
|
|
This article shows you how to extract the meaningful bits of information from raw text and how to identify their roles. Let’s first look into why identifying roles is important. |

Take 40% off Getting Started with Natural Language Processing by entering fcckochmar into the discount code box at checkout at manning.com.
Understanding word types
The first fact to notice is that there‘s a conceptual difference between the bits of the expression like “[Harry] [met] [Sally]”: “Harry” and “Sally” both refer to people participating in the event, and “met” represents an action. When we humans read text like this, we subconsciously determine the roles each word or expression plays along those lines: to us, words like “Harry” and “Sally” can only represent participants of an action but can’t denote an action itself, and words like “met” can only denote an action. This helps us get at the essence of the message quickly: we read “Harry met Sally” and we understand [HarryWHO] [metDID_WHAT] [SallyWHOM].
This recognition of word types has two major effects: the first effect is that the straightforward unambiguous use of words in their traditional functions helps us interpret the message. Funnily enough, this applies even when we don’t know the meaning of the words. Our expectations about how words are combined in sentences and what roles they play are strong, and when we don’t know what a word means such expectations readily suggest what it might mean: e.g., we might not be able to exactly pin it down, but we can still say that an unknown word means some sort of an object or some sort of an action. This “guessing game” is familiar to anyone who has ever tried learning a foreign language and had to interpret a few unknown words based on other, familiar words in the context. Even if you are a native speaker of English and never tried learning a different language, you can still try playing a guessing game, for example, with nonsensical poetry. Here’s an excerpt from “Jabberwocky”, a famous nonsensical poem by Lewis Carroll:[1]

Figure 1. An example of text where the word meaning can only be guessed
Some of the words here are familiar to anyone, but what do “Jabberwock”, “Bandersnatch” and “frumious” mean? It’s impossible to give a precise definition for any of them because these words don’t exist in English or any other language, and their meaning is anybody’s guess. One can say with high certainty that “Jabberwock” and “Bandersnatch” are some sort of creatures, and “frumious” is some sort of quality.[2] How do we make such guesses? You might notice that the context for these words gives us some clues: for example, we know what “beware” means. It’s an action, and as an action it requires some participants: one doesn’t normally “beware”, one needs to beware of someone or something. We expect to see this someone or something, and here comes “Jabberwock”. Another clue is given away by the word “the” which normally attaches itself to objects (like “the car”) or creatures (like “the dog”), and we arrive at an interpretation of “Jabberwock” and “Bandersnatch” being creatures. Finally, in “the frumious Bandersnatch” the only possible role for “frumious” is some quality because this is how it typically works in language: e.g. “the red car” or “the big dog”.
The second effect that the expectations about the roles that words play have on our interpretation is that we tend to notice when these roles are ambiguous or somehow violated, because such violations create a discordance. This is why ambiguity in language is a rich source of jokes and puns, intentional or not. Here’s one expressed in a news headline:

Figure 2. An example of ambiguity in action
What is the first reading that you get? You wouldn’t be the only one if you read this as if “Police help a dog to bite a victim”, but common sense suggests that the intended meaning is probably “Police help a victim with a dog bite (or, that was bitten by a dog)”. News headlines are rich in ambiguities like that because they use a specific format aimed at packing the maximum amount of information in a shortest possible expression. This sometimes comes at a price as both “Police help a dog to bite a victim” and “Police help a victim with a dog bite (that was bitten by a dog)” are clearer but longer than “Police help dog bite victim” that a newspaper might prefer to use. This ambiguity isn’t necessarily intentional, but it’s easy to see how this can be used to make endless jokes.
What exactly causes confusion here? It’s clear that “police” denotes a participant in an event, and “help” denotes the action. “Dog” and “victim” also seem to unambiguously be participants of an action, but things are less clear with “bite”. “Bite” can denote an action as in “Dog bites a victim” or a result of an action as in “He has mosquito bites.” In both cases, what we read is a word “bites”, and it doesn’t give away any further clues as to what it means, but in “Dog bites a victim” it answers the question “What does the dog do?” and in “He has mosquito bites” it answers the question “What does he have?”. Now, when you see a headline like “Police help dog bite victim”, your brain doesn’t know straight away which path to follow:
- Path 1: “bite” is an action answering the question “what does one do?” → “Police help dog [biteDO_WHAT] victim”
- Path 2: “bite” is the result of an action answering the question “what happened?” → “Police help dog [biteWHAT] victim”.
Apart from the humorous effect of such confusions, ambiguity may also slow the information processing down and lead to misinterpretations. Try solving Exercise 1 to see how the same expression may lead to completely different readings.
Solution: These are quite well-known examples that are widely used in NLP courses to exemplify ambiguity in language and its effect on interpretation.
In (1), “I” certainly denotes a person, and “can” certainly denotes an action, but “can” as an action has two potential meanings: it can denote ability “I can” = “I am able to” or the action of putting something in cans.[3] “Fish” can denote an animal as in “freshwater fish” (or a product as in “fish and chips”), or it can denote an action as in “learn to fish”. In combination with the two meanings of “can” these can produce two completely different readings of the same sentence: either “I can fish” means “I am able / I know how to fish” or “I put fish in cans”.
In (2), “I” is a person and “saw” is an action, but “duck” may mean an animal or an action of ducking. In the first case, the sentence means that I saw a duck that belongs to her, and in the second it means that I witnessed how she ducked – once again, completely different meanings of what seems to be the same sentence!

Figure 3. Ambiguity might result in some serious misunderstanding[4]
This far, we’ve been using the terminology quite frivolously: we’ve been defining words as denoting actions or people or qualities, but in fact there are more standard terms for that. The types of words defined by the different functions that words might fulfill are called parts-of-speech, and we distinguish between a number of such types:
- words that denote objects, animals, people, places and concepts are called nouns;
- words that denote states, actions and occurrences are called verbs;
- words that denote qualities of objects, animals, people, places and concepts are called adjectives;
- those for qualities of actions, states and occurrences are called adverbs.
Table 1 provides some examples and descriptions of different parts-of-speech:
Table 1. Examples of words of different parts-of-speech
|
Part-of-speech Nouns |
What it denotes Objects, people, animals, places, concepts, time references |
Examples car, Einstein, dog, Paris, calculation, Friday |
|
Verbs |
Actions, states, occurrences |
meet, stay, become, happen |
|
Adjectives |
Qualities of objects, people, animals, places, concepts |
red car, clever man, big dog, beautiful city, fast calculation |
|
Adverbs |
Qualities of actions, states, occurrences |
meet recently, stay longer, just become, happen suddenly |
|
Articles |
Don’t have a precise meaning of their own, but show whether the noun they are attached to is identifiable in context (it is clear what / who the noun is referring to) or not (the noun hasn’t been mentioned before) |
I saw a man = This man is mentioned for the first time (“a” is an indefinite article) The man is clever = This suggests that it should be clear from the context which particular man we are talking about (“the” is a definite article) |
|
Prepositions |
Don’t have a precise meaning of their own, but serve as a link between two words or groups of words: for example, linking a verb denoting action with nouns denoting participants, or a noun to its attributes |
meet on Friday – links action to time meet with administration – links action to participants meet at house – links action to location a man with a hat – links a noun to its attribute |
This isn’t a comprehensive account of all parts-of-speech in English, but with this brief guide you should be able to recognize the roles of the most frequent words in text and this suite of word types should provide you with the necessary basis for implementation of your own information extractor.
Why do we care about the identification of word types in the context of information extraction and other tasks? You’ve seen above that correct and straightforward identification of types helps information processing, although ambiguities lead to misunderstandings. This is precisely what happens with the automated language processing: machines like humans can extract information from text better and more efficiently if they can recognize the roles played by different words, although misidentification of these roles may lead to mistakes of various kinds. For instance, having identified that “Jabberwock” is a noun and some sort of a creature, a machine might be able to answer a question like “Who is Jabberwock?” (e.g., “Someone / Something with jaws that bite and claws that catch”), although if a machine processed “I can fish” as “I know how to fish” it wouldn’t be able to answer the question “What did you put in cans?”
Luckily, there are NLP algorithms that can detect word types in text, and such algorithms are called part-of-speech taggers (or POS taggers). Figure 4 presents a mental model to help you put POS taggers into the context of other NLP techniques:

Figure 4. Mental Model that visualizes the flow of information between different NLP components
As POS tagging is an essential part of many tasks in language processing, all NLP toolkits contain a tagger and often you need to include it in your processing pipeline to get at the essence of the message. Let’s now look into how this works in practice.
Part-of-speech tagging with spaCy
I want to introduce spaCy[5] – a useful NLP library that you can put under your belt. A number of reasons to look into spaCy in this book are:
- NLTK and spaCy have their complementary strengths, and it’s good to know how to use both;
- spaCy is an actively supported and fast-developing library that keeps up-to-date with the advances in NLP algorithms and models;
- A large community of people work with this library, and you can find code examples of various applications implemented with or for spaCy on their webpage,[6] as well as find answers to your questions on their github;
- spaCy is actively used in industry; and
- It includes a powerful set of tools particularly applicable to large-scale information extraction.
Unlike NLTK that treats different components of language analysis as separate steps, spaCy builds an analysis pipeline from the beginning and applies this pipeline to text. Under the hood, the pipeline already includes a number of useful NLP tools which are run on input text without you needing to call on them separately. These tools include, among others, a tokenizer and a POS tagger. You apply the whole lot of tools with a single line of code calling on the spaCy processing pipeline, and then your program stores the result in a convenient format until you need it. This also ensures that the information is passed between the tools without you taking care of the input-output formats. Figure 5 visualizes spaCy’s NLP pipeline, that we’re going to discuss in more detail next:

Figure 5. spaCy’s processing pipeline with some intermediate results[7]
Machines, unlike humans, don’t treat input text as a sequence of sentences or words – for machines, text is a sequence of symbols. The first step that we applied before was splitting text into words – this step is performed by a tool called tokenizer. Tokenizer uses raw text as an input and returns a list of words as an output. For example, if you pass it a sequence of symbols like “Harry, who Sally met”, it returns a list of tokens [“Harry”, “,”, “who”, …] Next, we apply a stemmer that converts each word to some general form: this tool takes a word as an input and returns its stem as an output. For instance, a stemmer returns a generic, base form “meet” for both “meeting” and “meets”. A stemmer can be run on a list of words, where it treats each word separately and returns a list of correspondent stems. Other tools require an ordered sequence of words from the original text: for example, we’ve seen that it’s easier to figure out that Jabberwock is a noun if we know that it follows a word like “the”; order matters for POS tagging. This means that each of the three tools – tokenizer, stemmer, POS tagger – requires a different type of input and produces a different type of output, and in order to apply them in sequence we need to know how to represent information for each of them. This is what spaCy’s processing pipeline does for you: it runs a sequence of tools and connects their outputs together.
For information retrieval we opted for stemming that converts different forms of a word to a common core. We said that it’s useful because it helps connect words together on a larger scale, but it also produces non-words: you won’t always be able to find stems of the words (e.g. something like “retriev”, the common stem of retrieval and retrieve) in a normal dictionary. An alternative to this tool is lemmatizer, which aims at converting different forms of a word to its base form which can be found in a dictionary: for instance, it returns a lemma retrieval that can be found in a dictionary. Such base form is called lemma. In its processing pipeline, spaCy uses a lemmatizer.
The starting point for spaCy’s processing pipeline is, as before, raw text: for example, “On Friday board members meet with senior managers to discuss future development of the company.” The processing pipeline applies tokenization to this text to extract individual words: [“On”, “Friday”, “board”, …]. The words are then passed to a POS tagger that assigns parts-of-speech (or POS) tags like [“ADP”, “PROPN”,[8] “NOUN”, …], to a lemmatizer that produces output like [“On”, “Friday”, …, “member”, …, “manager”, …], and to a bunch of other tools.
You may notice that the processing tools in Figure 5 are comprised within a pipeline called nlp. As you’ll shortly see in the code, calling on nlp pipeline makes the program first invoke all the pre-trained tools and then applies them to the input text. The output of all the steps gets stored in a “container” called Doc – it contains a sequence of tokens extracted from input text and processed with the tools. Here’s where spaCy implementation comes close to object-oriented programming: the tokens are represented as Token objects with a specific set of attributes. If you’ve done object-oriented programming before, you’ll hopefully see the connection soon. If not, here’s a brief explanation: imagine you want to describe a set of cars. All cars share the list of attributes they have: with respect to cars, you may want to talk about the car model, size, color, year of production, body style (e.g. saloon, convertible), type of engine, etc. At the same time, such attributes as wingspan or wing area won’t be applicable to cars – they rather relate to planes. You can define a class of objects called Car and require that each object car of this class should have the same information fields, for instance calling on car.model should return the name of the model of the car, for example car.model=“Volkswagen Beetle”, and car.production_year should return the year the car was made, for example car.production_year=“2003”, etc.
This is the approach taken by spaCy to represent tokens in text: after tokenization, each token (word) is packed up in an object Token that has a number of attributes. For instance:
token.textcontains the original word itself;token.lemma_stores the lemma (base form) of the word;[9]token.pos_– its part-of-speech tag;token.i– the index position of the word in text;token.lower_– lowercase form of the word;
and so on.
The nlp pipeline aims to fill in the information fields like lemma, pos and others with the values specific for each particular token. Because different tools within the pipeline provide different bits of information, the values for the attributes are added on the go. Figure 6 visualizes this process for the words “on” and “members” in the text “On Friday board members meet with senior managers to discuss future development of the company”:

Figure 6. Processing of words “On” and “members” within the nlp pipeline
Now, let’s see how this is implemented in Python code. Listing 1 provides you with an example.
Listing 1. Code exemplifying how to run spaCy’s processing pipeline
import spacy #A
nlp = spacy.load("en_core_web_sm") #B
doc = nlp("On Friday board members meet with senior managers " +
"to discuss future development of the company.") #C
rows = []
rows.append(["Word", "Position", "Lowercase", "Lemma", "POS", "Alphanumeric", "Stopword"]) #D
for token in doc:
rows.append([token.text, str(token.i), token.lower_, token.lemma_,
token.pos_, str(token.is_alpha), str(token.is_stop)]) #E
columns = zip(*rows) #F
column_widths = [max(len(item) for item in col) for col in columns] #G
for row in rows:
print(''.join(' {:{width}} '.format(row[i], width=column_widths[i])
for i in range(0, len(row)))) #H
#A Start by importing spaCy library
#B spacy.load command initializes the nlp pipeline. The input to the command is a particular type of data (model) that the language tools were trained on. All models use the same naming conventions (en_core_web_), which means that it’s a set of tools trained on English Web data; the last bit denotes the size of data the model was trained on, where sm stands for ‘small’[10]
#C Provide the nlp pipeline with input text
#D Let’s print the output in a tabular format. For clarity, add a header to the printout
#E Add the attributes of each token in the processed text to the output for printing
#F Python’s zip function[11] allows you to reformat input from row-wise representation to column-wise
#G As each column contains strings of variable lengths, calculate the maximum length of strings in each column to allow enough space in the printout
#H Use format functionality to adjust the width of each column in each row as you print out the results[12]
Here’s the output that this code returns for some selected words from the input text:
Word Position Lowercase Lemma POS Alphanumeric Stopword On 0 on on ADP True False Friday 1 friday friday PROPN True False ... members 3 members member NOUN True False ... to 8 to to PART True True discuss 9 discuss discuss VERB True False ... . 15 . . PUNCT False False
This output tells you:
- The first item in each line is the original word from text – it’s returned by
token.text; - The second is the position in text, which starts as all other indexing in Python from zero – this is identified by
token.i; - The third item is the lowercase version of the original word. You may notice that it changes the forms of “On” and “Friday”. This is returned by
token.lower_; - The fourth item is the lemma of the word, which returns “member” for “members” and “manager” for “managers”. Lemma is identified by
token.lemma_; - The fifth item is the part-of-speech tag. Most of the tags should be familiar to you by now. The new tags in this piece of text are PART, which stands for “particle” and is assigned to particle “to” in “to discuss”, and PUNCT for punctuation marks. POS tags are returned by
token.pos_; - The sixth item is a True/False value returned by
token.is_alpha, which checks whether a word contains alphabetic characters only. This attribute is False for punctuation marks and some other sequences that don’t consist of letters only, and it’s useful for identifying and filtering out punctuation marks and other non-words; - Finally, the last, seventh item in the output is a True/False value returned by
token.is_stop, which checks whether a word is in a stopwords list – a list of highly frequent words in language that you might want to filter out in many NLP applications, as they aren’t likely to be informative. For example, articles, prepositions and particles have theiris_stopvalues set to True as you can see in the output above.
Solution: Despite the fact that a text like “Jabberwocky” contains non-English words, or possibly non-words at all, this Python code is able to tell that “Jabberwock” and “Bandersnatch” are some creatures that have specific names (it assigns a tag PROPN, proper noun to both of them), and that “frumious” is an adjective. How does it do that? Here’s a glimpse under the hood of a typical POS tagging algorithm (see Figure 7):

Figure 7. A glimpse under the hood of a typical POS tagging algorithm
We’ve said earlier that when we try to figure out what type of a word something like “Jabberwock” is we rely on the context. In particular, the previous words are important to take into account: if we see “the”, chances that the next word is a noun or an adjective are high, but a chance that we see a verb next is minimal – verbs shouldn’t follow articles in grammatically correct English. Technically, we rely on two types of intuitions: we use our expectations about what types of words typically follow other types of words, and we also rely on our knowledge that words like “fish” can be nouns or verbs but hardly anything else. We perform the task of word type identification in sequence. For instance, in the example from Figure 7, when the sentence begins, we already have certain expectations about what type of a word we may see first – quite often, it’s a noun or a pronoun (like “I”). Once we’ve established that it’s likely for a pronoun to start a sentence, we also rely on our intuitions about how likely it is that such a pronoun will be exactly “I”. Then we move on and expect to see a particular range of word types after a pronoun – almost certainly it should be a normal verb or a modal verb (as verbs denoting obligations like “should” and “must” or abilities like “can” and “may” are technically called). More rarely, it may be a noun (like “I, Jabberwock”), an adjective (“I, frumious Bandersnatch”), or some other part of speech. Once we’ve decided that it’s a verb, we assess how likely it is that this verb is “can”; if we’ve decided that it’s a modal verb, we assess how likely it is that this modal verb is “can”, etc. We proceed like that until we reach the end of the sentence, and this is where we assess which interpretation we find more likely. This is one possible step-wise explanation of how our brain processes information, on which part-of-speech tagging is based.
The POS tagging algorithm takes into account two types of expectations: an expectation that a certain type of a word (like modal verb) may follow a certain other type of a word (like pronoun), and an expectation that if it’s a modal verb such a verb may be “can”. These “expectations” are calculated using the data: for example, to find out how likely it is that a modal verb follows a pronoun, we calculate the proportion of times we see a modal verb following a pronoun in data among all the cases where we saw a pronoun. For instance, if we saw ten pronouns like “I” and “we” in data before, and five times out of those ten these pronouns were followed by a modal verb like “can” or “may” (as in “I can” and “we may”), what’s the likelihood, or probability, or seeing a modal verb following a pronoun be? Figure 8 gives a hint on how probability can be estimated:

Figure 8. If modal verb follows pronoun 5 out of 10 times, the probability is 5/10
We can calculate it as:
Probability(modal verb follows pronoun) = 5 / 10
or in general case:
Probability(modal verb follows pronoun) = How_often(pronoun is followed by verb) / How_often(pronoun is followed by any type of word, modal verb or not)
To estimate how likely (or how probable) it is that the pronoun is “I”, we need to take the number of times we’ve seen a pronoun “I” and divide it by the number of times we’ve seen any pronouns in the data. If among those ten pronouns that we’ve seen in the data before seven were “I” and three were “we”, the probability of seeing a pronoun “I” is estimated as Figure 9 illustrates:

Figure 9. If 7 times out of 10 the pronoun is “I”, the probability of a word being “I’ given that we know the POS of such a word is pronoun is 7/10
Probability(pronoun being “I”) = 7 / 10
or in general case:
Probability(pronoun being “I”) = How_often(we’ve seen a pronoun “I”) / How_often(we’ve seen any pronoun, “I” or other)
In the end, the algorithm goes through the sequence of tags and words one by one, and takes all the probabilities into account. Because the probability of each decision, each tag and each word is a separate component in the process, these individual probabilities are multiplied. To find out how probable it is that “I can fish” means “I am able / know how to fish”, the algorithm calculates:
Probability(“I can fish” is “pronoun modal_verb verb”) = probability(a pronoun starts a sentence) * probability(this pronoun is “I”) * probability(a pronoun is followed by a modal verb) * probability(this modal verb is “can”) * … * probability(a verb finishes a sentence)
This probability gets compared with the probabilities of all the alternative interpretations, like “I can fish” = “I put fish in cans”:
Probability(“I can fish” is “pronoun verb noun”) = probability(a pronoun starts a sentence) * probability(this pronoun is “I”) * probability(a pronoun is followed by a verb) * probability(this verb is “can”) * … * probability(a noun finishes a sentence)
In the end, the algorithm compares the calculated probabilities for the possible interpretations and chooses the one which is more likely, i.e. has higher probability.
That’s all for this article. We’re going to move onto syntactic parsing in part 2.
If you want to learn more about the book, you can preview its contents on our browser-based liveBook platform here.
[2] A blend of “fuming” and “furious”, according to Lewis Carroll himself.
[3] Formally, when a word has several meanings this is called lexical ambiguity.
[5] To get more information on the library, check https://spacy.io. Installation instructions walk you through the installation process depending on the operating system you’re using: https://spacy.io/usage#quickstart.
[8] In the scheme used by spaCy, prepositions are referred to as “adposition” and use a tag ADP. Words like “Friday” or “Obama” are tagged with PROPN, which stands for “proper nouns” reserved for names of known individuals, places, time references, organizations, events and such. For more information on the tags, see documentation here: https://spacy.io/api/annotation.
[9] You may notice that some attributes are called on using an underscore, like token.lemma_. This is applicable when spaCy has two versions for the same attribute: for example, token.lemma returns an integer version of the lemma, which represents a unique identifier of the lemma in the vocabulary of all lemmas existing in English, and token.lemma_ returns a Unicode (plain text) version of the same thing – see the description of the attributes on https://spacy.io/api/token.
[10] Check out the different language models available for use with spaCy: https://spacy.io/models/en. Small model (en_core_web_sm) is suitable for most purposes and it’s more efficient to upload and use, but larger models like en_core_web_md (medium) and en_core_web_lg (large) are more powerful and some NLP tasks require the use of such larger models.
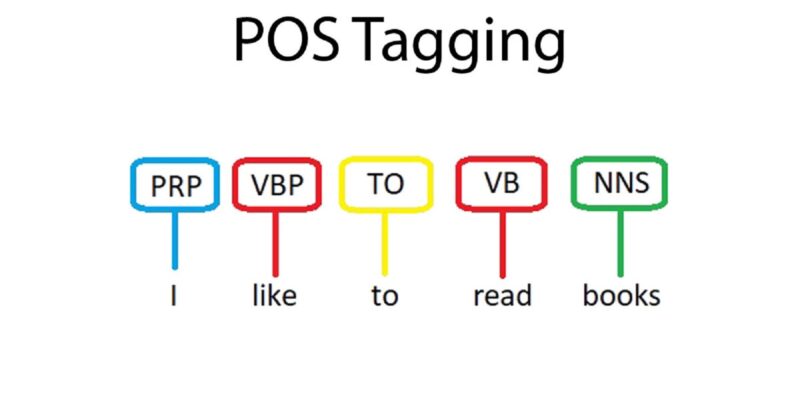
As discussed in Stages of Natural Language Processing, Syntax Analysis deals with the arrangement of words to form a structure that makes grammatical sense. A sentence is syntactically correct when the Parts of Speech of the sentence follow the rules of grammar. To achieve this, the given sentence structure is compared with the common language rules.
Part of Speech
Part of Speech is the classification of words based on their role in the sentence. The major POS tags are Nouns, Verbs, Adjectives, Adverbs. This category provides more details about the word and its meaning in the context. A sentence consists of words with a sensible Part of Speech structure.
For example: Book the flight!
This sentence contains Noun (Book), Determinant (the) and a Verb (flight).
Part Of Speech Tagging
POS tagging refers to the automatic assignment of a tag to words in a given sentence. It converts a sentence into a list of words with their tags. (word, tag). Since this task involves considering the sentence structure, it cannot be done at the Lexical level. A POS tagger considers surrounding words while assigning a tag.
For example, the previous sentence, “Book the flight”, will become a list of each word with its corresponding POS tag – [(“Book”, “Verb”), (“the”, “Det”), (“flight”, “Noun”)].
Similarly, “I like to read book” is represented as: [(“I”, “Preposition”), (“like”, “Verb”), (“to”, “To”), (“read”, “Verb”), (“books”, “Noun”)]. Notice how the word Book appears in both sentences. However, in the first example, it acts as a Verb but takes the role of a Noun in the latter.
Although we are using the generic names of the tags, in real practice, we refer a tagset for tags. The Penn TreeBank Tag Set is most used for the English language. Some examples from Penn Treebank:
| Part Of Speech | Tag |
| Noun (Singular) | NN |
| Noun (Plural) | NNS |
| Verb | VB |
| Determiner | DT |
| Adjective | JJ |
| Adverb | RB |
Difficulties in POS Tagging
Similar to most NLP problems, POS tagging suffers from ambiguity. In the sentences, “Book the flight” and “I like to read books”, we see that book can act as a Verb or Noun. Similarly, many words in the English dictionary has multiple possible POS tags.
- This (Preposition) is a car
- This (Determiner) car is red
- You can go this (Adverb) far only.
These sentences use the word “This” in various contexts. However, how can one assign the correct tag to the words?
POS Tagging Approaches
-
Rule-Based POS Tag
- Get all the possible POS tags for individual words: A – Article; Book – Noun or Verb
- Use the rules to assign the correct POS tag: As per the possible tags, “A” is an Article and we can assign it directly. But, a book can either be a Noun or a Verb. However, if we consider “A Book”, A is an article and following our rule above, Book has to be a Noun. Thus, we assign the tag of Noun to book.
-
Stochastic Tagger
- Word Frequency: In this approach, we find the tag that is most assigned to the word. For example: Given a training corpus, “book” occurs 10 times – 6 times as Noun, 4 times as a Verb; the word book will always be assigned as “Noun” since it occurs the most in the training set. Hence, a Word Frequency Approach is not very reliable.
- Tag Sequence Frequency: Here, the best tag for a word is determined using the probability the tags of N previous words, i.e. it considers the tags for the words preceding book. Although this approach provides better results than a Word Frequency Approach, it may still not provide accurate results for rare structures. Tag Sequence Frequency is also referred to as the N-gram approach.
This is one of the oldest approaches to POS tagging. It involves using a dictionary consisting of all the possible POS tags for a given word. If any of the words have more than one tag, hand-written rules are used to assign the correct tag based on the tags of surrounding words.
For example, if the preceding of a word an article, then the word has to be a noun.
Consider the words: A Book
POS Tag: [(“A”, “Article”), (“Book”, “Noun”)]
Similarly, various rules are written or machine-learned for other cases. Using these rules, it is possible to build a Rule-based POS tagger.
A Stochastic Tagger, a supervised model, involves using with frequencies or probabilities of the tags in the given training corpus to assign a tag to a new word. These taggers entirely rely on statistics of the tag occurrence, i.e. probability of the tags.
Based on the words used for determining a tag, Stochastic Taggers are divided into 2 parts:
Note: There are other methods for POS tagging as well, including Deep Learning approach. However, for most applications, N-gram model provides great results to work with.
Part of Speech Tagging in NLTK
NLTK comes with a POS Tagger to use off-the-shelf. The tagger takes tokens as input and returns a tuple of word with it’s corresponding POS tag. If you are following the series, you already have the required packages. However, if you directly landed on this blog, we recommend to go through Tokenization and Stopwords and Filtering. Once you have the necessary downloads, you can use the POS tagger directly.
""" This block of code snippet is stolen from our blog on Stopwords and Filtering """
import nltk
import string
text = "This is an example text for stopword removal and filtering. This is done using NLTK's stopwords."
words = nltk.word_tokenize(text)
stopwords = nltk.corpus.stopwords.words("english")
# Extending the stopwords list
stopwords.extend(string.punctuation)
# Remove stop words and tokens with length < 2
cleaned = [word.lower() for word in words if (word not in stopwords) and len(word) > 2]
""" End of stolen code """
# Assign POS Tags to the words
tagged = nltk.pos_tag(cleaned)
print(tagged)Output
[("this", "DT"), ("example", "NN"), ("text", "NN"), ("stopword", "NN"), ("removal", "NN"), ("filtering", "VBG"), ("this", "DT"), ("done", "VBN"), ("using", "VBG"), ("nltk", "JJ"), ("stopwords", "NNS")]Thus, we successfully got POS tags for the given text input.
Further in the series: Hidden Markov Model (HMM) Tagger in NLP
References
- Part-of-speech tagging – Wikipedia
- NLP Guide: Identifying Part of Speech Tags using Conditional Random Fields
- Categorizing and Tagging Words (nltk.org)

Deep Mehta is a Machine Learning Engineer, Web Developer and Technical Blogger, currently pursuing Masters in Computer Science from New York University. In addition to being one of the founders of byteiota.com, he is an enthusiast in the domain of Artificial Intelligence. When he isn’t working, he is either reading or writing a blog.
- Website
Part of Speech Tagging
As an initial review of parts of speech, if you need a refresher, the following Schoolhouse Rocks videos should get you squared away:
- A noun is a person, place, or thing.
- Interjections
- Pronouns
- Verbs
- Unpack your adjectives
- Lolly Lolly Lolly Get Your Adverbs Here
- Conjunction Junction (personal fave)
Aside from those, you can also learn how bills get passed, about being a victim of gravity, a comparison of the decimal to other numeric systems used by alien species (I recommend the Chavez remix), and a host of other useful things.
Basic idea
With part-of-speech tagging, we classify a word with its corresponding part of speech. The following provides an example.
| JJ | JJ | NNS | VBP | RB |
| Colorless | green | ideas | sleep | furiously. |
We have two adjectives (JJ), a plural noun (NNS), a verb (VBP), and an adverb (RB).
Common analysis may then be used to predict POS given the current state of the text, comparing the grammar of different texts, human-computer interaction, or translation from one language to another. In addition, using POS information would make for richer sentiment analysis as well.
POS Examples
The following approach to POS-tagging is very similar to what we did for sentiment analysis as depicted previously. We have a POS dictionary, and can use an inner join to attach the words to their POS. Unfortunately, this approach is unrealistically simplistic, as additional steps would need to be taken to ensure words are correctly classified. For example, without more information, we are unable to tell if some words are being used as nouns or verbs (human being vs. being a problematic part of speech). However, this example can serve as a starting point.
Barthelme & Carver
In the following we’ll compare three texts from Donald Barthelme:
- The Balloon
- The First Thing The Baby Did Wrong
- Some Of Us Had Been Threatening Our Friend Colby
As another comparison, I’ve included Raymond Carver’s What we talk about when we talk about love, the unedited version. First we’ll load an unnested object from the sentiment analysis, the barth object. Then for each work we create a sentence id, unnest the data to words, join the POS data, then create counts/proportions for each POS.
Next we read in and process the Carver text in the same manner.
This visualization depicts the proportion of occurrence for each part of speech across the works. It would appear Barthelme is fairly consistent, and also that relative to the Barthelme texts, Carver preferred nouns and pronouns.
More taggin’
More sophisticated POS tagging would require the context of the sentence structure. Luckily there are tools to help with that here, in particular via the openNLP package. In addition, it will require a certain language model to be installed (English is only one of many available). I don’t recommend doing so unless you are really interested in this (the openNLPmodels.en package is fairly large).
We’ll reexamine the Barthelme texts above with this more involved approach. Initially we’ll need to get the English-based tagger we need and load the libraries.
Next comes the processing. This more or less follows the help file example for ?Maxent_POS_Tag_Annotator. Given the several steps involved I show only the processing for one text for clarity. Ideally you’d write a function, and use a group_by approach, to process each of the texts of interest.
Let’s take a look. I’ve also done the other Barthelme texts as well for comparison.
| word | pos | text |
|---|---|---|
| The | DT | baby |
| first | JJ | baby |
| thing | NN | baby |
| the | DT | baby |
| baby | NN | baby |
| did | VBD | baby |
| wrong | JJ | baby |
| was | VBD | baby |
| to | TO | baby |
| tear | VB | baby |
| pages | NNS | baby |
| out | IN | baby |
| of | IN | baby |
| her | PRP$ | baby |
| books | NNS | baby |
As we can see, we have quite a few more POS to deal with here. They come from the Penn Treebank. The following table notes what the acronyms stand for. I don’t pretend to know all the facets to this.
Plotting the differences, we now see a little more distinction between The Balloon and the other two texts. It is more likely to use the determiners, adjectives, singular nouns, and less likely to use personal pronouns and verbs (including past tense).
Tagging summary
For more information, consult the following:
- Penn Treebank
- Maxent function
As with the sentiment analysis demos, the above should be seen only starting point for getting a sense of what you’re dealing with. The ‘maximum entropy’ approach is just one way to go about things. Other models include hidden Markov models, conditional random fields, and more recently, deep learning techniques. Goals might include text prediction (i.e. the thing your phone always gets wrong), translation, and more.
POS Exercise
As this is a more involved sort of analysis, if nothing else in terms of the tools required, as an exercise I would suggest starting with a cleaned text, and seeing if the above code in the last example can get you to the result of having parsed text. Otherwise, assuming you’ve downloaded the appropriate packages, feel free to play around with some strings of your choosing as follows.
Contents
- 1 Introduction
- 2 What is POS Tagging?
- 2.1 Why POS tag is used
- 3 POS Tagging in Spacy Library
- 3.1 Spacy POS Tags List
- 3.2 Spacy POS Tagging Example
- 4 Fine Grained POS Tag
- 4.1 Fine Grained POS Tag list
- 5 Morphology
- 6 Counting POS Tags in Spacy
- 6.1 Counting fine-grained tags
- 7 Visualizing the POS Tags in Spacy
-
- 7.0.1 Parameters
- 7.1 Visualizing POS Tags in Long Texts in Spacy
-
Introduction
In this article, we will take you through the tutorial for Part of Speech or POS Tagging in Spacy library of Python. We will first understand what is POS tagging and why it is used and finally, see some examples of it in Spacy.
What is POS Tagging?
The Part of speech tagging or POS tagging is the process of marking a word in the text to a particular part of speech based on both its context and definition. In simple language, we can say that POS tagging is the process of identifying a word as nouns, pronouns, verbs, adjectives, etc.
Why POS tag is used
Some words can function in more than one way when used in different circumstances. The POS Tagging here plays a crucial role to understand in what context the word is used in the sentence. POS Tagging is useful in sentence parsing, information retrieval, sentiment analysis, etc.
- Also Read – Tutorial on POS Tagging and Chunking in NLTK Python
POS Tagging in Spacy Library
Spacy provides a bunch of POS tags such as NOUN (noun), PUNCT (punctuation), ADJ(adjective), ADV(adverb), etc. It has a trained pipeline and statistical models which enable spaCy to make classification of which tag or label a token belongs to. For example, a word following “the” in English is most likely a noun.
Ad

Spacy POS Tags List
Every token is assigned a POS Tag in Spacy from the following list:
| POS | DESCRIPTION | EXAMPLES |
|---|---|---|
| ADJ | adjective | *big, old, green, incomprehensible, first* |
| ADP | adposition | *in, to, during* |
| ADV | adverb | *very, tomorrow, down, where, there* |
| AUX | auxiliary | *is, has (done), will (do), should (do)* |
| CONJ | conjunction | *and, or, but* |
| CCONJ | coordinating conjunction | *and, or, but* |
| DET | determiner | *a, an, the* |
| INTJ | interjection | *psst, ouch, bravo, hello* |
| NOUN | noun | *girl, cat, tree, air, beauty* |
| NUM | numeral | *1, 2017, one, seventy-seven, IV, MMXIV* |
| PART | particle | *’s, not,* |
| PRON | pronoun | *I, you, he, she, myself, themselves, somebody* |
| PROPN | proper noun | *Mary, John, London, NATO, HBO* |
| PUNCT | punctuation | *., (, ), ?* |
| SCONJ | subordinating conjunction | *if, while, that* |
| SYM | symbol | *$, %, §, ©, +, −, ×, ÷, =, :), 😝* |
| VERB | verb | *run, runs, running, eat, ate, eating* |
| X | other | *sfpksdpsxmsa* |
| SPACE | space |
Spacy POS Tagging Example
POS Tagging in Spacy library is quite easy as seen in the below example. We just instantiate a Spacy object as doc. We iterate over doc object and use pos_ , tag_, to print the POS tag. Spacy also lets you access the detailed explanation of POS tags by using spacy.explain() function which is also printed in the same iteration along with POS tags.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Get busy living or get busy dying.")
print(f"{'text':{8}} {'POS':{6}} {'TAG':{6}} {'Dep':{6}} {'POS explained':{20}} {'tag explained'} ")
for token in doc:
print(f'{token.text:{8}} {token.pos_:{6}} {token.tag_:{6}} {token.dep_:{6}} {spacy.explain(token.pos_):{20}} {spacy.explain(token.tag_)}')
[Out] :
text POS TAG Dep POS explained tag explained Get AUX VB ROOT auxiliary verb, base form busy ADJ JJ amod adjective adjective living NOUN NN dobj noun noun, singular or mass or CCONJ CC cc coordinating conjunction conjunction, coordinating get AUX VB conj auxiliary verb, base form busy ADJ JJ acomp adjective adjective dying VERB VBG xcomp verb verb, gerund or present participle . PUNCT . punct punctuation punctuation mark, sentence closer
Fine Grained POS Tag
Spacy also provides a fine-grained tag that further categorizes a token in different sub-categories. For example, when a word is an adjective it further categorizes it as JJR (comparative adjective), JJS (superlative adjective), or AFX (affix adjective). We can get the list of fine grained tags in Spacy by using nlp.pipe_labels[‘tagger’] as shown in the below example.
In [2]
import spacy
nlp = spacy.load("en_core_web_sm")
tag_lst = nlp.pipe_labels['tagger']
print(len(tag_lst))
print(tag_lst)
[Out] :
50 ['$', "''", ',', '-LRB-', '-RRB-', '.', ':', 'ADD', 'AFX', 'CC', 'CD', 'DT', 'EX', 'FW', 'HYPH', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NFP', 'NN', 'NNP', 'NNPS', 'NNS', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB', 'XX', '_SP', '``']
Fine Grained POS Tag list
Below is a POS tag list, their description, Fine-grained Tag, their description, Morphology, and some examples.
| POS | POS_Description | Fine-grained Tag | Description | Morphology | EXAMPLE | |
|---|---|---|---|---|---|---|
| 0 | ADJ | adjective | AFX | affix | Hyph=yes | The Flintstones were a **pre**-historic family. |
| 1 | ADJ | adjective | JJ | adjective | Degree=pos | This is a **good** sentence. |
| 2 | ADJ | adjective | JJR | adjective, comparative | Degree=comp | This is a **better** sentence. |
| 3 | ADJ | adjective | JJS | adjective, superlative | Degree=sup | This is the **best** sentence. |
| 4 | ADJ | adjective | PDT | predeterminer | AdjType=pdt PronType=prn | Waking up is **half** the battle. |
| 5 | ADJ | adjective | PRP$ | pronoun, possessive | PronType=prs Poss=yes | **His** arm hurts. |
| 6 | ADJ | adjective | WDT | wh-determiner | PronType=int rel | It’s blue, **which** is odd. |
| 7 | ADJ | adjective | WP$ | wh-pronoun, possessive | Poss=yes PronType=int rel | We don’t know **whose** it is. |
| 8 | ADP | adposition | IN | conjunction, subordinating or preposition | It arrived **in** a box. | |
| 9 | ADV | adverb | EX | existential there | AdvType=ex | **There** is cake. |
| 10 | ADV | adverb | RB | adverb | Degree=pos | He ran **quickly**. |
| 11 | ADV | adverb | RBR | adverb, comparative | Degree=comp | He ran **quicker**. |
| 12 | ADV | adverb | RBS | adverb, superlative | Degree=sup | He ran **fastest**. |
| 13 | ADV | adverb | WRB | wh-adverb | PronType=int rel | **When** was that? |
| 14 | CONJ | conjunction | CC | conjunction, coordinating | ConjType=coor | The balloon popped **and** everyone jumped. |
| 15 | DET | determiner | DT | determiner | **This** is **a** sentence. | |
| 16 | INTJ | interjection | UH | interjection | **Um**, I don’t know. | |
| 17 | NOUN | noun | NN | noun, singular or mass | Number=sing | This is a **sentence**. |
| 18 | NOUN | noun | NNS | noun, plural | Number=plur | These are **words**. |
| 19 | NOUN | noun | WP | wh-pronoun, personal | PronType=int rel | **Who** was that? |
| 20 | NUM | numeral | CD | cardinal number | NumType=card | I want **three** things. |
| 21 | PART | particle | POS | possessive ending | Poss=yes | Fred**’s** name is short. |
| 22 | PART | particle | RP | adverb, particle | Put it **back**! | |
| 23 | PART | particle | TO | infinitival to | PartType=inf VerbForm=inf | I want **to** go. |
| 24 | PRON | pronoun | PRP | pronoun, personal | PronType=prs | **I** want **you** to go. |
| 25 | PROPN | proper noun | NNP | noun, proper singular | NounType=prop Number=sign | **Kilroy** was here. |
| 26 | PROPN | proper noun | NNPS | noun, proper plural | NounType=prop Number=plur | The **Flintstones** were a pre-historic family. |
| 27 | PUNCT | punctuation | -LRB- | left round bracket | PunctType=brck PunctSide=ini | rounded brackets **(**also called parentheses) |
| 28 | PUNCT | punctuation | -RRB- | right round bracket | PunctType=brck PunctSide=fin | rounded brackets (also called parentheses**)** |
| 29 | PUNCT | punctuation | , | punctuation mark, comma | PunctType=comm | I**,**me and myself. |
| 30 | PUNCT | punctuation | : | punctuation mark, colon or ellipsis | colon **:** is a punctuation mark | |
| 31 | PUNCT | punctuation | . | punctuation mark, sentence closer | PunctType=peri | Punctuation at the end of sentence**.** |
| 32 | PUNCT | punctuation | ” | closing quotation mark | PunctType=quot PunctSide=fin | “machine learning**”** |
| 33 | PUNCT | punctuation | “” | closing quotation mark | PunctType=quot PunctSide=fin | **””** |
| 34 | PUNCT | punctuation | “ | opening quotation mark | PunctType=quot PunctSide=ini | **”**machine learning” |
| 35 | PUNCT | punctuation | HYPH | punctuation mark, hyphen | PunctType=dash | ML site **-** machinelearningknowledge.ai |
| 36 | PUNCT | punctuation | LS | list item marker | NumType=ord | |
| 37 | PUNCT | punctuation | NFP | superfluous punctuation | ||
| 38 | SYM | symbol | # | symbol, number sign | SymType=numbersign | This is hash**#** symbol. |
| 39 | SYM | symbol | $ | symbol, currency | SymType=currency | Dollar **$** is the name of more than 20 curre… |
| 40 | SYM | symbol | SYM | symbol | this is a symbol **$** | |
| 41 | VERB | verb | BES | auxiliary “be” | Let it **be**. | |
| 42 | VERB | verb | HVS | forms of “have” | I**’ve** seen the Queen | |
| 43 | VERB | verb | MD | verb, modal auxiliary | VerbType=mod | This **could** work. |
| 44 | VERB | verb | VB | verb, base form | VerbForm=inf | I want to **go**. |
| 45 | VERB | verb | VBD | verb, past tense | VerbForm=fin Tense=past | This **was** a sentence. |
| 46 | VERB | verb | VBG | verb, gerund or present participle | VerbForm=part Tense=pres Aspect=prog | I am **going**. |
| 47 | VERB | verb | VBN | verb, past participle | VerbForm=part Tense=past Aspect=perf | The treasure was **lost**. |
| 48 | VERB | verb | VBP | verb, non-3rd person singular present | VerbForm=fin Tense=pres | I **want** to go. |
| 49 | VERB | verb | VBZ | verb, 3rd person singular present | VerbForm=fin Tense=pres Number=sing Person=3 | He **wants** to go. |
| 50 | X | other | ADD | [email protected] | ||
| 51 | X | other | FW | foreign word | Foreign=yes | Hello in spanish is **Hola** |
| 52 | X | other | GW | additional word in multi-word expression | ||
| 53 | X | other | XX | unknown | ||
| 54 | SPACE | space | _SP | space | ||
| 55 | NIL | missing tag |
The theory of parts of
speech and their interaction
Parts of
speech occupy the central position in the language system as they
present the meeting point of lexicon and grammar of language. The
word possesses (обладать)
three main aspects: meaning, form and function. They are the criteria
of classifying the lexicon into parts of speech.
Words
belonging to one part of speech possess a common categorical meaning.
Categorical
meanings
are such generalized abstract meaning as substance for nouns, action
for verbs, property for adjective (прил)
and property of property for adverbs. The semantic properties of
words are projected (проектировать)
into their functional (syntactic) properties.
Primary
(осн)
syntactic
function
are: subject, object and predicative for nouns;
attribute
and predicative for adjectives; adverbial modifier for adverbs.
All words
in English are subdivided into notional
and functional.
Notional parts of speech:
nouns, verbs, adjectives, adverbs.
Functional : prepositions,
conjunctions, interjections, particles, articles.

Notional functional

Meaning lexical meaning no
lexical meaning
Form system of grammatical
form no grammatical forms

F unction
unction
independent part of the Ǿ
sentence
The first common
classification : they are not homogeneous
Functional
verbs: auxiliary verb; Modal verb; Modelyzed; Phasal; link-verbs
The parts
of speech are characterized by a field,
they may occupied the central and periphery.
Periphery
is a zone where parts of speech interact with each other.
Common
zone
– words, which share nominal and adjectable characteristics.
The process
of interaction can be interpreted as the use of one part of speech in
the sphere of another part of speech. The most common way of
functional interaction between parts of speech is the syntactic or
functional transposition.
Functional,
or syntactic transposition
is a syntagmatic process which consists in the use of a word
belonging to one part of speech in the syntactic function
characteristic of another part of speech.
Transposition
– no a new word appears ( the best die young–лучшее
умереть
молодым,
the best- лучший).
Functions of transposition are compensatory (We served ourselves
Chinese style Мы
обслуживаем
себя
по-китайски./adverb
instead adjective/) and expressive ( He thinks the world of you.
(он думает
вы для него весь мир)/noun
instead
adverb)
Соседние файлы в папке Теор.грамматика
- #
- #
- #
- #
- #
- #