
Время на прочтение
16 мин
Количество просмотров 54K
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
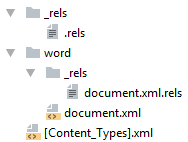
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>word/document.xml
Основное содержимое документа.
word/document.xml
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math"
xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"
xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing"
xmlns:w10="urn:schemas-microsoft-com:office:word"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml"
xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup"
xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk"
xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml"
xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape"
mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"
w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
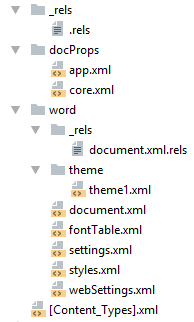
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.sh.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
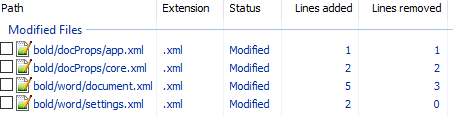
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@
- <TotalTime>0</TotalTime>
+ <TotalTime>1</TotalTime>Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@
- <cp:revision>1</cp:revision>
+ <cp:revision>2</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created>
- <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified>
+ <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
diff
@@ -1,24 +1,26 @@
<w:body>
- <w:p w:rsidR="0076695C" w:rsidRPr="00290C70" w:rsidRDefault="00290C70">
+ <w:p w:rsidR="0076695C" w:rsidRPr="00F752CF" w:rsidRDefault="00290C70">
<w:pPr>
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
</w:pPr>
- <w:r>
+ <w:r w:rsidRPr="00F752CF">
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
- <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:sectPr w:rsidR="0076695C" w:rsidRPr="00F752CF">Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
<w:rPr>
+ <w:b/>в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@
+ <w:proofState w:spelling="clean"/>
@@ -17,10 +18,11 @@
+ <w:rsid w:val="00F752CF"/>Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
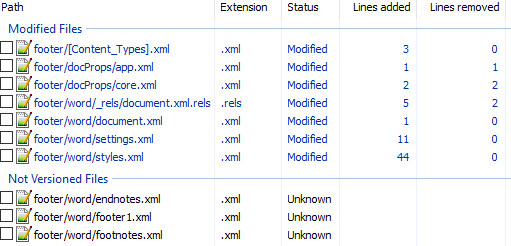
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
+ <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/>
+ <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/>
+ <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
diff
@@ -1,8 +1,11 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
+ <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/>
+ <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/>
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>
- <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
- <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>
</Relationships>Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
@@ -3,6 +3,9 @@
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:footerReference w:type="default" r:id="rId6"/>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/>
<w:cols w:space="708"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
diff
@@ -1,19 +1,30 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15">
<w:zoom w:percent="100"/>
+ <w:proofState w:spelling="clean"/>
<w:defaultTabStop w:val="708"/>
<w:characterSpacingControl w:val="doNotCompress"/>
+ <w:footnotePr>
+ <w:footnote w:id="-1"/>
+ <w:footnote w:id="0"/>
+ </w:footnotePr>
+ <w:endnotePr>
+ <w:endnote w:id="-1"/>
+ <w:endnote w:id="0"/>
+ </w:endnotePr>
<w:compat>
<w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/>
<w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
</w:compat>
<w:rsids>
<w:rsidRoot w:val="00290C70"/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:rsid w:val="001B0DE6"/>А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
diff
@@ -480,6 +480,50 @@
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman"/>
<w:b/>
<w:sz w:val="28"/>
</w:rPr>
</w:style>
+ <w:style w:type="paragraph" w:styleId="a4">
+ <w:name w:val="header"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a5"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a5">
+ <w:name w:val="Верхний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a4"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
+ <w:style w:type="paragraph" w:styleId="a6">
+ <w:name w:val="footer"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a7"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a7">
+ <w:name w:val="Нижний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a6"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
</w:styles>Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B">
<w:pPr>
<w:pStyle w:val="a6"/>
</w:pPr>
<w:r>
<w:t>123</w:t>
</w:r>
</w:p>
</w:ftr>Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels. - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ.
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
<xml>TEST</xml>В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/>
<xsl:template match="/">
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>
<xsl:value-of select="//xml/text()"/>
</w:t>
</w:r>
</w:p>
</w:ftr>
</xsl:template>
</xsl:stylesheet>Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml") В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>TEST</w:t>
</w:r>
</w:p>
</w:ftr>Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Relationship
Id="rId0"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer"
Target="footer0.xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/content-types" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Override
PartName="/word/footer0.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>В результате
Весь код опубликован. Работает он так:
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т… к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула
Как я разбирал docx с помощью XSLT
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом

Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types"> <Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/> <Default Extension="xml" ContentType="application/xml"/> <Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/> </Types>
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument" Target="word/document.xml"/> </Relationships>
word/document.xml
Основное содержимое документа.
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" mc:Ignorable="w14 wp14"> <w:body> <w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5"> <w:r> <w:t>Test</w:t> </w:r> <w:bookmarkStart w:id="0" w:name="_GoBack"/> <w:bookmarkEnd w:id="0"/> </w:p> <w:sectPr w:rsidR="005F670F"> <w:pgSz w:w="12240" w:h="15840"/> <w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/> <w:cols w:space="720"/> <w:docGrid w:linePitch="360"/> </w:sectPr> </w:body> </w:document>
Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> </Relationships>
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@ - <TotalTime>0</TotalTime> + <TotalTime>1</TotalTime>
Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@ - <cp:revision>1</cp:revision> + <cp:revision>2</cp:revision> <dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created> - <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified> + <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
«`diff
@@ -1,24 +1,26 @@
—
+
+
—
+
+
Test
—
+
«`
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@ + <w:proofState w:spelling="clean"/> @@ -17,10 +18,11 @@ + <w:rsid w:val="00F752CF"/>
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@ <Default Extension="xml" ContentType="application/xml"/> <Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/> + <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/> + <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/> + <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:
Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
«`diff
@@ -1,8 +1,11 @@
+
+
—
—
+
+
+
«`
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
«`diff
@@ -3,6 +3,9 @@
+
+
+
«`
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@ </w:r> <w:bookmarkStart w:id="0" w:name="_GoBack"/> <w:bookmarkEnd w:id="0"/> </w:p> <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70"> + <w:footerReference w:type="default" r:id="rId6"/> <w:pgSz w:w="11906" w:h="16838"/> <w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/> <w:cols w:space="708"/> <w:docGrid w:linePitch="360"/> </w:sectPr>
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
@@ -1,19 +1,30 @@ <?xml version="1.0" encoding="UTF-8" standalone="yes"?> <w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15"> <w:zoom w:percent="100"/> + <w:proofState w:spelling="clean"/> <w:defaultTabStop w:val="708"/> <w:characterSpacingControl w:val="doNotCompress"/> + <w:footnotePr> + <w:footnote w:id="-1"/> + <w:footnote w:id="0"/> + </w:footnotePr> + <w:endnotePr> + <w:endnote w:id="-1"/> + <w:endnote w:id="0"/> + </w:endnotePr> <w:compat> <w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/> <w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> <w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> <w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> <w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/> </w:compat> <w:rsids> <w:rsidRoot w:val="00290C70"/> + <w:rsid w:val="000A7B7B"/> + <w:rsid w:val="001B0DE6"/>
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
«`diff
@@ -480,6 +480,50 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
«`
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B"> <w:pPr> <w:pStyle w:val="a6"/> </w:pPr> <w:r> <w:t>123</w:t> </w:r> </w:p> </w:ftr>
Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:
Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ
- Добавляем наш нижний колонтитул
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0"> <xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/> <xsl:template match="/"> <w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:p> <w:r> <w:rPr> <w:lang w:val="en-US"/> </w:rPr> <w:t> <xsl:value-of select="//xml/text()"/> </w:t> </w:r> </w:p> </w:ftr> </xsl:template> </xsl:stylesheet>
Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml")
В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:p> <w:r> <w:rPr> <w:lang w:val="en-US"/> </w:rPr> <w:t>TEST</w:t> </w:r> </w:p> </w:ftr>
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
«`xml
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
</spoiler>
#### Прописываем ссылки в документе
Далее надо в каждый тег `<w:sectPr>` добавить тег `<w:footerReference>` или заменить в нём ссылку на наш нижний колонтитул. [Оказалось](https://msdn.microsoft.com/en-us/library/documentformat.openxml.wordprocessing.footerreference(v=office.14).aspx), что у каждого тега `<w:sectPr>` может быть 3 тега `<w:footerReference>` - для первой страницы, четных страниц и всего остального:
<spoiler title="XSLT">
```xml
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
«`xml
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
</spoiler>
#### В результате
Весь код [опубликован](https://github.com/intersystems-ru/Converter/blob/master/Converter/Footer.cls.xml). Работает он так:
```cos
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")
Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т..к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула
With approximately one billion people using Microsoft Office, the DOCX format is the most popular de facto standard for exchanging document files between offices. Its closest competitor — the ODT format — is only supported by Open/LibreOffice and some open source products, making it far from standard. The PDF format is not a competitor because PDFs can’t be edited and they don’t contain a full document structure, so they can only take limited local changes like watermarks, signatures, and the like. This is why most business documents are created in the DOCX format; there’s no good alternative to replace it.
While DOCX is a complex format, you may want to parse it manually for simpler tasks such as indexing, converting to TXT and making other small modifications. I’d like to give you enough information on DOCX internals so you don’t have to reference the ECMA specifications, a massive 5,000 page manual.
The best way to understand the format is to create a simple one-word document with MSWord and observe how editing the document changes the underlying XML. You’ll face some cases where the DOCX doesn’t format properly in MS Word and you don’t know why, or come across instances when it’s not evident how to generate the desired formatting. Seeing and understanding exactly what’s going on in the XML will help that.
I worked for about a year on a collaborative DOCX editor, CollabOffice, and I want to share some of that knowledge with the developer community. In this article I will explain the DOCX file structure, summarising information that is scattered over the internet. This article is an intermediary between the huge, complex ECMA specification and the simple internet tutorials currently available. You can find the files that accompany this article in the toptal-docx project on my github account.
A Simple DOCX file
A DOCX file is a ZIP archive of XML files. If you create a new, empty Microsoft Word document, write a single word ‘Test’ inside and unzip it contents, you will see the following file structure:
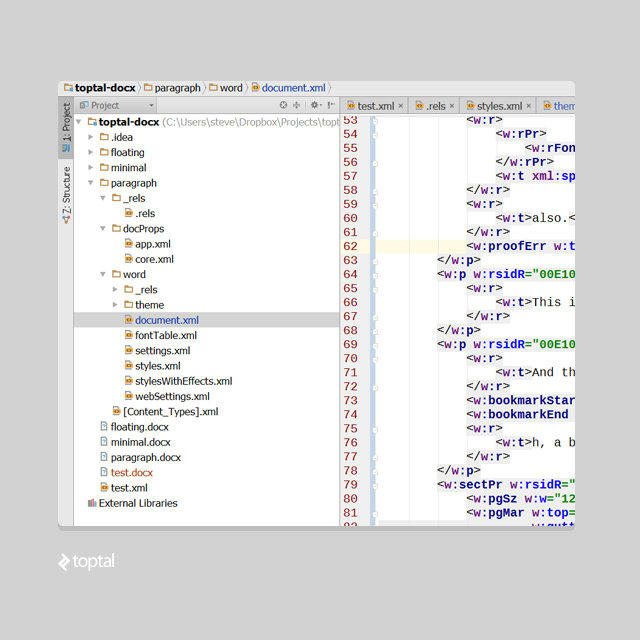
Even though we’ve created a simple document, the save process in Microsoft Word has generated default themes, document properties, font tables, and so on, in XML format.
All the files inside a DOCX are XML files, even those with the «.rels» extension.
To start, let us remove the unused stuff and focus on document.xml, which contains the main text elements. When you delete a file, make sure you have deleted all the relationship references to it from other the xml files. Here is a code-diff example on how I’ve cleared dependencies to app.xml and core.xml. If you have any unresolved/missing references, MSWord will consider the file broken.
Here’s the structure of our simplified, minimal DOCX document (and here’s the project on github):
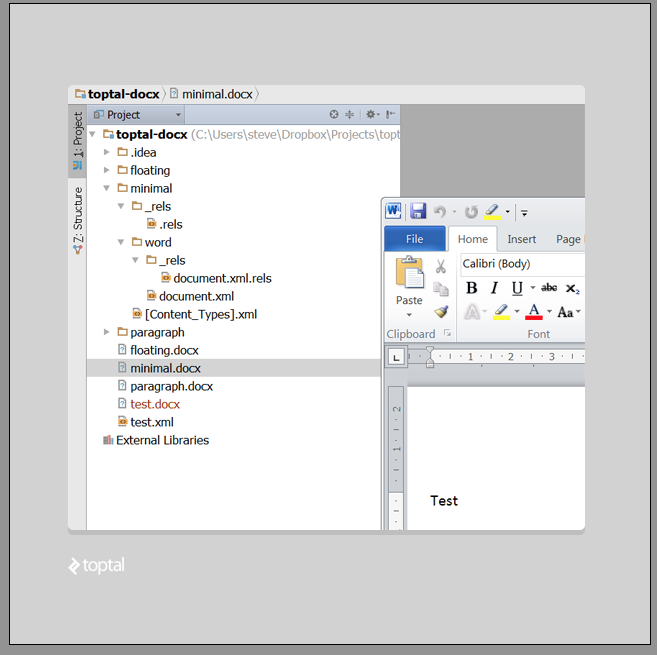
Let’s break it down by file from here, from the top:
_rels/.rels
This defines the reference that tells MS Word where to look for the document contents. In this case, it references word/document.xml:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>
_rels/document.xml.rels
This file defines references to resources, such as images, embedded in the document content. Our simple document has no embedded resources, so the relationship tag is empty:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>
[Content_Types].xml
[Content_Types].xml contains information about the types of media inside the document. Since we only have text content, it’s pretty simple:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>
document.xml
Finally, here is the main XML with the document’s text content. I have removed some of namespace declarations for clarity, but you can find the full version of the file in the github project. In that file you’ll find that some of the namespace references in the document are unused, but you shouldn’t delete them because MS Word needs them.
Here’s our simplified example:
<w:document>
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r><w:t>Test</w:t></w:r>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720"
w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>
The main node <w:document> represents the document itself, <w:body> contains paragraphs, and nested within <w:body> are page dimensions defined by <w:sectPr>.
<w:rsidR> is an attribute that you can ignore; it’s used by MS Word internals.
Let’s take a look at a more complex document with three paragraphs. I have highlighted the XML with the same colors on the screenshot from Microsoft Word, so you can see the correlation:

<w:p w:rsidR="0081206C" w:rsidRDefault="00E10CAE"> <w:r> <w:t xml:space="preserve">This is our example first paragraph. It's default is left aligned, and now I'd like to introduce</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/> <w:color w:val="000000"/> </w:rPr> <w:t>some bold</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/> <w:b/> <w:color w:val="000000"/> </w:rPr> <w:t xml:space="preserve"> text</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/> <w:color w:val="000000"/> </w:rPr> <w:t xml:space="preserve">, </w:t> </w:r> <w:proofErr w:type="gramStart"/> <w:r> <w:t xml:space="preserve">and also change the</w:t> </w:r> <w:r w:rsidRPr="00E10CAE"> <w:rPr><w:rFonts w:ascii="Impact" w:hAnsi="Impact"/> </w:rPr> <w:t>font style</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:ascii="Impact" w:hAnsi="Impact"/> </w:rPr> <w:t xml:space="preserve"> </w:t> </w:r> <w:r> <w:t>to 'Impact'.</w:t></w:r> </w:p> <w:p w:rsidR="00E10CAE" w:rsidRDefault="00E10CAE"> <w:r> <w:t>This is new paragraph.</w:t> </w:r></w:p> <w:p w:rsidR="00E10CAE" w:rsidRPr="00E10CAE" w:rsidRDefault="00E10CAE"> <w:r> <w:t>This is one more paragraph, a bit longer.</w:t> </w:r> </w:p>
Paragraph Structure
A simple document consists of paragraphs, a paragraph consists of runs (a series of text with the same font, color, etc), and runs consist of characters (such as <w:t>).<w:t> tags may have several characters inside, and there might be a few in the same run.
Again, we can ignore <w:rsidR>.
Text properties
Basic text properties are font, size, color, style, and so on. There are about 40 tags that specify text appearance. As you can see in our three paragraph example, each run has its own properties inside <w:rPr>, specifying <w:color>, <w:rFonts> and boldness <w:b>.
An important thing to note is that properties make a distinction between the two groups of characters, normal and complex script (Arabic, for instance), and that the properties have a different tag depending on which type of character it’s affecting.
Most normal script property tags have a matching complex script tag with an added “C” specifying the property is for complex scripts. For example: <w:i> (italic) becomes <w:iCs>, and the bold tag for normal script, <w:b>, becomes <w:bCs> for complex script.
Styles
There’s an entire toolbar in Microsoft Word dedicated to styles: normal, no spacing, heading 1, heading 2, title, and so on. These styles are stored in /word/styles.xml (note: in the first step in our simple example, we removed this XML from DOCX. Make a new DOCX to see this).
Once you have text defined as a style, you will find reference to this style inside the paragraph properties tag, <w:pPr>. Here’s an example where I’ve defined my text with the style Heading 1:
<w:p>
<w:pPr>
<w:pStyle w:val="Heading1"/>
</w:pPr>
<w:r>
<w:t>My heading 1</w:t>
</w:r>
</w:p>
and here is the style itself from styles.xml:
<w:style w:type="paragraph" w:styleId="Heading1">
<w:name w:val="heading 1"/>
<w:basedOn w:val="Normal"/>
<w:next w:val="Normal"/>
<w:link w:val="Heading1Char"/>
<w:uiPriority w:val="9"/>
<w:qFormat/>
<w:rsid w:val="002F7F18"/>
<w:pPr>
<w:keepNext/>
<w:keepLines/>
<w:spacing w:before="480" w:after="0"/>
<w:outlineLvl w:val="0"/>
</w:pPr>
<w:rPr>
<w:rFonts w:asciiTheme="majorHAnsi" w:eastAsiaTheme="majorEastAsia" w:hAnsiTheme="majorHAnsi"
w:cstheme="majorBidi"/>
<w:b/>
<w:bCs/>
<w:color w:val="365F91" w:themeColor="accent1" w:themeShade="BF"/>
<w:sz w:val="28"/>
<w:szCs w:val="28"/>
</w:rPr>
</w:style>
The <w:style/w:rPr/w:b> xpath specifies that the font is bold, and <w:style/w:rPr/w:color> indicates the font color. <w:basedOn> instructs MSWord to use “Normal” style for any missing properties.
Property Inheritance
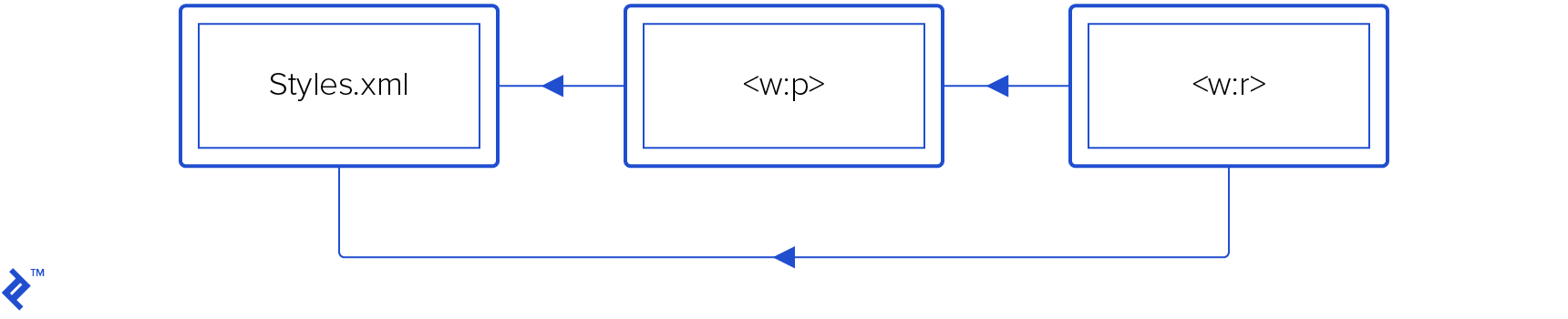
Text properties are inherited. A run has its own properties (w:p/w:r/w:rPr/*), but it also inherits properties from paragraph (w:r/w:pPr/*), and both can reference style properties from the /word/styles.xml.
<w:r>
<w:rPr>
<w:rStyle w:val="DefaultParagraphFont"/>
<w:sz w:val="16"/>
</w:rPr>
<w:tab/>
</w:r>
Paragraphs and runs start with default properties: w:styles/w:docDefaults/w:rPrDefault/*
and w:styles/w:docDefaults/w:pPrDefault/*. To get the end result of a character’s properties you should:
- Use default run/paragraph properties
- Append run/paragraph style properties
- Append local run/paragraph properties
- Append result run properties over paragraph properties
When I say “append” B to A, I mean to iterate through all B properties and override all A’s properties, leaving all non-intersecting properties as-is.
One more place where default properties may be located is in the <w:style> tag with w:type="paragraph" and w:default="1". Note, that characters themselves inside a run never have a default style, so <w:style w:type="character" w:default="1"> doesn’t actually affect any text.
1554402290400-dbb29eef3ba6035df7ad726dfc99b2af.png)
Characters in a run can inherit from its paragraph and both can inherit from styles.xml.
Toggle properties
Some of the properties are “toggle” properties, such as <w:b> (bold) or <w:i> (italic); these attributes behave like an XOR operator.
This means if the parent style is bold and a child run is bold, the result will be regular, non-bold text.
You have to do lots of testing and reverse-engineering to handle toggle attributes correctly. Take a look at paragraph 17.7.3 of ECMA-376 Open XML specification to get the formal, detailed rules for toggle properties/
Toggle properties are the most complex for a layouter to handle correctly.
Fonts
Fonts follow the same common rules as other text attributes, but font property default values are specified in a separate theme file, referenced under word/_rels/document.xml.rels like this:
<Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
Based on the above reference, the default font name will be found in word/theme/themes1.xml, inside a <a:theme> tag, a:themeElements/a:fontScheme/a:majorFont or a:minorFont tag.
The default font size is 10 unless the w:docDefaults/w:rPrDefault tag is missing, then it is size 11.
Text alignment
Text alignment is specified by a <w:jc> tag with four w:val modes available: "left", "center", "right" and "both".
"left" is the default mode; text is started at the left of paragraph rectangle (usually the page width). (This paragraph is aligned to the left, which is standard.)
"center" mode, predictably, centers all characters inside the page width. (Again, this paragraph exemplifies centered alignment.)
In "right" mode, paragraph text is aligned to the right margin. (Notice how this text is aligned to the right side.)
"both" mode puts extra spacing between words so that lines get wider and occupy the full paragraph width, with the exception of the last line which is left aligned. (This paragraph is a demonstration of that.)
Images
DOCX supports two sorts of images: inline and floating.
Inline images appear inside a paragraph along with the other characters, <w:drawing> is used instead of using <w:t> (text). You can find image ID with the following xpath syntax:
w:drawing/wp:inline/a:graphic/a:graphicData/pic:pic/pic:blipFill/a:blip/@r:embed
The image ID is used to look up the filename in the word/_rels/document.xml.rels file, and it should point to gif/jpeg file inside word/media subfolder. (See the github project’s word/_rels/document.xml.rels file, where you can see the image ID.)
Floating images are placed relative to paragraphs with text flowing around them. (Here’s th github project sample document with a floating image.)
Floating images use <wp:anchor> instead of <w:drawing>, so if you delete any text inside <w:p>, be careful with the anchors if you don’t want the images removed.

MS Word’s image options refer to image alignment as «text wrapping mode».
Tables
XML tags for tables are similar to HTML table markup– is the same as <table>, matches with <tr>, etc.
<w:tbl>, the table itself, has table properties <w:tblPr>, and each column property is presented by <w:gridCol> inside <w:tblGrid>. Rows follow one by one as <w:tr> tags and each row should have same number of columns as specified in <w:tblGrid>:
<w:tbl>
<w:tblPr>
<w:tblW w:w="5000" w:type="pct" />
</w:tblPr>
<w:tblGrid><w:gridCol/><w:gridCol/></w:tblGrid>
<w:tr>
<w:tc><w:p><w:r><w:t>left</w:t></w:r></w:p></w:tc>
<w:tc><w:p><w:r><w:t>right</w:t></w:r></w:p></w:tc>
</w:tr>
</w:tbl>
Width for table columns can be specified in the <w:tblW> tag, but if you don’t define it MS Word will use its internal algorithms to find the optimal width of columns for the smallest effective table size.
Units
Many XML attributes inside DOCX specify sizes or distances. While they’re integers inside the XML, they all have different units so some conversion is necessary. The topic is a complicated one, so I’d recommend this article by Lars Corneliussen on units in DOCX files. The table he presents is useful, though with a small misprint: inches should be pt/72, not pt*72.
Here’s a cheat sheet:
| COMMON DOCX XML UNIT CONVERSIONS | ||||||
| 20th of a point | Points dxa/20 |
Inches pt/72 |
Centimeters in*2,54 |
Font half size pt/144 |
EMU in*914400 |
|
| Example | 11906 | 595.3 | 8,27… | 21.00086… | 4,135 | 7562088 |
| Tags using this | pgSz/pgMar/w:spacing | w:sz | wp:extent, a:ext |
Tips for Implementing a Layouter
If you want to convert a DOCX file (to PDF, for instance), draw it on canvas, or count number of pages, you’ll have to implement a layouter. A layouter is an algorithm for calculating character positions from a DOCX file.
This is a complex task if you need 100 percent fidelity rendering. The amount of time needed to implement a good layouter is measured in man-years, but if you only need a simple, limited one, it can be done relatively quickly.
A layouter fills a parent rectangle, which is usually a rectangle of the page. It add words from a run one by one. When the current line overflows, it starts a new one. If the paragraph is too high for the parent rectangle, it’s wrapped to the next page.
Here are some important things to keep in mind if you decide to implement a layouter:
- The layouter should take care about text alignment and text floating over images
- It should be capable of handling nested objects, such as nested tables
- If you want to provide full support for such images, you’ll have to implement a layouter with at least two passes, the first step collects floating images’ positions and the second fills empty space with text characters.
- Be aware of indentations and spacings. Each paragraph has spacing before and after, and these numbers are specified by the
w:spacingtag. Vertical spacing is specified byw:afterandw:beforetags. Note that line spacing is specified byw:line, but this is not the size of the line as one may expect. To get the size of the line, take the current font height, multiply byw:lineand divide by 12. - DOCX files contain no information about pagination. You won’t find the number of pages in the document unless you calculate how much space you need for each line to ascertain the number of pages. If you need to find exact coordinates of each character on the page, be sure to take into account all spacings, indentations and sizes.
- If you implement a full-featured DOCX layouter that handles tables, note the special cases when tables span multiple pages. A cell which causes a page overflow also affects other cells.
- Creating an optimal algorithm for calculating a table columns’ width is a challenging math problem and word processors and layouters usually use some suboptimal implementations. I propose using the algorithm from W3C HTML table documentation as a first approximation. I haven’t found a description of the algorithm used by MS Word, and Microsoft has fine-tuned the algorithm over time so different versions of Word may lay out tables slightly differently.
If something is unclear: reverse-engineer the XML!
When it’s not obvious how this or that XML tag works inside MS Word, there are two main approaches to figuring it out:
-
Create the desired content step-by-step. Start with a simple docx file. Save each step to its own file, as in
1.docx,2.docx, for example. Unzip each of them and use a visual diff tool for folder comparison to see which tags appear after your changes. (For a commercial option, try Araxis Merge, or for a free option, WinMerge.) -
If you generate a DOCX file that MS Word doesn’t like, work backwards. Simplify your XML step by step. At some point you will learn which change MS Word found incorrect.
DOCX is quite complex, isn’t it?
It is complex, and Microsoft’s license forbids using MS Word on the server side for processing DOCX– this is pretty standard for commercial products. Microsoft has, however, provided the XSLT file to handle most DOCX tags, but it won’t give you 100 percent or even 99 percent fidelity. Processes such as text wrapping over images are not supported, but you will be able to support the majority of documents. (If you don’t need complexity, consider using Markdown as an alternative.)
If you have a sufficient budget (there is no free DOCX rendering engine), you may want to use commercial products such as Aspose or docx4j. The most popular free solution is LibreOffice for converting between DOCX and other formats, including PDF. Unfortunately, LibreOffice contains many small bugs during conversion, and since it’s a sophisticated, open-source C++ product, it’s slow and difficult to fix fidelity issues.
Alternatively, if you find DOCX layouting too complicated to implement yourself, you can also convert it to HTML and use a browser to render it. You can also consider one of Toptal’s freelance XML developers.
DOCX Resources for further reading
- ECMA DOCX specification
- OpenXML library for DOCX manipulation from C#. It doesn’t contain information on layouting or rendering code, but offers a class hierarchy matching each possible XML node in DOCX.
- You can always search or ask on stackoverflow with keywords like docx4j, OpenXML and docx; there are people in the community who are knowledgeable.
Сегодняшним постом я хочу начать серию материалов. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
 Сегодняшним постом я хочу начать еще одну серию. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
Сегодняшним постом я хочу начать еще одну серию. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
Прежде чем перейти к содержательной части некоторый предваряющий disclaimer (традиционно ![]() ):
):
● Я в основном буду касаться современных офисных форматов, тех что появились в редакции Office 2007. Их еще называют XML-based форматами, в противовес старым бинарным (и это закрепилось в расширении файлов: docx, pptx, xlsx, … – в противовес doc, ppt, xls, …), ну или просто Open XML
● Некоторая часть статей (по крайней мере в самом начале) будет основана на материалах Open XML Developer Workshop (контент и видео), который вел Doug Mahugh. Если вам не хочется ждать моих статей рекомендую обратиться к этим материалам
● Еще одним хорошим подспорьем для изучающих Open XML будет книга Воутер Ван Вугт. OpenXML. Кратко и доступно. Ранее она в электронном виде была доступна в блоге евангелиста Microsoft Владимира Габриеля, но теперь – увы. Так что, если вам интересно и не хочется тратить время на поиск, можете взять здесь.
Вроде бы все. Можно приступать.
Что такое Open Packaging Conventions?
В двух словах, это формат контейнеров, поддерживающих хранение как структурированных (XML), так и неструктурированных компонентов (картинки, видео, бинарные компоненты, …) в одном файле.
Краткая но довольно информативная статья об OPC есть на wikipedia.
Что можно сказать в общем об этом стандарте/формате? Я бы выделил такие моменты:
● Формальное описание является частью ECMA-376. Office Open XML File Formats, более конкретно – второй частью Part 2 — Open Packaging Conventions.
● Сам стандарт описывает только структуру хранения и самые общие метаданные (типа автора, даты,…) поэтому потенциально в таком контейнере можно хранить практически что угодно.
Например, вот несколько форматов, основанных на OPC от самого Microsoft:
o .docx, pptx, xlsx, .vsdx – форматы Word, Power Point, Excel и Visio
o .xps (.oxps) – формат “электронной бумаги” или формат c фиксированной разметкой, предназначенный для передачи документов без искажения форматирования (в чем-то аналог PDF).
o .vsix – формат расширений Visual Studio, начиная с версии 2010
o .cspkg – формат пакетов для Windows Azure Cloud Services
o .appx – формат пакетов приложений Windows Store (для Windows 
Что представляют собой контейнеры в OPC?
Тут нужно сделать одну существенную оговорку: сам стандарт разбивает описание контейнеров на 2 части: абстрактную модель (которая описывает из каких элементов состоят контейнеры, но ни слова не говорит о том как это должно храниться физически) и физический формат пакета, т.е. конкретную реализацию.
Т.е. в чистой теории, контейнер в OPC может храниться единый файл, а может, например, как набор отдельных ресурсов на Web-сервере. Но (!) на текущий момент определена только 1 реализация – в виде единого файла ZIP-архива.
Структура контейнеров в OPC
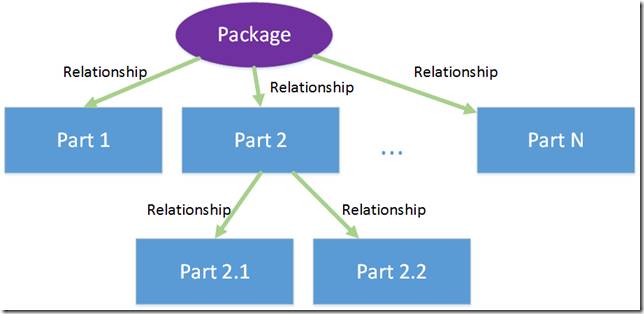
Вообще говоря, концептуальная схема пакетов в Open Packaging Conventions очень проста, она включает в себя всего два элемента:
● компоненты (parts), которые собственно и содержат хранящийся контент (любой: xml, image, video, …)
● отношения (relationships), которые определяют
o предназначение (смысл/семантику) каждой части
o отношения между частями, а также между частями и пакетом целиком
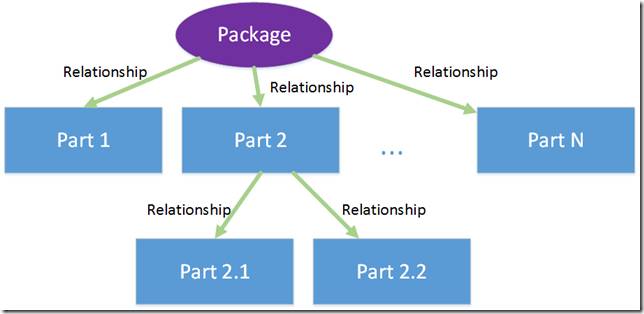
Компоненты
Как уже было сказано выше компонент в OPC это и есть основная единица хранения контента. Каждый компонент характеризуется 2-я составляющими: именем и типом содержимого.
Имя компонента состоит из набора сегментов, начинающихся с прямого слэша (“/”), вот несколько примеров:
● /hello/world/doc.xml
● /docProps/app.xml
● /image4.png
В спецификации приведены более формальные правила построения имен, из которых я укажу только основные (на мой взгляд):
● все имена должны начинаться с прямого слэша (“/”) и не должны им заканчиваться
● имя недолжно содержать пустых сегментов (т.е. /images//image1.jpg – неправильное имя)
● сегменты могут состоять из букв, цифр и знаков «!«, «$«, «&«, «‘«, «(«, «)«, «*«, «+«, «,«, «;«, «=«, «-«, «.«, «_«, «~«, «:«, «@»
● ни одно имя компонента не должно строиться как имя уже существующего компонента + новый сегмент. Т.е. если есть компонент с именем /abc/abc, то компонент с именем /abc/abc/a существовать не может, зато вполне может существовать компонент с именем /abc/abcde
● имена могут записываться Unicode-символами или использовать кодирование в виде /a/%D1%86.xml
Тип содержимого компонента задается в соответствии с RFC 2616 (раздел Media Types) т.е. в виде <type>/<subtype>:
● application/xml
● image/jpeg
● application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml
Связи
Любой компонент в пакете (а также сам пакет) может ссылаться на другие компоненты или некоторые ресурсы за пределами пакета. Для представления этих ссылок введен специальный механизм связей. По большому счету, связи позволяют решить 2 задачи:
● получить список связанных с компонентом ресурсов, без необходимости анализировать его содержимое (которое может быть очень большим, иметь разную структуру, быть зашифрованным или вообще не поддерживать хранение ссылок)
● поменять набор связей компонента, не меняя его содержимого (которое может быть, например, зашифровано или защищено цифровой подписью)
Создавая свой пакет вы, конечно же, можете не использовать связи. Вместо этого везде в коде использовать фиксированные имена компонент, а где нужны списки связанных ресурсов, ссылаться на них прямо из самих компонент. Однако, рекомендации “лучших собаководов” все же советуют использовать связи везде, где это возможно.
Информация о связях для каждого компонента (а также самого пакета), хранится в специальных компонентах связей (relationships parts) тип содержимого которых application/vnd.openxmlformats-package.relationships+xml
Имена компонентов связи строятся из имени исходных компонент, к которым:
● добавляется предпоследний сегмент с именем _rels
● дописывается “расширение” .rels
Связи самого пакета хранятся в специальном компоненте с именем /_rels/.rels
Например, если в пакете у нас есть компонент с именем /document/mainPart.xml и два связанных компонента с картинками (пусть их мена будут /images/image1.png и /images/image2.jpeg), то пакет для них будет иметь следующую структуру:
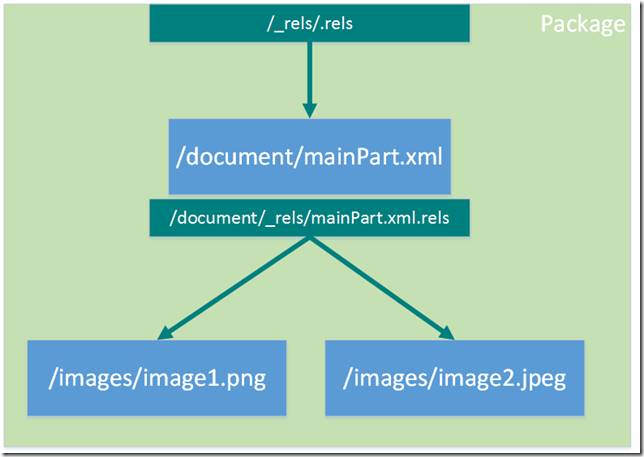
Содержимое компонента связи представляет собой XML следующего формата:
<?xml version=»1.0″ encoding=»UTF-8″ standalone=»yes»?>
<Relationships xmlns=»http://schemas.openxmlformats.org/package/2006/relationships»>
<Relationship Id=»rId1″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles»
Target=»styles.xml» />
<Relationship Id=»rId2″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme»
Target=»theme/theme1.xml» />
<Relationship Id=»rId3″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable»
Target=»fontTable.xml» />
<Relationship Id=»rId4″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/image»
Target=»file:///C:UsersPublicPicturesSample%20PicturesDesert.jpg»
TargetMode=»External» />
</Relationships>
Как уже наверняка понятно из приведенного фрагмента, каждый тэг <Relationship> определяет одну связь. Его атрибуты:
|
Id |
Идентификатор связи. На него ссылаются из содержимого компонент, когда необходимо использовать конкретную связь. |
|
Type |
Тип связи. По сути дела тип указывает семантику связи. Например, две разных связи могут указывать на 2 компонента типа image/jpeg, но одно изображение будет картинкой в тексте документа, а второе – миниатюрой (thumbnail) всей страницы целиком. |
|
TargetMode |
(Необязательный) Принимает одно из возможных значений: · Internal (значение по умолчанию) – указывает, что связь ссылается на компонент пакета · External – связь указывает на ресурс за пределами пакета |
|
Target |
Адрес ресурса или компонента на который ссылается связь |
Важный момент: для обращения к компонентам и внешним ресурсам можно использовать как абсолютные адреса (для компонент это будет их полное имя), так и относительные. В последнем случае полное имя компоненты рассматривается как путь в файловой системе, каждый сегмент, кроме последнего – имя “папки”, а последний – имя “файла”. Вот несколько примеров такой адресации:
|
Имя исходного компонента |
Относительный адрес |
Результирующий адрес |
|
/mydoc/markup/page.xml |
picture.jpg |
/mydoc/markup/picture.jpg |
|
/mydoc/markup/page.xml |
images/picture.jpg |
/mydoc/markup/images/picture.jpg |
|
/mydoc/markup/page.xml |
./picture.jpg |
/mydoc/markup/picture.jpg |
|
/mydoc/markup/page.xml |
../picture.jpg |
/mydoc/picture.jpg |
|
/mydoc/markup/page.xml |
/images/picture.jpg |
/mydoc/images/picture.jpg |
|
/ |
images/picture.jpg |
/images/picture.jpg |
Вот, по большому счету и все, что касается модели пакета в OPC. Осталось сказать несколько слов о физической реализации пакетов
Пакеты на основе ZIP-архивов
Как уже было сказано выше, в спецификации OPC определена только одна реализация пакетов – на основе ZIP архивов. Она достаточно проста, поэтому я приведу её обзорно:
● все компоненты, как обычные, так и компоненты связей, хранятся в виде одного или нескольких файлов внутри архива (при этом логически они все равно адресуются как единое целое)
● для хранения типа контента каждого компонента в архиве создается специальный файл с именем [Content_Types].xml
Внутри файла [Content_Types].xml хранится XML следующего вида:
<?xml version=»1.0″ encoding=»UTF-8″ standalone=»yes»?>
<Types xmlns=»http://schemas.openxmlformats.org/package/2006/content-types»>
<Default Extension=»png» ContentType=»image/png»/>
<Default Extension=»jpeg» ContentType=»image/jpeg»/>
<Default Extension=»rels» ContentType=»application/vnd.openxmlformats-package.relationships+xml»/>
<Default Extension=»xml» ContentType=»application/xml»/>
<Override PartName=»/word/document.xml»
ContentType=»application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml»/>
<Override PartName=»/word/styles.xml»
ContentType=»application/vnd.openxmlformats-officedocument.wordprocessingml.styles+xml»/>
</Types>
Собственно, общая схема, я думаю, понятна и так: для описания типов используется два подхода:
● указание типа по расширению (тэг <Default>)
● явное указание типа для конкретного компонента (тэг <Override>)
Как заглянуть внутрь OPC-пакета?
Итак, надеюсь вас уже заинтриговало мое объяснение базовых принципов и вы уже жаждите приступить к практическому изучению (т.е. взять и разобрать по косточкам какой-нибудь офисный файл) ![]() .
.
Вот несколько способов как это можно сделать:
● Прямой (“рукопашный”) способ. Т.к. физическая реализация OPC есть ни что иное, как обычный ZIP-архив, то самый простой способ его изучить – распаковать и работать как с обычной папкой (ну или воспользоваться любимым архиватором).
o Плюс подхода – будете глубже понимать устройство.
o Минусы:
▪ Сложно отслеживать связи между компонентами (а именно они образуют структуру, а вовсе не “папки” архива)
▪ Довольно муторно редактировать, если захочется экспериментов (нужно добавлять файлы для компонентов, править файлы связей да еще и не забывать про указание типа контента, если он не стандартный)
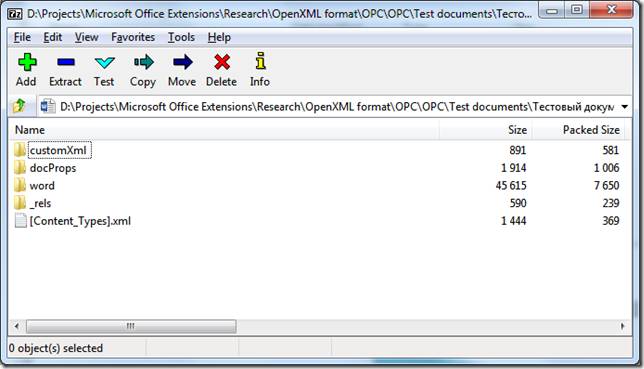
● Open XML Package Editor Power Tool for Visual Studio 2010. Расширение для Visual Studio. Умеет открывать файлы в формате OPC, показывать и редактировать их логическую структуру (добавлять/удалять/редактировать компоненты и связи). Для редактирования содержимого компонент используется редакторы самой VS, что очень удобно для экспериментов (XML редактор в VS явно не самый плохой, особенно если в наличии есть хорошие XSD-описания).
o Минусы:
▪ Так и не нашел способа создать пакет с 0 (но это редко нужно, да и обходится созданием пакета вручную).
▪ Требует Visual Studio.
▪ Работает только в 2010 версии VS. Увы, для более новых версий студии пакет так и не обновился, хотя почти наверняка он заработает без доработок в любой последующей. А доработать установщик пакета руками не получается, т.к. это не обычный vsix ![]()
● Standalone приложение от Воутера Ван Вугта Open XML Package Explorer. По возможностям оно близко к предыдущему расширению для VS, но не требует ничего для установки, кроме .Net 3.0. У него даже есть встроенный редактор XML, правда уступающий редактору от VS. К сожалению, приложение давно не обновлялось имеет ряд неприятных ошибок… но пользоваться можно.
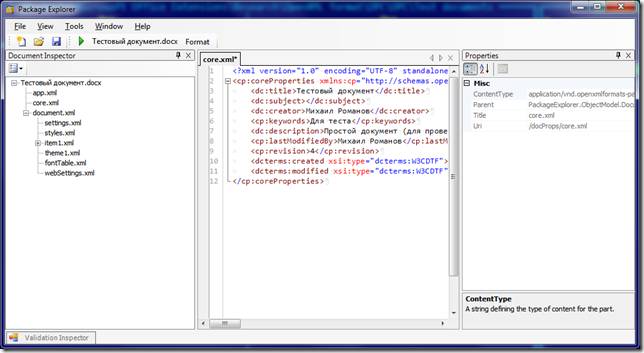
Пара слов в заключение
Как видите, стандарт OPC в своей основе довольно прост и функционален. Однако остались еще ряд нераскрытых тем. В частности мы не рассмотрели ряд возможностей, заложенных в формат OPC:
● базовые метаданные пакета (core properties)
● иконки пакета (thumbnails)
● цифровые подписи (digital signatures)
Ну и, конечно, мы еще ни слова не проговорили об API для работы с OPC пакетами.
Источник: Блог Михаила Романова.
Как сделать файл xml из word?

XML-формат предназначен для хранения данных, которые могут пригодиться в работе некоторых программ, сайтов и поддержки определённых языков разметки. Создать и открыть файл с таким форматом не сложно. Это вполне можно сделать, даже если на компьютере не установлено какое-либо специализированное программное обеспечение.
Немного об XML
Сам по себе XML — это язык разметки, чем-то похожий на HTML, который используется на веб-страницах. Но если последний применяется только для вывода информации и её правильной разметки, то XML позволяет её структурировать определённым образом, что делает этот язык чем-то похожим на аналог базы данных, который не требует наличия СУБД.
Создавать XML-файлы можно как при помощи специализированных программ, так и встроенным в Windows текстовым редактором. От вида используемого ПО зависит удобство написания кода и уровень его функциональности.
Способ 1: Visual Studio
Вместо этого редактора кода от Microsoft можно использовать любой его аналог от других разработчиков. По факту Visual Studio является более расширенной версией обычного «Блокнота». Код теперь имеет специальную подсветку, ошибки выделяются или исправляются автоматически, также в программу уже загружены специальные шаблоны, которые позволяют упростить создание XML-файлов больших объёмов.
Для начала работы вам нужно создать файл. Нажмите по пункту «Файл» в верхней панели и из выпадающего меню выберите «Создать…». Откроется список, где указывается пункт «Файл».

Вас перебросит в окно с выбором расширения файла, соответственно выбирайте пункт «XML-файл».

В только что созданном файле уже будет первая строка с кодировкой и версией. По умолчанию прописана первая версия и кодировка UTF-8, которые вы можете поменять в любое время. Дальше для создания полноценного XML-файла вам нужно прописать всё то, что было в предыдущей инструкции.
По завершении работы снова выберите в верхней панели «Файл», а там из выпадающего меню пункт «Сохранить всё».
Способ 2: Microsoft Excel
Можно создать XML-файл и не прописывая код, например, при помощи современных версий Microsoft Excel, который позволяет сохранять таблицы с данным расширением. Однако нужно понимать, что в этом случае создать что-то более функциональное обычной таблицы не получится.
Такой способ больше подойдёт тем, кто не хочет или не умеет работать с кодом. Однако в этом случае пользователь может столкнуться с определёнными проблемами при перезаписи файла в XML-формат. К сожалению, проделать операцию преобразования обычной таблицы в XML можно только на самых новых версиях MS Excel. Чтобы это сделать, используйте следующую пошаговую инструкцию:
- Заполните таблицу каким-либо контентом.
- Нажмите на кнопку «Файл», что в верхнем меню.
- Откроется специальное окно, где нужно нажать на «Сохранить как…». Этот пункт можно найти в левом меню.
- Укажите папку, куда необходимо сохранить файл. Папка указывается в центральной части экрана.
- Теперь вам нужно указать название файла, а в разделе «Тип файла» из выпадающего меню выбрать
«XML-данные». - Нажмите на кнопку «Сохранить».
Способ 3: Блокнот
Для работы с XML вполне подойдёт даже обычный «Блокнот», однако пользователю, который не знаком с синтаксисом языка, придётся трудно, так как в нём нужно прописывать различные команды и теги. Несколько проще и значительно продуктивнее процесс будет идти в специализированных программах для редактирования кода, например, в Microsoft Visual Studio. В них есть специальная подсветка тегов и всплывающие подсказки, что значительно упрощает работу человеку, плохо знакомому с синтаксисом этого языка.
Для этого способа не потребуется что-либо скачивать, так как в операционную систему уже встроен «Блокнот». Давайте попробуем сделать в нём простую XML-таблицу по данной инструкции:
- Создайте обычный текстовый документ с расширением TXT. Разместить его можно где угодно. Откройте его.
- Начните прописывать в нём первые команды. Для начала нужно задать всему файлу кодировку и указать версию XML, делается это следующей командой:
Первое значение — это версия, её менять не обязательно, а второе значение — это кодировка. Рекомендуется использовать кодировку UTF-8, так как большинство программ и обработчиков работают с ней корректно. Однако её можно изменить на любую другую, просто прописав нужное название.
Внутри тега теперь можно прописать более подробные параметры, в данном случае это информация о неком Иване Иванове. Пропишем ему возраст и должность. Выглядеть это будет так:
Примерно так у вас должен выглядеть готовый результат:

XML-компиляторы должны обработать этот код в виде таблицы с одной колонкой, где указаны данные о неком Иване Иванове.
В «Блокноте» вполне можно сделать несложные таблицы наподобие этой, но при создании более объёмных массивов данных могут возникнуть сложности, так как в обычном «Блокноте» нет функций исправления ошибок в коде или их подсветки.
Как видите в создании XML-файла нет ничего сложного. При желании его может создать любой пользователь, который более-менее умеет работать на компьютере. Однако для создания полноценного XML-файла рекомендуется изучить данный язык разметки, хотя бы на примитивном уровне.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Конвертер файлов / Документы / Конвертировать в DOC / XML конвертер / DOC в XML
Вы можете перевести DOC документ в XML и во множество других форматов с помощью бесплатного онлайн конвертера.
Как сконвертировать xml в doc?
Выберите файл с компьютера, Google Диска, Dropbox или перетащите его на страницу
Выберите xml или любой другой формат, который вам нужен (более 100 поддерживаемых форматов)
Скачайте ваш xml файл
Подождите пока ваш файл сконвертируется и вы сразу сможете его скачать xml -файл
Microsoft Word Document
DOC – специальное расширение, соответствующее документам, созданным в текстовом редакторе Microsoft World, до версии 2007 года. В этом формате хранятся сведения о форматировании текстового документа – абзацы, списки, отступы, выравнивания и многое другое. Файлы DOC могут включать в себя не только текстовую информацию, но и многочисленные изображения, графики, сценарии, диаграммы. DOC представляет собой расширение в формате двоичного файла, который начинается с информационного блока, выступающего ключевым элементом всей совокупности файлов данных. Такие двоичные файлы включают в себя довольно большой объем информации о форматировании текстового документа. Традиционно расширение получило широкое распространение для создания документов текстового формата в большом диапазоне ОС. Файлы в этом формате открываются любыми, в том числе современными версиями редактора Word или его аналогами из бесплатных пакетов вроде Open Office, Libre Office или утилитами наподобие Corel WordPerfect.
Первые версии файлового формата DOC приоритетно ориентировались на содержание форматированного текста, но со временем к нему добавилось большое количество встроенных объектов, среди которых встречаются как диаграммы и графики, так и различные медиа-файлы (звуки, видео). Файлы с расширением DOC способны содержать данные о слиянии, благодаря чему шаблон обработки слов может применяться вместе с таблицей либо базой данных.
Как xml перевести в word
Содержание статьи

- Как xml перевести в word
- Как открыть документ формата docx
- Как создать xml документ
Перевести xml в doc можно несколькими способами:
- используя возможности программы word;
- при помощи специальных онлайн-сервисов.
Подробнее разберем каждый из способов.
С помощью программы Word
Первым делом понадобится запустить Word. Сделать это можно через ярлык на рабочем столе или меню «Пуск». Затем необходимо открыть нужный xml файл. Чтобы сделать это, надо:
- Нажать на кнопку «Файл», расположенную в верхней левой части экрана.
- В открывшемся меню кликнуть на пункт «Открыть». Справа появится изображение папки с надписью «Обзор». При нажатии на нее откроется корневой каталог, в котором нужно найти xml-файл.


После этого потребуется снова кликнуть на кнопку «Файл» и щелкнуть мышкой на пункт «Сохранить как». Затем пользователь должен указать место для сохранения и в поле «Тип файла» выбрать «Документ word».

В указанном месте на компьютере появится файл с расширением doc. Теперь его можно спокойно открывать программой word или другим текстовым редактором.
При помощи онлайн-сервисов
Сделать это можно на специальных сайтах — конвертерах. Они предназначены для трансформации файлов из одного формата в другой. Таких сайтов в сети существует огромное множество, вот лишь некоторые из них:
- onlineconvertfree.com;
- coolutils.com;
- online-converting.ru;
- zamzar.com.
Рассмотрим процесс конвертации на примере сайте onlineconvertfree.com. Для этого потребуется зайти на ресурс и кликнуть по надписи «Конвертировать в», что находится сверху. Откроется выпадающее меню, в котором необходимо нажать на «Документы конвертер». Пользователь попадет на страницу, где расположена синяя кнопка «Выберите файл»

Дальнейший порядок действий будет выглядеть следующим образом:
- Нажать на кнопку и загрузить xml-файл.
- В появившемся окне выбрать пункт «в doc».
- Подождать, пока закончится процесс конвертации. Его скорость зависит от размера файла.
- Скачать готовый файл на компьютер.
После выполнения вышеуказанных действий его можно будет открыть в программе word. Конвертация файлов при помощи других сервисов проходит аналогичным образом, могут лишь немного отличаться названия разделов.
Перевести xml в doc не сложно, главное действовать по инструкции. Преобразовать файл возможно двумя способами. После конвертации его получится открыть и редактировать в word.
Как перевести документ Word в формат XML?
Как сделать файл xml из word?

XML-формат предназначен для хранения данных, которые могут пригодиться в работе некоторых программ, сайтов и поддержки определённых языков разметки. Создать и открыть файл с таким форматом не сложно. Это вполне можно сделать, даже если на компьютере не установлено какое-либо специализированное программное обеспечение.
Немного об XML
Сам по себе XML — это язык разметки, чем-то похожий на HTML, который используется на веб-страницах. Но если последний применяется только для вывода информации и её правильной разметки, то XML позволяет её структурировать определённым образом, что делает этот язык чем-то похожим на аналог базы данных, который не требует наличия СУБД.
Создавать XML-файлы можно как при помощи специализированных программ, так и встроенным в Windows текстовым редактором. От вида используемого ПО зависит удобство написания кода и уровень его функциональности.
Способ 1: Visual Studio
Вместо этого редактора кода от Microsoft можно использовать любой его аналог от других разработчиков. По факту Visual Studio является более расширенной версией обычного «Блокнота». Код теперь имеет специальную подсветку, ошибки выделяются или исправляются автоматически, также в программу уже загружены специальные шаблоны, которые позволяют упростить создание XML-файлов больших объёмов.
Для начала работы вам нужно создать файл. Нажмите по пункту «Файл» в верхней панели и из выпадающего меню выберите «Создать…». Откроется список, где указывается пункт «Файл».
Вас перебросит в окно с выбором расширения файла, соответственно выбирайте пункт «XML-файл».
В только что созданном файле уже будет первая строка с кодировкой и версией. По умолчанию прописана первая версия и кодировка UTF-8, которые вы можете поменять в любое время. Дальше для создания полноценного XML-файла вам нужно прописать всё то, что было в предыдущей инструкции.
По завершении работы снова выберите в верхней панели «Файл», а там из выпадающего меню пункт «Сохранить всё».
Способ 2: Microsoft Excel
Можно создать XML-файл и не прописывая код, например, при помощи современных версий Microsoft Excel, который позволяет сохранять таблицы с данным расширением. Однако нужно понимать, что в этом случае создать что-то более функциональное обычной таблицы не получится.
Такой способ больше подойдёт тем, кто не хочет или не умеет работать с кодом. Однако в этом случае пользователь может столкнуться с определёнными проблемами при перезаписи файла в XML-формат. К сожалению, проделать операцию преобразования обычной таблицы в XML можно только на самых новых версиях MS Excel. Чтобы это сделать, используйте следующую пошаговую инструкцию:
- Заполните таблицу каким-либо контентом.
- Нажмите на кнопку «Файл», что в верхнем меню.
- Откроется специальное окно, где нужно нажать на «Сохранить как…». Этот пункт можно найти в левом меню.
- Укажите папку, куда необходимо сохранить файл. Папка указывается в центральной части экрана.
- Теперь вам нужно указать название файла, а в разделе «Тип файла» из выпадающего меню выбрать
«XML-данные». - Нажмите на кнопку «Сохранить».
Способ 3: Блокнот
Для работы с XML вполне подойдёт даже обычный «Блокнот», однако пользователю, который не знаком с синтаксисом языка, придётся трудно, так как в нём нужно прописывать различные команды и теги. Несколько проще и значительно продуктивнее процесс будет идти в специализированных программах для редактирования кода, например, в Microsoft Visual Studio. В них есть специальная подсветка тегов и всплывающие подсказки, что значительно упрощает работу человеку, плохо знакомому с синтаксисом этого языка.
Для этого способа не потребуется что-либо скачивать, так как в операционную систему уже встроен «Блокнот». Давайте попробуем сделать в нём простую XML-таблицу по данной инструкции:
- Создайте обычный текстовый документ с расширением TXT. Разместить его можно где угодно. Откройте его.
- Начните прописывать в нём первые команды. Для начала нужно задать всему файлу кодировку и указать версию XML, делается это следующей командой:
Первое значение — это версия, её менять не обязательно, а второе значение — это кодировка. Рекомендуется использовать кодировку UTF-8, так как большинство программ и обработчиков работают с ней корректно. Однако её можно изменить на любую другую, просто прописав нужное название.
Примерно так у вас должен выглядеть готовый результат:
XML-компиляторы должны обработать этот код в виде таблицы с одной колонкой, где указаны данные о неком Иване Иванове.
В «Блокноте» вполне можно сделать несложные таблицы наподобие этой, но при создании более объёмных массивов данных могут возникнуть сложности, так как в обычном «Блокноте» нет функций исправления ошибок в коде или их подсветки.
Как видите в создании XML-файла нет ничего сложного. При желании его может создать любой пользователь, который более-менее умеет работать на компьютере. Однако для создания полноценного XML-файла рекомендуется изучить данный язык разметки, хотя бы на примитивном уровне.
Мы рады, что смогли помочь Вам в решении проблемы.
Как сделать файл xml из word? — Информатизация

Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
Основное содержимое документа.
word/document.xml
- — сам документ
- — тело документа
- — параграф
- — run (фрагмент) текста
- — сам текст
- — описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML. Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.sh.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold.
- Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold.
- Изначально diff выглядел следующим образом:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@— 1+ 2 2017-02-07T19:37:00Z— 2017-02-07T19:37:00Z
Изменение версии документа и даты модификации нас также не интересует.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением ) и проверяем что документ открывается и показывает то, что ожидалось. 8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула. Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
word/styles.xml
diff@@ -480,6 +480,50 @@
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на .
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег надо добавить
Уменьшаем diff до этого набора изменений:
Затем запаковываем документ и открываем его. Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels.
- В word/document.xml в тег добавляем тег или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = «%3 %1 -d %2»;
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile(«in.xml», «footer.xsl», footer0.xml»)
В результате получится файл нижнего колонтитула footer0.xml:
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует. Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
Прописываем ссылки в документе
Далее надо в каждый тег добавить тег или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега может быть 3 тега — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
В результате
Весь код опубликован. Работает он так:
do ##class(Converter.Footer).modifyFooter(«in.docx», «out.docx», «TEST»)
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Есть документ Word, как сохранить его с другими параметрами?

Есть документ Word, как сохранить его с другими параметрами?
Как известно, компания Микрософт преуспела в создании различных версий программы Word, при этом у пользователей вызывали недоумение некоторые нововведения, но в целом, надо отметить, текстовый редактор стал более совершеннее и многофункциональнее.
Кто помнит, первоначальный формат сохранения документов был с расширением .doc. Для нынешнего поколения пользователей известно, в большинстве своем, расширение .docx для файлов Word.
Давайте поговорим на профессиональном языке о новом формате сохранения текстовых документов ворд, и затем узнаем, как можно сохранить документ, который уже был ранее создан и сохранён, но уже с другими параметрами. Ведь их несколько у программы ворд.
О новом формате сохранения документов в ms word
Новый формат Word– Microsoft Office Open XML При сохранении документа по умолчанию задается новый тип файла – .docx, основанный на поддержке языка XML. Хотя такой формат и не является новинкой в полном смысле этого слова – еще в 1999 году появились первые способы данной поддержки в «Office» 2000, – он стал следующим шагом в сохранении документов.
Тотальное внедрение этого формата, прежде всего, связано с переводом Microsoft Office на открытые стандарты, обеспечивающие более оперативное создание и взаимодействие документов, ускоренный обмен данными с другими корпоративными бизнес-приложениями.
Другие публикации каналаСохраняем правильно документ Word: а как это делаете вы?Видите ли вы, что делаете в программе Word?Подложка, фон и текстовое поле: много ли знаете об этом?Пять фишек, которые помогут улучшить работу в WordЧем панель инструментов Word отличается от панели быстрого доступа
Форматом сохранения документов по умолчанию стал ZIP-контейнер, доступный на бесплатной основе и соответствующий спецификации Open Packaging Conventions. Он пришел на смену бинарному формату хранения документов, использовавшемуся в предыдущих версиях «MS Office».
Данный XML-формат представляет собой обычный ZIP-архив, который выполняет роль контейнера и называется package. Уже в нем размещаются различные компоненты документа, называемые частями (part) и элементами (item).
При этом части являются фрагментами документа и отвечают за его содержимое, а элементы, в свою очередь, представляют собой метаданные, расписывающие, каким образом эти части собираются вместе и как отображены. Но не все части документа могут быть сохранены в XML-формате.
Графические изображения форматов PNG, JPG, TIFF хранятся в оригинальном виде, что, впрочем, делает доступ к ним более удобным. Помимо этого, в бинарном виде сохраняются и внедренные в документы OLE-объекты.
Таким образом, благодаря автоматическому сжатию документа размер его может быть на 70–80% меньше исходного. Помимо этого, облегчен процесс восстановления данных в случае сбоя за счет модульной схемы хранения данных.
Так как OLE_объекты и макросы (код VBA) хранятся в отдельной секции, документы в целом становятся менее уязвимыми для вирусов и зловредных макрокоманд.
Какие форматы сохранения документов Word существуют?
Все новые расширения файлов в Word базируются на именах предыдущих, с учетом – с макросами или без:
– .docx– документ Office Word XML (формат Word по умолчанию, без хранения макрокода VBA), формат Word 2019, Word 2016, Word 2013, Word 2010 и Office Word 2007;
– .docm – документ Office Word XML с макросами (формат Word с возможностью хранения макрокода VBA), для Word 2019, Word 2016, Word 2013, Word 2010 и Office Word 2007;
– .dotx – шаблон Office Word XML (формат шаблона Word по умолчанию), для создания новых шаблонов Word 2019, Word 2016, Word 2013, Word 2010 и Office Word 2007, не содержащих макросы.
– .dotm – шаблон Office Word XML с макросами (формат шаблона Word возможностью хранения макрокода VBA), для создания новых шаблонов Word 2019, Word 2016, Word 2013, Word 2010 и Office Word 2007, содержащих макросы. Этот формат файлов следует использовать пользователям, которые хотят включить настройки пользовательского интерфейса или макросы в шаблон;
Таким образом, если необходимо открыть XML-файл с разрешением .docx, его можно будет просмотреть обычным архиватором WinRar или WinZip.
Документ Word 97–2003 – как уже говорилось, привычный формат сохранения данных в начале двухтысячных. Документ, созданный в последних версиях Word со всеми новыми возможностями программы, при сохранении в данном формате теряет некоторые свои характеристики.
В каких еще форматах можно сохранять документы в word?
Поскольку нет предела совершенству, разработчики предлагают в программе Word сохранять в самых разных форматах (см. таблицу)
Форматы сохранения файлов в программе Word
А теперь давайте представим, что у вас есть документ, который называется Документ Васи.doc или Это документ Маруси.txt
Как видите есть отличия в формате сохранения документов от тех, которые предлагает последняя версия программы MS Word, например, это было бы Документ Васи.docx или Это документ Маруси.dotx не так ли? Так давайте рассмотрим, как же изменить эти и другие параметры?
Как сохранить ранее сохраненный документ, но с другими параметрами?
Чтобы сохранить созданный ранее документ, но теперь уже под другим Именем или по другому Адресу (в другой папке) или с другим Типом расширения (форматом), воспользуйтесь одним из способов, представленных ниже:
1 способ: при открытом окне документа нажимаем на клавиатуре клавишу F12.
В появившемся окне выбираем Папку, даём Имя файлу, раскрываем меню с Типом файла и далее нажимаем ОК (см. Рис.)
Сохранение документа с другим параметром формата
1. В верхнем левом углу окна программы щелкаем по кнопке «Файл».
2. В меню типичных команд выбираем пункт «Сохранить как».
3. Сколько бы раз до этого документ ни был сохранен, по этой команде вновь откроется окно сохранения документа (см. выше Рис.), в котором можно снова выбрать все параметры сохранения.
Сохраняем правильно документ Word: а как это делаете вы>>
4. Задаем новое имя или выбираем новое место для сохранения документа, или же и то, и другое, и далее следуем всем инструкциям для обычного сохранения.
5. Завершаем сохранение щелчком по кнопке «Сохранить» или нажатием клавиши Enter.
Важно! С этого момента работа будет продолжаться только с документом, сохраненным с новыми параметрами, а документ, первоначально открытый для использования, будет автоматически закрыт без изменения.
В статье мы рассмотрели форматы (расширения) сохранения документов в программе Word.
Ставьте лайк и в последующих уроках и статьях я вам расскажу, как создавать стили, быстро редактировать документы, создавать оглавление и многое другое. Подписывайтесь на канал «Изучаем Word: шаг за шагом», чтобы статьи появлялись в вашей ленте. А также давайте добавим статью в #база знаний с помощью хештега. До встречи!
Перевод ворд в xml

Перевести xml в doc можно несколькими способами:
- используя возможности программы word;
- при помощи специальных онлайн-сервисов.
Подробнее разберем каждый из способов.
С помощью программы word
Первым делом понадобится запустить Word. Сделать это можно через ярлык на рабочем столе или меню «Пуск». Затем необходимо открыть нужный xml файл. Чтобы сделать это, надо:
- Нажать на кнопку «Файл», расположенную в верхней левой части экрана.
- В открывшемся меню кликнуть на пункт «Открыть». Справа появится изображение папки с надписью «Обзор». При нажатии на нее откроется корневой каталог, в котором нужно найти xml-файл.
После этого потребуется снова кликнуть на кнопку «Файл» и щелкнуть мышкой на пункт «Сохранить как». Затем пользователь должен указать место для сохранения и в поле «Тип файла» выбрать «Документ word».
В указанном месте на компьютере появится файл с расширением doc. Теперь его можно спокойно открывать программой word или другим текстовым редактором.
При помощи онлайн-сервисов
Сделать это можно на специальных сайтах — конвертерах. Они предназначены для трансформации файлов из одного формата в другой. Таких сайтов в сети существует огромное множество, вот лишь некоторые из них:
- onlineconvertfree.com;
- coolutils.com;
- online-converting.ru;
- zamzar.com.
Рассмотрим процесс конвертации на примере сайте onlineconvertfree.com. Для этого потребуется зайти на ресурс и кликнуть по надписи «Конвертировать в», что находится сверху. Откроется выпадающее меню, в котором необходимо нажать на «Документы конвертер». Пользователь попадет на страницу, где расположена синяя кнопка «Выберите файл»
Дальнейший порядок действий будет выглядеть следующим образом:
- Нажать на кнопку и загрузить xml-файл.
- В появившемся окне выбрать пункт «в doc».
- Подождать, пока закончится процесс конвертации. Его скорость зависит от размера файла.
- Скачать готовый файл на компьютер.
После выполнения вышеуказанных действий его можно будет открыть в программе word. Конвертация файлов при помощи других сервисов проходит аналогичным образом, могут лишь немного отличаться названия разделов.
Перевести xml в doc не сложно, главное действовать по инструкции. Преобразовать файл возможно двумя способами. После конвертации его получится открыть и редактировать в word.
Как сделать файл xml из word?
XML-формат предназначен для хранения данных, которые могут пригодиться в работе некоторых программ, сайтов и поддержки определённых языков разметки. Создать и открыть файл с таким форматом не сложно. Это вполне можно сделать, даже если на компьютере не установлено какое-либо специализированное программное обеспечение.