением смыслов исходного языка в соответствующие переводы целевых слов.
- Задача наведения смысла слов и устранения неоднозначности — это комбинированная оценка задачи, при которой сначала индуцируется инвентаризация смысла из фиксированного обучающего набора данных, состоящего из многозначных слов и предложения, в котором они встречаются, затем WSD выполняется на другом наборе данных тестирования.
Программное обеспечение
- Babelfy, унифицированная современная система для многоязычного устранения неоднозначности в словах и связывания сущностей
- BabelNet API, Java API для многоязычного устранения неоднозначности в словах на основе знаний на 6 различных языках с использованием семантической сети BabelNet
- WordNet :: SenseRelate, проект, который включает бесплатные системы с открытым исходным кодом для устранения неоднозначности смысла слов и устранения неоднозначности лексического образца
- UKB: Graph Base WSD, набор программ для выполнения устранения неоднозначности в словах на основе графов и лексическое сходство / relatedness с использованием уже существующей базы лексических знаний
- pyWSD, python, реализации технологий Word Sense Disambiguation (WSD)
См. также
 Портал лингвистики
Портал лингвистики
- Неоднозначность
- Контролируемый естественный язык
- Связывание сущностей
- Алгоритм Леска
- Лексическая подстановка
- Тегирование части речи
- Многозначность
- Семевал
- Семантическая унификация
- Судебная интерпретация
- Устранение неоднозначности границы предложения
- Синтаксис двусмысленность
- смысл слова
- индукция смысла слова
примечания
цитируемые работы
- Agirre, E.; Lopez de Lacalle, A.; Сороа, А. (2009). «WSD, основанный на знаниях, в определенных доменах: более эффективный, чем общий контролируемый WSD» (PDF). Proc. из IJCAI. CS1 maint: ref = harv (ссылка )
- Агирре, Э.; М. Стивенсон. 2006. Источники знаний для WSD. В Устранение неоднозначности в словах: алгоритмы и приложения, E. Agirre и P. Edmonds, Eds. Springer, New York, NY.
- Bar-Hillel, Y. (1964). Язык и информация. Reading, MA: Addison-Wesley. CS1 maint: ref = harv (ссылка )
- Buitelaar, P.; B. Magnini, C. Strapparava и P. Vossen. 2006. WSD для конкретных доменов. Устранение неоднозначности в словесном смысле: алгоритмы и приложения, Э. Агирре и П. Эдмондс, Eds. Springer, New York, NY.
- Chan, YS; HT Ng. 2005. Расширение масштабов устранения неоднозначности слов с помощью параллельных текстов. In Proceedings of the 20th National Conference on Artificial Intelligence (AAAI, Pittsburgh, PA).
- Эдмондс, П. 2000. Разработка задания для SENSEVAL-2. Техническое примечание. Университет Брайтона, Брайтон. Великобритания
- Феллбаум, Кристиан (1997 «Анализ рукописного задания». Материалы семинара ANLP-97 по разметке текста с помощью лексической семантики: Why, Wh у, а как? Вашингтон, округ Колумбия, США. CS1 maint: ref = harv (ссылка )
- Gliozzo, A.; B. Magnini and C. Strapparava. 2004. Неконтролируемая оценка релевантности предметной области для устранения неоднозначности смысла слов. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP, Barcelona, Spain).
- Ide, N.; T. Erjavec, D. Tufis. 2002. Смысловая дискриминация с параллельные корпуса. In Proceedings of ACL Workshop on Word Sense Disambiguation: Recent Successes and Future Directions (Philadelphia, PA).
- Kilgarriff, A. 1997. Я не верю в смысл слов. Comput. Human. 31 (2), pp. 91–113.
- Kilgarriff, A.; G. Grefenstette. 2003. Введение в специальный выпуск в Интернете как корпус. Computational Linguistics 29 (3), pp. 333–347
- Килгаррифф, Адам; Джозеф Розенцвейг, English Senseval: Report and Results, май – июнь, 2000 г., Брайтонский университет
- Lapata, M.; and F. Keller. 2007. Информационно-поисковый подход к смысловому рангу Инж. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (HLT-NAACL, Rochester, NY).
- Ленат, Д. «Компьютеры против здравого смысла. «. Проверено 10 декабря 2008 г. (GoogleTachTalks на YouTube)
- Lenat, D.; Р. В. Гуха. 1989. Построение больших систем, основанных на знаниях, Эддисон-Уэсли
- Леск; М. 1986. Автоматическое устранение неоднозначности с использованием машиночитаемых словарей: Как отличить сосновую шишку от рожка мороженого. В Proc. SIGDOC-86: 5-я Международная конференция по системной документации, Торонто, Канада.
- Литковски, К. С. 2005. Вычислительные лексиконы и словари. В Энциклопедии языка и лингвистики (2-е изд.), К. Р. Браун, под ред. Elsevier Publishers, Оксфорд, Великобритания
- Магнини, Б. Г. Кавалья. 2000. Интеграция кодов предметных полей в WordNet. В материалах 2-й конференции по языковым ресурсам и оценке (LREC, Афины, Греция).
- McCarthy, D.; Р. Кёлинг, Дж. Уидс, Дж. Кэрролл. 2007. Неконтролируемое приобретение преобладающих значений слов. Компьютерная лингвистика 33 (4): 553–590.
- McCarthy, D.; Р. Навильи. 2009. The English Lexical Substitution Task, Language Resources and Evaluation, 43 (2), Springer.
- Mihalcea, R. 2007. Использование Википедии для автоматического устранения неоднозначности слов. В Proc. Североамериканского отделения Ассоциации компьютерной лингвистики (NAACL 2007), Рочестер, апрель 2007 г.
- Mohammad, S; Г. Херст. 2006. Определение преобладания смысла слов с использованием тезауруса. В материалах 11-й конференции Европейского отделения Ассоциации компьютерной лингвистики (EACL, Тренто, Италия).
- Navigli, R. 2006. Значимая кластеризация смыслов помогает повысить эффективность устранения неоднозначности слов. Proc. 44-го ежегодного собрания Ассоциации компьютерной лингвистики совместно с 21-й Международной конференцией по компьютерной лингвистике (COLING-ACL 2006), Сидней, Австралия.
- Navigli, R.; А. Ди Марко. Кластеризация и диверсификация результатов веб-поиска с помощью Word Sense Induction на основе графиков. Компьютерная лингвистика, 39 (3), MIT Press, 2013, стр. 709–754.
- Navigli, R.; Г. Крисафулли. Использование словесных чувств для улучшения кластеризации результатов веб-поиска. Proc. конференции 2010 г. по эмпирическим методам обработки естественного языка (EMNLP 2010), MIT Stata Center, Массачусетс, США.
- Navigli, R.; М. Лапата. Экспериментальное исследование связности графов для неконтролируемого устранения неоднозначности смысла слов. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 32 (4), IEEE Press, 2010.
- Navigli, R.; К. Литковски, О. Харгрейвс. 2007. SemEval-2007 Задание 07: Общее задание на английском языке со всеми словами. Proc. семинара Semeval-2007 (SemEval ) на 45-м ежегодном собрании Ассоциации компьютерной лингвистики (ACL 2007), Прага, Чешская Республика.
- Navigli, R.; P. Веларди. 2005. Структурные семантические взаимосвязи: основанный на знаниях подход к устранению смысловой неоднозначности. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 27 (7).
- Palmer, M.; О. Бабко-Малая и Х. Т. Данг. 2004. Различная степень детализации для разных приложений. В материалах 2-го семинара по масштабируемым системам понимания естественного языка в HLT / NAACL (Бостон, Массачусетс).
- Ponzetto, S.P.; Р. Навильи. Богатый знаниями Word Sense Disambiguation, конкурирующий с контролируемыми системами. В Proc. 48-го Annual Meeting of the Association for Computational Linguistics (ACL), 2010.
- Pradhan, S.; E. Loper, D. Dligach, M. Palmer. 2007. SemEval-2007 Task 17: English lexical sample, SRL and all words. Proc. of Semeval-2007 Workshop (SEMEVAL), in the 45th Annual Meeting of the Association for Computational Linguistics (ACL 2007), Prague, Czech Republic.
- Schütze, H. 1998. Automatic word sense discrimination. Computational Linguistics, 24(1): 97–123.
- Snow, R.; S. Prakash, D. Jurafsky, A. Y. Ng. 2007. Learning to Merge Word Senses, Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL).
- Snyder, B.; M. Palmer. 2004. The English all-words task. In Proc. of the 3rd International Workshop on the Evaluation of Systems for the Semantic Analysis of Text (Senseval-3), Barcelona, Spain.
- Weaver, Warren (1949). «Translation» (PDF). In Locke, W.N.; Booth, A.D. (eds.). Machine Translation of Languages: Fourteen Essays. Cambridge, MA: MIT Press.CS1 maint: ref=harv (link)
- Wilks, Y.; B. Slator, L. Guthrie. 1996. Electric Words: dictionaries, computers and meanings. Cambridge, MA: MIT Press.
- Yarowsky, D. Word-sense disambiguation using statistical models of Roget’s categories trained on large corpora. In Proc. of the 14th conference on Computational linguistics (COLING), 1992.
- Yarowsky, D. 1995. Unsupervised word sense disambiguation rivaling supervised methods. In Proc. of the 33rd Annual Meeting of the Association for Computational Linguistics.
External links and suggested reading
- Computational Linguistics Special Issue on Word Sense Disambiguation (1998)
- Evaluation Exercises for Word Sense Disambiguation The de facto standard benchmarks for WSD systems.
- Roberto Navigli. Word Sense Disambiguation: A Survey, ACM Computing Surveys, 41(2), 2 009, pp. 1–69. An up-to-date state of the art of the field.
- Word Sense Disambiguation as defined in Scholarpedia
- Word Sense Disambiguation: The State of the Art (PDF) A comprehensive overview By Prof. Nancy Ide Jean Véronis (1998).
- Word Sense Disambiguation Tutorial, by Rada Mihalcea and Ted Pedersen (2005).
- Well, well, well… Word Sense Disambiguation with Google n-Grams, by Craig Trim (2013).
- Word Sense Disambiguation: Algorithms and Applications, edited by Eneko Agirre and Philip Edmonds (2006), Springer. Covers the entire field with chapters contributed by leading researchers. www.wsdbook.org site of the book
- Bar-Hillel, Yehoshua. 1964. Language and Information. New York: Addison-Wesley.
- Edmonds, Philip Adam Kilgarriff. 2002. Introduction to the special issue on evaluating word sense disambiguation systems. Journal of Natural Language Engineering, 8(4):279-291.
- Edmonds, Philip. 2005. Lexical disambiguation. The Elsevier Encyclopedia of Language and Linguistics, 2nd Ed., ed. by Keith Brown, 607-23. Oxford: Elsevier.
- Ide, Nancy Jean Véronis. 1998. Word sense disambiguation: The state of the art. Computational Linguistics, 24(1):1-40.
- Jurafsky, Daniel James H. Martin. 2000. Speech and Language Processing. New Jersey, USA: Prentice Hall.
- Litkowski, K. C. 2005. Computational lexicons and dictionaries. In Encyclopaedia of Language and Linguistics (2nd ed.), K. R. Brown, Ed. Elsevier Publishers, Oxford, U.K., 753–761.
- Manning, Christopher D. Hinrich Schütze. 1999. Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press. Foundations of Statistical Natural Language Processing
- Mihalcea, Rada. 2007. Word sense disambiguation. Encyclopedia of Machine Learning. Springer-Verlag.
- Resnik, Philip and David Yarowsky. 2000. Distinguishing systems and distinguishing senses: New evaluation methods for word sense disambiguation, Natural Language Engineering, 5(2):113-133. [2]
- Yarowsky, David. 2001. Word sense disambiguation. Handbook of Natural Language Processing, ed. by Dale et al., 629-654. New York: Marcel Dekker.
We understand that words have different meanings based on the context of its usage in the sentence. If we talk about human languages, then they are ambiguous too because many words can be interpreted in multiple ways depending upon the context of their occurrence.
Word sense disambiguation, in natural language processing (NLP), may be defined as the ability to determine which meaning of word is activated by the use of word in a particular context. Lexical ambiguity, syntactic or semantic, is one of the very first problem that any NLP system faces. Part-of-speech (POS) taggers with high level of accuracy can solve Word’s syntactic ambiguity. On the other hand, the problem of resolving semantic ambiguity is called WSD (word sense disambiguation). Resolving semantic ambiguity is harder than resolving syntactic ambiguity.
For example, consider the two examples of the distinct sense that exist for the word “bass” −
-
I can hear bass sound.
-
He likes to eat grilled bass.
The occurrence of the word bass clearly denotes the distinct meaning. In first sentence, it means frequency and in second, it means fish. Hence, if it would be disambiguated by WSD then the correct meaning to the above sentences can be assigned as follows −
-
I can hear bass/frequency sound.
-
He likes to eat grilled bass/fish.
Evaluation of WSD
The evaluation of WSD requires the following two inputs −
A Dictionary
The very first input for evaluation of WSD is dictionary, which is used to specify the senses to be disambiguated.
Test Corpus
Another input required by WSD is the high-annotated test corpus that has the target or correct-senses. The test corpora can be of two types &minsu;
-
Lexical sample − This kind of corpora is used in the system, where it is required to disambiguate a small sample of words.
-
All-words − This kind of corpora is used in the system, where it is expected to disambiguate all the words in a piece of running text.
Approaches and Methods to Word Sense Disambiguation (WSD)
Approaches and methods to WSD are classified according to the source of knowledge used in word disambiguation.
Let us now see the four conventional methods to WSD −
Dictionary-based or Knowledge-based Methods
As the name suggests, for disambiguation, these methods primarily rely on dictionaries, treasures and lexical knowledge base. They do not use corpora evidences for disambiguation. The Lesk method is the seminal dictionary-based method introduced by Michael Lesk in 1986. The Lesk definition, on which the Lesk algorithm is based is “measure overlap between sense definitions for all words in context”. However, in 2000, Kilgarriff and Rosensweig gave the simplified Lesk definition as “measure overlap between sense definitions of word and current context”, which further means identify the correct sense for one word at a time. Here the current context is the set of words in surrounding sentence or paragraph.
Supervised Methods
For disambiguation, machine learning methods make use of sense-annotated corpora to train. These methods assume that the context can provide enough evidence on its own to disambiguate the sense. In these methods, the words knowledge and reasoning are deemed unnecessary. The context is represented as a set of “features” of the words. It includes the information about the surrounding words also. Support vector machine and memory-based learning are the most successful supervised learning approaches to WSD. These methods rely on substantial amount of manually sense-tagged corpora, which is very expensive to create.
Semi-supervised Methods
Due to the lack of training corpus, most of the word sense disambiguation algorithms use semi-supervised learning methods. It is because semi-supervised methods use both labelled as well as unlabeled data. These methods require very small amount of annotated text and large amount of plain unannotated text. The technique that is used by semisupervised methods is bootstrapping from seed data.
Unsupervised Methods
These methods assume that similar senses occur in similar context. That is why the senses can be induced from text by clustering word occurrences by using some measure of similarity of the context. This task is called word sense induction or discrimination. Unsupervised methods have great potential to overcome the knowledge acquisition bottleneck due to non-dependency on manual efforts.
Applications of Word Sense Disambiguation (WSD)
Word sense disambiguation (WSD) is applied in almost every application of language technology.
Let us now see the scope of WSD −
Machine Translation
Machine translation or MT is the most obvious application of WSD. In MT, Lexical choice for the words that have distinct translations for different senses, is done by WSD. The senses in MT are represented as words in the target language. Most of the machine translation systems do not use explicit WSD module.
Information Retrieval (IR)
Information retrieval (IR) may be defined as a software program that deals with the organization, storage, retrieval and evaluation of information from document repositories particularly textual information. The system basically assists users in finding the information they required but it does not explicitly return the answers of the questions. WSD is used to resolve the ambiguities of the queries provided to IR system. As like MT, current IR systems do not explicitly use WSD module and they rely on the concept that user would type enough context in the query to only retrieve relevant documents.
Text Mining and Information Extraction (IE)
In most of the applications, WSD is necessary to do accurate analysis of text. For example, WSD helps intelligent gathering system to do flagging of the correct words. For example, medical intelligent system might need flagging of “illegal drugs” rather than “medical drugs”
Lexicography
WSD and lexicography can work together in loop because modern lexicography is corpusbased. With lexicography, WSD provides rough empirical sense groupings as well as statistically significant contextual indicators of sense.
Difficulties in Word Sense Disambiguation (WSD)
Followings are some difficulties faced by word sense disambiguation (WSD) −
Differences between dictionaries
The major problem of WSD is to decide the sense of the word because different senses can be very closely related. Even different dictionaries and thesauruses can provide different divisions of words into senses.
Different algorithms for different applications
Another problem of WSD is that completely different algorithm might be needed for different applications. For example, in machine translation, it takes the form of target word selection; and in information retrieval, a sense inventory is not required.
Inter-judge variance
Another problem of WSD is that WSD systems are generally tested by having their results on a task compared against the task of human beings. This is called the problem of interjudge variance.
Word-sense discreteness
Another difficulty in WSD is that words cannot be easily divided into discrete submeanings.
109 papers with code •
13 benchmarks
• 16 datasets
The task of Word Sense Disambiguation (WSD) consists of associating words in context with their most suitable entry in a pre-defined sense inventory. The de-facto sense inventory for English in WSD is WordNet.
For example, given the word “mouse” and the following sentence:
“A mouse consists of an object held in one’s hand, with one or more buttons.”
we would assign “mouse” with its electronic device sense (the 4th sense in the WordNet sense inventory).
Benchmarks
These leaderboards are used to track progress in Word Sense Disambiguation
Libraries
Use these libraries to find Word Sense Disambiguation models and implementations