

Australian father sets world record with more than 3,200 push ups in an hour
Brazil’s Supreme Court orders Bolsonaro to testify on January 8 riots
SpaceX’s Starship rocket, the most powerful ever built, receives government approval for launch
Top French court backs unpopular plans to raise retirement age to 64
Fuzzy first photo of a black hole gets a sharp makeover
Two years after its first flight, Ingenuity helicopter goes for 50 on Mars
A fireball landed in the US last week, and now there’s a reward to find it
Houthis try to reassure skeptics they won’t seek full control of Yemen, as Saudis eye exit
Female bear that killed jogger gets stay of execution in Italy
Paper airplane designed by Boeing engineers breaks world distance record
Juice mission launches to explore Jupiter’s icy ocean worlds
France braces for ruling on Macron’s plan to raise retirement age
World leaders are lining up to meet Xi Jinping. Should the US be worried?

The convicted murderer suspected of faking his own death in a South African prison fire

South Korea is paying ‘lonely young people’ $500 a month to re-enter society

Важно! Представленные ниже способы подходят для решения задачи в том случае, если разрыв страницы был выполнен инструментами MS Word, а не многочисленным нажатием Enter.
Способ 1: Удаление вручную
Откройте документ и установите курсор вплотную к первой таблице. Нажмите кнопку Delete столько раз (чаще всего два), сколько необходимо для слияния двух объектов.
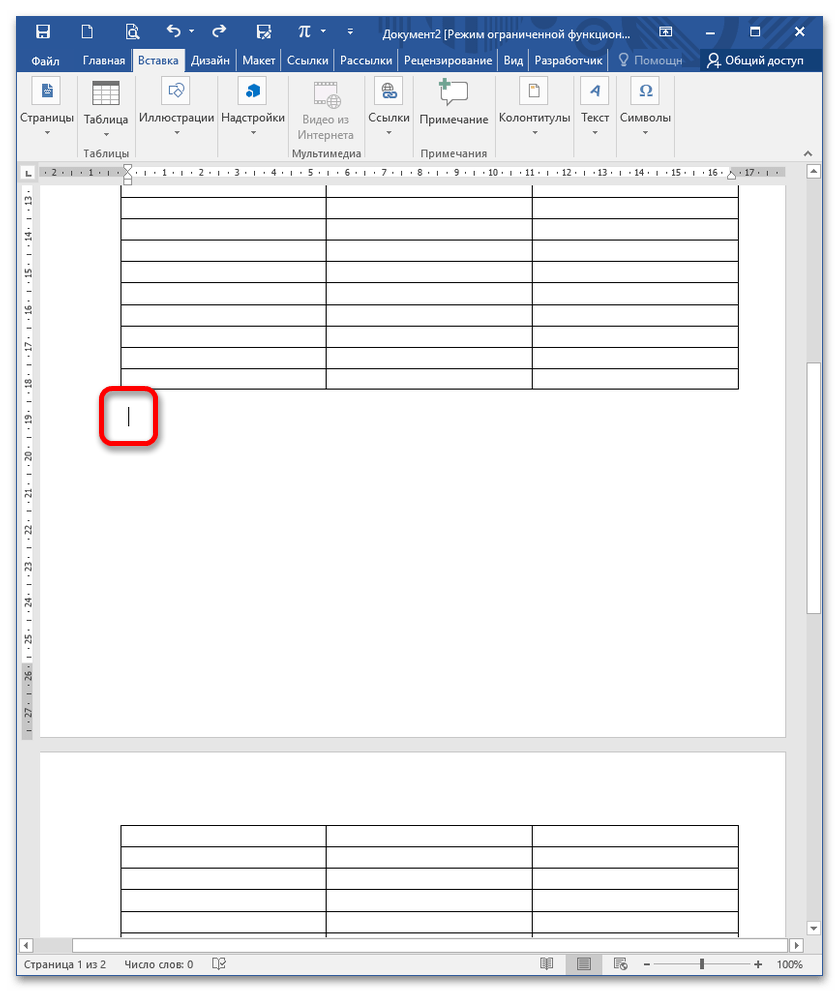
Вариация этого способа заключается в удалении самого разрыва страницы, который просматривается через CTRL+SHIFT+8 (выше основной клавиатуры). Нажав указанное сочетание, вы увидите надпись «Разрыв страницы». Наведите мышку на левое поле напротив этой строки и кликните один раз.
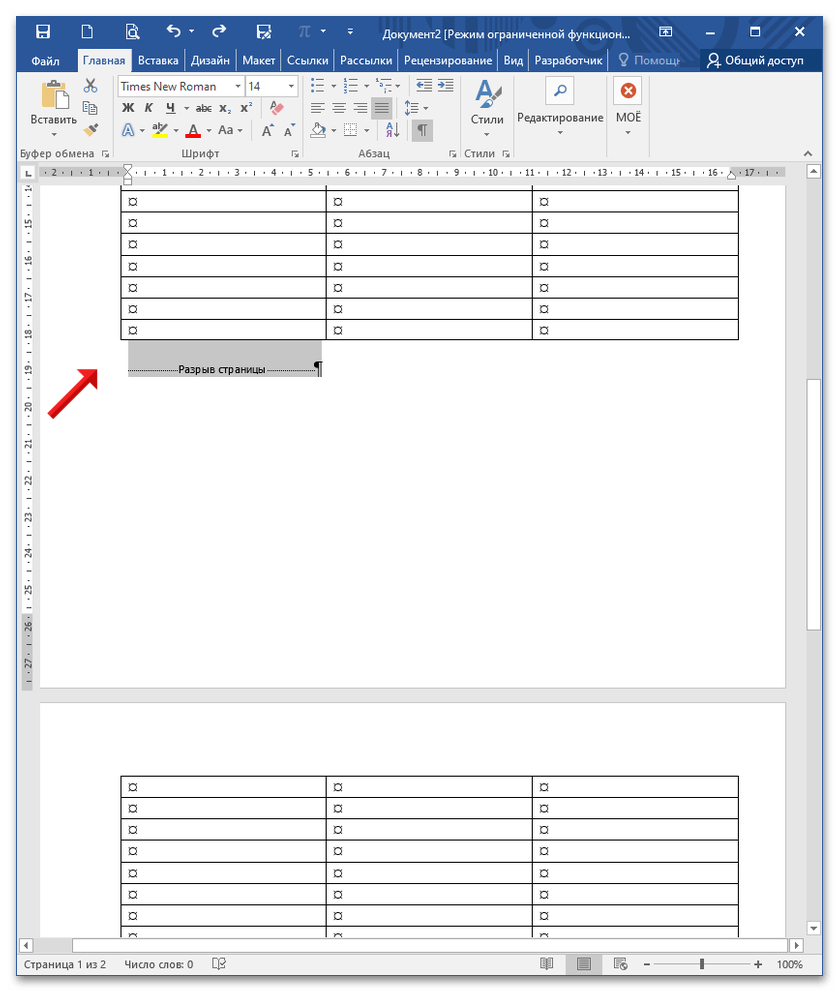
Вся строка выделится, дважды нажмите Delete (первый удаляет разрыв, второй – пустую строку). Воспользуйтесь клавишами CTRL+SHIFT+8, чтобы убрать отображение непечатных символов.
Подробнее: Как убрать разрыв страницы в Microsoft Word
Способ 2: Вырезание
Выделите нижнюю таблицу, нажав на «снежинку» в левом верхнем углу, и затем воспользуйтесь клавишами CTRL+X (объект вырезается и помещается в буфер обмена).
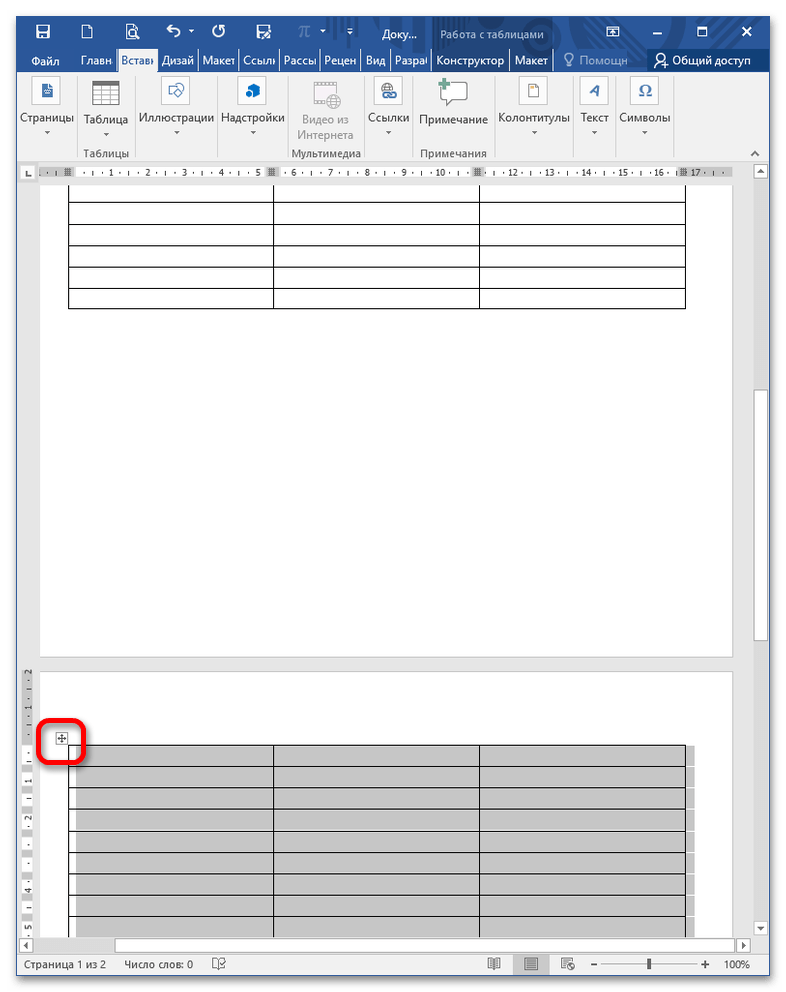
Установите курсор вплотную к верхней таблице и зажмите CTRL+V (вставка из буфера обмена). Оба объекта сольются в один, но только если в параметрах вставки выбрать опцию «Объединить таблицы».
Способ 3: Замена
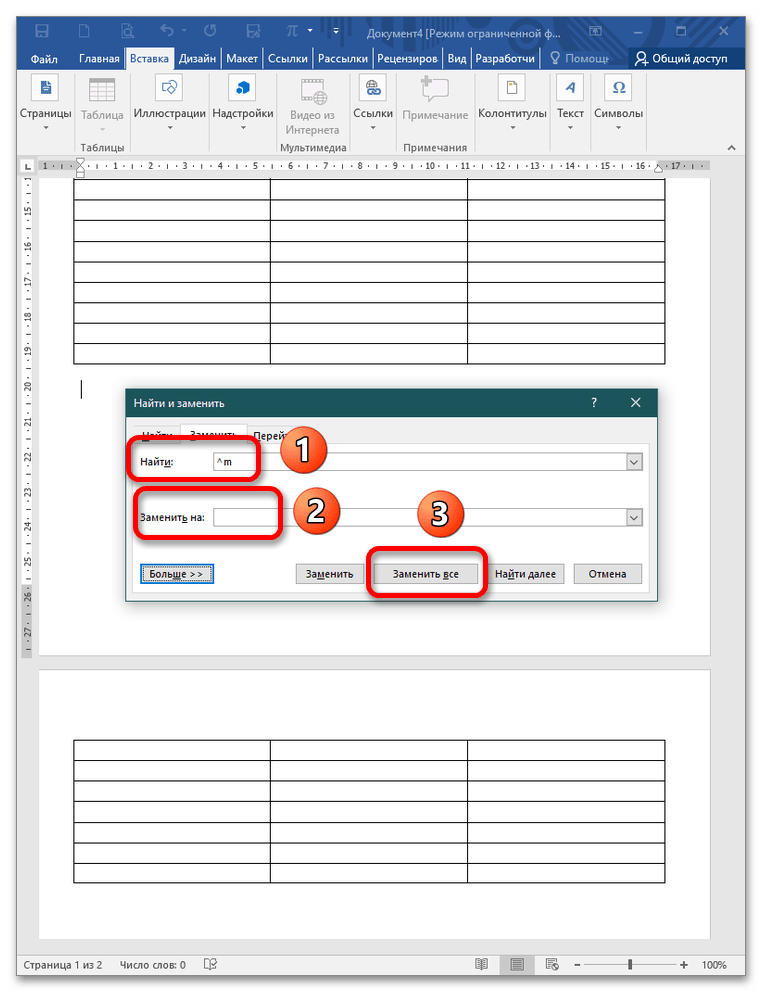
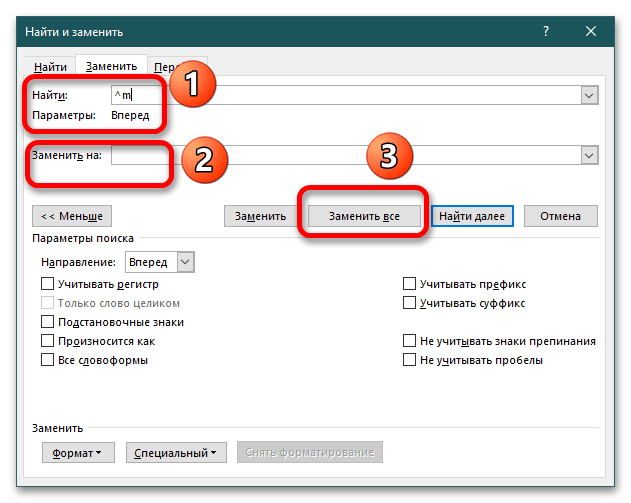
- В открытом документе нажмите CTRL+H для вызова окна «Найти и заменить». В графе «Найти» пропишите команду
^m, в поле «Заменить на» оставьте пустую строку без пробелов и щелкните «Заменить все». Помните, что поиск начинается с того места, где расположен курсор. Поэтому предварительно выделите ту часть документа, где должна произойти замена. Если в документе много таблиц, то слияние произойдет во всех объектах. - Если отобразить непечатные знаки, можно увидеть, что пустая строка между двумя таблицами сохранилась, но разрыв был удален. В таком случае воспользуйтесь кнопкой Delete, чтобы убрать лишний абзац.
Подробнее: Использование средства замены в Ворде
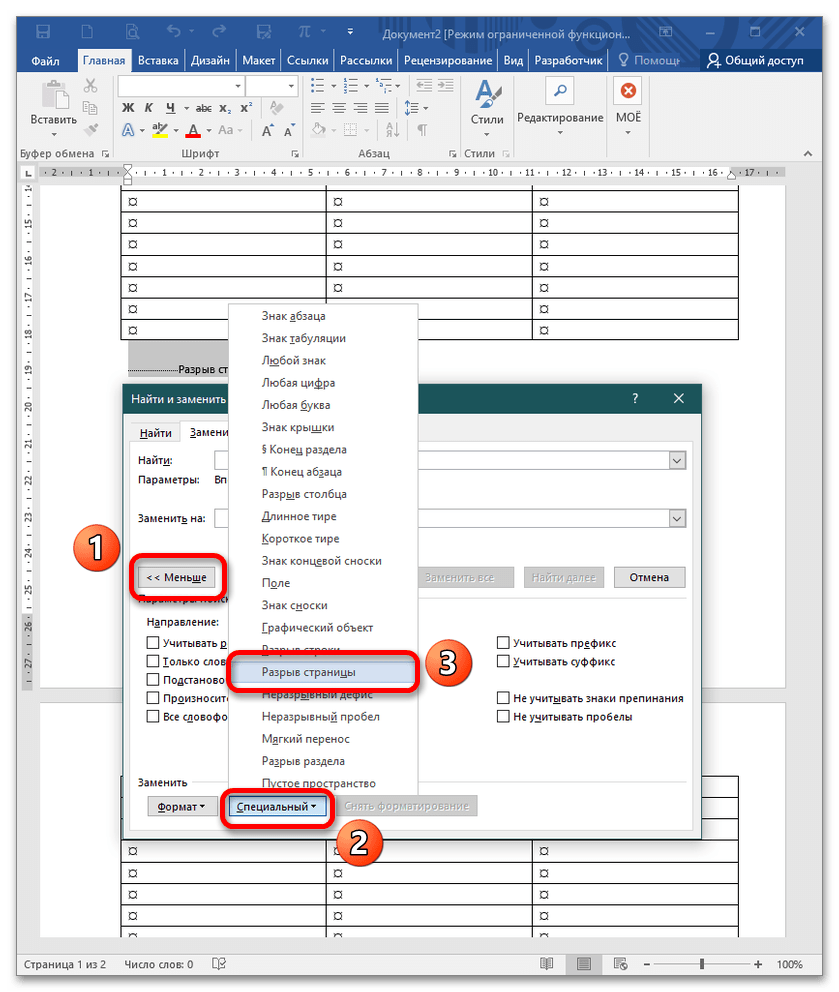
- Если не получается прописать команду вручную, можно открыть настройки окна «Найти и заменить». Для этого вызовите его через CTRL+H, воспользуйтесь кнопкой «Больше» (после клика она превратится в «Меньше») и щелкните на «Специальный». В раскрытом списке выберите «Разрыв страницы».
- Команда автоматически пропишется в поле «Найти», далее повторите пункт 1 текущей инструкции.

Еще статьи по данной теме:
Помогла ли Вам статья?
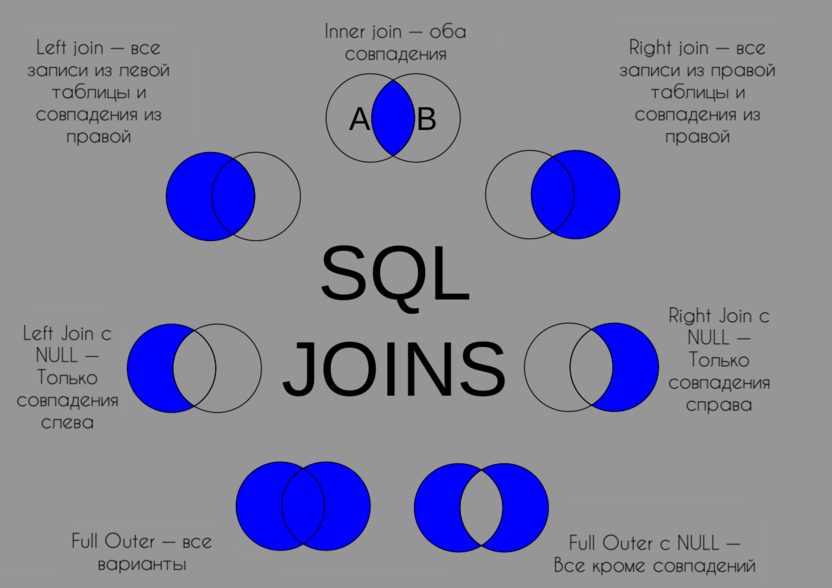
Поговорим о том, как работает Join в SQL-базах данных. Для чего нужна эта директива, какие возможности она открывает и как правильно ее использовать.
Что такое SQL Join?
SQL Join – одна из наиболее часто используемых команд в SQL-синтаксисе. Она используется для поиска информации в базах данных по заранее определенным критериям. В частности, Join отвечает за объединение нескольких групп данных в единый поток информации.
И это действительно необходимо, потому что в 100% случаев контент в реляционных базах данных с поддержкой SQL-синтаксиса делится на множество таблиц, фильтровать данные в которых можно с помощью специальных команд и запросом информации из общего пула таблиц.
SQL Join помогает настроить фильтр поиска в базе данных, опираясь на взаимосвязи между различными элементами БД и их отличительные черты (теги, ID, наименования и т.п.).
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
SQL Inner Join
Этот режим объединения результатов поиска в базах данных SQL включается автоматически. Если вы не укажете намеренно тип Join, то сработает именно Inner Join. С помощью него можно указать сразу два критерия (две таблицы) и по ним отсеять контент.
Достаточно прописать SQL-запрос в духе:
SELECT * FROM table-1 JOIN table-2 ON table-1.parameter=table-2.parameter WHERE table-1.parameter IS ‘myData’
Фактически мы пытаемся выудить данные из первой таблицы и объединить их с данными из второй таблицы, при этом фильтруя только те записи, в которых совпадает значение параметра. В первой таблице оно приравнивается к myData.
На практике это может использоваться на сайте с музыкальными инструментами, например. Можно запрашивать гитары конкретного бренда, при этом еще и выбирая дополнительное условие в духе количества струн.
SELECT * FROM SevenStringGuitars JOIN Ibanez ON SevenStringGuitar.brandId=Ibanez.brandId
Таким SQL-запросом мы можем отфильтровать все инструменты бренда Ibanez в категории «Гитары» с 7 струнами.
SQL Self Join
Запросы Self Join полезны в тех случаях, когда необходимо выполнить фильтрацию контента внутри одной таблицы. Например, у вас есть список товаров в базе данных. У каждого из них указан свой бренд, но есть и те, что поставляются одним производителем. Self Join можно использовать для объединения двух стеков информации из одной таблицы.
Например, можно запросить информацию о наименовании товара и параллельно обратиться к базе с названием бренда. Результатом работы функции станет появление нового списка товаров, соответствующего критериям.
SQL-команда в этом случае может выглядеть следующим образом:
SELECT * FROM products JOIN products ON table.product=table.brand
Такой сценарий полезен практически в любом виде баз данных, так как в одной таблице нередко может храниться информация о товарах или контенте, имеющим большое количество общих параметров.
SQL Cross Join
Самый специфичный вариант фильтрации данных. Он подразумевает сбор сразу всех комбинаций элементов из нескольких таблиц, без обращения к какой-либо дополнительной информации (не требуется указывать id или любую другую строку в таблице).
Стандартный SQL-запрос с Cross Join может выглядеть следующим образом:
SELECT * FROM table-1 CROSS JOIN table-2
Этого достаточно, чтобы создать новый список элементов, в котором будут собраны все строки из базы данных, отфильтрованные только по выбранным таблицам.
Полученный набор данных называют декартовым произведением. Схематично его часто изображают как большое количество перекрестий между двумя группами элементов.
Такой вид JOIN применяется в онлайн-магазинах для вывода всех возможных пар по выбранным характеристикам одежды (цвету и размеру или другим параметрам).
SQL Outer Join
Outer Join – это своего рода противоположность Inner Join. Как понятно из названия, Outer Join предоставляет информацию не только из внутренней части поиска, но и из внешней. То есть программа ищет не только точечные совпадения по выбранным ранее критериям, а позволяет немного ослабить «хватку» и предоставить более «свободные» результаты поиска, включающие в себя элементы из таблиц, которые хоть и совпадают с критериями в SQL-запросе, но не полностью.
Когда такой подход может понадобиться? Например, для скрупулезной фильтрации товаров. Если вы готовы покупать продукцию компании «Шестерочка» и не против, если среди нее окажется молоко, но при этом вы точно не хотите покупать молоко других производителей, то вам подойдет подобный фильтр. Он позволяет дать одному из критериев поиска что-то в духе привилегий.
Разновидности Outer Join
Внешние Join-запросы существуют не в единственном виде, а сразу в трех вариациях. Каждый вариант по-своему обрабатывает информацию и в итоге выдает разные результаты.
Left
Левое объединение подразумевает как раз выше описанный сценарий. Когда мы берем одну таблицу, подключаем вторую и при этом показываем не только точные совпадения, но еще и весь список строк, полученных из левой таблицы, для которых не нашлось пары в правой таблице.
На практике это может выглядеть так:
SELECT * FROM table1 LEFT JOIN table2 ON table1.parameter=table2.parameter
Теперь мы объединяем первую и вторую таблицу, доставая информацию как о совпадениях по заданным параметрам, так и по контенту без пары в левой таблице.
При желании, надстраивая подобный фильтр, можно вовсе исключить целую категорию строк:
SELECT * FROM table1 LEFT JOIN table2 ON table1.parameter=table2.parameter WHERE table2.parameter IS NULL
На живом примере фильтрация такого рода может выглядеть так:
SELECT * FROM Russian LEFT JOIN Rap ON Russian.genreId=Rap.genreId
Представим, что мы запустили продвинутый поиск на сайте с музыкальными альбомами. Мы хотим послушать что-то на русском языке. Причем готовы даже оценить качество отечественного рэпа. При этом в целом мы рэп не любим и не хотим, чтобы он попадался на каких-то других языках.
Right
Понятно, что правое объединение будет работать в обратную сторону и покажет элементы из правой таблицы, для которых не нашлось пары в левой.
Получится следующий SQL-запрос:
SELECT * FROM table1 RIGHT JOIN table2 ON table1.parameter=table2.parameter
Если взять пример из предыдущей главы, то в реальности можно обернуть ситуацию в противоположную сторону. Искать только рэп-музыку, исключив все русское, кроме хип-хопа. Получится что-то в духе:
SELECT * FROM Russian RIGHT JOIN Rap ON Russian.genreId=Rap.genreId
Full
Это вариант для тех, кто хочет использовать сразу два разных критерия для поиска какого-либо контента. Снова вернемся к примеру с музыкальным приложением. Join Full может пригодиться, если вы хотите послушать либо что-то на русском, либо любой рэп. Вам не важны какие-либо другие параметры. Вас волнуют исключительно две характеристики. При этом вам не так важно, будут ли они пересекаться. То есть вам все равно, будет рэп на русском или же на русском будет какой-то агрессивный металл.
SQL-запрос с таким Join мог бы выглядеть следующим образом:
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.parameter=table2.parameter
Можно исключить из результатов фильтрации все пары. То есть можно выбрать только рэп, но ни в коем случае не русский, и русскую музыку, но ни в коем случае не рэп (вполне могу понять такой выбор, кстати говоря).
Чтобы это сделать, необходимо написать следующий SQL-запрос.
SELECT * FROM Russian FULL OUTER JOIN Rap ON Russian.genreId=Rap.genreId WHERE Russian.genreId IS NULL OR Rap.genreId IS NULL
Теперь вы увидите в результатах поиска только непарные строки.
Вместо заключения
SQL Join – мощнейший инструмент для фильтрации строк в базах данных. Благодаря ему можно легко находить именно ту информацию, что нужна, а не возиться с недоделанными фильтрами, которые обычно предоставляют разработчики сайтов и приложений. Жаль, что такие мощные механизмы поиска доступны далеко не везде. Но, создавая собственные продукты, вы можете их реализовать. Power-пользователи точно останутся довольны.
SQL — Simple Query Language, то есть «простой язык запросов». Его создали, чтобы работать с реляционными базами данных. В таких базах данные представлены в виде таблиц. Зависимости между несколькими таблицами задают с помощью связующих — реляционных столбцов.
Когда запрашиваем данные из одной таблицы, работа со связующими столбцами не нужна. Но если нужно агрегировать данные из нескольких, стоит описать правила: как будут связаны строки на основе значений связующих столбцов. Тогда на помощь и приходит оператор join.
Что такое оператор join в SQL
Join — оператор, который используют, чтобы объединять строки из двух или более таблиц на основе связующего столбца между ними. Такой столбец еще называют ключом.
Предположим, что у нас есть таблица заказов — Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
И таблица клиентов — Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Столбец CustomerID в таблице заказов соотносится со столбцом CustomerID в таблице клиентов. То есть он — связующий двух таблиц. Чтобы узнать, когда, какой клиент и какой заказ оформил, составьте запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат запроса будет выглядеть так:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
Общий синтаксис оператора join:
JOIN <Название таблицы для присоединения> ON <Условие присоединения на основе связующих столбцов>
Соединять можно и больше двух таблиц: к запросу добавьте еще один оператор join. Например, в дополнение к предыдущим двум таблицам у нас есть таблица продавцов — Managers:
| OrderID | ManagerName | ContactDate |
| 304101 | Артём Лапин | 05-05-2021 |
| 304102 | Егор Орлов | 15-06-2021 |
| 304103 | Евгений Соколов | 20-07-2021 |
Таблица продавцов связана с таблицей заказов столбцом OrderID. Чтобы в дополнение к предыдущему запросу узнать, какой продавец обслуживал заказ, составьте следующий запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate, Managers.ManagerName FROM Orders JOIN Customers ON Orders.CustomerID=Customers.CustomerID JOIN Managers ON Orders.OrderId=Managers.OrderId
Результат:
| OrderID | CustomerName | OrderDate | ManagerName |
| 304101 | Балалайка Сервис | 10-05-2021 | Артём Лапин |
| 304103 | Редиска Менеджмент | 25-07-2021 | Евгений Соколов |
Внутреннее соединение INNER JOIN
Если использовать оператор INNER JOIN, в результат запроса попадут только те записи, для которых выполняется условие объединения. Еще одно условие — записи должны быть в обеих таблицах. В финальный результат из примера выше не попали записи с CustomerID=23 и OrderID=304102: для них нет соответствия в таблицах.
Общий синтаксис запроса INNER JOIN:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;

Иллюстрация работы INNER JOIN
Слово INNER в запросе можно опускать, тогда общий синтаксис запроса будет выглядеть так:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
Внешние соединения OUTER JOIN
Если использовать внешнее соединение, то в результат запроса попадут не только записи с совпадениями в обеих таблицах, но и записи одной из таблиц целиком. Этим внешнее соединение отличается от внутреннего.
Указание таблицы, из которой нужно выбрать все записи без фильтрации, называется направлением соединения.
LEFT OUTER JOIN / LEFT JOIN
В финальный результат такого соединения попадут все записи из левой, первой таблицы. Даже если не будет ни одного совпадения с правой. И записи из второй таблицы, для которых выполняется условие объединения.

Иллюстрация работы LEFT JOIN
Синтаксис:
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name;
Пример:
Таблица Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders LEFT JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304102 | null | 20-06-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
RIGHT OUTER JOIN / RIGHT JOIN
В финальный результат этого соединения попадут все записи из правой, второй таблицы. Даже если не будет ни одного совпадения с левой. И записи из первой таблицы, для которых выполняется условие объединения.

Иллюстрация работы RIGHT JOIN
Синтаксис:
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;
Пример:
Таблица Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders RIGHT JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| null | Рога и копыта | null |
| 304103 | Редиска Менеджмент | 25-07-2021 |
FULL OUTER JOIN / FULL JOIN
В финальный результат такого соединения попадут все записи из обеих таблиц. Независимо от того, выполняется условие объединения или нет.

Иллюстрация работы FULL JOIN
Синтаксис:
SELECT column_name(s) FROM table1 FULL JOIN table2 ON table1.column_name = table2.column_name;
Пример:
Таблица Orders
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders FULL JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304102 | null | 20-06-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
| null | Рога и копыта | null |
Перекрестное соединение CROSS JOIN
Этот оператор отличается от предыдущих операторов соединения: ему не нужно задавать условие объединения (ON table1.column_name = table2.column_name). Записи в таблице с результатами — это результат объединения каждой записи из левой таблицы с записями из правой. Такое действие называют декартовым произведением.

Иллюстрация работы CROSS JOIN
Синтаксис:
SELECT column_name(s) FROM table1 CROSS JOIN table2;
Пример:
Таблица Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
</p> SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders CROSS JOIN Customers;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304101 | Рога и копыта | 10-05-2021 |
| 304101 | Редиска Менеджмент | 10-05-2021 |
| 304102 | Балалайка Сервис | 20-06-2021 |
| 304102 | Рога и копыта | 20-06-2021 |
| 304102 | Редиска Менеджмент | 20-06-2021 |
| 304103 | Балалайка Сервис | 25-07-2021 |
| 304103 | Рога и копыта | 25-07-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
Соединение SELF JOIN
Его используют, когда в запросе нужно соединить несколько записей из одной и той же таблицы.
В SQL нет отдельного оператора, чтобы описать SELF JOIN соединения. Поэтому, чтобы описать соединения данных из одной и той же таблицы, воспользуйтесь операторами JOIN или WHERE.
Учтите, что в одном запросе нельзя дважды использовать имя одной и той же таблицы: иначе запрос вернет ошибку. Поэтому, чтобы выполнить соединение таблицы SQL с самой собой, в запросе ей присваивают два разных временных имени — алиаса.
Синтаксис соединения SELF JOIN при использовании оператора JOIN:
SELECT column_name(s) FROM table1 a1 JOIN table1 a2 ON a1.column_name = a2.column_name;
Оператор JOIN может быть любым: используйте LEFT JOIN, RIGHT JOIN. Результат будет таким же, как когда объединяли две разные таблицы.
Синтаксис соединения SELF JOIN при использовании оператора WHERE:
SELECT column_name(s) FROM table1 a1, table1 a2 WHERE a1.common_col_name = a2.common_col_name;
Пример:
Талица Students:
| StudentID | Name | CourseID | Duration |
| 1 | Артём | 1 | 3 |
| 2 | Пётр | 2 | 4 |
| 1 | Артём | 2 | 4 |
| 3 | Борис | 3 | 2 |
| 2 | Ирина | 3 | 5 |
Запрос с оператором WHERE:
SELECT s1.StudentID, s1.Name FROM Students AS s1, Students s2 WHERE s1.StudentID = s2.StudentID AND s1.CourseID <> s2.CourseID;
Результат:
| StudentID | Name |
| 1 | Артём |
| 2 | Ирина |
| 1 | Артём |
| 2 | Пётр |
Запрос с оператором JOIN:
SELECT s1.StudentID, s1.Name FROM Students s1 JOIN Students s2 ON s1.StudentID = s2.StudentID AND s1.CourseID <> s2.CourseID GROUP BY StudentID;
Результат:
| StudentID | Name |
| 1 | Артём |
| 2 | Ирина |
Главное о join в SQL
- В SQL используют операторы соединения join, чтобы объединять данные из нескольких таблиц. Когда результат должен содержать только данные двух таблиц с общим ключом, применяют INNER JOIN или просто JOIN.
- Если нужен полный список записей одной из таблиц, объединенных с данными из другой, используют операторы LEFT и RIGHT JOIN.
- Если результат должен содержать полный список записей обеих таблиц, где некоторые записи объединены, применяют оператор FULL JOIN.
- Если нужно декартово произведение двух таблиц, используют оператор CROSS JOIN. Хотите соединить данные из одной и той же таблицы между собой — нужен SELF JOIN.
Научитесь писать SQL-запросы на курсе «Аналитик данных» Skypro. Изучите агрегатные функции, подзапросы и WITH, JOIN, оконные функции и многое другое, а еще — решите бизнес-задачу с помощью SQL.
Еще в программе: базовые формулы Excel, работа в Power Pivot и Power Query, Python для анализа данных. Справитесь и без опыта в IT: учим с азов, ведем до диплома и помогаем найти работу.
Категории новостей
задний план
Категории новостей — это общий сценарий приложений в текстовых категориях. В традиционном режиме классификации он часто проверяется искусственными новостями, тем самым классифицируя новости. Но этот путь не эффективен.
- Возможность предварительной обработки текстовых данных
- Возможность генерировать слово облачную карту через Python
- Это может быть выбрано путем анализа дисперсии.
- Текстовые данные могут быть классифицированы в соответствии с содержанием текста.
1, набор данных нагрузки
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import warnings
plt.rcParams["font.family"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
plt.rcParams["font.size"] = 15
warnings.filterwarnings("ignore")
%matplotlib inline
news = pd.read_csv("./news.csv", encoding="utf-8")
display(news.head())
2, предварительная обработка данных
2.1 Пропущенная обработка ценностей
news.info()
## Используйте заголовок новостей, чтобы заполнить пропущенный контент новостей
index = news[news.content.isnull()].index
news["content"][index]=news["headline"][index]
news.isnull().sum()2.2 Повторите ценность Обработки
### пользовательский фон
wc = WordCloud(font_path=r"C:WindowsFontsSTFANGSO.ttf", mask=plt.imread("./imgs/map3.jpg"))
plt.figure(figsize=(15,10))
img = wc.generate_from_frequencies(c)
plt.imshow(img)
plt.axis("off")print(news[news.duplicated()])
news.drop_duplicates(inplace=True)2.3 Очистка контента текста
Import Re #### Подзывы обработки текста, скомпилированные регулярные объекты для обработки текста
re_obj = re.compile(r"['~`!#$%^&*()_+-=|';:/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}':【】《》‘’“”s]+")
def clear(text):
return re_obj.sub("", text)
news["content"] = news["content"].apply(clear)
news.sample(10)
2,4 балла
import jieba
Def cut_word (tex): ### слово, разделив слова с использованием метода LCUT Jieba, генерируют список,
#### cut () генерировать генератор, не занимает пространство, ни небольшое пространство, используя список () можно преобразовать в список
return jieba.lcut(text)
news["content"] = news["content"].apply(cut_word)
news.sample(5)
2.5 Утилизация
Def get_stopword (): #### Удалить дезактивацию, это большое количество слов в тексте, сокращение хранения и сокращения вычисления времени для классификации бесполезных слов
S = SET () ### Данные сопоставления клавиш после обработки хешей хранятся в порядке индекса.
with open("./stopword.txt", encoding="utf-8") as f:
for line in f:
s.add(line.strip())
return s
def remove_stopword(words):
return [word for word in words if word not in stopword]
stopword = get_stopword()
news["content"] = news["content"].apply(remove_stopword)
news.sample(5)
3, разведка данных
3.1 Распределение количества
### данные исследовать описательный анализ
### статистика тега
t = news["tag"].value_counts()
print(t)
t.plot(kind="bar")
3.2-летняя статистика
### год распределение количества Укажите развернуть = true для генерации dataframe
"""
Str.split () имеет три параметра: первый параметр - это содержимое в кавычках: это основа списка, которая может быть пространством, символом, строкой и т. Д.
Второй параметр - это предыдущее использование Expand = True, и этот параметр напрямую преобразует результат столбца в DataFrame.
N = номер третьего параметра - это количество раз предел.
Если я хочу найти основу из самого правого начала, я могу использовать RSPLIT (), RSPLIT и SPLIC ().
Начиная со правого, начиная с левого.
"""
t = news["date"].str.split("-", expand=True)
t2 = t[0].value_counts()
t2.plot(kind="bar")
3.3 Словарная статистика
### словарная статистика
##
from itertools import chain
from collections import Counter
Li_2d = news [«Контент»]. TOLIST () ### Включите двухмерные массивы
### 2D номер набор переноса в однократное массив
li_1d = list(chain.from_iterable(li_2d))
Print (F »Словарь: {len (li_1d)})
c = Counter(li_1d)
Печать (F »не повторяет количество слов: {len (c)}")
print(c.most_common(15))
common = c.most_common(15)
d = dict(common)
plt.figure(figsize=(15,5))
plt.bar(d.keys(), d.values())
3.4 генерировать слово облачная карта
### .
from wordcloud import WordCloud
wc = WordCloud(font_path=r"C:WindowsFontsSTFANGSO.ttf", width=800, height=600, background_color='green')
Jog_word = "" ".join (li_1d) #### слово облачная карта должна быть создана в формате пространства
img = wc.generate(join_word)
plt.figure(figsize=(15,10))
plt.imshow(img)
plt.axis("off")
wc.to_file("wordcloud.png") 
# Пользовательский фон
wc = WordCloud(font_path=r"C:WindowsFontsSTFANGSO.ttf", mask=plt.imread("./imgs/map3.jpg"))
plt.figure(figsize=(15,10))
img = wc.generate_from_frequencies(c)
plt.imshow(img)
plt.axis("off")
4, квантование текста
Процесс преобразования текста в числовые векторы функции называется текстовым квантованием. Текст количественно определяется и может быть разделен на следующие этапы:
- Слова, разделенные в текст, беспрецедентные слова
- Преобразуйте слова в числовые типы.
4.1 модели фразы
Модель фразы — это способ количественной оценки текста. В модели фразы каждый документ представляет собой образец, каждое не повторяющееся слово представляет собой функцию, а количество слов, появляющихся в документе в качестве значения функции.
4.2 TF-IDF
Некоторые слова, мы не можем измерить только в текущем документе и рассмотреть его в корпусе, количество раз в других документах.
Частота слова TF, относится к количеству слов, которые кажутся словами в документе.
Частота обратного документа IDF
Метод расчета:

from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
docs = [
"Where there is a will, there is a way",
"There is no royal road to learning."
]
bag = count.fit_transform(docs)
### Сумка - это редкая матрица
print(bag)
### Позвоните в метод Toarriay (), преобразуйте редкую матрицу в густую матрицу
print(bag.toarray()) 
Печать (count.get_feature_names ()) ### Функция
Печать (count.vocabulary_) ### Слово и отображение номера
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
docs = [
"Where there is a will, there is a way",
"There is no royal road to learning."
]
bag = count.fit_transform(docs)
### Сумка - это редкая матрица
print(bag)
### Позвоните в метод Toarriay (), преобразуйте редкую матрицу в густую матрицу
print(bag.toarray())
from sklearn.feature_extraction.text import TfidfVectorizer
docs = [
"Where there is a will, there is a way",
"There is no royal road to learning."
]
tfidf = TfidfVectorizer()
t = tfidf.fit_transform(docs)
print(t.toarray())5, установить модель
5.1 Наборы по строительству и тестовые наборы
## текст для количественной оценки типов строк, которые должны пройти пространство разделения
def join(text_list):
return " ".join(text_list)
news["content"] = news["content"].apply(join)Новости [«TAG»] = Новости [«Тег»]. Карта ({"подробный полный текст": 0 ": 0": 0, "International": 1})
news["tag"].value_counts()from sklearn.model_selection import train_test_split
X = news["content"]
y = news["tag"]
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.25)5.2 Выбор объекта
Vec = tfidfvectorizer (ngram_range = (1, 2)) #### Две характеристики, близкие к двумерной функции
X_train_vec = vec.fit_transform(X_train)
X_test_vec = vec.transform(X_test)
display(X_train_vec, X_test_vec)5.2.1 Анализ дисперсии
После использования модели фразы для количественного определения, будут чрезмерные характеристики, которые вызывают огромное давление на хранение и расчет, а не все функции помогают моделированию.
Используйте дисперсию анализа для выполнения выбора функций.
from sklearn.feature_selection import f_classif
# Prouch согласно Y, рассчитайте X, каждая характеристика каждой функции и значения P
Чем больше значение #f, тем меньше значение p.
f_classif(X_train_vec, y_train)from sklearn.feature_selection import SelectKBest
X_train_vec = X_train_vec.astype(np.float32)
X_test_vec = X_test_vec.astype(np.float32)
selector = SelectKBest(f_classif, k=min(20000, X_train_vec.shape[1]))
selector.fit(X_train_vec, y_train)
X_train_vec = selector.transform(X_train_vec)
X_test_vec = selector.transform(X_test_vec)
print(X_train_vec.shape, X_test_vec.shape)5.3 Логическая регрессия
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
param=[{"penalty":["l1","l2"],"C":[0.1,1,10],"solver":["liblinear"]},
{"penalty":["elasticnet"],"C":[0.1,1,10],"solver":["saga"], "l1_ratio":[0.5]}]
gs = GridSearchCV(estimator=LogisticRegression(), param_grid=param, cv = 5, scoring="f1",n_jobs=-1,verbose=10)
gs.fit(X_train_vec, y_train)
print(gs.best_params_)
y_hat = gs.best_estimator_.predict(X_test_vec)
print(classification_report(y_test,y_hat))
5.4 Простые байес
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB, ComplementNB
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer
### определить функциональный преобразователь для преобразования редкой матрицы в плотную матрицу
steps = [("dense",FunctionTransformer(func=lambda X:X.toarray(), accept_sparse=True)),
("model", None)]
pipe = Pipeline(steps=steps)
param = {"model":[GaussianNB(), BernoulliNB(), MultinomialNB(), ComplementNB()]}
gs = GridSearchCV(estimator=pipe, param_grid=param, cv=5, scoring="f1", n_jobs=-1,verbose=10)
gs.fit(X_train_vec, y_train)
gs.best_estimator_.predict(X_test_vec)
print(classification_report(y_test, y_hat))