
For example i have a file:
$ cat file
i am the first example.
i am the second line.
i do a question about a file.
and i need:
example, line, file
i intent with «awk» but the problem is that the words are in different space
asked May 17, 2013 at 20:02
![]()
1
Try
$ awk 'NF>1{print $NF}' file
example.
line.
file.
To get the result in one line as in your example, try:
{
sub(/./, ",", $NF)
str = str$NF
}
END { print str }
output:
$ awk -f script.awk file
example, line, file,
Pure bash:
$ while read line; do [ -z "$line" ] && continue ;echo ${line##* }; done < file
example.
line.
file.
answered May 17, 2013 at 20:05
![]()
Fredrik PihlFredrik Pihl
44.2k7 gold badges83 silver badges130 bronze badges
4
You can do it easily with grep:
grep -oE '[^ ]+$' file
(-E use extended regex; -o output only the matched text instead of the full line)
answered May 18, 2013 at 5:05
![]()
ricirici
232k28 gold badges234 silver badges338 bronze badges
1
You can do something like this in awk:
awk '{ print $NF }'
Edit: To avoid empty line :
awk 'NF{ print $NF }'
![]()
P….
17k2 gold badges30 silver badges52 bronze badges
answered May 17, 2013 at 20:05
![]()
Hal CanaryHal Canary
2,10417 silver badges17 bronze badges
1
Another way of doing this in plain bash is making use of the rev command like this:
cat file | rev | cut -d" " -f1 | rev | tr -d "." | tr "n" ","
Basically, you reverse the lines of the file, then split them with cut using space as the delimiter, take the first field that cut produces and then you reverse the token again, use tr -d to delete unwanted chars and tr again to replace newline chars with ,
Also, you can avoid the first cat by doing:
rev < file | cut -d" " -f1 | rev | tr -d "." | tr "n" ","
answered May 18, 2013 at 0:09
![]()
higuarohiguaro
15.6k4 gold badges37 silver badges42 bronze badges
2
tldr;
$ awk '{print $NF}' file.txt | paste -sd, | sed 's/,/, /g'
For a file like this
$ cat file.txt
The quick brown fox
jumps over
the lazy dog.
the given command will print
fox, over, dog.
How it works:
awk '{print $NF}': prints the last field of every linepaste -sd,: readsstdinserially (-s, one file at a time) and writes fields comma-delimited (-d,)sed 's/,/, /g':substitutes","with", "globally (for all instances)
References:
- https://linux.die.net/man/1/awk
- https://linux.die.net/man/1/paste
- https://linux.die.net/man/1/sed
answered Mar 16, 2016 at 17:50
![]()
rubicksrubicks
4,7721 gold badge28 silver badges40 bronze badges
1
there are many ways. as awk solutions shows, it’s the clean solution
sed solution is to delete anything till the last space. So if there is no space at the end, it should work
sed 's/.* //g' <file>
you can avoid sed also and go for a while loop.
while read line
do [ -z "$line" ] && continue ;
echo $line|rev|cut -f1 -d' '|rev
done < file
it reads a line, reveres it, cuts the first (i.e. last in the original) and restores back
the same can be done in a pure bash way
while read line
do [ -z "$line" ] && continue ;
echo ${line##* }
done < file
it is called parameter expansion
answered May 17, 2013 at 20:26
![]()
abasuabasu
2,44419 silver badges22 bronze badges
0
If you want to start a perl one-liner for last word:
perl -lane 'print "$F[-1]"'
… where -a gives autosplit into @F and $F[-1] is the last element.
To turn into list with commas:
perl -ane 'print "$F[-1]" . (eof() ? "n":",")'
answered May 20, 2022 at 20:58
![]()
steveslivastevesliva
5,1981 gold badge16 silver badges39 bronze badges
I’m attempting to take the last word or phrase using grep for a specific pattern. In this example, it would be the from the last comma to the end of the line:
Blah,3,33,56,5,Foo 30,,,,,,,3,Great Value
And so the wanted output for that line would be «Great Value». All the lines are different lengths as well, but always have a single comma preceding the last words.
Basically, I would like to simply output from the last comma to the end of the line. Thank you!
![]()
asked Jan 25, 2017 at 3:51
![]()
4
Here:
grep -o '[^,]+$'
-
[^,]+matches one or more characters that are not,at the end of the line ($) -
-oprints only the matched portion
Example:
% grep -o '[^,]+$' <<<'Blah,3,33,56,5,Foo 30,,,,,,,3,Great Value'
Great Value
answered Jan 25, 2017 at 3:54
![]()
heemaylheemayl
53.8k8 gold badges121 silver badges139 bronze badges
4
Always like to see an awk solution so here it is (upvoted the proper solution!):
% awk -F, '{print $NF}' <<<'Blah,3,33,56,5,Foo 30,,,,,,,3,Great Value'
Great Value
answered Jan 25, 2017 at 5:16
![]()
Paul EvansPaul Evans
8986 silver badges8 bronze badges
1
May be this will give you the desired output
Command :
#!/bin/bash
echo "Blah,3,33,56,5,Foo 30,,,,,,,3,Great Value" | rev | awk -F',' '{ print $1 }' | rev
Output :
Great Value
Tested on this website : https://rextester.com/KNMI75463
answered Nov 27, 2020 at 20:14
![]()
codeholic24codeholic24
2973 silver badges14 bronze badges
@echo off
findstr /N . input.txt | findstr /I ^2.*alive$ > NUL
IF %ERRORLEVEL% EQU 0 (Echo Hi) ELSE (Echo Hello)
pause
This batch reads in your text file with the /N switch, wich puts a number in front of every line, like:
1:This is a test,
2:and I am alive
3:Not?
The new text is piped to the second findstr, which uses the RegEx pattern ^2.*alive$ to find a line which begins with 2 and ends with alive. That was the hard part.
Since findstr sets its errorlevel to 0 if at least one match is found, we can use a simple IF statement to echo «Hi» or «Hello».
Batch in detail
findstrsearches for strings in files/Nputs a line number in front of every line.is a wildcard for any single character. It tells findstr to search for everything|is the pipe command. The output from the first command is passed as input for the second one/Itells findstr to search case-insensitive so «Alive» and «alive» are both found^is a RegEx term and stands for a line beginning.*is a RegEx term and stands for an indefinite number of character$is a RegEx term and stands for a line ending> NULhides the findstr output so the matching line isn’t displayed in the CMD windowIF condition (command) ELSE (command)is a simple IF condition%ERRORLEVEL% EQU 0is the exit code of findstr. «EQU» stands for «equel»
Edit (example taken from OP’ comment below)

-
Your «Alive» isn’t at the 2nd line. Its the 5th
-
After «Alive» are three spaces in your example so
alive$doesn’t matchChange
^2.*alive$to5.*alive. Or even better^5.* Alive $
Note the spaces.
|
|




 SUMMER IS HERE !!!!
SUMMER IS HERE !!!!  Thanks!
Thanks!

10 More Discussions You Might Find Interesting
1. Shell Programming and Scripting
Find word in a line and output in which line the word occurs / no. of times it occurred
I have a file: file.txt, which contains the following data in it.
This is a file, my name is Karl, what is this process, karl is karl junior, file is a test file, file’s name is file.txt
My name is not Karl, my name is Karl Joey
What is your name?
Do you know your name and… (3 Replies)
Discussion started by: anuragpgtgerman
2. Shell Programming and Scripting
Read a File line by line and split into array word by word
Hi All,
Hope you guys had a wonderful weekend
I have a scenario where in which I have to read a file line by line
and check for few words before redirecting to a file
I have searched the forum but,either those answers dint work (perhaps because of my wrong under standing of how IFS… (6 Replies)
Discussion started by: Kingcobra
3. Shell Programming and Scripting
Appending lines with word frequencies, ordering and indexing a column
Dear All,
I have the following input data:
w1 20 g1
w1 10 g1
w2 12 g1
w2 23 g1
w3 10 g1
w3 17 g1
w3 12.5 g1
w3 21 g1
w4 11 g1
w4 13.2 g1
w4 23 g1
w4 18 g1
First I seek to find the word frequencies in col1 and sort col2 in ascending order for each change in a col1 word. Second,… (5 Replies)
Discussion started by: Ghetz
4. Shell Programming and Scripting
Appending the first word of each line to the end of each line
Hi Experts,
Am relatively new to shell programming so would appreciate some help in this regard.
I am looking at reading from a file, line by line, picking the first word of each line and appending it to the end of the line.
Any suggestions?
INPUT FILE —
3735051 :… (7 Replies)
Discussion started by: hj007
5. Shell Programming and Scripting
Print word 1 in line 1 and word 2 in line 2 if it matches a pattern
i have a file in this pattern
MATCH1 word1 IMAGE word3 word4
MATCH2 word1 word2 word3 word4
MATCH2 word1 word2 word3 word4
MATCH2 word1 word2 word3 word4
MATCH2 word1 word2 word3 word4
MATCH1 word1 IMAGE word3 word4
MATCH2 word1 word2 word3 word4
MATCH2 word1 word2 word3 word4
MATCH2 word1… (7 Replies)
Discussion started by: bangaram
6. UNIX for Dummies Questions & Answers
regular expression for replacing the fist word with a last word in line
I have a File with the below contents
File1
I have no prior experience in unix. I have just started to work in unix.
My experience in unix is 0. My Total It exp is 3 yrs.
I need to replace the first word in each line with the last word for example
unix have no prior experience in… (2 Replies)
Discussion started by: kri_swami
7. Shell Programming and Scripting
awk;sed appending line to previous line….
I know this has been asked before but I just can’t parse the syntax as explained. I have a set of files that has user information spread out over two lines that I wish to merge into one:
User1NameLast User1NameFirst User1Address
E-Mail:User1email
User2NameLast User2NameFirst User2Address… (11 Replies)
Discussion started by: walkerwheeler
8. Shell Programming and Scripting
sed: appending alternate line after previous line
Hi all,
I have to append every alternate line after its previous line. For example if my file has following contents
line 1: unix is an OS
line 2: it is open source
line 3: it supports shell programming
line 4: we can write shell scripts
Required output should be
line1: unix is an OS it is… (4 Replies)
Discussion started by: rish_max
9. Shell Programming and Scripting
Appending the line number and a seperator to each line of a file ?
Hi, I am a newb as far as shell scripting and SED goes so bear with me on this one.
I want to basically append to each line in a file a delimiter character and the line’s line number e.g
Change the file from :-
aaaaaa
bbbbbb
cccccc
to:-
aaaaaa;1
bbbbbb;2
cccccc;3
I have worked… (4 Replies)
Discussion started by: pjcwhite
10. Shell Programming and Scripting
Can a shell script pull the first word (or nth word) off each line of a text file?
Greetings.
I am struggling with a shell script to make my life simpler, with a number of practical ways in which it could be used. I want to take a standard text file, and pull the ‘n’th word from each line such as the first word from a text file.
I’m struggling to see how each line can be… (5 Replies)
Discussion started by: tricky
Как быстро выделить все последние строки из документа Word? В этом уроке вы узнаете, как быстро выбрать все последние строки в абзацах Word.
Выделить все последние строки в абзацах одну за другой в Word
Жирным шрифтом все последние строки в абзацах, запустив VBA
Выделите все последние строки в абзацах с помощью Kutools for Word
 Выделить все последние строки в абзацах одну за другой в Word
Выделить все последние строки в абзацах одну за другой в Word
Удивительный! Используйте эффективные вкладки в Word (Office), например Chrome, Firefox и New Internet Explorer!

Подробнее Скачать бесплатно
1. Сначала выберите одну последнюю строку.
2. Держать Ctrl и выберите вручную все оставшиеся последние строки в абзацах. Примечание. Этот метод очень утомителен, если нужно выбрать сотни строк.
Жирным шрифтом все последние строки в абзацах, запустив VBA
1: Нажмите Alt + F11 для открытия Microsoft Visual Basic для приложений окно;
2: нажмите Модули от Вставить вкладку, скопируйте и вставьте следующий код VBA в Модули окно;
3: нажмите Run  или нажмите F5 применить VBA.
или нажмите F5 применить VBA.
Код VBA выделен жирным шрифтом все последние строки:
Поджирные последние строки ()
Для каждого p в ActiveDocument.Paragraphs
Выбор.Начало = p.Диапазон.Конец — 2
Selection.Bookmarks (» Line»). Range.Font.Bold = True
Download
End Sub
Выделите все последние строки в абзацах с помощью Kutools for Word
Работы С Нами Kutools for Word‘s Выбрать последние строки абзаца Утилита, вы можете не только быстро выбрать все последние строки в абзацах, но также можете выбрать последние строки в абзацах из таблиц.
Kutools for Word, удобная надстройка, включает группы инструментов, облегчающих вашу работу и расширяющих ваши возможности обработки текстовых документов. Бесплатная пробная версия на 45 дней! Get It Now!
Шаг 1. Пожалуйста, примените эту утилиту, нажав Кутулс > Пункт > Выбрать последние строки абзаца, см. снимок экрана:

Шаг 2. Выберите один из стилей в раскрывающемся списке в Строки последнего абзаца диалог. Смотрите скриншот:
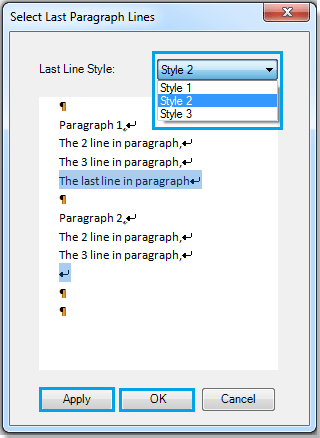
Шаг 3. Нажмите Применить or OK. Для Стиль 1 вы решите подать заявку, вы увидите результат, как показано на скриншотах ниже:
Если вы хотите выбрать все последние строки из таблиц, выберите Стиль 3. После применения утилиты вы увидите следующий результат:
Примечание: Какой бы стиль вы ни выбрали, с помощью этой утилиты можно выбрать только последние строки, если формат ваших абзацев такой же, как и стиль. Эта утилита не может выбрать последние строки в выделении
Щелкните здесь, чтобы узнать больше о выборе строк последнего абзаца.
Относительные статьи:
- Выделить все более короткие абзацы в Word
- Выделение абзацев без заголовка в Word
- Выделить все абзацы заголовков в Word
Рекомендуемые инструменты для повышения производительности Word


Kutools For Word — Более 100 расширенных функций для Word, сэкономьте 50% времени
- Сложные и повторяющиеся операции можно производить разово за секунды.
- Вставляйте сразу несколько изображений из папок в документ Word.
- Объединяйте и объединяйте несколько файлов Word из папок в одну в желаемом порядке.
- Разделите текущий документ на отдельные документы в соответствии с заголовком, разрывом раздела или другими критериями.
- Преобразование файлов между Doc и Docx, Docx и PDF, набор инструментов для общих преобразований и выбора и т. Д.
Комментарии (0)
Оценок пока нет. Оцените первым!