
Comparative Study
doi: 10.3766/jaaa.23.2.3.
Affiliations
-
PMID:
22353677
-
DOI:
10.3766/jaaa.23.2.3
Comparative Study
The Words-in-Noise Test (WIN), list 3: a practice list
Richard H Wilson et al.
J Am Acad Audiol.
2012 Feb.
Abstract
Background:
The Words-in-Noise Test (WIN) was developed as an instrument to quantify the ability of listeners to understand monosyllabic words in background noise using multitalker babble (Wilson, 2003). The 50% point, which is calculated with the Spearman-Kärber equation (Finney, 1952), is used as the evaluative metric with the WIN materials. Initially, the WIN was designed as a 70-word instrument that presented ten unique words at each of seven signal-to-noise ratios from 24 to 0 dB in 4 dB decrements. Subsequently, the 70-word list was parsed into two 35-word lists that achieved equivalent recognition performances (Wilson and Burks, 2005). This report involves the development of a third list (WIN List 3) that was developed to serve as a practice list to familiarize the participant with listening to words presented in background babble.
Purpose:
To determine-on young listeners with normal hearing and on older listeners with sensorineural hearing loss-the psychometric properties of the WIN List 3 materials.
Research design:
A quasi-experimental, repeated-measures design was used.
Study sample:
Twenty-four young adult listeners (M = 21.6 yr) with normal pure-tone thresholds (≤ 20 dB HL at 250 to 8000 Hz) and 24 older listeners (M = 65.9 yr) with sensorineural hearing loss participated.
Data collection and analysis:
The level of the babble was fixed at 80 dB SPL with the level of the words varied from 104 to 80 dB SPL in 4 dB decrements.
Results:
For listeners with normal hearing, the 50% points for Lists 1 and 2 were similar (4.3 and 5.1 dB S/N, respectively), both of which were lower than the 50% point for List 3 (7.4 dB S/N). A similar relation was observed with the listeners with hearing loss, 50% points for Lists 1 and 2 of 12.2 and 12.4 dB S/N, respectively, compared to 15.8 dB S/N for List 3. The differences between Lists 1 and 2 and List 3 were significant. The relations among the psychometric functions and the relations among the individual data both reflected these differences.
Conclusions:
The significant ∼3 dB difference between performances on WIN Lists 1 and 2 and on WIN List 3 by the listeners with normal hearing and the listeners with hearing loss dictates caution with the use of List 3. The use of WIN List 3 should be reserved for ancillary purposes in which equivalent recognition performances are not required, for example, as a practice list or a stand alone measure.
American Academy of Audiology.
Similar articles
-
A comparison of two word-recognition tasks in multitalker babble: Speech Recognition in Noise Test (SPRINT) and Words-in-Noise Test (WIN).
Wilson RH, Cates WB.
Wilson RH, et al.
J Am Acad Audiol. 2008 Jul-Aug;19(7):548-56. doi: 10.3766/jaaa.19.7.4.
J Am Acad Audiol. 2008.PMID: 19248731
-
The Revised Speech Perception in Noise Test (R-SPIN) in a multiple signal-to-noise ratio paradigm.
Wilson RH, McArdle R, Watts KL, Smith SL.
Wilson RH, et al.
J Am Acad Audiol. 2012 Sep;23(8):590-605. doi: 10.3766/jaaa.23.7.9.
J Am Acad Audiol. 2012.PMID: 22967734
Clinical Trial.
-
Revising the routine audiologic test battery to examine sources of interpatient variability.
Ochs MT.
Ochs MT.
J Am Acad Audiol. 1990 Oct;1(4):217-26.
J Am Acad Audiol. 1990.PMID: 2132606
Review.
-
Adaptation to noise in normal and impaired hearing.
Marrufo-Pérez MI, Lopez-Poveda EA.
Marrufo-Pérez MI, et al.
J Acoust Soc Am. 2022 Mar;151(3):1741. doi: 10.1121/10.0009802.
J Acoust Soc Am. 2022.PMID: 35364964
Review.
Publication types
MeSH terms
Substances
LinkOut — more resources
-
Miscellaneous
- NCI CPTAC Assay Portal
Yones Lotfi

,
Samira Salim
,
Saiedeh Mehrkian
,
Tayebeh Ahmadi
,
Akbar Biglarian
Abstract
Background and Aim: different tests have been developed to evaluate reduced ability of speech perception in noise, and the words-in-noise test is one of the easiest ones in terms of speech materials. This study aimed to develop and determine the validity and reliability of the Persian version of the words-in-noise (WIN) test for 7 to 12-year-old children.
Methods: This research is a tool-making, non-empirical study including three main stages: first, development of the Persian version of the WIN test (including 2 lists each one designed at each of 7 different signal to noise ratios), second, the assessment of its content validity, and third, its administration on sixty three 7-to 12-year-old normal hearing children (36 boys and 27 girls) with a mean age of 9.32 (SD=1.66) years old, in order to assess the reliability of the test (list equivalency). Participants were selected from the students of primary schools in Tehran.
Results: The content validity ratio for each item was above 0.62. List 1 and 2 of the WIN test were highly correlated (p<0.05). The test-retest correlations were statistically significant for both lists (p<0.05). There was no significant difference between the scores of the left and right ears and gender (p>0.05). The Mean of speech in noise ratio (SNR) 50% for each list was also determined.
Conclusion: Based on the study results, it is concluded that the Persian version of the WIN test has acceptable content validity and reliability and can be used in clinical and research studies.
- About this article
- How to cite
- References
1. Wong PCM, Uppunda AK, Parrish TB, Dhar S. Cortical mechanisms of speech perception in noise. , J Speech Lang Hear Res. 2008;51(4):1026-41.
2. Medwetsky L. Mechanisms underlying central auditory processing. In: Medwetsky L, Burkard R, Hood L, editors. Handbook of clinical audiology. 6th ed. Philadelphia: Lippincott William & Wilkins; 2009. p. 584-610.
3. Lewis D, Hoover B, Choi S, Stelmachowicz P. Relationship between speech perception in noise and phonological awareness skills for children with normal hearing. Ear Hear. 2010;31(6):761-8.
4. Crandell CC, Smaldino JJ. Classroom acoustics for children with normal hearing and with hearing impairment. Lang Speech Hear Serv Sch. 2000;31(4):362-70.
5. Klatte M, Lachmann T, Meis M. Effects of noise and reverberation on speech perception and listening comprehension of children and adults in a classroom-like setting. Noise Health. 2010;12(49):270-82.
6. Schafer EC. Speech perception in noise measures for children: a critical review and case studies. J Educ Audiol. 2010;16:4-15.
7. Nittrouer S, Caldwell-Tarr A, Tarr E, Lowenstein JH, Rice C, Moberly AC. Improving speech-in-noise recog¬nition for children with hearing loss: potential effects of language abilities, binaural summation, and head shadow. Int J Audiol. 2013;52(8):513-25.
8. Fallon M. Children’s perception of speech in noise. Toronto: University of Toronto; 2001.
9. Wilson RH, Farmer NM, Gandhi A, Shelburne E, Weaver J. Normative data for the Words-in-Noise Test for 6- to 12-year-old children. J Speech Lang Hear Res. 2010;53(5):1111-21.
10. Wilson RH, Cates WB. A comparison of two word-recognition tasks in multitalker babble: Speech Recognition in Noise Test (SPRINT) and Words-in-Noise test (WIN). J Am Acad Audiol. 2008;19(7):548-56.
11. Wilson RH, Watts KL. The Words-in-Noise test (WIN), list 3: a practice list. J Am Acad Audiol. 2012;23(2):92-6.
12. Wilson RH, Carnell CS, Cleghorn AL. The Words-in-Noise (WIN) test with multitalker babble and speech-spectrum noise maskers. J Am Acad Audiol. 2007;18(6):522-9.
13. Wilson RH, McArdle R. Intra- and inter-session test, retest reliability of the Words-in-Noise (WIN) test. J Am Acad Audiol. 2007;18(10):813-25.
14. Nematzadeh S. Identification of Iranian primary school students core vocabulary: a brief report of a national project. Journal of Curriculum Studies. 2008;3(9):8-17.
15. Lawshe CH. A quantitative approach to content validity. Pers Psychol. 1975;28(4):563-75.
16. Wilson RH. Development of a speech-in-multitalker-babble paradigm to assess word-recognition performance. J Am Acad Audiol. 2003;14(9):453-70.
17. Wilson RH, Abrams HB, Pillion AL. A word-recognition task in multitalker babble using a descending presentation mode from 24 dB to 0 dB signal to babble. J Rehabil Res Dev. 2003;40(4):321-7.
18. Wilson RH, McArdle RA, Smith SL. An evaluation of the BKB-SIN, HINT, QuickSIN, and WIN materials on listeners with normal hearing and listeners with hearing loss. J Speech Lang Hear Res. 2007;50(4):844-56.
19. McArdle R, Wilson RH. Speech perception in noise: the basics. Perspect Hear Hear Disord Res Res Diagn. 2009;13(1):4-13.
20. Emami SF. Word recognition score in white noise test in healthy listeners. Sch. J. App. Med. Sci. 2015;3(1A):29-33.
| Files |
|
|
| Issue | Vol 25 No 4 (2016) |  |
| Section | Research Article(s) | |
| Keywords | ||
|
Speech perception in noise words-in-noise test validity reliability |
Choosing the right hearing aid isn’t always easy. Not only do many patients have budget constraints that limit them to a certain price spectrum, but different patients have different types of hearing loss.
To reduce the guesswork and match patients with the best hearing aids for their hearing loss, audiologists conduct a variety of hearing tests. Basic pure-tone hearing tests are still the gold standard in fitting hearing aids (like our online hearing test), yet now, speech hearing tests that simulate real-world noise conditions – called speech-in-noise (SIN) testing – are adding even more detail to existing hearing assessment methodologies.
Below, we’ll help you understand what speech-in-noise testing entails, how it works, and how it can provide more detail to a normal hearing loss assessment.
Why Should You Consider Speech-in-Noise Testing?
The first complaint most hearing loss patients report is the inability to understand voices in noisy environments. Therefore, it makes sense that hearing loss evaluations should simulate listening to speech in noise – as SIN testing does – to evaluate your comprehension abilities in these situations.
Moreover, a survey of patients with hearing aids revealed that the most common problems patients encounter with their hearing aids is poor performance in noisy environments. Here’s what the survey found about hearing aid performance in noise:
- 14% of hearing aid users were not happy with the performance of their hearing aids in noise.
- 11% of hearing aid users “loved” the performance of their hearing aids in noise.
- 75% of hearing aid users said they were somewhere between “loving” and “being dissatisfied with” their hearing aids in noise.
All in all, these points make a strong case for why you should request a speech-in-noise (SIN) test for the most accurate assessment of your hearing loss possible.
What Does SIN Testing Tell Your Audiologist?
SIN tests simulate a wide variety of real-world speech-in-noise listening conditions. This provides your audiologist or hearing care provider with detailed insights into your condition, not only to select an appropriate hearing aid but also to achieve the most effective fine-tuning of your hearing aid.
Here are the kinds of questions SIN testing can answer for your audiologist:
- Do you need a hearing aid with directional microphones?
- Do you need the most powerful noise reduction technology?
- Do you need a hearing aid with “signal processing” to reduce background noise distractions?
- Do you need any of these features at all?
If you’re lucky, the fourth question will apply to you – and SIN testing will reveal that you don’t need any expensive bells and whistles on your hearing aid, and the most inexpensive solution will suffice. On the other hand, if you do need advanced hearing aid features, SIN testing will help your audiologist pinpoint exactly what kind of hearing aid to select, and what kinds of results you can expect from using the device.
By evaluating these factors, the SIN test provides patients and audiologists with the insights they need for the best hearing aid selection and fine-tuning. That way, patients are more likely to use their hearing aids and receive the benefits they’re looking for – instead of simply putting their hearing aids aside.

Types of SIN Tests
There are a variety of speech-in-noise tests that audiologists use to evaluate hearing. These include:
- Hearing in Noise Test (HINT): The HINT plays pre-recorded statements with key words in them that the test taker needs to identify and understand.
- Words in Noise (WIN): The WIN is a test distributed by the VA. It plays different monosyllabic words that must be identified in different simulated background noise conditions.
- QuickSIN: The QuickSIN can be obtained through Etymotic Research. It’s a sentence-based listening test for adults where recordings are played in different simulated background noise conditions.
- Bamford-Kowal-Bench SIN (BKB-SIN): This test is similar to QuickSIN, but it is appropriate for both adults and children.
- Connected Speech Test (CST): This test is given in paragraph form, sentence by sentence, under a selected fixed background noise level. The test determines the ability to hear and comprehend connected speech.
- Speech Perception in Noise Test (SPIN): This test evaluates the ability to hear sentences under a selected fixed background noise level.
Hearing Loss Isn’t Always in the Ears
Your ability to understand speech in noise isn’t always about your ears. While your ears’ ability to hear voices clearly is essential to understanding speech, your brain also needs to process the language for complete comprehension. Some patients compensate for hearing loss with highly-developed speech processing skills. If they miss a few words, their brains can still interpret the gist of what people are saying.
A hearing loss patient could be suffering from ear damage, a central auditory nervous system disorder, cognitive decline – or all of the above.
- Are you suffering from cognitive decline?
- Are you suffering from ear damage?
- Are you suffering from a central auditory nervous system disorder?
- Are you suffering from all or just one of the above?
Imagine that your SIN test reveals that no hearing assistance techniques are able to help you overcome your hearing loss challenges. Your hearing care provider can then refer you to a medical practitioner for cognition testing to ensure that you aren’t suffering cognitive decline. The sooner you know, the sooner you can treat the right problem to improve your hearing.
Ask Your Audiologist About SIN Testing for the Most Accurate Hearing test
SIN testing simulates real-world background noise conditions, requires you to listen to and try to understand voices in noise, and it can be used to test your hearing while you try different types of hearing assistance.
Considering the superiority of SIN testing, you should ask your hearing care provider for SIN (speech-in-noise) testing before selecting a hearing aid. This will ensure that you don’t waste money on a hearing solution that isn’t going to work, and it will help you fine-tune your hearing aid effectively. Ultimately, getting SIN testing can make you happier with the performance of your hearing aid in the long run.
MDHearing: Send Your Hearing Tests Results to Our Audiologists!
At MDHearing, we recommend that you visit a hearing clinic or audiologist for a professional hearing exam before choosing one of our products. We also recommend that you ask for SIN testing to ensure you get the most accurate hearing test results.
Then you can send your test results to the audiologist team at MDHearing. We’ll review your test results and recommend which MDHearing product is best for your needs.
Shop MDHearing Products
At MDHearing, we sell high-quality, FDA-registered hearing aids for thousands of dollars less than comparable brands. Priced between $399.99 and $1,199.99 per pair, MDHearings products also come with a 100% money-back guarantee, so there’s no risk in giving them a try.

After ordering your hearing aid from MDHearing, you’ll receive it in just a few days. Our on-call hearing aid specialists can walk you through the process of adjusting and fine-tuning your hearing aid to fit your hearing loss profile.
Here are three of our most popular hearing aids:
- MDHearing AIR: Priced at just $399.99 per pair, the AIR features advanced digital technology, feedback cancellation, and settings for four listening environments (quiet, social, noisy, and restaurant).
- MDHearing VOLT: Priced at just $599.99 per pair, the VOLT is our rechargeable model that features intelligent directional microphones, feedback cancellation, and background noise management technology to clarify sounds in four different listening environments.
- MDHearing CORE: Priced at just $1,199.99 per pair, the CORE offers Bluetooth connectivity and a smartphone app for easy fine-tuning and adjustments. It also features intelligent directional microphones, feedback cancellation, and background noise management technology to clarify important sounds and voices in four listening environments.
To learn more about MDHearing and its catalog of affordable, high-quality digital hearing aids, browse our website now.
BROWSE HEARING AIDS
@article{Wilson2007TheW,
title={The Words-in-Noise (WIN) test with multitalker babble and speech-spectrum noise maskers.},
author={Richard H. Wilson and Crystal S Carnell and Amber L Cleghorn},
journal={Journal of the American Academy of Audiology},
year={2007},
volume={18 6},
pages={
522-9
}
}
The Words-in-Noise (WIN) test uses monosyllabic words in seven signal-to-noise ratios of multitalker babble (MTB) to evaluate the ability of individuals to understand speech in background noise. The purpose of this study was to evaluate the criterion validity of the WIN by comparing recognition performances under MTB and speech-spectrum noise (SSN) using listeners with normal hearing and listeners with hearing loss. The MTB and SSN had identical rms and similar spectra but different amplitude…
Figures and Tables from this paper
79 Citations
References
SHOWING 1-10 OF 39 REFERENCES
Speech-in-noise (SIN) testing provides a useful window into the status of a patient’s auditory system. It can be used for clinical diagnosis and measurement of functional capacity of the hearing system, providing clinicians with highly valuable information while requiring minimal clinical time. However, SIN tests are infrequently used except where required for cochlear implants or auditory fitness-for-duty evaluations. As such, we explore the benefits of SIN tests, highlighting an inexpensive setup to complete SIN testing outside of a sound booth.

SIN test setups to evaluate functional benefit from hearing device tests. hearing tests, audiology, hearing loss

In-office system for speech-in-noise testing. hearing tests, audiology, hearing loss

Measuring a set distance to ensure proper calibration of the speech-in-noise testing system. hearing tests, audiology, hearing loss
WHAT TESTS ARE AVAILABLE?
SIN tests are used to evaluate hearing ability in noise for both adults and children. For adults, sentence- and word-level tests are available. In English, the Quick Speech-In-Noise Test (QuickSIN; Etymotic Research) is the most commonly used test. It uses the IEEE sentence corpus divided into 12 groups of sentences that are played at a high signal-to-noise ratio (SNR) of +25 dB to a low SNR of 0 dB SNR. The stimulus is a female voice, and the noise is composed of a four-talker male and female babble. The QuickSIN takes one minute per list. Most clinicians use two or three sentences to obtain an SNR loss, which is the difference between a normal hearing population’s performance and a patient’s test performance (SNR to obtain 50 percent correct). The AzBio (Auditory Potential, LLC) sentence corpus—widely used especially in cochlear implant candidacy evaluations—uses conversational-style sentences presented at a fixed SNR and scored based on the percentage of correct keywords.1 The stimulus includes several male and female talkers, while the noise is a 10-talker babble. Other sentence-level tests in English include the Speech Perception in Noise Test-Revised (SPIN-R) and the Bamford-Kowell-Bench Speech-In-Noise (BKB-SIN) Test. At the word level, clinicians can use the Words-In-Noise (WIN) test. Previously, the Hearing In Noise Test (HINT) was also used, but it’s no longer available for purchase.
Choosing a test for children can be challenging as the test must be appropriate for the child’s language and cognitive levels. For older children (ages 5 and up), the BKB-SIN provides a similar SNR loss measure as the QuickSIN for adults. Like AzBio, BabyBio sentences can be used for children and presented at a fixed SNR. For younger children ages 3 to 6 years old, the Pediatric Speech Intelligibility (PSI) test, a closed-set task using picture pointing with a single competing talker, can be used.
A NOTE ON TEST LIMITATIONS
Clinicians should consider the patient’s language and cognitive levels prior to administering a SIN test. For deaf and hard-of-hearing (DHH) children, language delays may limit the use of a specific SIN test. However, clinicians should not feel limited in trying SIN testing with children. In our clinic, the youngest child to complete the PSI was 2 years and 9 months old, and 3- to 4-year-old children are regularly tested in noise. Adults with developmental disabilities or acquired memory impairments may not be able to complete SIN testing at an age-appropriate level, and different tests may need to be employed. Additionally, patients whose first language is not the same as the language used in the test material may score more poorly than expected on the test. Some SIN tests are available in languages other than English, though clinicians should always ensure that their chosen test has been appropriately validated.
DIAGNOSTIC USE OF SIN TESTING
SIN tests can be used to understand a patient’s auditory system status, providing a valuable look at the patient’s complaints and the underlying physiology. The primary concern of many patients is difficulty hearing in noise, which pure tone audiometry in quiet, while useful for quantifying hearing sensitivity, cannot address. For these patients, a SIN test can provide useful information about their real-world complaint. The QuickSIN, for example, can be administered in as little as two minutes in a binaural condition. Ongoing research in our clinic and at Stanford University suggest that, in the future, audiologists may be able to replace word-recognition in quiet (WRS) with a QuickSIN test, which predicts WRS scores well. Additionally, we theorize that SIN tests may be used to identify a retrocochlear site of lesion when results are compared between ears; research is ongoing to evaluate this possibility.
Hidden hearing loss (HHL), a condition where patients report hearing difficulty in the presence of normal hearing thresholds (previously known as obscure auditory dysfunction), has been a recent hot topic in hearing science. For some patients with HHL, SIN tests will reveal a deficit not otherwise seen on an audiogram. Furthermore, most test batteries for central auditory processing disorders (APD) have used SIN tests for many years, calling this auditory figure-ground testing. In both cases, SIN test requires more auditory system resources and evaluates higher-order auditory system processes than those assessed using pure tone audiometry or speech perception in quiet.
FUNCTIONAL USE OF SIN TESTING
In addition to understanding a patient’s auditory abilities, SIN tests have been widely recommended as a tool for both prediction of benefit from amplification and validation of benefit from amplification.2 For validating amplification benefit, SIN tests can be set up to compare aided and unaided hearing using either hearing aids or cochlear implants. Clinicians can choose between three types of SIN testing setups to best address a patient’s concerns and evaluate hearing aid performance. On the left panel of Figure 1, speech and noise are spatially separated, which will take advantage of directional microphone benefits.
To predict benefit from hearing amplification, clinicians can interpret unaided SIN test results. For example, a patient with a high SNR loss on the QuickSIN may not show as much benefit from hearing aids as a patient with a low SNR loss. Patients with poor performance on SIN tests may benefit from technology that improves the real-world SNR, including directional microphones, remote microphone technology, or FM system technology. Patients with asymmetric hearing loss may also benefit from unilateral SIN testing. A patient with an acoustic neuroma, for example, may have a worse SNR loss in the ear with the neuroma. A patient with a high SNR loss in one ear may not find significant benefit in noise from unilateral amplification since the hearing aids may provide increased distortion rather than clarity of speech.
Evaluating the functional benefit of amplification using SIN tests can be particularly beneficial for patients with single-sided deafness (SSD) because the results of testing with demonstration devices can predict real-world outcomes.3 Snapp and Telischi’s protocol for assessing patients with SSD requires patients to perform SIN tests with speech to the worse ear and noise to the better ear, with comparisons between aided and unaided conditions.4 The American Academy of Audiology has a similar guideline. Following this protocol allows the audiologist to predict both surgical and non-surgical outcomes for the patient with SSD and recommend the best hearing device for the patient. It can be used pre-intervention for hearing device selection and post-intervention for validation of hearing device benefit.
EVALUATING SIN OUTSIDE OF AUDIOMETRIC TESTS
A significant limitation of using SIN tests for hearing device validation is the accessibility of sound field systems in audiometric test suites. In busy audiology practices, clinicians may prioritize sound booth time for diagnostic audiometric evaluations or not have space in a sound booth to install a sound field system. In these cases, building a sound field system in a non-acoustically treated room may be a reasonable option to allow clinicians to use SIN tests more regularly. In practice, there is no significant limitation in using a quiet room instead of a sound booth for SIN testing since SIN tests are completed at a suprathreshold level. Here we present an inexpensive system that we use in our clinic’s hearing aid fitting rooms.
As shown in Figure 2, this system comprises a single powered studio monitor speaker and a digital music player. A pair of speakers can also be used to split the stimulus and noise for utilizing directional microphones effectively. The digital music player must be able to play uncompressed files (such as .WAV files) or lossless compression files (such as .FLAC files). SIN test files can be ripped from a CD using free online software, then installed on the music player. Compressed file formats, including .MP3 or .AAC files as created by Apple products, should not be used for audiologic testing as they add a layer of compression that may result in test files that are not similar to the stimuli used in validation studies.
The clinician must then calibrate the system using a sound level meter to ensure that the stimulus is produced at a consistent level. We suggest the use of 60 dBA as a reasonable level for the validation of hearing device benefit. As shown in Figure 3, the patient should be seated at an appropriate distance to ensure the level is calibrated, and all volume at any levels should be fixed on the speakers and the music player. The system could also be used for tests of speech perception in quiet, such as the California Consonant Test, which may also help show the benefit from hearing devices.
The system shown in Figures 2 and 3 comprises a Samsung Clip Jam music player and a pair of Mackie CR3 monitor speakers; it costs less than $125, plus the cost of the QuickSIN test ($180 from Etymotic Research). The same system could be effectively put together with any high-quality speaker and digital music player. To evaluate the benefits of a directional microphone, the same system could be used with two speakers, one speaker in front and one behind the patient, and the split track version of the QuickSIN test. The benefits of validating hearing aids outweigh these reasonable costs.
Overall, SIN tests provide a significant benefit for audiology patients and should be regularly used for diagnostic and functional testing, as well as for validation of device benefit. Various SIN tests can be administered with little clinical time, proving to be valuable to both clinician and patient.
REFERENCES
1. Spahr, et al. Ear Hear. 2012 Jan-Feb;33(1):112-7. doi: 10.1097/AUD.0b013e31822c2549.
2. Beck and Nilson. Hear Rev. 2013:20(5):24.
3. Snap, et al. J Am Acad Audiol. 2010 Nov-Dec;21(10):654-62. doi: 10.3766/jaaa.21.10.5.
Snapp and Telischi Audiology Today 2008 20 4 21 28
Tech Topic | September 2017 Hearing Review
A discussion of signal-to-noise ratio problems and solutions, and a summary of findings of a study involving Oticon Opn hearing aids.
The most common problem experienced by people with hearing loss and people wearing traditional hearing aids is not that sound isn’t loud enough. The primary issue is understanding speech-in-noise (SIN). Hearing is the ability to perceive sound, whereas listening is the ability to make sense of, or assign meaning to, sound.
As typical hearing loss (ie, presbycusis, noise-induced hearing loss) progresses, outer hair cell loss increases and higher frequencies become increasingly inaudible. As hearing loss progresses from mild (26 to 40 dB HL) to moderate (41 to 70 dB) and beyond, distortions increase, disrupting spectral, timing, and loudness perceptions. The amount of distortions vary, and listening results are not predictable based on an audiogram, nor are they predictable based on word recognition scores from speech in quiet.1,2
To provide maximal understanding of speech in difficult listening situations, the goal of hearing aid amplification is twofold: Make speech sounds audible and increase the signal-to-noise ratio (SNR).1 That is, the goal is to make it easier for the brain to identify, locate, separate, recognize, and interpret speech sounds. “Speech” (in this article) is the spoken signal of primary interest and “noise” is the secondary sound of other people speaking (ie, “speech babble noise”).
The essence of the SIN problem is that the primary speech sounds and secondary sounds (ie, noise) are essentially the same thing! That is, both speech and speech babble noise originate with human voices with similar spectral and loudness attributes, rendering the “SIN” problem difficult to solve.
Signal-to-Noise Ratio (SNR) Loss
Killion1 reported people with substantial difficulty understanding speech-in-noise may have significant “SNR loss.” Of note, the SNR loss is unrelated to, and cannot be predicted from, the audiogram. Killion defines SNR loss as the increased SNR needed by an individual with difficulty understanding speech in noise, as compared to someone without difficulty understanding speech in noise. He reports people with relatively normal/typical SNR ability may require a 2 dB SNR to understand 50% of the sentences spoken in noise, whereas people with mild-moderate sensorineural hearing loss may require an 8 dB SNR to achieve the same 50% performance. Therefore, for the person who needs an 8 dB SNR, we subtract 2 dB (normal performance) from their 8 dB score, resulting in a 6 dB SNR loss.
Wilson2 evaluated more than 3,400 veterans. He, too, reported speech in quiet testing does not predict speech-in-noise ability, as the two tests (speech in quiet, speech-in-noise) reflect different domains of auditory function. He suggested the Words-in-Noise (WIN) test should be used as the “stress test” for auditory function.
Beck and Flexer3 reported, “Listening is where hearing meets the brain.” They said the ability to listen (ie, to make sense of sound) is arguably a more important construct, and reflects a more realistic representation of how people manage in the noisy real world, than does pure-tone hearing thresholds reflected on an audiogram. Indeed, many animals (including dogs and cats) “hear” better than humans. However, humans are atop the food chain not because of their hearing, but due to their ability to listen—to apply meaning to sound. As such, a speech-in-noise test is more of a listening test than a hearing test. Specifically, listening in noise depends on a multitude of cognitive factors beyond loudness and audibility, and includes speed of processing, working memory, attention, and more.
McShefferty et al4 report SNR plays a vital role for hearing-impaired and normal-hearing listeners. However, the smallest detectable SNR difference for a person with normal hearing is about 3 dB, and they report for more clinically-relevant tasks, a 6 to 8 dB SNR may be required.
In this article, we’ll address concepts and ideas associated with understanding speech- in-noise, and, importantly, we’ll share results obtained while comparing SIN results with Oticon Opn and two major competitors, in a realistic acoustic environment.
Traditional Strategies to Minimize Background Noise
As noted above, the primary problem associated with hearing loss and hearing aid amplification in understanding speech, is noise. The major focus over the last four decades or so has been to reduce background noise. Two processing strategies have been employed in modern hearing aid amplification systems to minimize background noise: digital noise reduction and directional microphones.
Digital Noise Reduction (DNR). Venema5 reports (p 335) the goal of DNR is noise reduction. DNR systems can recognize and reduce the signature amplitude of steady-state noise using various amplitude modulation (AM) detection systems. AM systems can identify differences in dynamic human speech as opposed to steady state noise sources, such as heating-ventilation/air-conditioning (HVAC) systems, electric motor and fan noise, 60 cycle noise, etc.6 However, DNR systems are less able to attenuate secondary dynamic human voices in close proximity to the hearing aid, such as nearby loud voices in restaurants, cocktail parties, etc, because the acoustic signature of people we desire to hear and the acoustic signature of other people in close proximity (ie, speech babble noise) are essentially the same.
Venema5 states (p 331) the broadband spectrum of speech and the broadband spectrum of noise intersect and overlap, and, consequently, are very much the same thing. Nonetheless, given multiple unintelligible speakers and a physical distance of perhaps 7-10 meters from the hearing aid microphone, Venema and Beck7 report the secondary signal (ie, speech babble noise) may present as (or morph into) more of steady state “noise-like” signal and be attenuated via DNR—providing additional comfort to the listener.
McCreery et al8 reported their evidence-based systematic review to examine “the efficacy of digital noise reduction and directional microphones.” They searched 26 databases seeking contemporary publications (published after 1980), resulting in four articles on DNR and seven articles on directional microphone studies. Of tremendous importance, McCreery and colleagues? concluded DNR did not improve or degrade speech understanding.
Beck and Behrens9 reported DNR may offer substantial “cognitive” benefits, including more rapid word learning rates for some children, less listening effort, improved recall of words, enhanced attention, and quicker word identification, as well as better neural coding of words. They suggested typical hearing aid fitting protocols should include activation of the DNR circuit.
Pittman et al10 reported DNR provides little or no benefit with regard to improved word recognition in noise. Likewise, McCreery and Walker11 note DNR circuits are routinely recommended for the purpose of improving listening comfort, but restated that, with regard to school-age children with hearing loss, DNR neither improved nor degraded speech understanding.
Directional Microphones (DMs). DMs (or “D-mics”) are the only technology proven to improve SNR. However, the likely perceived benefit from DMs in the real world, due to the prevalence of open canal fittings, is often only 1-2 dB.7 Directivity Indexes (DIs) indicating 4-6 dB improvement are generally not “real world” measures. That is, DIs are generally measured on manikins, in an anechoic chamber, based on pure tones, and DIs quantify and compare sounds coming from the front versus all other directions.
Nonetheless, although an SNR improvement of 1-2 dB may appear small, every 1 dB SNR improvement may provide a 10% word recognition score increase.5,12,13
In their extensive review of the published literature, McCreery et al8 reported that, in controlled optimal situations, DMs did improve speech recognition; yet they cautioned the effectiveness of DMs in real-world situations was not yet well-documented and additional research is needed prior to making conclusive statements.
Brimijoin and colleauges14 stated directionality potentially makes it difficult to orient effectively in complex acoustic environments. Picou et al15 reported directional processing did reduce interaural loudness differences (ILDs), and localization was disrupted in extreme situations without visual cues. Research by Best and colleagues16 found narrow directionality is only viable when the acoustic environment is highly predictable. Mejia et al17 indicated, as beam-width narrows, the possible SNR enhancement increases; however, as the beam-width narrows, the possibility also increases that “listeners will misalign their heads, thus decreasing sensitivity to the target…” Geetha et al18 reported “directionality in binaural hearing aids without wireless communication” may disrupt interaural timing and interaural loudness cues, leading to “poor performance in localization as well as in speech perception in noise…”
New Strategies to Minimize Background Noise
Research by Shinn-Cunningham and Best19 suggests the ability to selectively attend depends on the ability to analyze the acoustic scene and form perceptual auditory objects properly. If analyzed correctly, attending to a particular sound source (ie, voice) while simultaneously suppressing background sounds may become easier as one successfully increases focus and attention.
Therefore, the purpose of a new strategy for minimizing background noise should be to facilitate the ability to attend to one primary sound source and switch attention when desired—which is what Oticon’s recently- released Multiple Speaker Access Technology (MSAT) has been designed to do.
Multiple Speaker Access Technology (MSAT). In 2016, Oticon introduced MSAT. The goals of MSAT are to selectively reduce disturbing noise while maintaining access to all distinct speech sounds and to support the ability of the user to select the voice they choose to attend to.
MSAT represents a new class of speech enhancement technology and is intended to replace current directional and noise reduction systems. MSAT does not isolate one talker; it maintains access to all distinct speakers. MSAT is built on three stages of sound processing:
1) Analyze provides two views of the acoustic environment. One view is from a 360 degree omni microphone; the other is a rear-facing cardioid microphone to identify which sounds originate from the sides and rear. The cardioid mic provides multiple noise estimates to provide a spatial weighting of noise.
2) Balance increases the SNR by constantly acquiring and mixing the two mics (similar to auditory brainstem response or radar) to obtain a rebalanced soundscape in which the loudest noise sources are attenuated. In general, the most important sounds are present in the omni view, while the most disturbing sounds are present in both omni and cardioid views. In essence, cardioid is subtracted from omni, to effectively create nulls in the direction of the noise sources, thus increasing the prominence of the primary speaker.
3) Noise Removal (NR) provides very fast removal of noise between words and up to 9 dB of noise attenuation. Importantly, if speech is detected in any band, Balance and NR systems are “frozen” so as to not isolate the front talker, but to preserve all talkers.
The Oticon Opn system uses MSAT and, therefore, it is neither directional nor omnidirectional. To be clear, the goal of DMs is to pick up more sound from the front of the listener, as compared to sounds from other angles, and D-mics do not help one tell the direction of sounds, nor do they increase the intensity of sounds coming from the front—or as Venema states (p 316), “they simply decrease the intensity of sounds coming from the sides and rear, or relative to sounds coming from the front…”5 According to Geetha et al,18 DMs are designed to provide attenuation of sounds emerging from the sides of the listener, and Venema5 states omnidirectional microphones are “equally sensitive to sounds coming from all directions…” Thus, omnidirectional microphones theoretically have a DI of 0.
Therefore, MSAT is neither an omni or a directional system, but does represent a new technology.
Spatial Cues. Of significant importance to understanding SIN is the ability to know where to focus one’s attention. Knowing “where to listen” is important with regard to increasing focus and attention. Spatial cues allow the listener to know where to focus attention and, consequently, what to ignore or dismiss.20 The specific spatial cues required to improve the ability to understand SIN are interaural level differences (ILDs) and interaural time differences (ITDs), such that the left and right ears receive unique spatial cues.
Sockalingham and Holmberg21 presented laboratory and real-world results demonstrating “strong user preference and statistically significant improved ratings of listening effort and statistically significant improvements in real-world performance resulting from Spatial Noise Management.”
Beck22 reported spatial hearing allows us to identify the origin/location of sound in space and attend to a “primary sound source in difficult listening situations” while ignoring secondary sounds. Knowing “where to listen” allows the brain to maximally listen in difficult/noisy listening situations, as the brain is better able to compare and contrast unique sounds from the left and right ears—in real time—to better determine where to focus attention.
Geetha et al18 stated speech in noise is challenging for people with sensorineural hearing loss (SNHL). To better understand speech in noise, the responsible acoustic cues are ITDs and ILDs. They report “…preservation of binaural cues is…crucial for localization as well as speech understanding…” and directionality in binaural amplification without synchronized wireless communication can disrupt ITDs and ILDs, leading to “…poor performance in localization…(and) speech perception in noise…”18
Oticon Opn uses Speech Guard™ LX to improve speech understanding in noise by preserving clear sound quality and speech details, such as spatial cues via ILDs and ITDs. It uses adaptive compression and combines linear amplification with fast compression to provide up to a 12 dB dynamic range window, preserving natural amplitude cues in speech signals. Likewise, Spatial Sound™ LX helps the user locate, follow, and shift focus to the primary speaker via advanced technologies to provide a more precise spatial awareness for identify where sounds originate.
The Oticon OPN SNR Study
In Pittman et al’s research,10 they stated, “Like the increasingly unique advances in hearing aid technology, equally unique approaches may be necessary to evaluate these new features…” The purpose of this study was to compare the results obtained using Oticon Opn to two other major manufacturers with regard to listeners’ ability to understand speech in noise in a lab-based, yet realistic, background noise situation.
Admittedly, despite the fact that no lab-based protocol perfectly replicates the real world, this study endeavored to realistically simulate what a listener experiences as three people speak sequentially from three locations, without prior knowledge as to which person would speak next.
Methods. A total of 25 German native-speaking participants (ie, listeners) with an average age of 73 years (SD: 6.2 years) with mild-to-moderate symmetric SNHL underwent listening tasks. Each participant wore the Oticon Opn 1 miniRITE with Open Sound Navigator set to the strongest noise reduction setting. Power domes were worn with each of the three hearing aids.
The results obtained with Opn were compared to the results from two other major manufacturers’ (Brand 1 and 2) solutions, using directionality and narrow directionality/beamforming (respectively). All hearing aids were fitted using the manufacturer’s fitting software and earmold recommendations, based on the hearing loss and other gathered data. The level of amplification for each hearing aid was provided according to NAL-NL2 rationale.
The primary measure reported here was the Speech Reception Threshold-50 (SRT-50). The SRT- 50 is a measure that reflects the SIN level at which the listener correctly identifies 50% of the sentence-based keywords correctly. For example, an SRT-50 of 5 dB indicates the listener correctly repeats 50% of the words when the SNR is 5 dB. Likewise, if the SRT is 12 dB, this indicates the listener requires an SNR of 12 dB to achieve 50% correct.
The goal of this study was to measure the listening benefit provided to the listeners in a real-life noisy acoustic situation in which the location of the sound source (ie, the person talking) could not be predicted. That is, three human talkers and one human listener were engaged in each segment of the study (Figure 1). There were 25 separate listeners.

Figure 1. Schematic representation of the acoustical conditions of the experiment.
Speech babble (ISTS) and background noise (speech-shaped) were delivered at 75 dB SPL. The German-language Oldenburg sentence test (OLSA)23 was delivered to each participant, while wearing each of the three hearing aids.
The OLSA Matrix Tests are commercially available and are accessible via software-based audiometers. We conducted these tests with an adaptive procedure targeting the 50% threshold of speech intelligibility in noise (the speech reception threshold, or SRT). As noted above, speech noise was held constant at 75 dB SPL while the OLSA speech stimuli loudness varied to determine the 50% SRT using a standard adaptive protocol. Each of the 25 listeners was seated centrally and was permitted to turn his/her head as desired to maximize their auditory and visual cues. The background speech noise was a mix of speech babble delivered continuously to the sound-field speakers at ±30° (relative to the listener) and simultaneously at 180° behind the listener, as illustrated in Figure 1. Each of the 25 listeners was seated centrally while three talkers were located in front of, as well as ±60° (left and right) of the listener. Target speech was randomly presented from one of the three talker locations. Listeners were free to turn their heads as desired.
Results. While listening to conversational speech, the average scores obtained from all three talkers by the 25 listeners using directionality (Brand 1) demonstrated an average SRT of -4.9 dB. Listeners using narrow directionality/beamforming (Brand 2) demonstrated an average SRT of -5.5 dB. Listeners wearing Oticon OPN had an average SRT of -6.3 dB (see Figures 2-4).
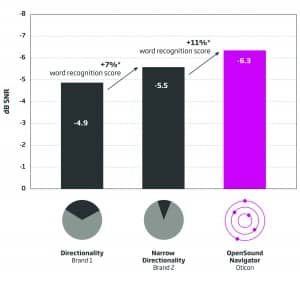
Figure 2. Overall results. Average improvement in SNR and anticipated improvement in word recognition. Bar heights represent the average SRT-50. Each improvement bar is statistically different from the others at p<0.05.
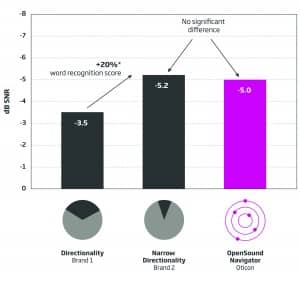
Figure 3. Average speech understanding of center speaker. The average SRT-50 for the hearing aid with directionality was significantly lower than the average SRT obtained with the two other hearing aids. The average SRT-50 obtained with the narrow directionality and OpenSound Navigator were not significantly different from each other, although narrow directionality and Open Sound Navigator were each statistically and significantly better than directionality. The right-facing arrow indicates an approximate 20% word recognition improvement using either narrow directionality or Open Sound Navigator, as compared to directionality.
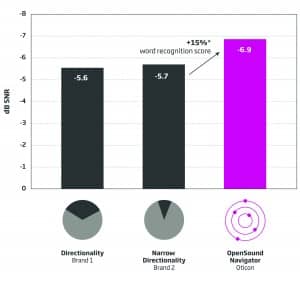
Figure 4. Left and right speaker results. The average SRT-50s obtained from speakers located at ±60° using directionality and narrow directionality were not significantly different from each other. The average SRT-50 obtained with Open Sound Navigator was statistically and significantly better than those obtained with other technologies. The right-facing arrow indicates 15% likely improvement in word recognition with Open Sound Navigator as compared to directionality or narrow directionality.
Of note, it is generally accepted that for, each decibel of SNR improvement, the listener likely gains some 10% with regard to word recognition scores.
Discussion
Realistic listening situations are difficult to replicate in a lab-based setting. Nonetheless, the lab-based setup described here is relatively new and is believed to better replicate real-life listening situations than is the typical “speech in front” and “noise in back” scenario.
Obviously, important speech sounds occur all around the listener while ambulating through work, recreational, and social situations. The goal of the amplification system, particularly in difficult listening situations, is to make speech sounds more audible while increasing the SNR to make it easier for the brain to identify, locate, separate, recognize, and interpret speech sounds.
Oticon’s Open Sound Navigator (OSN) with Multi Speaker Access Technology (MSAT) has been shown to allow (on average) improved SNR-50s and improved word recognition scores in noisy situations, such as when speech and noise surrounds the listener. OSN with MSAT allows essentially the same word recognition scores as the best narrow directional protocols when speech originates in front of the listener, while dramatically improving access to speakers on the sides and, therefore, delivering an improved sound experience. OSN with MSAT effectively demonstrates improved word recognition scores in noise when speech originates around the listener.
The results of this study demonstrate that Oticon’s Open Sound Navigator provides overall improved overall word recognition in noise when compared to directional and narrow directionality/beamforming systems. We hypothesize these results are due to Multiple Speaker Access Technology, as well as the maintenance of spatial cues and many other advanced features available in Oticon Opn.

Correspondence can be addressed to HR or Dr Beck at: [email protected]
Citation for this article: Beck DL, LeGoff N. Speech-in-noise test results for Oticon Opn. Hearing Review. 2017;24(9):26-30.
References
-
Killion MC. New Thinking on Hearing in Noise—A Generalized Articulation Index. Seminars Hearing. 2002;23(1):57-75.
-
Wilson RH. Clinical experience with the words-in-noise test on 3430 veterans: comparisons with pure-tone thresholds and word recognition in quiet. J Am Acad Audiol. 2011;22(7)[Jul-Aug]:405-423.
-
Beck DL, Flexer C. Listening is where hearing meets brain…in children and adults. Hearing Review. 2011;18(2):30-35.
-
McShefferty D, Whitmer WM, Akeroyd MA. The just noticeable difference in speech t0 noise ratio. Trends in Hearing. February 12, 2015;19.
-
Venema TH. Compression for Clinicians. A Compass for Hearing Aid Fittings. 3rd ed. San Diego: Plural Publishing;2017.
-
Mueller HG, Ricketts TA, Bentler R. Speech Mapping and Probe Microphone Measurements. San Diego: Plural Publishing;2017.
-
Beck DL, Venema TH. Noise reduction, compression for clinicians, and more: An interview with Ted Venema, PhD. Online July 27, 2017. Available at: https://hearingreview.com/2017/07/noise-reduction-compression-clinicians-interview-ted-venema-phd/
-
McCreery RW, Venediktov RA, Coleman JJ, Leech HM. An evidence-based systematic review of directional microphones and digital noise reduction hearing aids in school-age children with hearing loss. Am J Audiol. 2012; 21(2)[Dec]:295-312.
-
Beck DL, Behrens T. The Surprising Success of Digital Noise Reduction. Hearing Review. 2016;23(5):20-22.
-
Pittman AL, Stewart EC, Willman AP, Odgear IS. Word recognition and learning–Effects of hearing loss and amplification feature. Trends Hearing. 2017; 21:1-13.
-
McCreery RW, Walker EA. Hearing aid candidacy and feature selection for children. In: Pediatric Amplification–Enhancing Auditory Access. San Diego: Plural Publishing;2017.
-
Chasin M. Slope of PI function is not 10%-per-dB in noise for all noises and for all patients. Hearing Review. 2013;22(10):12.
-
Taylor B, Mueller HG. Fitting and Dispensing Hearing Aids. 2nd ed. San Diego: Plural Publishing;2017.
-
Brimijoin WO, Whitmer WM, McShefferty D, Akeroyd MA. The effect of hearing aid microphone mode on performance in an auditory orienting task. Ear Hear. 2014;35(5)[Sep-Oct]:e204-212.
-
Picou EM, Aspell E, Ricketts TA. Potential benefits and limitations of three types of directional processing in hearing aids. Ear Hear. 2014;35(3)[May-Jun]:339-352.
-
Best V, Mejia J, Freeston K, van Hoesel RJ, Dillon H. An evaluation of the performance of two binaural beamformers in complex and dynamic multitalker environments. Int J Audiol. 2015;54(10):727-735.
-
Mejia J, Dillon H, van Hoesel R, et al. Loss of speech perception in noise–Causes and compensation. Proceedings of ISAAR 2015: Individual Hearing Loss–Characterization, Modelling, Compensation Strategies. 5th Symposium on Auditory and Audiological Research. Danavox Jubilee Foundation. August 2015:209.
-
Geetha C, Tanniru K, Rajan RR. Efficacy of directional microphones in hearing aids equipped with wireless synchronization technology. J Int Advanced Otol. 2017; 13(1):113-117.
-
Shinn-Cunningham B, Best V. Selective Attention in normal and impaired hearing. Trends in Hearing. 2008;12(4):283-299.
-
Beck DL, Sockalingam R. Facilitating spatial hearing through advanced hearing aid technology. Hearing Review. 2010;17(4):44-47.
-
Sockalingam R, Holmberg M. Evidence of the effectiveness of a spatial noise management system. Hearing Review. 2010; 17(9):44-47.
-
Beck DL. BrainHearing: Maximizing hearing and listening. Hearing Review. 2015;21(3):20-23. Available at: https://hearingreview.com/2015/02/brainhearing-maximizing-hearing-listening
-
Hörtech. Oldenburg Sentence Test (OLSA). Oldenburg, Germany: Hörtech. Available at: http://www.hoertech.de/en/medical-devices/olsa.html
By Douglas L. Beck and Lauren Benitez
This article is a part of the May/June 2019, Volume 31, Number 3, Audiology Today issue.
Hearing-care professionals (HCPs) and hearing aid wearers report the chief complaint secondary to hearing loss and to wearing traditional hearing aids, is the inability to understand speech-in-noise (SIN; see Beck et al, 2019). Beck et al (2018) reported that, in addition to the 37 million Americans with audiometric hearing loss, 26 million have hearing difficulty and/or difficulty understanding SIN, despite clinically normal thresholds. As such, helping people hear (i.e., to perceive sound) and helping people listen (i.e., to comprehend, or apply meaning to sound) remains paramount.
Many excellent SIN tests are commercially available (see Wilson et al, 2007 for a review). Nonetheless, despite the fact that the American Academy of Audiology (Academy) and the American Speech–Language–Hearing Association (ASHA) Best Practice (BP) statements recommend SIN testing, it appears that fewer than 15 percent of audiologists perform SIN tests routinely (Beck, 2017; Clark, 2017). It is unclear why SIN testing is not applied universally. Perhaps the associated acquisition costs, the negligible reimbursement rates, and/or the administration time impede their clinical use?
Regardless, we believe a SIN score acquired on an individual, regardless of his or her audiogram, represents the single most important measure of auditory function. Unaided and aided SIN scores not only reflect the reason the patient sought help (i.e., the unaided SIN score) but also indicate how much help he or she has received through amplification (i.e., the aided SIN score). In this article, we will outline a SIN protocol that may be free or relatively inexpensive (depending on the equipment you already own, and the cost of calibration).
Our SIN protocol takes less than 120 seconds to administer and is quick, reliable, and clinically useful. In addition, we will present pilot data acquired on eight individuals with and without audiometric hearing loss, and we will offer some calibration guidelines (Appendix).
Background
Jerger (2018) recently reviewed two important articles from the 1940s. The Harvard Report (1946) indicated monosyllabic word testing has “rather low reliability” even when carefully standardized. The Harvard Report suggested that measuring the signal-to-noise ratio (SNR, the level difference required for speech to be comprehended in a background of noise) was an intriguing idea. Jerger reflected favorably on The Harvard Report for indicating that an SNR measure would be a better metric reflecting individual differences in challenging acoustic environments. Carhart (1946) also indicated clear benefits associated with obtaining an SNR measure to reflect speech understanding in difficult noisy situations.
An individual’s SIN performance cannot be reliably predicted from his or her speech-in-quiet (SIQ) performance. That is, knowing that a person has excellent word recognition in quiet using monosyllabic words (such as the NU-6, or the CID W-22 word lists) simply does not indicate how the individual will perform in speech babble.
Wilson (2011) evaluated 3,430 veterans and reported SIN scores cannot be predicted based on an audiogram, and word recognition in quiet does not predict SIN ability. Therefore, the audiologist should establish/quantify the degree of SIN impairment (as indicated by the SNR-50, see below). Of note, a group of individuals with mild–moderate sensorineural hearing loss (SNHL) is likely to have a broad range of SIN abilities, which interestingly, may be analogous to the range of people with normal pure-tone thresholds (Vermiglio et al, 2012; Vermiglio et al, 2019).
Improving SIN ability generally is accomplished through an improved SNR. Indeed, familiar technologies including adaptive and nonadaptive directional microphones, beam-forming microphones, and various adaptive and nonadaptive noise-reduction protocols and algorithms have been incorporated into hearing aids to essentially improve the SNR, thereby improving the wearer’s SIN ability.
SNR-50
The SNR required to obtain a score of 50 percent correct is referred to (throughout this article) as the “SNR-50.” Of note, establishing the SNR-50 (in this protocol) is very similar to obtaining a pure-tone threshold. The primary speech signal is held constant at the most comfortable loudness (MCL) while four-talker speech babble ascends and descends. The SNR-50 is established when the subject repeats half of the target words (50 percent) correctly. However, instead of 5- and 10-dB steps (as prescribed for pure-tone thresholds), we use 1- and 2-dB steps to rapidly acquire a repeatable SNR-50.
With regard to the QuickSIN, Killion (2002) reported adults with normal hearing needed an average SNR-50 of 2 dB to repeat 50 percent of the words correctly, and people with mild–moderate SNHL required an average SNR-50 of 8 dB. These same values offer guidance as to expected SNR-50s in this pilot study. Dillion (2012) reported that for every 10 dB of hearing loss, the subject requires an additional 1–3 dB of SNR to maintain their unaided intelligibility.
| 250 Hz (25 dB) |
| 500 Hz (25 dB) |
| 750 Hz (25 dB) |
| 1000 Hz 25 dB) |
| 1,500 Hz (30 dB) |
| 2,000 Hz (30 dB) |
| 3,000 Hz (30 dB) |
| 4,000 Hz (35 dB) |
| 6,000 Hz (35 dB) |
| 8,000 Hz (25 dB) |
SNR-50 Examples
Given a primary speech message originating in front of a listener at 70 dB SPL, a person with normal hearing and normal listening ability might be expected to repeat half the words correctly in the presence of a 68 dB four-talker babble originating behind the listener. Further, a listener with a mild–moderate SNHL, given the same speech signal of 70 dB SPL, would likely require an 8-dB SNR (babble at 62 dB SPL) to repeat 50 percent of the words correctly. To be clear, the relationship between pure-tone thresholds and SIN ability is highly variable and not predictable.
SIN and SNR-50 Pearls
#1
The anticipated SNR-50 values described here (2 dB for people with hearing within normal limits; 8 dB for people with mild-moderate SNHL) are estimates and serve as guidelines only. Each person must be tested to determine his or her SNR-50 unaided and in the sound field. Local normative values should be established for each test facility after proper calibration, to be sure results are in alignment with generally accepted values. Of note, we do not recommend using headphones or insert earphones as our goal is to replicate, as best we can, the real-world difficulty experienced in cocktail parties, restaurants, and similar acoustically challenging situations. Therefore, a calibrated sound-field test is required.
#2
We recommend four-talker speech babble rather than speech-spectrum noise, white noise, pink noise, etc. Artificial noises do not contain linguistic information, and therefore, artificial noises may be easier to ignore. However, some people do perform better in four-talker babble rather than steady-state noise (Vermiglio et al, 2019). In general, we anticipate four-talker babble better replicates real-world difficulty; yet if the four-talker babble task is too difficult, we recommend switching to an artificial noise as needed for unaided and aided measures (apples to apples).
#3
We believe that if the primary goal of SIN testing is to determine the SNR-50, and the secondary goal is to select amplification, step sizes of 4 or 5 dB are too large to define subtle, yet important, differences in hearing aid benefit. That is, if hearing aids A, B, C, and D improve the SNR-50 by 1, 2, 3, and 4 dB, respectively, these would appear the same given a 5-dB step size. Of note, a 1-dB improvement in SNR may facilitate 8 percent to 10 percent improvement in word recognition (Taylor and Mueller, 2017), and is thus, important to quantify.
#4
Although we realize “speech in front” and “babble in rear” is not a realistic representation of all SIN tasks, this simple two-speaker arrangement can be easily facilitated in many sound booths and may also be set up outside the booth. That is, SIN tests are suprathreshold tests and may not require a sound booth (unless the ambient noise floor is excessively high) as long as the entire system is professionally calibrated for speech stimuli and four-talker babble (see Appendix). A simple, repeatable, “apples-to-apples” approach is advocated.
#5
We used the NU-6 word lists as our primary stimuli. However, all word lists are not necessarily equivalent regarding difficulty, audibility, vocabulary, and more. Some word lists have been found to be equivalent in quiet, but not in noise. As such, one should review the literature to choose the best primary stimuli (in any language) for their protocol and to establish their own clinical norms, in tandem with the protocol described here. Important readings on selecting and using words lists includes: Lawson (2012), Loven and Hawkins (1983), and Stockley and Green (2000). Regardless of the selected word lists, we recommend the use of digital recordings of your preferred word list and your own established clinical norms (as above), as hardware, software, protocols, word lists, and calibration protocols vary.
| SUBJECT | AGE | UNAIDED SNR-50 70 dB | P1 AIDED SNR-50 | P2 AIDED SNR-50 |
| 1 | 63 | +6 dB | +3 dB | +1 dB |
| 2 | 75 | CNT | +9 dB | +6 dB |
| 3 | 23 | +5 dB | +4 dB | +1 dB |
| 4 | 36 | +6 dB | +4 dB | +1 dB |
| 5 | 47 | +4 dB | +3 dB | +3 dB |
| 6 | 56 | +7 dB | +4 dB | +3 dB |
| 7 | 32 | +8 dB | +3 dB | +3 dB |
| 8 | 59 | +7 dB | +3 dB | +1 dB |
Eight adult volunteers participated in our pilot testing, with and without hearing loss. Each received otoscopy and a typical air-bone-speech evaluation. Unaided and aided sound field tests were obtained using the calibrated sound field (see Appendix). The recorded NU-6 word lists were presented through the front speaker at 70 dB SPL, and four-talker speech babble was delivered through the rear speaker. The task was explained, “Your task is to try to ignore all the voices from behind you. Please repeat the words you hear from the front speaker.”
During all SIN presentations, the front speaker loudness was held constant at 70 dB SPL, and only the rear-speaker loudness varied. Although we pre-set our front speaker to 70 dB SPL, it seems reasonable to set this to the MCL level or perhaps MCL plus 5 dB, to assure audibility (as needed), while not exceeding uncomfortable loudness (UCL) levels.
The first trial (“introductory task”) was presented with speech in the front speaker at 70 dB SPL and four-talker babble presented through the rear speaker at 55 dB SPL (15 dB SNR). This was an easy task for all participants. The introductory level allowed for a quick practice session during which we confirmed the task was understood by the listener. Of note, our protocol is similar to that used in pure-tone audiometry when bracketing thresholds. For example, using the 15 dB SNR, all participants easily got three words in a row correct.
Consequently, we reduced the SNR to 10 dB (i.e., made the babble louder by 5 dB, resulting in a 10 dB SNR), and for most people, this too, was rather easy. If the subject was only able to repeat one or two of the next three words correctly, we made the task easier by decreasing the babble by 2 dB (resulting in a 12 dB SNR) and then bracketed in 1-dB steps. The entire procedure from an introductory 15 dB SNR to their bracketed SNR-50 threshold usually involved fewer than 25 words and required less than two minutes.
In our pilot program, to avoid overamplification and uncomfortably loud presentations for people with thresholds within normal limits, we placed the following values into the Genie SoftwareTM, and programmed the Oticon Opn 1TM hearing aids using the following fictitious thresholds (all were fitted with open domes, see TABLE 1).
The first test session was accomplished with the following parameters (Program 1, aka P1):
Open Sound Transition Selected by Genie, Noise Reduction Complex, Directionality OPN, Gain Control 100% (Level 3), VAC+.
The second test session was accomplished using the same parameters, except the noise reduction was reset to maximum (Program 2, aka P2).
Note: For aided presentations, before presenting the primary-speech stimulus in front, it may be important to wait 3–5 seconds (or longer) each time the four-talker babble loudness changes, to allow the noise-reduction algorithm to activate. In our pilot test, we used Oticon Opn 1TM devices in which the noise-reduction circuit activates in less than 25 milliseconds.
Discussion
The most common complaint from people with SNHL and with traditional hearing aids is their inability to understand SIN (Beck et al, 2019). As such, obtaining a pre- and postfitting SNR-50 is important. In this article, we have demonstrated a simple protocol that can rapidly determine SIN thresholds and can be used to validate and verify important differences between unaided and aided responses. This pilot study was executed to reinforce the necessity of SIN testing and to offer a quick, inexpensive, and rational SIN protocol to help determine a patients’s unaided (baseline) and aided SIN performance, as demonstrated by their unaided and aided SNR-50.
Appendix
Equipment – MedRx Stealth or MedRx ARC with Free Field Speakers
Stimulus – NU-6 Word Lists
Babble – Auditec Speech Babble (included with all MedRx Audiometers)
Calibration – Calibrations should be performed by a trained technician with speakers at ear level. Speakers should be placed (ideally) at 0- and 180-degree azimuth at 1 meter from subject’s head. If the speakers must be moved, mark the exact location of the speakers and subject chair. Each audiometer has variable calibration protocols. MedRx audiometers must have full free-field calibrations performed for accurate speech testing. Calibration frequencies include 125–8000 Hz, white noise, speech weighted noise and speech tone.
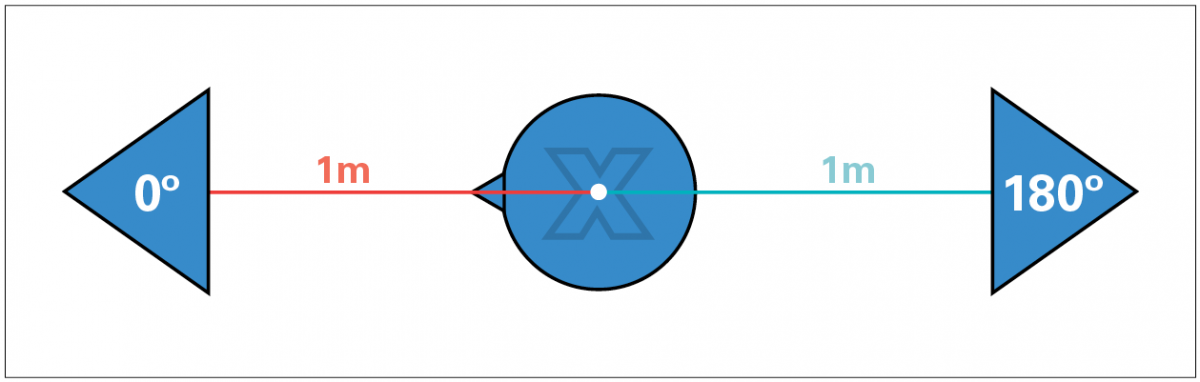
FIGURE 1. Subject and speaker diagram where X marks the placement of the calibration microphone.
To perform free-field calibration, the microphone location must estimate the center of the subject’s head position (marked by an X in Figure 1). All measurements should be made with the microphone in this static position. Set the sound level meter (SLM) to SPL mode (see FIGURE 2).
- Subject and speaker diagram where X marks the calibration microphone (FIGURE 1).
- Speakers at 0 degrees (right channel) and 180 degrees (left channel).
- MedRx free-field calibrations (completed by certified technician).
- Complete full pure-tone, free-field calibration using warble tones.
- MedRx equipment must have white noise, speech babble (A Weighted), speech-tone calibrated (1000 Hz cal. tone).
- Save calibration.
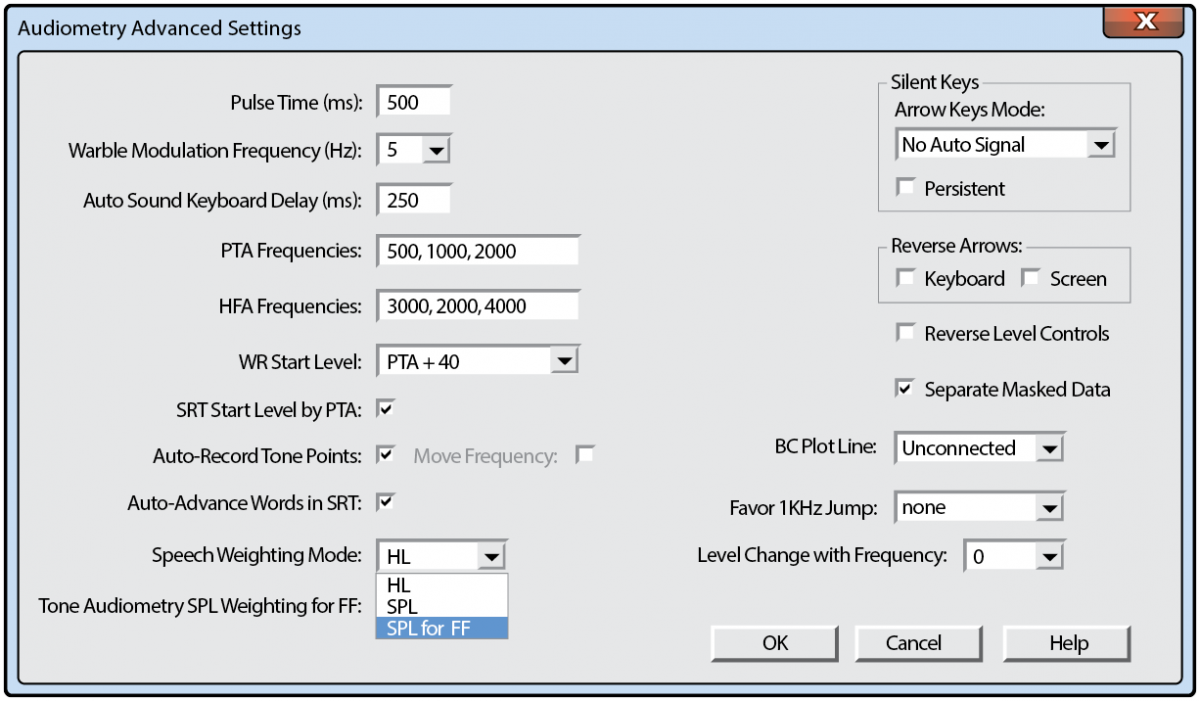
FIGURE 2. Avant advanced audiometry settings, set free field to SPL.
Special Thanks
The authors offer thanks and appreciation to Andy Vermiglio, AuD, and Caleb Sparkman, AuD, for their review and valuable input regarding the preparation of this manuscript.
References
Beck DL. (2017) Best practices in hearing aid dispensing: An interview with Michael Valente, PhD. Hear Rev 24(12):39–41.
Beck DL, Danhauer JL, Abrams HB, Atcherson SR, Brown DK, Chasin M, Clark JG, De Placido C, Edwards B, Fabry DA, Flexer C, Fligor B, Frazer G, Galster JA, Gifford L, Johnson CE, Madell J, Moore DR, Roeser RJ, Saunders GH, Searchfield GD, Spankovich C, Valente M, Wolfe J. (2018) Audiologic considerations for people with normal hearing sensitivity yet hearing difficulty and/or speech-in-noise problems. Hear Rev 25(10):28–38.
Beck DL, Ng E, Jensen JJ. (2019): A scoping review 2019: OpenSound Navigator. Hear Rev 26(2):28–31.
Clark, JG, Huff C, Earl B. (2017) Clinical practice report card–Are we meeting best practice standards for adult hearing rehabilitation? Audiol Today 29(6):15–25.
Carhart R. (1946) Tests for selection of hearing aids. Laryngoscope 56(12):780–794.
Dillon H. (2012) Hearing Aids. (2d Ed) Thieme Publishers.
The Harvard Report. (1946) Davis H, Hudgins CV, Marquis RJ, et al. The Selection of Hearing Aids. Laryngoscope 56(3):85–115.
Jerger J. (2018) Lessons from the past: Two influential articles in the early history of audiology. Hear Rev. Published Dec 5.
Killion MC. (2002) New thinking on hearing in noise: a generalized articulation index. Sem Hear 23(1):57–75.
Lawson G. (2012) Speech Audiometry, Word Recognition, and Binomial Variables: Interview with Gary Lawson. www.audiology.org/news/speech-audiometry-word-recognition-and-binomial-variables-interview-gary-lawson-phd.
Loven F, Hawkins D. (1983) Interlist equivalency of the CID W-22 word lists presented in quiet and in noise. Ear Hear 4:91–97.
Stockley KB, Green WB. (2000) Interlist equivalency of the Northwestern University auditory test No. 6 in quiet and noise with adult hearing-impaired individuals. J Am Acad Audiol 11:91–96.
Taylor B, Mueller G. (2017) Fitting and Dispensing Hearing Aids (2d ed) Plural Publishing.
Vermiglio AJ, Herring CC, Heeke P, Post CE, Fang X. (2019) Sentence recognition in steady-state speech-shaped noise versus four-talker babble. J Am Acad Audiol 30(1):54–65.
Vermiglio AJ, Soli SD, Freed DJ, Fisher LM. (2012) The relationship between high-frequency pure-tone hearing loss, hearing in noise test (HINT) thresholds, and the articulation index. J Am Acad Audiol 23(10):779–788.
Wilson RH. (2011) Clinical experience with the words-in-noise test on 3430veterans: comparisons with pure-tone thresholds and word recognition in quiet. J Am Acad Audiol 22(7):405–423.
Speech-awareness thresholds
Speech-awareness threshold (SAT) is also known as speech-detection threshold (SDT). The objective of this measurement is to obtain the lowest level at which speech can be detected at least half the time. This test does not have patients repeat words; it requires patients to merely indicate when speech stimuli are present.
Speech materials usually used to determine this measurement are spondees. Spondaic words are 2-syllable words spoken with equal emphasis on each syllable (eg, pancake, hardware, playground). Spondees are used because they are easily understandable and contain information within each syllable sufficient to allow reasonably accurate guessing.
The SAT is especially useful for patients too young to understand or repeat words. It may be the only behavioral measurement that can be made with this population. The SAT may also be used for patients who speak another language or who have impaired language function because of neurological insult.
For patients with normal hearing or somewhat flat hearing loss, this measure is usually 10-15 dB better than the speech-recognition threshold (SRT) that requires patients to repeat presented words. For patients with sloping hearing loss, this measurement can be misleading with regard to identifying the overall degree of loss.
If a patient has normal hearing in a low frequency, the SAT will be closely related to the threshold for that frequency, and it will not indicate greater loss in higher frequencies.
Speech-recognition threshold
The speech-recognition threshold (SRT) is sometimes referred to as the speech-reception threshold.
[2] The objective of this measure is to obtain the lowest level at which speech can be identified at least half the time.
Spondees are usually used for this measurement. Lists of spondaic words commonly used to obtain the SRT are contained within the Central Institute for the Deaf (CID) Auditory List W-1 and W-2.
In addition to determining softest levels at which patients can hear and repeat words, the SRT is also used to validate pure-tone thresholds because of high correlation between the SRT and the average of pure-tone thresholds at 500, 1000, and 2000 Hz.
In clinical practice, the SRT and 3-frequency average should be within 5-12 dB. This correlation holds true if hearing loss in the 3 measured frequencies is relatively similar. If 1 threshold within the 3 frequencies is significantly higher than the others, the SRT will usually be considerably better than the 3-frequency average. In this case, a 2-frequency average is likely to be calculated and assessed for agreement with the SRT.
Other clinical uses of the SRT include establishing the sound level to present suprathreshold measures and determining appropriate gain during hearing aid selection.
Suprathreshold word-recognition testing
The primary purpose of suprathreshold word-recognition testing is to estimate ability to understand and repeat single-syllable words presented at conversational or another suprathreshold level. This type of testing is also referred to as word-discrimination testing or speech-discrimination testing.
Initial word lists compiled for word-recognition testing were phonetically balanced (PB). This term indicated that phonetic composition of the lists was equivalent and representative of connected English discourse.
The original PB lists were created at the Harvard Psycho-Acoustic Laboratory and are referred to as the PB-50 lists. The PB-50 lists contain 50 single-syllable words in 20 lists consisting of 1000 different monosyllabic words. Several years later, the CID W-22 word lists were devised, primarily using words selected from the PB-50 lists. Another word list (devised from a grouping of 200 consonant-nucleus-consonant [CNC] words) is called the Northwestern University Test No. 6 (NU-6). Recorded tape and CD versions of all these word-recognition tests are commercially available.
The PB-50, CID W-22, and NU-6 word lists each contain 50 words that are presented at specified sensation levels. Words can be presented via tape, CD, or monitored live voice. Patients are asked to repeat words to the audiologist. Each word repeated correctly is valued at 2%, and scores are tallied as a percent-correct value.
Varying the presentation level of monosyllabic words reveals a variety of performance-intensity functions for these word lists. In general, presenting words at 25-40 dB sensation level (refer to the SRT) allows patients to achieve maximum scores. Lowering the level results in lower scores. For individuals with hearing loss, words can be presented at a comfortable loudness level or at the highest reasonable level before discomfort occurs.
When words are presented at the highest reasonable level and the word-recognition score is 80% or better, testing can be discontinued. If the score is lower than 80%, further testing at lower presentation levels is recommended. If scores at lower levels are better than those obtained at higher presentation levels, «roll over» has occurred, and these scores indicate a possible retrocochlear (or higher) site of lesion.
Another use of suprathreshold word-recognition testing is to verify speech-recognition improvements achieved by persons with hearing aids. Testing can be completed at conversational levels in the sound field without the use of hearing aids and then again with hearing aids fitted to the patient. Score differences can be used as a method to assess hearing with hearing aids and can be used as a pretest and posttest to provide a percent-improvement score
Speech audiogram. Video courtesy of Benjamin Daniel Liess, MD.
Sentence testing
To evaluate ability to hear and understand everyday speech, various tests have been developed that use sentences as test items. Sentences can provide information regarding the time domain of everyday speech and can approximate contextual characteristics of conversational speech.
Everyday sentence test
This is the first sentence test developed at the CID in the 1950s.
Clinical use of this test is limited, because its reliability as a speech-recognition test for sentences remains undemonstrated.
Synthetic-sentence identification test
The synthetic-sentence identification (SSI) test was developed in the late 1960s. SSI involves a set of 10 synthetic sentences. Sentences used in this test were constructed so that each successive group of 3 words in a sentence is itself meaningful but the entire sentence is not.
Because the sentences are deemed insufficiently challenging in quiet environments, a recommendation has been made that sentences be administered in noise at a signal-to-noise (S/N) ratio of 0 dB, which presents both sentences and noise at equal intensity level.
Speech perception in noise test
The speech perception in noise (SPIN) test is another sentence-identification test. The SPIN test was originally developed in the late 1970s and was revised in the mid 1980s.
The revised SPIN test consists of 8 lists of 50 sentences. The last word of each sentence is considered the test item. Half of listed sentences contain test items classified as having high predictability, indicating that the word is very predictable given the sentence context. The other half of listed sentences contain test items classified as having low predictability, indicating that the word is not predictable given sentence context. Recorded sentences come with a speech babble-type noise that can be presented at various S/N ratios.
Speech in noise test
The speech in noise (SIN) test, developed in the late 1990s, contains 5 sentences with 5 key words per test condition. Two signal levels (70 and 40 dB) and 4 S/N ratios are used at each level. A 4-talker babble is used as noise. This recorded test can be given to patients with hearing aids in both the unaided and aided conditions.
Results are presented as performance-intensity functions in noise. A shorter version of the SIN, the QuickSIN, was developed in 2004. The QuickSIN has been shown to be effective, particularly when verifying open-fit behind-the-ear hearing aids.
Hearing in noise test
The hearing in noise test (HINT) is designed to measure speech recognition thresholds in both quiet and noise. The test consists of 25 lists of 10 sentences and noise matched to long-term average speech.
Using an adaptive procedure, a reception threshold for sentences is obtained while noise is presented at a constant level. Results can be compared with normative data to determine the patient’s relative ability to hear in noise.
Words in noise test
The Words-in-Noise Test (WIN), developed in the early 2000s, provides an open set word-recognition task without linguistic context. The test is composed of monosyllabic words from the NU-6 word lists presented in multitalker babble. The purpose of the test is to determine the signal-to-babble (S/B) ratio in decibels for those with normal and impaired hearing. The WIN is similar to the QuickSIN in providing information about speech recognition performance.
The WIN is used to measure performance of basic auditory function when working memory and linguistic context is reduced or eliminated. This measure, by using monosyllabic words in isolation, evaluates the listener’s ability to recognize speech using acoustic cues alone and by eliminating syntactical and semantic cues founds in sentences. The WIN materials allow for the same words to be spoken by the same speaker for both speech-in-quiet and speech-in-noise data collection.
Bamford-Kowal-Bench speech in noise test
Bamford-Kowal-Bench Speech-in-Noise Test (BKB-SIN) was developed by Etymotic Research in the early to mid 2000s. The primary population for this test include children and candidates or recipients of cochlear implants.
Like the HINT, the BKB-SIN uses Americanized BKB sentences.
[3] These words are characterized as short, and the sentences are highly redundant; they contain semantic and syntactic contextual cues developed at a first grade reading level. Compared to the HINT, which uses speech-spectrum noise, the BKB-SIN uses multitalker babble. Clinicians can expect better recognition performance on the BKB-SIN and HINT in comparison to the QuickSIN and WIN because of the additional semantic context provided by the BKB sentences.
Selecting proper speech in noise testing
QuickSIN and WIN materials are best for use in discriminating those who have hearing loss from normal hearing individuals. The BKB-SIN and HINT materials are less able to identify those with hearing loss.
[4, 5] Therefore, the QuickSIN or WIN is indicated as part of the routine clinical protocol as a speech in noise task. The choice of QuickSIN or WIN is strictly a matter of clinician preference; however, the clinician must also consider whether or not the patient can handle monosyllabic words (WIN) or needs some support from sentence context (QuickSIN).
The BKB-SIN and HINT materials are easier to recognize because of the semantic content, making them excellent tools for young children or individuals with substantial hearing loss, including cochlear implant candidates and new recipients.
Most comfortable loudness level and uncomfortable loudness level
Most comfortable loudness level
The test that determines the intensity level of speech that is most comfortably loud is called the most comfortable loudness level (MCL) test.
For most patients with normal hearing, speech is most comfortable at 40-50 dB above the SRT. This sensation level is reduced for many patients who have sensorineural hearing loss (SNHL). Because of this variation, MCL can be used to help determine hearing aid gain for patients who are candidates for amplification.
MCL measurement can be obtained using cold running or continuous speech via recorded or monitored live-voice presentation. Patients are instructed to indicate when speech is perceived to be at the MCL. Initial speech levels may be presented at slightly above SRT and then progressively increased until MCL is achieved. Once MCL is achieved, a speech level is presented above initial MCL and reduced until another MCL is obtained. This bracketing technique provides average MCL.
Uncomfortable loudness level
One reason to establish uncomfortable loudness level (UCL) is to determine the upper hearing limit for speech. This level provides the maximum level at which word-recognition tests can be administered. UCL can also indicate maximum tolerable amplification.
Another reason to establish UCL is to determine the dynamic speech range. Dynamic range represents the limits of useful hearing in each ear and is computed by subtracting SRT from UCL. For many patients with SNHL, this range can be extremely limited because of recruitment or abnormal loudness perception.
UCL speech materials can be the same as for MCL. The normal ear should be able to accept hearing levels of 90-100 dB. Patients are instructed to indicate when presented speech is uncomfortably loud. Instructions are critical, since patients must allow speech above MCL before indicating discomfort.