
I am writing some C# VSTO code that reads a Microsoft Word document and saves it to Filtered HTML. When I perform this function on a generic Word document, the output of the html file uses a Windows Charset as witnessed here:
<meta http-equiv=Content-Type content="text/html; charset=windows-1252">
If I open a document and go to File->Options->Advanced->Web Options, I can choose UTF8, and the resulting filtered html document output looks like this:
<meta http-equiv=Content-Type content="text/html; charset=utf-8">
I want to write c# code that saves any Word document to filtered html with utf-8. After doing some research, I found some people saying the «SaveAs2» function does not work (even though Microsoft documents it as a feature). That means, this code does not work for me:
doc.SaveAs2("C:\Temp\Test.htm", MsWord.WdSaveFormat.wdFormatFilteredHTML, Encoding: "65001");
(note: I tried putting the 65001 in quotes and without quotes.. neither throw errors, but neither works).
Next, I moved on to setting the web options for the document like this:
doc = app.Documents.Open("C:\Temp\Test.docx");
doc.WebOptions.Encoding = Microsoft.Office.Core.MsoEncoding.msoEncodingUTF8;
doc.SaveAs2(destFile, MsWord.WdSaveFormat.wdFormatFilteredHTML);
To the best of my knowledge the above code performs the same exact function as my manually opening a file, going to file->options…, setting to UTF-8 and saving the file to filtered html, yet the output still looks like this:
<meta http-equiv=Content-Type content="text/html; charset=windows-1252">
Is there a way to force Microsoft Word to output a file to UTF-8 without having to manually configure the document first?
Чтобы правильно отобразить HTML страницу, веб браузер должен знать, какой набор символов использовать.
Что такое кодировка символов?
ASCII была первая стандартная кодировка символов (также называется набор символов).
ASCII определенны 128 различных буквенно-цифровых символов, которые могут быть использованы в интернете: числа от (0-9),
английские буквы (A-Z), и некоторые специальные символы, такие как ! $ + — ( ) @ < > .
ANSI (Windows-1252) был оригинальным Windows набор символов, с поддержкой 256 различных кодов символов.
ISO-8859-1 была кодировка по умолчанию для HTML 4. Этот набор символов тоже поддерживается 256 различных кодов символов.
Потому что ANSI и ISO-8859-1 были настолько ограничены, что HTML 4 также поддерживает UTF-8.
UTF-8 (Юникод) охватывает практически все знаки и символы в мире.
Кодировка по умолчанию для HTML5 является UTF-8.
HTML Атрибут charset
Для корректного отображения HTML страницы веб браузер должен знать набор символов, используемый на этой странице.
Это указано в теге <meta>:
Если браузер обнаруживает ISO-8859-1 на веб странице, он по умолчанию использует ANSI.
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
| Число | ASCII | ANSI | 8859 | UTF-8 | Описание |
|---|---|---|---|---|---|
| 32 | Пространство | ||||
| 33 | ! | ! | ! | ! | Восклицательный знак |
| 34 | « | « | « | « | Кавычки двойные |
| 35 | # | # | # | # | Знак числа |
| 36 | $ | $ | $ | $ | Знак доллара |
| 37 | % | % | % | % | Знак процента |
| 38 | & | & | & | & | Амперсанд |
| 39 | ‘ | ‘ | ‘ | ‘ | Кавычки одинарные |
| 40 | ( | ( | ( | ( | Левая собка |
| 41 | ) | ) | ) | ) | Правая скобка |
| 42 | * | * | * | * | Звездочка |
| 43 | + | + | + | + | Плюс |
| 44 | , | , | , | , | Запятая |
| 45 | — | — | — | — | Дефис-минус |
| 46 | . | . | . | . | Точка |
| 47 | / | / | / | / | Косая черта |
| 48 | 0 | 0 | 0 | 0 | Число нуль |
| 49 | 1 | 1 | 1 | 1 | Число один |
| 50 | 2 | 2 | 2 | 2 | Число два |
| 51 | 3 | 3 | 3 | 3 | Число три |
| 52 | 4 | 4 | 4 | 4 | Число четыре |
| 53 | 5 | 5 | 5 | 5 | Число пять |
| 54 | 6 | 6 | 6 | 6 | Число шесть |
| 55 | 7 | 7 | 7 | 7 | Число семь |
| 56 | 8 | 8 | 8 | 8 | Число восемь |
| 57 | 9 | 9 | 9 | 9 | Число девять |
| 58 | : | : | : | : | Двоеточие |
| 59 | ; | ; | ; | ; | Точка с запятой |
| 60 | < | < | < | < | Знак меньше чем |
| 61 | = | = | = | = | Знак равенства |
| 62 | > | > | > | > | Знак больше чем |
| 63 | ? | ? | ? | ? | Знак вопроса |
| 64 | @ | @ | @ | @ | Коммерческая в |
| 65 | A | A | A | A | Латинская буква A |
| 66 | B | B | B | B | Латинская буква B |
| 67 | C | C | C | C | Латинская буква C |
| 68 | D | D | D | D | Латинская буква D |
| 69 | E | E | E | E | Латинская буква E |
| 70 | F | F | F | F | Латинская буква F |
| 71 | G | G | G | G | Латинская буква G |
| 72 | H | H | H | H | Латинская буква H |
| 73 | I | I | I | I | Латинская буква I |
| 74 | J | J | J | J | Латинская буква J |
| 75 | K | K | K | K | Латинская буква K |
| 76 | L | L | L | L | Латинская буква L |
| 77 | M | M | M | M | Латинская буква M |
| 78 | N | N | N | N | Латинская буква N |
| 79 | O | O | O | O | Латинская буква O |
| 80 | P | P | P | P | Латинская буква P |
| 81 | Q | Q | Q | Q | Латинская буква Q |
| 82 | R | R | R | R | Латинская буква R |
| 83 | S | S | S | S | Латинская буква S |
| 84 | T | T | T | T | Латинская буква T |
| 85 | U | U | U | U | Латинская буква U |
| 86 | V | V | V | V | Латинская буква V |
| 87 | W | W | W | W | Латинская буква W |
| 88 | X | X | X | X | Латинская буква X |
| 89 | Y | Y | Y | Y | Латинская буква Y |
| 90 | Z | Z | Z | Z | Латинская буква Z |
| 91 | [ | [ | [ | [ | Левая квадратная скобка |
| 92 | Обратный солидус | ||||
| 93 | ] | ] | ] | ] | Правая квадратная скобка |
| 94 | ^ | ^ | ^ | ^ | Циркумфлекс ударение |
| 95 | _ | _ | _ | _ | Низкая линия |
| 96 | ` | ` | ` | ` | Знак ударения |
| 97 | a | a | a | a | Латинская строчная буква a |
| 98 | b | b | b | b | Латинская строчная буква b |
| 99 | c | c | c | c | Латинская строчная буква c |
| 100 | d | d | d | d | Латинская строчная буква d |
| 101 | e | e | e | e | Латинская строчная буква e |
| 102 | f | f | f | f | Латинская строчная буква f |
| 103 | g | g | g | g | Латинская строчная буква g |
| 104 | h | h | h | h | Латинская строчная буква h |
| 105 | i | i | i | i | Латинская строчная буква i |
| 106 | j | j | j | j | Латинская строчная буква j |
| 107 | k | k | k | k | Латинская строчная буква k |
| 108 | l | l | l | l | Латинская строчная буква l |
| 109 | m | m | m | m | Латинская строчная буква m |
| 110 | n | n | n | n | Латинская строчная буква n |
| 111 | o | o | o | o | Латинская строчная буква o |
| 112 | p | p | p | p | Латинская строчная буква p |
| 113 | q | q | q | q | Латинская строчная буква q |
| 114 | r | r | r | r | Латинская строчная буква r |
| 115 | s | s | s | s | Латинская строчная буква s |
| 116 | t | t | t | t | Латинская строчная буква t |
| 117 | u | u | u | u | Латинская строчная буква u |
| 118 | v | v | v | v | Латинская строчная буква v |
| 119 | w | w | w | w | Латинская строчная буква w |
| 120 | x | x | x | x | Латинская строчная буква x |
| 121 | y | y | y | y | Латинская строчная буква y |
| 122 | z | z | z | z | Латинская строчная буква z |
| 123 | { | { | { | { | Левая фигурная скобка |
| 124 | | | | | | | | | Вертикальная линия |
| 125 | } | } | } | } | Правая фигурная скобка |
| 126 | ~ | ~ | ~ | ~ | Тильда |
| 127 | DEL | ||||
| 128 | € | Знак евро | |||
| 129 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 130 | ‚ | Одинарная 9 низкая кавычка | |||
| 131 | ƒ | Латинская строчная буква f с крючком | |||
| 132 | „ | Двойная 9 низкая кавычка | |||
| 133 | … | Горизонтальное многоточие | |||
| 134 | † | Кинжал | |||
| 135 | ‡ | Двойной кинжал | |||
| 136 | ˆ | Письмо модификатор облеченным ударением | |||
| 137 | ‰ | Знак промилле | |||
| 138 | Š | Латинская буква S с caron | |||
| 139 | ‹ | Одинарный угол влево низкая кавычка | |||
| 140 | Œ | Латинская заглавная лигатура OE | |||
| 141 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 142 | Ž | Латинская буква Z с caron | |||
| 143 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 144 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 145 | ‘ | Левая одинарная низкая кавычка | |||
| 146 | ’ | Правая одинарная низкая кавычка | |||
| 147 | “ | Левая двойная низкая кавычка | |||
| 148 | ” | Правая двойная низкая кавычка | |||
| 149 | • | Маркер | |||
| 150 | – | Тире | |||
| 151 | — | Длинное тире | |||
| 152 | ˜ | Маленькая тильда | |||
| 153 | ™ | Знак торговой марки | |||
| 154 | š | Латинская строчная буква s с caron | |||
| 155 | › | Одинарный угол вправо низкая кавычка | |||
| 156 | œ | Латинская строчная лигатура oe | |||
| 157 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 158 | ž | Латинская строчная буква z с caron | |||
| 159 | Ÿ | Латинская буква Y с diaeresis | |||
| 160 | Неразрывный пробел | ||||
| 161 | ¡ | ¡ | ¡ | Перевернутый восклицательный знак | |
| 162 | ¢ | ¢ | ¢ | Знак цента | |
| 163 | £ | £ | £ | Знак фунта | |
| 164 | ¤ | ¤ | ¤ | Знак валюты | |
| 165 | ¥ | ¥ | ¥ | Знак иены | |
| 166 | ¦ | ¦ | ¦ | Прерывистая полоса | |
| 167 | § | § | § | Знак раздела | |
| 168 | ¨ | ¨ | ¨ | Трема | |
| 169 | © | © | © | Знак авторского права | |
| 170 | ª | ª | ª | Женский порядковый индикатор | |
| 171 | « | « | « | Двойной угол влево | |
| 172 | ¬ | ¬ | ¬ | Знак нет | |
| 173 | | | | Мягкий дефис | |
| 174 | ® | ® | ® | Зарегистрированный знак | |
| 175 | ¯ | ¯ | ¯ | Макрон | |
| 176 | ° | ° | ° | Знак степени | |
| 177 | ± | ± | ± | Плюс-минус | |
| 178 | ² | ² | ² | Верхний индекс два | |
| 179 | ³ | ³ | ³ | Верхний индекс три | |
| 180 | ´ | ´ | ´ | Острый знак ударения | |
| 181 | µ | µ | µ | Микро знак | |
| 182 | ¶ | ¶ | ¶ | Знак абзаца | |
| 183 | · | · | · | Точка посередине | |
| 184 | ¸ | ¸ | ¸ | Седиль | |
| 185 | ¹ | ¹ | ¹ | Верхний индекс один | |
| 186 | º | º | º | Мужской порядковый индикатор | |
| 187 | » | » | » | Двойной угол вправо | |
| 188 | ¼ | ¼ | ¼ | Грубая дробь одна четвертая | |
| 189 | ½ | ½ | ½ | Грубая дробь одна вторая | |
| 190 | ¾ | ¾ | ¾ | Грубая дробь три четвертых | |
| 191 | ¿ | ¿ | ¿ | Перевернутый вопросительный знак | |
| 192 | À | À | À | Латинская буква A с grave | |
| 193 | Á | Á | Á | Латинская буква A с acute | |
| 194 | Â | Â | Â | Латинская буква A с circumflex | |
| 195 | Ã | Ã | Ã | Латинская буква A с tilde | |
| 196 | Ä | Ä | Ä | Латинская буква A с diaeresis | |
| 197 | Å | Å | Å | Латинская буква A с ring above | |
| 198 | Æ | Æ | Æ | Латинская буква AE | |
| 199 | Ç | Ç | Ç | Латинская буква C с cedilla | |
| 200 | È | È | È | Латинская буква E с grave | |
| 201 | É | É | É | Латинская буква E с acute | |
| 202 | Ê | Ê | Ê | Латинская буква E с circumflex | |
| 203 | Ë | Ë | Ë | Латинская буква E с diaeresis | |
| 204 | Ì | Ì | Ì | Латинская буква I с grave | |
| 205 | Í | Í | Í | Латинская буква I с acute | |
| 206 | Î | Î | Î | Латинская буква I с circumflex | |
| 207 | Ï | Ï | Ï | Латинская буква I с diaeresis | |
| 208 | Ð | Ð | Ð | Латинская буква Eth | |
| 209 | Ñ | Ñ | Ñ | Латинская буква N с tilde | |
| 210 | Ò | Ò | Ò | Латинская буква O с grave | |
| 211 | Ó | Ó | Ó | Латинская буква O с acute | |
| 212 | Ô | Ô | Ô | Латинская буква O с circumflex | |
| 213 | Õ | Õ | Õ | Латинская буква O с tilde | |
| 214 | Ö | Ö | Ö | Латинская буква O с diaeresis | |
| 215 | × | × | × | Знак умножения | |
| 216 | Ø | Ø | Ø | Латинская буква O с stroke | |
| 217 | Ù | Ù | Ù | Латинская буква U с grave | |
| 218 | Ú | Ú | Ú | Латинская буква U с acute | |
| 219 | Û | Û | Û | Латинская буква U с circumflex | |
| 220 | Ü | Ü | Ü | Латинская буква U с diaeresis | |
| 221 | Ý | Ý | Ý | Латинская буква Y с acute | |
| 222 | Þ | Þ | Þ | Латинская буква thorn | |
| 223 | ß | ß | ß | Латинская строчная буква sharp s | |
| 224 | à | à | à | Латинская строчная буква a с grave | |
| 225 | á | á | á | Латинская строчная буква a с acute | |
| 226 | â | â | â | Латинская строчная буква a с circumflex | |
| 227 | ã | ã | ã | Латинская строчная буква a с tilde | |
| 228 | ä | ä | ä | Латинская строчная буква a с diaeresis | |
| 229 | å | å | å | Латинская строчная буква a с ring above | |
| 230 | æ | æ | æ | Латинская строчная буква ae | |
| 231 | ç | ç | ç | Латинская строчная буква c с cedilla | |
| 232 | è | è | è | Латинская строчная буква e с grave | |
| 233 | é | é | é | Латинская строчная буква e с acute | |
| 234 | ê | ê | ê | Латинская строчная буква e с circumflex | |
| 235 | ë | ë | ë | Латинская строчная буква e с diaeresis | |
| 236 | ì | ì | ì | Латинская строчная буква i с grave | |
| 237 | í | í | í | Латинская строчная буква i с acute | |
| 238 | î | î | î | Латинская строчная буква i с circumflex | |
| 239 | ï | ï | ï | Латинская строчная буква i с diaeresis | |
| 240 | ð | ð | ð | Латинская строчная буква eth | |
| 241 | ñ | ñ | ñ | Латинская строчная буква n с tilde | |
| 242 | ò | ò | ò | Латинская строчная буква o с grave | |
| 243 | ó | ó | ó | Латинская строчная буква o с acute | |
| 244 | ô | ô | ô | Латинская строчная буква o с circumflex | |
| 245 | õ | õ | õ | Латинская строчная буква o с tilde | |
| 246 | ö | ö | ö | Латинская строчная буква o с diaeresis | |
| 247 | ÷ | ÷ | ÷ | division sign | |
| 248 | ø | ø | ø | Латинская строчная буква o с stroke | |
| 249 | ù | ù | ù | Латинская строчная буква u с grave | |
| 250 | ú | ú | ú | Латинская строчная буква u с acute | |
| 251 | û | û | û | Латинская строчная буква с circumflex | |
| 252 | ü | ü | ü | Латинская строчная буква u с diaeresis | |
| 253 | ý | ý | ý | Латинская строчная буква y с acute | |
| 254 | þ | þ | þ | Латинская строчная буква thorn | |
| 255 | ÿ | ÿ | ÿ | Латинская строчная буква y с тремой |
ASCII Набор символов
ASCII используются значения от 0 до 31 (и 127) для управляющих символов.
ASCII используются значения от 32 до 126 для букв, цифр и символов.
ASCII не используйте значения от 128 до 255.
ANSI Набор символов (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентична кодировке utf-8 для значений от 160 до 255.
ISO-8859-1 Набор символов
8859-1 идентичен ASCII для значений от 0 до 127.
8859-1 не используйте значения от 128 до 159.
8859-1 идентична кодировке utf-8 для значений от 160 до 255.
UTF-8 Набор символов
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не используйте значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжается от значение 256 с более чем 10 000 различных символов.
Для более близкого взгляда, изучите наш Полный набор символов HTML справочник.
Правило CSS @charset
Вы можете использовать CSS правило @charset для указания кодировки символов, используемой в таблице стилей:
Пример
Установите кодировку таблицы стилей в Юникод UTF-8:
@charset «UTF-8»;
Подробнее о компании читайте здесь CSS Правило @charset.
Question
How should I declare the encoding of my HTML file?
You should always specify the encoding used for an HTML or XML page. If you don’t, you risk that characters in your content are incorrectly interpreted. This is not just an issue of human readability, increasingly machines need to understand your data too. A character encoding declaration is also needed to process non-ASCII characters entered by the user in forms, in URLs generated by scripts, and so forth. This article describes how to do this for an HTML file.
If you need to better understand what characters and character encodings are, see the article Character encodings for beginners. For information about declaring encodings for CSS style sheets, see CSS character encoding declarations.
Quick answer
Always declare the encoding of your document using a meta element with a charset attribute, or using the http-equiv and content attributes (called a pragma directive). The declaration should fit completely within the first 1024 bytes at the start of the file, so it’s best to put it immediately after the opening head tag.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
...<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=utf-8">
...It doesn’t matter which you use, but it’s easier to type the first one. It also doesn’t matter whether you type UTF-8 or utf-8.
You should always use the UTF-8 character encoding. (Remember that this means you also need to save your content as UTF-8.) See what you should consider if you really cannot use UTF-8.
If you have access to the server settings, you should also consider whether it makes sense to use the HTTP header. Note however that, since the HTTP header has a higher precedence than the in-document meta declarations, content authors should always take into account whether the character encoding is already declared in the HTTP header. If it is, the meta element must be set to declare the same encoding.
You can detect any encodings sent by the HTTP header using the Internationalization Checker.
Details
What about the byte-order mark?
If you have a UTF-8 byte-order mark (BOM) at the start of your file then modern browsers will use that to determine that the encoding of your page is UTF-8. It has a higher precedence than any other declaration, including the HTTP header.
You could skip the meta encoding declaration if you have a BOM, but we recommend that you keep it, since it helps people looking at the source code to ascertain what the encoding of the page is.
Read more about the byte-order mark.
Should I declare the encoding in the HTTP header?
Use character encoding declarations in HTTP headers if it makes sense, and if you are able, for any type of content, but in conjunction with an in-document declaration.
Content authors should always ensure that HTTP declarations are consistent with the in-document declarations.
Pros and cons of using the HTTP header
One advantage of using the HTTP header is that user agents can find the character encoding information sooner when it is sent in the HTTP header.
On the other hand, there are a number of potential disadvantages:
-
It may be difficult for content authors to change the encoding information for static files on the server – especially when dealing with an ISP.
Authors will need knowledge of and access to the server settings. -
Server settings may get out of synchronization with the document for one reason or another. This may happen, for example, if you
rely on the server default, and that default is changed. This is a very bad situation, since the higher precedence of the HTTP information versus the
in-document declaration may cause the document to become unreadable. -
There are potential problems for both static and dynamic documents if they are not read from a server; for example, if they are saved to a
location such as a CD or hard disk. In these cases any encoding information from an HTTP header is not available.Similarly, if the character encoding is only declared in the HTTP header, this information is no longer available for files during editing, or when they are
processed by such things as XSLT or scripts, or when they are sent for translation, etc.
So should I use this method?
If serving files via HTTP from a server, it is never a problem to send information about the character encoding of the document in the HTTP header, as long as that information is correct.
On the other hand, because of the disadvantages listed above we recommend that you should always declare the encoding information inside the document as well. An in-document declaration also helps developers, testers, or translation production managers who want to visually check the encoding of a document.
(Some people would argue that it is rarely appropriate to declare the encoding in the HTTP header if you are going to repeat it in the
content of the document. In this case, they are proposing that the HTTP header say nothing about the document encoding. Note that this would usually mean
taking action to disable any server defaults.)
Working with polyglot and XML formats
XHTML5: An XHTML5 document is served as XML and has XML syntax. XML parsers do not recognise the encoding declarations in meta elements. They only recognise the XML declaration. Here is an example:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html ....
The XML declaration is only required if the page is not being served as UTF-8 (or UTF-16), but it can be useful to include it so that developers, testers, or translation production managers can visually check the encoding of a document by looking at the source.
Polyglot markup: A page that uses polyglot markup uses a subset of HTML with XML syntax that can be parsed either by an HTML or an XML parser. It is described in Polyglot Markup: A robust profile of the HTML5 vocabulary.
Since a polyglot document must be in UTF-8, you don’t need to, and indeed must not, use the XML declaration. On the other hand, if the file is to be read as HTML you will need to declare the encoding using a meta element, the byte-order mark or the HTTP header.
Since a declaration in a meta element will only be recognized by an HTML parser, if you use the approach with the content attribute its value should start with text/html;.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
If you use the meta element with a charset attribute this is not something you need to consider.
Additional information
The information in this section relates to things you should not normally need to know, but which are included here for completeness.
Working with non-UTF-8 encodings
Using UTF-8 not only simplifies authoring of pages, it avoids unexpected results on form submission and URL encodings, which use the document’s character encoding by default. If you really can’t avoid using a non-UTF-8 character encoding you will need to choose from a limited set of encoding names to ensure maximum interoperability and the longest possible term of readability for your content.
Until recently the IANA registry was the place to find names for encodings. The IANA registry has multiple names for the same encoding, in which case you are supposed to use the name designated as
‘preferred’.
Nowadays, you should use the Encoding specification, which provides a list that has been tested against actual browser implementations. You can find the list in the table in the section called Names and labels. It is best to use the names in the left column of that table.
Note, however, that the presence of a name in either of these sources doesn’t necessarily mean that it is OK to use that encoding. Several of the encodings are problematic. If you really can’t use UTF-8, you should carefully consider the advice in the article Choosing & applying a character encoding.
Do not invent your own encoding names preceded by x-. This is a bad idea since it
limits interoperability.
Working with legacy HTML formats
HTML 4.01 doesn’t specify the use of the charset attribute with the meta element, but any recent major browser will still detect it and use it, even if the page is declared to be HTML4 rather than HTML5. This section is only relevant if you have some other reason than serving to a browser for conforming to an older format of HTML. It describes any differences from the Details section above.
For pages served as XML, see Working with polyglot and XML formats.
HTML4: As mentioned just above, you need to use the pragma directive for full conformance with HTML 4.01, rather than the charset attribute.
XHTML 1.x served as text/html: Also needs the pragma directive for full conformance with HTML 4.01, rather than the charset attribute. You do not need to use the XML declaration, since the file is being served as HTML.
XHTML 1.x served as XML: Use the encoding attribute of the XML declaration on the first line of the page. Ensure there is nothing before it, including spaces (although a byte-order mark is OK).
The charset attribute on a link
HTML5 deprecated the use of the charset attribute on an a or link element, so you should avoid using it. It originated in the HTML 4.01 specification for use with the a, link and script elements and was supposed to indicate the encoding of the document you are linking to.
It was intended for use on an embedded link element like this:
![]() Bad code. Don’t copy!
Bad code. Don’t copy!
See our <a href="/mysite/mydoc.html" charset="iso-8859-15">list of publications</a>.
The idea was that the browser would be able to apply the right encoding to the document it retrieves if no encoding is specified for the document in any other way.
There were always issues with the use of this attribute. Firstly, it is not well supported by major browsers. One reason not to support this attribute is that if browsers do so without special additional rules it would be an XSS attack vector. Secondly, it is hard to ensure that the information is correct at any given time. The author of the document pointed to may well change the encoding of the document without you knowing. If the author still hasn’t specified the encoding of their document, you will now be asking the browser to apply an incorrect encoding. And thirdly, it shouldn’t be necessary anyway if people follow the guidelines in this article and mark up their documents properly. That is a much better approach.
This way of indicating the encoding of a document has the lowest precedence (ie. if the encoding is declared in any other way, this will be ignored). This means that you couldn’t use this to correct incorrect declarations either.
Working with UTF-16
According to the results of a Google sample of several billion pages, less than 0.01% of pages on the Web are encoded in UTF-16. UTF-8 accounted for over 80% of all Web pages, if you include its subset, ASCII, and over 60% if you don’t. You are strongly discouraged from using UTF-16 as your page encoding.
If, for some reason, you have no choice, here are some rules for declaring the encoding. They are different from those for other encodings.
The HTML5 specification forbids the use of the meta element to declare UTF-16, because the values must be ASCII-compatible. Instead you should ensure that you always have a byte-order mark at the very start of a UTF-16 encoded file. In effect, this is the in-document declaration.
Furthermore, if your page is encoded as UTF-16, do not declare your file to be «UTF-16BE» or «UTF-16LE», use «UTF-16» only. The byte-order mark at the beginning of your file will indicate whether the encoding scheme is little-endian or big-endian. (This is because content explicitly encoded as, say, UTF-16BE should not use a byte-order mark; but HTML5 requires a byte-order mark for UTF-16 encoded pages.)
Further reading
-
Getting started? Introducing Character Sets and Encodings
-
Tutorial, Handling character encodings in HTML and CSS
-
Related links, Authoring HTML & CSS
- Characters
- Declaring the character encoding for HTML
- Choosing and applying a character encoding
-
Related links, Setting up a server
- Characters

Introduction to UTF-8 in HTML
UTF-8 is defined as the default character encoding for HTML5 used to display an HTML page perfectly. It encourages web developers to use UTF-8 as it covers all the characters and symbols in the entity that uses one byte and works well in all the browsers. Unicode Transformation Format – 8 bits are a method converts typed character into machine-readable code. The charset attribute is used to perform a character encoding for the HTML.
Syntax of UTF-8 in HTML
Specification of UTF-8 Character encoding in the <meta> tag is given as:
<meta charset="UTF-8">Here meta gives data about the HTML document but is machine-readable. And their elements specify a keyword, last modified etc. This meta tag contains the charset, which tells the web browser while accessing the page.
Encoding is how the given numbers are converted to binary numbers, which a machine understood. Here each character is made up of one or more bytes respectively.
How does UTF-8 Works in HTML?
- The most popular encoding character is ASCII; as the internet grew up globally, the only supported Latin is not efficient; that’s why an industry moved on to Unicode as the best option. UTF-8 is the encoding for Unicode, which assigns a unique value called code point for all the characters and emojis. This encoding system solves the issue in ASCII space and is considered to be a dominant encoding for the W3C. And recommended that all e-mail messages could be created using UTF-8. This checks if the page explicitly declares as UTF-8 using a meta tag at the beginning of the document. The significant bit of UTF-8 is defined as 8,16, 24 or 32 bits as they are encoded as one to four bytes. UTF-8 is considered to be a global standard for existing applications as it understands more applications. This encoding helps to encode text and transfer data. UTF-8 encoding s most preferable on most websites. This standard covers all characters, symbols, punctuation all over the world.
- UTF-8 treats a range 0-127 as ASCII code and later up to 192 as shift keys. And the next characters, 224-239, has to be double shifted. Therefore, it is termed multi-byte variable encoding.
- Unicode assigns unique code to every character in a human language. The character set (Grouping all available characters into a specific set) could be overridden using the lang attribute. This Unicode translates into a Binary and vice-versa. It prevents unexpected results during form submission applications. UTF-8 should be considered when we find web pages are lagging inordinate amount of space. Storing UTF-8 text into a binary meanwhile char becomes binary, varchar shows to VARBINARY in SQL.
As an example, let’s take the text Hi, EDUCBA!
The UTF-8-character Encoding is given as below:
01001000 01101001 00101100 01100101 01000100 01010101 01000011 01000010 01000001 00100001
Which converts into a machine-readable binary structure.
Key Importance to Use UTF-8
- It is deliberately compatible with encoding standard ASCII.
- This preferred HTML encoding uses less space and supports many languages.
- This benefits the SEO. Suppose you use two standards, then it leads to a decoding issue that wrongly impacts the SEO. It means we need to implement the character correctly to Help SEO efforts.
Next, we shall see how the Unicode representation is important while taking up foreign languages in the content.
Examples of UTF-8 in HTML
Given below are the examples of UTF-8 in HTML:
Example #1
Simple example with the paragraph content.
Code:
new.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Page Title</title>
<style>
body {
background-color: red;
text-align: center;
color: yellow;
font-family: Arial, Helvetica, sans-serif;
}
</style>
</head>
<body>
<h1>!مرحبا بالعالم</h1>
<h2>你叫什么名字?<h2>
<p>This is Chinese Language.</p>
<p>This is the code demonstrating encoding Process</p>
</body>
</html>Explanation:
- The screenshot below shows the content displayed in the Chinese language as well as in English. This is because when the above HTML code is executed in a modern Browser, it normally refers to Unicode.
Output:

Example #2
Using Buttons for the input text.
Code:
lang.html
<!DOCTYPE HTML >
<html>
<head>
<title>HTML sample -buttons</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<form action="addressing" method="post">
<fieldset>
<legend>Selection list</legend>
Checkbox: <input type="checkbox" name="King" value="one"><br>
RadioButton1: <input type="radio" name="Queen" value="two"><br>
RadioButton2: <input type="radio" name="Jack" value="three"
checked="checked"><br>
</fieldset>
<fieldset>
<legend>Give Input</legend>
Login Id: <input type="text" name="Login name"><br>
Password: <input type="password" name="Strong Password"><br>
</fieldset>
<fieldset>
<legend>Designation</legend>
<p><input type="checkbox" name=" Software Engineer"> Software Engineer</p>
<p><input type="checkbox" name="Data Analyst"> Data Analyst</p>
<p><input type="checkbox" name="Web Developer"> Web Developer</p>
<p><input type="checkbox" name=" Senior Analyst"> Senior Analyst</p>
</fieldset>
<p><input type="submit" value="press"> <input type="reset"></p>
</form>
</body>
</html>Explanation:
- The screenshot below shows the input content displayed in the Chinese language as well as in English. This is because when the above HTML code is executed in a modern Browser, it normally refers to Unicode.
Output:
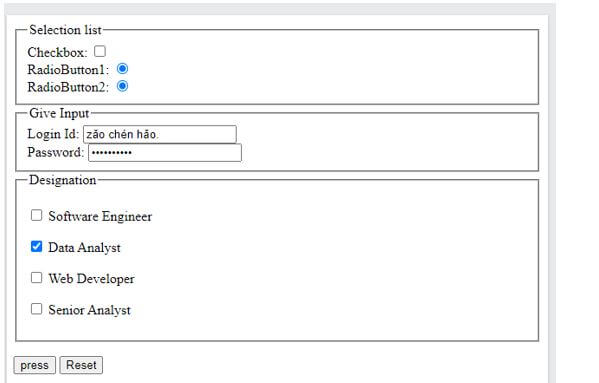
Example #3
Code using foreign-language content.
Code:
mett.html
<!DOCTYPE html>
<html>
<head>
<title>
HTML UTF-8 Charset
</title>
<meta name="keywords"
charset="UTF-8"
content="Meta Tags, Metadata" />
</head>
<body style="text-align:left">
<H1>Hi Instructor!</H1>
<h2>
This is my formal e-mail for the joining.
</h2>
<h3>Hola, me llamo Juan </h3>
<b>Mucho gusto </b>
</body>
</html>Explanation:
- The above code uses the Spanish language to check the compatibility in the web browser.
Output:

Example #4
Using JavaScript.
Code:
name.js
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>UTF-8 Charset</title>
<style>
span {
color: blue;
}
span.name {
color: red;
font-weight: bolder;
}
</style>
<script src="https://code.jquery.com/jquery-3.5.0.js"></script>
</head>
<body>
<div>
<span>Thomas,</span>
<span>John Betson,</span>
<span>Valli Tromson</span>
</div>
<div>
<span>आभरणा,</span>
<span>आचुथान,</span>
<span>अभिनंध</span>
</div>
<script>
$( "div span:first-child" )
.css( "text-decoration", "Underline" )
.hover(function() {
$( this ).addClass( "name" );
});
</script>
</body>
</html>Explanation:
- The above code uses functions to class the respective class. Before that, we have declared metadata for the encoding process. Here we have assigned an <span> element with another language. Unfortunately, ASCII doesn’t have compatibility to access. Therefore, we have declared UTF-8 to support the type.
Output:
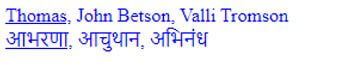
Conclusion
So that’s all about the encoding of UTF-8 in HTML. We have gone through Unicode and encodes in the HTML briefly and the implementation of HTML and JavaScript. In this emerging software world, the character sets are not made so feasible; therefore, there comes character encoding schemes to be done with the HTML and other programming languages. Therefore, it is said that it is best to use UTF-8 everywhere where it doesn’t need any conversions encoding.
Recommended Articles
This is a guide to UTF-8 in HTML. Here we discuss the introduction, working, key importance to use UTF-8 and examples, respectively. You may also have a look at the following articles to learn more –
- HTML Reset Button
- HTML Search Bar
- Canvas Tag in HTML
- HTML Schriftart
Нужно правильно раскодировать сигналы, которые наш мозг получает из окружающей среды. Проще говоря, следует правильно «настроить» свой взгляд на жизнь. Ну, вроде не полупустой кошелек, а наполовину полный. То есть, требуется использовать нужную кодировку. Для интернета чаще всего правильной является кодировка utf:

- Немного о кодировках
- Кодировка UTF-8
- Как установить кодировку в HTML и PHP
- Глобальные настройки кодировки
- Изменение кодировки базы данных
Наверное, не является секретом тот факт, что основным типом содержимого во всемирном веб-пространстве является текст. Конечно, сейчас с этим утверждением можно поспорить, но буквально какой-то десяток лет назад это было так.
Но передача текста в цифровом формате происходит совсем иначе, чем у нас на экране. Для перевода текста в машинный код используется двоичная система исчисления, состоящая лишь из 0 и 1.
Следующим этапом передачи текста в виртуальном пространстве является его отображение на клиентских машинах с помощью браузера, интерпретирующего html. Вот тут и начинается самое интересное, когда браузер клиента и веб-страница содержат в себе текстовые данные в разных кодировках. Тогда пользователь на своем мониторе видит не текст, а какие-то непонятные (нечитаемые) символы:

Чаще всего нужно всего лишь поменять кодировку веб-страницы на кодировку utf8. Ведь она является наиболее распространенной во всем интернете.
Наиболее распространенная среди стандартизированных и общепринятых текстовых кодировок. Расшифровывается как «восьмибитный формат преобразования Юникода» или «Unicode Transformation Format».
Стандарт был разработан еще в 1992 году. В настоящее время он широко применяется не только во всемирной паутине, но и на прикладном уровне (локальные машины и операционные системы). Основным достоинством кодировки является ее совместимость с ASCII:

ASCII («American standard code for information interchange») еще одна (но более старая) кодировка представления текстовых данных. В ее таблице символов значения печатных и непечатных знаков заданы с помощью чисел в шестнадцатеричной системе исчисления.
При использовании UTF-8 для передачи данных в формате ASCII используются 7 первых битов. Последний (восьмой) служит для вывода «мусора» (некорректно раскодированных данных). Что при использовании кодировки для латинских символов существенно уменьшает объем текстовых данных.
Как уже говорилось, часто для корректного отображения текста достаточно лишь поменять кодировку документа. Рассмотрим, как это можно сделать в различных дисциплинах, применяемых для построения веб-пространства.
Для установки utf 8 кодировки в html используется специальный тег <meta>. Он объединяет в себе в форме атрибутов значение метатегов.
Метатеги используются для передачи и хранения информации, предназначенной для браузеров и поисковиков. Одним из атрибутов тега является charset. Он служит для установки кодировки веб-страницы. Пример использования:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />

Также можно установить кодировку некоторым элементам страницы. Например, ссылке. Для этого также используется атрибут charset, значением которого выступает нужная кодировка:
<a href="mydoc.html" charset="utf-8">list of publications</a>
Кроме этого можно присваивать значения непосредственно заголовкам http, которые передаются вместе с ответом на запрос от браузера к серверу. В таком случае кодировка сайта utf 8, переданная через заголовок, будет доминирующей над значением, заданным внутри веб-страницы.
Многие из страниц ресурсов не являются статическими, а динамически создаются благодаря использованию серверных языков программирования. Чаще всего для построения сайтов применяют PHP. Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Для установки и модификации значений заголовка используется функция header(). Ее синтаксис:
void header ( string $string [, bool $replace = true [, int $http_response_code ]] )
Пример записи:
header('Content-Type: text/html; charset= utf-8');
Чтобы корректно задать в php кодировку utf 8, вызов функции header() в коде должен находиться выше всех тегов html.
Описанные выше методы могут использоваться для отдельных веб-страниц или небольших сайтов. Но что делать, если вы имеете дело с ресурсом, состоящим из нескольких сотен страниц и десятка разделов? Давайте разберемся, как установить кодировку utf 8 для всего сайта.
Для этого нужно вносить изменения в дополнительный файл конфигурации ресурса. Он носит название .htaccess. Сначала его нужно открыть в любом текстовом редакторе, а затем добавить туда строку:

В качестве более глобального способа изменения кодировки стоит рассмотреть пример на основе любого локального сервера. Для большей наглядности мы возьмем Denwer, который довольно широко распространен в наших краях.
Чтобы изменить кодировку всех ресурсов, размещенных на нашем сервере Apache, нужно отредактировать содержимое конфигурационного файла httpd.conf. Он находится по пути:
Как и в предыдущем примере, в нем нужно заменить значение AddDefaultCharset на нужное. В нашем случае это utf-8:

Изменение кодировки рассмотрим на примере MySQL. Так как это одна из самых востребованных и распространенных СУБД, применяемых в сайтостроении. Все изменения можно произвести в файле my.ini. В Денвере он находится по пути:
Здесь нужно поменять значение нескольких полей на utf-8:
- default-character-set;
- character-set-server;
- init-connect = «set names»;
- default-character-set.
И затем добавить строку skip-character-set-client-handshake:

Подобные изменения можно внести не только для всех баз данных на сервере, но и для отдельно взятой в php базы mysql. Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin.
Сначала узнаем, какие кодировки установлены по умолчанию в нашей базе данных. Для этого вводим запрос SQL:
SHOW VARIABLES LIKE 'char%';
Вот какой ответ мы должны получить:

Если какие-либо значения нас не удовлетворяют, то нужно их изменить. Воспользуемся для этого запросом к ядру сервера СУБД:
ALTER DATABASE `my_db1` DEFAULT CHARACTER SET utf8;
В результате мы получим новые значения переменных character_set_connection, character_set_results и character_set_client.
К сожалению, не все так просто обстоит с изменением кодировки в таблицах Excel. Для этого придется воспользоваться сторонней программой для перекодирования файлов. Или обработать данные с помощью громоздких функций.
Мы рассмотрели все основные способы изменения веб-документов на кодировку utf. Надеемся, что этот материал поможет вам не только выбрать правильную кодировку текста, но и «установить» правильный взгляд на жизнь.