
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
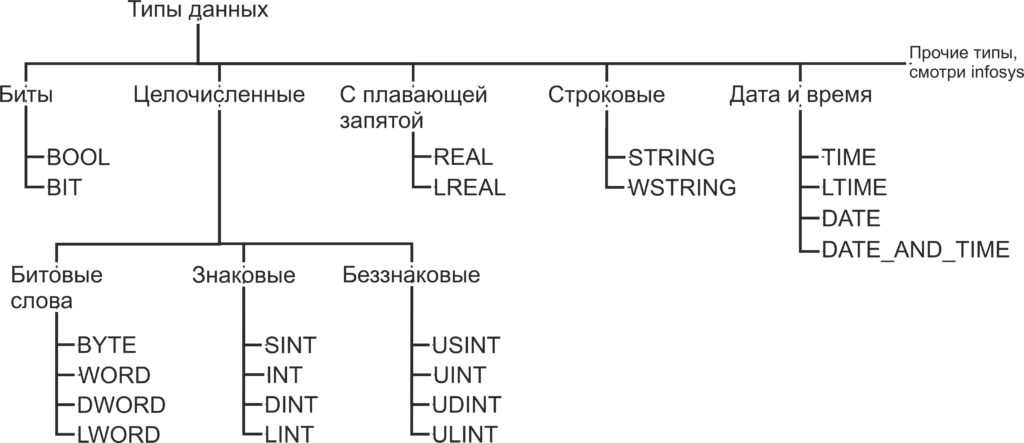
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
From Wikipedia, the free encyclopedia
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of words[edit]
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choice[edit]
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architectures[edit]
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressing[edit]
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of two[edit]
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size families[edit]
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizes[edit]
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See also[edit]
- Integer (computer science)
Notes[edit]
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is
 . This gives an equivalent of about 9.51 bits for 6 trits.
. This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign

References[edit]
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
stesl писал(а): ↑23 мар 2021, 10:37
Тип Word — это целочисленный беззнаковый тип данных, в два байта. Диапазон 0-65535. Используется везде, где оказывается нужным.
Не путайте Word с UInt (unsigned integer16), он не относится к целочисленным, так как не кодирует числовые значения и не совместим с математическими операциями.
Потому что:
Sergy6661 писал(а): ↑23 мар 2021, 12:54
Вот для упаковки-распаковки битовых переменных и используется в основном.
Но не в основном, а только для этого. Если конечно в конкретном ПЛК не срабатывает неявное преобразование, из-за которого кажется, что Word — это целое число.
Отправлено спустя 21 минуту 7 секунд:
Не, иначе объясню:
Word — это когда ты в 16 бит записал 16 булевых значений, каждый из которых что-то значит в смысле true/false. Например, при управлении сервоприводом или частотником.
Int16, UInt16 — это числа, отдельные биты не представляют интереса (хотя бывают редкие исключения).
Математические операции умеют работать с числами, то есть Add(), Sub(), Mul(), Div() работают с Int16/UInt16, а с Word работает подозрительно, подсвечивает типа «глянь, что за дрянь ты задумал?», но воспринимает как число 0-65535. Извините, правда, зачем вы складываете слово управления частотника с числом -85?
Зато сдвиговые операции и операции со словами типа ANDW(), ORW(), NOT(W), XORW() работают именно со словами и подозрительно с целыми числами.
Это разные типы данных, хотя все они 16 бит.
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of wordsEdit
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choiceEdit
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architecturesEdit
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressingEdit
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of twoEdit
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size familiesEdit
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizesEdit
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See alsoEdit
- Integer (computer science)
NotesEdit
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is . This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign
ReferencesEdit
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
Размер машинного слова и типы данных
Размер машинного слова и типы данных
Машинное слово (word) — это количество данных, которые процессор может обработать за одну операцию. Здесь можно применить аналогию документа, состоящего из символов (character, 8 бит) и страниц (много слов). Слово— это некоторое количество битов, как правило 16, 32 или 64. Когда говорят о «n-битовой» машине, то чаще всего имеют в виду размер машинного слова. Например, когда говорят, что процессор Intel Pentium — это 32-разрядный процессор, то обычно имеют в виду размер машинного слова, равный 32 бит, или 4 байт.
Размер процессорных регистров общего назначения равен размеру машинного слова этого процессора. Обычно разрядность остальных компонентов этой же аппаратной платформы в точности равна размеру машинного слова. Кроме того, по крайней мере для аппаратных платформ, которые поддерживаются ОС Linux, размер адресного пространства соответствует размеру машинного слова[92]. Следовательно, размер указателя равен размеру машинного слова. В дополнение к этому, размер типа long языка С также равен размеру машинного слова. Например, для аппаратной платформы Alpha размер машинного слова равен 64 бит. Следовательно, регистры, указатели и тип long имеют размер 64 бит. Тип int для этой платформы имеет размер 32 бит. Машины платформы Alpha могут обработать 64 бит — одно слово с помощью одной операции.
Слова, двойные слова и путаница
Для некоторых операционных систем и процессоров стандартную порцию данных не называют машинным словом. Вместо этого, словом называется некоторая фиксированная порция данных, название которой выбрано случайным образом или имеет исторические корни. Например, в некоторых системах данные могут разбиваться на байты (byte — 8 бит), слова (word — 16 бит), двойные слова (double word — 32 бит) и четверные слова (quad word — 64 бит), несмотря на то что на самом деле система является 32-разрядной. В этой книге и вообще в контексте операционной системы Linux под машинным словом понимают стандартную порцию данных процессора, как обсуждалось ранее.
Для каждой аппаратной платформы, поддерживаемой операционной системой Linux, в файле <asm/types.h> определяется константа BITTS_PER_LONG, которая равна размеру типа long языка С и совпадает с размером машинного слова системы. Полный список всех поддерживаемых аппаратных платформ и их размеры машинного слова приведены в табл. 19.1.
Таблица 19.1. Поддерживаемые аппаратные платформы
Аппаратная платформа
Описание
Размер машинного слова
alpha
Digital Alpha
64 бит
arm
ARM и StrongARM
32 бит
cris
CRIS
32 бит
h8300
H8/300
32 бит
I386
Intel x86
32 бит
ia64
IA-64
64 бит
m68k
Motorola 68k
32 бит
m86knommu
m68k без устройства MMU
32 бит
mips
MIPS
32 бит
mips64
64-разрядная MIPS
64 бит
parisc
HP PA-RISC
32 бит, или 64 бит
ppc
PowerPC
32 бит
ppc64
POWER
64 бит
s390
IBM S/390
32 бит, или 64 бит
sh
Hitachi SH
32 бит
sparс
SPARC
32 бит
sparc64
UltraSPARC
64 бит
um
Usermode Linux
32 бит, или 64 бит
v850
v850
32 бит
x86_64
X86-64
64 бит
Стандарт языка С явно указывает, что размер памяти, которую занимают переменные стандартных типов данных, зависит от аппаратной реализации[93], при этом также определяется минимально возможный размер типа. Неопределенность размеров стандартных типов языка С для различных аппаратных платформ имеет свои положительные и отрицательные стороны. К плюсам можно отнести то, что для стандартных типов языка С можно пользоваться преимуществами, связанными с размером машинного слова, а также отсутствие необходимости явного указания размера. Для ОС Linux размер типа long гарантированно равен размеру машинного слова. Это не совсем соответствует стандарту ANSI С, однако является стандартной практикой в ОС Linux. Как недостаток можно отметить, что при разработке кода нельзя рассчитывать на то, что данные определенного типа занимают в памяти определенный размер. Более того, нельзя гарантировать, что переменные типа int занимают столько же памяти, сколько и переменные типа long[94].
Ситуация еще более запутывается тем, что одни и те же типы данных в пространстве пользователя и в пространстве ядра не обязательно должны соответствовать друг другу. Аппаратная платформа sparc64 предоставляет 32-разрядное пространство пользователя, а поэтому указатели, типы int и long имеют размер 32 бит. Однако в пространстве ядра для аппаратной платформы размер типа int равен 32 бит, а размер указателей и типа long равен 64 бит. Тем не менее такая ситуация не является обычной.
Всегда необходимо помнить о следующем.
• Как и требует стандарт языка С, размер типа char всегда равен 8 бит (1 байт),
• Нет никакой гарантии, что размер типа int для всех поддерживаемых аппаратных платформ будет равен 32 бит, хотя сейчас для всех платформ он равен именно этому числу.
• То же касается и типа short, который для всех поддерживаемых аппаратных платформ сейчас равен 16 бит.
• Никогда нельзя надеяться, что тип long или указатель имеет некоторый заданный размер. Этот размер для поддерживаемых аппаратных платформ может быть равен 32, или 64 бит.
• Так как размер типа long разный для различных аппаратных платформ, никогда нельзя предполагать, что sizeof(int) == sizeof(long).
• Точно так же нельзя предполагать, что размер типа int и размер указателя совпадают.
Читайте также
Типы данных
Типы данных
Приведенные в этой главе таблицы взяты непосредственно из оперативной справочной системы и представляют единую модель данных Windows (Windows Uniform Data Model). Определения типов можно найти в заголовочном файле BASETSD.H, входящем в состав интегрированной среды разработки
Типы данных
Типы данных
В JScript поддерживаются шесть типов данных, главными из которых являются числа, строки, объекты и логические данные. Оставшиеся два типа — это null (пустой тип) и undefined (неопределенный
14.5.1 Типы данных
14.5.1 Типы данных
Файл может содержать текст ASCII, EBCDIC или двоичный образ данных (существует еще тип, называемый локальным или логическим байтом и применяемый для компьютеров с размером байта в 11 бит). Текстовый файл может содержать обычный текст или текст, форматированный
20.10.3 Типы данных MIB
20.10.3 Типы данных MIB
Причиной широкого распространения SNMP стало то, что проектировщики придерживались правила «Будь проще!»? Все данные MIB состоят из простых скалярных переменных, хотя отдельные части MIB могут быть логически организованы в таблицы.? Только небольшое число
Типы данных
Типы данных
Несмотря на то, что типы данных подробно описаны в документации (см. [1, гл. 4]), необходимо рассмотреть ряд понятий, которые будут часто использоваться в последующих главах книги. Помимо изложения сведений общего характера будут рассмотрены также примеры
Типы данных
Типы данных
Один из этапов проектирования базы данных заключается в объявлении типа каждого поля, что позволяет процессору базы данных эффективно сохранять и извлекать данные. В SQL Server предусмотрено использование 21 типа данных, которые перечислены в табл. 1.1.Таблица 1.1.
Глава 2 Ввод данных. Типы, или форматы, данных
Глава 2
Ввод данных. Типы, или форматы, данных
Работа с документами Excel сопряжена с вводом и обработкой различных данных, то есть ин формации, которая может быть текстовой, числовой, финансовой, статистической и т. д.
МУЛЬТИМЕДИЙНЫЙ КУРС
Методы ввода и обработки данных
Ключевые слова, используемые для спецификации типа данных
Ключевые слова, используемые для спецификации типа данных
Ключевые слова для спецификации типов данных в операторах DDL представлены здесь в качестве краткой справки. Точный синтаксис см. в соответствующей главе, связанной с типами данных этой части книги, а также в
Типы данных
Типы данных
Многие языки программирования при объявлении переменной требуют указывать, какой тип данных будет ей присваиваться. Например, в языке Java кодint i = 15;объявит переменную целого типа int с именем i и присвоит ей значение 15. В этом случае тип данных ставится в
12.2. Типы баз данных
12.2. Типы баз данных
Группу связанных между собой элементов данных называют обычно записью. Известны три основных типа организации данных и связей между ними: иерархический (в виде дерева), сетевой и реляционный.Иерархическая БДВ иерархической БД существует
5.2.4. Типы данных
5.2.4. Типы данных
Мы можем вводить в ячейки следующие данные: текст, числа, даты, также приложение Numbers предоставляет возможность добавлять флажки, ползунки и другие элементы управления. Аналогично MS Excel для выравнивания чисел, дат и текстовых данных в Numbers существуют
Слова, слова, слова… Автор: Евгений Козловский.
Слова, слова, слова…
Автор: Евгений Козловский.
© 2004, Издательский дом | http://www.computerra.ru/Журнал «Домашний компьютер» | http://dk.compulenta.ru/Этот материал Вы всегда сможете найти по его постоянному адресу: /2006/120/276445/Интересно, сколько двенадцатизначных чисел вы способны оперативно
Размер головного мозга и размер социального окружения
Размер головного мозга и размер социального окружения
Дискуссии по поводу взаимосвязи между размером головного мозга какого-либо организма и размером группы, к которой этот организм принадлежит, ведутся нейробиологами уже давно. При этом взаимосвязь с социальной
Is a machine WORD always the same or does it depend on the machine architecture?
And is the meaning of the word WORD context sensitive or generally applicable?
![]()
Bo Persson
90.1k31 gold badges146 silver badges203 bronze badges
asked Mar 7, 2009 at 10:44
![]()
prinzdezibelprinzdezibel
11k17 gold badges55 silver badges61 bronze badges
1
The machine word size depends on the architecture, but also how the operating system is running the application.
In Windows x64 for example an application can be run either as a 64 bit application (having a 64 bit mahine word), or as a 32 bit application (having a 32 bit machine word). So the size of a machine word can differ even on the same machine.
The term WORD has different meaning depending on how it’s used. It can either mean a machine word, or a type with a specific size. In x86 assembly language WORD, DOUBLEWORD (DWORD) and QUADWORD (QWORD) are used for 2, 4 and 8 byte sizes, regardless of the machine word size.
answered Mar 7, 2009 at 10:53
![]()
A word is typically the «native» data size of the CPU. That is, on a 16-bit CPU, a word is 16 bits, on a 32-bit CPU, it’s 32 and so on.
And the exception, of course, is x86, where a word is 16 bit wide (because x86 was originally a 16-bit CPU), a DWORD is 32-bit (because it became a 32-bit CPU), and a QWORD is 64-bit (because it now has 64-bit extensions bolted on)
answered Mar 7, 2009 at 10:50
![]()
jalfjalf
241k51 gold badges342 silver badges549 bronze badges
3
It depends upon the machine architecture. This document explains some basics about this.
answered Mar 7, 2009 at 10:50
![]()
VinayVinay
4,7337 gold badges33 silver badges43 bronze badges
Yes.
Ok, let me be a bit clearer. Assuming we are talking about words of memory, there are two broad definitions.
First, a word is often the natural size of a single item that can be accessed atomically in the hardware. That is very much a platform dependent size, but is usually 16, 32, or 64 bits, but other sizes have been found in the wild.
Second, it is often used to specifically mean a 16-bit value. In that context, you will see DWORD used to mean a 32-bit value. This usage is common on x86 platforms, especially Windows, but was used on DEC PDP-11 and VAX, and Motorola 68000 descendants as well.
Telling which is the intended usage depends on context…
answered Mar 7, 2009 at 10:54
![]()
RBerteigRBerteig
41.4k7 gold badges88 silver badges125 bronze badges
WORD is a Windows specific 16-bit integer type, and is hardware independent.
If you mean a machine word, then there’s no need to shout.
answered Mar 7, 2009 at 10:57
![]()
Pete KirkhamPete Kirkham
48.7k5 gold badges92 silver badges168 bronze badges
16 bits (2 bytes) to a word is universal for x86.
answered Mar 7, 2009 at 10:50
![]()
NickNick
13.2k17 gold badges63 silver badges100 bronze badges
All you youngsters yappin’ on about 32 bit thiss and 64 bit that: you know, there were and are other machine architectures than the x86 family. A PDP-11 had 40-bit words, f’rinstance.
But the simplest answer is just to search Wikipedia.
answered Mar 7, 2009 at 10:56
![]()
Pontus GaggePontus Gagge
17.1k1 gold badge38 silver badges50 bronze badges
3
A «word» in small letters depends on the architecture.
A «WORD» in capital letters, as defined in Windows SDK, is 16 bits.
Similarly:
«DWORD» — (double word) 32 bits.
«QWORD» … 64 bits.
answered Mar 7, 2009 at 10:58
![]()
Jimmy JJimmy J
1,9531 gold badge14 silver badges20 bronze badges
My understanding is that a WORD is the amount of bits that can be shoved into the CPU with one action (on a particular machine), so in a 8bit-architecture it is 8 bits and on a modern 64-bit architecture it is 64 bits.
![]()
answered Mar 7, 2009 at 10:51
![]()
Peter MiehlePeter Miehle
5,9642 gold badges38 silver badges55 bronze badges
1
Базовый блок памяти, обрабатываемый компьютером
В вычислениях, слово — это естественная единица данных, используемая конкретной конструкцией процессора . Слово — это фрагмент данных фиксированного размера, обрабатываемый как единица набором команд или аппаратными средствами процессора. Количество бит в слове (размер слова, ширина слова или длина слова) является важной характеристикой любой конкретной конструкции процессора или компьютерной архитектуры.
Размер слова отражается во многих аспектах устройства и работы компьютера; большинство регистров в процессоре обычно имеют размер слова, и самый большой фрагмент данных, который может быть передан в и из рабочей памяти за одну операцию, — это слово из многих ( не все) архитектуры. Наибольший возможный размер адреса, используемый для обозначения места в памяти, обычно является аппаратным словом (здесь «аппаратное слово» означает полноразмерное естественное слово процессора, в отличие от любого другого используемого определения).
Некоторые из самых ранних компьютеров (а также несколько современных) использовали двоично-десятичное, а не обычное двоичное, обычно с размером слова 10 или 12 десятичные цифры, а некоторые ранние десятичные компьютеры вообще не имели фиксированной длины слова. Ранние двоичные системы имели тенденцию использовать длину слова, несколько кратную 6-битному, причем 36-битное слово было особенно распространено на мэйнфреймах компьютерах. Введение ASCII привело к переходу к системам с длиной слова, кратной 8-битной, с 16-битными машинами, которые были популярны в 1970-х годах до перехода на современные процессоры с 32 или 64 битами. Конструкции специального назначения, такие как процессоры цифровых сигналов, могут иметь любую длину слова от 4 до 80 бит.
Размер слова иногда может отличаться от ожидаемого из-за обратной совместимости с более ранними компьютерами. Если несколько совместимых вариантов или семейство процессоров имеют общую архитектуру и набор инструкций, но различаются размером слов, их документация и программное обеспечение могут стать сложными в системе обозначений, чтобы учесть разницу (см. Семейства размеров ниже).
Содержание
- 1 Использование слов
- 2 Выбор размера слова
- 2.1 Архитектура переменных слов
- 2.2 Адресация слов и байтов
- 2.3 Степени двух
- 3 Семейство размеров
- 4 Таблица размеров слов
- 5 См. Также
- 6 Ссылки
Использование слов
В зависимости от того, как устроен компьютер, единицы размера слова могут использоваться для:
- Фиксированной точки числа
- Держатели для фиксированной точки, обычно целого числа, числовые значения могут быть доступны в одном или нескольких разных размерах, но один из доступных размеров почти всегда будет слово. Другие размеры, если таковые имеются, скорее всего, будут кратны или дроби размера слова. Меньшие размеры обычно используются только для эффективного использования памяти; при загрузке в процессор их значения обычно попадают в более крупный держатель размером с слово.
- Числа с плавающей запятой
- Держатели для числовых значений с плавающей запятой обычно либо слово или кратное слово.
- Адреса
- Держатели для адресов памяти должны иметь размер, способный выражать необходимый диапазон значений, но не быть чрезмерно большим, поэтому часто используемый размер слово, хотя оно также может быть кратным или дробной части размера слова.
- Регистры
- Регистры процессора имеют размер, соответствующий типу данных, которые они хранят, например целые числа, числа с плавающей запятой или адреса. Многие компьютерные архитектуры используют регистры общего назначения, которые могут хранить данные в нескольких представлениях.
- Передача памяти и процессора
- Когда процессор считывает данные из подсистемы памяти в зарегистрировать или записать значение регистра в память, объем передаваемых данных часто выражается словом. Исторически такое количество битов, которое могло быть передано за один цикл, в некоторых средах также называлось катеной (например, Bull GAMMA 60 [fr ]). В простых подсистемах памяти слово передается по шине данных памяти, которая обычно имеет ширину слова или полуслова. В подсистемах памяти, которые используют кеши, передача размером с слово — это передача между процессором и первым уровнем кеша; на более низких уровнях иерархии памяти обычно используются более крупные передачи (кратные размеру слова).
- Единица разрешения адреса
- В данной архитектуре, последовательные значения адреса обозначают последовательные единицы памяти; эта единица — единица разрешения адреса. На большинстве компьютеров единицей измерения является либо символ (например, байт), либо слово. (Некоторые компьютеры использовали битовое разрешение.) Если единицей измерения является слово, то можно получить доступ к большему объему памяти, используя адрес заданного размера за счет дополнительной сложности доступа к отдельным символам. С другой стороны, если единицей измерения является байт, то можно адресовать отдельные символы (т. Е. Выбирать во время операции с памятью).
- Инструкции
- Машинные команды обычно имеют размер слова архитектуры, например, в архитектурах RISC, или кратное размеру «char», составляющее его долю. Это естественный выбор, поскольку инструкции и данные обычно используют одну и ту же подсистему памяти. В гарвардской архитектуре размеры слов инструкций и данных не должны быть связаны, поскольку инструкции и данные хранятся в разных запоминающих устройствах; например, процессор в электронном телефонном коммутаторе 1ESS имел 37-битные инструкции и 23-битные слова данных.
Выбор размера слова
При проектировании компьютерной архитектуры выбор размер слова имеет существенное значение. Существуют конструктивные соображения, которые поощряют определенные размеры битовых групп для конкретных целей (например, для адресов), и эти соображения указывают на разные размеры для разных целей. Однако соображения экономии при проектировании настоятельно требуют использования одного размера или очень небольшого числа размеров, связанных кратными или дробными (частичными) размерами с основным размером. Этот предпочтительный размер становится размером слова архитектуры.
Размер символа был в прошлом (кодировка символов с предварительной переменной размером ) одно из влияний на единицу разрешения адреса и выбор размера слова. До середины 1960-х символы чаще всего хранились в шести битах; это позволяло использовать не более 64 символов, поэтому алфавит был ограничен прописными буквами. Поскольку во времени и пространстве эффективно иметь размер слова, кратный размеру символа, размеры слова в этот период обычно были кратны 6 битам (в двоичных машинах). Тогда обычным выбором было 36-битное слово, которое также является хорошим размером для числовых свойств формата с плавающей запятой.
После внедрения дизайна IBM System / 360, в котором использовались восьмибитные символы и поддерживались строчные буквы, стандартный размер символа (или более точно, байт ) стал восемью битами. После этого размер слов, естественно, был кратен восьми битам, причем обычно использовались 16, 32 и 64 бит.
Архитектуры с переменной длиной слова
Ранние разработки машин включали некоторые, в которых использовалось то, что часто называют переменной длиной слова. В этом типе организации числовой операнд не имеет фиксированной длины, а его конец обнаруживается при обнаружении символа со специальной маркировкой, часто называемой словесным знаком. Такие машины часто использовали десятичные дроби с двоичным кодом для чисел. К этому классу машин относились IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401 и IBM 1620.
Большинство этих машин работают с одной единицей памяти за раз, и поскольку каждая инструкция или данные имеют длину в несколько единиц, каждая инструкция занимает несколько циклов только для доступ к памяти. Из-за этого эти машины часто довольно медленные. Например, выборка инструкций в IBM 1620 Model I занимает 8 циклов только для чтения 12 цифр инструкции (Model II сократила это до 6 циклов или 4 циклов, если инструкция не нуждалась в обоих адресных полях). Выполнение инструкции занимало совершенно разное количество циклов в зависимости от размера операндов.
Адресация слов и байтов
Модель памяти в архитектуре сильно зависит от размера слова. В частности, в качестве слова часто выбирается разрешение адреса памяти, то есть наименьшая единица, которая может быть обозначена адресом. В этом подходе используется машина с адресацией по словам, значения адресов, которые отличаются на единицу, обозначают соседние слова памяти. Это естественно для машин, которые почти всегда работают с единицами слова (или нескольких слов), и имеет то преимущество, что позволяет командам использовать поля минимального размера для хранения адресов, что позволяет использовать меньший размер команды или большее разнообразие инструкций.
Когда обработка байтов должна составлять значительную часть рабочей нагрузки, обычно более выгодно использовать байт, а не слово в качестве единицы разрешения адреса. Значения адресов, которые отличаются на единицу, обозначают соседние байты в памяти. Это позволяет напрямую обращаться к произвольному символу в строке символов. Слово все еще может быть адресовано, но используемый адрес требует на несколько бит больше, чем альтернатива разрешения слова. Размер слова должен быть целым числом, кратным размеру символа в этой организации. Такой подход к адресации использовался в IBM 360 и с тех пор является наиболее распространенным подходом в машинах, разработанных.
В машине с побайтовой ориентацией (с байтовой адресацией ) перемещение одного байта из одного произвольного местоположения в другое обычно:
- ЗАГРУЗИТЬ исходный байт
- СОХРАНИТЕ результат обратно в целевой байт
. К отдельным байтам можно получить доступ на машине, ориентированной на слова, одним из двух способов. Байтами можно манипулировать с помощью комбинации операций сдвига и маски в регистрах. Для перемещения одного байта из одного произвольного места в другое может потребоваться эквивалент следующего:
- ЗАГРУЗИТЬ слово, содержащее исходный байт
- SHIFT исходное слово, чтобы выровнять желаемый байт с правильной позицией в целевом объекте слово
- И исходное слово с маской для обнуления всех битов, кроме желаемых
- ЗАГРУЗИТЬ слово, содержащее целевой байт
- И целевое слово с маской до нуля из целевого байта
- OR регистры, содержащие исходное и целевое слова, чтобы вставить исходный байт
- СОХРАНИТЬ результат обратно в целевое местоположение
В качестве альтернативы многие машины, ориентированные на слова, реализуют байтовые операции с инструкциями, используя специальные байтовые указатели в регистрах или в памяти. Например, указатель байта PDP-10 содержал размер байта в битах (позволяющий получить доступ к байтам разного размера), битовую позицию байта в слове и адрес слова данные. Инструкции могут автоматически настраивать указатель на следующий байт, например, при операциях загрузки и депонирования (сохранения).
Степени двух
Разные объемы памяти используются для хранения значений данных с разной степенью точности. Обычно используемые размеры — это степень двух, кратных единице разрешения адреса (байту или слову). Преобразование индекса элемента в массиве в адрес элемента требует только операции shift, а не умножения. В некоторых случаях эта связь позволяет избежать использования операций деления. В результате большинство современных компьютерных разработок имеют размеры слова (и другие размеры операндов), которые в два раза превышают размер байта.
Семейства размеров
По мере того, как компьютерные конструкции становились все более сложными, центральное значение размера одного слова для архитектуры уменьшалось. Хотя более мощное оборудование может использовать более широкий спектр размеров данных, рыночные силы оказывают давление на поддержание обратной совместимости при одновременном расширении возможностей процессора. В результате то, что могло быть центральным размером слова в новом дизайне, должно сосуществовать в качестве альтернативного размера к исходному размеру слова в обратно совместимом дизайне. Исходный размер слова остается доступным в будущих проектах, формируя основу семейства размеров.
В середине 1970-х годов DEC разработал VAX как 32-битный преемник 16-битного PDP-11. Они использовали слово для 16-битной величины, а длинное слово — для 32-битной величины. Это отличалось от более ранних машин, где естественная единица адресации памяти называлась словом, а величина, равная половине слова, называлась полусловом. В соответствии с этой схемой квадраслово VAX составляет 64 бита. Они продолжили эту терминологию слова / длинного слова / четверного слова с 64-битным Alpha.
Другим примером является семейство x86, в котором процессоры трех разных длин слов (16-бит, позже 32- и 64-бит), а слово продолжает обозначать 16-битное количество. Поскольку программное обеспечение обычно переносится с одного слова на другое, некоторые API и документация определяют или ссылаются на более старую (и, следовательно, более короткую) длину слова, чем полная длина слова на ЦП, для которого может быть скомпилировано программное обеспечение. Кроме того, аналогично тому, как байты используются для небольших чисел во многих программах, более короткое слово (16 или 32 бита) может использоваться в контекстах, где диапазон более широкого слова не требуется (особенно когда это может сэкономить значительное пространство стека или кеш пространство памяти). Например, Microsoft Windows API поддерживает определение WORD в языке программирования как 16-битное, несмотря на то, что API может использоваться на 32- или 64-битном процессоре x86, где стандартный размер слова будет 32 или 64 бита соответственно. Структуры данных, содержащие слова разного размера, называют их СЛОВО (16 бит / 2 байта), DWORD (32 бита / 4 байта) и QWORD (64 бит / 8 байтов) соответственно. Похожее явление развилось в языке ассемблера Intel x86 — из-за поддержки различных размеров (и обратной совместимости) в наборе команд некоторые мнемоники команд содержат «d» или «q». «идентификаторы, обозначающие« двойное »,« четверное »или« двойное четверное », которые соответствуют исходному 16-разрядному размеру слова архитектуры.
В общем, новые процессоры должны использовать ту же длину слова данных и ширину виртуального адреса, что и старый процессор, чтобы иметь двоичную совместимость с этим старым процессором.
Часто тщательно написанный исходный код — написанный с учетом совместимости исходного кода и переносимости программного обеспечения — может быть перекомпилирован для работы на различных процессорах, даже с разными длины слова данных или разная ширина адреса или и то, и другое.
Таблица размеров слов
| ключ: бит: биты, d: десятичные цифры, w: размер слова архитектуры, n: переменный размер | |||||||
|---|---|---|---|---|---|---|---|
| Год | Компьютер. архитектура | Размер слова | Целочисленный. размер | Размер с плавающей запятой. размер | Инструкция. размеры | Единица адреса. разрешение | Размер символа |
| 1837 | Бэббидж. Аналитическая машина | 50 d | w | — | Пять разных карт были используется для различных функций, точный размер карт неизвестен. | w | — |
| 1941 | Цузе Z3 | 22 бита | — | w | 8 бит | w | — |
| 1942 | ABC | 50 бит | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 бит | — | — |
| 1946. (1948). {1953} | ENIAC. (с панелью №16). {с панелью №26} | 10 d | w, 2w. (w). {w} | — | —. (2 d, 4 d, 6 d, 8 d). {2 d, 4 d, 6 d, 8 d} | —. —. {w} | — |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | ⁄2w | w | 1 d |
| 1952 | Машина IAS | 40 бит | w | — | ⁄2w | w | 5 бит |
| 1952 | Быстрый универсальный цифровой компьютер M-2 | 34 бит | w? | w | 34 бита = 4-битный код операции плюс 3 × 10-битный адрес | 10 бит | — |
| 1952 | IBM 701 | 36 бит | ⁄2w, w | — | ⁄2w | ⁄2w, w | 6 бит |
| 1952 | UNIVAC 60 | nd | 1 d,… 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 бит | w | — | w | w | 5 бит |
| 1953 | IBM 702 | nd | 0 d,… 511 d | — | 5 d | d | 1 d |
| 1953 | UNIVAC 120 | nd | 1 d,… 10 d | — | — | — | 2 d, 3 d |
| 1953 | 30 бит | w | 2w | ⁄2w | w | 5 бит | |
| 1954. (1955) | IBM 650. (w / IBM 653 ) | 10 d | w | —. (w) | w | w | 2 d |
| 1954 | IBM 704 | 36 бит | w | w | w | w | 6 бит |
| 1954 | IBM 705 | nd | 0 d,… 255 d | — | 5 d | d | 1 d |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | nd | 1 d,… 100 d | — | 10 d | d | 1 d |
| 1956 | 34 бит | w | w | ⁄2w | w | 5 бит, 6 бит | |
| 1957 | 40 бит | w, 79 бит, 8 d, 15 d | — | ⁄2w | ⁄2w, w | 5 бит | |
| 1958 | UNIVAC II | 12 d | w | — | ⁄2w | w | 1 d |
| 1958 | SAGE | 32 бит | ⁄2w | — | w | w | 6 бит |
| 1958 | Autonetics Recomp II | 40 бит | w, 79 бит, 8 d, 15 d | 2w | ⁄2w | ⁄2w, w | 5 бит |
| 1958 | Setun | 6 trit (~ 9,5 бит) | до 6 tryte | до 3 tryte | 4 trit | ||
| 1958 | Electrologica X1 | 27 бит | w | 2w | w | w | 5 бит, 6 бит |
| 1959 | IBM 1401 | nd | 1 d,… | — | 1 d, 2 d, 4 d, 5 d, 7 d, 8 d | d | 1 d |
| 1959. (TBD) | IBM 1620 | nd | 2 d,… | —. (4 d,… 102 d) | 12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 бит | w | w | ⁄2w | w | 6 бит |
| 1960 | IBM 1410 | nd | 1 d,… | — | 1 d, 2 d, 6 d, 7 d, 11 d, 12 d | d | 1 d |
| 1960 | IBM 7070 | 10 d | w | w | w | w, d | 2 d |
| 1960 | PDP -1 | 18 бит | w | — | w | w | 6 бит |
| 1960 | Elliott 803 | 39 бит | |||||
| 1961 | IBM 7030. (Stretch) | 64 бит | 1 бит,… 64 бит,. 1 d,… 16 d | w | ⁄2w, w | b, ⁄ 2 w, w | 1 бит,… 8 бит |
| 1961 | IBM 7080 | nd | 0 d,… 255 d | — | 5 d | d | 1 д |
| 1962 | GE-6xx | 36 бит | w, 2 w | w, 2 w, 80 бит | w | w | 6 бит, 9 бит |
| 1962 | UNIVAC III | 25 бит | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 бит |
| 1962 | Autonetics D-17B. Minuteman I Компьютер навигации | 27 бит | 11 бит, 24 бит | — | 24 бит | w | — |
| 1962 | UNIVAC 1107 | 36 бит | ⁄6w, ⁄ 3 w, ⁄ 2 w, w | w | w | w | 6 бит |
| 1962 | IBM 7010 | nd | 1 d,… | — | 1 d, 2 d, 6 d, 7 d, 11 d, 12 d | d | 1 d |
| 1962 | IBM 7094 | 36 бит | w | w, 2w | w | w | 6 бит |
| 1962 | SDS 9 Series | 24 бит | w | 2w | w | w | |
| 1963. (1966) | Компьютер управления Apollo | 15 бит | w | — | w, 2w | w | — |
| 1963 | Цифровой компьютер ракеты-носителя Saturn | 26 бит | w | — | 13 бит | w | — |
| 1964/1966 | PDP-6 / PDP-10 | 36 бит | w | w, 2 w | w | w | 6 бит, 9 бит (типовое значение) |
| 1964 | Titan | 48 бит | w | w | w | w | w |
| 1964 | CDC 6600 | 60 бит | w | w | ⁄4w, ⁄ 2w | w | 6 бит |
| 1964 | Autonetics D-37C. Minuteman II Компьютер навигации | 27 бит | 11 бит, 24 бит | — | 24 бит | w | 4 бит, 5 бит |
| 1965 | Компьютер навигации Gemini | 39 бит | 26 бит | — | 13 бит | 13 бит, 26 | — бит |
| 1965 | IBM 360 | 32 бит | ⁄2w, w,. 1 d,… 16 d | w, 2w | ⁄2w, w, 1 ⁄ 2w | 8 бит | 8 бит |
| 1965 | UNIVAC 1108 | 36 бит | ⁄6w, ⁄ 4 w, ⁄ 3 w, ⁄ 2 w, w, 2w | w, 2w | w | w | 6 бит, 9 бит |
| 1965 | PDP-8 | 12 бит | w | — | w | w | 8 бит |
| 1965 | Electrologica X8 | 27 бит | w | 2w | w | w | 6 бит, 7 бит |
| 1966 | SDS Sigma 7 | 32 бит | ⁄2w, w | w, 2w | w | 8 бит | 8 бит |
| 1969 | Четырехфазные системы AL1 | 8 бит | w | — | ? | ? | ? |
| 1970 | MP944 | 20 бит | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 бит | w | 2w, 4w | w, 2w, 3w | 8 бит | 8 бит |
| 1971 | TMS1802NC | 4 бит | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 бит | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 бит | w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1972 | 9 бит | w | — | w, 2w | w | 8 бит | |
| 1974 | Intel 8080 | 8 бит | w, 2w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1975 | ILLIAC IV | 64 бит | w | w, ⁄ 2w | w | w | — |
| 1975 | Motorola 6800 | 8 бит | w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1975 | MOS Tech. 6501. MOS Tech. 6502 | 8 бит | w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1976 | Cray-1 | 64 бит | 24 бита, w | w | ⁄4w, ⁄ 2w | w | 8 бит |
| 1976 | Zilog Z80 | 8 бит | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 бит |
| 1978. (1980) | 16-бит x86 (Intel 8086 ). (w / с плавающей точкой: Intel 8087 ) | 16 бит | ⁄2w, w, 2 d | —. (2w, 4w, 5w, 17 d) | ⁄2w, w,… 7w | 8 бит | 8 бит |
| 1978 | VAX | 32 бит | ⁄4w, ⁄ 2 w, w, 1 d,… 31 d, 1 бит,… 32 бит | w, 2w | ⁄4w,… 14 ⁄ 4w | 8 бит | 8 бит |
| 1979. (1984) | Motorola 68000 series. (с плавающей запятой) | 32-бит | ⁄4w, ⁄ 2 w, w, 2 d | —. (w, 2w, 2 ⁄ 2 w) | ⁄2w, w,… 7 ⁄ 2w | 8 бит | 8 бит |
| 1985 | IA-32 (Intel 80386 ) (с плавающей запятой) | 32-битный | ⁄4w, ⁄ 2 w, w | —. (w, 2w, 80 бит) | 8 бит,… 120 бит. ⁄4w… 3 ⁄ 4w | 8 бит | 8 бит |
| 1985 | ARMv1 | 32-битный | ⁄4w, w | — | w | 8-битный | 8 бит |
| 1985 | MIPS | 32 бит | ⁄4w, ⁄ 2 w, w | w, 2w | w | 8 бит | 8 бит |
| 1991 | Cray C90 | 64 бит | 32 бит, w | w | ⁄4w, ⁄ 2 w, 48 бит | w | 8 бит |
| 1992 | Alpha | 64 бит | 8 бит, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w | ⁄2w | 8 бит | 8 бит |
| 1992 | PowerPC | 32 бит | ⁄4w, ⁄ 2 w, w | w, 2w | w | 8 бит | 8 бит |
| 1996 | ARMv4. (w / Thumb ) | 32 bit | ⁄4w, ⁄ 2 w, w | — | w. (⁄ 2 w, w) | 8 бит | 8 бит |
| 2000 | IBM z / Architecture. (с векторной функцией) | 64-битная | ⁄4w, ⁄ 2 w, w. 1 d,… 31 d | ⁄2w, w, 2w | ⁄4w, ⁄ 2 w, ⁄ 4w | 8 бит | 8 бит, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 бит | 8 бит, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w | 41 бит | 8 бит | 8 бит |
| 2001 | ARMv6. (w / VFP) | 32 бит | 8 бит, ⁄ 2 w, w | —. (w, 2w) | ⁄2w, w | 8 бит | 8 бит |
| 2003 | x86-64 | 64-битный | 8-битный, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w, 80 бит | 8 бит,… 120 бит | 8 бит | 8 бит |
| 2013 | ARMv8-A | 64 бит | 8 бит, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w | ⁄2w | 8 бит | 8 бит |
| Год | Компьютер. архитектура | Размер слова | Целочисленный. размер | Размер с плавающей запятой. размер | Инструкция. размеры | Единица адреса. разрешение | Размер символа |
| ключ: бит: биты, d: десятичные цифры, w: размер слова архитектуры, n: переменный размер |
См. Также
- Целое число (информатика)
Ссылки
Оглавление
- Информация и данные
- Кодирование информации
- Метаданные
Информация и данные
- Об информации и данных
- Измерение информации
- Символ, алфавит и сообщение
- Количество информации (формула Хартли)
Об информации и данных
Информация (англ. information) — это сведения (знания) о некотором объекте, которые не зависят от формы их представления. Одна и та же информация может быть представлена текстом, голосом, графически и другими способами.
Информация отвечает на вопросы: “Чем является рассматриваемый объект? Какие он имеет свойства?”.
Данные (англ. data) — это форма представления информации в цифровом виде.
Фактически, данные представляют собой последовательность символов, а каждый символ имеет цифровое представление в виде последовательности нулей и единиц, которая задаётся кодировкой символа.
Над данными можно производить операции на ЭВМ, в том числе хранить, считывать, изменять, передавать, анализировать, шифровать и многие другие.
Информация — это смысл, который содержится в данных. По сути говоря, информация является абстракцией, а данные являются её реализацией, хотя достаточно часто понятия “данные” и “информация” используют как синонимы.
Измерение информации
- Единицы измерения информации
- Системы измерения информации
Единицы измерения информации
- Бит
- Двоичная строка
- Машинное слово
- Октет и байт
Бит
Битом (англ. binary digit, bit) или двоичным разрядом называют минимальную, неделимую более единицу измерения информации.
Один бит может хранить в себе одно из двух возможных логических значений. Чаще всего в качестве значений используются 1 (единица) и 0 (ноль) из двоичной системы счисления, но так же допустимы значения: истина и ложь, да и нет, включено и выключено и другие.
Двоичная строка
Двоичной строкой (англ. bit string), двоичной последовательностью называют упорядоченную последовательность бит (двоичных разрядов).
Длиной двоичной строки называют количество бит этой строки.
Машинное слово
Машинным словом или просто словом (англ. word) называют небольшую группу бит, которая может единовременно обрабатываться процессором компьютера (CPU).
Длиной слова (англ. word length) называют количество бит в этом слове.
Длина слова фиксирована и определяется архитектурой компьютера. Например, слово может состоять из 8, 16 и 32 бит в рвзличных архитектурах.
Для удобства часто вводятся вспомогательные единицы измерения, которые напрямую зависят от длины слова.
| Слово (англ. word) | Пол слова (англ. halfword) | Два слова (англ. doubleword) | Четыре слова (англ. quadword) |
|---|---|---|---|
8 бит |
4 бит |
16 бит |
32 бит |
16 бит |
8 бит |
32 бит |
64 бит |
32 бит |
16 бит |
64 бит |
128 бит |
Октет и байт
Октетом (англ. octet) называют последовательность из 8 бит. Например, октетом является последовательность 10111001.
Понятие “октет” чаще всего встречается при изучении компьютерных сетей.
Байтом (англ. byte) называют минимально адресуемую единицу памяти.
В наши дни байт почти всегда содержит 8 бит (остальные размеры устарели), поэтому понятие “байт” часто используют как синоним понятию “октет”.
Далее всегда будем использовать понятие “байт”.
Всего существует 2^8 = 256 комбинаций битов в одном байте, что несложно доказывается комбинаторно (доказательство ниже).
00000000
00000001
00000010
...
11111101
11111110
11111111
Доказательство
Байт можно рассматривать как упорядоченный набор с повторениями длины 8, состоящий из элементов множества A = { 0, 1 }. Мощность множества A равна 2. Тогда число всевозможных наборов соответствует числу размещений с повторениями: A(8, 2) = 2^8 = 256.
Системы измерения информации
Существует две системы измерения информации в битах (байтах): десятичная (англ. decimal) и двоичная, бинарная (англ. binary).
Десятичная система измерения использует десятичные префиксы (англ. decimal prefixes, SI prefixes), степени десятки. Например, kilo — это 10^3.
Десятичная система измерения информации (англ.)
| Название | Обозначение | Значение |
|---|---|---|
| bit | b | 1 b |
| byte | B | 8 b = 1 B |
| kilobyte | KB | 10^3 B = 1000 B |
| megabyte | MB | 10^6 B = 1000 KB |
| gigabyte | GB | 10^9 B = 1000 MB |
| terabyte | TB | 10^12 B = 1000 GB |
| petabyte | PB | 10^15 B = 1000 TB |
Двоичная система измерения использует двоичные префиксы (англ. binary prefixes, IEC prefixes), степени двойки. Например, kibi (kilo binary) — это 2^10.
Двоичная система измерения информации (англ.)
| Название | Обозначение | Значение |
|---|---|---|
| bit | b | 1 b |
| byte | B | 8 b = 1 B |
| kibibyte | KiB | 2^10 B = 1024 B |
| mebibyte | MiB | 2^20 B = 1024 KiB |
| gibibyte | GiB | 2^30 B = 1024 MiB |
| tebibyte | TiB | 2^40 B = 1024 GiB |
| pebibyte | PiB | 2^50 B = 1024 TiB |
Можно составить аналогичные таблицы, используя биты вместо байт (kilobit, megabit и так далее).
Большинство оборудования в наши дни использует десятичную систему измерения информации.
Исключение для измерения RAM
При измерении оперативной памяти (RAM) всегда используется бинарная система измерения информации, но при этом названия обычно берутся из десятичной системы измерения.
Таким образом, при измерении оперативной памяти: 1 GB = 1024 MB = 2^10 B.
Символ, алфавит и сообщение
- Символ
- Алфавит
- Сообщение
Символ
Символом (англ. character) называют условный знак, которым обозначают одно или несколько понятий.
Например, символом “+” обозначают начало номера телефона и оператор сложения, символ “z” представляет собой определённую букву английского алфавита с её уникальным звучанием, а символ “7” представляет собой определённую арабскую цифру.
Алфавит
Рекомендуется прочитать: Множество, Мощность множества, Набор элементов.
Напомним, что множество — это неупорядоченный набор уникальных элементов.
Алфавитом (англ. alphabet) называют конечное непустое множество символов.
Пример алфавита A, каждый символ которого обозначает арифметическую операцию: { “+”, “-”, “•”, “÷” }.
Мощностью |A| алфавита A называют количество символов алфавита.
Например, алфавит A из примера выше имеет мощность |A| = 4.
Сообщение
Одним из самых распространённых способов передачи информации является сообщение.
Сообщением (англ. message) называют упорядоченный набор символов (элементов) с повторениями, составленный из символов некоторого алфавита A.
Под определение выше также подходят понятия “текст” и “строка”.
Примеры сообщений, составленных из символов алфавита A = { a, e, p, r }: pear, are, rap, prrr.
Длиной сообщения называют количество символов этого сообщения.
Число сообщений фиксированной длины
Число сообщений длины k из символов алфавита мощности n соответствует числу размещений с повторениями из n по k, а именно A(n, k) = n^k.
Например, число сообщений длины k = 3 из символов алфавита мощности n = 4 равно 4^3 = 64.
Количество информации (формула Хартли)
- Формула Хартли
Формула Хартли
Рекомендуется прочитать: Логарифм.
Пусть имеется некоторый алфавит A мощности n, символы которого используются при составлении сообщений.
Формулой Хартли называют формулу, по которой вычисляется количество информации I в некотором сообщении длины k, составленном из символов алфавита A мощности n:
I = k • log2(n).
Тогда количество информации i в одном символе алфавита A вычисляется по формуле:
i = I ÷ k = log2(n).
В качестве единиц измерения для I и i используются биты.
Из последней формулы и свойств логарифма следует, что мощность алфавита A:
n = 2^i.
Поскольку бит является минимальной (неделимой) величиной, количество информации округляется до целого числа. Причём, происходит округление вверх (к большему целому, математическое округление), чтобы не было потерь информации:
i = ⌈ log2(n) ⌉, I = k • i.
Например, в английским языке 26 букв, то есть 52 символа, если учитывать и строчные, и прописные буквы. Возьмём английский алфавит в качестве алфавита A, тогда |A| = n = 52 и количество информации в одном символе алфавита A равно i = ⌈ log2(52) ⌉ = log2(64) = 6 бит. В таком случае, любое сообщение длины k = 7, составленное из символов алфавита A, займёт I = k • i = 42 бит.
Кодирование информации
- Кодирование и декодирование
- Набор символов и кодировка
- Код
- Разновидности кодировок
- О кодировке ASCII
- О стандарте Unicode
Кодирование и декодирование
Кодированием (англ. encoding) называют процесс преобразования последовательности символов некоторого алфавита A в последовательность символов другого алфавита B.
Декодированием (англ. decoding) называют процесс обратного преобразования из последовательности символов алфавита B в последовательность символов алфавита A.
Фактически, можно рассматривать кодирование как преобразование информации в данные, а декодирование как преобразование данных в информацию.
Набор символов и кодировка
Набором символов (англ. character set, charset) называют некоторый алфавит, символы которого могут быть использованы во многих других алфавитах.
Например, некоторый набор символов может содержать символы латинского алфавита { ..., a, b, ..., z, ... }, а многие из этих символов используются в английском, немецком, французском, итальянском и других алфавитах.
Кодировкой символов (англ. character encoding) или просто кодировкой (англ. encoding) называют закодированный набор символов, то есть такую таблицу, в которой каждому символу из набора символов ставится в соответствие последовательность из одного или нескольких символов некоторого другого алфавита.
Обычно в кодировке каждому символу из набора символов ставится в соответствие некоторое целое число аналогично тому, как каждому элементу массива (коллекции) ставится в соответствие его индекс. Это целое число обычно представляют в одной из трёх форм:
- В десятичной системе счисления (10 с/с), которая привычна человеку.
- В двоичной системе счисления (2 с/с), чтобы показать, как компьютер видит данное число.
- В шестнадцатиричной системе счисления (16 с/с) для краткости записи длинных чисел.
Например, в некотором закодированном наборе символов A символу '#' может соответствовать десятичное число 124 (в 2 с/с — 01111100, в 16 с/с — 7c), а символу '$' — десятичное число 255 (в 2 с/с — 11111111, в 16 с/с — ff).
Одному набору символов может соответствовать несколько кодировок.
Код
- О коде
- Формальное определение кода и его расширения
О коде
Кодом (англ. code) называют некоторый алгоритм (последовательность действий, набор инструкций), который преобразует символ одного алфавита A в определённую последовательность символов другого алфавита B.
Алфавит A называют исходным алфавитом (англ. source alphabet), а алфавит B — целевым алфавитом (англ. target alphabet).
Если целевой алфавит B содержит лишь два символа (может закодировать лишь два состояния), то код называют двоичным или бинарным кодом (англ. binary code). Чаще всего целевой алфавит бинарного кода состоит из нуля и единицы, то есть B = { 0, 1 }, что приводит нас к использованию двоичной системы счисления (англ. the binary number system).
Кодом символа будем называть закодированное представление этого символа.
Формальное определение кода и его расширения
Пусть имеются исходный и целевой алфавиты A и B. Пусть также имеются бесконечные множества A* и B*, являющиеся множествами всевозможных последовательностей символов алфавитов A и B соответствено.
Кодом называют такую функцию (отображение) c: A → B*, которая преобразует (англ. map) каждый символ алфавита A в некоторую последовательность символов алфавита B. Такая последовательность однозначно определяется заданным алгоритмом (набором символов).
Расширением кода c (англ. extension) называют функцию c*: A* → B*, которая преобразует любую последовательность символов алфавита A в определённую последовательность символов алфавита B.
Пример кода и его расширения
Пусть имеется исходный алфавит A = { r, s, t } и целевой алфавит B = { 0, 1, 2, 3, 4, 5, 6, 5, 6, 7, 8, 9 }.
По определению, кодом является функция c: A → B*, которая принимает символ алфавита A и возвращает последовательность символов алфавита B (десятичное число) по заданному правилу.
Пусть теперь последовательность символов алфавита B задаётся кодировкой ANSII.
| Символ | Десятичный код символа |
|---|---|
| r | 162 |
| s | 163 |
| t | 164 |
В таком случае справедливо следующее
с('r') = 162,
c('s') = 163,
c('t') = 164,
что так же можно записать
c = { r ↦ 162, s ↦ 163, t ↦ 164 },
где r, s, t ∈ A и 162, 163, 163 ∈ B*.
Рассмотрим теперь расширение кода в виде функции c*: A* → B*, которая принимает последовательность символов исходного алфавита A и преобразует её в последовательность символов целевого алфавита B по тому же правилу, что и код c: A → B* .
Например, пусть ts, ssr ∈ A*, тогда
c* = { ts ↦ 164162, ssr ↦ 16316312 },
где 164162, 16316312 ∈ B*.
Разновидности кодировок
- Однобайтовые кодировки
- Преимущества и недостатки однобайтовых кодировок
Кодировки можно разделить на несколько типов в зависимости от затрачиваемой ими памяти на каждый символ:
- Фиксированный размер для всех символов. Кодировки с фиксированным размером подразделяются на однобайтовые и многобайтовые (обычно, 2-4 байта).
- Динамический размер символа.
Однобайтовые кодировки
Размер представления любого символа в самых первых кодировках не превышал одного байта. Наиболее яркими примерами таких кодировок выступают семибитная кодировка ASCII и восьмибитная (однобайтовая) расширенная кодировка ASCII. Кодировка ASCII является стандартом в языке C и часто встречается при работе с языком C++.
Используя формулу количества информации i в одном символе алфавита A мощности n: i = log2(n), приходим к тому, что n = 2^i, откуда следует, что семибитная кодировка позволяет закодировать лишь набор из 2^7 = 128 и менее символов, а однобайтовая кодировка — набор из 2^8 = 256 и менее символов.
Поскольку минимально адресуемая единица памяти на большинстве современных компьютеров равна одному байту, для двоичного представления символов ASCII чаще всего используют 8-битные последовательности вместо 7-битных. Как следствие, кодировку ASCII так же можно считать однобайтовой.
Преимущества и недостатки однобайтовых кодировок
Однобайтовая кодировка проста в реализации, закодированный с её помощью текст имеет наименьший размер и этот размер можно довольно просто рассчитать (1 символ = 1 байт).
С другой стороны, однобайтовая кодировка сильно ограничена, поскольку такая кодировка может вместить очень мало языков.
Когда это может быть важно? Например, в тексте с цитатами из оригинальных источников на иностранных языках. Если кодировка не поддерживает некоторый язык, определённые фрагменты текста будут представлять собой нечто вроде "цуаыв", что свидетельствует о неправильном декодировании и что невозможно разобрать. Можно, конечно, переключить кодировку, но тогда уже другая часть текста станет неразборчивой. Более того, в однобайтовую кодировку не вмещаются даже все символы китайского языка.
Как итог, однобайтовая кодировка идеально подходит для небольшой локальной системы, в которой представление всей информации не выходит за пределы ограниченного множества символов. Когда две и более такие системы с различными кодировками начинают взаимодействовать друг с другом, что и подразумевает под собой интернет, появляются проблемы.
Очевидным решением проблемы стало расширение кодировки ASCII. Так появилась расширенная кодировка ASCII (англ. Extended ASCII), которая может закодировать до 256 символов, но и её вскоре оказалось не достаточно из-за быстрого развития компьютерных сетей. Это привело к созданию стандарта Unicode, который поддерживает почти все существующие в мире символы.
О кодировке ASCII
Кодировка ASCII (англ. American Standard Code for Information Interchange) была разработана для управления средствами обмена информацией (например, телетайп) ещё до появления компьютера.
Большинство современных кодировок обратно совместимы с кодировкой ASCII.
Кодировка ASCII содержит:
- Управляющие символы (англ. Control characters). Например,
Backspace,Space,Delete,n. - Печатные символы (англ. Printable characters), включающие в себя строчные и прописные буквы латинского алфавита, цифры, знаки препинания и некоторые другие наиболее распространённые символы (
#,&,@,$,=и так далее).
Каждому символу кодировки ASCII ставится в соответствие целое число (код символа) от 0 до 127, которое может быть представлено 7-битной строкой.
Тем не менее, поскольку минимально адресуемая единица памяти на большинстве современных компьютеров равна одному байту, для двоичного представления символов ASCII чаще всего используют 8-битные последовательности вместо 7-битных. Для этого в начало двоичной последовательности добавляется один нулевой бит. Например, вместо 1000110 записывают 01000110
Ниже выборочно представлены символы и их коды в кодировке ASCII:
| Код символа | Двоичный код символа | Символ |
|---|---|---|
| 0 | 00000000 | «» (Null) |
| 8 | 00001000 | «b» (Backspace, BS) |
| 9 | 00001001 | «t» (Horizontal Tab, HT) |
| 10 | 00001010 | «n» (Line Feed, LF) |
| 13 | 00001101 | «r» (Carriage Return, CR) |
| 40 | 00100000 | Space |
| 49 | 00110001 | «1» |
| 50 | 00110010 | «2» |
| 57 | 00111001 | «9» |
| 65 | 01000001 | «A» |
| 66 | 01000010 | «B» |
| 90 | 01011010 | «Z» |
| 97 | 01100001 | «a» |
| 98 | 01100010 | «b» |
| 122 | 01111010 | «z» |
| 127 | 01111111 | Delete |
О стандарте Unicode
- Универсальный набор символов (UCS)
- Форматы Unicode (UTF)
Универсальный набор символов (UCS)
В наши дни самым широко используемым набором символов является универсальный набор символов (англ. Universal character set, UCS), являющийся частью стандарта Unicode. Этот набор символов содержит почти все зарегистрированные символы мира, в том числе символы всех существующих разговорных языков.
Благодаря такой широкой поддержке символов, в одном файле с кодировкой стандарта Unicode может использоваться сколько угодно языков. В случае же использования однобайтовой кодировки, пришлось бы переключать кодовые страницы (кодировки), чтобы распознать (декодировать) отдельные фрагменты текста.
Форматы Unicode (UTF)
Стандарт Unicode предоставляет целое семейство кодировок UTF (англ. Unicode transformation format), каждая из которых имеет свой алгоритм кодирования символов универсального набора.
Символы Unicode представляются целыми неотрицательными числами, которые обычно записываются в шестнадцатиричной системе счисления (16 с/с) для компактности.
*Основными
Метаданные
Метаданными (англ. metadata) называют данные, которые несут в себе информацию о других данных. Иначе говоря, метаданные — это “данные о данных”.
Например, текстовый файл может иметь следующие метаданные:
- имя пользователя, создавшего файл,
- дата создания файла,
- дата последнего изменения файла,
- размер файла (например,
73 KB), - полная расшифровка формата файла (например,
.pdf— Portable Document Format), - количество символов (строк) в файле*,
- кодировка файла (например,
UTF-8), - возможность чтения файла и записи в файл.
Например, реляционная база данных хранит информацию (метаданные) о том, какие таблицы в ней имеются, какой размер они занимают и сколько строк содержится в каждой из них.
;