
Инструкция по использованию сервиса
Общее
1. Проработанный удобный интерфейс, где каждая кнопка сделана для гибкого управления ядром. Все второстепенные элементы максимально уменьшены и главный акцент сделан на рабочую область. Разделена логика работы: слева окно для запросов, справа — группы.
2. Добавлена возможность работы с большим количеством фраз практически без лагов. На скриншоте выше пример ядра из 100 000 фраз по шкафам. (500 страниц! По 200 фраз на каждую). Все это в вашем браузере с любой точки мира!
3. Убойная скорость сбора и считывания данных. Вот логи сбора фраз и частотностей ядра на 100 000 запросов по скриншоту выше. В целом, весь проект был готов за 5-6 минут. Однако, следует отметить, что в час пик (примерно с обеда и до 19:00 по МСК) сервера яндекса сильно нагружены и скорость может падать.
4. Быстрая сортировка по любому из столбцов для удобного анализа вашего ядра. При нажатии на любой столбец в таблице.
5. Теперь вы можете добавить свои запросы в ядро (Кнопка «+ Запросы«). Это могут быть запросы из каких-либо баз, либо конкурентов или из метрики. Все, что угодно, чтобы сделать ваше ядро полноценным и большим! Вам не стоит переживать из-за дублей. Каждая фраза проходит анализ и явные дубли удаляются налету автоматически.
6. Появились настройки сбора. Вы можете как обновить частоты вашего ядра, так и собрать пропуски (например, вновь добавленных фраз).
7. Быстрый поиск по ядру. Благодаря умному поиску вы запросто найдете любые запросы и слова, которые вам потребуются. Если добавить в конце слова * (звездочку), то он будет искать точное вхождение слова. Без звездочки, любое вхождение. Например, если искать по предлогу «на» без звездочки,то найдет все слова содержащее сочетание букв «на» (например, налегке, насморк, найди и т.д.). Если искать «на*», то покажет только предлоги.
Так же появилась очень полезная функция двойного поиска. Пишем «слово|слово», если поставить * (звездочку), то будет идти поиск по целым словам.
8. Постраничная навигация. Удобная система навигации позволит вам быстро перемещаться даже по большому ядру. При наведении мышки на страницы, появляется блок содержащий все страницы. Так же реализована система горячих клавиш. При нажатии Ctrl + → (стрелка вправо), страница вперед. При нажатии ctrl + ← (стрелка влево), страница назад.
9. Множественный выбор строк: Выделяете строку кликом мышки, потом зажимаете SHIFT и выделяете другую строку кликом мышки. Так выделится весь интервал нужных строк.
10. Кнопки действия
- «Выделить все» (выделяет все запросы на данной странице),
- «Сгруппировать» (группирует выделенные запросы, подробнее ниже),
- «В буфер» (копирует активную страницу с запросами в буфер),
- «Удалить» (удаляет выбранные запросы),
- «Выгрузить» (Выгрузка в формате .csv)
Стеммер
1. Удобный стеммер, который показывает наиболее частые слова в вашем ядре. Многие помнят его с прошлой версии word-keeper, но теперь это еще более удобный инструмент. Теперь можно выделять как группы слов, так и отдельные слова. Также помимо действия «удалить» из ядра все строки с этим словом, появилась кнопка «В группу». Что позволяет быстро создавать группы на основе выбранного слова. При нажатии на слово оно переносится в быстрый поиск. Для выделения множества слов нужно зажать SHIFT и кликнуть мышкой.
2. Полностью отзывчивый модуль. Система следит за вашими действиями с ядром и моментально реагирует на любое удаление фраз из базы. Это будет автоматически обновлять ваш стеммер и вам не придется обновлять его вручную.
3. Кнопка «Обновить» полностью заново пересобирает стеммер. Нужна при добавлении новых слов или изменении конфигурации (подробнее ниже).
4. Настройка «С группами» и «Без групп». Позволяет понять стеммеру какие слова показывать Вам и как удалять из ядра. Если выбрать «с группами», то вы увидите общий список слов из ВСЕГО ядра. Если «без групп», то фразы, которые сгруппированы уже не будут использованы стеммером (ни для удаления, ни для группировки). Он их будет игнорировать. Если вы изменили настройку, то нужно пересобрать стеммер по кнопке «Обновить».
5. Постраничная навигация такая же как и в основном ядре. При наведении мышки показывается блок со страницами. Горячие клавиши: при нажатии SHIFT + → (стрелка вправо), страница вперед. При нажатии SHIFT + ← (стрелка влево), страница назад.
Группы
1. Вы легко можете создавать группы из таблицы запросов. Для этого нужно выделить требуемые запросы и нажать «Сгруппировать». Из стеммера группы можно создать по нажатию одной кнопки «В группу». Из самой вкладки «Группы» при нажатии на кнопку «Новая группа». Для добавления последующих запросов предусмотрен интерфейс Drag & Drop, т.е. выделил запросы и перетащил в нужную группу. Группы можно сворачивать и разворачивать.
2. Также теперь появилась возможность создавать древовидную структуру своих групп. Т.е. создание любого количества групп и подгрупп.
3. Группы можно переименовывать. Зажать CTRL + клик мышкой по названию. После редактирования нажать ENTER.
4. Возможность удалять группы по кнопке «удалить».
5. Задавать родительские группы можно с помощью выпадающего списка «Родитель». Выделяем нужную группу и из списка выбираем требуемого родителя.
6. Вы можете посмотреть запросу сразу из множества групп. Для этого зажмите SHIFT и нажимайте по нужным группам.
Заметки
1. Область заметок для ваших записей, чтобы не забыть что-то важное.
Инструменты
1. Пока реализован только один инструмент. Удаление фраз ниже определенной частотности. Но постепенно буду добавлять новое.
Настройки
1. Здесь будут выводиться различные настройки ядра, которые вы сможете поменять. Сейчас это название и регион. Далее будет все постепенно улучшаться.
Добавление нового ядра
1. Можно выбрать любой из регионов. Указать количество собираемых фраз (подробнее ниже). Собираемые частотности. Очень важно: добавлена возможность сбора самой важной частотки «[!W]». Я думаю нет смысла говорить, насколько она важна в продвижении.
2. Доступен выбор стоплиста, который вы можете составить сами в разделе «Стоплисты».
3. Доступна настройка что именно собирать. Всего два режима: «Все фразы и нужные частотности из wordstat» и «Только частотности по моим фразам». Первый режим парсит фразы и частотки из вордстат, второй — парсит только нужные частотки по вашему списку фраз.
Стоплисты
1. Вы можете составлять собственные базы стоплистов и применять потом их на любых своих проектах. При сборе ядра они будут учитываться. Это удобно! При добавлении нового проекта, ваши слова будут просканированы и явные дубли будут удалены автоматически.
Список всех проектов
1. Возможность видеть очередь вашего проекта. Возможность выгрузки. Также появилась новая функция: клонирование. Создает абсолютную копию вашего ядра.
Обсуждение (Интерактивный чат)
1. У проекта есть интерактивное обсуждение в виде простенького чата. Дописал модуль, согласно пожеланиям. В дальнейшем он будет еще улучшен. Но пока это второстепенное. Добавлены даты. Добавлена возможность ответа по нажатию на ник, улучшен интерфейс.
25.01.2020
На правах рекламы
Всем приветы! Прилетел мне тут интересный сервис на обзор. Как обычно, ничего не ожидал. Просто пошел тестить.
Итак, сервис называется Word keeper и предназначен для сбора ключей. Тут вы такие: “а, ну его нахер, есть же Кей Коллектор”. Но не спешите, в сервисе есть смысл, и этот смысл в просто нереальной СКОРОСТИ! Видели мультик про Макквина? Вот это Макквин для парсинга ключей =))
Содержание
- Мои впечатления
- Группировка
- Кому зайдет?
Мои впечатления
В общем, собирал я через него семантику на 2 малостраничника. Ну как, малостраничника, скорее узких сайта.
Закинул 10-15 основных ключей по которым надо парсить вордстат, нажал “старт” и хотел уже пойти заваривать чай, но секунд через 15, статус задачи показал “готово”. Я, если честно, думал, что-то глюкнуло, зашел в задачку, смотрю, 3500+ ключей с частотками, которые я выбрал!
Да ну нафиг!?
Короче, я не знаю как, но он парсит Вордстат просто со скоростью звука! 1 минута на 10000 ключей, может даже быстрее.
Парсить, к слову, он умеет только вордстат и поисковые подсказки, ну да мне больше и не надо.

p.s. Почему-то показал отрицательное количество фраз. Я там сначала парсил Вордстат, потом в эту же группу парсинг подсказок запустил и после чистки стало отрицательное число. На результат это не влияет, баг какой-то, видать.
Ну так вот, после парсинга хотел выгрузить в Кей Коллектор, там даже формат такой для экспорта есть. Но увидел, что там еще и группировать можно и залип.
Группировка
Могу сказать, что довольно удобно работать с группировкой. Во-первых потому что работает все очень БЫСТРО! Только ввел слов, все уже на экране. Прикольно. Я то привык ждать всех этих подгрузок.
Для группировки набор инструментов тоже весьма интересный.
- Ну, во-первых, все это в окне браузера! Не нужно тыкаться по программам, ждать загрузки, запускать виртуалку, если у тебя мак.
- Во-вторых. Ну реально быстро. Не могу перестать об этом говорить =)
- Есть простые мастхэв инструменты, типа стоп слов и обрезки по частотке. Можно убрать все ниже “!10” в 1 клик. Но это стандартно, это есть везде.
- А вот такую штуку я видел впервые, двоичный поиск или что-то типа такого. В общем, суть в том, что вводишь 2 слова через |. Например Вебмастер|Pasagir и он ищет все ключи в которых есть и 1 и 2 слово. Очень удобно! В КК тоже такое есть, но там надо заходить в фильтр, а здесь без лишних телодвижений.
- Слева ключи, справа блок с группами. Можно делать иерархию, перетягивать слова мышкой, в общем все блага цивилизации. А можно просто выделить ключи и нажать “в группу” и они автоматически сгруппируются в группу и поместятся в папку, которая будет названа в честь самого частотного ключа в группе.
- Еще мне понравился быстрый фильтр по словам в правой части экрана.

Крутая штука. Сразу показывает какие слова часто встречаются в ядре, по ним удобно фильтровать и группировать ядро - А еще охренительная штука! Можно в 1 клик сравнить выдачу по разным ключам. Все работает прям из интерфейса, по клику на “сравнить топ”. Я очень часто юзаю эту функцию. Раньше всегда в арсенкин ходил для этого.

Одинаковые страницы подсвечиваются


Что мне не понравилось:
- Невозможность запустить сразу парсинг и по вордстату и по подсказкам.
- Где поле для фильтра по словам “быстрый поиск”, там нет крестика, который бы очищал поиск. Приходится каждый раз после обработки выдачи по слову, стирать его вручную прежде чем ввести новое.
В общем, за 2 часа я отфильтровал и разгруппировал ядро, в котором от 3500 осталось 500 слов и 12 групп. Это весьма и весьма неплохо!
Кому зайдет?
Считаю, это достойный инструмент для сбора ядра. Который может как дополнить, так и заменить другие. Зависит от задач, которые у вас стоят. Но я бы однозначно потестил.
Особенно круто сервис зайдет:
- Если нужно парсить МНОГО и БЫСТРО!
- Если сбор ключей – одна из основных задач
- Если у тебя мак =)
- Если ты новичок и не хочешь ничего покупать, то здесь есть и бесплатный тариф и нормальный тариф за 100 руб/мес.
На сайте есть подробные инструкции со скринами по каждой функции, хотя в общем-то большая часть и так интуитивно понятна.
Ссылка на сервис – https://word-keeper.ru
По промокоду PASAGIR – скидка 15% на любой тариф на 1 месяц.
Буду рад видеть среди моих подписчиков!
- ВКонтакте большое активное комьюнити вебмастеров
- Инстаграм жизнь вебмастера, много кейсов, годнота в сторис.
- Телега Отчеты по реалити и наблюдения о манимейкинге.
Подпишись на Пасажира, будет интересно!
Email*
Прошло уже больше года, как я запустил первую версию word-keeper и в июле месяце успешно закрыл его в личное пользование  За это время было собрано более 1500 семантических ядер, сотни тысяч фраз скачено из wordstat, зарегалось более 300 человек. Были и постоянные пользователи. Это был маленький и приятный успех с учетом огромной конкуренции в этой сфере. Сервис был полностью бесплатный…
За это время было собрано более 1500 семантических ядер, сотни тысяч фраз скачено из wordstat, зарегалось более 300 человек. Были и постоянные пользователи. Это был маленький и приятный успех с учетом огромной конкуренции в этой сфере. Сервис был полностью бесплатный…
Но все, наверняка, знают каким трудом дается парсинг с wordstat, маленькая скорость, частые ошибки, куча прокси серверов, поиск качественных аккаунтов, постоянно сбои в частотностях (путаются). А если захотите использовать сервисы, то это бешеные ценники, где можно разориться при сборе большого ядра.
Я предлагаю свое решение парсинга актуальных данных из wordstat. Которое ускоряет сбор фраз в десятки раз и освобождает вас от головной боли капчи, прокси и т.д.. И это никакие не базы, а абсолютно актуальные данные за месяц из яндекса. Ссылка на сервис -> word-keeper.ru
Внимание! Сервис в данный момент на стадии тестирования, т.к. работает на новой системе, и могут появляться некоторые баги. Всех прежних пользователей просьба пройти регистрацию заново. Мобильная версия сайта не предусмотрена!
Встречайте, word-keeper 2.0 !
Так что будет в новом арсенале сборщика слов?
![]() Новый Word-keeper
Новый Word-keeper
Общее
1. Проработанный удобный интерфейс, где каждая кнопка сделана для гибкого управления ядром. Все второстепенные элементы максимально уменьшены и главный акцент сделан на рабочую область.
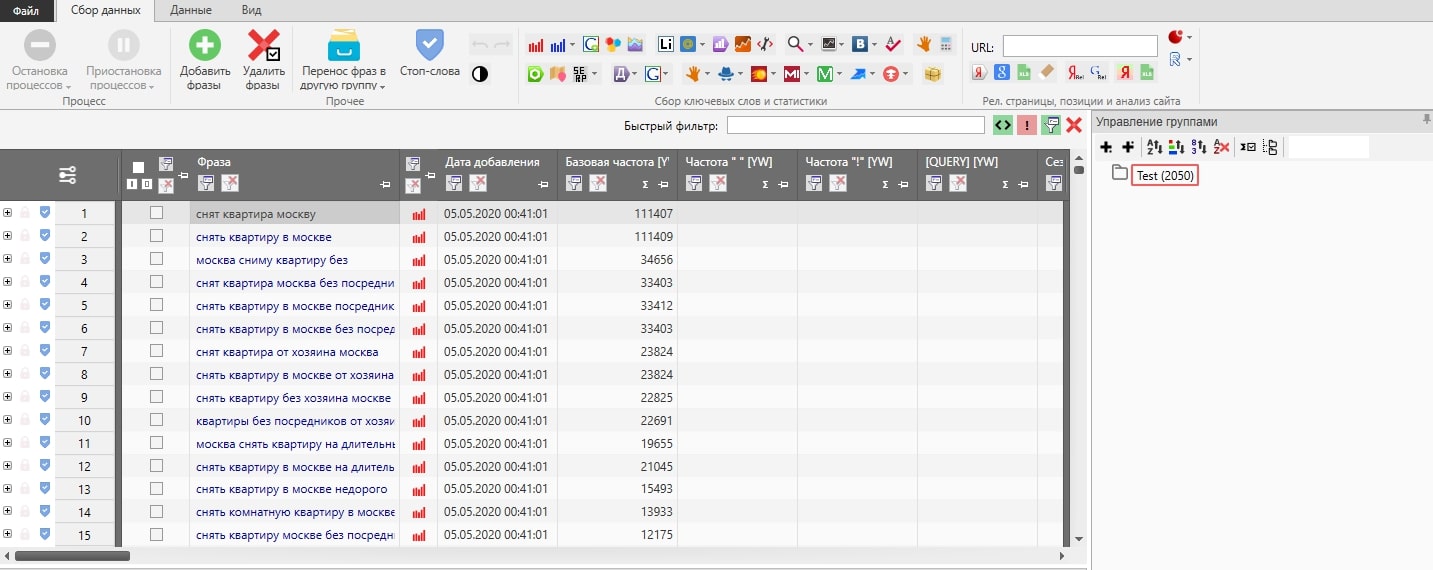
 Ядро
Ядро
2. Добавлена возможность работы с большим количеством фраз практически без лагов. На скриншоте выше пример ядра из 100 000 фраз по шкафам. (500 страниц! По 200 фраз на каждую). Все это в вашем браузере с любой точки мира!
3. Убойная скорость сбора и считывания данных. Вот логи сбора фраз и частотностей ядра на 100 000 запросов по скриншоту выше. В целом, весь проект был готов за 5-6 минут. Однако, следует отметить, что в час пик (примерно с обеда и до 19:00 по МСК) сервера яндекса сильно нагружены и скорость может падать.
 Логи сбора ядра на 100 000 фраз
Логи сбора ядра на 100 000 фраз
4. Быстрая сортировка по любому из столбцов для удобного анализа вашего ядра.
5. Теперь вы можете добавить свои запросы в ядро (Кнопка «+ Запросы»). Это могут быть запросы из каких-либо баз, либо конкурентов или из метрики. Все, что угодно, чтобы сделать ваше ядро полноценным и большим! Вам не стоит переживать из-за дублей. Каждая фраза проходит анализ и явные дубли удаляются налету автоматически.

Добавляйте сколько угодно фраз в ядро!
6. Появились настройки сбора. Вы можете как обновить частоты вашего ядра, так и собрать пропуски (например, вновь добавленных фраз).
 Настройки сбора
Настройки сбора
7. Быстрый поиск по ядру. Благодаря умному поиску вы запросто найдете любые запросы и слова, которые вам потребуются. Если добавить в конце слова * (звездочку), то он будет искать точное вхождение слова. Без звездочки, любое вхождение. Например, если искать по предлогу «на» без звездочки,то найдет все слова содержащее сочетание букв «на» (например, налегке, насморк, найди и т.д.). Если искать «на*», то покажет только предлоги.
 Умный поиск
Умный поиск
Так же появилась очень полезная функция двойного поиска. Пишем «слово|слово», если поставить * (звездочку), то будет идти поиск по целым словам.
 Хитрый двойной поиск. Очень удобная штука!
Хитрый двойной поиск. Очень удобная штука!
8. Постраничная навигация. Удобная система навигации позволит вам быстро перемещаться даже по большому ядру. При наведении мышки на страницы, появляется блок содержащий все страницы. Так же реализована система горячих клавиш. При нажатии Ctrl + → (стрелка вправо), страница вперед. При нажатии ctrl + ← (стрелка влево), страница назад.
 Навигация по ядру
Навигация по ядру
9. Кнопки действия
- «Выделить все» (выделяет все запросы на данной странице),
- «Сгруппировать» (группирует выделенные запросы, подробнее ниже),
- «Удалить» (удаляет выбранные запросы),
- «Выгрузить» (Выгрузка в формате .csv)
Стеммер
1. Удобный стеммер, который показывает наиболее частые слова в вашем ядре. Многие помнят его с прошлой версии word-keeper, но теперь это еще более удобный инструмент. Теперь можно выделять как группы слов, так и отдельные слова. Также помимо действия «удалить» из ядра все строки с этим словом, появилась кнопка «В группу». Что позволяет быстро создавать группы на основе выбранного слова. При нажатии на слово оно переносится в быстрый поиск. Для выделения слова нужно зажать CTRL и кликнуть мышкой.
 Интерфейс стеммера
Интерфейс стеммера
2. Полностью отзывчивый модуль. Система следит за вашими действиями с ядром и моментально реагирует на любое удаление фраз из базы. Это будет автоматически обновлять ваш стеммер и вам не придется обновлять его вручную.
3. Кнопка «Обновить» полностью заново пересобирает стеммер. Нужна при добавлении новых слов или изменении конфигурации (подробнее ниже).
4. Настройка «С учетом групп» и «Без учета групп». Позволяет понять стеммеру какие слова показывать Вам. Если выбрать «с учетом групп», то вы увидите общий список слов из ВСЕГО ядра. Если «без учета групп», то фразы, которые сгруппированы уже не будут использованы стеммером (ни для удаления, ни для группировки). Он их будет игнорировать. Если вы изменили настройку, то нужно пересобрать стеммер по кнопке «Обновить».
5. Постраничная навигация такая же как и в основном ядре. При наведении мышки показывается блок со страницами. Горячие клавиши: при нажатии SHIFT + → (стрелка вправо), страница вперед. При нажатии SHIFT + ← (стрелка влево), страница назад.
Группы
1. Вы легко можете создавать группы из таблицы запросов или стеммера по нажатию одной кнопки. Для добавления последующих запросов предусмотрен интерфейс Drag & Drop, т.е. выделил запросы и перетащил в нужную группу. Группы и папки можно сворачивать и разворачивать.
 Интерфейс групп
Интерфейс групп
2. Также теперь появилась возможность создавать папки, куда вы сможете прятать группы. Для этого надо нажать на белые квадратики справа и вверху в панели выбрать папку куда переместить выделенные группы.
3. Группы и папки можно переименовывать. Зажать CTRL + клик мышкой по названию.
4. Возможность удалять группы и папки. Зажать CTRL + клик мышкой надписи «Del». Сделано для защиты от случайных нажатий. (Позже будет доработано.)
5. При нажатии на частоту (на скриншоте выше «[!W]») она будет меняться. Вы сможете выбрать удобный для себя показатель.
6. Кнопка «В буфер» копирует все запросы из группы.
Заметки
1. Область заметок для ваших записей, чтобы не забыть что-то важное.
 Заметки
Заметки
Инструменты
1. Пока реализован только один инструмент. Удаление фраз ниже определенной частотности. Но постепенно буду добавлять новое.
 Инструменты будут и дальше обновляться
Инструменты будут и дальше обновляться
Настройки
1. Здесь будут выводиться различные настройки ядра, которые вы сможете поменять. Сейчас это название и регион. Далее будет все постепенно улучшаться.
 Настройки вашего ядра
Настройки вашего ядра
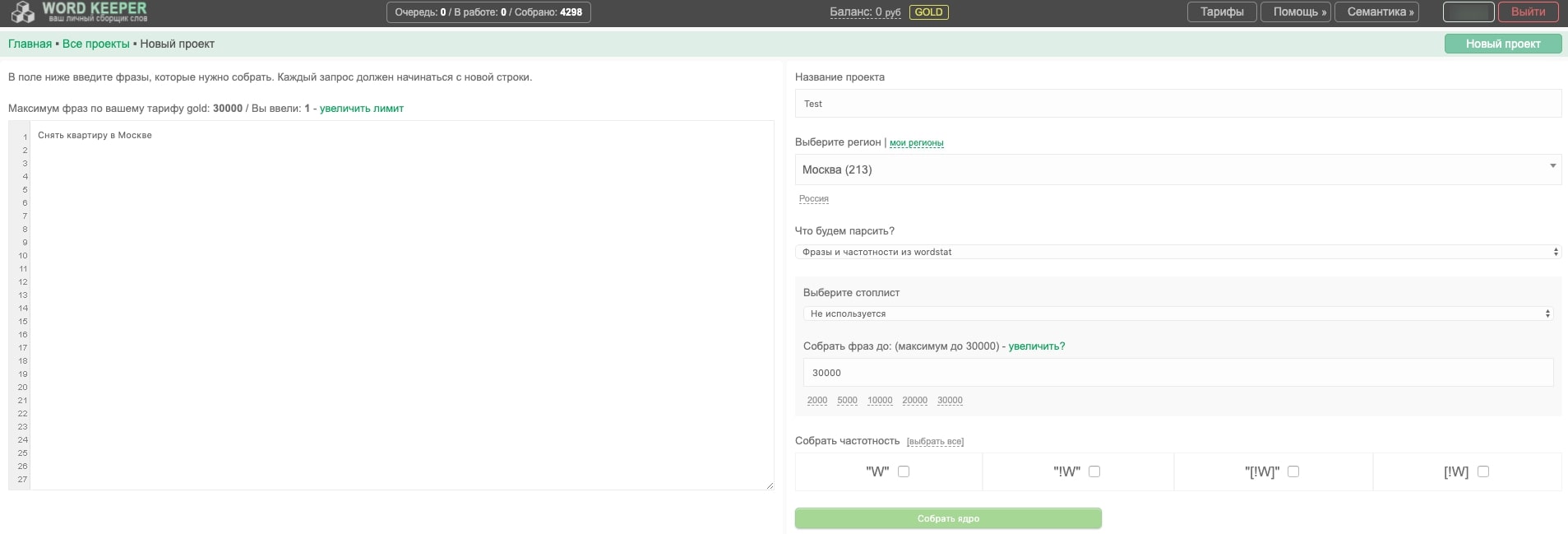
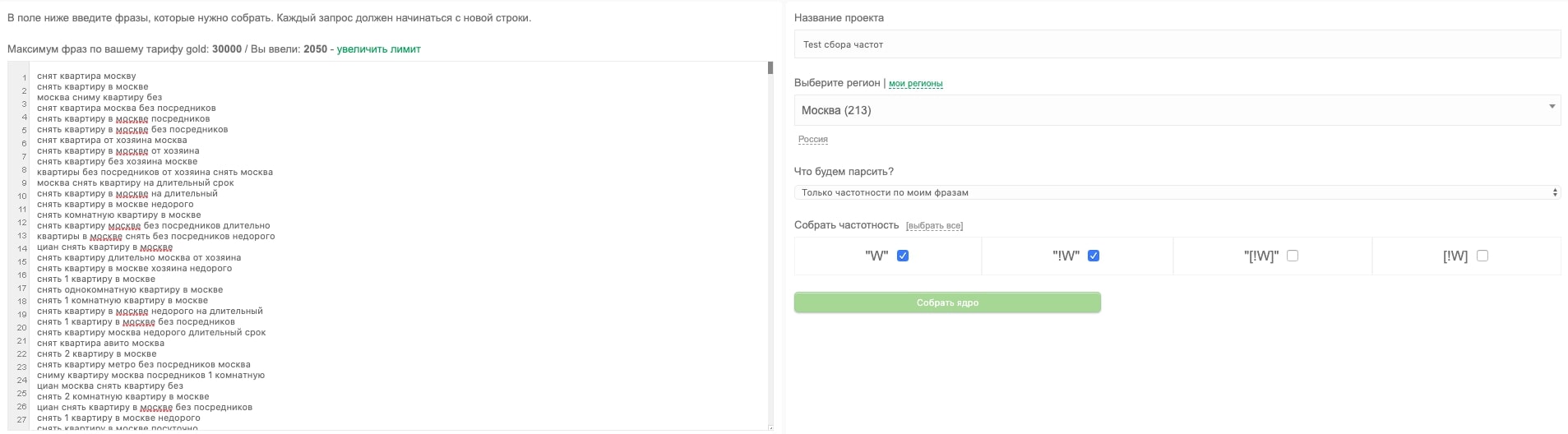
Добавление нового ядра
1. Можно выбрать любой из регионов. Указать количество собираемых фраз (подробнее ниже). Собираемые частотности. Очень важно: добавлена возможность сбора самой важной частотки «[!W]». Я думаю нет смысла говорить, насколько она важна в продвижении.
2. Доступен выбор стоплиста, который вы можете составить сами в разделе «Стоплисты».
3. Доступна настройка что именно собирать. Всего два режима: «Все фразы и нужные частотности из wordstat» и «Только частотности по моим фразам». Первый режим парсит фразы и частотки из вордстат, второй — парсит только нужные частотки по вашему списку фраз.
 Добавление нового ядра
Добавление нового ядра
Стоплисты
1. Вы можете составлять собственные базы стоплистов и применять потом их на любых своих проектах. При сборе ядра они будут учитываться. Это удобно! При добавлении нового проекта, ваши слова будут просканированы и явные дубли будут удалены автоматически.
 Стоплисты
Стоплисты
Список всех проектов
1. Возможность видеть очередь вашего проекта. Возможность выгрузки. Также появилась новая функция: клонирование. Создает абсолютную копию вашего ядра.
 Список всех проектов
Список всех проектов
Обсуждение (Интерактивный чат)
1. У проекта есть интерактивное обсуждение в виде простенького чата. Дописал модуль, согласно пожеланиям. В дальнейшем он будет еще улучшен. Но пока это второстепенное. Добавлены даты. Добавлена возможность ответа по нажатию на ник, улучшен интерфейс.
 Чат проекта
Чат проекта
Итог. Ограничения и чем все это обернется?
Сейчас сервис полностью БЕСПЛАТНЫЙ, так как продолжаю отлавливать баги и причесывать код. Но это продлится недолго.
Хочется сказать, что я потратил огромное количество сил. Это тысячи строк кода, и сотни часов. В этот раз я решил, что такие труды должны хоть как-то окупаться. И чтобы я мог поддерживать и улучшать дальше сервис, в ближайшем будущем внесу изменения.
На проекте сейчас предусмотрены 3 типа пользователей:
- Silver (максимально фраз в 1 проекте до 10 000 фраз).
- Gold (максимально фраз в 1 проекте до 30 000 фраз)
- VIP (максимально фраз в 1 проекте до 60 000 фраз)
Каждый новый пользователь имеет статус Silver. На данный момент никаких больше ограничений нет.
В дальнейшем, после окончательной доработки проекта, будут внесены и другие изменения, а также введены тарифы и стоимость обработки каждого запроса составит всего 0.005 руб. (5 руб за 1000 фраз).
Но сейчас сервис полностью БЕСПЛАТНЫЙ, и вы можете попробовать его возможности. Самые активные пользователи получат от меня бонусы!
Источник
Комментарии:
Войдите или зарегистрируйтесь чтобы оставить комментарий
- Скорость сбора фраз
- Количество фраз
- Скорость сбора частот
- Точность
- Гибкость настроек
- Цена
- Итог
Для большинства SEO-специалистов Key Collector является основным инструментом по сбору семантики. Отличную поддержку, огромный функционал и безотказность, как у автомата Калашникова, оценило не одно поколение сеошников. Но программа не лишена недостатков, чем активно пользуются конкуренты.
Сегодня мы рассмотрим скоростной онлайн-сервис по сбору фраз и частотностей из Яндекс Wordstat – Word Keeper. Основное отличие Word Keeper от Key Collector в том, что это онлайн-сервис, а не десктопное приложение, что даёт возможность комфортно работать с семантикой пользователям на macOS и Linux.
Поскольку Word Keeper заточен ТОЛЬКО под парсинг фраз и частот из Яндекс Wordstat, будет правильным провести сравнение только с аналогичным функционалом у Key Collector, который имеет на борту и десятки других функций. Итак, поехали!
Для теста мы проведём парсинг по фразе «Снять квартиру в Москве». Регион – Москва.
Скорость сбора фраз
Начнём с Word Keeper. Создаём проект и запускаем сбор фраз.

Процесс занял всего 11 секунд.
Теперь на очереди Key Collector.
Скорость работы Key Collector не зависит от мощности компьютера пользователя, но зависит от стабильности интернет-соединения и необходимости использования VPN.
Мы провели тесты на конфигурациях:
- Intel i5-5350U | 8 Gb DDR3 | SSD, ОС Windows 10 Pro Build 18362.778, скорость канала VPN 20 Мбит/с. Процесс занял 19 мин 56 сек.
- Intel i5-4570 | 8 Gb DDR3 | SSD, ОС Windows 10 Enterprise LTSC Build 14393.3630, скорость канала VPN 40 Мбит/с. Процесс занял 19 мин 45 сек.
- Intel Pentium G2020 | 4 Gb DDR3 | HD, ОС Windows 10 Home. Процесс занял 20 минут.
Основное преимущество Word Keeper – скорость сбора не зависит от ОС, стабильности канала VPN и прочих особенностей, которые влияют на работу десктопных приложений, потому что все процессы обрабатываются на сервере.

Количество фраз
При сборе с помощью сервиса Word Keeper мы получили 2886 фраз, Key Collector упёрся в свой потолок в 2050 фраз для одного запроса. Максимальное количество фраз, которое можно получить с помощью Word Keeper в одном проекте, зависит от тарифа и составляет до 50 000 фраз.

Скорость сбора частот
Для тестового сбора частот мы взяли 2050 фраз, которые получили из Key Collector, и загрузили их вручную в Word Keeper.
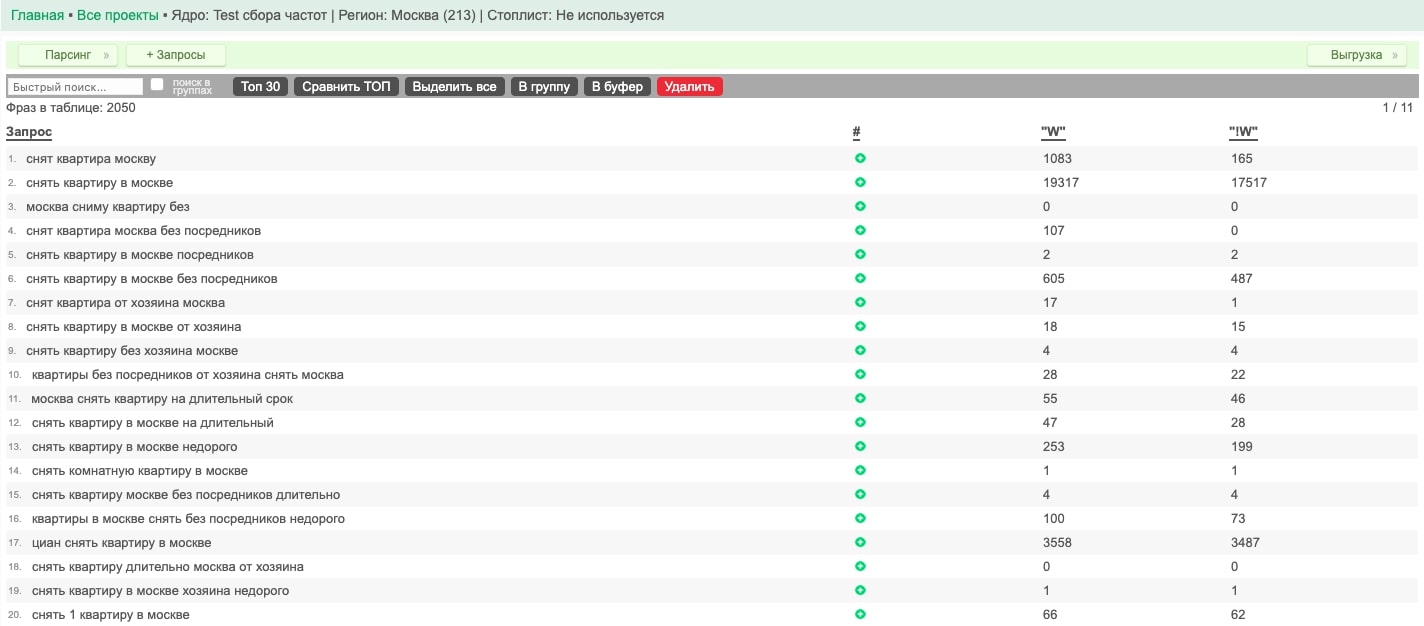
Процесс сбора частот также занял всего 11 сек.
Key Collector справился с этим объёмом примерно за 24 мин. Скорость сбора частот зависит от количества потоков и закапченности аккаунтов, указанных в настройках Key Collector.
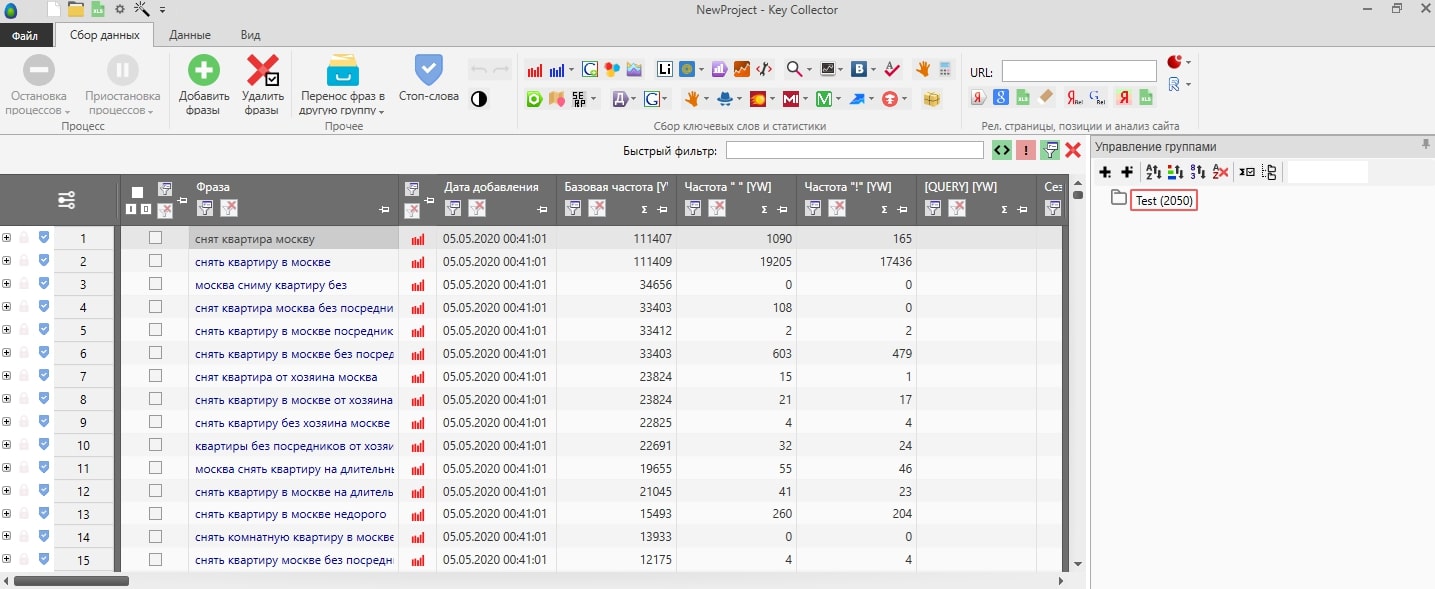
Преимущество в сборе частот с помощью Word Keeper – скорость сбора никак не зависит от канала интернет-соединения, а о том, что существует капча, вообще можно забыть.

Точность
Данные, полученные при сборе частот, мы свели в отдельную таблицу.
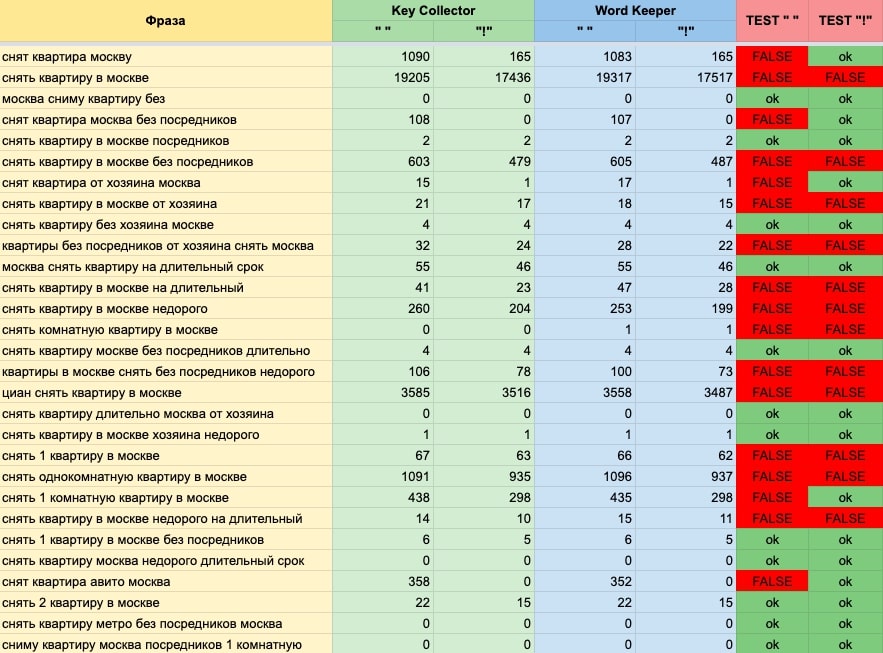
Для наглядности в колонках TEST производим сравнение значений частот, результат теста в случае разбежности подсветим более ярким цветом. Как видим, у нас присутствует расхождение между данными, полученными с помощью Word Keeper и Key Collector. Разница относительно чисел совсем небольшая.
Проверим вручную по трём запросам, по которым отличаются частоты, кто же будет точнее.
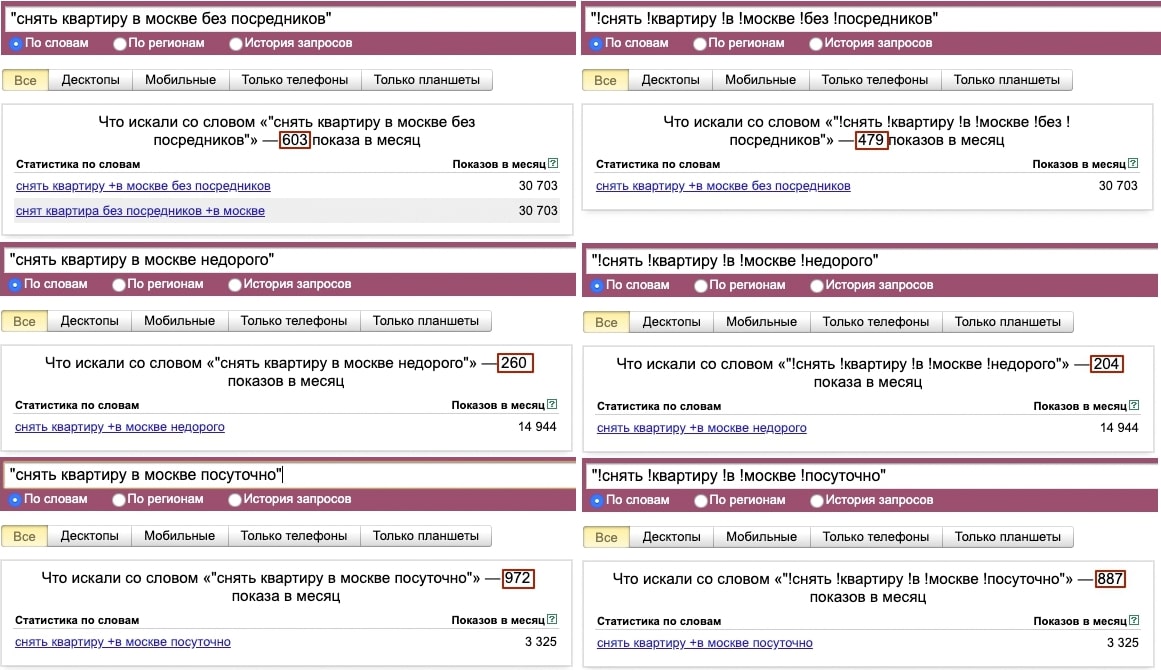
Сведём результат контрольной проверки в одну таблицу.
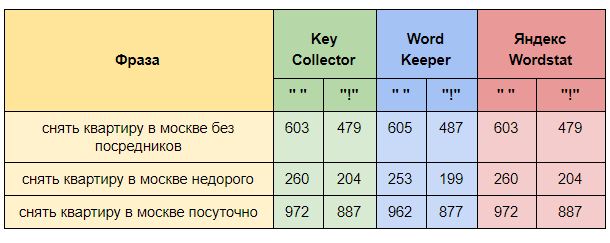
В итоге мы видим, что Key Collector отдаёт более точные данные.

Гибкость настроек
В таблицу мы вынесли основные настройки, которые могут пригодиться при сборе фраз и частот.
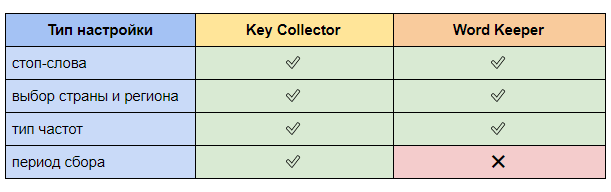
В Word Keeper нет возможности изменять период сбора частот, по умолчанию он составляет 30 дней.

Цена
Лицензия Key Collector бессрочная, и её цена при первой покупке составляет 1800 руб. Сервисом Word Keeper можно пользоваться лишь по подписке, начиная от 100 руб/мес за тариф BRONZE, который имеет только базовые возможности.
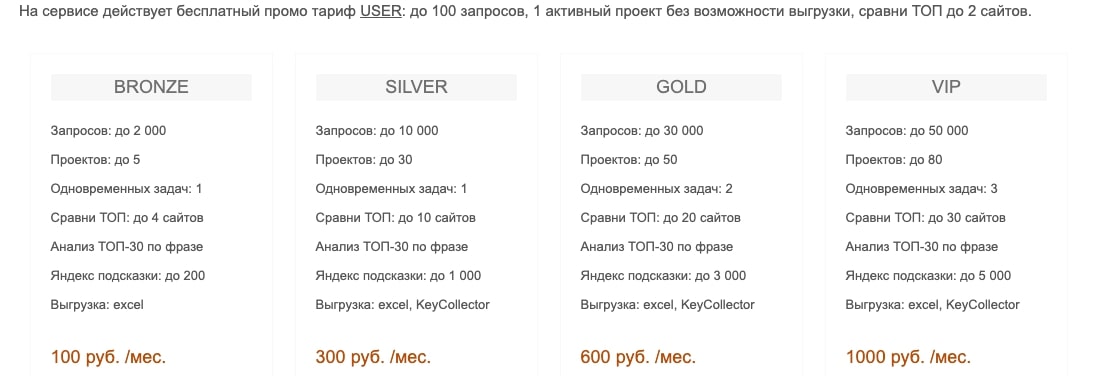
Бессрочная лицензия выгоднее ежемесячной подписки.

Итог
Оба инструмента имеют как сильные, так и слабые стороны при сборе фраз и частот, которые мы наглядно показали, и прежде всего они отлично дополняют друг друга.
Word Keeper – узконаправленный инструмент с единственной задачей: собрать быстро и максимально много фраз и частот из Яндекс Wordstat, хотя функционал сервиса постепенно пополняется.
Word Keeper подойдёт для работы с очень большими объёмами семантики и может в разы ускорить рабочий процесс, полностью исключая время, необходимое для парсинга. В случае сбора частот в проектах с десятками тысяч фраз использование Word Keeper – одно из самых быстрых решений.
Но в целом без гибкости настроек и точности Key Collector никак не обойтись, так как это универсальный инструмент, переплюнуть функционал которого ещё не удалось никому.
Если вы не уверены в своих силах, пишите нам: продвинем сайт в ТОП по приоритетным запросам как можно быстрее!
Заказать продвижение
Еще по теме:
- 10 примеров применения операторов поиска Яндекс и Google
- Как провести аудит ссылочной массы сайта с помощью Ahrefs
- Обзор ТОП-6 лучших парсеров сайтов
- Аудит сайта при помощи плагина SeoTools для Excel — подробная инструкция
- Новая версия Google Search Console – обзор доступных инструментов. Январь 2019
В работе SEO-специалиста есть необходимость отслеживать различные показатели своего сайта и сайтов конкурентов, например: количество страниц в индексе, наличие санкций, релевантность текстов, учет ссылок и…
Преимущества и недостатки Ahrefs, доступные инструменты, детальный разбор возможностей и советы по анализу ссылочной массы вашего сайта и сайтов конкурентов. Читайте в статье, как проанализировать…
Screaming Frog SEO Spider 9.2 ComparseR 1.0.129 Netpeak Spider 3.0 Xenu’s Link Sleuth WildShark SEO Spider Majento SiteAnalayzer Выводы Сегодня представить технический анализ сайта без…
Как спарсить метаданные с помощью Excel, проверить битые ссылки, получить данные из поисковых систем? В сегодняшней статье мы рассмотрим возможности плагина SeoTools – одного из…
Мы планировали сделать обзор новой версии Google Search Console, когда её обновление будет полностью закончено, и в новой панели будут доступны все инструменты. Но прошёл…

SEO-аналитик
Работу в сфере IT начинал с должности контент-менеджера. Уже при создании своих личных проектов постепенно узнавал, что такое SEO, увлекло. Вдохновляюсь сложными и интересными задачами.
Мои увлечения: велоспорт и книги.
Девиз: «Другой жизни не будет!»
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
Парсить ключи вручную – звучит очень долго и муторно. Автоматический парсинг занимает считанные минуты, тогда как на ручной может уйти несколько дней или недель.
Конечно, если у вас не больше 20-30 исходных ключевиков, быстрее всё сделать руками и не заморачиваться с сервисом. Многие из них к тому же платные. Но когда ключей сотни и тысячи, автоматизация сделает значительную часть работы за вас.
В этой статье – краткий обзор самых популярных сервисов сбора семантического ядра, которые пригодятся всем PPC- и SEO-специалистам.
Key Collector
Самая известная программа по работе с семантикой в целом. Её функционал позволяет парсить не просто список ключей, а ключей:
- Из самых разных популярных источников (среди них – рекламные сервисы Yandex Wordstat, Google Ads, Rambler Adstat) и поисковых подсказок систем;
- Вместе со статистикой из Liveinternet, Google Analytics, Яндекс.Метрики, Яндекс.Вебмастер, Serpstat и других сервисов;
- С учетом конкретного региона и сезонности;
- По нужной глубине поиска;
- С оценками стоимости продвижения, популярности, конкуренции, трафика и других параметров;
- Со значениями частотности;
- С возможностью последующей группировки (кластеризации);
- С возможностью составления минус-списков.
Чтобы воспользоваться всеми возможностями Key Collector, нужно установить программу на компьютер.
Стоит такое удовольствие 2 200 рублей при покупке одной лицензии. Если нужно устанавливать программу на 2 и более рабочих местах, стоимость отдельной лицензии снижается. Например, каждая вторая и десятая стоит 1 700 рублей, а каждая одиннадцатая – 1 500 рублей.
За эту стоимость вы получаете постоянно обновляемый инструмент со множеством функций, который довольно легко освоить самостоятельно с нуля и в котором можно работать с большими объемами семантики.
Подробно все функции и фишки Key Collector мы разобрали в этой статье.
Недостатки: большая нагрузка на компьютер, из-за чего он может глючить. И второе – программу не получится запустить на MacOS.
Словоеб
Бесплатный аналог Key Collector – тот же принцип работы и в целом тот же интерфейс.

Функционал по сравнению с KK ограниченный, но его вполне достаточно для небольших проектов.
Итак, Словоеб выполняет парсинг:
- Левой и правой колонок Wordstat;
- Rambler.Adstat;
- Поисковых подсказок Яндекса и Google.
В целом сервис делает всю ту же самую работу, что и вы при сборе ключей в Yandex Wordstat, но автоматически, освобождая вам время на выполнение других задач.
Да, в нем нет многих функций, в том числе чистки и группировки семантики, выгрузки результатов, но этим оправдана его «бесплатность».
Подробное руководство по тому, как работать в Словоебе, смотрите здесь.
SpyWords
Облачный сервис для выгрузки ключевых слов (не парсер!), которыми пользуются ваши конкуренты и в целом для мониторинга конкурентов (домены, объявления, анализ ниши).
С помощью онлайн-сервиса SpyWords вы можете найти ключевые фразы, которые используют конкуренты в Яндекс или Google, и добавить их в свои рекламные кампании, если семантика нужна для контекстной рекламы.

Плюсом к этому можно посмотреть тексты их объявлений, позиции в выдаче, дневной бюджет.
Если внимательнее разбирать отчеты SpyWords, можно найти ключи и нишу, где большой спрос, но мало конкурентов или дешевые клики.
Примечательно, что база запросов большая и регулярно обновляется.
Сервис доступен только платно – от 1 978 рублей в месяц без учета скидок.
Keys.so
Также облачный сервис наподобие SpyWords. Похожие задачи, но чуть больше функционала и, соответственно, выше стоимость.
В нем также есть база ключевых слов, из которой вы можете выгружать ключи конкурентов. Помимо всего этого, вы можете найти ключи по конкретному URL сайта, найти синонимы, дополняющие слова и т.д.
Стоит сервис от 1 500 рублей в месяц при стартовом тарифе. Если платить за год, в месяц выходит по 1 050 рублей.
Rush Analytics
Это платный сервис, который автоматизирует задачи при парсинге семантического ядра, а именно:
- Проверяет позиции в Яндекс и Google;
- Выполняет кластеризацию запросов;
- Собирает ключевые слова на основе поисковых подсказок;
- Собирает данные из Яндекс.Wordstat в облаке;
- Проверяет индексацию URL;
- Анализирует текст и другие зоны страниц.
С помощью Rush Analytics можно удобно и быстро собрать ключевые слова из Яндекс Wordstat (левой и правой колонок) и Google Рекламы, а также поисковые подсказки.
Всё просто: вы задаете свой запрос, по которому хотите найти похожие, и получаете результаты, вместе с данными по частотности. Без риска «схватить» капчу.
Всё начинаете с создания задачи.

Далее по порядку задаете регион и настройки сбора семантики.
Вы можете собирать ключи из левой и правой колонок или с данными по частотности. Укажите, сколько страниц выдачи Вордстата использовать для сбора запросов. Естественно, чем больше страниц – тем больше результатов.
Также в Rush Analytics есть возможность почистить семантику от стоп-слов – для этого сервис предлагает готовые списки стоп-слов по тематикам.
Когда всё готово, отслеживайте процесс сбора на странице задач.
Сервис включает бесплатный триал на 14 дней, после этого стоит от 500 рублей в месяц.
Это условно бесплатный инструмент, с помощью которого можно также собрать подсказки автозаполнения с Google, YouTube, Bing, Amazon, eBay и App Store.
Чтобы им воспользоваться бесплатно, регистрация не нужна. Просто вводите запросы и получаете результаты.

Слева можно использовать фильтр для результатов и задать минус-слова.
Правда, чтобы перейти на русскоязычную версию сайта, нужно переключить язык внизу страницы.
Результаты со статистикой доступны только в платной версии. Цена вопроса – от 48 долларов в месяц.
Букварикс
Букварикс помогает подбирать и выгружать ключевые слова по запросу / запросам или по домену / доменам сайтов.

Причем при подборе по списку запросов можно задавать минус-слова, чтобы сразу исключать из результатов нецелевые фразы.
Дополнительно есть опция «Анализ доменов», благодаря которой вы можете:
- Выяснить, какие слова подойдут для заданного вами сайта;
- Подсмотреть, какие ключи используют ваши конкуренты, но не используете вы.
Еще одна фишка сервиса – бесплатная база 40+ миллионов уникальных рекламных объявлений Яндекс.Директ по России, Украине, Беларуси, Казахстану, которые можно использовать для вдохновения.
Минус – много мусорных запросов и с нулевой частотностью, поэтому нужно обязательно проверять результаты вручную.
На выбор есть бесплатный онлайн-инструмент, бесплатная десктоп-версия и платный бизнес-аккаунт за 995 рублей (695 по скидке).
SemRush
Этот инструмент в бесплатной версии позволяет сформировать под один запрос по 10 фраз в широком и фразовом соответствии под заданный вами регион. По каждой вы видите частотность.
Чтобы начать поиск, нужна регистрация.
Регион вы задаете в начале:

В процессе вы можете посмотреть фразы по этому же ключу, но по другим регионам и почерпнуть оттуда идеи.
Сервис заточен под Google и, к сожалению, в нем не предусмотрена возможность подбирать семантику по списку ключевиков.
Стоимость начинается от $119,95 в месяц и повышается в зависимости от количества рабочих мест и функций.
Serpstat
Serpstat – многофункциональная программа. Она позволяет скачать не только поисковые запросы, по которым рекламируются ваши конкуренты, но и их тексты объявлений и посадочные страницы. А также оценить уровень конкуренции (частотность и цену за клик) по заданному вами ключу.
Все ключи и объявления можно выгружать.
Примерно так выглядит отчет Serpstat:

Минимальный ценник программы без учета скидок – 69 долларов в месяц. Функционала за такую стоимость вполне достаточно для небольших компаний и фрилансеров, кто работает в области SEO и PPC.
Word Keeper
Облачный парсер Wordstat и поисковых подсказок. Основное преимущество – работает в разы быстрее Key Collector.
Также Word Keeper позволяет выгружать топ-30 выдачи по ключевому слову, экспортировать результаты парсинга в Excel и файл программы KK.

Недостатки: отсутствие функций для группировки и чистки результатов.
Чтобы начать им пользоваться, нужно пополнить баланс на 400 рублей минимум. Плюс каждому при регистрации выдается +100 лимитов.
Что не так с автоматическим сбором семантики
Во многих случаях автоматизация решит задачу быстрее и эффективнее. Но слепо на неё полагаться нельзя.
Во-первых, не всегда семантическое соответствие гарантирует смысловое соответствие. Машинный интеллект не сможет выявить все синонимы и переформулировки, или может отнести какие-то варианты к синонимам по ошибке.
Особенно если вы имеете дело со сложными продуктами. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка».
Но среди результатов в Wordstat мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Это разные продукты, а значит, разный спрос. Выявить это можно только вручную.
Во-вторых, очистка семантического ядра от «мусора». Этот процесс почти невозможно автоматизировать полностью. Готовых минус-списков и данных об отказах из систем аналитики недостаточно для 100% точности.
При выборе инструмента для сбора семантического ядра ориентируйтесь на то, из каких источников он ищет поисковые запросы, смотрит ли поисковые подсказки и учитывает ли минус-слова по вашей тематике. И обязательно проверяйте результаты автоматического парсинга!
Хотите тоже написать статью для читателей Yagla? Если вам есть что рассказать про маркетинг, аналитику, бизнес, управление, карьеру для новичков, маркетологов и предпринимателей. Тогда заведите себе блог на Yagla прямо сейчас и пишите статьи. Это бесплатно и просто