
Natural Language Processing — Introduction
Language is a method of communication with the help of which we can speak, read and write. For example, we think, we make decisions, plans and more in natural language; precisely, in words. However, the big question that confronts us in this AI era is that can we communicate in a similar manner with computers. In other words, can human beings communicate with computers in their natural language? It is a challenge for us to develop NLP applications because computers need structured data, but human speech is unstructured and often ambiguous in nature.
In this sense, we can say that Natural Language Processing (NLP) is the sub-field of Computer Science especially Artificial Intelligence (AI) that is concerned about enabling computers to understand and process human language. Technically, the main task of NLP would be to program computers for analyzing and processing huge amount of natural language data.
History of NLP
We have divided the history of NLP into four phases. The phases have distinctive concerns and styles.
First Phase (Machine Translation Phase) — Late 1940s to late 1960s
The work done in this phase focused mainly on machine translation (MT). This phase was a period of enthusiasm and optimism.
Let us now see all that the first phase had in it −
-
The research on NLP started in early 1950s after Booth & Richens’ investigation and Weaver’s memorandum on machine translation in 1949.
-
1954 was the year when a limited experiment on automatic translation from Russian to English demonstrated in the Georgetown-IBM experiment.
-
In the same year, the publication of the journal MT (Machine Translation) started.
-
The first international conference on Machine Translation (MT) was held in 1952 and second was held in 1956.
-
In 1961, the work presented in Teddington International Conference on Machine Translation of Languages and Applied Language analysis was the high point of this phase.
Second Phase (AI Influenced Phase) – Late 1960s to late 1970s
In this phase, the work done was majorly related to world knowledge and on its role in the construction and manipulation of meaning representations. That is why, this phase is also called AI-flavored phase.
The phase had in it, the following −
-
In early 1961, the work began on the problems of addressing and constructing data or knowledge base. This work was influenced by AI.
-
In the same year, a BASEBALL question-answering system was also developed. The input to this system was restricted and the language processing involved was a simple one.
-
A much advanced system was described in Minsky (1968). This system, when compared to the BASEBALL question-answering system, was recognized and provided for the need of inference on the knowledge base in interpreting and responding to language input.
Third Phase (Grammatico-logical Phase) – Late 1970s to late 1980s
This phase can be described as the grammatico-logical phase. Due to the failure of practical system building in last phase, the researchers moved towards the use of logic for knowledge representation and reasoning in AI.
The third phase had the following in it −
-
The grammatico-logical approach, towards the end of decade, helped us with powerful general-purpose sentence processors like SRI’s Core Language Engine and Discourse Representation Theory, which offered a means of tackling more extended discourse.
-
In this phase we got some practical resources & tools like parsers, e.g. Alvey Natural Language Tools along with more operational and commercial systems, e.g. for database query.
-
The work on lexicon in 1980s also pointed in the direction of grammatico-logical approach.
Fourth Phase (Lexical & Corpus Phase) – The 1990s
We can describe this as a lexical & corpus phase. The phase had a lexicalized approach to grammar that appeared in late 1980s and became an increasing influence. There was a revolution in natural language processing in this decade with the introduction of machine learning algorithms for language processing.
Study of Human Languages
Language is a crucial component for human lives and also the most fundamental aspect of our behavior. We can experience it in mainly two forms — written and spoken. In the written form, it is a way to pass our knowledge from one generation to the next. In the spoken form, it is the primary medium for human beings to coordinate with each other in their day-to-day behavior. Language is studied in various academic disciplines. Each discipline comes with its own set of problems and a set of solution to address those.
Consider the following table to understand this −
| Discipline | Problems | Tools |
|---|---|---|
|
Linguists |
How phrases and sentences can be formed with words? What curbs the possible meaning for a sentence? |
Intuitions about well-formedness and meaning. Mathematical model of structure. For example, model theoretic semantics, formal language theory. |
|
Psycholinguists |
How human beings can identify the structure of sentences? How the meaning of words can be identified? When does understanding take place? |
Experimental techniques mainly for measuring the performance of human beings. Statistical analysis of observations. |
|
Philosophers |
How do words and sentences acquire the meaning? How the objects are identified by the words? What is meaning? |
Natural language argumentation by using intuition. Mathematical models like logic and model theory. |
|
Computational Linguists |
How can we identify the structure of a sentence How knowledge and reasoning can be modeled? How we can use language to accomplish specific tasks? |
Algorithms Data structures Formal models of representation and reasoning. AI techniques like search & representation methods. |
Ambiguity and Uncertainty in Language
Ambiguity, generally used in natural language processing, can be referred as the ability of being understood in more than one way. In simple terms, we can say that ambiguity is the capability of being understood in more than one way. Natural language is very ambiguous. NLP has the following types of ambiguities −
Lexical Ambiguity
The ambiguity of a single word is called lexical ambiguity. For example, treating the word silver as a noun, an adjective, or a verb.
Syntactic Ambiguity
This kind of ambiguity occurs when a sentence is parsed in different ways. For example, the sentence “The man saw the girl with the telescope”. It is ambiguous whether the man saw the girl carrying a telescope or he saw her through his telescope.
Semantic Ambiguity
This kind of ambiguity occurs when the meaning of the words themselves can be misinterpreted. In other words, semantic ambiguity happens when a sentence contains an ambiguous word or phrase. For example, the sentence “The car hit the pole while it was moving” is having semantic ambiguity because the interpretations can be “The car, while moving, hit the pole” and “The car hit the pole while the pole was moving”.
Anaphoric Ambiguity
This kind of ambiguity arises due to the use of anaphora entities in discourse. For example, the horse ran up the hill. It was very steep. It soon got tired. Here, the anaphoric reference of “it” in two situations cause ambiguity.
Pragmatic ambiguity
Such kind of ambiguity refers to the situation where the context of a phrase gives it multiple interpretations. In simple words, we can say that pragmatic ambiguity arises when the statement is not specific. For example, the sentence “I like you too” can have multiple interpretations like I like you (just like you like me), I like you (just like someone else dose).
NLP Phases
Following diagram shows the phases or logical steps in natural language processing −
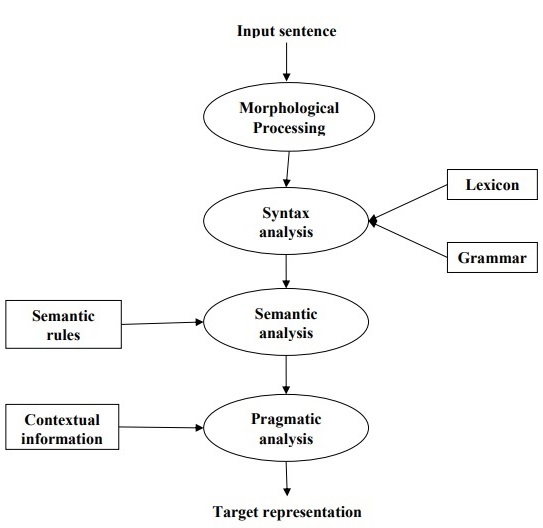
Morphological Processing
It is the first phase of NLP. The purpose of this phase is to break chunks of language input into sets of tokens corresponding to paragraphs, sentences and words. For example, a word like “uneasy” can be broken into two sub-word tokens as “un-easy”.
Syntax Analysis
It is the second phase of NLP. The purpose of this phase is two folds: to check that a sentence is well formed or not and to break it up into a structure that shows the syntactic relationships between the different words. For example, the sentence like “The school goes to the boy” would be rejected by syntax analyzer or parser.
Semantic Analysis
It is the third phase of NLP. The purpose of this phase is to draw exact meaning, or you can say dictionary meaning from the text. The text is checked for meaningfulness. For example, semantic analyzer would reject a sentence like “Hot ice-cream”.
Pragmatic Analysis
It is the fourth phase of NLP. Pragmatic analysis simply fits the actual objects/events, which exist in a given context with object references obtained during the last phase (semantic analysis). For example, the sentence “Put the banana in the basket on the shelf” can have two semantic interpretations and pragmatic analyzer will choose between these two possibilities.
NLP — Linguistic Resources
In this chapter, we will learn about the linguistic resources in Natural Language Processing.
Corpus
A corpus is a large and structured set of machine-readable texts that have been produced in a natural communicative setting. Its plural is corpora. They can be derived in different ways like text that was originally electronic, transcripts of spoken language and optical character recognition, etc.
Elements of Corpus Design
Language is infinite but a corpus has to be finite in size. For the corpus to be finite in size, we need to sample and proportionally include a wide range of text types to ensure a good corpus design.
Let us now learn about some important elements for corpus design −
Corpus Representativeness
Representativeness is a defining feature of corpus design. The following definitions from two great researchers − Leech and Biber, will help us understand corpus representativeness −
-
According to Leech (1991), “A corpus is thought to be representative of the language variety it is supposed to represent if the findings based on its contents can be generalized to the said language variety”.
-
According to Biber (1993), “Representativeness refers to the extent to which a sample includes the full range of variability in a population”.
In this way, we can conclude that representativeness of a corpus are determined by the following two factors −
-
Balance − The range of genre include in a corpus
-
Sampling − How the chunks for each genre are selected.
Corpus Balance
Another very important element of corpus design is corpus balance – the range of genre included in a corpus. We have already studied that representativeness of a general corpus depends upon how balanced the corpus is. A balanced corpus covers a wide range of text categories, which are supposed to be representatives of the language. We do not have any reliable scientific measure for balance but the best estimation and intuition works in this concern. In other words, we can say that the accepted balance is determined by its intended uses only.
Sampling
Another important element of corpus design is sampling. Corpus representativeness and balance is very closely associated with sampling. That is why we can say that sampling is inescapable in corpus building.
-
According to Biber(1993), “Some of the first considerations in constructing a corpus concern the overall design: for example, the kinds of texts included, the number of texts, the selection of particular texts, the selection of text samples from within texts, and the length of text samples. Each of these involves a sampling decision, either conscious or not.”
While obtaining a representative sample, we need to consider the following −
-
Sampling unit − It refers to the unit which requires a sample. For example, for written text, a sampling unit may be a newspaper, journal or a book.
-
Sampling frame − The list of al sampling units is called a sampling frame.
-
Population − It may be referred as the assembly of all sampling units. It is defined in terms of language production, language reception or language as a product.
Corpus Size
Another important element of corpus design is its size. How large the corpus should be? There is no specific answer to this question. The size of the corpus depends upon the purpose for which it is intended as well as on some practical considerations as follows −
-
Kind of query anticipated from the user.
-
The methodology used by the users to study the data.
-
Availability of the source of data.
With the advancement in technology, the corpus size also increases. The following table of comparison will help you understand how the corpus size works −
| Year | Name of the Corpus | Size (in words) |
|---|---|---|
| 1960s — 70s | Brown and LOB | 1 Million words |
| 1980s | The Birmingham corpora | 20 Million words |
| 1990s | The British National corpus | 100 Million words |
| Early 21st century | The Bank of English corpus | 650 Million words |
In our subsequent sections, we will look at a few examples of corpus.
TreeBank Corpus
It may be defined as linguistically parsed text corpus that annotates syntactic or semantic sentence structure. Geoffrey Leech coined the term ‘treebank’, which represents that the most common way of representing the grammatical analysis is by means of a tree structure. Generally, Treebanks are created on the top of a corpus, which has already been annotated with part-of-speech tags.
Types of TreeBank Corpus
Semantic and Syntactic Treebanks are the two most common types of Treebanks in linguistics. Let us now learn more about these types −
Semantic Treebanks
These Treebanks use a formal representation of sentence’s semantic structure. They vary in the depth of their semantic representation. Robot Commands Treebank, Geoquery, Groningen Meaning Bank, RoboCup Corpus are some of the examples of Semantic Treebanks.
Syntactic Treebanks
Opposite to the semantic Treebanks, inputs to the Syntactic Treebank systems are expressions of the formal language obtained from the conversion of parsed Treebank data. The outputs of such systems are predicate logic based meaning representation. Various syntactic Treebanks in different languages have been created so far. For example, Penn Arabic Treebank, Columbia Arabic Treebank are syntactic Treebanks created in Arabia language. Sininca syntactic Treebank created in Chinese language. Lucy, Susane and BLLIP WSJ syntactic corpus created in English language.
Applications of TreeBank Corpus
Followings are some of the applications of TreeBanks −
In Computational Linguistics
If we talk about Computational Linguistic then the best use of TreeBanks is to engineer state-of-the-art natural language processing systems such as part-of-speech taggers, parsers, semantic analyzers and machine translation systems.
In Corpus Linguistics
In case of Corpus linguistics, the best use of Treebanks is to study syntactic phenomena.
In Theoretical Linguistics and Psycholinguistics
The best use of Treebanks in theoretical and psycholinguistics is interaction evidence.
PropBank Corpus
PropBank more specifically called “Proposition Bank” is a corpus, which is annotated with verbal propositions and their arguments. The corpus is a verb-oriented resource; the annotations here are more closely related to the syntactic level. Martha Palmer et al., Department of Linguistic, University of Colorado Boulder developed it. We can use the term PropBank as a common noun referring to any corpus that has been annotated with propositions and their arguments.
In Natural Language Processing (NLP), the PropBank project has played a very significant role. It helps in semantic role labeling.
VerbNet(VN)
VerbNet(VN) is the hierarchical domain-independent and largest lexical resource present in English that incorporates both semantic as well as syntactic information about its contents. VN is a broad-coverage verb lexicon having mappings to other lexical resources such as WordNet, Xtag and FrameNet. It is organized into verb classes extending Levin classes by refinement and addition of subclasses for achieving syntactic and semantic coherence among class members.
Each VerbNet (VN) class contains −
A set of syntactic descriptions or syntactic frames
For depicting the possible surface realizations of the argument structure for constructions such as transitive, intransitive, prepositional phrases, resultatives, and a large set of diathesis alternations.
A set of semantic descriptions such as animate, human, organization
For constraining, the types of thematic roles allowed by the arguments, and further restrictions may be imposed. This will help in indicating the syntactic nature of the constituent likely to be associated with the thematic role.
WordNet
WordNet, created by Princeton is a lexical database for English language. It is the part of the NLTK corpus. In WordNet, nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms called Synsets. All the synsets are linked with the help of conceptual-semantic and lexical relations. Its structure makes it very useful for natural language processing (NLP).
In information systems, WordNet is used for various purposes like word-sense disambiguation, information retrieval, automatic text classification and machine translation. One of the most important uses of WordNet is to find out the similarity among words. For this task, various algorithms have been implemented in various packages like Similarity in Perl, NLTK in Python and ADW in Java.
NLP — Word Level Analysis
In this chapter, we will understand world level analysis in Natural Language Processing.
Regular Expressions
A regular expression (RE) is a language for specifying text search strings. RE helps us to match or find other strings or sets of strings, using a specialized syntax held in a pattern. Regular expressions are used to search texts in UNIX as well as in MS WORD in identical way. We have various search engines using a number of RE features.
Properties of Regular Expressions
Followings are some of the important properties of RE −
-
American Mathematician Stephen Cole Kleene formalized the Regular Expression language.
-
RE is a formula in a special language, which can be used for specifying simple classes of strings, a sequence of symbols. In other words, we can say that RE is an algebraic notation for characterizing a set of strings.
-
Regular expression requires two things, one is the pattern that we wish to search and other is a corpus of text from which we need to search.
Mathematically, A Regular Expression can be defined as follows −
-
ε is a Regular Expression, which indicates that the language is having an empty string.
-
φ is a Regular Expression which denotes that it is an empty language.
-
If X and Y are Regular Expressions, then
-
X, Y
-
X.Y(Concatenation of XY)
-
X+Y (Union of X and Y)
-
X*, Y* (Kleen Closure of X and Y)
-
are also regular expressions.
-
If a string is derived from above rules then that would also be a regular expression.
Examples of Regular Expressions
The following table shows a few examples of Regular Expressions −
| Regular Expressions | Regular Set |
|---|---|
| (0 + 10*) | {0, 1, 10, 100, 1000, 10000, … } |
| (0*10*) | {1, 01, 10, 010, 0010, …} |
| (0 + ε)(1 + ε) | {ε, 0, 1, 01} |
| (a+b)* | It would be set of strings of a’s and b’s of any length which also includes the null string i.e. {ε, a, b, aa , ab , bb , ba, aaa…….} |
| (a+b)*abb | It would be set of strings of a’s and b’s ending with the string abb i.e. {abb, aabb, babb, aaabb, ababb, …………..} |
| (11)* | It would be set consisting of even number of 1’s which also includes an empty string i.e. {ε, 11, 1111, 111111, ……….} |
| (aa)*(bb)*b | It would be set of strings consisting of even number of a’s followed by odd number of b’s i.e. {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, …………..} |
| (aa + ab + ba + bb)* | It would be string of a’s and b’s of even length that can be obtained by concatenating any combination of the strings aa, ab, ba and bb including null i.e. {aa, ab, ba, bb, aaab, aaba, …………..} |
Regular Sets & Their Properties
It may be defined as the set that represents the value of the regular expression and consists specific properties.
Properties of regular sets
-
If we do the union of two regular sets then the resulting set would also be regula.
-
If we do the intersection of two regular sets then the resulting set would also be regular.
-
If we do the complement of regular sets, then the resulting set would also be regular.
-
If we do the difference of two regular sets, then the resulting set would also be regular.
-
If we do the reversal of regular sets, then the resulting set would also be regular.
-
If we take the closure of regular sets, then the resulting set would also be regular.
-
If we do the concatenation of two regular sets, then the resulting set would also be regular.
Finite State Automata
The term automata, derived from the Greek word «αὐτόματα» meaning «self-acting», is the plural of automaton which may be defined as an abstract self-propelled computing device that follows a predetermined sequence of operations automatically.
An automaton having a finite number of states is called a Finite Automaton (FA) or Finite State automata (FSA).
Mathematically, an automaton can be represented by a 5-tuple (Q, Σ, δ, q0, F), where −
-
Q is a finite set of states.
-
Σ is a finite set of symbols, called the alphabet of the automaton.
-
δ is the transition function
-
q0 is the initial state from where any input is processed (q0 ∈ Q).
-
F is a set of final state/states of Q (F ⊆ Q).
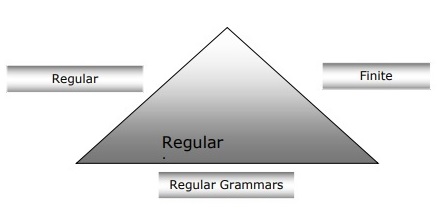
Relation between Finite Automata, Regular Grammars and Regular Expressions
Following points will give us a clear view about the relationship between finite automata, regular grammars and regular expressions −
-
As we know that finite state automata are the theoretical foundation of computational work and regular expressions is one way of describing them.
-
We can say that any regular expression can be implemented as FSA and any FSA can be described with a regular expression.
-
On the other hand, regular expression is a way to characterize a kind of language called regular language. Hence, we can say that regular language can be described with the help of both FSA and regular expression.
-
Regular grammar, a formal grammar that can be right-regular or left-regular, is another way to characterize regular language.
Following diagram shows that finite automata, regular expressions and regular grammars are the equivalent ways of describing regular languages.
Types of Finite State Automation (FSA)
Finite state automation is of two types. Let us see what the types are.
Deterministic Finite automation (DFA)
It may be defined as the type of finite automation wherein, for every input symbol we can determine the state to which the machine will move. It has a finite number of states that is why the machine is called Deterministic Finite Automaton (DFA).
Mathematically, a DFA can be represented by a 5-tuple (Q, Σ, δ, q0, F), where −
-
Q is a finite set of states.
-
Σ is a finite set of symbols, called the alphabet of the automaton.
-
δ is the transition function where δ: Q × Σ → Q .
-
q0 is the initial state from where any input is processed (q0 ∈ Q).
-
F is a set of final state/states of Q (F ⊆ Q).
Whereas graphically, a DFA can be represented by diagraphs called state diagrams where −
-
The states are represented by vertices.
-
The transitions are shown by labeled arcs.
-
The initial state is represented by an empty incoming arc.
-
The final state is represented by double circle.
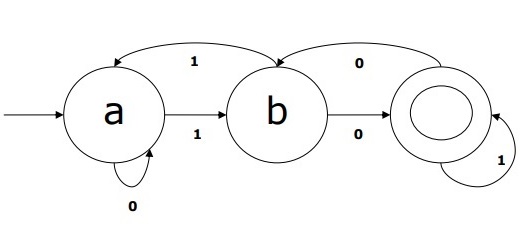
Example of DFA
Suppose a DFA be
-
Q = {a, b, c},
-
Σ = {0, 1},
-
q0 = {a},
-
F = {c},
-
Transition function δ is shown in the table as follows −
| Current State | Next State for Input 0 | Next State for Input 1 |
|---|---|---|
| A | a | B |
| B | b | A |
| C | c | C |
The graphical representation of this DFA would be as follows −
Non-deterministic Finite Automation (NDFA)
It may be defined as the type of finite automation where for every input symbol we cannot determine the state to which the machine will move i.e. the machine can move to any combination of the states. It has a finite number of states that is why the machine is called Non-deterministic Finite Automation (NDFA).
Mathematically, NDFA can be represented by a 5-tuple (Q, Σ, δ, q0, F), where −
-
Q is a finite set of states.
-
Σ is a finite set of symbols, called the alphabet of the automaton.
-
δ :-is the transition function where δ: Q × Σ → 2 Q.
-
q0 :-is the initial state from where any input is processed (q0 ∈ Q).
-
F :-is a set of final state/states of Q (F ⊆ Q).
Whereas graphically (same as DFA), a NDFA can be represented by diagraphs called state diagrams where −
-
The states are represented by vertices.
-
The transitions are shown by labeled arcs.
-
The initial state is represented by an empty incoming arc.
-
The final state is represented by double circle.
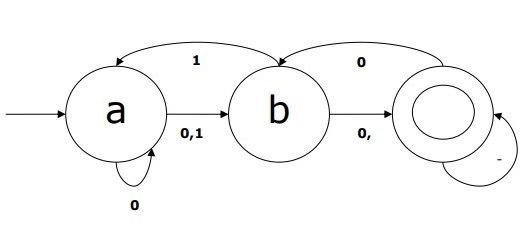
Example of NDFA
Suppose a NDFA be
-
Q = {a, b, c},
-
Σ = {0, 1},
-
q0 = {a},
-
F = {c},
-
Transition function δ is shown in the table as follows −
| Current State | Next State for Input 0 | Next State for Input 1 |
|---|---|---|
| A | a, b | B |
| B | C | a, c |
| C | b, c | C |
The graphical representation of this NDFA would be as follows −
Morphological Parsing
The term morphological parsing is related to the parsing of morphemes. We can define morphological parsing as the problem of recognizing that a word breaks down into smaller meaningful units called morphemes producing some sort of linguistic structure for it. For example, we can break the word foxes into two, fox and -es. We can see that the word foxes, is made up of two morphemes, one is fox and other is -es.
In other sense, we can say that morphology is the study of −
-
The formation of words.
-
The origin of the words.
-
Grammatical forms of the words.
-
Use of prefixes and suffixes in the formation of words.
-
How parts-of-speech (PoS) of a language are formed.
Types of Morphemes
Morphemes, the smallest meaning-bearing units, can be divided into two types −
-
Stems
-
Word Order
Stems
It is the core meaningful unit of a word. We can also say that it is the root of the word. For example, in the word foxes, the stem is fox.
-
Affixes − As the name suggests, they add some additional meaning and grammatical functions to the words. For example, in the word foxes, the affix is − es.
Further, affixes can also be divided into following four types −
-
Prefixes − As the name suggests, prefixes precede the stem. For example, in the word unbuckle, un is the prefix.
-
Suffixes − As the name suggests, suffixes follow the stem. For example, in the word cats, -s is the suffix.
-
Infixes − As the name suggests, infixes are inserted inside the stem. For example, the word cupful, can be pluralized as cupsful by using -s as the infix.
-
Circumfixes − They precede and follow the stem. There are very less examples of circumfixes in English language. A very common example is ‘A-ing’ where we can use -A precede and -ing follows the stem.
Word Order
The order of the words would be decided by morphological parsing. Let us now see the requirements for building a morphological parser −
Lexicon
The very first requirement for building a morphological parser is lexicon, which includes the list of stems and affixes along with the basic information about them. For example, the information like whether the stem is Noun stem or Verb stem, etc.
Morphotactics
It is basically the model of morpheme ordering. In other sense, the model explaining which classes of morphemes can follow other classes of morphemes inside a word. For example, the morphotactic fact is that the English plural morpheme always follows the noun rather than preceding it.
Orthographic rules
These spelling rules are used to model the changes occurring in a word. For example, the rule of converting y to ie in word like city+s = cities not citys.
Natural Language Processing — Syntactic Analysis
Syntactic analysis or parsing or syntax analysis is the third phase of NLP. The purpose of this phase is to draw exact meaning, or you can say dictionary meaning from the text. Syntax analysis checks the text for meaningfulness comparing to the rules of formal grammar. For example, the sentence like “hot ice-cream” would be rejected by semantic analyzer.
In this sense, syntactic analysis or parsing may be defined as the process of analyzing the strings of symbols in natural language conforming to the rules of formal grammar. The origin of the word ‘parsing’ is from Latin word ‘pars’ which means ‘part’.
Concept of Parser
It is used to implement the task of parsing. It may be defined as the software component designed for taking input data (text) and giving structural representation of the input after checking for correct syntax as per formal grammar. It also builds a data structure generally in the form of parse tree or abstract syntax tree or other hierarchical structure.
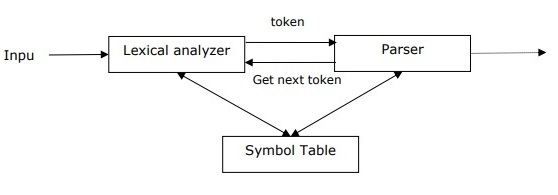
The main roles of the parse include −
-
To report any syntax error.
-
To recover from commonly occurring error so that the processing of the remainder of program can be continued.
-
To create parse tree.
-
To create symbol table.
-
To produce intermediate representations (IR).
Types of Parsing
Derivation divides parsing into the followings two types −
-
Top-down Parsing
-
Bottom-up Parsing
Top-down Parsing
In this kind of parsing, the parser starts constructing the parse tree from the start symbol and then tries to transform the start symbol to the input. The most common form of topdown parsing uses recursive procedure to process the input. The main disadvantage of recursive descent parsing is backtracking.
Bottom-up Parsing
In this kind of parsing, the parser starts with the input symbol and tries to construct the parser tree up to the start symbol.
Concept of Derivation
In order to get the input string, we need a sequence of production rules. Derivation is a set of production rules. During parsing, we need to decide the non-terminal, which is to be replaced along with deciding the production rule with the help of which the non-terminal will be replaced.
Types of Derivation
In this section, we will learn about the two types of derivations, which can be used to decide which non-terminal to be replaced with production rule −
Left-most Derivation
In the left-most derivation, the sentential form of an input is scanned and replaced from the left to the right. The sentential form in this case is called the left-sentential form.
Right-most Derivation
In the left-most derivation, the sentential form of an input is scanned and replaced from right to left. The sentential form in this case is called the right-sentential form.
Concept of Parse Tree
It may be defined as the graphical depiction of a derivation. The start symbol of derivation serves as the root of the parse tree. In every parse tree, the leaf nodes are terminals and interior nodes are non-terminals. A property of parse tree is that in-order traversal will produce the original input string.
Concept of Grammar
Grammar is very essential and important to describe the syntactic structure of well-formed programs. In the literary sense, they denote syntactical rules for conversation in natural languages. Linguistics have attempted to define grammars since the inception of natural languages like English, Hindi, etc.
The theory of formal languages is also applicable in the fields of Computer Science mainly in programming languages and data structure. For example, in ‘C’ language, the precise grammar rules state how functions are made from lists and statements.
A mathematical model of grammar was given by Noam Chomsky in 1956, which is effective for writing computer languages.
Mathematically, a grammar G can be formally written as a 4-tuple (N, T, S, P) where −
-
N or VN = set of non-terminal symbols, i.e., variables.
-
T or ∑ = set of terminal symbols.
-
S = Start symbol where S ∈ N
-
P denotes the Production rules for Terminals as well as Non-terminals. It has the form α → β, where α and β are strings on VN ∪ ∑ and least one symbol of α belongs to VN
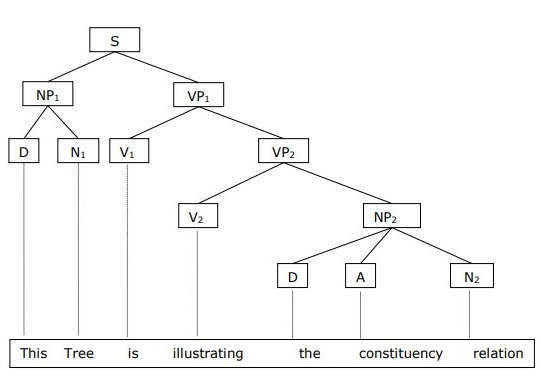
Phrase Structure or Constituency Grammar
Phrase structure grammar, introduced by Noam Chomsky, is based on the constituency relation. That is why it is also called constituency grammar. It is opposite to dependency grammar.
Example
Before giving an example of constituency grammar, we need to know the fundamental points about constituency grammar and constituency relation.
-
All the related frameworks view the sentence structure in terms of constituency relation.
-
The constituency relation is derived from the subject-predicate division of Latin as well as Greek grammar.
-
The basic clause structure is understood in terms of noun phrase NP and verb phrase VP.
We can write the sentence “This tree is illustrating the constituency relation” as follows −
Dependency Grammar
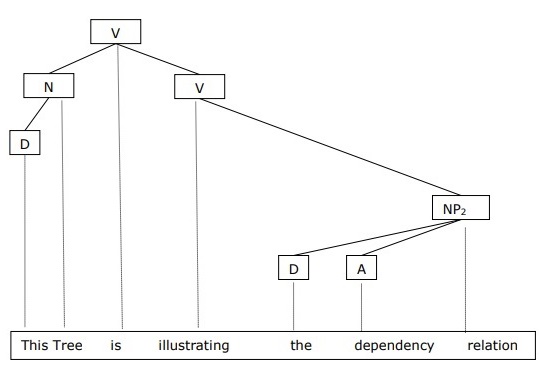
It is opposite to the constituency grammar and based on dependency relation. It was introduced by Lucien Tesniere. Dependency grammar (DG) is opposite to the constituency grammar because it lacks phrasal nodes.
Example
Before giving an example of Dependency grammar, we need to know the fundamental points about Dependency grammar and Dependency relation.
-
In DG, the linguistic units, i.e., words are connected to each other by directed links.
-
The verb becomes the center of the clause structure.
-
Every other syntactic units are connected to the verb in terms of directed link. These syntactic units are called dependencies.
We can write the sentence “This tree is illustrating the dependency relation” as follows;
Parse tree that uses Constituency grammar is called constituency-based parse tree; and the parse trees that uses dependency grammar is called dependency-based parse tree.
Context Free Grammar
Context free grammar, also called CFG, is a notation for describing languages and a superset of Regular grammar. It can be seen in the following diagram −
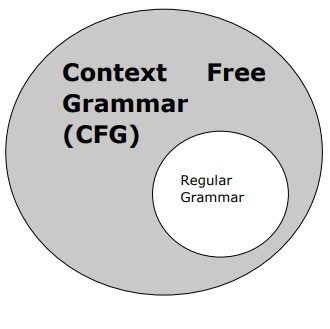
Definition of CFG
CFG consists of finite set of grammar rules with the following four components −
Set of Non-terminals
It is denoted by V. The non-terminals are syntactic variables that denote the sets of strings, which further help defining the language, generated by the grammar.
Set of Terminals
It is also called tokens and defined by Σ. Strings are formed with the basic symbols of terminals.
Set of Productions
It is denoted by P. The set defines how the terminals and non-terminals can be combined. Every production(P) consists of non-terminals, an arrow, and terminals (the sequence of terminals). Non-terminals are called the left side of the production and terminals are called the right side of the production.
Start Symbol
The production begins from the start symbol. It is denoted by symbol S. Non-terminal symbol is always designated as start symbol.
Natural Language Processing — Semantic Analysis
The purpose of semantic analysis is to draw exact meaning, or you can say dictionary meaning from the text. The work of semantic analyzer is to check the text for meaningfulness.
We already know that lexical analysis also deals with the meaning of the words, then how is semantic analysis different from lexical analysis? Lexical analysis is based on smaller token but on the other side semantic analysis focuses on larger chunks. That is why semantic analysis can be divided into the following two parts −
Studying meaning of individual word
It is the first part of the semantic analysis in which the study of the meaning of individual words is performed. This part is called lexical semantics.
Studying the combination of individual words
In the second part, the individual words will be combined to provide meaning in sentences.
The most important task of semantic analysis is to get the proper meaning of the sentence. For example, analyze the sentence “Ram is great.” In this sentence, the speaker is talking either about Lord Ram or about a person whose name is Ram. That is why the job, to get the proper meaning of the sentence, of semantic analyzer is important.
Elements of Semantic Analysis
Followings are some important elements of semantic analysis −
Hyponymy
It may be defined as the relationship between a generic term and instances of that generic term. Here the generic term is called hypernym and its instances are called hyponyms. For example, the word color is hypernym and the color blue, yellow etc. are hyponyms.
Homonymy
It may be defined as the words having same spelling or same form but having different and unrelated meaning. For example, the word “Bat” is a homonymy word because bat can be an implement to hit a ball or bat is a nocturnal flying mammal also.
Polysemy
Polysemy is a Greek word, which means “many signs”. It is a word or phrase with different but related sense. In other words, we can say that polysemy has the same spelling but different and related meaning. For example, the word “bank” is a polysemy word having the following meanings −
-
A financial institution.
-
The building in which such an institution is located.
-
A synonym for “to rely on”.
Difference between Polysemy and Homonymy
Both polysemy and homonymy words have the same syntax or spelling. The main difference between them is that in polysemy, the meanings of the words are related but in homonymy, the meanings of the words are not related. For example, if we talk about the same word “Bank”, we can write the meaning ‘a financial institution’ or ‘a river bank’. In that case it would be the example of homonym because the meanings are unrelated to each other.
Synonymy
It is the relation between two lexical items having different forms but expressing the same or a close meaning. Examples are ‘author/writer’, ‘fate/destiny’.
Antonymy
It is the relation between two lexical items having symmetry between their semantic components relative to an axis. The scope of antonymy is as follows −
-
Application of property or not − Example is ‘life/death’, ‘certitude/incertitude’
-
Application of scalable property − Example is ‘rich/poor’, ‘hot/cold’
-
Application of a usage − Example is ‘father/son’, ‘moon/sun’.
Meaning Representation
Semantic analysis creates a representation of the meaning of a sentence. But before getting into the concept and approaches related to meaning representation, we need to understand the building blocks of semantic system.
Building Blocks of Semantic System
In word representation or representation of the meaning of the words, the following building blocks play an important role −
-
Entities − It represents the individual such as a particular person, location etc. For example, Haryana. India, Ram all are entities.
-
Concepts − It represents the general category of the individuals such as a person, city, etc.
-
Relations − It represents the relationship between entities and concept. For example, Ram is a person.
-
Predicates − It represents the verb structures. For example, semantic roles and case grammar are the examples of predicates.
Now, we can understand that meaning representation shows how to put together the building blocks of semantic systems. In other words, it shows how to put together entities, concepts, relation and predicates to describe a situation. It also enables the reasoning about the semantic world.
Approaches to Meaning Representations
Semantic analysis uses the following approaches for the representation of meaning −
-
First order predicate logic (FOPL)
-
Semantic Nets
-
Frames
-
Conceptual dependency (CD)
-
Rule-based architecture
-
Case Grammar
-
Conceptual Graphs
Need of Meaning Representations
A question that arises here is why do we need meaning representation? Followings are the reasons for the same −
Linking of linguistic elements to non-linguistic elements
The very first reason is that with the help of meaning representation the linking of linguistic elements to the non-linguistic elements can be done.
Representing variety at lexical level
With the help of meaning representation, unambiguous, canonical forms can be represented at the lexical level.
Can be used for reasoning
Meaning representation can be used to reason for verifying what is true in the world as well as to infer the knowledge from the semantic representation.
Lexical Semantics
The first part of semantic analysis, studying the meaning of individual words is called lexical semantics. It includes words, sub-words, affixes (sub-units), compound words and phrases also. All the words, sub-words, etc. are collectively called lexical items. In other words, we can say that lexical semantics is the relationship between lexical items, meaning of sentences and syntax of sentence.
Following are the steps involved in lexical semantics −
-
Classification of lexical items like words, sub-words, affixes, etc. is performed in lexical semantics.
-
Decomposition of lexical items like words, sub-words, affixes, etc. is performed in lexical semantics.
-
Differences as well as similarities between various lexical semantic structures is also analyzed.
NLP — Word Sense Disambiguation
We understand that words have different meanings based on the context of its usage in the sentence. If we talk about human languages, then they are ambiguous too because many words can be interpreted in multiple ways depending upon the context of their occurrence.
Word sense disambiguation, in natural language processing (NLP), may be defined as the ability to determine which meaning of word is activated by the use of word in a particular context. Lexical ambiguity, syntactic or semantic, is one of the very first problem that any NLP system faces. Part-of-speech (POS) taggers with high level of accuracy can solve Word’s syntactic ambiguity. On the other hand, the problem of resolving semantic ambiguity is called WSD (word sense disambiguation). Resolving semantic ambiguity is harder than resolving syntactic ambiguity.
For example, consider the two examples of the distinct sense that exist for the word “bass” −
-
I can hear bass sound.
-
He likes to eat grilled bass.
The occurrence of the word bass clearly denotes the distinct meaning. In first sentence, it means frequency and in second, it means fish. Hence, if it would be disambiguated by WSD then the correct meaning to the above sentences can be assigned as follows −
-
I can hear bass/frequency sound.
-
He likes to eat grilled bass/fish.
Evaluation of WSD
The evaluation of WSD requires the following two inputs −
A Dictionary
The very first input for evaluation of WSD is dictionary, which is used to specify the senses to be disambiguated.
Test Corpus
Another input required by WSD is the high-annotated test corpus that has the target or correct-senses. The test corpora can be of two types &minsu;
-
Lexical sample − This kind of corpora is used in the system, where it is required to disambiguate a small sample of words.
-
All-words − This kind of corpora is used in the system, where it is expected to disambiguate all the words in a piece of running text.
Approaches and Methods to Word Sense Disambiguation (WSD)
Approaches and methods to WSD are classified according to the source of knowledge used in word disambiguation.
Let us now see the four conventional methods to WSD −
Dictionary-based or Knowledge-based Methods
As the name suggests, for disambiguation, these methods primarily rely on dictionaries, treasures and lexical knowledge base. They do not use corpora evidences for disambiguation. The Lesk method is the seminal dictionary-based method introduced by Michael Lesk in 1986. The Lesk definition, on which the Lesk algorithm is based is “measure overlap between sense definitions for all words in context”. However, in 2000, Kilgarriff and Rosensweig gave the simplified Lesk definition as “measure overlap between sense definitions of word and current context”, which further means identify the correct sense for one word at a time. Here the current context is the set of words in surrounding sentence or paragraph.
Supervised Methods
For disambiguation, machine learning methods make use of sense-annotated corpora to train. These methods assume that the context can provide enough evidence on its own to disambiguate the sense. In these methods, the words knowledge and reasoning are deemed unnecessary. The context is represented as a set of “features” of the words. It includes the information about the surrounding words also. Support vector machine and memory-based learning are the most successful supervised learning approaches to WSD. These methods rely on substantial amount of manually sense-tagged corpora, which is very expensive to create.
Semi-supervised Methods
Due to the lack of training corpus, most of the word sense disambiguation algorithms use semi-supervised learning methods. It is because semi-supervised methods use both labelled as well as unlabeled data. These methods require very small amount of annotated text and large amount of plain unannotated text. The technique that is used by semisupervised methods is bootstrapping from seed data.
Unsupervised Methods
These methods assume that similar senses occur in similar context. That is why the senses can be induced from text by clustering word occurrences by using some measure of similarity of the context. This task is called word sense induction or discrimination. Unsupervised methods have great potential to overcome the knowledge acquisition bottleneck due to non-dependency on manual efforts.
Applications of Word Sense Disambiguation (WSD)
Word sense disambiguation (WSD) is applied in almost every application of language technology.
Let us now see the scope of WSD −
Machine Translation
Machine translation or MT is the most obvious application of WSD. In MT, Lexical choice for the words that have distinct translations for different senses, is done by WSD. The senses in MT are represented as words in the target language. Most of the machine translation systems do not use explicit WSD module.
Information Retrieval (IR)
Information retrieval (IR) may be defined as a software program that deals with the organization, storage, retrieval and evaluation of information from document repositories particularly textual information. The system basically assists users in finding the information they required but it does not explicitly return the answers of the questions. WSD is used to resolve the ambiguities of the queries provided to IR system. As like MT, current IR systems do not explicitly use WSD module and they rely on the concept that user would type enough context in the query to only retrieve relevant documents.
Text Mining and Information Extraction (IE)
In most of the applications, WSD is necessary to do accurate analysis of text. For example, WSD helps intelligent gathering system to do flagging of the correct words. For example, medical intelligent system might need flagging of “illegal drugs” rather than “medical drugs”
Lexicography
WSD and lexicography can work together in loop because modern lexicography is corpusbased. With lexicography, WSD provides rough empirical sense groupings as well as statistically significant contextual indicators of sense.
Difficulties in Word Sense Disambiguation (WSD)
Followings are some difficulties faced by word sense disambiguation (WSD) −
Differences between dictionaries
The major problem of WSD is to decide the sense of the word because different senses can be very closely related. Even different dictionaries and thesauruses can provide different divisions of words into senses.
Different algorithms for different applications
Another problem of WSD is that completely different algorithm might be needed for different applications. For example, in machine translation, it takes the form of target word selection; and in information retrieval, a sense inventory is not required.
Inter-judge variance
Another problem of WSD is that WSD systems are generally tested by having their results on a task compared against the task of human beings. This is called the problem of interjudge variance.
Word-sense discreteness
Another difficulty in WSD is that words cannot be easily divided into discrete submeanings.
Natural Language Discourse Processing
The most difficult problem of AI is to process the natural language by computers or in other words natural language processing is the most difficult problem of artificial intelligence. If we talk about the major problems in NLP, then one of the major problems in NLP is discourse processing − building theories and models of how utterances stick together to form coherent discourse. Actually, the language always consists of collocated, structured and coherent groups of sentences rather than isolated and unrelated sentences like movies. These coherent groups of sentences are referred to as discourse.
Concept of Coherence
Coherence and discourse structure are interconnected in many ways. Coherence, along with property of good text, is used to evaluate the output quality of natural language generation system. The question that arises here is what does it mean for a text to be coherent? Suppose we collected one sentence from every page of the newspaper, then will it be a discourse? Of-course, not. It is because these sentences do not exhibit coherence. The coherent discourse must possess the following properties −
Coherence relation between utterances
The discourse would be coherent if it has meaningful connections between its utterances. This property is called coherence relation. For example, some sort of explanation must be there to justify the connection between utterances.
Relationship between entities
Another property that makes a discourse coherent is that there must be a certain kind of relationship with the entities. Such kind of coherence is called entity-based coherence.
Discourse structure
An important question regarding discourse is what kind of structure the discourse must have. The answer to this question depends upon the segmentation we applied on discourse. Discourse segmentations may be defined as determining the types of structures for large discourse. It is quite difficult to implement discourse segmentation, but it is very important for information retrieval, text summarization and information extraction kind of applications.
Algorithms for Discourse Segmentation
In this section, we will learn about the algorithms for discourse segmentation. The algorithms are described below −
Unsupervised Discourse Segmentation
The class of unsupervised discourse segmentation is often represented as linear segmentation. We can understand the task of linear segmentation with the help of an example. In the example, there is a task of segmenting the text into multi-paragraph units; the units represent the passage of the original text. These algorithms are dependent on cohesion that may be defined as the use of certain linguistic devices to tie the textual units together. On the other hand, lexicon cohesion is the cohesion that is indicated by the relationship between two or more words in two units like the use of synonyms.
Supervised Discourse Segmentation
The earlier method does not have any hand-labeled segment boundaries. On the other hand, supervised discourse segmentation needs to have boundary-labeled training data. It is very easy to acquire the same. In supervised discourse segmentation, discourse marker or cue words play an important role. Discourse marker or cue word is a word or phrase that functions to signal discourse structure. These discourse markers are domain-specific.
Text Coherence
Lexical repetition is a way to find the structure in a discourse, but it does not satisfy the requirement of being coherent discourse. To achieve the coherent discourse, we must focus on coherence relations in specific. As we know that coherence relation defines the possible connection between utterances in a discourse. Hebb has proposed such kind of relations as follows −
We are taking two terms S0 and S1 to represent the meaning of the two related sentences −
Result
It infers that the state asserted by term S0 could cause the state asserted by S1. For example, two statements show the relationship result: Ram was caught in the fire. His skin burned.
Explanation
It infers that the state asserted by S1 could cause the state asserted by S0. For example, two statements show the relationship − Ram fought with Shyam’s friend. He was drunk.
Parallel
It infers p(a1,a2,…) from assertion of S0 and p(b1,b2,…) from assertion S1. Here ai and bi are similar for all i. For example, two statements are parallel − Ram wanted car. Shyam wanted money.
Elaboration
It infers the same proposition P from both the assertions − S0 and S1 For example, two statements show the relation elaboration: Ram was from Chandigarh. Shyam was from Kerala.
Occasion
It happens when a change of state can be inferred from the assertion of S0, final state of which can be inferred from S1 and vice-versa. For example, the two statements show the relation occasion: Ram picked up the book. He gave it to Shyam.
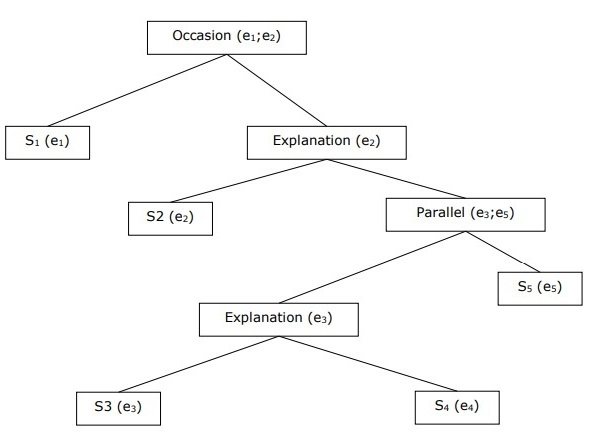
Building Hierarchical Discourse Structure
The coherence of entire discourse can also be considered by hierarchical structure between coherence relations. For example, the following passage can be represented as hierarchical structure −
-
S1 − Ram went to the bank to deposit money.
-
S2 − He then took a train to Shyam’s cloth shop.
-
S3 − He wanted to buy some clothes.
-
S4 − He do not have new clothes for party.
-
S5 − He also wanted to talk to Shyam regarding his health
Reference Resolution
Interpretation of the sentences from any discourse is another important task and to achieve this we need to know who or what entity is being talked about. Here, interpretation reference is the key element. Reference may be defined as the linguistic expression to denote an entity or individual. For example, in the passage, Ram, the manager of ABC bank, saw his friend Shyam at a shop. He went to meet him, the linguistic expressions like Ram, His, He are reference.
On the same note, reference resolution may be defined as the task of determining what entities are referred to by which linguistic expression.
Terminology Used in Reference Resolution
We use the following terminologies in reference resolution −
-
Referring expression − The natural language expression that is used to perform reference is called a referring expression. For example, the passage used above is a referring expression.
-
Referent − It is the entity that is referred. For example, in the last given example Ram is a referent.
-
Corefer − When two expressions are used to refer to the same entity, they are called corefers. For example, Ram and he are corefers.
-
Antecedent − The term has the license to use another term. For example, Ram is the antecedent of the reference he.
-
Anaphora & Anaphoric − It may be defined as the reference to an entity that has been previously introduced into the sentence. And, the referring expression is called anaphoric.
-
Discourse model − The model that contains the representations of the entities that have been referred to in the discourse and the relationship they are engaged in.
Types of Referring Expressions
Let us now see the different types of referring expressions. The five types of referring expressions are described below −
Indefinite Noun Phrases
Such kind of reference represents the entities that are new to the hearer into the discourse context. For example − in the sentence Ram had gone around one day to bring him some food − some is an indefinite reference.
Definite Noun Phrases
Opposite to above, such kind of reference represents the entities that are not new or identifiable to the hearer into the discourse context. For example, in the sentence — I used to read The Times of India – The Times of India is a definite reference.
Pronouns
It is a form of definite reference. For example, Ram laughed as loud as he could. The word he represents pronoun referring expression.
Demonstratives
These demonstrate and behave differently than simple definite pronouns. For example, this and that are demonstrative pronouns.
Names
It is the simplest type of referring expression. It can be the name of a person, organization and location also. For example, in the above examples, Ram is the name-refereeing expression.
Reference Resolution Tasks
The two reference resolution tasks are described below.
Coreference Resolution
It is the task of finding referring expressions in a text that refer to the same entity. In simple words, it is the task of finding corefer expressions. A set of coreferring expressions are called coreference chain. For example — He, Chief Manager and His — these are referring expressions in the first passage given as example.
Constraint on Coreference Resolution
In English, the main problem for coreference resolution is the pronoun it. The reason behind this is that the pronoun it has many uses. For example, it can refer much like he and she. The pronoun it also refers to the things that do not refer to specific things. For example, It’s raining. It is really good.
Pronominal Anaphora Resolution
Unlike the coreference resolution, pronominal anaphora resolution may be defined as the task of finding the antecedent for a single pronoun. For example, the pronoun is his and the task of pronominal anaphora resolution is to find the word Ram because Ram is the antecedent.
Part of Speech (PoS) Tagging
Tagging is a kind of classification that may be defined as the automatic assignment of description to the tokens. Here the descriptor is called tag, which may represent one of the part-of-speech, semantic information and so on.
Now, if we talk about Part-of-Speech (PoS) tagging, then it may be defined as the process of assigning one of the parts of speech to the given word. It is generally called POS tagging. In simple words, we can say that POS tagging is a task of labelling each word in a sentence with its appropriate part of speech. We already know that parts of speech include nouns, verb, adverbs, adjectives, pronouns, conjunction and their sub-categories.
Most of the POS tagging falls under Rule Base POS tagging, Stochastic POS tagging and Transformation based tagging.
Rule-based POS Tagging
One of the oldest techniques of tagging is rule-based POS tagging. Rule-based taggers use dictionary or lexicon for getting possible tags for tagging each word. If the word has more than one possible tag, then rule-based taggers use hand-written rules to identify the correct tag. Disambiguation can also be performed in rule-based tagging by analyzing the linguistic features of a word along with its preceding as well as following words. For example, suppose if the preceding word of a word is article then word must be a noun.
As the name suggests, all such kind of information in rule-based POS tagging is coded in the form of rules. These rules may be either −
-
Context-pattern rules
-
Or, as Regular expression compiled into finite-state automata, intersected with lexically ambiguous sentence representation.
We can also understand Rule-based POS tagging by its two-stage architecture −
-
First stage − In the first stage, it uses a dictionary to assign each word a list of potential parts-of-speech.
-
Second stage − In the second stage, it uses large lists of hand-written disambiguation rules to sort down the list to a single part-of-speech for each word.
Properties of Rule-Based POS Tagging
Rule-based POS taggers possess the following properties −
-
These taggers are knowledge-driven taggers.
-
The rules in Rule-based POS tagging are built manually.
-
The information is coded in the form of rules.
-
We have some limited number of rules approximately around 1000.
-
Smoothing and language modeling is defined explicitly in rule-based taggers.
Stochastic POS Tagging
Another technique of tagging is Stochastic POS Tagging. Now, the question that arises here is which model can be stochastic. The model that includes frequency or probability (statistics) can be called stochastic. Any number of different approaches to the problem of part-of-speech tagging can be referred to as stochastic tagger.
The simplest stochastic tagger applies the following approaches for POS tagging −
Word Frequency Approach
In this approach, the stochastic taggers disambiguate the words based on the probability that a word occurs with a particular tag. We can also say that the tag encountered most frequently with the word in the training set is the one assigned to an ambiguous instance of that word. The main issue with this approach is that it may yield inadmissible sequence of tags.
Tag Sequence Probabilities
It is another approach of stochastic tagging, where the tagger calculates the probability of a given sequence of tags occurring. It is also called n-gram approach. It is called so because the best tag for a given word is determined by the probability at which it occurs with the n previous tags.
Properties of Stochastic POST Tagging
Stochastic POS taggers possess the following properties −
-
This POS tagging is based on the probability of tag occurring.
-
It requires training corpus
-
There would be no probability for the words that do not exist in the corpus.
-
It uses different testing corpus (other than training corpus).
-
It is the simplest POS tagging because it chooses most frequent tags associated with a word in training corpus.
Transformation-based Tagging
Transformation based tagging is also called Brill tagging. It is an instance of the transformation-based learning (TBL), which is a rule-based algorithm for automatic tagging of POS to the given text. TBL, allows us to have linguistic knowledge in a readable form, transforms one state to another state by using transformation rules.
It draws the inspiration from both the previous explained taggers − rule-based and stochastic. If we see similarity between rule-based and transformation tagger, then like rule-based, it is also based on the rules that specify what tags need to be assigned to what words. On the other hand, if we see similarity between stochastic and transformation tagger then like stochastic, it is machine learning technique in which rules are automatically induced from data.
Working of Transformation Based Learning(TBL)
In order to understand the working and concept of transformation-based taggers, we need to understand the working of transformation-based learning. Consider the following steps to understand the working of TBL −
-
Start with the solution − The TBL usually starts with some solution to the problem and works in cycles.
-
Most beneficial transformation chosen − In each cycle, TBL will choose the most beneficial transformation.
-
Apply to the problem − The transformation chosen in the last step will be applied to the problem.
The algorithm will stop when the selected transformation in step 2 will not add either more value or there are no more transformations to be selected. Such kind of learning is best suited in classification tasks.
Advantages of Transformation-based Learning (TBL)
The advantages of TBL are as follows −
-
We learn small set of simple rules and these rules are enough for tagging.
-
Development as well as debugging is very easy in TBL because the learned rules are easy to understand.
-
Complexity in tagging is reduced because in TBL there is interlacing of machinelearned and human-generated rules.
-
Transformation-based tagger is much faster than Markov-model tagger.
Disadvantages of Transformation-based Learning (TBL)
The disadvantages of TBL are as follows −
-
Transformation-based learning (TBL) does not provide tag probabilities.
-
In TBL, the training time is very long especially on large corpora.
Hidden Markov Model (HMM) POS Tagging
Before digging deep into HMM POS tagging, we must understand the concept of Hidden Markov Model (HMM).
Hidden Markov Model
An HMM model may be defined as the doubly-embedded stochastic model, where the underlying stochastic process is hidden. This hidden stochastic process can only be observed through another set of stochastic processes that produces the sequence of observations.
Example
For example, a sequence of hidden coin tossing experiments is done and we see only the observation sequence consisting of heads and tails. The actual details of the process — how many coins used, the order in which they are selected — are hidden from us. By observing this sequence of heads and tails, we can build several HMMs to explain the sequence. Following is one form of Hidden Markov Model for this problem −
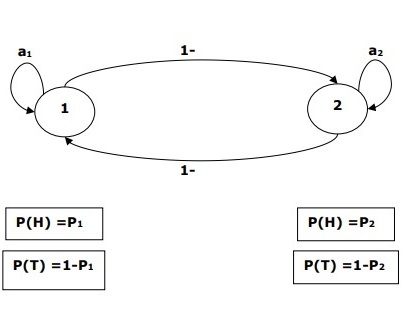
We assumed that there are two states in the HMM and each of the state corresponds to the selection of different biased coin. Following matrix gives the state transition probabilities −
$$A = begin{bmatrix}a11 & a12 \a21 & a22 end{bmatrix}$$
Here,
-
aij = probability of transition from one state to another from i to j.
-
a11 + a12 = 1 and a21 + a22 =1
-
P1 = probability of heads of the first coin i.e. the bias of the first coin.
-
P2 = probability of heads of the second coin i.e. the bias of the second coin.
We can also create an HMM model assuming that there are 3 coins or more.
This way, we can characterize HMM by the following elements −
-
N, the number of states in the model (in the above example N =2, only two states).
-
M, the number of distinct observations that can appear with each state in the above example M = 2, i.e., H or T).
-
A, the state transition probability distribution − the matrix A in the above example.
-
P, the probability distribution of the observable symbols in each state (in our example P1 and P2).
-
I, the initial state distribution.
Use of HMM for POS Tagging
The POS tagging process is the process of finding the sequence of tags which is most likely to have generated a given word sequence. We can model this POS process by using a Hidden Markov Model (HMM), where tags are the hidden states that produced the observable output, i.e., the words.
Mathematically, in POS tagging, we are always interested in finding a tag sequence (C) which maximizes −
P (C|W)
Where,
C = C1, C2, C3… CT
W = W1, W2, W3, WT
On the other side of coin, the fact is that we need a lot of statistical data to reasonably estimate such kind of sequences. However, to simplify the problem, we can apply some mathematical transformations along with some assumptions.
The use of HMM to do a POS tagging is a special case of Bayesian interference. Hence, we will start by restating the problem using Bayes’ rule, which says that the above-mentioned conditional probability is equal to −
(PROB (C1,…, CT) * PROB (W1,…, WT | C1,…, CT)) / PROB (W1,…, WT)
We can eliminate the denominator in all these cases because we are interested in finding the sequence C which maximizes the above value. This will not affect our answer. Now, our problem reduces to finding the sequence C that maximizes −
PROB (C1,…, CT) * PROB (W1,…, WT | C1,…, CT) (1)
Even after reducing the problem in the above expression, it would require large amount of data. We can make reasonable independence assumptions about the two probabilities in the above expression to overcome the problem.
First Assumption
The probability of a tag depends on the previous one (bigram model) or previous two (trigram model) or previous n tags (n-gram model) which, mathematically, can be explained as follows −
PROB (C1,…, CT) = Πi=1..T PROB (Ci|Ci-n+1…Ci-1) (n-gram model)
PROB (C1,…, CT) = Πi=1..T PROB (Ci|Ci-1) (bigram model)
The beginning of a sentence can be accounted for by assuming an initial probability for each tag.
PROB (C1|C0) = PROB initial (C1)
Second Assumption
The second probability in equation (1) above can be approximated by assuming that a word appears in a category independent of the words in the preceding or succeeding categories which can be explained mathematically as follows −
PROB (W1,…, WT | C1,…, CT) = Πi=1..T PROB (Wi|Ci)
Now, on the basis of the above two assumptions, our goal reduces to finding a sequence C which maximizes
Πi=1…T PROB(Ci|Ci-1) * PROB(Wi|Ci)
Now the question that arises here is has converting the problem to the above form really helped us. The answer is — yes, it has. If we have a large tagged corpus, then the two probabilities in the above formula can be calculated as −
PROB (Ci=VERB|Ci-1=NOUN) = (# of instances where Verb follows Noun) / (# of instances where Noun appears) (2)
PROB (Wi|Ci) = (# of instances where Wi appears in Ci) /(# of instances where Ci appears) (3)
Natural Language Processing — Inception
In this chapter, we will discuss the natural language inception in Natural Language Processing. To begin with, let us first understand what is Natural Language Grammar.
Natural Language Grammar
For linguistics, language is a group of arbitrary vocal signs. We may say that language is creative, governed by rules, innate as well as universal at the same time. On the other hand, it is humanly too. The nature of the language is different for different people. There is a lot of misconception about the nature of the language. That is why it is very important to understand the meaning of the ambiguous term ‘grammar’. In linguistics, the term grammar may be defined as the rules or principles with the help of which language works. In broad sense, we can divide grammar in two categories −
Descriptive Grammar
The set of rules, where linguistics and grammarians formulate the speaker’s grammar is called descriptive grammar.
Perspective Grammar
It is a very different sense of grammar, which attempts to maintain a standard of correctness in the language. This category has little to do with the actual working of the language.
Components of Language
The language of study is divided into the interrelated components, which are conventional as well as arbitrary divisions of linguistic investigation. The explanation of these components is as follows −
Phonology
The very first component of language is phonology. It is the study of the speech sounds of a particular language. The origin of the word can be traced to Greek language, where ‘phone’ means sound or voice. Phonetics, a subdivision of phonology is the study of the speech sounds of human language from the perspective of their production, perception or their physical properties. IPA (International Phonetic Alphabet) is a tool that represents human sounds in a regular way while studying phonology. In IPA, every written symbol represents one and only one speech sound and vice-versa.
Phonemes
It may be defined as one of the units of sound that differentiate one word from other in a language. In linguistic, phonemes are written between slashes. For example, phoneme /k/ occurs in the words such as kit, skit.
Morphology
It is the second component of language. It is the study of the structure and classification of the words in a particular language. The origin of the word is from Greek language, where the word ‘morphe’ means ‘form’. Morphology considers the principles of formation of words in a language. In other words, how sounds combine into meaningful units like prefixes, suffixes and roots. It also considers how words can be grouped into parts of speech.
Lexeme
In linguistics, the abstract unit of morphological analysis that corresponds to a set of forms taken by a single word is called lexeme. The way in which a lexeme is used in a sentence is determined by its grammatical category. Lexeme can be individual word or multiword. For example, the word talk is an example of an individual word lexeme, which may have many grammatical variants like talks, talked and talking. Multiword lexeme can be made up of more than one orthographic word. For example, speak up, pull through, etc. are the examples of multiword lexemes.
Syntax
It is the third component of language. It is the study of the order and arrangement of the words into larger units. The word can be traced to Greek language, where the word suntassein means ‘to put in order’. It studies the type of sentences and their structure, of clauses, of phrases.
Semantics
It is the fourth component of language. It is the study of how meaning is conveyed. The meaning can be related to the outside world or can be related to the grammar of the sentence. The word can be traced to Greek language, where the word semainein means means ‘to signify’, ‘show’, ‘signal’.
Pragmatics
It is the fifth component of language. It is the study of the functions of the language and its use in context. The origin of the word can be traced to Greek language where the word ‘pragma’ means ‘deed’, ‘affair’.
Grammatical Categories
A grammatical category may be defined as a class of units or features within the grammar of a language. These units are the building blocks of language and share a common set of characteristics. Grammatical categories are also called grammatical features.
The inventory of grammatical categories is described below −
Number
It is the simplest grammatical category. We have two terms related to this category −singular and plural. Singular is the concept of ‘one’ whereas, plural is the concept of ‘more than one’. For example, dog/dogs, this/these.
Gender
Grammatical gender is expressed by variation in personal pronouns and 3rd person. Examples of grammatical genders are singular − he, she, it; the first and second person forms − I, we and you; the 3rd person plural form they, is either common gender or neuter gender.
Person
Another simple grammatical category is person. Under this, following three terms are recognized −
-
1st person − The person who is speaking is recognized as 1st person.
-
2nd person − The person who is the hearer or the person spoken to is recognized as 2nd person.
-
3rd person − The person or thing about whom we are speaking is recognized as 3rd person.
Case
It is one of the most difficult grammatical categories. It may be defined as an indication of the function of a noun phrase (NP) or the relationship of a noun phrase to a verb or to the other noun phrases in the sentence. We have the following three cases expressed in personal and interrogative pronouns −
-
Nominative case − It is the function of subject. For example, I, we, you, he, she, it, they and who are nominative.
-
Genitive case − It is the function of possessor. For example, my/mine, our/ours, his, her/hers, its, their/theirs, whose are genitive.
-
Objective case − It is the function of object. For example, me, us, you, him, her, them, whom are objective.
Degree
This grammatical category is related to adjectives and adverbs. It has the following three terms −
-
Positive degree − It expresses a quality. For example, big, fast, beautiful are positive degrees.
-
Comparative degree − It expresses greater degree or intensity of the quality in one of two items. For example, bigger, faster, more beautiful are comparative degrees.
-
Superlative degree − It expresses greatest degree or intensity of the quality in one of three or more items. For example, biggest, fastest, most beautiful are superlative degrees.
Definiteness and Indefiniteness
Both these concepts are very simple. Definiteness as we know represents a referent, which is known, familiar or identifiable by the speaker or hearer. On the other hand, indefiniteness represents a referent that is not known, or is unfamiliar. The concept can be understood in the co-occurrence of an article with a noun −
-
definite article − the
-
indefinite article − a/an
Tense
This grammatical category is related to verb and can be defined as the linguistic indication of the time of an action. A tense establishes a relation because it indicates the time of an event with respect to the moment of speaking. Broadly, it is of the following three types −
-
Present tense − Represents the occurrence of an action in the present moment. For example, Ram works hard.
-
Past tense − Represents the occurrence of an action before the present moment. For example, it rained.
-
Future tense − Represents the occurrence of an action after the present moment. For example, it will rain.
Aspect
This grammatical category may be defined as the view taken of an event. It can be of the following types −
-
Perfective aspect − The view is taken as whole and complete in the aspect. For example, the simple past tense like yesterday I met my friend, in English is perfective in aspect as it views the event as complete and whole.
-
Imperfective aspect − The view is taken as ongoing and incomplete in the aspect. For example, the present participle tense like I am working on this problem, in English is imperfective in aspect as it views the event as incomplete and ongoing.
Mood
This grammatical category is a bit difficult to define but it can be simply stated as the indication of the speaker’s attitude towards what he/she is talking about. It is also the grammatical feature of verbs. It is distinct from grammatical tenses and grammatical aspect. The examples of moods are indicative, interrogative, imperative, injunctive, subjunctive, potential, optative, gerunds and participles.
Agreement
It is also called concord. It happens when a word changes from depending on the other words to which it relates. In other words, it involves making the value of some grammatical category agree between different words or part of speech. Followings are the agreements based on other grammatical categories −
-
Agreement based on Person − It is the agreement between subject and the verb. For example, we always use “I am” and “He is” but never “He am” and “I is”.
-
Agreement based on Number − This agreement is between subject and the verb. In this case, there are specific verb forms for first person singular, second person plural and so on. For example, 1st person singular: I really am, 2nd person plural: We really are, 3rd person singular: The boy sings, 3rd person plural: The boys sing.
-
Agreement based on Gender − In English, there is agreement in gender between pronouns and antecedents. For example, He reached his destination. The ship reached her destination.
-
Agreement based on Case − This kind of agreement is not a significant feature of English. For example, who came first − he or his sister?
Spoken Language Syntax
The written English and spoken English grammar have many common features but along with that, they also differ in a number of aspects. The following features distinguish between the spoken and written English grammar −
Disfluencies and Repair
This striking feature makes spoken and written English grammar different from each other. It is individually known as phenomena of disfluencies and collectively as phenomena of repair. Disfluencies include the use of following −
-
Fillers words − Sometimes in between the sentence, we use some filler words. They are called fillers of filler pause. Examples of such words are uh and um.
-
Reparandum and repair − The repeated segment of words in between the sentence is called reparandum. In the same segment, the changed word is called repair. Consider the following example to understand this −
Does ABC airlines offer any one-way flights uh one-way fares for 5000 rupees?
In the above sentence, one-way flight is a reparadum and one-way flights is a repair.
Restarts
After the filler pause, restarts occurs. For example, in the above sentence, restarts occur when the speaker starts asking about one-way flights then stops, correct himself by filler pause and then restarting asking about one-way fares.
Word Fragments
Sometimes we speak the sentences with smaller fragments of words. For example, wwha-what is the time? Here the words w-wha are word fragments.
NLP — Information Retrieval
Information retrieval (IR) may be defined as a software program that deals with the organization, storage, retrieval and evaluation of information from document repositories particularly textual information. The system assists users in finding the information they require but it does not explicitly return the answers of the questions. It informs the existence and location of documents that might consist of the required information. The documents that satisfy user’s requirement are called relevant documents. A perfect IR system will retrieve only relevant documents.
With the help of the following diagram, we can understand the process of information retrieval (IR) −
It is clear from the above diagram that a user who needs information will have to formulate a request in the form of query in natural language. Then the IR system will respond by retrieving the relevant output, in the form of documents, about the required information.
Classical Problem in Information Retrieval (IR) System
The main goal of IR research is to develop a model for retrieving information from the repositories of documents. Here, we are going to discuss a classical problem, named ad-hoc retrieval problem, related to the IR system.
In ad-hoc retrieval, the user must enter a query in natural language that describes the required information. Then the IR system will return the required documents related to the desired information. For example, suppose we are searching something on the Internet and it gives some exact pages that are relevant as per our requirement but there can be some non-relevant pages too. This is due to the ad-hoc retrieval problem.
Aspects of Ad-hoc Retrieval
Followings are some aspects of ad-hoc retrieval that are addressed in IR research −
-
How users with the help of relevance feedback can improve original formulation of a query?
-
How to implement database merging, i.e., how results from different text databases can be merged into one result set?
-
How to handle partly corrupted data? Which models are appropriate for the same?
Information Retrieval (IR) Model
Mathematically, models are used in many scientific areas having objective to understand some phenomenon in the real world. A model of information retrieval predicts and explains what a user will find in relevance to the given query. IR model is basically a pattern that defines the above-mentioned aspects of retrieval procedure and consists of the following −
-
A model for documents.
-
A model for queries.
-
A matching function that compares queries to documents.
Mathematically, a retrieval model consists of −
D − Representation for documents.
R − Representation for queries.
F − The modeling framework for D, Q along with relationship between them.
R (q,di) − A similarity function which orders the documents with respect to the query. It is also called ranking.
Types of Information Retrieval (IR) Model
An information model (IR) model can be classified into the following three models −
Classical IR Model
It is the simplest and easy to implement IR model. This model is based on mathematical knowledge that was easily recognized and understood as well. Boolean, Vector and Probabilistic are the three classical IR models.
Non-Classical IR Model
It is completely opposite to classical IR model. Such kind of IR models are based on principles other than similarity, probability, Boolean operations. Information logic model, situation theory model and interaction models are the examples of non-classical IR model.
Alternative IR Model
It is the enhancement of classical IR model making use of some specific techniques from some other fields. Cluster model, fuzzy model and latent semantic indexing (LSI) models are the example of alternative IR model.
Design features of Information retrieval (IR) systems
Let us now learn about the design features of IR systems −
Inverted Index
The primary data structure of most of the IR systems is in the form of inverted index. We can define an inverted index as a data structure that list, for every word, all documents that contain it and frequency of the occurrences in document. It makes it easy to search for ‘hits’ of a query word.
Stop Word Elimination
Stop words are those high frequency words that are deemed unlikely to be useful for searching. They have less semantic weights. All such kind of words are in a list called stop list. For example, articles “a”, “an”, “the” and prepositions like “in”, “of”, “for”, “at” etc. are the examples of stop words. The size of the inverted index can be significantly reduced by stop list. As per Zipf’s law, a stop list covering a few dozen words reduces the size of inverted index by almost half. On the other hand, sometimes the elimination of stop word may cause elimination of the term that is useful for searching. For example, if we eliminate the alphabet “A” from “Vitamin A” then it would have no significance.
Stemming
Stemming, the simplified form of morphological analysis, is the heuristic process of extracting the base form of words by chopping off the ends of words. For example, the words laughing, laughs, laughed would be stemmed to the root word laugh.
In our subsequent sections, we will discuss about some important and useful IR models.
The Boolean Model
It is the oldest information retrieval (IR) model. The model is based on set theory and the Boolean algebra, where documents are sets of terms and queries are Boolean expressions on terms. The Boolean model can be defined as −
-
D − A set of words, i.e., the indexing terms present in a document. Here, each term is either present (1) or absent (0).
-
Q − A Boolean expression, where terms are the index terms and operators are logical products − AND, logical sum − OR and logical difference − NOT
-
F − Boolean algebra over sets of terms as well as over sets of documents
If we talk about the relevance feedback, then in Boolean IR model the Relevance prediction can be defined as follows −
-
R − A document is predicted as relevant to the query expression if and only if it satisfies the query expression as −
((𝑡𝑒𝑥𝑡 ˅ 𝑖𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛) ˄ 𝑟𝑒𝑟𝑖𝑒𝑣𝑎𝑙 ˄ ˜ 𝑡ℎ𝑒𝑜𝑟𝑦)
We can explain this model by a query term as an unambiguous definition of a set of documents.
For example, the query term “economic” defines the set of documents that are indexed with the term “economic”.
Now, what would be the result after combining terms with Boolean AND Operator? It will define a document set that is smaller than or equal to the document sets of any of the single terms. For example, the query with terms “social” and “economic” will produce the documents set of documents that are indexed with both the terms. In other words, document set with the intersection of both the sets.
Now, what would be the result after combining terms with Boolean OR operator? It will define a document set that is bigger than or equal to the document sets of any of the single terms. For example, the query with terms “social” or “economic” will produce the documents set of documents that are indexed with either the term “social” or “economic”. In other words, document set with the union of both the sets.
Advantages of the Boolean Mode
The advantages of the Boolean model are as follows −
-
The simplest model, which is based on sets.
-
Easy to understand and implement.
-
It only retrieves exact matches
-
It gives the user, a sense of control over the system.
Disadvantages of the Boolean Model
The disadvantages of the Boolean model are as follows −
-
The model’s similarity function is Boolean. Hence, there would be no partial matches. This can be annoying for the users.
-
In this model, the Boolean operator usage has much more influence than a critical word.
-
The query language is expressive, but it is complicated too.
-
No ranking for retrieved documents.
Vector Space Model
Due to the above disadvantages of the Boolean model, Gerard Salton and his colleagues suggested a model, which is based on Luhn’s similarity criterion. The similarity criterion formulated by Luhn states, “the more two representations agreed in given elements and their distribution, the higher would be the probability of their representing similar information.”
Consider the following important points to understand more about the Vector Space Model −
-
The index representations (documents) and the queries are considered as vectors embedded in a high dimensional Euclidean space.
-
The similarity measure of a document vector to a query vector is usually the cosine of the angle between them.
Cosine Similarity Measure Formula
Cosine is a normalized dot product, which can be calculated with the help of the following formula −
$$Score lgroup vec{d} vec{q} rgroup= frac{sum_{k=1}^m d_{k}:.q_{k}}{sqrt{sum_{k=1}^mlgroup d_{k}rgroup^2}:.sqrt{sum_{k=1}^m}mlgroup q_{k}rgroup^2 }$$
$$Score lgroup vec{d} vec{q}rgroup =1:when:d =q $$
$$Score lgroup vec{d} vec{q}rgroup =0:when:d:and:q:share:no:items$$
Vector Space Representation with Query and Document
The query and documents are represented by a two-dimensional vector space. The terms are car and insurance. There is one query and three documents in the vector space.
The top ranked document in response to the terms car and insurance will be the document d2 because the angle between q and d2 is the smallest. The reason behind this is that both the concepts car and insurance are salient in d2 and hence have the high weights. On the other side, d1 and d3 also mention both the terms but in each case, one of them is not a centrally important term in the document.
Term Weighting
Term weighting means the weights on the terms in vector space. Higher the weight of the term, greater would be the impact of the term on cosine. More weights should be assigned to the more important terms in the model. Now the question that arises here is how can we model this.
One way to do this is to count the words in a document as its term weight. However, do you think it would be effective method?
Another method, which is more effective, is to use term frequency (tfij), document frequency (dfi) and collection frequency (cfi).
Term Frequency (tfij)
It may be defined as the number of occurrences of wi in dj. The information that is captured by term frequency is how salient a word is within the given document or in other words we can say that the higher the term frequency the more that word is a good description of the content of that document.
Document Frequency (dfi)
It may be defined as the total number of documents in the collection in which wi occurs. It is an indicator of informativeness. Semantically focused words will occur several times in the document unlike the semantically unfocused words.
Collection Frequency (cfi)
It may be defined as the total number of occurrences of wi in the collection.
Mathematically, $df_{i}leq cf_{i}:and:sum_{j}tf_{ij} = cf_{i}$
Forms of Document Frequency Weighting
Let us now learn about the different forms of document frequency weighting. The forms are described below −
Term Frequency Factor
This is also classified as the term frequency factor, which means that if a term t appears often in a document then a query containing t should retrieve that document. We can combine word’s term frequency (tfij) and document frequency (dfi) into a single weight as follows −
$$weight left ( i,j right ) =begin{cases}(1+log(tf_{ij}))logfrac{N}{df_{i}}:if:tf_{i,j}:geq1\0 ::::::::::::::::::::::::::::::::::::: if:tf_{i,j}:=0end{cases}$$
Here N is the total number of documents.
Inverse Document Frequency (idf)
This is another form of document frequency weighting and often called idf weighting or inverse document frequency weighting. The important point of idf weighting is that the term’s scarcity across the collection is a measure of its importance and importance is inversely proportional to frequency of occurrence.
Mathematically,
$$idf_{t} = logleft(1+frac{N}{n_{t}}right)$$
$$idf_{t} = logleft(frac{N-n_{t}}{n_{t}}right)$$
Here,
N = documents in the collection
nt = documents containing term t
User Query Improvement
The primary goal of any information retrieval system must be accuracy − to produce relevant documents as per the user’s requirement. However, the question that arises here is how can we improve the output by improving user’s query formation style. Certainly, the output of any IR system is dependent on the user’s query and a well-formatted query will produce more accurate results. The user can improve his/her query with the help of relevance feedback, an important aspect of any IR model.
Relevance Feedback
Relevance feedback takes the output that is initially returned from the given query. This initial output can be used to gather user information and to know whether that output is relevant to perform a new query or not. The feedbacks can be classified as follows −
Explicit Feedback
It may be defined as the feedback that is obtained from the assessors of relevance. These assessors will also indicate the relevance of a document retrieved from the query. In order to improve query retrieval performance, the relevance feedback information needs to be interpolated with the original query.
Assessors or other users of the system may indicate the relevance explicitly by using the following relevance systems −
-
Binary relevance system − This relevance feedback system indicates that a document is either relevant (1) or irrelevant (0) for a given query.
-
Graded relevance system − The graded relevance feedback system indicates the relevance of a document, for a given query, on the basis of grading by using numbers, letters or descriptions. The description can be like “not relevant”, “somewhat relevant”, “very relevant” or “relevant”.
Implicit Feedback
It is the feedback that is inferred from user behavior. The behavior includes the duration of time user spent viewing a document, which document is selected for viewing and which is not, page browsing and scrolling actions, etc. One of the best examples of implicit feedback is dwell time, which is a measure of how much time a user spends viewing the page linked to in a search result.
Pseudo Feedback
It is also called Blind feedback. It provides a method for automatic local analysis. The manual part of relevance feedback is automated with the help of Pseudo relevance feedback so that the user gets improved retrieval performance without an extended interaction. The main advantage of this feedback system is that it does not require assessors like in explicit relevance feedback system.
Consider the following steps to implement this feedback −
-
Step 1 − First, the result returned by initial query must be taken as relevant result. The range of relevant result must be in top 10-50 results.
-
Step 2 − Now, select the top 20-30 terms from the documents using for instance term frequency(tf)-inverse document frequency(idf) weight.
-
Step 3 − Add these terms to the query and match the returned documents. Then return the most relevant documents.
Applications of NLP
Natural Language Processing (NLP) is an emerging technology that derives various forms of AI that we see in the present times and its use for creating a seamless as well as interactive interface between humans and machines will continue to be a top priority for today’s and tomorrow’s increasingly cognitive applications. Here, we are going to discuss about some of the very useful applications of NLP.
Machine Translation
Machine translation (MT), process of translating one source language or text into another language, is one of the most important applications of NLP. We can understand the process of machine translation with the help of the following flowchart −
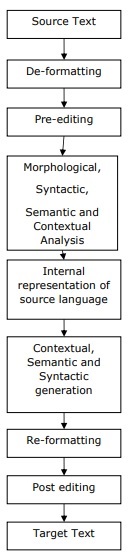
Types of Machine Translation Systems
There are different types of machine translation systems. Let us see what the different types are.
Bilingual MT System
Bilingual MT systems produce translations between two particular languages.
Multilingual MT System
Multilingual MT systems produce translations between any pair of languages. They may be either uni-directional or bi-directional in nature.
Approaches to Machine Translation (MT)
Let us now learn about the important approaches to Machine Translation. The approaches to MT are as follows −
Direct MT Approach
It is less popular but the oldest approach of MT. The systems that use this approach are capable of translating SL (source language) directly to TL (target language). Such systems are bi-lingual and uni-directional in nature.
Interlingua Approach
The systems that use Interlingua approach translate SL to an intermediate language called Interlingua (IL) and then translate IL to TL. The Interlingua approach can be understood with the help of the following MT pyramid −
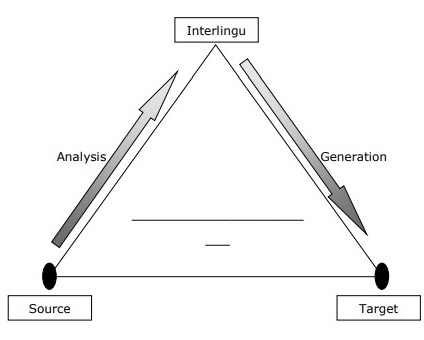
Transfer Approach
Three stages are involved with this approach.
-
In the first stage, source language (SL) texts are converted to abstract SL-oriented representations.
-
In the second stage, SL-oriented representations are converted into equivalent target language (TL)-oriented representations.
-
In the third stage, the final text is generated.
Empirical MT Approach
This is an emerging approach for MT. Basically, it uses large amount of raw data in the form of parallel corpora. The raw data consists of the text and their translations. Analogybased, example-based, memory-based machine translation techniques use empirical MTapproach.
Fighting Spam
One of the most common problems these days is unwanted emails. This makes Spam filters all the more important because it is the first line of defense against this problem.
Spam filtering system can be developed by using NLP functionality by considering the major false-positive and false-negative issues.
Existing NLP models for spam filtering
Followings are some existing NLP models for spam filtering −
N-gram Modeling
An N-Gram model is an N-character slice of a longer string. In this model, N-grams of several different lengths are used simultaneously in processing and detecting spam emails.
Word Stemming
Spammers, generators of spam emails, usually change one or more characters of attacking words in their spams so that they can breach content-based spam filters. That is why we can say that content-based filters are not useful if they cannot understand the meaning of the words or phrases in the email. In order to eliminate such issues in spam filtering, a rule-based word stemming technique, that can match words which look alike and sound alike, is developed.
Bayesian Classification
This has now become a widely-used technology for spam filtering. The incidence of the words in an email is measured against its typical occurrence in a database of unsolicited (spam) and legitimate (ham) email messages in a statistical technique.
Automatic Summarization
In this digital era, the most valuable thing is data, or you can say information. However, do we really get useful as well as the required amount of information? The answer is ‘NO’ because the information is overloaded and our access to knowledge and information far exceeds our capacity to understand it. We are in a serious need of automatic text summarization and information because the flood of information over internet is not going to stop.
Text summarization may be defined as the technique to create short, accurate summary of longer text documents. Automatic text summarization will help us with relevant information in less time. Natural language processing (NLP) plays an important role in developing an automatic text summarization.
Question-answering
Another main application of natural language processing (NLP) is question-answering. Search engines put the information of the world at our fingertips, but they are still lacking when it comes to answer the questions posted by human beings in their natural language. We have big tech companies like Google are also working in this direction.
Question-answering is a Computer Science discipline within the fields of AI and NLP. It focuses on building systems that automatically answer questions posted by human beings in their natural language. A computer system that understands the natural language has the capability of a program system to translate the sentences written by humans into an internal representation so that the valid answers can be generated by the system. The exact answers can be generated by doing syntax and semantic analysis of the questions. Lexical gap, ambiguity and multilingualism are some of the challenges for NLP in building good question answering system.
Sentiment Analysis
Another important application of natural language processing (NLP) is sentiment analysis. As the name suggests, sentiment analysis is used to identify the sentiments among several posts. It is also used to identify the sentiment where the emotions are not expressed explicitly. Companies are using sentiment analysis, an application of natural language processing (NLP) to identify the opinion and sentiment of their customers online. It will help companies to understand what their customers think about the products and services. Companies can judge their overall reputation from customer posts with the help of sentiment analysis. In this way, we can say that beyond determining simple polarity, sentiment analysis understands sentiments in context to help us better understand what is behind the expressed opinion.
Natural Language Processing — Python
In this chapter, we will learn about language processing using Python.
The following features make Python different from other languages −
-
Python is interpreted − We do not need to compile our Python program before executing it because the interpreter processes Python at runtime.
-
Interactive − We can directly interact with the interpreter to write our Python programs.
-
Object-oriented − Python is object-oriented in nature and it makes this language easier to write programs because with the help of this technique of programming it encapsulates code within objects.
-
Beginner can easily learn − Python is also called beginner’s language because it is very easy to understand, and it supports the development of a wide range of applications.
Prerequisites
The latest version of Python 3 released is Python 3.7.1 is available for Windows, Mac OS and most of the flavors of Linux OS.
-
For windows, we can go to the link www.python.org/downloads/windows/ to download and install Python.
-
For MAC OS, we can use the link www.python.org/downloads/mac-osx/.
-
In case of Linux, different flavors of Linux use different package managers for installation of new packages.
-
For example, to install Python 3 on Ubuntu Linux, we can use the following command from terminal −
-
$sudo apt-get install python3-minimal
To study more about Python programming, read Python 3 basic tutorial – Python 3
Getting Started with NLTK
We will be using Python library NLTK (Natural Language Toolkit) for doing text analysis in English Language. The Natural language toolkit (NLTK) is a collection of Python libraries designed especially for identifying and tag parts of speech found in the text of natural language like English.
Installing NLTK
Before starting to use NLTK, we need to install it. With the help of following command, we can install it in our Python environment −
pip install nltk
If we are using Anaconda, then a Conda package for NLTK can be built by using the following command −
conda install -c anaconda nltk
Downloading NLTK’s Data
After installing NLTK, another important task is to download its preset text repositories so that it can be easily used. However, before that we need to import NLTK the way we import any other Python module. The following command will help us in importing NLTK −
import nltk
Now, download NLTK data with the help of the following command −
nltk.download()
It will take some time to install all available packages of NLTK.
Other Necessary Packages
Some other Python packages like gensim and pattern are also very necessary for text analysis as well as building natural language processing applications by using NLTK. the packages can be installed as shown below −
gensim
gensim is a robust semantic modeling library which can be used for many applications. We can install it by following command −
pip install gensim
pattern
It can be used to make gensim package work properly. The following command helps in installing pattern −
pip install pattern
Tokenization
Tokenization may be defined as the Process of breaking the given text, into smaller units called tokens. Words, numbers or punctuation marks can be tokens. It may also be called word segmentation.
Example
Input − Bed and chair are types of furniture.

We have different packages for tokenization provided by NLTK. We can use these packages based on our requirements. The packages and the details of their installation are as follows −
sent_tokenize package
This package can be used to divide the input text into sentences. We can import it by using the following command −
from nltk.tokenize import sent_tokenize
word_tokenize package
This package can be used to divide the input text into words. We can import it by using the following command −
from nltk.tokenize import word_tokenize
WordPunctTokenizer package
This package can be used to divide the input text into words and punctuation marks. We can import it by using the following command −
from nltk.tokenize import WordPuncttokenizer
Stemming
Due to grammatical reasons, language includes lots of variations. Variations in the sense that the language, English as well as other languages too, have different forms of a word. For example, the words like democracy, democratic, and democratization. For machine learning projects, it is very important for machines to understand that these different words, like above, have the same base form. That is why it is very useful to extract the base forms of the words while analyzing the text.
Stemming is a heuristic process that helps in extracting the base forms of the words by chopping of their ends.
The different packages for stemming provided by NLTK module are as follows −
PorterStemmer package
Porter’s algorithm is used by this stemming package to extract the base form of the words. With the help of the following command, we can import this package −
from nltk.stem.porter import PorterStemmer
For example, ‘write’ would be the output of the word ‘writing’ given as the input to this stemmer.
LancasterStemmer package
Lancaster’s algorithm is used by this stemming package to extract the base form of the words. With the help of following command, we can import this package −
from nltk.stem.lancaster import LancasterStemmer
For example, ‘writ’ would be the output of the word ‘writing’ given as the input to this stemmer.
SnowballStemmer package
Snowball’s algorithm is used by this stemming package to extract the base form of the words. With the help of following command, we can import this package −
from nltk.stem.snowball import SnowballStemmer
For example, ‘write’ would be the output of the word ‘writing’ given as the input to this stemmer.
Lemmatization
It is another way to extract the base form of words, normally aiming to remove inflectional endings by using vocabulary and morphological analysis. After lemmatization, the base form of any word is called lemma.
NLTK module provides the following package for lemmatization −
WordNetLemmatizer package
This package will extract the base form of the word depending upon whether it is used as a noun or as a verb. The following command can be used to import this package −
from nltk.stem import WordNetLemmatizer
Counting POS Tags–Chunking
The identification of parts of speech (POS) and short phrases can be done with the help of chunking. It is one of the important processes in natural language processing. As we are aware about the process of tokenization for the creation of tokens, chunking actually is to do the labeling of those tokens. In other words, we can say that we can get the structure of the sentence with the help of chunking process.
Example
In the following example, we will implement Noun-Phrase chunking, a category of chunking which will find the noun phrase chunks in the sentence, by using NLTK Python module.
Consider the following steps to implement noun-phrase chunking −
Step 1: Chunk grammar definition
In this step, we need to define the grammar for chunking. It would consist of the rules, which we need to follow.
Step 2: Chunk parser creation
Next, we need to create a chunk parser. It would parse the grammar and give the output.
Step 3: The Output
In this step, we will get the output in a tree format.
Running the NLP Script
Start by importing the the NLTK package −
import nltk
Now, we need to define the sentence.
Here,
-
DT is the determinant
-
VBP is the verb
-
JJ is the adjective
-
IN is the preposition
-
NN is the noun
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
Next, the grammar should be given in the form of regular expression.
grammar = "NP:{<DT>?<JJ>*<NN>}"
Now, we need to define a parser for parsing the grammar.
parser_chunking = nltk.RegexpParser(grammar)
Now, the parser will parse the sentence as follows −
parser_chunking.parse(sentence)
Next, the output will be in the variable as follows:-
Output = parser_chunking.parse(sentence)
Now, the following code will help you draw your output in the form of a tree.
output.draw()
Слайд 1Lecture 3
Semantic Structure of the Word
and Its Changes

Слайд 2Plan:
Semantics / semasiology. Different approaches to word-meaning.
Types
of word-meaning.
Polysemy. Semantic structure of words.
Meaning and context.
Change of word-meaning: the causes, nature and results.

Слайд 3List of Terms:
semantics
referent
referential meaning
grammatical meaning
lexical meaning
denotational meaning
connotational
meaning
polysemantic word
polysemy
lexical-semantic variants
basic meaning
peripheral meaning
primary meaning
secondary meaning
radiation
concatenation
lexical
context
grammatical context
thematic context
ellipsis
differentiation of synonyms
linguistic analogy
metaphor
metonymy
restriction of meaning
extension of meaning
ameliorative development of meaning
pejorative development of meaning

Слайд 4
It is meaning that makes language
useful.
George A. Miller,
The science of
word, 1991

Слайд 5
1. Semantics / semasiology. Different approaches to
word-meaning

Слайд 6
The function of the word
as a unit of communication is possible
by its possessing a meaning.
Among the word’s various characteristics meaning is the most important.

Слайд 7
«The Meaning of Meaning» (1923) by C.K.
Ogden and I.A. Richards – about 20
definitions of meaning

Слайд 8Meaning of a linguistic unit, or linguistic
meaning, is studied by semantics
(from Greek
– semanticos ‘significant’)

Слайд 9
This linguistic study was pointed
out in 1897 by M. Breal

Слайд 10
Semasiology is a synonym for
‘semantics’
(from Gk. semasia ‘meaning’
+ logos ‘learning’)

Слайд 11Different Approaches to Word Meaning:
ideational (or conceptual)
referential
functional

Слайд 12
The ideational theory can be
considered the earliest theory of meaning.
It states that meaning originates in the mind in the form of ideas, and words are just symbols of them.

Слайд 13A difficulty:
not clear why communication and
understanding are possible if linguistic expressions stand
for individual personal ideas.

Слайд 14Meaning:
a concept with specific structure.

Слайд 15
Do people speaking different languages have different
conceptual systems?
If people speaking different languages
have the same conceptual systems why are identical concepts expressed by correlative words having different lexical meanings?

Слайд 16
finger ‘one of 10 movable parts of
joints at the end of each human
hand, or one of 8 such parts as opposed to the thumbs‘
and
палец ‘подвижная конечная часть кисти руки, стопы ноги или лапы животного’

Слайд 17
Referential theory is based
on interdependence of things, their concepts and
names.

Слайд 18
The complex relationships between referent
(object denoted by the word), concept and
word are traditionally represented by the following triangle:
Thought = concept
Symbol = word Referent = object

Слайд 19
an animal, with 4
legs and a
tail, can bark and bite
dog
Слайд 20Meaning concept
different words having
different meanings may be used to express
the same concept

Слайд 21Concept of dying
die
pass away
kick the
bucket
join the majority, etc

Слайд 22Meaning symbol
In different languages:
a
word with the same meaning have different
sound forms (dog, собака)
words with the same sound forms have different meaning (лук, look)

Слайд 23Meaning referent
to denote one
and the same object we can give
it different names

Слайд 24A horse
in various contexts:
horse,
animal,
creature,
it,
etc.

Слайд 25Word meaning:
the interrelation of
all three components of the semantic triangle:
symbol, concept and referent, though meaning is not equivalent to any of them.

Слайд 26
Functionalists study word meaning by
analysis of the way the word is
used in certain contexts.

Слайд 27
The meaning of a
word is its use in language.

Слайд 28cloud and cloudy
have different meanings because
in speech they function differently and occupy
different positions in relation to other words.

Слайд 29Meaning:
a component of the word
through which a concept is communicated

Слайд 31According to the conception of word meaning
as a specific structure:
functional meaning: part of
speech meaning (nouns usually denote «thingness», adjectives – qualities and states)
grammatical: found in identical sets of individual forms of different words (she goes/works/reads, etc.)
lexical: the component of meaning proper to the word as a linguistic unit highly individual and recurs in all the forms of a word (the meaning of the verb to work ‘to engage in physical or mental activity’ that is expressed in all its forms: works, work, worked, working, will work)

Слайд 32Lexical Meaning:
denotational
connotational

Слайд 33
Denotational lexical meaning provides correct reference of
a word to an individual object or
a concept.
It makes communication possible and is explicitly revealed in the dictionary definition (chair ‘a seat for one person typically having four legs and a back’).

Слайд 35
Connotational lexical meaning is an
emotional colouring of the word. Unlike denotational
meaning, connotations are optional.

Слайд 36Connotations:
Emotive charge may be inherent in word
meaning (like in attractive, repulsive) or may
be created by prefixes and suffixes (like in piggy, useful, useless).
It’s always objective because it doesn’t depend on a person’s perception.

Слайд 37
2. Stylistic reference refers the word to
a certain style:
neutral words
colloquial
bookish, or literary words
Eg. father – dad – parent .

Слайд 38
3. Evaluative connotations express approval or disapproval
(charming, disgusting).
4. Intensifying connotations are expressive and
emphatic (magnificent, gorgeous)

Слайд 39
Denotative component
Lonely = alone, without company
To glare
= to look
Connotative component
+ melancholy, sad
(emotive con.)
+ 1) steadily, lastingly (con. of duration)
+ 2) in anger, rage (emotive con.)

Слайд 40
3. Polysemy. Semantic structure of words. Meaning
and context

Слайд 41
A polysemantic word is a word having
more than one meaning.
Polysemy is the ability
of words to have more than one meaning.

Слайд 42
Most English words
are polysemantic.
A well-developed polysemy
is a great advantage in a language.

Слайд 43Monosemantic Words:
terms (synonym, bronchitis, molecule),
pronouns (this,
my, both),
numerals, etc.

Слайд 44The main causes of polysemy:
a large number
of:
1) monosyllabic words;
2) words of
long duration (that existed for centuries).

Слайд 45The sources of polysemy:
1) the process of
meaning change (meaning specialization: is used in
more concrete spheres);
2) figurative language (metaphor and metonymy);
3) homonymy;
4) borrowing of meanings from other languages.

Слайд 46blanket
a woolen covering used on beds,
a covering
for keeping a house warm,
a covering
of any kind (a blanket of snow),
covering in most cases (used attributively), e.g. we can say: a blanket insurance policy.

Слайд 47
Meanings of a polysemantic word
are organized in a semantic structure

Слайд 48Lexical-semantic variant
one of the meanings of
a polysemantic word used in speech

Слайд 49A Word’s Semantic Structure Is Studied:
Diachronically (in
the process of its historical development): the
historical development and change of meaning becomes central. Focus: the process of acquiring new meanings.
Synchronically (at a certain period of time): a co-existence of different meanings in the semantic structure of the word at a certain period of language development. Focus: value of each individual meaning and frequency of its occurrence.

Слайд 50
The meaning first registered in the language
is called primary.
Other meanings are secondary,
or derived, and are placed after the primary one.

Слайд 51table
a piece of furniture
(primary meaning)
the persons seated at the
table
the food put on the table, meals
a thin flat piece of stone, metal, wood
slabs of stone
words cut into them or written on them
an orderly arrangement of facts
part of a machine-tool on which the work is put to be operated on
a level area, a plateau

Слайд 52
The meaning that first occurs to our
mind, or is understood without a special
context is called the basic or main meaning.
Other meanings are called peripheral or minor.

Слайд 53Fire
1. flame (main meaning)
2. an instance of destructive burning
e.g. a forest fire
4. the shooting of guns
e.g. to open fire
3. burning material in a stone, fireplace
e.g. a camp fire
5. strong feeling, passion
e.g. speech lacking fire

Слайд 54Processes of the Semantic Development of a
Word:
radiation (the primary meaning stands in the
center and the secondary meanings proceed out of it like rays. Each secondary meaning can be traced to the primary meaning)
concatenation (secondary meanings of a word develop like a chain. It is difficult to trace some meanings to the primary one)

Слайд 55crust
hard outer part of bread
hard
part of anything (a pie, a cake)
harder
layer over soft snow
a sullen gloomy person
Impudence

Слайд 56
Polysemy exists not in speech but
in the language.
It’s easy to identify
the main meaning of a separate word. Other meanings are revealed in context.

Слайд 57Context:
linguistic
1. lexical – a
number of lexical units around the word
which enter into interaction with it (i.e. words combined with a polysemantic word are important).
2. grammatical – a number of lexical units around the world viewed on the level of parts of speech.
3. thematic – a very broad context, sometimes a text or even a book.
extralinguistic – different cultural, social, historical factors

Слайд 58
4. Change of word-meaning: the causes, nature
and results

Слайд 59
The meaning of a word can
change in a course of time.

Слайд 60Causes of Change of
Word-meaning:
1. Extralinguistic (various
changes in the life of a speech
community, in economic and social structure, in ideas, scientific concepts)
e.g. “car” meant ‘a four-wheeled wagon’; now – ‘a motor-car’, ‘a railway carriage’ (in the USA)
“paper” is not connected anymore with “papyrus” – the plant from which it formerly was made.
2. Linguistic (factors acting within the language system)

Слайд 61Linguistic Causes:
1. ellipsis – in a phrase
made up of two words one of
these is omitted and its meaning is transferred to its partner.
e.g. “to starve” in O.E. = ‘to die’ + the word “hunger”. In the 16th c. “to starve” = ‘to die of hunger’.
e.g. daily = daily newspaper

Слайд 62Linguistic Causes:
2. differentiation (discrimination) of synonyms
– when a new word is borrowed
it may become a perfect synonym for the existing one. They have to be differentiated; otherwise one of them will die.
e.g. “land” in O.E. = both ‘solid part of earth’s surface’ and ‘the territory of the nation’. In the middle E. period the word “country” was borrowed as its synonym; ‘the territory of a nation’ came to be denoted mainly by “country”.

Слайд 63Linguistic Causes:
3. linguistic analogy – if one
of the members of the synonymic set
acquires a new meaning, other members of this set change their meaning too.
e.g. “to catch” acquired the meaning ‘to understand’; its synonyms “to grasp” and “to get” acquired this meaning too.

Слайд 64
The nature of semantic changes
is based on the secondary application of
the word form to name a different yet related concept.
Conditions to any semantic change: some connection between the old meaning and the new.

Слайд 65Association between Old Meaning and New:
similarity of
meanings or metaphor – a semantic process
of associating two referents one of which in some way resembles the other
contiguity (closeness) of meanings or metonymy – a semantic process of associating two referents one of which makes part of the other or is closely connected with it

Слайд 66Types of Metaphor:
a) similarity of shape, e.g.
head (of a cabbage), bottleneck, teeth (of
a saw, a comb);
b) similarity of position, e.g. foot (of a page, of a mountain), head (of a procession);
c) similarity of function, behavior, e.g. a bookworm (a person who is fond of books);
d) similarity of color, e.g. orange, hazel, chestnut.

Слайд 67Types of Metonymy:
‘material — object of it’
(She is wearing a fox);
‘container — containее’
(I ate three plates);
‘place — people’ (The city is asleep);
‘object — a unit of measure’ (This horse came one neck ahead);
‘producer — product’ (We bought a Picasso);
‘whole — part’ (We have 10 heads here);
‘count — mass’ (We ate rabbit)

Слайд 68Results of Semantic Change:
changes in the denotational
component
changes in the connotational meaning

Слайд 69Changes in the Denotational Component:
restriction – a
word denotes a restricted number of referents.
e.g. “fowl” in O.E. = ‘any bird’, but now ‘a domestic hen or chicken’
extension – the application of the word to a wider variety of referents
e.g. ‘‘a cook’’ was not applied to women until the 16th century.

Слайд 70
generalization – the word with the extended
meaning passes from the specialized vocabulary into
common use and the meaning becomes more general.
e.g. “camp” = ‘the place where troops are lodged in tents’; now – ‘temporary quarters’.
specialization – the word with the new meaning comes to be used in the specialized vocabulary of some limited group.
e.g. “to glide” = ‘to move gently and smoothly’ and now has acquired a special meaning – ‘to fly with no engine’.

Слайд 71Changes in the Connotational Meaning:
pejorative development (degradation)
– the acquisition by the word of
some derogatory emotive charge.
e.g. “accident” ‘a happening causing loss or injury’ came from more neutral ‘something that happened’;
ameliorative development (elevation) – the improvement of the connotational component of meaning.
e.g. “a minister” denoted a servant, now – ‘a civil servant of higher rank, a person administering a department of state’

Слайд 72List of Literature:
Антрушина, Г. Б. Лексикология английского
языка: учебник для студ. пед. ин-тов по
спец. № 2103 «Иностр. яз.» / Г. Б. Антрушина, О. В. Афанасьева, Н. Н. Морозова; под ред. Г. Б. Антрушиной. – М.: Высш. школа, 1985. – С. 129–142, 147–160.
Воробей, А. Н. Глоссарий лингвистических терминов / А. Н. Воробей, Е. Г. Карапетова. – Барановичи: УО «БарГУ», 2004. – 108 с.
Дубенец, Э. М. Современный английский язык. Лексикология: пособие для студ. гуманит. вузов / Э. М. Дубенец. – М. / СПб.: ГЛОССА / КАРО, 2004. – С. 74–82, 123–127.
Лексикология английского языка: учебник для ин-тов и фак-тов иностр. яз. / Р. З. Гинзбург [и др.]; под общ. ред. Р. З. Гинзбург. – 2-е изд., испр. и доп. – М.: Высш. школа, 1979. – С. 13–23, 28–39, 47–51.
Лещева, Л. М. Слова в английском языке. Курс лексикологии современного английского языка: учебник для студ. фак-в и отдел. английского языка (на англ. яз.) / Л. М. Лещева. – Минск: Академия управления при Президенте Республики Беларусь, 2001. – С. 36–56.

Слайды и текст этой презентации
Слайд 1 Cлайд №1")
Слайд 2
Описание слайда:
Plan:
Semantics / semasiology. Different approaches to word-meaning.
Types of word-meaning.
Polysemy. Semantic structure of words. Meaning and context.
Change of word-meaning: the causes, nature and results.
Слайд 3
Описание слайда:
List of Terms:
semantics
referent
referential meaning
grammatical meaning
lexical meaning
denotational meaning
connotational meaning
polysemantic word
polysemy
lexical-semantic variants
basic meaning
peripheral meaning
primary meaning
secondary meaning
Слайд 4
Описание слайда:
It is meaning that makes language useful.
George A. Miller,
The science of word, 1991
Слайд 5
Описание слайда:
1. Semantics / semasiology. Different approaches to word-meaning
Слайд 6
Описание слайда:
The function of the word as a unit of communication is possible by its possessing a meaning.
Among the word’s various characteristics meaning is the most important.
Слайд 7 by C.K. Ogden and I.A. Richards – about 20 definitions of meaning")
Описание слайда:
«The Meaning of Meaning» (1923) by C.K. Ogden and I.A. Richards – about 20 definitions of meaning
Слайд 8 Cлайд №8")
Слайд 9
Описание слайда:
This linguistic study was pointed out in 1897 by M. Breal
Слайд 10")
Описание слайда:
Semasiology is a synonym for ‘semantics’
(from Gk. semasia ‘meaning’ + logos ‘learning’)
Слайд 11
referential
functional")
Описание слайда:
Different Approaches to Word Meaning:
ideational (or conceptual)
referential
functional
Слайд 12
Описание слайда:
The ideational theory can be considered the earliest theory of meaning.
It states that meaning originates in the mind in the form of ideas, and words are just symbols of them.
Слайд 13
Описание слайда:
A difficulty:
not clear why communication and understanding are possible if linguistic expressions stand for individual personal ideas.
Слайд 14
Описание слайда:
Meaning:
a concept with specific structure.
Слайд 15
Описание слайда:
Do people speaking different languages have different conceptual systems?
If people speaking different languages have the same conceptual systems why are identical concepts expressed by correlative words having different lexical meanings?
Слайд 16
Описание слайда:
finger ‘one of 10 movable parts of joints at the end of each human hand, or one of 8 such parts as opposed to the thumbs‘
and
палец ‘подвижная конечная часть кисти руки, стопы ноги или лапы животного’
Слайд 17
Описание слайда:
Referential theory is based on interdependence of things, their concepts and names.
Слайд 18, concept and word are traditionally represented by the following triangle:
Thought = concept
Symbol = word Referent = object")
Описание слайда:
The complex relationships between referent (object denoted by the word), concept and word are traditionally represented by the following triangle:
Thought = concept
Symbol = word Referent = object
Слайд 19
Описание слайда:
an animal, with 4
legs and a tail, can bark and bite
dog
Слайд 20
Описание слайда:
Meaning concept
different words having different meanings may be used to express the same concept
Слайд 21
Описание слайда:
Concept of dying
die
pass away
kick the bucket
join the majority, etc
Слайд 22
words with the same sound forms have different meaning (лук, look)")
Описание слайда:
Meaning symbol
In different languages:
a word with the same meaning have different sound forms (dog, собака)
words with the same sound forms have different meaning (лук, look)
Слайд 23
Описание слайда:
Meaning referent
to denote one and the same object we can give it different names
Слайд 24
Описание слайда:
A horse
in various contexts:
horse,
animal,
creature,
it, etc.
Слайд 25
Описание слайда:
Word meaning:
the interrelation of all three components of the semantic triangle: symbol, concept and referent, though meaning is not equivalent to any of them.
Слайд 26
Описание слайда:
Functionalists study word meaning by analysis of the way the word is used in certain contexts.
Слайд 27
Описание слайда:
The meaning of a word is its use in language.
Слайд 28
Описание слайда:
cloud and cloudy
have different meanings because in speech they function differently and occupy different positions in relation to other words.
Слайд 29
Описание слайда:
Meaning:
a component of the word through which a concept is communicated
Слайд 30
Описание слайда:
2. Types of word-meaning
Слайд 31
grammatical: found in identical sets of individual forms of different words (she goes/works/reads, etc.)
lexical: the component of meaning proper to the word as a linguistic unit highly individual and recurs in all the forms of a word (the meaning of the verb to work 'to engage in physical or mental activity' that is expressed in all its forms: works, work, worked, working, will work)")
Описание слайда:
According to the conception of word meaning as a specific structure:
functional meaning: part of speech meaning (nouns usually denote «thingness», adjectives – qualities and states)
grammatical: found in identical sets of individual forms of different words (she goes/works/reads, etc.)
lexical: the component of meaning proper to the word as a linguistic unit highly individual and recurs in all the forms of a word (the meaning of the verb to work ‘to engage in physical or mental activity’ that is expressed in all its forms: works, work, worked, working, will work)
Слайд 32
Описание слайда:
Lexical Meaning:
denotational
connotational
Слайд 33.")
Описание слайда:
Denotational lexical meaning provides correct reference of a word to an individual object or a concept.
It makes communication possible and is explicitly revealed in the dictionary definition (chair ‘a seat for one person typically having four legs and a back’).
Слайд 34
Описание слайда:
to glare – to look
Слайд 35
Описание слайда:
Connotational lexical meaning is an emotional colouring of the word. Unlike denotational meaning, connotations are optional.
Слайд 36 or may be created by prefixes and suffixes (like in piggy, useful, useless).
It’s always objective because it doesn’t depend on a person’s perception.")
Описание слайда:
Connotations:
Emotive charge may be inherent in word meaning (like in attractive, repulsive) or may be created by prefixes and suffixes (like in piggy, useful, useless).
It’s always objective because it doesn’t depend on a person’s perception.
Слайд 37
Описание слайда:
2. Stylistic reference refers the word to a certain style:
neutral words
colloquial
bookish, or literary words
Eg. father – dad – parent .
Слайд 38.
4. Intensifying connotations are expressive and emphatic (magnificent, gorgeous)")
Описание слайда:
3. Evaluative connotations express approval or disapproval (charming, disgusting).
4. Intensifying connotations are expressive and emphatic (magnificent, gorgeous)
Слайд 39
Описание слайда:
Denotative component
Lonely = alone, without company
To glare = to look
Слайд 40
Описание слайда:
3. Polysemy. Semantic structure of words. Meaning and context
Слайд 41
Описание слайда:
A polysemantic word is a word having more than one meaning.
Polysemy is the ability of words to have more than one meaning.
Слайд 42
Описание слайда:
Most English words are polysemantic.
A well-developed polysemy is a great advantage in a language.
Слайд 43,
pronouns (this, my, both),
numerals, etc.")
Описание слайда:
Monosemantic Words:
terms (synonym, bronchitis, molecule),
pronouns (this, my, both),
numerals, etc.
Слайд 44 monosyllabic words;
2) words of long duration (that existed for centuries).")
Описание слайда:
The main causes of polysemy:
a large number of:
1) monosyllabic words;
2) words of long duration (that existed for centuries).
Слайд 45 the process of meaning change (meaning specialization: is used in more concrete spheres);
2) figurative language (metaphor and metonymy);
3) homonymy;
4) borrowing of meanings from other languages.")
Описание слайда:
The sources of polysemy:
1) the process of meaning change (meaning specialization: is used in more concrete spheres);
2) figurative language (metaphor and metonymy);
3) homonymy;
4) borrowing of meanings from other languages.
Слайд 46,
covering in most cases (used attributively), e.g. we can say: a blanket insurance policy.")
Описание слайда:
blanket
a woolen covering used on beds,
a covering for keeping a house warm,
a covering of any kind (a blanket of snow),
covering in most cases (used attributively), e.g. we can say: a blanket insurance policy.
Слайд 47
Описание слайда:
Meanings of a polysemantic word are organized in a semantic structure
Слайд 48
Описание слайда:
Lexical-semantic variant
one of the meanings of a polysemantic word used in speech
Слайд 49: the historical development and change of meaning becomes central. Focus: the process of acquiring new meanings.
Synchronically (at a certain period of time): a co-existence of different meanings in the semantic structure of the word at a certain period of language development. Focus: value of each individual meaning and frequency of its occurrence.")
Описание слайда:
A Word’s Semantic Structure Is Studied:
Diachronically (in the process of its historical development): the historical development and change of meaning becomes central. Focus: the process of acquiring new meanings.
Synchronically (at a certain period of time): a co-existence of different meanings in the semantic structure of the word at a certain period of language development. Focus: value of each individual meaning and frequency of its occurrence.
Слайд 50
Описание слайда:
The meaning first registered in the language is called primary.
Other meanings are secondary, or derived, and are placed after the primary one.
Слайд 51
the persons seated at the table
the food put on the table, meals
a thin flat piece of stone, metal, wood
slabs of stone
words cut into them or written on them
an orderly arrangement of facts
part of a machine-tool on which the work is put to be operated on
a level area, a plateau")
Описание слайда:
table
a piece of furniture (primary meaning)
the persons seated at the table
the food put on the table, meals
a thin flat piece of stone, metal, wood
slabs of stone
words cut into them or written on them
an orderly arrangement of facts
part of a machine-tool on which the work is put to be operated on
a level area, a plateau
Слайд 52
Описание слайда:
The meaning that first occurs to our mind, or is understood without a special context is called the basic or main meaning.
Other meanings are called peripheral or minor.
Слайд 53")
Описание слайда:
Fire
1. flame (main meaning)
Слайд 54
concatenation (secondary meanings of a word develop like a chain. It is difficult to trace some meanings to the primary one)")
Описание слайда:
Processes of the Semantic Development of a Word:
radiation (the primary meaning stands in the center and the secondary meanings proceed out of it like rays. Each secondary meaning can be traced to the primary meaning)
concatenation (secondary meanings of a word develop like a chain. It is difficult to trace some meanings to the primary one)
Слайд 55
harder layer over soft snow
a sullen gloomy person
Impudence")
Описание слайда:
crust
hard outer part of bread
hard part of anything (a pie, a cake)
harder layer over soft snow
a sullen gloomy person
Impudence
Слайд 56
Описание слайда:
Polysemy exists not in speech but in the language.
It’s easy to identify the main meaning of a separate word. Other meanings are revealed in context.
Слайд 57.
2. grammatical – a number of lexical units around the world viewed on the level of parts of speech.
3. thematic – a very broad context, sometimes a text or even a book.
extralinguistic – different cultural, social, historical factors")
Описание слайда:
Context:
linguistic
1. lexical – a number of lexical units around the word which enter into interaction with it (i.e. words combined with a polysemantic word are important).
2. grammatical – a number of lexical units around the world viewed on the level of parts of speech.
3. thematic – a very broad context, sometimes a text or even a book.
extralinguistic – different cultural, social, historical factors
Слайд 58
Описание слайда:
4. Change of word-meaning: the causes, nature and results
Слайд 59
Описание слайда:
The meaning of a word can change in a course of time.
Слайд 60
e.g. “car” meant ‘a four-wheeled wagon’; now – ‘a motor-car’, ‘a railway carriage’ (in the USA)
“paper” is not connected anymore with “papyrus” – the plant from which it formerly was made.
2. Linguistic (factors acting within the language system)")
Описание слайда:
Causes of Change of
Word-meaning:
1. Extralinguistic (various changes in the life of a speech community, in economic and social structure, in ideas, scientific concepts)
e.g. “car” meant ‘a four-wheeled wagon’; now – ‘a motor-car’, ‘a railway carriage’ (in the USA)
“paper” is not connected anymore with “papyrus” – the plant from which it formerly was made.
2. Linguistic (factors acting within the language system)
Слайд 61
Описание слайда:
Linguistic Causes:
1. ellipsis – in a phrase made up of two words one of these is omitted and its meaning is transferred to its partner.
e.g. “to starve” in O.E. = ‘to die’ + the word “hunger”. In the 16th c. “to starve” = ‘to die of hunger’.
e.g. daily = daily newspaper
Слайд 62 of synonyms – when a new word is borrowed it may become a perfect synonym for the existing one. They have to be differentiated; otherwise one of them will die.
e.g. “land” in O.E. = both ‘solid part of earth’s surface’ and ‘the territory of the nation’. In the middle E. period the word “country” was borrowed as its synonym; ‘the territory of a nation’ came to be denoted mainly by “country”.")
Описание слайда:
Linguistic Causes:
2. differentiation (discrimination) of synonyms – when a new word is borrowed it may become a perfect synonym for the existing one. They have to be differentiated; otherwise one of them will die.
e.g. “land” in O.E. = both ‘solid part of earth’s surface’ and ‘the territory of the nation’. In the middle E. period the word “country” was borrowed as its synonym; ‘the territory of a nation’ came to be denoted mainly by “country”.
Слайд 63
Описание слайда:
Linguistic Causes:
3. linguistic analogy – if one of the members of the synonymic set acquires a new meaning, other members of this set change their meaning too.
e.g. “to catch” acquired the meaning ‘to understand’; its synonyms “to grasp” and “to get” acquired this meaning too.
Слайд 64
Описание слайда:
The nature of semantic changes is based on the secondary application of the word form to name a different yet related concept.
Conditions to any semantic change: some connection between the old meaning and the new.
Слайд 65 of meanings or metonymy – a semantic process of associating two referents one of which makes part of the other or is closely connected with it")
Описание слайда:
Association between Old Meaning and New:
similarity of meanings or metaphor – a semantic process of associating two referents one of which in some way resembles the other
contiguity (closeness) of meanings or metonymy – a semantic process of associating two referents one of which makes part of the other or is closely connected with it
Слайд 66 similarity of shape, e.g. head (of a cabbage), bottleneck, teeth (of a saw, a comb);
b) similarity of position, e.g. foot (of a page, of a mountain), head (of a procession);
c) similarity of function, behavior, e.g. a bookworm (a person who is fond of books);
d) similarity of color, e.g. orange, hazel, chestnut.")
Описание слайда:
Types of Metaphor:
a) similarity of shape, e.g. head (of a cabbage), bottleneck, teeth (of a saw, a comb);
b) similarity of position, e.g. foot (of a page, of a mountain), head (of a procession);
c) similarity of function, behavior, e.g. a bookworm (a person who is fond of books);
d) similarity of color, e.g. orange, hazel, chestnut.
Слайд 67;
'container — containее' (I ate three plates);
'place — people' (The city is asleep);
'object — a unit of measure' (This horse came one neck ahead);
'producer — product' (We bought a Picasso);
'whole — part' (We have 10 heads here);
'count — mass' (We ate rabbit)")
Описание слайда:
Types of Metonymy:
‘material — object of it’ (She is wearing a fox);
‘container — containее’ (I ate three plates);
‘place — people’ (The city is asleep);
‘object — a unit of measure’ (This horse came one neck ahead);
‘producer — product’ (We bought a Picasso);
‘whole — part’ (We have 10 heads here);
‘count — mass’ (We ate rabbit)
Слайд 68
Описание слайда:
Results of Semantic Change:
changes in the denotational component
changes in the connotational meaning
Слайд 69
Описание слайда:
Changes in the Denotational Component:
restriction – a word denotes a restricted number of referents.
e.g. “fowl” in O.E. = ‘any bird’, but now ‘a domestic hen or chicken’
extension – the application of the word to a wider variety of referents
e.g. ‘‘a cook’’ was not applied to women until the 16th century.
Слайд 70
Описание слайда:
generalization – the word with the extended meaning passes from the specialized vocabulary into common use and the meaning becomes more general.
e.g. “camp” = ‘the place where troops are lodged in tents’; now – ‘temporary quarters’.
specialization – the word with the new meaning comes to be used in the specialized vocabulary of some limited group.
e.g. “to glide” = ‘to move gently and smoothly’ and now has acquired a special meaning – ‘to fly with no engine’.
Слайд 71 – the acquisition by the word of some derogatory emotive charge.
e.g. “accident” ‘a happening causing loss or injury’ came from more neutral ‘something that happened’;
ameliorative development (elevation) – the improvement of the connotational component of meaning.
e.g. “a minister” denoted a servant, now – ‘a civil servant of higher rank, a person administering a department of state’")
Описание слайда:
Changes in the Connotational Meaning:
pejorative development (degradation) – the acquisition by the word of some derogatory emotive charge.
e.g. “accident” ‘a happening causing loss or injury’ came from more neutral ‘something that happened’;
ameliorative development (elevation) – the improvement of the connotational component of meaning.
e.g. “a minister” denoted a servant, now – ‘a civil servant of higher rank, a person administering a department of state’
Слайд 72 / Л. М. Лещева. – Минск: Академия управления при Президенте Республики Беларусь, 2001. – С. 36–56.")
Описание слайда:
List of Literature:
Антрушина, Г. Б. Лексикология английского языка: учебник для студ. пед. ин-тов по спец. № 2103 «Иностр. яз.» / Г. Б. Антрушина, О. В. Афанасьева, Н. Н. Морозова; под ред. Г. Б. Антрушиной. – М.: Высш. школа, 1985. – С. 129–142, 147–160.
Воробей, А. Н. Глоссарий лингвистических терминов / А. Н. Воробей, Е. Г. Карапетова. – Барановичи: УО «БарГУ», 2004. – 108 с.
Дубенец, Э. М. Современный английский язык. Лексикология: пособие для студ. гуманит. вузов / Э. М. Дубенец. – М. / СПб.: ГЛОССА / КАРО, 2004. – С. 74–82, 123–127.
Лексикология английского языка: учебник для ин-тов и фак-тов иностр. яз. / Р. З. Гинзбург [и др.]; под общ. ред. Р. З. Гинзбург. – 2-е изд., испр. и доп. – М.: Высш. школа, 1979. – С. 13–23, 28–39, 47–51.
Лещева, Л. М. Слова в английском языке. Курс лексикологии современного английского языка: учебник для студ. фак-в и отдел. английского языка (на англ. яз.) / Л. М. Лещева. – Минск: Академия управления при Президенте Республики Беларусь, 2001. – С. 36–56.
Скачать материал

Скачать материал






- Сейчас обучается 268 человек из 64 регионов


Описание презентации по отдельным слайдам:
-

1 слайд
Word Meaning
Lecture # 6
Grigoryeva M. -
2 слайд
Word Meaning
Approaches to word meaning
Meaning and Notion (понятие)
Types of word meaning
Types of morpheme meaning
Motivation
-
3 слайд
Each word has two aspects:
the outer aspect
( its sound form)
catthe inner aspect
(its meaning)
long-legged, fury animal with sharp teeth
and claws -
4 слайд
Sound and meaning do not always constitute a constant unit even in the same language
EX a temple
a part of a human head
a large church -
5 слайд
Semantics (Semasiology)
Is a branch of lexicology which studies the
meaning of words and word equivalents -
6 слайд
Approaches to Word Meaning
The Referential (analytical) approachThe Functional (contextual) approach
Operational (information-oriented) approach
-
7 слайд
The Referential (analytical) approach
formulates the essence of meaning by establishing the interdependence between words and things or concepts they denotedistinguishes between three components closely connected with meaning:
the sound-form of the linguistic sign,
the concept
the actual referent -
8 слайд
Basic Triangle
concept (thought, reference) – the thought of the object that singles out its essential features
referent – object denoted by the word, part of reality
sound-form (symbol, sign) – linguistic sign
concept – flowersound-form referent
[rәuz] -
9 слайд
In what way does meaning correlate with
each element of the triangle ?In what relation does meaning stand to
each of them? -
10 слайд
Meaning and Sound-form
are not identical
different
EX. dove — [dΛv] English sound-forms
[golub’] Russian BUT
[taube] German
the same meaning -
11 слайд
Meaning and Sound-form
nearly identical sound-forms have different meanings in different languages
EX. [kot] Russian – a male cat
[kot] English – a small bed for a childidentical sound-forms have different meanings (‘homonyms)
EX. knight [nait]
night [nait] -
12 слайд
Meaning and Sound-form
even considerable changes in sound-form do not affect the meaningEX Old English lufian [luvian] – love [l Λ v]
-
13 слайд
Meaning and Concept
concept is a category of human cognitionconcept is abstract and reflects the most common and typical features of different objects and phenomena in the world
meanings of words are different in different languages
-
14 слайд
Meaning and Concept
identical concepts may have different semantic structures in different languagesEX. concept “a building for human habitation” –
English Russian
HOUSE ДОМ+ in Russian ДОМ
“fixed residence of family or household”
In English HOME -
15 слайд
Meaning and Referent
one and the same object (referent) may be denoted by more than one word of a different meaning
cat
pussy
animal
tiger -
16 слайд
Meaning
is not identical with any of the three points of the triangle –
the sound form,
the concept
the referentBUT
is closely connected with them. -
17 слайд
Functional Approach
studies the functions of a word in speech
meaning of a word is studied through relations of it with other linguistic units
EX. to move (we move, move a chair)
movement (movement of smth, slow movement)The distriution ( the position of the word in relation to
others) of the verb to move and a noun movement is
different as they belong to different classes of words and
their meanings are different -
18 слайд
Operational approach
is centered on defining meaning through its role in
the process of communicationEX John came at 6
Beside the direct meaning the sentence may imply that:
He was late
He failed to keep his promise
He was punctual as usual
He came but he didn’t want toThe implication depends on the concrete situation
-
19 слайд
Lexical Meaning and Notion
Notion denotes the reflection in the mind of real objectsNotion is a unit of thinking
Lexical meaning is the realization of a notion by means of a definite language system
Word is a language unit -
20 слайд
Lexical Meaning and Notion
Notions are international especially with the nations of the same cultural levelMeanings are nationally limited
EX GO (E) —- ИДТИ(R)
“To move”
BUT !!!
To GO by bus (E)
ЕХАТЬ (R)EX Man -мужчина, человек
Она – хороший человек (R)
She is a good person (E) -
21 слайд
Types of Meaning
Types of meaninggrammatical
meaninglexico-grammatical
meaning
lexical meaning
denotational
connotational -
22 слайд
Grammatical Meaning
component of meaning recurrent in identical sets of individual forms of different wordsEX. girls, winters, toys, tables –
grammatical meaning of pluralityasked, thought, walked –
meaning of past tense -
23 слайд
Lexico-grammatical meaning
(part –of- speech meaning)
is revealed in the classification of lexical items into:
major word classes (N, V, Adj, Adv)
minor ones (artc, prep, conj)words of one lexico-grammatical class have the same paradigm
-
24 слайд
Lexical Meaning
is the meaning proper to the given linguistic unit in all its forms and distributionsEX . Go – goes — went
lexical meaning – process of movement -
25 слайд
PRACTICE
Group the words into 3 column according to the grammatical, lexical or part-of –speech meaning
Boy’s, nearest, at, beautiful,
think, man, drift, wrote,
tremendous, ship’s, the most beautiful,
table, near, for, went, friend’s,
handsome, thinking, boy,
nearer, thought, boys,
lamp, go, during. -
26 слайд
Grammatical
The case of nouns: boy’s, ship’s, friend’s
The degree of comparison of adj: nearest, the most beautiful
The tense of verbs: wrote, went, thoughtLexical
Think, thinking, thought
Went, go
Boy’s, boy, boys
Nearest, near, nearer
At, for, during (“time”)
Beautiful, the most beautifulPart-of-speech
Nouns—verbs—adj—-prep -
27 слайд
Aspects of Lexical meaning
The denotational aspectThe connotational aspect
The pragmatic aspect
-
28 слайд
Denotational Meaning
“denote” – to be a sign of, stand as a symbol for”establishes the correlation between the name and the object
makes communication possibleEX booklet
“a small thin book that gives info about smth” -
29 слайд
PRACTICE
Explain denotational meaningA lion-hunter
To have a heart like a lion
To feel like a lion
To roar like a lion
To be thrown to the lions
The lion’s share
To put your head in lion’s mouth -
30 слайд
PRACTICE
A lion-hunter
A host that seeks out celebrities to impress guests
To have a heart like a lion
To have great courage
To feel like a lion
To be in the best of health
To roar like a lion
To shout very loudly
To be thrown to the lions
To be criticized strongly or treated badly
The lion’s share
Much more than one’s share
To put your head in lion’s mouth -
31 слайд
Connotational Meaning
reflects the attitude of the speaker towards what he speaks about
it is optional – a word either has it or notConnotation gives additional information and includes:
The emotive charge EX Daddy (for father)
Intensity EX to adore (for to love)
Imagery EX to wade through a book
“ to walk with an effort” -
32 слайд
PRACTICE
Give possible interpretation of the sentencesShe failed to buy it and felt a strange pang.
Don’t be afraid of that woman! It’s just barking!
He got up from his chair moving slowly, like an old man.
The girl went to her father and pulled his sleeve.
He was longing to begin to be generous.
She was a woman with shiny red hands and work-swollen finger knuckles. -
33 слайд
PRACTICE
Give possible interpretation of the sentences
She failed to buy it and felt a strange pang.
(pain—dissatisfaction that makes her suffer)
Don’t be afraid of that woman! It’s just barking!
(make loud sharp sound—-the behavior that implies that the person is frightened)
He got up from his chair moving slowly, like an old man.
(to go at slow speed—was suffering or was ill)
The girl went to her father and pulled his sleeve.
(to move smth towards oneself— to try to attract smb’s attention)
He was longing to begin to be generous.
(to start doing— hadn’t been generous before)
She was a woman with shiny red hands and work-swollen finger knuckles.
(colour— a labourer involved into physical work ,constant contact with water) -
34 слайд
The pragmatic aspect of lexical meaning
the situation in which the word is uttered,
the social circumstances (formal, informal, etc.),
social relationships between the interlocutors (polite, rough, etc.),
the type and purpose of communication (poetic, official, etc.)EX horse (neutral)
steed (poetic)
nag (slang)
gee-gee (baby language) -
35 слайд
PRACTICE
State what image underline the meaningI heard what she said but it didn’t sink into my mind.
You should be ashamed of yourself, crawling to the director like that.
They seized on the idea.
Bill, chasing some skirt again?
I saw him dive into a small pub.
Why are you trying to pin the blame on me?
He only married her for her dough. -
36 слайд
PRACTICE
State what image underline the meaning
I heard what she said but it didn’t sink into my mind.
(to understand completely)
You should be ashamed of yourself, crawling to the director like that.
(to behave humbly in order to win favour)
They seized on the idea.
(to be eager to take and use)
Bill, chasing some skirt again?
(a girl)
I saw him dive into a small pub.
(to enter suddenly)
Why are you trying to pin the blame on me?
(to blame smb unfairly)
He only married her for her dough.
(money) -
37 слайд
Types of Morpheme Meaning
lexical
differential
functional
distributional -
38 слайд
Lexical Meaning in Morphemes
root-morphemes that are homonymous to words possess lexical meaning
EX. boy – boyhood – boyishaffixes have lexical meaning of a more generalized character
EX. –er “agent, doer of an action” -
39 слайд
Lexical Meaning in Morphemes
has denotational and connotational components
EX. –ly, -like, -ish –
denotational meaning of similiarity
womanly , womanishconnotational component –
-ly (positive evaluation), -ish (deragotary) женственный — женоподобный -
40 слайд
Differential Meaning
a semantic component that serves to distinguish one word from all others containing identical morphemesEX. cranberry, blackberry, gooseberry
-
41 слайд
Functional Meaning
found only in derivational affixes
a semantic component which serves to
refer the word to the certain part of speechEX. just, adj. – justice, n.
-
42 слайд
Distributional Meaning
the meaning of the order and the arrangement of morphemes making up the word
found in words containing more than one morpheme
different arrangement of the same morphemes would make the word meaningless
EX. sing- + -er =singer,
-er + sing- = ? -
43 слайд
Motivation
denotes the relationship between the phonetic or morphemic composition and structural pattern of the word on the one hand, and its meaning on the othercan be phonetical
morphological
semantic -
44 слайд
Phonetical Motivation
when there is a certain similarity between the sounds that make up the word and those produced by animals, objects, etc.EX. sizzle, boom, splash, cuckoo
-
45 слайд
Morphological Motivation
when there is a direct connection between the structure of a word and its meaning
EX. finger-ring – ring-finger,A direct connection between the lexical meaning of the component morphemes
EX think –rethink “thinking again” -
46 слайд
Semantic Motivation
based on co-existence of direct and figurative meanings of the same wordEX a watchdog –
”a dog kept for watching property”a watchdog –
“a watchful human guardian” (semantic motivation) -
-
48 слайд
Analyze the meaning of the words.
Define the type of motivation
a) morphologically motivated
b) semantically motivatedDriver
Leg
Horse
Wall
Hand-made
Careless
piggish -
49 слайд
Analyze the meaning of the words.
Define the type of motivation
a) morphologically motivated
b) semantically motivated
Driver
Someone who drives a vehicle
morphologically motivated
Leg
The part of a piece of furniture such as a table
semantically motivated
Horse
A piece of equipment shaped like a box, used in gymnastics
semantically motivated -
50 слайд
Wall
Emotions or behavior preventing people from feeling close
semantically motivated
Hand-made
Made by hand, not machine
morphologically motivated
Careless
Not taking enough care
morphologically motivated
Piggish
Selfish
semantically motivated -
51 слайд
I heard what she said but it didn’t sink in my mind
“do down to the bottom”
‘to be accepted by mind” semantic motivationWhy are you trying to pin the blame on me?
“fasten smth somewhere using a pin” –
”to blame smb” semantic motivationI was following the man when he dived into a pub.
“jump into deep water” –
”to enter into suddenly” semantic motivationYou should be ashamed of yourself, crawling to the director like that
“to move along on hands and knees close to the ground” –
“to behave very humbly in order to win favor” semantic motivation

Types...")

cat
the in...")

Is a branch of lexicology which studies the
meaning o...")
 approach
The Function...")
 approachformulates the essence of meaning by es...")
 – the thought of the object that s...")

![Meaning and Sound-formare not identical
different
EX. dove - [dΛv]...](https://documents.infourok.ru/2d0c9b9d-1c12-4da2-8c1e-80496902c301/slide_10.jpg "Meaning and Sound-formare not identical
different
EX. dove - [dΛv]...")




 may be denoted by mor...")







 is revealed in the cla...")
























 morpholo...")
 morpholo...")


Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 210 152 материала в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 22.10.2020
- 141
- 0
- 21.09.2020
- 530
- 1
- 18.09.2020
- 256
- 0
- 11.09.2020
- 191
- 1
- 21.08.2020
- 198
- 0
- 18.08.2020
- 123
- 0
- 03.07.2020
- 94
- 0
- 06.06.2020
- 73
- 0
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Формирование компетенций межкультурной коммуникации в условиях реализации ФГОС»
-
Курс профессиональной переподготовки «Клиническая психология: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Введение в сетевые технологии»
-
Курс повышения квалификации «История и философия науки в условиях реализации ФГОС ВО»
-
Курс повышения квалификации «Основы построения коммуникаций в организации»
-
Курс повышения квалификации «Организация практики студентов в соответствии с требованиями ФГОС медицинских направлений подготовки»
-
Курс повышения квалификации «Правовое регулирование рекламной и PR-деятельности»
-
Курс повышения квалификации «Организация маркетинга в туризме»
-
Курс повышения квалификации «Источники финансов»
-
Курс профессиональной переподготовки «Техническая диагностика и контроль технического состояния автотранспортных средств»
-
Курс профессиональной переподготовки «Осуществление и координация продаж»
-
Курс профессиональной переподготовки «Технический контроль и техническая подготовка сварочного процесса»
-
Курс профессиональной переподготовки «Управление качеством»
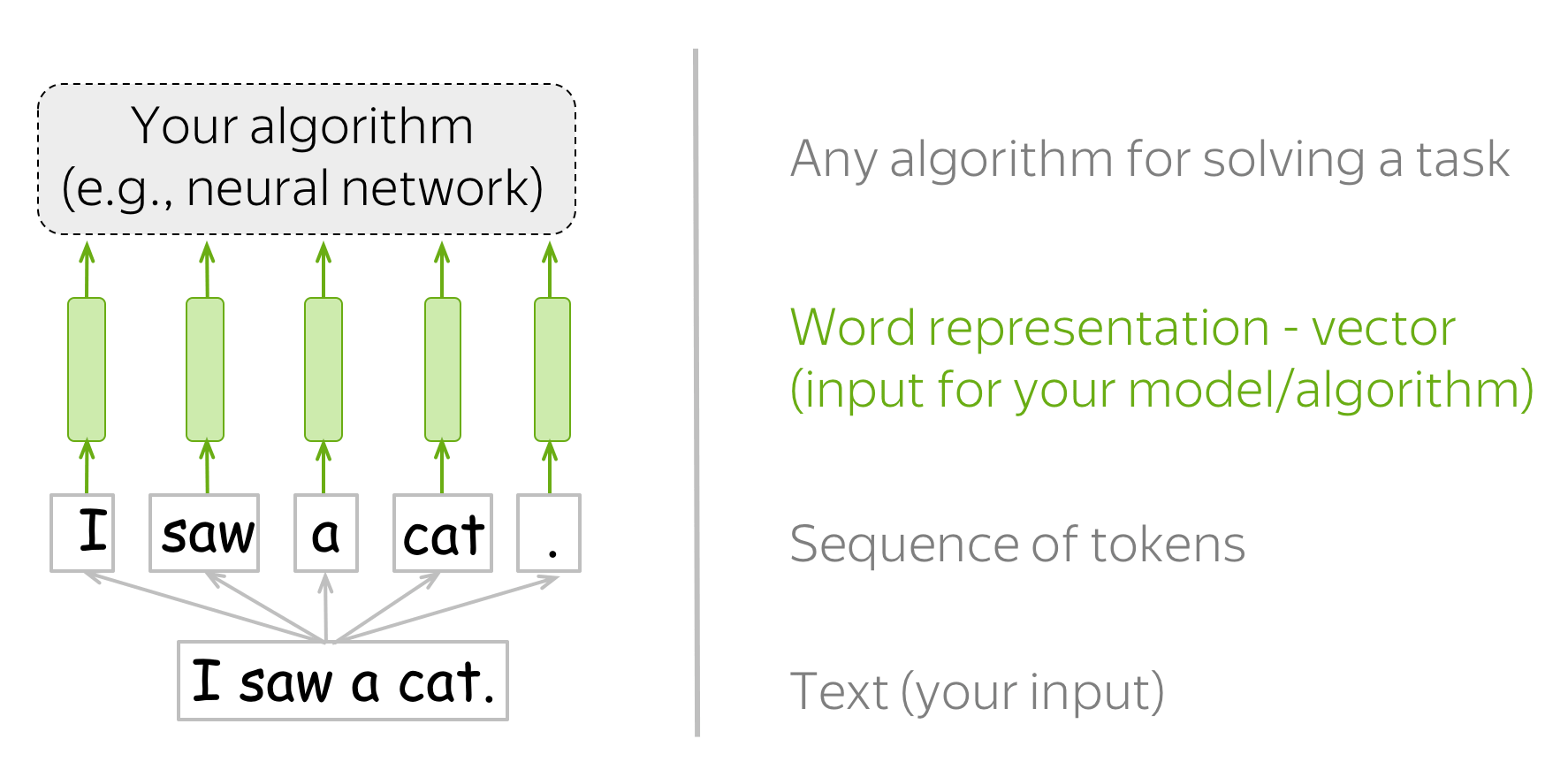
The way machine learning models «see» data is different from how we (humans) do. For example, we can easily
understand the text «I saw a cat»,
but our models can not — they need vectors of features.
Such vectors, or word embeddings, are representations of words which can be fed into your model.
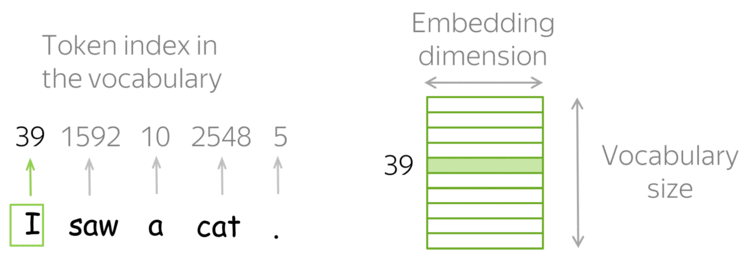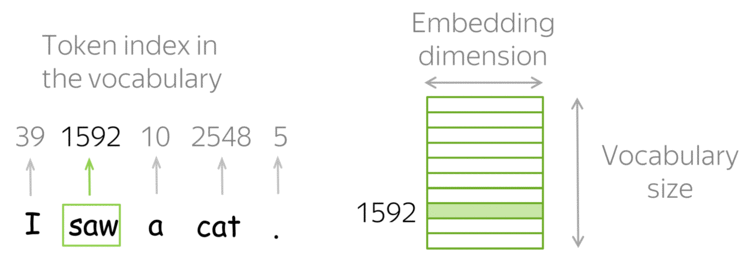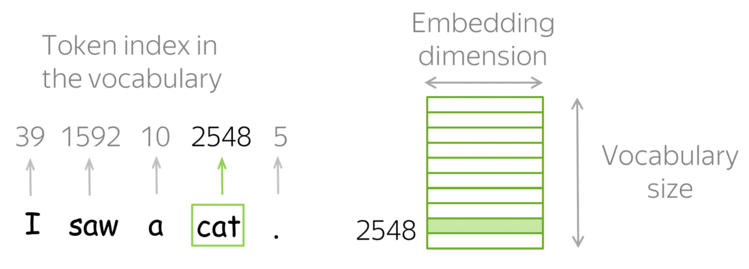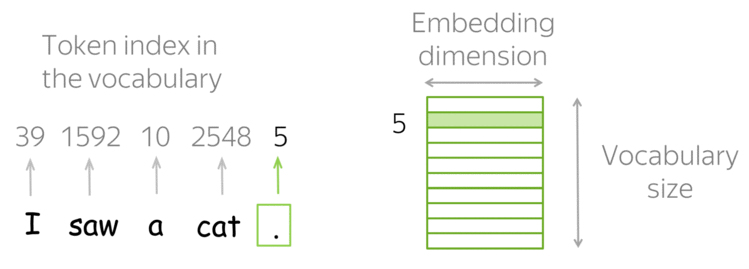
How it works: Look-up Table (Vocabulary)
In practice, you have a vocabulary of allowed words; you choose this vocabulary in advance.
For each vocabulary word, a look-up table contains its embedding. This embedding can be found
using the word index in the vocabulary (i.e., you
to look up the embedding in the table using word index).
To account for unknown words (the ones which are not in the vocabulary), usually a vocabulary
contains a special token
UNK. Alternatively, unknown tokens
can be ignored
or assigned a zero vector.
The main question of this lecture is: how do we get these word vectors?
Represent as Discrete Symbols: One-hot Vectors
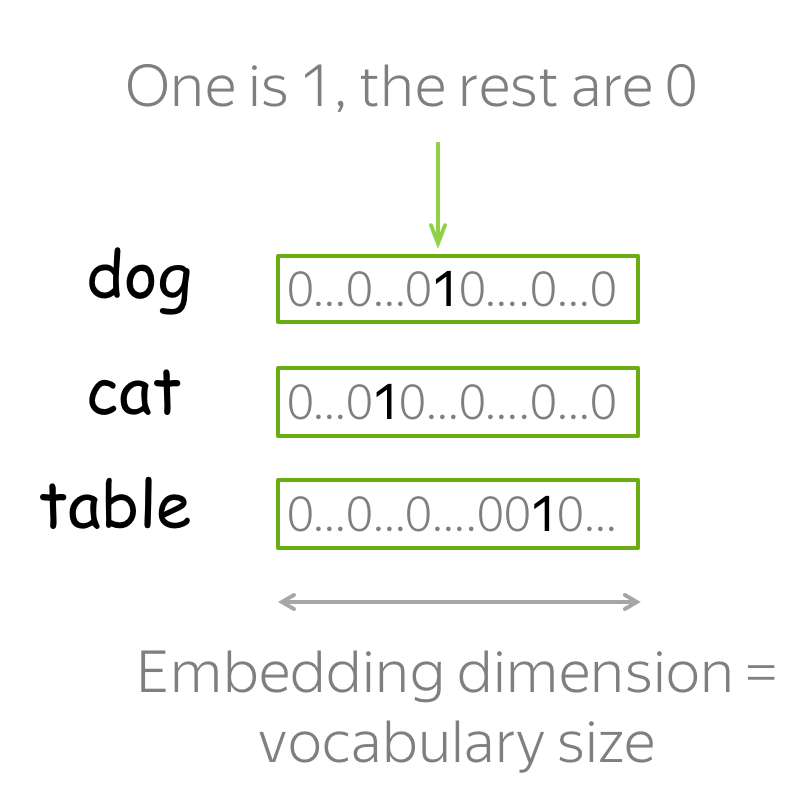
The easiest you can do is to represent words as one-hot vectors: for the i-th word in the vocabulary,
the vector has 1 on the i-th dimension and 0 on the rest. In Machine Learning, this is the most simple way to represent
categorical features.
You probably can guess why one-hot vectors are not the best way to represent words. One of the problems is that
for large vocabularies, these vectors will be very long: vector dimensionality is equal to the vocabulary size.
This is undesirable in practice, but this problem is not the most crucial one.
What is really important, is that these vectors know nothing
about the words they represent. For example, one-hot vectors «think» that
cat is as close to
dog as it is to
table!
We can say that one-hot vectors do not capture meaning.
But how do we know what is meaning?
Distributional Semantics
To capture meaning of words in their vectors, we first need to define
the notion of meaning that can be used in practice.
For this, let us try to understand how we, humans, get to know which words have similar meaning.
![]()
![]()
Once you saw how the unknown word used in different contexts,
you were able to understand it’s meaning.
How did you do this?
The hypothesis is that your brain searched for other words
that can be used in the same contexts, found some (e.g., wine), and
made a conclusion that tezgüino has meaning
similar to those other words.
This is the distributional hypothesis:
Words which frequently appear in similar contexts have
similar meaning.
Lena:
Often you can find it formulated as «You shall know a word by the company it keeps» with the reference
to J. R. Firth in 1957, but
actually there
were a lot more people
responsible, and much earlier. For example,
Harris, 1954.
This is an extremely valuable idea: it can be used in practice to make word vectors capture
their meaning. According to the distributional hypothesis, «to capture meaning» and
«to capture contexts» are inherently the same.
Therefore,
all we need to do is to put information about word
contexts into word representation.
Main idea: We need to put information about word
contexts into word representation.
All we’ll be doing at this lecture is looking at different ways to do this.
Count-Based Methods
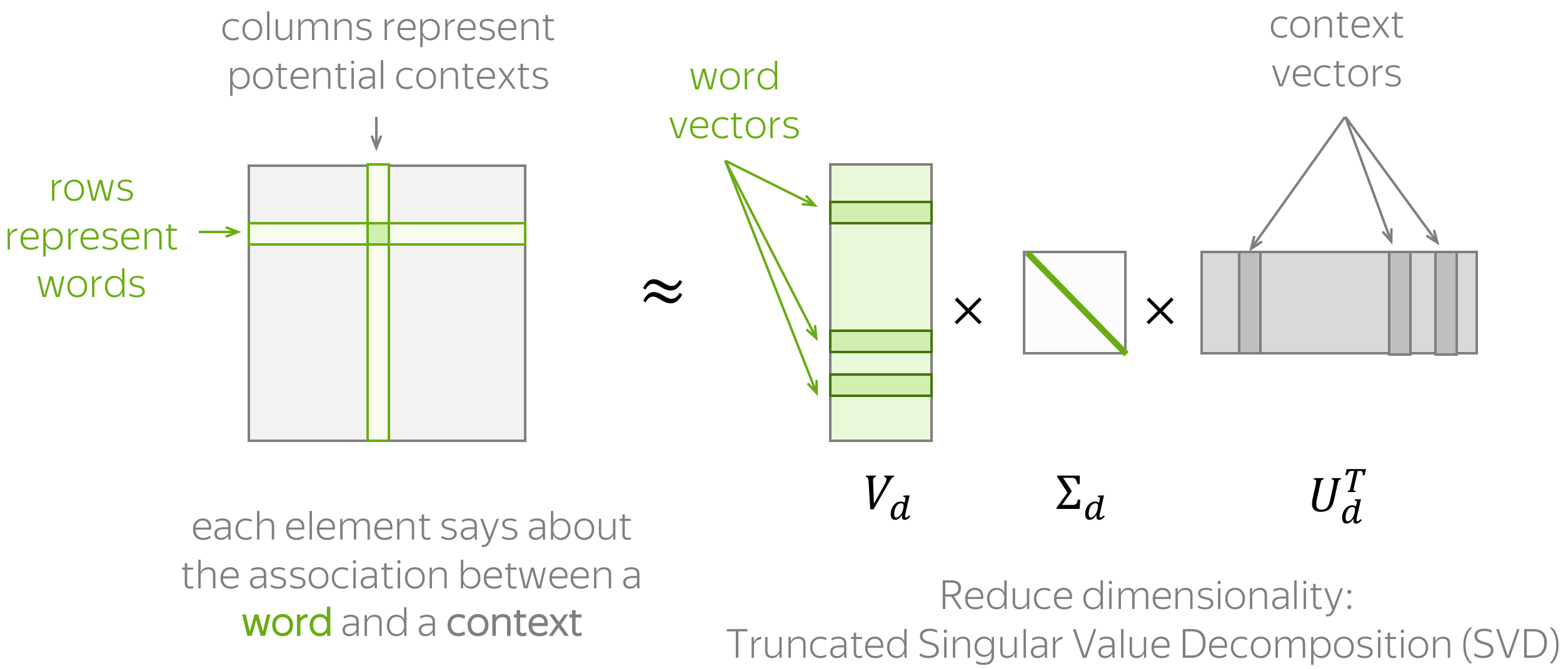
Let’s remember our main idea:
Main idea:
We have to put information about contexts into word vectors.
Count-based methods take this idea quite literally:
How:
Put this information manually based on global corpus statistics.
The general procedure is illustrated above and consists of the two steps: (1)
construct a word-context matrix, (2) reduce its dimensionality. There are two reasons to reduce dimensionality.
First, a raw matrix is very large. Second, since a lot of words appear in only a few of possible contexts,
this matrix potentially has a lot of uninformative elements (e.g., zeros).
To estimate
similarity between words/contexts, usually you need to evaluate
the dot-product of normalized word/context vectors (i.e., cosine similarity).

To define a count-based method, we need to define two things:
- possible contexts (including what does it mean that a word appears in a context),
- the notion of association, i.e., formulas for computing matrix elements.
Below we provide a couple of popular ways of doing this.
Simple: Co-Occurence Counts

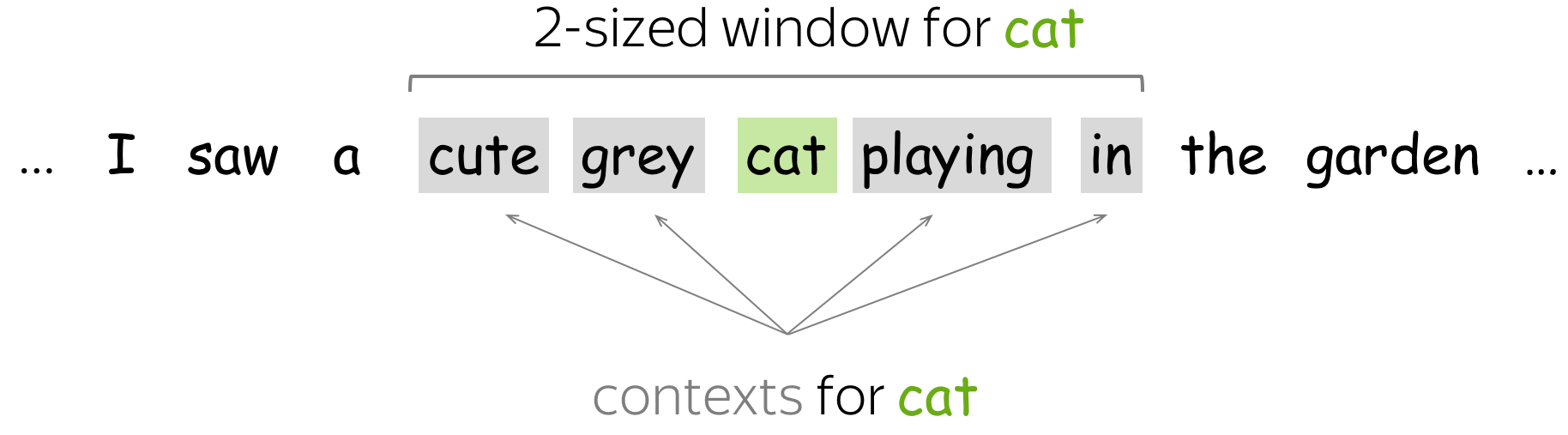
The simplest approach is to define contexts as each word in an L-sized window.
Matrix element for a word-context pair (w, c) is the number of times w appears in context c.
This is the very basic (and very, very old) method for obtaining embeddings.
![]()
The (once) famous HAL model (1996)
is also a modification of this approach.
Learn more from this exercise
in the Research Thinking section.
Positive Pointwise Mutual Information (PPMI)

Here contexts are defined as before, but the measure of
the association between word and context is more clever: positive PMI (or PPMI for short).
PPMI measure is widely regarded as state-of-the-art for pre-neural distributional-similarity models.
Important: relation to neural models!
Turns out, some of the neural methods we will consider (Word2Vec) were shown
to implicitly approximate the factorization of a (shifted) PMI matrix. Stay tuned!
Latent Semantic Analysis (LSA): Understanding Documents
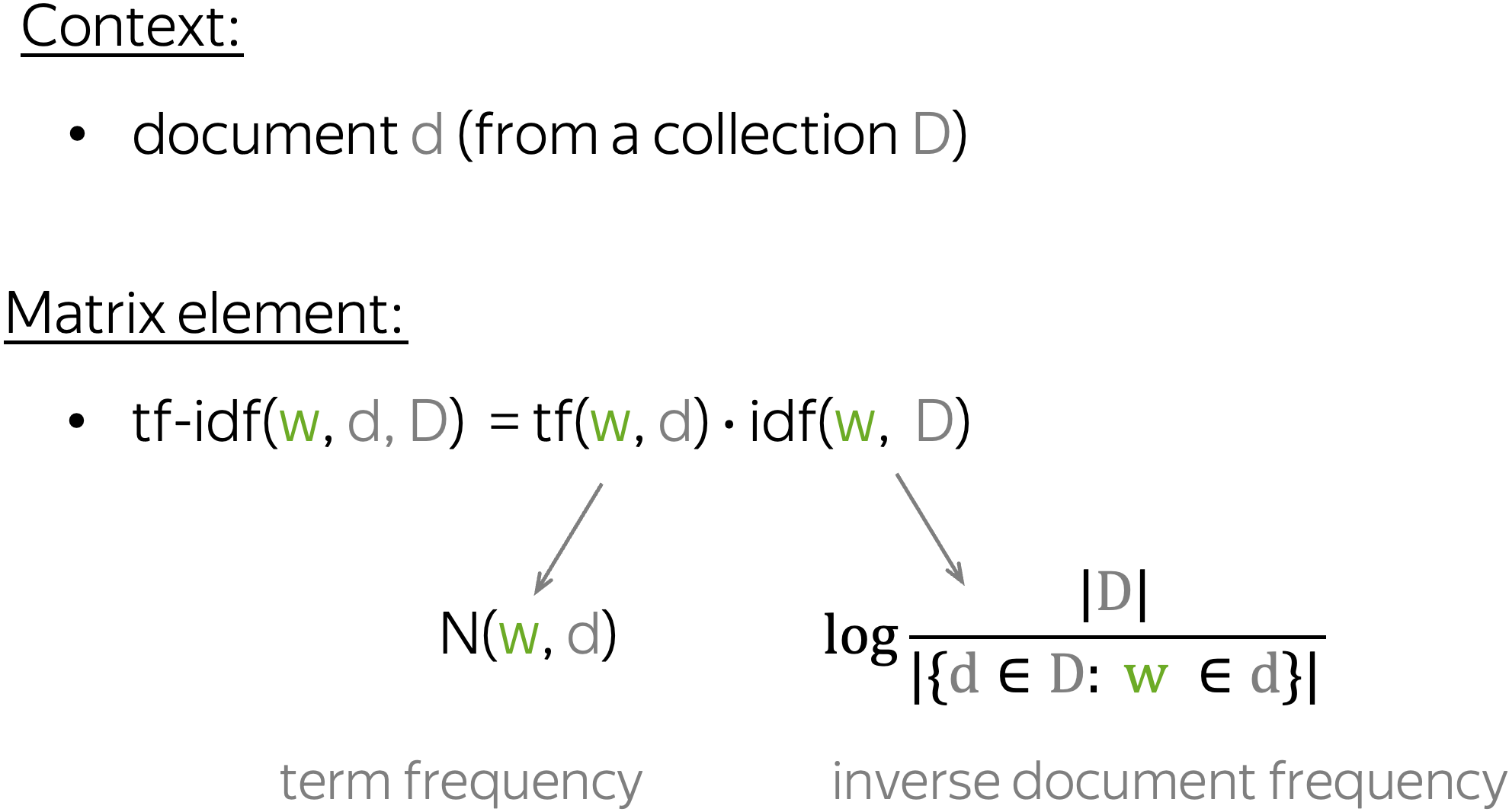
Latent Semantic Analysis (LSA) analyzes a collection of documents.
While in the previous approaches contexts served only to get word vectors
and were thrown away afterward, here we are also interested
in context, or, in this case, document vectors. LSA is one of the simplest topic models:
cosine similarity between document vectors can be used to measure similarity between documents.
The term «LSA» sometimes refers to a more general approach of applying SVD to a term-document
matrix where the term-document elements can be computed in different ways
(e.g., simple co-occurrence, tf-idf, or some other weighting).
Animation alert!
LSA wikipedia page has a nice
animation of the topic detection process in a document-word matrix — take a look!
Word2Vec: a Prediction-Based Method
Let us remember our main idea again:
Main idea:
We have to put information about contexts into word vectors.
While count-based methods took this idea quite literally, Word2Vec uses it in a different manner:
How:
Learn word vectors by teaching them to predict contexts.

Word2Vec is a model whose parameters are word vectors. These parameters are optimized iteratively
for a certain objective. The objective forces word vectors to «know» contexts a word can appear in:
the vectors are trained to predict possible contexts of the corresponding words.
As you remember from the distributional hypothesis, if vectors «know» about contexts, they «know» word meaning.
Word2Vec is an iterative method. Its main idea is as follows:
- take a huge text corpus;
- go over the text with a sliding window, moving one word at a time. At each step, there is a central word
and context words (other words in this window); - for the central word, compute probabilities of context words;
- adjust the vectors to increase these probabilities.
![]()
![]()
Objective Function: Negative Log-Likelihood
For each position (t =1, dots, T) in a text corpus,
Word2Vec predicts context words within a m-sized window given the central
word (color{#88bd33}{w_t}):
[color{#88bd33}{mbox{Likelihood}} color{black}= L(theta)=
prodlimits_{t=1}^Tprodlimits_{-mle j le m, jneq 0}P(color{#888}{w_{t+j}}|color{#88bd33}{w_t}color{black}, theta), ]
where (theta) are all variables to be optimized.
The objective function (aka loss function or
cost function) (J(theta)) is the average negative log-likelihood:
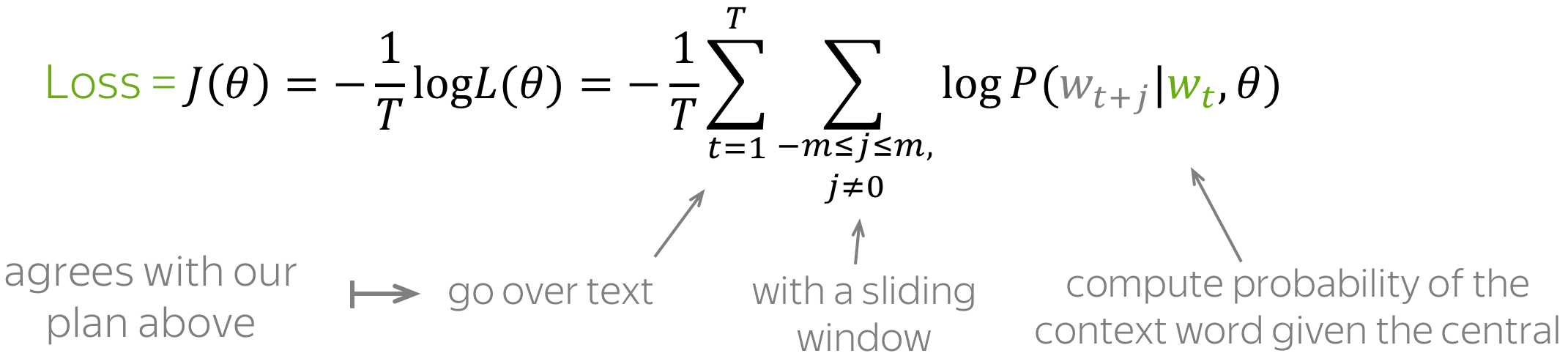
Note how well the loss agrees with our plan main above: go over text with a
sliding window and compute probabilities.
Now let’s find out how to compute these probabilities.
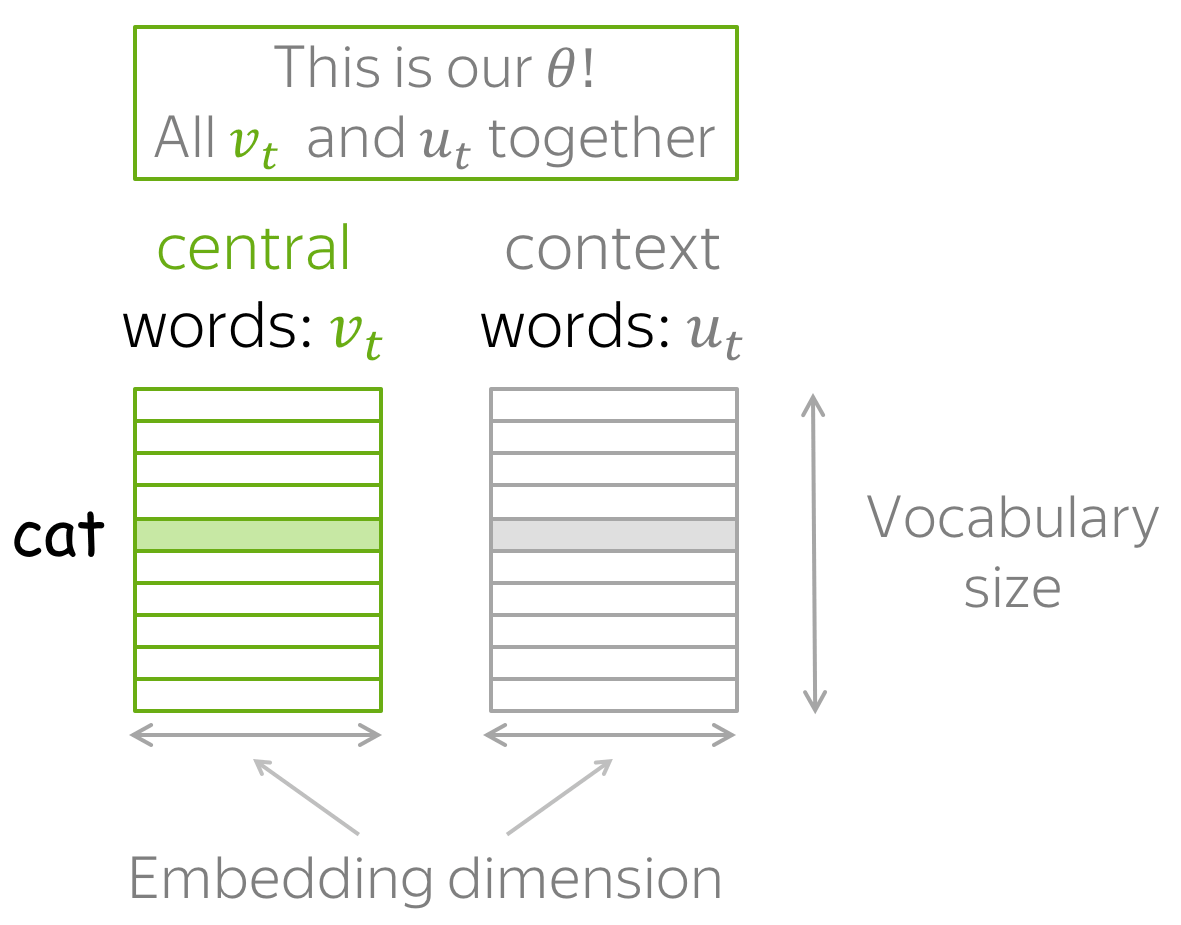
How to calculate (P(color{#888}{w_{t+j}}color{black}|color{#88bd33}{w_t}color{black}, theta))?
For each word (w) we will have two vectors:
- (color{#88bd33}{v_w}) when it is a central word;
- (color{#888}{u_w}) when it is a context word.
(Once the vectors are trained, usually we throw away context vectors and use
only word vectors.)
Then for the central word (color{#88bd33}{c}) (c — central) and
the context word (color{#888}{o}) (o — outside word)
probability of the context word is
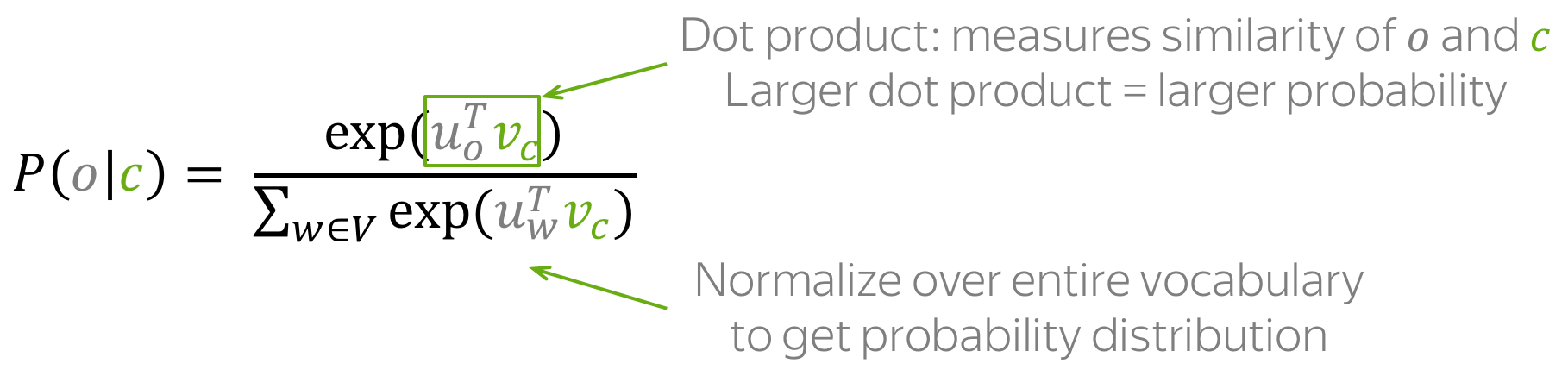
Note: this is the softmax function! (click for the details)
The function above is an example of the softmax function:
[softmax(x_i)=frac{exp(x_i)}{sumlimits_{j=i}^nexp(x_j)}.]
Softmax maps arbitrary values (x_i) to a probability
distribution (p_i):
- «max» because the largest (x_i) will have the largest probability (p_i);
- «soft» because all probabilities are non-zero.
You will deal with this function quite a lot over the NLP course (and in Deep Learning in general).
![]()
How to: go over the illustration. Note that for
central words and context words, different
vectors are used. For example, first the word a is central and
we use (color{#88bd33}{v_a}), but when it becomes context,
we use (color{#888}{u_a}) instead.
![]()
How to train: by Gradient Descent, One Word at a Time
Let us recall that our parameters (theta) are vectors (color{#88bd33}{v_w}) and (color{#888}{u_w})
for all words in the vocabulary. These vectors are learned by optimizing the training objective via gradient descent
(with some learning rate (alpha)):
[theta^{new} = theta^{old} — alpha nabla_{theta} J(theta).]
One word at a time
We make these updates one at a time: each update is for
a single pair of a center word and one of its context words.
Look again at the loss function:
[color{#88bd33}{mbox{Loss}}color{black} =J(theta)= -frac{1}{T}log L(theta)=
-frac{1}{T}sumlimits_{t=1}^T
sumlimits_{-mle j le m, jneq 0}log P(color{#888}{w_{t+j}}color{black}|color{#88bd33}{w_t}color{black}, theta)=
frac{1}{T} sumlimits_{t=1}^T
sumlimits_{-mle j le m, jneq 0} J_{t,j}(theta). ]
For the center word (color{#88bd33}{w_t}), the loss contains a distinct term
(J_{t,j}(theta)=-log P(color{#888}{w_{t+j}}color{black}|color{#88bd33}{w_t}color{black}, theta)) for each of its context words
(color{#888}{w_{t+j}}).
Let us look in more detail at just this one term and try to understand how to make an update for this step. For example,
let’s imagine we have a sentence

with the central word cat,
and four context words.
Since we are going to look at just one step, we will pick only one of the context words; for example, let’s take
cute.
Then
the loss term for the central word cat
and the context word cute is:
[ J_{t,j}(theta)= -log P(color{#888}{cute}color{black}|color{#88bd33}{cat}color{black}) =
-log frac{expcolor{#888}{u_{cute}^T}color{#88bd33}{v_{cat}}}{
sumlimits_{win Voc}exp{color{#888}{u_w^T}color{#88bd33}{v_{cat}} }} =
-color{#888}{u_{cute}^T}color{#88bd33}{v_{cat}}color{black}
+ log sumlimits_{win Voc}exp{color{#888}{u_w^T}color{#88bd33}{v_{cat}}}color{black}{.}
]
Note which parameters are present at this step:
- from vectors for central words, only (color{#88bd33}{v_{cat}});
- from vectors for context words, all (color{#888}{u_w}) (for all words in
the vocabulary).
Only these parameters will be updated at the current step.
Below is the schematic illustration of
the derivations for this step.
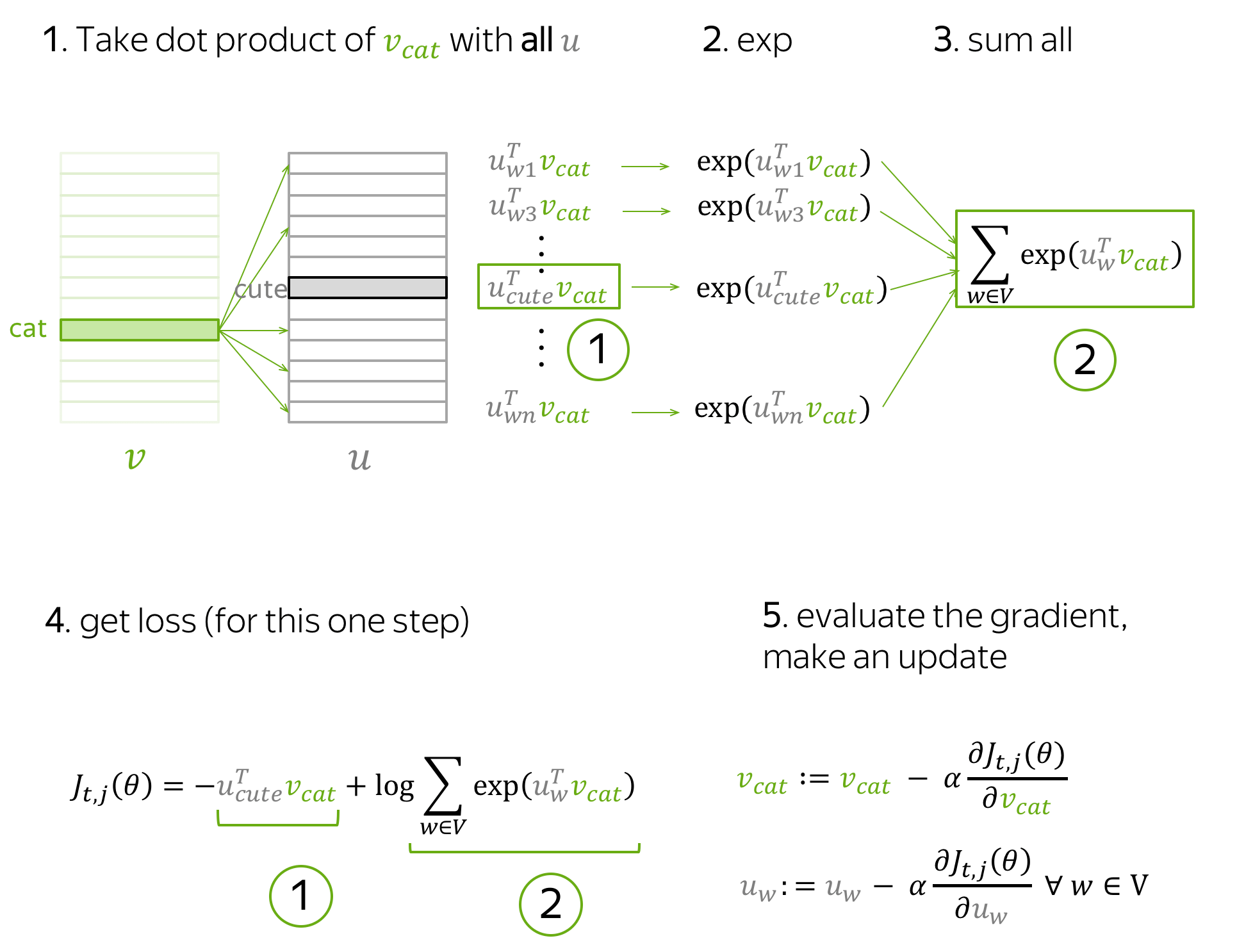
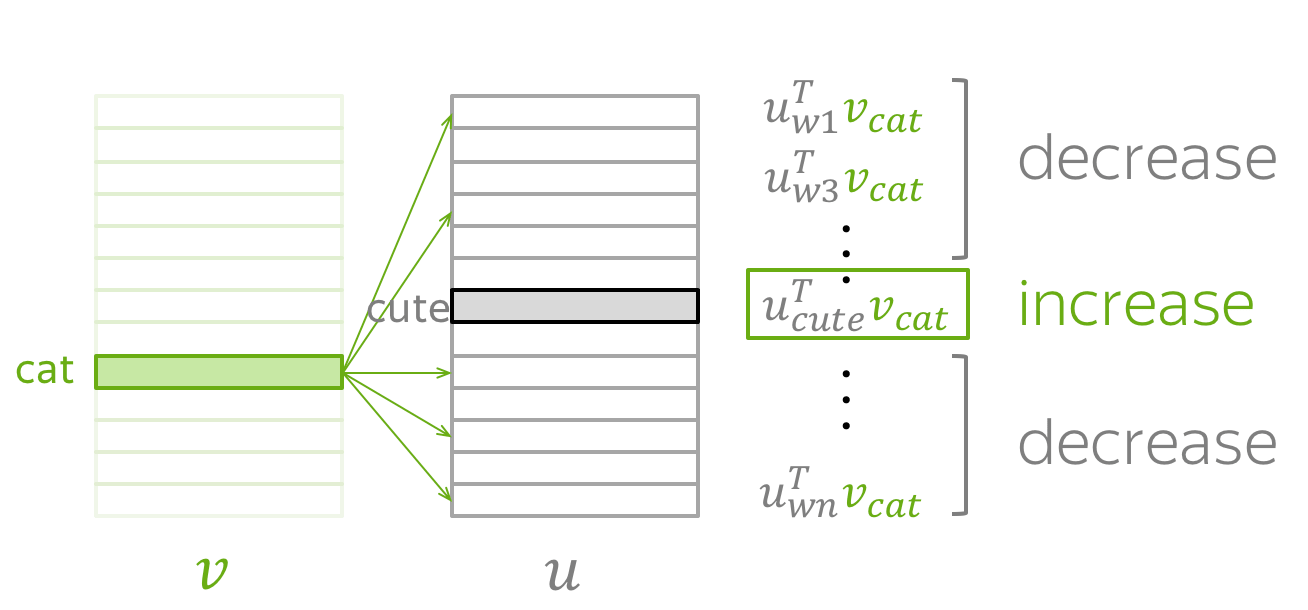
By making an update to minimize (J_{t,j}(theta)), we force the parameters to
increase similarity (dot product)
of (color{#88bd33}{v_{cat}}) and (color{#888}{u_{cute}}) and, at the same time,
to decrease
similarity between (color{#88bd33}{v_{cat}}) and (color{#888}{u_{w}}) for all other words (w) in the vocabulary.
This may sound a bit strange: why do we want to decrease similarity between (color{#88bd33}{v_{cat}})
and all other words, if some of them are also valid context words (e.g.,
grey,
playing,
in on our example sentence)?
But do not worry: since we make updates for each context word (and for all central words in your text),
on average over all updates
our vectors will learn
the distribution of the possible contexts.
Faster Training: Negative Sampling
In the example above, for each pair of a central word and its context word, we had to update all vectors
for context words. This is highly inefficient: for each step, the time needed to make an update is proportional
to the vocabulary size.
But why do we have to consider all context vectors in the vocabulary at each step?
For example, imagine that at the current step we consider context vectors not for all words,
but only for the current target (cute)
and several randomly chosen words. The figure shows the intuition.
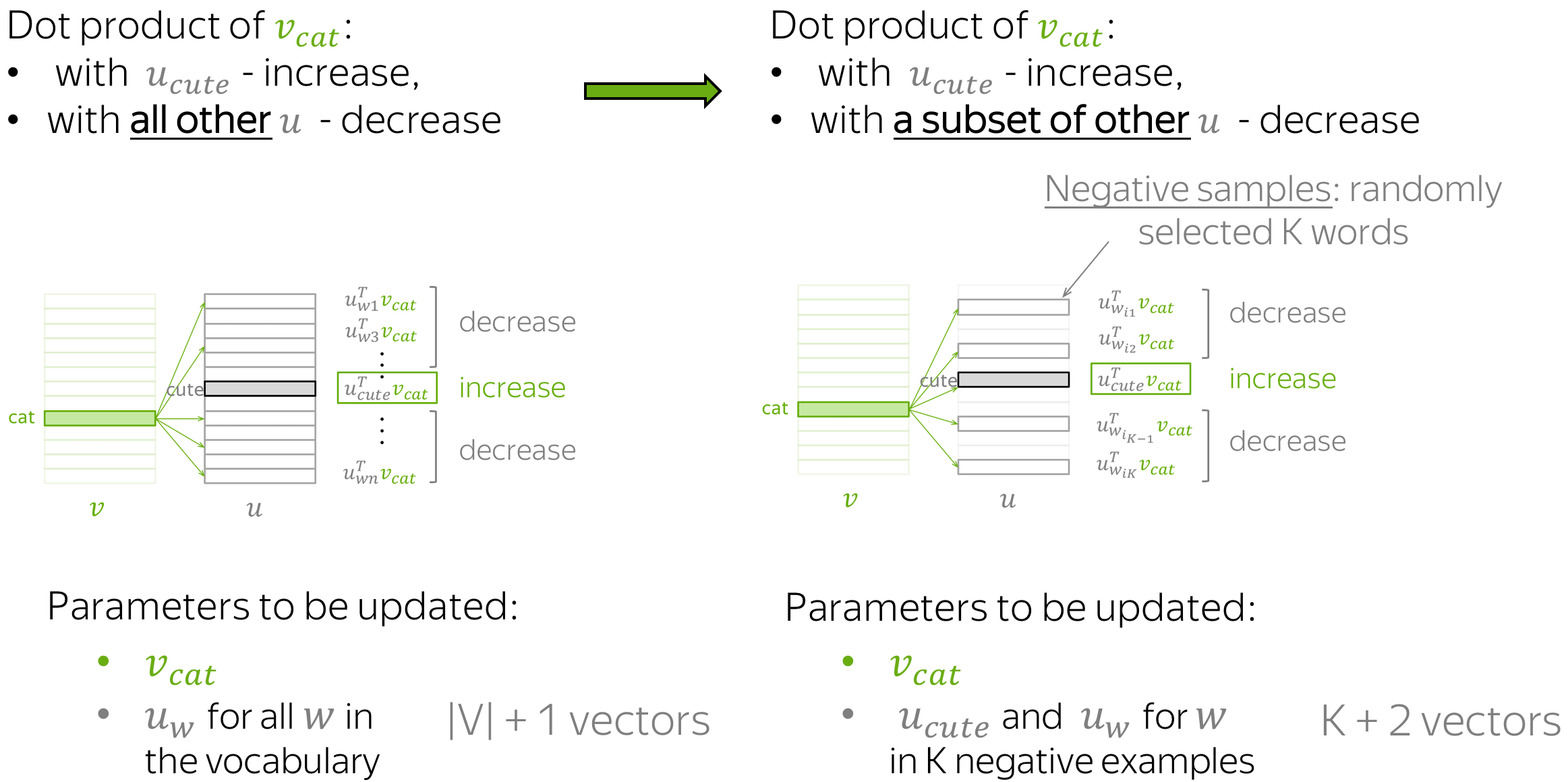
As before, we are increasing similarity between
(color{#88bd33}{v_{cat}}) and (color{#888}{u_{cute}}). What is different, is that now we
decrease similarity between (color{#88bd33}{v_{cat}}) and context vectors not for all words, but only
with a subset of K «negative» examples.
Since we have a large corpus, on average over all updates we will update each vector sufficient number of times,
and the vectors will still be able to learn the relationships between words quite well.
Formally, the new loss function for this step is:
[ J_{t,j}(theta)=
-logsigma(color{#888}{u_{cute}^T}color{#88bd33}{v_{cat}}color{black}) —
sumlimits_{win {w_{i_1},dots, w_{i_K}}}logsigma({-color{#888}{u_w^T}color{#88bd33}{v_{cat}}}color{black}),
]
where (w_{i_1},dots, w_{i_K}) are the K negative examples chosen at this step
and (sigma(x)=frac{1}{1+e^{-x}}) is the sigmoid function.
Note that
(sigma(-x)=frac{1}{1+e^{x}}=frac{1cdot e^{-x}}{(1+e^{x})cdot e^{-x}} =
frac{e^{-x}}{1+e^{-x}}= 1- frac{1}{1+e^{x}}=1-sigma(x)). Then the loss can also be written as:
[ J_{t,j}(theta)=
-logsigma(color{#888}{u_{cute}^T}color{#88bd33}{v_{cat}}color{black}) —
sumlimits_{win {w_{i_1},dots, w_{i_K}}}log(1-sigma({color{#888}{u_w^T}color{#88bd33}{v_{cat}}}color{black})).
]
![]()
How the gradients and updates change when using negative sampling?
The Choice of Negative Examples
Each word has only a few «true» contexts. Therefore, randomly chosen words are very likely to be «negative», i.e. not
true contexts. This simple idea is used not only to train Word2Vec efficiently but also in many other
applications, some of which we will see later in the course.
Word2Vec randomly samples negative examples based on the empirical distribution of words.
Let (U(w)) be a unigram distribution of words, i.e. (U(w)) is the frequency of the word (w)
in the text corpus. Word2Vec modifies this distribution to sample less frequent words more often:
it samples proportionally to (U^{3/4}(w)).
Word2Vec variants: Skip-Gram and CBOW
There are two Word2Vec variants: Skip-Gram and CBOW.
Skip-Gram is the model we considered so far: it predicts context words given the central word.
Skip-Gram with negative sampling is the most popular approach.
CBOW (Continuous Bag-of-Words) predicts the central word from the sum of context vectors. This simple sum of
word vectors is called «bag of words», which gives the name for the model.
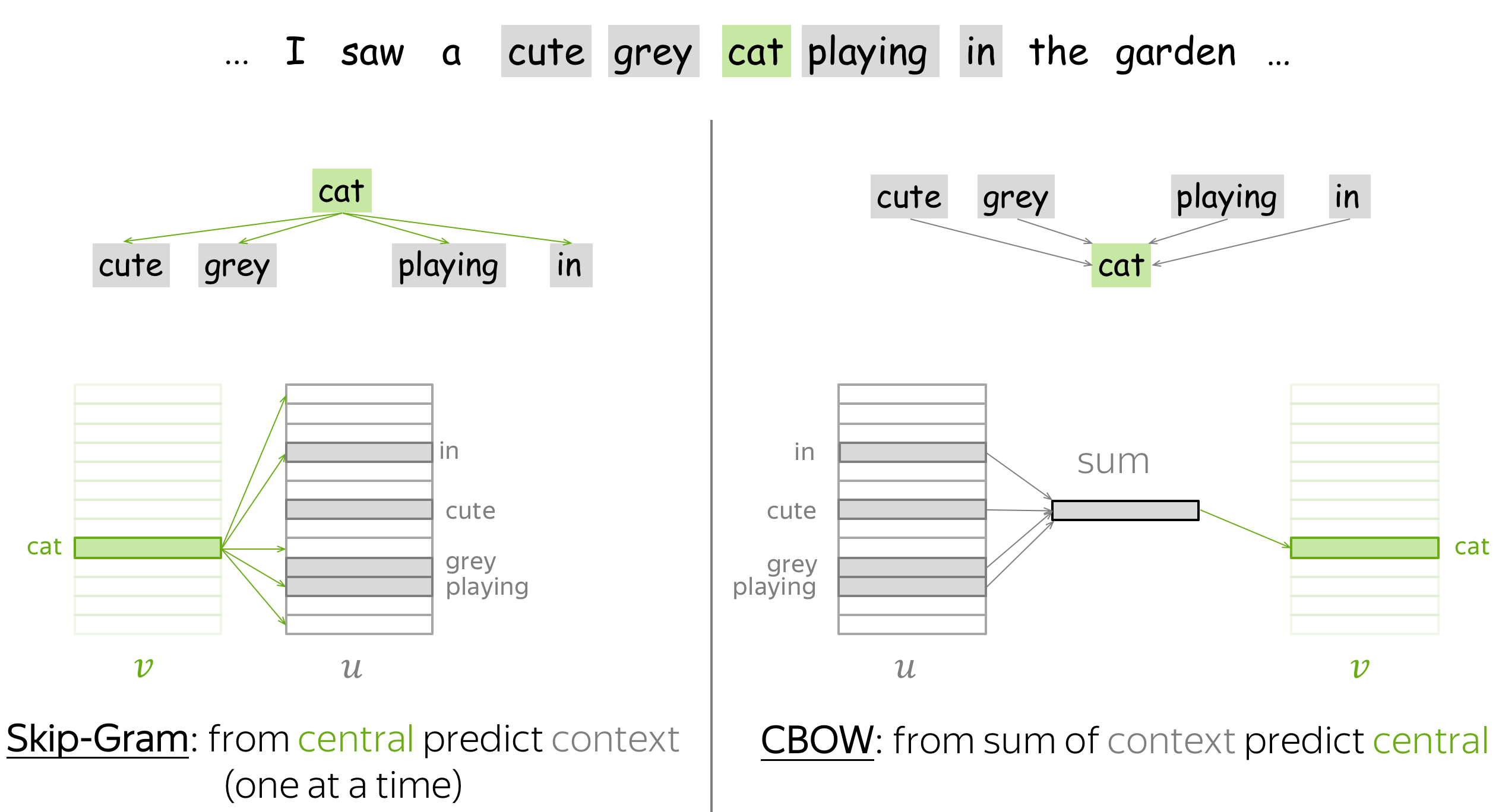
Additional Notes
The original Word2Vec papers are:
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Words and Phrases and their Compositionality
You can look into them for the details on the experiments, implementation and hyperparameters. Here we will
provide some of the most important things you need to know.
The Idea is Not New
The idea to learn word vectors (distributed representations) is not new. For example, there were attempts to
learn word vectors as part of a larger network and then extract the embedding layer. (For the details on the
previous methods, you can look, for example, at the summary in the original Word2Vec papers).
What was very unexpected in Word2Vec, is its ability to learn high-quality word vectors
very fast on huge datasets and for
large vocabularies. And of course, all the fun properties we will see in the
Analysis and Interpretability section quickly made Word2Vec very famous.
Why Two Vectors?
As you remember, in Word2Vec we train two vectors for each word: one when it is a central word and another
when it is a context word. After training, context vectors are thrown away.
This is one of the tricks that made Word2Vec so simple. Look again at the loss function (for one step):
[ J_{t,j}(theta)=
-color{#888}{u_{cute}^T}color{#88bd33}{v_{cat}}color{black} —
log sumlimits_{win V}exp{color{#888}{u_w^T}color{#88bd33}{v_{cat}}}color{black}{.}
]
When central and context words have different vectors, both the first term and dot products inside the exponents
are linear with respect to the parameters (the same for the negative training objective).
Therefore, the gradients are easy to compute.
![]()
Repeat the derivations (loss and the gradients) for the case with one vector for each word
((forall w in V, color{#88bd33}{v_{w}}color{black}{ = }color{#888}{u_{w}}) ).
![]()
While the standard practice is to throw away context vectors, it was shown that
averaging word and context vectors may be more beneficial.
More details are here.
Better training
![]()
There’s one more trick: learn more from this exercise
in the Research Thinking section.
Relation to PMI Matrix Factorization
![]()
Word2Vec SGNS (Skip-Gram with Negative Sampling)
implicitly approximates the factorization of a (shifted) PMI matrix.
Learn more here.
The Effect of Window Size
The size of the sliding window has a strong effect on the resulting
vector similarities.
For example, this paper notes that
larger windows tend to produce more topical similarities
(i.e. dog,
bark and
leash will be grouped together,
as well as
walked,
run and
walking),
while smaller windows tend to produce more functional and syntactic similarities
(i.e. Poodle,
Pitbull,
Rottweiler, or
walking,
running,
approaching).
(Somewhat) Standard Hyperparameters
As always, the choice of hyperparameters usually depends on the task at hand;
you can look at the original papers for more details.
Somewhat standard setting is:
- Model: Skip-Gram with negative sampling;
- Number of negative examples: for smaller datasets, 15-20; for huge datasets
(which are usually used) it can be 2-5. - Embedding dimensionality: frequently used value is 300, but other
variants (e.g., 100 or 50) are also possible. For theoretical explanation of the optimal dimensionality,
take a look at the Related Papers section. - Sliding window (context) size: 5-10.
GloVe: Global Vectors for Word Representation
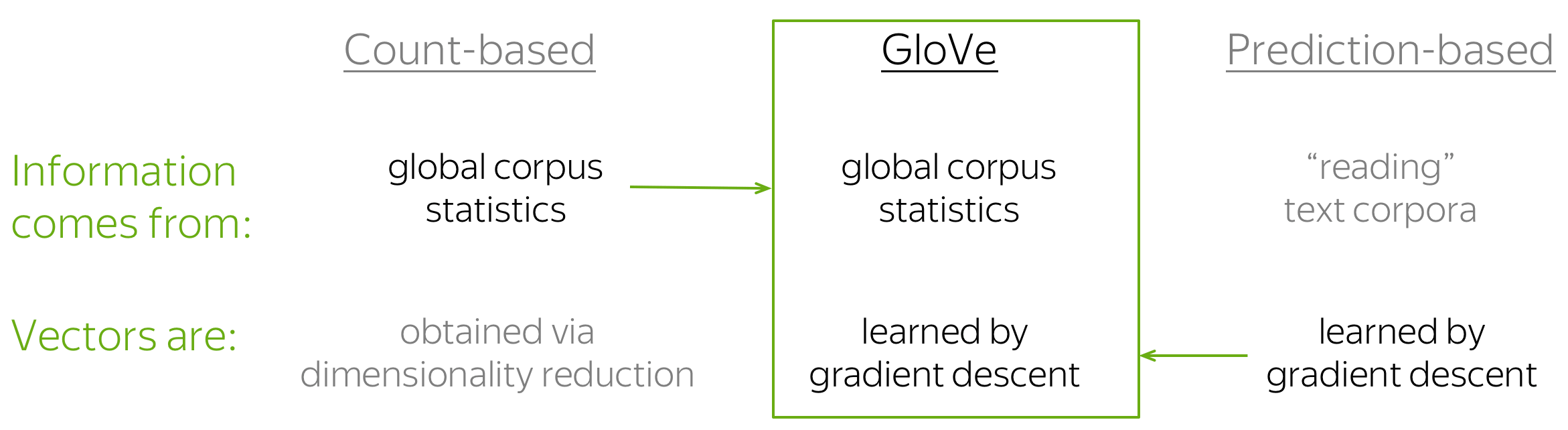
The GloVe model is a combination of
count-based methods and prediction methods (e.g., Word2Vec). Model name, GloVe, stands
for «Global Vectors», which reflects its idea: the method uses
global information from corpus to learn vectors.
As we saw earlier, the simplest count-based method uses
co-occurrence counts to measure the association between word
w
and context c:
N(w, c).
GloVe also uses these counts to construct the loss function:
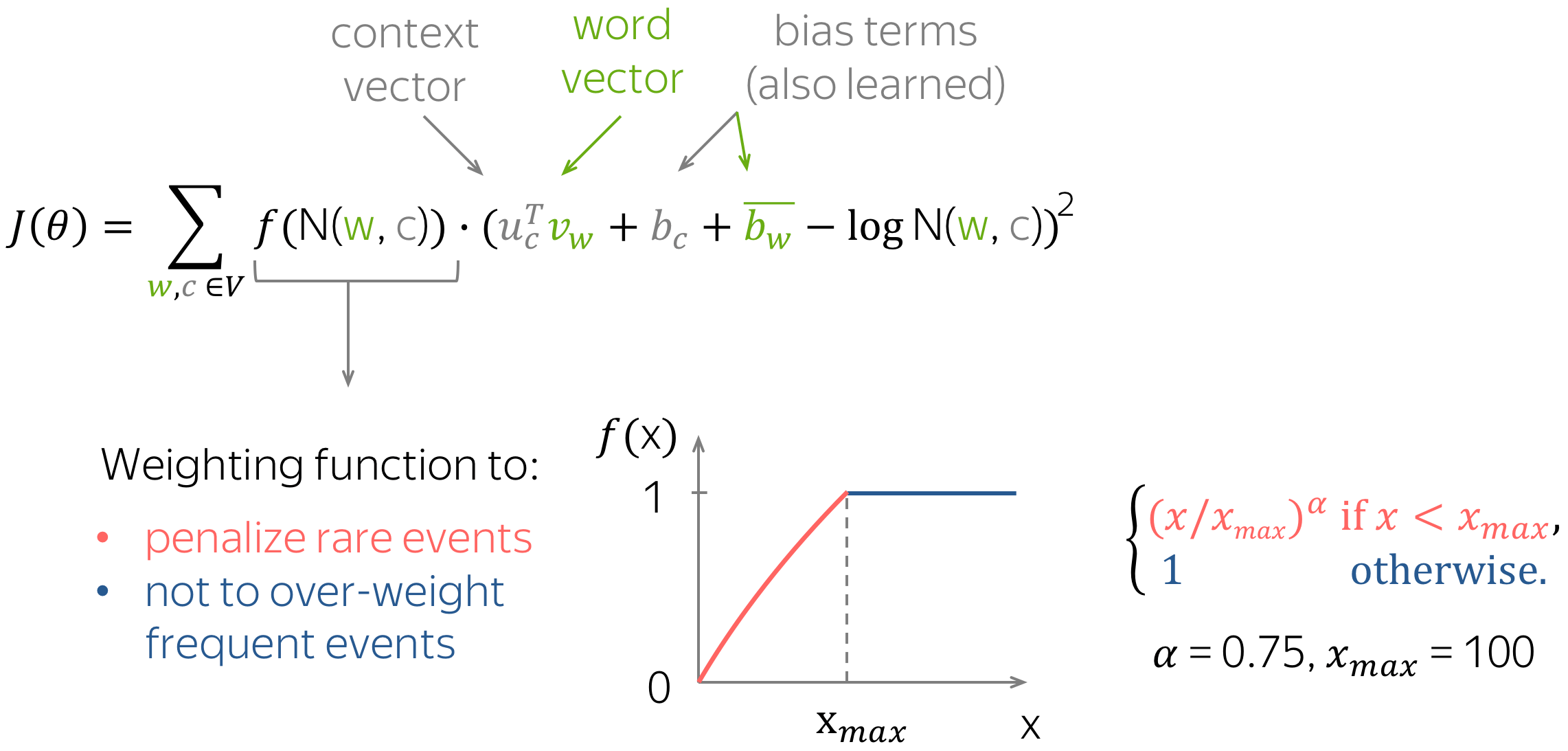
Similar to Word2Vec, we also have different vectors for
central and context words — these are our parameters.
Additionally, the method has a scalar bias term for each word vector.
What is especially interesting, is the way GloVe controls the influence of rare and frequent words:
loss for each pair (w, c) is weighted in a way that
- rare events are penalized,
- very frequent events are not over-weighted.
Lena:
The loss function looks reasonable as it is, but
the original GloVe paper
has very nice motivation leading to the above formula. I will not provide it here
(I have to finish the lecture at some point, right?..), but
you can read it yourself — it’s really, really nice!
Evaluation of Word Embeddings
How can we understand that one method for getting word embeddings is better than another?
There are two types of evaluation (not only for word embeddings): intrinsic and extrinsic.
Intrinsic Evaluation: Based on Internal Properties

This type of evaluation looks at the internal properties of embeddings, i.e.
how well they capture meaning. Specifically, in the
Analysis and Interpretability section,
we will discuss in detail how we can evaluate embeddings on word similarity and word analogy tasks.
Extrinsic Evaluation: On a Real Task
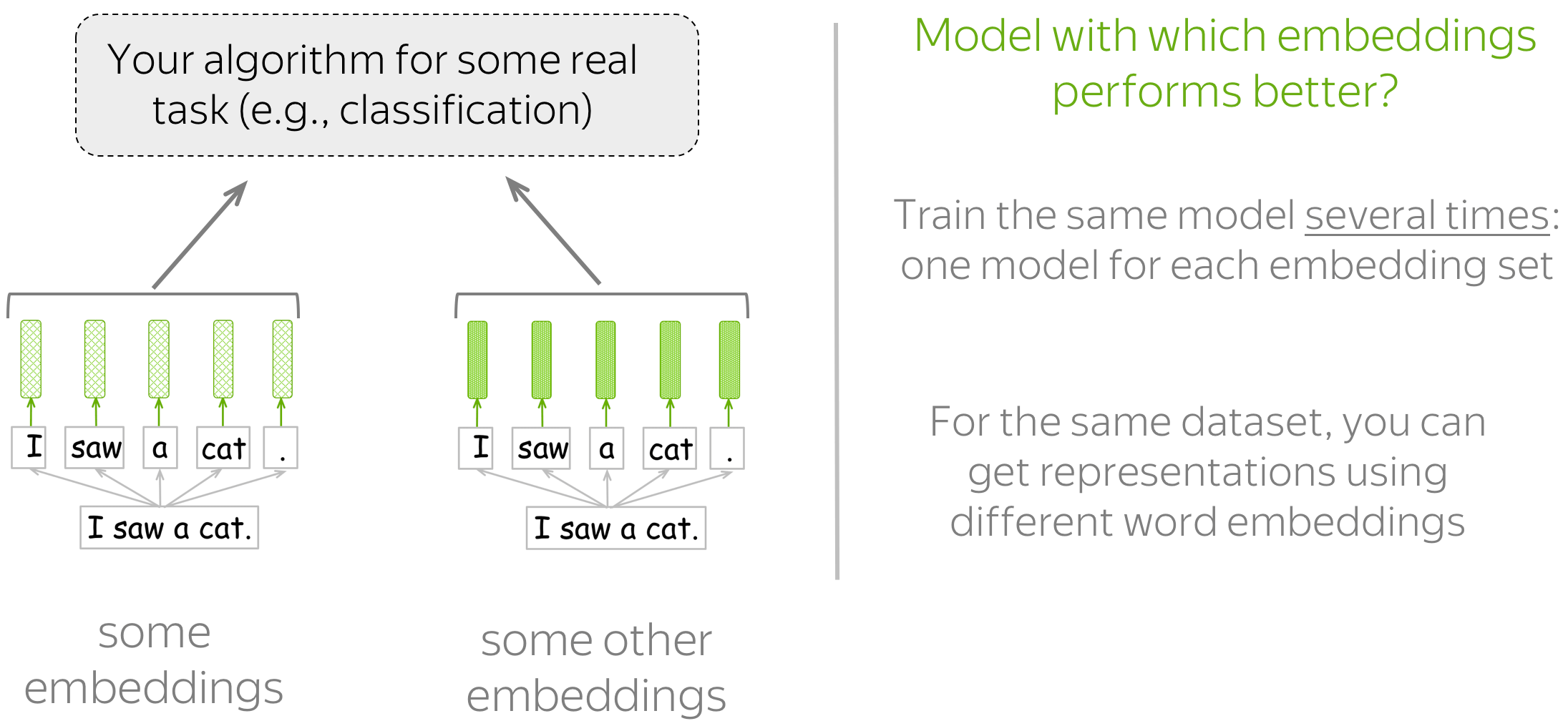
This type of evaluation tells which embeddings are better for the task you really care about (e.g.,
text classification, coreference resolution, etc.).
In this setting, you have to train the model/algorithm for the real task several times: one model for each of the
embeddings you want to evaluate. Then, look at the quality of these models to decide which
embeddings are better.
How to Choose?

One thing you have to get used to is that there is no perfect solution and no right answer
for all situations: it always depends on many things.
Regarding evaluation, you usually care about quality of the task you want to solve. Therefore,
you are likely to be more interested in extrinsic evaluation. However, real-task models
usually require a lot of time and resources to train, and training several of them may
be too expensive.
In the end, this is your call to make 
![]()
Analysis and Interpretability
Lena: For word embeddings, most of the content of
this part is usually considered as evaluation (intrinsic evaluation). However,
since looking at what a model learned (beyond task-specific metrics) is the kind of thing
people usually do for analysis, I believe it can be presented here, in the analysis section.
Take a Walk Through Space… Semantic Space!
Semantic spaces aim to create representations of natural language that capture meaning.
We can say that (good) word embeddings form semantic space and will refer to
a set of word vectors in a multi-dimensional space as «semantic space».
Below is shown semantic space formed by GloVe vectors trained on twitter data (taken from
gensim). Vectors were
projected to two-dimensional space using t-SNE; these are only the top-3k most frequent words.
![]()
How to: Walk through semantic space and try to find:
- language clusters: Spanish, Arabic, Russian, English. Can you find more languages?
- clusters for: food, family, names, geographical locations. What else can you find?
![]()
Nearest Neighbors

The example is
from the GloVe project page.
During your walk through semantic space, you probably noticed that the points (vectors) which are nearby
usually have close meaning. Sometimes, even rare words are understood very well. Look at the example:
the model understood that words such as leptodactylidae
or litoria are close to
frog.
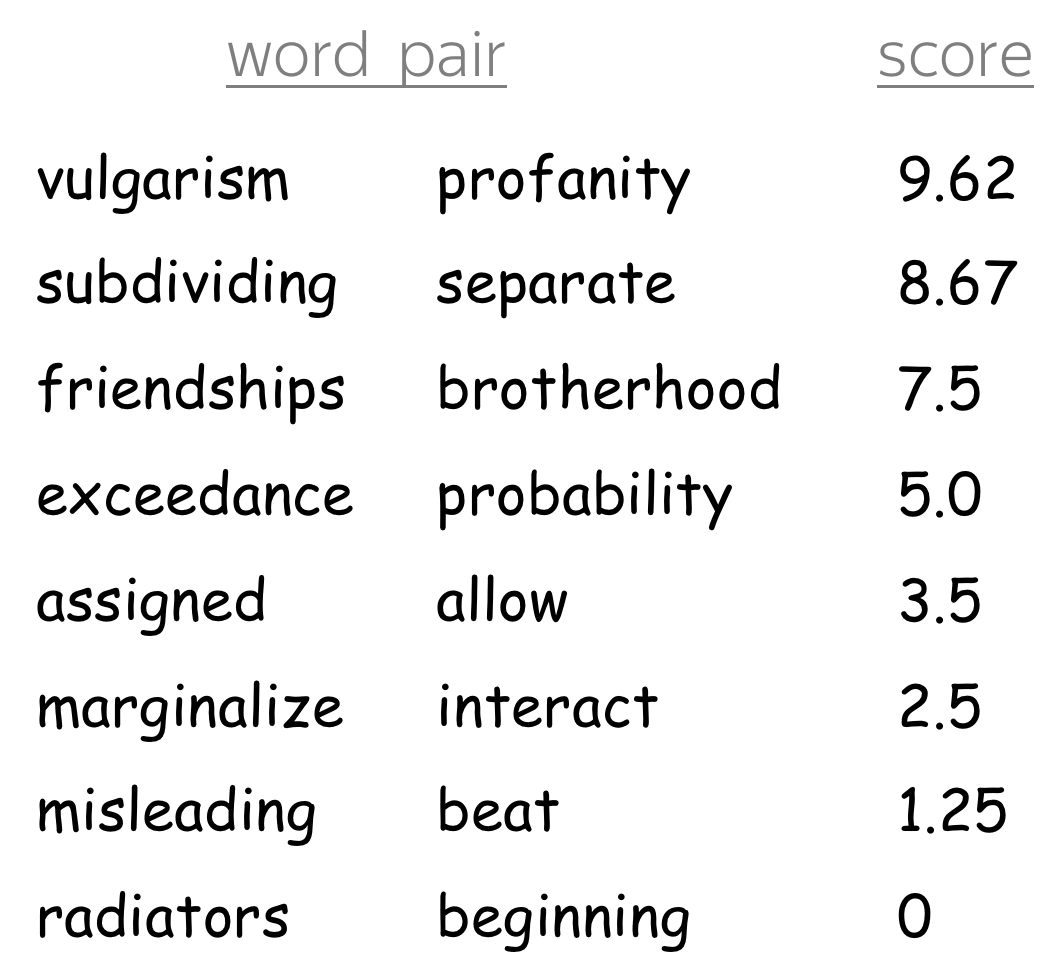
Several pairs from the
Rare Words similarity benchmark.
Word Similarity Benchmarks
«Looking» at nearest neighbors (by cosine similarity or Euclidean distance) is one of the
methods to estimate the quality of the learned embeddings. There are several
word similarity benchmarks (test sets). They consist
of word pairs with a similarity score according to human judgments.
The quality of embeddings is estimated as
the correlation between the two similarity scores (from model and from humans).
Linear Structure
While similarity results are encouraging, they are not surprising: all in all,
the embeddings were trained specifically to reflect word similarity.
What is surprising, is that many semantic and syntactic relationships between words
are (almost) linear in word vector space.
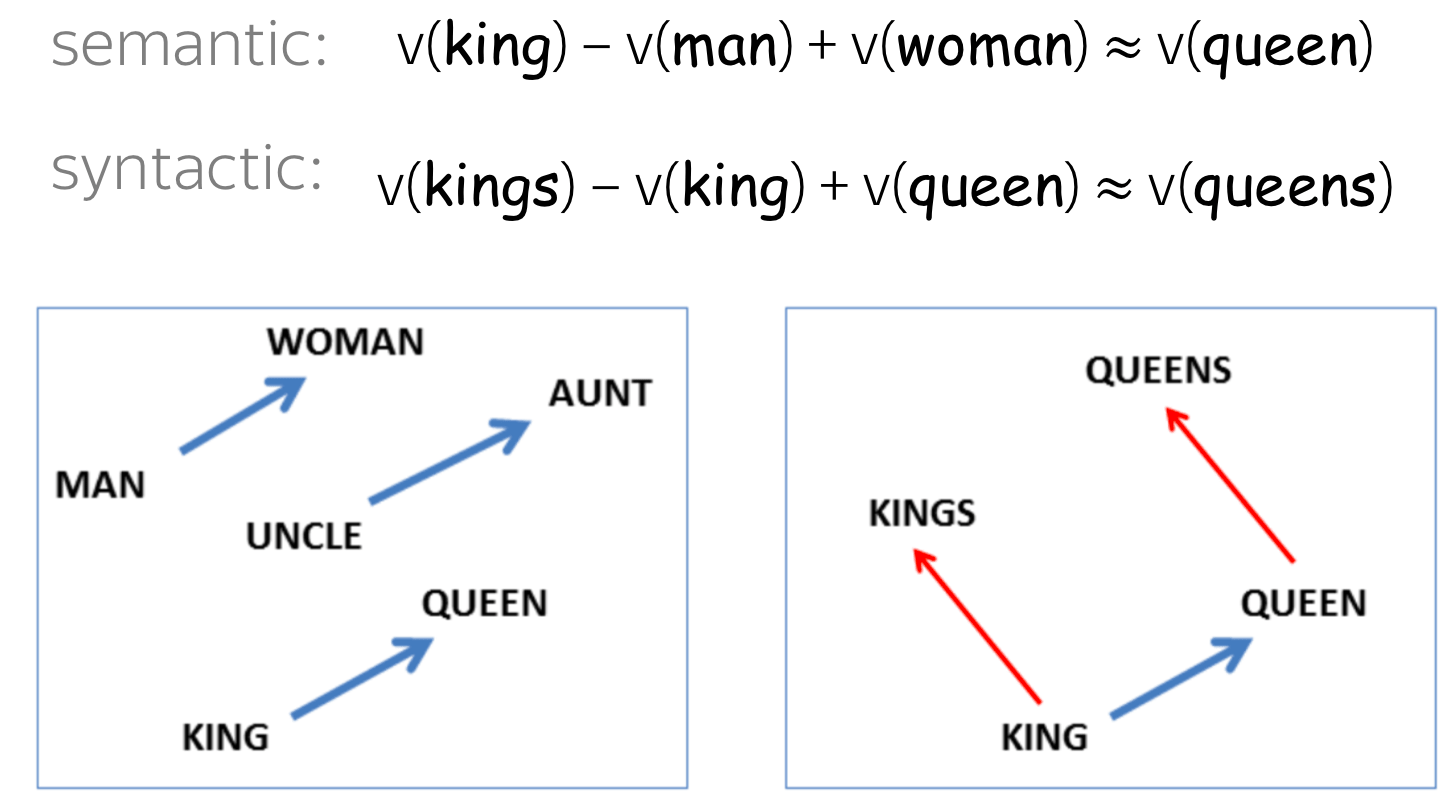
For example, the difference between
king and
queen
is (almost) the same as between
man
and woman.
Or a word that is similar to
queen
in the same sense that
kings is similar to
king turns out to be
queens.
The
man-woman (approx)
king-queen example
is probably the most popular one, but there are also many other relations and funny examples.
Below are examples for the country-capital relation
and a couple of syntactic relations.
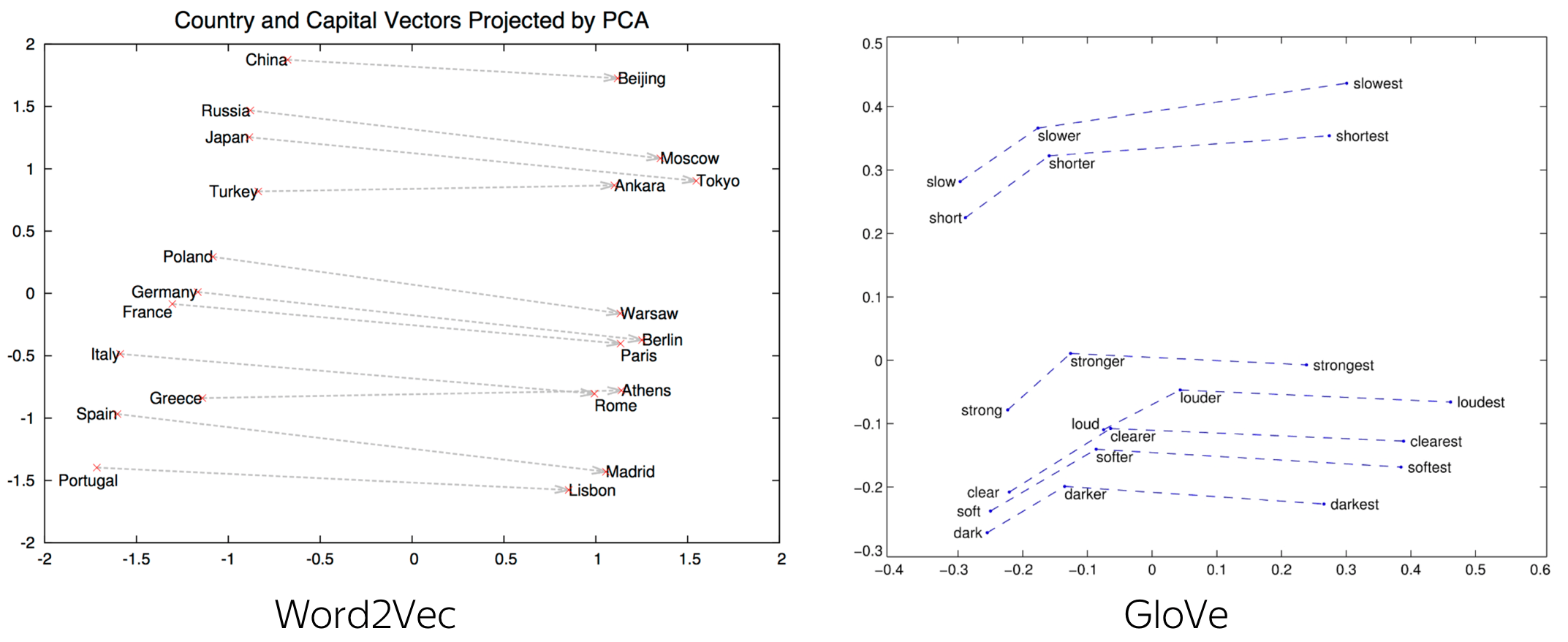
![]()
At ICML 2019, it was shown that there’s actually a theoretical explanation for
analogies in Word2Vec.
More details are here.
Lena: This paper,
Analogies Explained: Towards Understanding Word Embeddings
by Carl Allen and Timothy Hospedales from the University of Edinburgh, received
Best Paper Honourable Mention award at ICML 2019 — well deserved!
Word Analogy Benchmarks
These near-linear relationships inspired a new type of evaluation:
word analogy evaluation.
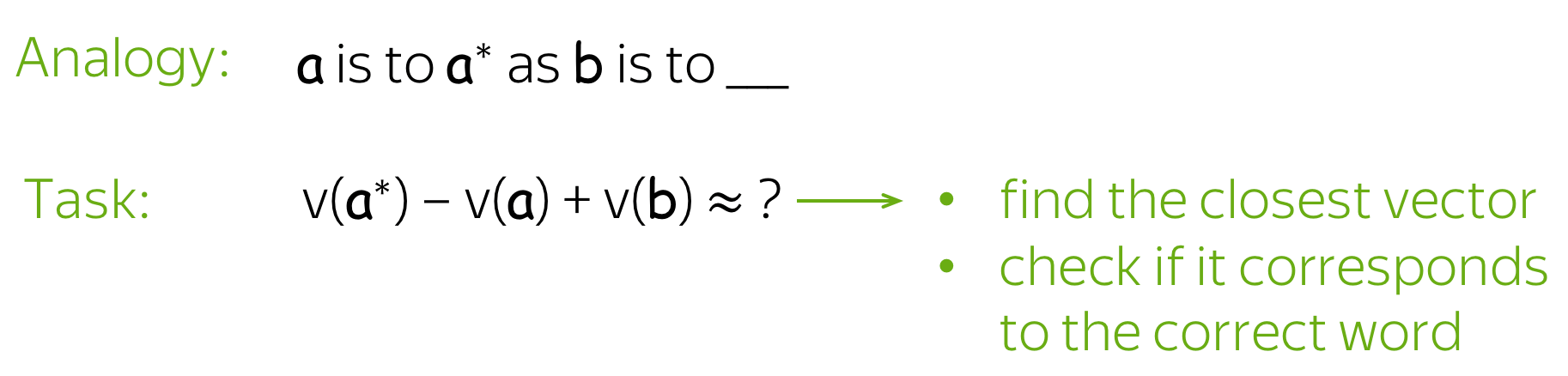
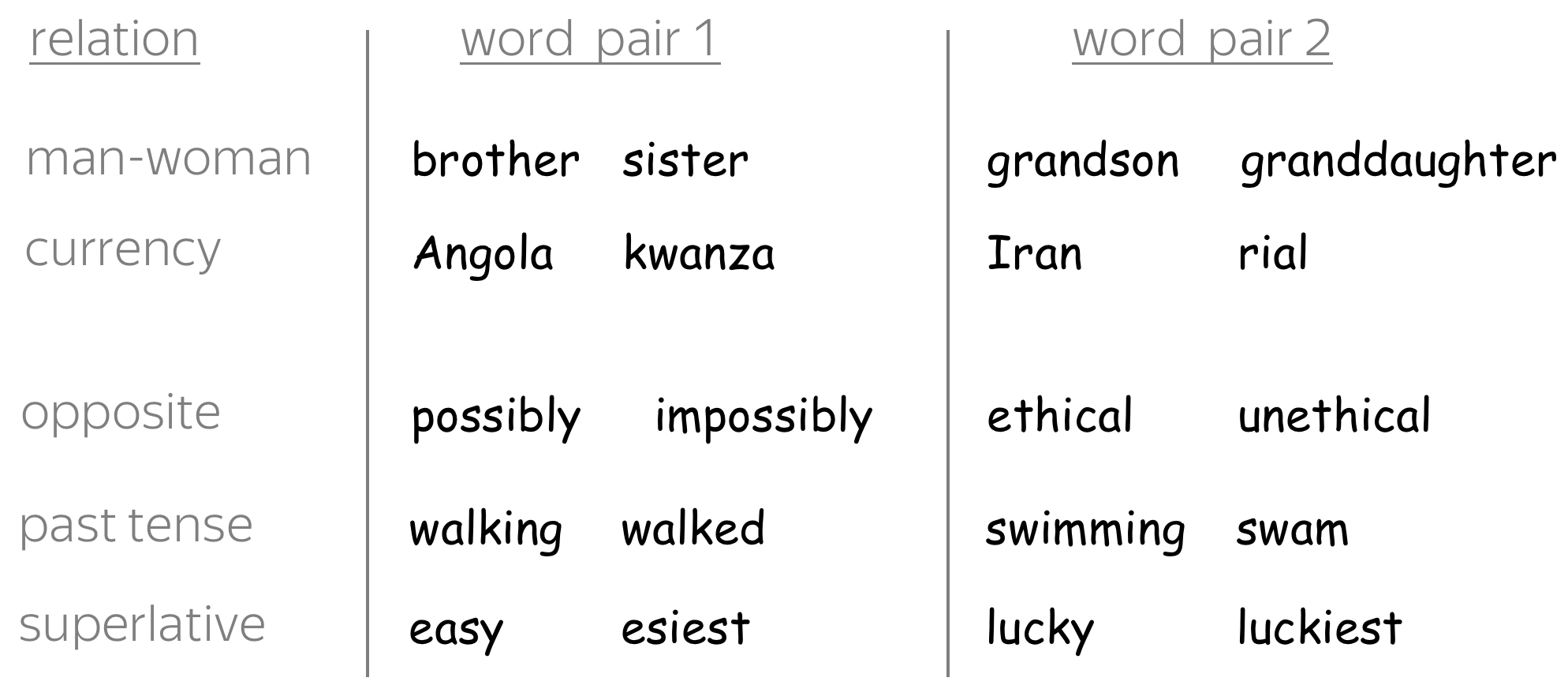
Examples of relations and word pairs from
the Google analogy test set.
Given two word pairs for the same relation, for example
(man, woman) and
(king, queen),
the task is to check if we can identify one of the words based on the rest of them.
Specifically, we have to check if the closest vector to
king — man + woman
corresponds to the word
queen.
Now there are several analogy benchmarks; these include
the standard benchmarks (MSR +
Google analogy test sets) and
BATS (the Bigger Analogy Test Set).
Similarities across Languages
We just saw that some relationships between words are (almost) linear in the embedding space.
But what happens across languages? Turns out, relationships between semantic spaces are also
(somewhat) linear: you can linearly map one semantic space to another so that
corresponding words in the two languages match in the new, joint semantic space.
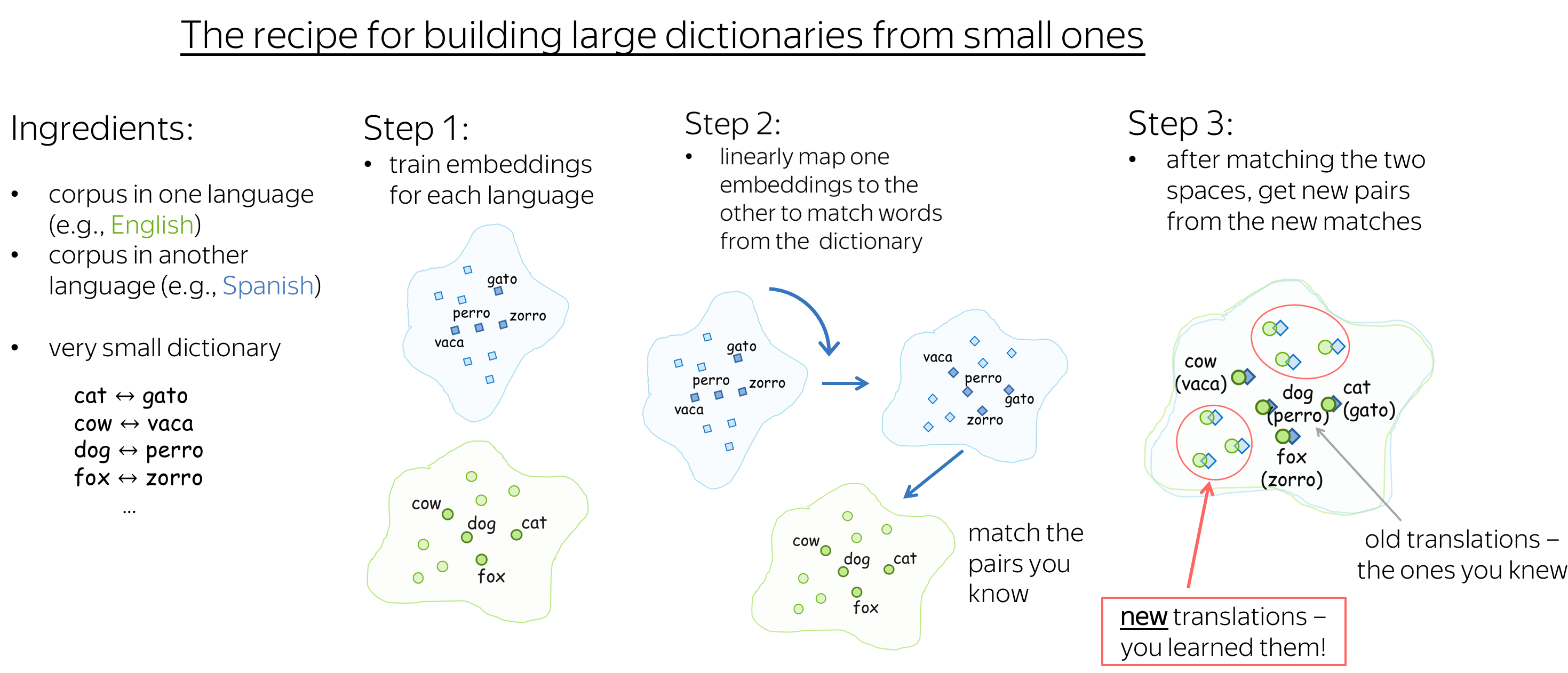
The figure above illustrates the approach proposed
by Tomas Mikolov et al. in 2013 not long after the original Word2Vec. Formally,
we are given a set of word pairs and their vector representations
({color{#88a635}{x_i}color{black}, color{#547dbf}{z_i}color{black} }_{i=1}^n),
where (color{#88a635}{x_i}) and (color{#547dbf}{z_i})
are vectors for i-th word in the source language and its translation in the target.
We want to find a transformation matrix W such that (Wcolor{#547dbf}{z_i}) approximates (color{#88a635}{x_i})
: «matches» words from the dictionary.
We pick (W) such that
[W = arg minlimits_{W}sumlimits_{i=1}^nparallel Wcolor{#547dbf}{z_i}color{black} — color{#88a635}{x_i}color{black}parallel^2,]
and learn this matrix by gradient descent.
In the original paper, the initial vocabulary consists of the 5k most frequent words with their translations,
and the rest is learned.
![]()
Later it turned out, that we don’t need a dictionary at all —
we can build a mapping between semantic spaces even
if we know nothing about languages! More details are
here.
![]()
Is the «true» mapping between languages indeed linear, or more complicated?
We can look at geometry of the learned semantic spaces and check.
More details are
here.
![]()
The idea to linearly map different embedding sets to (nearly) match them can also be used
for a very different task!
Learn more
in the Research Thinking section.
![]()
Research Thinking
How to
- Read the short description at the beginning — this is our starting point,
something known. - Read a question and think: for a minute, a day, a week, … —
give yourself some time! Even if you are not thinking about it constantly,
something can still come to mind. - Look at the possible answers — previous attempts to answer/solve this problem.
Important:
You are not supposed to come up with
something exactly like here — remember, each paper usually takes the authors several
months of work. It’s a habit of thinking about these things that counts!
All the rest a scientist needs is time: to try-fail-think
until it works.
It’s well-known that you will learn something easier if you are not just given the answer right away,
but if you think about it first. Even if you don’t want to be a researcher, this is still a good way
to learn things!
Count-Based Methods
Improve Simple Co-Occurrence Counts
The simplest co-occurrence counts treat context words equally, although these words
are at different relative positions from the central word.
For example, from one sentence
the central word cat
will get a co-occurrence count of 1 for each of the words
cute,
grey,
playing,
in (look at the example to the right).

?
Are context words at different distances equally important?
If not, how can we modify co-occurrence counts?
Possible answers

Intuitively, words that are closer to the central are more important; for example,
immediate neighbors are more informative than words at distance 3.
We can use this to modify the model: when evaluating counts,
let’s give closer words more weight. This idea was used in the
HAL model (1996),
which once was very famous. They modified counts as shown in the example.
?
In language, word order is important; specifically, left and right contexts have different meanings.
How can we distinguish between the left and right contexts?
One of the existing approaches

Here the weighting idea we saw above would not work: we can not say which
contexts, left or right, are more important.
What we have to do is to evaluate co-occurrences to the left and to the right separately.
For each context word, we will have two different counts: one when it is a left context and
another when it is the right context. This means that our co-occurrence matrix will have
|V| rows and 2|V| columns.
This idea was also used in the
HAL model (1996).
Look at the example; note that for cute,
we have left co-occurrence count, for
cat — right.
Word2Vec
Are all context words equally important for training?
During Word2Vec training, we make an update for each of the context words.
For example, for the central word cat
we make an update for each of the words
cute,
grey,
playing,
in.

?
Are all context words equally important?
Which word types give more/less information than others?
Think about some characteristics of words
that can influence their importance. Do not forget the previous exercise!
Possible answers
- word frequency
We can expect that frequent words usually give less information than rare ones.
For example, the fact that cat
appears in context of in
does not tell us much about the meaning of
cat: the word
in serves as a context for many other words.
In contrast,
cute,
grey and
playing
already give us some idea about
cat. -
distance from the central word
As we discussed in the previous exercise
on count-based methods, words that are closer to the central may be more important.
?
How can we use this to modify training?
Tricks from the original Word2Vec
1. Word Frequency
To account for different informativeness of rare and frequent words,
Word2Vec uses a simple subsampling
approach: each word (w_i) in the training set is ignored with probability
computed by the formula
[P(w_i)=1 — sqrt{frac{thr}{f(w_i)}}]
where (f(w_i)) is the word frequency and (thr) is the chosen threshold
(in the original paper, (thr=10^{-5})).
This formula preserves the ranking of the frequencies, but aggressively subsamples words whose
frequency is greater than (thr).
Interestingly, this heuristic
works well in practice:
it accelerates learning and even significantly improves the
accuracy of the learned vectors of the rare words.
2. Distance from the central word

As in the previous exercise
on count-based methods, we can assign higher weights to the words which are closer to
the central.
At the first glance, you won’t see any weights in the original Word2Vec implementation.
However, at each step it samples the size of the context window from 1 to L. Therefore,
words which are closer to central are used more frequently than the distant ones.
In the original work this was (probably) done for efficiency (fewer updates for each step),
but this also has the effect similar to assigning weights.
Use Information About Subwords («invent» FastText)
Usually, we have a look-up table where each word is assigned a distinct vector.
By construction, these vectors do not have any idea about subwords they consist of:
all information they have is what they learned from contexts.

?
Imagine that word embeddings have some understanding of subwords they consist of.
Why can this be useful?
Possible answers
- better understanding of morphology
By assigning a distinct vector to each word, we ignore morphology. Giving information about
subwords can let the model know that different tokens can be forms of the same word. - representations for unknown words
Usually, we can represent only those words, which are present in the vocabulary.
Giving information about
subwords can help to represent out-of-vocabulary words relying of their spelling. - handling misspellings
Even if one character in a word is wrong, this is another token, and,
therefore, a completely different embedding
(or even unknown word). With information about subwords, misspelled word would still
be similar to the original one.
?
How can we incorporate information about subwords into embeddings? Let’s assume that the training pipeline
is fixed, e.g., Skip-Gram with Negative sampling.
One of the existing approaches (FastText)
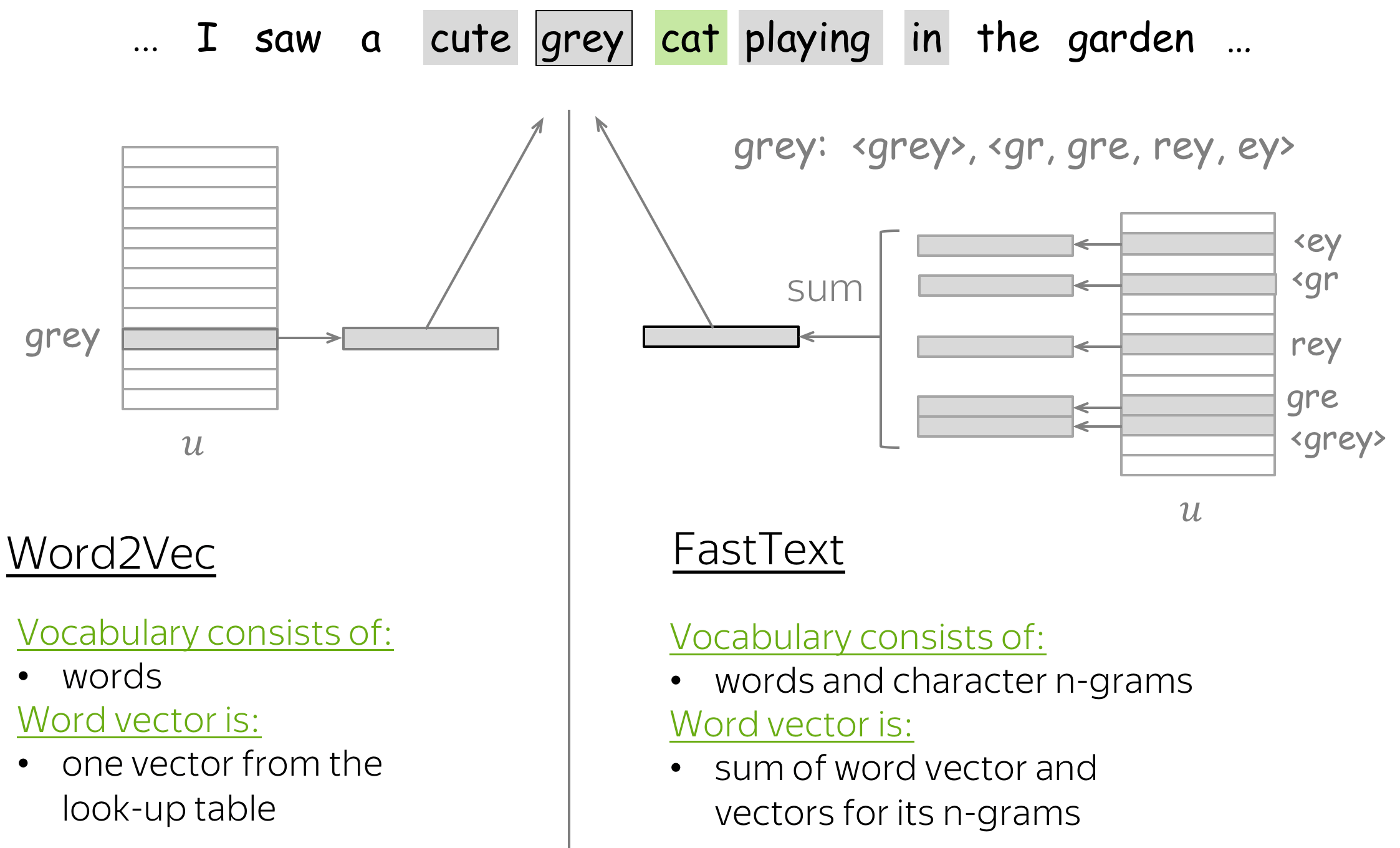
One of the possible approaches is to compose a word vector from vectors for its subwords.
For example, popular
FastText embeddings
operate as shown in the illustration. For each word, they add special start and end
characters for each word. Then, in addition to the vector for this word, they also use vectors
for character n-grams (which are also in the vocabulary). Representation of a word
us sum of vectors for the word and its subwords, as shown in the picture.
Note that this changes only the way we form word vector; the whole training pipeline is the same
as in the standard Word2Vec.
Semantic Change
Detect Words that Changed Their Usage
Imagine you have text corpora from different sources:
time periods, populations, geographic regions, etc.
In digital humanities and computational social science, people
often want to find words that used differently in these corpora.
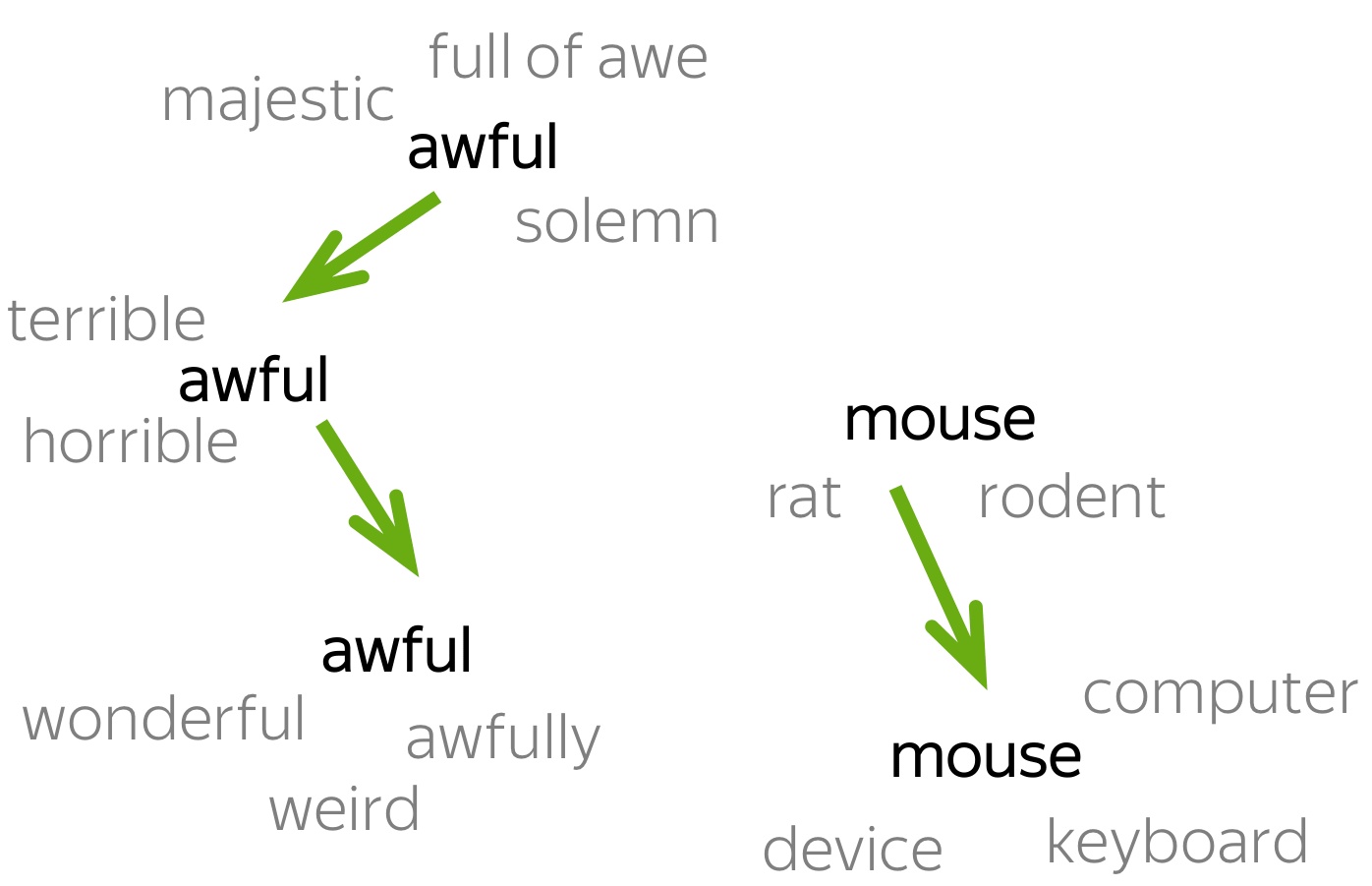
?
Given two text corpora, how would you detect which words are used differently/have different meaning?
Do not be shy to think about very simple ways!
Some of the existing attempts
ACL 2020: train embeddings, look at the neighbors

A very simple approach
is to train embeddings (e.g., Word2Vec) and look at the closest neighbors.
If a word’s closest neighbors are different for the two corpora, the word changed
its meaning: remember that word embeddings reflect contexts they saw!
This approach was proposed in
this ACL 2020 paper. Formally, for each word the authors take k nearest neighbors
in the two embeddings sets and count how many neighbors are the same. Large intersection
means that the meaning is not different, small intersection — meaning is different.
Lena: Note that while the approach is recent,
it is extremely simple and works better than previous more complicated ideas.
Never be afraid to try simple things — you’ll be surprised how often they work!
Previous popular approach: align two embedding sets

The previous popular approach
was to align two embeddings sets and to find word
whose embeddings do not match well. Formally, let (color{#88a635}{W_1}color{black}, color{#547dbf}{W_2}color{black} in
mathbb{R}^{dtimes |V|})
be embedding sets trained on different corpora.
To align the learned embeddings, the authors find the rotation
(R = arg maxlimits_{Q^TQ=I}parallel color{#547dbf}{W_2}color{black}Q — color{#88a635}{W_1}color{black}parallel_F) — this
is called Orthogonal Procrustes. Using this rotation, we can align embedding sets
and find words which do not match well: these are the words that change
meaning with the corpora.
Lena: You will implement Ortogonal
Proctustes in your homework to align Russian and Ukranian embeddings. Find the notebook in
the course repo.
![]()
Have Fun!
Semantic Space Surfer
Usually, we want word embeddings to reason as humans do. But let’s try the opposite:
you will try to think as word embeddings.
You will see the analogical example, e.g. king — man + woman = ?,
and several possible answers. The task is to guess what word embeddings think.
Complete the task
(10 examples) and get a Semantic Space Surfer Certificate!
Word embeddings: we used glove-twitter-100
from gensim-data.
Big thanks
Just Heuristic for the help with technical issues! Just Heuristic — Just Fun!

Word Meaning Lecture # 6 Grigoryeva M.
 Types of word meaning")
Word Meaning Approaches to word meaning Meaning and Notion (понятие) Types of word meaning Types of morpheme meaning Motivation
 cat the")
Each word has two aspects: the outer aspect ( its sound form) cat the inner aspect (its meaning) long-legged, fury animal with sharp teeth and claws

Sound and meaning do not always constitute a constant unit even in the same language EX a temple a part of a human head a large church
 Is a branch of lexicology which studies the meaning of words and")
Semantics (Semasiology) Is a branch of lexicology which studies the meaning of words and word equivalents
 approach The Functional (contextual) approach Operational (information-oriented)")
Approaches to Word Meaning The Referential (analytical) approach The Functional (contextual) approach Operational (information-oriented) approach
 approach formulates the essence of meaning by establishing the interdependence between")
The Referential (analytical) approach formulates the essence of meaning by establishing the interdependence between words and things or concepts they denote distinguishes between three components closely connected with meaning: the sound-form of the linguistic sign, the concept the actual referent
 – the thought of the object")
Basic Triangle concept – flower concept (thought, reference) – the thought of the object that singles out its essential features referent – object denoted by the word, part of reality sound-form (symbol, sign) – linguistic sign sound-form [rәuz] referent

In what way does meaning correlate with each element of the triangle ? • In what relation does meaning stand to each of them? •
![Meaning and Sound-form are not identical different EX. dove - [dΛv] English [golub’] Russian](https://present5.com/presentation/54919015_285694613/image-10.jpg "Meaning and Sound-form are not identical different EX. dove - [dΛv] English [golub’] Russian")
Meaning and Sound-form are not identical different EX. dove — [dΛv] English [golub’] Russian [taube] German sound-forms BUT the same meaning
![Meaning and Sound-form nearly identical sound-forms have different meanings in different languages EX. [kot]](https://present5.com/presentation/54919015_285694613/image-11.jpg "Meaning and Sound-form nearly identical sound-forms have different meanings in different languages EX. [kot]")
Meaning and Sound-form nearly identical sound-forms have different meanings in different languages EX. [kot] Russian – a male cat [kot] English – a small bed for a child identical sound-forms have different meanings (‘homonyms) EX. knight [nait]

Meaning and Sound-form even considerable changes in sound-form do not affect the meaning EX Old English lufian [luvian] – love [l Λ v]

Meaning and Concept concept is a category of human cognition concept is abstract and reflects the most common and typical features of different objects and phenomena in the world meanings of words are different in different languages

Meaning and Concept identical concepts may have different semantic structures in different languages EX. concept “a building for human habitation” – English Russian HOUSE ДОМ + in Russian ДОМ “fixed residence of family or household” In English HOME
 may be denoted by more")
Meaning and Referent one and the same object (referent) may be denoted by more than one word of a different meaning cat pussy animal tiger

Meaning is not identical with any of the three points of the triangle – the sound form, the concept the referent BUT is closely connected with them.

Functional Approach studies the functions of a word in speech meaning of a word is studied through relations of it with other linguistic units EX. to move (we move, move a chair) movement (movement of smth, slow movement) The distriution ( the position of the word in relation to others) of the verb to move and a noun movement is different as they belong to different classes of words and their meanings are different

Operational approach is centered on defining meaning through its role in the process of communication EX John came at 6 Beside the direct meaning the sentence may imply that: He was late He failed to keep his promise He was punctual as usual He came but he didn’t want to The implication depends on the concrete situation

Lexical Meaning and Notion denotes the Lexical meaning is reflection in the realization of a mind of real objects notion by means of a definite language system Notion is a unit of Word is a language thinking unit

Lexical Meaning and Notions are Meanings are internationally limited especially with the nations of the same EX GO (E) —- ИДТИ(R) cultural level “To move” BUT !!! To GO by bus (E) ЕХАТЬ (R) EX Man -мужчина, человек Она – хороший человек (R) She is a good person (E)

Types of Meaning Types grammatical meaning of meaning lexico-grammatical meaning lexical meaning denotational connotational

Grammatical Meaning component of meaning recurrent in identical sets of individual forms of different words EX. girls, winters, toys, tables – grammatical meaning of plurality asked, thought, walked – meaning of past tense
 is revealed in the classification of lexical items")
Lexico-grammatical meaning (part –of- speech meaning) is revealed in the classification of lexical items into: major word classes (N, V, Adj, Adv) minor ones (artc, prep, conj) words of one lexico-grammatical class have the same paradigm

Lexical Meaning is the meaning proper to the given linguistic unit in all its forms and distributions EX. Go – goes — went lexical meaning – process of movement

PRACTICE Group the words into 3 column according to the grammatical, lexical or part-of –speech meaning • • Boy’s, nearest, at, beautiful, think, man, drift, wrote, tremendous, ship’s, the most beautiful, table, near, for, went, friend’s, handsome, thinking, boy, nearer, thought, boys, lamp, go, during.

• Grammatical 1. The case of nouns: boy’s, ship’s, friend’s 2. The degree of comparison of adj: nearest, the most beautiful 3. The tense of verbs: wrote, went, thought • Lexical 1. Think, thinking, thought 2. Went, go 3. Boy’s, boys 4. Nearest, nearer 5. At, for, during (“time”) 6. Beautiful, the most beautiful • Part-of-speech Nouns—verbs—adj—-prep

Aspects of Lexical meaning The denotational aspect The connotational aspect The pragmatic aspect

Denotational Meaning “denote” – to be a sign of, stand as a symbol for” establishes the correlation between the name and the object makes communication possible EX booklet “a small thin book that gives info about smth”

PRACTICE Explain denotational meaning • • A lion-hunter To have a heart like a lion To feel like a lion To roar like a lion To be thrown to the lions The lion’s share To put your head in lion’s mouth

PRACTICE • A lion-hunter A host that seeks out celebrities to impress guests • To have a heart like a lion To have great courage • To feel like a lion To be in the best of health • To roar like a lion To shout very loudly • To be thrown to the lions To be criticized strongly or treated badly • The lion’s share Much more than one’s share • To put your head in lion’s mouth

Connotational Meaning reflects the attitude of the speaker towards what he speaks about it is optional – a word either has it or not Connotation gives additional information and includes: The emotive charge EX Daddy (for father) Intensity EX to adore (for to love) Imagery EX to wade through a book “ to walk with an effort”

PRACTICE Give possible interpretation of the sentences • She failed to buy it and felt a strange pang. • Don’t be afraid of that woman! It’s just barking! • He got up from his chair moving slowly, like an old man. • The girl went to her father and pulled his sleeve. • He was longing to begin to be generous. • She was a woman with shiny red hands and workswollen finger knuckles.

PRACTICE Give possible interpretation of the sentences • She failed to buy it and felt a strange pang. (pain—dissatisfaction that makes her suffer) • Don’t be afraid of that woman! It’s just barking! (make loud sharp sound—-the behavior that implies that the person is frightened) • He got up from his chair moving slowly, like an old man. (to go at slow speed—was suffering or was ill) • The girl went to her father and pulled his sleeve. (to move smth towards oneself— to try to attract smb’s attention) • He was longing to begin to be generous. (to start doing— hadn’t been generous before) • She was a woman with shiny red hands and work-swollen finger knuckles. (colour— a labourer involved into physical work , constant contact with water)

The pragmatic aspect of lexical meaning the situation in which the word is uttered, the social circumstances (formal, informal, etc. ), social relationships between the interlocutors (polite, rough, etc. ), the type and purpose of communication (poetic, official, etc. ) EX horse (neutral) steed (poetic) nag (slang) gee-gee (baby language)

PRACTICE State what image underline the meaning • I heard what she said but it didn’t sink into my mind. • You should be ashamed of yourself, crawling to the director like that. • They seized on the idea. • Bill, chasing some skirt again? • I saw him dive into a small pub. • Why are you trying to pin the blame on me? • He only married her for her dough.

PRACTICE State what image underline the meaning • I heard what she said but it didn’t sink into my mind. • (to understand completely) • You should be ashamed of yourself, crawling to the director like that. (to behave humbly in order to win favour) • They seized on the idea. (to be eager to take and use) • Bill, chasing some skirt again? (a girl) • I saw him dive into a small pub. (to enter suddenly) • Why are you trying to pin the blame on me? (to blame smb unfairly) • He only married her for her dough. (money)

Types of Morpheme Meaning lexical differential functional distributional

Lexical Meaning in Morphemes root-morphemes that are homonymous to words possess lexical meaning EX. boy – boyhood – boyish affixes have lexical meaning of a more generalized character EX. –er “agent, doer of an action”

Lexical Meaning in Morphemes has denotational and connotational components EX. –ly, -like, -ish – denotational meaning of similiarity womanly , womanish connotational component – -ly (positive evaluation), -ish (deragotary) женственный женоподобный

Differential Meaning a semantic component that serves to distinguish one word from all others containing identical morphemes EX. cranberry, blackberry, gooseberry

Functional Meaning found only in derivational affixes a semantic component which serves to refer the word to the certain part of speech EX. just, adj. – justice, n.

Distributional Meaning the meaning of the order and the arrangement of morphemes making up the word found in words containing more than one morpheme different arrangement of the same morphemes would make the word meaningless EX. sing- + -er =singer, -er + sing- = ?

Motivation denotes the relationship between the phonetic or morphemic composition and structural pattern of the word on the one hand, and its meaning on the other can be phonetical morphological semantic

Phonetical Motivation when there is a certain similarity between the sounds that make up the word and those produced by animals, objects, etc. EX. sizzle, boom, splash, cuckoo

Morphological Motivation when there is a direct connection between the structure of a word and its meaning EX. finger-ring – ring-finger, A direct connection between the lexical meaning of the component morphemes EX think –rethink “thinking again”

Semantic Motivation based on co-existence of direct and figurative meanings of the same word EX a watchdog – ”a dog kept for watching property” a watchdog – “a watchful human guardian” (semantic motivation)

• PRACTICE
 morphologically motivated")
Analyze the meaning of the words. Define the type of motivation a) morphologically motivated b) semantically motivated • Driver • Leg • Horse • Wall • Hand-made • Careless • piggish
 morphologically motivated")
Analyze the meaning of the words. Define the type of motivation a) morphologically motivated b) semantically motivated • Driver Someone who drives a vehicle morphologically motivated • Leg The part of a piece of furniture such as a table semantically motivated • Horse A piece of equipment shaped like a box, used in gymnastics semantically motivated

• Wall Emotions or behavior preventing people from feeling close semantically motivated • Hand-made Made by hand, not machine morphologically motivated • Careless Not taking enough care morphologically motivated • Piggish Selfish semantically motivated

what she said but it didn’t sink in my mind “do down to the bottom” ‘to be accepted by mind” semantic motivation I heard Why are you trying to pin the blame on me? “fasten smth somewhere using a pin” – ”to blame smb” semantic motivation I was following the man when he dived into a pub. “jump into deep water” – ”to enter into suddenly” semantic motivation You should be ashamed of yourself, crawling to the director like that “to move along on hands and knees close to the ground” – “to behave very humbly in order to win favor” semantic motivation
From Wikipedia, the free encyclopedia
The following outline is provided as an overview of and topical guide to natural-language processing:
natural-language processing – computer activity in which computers are entailed to analyze, understand, alter, or generate natural language. This includes the automation of any or all linguistic forms, activities, or methods of communication, such as conversation, correspondence, reading, written composition, dictation, publishing, translation, lip reading, and so on. Natural-language processing is also the name of the branch of computer science, artificial intelligence, and linguistics concerned with enabling computers to engage in communication using natural language(s) in all forms, including but not limited to speech, print, writing, and signing.
Natural-language processing[edit]
Natural-language processing can be described as all of the following:
- A field of science – systematic enterprise that builds and organizes knowledge in the form of testable explanations and predictions about the universe.[1]
- An applied science – field that applies human knowledge to build or design useful things.
- A field of computer science – scientific and practical approach to computation and its applications.
- A branch of artificial intelligence – intelligence of machines and robots and the branch of computer science that aims to create it.
- A subfield of computational linguistics – interdisciplinary field dealing with the statistical or rule-based modeling of natural language from a computational perspective.
- A field of computer science – scientific and practical approach to computation and its applications.
- An application of engineering – science, skill, and profession of acquiring and applying scientific, economic, social, and practical knowledge, in order to design and also build structures, machines, devices, systems, materials and processes.
- An application of software engineering – application of a systematic, disciplined, quantifiable approach to the design, development, operation, and maintenance of software, and the study of these approaches; that is, the application of engineering to software.[2][3][4]
- A subfield of computer programming – process of designing, writing, testing, debugging, and maintaining the source code of computer programs. This source code is written in one or more programming languages (such as Java, C++, C#, Python, etc.). The purpose of programming is to create a set of instructions that computers use to perform specific operations or to exhibit desired behaviors.
- A subfield of artificial intelligence programming –
- A subfield of computer programming – process of designing, writing, testing, debugging, and maintaining the source code of computer programs. This source code is written in one or more programming languages (such as Java, C++, C#, Python, etc.). The purpose of programming is to create a set of instructions that computers use to perform specific operations or to exhibit desired behaviors.
- An application of software engineering – application of a systematic, disciplined, quantifiable approach to the design, development, operation, and maintenance of software, and the study of these approaches; that is, the application of engineering to software.[2][3][4]
- An applied science – field that applies human knowledge to build or design useful things.
- A type of system – set of interacting or interdependent components forming an integrated whole or a set of elements (often called ‘components’ ) and relationships which are different from relationships of the set or its elements to other elements or sets.
- A system that includes software – software is a collection of computer programs and related data that provides the instructions for telling a computer what to do and how to do it. Software refers to one or more computer programs and data held in the storage of the computer. In other words, software is a set of programs, procedures, algorithms and its documentation concerned with the operation of a data processing system.
- A type of technology – making, modification, usage, and knowledge of tools, machines, techniques, crafts, systems, methods of organization, in order to solve a problem, improve a preexisting solution to a problem, achieve a goal, handle an applied input/output relation or perform a specific function. It can also refer to the collection of such tools, machinery, modifications, arrangements and procedures. Technologies significantly affect human as well as other animal species’ ability to control and adapt to their natural environments.
- A form of computer technology – computers and their application. NLP makes use of computers, image scanners, microphones, and many types of software programs.
- Language technology – consists of natural-language processing (NLP) and computational linguistics (CL) on the one hand, and speech technology on the other. It also includes many application oriented aspects of these. It is often called human language technology (HLT).
- A form of computer technology – computers and their application. NLP makes use of computers, image scanners, microphones, and many types of software programs.
Prerequisite technologies[edit]
The following technologies make natural-language processing possible:
- Communication – the activity of a source sending a message to a receiver
- Language –
- Speech –
- Writing –
- Computing –
- Computers –
- Computer programming –
- Information extraction –
- User interface –
- Software –
- Text editing – program used to edit plain text files
- Word processing – piece of software used for composing, editing, formatting, printing documents
- Input devices – pieces of hardware for sending data to a computer to be processed[5]
- Computer keyboard – typewriter style input device whose input is converted into various data depending on the circumstances
- Image scanners –
- Language –
Subfields of natural-language processing[edit]
- Information extraction (IE) – field concerned in general with the extraction of semantic information from text. This covers tasks such as named-entity recognition, coreference resolution, relationship extraction, etc.
- Ontology engineering – field that studies the methods and methodologies for building ontologies, which are formal representations of a set of concepts within a domain and the relationships between those concepts.
- Speech processing – field that covers speech recognition, text-to-speech and related tasks.
- Statistical natural-language processing –
- Statistical semantics – a subfield of computational semantics that establishes semantic relations between words to examine their contexts.
- Distributional semantics – a subfield of statistical semantics that examines the semantic relationship of words across a corpora or in large samples of data.
- Statistical semantics – a subfield of computational semantics that establishes semantic relations between words to examine their contexts.
[edit]
Natural-language processing contributes to, and makes use of (the theories, tools, and methodologies from), the following fields:
- Automated reasoning – area of computer science and mathematical logic dedicated to understanding various aspects of reasoning, and producing software which allows computers to reason completely, or nearly completely, automatically. A sub-field of artificial intelligence, automatic reasoning is also grounded in theoretical computer science and philosophy of mind.
- Linguistics – scientific study of human language. Natural-language processing requires understanding of the structure and application of language, and therefore it draws heavily from linguistics.
- Applied linguistics – interdisciplinary field of study that identifies, investigates, and offers solutions to language-related real-life problems. Some of the academic fields related to applied linguistics are education, linguistics, psychology, computer science, anthropology, and sociology. Some of the subfields of applied linguistics relevant to natural-language processing are:
- Bilingualism / Multilingualism –
- Computer-mediated communication (CMC) – any communicative transaction that occurs through the use of two or more networked computers.[6] Research on CMC focuses largely on the social effects of different computer-supported communication technologies. Many recent studies involve Internet-based social networking supported by social software.
- Contrastive linguistics – practice-oriented linguistic approach that seeks to describe the differences and similarities between a pair of languages.
- Conversation analysis (CA) – approach to the study of social interaction, embracing both verbal and non-verbal conduct, in situations of everyday life. Turn-taking is one aspect of language use that is studied by CA.
- Discourse analysis – various approaches to analyzing written, vocal, or sign language use or any significant semiotic event.
- Forensic linguistics – application of linguistic knowledge, methods and insights to the forensic context of law, language, crime investigation, trial, and judicial procedure.
- Interlinguistics – study of improving communications between people of different first languages with the use of ethnic and auxiliary languages (lingua franca). For instance by use of intentional international auxiliary languages, such as Esperanto or Interlingua, or spontaneous interlanguages known as pidgin languages.
- Language assessment – assessment of first, second or other language in the school, college, or university context; assessment of language use in the workplace; and assessment of language in the immigration, citizenship, and asylum contexts. The assessment may include analyses of listening, speaking, reading, writing or cultural understanding, with respect to understanding how the language works theoretically and the ability to use the language practically.
- Language pedagogy – science and art of language education, including approaches and methods of language teaching and study. Natural-language processing is used in programs designed to teach language, including first- and second-language training.
- Language planning –
- Language policy –
- Lexicography –
- Literacies –
- Pragmatics –
- Second-language acquisition –
- Stylistics –
- Translation –
- Computational linguistics – interdisciplinary field dealing with the statistical or rule-based modeling of natural language from a computational perspective. The models and tools of computational linguistics are used extensively in the field of natural-language processing, and vice versa.
- Computational semantics –
- Corpus linguistics – study of language as expressed in samples (corpora) of «real world» text. Corpora is the plural of corpus, and a corpus is a specifically selected collection of texts (or speech segments) composed of natural language. After it is constructed (gathered or composed), a corpus is analyzed with the methods of computational linguistics to infer the meaning and context of its components (words, phrases, and sentences), and the relationships between them. Optionally, a corpus can be annotated («tagged») with data (manually or automatically) to make the corpus easier to understand (e.g., part-of-speech tagging). This data is then applied to make sense of user input, for example, to make better (automated) guesses of what people are talking about or saying, perhaps to achieve more narrowly focused web searches, or for speech recognition.
- Metalinguistics –
- Sign linguistics – scientific study and analysis of natural sign languages, their features, their structure (phonology, morphology, syntax, and semantics), their acquisition (as a primary or secondary language), how they develop independently of other languages, their application in communication, their relationships to other languages (including spoken languages), and many other aspects.
- Applied linguistics – interdisciplinary field of study that identifies, investigates, and offers solutions to language-related real-life problems. Some of the academic fields related to applied linguistics are education, linguistics, psychology, computer science, anthropology, and sociology. Some of the subfields of applied linguistics relevant to natural-language processing are:
- Human–computer interaction – the intersection of computer science and behavioral sciences, this field involves the study, planning, and design of the interaction between people (users) and computers. Attention to human-machine interaction is important, because poorly designed human-machine interfaces can lead to many unexpected problems. A classic example of this is the Three Mile Island accident where investigations concluded that the design of the human–machine interface was at least partially responsible for the disaster.
- Information retrieval (IR) – field concerned with storing, searching and retrieving information. It is a separate field within computer science (closer to databases), but IR relies on some NLP methods (for example, stemming). Some current research and applications seek to bridge the gap between IR and NLP.
- Knowledge representation (KR) – area of artificial intelligence research aimed at representing knowledge in symbols to facilitate inferencing from those knowledge elements, creating new elements of knowledge. Knowledge Representation research involves analysis of how to reason accurately and effectively and how best to use a set of symbols to represent a set of facts within a knowledge domain.
- Semantic network – study of semantic relations between concepts.
- Semantic Web –
- Semantic network – study of semantic relations between concepts.
- Machine learning – subfield of computer science that examines pattern recognition and computational learning theory in artificial intelligence. There are three broad approaches to machine learning. Supervised learning occurs when the machine is given example inputs and outputs by a teacher so that it can learn a rule that maps inputs to outputs. Unsupervised learning occurs when the machine determines the inputs structure without being provided example inputs or outputs. Reinforcement learning occurs when a machine must perform a goal without teacher feedback.
- Pattern recognition – branch of machine learning that examines how machines recognize regularities in data. As with machine learning, teachers can train machines to recognize patterns by providing them with example inputs and outputs (i.e. Supervised Learning), or the machines can recognize patterns without being trained on any example inputs or outputs (i.e. Unsupervised Learning).
- Statistical classification –
Structures used in natural-language processing[edit]
- Anaphora – type of expression whose reference depends upon another referential element. E.g., in the sentence ‘Sally preferred the company of herself’, ‘herself’ is an anaphoric expression in that it is coreferential with ‘Sally’, the sentence’s subject.
- Context-free language –
- Controlled natural language – a natural language with a restriction introduced on its grammar and vocabulary in order to eliminate ambiguity and complexity
- Corpus – body of data, optionally tagged (for example, through part-of-speech tagging), providing real world samples for analysis and comparison.
- Text corpus – large and structured set of texts, nowadays usually electronically stored and processed. They are used to do statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific subject (or domain).
- Speech corpus – database of speech audio files and text transcriptions. In Speech technology, speech corpora are used, among other things, to create acoustic models (which can then be used with a speech recognition engine). In Linguistics, spoken corpora are used to do research into phonetic, conversation analysis, dialectology and other fields.
- Grammar –
- Context-free grammar (CFG) –
- Constraint grammar (CG) –
- Definite clause grammar (DCG) –
- Functional unification grammar (FUG) –
- Generalized phrase structure grammar (GPSG) –
- Head-driven phrase structure grammar (HPSG) –
- Lexical functional grammar (LFG) –
- Probabilistic context-free grammar (PCFG) – another name for stochastic context-free grammar.
- Stochastic context-free grammar (SCFG) –
- Systemic functional grammar (SFG) –
- Tree-adjoining grammar (TAG) –
- Natural language –
- n-gram – sequence of n number of tokens, where a «token» is a character, syllable, or word. The n is replaced by a number. Therefore, a 5-gram is an n-gram of 5 letters, syllables, or words. «Eat this» is a 2-gram (also known as a bigram).
- Bigram – n-gram of 2 tokens. Every sequence of 2 adjacent elements in a string of tokens is a bigram. Bigrams are used for speech recognition, they can be used to solve cryptograms, and bigram frequency is one approach to statistical language identification.
- Trigram – special case of the n-gram, where n is 3.
- Ontology – formal representation of a set of concepts within a domain and the relationships between those concepts.
- Taxonomy – practice and science of classification, including the principles underlying classification, and the methods of classifying things or concepts.
- Hyponymy and hypernymy – the linguistics of hyponyms and hypernyms. A hyponym shares a type-of relationship with its hypernym. For example, pigeon, crow, eagle and seagull are all hyponyms of bird (their hypernym); which, in turn, is a hyponym of animal.
- Taxonomy for search engines – typically called a «taxonomy of entities». It is a tree in which nodes are labelled with entities which are expected to occur in a web search query. These trees are used to match keywords from a search query with the keywords from relevant answers (or snippets).
- Taxonomy – practice and science of classification, including the principles underlying classification, and the methods of classifying things or concepts.
- Textual entailment – directional relation between text fragments. The relation holds whenever the truth of one text fragment follows from another text. In the TE framework, the entailing and entailed texts are termed text (t) and hypothesis (h), respectively. The relation is directional because even if «t entails h», the reverse «h entails t» is much less certain.
- Triphone – sequence of three phonemes. Triphones are useful in models of natural-language processing where they are used to establish the various contexts in which a phoneme can occur in a particular natural language.
Processes of NLP[edit]
Applications[edit]
- Automated essay scoring (AES) – the use of specialized computer programs to assign grades to essays written in an educational setting. It is a method of educational assessment and an application of natural-language processing. Its objective is to classify a large set of textual entities into a small number of discrete categories, corresponding to the possible grades—for example, the numbers 1 to 6. Therefore, it can be considered a problem of statistical classification.
- Automatic image annotation – process by which a computer system automatically assigns textual metadata in the form of captioning or keywords to a digital image. The annotations are used in image retrieval systems to organize and locate images of interest from a database.
- Automatic summarization – process of reducing a text document with a computer program in order to create a summary that retains the most important points of the original document. Often used to provide summaries of text of a known type, such as articles in the financial section of a newspaper.
- Types
- Keyphrase extraction –
- Document summarization –
- Multi-document summarization –
- Methods and techniques
- Extraction-based summarization –
- Abstraction-based summarization –
- Maximum entropy-based summarization –
- Sentence extraction –
- Aided summarization –
- Human aided machine summarization (HAMS) –
- Machine aided human summarization (MAHS) –
- Types
- Automatic taxonomy induction – automated construction of tree structures from a corpus. This may be applied to building taxonomical classification systems for reading by end users, such as web directories or subject outlines.
- Coreference resolution – in order to derive the correct interpretation of text, or even to estimate the relative importance of various mentioned subjects, pronouns and other referring expressions need to be connected to the right individuals or objects. Given a sentence or larger chunk of text, coreference resolution determines which words («mentions») refer to which objects («entities») included in the text.
- Anaphora resolution – concerned with matching up pronouns with the nouns or names that they refer to. For example, in a sentence such as «He entered John’s house through the front door», «the front door» is a referring expression and the bridging relationship to be identified is the fact that the door being referred to is the front door of John’s house (rather than of some other structure that might also be referred to).
- Dialog system –
- Foreign-language reading aid – computer program that assists a non-native language user to read properly in their target language. The proper reading means that the pronunciation should be correct and stress to different parts of the words should be proper.
- Foreign-language writing aid – computer program or any other instrument that assists a non-native language user (also referred to as a foreign-language learner) in writing decently in their target language. Assistive operations can be classified into two categories: on-the-fly prompts and post-writing checks.
- Grammar checking – the act of verifying the grammatical correctness of written text, especially if this act is performed by a computer program.
- Information retrieval –
- Cross-language information retrieval –
- Machine translation (MT) – aims to automatically translate text from one human language to another. This is one of the most difficult problems, and is a member of a class of problems colloquially termed «AI-complete», i.e. requiring all of the different types of knowledge that humans possess (grammar, semantics, facts about the real world, etc.) in order to solve properly.
- Classical approach of machine translation – rules-based machine translation.
- Computer-assisted translation –
- Interactive machine translation –
- Translation memory – database that stores so-called «segments», which can be sentences, paragraphs or sentence-like units (headings, titles or elements in a list) that have previously been translated, in order to aid human translators.
- Example-based machine translation –
- Rule-based machine translation –
- Natural-language programming – interpreting and compiling instructions communicated in natural language into computer instructions (machine code).
- Natural-language search –
- Optical character recognition (OCR) – given an image representing printed text, determine the corresponding text.
- Question answering – given a human-language question, determine its answer. Typical questions have a specific right answer (such as «What is the capital of Canada?»), but sometimes open-ended questions are also considered (such as «What is the meaning of life?»).
- Open domain question answering –
- Spam filtering –
- Sentiment analysis – extracts subjective information usually from a set of documents, often using online reviews to determine «polarity» about specific objects. It is especially useful for identifying trends of public opinion in the social media, for the purpose of marketing.
- Speech recognition – given a sound clip of a person or people speaking, determine the textual representation of the speech. This is the opposite of text to speech and is one of the extremely difficult problems colloquially termed «AI-complete» (see above). In natural speech there are hardly any pauses between successive words, and thus speech segmentation is a necessary subtask of speech recognition (see below). In most spoken languages, the sounds representing successive letters blend into each other in a process termed coarticulation, so the conversion of the analog signal to discrete characters can be a very difficult process.
- Speech synthesis (Text-to-speech) –
- Text-proofing –
- Text simplification – automated editing a document to include fewer words, or use easier words, while retaining its underlying meaning and information.
Component processes[edit]
- Natural-language understanding – converts chunks of text into more formal representations such as first-order logic structures that are easier for computer programs to manipulate. Natural-language understanding involves the identification of the intended semantic from the multiple possible semantics which can be derived from a natural-language expression which usually takes the form of organized notations of natural-languages concepts. Introduction and creation of language metamodel and ontology are efficient however empirical solutions. An explicit formalization of natural-languages semantics without confusions with implicit assumptions such as closed-world assumption (CWA) vs. open-world assumption, or subjective Yes/No vs. objective True/False is expected for the construction of a basis of semantics formalization.[7]
- Natural-language generation – task of converting information from computer databases into readable human language.
Component processes of natural-language understanding[edit]
- Automatic document classification (text categorization) –
- Automatic language identification –
- Compound term processing – category of techniques that identify compound terms and match them to their definitions. Compound terms are built by combining two (or more) simple terms, for example «triple» is a single word term but «triple heart bypass» is a compound term.
- Automatic taxonomy induction –
- Corpus processing –
- Automatic acquisition of lexicon –
- Text normalization –
- Text simplification –
- Deep linguistic processing –
- Discourse analysis – includes a number of related tasks. One task is identifying the discourse structure of connected text, i.e. the nature of the discourse relationships between sentences (e.g. elaboration, explanation, contrast). Another possible task is recognizing and classifying the speech acts in a chunk of text (e.g. yes-no questions, content questions, statements, assertions, orders, suggestions, etc.).
- Information extraction –
- Text mining – process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as statistical pattern learning.
- Biomedical text mining – (also known as BioNLP), this is text mining applied to texts and literature of the biomedical and molecular biology domain. It is a rather recent research field drawing elements from natural-language processing, bioinformatics, medical informatics and computational linguistics. There is an increasing interest in text mining and information extraction strategies applied to the biomedical and molecular biology literature due to the increasing number of electronically available publications stored in databases such as PubMed.
- Decision tree learning –
- Sentence extraction –
- Terminology extraction –
- Text mining – process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as statistical pattern learning.
- Latent semantic indexing –
- Lemmatisation – groups together all like terms that share a same lemma such that they are classified as a single item.
- Morphological segmentation – separates words into individual morphemes and identifies the class of the morphemes. The difficulty of this task depends greatly on the complexity of the morphology (i.e. the structure of words) of the language being considered. English has fairly simple morphology, especially inflectional morphology, and thus it is often possible to ignore this task entirely and simply model all possible forms of a word (e.g. «open, opens, opened, opening») as separate words. In languages such as Turkish, however, such an approach is not possible, as each dictionary entry has thousands of possible word forms.
- Named-entity recognition (NER) – given a stream of text, determines which items in the text map to proper names, such as people or places, and what the type of each such name is (e.g. person, location, organization). Although capitalization can aid in recognizing named entities in languages such as English, this information cannot aid in determining the type of named entity, and in any case is often inaccurate or insufficient. For example, the first word of a sentence is also capitalized, and named entities often span several words, only some of which are capitalized. Furthermore, many other languages in non-Western scripts (e.g. Chinese or Arabic) do not have any capitalization at all, and even languages with capitalization may not consistently use it to distinguish names. For example, German capitalizes all nouns, regardless of whether they refer to names, and French and Spanish do not capitalize names that serve as adjectives.
- Ontology learning – automatic or semi-automatic creation of ontologies, including extracting the corresponding domain’s terms and the relationships between those concepts from a corpus of natural-language text, and encoding them with an ontology language for easy retrieval. Also called «ontology extraction», «ontology generation», and «ontology acquisition».
- Parsing – determines the parse tree (grammatical analysis) of a given sentence. The grammar for natural languages is ambiguous and typical sentences have multiple possible analyses. In fact, perhaps surprisingly, for a typical sentence there may be thousands of potential parses (most of which will seem completely nonsensical to a human).
- Shallow parsing –
- Part-of-speech tagging – given a sentence, determines the part of speech for each word. Many words, especially common ones, can serve as multiple parts of speech. For example, «book» can be a noun («the book on the table») or verb («to book a flight»); «set» can be a noun, verb or adjective; and «out» can be any of at least five different parts of speech. Some languages have more such ambiguity than others. Languages with little inflectional morphology, such as English are particularly prone to such ambiguity. Chinese is prone to such ambiguity because it is a tonal language during verbalization. Such inflection is not readily conveyed via the entities employed within the orthography to convey intended meaning.
- Query expansion –
- Relationship extraction – given a chunk of text, identifies the relationships among named entities (e.g. who is the wife of whom).
- Semantic analysis (computational) – formal analysis of meaning, and «computational» refers to approaches that in principle support effective implementation.
- Explicit semantic analysis –
- Latent semantic analysis –
- Semantic analytics –
- Sentence breaking (also known as sentence boundary disambiguation and sentence detection) – given a chunk of text, finds the sentence boundaries. Sentence boundaries are often marked by periods or other punctuation marks, but these same characters can serve other purposes (e.g. marking abbreviations).
- Speech segmentation – given a sound clip of a person or people speaking, separates it into words. A subtask of speech recognition and typically grouped with it.
- Stemming – reduces an inflected or derived word into its word stem, base, or root form.
- Text chunking –
- Tokenization – given a chunk of text, separates it into distinct words, symbols, sentences, or other units
- Topic segmentation and recognition – given a chunk of text, separates it into segments each of which is devoted to a topic, and identifies the topic of the segment.
- Truecasing –
- Word segmentation – separates a chunk of continuous text into separate words. For a language like English, this is fairly trivial, since words are usually separated by spaces. However, some written languages like Chinese, Japanese and Thai do not mark word boundaries in such a fashion, and in those languages text segmentation is a significant task requiring knowledge of the vocabulary and morphology of words in the language.
- Word-sense disambiguation (WSD) – because many words have more than one meaning, word-sense disambiguation is used to select the meaning which makes the most sense in context. For this problem, we are typically given a list of words and associated word senses, e.g. from a dictionary or from an online resource such as WordNet.
- Word-sense induction – open problem of natural-language processing, which concerns the automatic identification of the senses of a word (i.e. meanings). Given that the output of word-sense induction is a set of senses for the target word (sense inventory), this task is strictly related to that of word-sense disambiguation (WSD), which relies on a predefined sense inventory and aims to solve the ambiguity of words in context.
- Automatic acquisition of sense-tagged corpora –
- W-shingling – set of unique «shingles»—contiguous subsequences of tokens in a document—that can be used to gauge the similarity of two documents. The w denotes the number of tokens in each shingle in the set.
Component processes of natural-language generation[edit]
Natural-language generation – task of converting information from computer databases into readable human language.
- Automatic taxonomy induction (ATI) – automated building of tree structures from a corpus. While ATI is used to construct the core of ontologies (and doing so makes it a component process of natural-language understanding), when the ontologies being constructed are end user readable (such as a subject outline), and these are used for the construction of further documentation (such as using an outline as the basis to construct a report or treatise) this also becomes a component process of natural-language generation.
- Document structuring –
History of natural-language processing[edit]
History of natural-language processing
- History of machine translation
- History of automated essay scoring
- History of natural-language user interface
- History of natural-language understanding
- History of optical character recognition
- History of question answering
- History of speech synthesis
- Turing test – test of a machine’s ability to exhibit intelligent behavior, equivalent to or indistinguishable from, that of an actual human. In the original illustrative example, a human judge engages in a natural-language conversation with a human and a machine designed to generate performance indistinguishable from that of a human being. All participants are separated from one another. If the judge cannot reliably tell the machine from the human, the machine is said to have passed the test. The test was introduced by Alan Turing in his 1950 paper «Computing Machinery and Intelligence,» which opens with the words: «I propose to consider the question, ‘Can machines think?'»
- Universal grammar – theory in linguistics, usually credited to Noam Chomsky, proposing that the ability to learn grammar is hard-wired into the brain.[8] The theory suggests that linguistic ability manifests itself without being taught (see poverty of the stimulus), and that there are properties that all natural human languages share. It is a matter of observation and experimentation to determine precisely what abilities are innate and what properties are shared by all languages.
- ALPAC – was a committee of seven scientists led by John R. Pierce, established in 1964 by the U. S. Government in order to evaluate the progress in computational linguistics in general and machine translation in particular. Its report, issued in 1966, gained notoriety for being very skeptical of research done in machine translation so far, and emphasizing the need for basic research in computational linguistics; this eventually caused the U. S. Government to reduce its funding of the topic dramatically.
- Conceptual dependency theory – a model of natural-language understanding used in artificial intelligence systems. Roger Schank at Stanford University introduced the model in 1969, in the early days of artificial intelligence.[9] This model was extensively used by Schank’s students at Yale University such as Robert Wilensky, Wendy Lehnert, and Janet Kolodner.
- Augmented transition network – type of graph theoretic structure used in the operational definition of formal languages, used especially in parsing relatively complex natural languages, and having wide application in artificial intelligence. Introduced by William A. Woods in 1970.
- Distributed Language Translation (project) –
Timeline of NLP software[edit]
| Software | Year | Creator | Description | Reference |
|---|---|---|---|---|
| Georgetown experiment | 1954 | Georgetown University and IBM | involved fully automatic translation of more than sixty Russian sentences into English. | |
| STUDENT | 1964 | Daniel Bobrow | could solve high school algebra word problems.[10] | |
| ELIZA | 1964 | Joseph Weizenbaum | a simulation of a Rogerian psychotherapist, rephrasing her (referred to as her not it) response with a few grammar rules.[11] | |
| SHRDLU | 1970 | Terry Winograd | a natural-language system working in restricted «blocks worlds» with restricted vocabularies, worked extremely well | |
| PARRY | 1972 | Kenneth Colby | A chatterbot | |
| KL-ONE | 1974 | Sondheimer et al. | a knowledge representation system in the tradition of semantic networks and frames; it is a frame language. | |
| MARGIE | 1975 | Roger Schank | ||
| TaleSpin (software) | 1976 | Meehan | ||
| QUALM | Lehnert | |||
| LIFER/LADDER | 1978 | Hendrix | a natural-language interface to a database of information about US Navy ships. | |
| SAM (software) | 1978 | Cullingford | ||
| PAM (software) | 1978 | Robert Wilensky | ||
| Politics (software) | 1979 | Carbonell | ||
| Plot Units (software) | 1981 | Lehnert | ||
| Jabberwacky | 1982 | Rollo Carpenter | chatterbot with stated aim to «simulate natural human chat in an interesting, entertaining and humorous manner». | |
| MUMBLE (software) | 1982 | McDonald | ||
| Racter | 1983 | William Chamberlain and Thomas Etter | chatterbot that generated English language prose at random. | |
| MOPTRANS | 1984 | Lytinen | ||
| KODIAK (software) | 1986 | Wilensky | ||
| Absity (software) | 1987 | Hirst | ||
| AeroText | 1999 | Lockheed Martin | Originally developed for the U.S. intelligence community (Department of Defense) for information extraction & relational link analysis | |
| Watson | 2006 | IBM | A question answering system that won the Jeopardy! contest, defeating the best human players in February 2011. | |
| MeTA | 2014 | Sean Massung, Chase Geigle, Cheng{X}iang Zhai | MeTA is a modern C++ data sciences toolkit featuringL text tokenization, including deep semantic features like parse trees; inverted and forward indexes with compression and various caching strategies; a collection of ranking functions for searching the indexes; topic models; classification algorithms; graph algorithms; language models; CRF implementation (POS-tagging, shallow parsing); wrappers for liblinear and libsvm (including libsvm dataset parsers); UTF8 support for analysis on various languages; multithreaded algorithms | |
| Tay | 2016 | Microsoft | An artificial intelligence chatterbot that caused controversy on Twitter by releasing inflammatory tweets and was taken offline shortly after. |
General natural-language processing concepts[edit]
- Sukhotin’s algorithm – statistical classification algorithm for classifying characters in a text as vowels or consonants. It was initially created by Boris V. Sukhotin.
- T9 (predictive text) – stands for «Text on 9 keys», is a USA-patented predictive text technology for mobile phones (specifically those that contain a 3×4 numeric keypad), originally developed by Tegic Communications, now part of Nuance Communications.
- Tatoeba – free collaborative online database of example sentences geared towards foreign-language learners.
- Teragram Corporation – fully owned subsidiary of SAS Institute, a major producer of statistical analysis software, headquartered in Cary, North Carolina, USA. Teragram is based in Cambridge, Massachusetts and specializes in the application of computational linguistics to multilingual natural-language processing.
- TipTop Technologies – company that developed TipTop Search, a real-time web, social search engine with a unique platform for semantic analysis of natural language. TipTop Search provides results capturing individual and group sentiment, opinions, and experiences from content of various sorts including real-time messages from Twitter or consumer product reviews on Amazon.com.
- Transderivational search – when a search is being conducted for a fuzzy match across a broad field. In computing the equivalent function can be performed using content-addressable memory.
- Vocabulary mismatch – common phenomenon in the usage of natural languages, occurring when different people name the same thing or concept differently.
- LRE Map –
- Reification (linguistics) –
- Semantic Web –
- Metadata –
- Spoken dialogue system –
- Affix grammar over a finite lattice –
- Aggregation (linguistics) –
- Bag-of-words model – model that represents a text as a bag (multiset) of its words that disregards grammar and word sequence, but maintains multiplicity. This model is a commonly used to train document classifiers
- Brill tagger –
- Cache language model –
- ChaSen, MeCab – provide morphological analysis and word splitting for Japanese
- Classic monolingual WSD –
- ClearForest –
- CMU Pronouncing Dictionary – also known as cmudict, is a public domain pronouncing dictionary designed for uses in speech technology, and was created by Carnegie Mellon University (CMU). It defines a mapping from English words to their North American pronunciations, and is commonly used in speech processing applications such as the Festival Speech Synthesis System and the CMU Sphinx speech recognition system.
- Concept mining –
- Content determination –
- DATR –
- DBpedia Spotlight –
- Deep linguistic processing –
- Discourse relation –
- Document-term matrix –
- Dragomir R. Radev –
- ETBLAST –
- Filtered-popping recursive transition network –
- Robby Garner –
- GeneRIF –
- Gorn address –
- Grammar induction –
- Grammatik –
- Hashing-Trick –
- Hidden Markov model –
- Human language technology –
- Information extraction –
- International Conference on Language Resources and Evaluation –
- Kleene star –
- Language Computer Corporation –
- Language model –
- LanguageWare –
- Latent semantic mapping –
- Legal information retrieval –
- Lesk algorithm –
- Lessac Technologies –
- Lexalytics –
- Lexical choice –
- Lexical Markup Framework –
- Lexical substitution –
- LKB –
- Logic form –
- LRE Map –
- Machine translation software usability –
- MAREC –
- Maximum entropy –
- Message Understanding Conference –
- METEOR –
- Minimal recursion semantics –
- Morphological pattern –
- Multi-document summarization –
- Multilingual notation –
- Naive semantics –
- Natural language –
- Natural-language interface –
- Natural-language user interface –
- News analytics –
- Nondeterministic polynomial –
- Open domain question answering –
- Optimality theory –
- Paco Nathan –
- Phrase structure grammar –
- Powerset (company) –
- Production (computer science) –
- PropBank –
- Question answering –
- Realization (linguistics) –
- Recursive transition network –
- Referring expression generation –
- Rewrite rule –
- Semantic compression –
- Semantic neural network –
- SemEval –
- SPL notation –
- Stemming – reduces an inflected or derived word into its word stem, base, or root form.
- String kernel –
Natural-language processing tools[edit]
- Google Ngram Viewer – graphs n-gram usage from a corpus of more than 5.2 million books
Corpora[edit]
- Text corpus (see list) – large and structured set of texts (nowadays usually electronically stored and processed). They are used to do statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory.
- Bank of English
- British National Corpus
- Corpus of Contemporary American English (COCA)
- Oxford English Corpus
Natural-language processing toolkits[edit]
The following natural-language processing toolkits are notable collections of natural-language processing software. They are suites of libraries, frameworks, and applications for symbolic, statistical natural-language and speech processing.
| Name | Language | License | Creators |
|---|---|---|---|
| Apertium | C++, Java | GPL | (various) |
| ChatScript | C++ | GPL | Bruce Wilcox |
| Deeplearning4j | Java, Scala | Apache 2.0 | Adam Gibson, Skymind |
| DELPH-IN | LISP, C++ | LGPL, MIT, … | Deep Linguistic Processing with HPSG Initiative |
| Distinguo | C++ | Commercial | Ultralingua Inc. |
| DKPro Core | Java | Apache 2.0 / Varying for individual modules | Technische Universität Darmstadt / Online community |
| General Architecture for Text Engineering (GATE) | Java | LGPL | GATE open source community |
| Gensim | Python | LGPL | Radim Řehůřek |
| LinguaStream | Java | Free for research | University of Caen, France |
| Mallet | Java | Common Public License | University of Massachusetts Amherst |
| Modular Audio Recognition Framework | Java | BSD | The MARF Research and Development Group, Concordia University |
| MontyLingua | Python, Java | Free for research | MIT |
| Natural Language Toolkit (NLTK) | Python | Apache 2.0 | |
| Apache OpenNLP | Java | Apache License 2.0 | Online community |
| spaCy | Python, Cython | MIT | Matthew Honnibal, Explosion AI |
| UIMA | Java / C++ | Apache 2.0 | Apache |
Named-entity recognizers[edit]
- ABNER (A Biomedical Named-Entity Recognizer) – open source text mining program that uses linear-chain conditional random field sequence models. It automatically tags genes, proteins and other entity names in text. Written by Burr Settles of the University of Wisconsin-Madison.
- Stanford NER (Named-Entity Recognizer) — Java implementation of a Named-Entity Recognizer that uses linear-chain conditional random field sequence models. It automatically tags persons, organizations, and locations in text in English, German, Chinese, and Spanish languages. Written by Jenny Finkel and other members of the Stanford NLP Group at Stanford University.
Translation software[edit]
- Comparison of machine translation applications
- Machine translation applications
- Google Translate
- DeepL
- Linguee – web service that provides an online dictionary for a number of language pairs. Unlike similar services, such as LEO, Linguee incorporates a search engine that provides access to large amounts of bilingual, translated sentence pairs, which come from the World Wide Web. As a translation aid, Linguee therefore differs from machine translation services like Babelfish and is more similar in function to a translation memory.
- UNL Universal Networking Language
- Yahoo! Babel Fish
- Reverso
Other software[edit]
- CTAKES – open-source natural-language processing system for information extraction from electronic medical record clinical free-text. It processes clinical notes, identifying types of clinical named entities — drugs, diseases/disorders, signs/symptoms, anatomical sites and procedures. Each named entity has attributes for the text span, the ontology mapping code, context (family history of, current, unrelated to patient), and negated/not negated. Also known as Apache cTAKES.
- DMAP –
- ETAP-3 – proprietary linguistic processing system focusing on English and Russian.[12] It is a rule-based system which uses the Meaning-Text Theory as its theoretical foundation.
- JAPE – the Java Annotation Patterns Engine, a component of the open-source General Architecture for Text Engineering (GATE) platform. JAPE is a finite state transducer that operates over annotations based on regular expressions.
- LOLITA – «Large-scale, Object-based, Linguistic Interactor, Translator and Analyzer». LOLITA was developed by Roberto Garigliano and colleagues between 1986 and 2000. It was designed as a general-purpose tool for processing unrestricted text that could be the basis of a wide variety of applications. At its core was a semantic network containing some 90,000 interlinked concepts.
- Maluuba – intelligent personal assistant for Android devices, that uses a contextual approach to search which takes into account the user’s geographic location, contacts, and language.
- METAL MT – machine translation system developed in the 1980s at the University of Texas and at Siemens which ran on Lisp Machines.
- Never-Ending Language Learning – semantic machine learning system developed by a research team at Carnegie Mellon University, and supported by grants from DARPA, Google, and the NSF, with portions of the system running on a supercomputing cluster provided by Yahoo!.[13] NELL was programmed by its developers to be able to identify a basic set of fundamental semantic relationships between a few hundred predefined categories of data, such as cities, companies, emotions and sports teams. Since the beginning of 2010, the Carnegie Mellon research team has been running NELL around the clock, sifting through hundreds of millions of web pages looking for connections between the information it already knows and what it finds through its search process – to make new connections in a manner that is intended to mimic the way humans learn new information.[14]
- NLTK –
- Online-translator.com –
- Regulus Grammar Compiler – software system for compiling unification grammars into grammars for speech recognition systems.
- S Voice –
- Siri (software) –
- Speaktoit –
- TeLQAS –
- Weka’s classification tools –
- word2vec – models that were developed by a team of researchers led by Thomas Milkov at Google to generate word embeddings that can reconstruct some of the linguistic context of words using shallow, two dimensional neural nets derived from a much larger vector space.
- Festival Speech Synthesis System –
- CMU Sphinx speech recognition system –
- Language Grid – Open source platform for language web services, which can customize language services by combining existing language services.
Chatterbots[edit]
Chatterbot – a text-based conversation agent that can interact with human users through some medium, such as an instant message service. Some chatterbots are designed for specific purposes, while others converse with human users on a wide range of topics.
Classic chatterbots[edit]
- Dr. Sbaitso
- ELIZA
- PARRY
- Racter (or Claude Chatterbot)
- Mark V Shaney
General chatterbots[edit]
- Albert One – 1998 and 1999 Loebner winner, by Robby Garner.
- A.L.I.C.E. – 2001, 2002, and 2004 Loebner Prize winner developed by Richard Wallace.
- Charlix
- Cleverbot (winner of the 2010 Mechanical Intelligence Competition)
- Elbot – 2008 Loebner Prize winner, by Fred Roberts.
- Eugene Goostman – 2012 Turing 100 winner, by Vladimir Veselov.
- Fred – an early chatterbot by Robby Garner.
- Jabberwacky
- Jeeney AI
- MegaHAL
- Mitsuku, 2013 and 2016 Loebner Prize winner[15]
- Rose — … 2015 — 3x Loebner Prize winner, by Bruce Wilcox.
- SimSimi – A popular artificial intelligence conversation program that was created in 2002 by ISMaker.
- Spookitalk – A chatterbot used for NPCs in Douglas Adams’ Starship Titanic video game.
- Ultra Hal – 2007 Loebner Prize winner, by Robert Medeksza.
- Verbot
Instant messenger chatterbots[edit]
- GooglyMinotaur, specializing in Radiohead, the first bot released by ActiveBuddy (June 2001-March 2002)[16]
- SmarterChild, developed by ActiveBuddy and released in June 2001[17]
- Infobot, an assistant on IRC channels such as #perl, primarily to help out with answering Frequently Asked Questions (June 1995-today)[18]
- Negobot, a bot designed to catch online pedophiles by posing as a young girl and attempting to elicit personal details from people it speaks to.[19]
Natural-language processing organizations[edit]
- AFNLP (Asian Federation of Natural Language Processing Associations) – the organization for coordinating the natural-language processing related activities and events in the Asia-Pacific region.
- Australasian Language Technology Association –
- Association for Computational Linguistics – international scientific and professional society for people working on problems involving natural-language processing.
[edit]
- Annual Meeting of the Association for Computational Linguistics (ACL)
- International Conference on Intelligent Text Processing and Computational Linguistics (CICLing)
- International Conference on Language Resources and Evaluation – biennial conference organised by the European Language Resources Association with the support of institutions and organisations involved in natural-language processing
- Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
- Text, Speech and Dialogue (TSD) – annual conference
- Text Retrieval Conference (TREC) – on-going series of workshops focusing on various information retrieval (IR) research areas, or tracks
Companies involved in natural-language processing[edit]
- AlchemyAPI – service provider of a natural-language processing API.
- Google, Inc. – the Google search engine is an example of automatic summarization, utilizing keyphrase extraction.
- Calais (Reuters product) – provider of a natural-language processing services.
- Wolfram Research, Inc. developer of natural-language processing computation engine Wolfram Alpha.
Natural-language processing publications[edit]
Books[edit]
- Connectionist, Statistical and Symbolic Approaches to Learning for Natural Language Processing – Wermter, S., Riloff E. and Scheler, G. (editors).[20] First book that addressed statistical and neural network learning of language.
- Speech and Language Processing: An Introduction to Natural Language Processing, Speech Recognition, and Computational Linguistics – by Daniel Jurafsky and James H. Martin.[21] Introductory book on language technology.
Book series[edit]
- Studies in Natural Language Processing – book series of the Association for Computational Linguistics, published by Cambridge University Press.
Journals[edit]
- Computational Linguistics – peer-reviewed academic journal in the field of computational linguistics. It is published quarterly by MIT Press for the Association for Computational Linguistics (ACL)
People influential in natural-language processing[edit]
- Daniel Bobrow –
- Rollo Carpenter – creator of Jabberwacky and Cleverbot.
- Noam Chomsky – author of the seminal work Syntactic Structures, which revolutionized Linguistics with ‘universal grammar’, a rule based system of syntactic structures.[22]
- Kenneth Colby –
- David Ferrucci – principal investigator of the team that created Watson, IBM’s AI computer that won the quiz show Jeopardy!
- Lyn Frazier –
- Daniel Jurafsky – Professor of Linguistics and Computer Science at Stanford University. With James H. Martin, he wrote the textbook Speech and Language Processing: An Introduction to Natural Language Processing, Speech Recognition, and Computational Linguistics
- Roger Schank – introduced the conceptual dependency theory for natural-language understanding.[23]
- Jean E. Fox Tree –
- Alan Turing – originator of the Turing Test.
- Joseph Weizenbaum – author of the ELIZA chatterbot.
- Terry Winograd – professor of computer science at Stanford University, and co-director of the Stanford Human-Computer Interaction Group. He is known within the philosophy of mind and artificial intelligence fields for his work on natural language using the SHRDLU program.
- William Aaron Woods –
- Maurice Gross – author of the concept of local grammar,[24] taking finite automata as the competence model of language.[25]
- Stephen Wolfram – CEO and founder of Wolfram Research, creator of the programming language (natural-language understanding) Wolfram Language, and natural-language processing computation engine Wolfram Alpha.[26]
- Victor Yngve –
See also[edit]
- Computer-assisted reviewing
- Data mining
- Watson (computer)
- Biomedical text mining
- Compound-term processing
- Computer-assisted reviewing
- Controlled natural language
- Deep linguistic processing
- Foreign-language reading aid
- Foreign-language writing aid
- Language technology
- Latent Dirichlet allocation (LDA)
- Latent semantic indexing
- List of natural-language processing projects
- LRE Map
- Natural-language programming
- Reification (linguistics)
- Semantic folding
- Spoken dialogue system
- Thought vector
- Transderivational search
- Word2vec
References[edit]
- ^ «… modern science is a discovery as well as an invention. It was a discovery that nature generally acts regularly enough to be described by laws and even by mathematics; and required invention to devise the techniques, abstractions, apparatus, and organization for exhibiting the regularities and securing their law-like descriptions.» —p.vii, J. L. Heilbron, (2003, editor-in-chief) The Oxford Companion to the History of Modern Science New York: Oxford University Press ISBN 0-19-511229-6
- «science». Merriam-Webster Online Dictionary. Merriam-Webster, Inc. Retrieved 2011-10-16.
3 a: knowledge or a system of knowledge covering general truths or the operation of general laws especially as obtained and tested through scientific method b: such knowledge or such a system of knowledge concerned with the physical world and its phenomena
- «science». Merriam-Webster Online Dictionary. Merriam-Webster, Inc. Retrieved 2011-10-16.
- ^ SWEBOK Pierre Bourque; Robert Dupuis, eds. (2004). Guide to the Software Engineering Body of Knowledge — 2004 Version. executive editors, Alain Abran, James W. Moore ; editors, Pierre Bourque, Robert Dupuis. IEEE Computer Society. p. 1. ISBN 0-7695-2330-7.
- ^ ACM (2006). «Computing Degrees & Careers». ACM. Archived from the original on 2011-06-17. Retrieved 2010-11-23.
- ^
Laplante, Phillip (2007). What Every Engineer Should Know about Software Engineering. Boca Raton: CRC. ISBN 978-0-8493-7228-5. Retrieved 2011-01-21. - ^ Input device Computer Hope
- ^ McQuail, Denis. (2005). Mcquail’s Mass Communication Theory. 5th ed. London: SAGE Publications.
- ^ Yucong Duan, Christophe Cruz (2011), [http –//www.ijimt.org/abstract/100-E00187.htm Formalizing Semantic of Natural Language through Conceptualization from Existence]. International Journal of Innovation, Management and Technology(2011) 2 (1), pp. 37–42.
- ^ «Tool Module: Chomsky’s Universal Grammar». thebrain.mcgill.ca.
- ^ Roger Schank, 1969, A conceptual dependency parser for natural language Proceedings of the 1969 conference on Computational linguistics, Sång-Säby, Sweden pages 1-3
- ^ McCorduck 2004, p. 286, Crevier 1993, pp. 76−79, Russell & Norvig 2003, p. 19
- ^ McCorduck 2004, pp. 291–296, Crevier 1993, pp. 134−139
- ^ «МНОГОЦЕЛЕВОЙ ЛИНГВИСТИЧЕСКИЙ ПРОЦЕССОР ЭТАП-3». Iitp.ru. Retrieved 2012-02-14.
- ^ «Aiming to Learn as We Do, a Machine Teaches Itself». New York Times. October 4, 2010. Retrieved 2010-10-05.
Since the start of the year, a team of researchers at Carnegie Mellon University — supported by grants from the Defense Advanced Research Projects Agency and Google, and tapping into a research supercomputing cluster provided by Yahoo — has been fine-tuning a computer system that is trying to master semantics by learning more like a human.
- ^ Project Overview, Carnegie Mellon University. Accessed October 5, 2010.
- ^ «Loebner Prize Contest 2013». People.exeter.ac.uk. 2013-09-14. Retrieved 2013-12-02.
- ^ Gibes, Al (2002-03-25). «Circle of buddies grows ever wider». Las Vegas Review-Journal (Nevada).
- ^ «ActiveBuddy Introduces Software to Create and Deploy Interactive Agents for Text Messaging; ActiveBuddy Developer Site Now Open: www.BuddyScript.com». Business Wire. 2002-07-15. Retrieved 2014-01-16.
- ^ Lenzo, Kevin (Summer 1998). «Infobots and Purl». The Perl Journal. 3 (2). Retrieved 2010-07-26.
- ^ Laorden, Carlos; Galan-Garcia, Patxi; Santos, Igor; Sanz, Borja; Hidalgo, Jose Maria Gomez; Bringas, Pablo G. (23 August 2012). Negobot: A conversational agent based on game theory for the detection of paedophile behaviour (PDF). ISBN 978-3-642-33018-6. Archived from the original (PDF) on 2013-09-17.
- ^ Wermter, Stephan; Ellen Riloff; Gabriele Scheler (1996). Connectionist, Statistical and Symbolic Approaches to Learning for Natural Language Processing. Springer.
- ^ Jurafsky, Dan; James H. Martin (2008). Speech and Language Processing. An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition (2nd ed.). Upper Saddle River (N.J.): Prentice Hall. p. 2.
- ^ «SEM1A5 — Part 1 — A brief history of NLP». Retrieved 2010-06-25.
- ^ Roger Schank, 1969, A conceptual dependency parser for natural language Proceedings of the 1969 conference on Computational linguistics, Sång-Säby, Sweden, pages 1-3
- ^ Ibrahim, Amr Helmy. 2002. «Maurice Gross (1934-2001). À la mémoire de Maurice Gross». Hermès 34.
- ^ Dougherty, Ray. 2001. Maurice Gross Memorial Letter.
- ^ «Programming with Natural Language Is Actually Going to Work—Wolfram Blog».
Bibliography[edit]
- Crevier, Daniel (1993). AI: The Tumultuous Search for Artificial Intelligence. New York, NY: BasicBooks. ISBN 0-465-02997-3.
- McCorduck, Pamela (2004), Machines Who Think (2nd ed.), Natick, MA: A. K. Peters, Ltd., ISBN 978-1-56881-205-2, OCLC 52197627.
- Russell, Stuart J.; Norvig, Peter (2003), Artificial Intelligence: A Modern Approach (2nd ed.), Upper Saddle River, New Jersey: Prentice Hall, ISBN 0-13-790395-2.
External links[edit]
How can we automatically identify the words of a text that are most
informative about the topic and genre of the text? Imagine how you might
go about finding the 50 most frequent words of a book. One method
would be to keep a tally for each vocabulary item, like that shown in 3.1.
The tally would need thousands of rows, and it would be an exceedingly
laborious process — so laborious that we would rather assign the task to a machine.
>>> fdist1 = FreqDist(text1) |
![[1]](https://www.nltk.org/book/callouts/callout1.gif)
![[2]](https://www.nltk.org/book/callouts/callout2.gif)
![[3]](https://www.nltk.org/book/callouts/callout3.gif)
Note
Your Turn:
Try the preceding frequency distribution example for yourself, for
text2. Be careful to use the correct parentheses and uppercase letters.
If you get an error message NameError: name ‘FreqDist’ is not defined,
you need to start your work with from nltk.book import *
Do any words produced in the last example help us grasp the topic or genre of this text?
Only one word, whale, is slightly informative! It occurs over 900 times.
The rest of the words tell us nothing about the text; they’re just English «plumbing.»
What proportion of the text is taken up with such words?
We can generate a cumulative frequency plot for these words,
using fdist1.plot(50, cumulative=True), to produce the graph in 3.2.
These 50 words account for nearly half the book!