
Word Processing
Andrew Prestage, in Encyclopedia of Information Systems, 2003
I. An Introduction to Word Processing
Word processing is the act of using a computer to transform written, verbal, or recorded information into typewritten or printed form. This chapter will discuss the history of word processing, identify several popular word processing applications, and define the capabilities of word processors.
Of all the computer applications in use, word processing is by far the most common. The ability to perform word processing requires a computer and a special type of computer software called a word processor. A word processor is a program designed to assist with the production of a wide variety of documents, including letters, memoranda, and manuals, rapidly and at relatively low cost. A typical word processor enables the user to create documents, edit them using the keyboard and mouse, store them for later retrieval, and print them to a printer. Common word processing applications include Microsoft Notepad, Microsoft Word, and Corel WordPerfect.
Word processing technology allows human beings to freely and efficiently share ideas, thoughts, feelings, sentiments, facts, and other information in written form. Throughout history, the written word has provided mankind with the ability to transform thoughts into printed words for distribution to hundreds, thousands, or possibly millions of readers around the world. The power of the written word to transcend verbal communications is best exemplified by the ability of writers to share information and express ideas with far larger audiences and the permanency of the written word.
The increasingly large collective body of knowledge is one outcome of the permanency of the written word, including both historical and current works. Powered by decreasing prices, increasing sophistication, and widespread availability of technology, the word processing revolution changed the landscape of communications by giving people hitherto unavailable power to make or break reputations, to win or lose elections, and to inspire or mislead through the printed word.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404001982
Computers and Effective Security Management1
Charles A. Sennewald, Curtis Baillie, in Effective Security Management (Sixth Edition), 2016
Word Processing
Word processing software can easily create, edit, store, and print text documents such as letters, memoranda, forms, employee performance evaluations (such as those in Appendix A), proposals, reports, security surveys (such as those in Appendix B), general security checklists, security manuals, books, articles, press releases, and speeches. A professional-looking document can be easily created and readily updated when necessary.
The length of created documents is limited only by the storage capabilities of the computer, which are enormous. Also, if multiple copies of a working document exist, changes to it should be promptly communicated to all persons who use the document. Specialized software, using network features, can be programmed to automatically route changes to those who need to know about updates.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128027745000241
Globalization
Jennifer DeCamp, in Encyclopedia of Information Systems, 2003
II.D.2.c. Rendering Systems
Special word processing software is usually required to correctly display languages that are substantially different from English, for example:
- 1.
-
Connecting characters, as in Arabic, Persian, Urdu, Hindi, and Hebrew
- 2.
-
Different text direction, as in the right-to-left capability required in Arabic, Persian, Urdu, and Hindi, or the right-to-left and top-to-bottom capability in formal Chinese
- 3.
-
Multiple accents or diacritics, such as in Vietnamese or in fully vowelled Arabic
- 4.
-
Nonlinear text entry, as in Hindi, where a vowel may be typed after the consonant but appears before the consonant.
Alternatives to providing software with appropriate character rendering systems include providing graphic files or elaborate formatting (e.g., backwards typing of Arabic and/or typing of Arabic with hard line breaks). However, graphic files are cumbersome to download and use, are space consuming, and cannot be electronically searched except by metadata. The second option of elaborate formatting often does not look as culturally appropriate as properly rendered text, and usually loses its special formatting when text is added or is upgraded to a new system. It is also difficult and time consuming to produce. Note that Microsoft Word 2000 and Office XP support the above rendering systems; Java 1.4 supports the above rendering systems except for vertical text.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404000800
Text Entry When Movement is Impaired
Shari Trewin, John Arnott, in Text Entry Systems, 2007
15.3.2 Abbreviation Expansion
Popular word processing programs often include abbreviation expansion capabilities. Abbreviations for commonly used text can be defined, allowing a long sequence such as an address to be entered with just a few keystrokes. With a little investment of setup time, those who are able to remember the abbreviations they have defined can find this a useful technique. Abbreviation expansion schemes have also been developed specifically for people with disabilities (Moulton et al., 1999; Vanderheiden, 1984).
Automatic abbreviation expansion at phrase/sentence level has also been investigated: the Compansion (Demasco & McCoy, 1992; McCoy et al., 1998) system was designed to process and expand spontaneous language constructions, using Natural Language Processing to convert groups of uninflected content words automatically into full phrases or sentences. For example, the output sentence “John breaks the window with the hammer” might derive from the user input text “John break window hammer” using such an approach.
With the rise of text messaging on mobile devices such as mobile (cell) phones, abbreviations are increasingly commonplace in text communications. Automatic expansion of many abbreviations may not be necessary, however, depending on the context in which the text is being used. Frequent users of text messaging can learn to recognize a large number of abbreviations without assistance.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123735911500152
Case Studies
Brett Shavers, in Placing the Suspect Behind the Keyboard, 2013
Altered evidence and spoliation
Electronic evidence in the form of word processing documents which were submitted by a party in litigation is alleged to have been altered. Altered electronic evidence has become a common claim with the ability to determine the changes becoming more difficult. How do you know if an email has been altered? What about a text document?
Case in Point
Odom v Microsoft and Best Buy, 2006
The Odom v Microsoft and Best Buy litigation primarily focused on Internet access offered to customers in which the customers were automatically billed for Internet service without their consent. One of the most surprising aspects of this case involved the altering of electronic evidence by an attorney for Best Buy. The attorney, Timothy Block, admitted to altering documents prior to producing the documents in discovery to benefit Best Buy.
Investigative Tips: All evidence needs to be validated for authenticity. The weight given in legal hearings depends upon the veracity of the evidence. Many electronic files can be quickly validated through hash comparisons. An example seen in Figure 11.4 shows two files with different file names, yet their hash values are identical. If one file is known to be valid, perhaps an original evidence file, any file matching the hash values would also be a valid and unaltered copy of the original file.

Figure 11.4. Two files with different file names, but having the same hash value, indicating the contents of the files are identical.
Alternatively, Figure 11.5 shows two files with the same file name but having different hash values. If there were a claim that both of these files are the same original files, it would be apparent that one of the files has been modified.

Figure 11.5. Two files with the same file names, but having different hash values, indicating the contents are not identical.
Finding the discrepancies or modifications of an electronic file can only be accomplished if there is a comparison to be made with the original file. Using Figure 11.5 as an example, given that the file having the MD5 hash value of d41d8cd98f00b204e9800998ecf8427e is the original, and where the second file is the alleged altered file, a visual inspection of both files should be able to determine the modifications. However, when only file exists, proving the file to be unaltered is more than problematic, it is virtually impossible.
In this situation of having a single file to verify as original and unaltered evidence, an analysis would only be able to show when the file was modified over time, but the actual modifications won’t be known. Even if the document has “track changed” enabled, which logs changes to a document, that would only capture changes that were tracked, as there may be more untracked and unknown changes.
As a side note to hash values, in Figure 11.5, the hash values are completely different, even though the only difference between the two sample files is a single period added to the text. Any modification, no matter how minor, results in a drastic different hash value.
The importance in validating files in relation to the identification of a suspect that may have altered a file is that the embedded metadata will be a key point of focus and avenue for case leads. As a file is created, copied, modified, and otherwise touched, the file and system metadata will generally be updated.
Having the dates and times of these updates should give rise to you that the updates occurred on some computer system. This may be on one or more computers even if the file existed on a flash drive. At some point, the flash drive was connected to a computer system, where evidence on a system may show link files to the file. Each of these instances of access to the file is an opportunity to create a list of possible suspects having access to those systems in use at each updated metadata fields.
In the Microsoft Windows operating systems, Volume Shadow Copies may provide an examiner with a string of previous versions of a document, in which the modifications between each version can be determined. Although not every change may have been incrementally saved by the Volume Shadow Service, such as if the file was saved to a flash drive, any previous versions that can be found will allow to find some of the modifications made.
Where a single file will determine the outcome of an investigation or have a dramatic effect on the case, the importance of ‘getting it right’ cannot be overstated. Such would be the case of a single file, modified by someone in a business office, where many persons had common access to the evidence file before it was known to be evidence. Finding the suspect that altered the evidence file may be simple if you were at the location close to the time of occurrence. Interviews of the employees would be easier as most would remember their whereabouts in the office within the last few days. Some may be able to tell you exactly where other employees were in the office, even point the suspect out directly.
But what if you are called in a year later? How about 2 or more years later? What would be the odds employees remembering their whereabouts on a Monday in July 2 years earlier? To identify a suspect at this point requires more than a forensic analysis of a computer. It will probably require an investigation into work schedules, lunch schedules, backup tapes, phone call logs, and anything else to place everyone somewhere during the time of the file being altered.
Potentially you may even need to examine the hard drive of a copy machine and maybe place a person at the copy machine based on what was copied at the time the evidence file was being modified. When a company’s livelihood is at stake or a person’s career is at risk, leave no stone unturned. If you can’t place a suspect at the scene, you might be able to place everyone else at a location, and those you can’t place, just made your list of possible suspects.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781597499859000113
When, How, and Why Do We Trust Technology Too Much?
Patricia L. Hardré, in Emotions, Technology, and Behaviors, 2016
Trusting Spelling and Grammar Checkers
We often see evidence that users of word processing systems trust absolutely in spelling and grammar checkers. From errors in business letters and on resumes to uncorrected word usage in academic papers, this nonstrategy emerges as epidemic. It underscores a pattern of implicit trust that if a word is not flagged as incorrect in a word processing system, then it must be not only spelled correctly but also used correctly. The overarching error is trusting the digital checking system too much, while the underlying functional problem is that such software identifies gross errors (such as nonwords) but cannot discriminate finer nuances of language requiring judgment (like real words used incorrectly). Users from average citizens to business executives have become absolutely comfortable with depending on embedded spelling and grammar checkers that are supposed to autofind, trusting the technology so much that they often do not even proofread. Like overtrust of security monitoring, these personal examples are instances of reduced vigilance due to their implicit belief that the technology is functionally flawless, that if the technology has not found an error, then an error must not exist.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128018736000054
Establishing a C&A Program
Laura Taylor, Matthew Shepherd Technical Editor, in FISMA Certification and Accreditation Handbook, 2007
Template Development
Certification Packages consist of a set of documents that all go together and complement one another. A Certification Package is voluminous, and without standardization, it takes an inordinate amount of time to evaluate it to make sure all the right information is included. Therefore, agencies should have templates for all the documents that they require in their Certification Packages. Agencies without templates should work on creating them. If an agency does not have the resources in-house to develop these templates, they should consider outsourcing this initiative to outside consultants.
A template should be developed using the word processing application that is the standard within the agency. All of the relevant sections that the evaluation team will be looking for within each document should be included. Text that will remain constant for a particular document type also should be included. An efficient and effective C&A program will have templates for the following types of C&A documents:
- ▪
-
Categorization and Certification Level Recommendation
- ▪
-
Hardware and Software Inventory
- ▪
-
Self-Assessment
- ▪
-
Security Awareness and Training Plan
- ▪
-
End-User Rules of Behavior
- ▪
-
Incident Response Plan
- ▪
-
Security Test and Evaluation Plan
- ▪
-
Privacy Impact Assessment
- ▪
-
Business Risk Assessment
- ▪
-
Business Impact Assessment
- ▪
-
Contingency Plan
- ▪
-
Configuration Management Plan
- ▪
-
System Risk Assessment
- ▪
-
System Security Plan
- ▪
-
Security Assessment Report
The later chapters in this book will help you understand what should be included in each of these types of documents. Some agencies may possibly require other types of documents as required by their information security program and policies.
Templates should include guidelines for what type of content should be included, and also should have built-in formatting. The templates should be as complete as possible, and any text that should remain consistent and exactly the same in like document types should be included. Though it may seem redundant to have the exact same verbatim text at the beginning of, say, each Business Risk Assessment from a particular agency, each document needs to be able to stand alone and make sense if it is pulled out of the Certification Package for review. Having similar wording in like documents also shows that the packages were developed consistently using the same methodology and criteria.
With established templates in hand, it makes it much easier for the C&A review team to understand what it is that they need to document. Even expert C&A consultants need and appreciate document templates. Finding the right information to include the C&A documents can by itself by extremely difficult without first having to figure out what it is that you are supposed to find—which is why the templates are so very important. It’s often the case that a large complex application is distributed and managed throughout multiple departments or divisions and it can take a long time to figure out not just what questions to ask, but who the right people are who will know the answers.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781597491167500093
Speech Recognition
John-Paul Hosom, in Encyclopedia of Information Systems, 2003
I.B. Capabilities and Limitations of Automatic Speech Recognition
ASR is currently used for dictation into word processing software, or in a “command-and-control” framework in which the computer recognizes and acts on certain key words. Dictation systems are available for general use, as well as for specialized fields such as medicine and law. General dictation systems now cost under $100 and have speaker-dependent word-recognition accuracy from 93% to as high as 98%. Command-and-control systems are more often used over the telephone for automatically dialing telephone numbers or for requesting specific services before (or without) speaking to a human operator. Telephone companies use ASR to allow customers to automatically place calls even from a rotary telephone, and airlines now utilize telephone-based ASR systems to help passengers locate and reclaim lost luggage. Research is currently being conducted on systems that allow the user to interact naturally with an ASR system for goals such as making airline or hotel reservations.
Despite these successes, the performance of ASR is often about an order of magnitude worse than human-level performance, even with superior hardware and long processing delays. For example, recognition of the digits “zero” through “nine” over the telephone has word-level accuracy of about 98% to 99% using ASR, but nearly perfect recognition by humans. Transcription of radio broadcasts by world-class ASR systems has accuracy of less than 87%. This relatively low accuracy of current ASR systems has limited its use; it is not yet possible to reliably and consistently recognize and act on a wide variety of commands from different users.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404001647
Prototyping
Rex Hartson, Pardha Pyla, in The UX Book (Second Edition), 2019
20.7 Software Tools for Making Wireframes
Wireframes can be sketched using any drawing or word processing software package that supports creating and manipulating shapes. While many applications suffice for simple wireframing, we recommend tools designed specifically for this purpose. We use Sketch, a drawing app, to do all the drawing. Craft is a plug-in to Sketch that connects it to InVision, allowing you to export Sketch screen designs to InVision to incorporate hotspots as working links.
In the “Build mode” of InVision, you work on one screen at a time, adding rectangular overlays that are the hotspots. For each hotspot, you specify what other screen you go to when someone clicks on that hotspot in “Preview mode.” You get a nice bonus using InVision: In the “operate” mode, you, or the user, can click anywhere in an open space in the prototype and it highlights all the available links. These tools are available only on Mac computers, but similar tools are available under Windows.
Beyond this discussion, it’s not wise to try to cover software tools for making prototypes in this kind of textbook. The field is changing fast and whatever we could say here would be out of date by the time you read this. Plus, it wouldn’t be fair to the numerous other perfectly good tools that didn’t get cited. To get the latest on software tools for prototyping, it’s better to ask an experienced UX professional or to do your research online.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128053423000205
Design Production
Rex Hartson, Partha S. Pyla, in The UX Book, 2012
9.5.3 How to Build Wireframes?
Wireframes can be built using any drawing or word processing software package that supports creating and manipulating shapes, such as iWork Pages, Keynote, Microsoft PowerPoint, or Word. While such applications suffice for simple wireframing, we recommend tools designed specifically for this purpose, such as OmniGraffle (for Mac), Microsoft Visio (for PC), and Adobe InDesign.
Many tools and templates for making wireframes are used in combination—truly an invent-as-you-go approach serving the specific needs of prototyping. For example, some tools are available to combine the generic-looking placeholders in wireframes with more detailed mockups of some screens or parts of screens. In essence they allow you to add color, graphics, and real fonts, as well as representations of real content, to the wireframe scaffolding structure.
In early stages of design, during ideation and sketching, you started with thinking about the high-level conceptual design. It makes sense to start with that here, too, first by wireframing the design concept and then by going top down to address major parts of the concept. Identify the interaction conceptual design using boxes with labels, as shown in Figure 9-4.
Take each box and start fleshing out the design details. What are the different kinds of interaction needed to support each part of the design, and what kinds of widgets work best in each case? What are the best ways to lay them out? Think about relationships among the widgets and any data that need to go with them. Leverage design patterns, metaphors, and other ideas and concepts from the work domain ontology. Do not spend too much time with exact locations of these widgets or on their alignment yet. Such refinement will come in later iterations after all the key elements of the design are represented.
As you flesh out all the major areas in the design, be mindful of the information architecture on the screen. Make sure the wireframes convey that inherent information architecture. For example, do elements on the screen follow a logical information hierarchy? Are related elements on the screen positioned in such a way that those relationships are evident? Are content areas indented appropriately? Are margins and indents communicating the hierarchy of the content in the screen?
Next it is time to think about sequencing. If you are representing a workflow, start with the “wake-up” state for that workflow. Then make a wireframe representing the next state, for example, to show the result of a user action such as clicking on a button. In Figure 9-6 we showed what happens when a user clicks on the “Related information” expander widget. In Figure 9-7 we showed what happens if the user clicks on the “One-up” view switcher button.
Once you create the key screens to depict the workflow, it is time to review and refine each screen. Start by specifying all the options that go on the screen (even those not related to this workflow). For example, if you have a toolbar, what are all the options that go into that toolbar? What are all the buttons, view switchers, window controllers (e.g., scrollbars), and so on that need to go on the screen? At this time you are looking at scalability of your design. Is the design pattern and layout still working after you add all the widgets that need to go on this screen?
Think of cases when the windows or other container elements such as navigation bars in the design are resized or when different data elements that need to be supported are larger than shown in the wireframe. For example, in Figures 9-5 and 9-6, what must happen if the number of photo collections is greater than what fits in the default size of that container? Should the entire page scroll or should new scrollbars appear on the left-hand navigation bar alone? How about situations where the number of people identified in a collection are large? Should we show the first few (perhaps ones with most number of associated photos) with a “more” option, should we use an independent scrollbar for that pane, or should we scroll the entire page? You may want to make wireframes for such edge cases; remember they are less expensive and easier to do using boxes and lines than in code.
As you iterate your wireframes, refine them further, increasing the fidelity of the deck. Think about proportions, alignments, spacing, and so on for all the widgets. Refine the wording and language aspects of the design. Get the wireframe as close to the envisioned design as possible within the constraints of using boxes and lines.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123852410000099
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
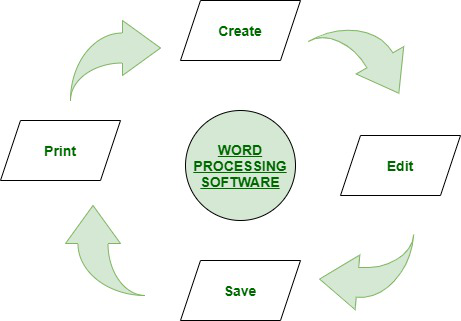
Word Processing Software :
The word “word processor” means it processes words with pages and paragraphs. Word processors are of 3 types which are electronic, mechanical, and software.
The word processing software is used to apply the basic editing and design and also helps in manipulating the text to your pages whereas the word processor, is a device that provides editing, input, formatting, and output of the given text with some additional features.
It is a type of computer software application or an electronic device. In today’s generation, the word processor has become the word processing software or programs that are running on general-purpose computers.
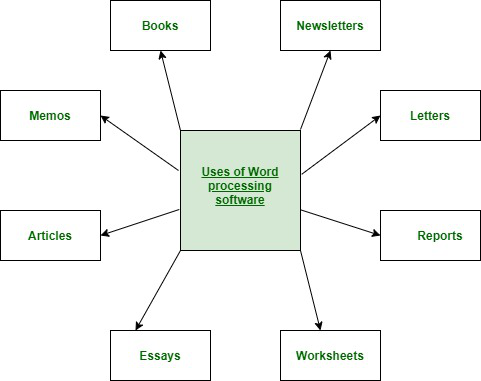
Examples or Applications of a Word Processing Software :
- Wordpad
- Microsoft Word
- Lotus word pro
- Notepad
- WordPerfect (Windows only),
- AppleWorks (Mac only),
- Work pages
- OpenOffice Writer
Features :
- They are stand-alone devices that are dedicated to the function.
- Their programs are running on general-purpose computers
- It is easy to use
- Helps in changing the shape and style of the characters of the paragraphs
- Basic editing like headers & footers, bullets, numbering is being performed by it.
- It has a facility for mail merge and preview.
Functions :
- It helps in Correcting grammar and spelling of sentences
- It helps in storing and creating typed documents in a new way.
- It provides the function of Creating the documents with basic editing, saving, and printing of it or same.
- It helps in Copy the text along with moving deleting and pasting the text within a given document.
- It helps in Formatting text like bold, underlining, font type, etc.
- It provides the function of creating and editing the formats of tables.
- It helps in Inserting the various elements from some other types of software.
Advantages :
- It benefits the environment by helping in reducing the amount of paperwork.
- The cost of paper and postage waste is being reduced.
- It is used to manipulate the document text like a report
- It provides various tools like copying, deleting and formatting, etc.
- It helps in recognizing the user interface feature
- It applies the basic design to your pages
- It makes it easier for you to perform repetitive tasks
- It is a fully functioned desktop publishing program
- It is time-saving.
- It is dynamic in nature for exchanging the data.
- It produces error-free documents.
- Provide security to our documents.
Disadvantages :
- It does not give you complete control over the look and feel of your document.
- It did not develop out of computer technology.
Like Article
Save Article
So I am not used to the language word macros are written in but I wanted to make a macro to set up the page in a particular way. Here is what I have so far. Which works fine at the moment probably not minimal code but I am not trying to learn the whole language today. What I wanted to do was to add a page number as well starting from zero at the selected pages. I did manage to figure out how to add a word number which applied to the whole document but not the selected section
Sub references()
'
' Macro3 Macro
'
'
Selection.Sort ExcludeHeader:=False, FieldNumber:="Paragraphs", _
SortFieldType:=wdSortFieldAlphanumeric, SortOrder:=wdSortOrderDescending, _
FieldNumber2:="", SortFieldType2:=wdSortFieldAlphanumeric, SortOrder2:= _
wdSortOrderAscending, FieldNumber3:="", SortFieldType3:= _
wdSortFieldAlphanumeric, SortOrder3:=wdSortOrderAscending, Separator:= _
wdSortSeparateByTabs, SortColumn:=False, CaseSensitive:=False, LanguageID _
:=wdEnglishIreland, SubFieldNumber:="Paragraphs", SubFieldNumber2:= _
"Paragraphs", SubFieldNumber3:="Paragraphs"
Selection.Sort BidiSort:=False, IgnoreThe:=True, IgnoreKashida:=False, _
IgnoreDiacritics:=False, IgnoreHe:=False
With Selection.ParagraphFormat
.LeftIndent = CentimetersToPoints(0)
.RightIndent = CentimetersToPoints(0)
.SpaceBefore = 0
.SpaceBeforeAuto = False
.SpaceAfter = 0
.SpaceAfterAuto = False
.LineSpacingRule = wdLineSpaceSingle
.Alignment = wdAlignParagraphJustify
.WidowControl = True
.KeepWithNext = False
.KeepTogether = False
.PageBreakBefore = False
.NoLineNumber = False
.Hyphenation = True
.FirstLineIndent = CentimetersToPoints(0)
.OutlineLevel = wdOutlineLevelBodyText
.CharacterUnitLeftIndent = 0
.CharacterUnitRightIndent = 0
.CharacterUnitFirstLineIndent = 0
.LineUnitBefore = 0
.LineUnitAfter = 0
.MirrorIndents = False
.TextboxTightWrap = wdTightNone
.CollapsedByDefault = False
.ReadingOrder = wdReadingOrderLtr
.AutoAdjustRightIndent = True
.DisableLineHeightGrid = False
.FarEastLineBreakControl = True
.WordWrap = True
.HangingPunctuation = True
.HalfWidthPunctuationOnTopOfLine = False
.AddSpaceBetweenFarEastAndAlpha = True
.AddSpaceBetweenFarEastAndDigit = True
.BaseLineAlignment = wdBaselineAlignAuto
End With
Dim iCount As Integer
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "^p^p"
.Replacement.Text = "^p"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = False
.MatchFuzzy = False
End With
Do While Selection.Find.Found = True And iCount < 1000
iCount = iCount + 1
'Jump back to the start of the document. Since you remove the
'footnote place holder this won't pick up old results
Selection.Find.Execute
'On the last loop you'll not find a result so check here
If Selection.Find.Found Then
''==================================
'' Do your footnote magic here
''==================================
'Reset the find parameters
With Selection.Find
.Text = "^p^p"
.Replacement.Text = "^p"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = False
.MatchFuzzy = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
End If
Loop
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "^p"
.Replacement.Text = "^p^p"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = False
.MatchFuzzy = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "^p^p^p"
.Replacement.Text = "^p"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = False
.MatchFuzzy = False
End With
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
Selection.Find.Execute Replace:=wdReplaceAll
With Selection.Find
.Text = "^p^p^p"
.Replacement.Text = "^p"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchByte = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = False
.MatchFuzzy = False
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Edited March 10, 2015 by fiveworlds
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of wordsEdit
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choiceEdit
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architecturesEdit
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressingEdit
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of twoEdit
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size familiesEdit
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizesEdit
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See alsoEdit
- Integer (computer science)
NotesEdit
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is . This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign
ReferencesEdit
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
Microsoft Word is a popular word processing software. It helps in arranging written text in a proper format and giving it a systematic look. This formatted look facilitates easier reading. It provides spell-check options, formatting functions like cut-copy-paste, and spots grammatical errors on a real-time basis. It also helps in saving and storing documents.
It’s also used to add images, preview the complete text before printing it; organize the data into lists and then summarize, compare and present the data graphically. It allows the header and footer to display descriptive information, and to produce personalized letters through mail. This software is used to create, format and edit any document. It allows us to share the resources such as clip arts, drawing tools, etc. available to all office programs.
In this chapter, you will learn about Concepts related to MS Word in detail. You will know about Word Processing Basics, Opening and Closing the Document, Text Creation and Manipulation, Formatting Text, and Table Manipulation.
Basics of Word Processing
Word processor is used to manipulate text documents. It is an application program that creates web pages, letters, and reports.
| Sr.No. | Word Processing Concepts & Description |
|---|---|
| 1 | Opening Word Processing Package
Word processing package is mostly used in offices on microcomputers. To open a new document, click on «Start» button and go to «All Programs» and click on «Microsoft Word». |
| 2 | Opening and Closing Documents
Word automatically starts with a blank page. For opening a new file, click on «New». |
| 3 | Page Setup
Page setup options are usually available in «Page Layout» menu. Parameters defined by the user help in determining how a printed page will appear. |
| 4 | Print Preview
This option is used to view the page or make adjustments before any document gets printed. |
| 5 | Cut, Copy and Paste
In this section, we shall learn how to use cut, copy and paste functions in Word. |
| 6 | Table Manipulation
Manipulation of table includes drawing a table, changing cell width and height, alignment of text in the cell, deletion/insertion of rows and columns, and borders and shading. |
Summary
This topic provides us with a clear idea about components of word processing basics, opening and closing the documents, text creation and manipulation, formatting the text, table manipulation, etc.