
DSSM
Deep Structured Semantic Model
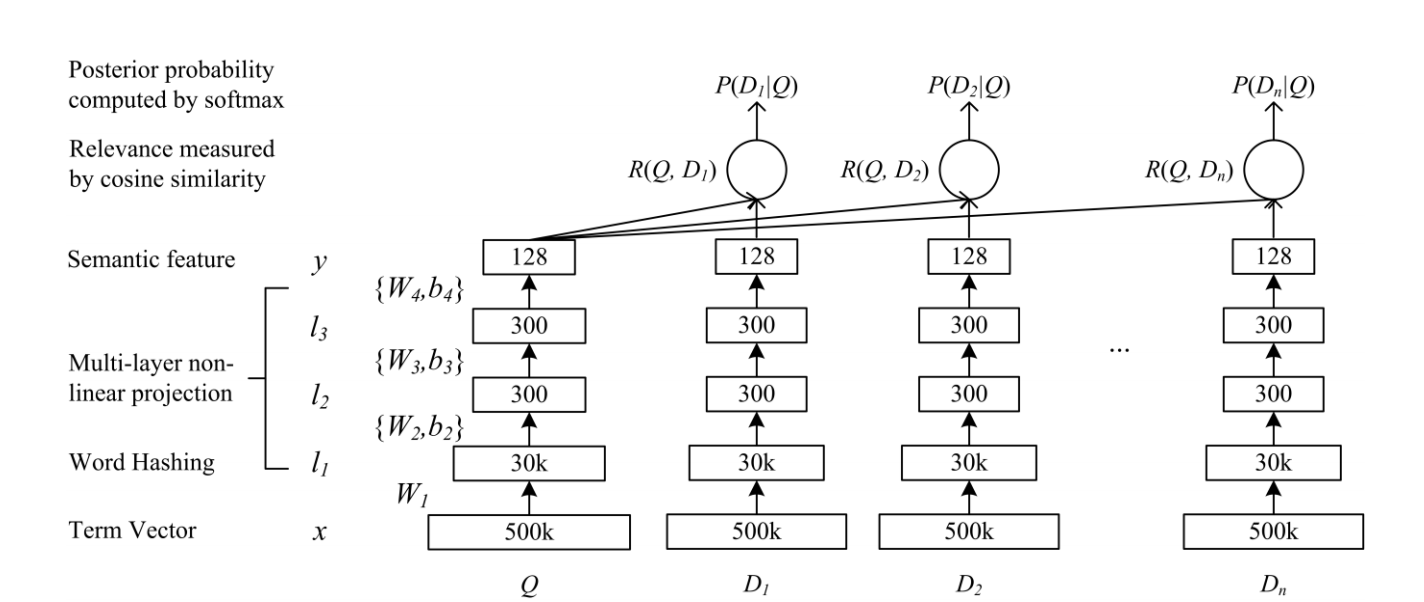
Структура DSSM
Learning Deep Structured Semantic Models for Web Search using Clickthrough DataИ его последующие статьи
A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation SystemsРеализация Демо.
1. Данные
Для DSSM входными данными является пара запросов, то есть короткое предложение запроса и соответствующий экран. Отображение разделено на клики и не клики, которые являются положительными и отрицательными соответственно. В то же время существуют разные назначения для последовательности кликов. Подробнее см. В документе.
У меня нет права открывать данные моего запроса. Найдите их самостоятельно.
2. word hashing
В исходном тексте используются 3 грамма, а для китайского я использую униграммы, потому что китайские иероглифы имеют определенное значение (есть также разобранные штрихи). Вместо этого для каждого грамма используется горячая кодировка, которая может значительно уменьшить размер короткого предложения. .
3. Структура
Структурная схема:

- Сопоставьте записи с векторами низкой размерности.
- Вычислите косинусное сходство между запросом и документом.
3.1 Ввод
Здесь используется визуализация TensorBoard, поэтому определено name_scope:
-
with tf.name_scope('input'): -
query_batch = tf.sparse_placeholder(tf.float32, shape=[None, TRIGRAM_D], name='QueryBatch') -
doc_positive_batch = tf.sparse_placeholder(tf.float32, shape=[None, TRIGRAM_D], name='DocBatch') -
doc_negative_batch = tf.sparse_placeholder(tf.float32, shape=[None, TRIGRAM_D], name='DocBatch') -
on_train = tf.placeholder(tf.bool)
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
3.2 Полностью связанный слой
Я использую трехслойный полностью связанный слой.Для каждого полностью связанного слоя, за исключением разных нейронов, все остальное одинаково, поэтому вы можете написать функцию для повторного использования. Чтобы
-
def add_layer(inputs, in_size, out_size, activation_function=None): -
wlimit = np.sqrt(6.0 / (in_size + out_size)) -
Weights = tf.Variable(tf.random_uniform([in_size, out_size], -wlimit, wlimit)) -
biases = tf.Variable(tf.random_uniform([out_size], -wlimit, wlimit)) -
Wx_plus_b = tf.matmul(inputs, Weights) + biases -
if activation_function is None: -
outputs = Wx_plus_b -
else: -
outputs = activation_function(Wx_plus_b) -
return outputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Среди них, для веса и смещения, используется особый метод инициализации в соответствии с бумагой:
-
wlimit = np.sqrt(6.0 / (in_size + out_size)) -
Weights = tf.Variable(tf.random_uniform([in_size, out_size], -wlimit, wlimit)) -
biases = tf.Variable(tf.random_uniform([out_size], -wlimit, wlimit))
- 1
- 2
- 3
- 1
- 2
- 3
Batch Normalization
-
def batch_normalization(x, phase_train, out_size): -
""" -
Batch normalization on convolutional maps. -
Ref.: http://stackoverflow.com/questions/33949786/how-could-i-use-batch-normalization-in-tensorflow -
Args: -
x: Tensor, 4D BHWD input maps -
out_size: integer, depth of input maps -
phase_train: boolean tf.Varialbe, true indicates training phase -
scope: string, variable scope -
Return: -
normed: batch-normalized maps -
""" -
with tf.variable_scope('bn'): -
beta = tf.Variable(tf.constant(0.0, shape=[out_size]), -
name='beta', trainable=True) -
gamma = tf.Variable(tf.constant(1.0, shape=[out_size]), -
name='gamma', trainable=True) -
batch_mean, batch_var = tf.nn.moments(x, [0], name='moments') -
ema = tf.train.ExponentialMovingAverage(decay=0.5) -
def mean_var_with_update(): -
ema_apply_op = ema.apply([batch_mean, batch_var]) -
with tf.control_dependencies([ema_apply_op]): -
return tf.identity(batch_mean), tf.identity(batch_var) -
mean, var = tf.cond(phase_train, -
mean_var_with_update, -
lambda: (ema.average(batch_mean), ema.average(batch_var))) -
normed = tf.nn.batch_normalization(x, mean, var, beta, gamma, 1e-3) -
return normed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Одиночный слой
-
with tf.name_scope('FC1'): -
# Функция активации стоит после BN, поэтому здесь None -
query_l1 = add_layer(query_batch, TRIGRAM_D, L1_N, activation_function=None) -
doc_positive_l1 = add_layer(doc_positive_batch, TRIGRAM_D, L1_N, activation_function=None) -
doc_negative_l1 = add_layer(doc_negative_batch, TRIGRAM_D, L1_N, activation_function=None) -
with tf.name_scope('BN1'): -
query_l1 = batch_normalization(query_l1, on_train, L1_N) -
doc_l1 = batch_normalization(tf.concat([doc_positive_l1, doc_negative_l1], axis=0), on_train, L1_N) -
doc_positive_l1 = tf.slice(doc_l1, [0, 0], [query_BS, -1]) -
doc_negative_l1 = tf.slice(doc_l1, [query_BS, 0], [-1, -1]) -
query_l1_out = tf.nn.relu(query_l1) -
doc_positive_l1_out = tf.nn.relu(doc_positive_l1) -
doc_negative_l1_out = tf.nn.relu(doc_negative_l1) -
······
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Объединить отрицательные образцы
-
with tf.name_scope('Merge_Negative_Doc'): -
# Объедините отрицательные образцы, плитка может выбрать, следует ли расширять отрицательные образцы. -
doc_y = tf.tile(doc_positive_y, [1, 1]) -
for i in range(NEG): -
for j in range(query_BS): -
# slice (input_, begin, size) slice API -
doc_y = tf.concat([doc_y, tf.slice(doc_negative_y, [j * NEG + i, 0], [1, -1])], 0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.3 Вычислить cos-подобие
-
with tf.name_scope('Cosine_Similarity'): -
# Cosine similarity -
# query_norm = sqrt(sum(each x^2)) -
query_norm = tf.tile(tf.sqrt(tf.reduce_sum(tf.square(query_y), 1, True)), [NEG + 1, 1]) -
# doc_norm = sqrt(sum(each x^2)) -
doc_norm = tf.sqrt(tf.reduce_sum(tf.square(doc_y), 1, True)) -
prod = tf.reduce_sum(tf.multiply(tf.tile(query_y, [NEG + 1, 1]), doc_y), 1, True) -
norm_prod = tf.multiply(query_norm, doc_norm) -
# cos_sim_raw = query * doc / (||query|| * ||doc||) -
cos_sim_raw = tf.truediv(prod, norm_prod) -
# gamma = 20 -
cos_sim = tf.transpose(tf.reshape(tf.transpose(cos_sim_raw), [NEG + 1, query_BS])) * 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.4 Определение функции потерь
-
with tf.name_scope('Loss'): -
# Train Loss -
# Преобразуется в матрицу вероятностей softmax. -
prob = tf.nn.softmax(cos_sim) -
# Возьмите только первый столбец, то есть вероятность положительного столбца выборки. -
hit_prob = tf.slice(prob, [0, 0], [-1, 1]) -
loss = -tf.reduce_sum(tf.log(hit_prob)) -
tf.summary.scalar('loss', loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.5 Выберите метод оптимизации
-
with tf.name_scope('Training'): -
# Optimizer -
train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(loss)
- 1
- 2
- 3
- 1
- 2
- 3
## 3.6 Начать обучение
-
# Создайте объект Saver для выборочного сохранения переменных или моделей. -
saver = tf.train.Saver() -
# with tf.Session(config=config) as sess: -
with tf.Session() as sess: -
sess.run(tf.global_variables_initializer()) -
train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/train', sess.graph) -
start = time.time() -
for step in range(FLAGS.max_steps): -
batch_id = step % FLAGS.epoch_steps -
sess.run(train_step, feed_dict=feed_dict(True, True, batch_id % FLAGS.pack_size, 0.5))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Полный код GitHubhttps://github.com/InsaneLife/dssm
Multi-view DSSM обеспечивает то же самое, вы можете обратиться к GitHub:multi_view_dssm_v3
Исходный CSDN:http://blog.csdn.net/shine19930820/article/details/79042567
Заявление об авторских правах: эта статья является оригинальной статьей блоггера. Укажите источник для перепечатки: http://blog.csdn.net/shine19930820 https://blog.csdn.net/shine19930820/article/details/79042567
ВышеDSSM Схема архитектуры обучения:
- Вход — это
queryСвязано с этим запросомdoc, Функция ввода здесь может быть самой простойone-hot, И нужноtrainРелевантность каждого документа по этому запросу ()DSSM(CTR используется вместо релевантности) -
Из-за этого
one-hotС вводом могут быть две проблемы:- в результате чего
vocabularyСлишком большой -
Появится
oovПроблемаСледовательно, первым слоем после входных объектов является создание
Word HashingingОперация
- в результате чего
- Далее идет традиционная нейронная сеть
li=f(Wili−1+bi),i=2,…,N−1y=f(WNlN−1+bN)li=f(Wili−1+bi),i=2,…,N−1y=f(WNlN−1+bN)
Вот
fФункция активации, которая вычисляется с использованием $ tanh $ в тексте: $ f (x) = frac {1-e ^ {- 2x}} {1 + e ^ {- 2x}} $ - Полученный $ y $ является семантическим признаком. Корреляцию между запросом и документом можно напрямую измерить по сходству между специальными идеями. Здесь косинус используется для вычисления
R(Q,D)=cosine(yQ,yD)=yTQyD||yQ||||yD||R(Q,D)=cosine(yQ,yD)=yQTyD||yQ||||yD||
- Последнее сходство можно использовать для тренировки корреляции между запросом и документом.
Поэтому всю конструкцию можно рассматривать как слойWord Hashing Пройдите тренировки послеDNN Интернет
Word Hashing
Word Hashing Это очень важный документtrick , В английских словах, напримерgood , Он может писать#good# , А затем разложить на триграммы#go goo ood od# , А затем налейте эти три грамма вbag-of-word Таким образом, это может быть очень эффективнымvocabulary Слишком большая проблема (потому что словарный запас слишком большой для реального веб-поиска), и она не появитсяoov Проблема в том, что английских слов всего 26, а комбинация из 3 букв ограничена, так что легко перечислить свет. Чтобы
Тогда возникает вопрос, будут ли два разных слова давать одни и те же триграммы, газета собрала статистику и сказала, что вероятность этого конфликта очень мала, 500K Слово может быть уменьшено до 30k размеров, а вероятность конфликта составляет 0,0044%.
Но на китайской сцене это
Word HashingСчитается, что это не так эффективно
Поскольку хеширование слов используется напрямую, поскольку контекстная информация не может быть записана
Обучение DSSM
Выше приведен процесс прямого расчета. При обучении вам необходимо рассчитать заданныеQuery Вниз иDoc Актуальность:
P(D|Q)=exp(γR(Q,D))∑di∈Dexp(γR(Q,D))P(D|Q)=exp(γR(Q,D))∑di∈Dexp(γR(Q,D))
В конце концов, функция потерь, которую ему нужно оптимизировать, выглядит так:
L(Λ)=−log∏(Q,D+)P(D+|Q)L(Λ)=−log∏(Q,D+)P(D+|Q)
$ D ^ + $ представляет документ, по которому щелкнули мышью, здесь максимальная вероятность повышения релевантности документа, по которому щелкнули
CDSSM
CDSSM (Также известный какCLSM : Сверточная латентно-семантическая модель) В определенной степени он может компенсироватьDSSM Проблема потери контекста, его структура тоже очень проста, в основномDNN Заменено наCNN

Его шаги вперед в основном рассчитываются следующим образом:
1. Используйте указанный размер скользящего окна, чтобы получить данные окна для входной последовательности (называемойword-n-gram )
2. Для этихword-n-gram Нажмитеletter-trigram Выполните преобразование для формирования вектора представления (на самом деле этоWord Hashing )
3. Выполните обработку сверточного слоя данных окна (окно содержит некоторый контекст)
4. Используйтеmax-pooling Слой, чтобы взять более важныеword-n-gram
5. Снова вычислите семантический вектор на уровне FC.
6. Окончательный результат по-прежнему составляет 128 измерений.
> из-за использованияCDSSM Также более целесообразно выполнить работу по семантическому сопоставлению
## DSSM-LSTM
Поскольку он предназначен для записи контекста входного предложения, это, несомненно,Lstm Эта модель лучше, поэтому есть другаяLstm СтроитьDSSM Модель

Это относительноCDSMM Поменять проще. Фактически, оригиналDSSM Модель заменена наLSTM модель…
MV-DSSM
MV-DSSM внутриMV ЗаMulti-View , В целом можно понимать как многовидовойDSSM , Некоторые из них нуждаются в обучении работе с исходным DSSMQuery с участием Doc Эти два типа встраивания одновременноDNN Все веса общие, иMV-DSSM Он может обучать более двух типов обучающих данных, а параметры модели глубины внутри не зависят друг от друга:

на основеMulti-View изDSSM Да, параметров больше. Из-за многовидового обучения входной корпус также может быть другим и степень свободы больше, но проблема, которая возникает с этим, заключается в том, что обучение будет становиться все более сложным ^ _ ^
подводить итоги
DSSM Модель класса фактически использует косинус на последнем шаге при вычислении подобия. Возможно, лучше подключить еще один MLP, потому что косинус полностью не содержит параметров.
DSSM Преимущества:
DSSMКажется, что в реальном сценарии поиска осуществимость очень высока. С одной стороны, данные о естественных кликах пользователя используются напрямую, и результат очень реалистичен. С другой стороны, документ в тексте может быть представлен заголовком, а эта часть может Вычисление семантического вектора выполняется в автономном режиме, и тогда семантическое сходство между запросом и документом весьма привлекательно.DSSMРезультаты можно не только отсортировать напрямую, но и поволноваться из-за того, что вы увидели в середине:semantic featureМожет действовать естественноword embeddingЧто ж
DSSM Недостатки:
- Информацию о пользователях сложно объединить (но она может быть основана на
MVDSSMТрансформация) - Кажется, что время обучения очень долгое
Справка
- Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.
- Shen, Yelong, et al. “A latent semantic model with convolutional-pooling structure for information retrieval.” Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. ACM, 2014.
- Palangi, Hamid, et al. “Semantic modelling with long-short-term memory for information retrieval.” arXiv preprint arXiv:1412.6629 (2014).
- Elkahky, Ali Mamdouh, Yang Song, and Xiaodong He. “A multi-view deep learning approach for cross domain user modeling in recommendation systems.” Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2015.
DSSM is a Deep Neural Network (DNN) used to model semantic similarity between a pair of strings.
In simple terms semantic similarity of two sentences is the similarity based on their meaning (i.e. semantics), and DSSM helps us capture that.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between them is based on the likeness of their meaning or semantic content as opposed to similarity which can be estimated regarding their syntactical representation (e.g. their string format)
The model can be extended to any number of pairs of strings.
Here, we will take two strings as input — a query and phrase.
The figure below depicts the architecutre of the model.
The Model
Well how do we build this model?
- Build a bag-of-words (BOW) representation for each string (query/phrases). This is referred to as
Term Vectorin the figure. - Convert the BOW to bag-of-CharTriGrams, executed in
Word Hashinglayer in the figure. - Perform three non-linear transformation, shown as
Multi-layer non-linear projectionin figure. - The above steps are applied to each string (query/phrases) and cosine similarity is calculated for each query-phrase pair. This is the layer
Relevance measured by cosine similarityin the figure. - Apply softmax to the outputs —
Posterior probability captured by softmaxin figure. The original paper uses softmax with a smoothing factor. We ignore the smoothing factor here.
A note on Word Hashing
Bag of Words representation is a poor representation of a sentence. Some of its problems are:
- It does not capture context or semantic meaning of a sentence. For instance “will this work” and “this will work” have the same BOW representation though they represent different meaning.
- It does not scale well. The size of a BOW vector is proportional to the size of vocabulary. As the vocabulary grows, the BOW becomes larger. For example, English has more than 170,000 words and new words are continuously added.
Word Hashing was introduced in the original work as a solution to the scaling problem faced by using BOW. We have more than 170,000 words in English vocabulary. Scaling becomes a problem as the current vocabulary size is large and addition of new words can make the problem worse. This can be solved if we break down each word to a bag of char-trigrams. As the number of char-trigrams are fixed and small, using a bag-of-CharTriGrams can be a good solution to this problem.
To get the char-trigrams for a word, we first append ‘#’ to both ends of the word and then spilt it into tri-grams.
For the word fruit ( #fruit# ), the char-trigrams are [#fr, fru, rui, uit, it#]
Code
Now we will look into the code required for each of the steps.
-
Steps 1 and 2
The following functions convert sentences to
bag-of-CharTriGrams.def gen_trigrams(): """ Generates all trigrams for characters from `trigram_chars` """ trigram_chars="0123456789abcdefghijklmnopqrstuvwxyz" t3=[''.join(x) for x in itertools.product(trigram_chars,repeat=3)] #len(words)>=3 t2_start=['#'+''.join(x) for x in itertools.product(trigram_chars,repeat=2)] #len(words)==2 t2_end=[''.join(x)+'#' for x in itertools.product(trigram_chars,repeat=2)] #len(words)==2 t1=['#'+''.join(x)+'#' for x in itertools.product(trigram_chars)] #len(words)==1 trigrams=t3+t2_start+t2_end+t1 vocab_size=len(trigrams) trigram_map=dict(zip(trigrams,range(1,vocab_size+1))) # trigram to index mapping, indices starting from 1 return trigram_mapdef sentences_to_bag_of_trigrams(sentences): """ Converts a sentence to bag-of-trigrams `sentences`: list of strings `trigram_BOW`: return value, (len(sentences),len(trigram_map)) size array """ trigram_map=gen_trigrams() trigram_BOW=np.zeros((len(sentences),len(trigram_map))) # one row for each sentence filter_pat=r'[!"#&()*+,-./:;<=>?[\]^_`{|}~tn]' # characters to filter out from the input for j,sent in enumerate(sentences): sent=re.sub(fiter_pat, '', sent).lower() # filter out special characters from input sent=re.sub(r"(s)s+", r"1", sent) # reduce multiple whitespaces to single whitespace words=sent.split(' ') indices=collections.defaultdict(int) for word in words: word='#'+word+'#' #print(word) for k in range(len(word)-2): # generate all trigrams for word `word` and update `indices` trig=word[k:k+3] idx=trigram_map.get(trig, 0) #print(trig,idx) indices[idx]=indices[idx]+1 for key,val in indices.items(): #covert `indices` dict to np array trigram_BOW[j,key]=val return trigram_BOW -
Step 3
We construct three Fully Connected (FC) layers of size 300,300 and 128 respectively
def FC_layer(X,INP_NEURONS,OUT_NEURONS, X_is_sparse=False): """ Create a Fully Connected layer `X`: input array/activations of previous layer `INP_NEURONS`: number of neurons in previous layer `OUT_NEURONS`: number of neurons in this layer `X_is_sparse`: bool value to indicate if input `X` is sparse or not. Default value is False """ limit=np.sqrt(6.0/(INP_NEURONS+OUT_NEURONS)) W=tf.Variable(tf.random_uniform( (INP_NEURONS,OUT_NEURONS), -limit, limit), #weight init name="weight") b=tf.Variable(tf.random_uniform((OUT_NEURONS),-limit, limit), name="bias") # bias prod=tf.sparse_tensor_dense_matmul(X,W) if X_is_sparse else tf.matmul(X,W) #linear transformation return tf.nn.tanh(prod+b) # non-linear (tanh) transformation -
Step 4
Calculate the cosine similarity of each pair.
def cosine_similarity(self,A,B): """ Function to calculate cosine similarity between two (batches of) vectors `A` and `B`: Inputs (shape => [batch_size,vector_size]) `sim`: Return value, cosine similarity of A and B """ Anorm=tf.nn.l2_normalize(A, dim=1) # normalize A Bnorm=tf.nn.l2_normalize(B, dim=1) # normalize B sim=tf.reduce_sum(Anorm*Bnorm, axis=1) # dot product of normalized A and normalized B return sim -
Step 5
Softmax and cross entropy function
# softmax and cross-entropy smax=tf.nn.softmax_cross_entropy_with_logits(logits=batch_cosine_similarities, labels=Y)
Finally we train the model and test it on a held out dataset.
Мешок слов (BoW) – это способ представления текстовых данных при моделировании в Машинном обучении (ML).

Модель набора слов проста для понимания и реализации и зарекомендовала себя с большим успехом в таких задачах, как Языковое моделирование (Language Modeling) и Классификация документов (Document Classification).
Проблема с текстом
Проблема с моделированием текста заключается в том, что он беспорядочный, а большинство Алгоритмов (Algorithm) машинного обучения предпочитают входные и выходные данные фиксированной длины.
Алгоритмы машинного обучения не могут работать напрямую с необработанным текстом: его необходимо преобразовать в числа а точнее, в векторы чисел. При языковой обработке векторы выводятся из текстовых данных, чтобы отразить различные лингвистические свойства текста. Это называется извлечением или Кодированием (Encoding) признаков. BoW – как раз и есть один из таких методов.
Подход очень простой и гибкий, и его можно использовать множеством способов для извлечения функций из документов.
Пакет слов – это представление текста, которое описывает «характер» присутствия слов в документе. Это подразумевает две вещи:
- Словарь – список уникальных присутствующих в тексте слов
- Мера присутствия таких слов в тексте
Это называется «мешком» слов, потому что всякая информация о порядке или структуре слов в документе отбрасывается. Модель заботится только о том, встречаются ли известные слова в документе, а не об их положении. В этом подходе мы изучаем на гистограмму частоты употребления слов в тексте, то есть рассматриваем ее как признак-столбец.
Интуиция подсказывает человеку, что тексты похожи, если имеют похожее содержание. Кроме того, только по содержанию мы можем кое-что узнать о значении документа.
Пакет слов может быть настолько простым или сложным, насколько нам хочется. Сложность возникает как при принятии решения о том, как составить словарь известных слов – Токенов (Token), так и при оценке меры их «присутствия». Мы рассмотрим обе эти проблемы более подробно.
Пример модели мешка слов
Шаг 1. Соберите данные
Ниже приведен фрагмент книги Чарльза Диккенса «Повесть о двух городах»:
It was the best of times,
It was the worst of times,
It was the age of wisdom,
It was the age of foolishness,
В этом небольшом примере давайте рассматривать каждую строку как отдельный «документ», а все четверостишие – как Корпус (Corpus) документов.
Шаг 2: Составьте словарь
Теперь мы можем составить список всех слов:
- “it”
- “was”
- “the”
- “best”
- “of”
- “times”
- “worst”
- “age”
- “wisdom”
- “foolishness”
Это словарь из 10 лексем корпуса, содержащего 24 слова.
Шаг 3. Создайте векторы документа
Следующим шагом будет оценка слов в каждом документе. Цель состоит в том, чтобы превратить каждый документ с произвольным текстом в вектор, который мы можем использовать в качестве Входных данных (Input Data) для Модели (Model) машинного обучения.
Самый простой метод оценки – отметить наличие слов как логическое значение, 0 – отсутствие, 1 – присутствие. Поскольку в словаре есть 10 слов, мы создадим таблицу, описывающую присутствие того или иного слова в документе № 1, то есть первой строке:

Двоичный вектор документа будет выглядеть следующим образом:
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]Остальные три документа выглядели бы следующим образом:
"it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
"it was the age of foolishness" = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]Теперь у нас есть последовательный способ извлечения функций из любого документа в нашем корпусе, и эти вектора подходят для моделирования.
Новые документы, слова из которых лишь отчасти «покрыты» ранее составленным словарем, по-прежнему могут кодироваться, при этом оцениваются только вхождение известных слов, а неизвестные игнорируются.
Управление словарным запасом
По мере увеличения размера словаря увеличивается и векторное представление документов.
В предыдущем примере длина вектора документа равна количеству известных слов.
Для очень большого корпуса, например, тысячи книг, длина вектора – тысячи или миллионы позиций. Кроме того, каждый документ может содержать очень мало известных слов. В результате получается вектор с множеством нулевых оценок, называемый Разреженным вектором (Sparse Vector).
Для разреженных векторов требуется больше памяти и вычислительных ресурсов при моделировании, а огромное количество позиций или измерений может сделать процесс моделирования очень сложным для традиционных алгоритмов. Таким образом, при использовании мешка слов возникает необходимость уменьшить размер словарного запаса.
Существуют простые методы очистки текста, которые можно использовать в качестве первого шага, например:
- Игнорирование регистра
- Игнорирование знаков препинания
- Игнорирование часто используемых неинформативных так называемых стоп-слов, например «а», «из» и т.д.
- Исправление слов с ошибками
- Сокращение слов до их граммтической основы – Cnемминг (Stemming)
Более сложный подход – создать словарь сгруппированных слов. Это одновременно изменяет объем словарного запаса и позволяет мешку слов выделить больше смысла из документа.
При таком подходе каждое слово или лексема называются «грамм». Создание словаря пар из двух слов, в свою очередь, называется моделью Биграмм (Bigram). Опять же, моделируются только биграммы, которые появляются в корпусе, а не все возможные биграммы.
N-грамм – это последовательность слов из N-знаков: биграмма – это последовательность из двух слов, таких как «пожалуйста, переверни», «переверни это» или «домашнее задание»; и триграмма – это последовательность из трех слов, например «пожалуйста, переверни свою» или «своя домашняя работа».
Например, биграммы в первой строке текста в предыдущем разделе: «Это были лучшие времена» выглядят следующим образом:
- “it was”
- “was the”
- “the best”
- “best of”
- “of times”
Словарь, который затем отслеживает тройки слов, называется моделью триграммы, а общий подход называется моделью N-граммы (N-gram), где N – количество сгруппированных слов.
Часто биграммы показывают лучшие результаты, чем модели Ngram, где N равен 1.
Оценка слов
После того, как словарный запас выбран, необходимо подсчитать наличие слов в примерах документов. В проработанном выше примере мы уже видели один очень простой подход к оценке: бинарная оценка наличия или отсутствия слов.
Некоторые дополнительные простые методы оценки включают в себя:
- Подсчет: сколько раз каждое слово встречается в документе.
- Частота появления каждого слова в документе
Хэширование слов
Хэш-функция сопоставляет данные с набором чисел фиксированного размера. Например, мы используем их , преобразуя имена в числа для скорейшего поиска.

Мы можем использовать Хеширование слов (Word Hashing) в нашем словаре. Это решает проблему наличия очень большого словарного запаса для большого текстового корпуса, потому что мы можем выбрать размер хэш-пространства, который, в свою очередь, равен размеру векторного представления документа.
TF-IDF
Проблема с оценкой частоты слов заключается в том, что в документе преобладают очень часто встречающиеся слова, но они могут не содержать столько информации для модели, сколько более редкие, специфические для предметной области слова.
Один из подходов состоит в том, чтобы изменить частоту слов в зависимости от того, как часто они появляются во всех документах, тем самым «штрафуя» часто встречающиеся предлоги («at»), артикли («the») и т.д. Такой подход к оценке называется Мера оценки важности слова в контексте документа (TF-IDF), где:
- Term Frequency (TF) –оценка частоты встречаемости слова в текущем документе.
Inverse Document Frequency (IDF) – оценка того, насколько редко слово встречается в документах.
Ограничения мешка слов
Модель набора слов очень проста для понимания и реализации и предлагает большую гибкость для настройки ваших конкретных текстовых данных. Тем не менее, она страдает некоторыми недостатками, такими как:
- Словарь требует тщательного проектирования, особенно управления размером, что влияет на разреженность представлений документа.
- Редкость: разреженные представления труднее моделировать как по вычислительным (пространственная и временная сложность), так и по информационным причинам. Модели должны использовать так мало информации в таком большом пространстве представлений.
- Значение: при отказе от порядка слов игнорируется контекст и, в свою очередь, значение слов в документе. Контекст и значение могут многое дать нашей модели. Человеку очевидна разница между фразами «this is interesting» и «is this interesting».
Автор оригинальной статьи: Jason Brownlee
Перевод
Ссылка на автора
Вы не можете вводить необработанный текст непосредственно в модели глубокого обучения.
Текстовые данные должны быть закодированы как числа, которые будут использоваться в качестве ввода или вывода для моделей машинного обучения и глубокого обучения.
Библиотека глубокого обучения Keras предоставляет некоторые основные инструменты, которые помогут вам подготовить ваши текстовые данные.
В этом руководстве вы узнаете, как использовать Keras для подготовки текстовых данных.
После завершения этого урока вы узнаете:
- Об удобных методах, которые можно использовать для быстрой подготовки текстовых данных.
- API Tokenizer, который можно использовать для данных обучения и использовать для кодирования документов обучения, проверки и тестирования.
- Диапазон из 4 различных схем кодирования документов, предлагаемых Tokenizer API.
Давайте начнем.

Обзор учебника
Этот урок разделен на 4 части; они есть:
- Разделите слова с помощью text_to_word_sequence.
- Кодирование с помощью one_hot.
- Хэш-кодирование с помощью hashing_trick.
- API Tokenizer
Разделить слова с помощью text_to_word_sequence
Хороший первый шаг при работе с текстом — разбить его на слова.
Слова называются токенами, а процесс разбиения текста на токены называется токенизацией.
Керас обеспечивает функция text_to_word_sequence () что вы можете использовать, чтобы разбить текст на список слов.
По умолчанию эта функция автоматически делает 3 вещи:
- Разбивает слова по пробелам (split = »«).
- Отфильтровывает пунктуацию (filters = ’!» # $% & Amp; () * +, -. /:; & Lt; = & gt;? @ [\] ^ _ `{|} ~ t n’).
- Преобразует текст в нижний регистр (нижний = True).
Вы можете изменить любое из этих значений по умолчанию, передав аргументы функции.
Ниже приведен пример использования функции text_to_word_sequence () для разделения документа (в данном случае простой строки) на список слов.
from keras.preprocessing.text import text_to_word_sequence
# define the document
text = 'The quick brown fox jumped over the lazy dog.'
# tokenize the document
result = text_to_word_sequence(text)
print(result)При выполнении примера создается массив, содержащий все слова в документе. Список слов печатается для ознакомления.
['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']Это хороший первый шаг, но перед началом работы с текстом необходима дополнительная предварительная обработка.
Кодирование с one_hot
Распространено представлять документ как последовательность целочисленных значений, где каждое слово в документе представлено как уникальное целое число.
Керас обеспечивает функция one_hot () что вы можете использовать для токенизации и целочисленного кодирования текстового документа за один шаг. Название предполагает, что оно создаст горячую кодировку документа, а это не так.
Вместо этого функция является оберткой для функции hashing_trick (), описанной в следующем разделе. Функция возвращает целочисленную версию документа. Использование хеш-функции означает, что возможны коллизии, и не всем словам будут присвоены уникальные целочисленные значения.
Как и в случае с функцией text_to_word_sequence () в предыдущем разделе, функция one_hot () делает текст строчными, отфильтровывает знаки препинания и разделяет слова на основе пробелов.
В дополнение к тексту должен быть указан размер словаря (всего слов). Это может быть общее количество слов в документе или более, если вы собираетесь кодировать дополнительные документы, содержащие дополнительные слова. Размер словаря определяет пространство хеширования, из которого хэшируются слова. В идеале это должно быть больше словарного запаса на некоторый процент (возможно, на 25%), чтобы минимизировать количество столкновений. По умолчанию используется функция hash, хотя, как мы увидим в следующем разделе, альтернативные хеш-функции могут быть указаны при непосредственном вызове функции hashing_trick ().
Мы можем использовать функцию text_to_word_sequence () из предыдущего раздела, чтобы разбить документ на слова, а затем использовать набор для представления только уникальных слов в документе. Размер этого набора может быть использован для оценки размера словарного запаса для одного документа.
Например:
from keras.preprocessing.text import text_to_word_sequence
# define the document
text = 'The quick brown fox jumped over the lazy dog.'
# estimate the size of the vocabulary
words = set(text_to_word_sequence(text))
vocab_size = len(words)
print(vocab_size)Мы можем поместить это вместе с функцией one_hot () и одним горячим кодированием слов в документе. Полный пример приведен ниже.
Размер словарного запаса увеличен на треть, чтобы минимизировать коллизии при хешировании слов.
from keras.preprocessing.text import one_hot
from keras.preprocessing.text import text_to_word_sequence
# define the document
text = 'The quick brown fox jumped over the lazy dog.'
# estimate the size of the vocabulary
words = set(text_to_word_sequence(text))
vocab_size = len(words)
print(vocab_size)
# integer encode the document
result = one_hot(text, round(vocab_size*1.3))
print(result)При выполнении примера сначала печатается размер словаря как 8. Кодированный документ затем печатается как массив целочисленных слов.
8
[5, 9, 8, 7, 9, 1, 5, 3, 8]Хеширование с помощью hashing_trick
Ограничение целочисленных и базовых кодировок состоит в том, что они должны поддерживать словарный запас слов и их отображение на целые числа.
Альтернативой этому подходу является использование односторонней хеш-функции для преобразования слов в целые числа. Это избавляет от необходимости отслеживать словарный запас, который быстрее и требует меньше памяти.
Керас обеспечивает функция hashing_trick () который маркирует, а затем целочисленно кодирует документ, как функция one_hot (). Это обеспечивает большую гибкость, позволяя вам указывать хеш-функцию как «hash» (по умолчанию) или другие хеш-функции, такие как встроенная функция md5 или ваша собственная функция.
Ниже приведен пример целочисленного кодирования документа с использованием хэш-функции md5.
from keras.preprocessing.text import hashing_trick
from keras.preprocessing.text import text_to_word_sequence
# define the document
text = 'The quick brown fox jumped over the lazy dog.'
# estimate the size of the vocabulary
words = set(text_to_word_sequence(text))
vocab_size = len(words)
print(vocab_size)
# integer encode the document
result = hashing_trick(text, round(vocab_size*1.3), hash_function='md5')
print(result)При выполнении примера печатается размер словаря и целочисленного документа.
Мы можем видеть, что использование другой хеш-функции приводит к непротиворечивым, но различным целым числам для слов, как функция one_hot () в предыдущем разделе.
8
[6, 4, 1, 2, 7, 5, 6, 2, 6]API Tokenizer
До сих пор мы рассматривали одноразовые удобные методы для подготовки текста с помощью Keras.
Keras предоставляет более сложный API для подготовки текста, который можно подогнать и использовать повторно для подготовки нескольких текстовых документов. Это может быть предпочтительным подходом для крупных проектов.
Керас обеспечивает Класс токенизатора для подготовки текстовых документов для глубокого изучения. Tokenizer должен быть сконструирован и затем помещен либо в необработанные текстовые документы, либо в целочисленные текстовые документы.
Например:
from keras.preprocessing.text import Tokenizer
# define 5 documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!']
# create the tokenizer
t = Tokenizer()
# fit the tokenizer on the documents
t.fit_on_texts(docs)После подбора токенизатор предоставляет 4 атрибута, которые вы можете использовать для запроса того, что вы узнали о ваших документах:
- word_counts: Словарь слов и их количество.
- word_docs: Словарь слов и сколько документов каждый появился в.
- word_index: Словарь слов и их уникально назначенных целых чисел.
- DOCUMENT_COUNT: Целое число от общего числа документов, которые были использованы для размещения токенизатора.
Например:
# summarize what was learned
print(t.word_counts)
print(t.document_count)
print(t.word_index)
print(t.word_docs)После того, как Tokenizer будет помещен в тренировочные данные, его можно использовать для кодирования документов в поездах или тестовых наборах данных.
Функция text_to_matrix () в Tokenizer может использоваться для создания одного вектора на каждый документ, предоставленный для каждого ввода. Длина векторов — это общий объем словарного запаса.
Эта функция предоставляет набор стандартных схем кодирования текста модели пакета слов, которые могут быть предоставлены через аргумент mode функции.
Доступные режимы включают в себя:
- «двоичный‘: Присутствует или нет каждое слово в документе. Это по умолчанию.
- «подсчитывать‘: Количество каждого слова в документе.
- «tfidf‘: Текстовая обратная оценка частоты документа (TF-IDF) для каждого слова в документе.
- «частота‘: Частота каждого слова в виде соотношения слов в каждом документе.
Мы можем соединить все это с проработанным примером.
from keras.preprocessing.text import Tokenizer
# define 5 documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!']
# create the tokenizer
t = Tokenizer()
# fit the tokenizer on the documents
t.fit_on_texts(docs)
# summarize what was learned
print(t.word_counts)
print(t.document_count)
print(t.word_index)
print(t.word_docs)
# integer encode documents
encoded_docs = t.texts_to_matrix(docs, mode='count')
print(encoded_docs)Выполнение примера подходит для Tokenizer с 5 небольшими документами. Детали подходящего Tokenizer напечатаны. Затем 5 документов кодируются с использованием подсчета слов.
Каждый документ кодируется как 9-элементный вектор с одной позицией для каждого слова и выбранным значением схемы кодирования для каждой позиции слова. В этом случае используется простой режим подсчета слов.
OrderedDict([('well', 1), ('done', 1), ('good', 1), ('work', 2), ('great', 1), ('effort', 1), ('nice', 1), ('excellent', 1)])
5
{'work': 1, 'effort': 6, 'done': 3, 'great': 5, 'good': 4, 'excellent': 8, 'well': 2, 'nice': 7}
{'work': 2, 'effort': 1, 'done': 1, 'well': 1, 'good': 1, 'great': 1, 'excellent': 1, 'nice': 1}
[[ 0. 0. 1. 1. 0. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 1. 1. 0. 0.]
[ 0. 1. 0. 0. 0. 0. 0. 1. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1.]]Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по этой теме, если вы хотите углубиться.
- API предварительной обработки текста Keras
- text_to_word_sequence Keras API
- one_hot Keras API
- hashing_trick Keras API
- API Tokenizer Keras
Резюме
В этом руководстве вы узнали, как использовать API Keras для подготовки текстовых данных к углубленному изучению.
В частности, вы узнали:
- Об удобных методах, которые можно использовать для быстрой подготовки текстовых данных.
- API Tokenizer, который можно использовать для данных обучения и использовать для кодирования документов обучения, проверки и тестирования.
- Диапазон из 4 различных схем кодирования документов, предлагаемых Tokenizer API.
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
From Wikipedia, the free encyclopedia
The bag-of-words model is a simplifying representation used in natural language processing and information retrieval (IR). In this model, a text (such as a sentence or a document) is represented as the bag (multiset) of its words, disregarding grammar and even word order but keeping multiplicity. The bag-of-words model has also been used for computer vision.[1]
The bag-of-words model is commonly used in methods of document classification where the (frequency of) occurrence of each word is used as a feature for training a classifier.[2]
An early reference to «bag of words» in a linguistic context can be found in Zellig Harris’s 1954 article on Distributional Structure.[3]
The Bag-of-words model is one example of a Vector space model.
Example implementation[edit]
The following models a text document using bag-of-words. Here are two simple text documents:
(1) John likes to watch movies. Mary likes movies too.
(2) Mary also likes to watch football games.
Based on these two text documents, a list is constructed as follows for each document:
"John","likes","to","watch","movies","Mary","likes","movies","too" "Mary","also","likes","to","watch","football","games"
Representing each bag-of-words as a JSON object, and attributing to the respective JavaScript variable:
BoW1 = {"John":1,"likes":2,"to":1,"watch":1,"movies":2,"Mary":1,"too":1}; BoW2 = {"Mary":1,"also":1,"likes":1,"to":1,"watch":1,"football":1,"games":1};
Each key is the word, and each value is the number of occurrences of that word in the given text document.
The order of elements is free, so, for example {"too":1,"Mary":1,"movies":2,"John":1,"watch":1,"likes":2,"to":1} is also equivalent to BoW1. It is also what we expect from a strict JSON object representation.
Note: if another document is like a union of these two,
(3) John likes to watch movies. Mary likes movies too. Mary also likes to watch football games.
its JavaScript representation will be:
BoW3 = {"John":1,"likes":3,"to":2,"watch":2,"movies":2,"Mary":2,"too":1,"also":1,"football":1,"games":1};
So, as we see in the bag algebra, the «union» of two documents in the bags-of-words representation is, formally, the disjoint union, summing the multiplicities of each element.
 .
.
Application[edit]
In practice, the Bag-of-words model is mainly used as a tool of feature generation. After transforming the text into a «bag of words», we can calculate various measures to characterize the text. The most common type of characteristics, or features calculated from the Bag-of-words model is term frequency, namely, the number of times a term appears in the text. For the example above, we can construct the following two lists to record the term frequencies of all the distinct words (BoW1 and BoW2 ordered as in BoW3):
(1) [1, 2, 1, 1, 2, 1, 1, 0, 0, 0] (2) [0, 1, 1, 1, 0, 1, 0, 1, 1, 1]
Each entry of the lists refers to the count of the corresponding entry in the list (this is also the histogram representation). For example, in the first list (which represents document 1), the first two entries are «1,2»:
- The first entry corresponds to the word «John» which is the first word in the list, and its value is «1» because «John» appears in the first document once.
- The second entry corresponds to the word «likes», which is the second word in the list, and its value is «2» because «likes» appears in the first document twice.
This list (or vector) representation does not preserve the order of the words in the original sentences. This is just the main feature of the Bag-of-words model. This kind of representation has several successful applications, such as email filtering.[1]
However, term frequencies are not necessarily the best representation for the text. Common words like «the», «a», «to» are almost always the terms with highest frequency in the text. Thus, having a high raw count does not necessarily mean that the corresponding word is more important. To address this problem, one of the most popular ways to «normalize» the term frequencies is to weight a term by the inverse of document frequency, or tf–idf. Additionally, for the specific purpose of classification, supervised alternatives have been developed to account for the class label of a document.[4] Lastly, binary (presence/absence or 1/0) weighting is used in place of frequencies for some problems (e.g., this option is implemented in the WEKA machine learning software system).
n-gram model[edit]
The Bag-of-words model is an orderless document representation — only the counts of words matter. For instance, in the above example «John likes to watch movies. Mary likes movies too», the bag-of-words representation will not reveal that the verb «likes» always follows a person’s name in this text. As an alternative, the n-gram model can store this spatial information. Applying to the same example above, a bigram model will parse the text into the following units and store the term frequency of each unit as before.
[ "John likes", "likes to", "to watch", "watch movies", "Mary likes", "likes movies", "movies too", ]
Conceptually, we can view bag-of-word model as a special case of the n-gram model, with n=1. For n>1 the model is named w-shingling (where w is equivalent to n denoting the number of grouped words). See language model for a more detailed discussion.
Python implementation[edit]
# Make sure to install the necessary packages first # pip install --upgrade pip # pip install tensorflow from tensorflow import keras from typing import List from keras.preprocessing.text import Tokenizer sentence = ["John likes to watch movies. Mary likes movies too."] def print_bow(sentence: List[str]) -> None: tokenizer = Tokenizer() tokenizer.fit_on_texts(sentence) sequences = tokenizer.texts_to_sequences(sentence) word_index = tokenizer.word_index bow = {} for key in word_index: bow[key] = sequences[0].count(word_index[key]) print(f"Bag of word sentence 1:n{bow}") print(f"We found {len(word_index)} unique tokens.") print_bow(sentence)
Hashing trick[edit]
A common alternative to using dictionaries is the hashing trick, where words are mapped directly to indices with a hashing function.[5] Thus, no memory is required to store a dictionary. Hash collisions are typically dealt via freed-up memory to increase the number of hash buckets. In practice, hashing simplifies the implementation of bag-of-words models and improves scalability.
Example usage: spam filtering[edit]
In Bayesian spam filtering, an e-mail message is modeled as an unordered collection of words selected from one of two probability distributions: one representing spam and one representing legitimate e-mail («ham»).
Imagine there are two literal bags full of words. One bag is filled with words found in spam messages, and the other with words found in legitimate e-mail. While any given word is likely to be somewhere in both bags, the «spam» bag will contain spam-related words such as «stock», «Viagra», and «buy» significantly more frequently, while the «ham» bag will contain more words related to the user’s friends or workplace.
To classify an e-mail message, the Bayesian spam filter assumes that the message is a pile of words that has been poured out randomly from one of the two bags, and uses Bayesian probability to determine which bag it is more likely to be in.
See also[edit]
- Additive smoothing
- Bag-of-words model in computer vision
- Document classification
- Document-term matrix
- Feature extraction
- Hashing trick
- Machine learning
- MinHash
- n-gram
- Natural language processing
- Vector space model
- w-shingling
- tf-idf
Notes[edit]
- ^ a b Sivic, Josef (April 2009). «Efficient visual search of videos cast as text retrieval» (PDF). IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 31, NO. 4. opposition. pp. 591–605.
- ^ McTear et al 2016, p. 167.
- ^ Harris, Zellig (1954). «Distributional Structure». Word. 10 (2/3): 146–62. doi:10.1080/00437956.1954.11659520.
And this stock of combinations of elements becomes a factor in the way later choices are made … for language is not merely a bag of words but a tool with particular properties which have been fashioned in the course of its use
- ^ Youngjoong Ko (2012). «A study of term weighting schemes using class information for text classification». SIGIR’12. ACM.
- ^ Weinberger, K. Q.; Dasgupta A.; Langford J.; Smola A.; Attenberg, J. (2009). «Feature hashing for large scale multitask learning». Proceedings of the 26th Annual International Conference on Machine Learning: 1113–1120. arXiv:0902.2206. Bibcode:2009arXiv0902.2206W.
References[edit]
- McTear, Michael (et al) (2016). The Conversational Interface. Springer International Publishing.