
Here’s a solution that achieves your stated objective. See it live here.
It makes use of std::map to maintain a count of the number of times that a (category, word) pair occurs.
std::istringstream is used to break the data first into rows, and then into words.
OUTPUT:
(colors, black) => 1
(colors, blue) => 4
(colors, brown) => 1
(colors, green) => 1
(colors, orange) => 1
(colors, purple) => 1
(colors, red) => 1
(colors, white) => 1
(colors, yellow) => 1
(ocean, aquatic) => 1
(ocean, blue) => 1
(ocean, water) => 1
(ocean, wet) => 1
(sky, air) => 1
(sky, big) => 1
(sky, blue) => 1
(sky, clouds) => 1
(sky, empty) => 1
(sky, high) => 1
(sky, vast) => 1
PROGRAM:
#include <iostream> // std::cout, std::endl
#include <map> // std::map
#include <sstream> // std::istringstream
#include <utility> // std::pair
int main()
{
// The data.
std::string content =
"colors red blue green yellow orange purplen"
"sky blue high clouds air empty vast bign"
"ocean wet water aquatic bluen"
"colors brown black blue white blue bluen";
// Load the data into an in-memory table.
std::istringstream table(content);
std::string row;
std::string category;
std::string word;
const char delim = ' ';
std::map<pair<std::string, std::string>, long> category_map;
std::pair<std::string, std::string> cw_pair;
long count;
// Read each row from the in-memory table.
while (!table.eof())
{
// Get a row of data.
getline(table, row);
// Allow the row to be read word-by-word.
std::istringstream words(row);
// Get the first word in the row; it is the category.
getline(words, category, delim);
// Get the remaining words in the row.
while (std::getline(words, word, delim)) {
cw_pair = std::make_pair(category, word);
// Maintain a count of each time a (category, word) pair occurs.
if (category_map.count(cw_pair) > 0) {
category_map[cw_pair] += 1;
} else {
category_map[cw_pair] = 1;
}
}
}
// Print out each unique (category, word) pair and
// the number of times that it occurs.
std::map<pair<std::string, std::string>, long>::iterator it;
for (it = category_map.begin(); it != category_map.end(); ++it) {
cw_pair = it->first;
category = cw_pair.first;
word = cw_pair.second;
count = it->second;
std::cout << "(" << category << ", " << word << ") => "
<< count << std::endl;
}
}
Repetition of data can diminish the worth of the content. Working as a writer, you must follow DRY (don’t repeat yourself) principle. The statistics such as word count or the number of occurrences of each word can let you analyze the content but it’s hard to do it manually for multiple documents. So in this article, I’ll demonstrate how to programmatically count words and the number of occurrences of each word in PDF, Word, Excel, PowerPoint, Ebook, Markup, and Email document formats using C#. For extracting text from documents, I’ll be using GroupDocs.Parser for .NET which is a powerful document parsing API.
Steps to count words and their occurrences in C
1. Create a new project.
2. Install GroupDocs.Parser for .NET using NuGet Package Manager.
3. Add the following namespaces.
using GroupDocs.Parser;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
Enter fullscreen mode
Exit fullscreen mode
4. Create an instance of the Parser class and load the document.
using (Parser parser = new Parser("sample.pdf"))
{
// your code goes here.
}
Enter fullscreen mode
Exit fullscreen mode
5. Extract the text from the document into a TextReader object using Parser.GetText() method.
using (TextReader reader = parser.GetText())
{
}
Enter fullscreen mode
Exit fullscreen mode
6. Split up the text into words, save them into a string array and perform word count.
Dictionary<string, int> stats = new Dictionary<string, int>();
string text = reader.ReadToEnd();
char[] chars = { ' ', '.', ',', ';', ':', '?', 'n', 'r' };
// split words
string[] words = text.Split(chars);
int minWordLength = 2;// to count words having more than 2 characters
// iterate over the word collection to count occurrences
foreach (string word in words)
{
string w = word.Trim().ToLower();
if (w.Length > minWordLength)
{
if (!stats.ContainsKey(w))
{
// add new word to collection
stats.Add(w, 1);
}
else
{
// update word occurrence count
stats[w] += 1;
}
}
}
Enter fullscreen mode
Exit fullscreen mode
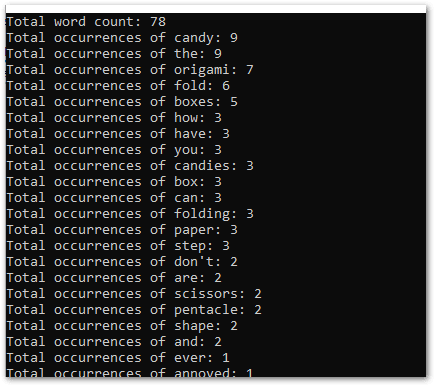
7. Order the words by their occurrence count and display the results.
// order the list by word count
var orderedStats = stats.OrderByDescending(x => x.Value);
// print total word count
Console.WriteLine("Total word count: {0}", stats.Count);
// print occurrence of each word
foreach (var pair in orderedStats)
{
Console.WriteLine("Total occurrences of {0}: {1}", pair.Key, pair.Value);
}
Enter fullscreen mode
Exit fullscreen mode
Complete Code
using (Parser parser = new Parser("sample.pdf"))
{
// Extract a text into the reader
using (TextReader reader = parser.GetText())
{
Dictionary<string, int> stats = new Dictionary<string, int>();
string text = reader.ReadToEnd();
char[] chars = { ' ', '.', ',', ';', ':', '?', 'n', 'r' };
// split words
string[] words = text.Split(chars);
int minWordLength = 2;// to count words having more than 2 characters
// iterate over the word collection to count occurrences
foreach (string word in words)
{
string w = word.Trim().ToLower();
if (w.Length > minWordLength)
{
if (!stats.ContainsKey(w))
{
// add new word to collection
stats.Add(w, 1);
}
else
{
// update word occurrence count
stats[w] += 1;
}
}
}
// order the collection by word count
var orderedStats = stats.OrderByDescending(x => x.Value);
// print total word count
Console.WriteLine("Total word count: {0}", stats.Count);
// print occurrence of each word
foreach (var pair in orderedStats)
{
Console.WriteLine("Total occurrences of {0}: {1}", pair.Key, pair.Value);
}
}
}
Enter fullscreen mode
Exit fullscreen mode
Results
Home »
C programs »
C string programs
In this program, we will learn how to count length of each word in a string in C language?
There are many string manipulation programs and string user defined functions, this is an another program in which we will learn to count the length of each word in given string.
In this exercise (C program) we will read a string, like «Hi there how are you?» and it will print the word length of each word like 2, 5, 3, 3, 4.
Input
Hi there how are you?Output
2, 5, 3, 3, 4
Program to count length of each word in a string in C
#include <stdio.h> #define MAX_WORDS 10 int main() { char text[100]={0}; // to store string int cnt[MAX_WORDS]={0}; //to store length of the words int len=0,i=0,j=0; //read string printf("Enter a string: "); scanf("%[^n]s",text); //to read string with spaces while(1) { if(text[i]==' ' || text[i]=='') { //check NULL if(text[i]=='') { if(len>0) { cnt[j++]=len; len=0; } break; //terminate the loop } cnt[j++]=len; len=0; } else { len++; } i++; } printf("Words length:n"); for(i=0;i<j;i++) { printf("%d, ",cnt[i]); } printf("bb n"); //to remove last comma return 0; }
Output
Enter a string: Hi there how are you? Words length: 2, 5, 3, 3, 4
C String Programs »
Yes this can be simplified to:
int main()
{
std::ifstream inputFile("Bob");
std::unordered_map<std::string, int> count;
std::for_each(std::istream_iterator<std::string>(inputFile),
std::istream_iterator<std::string>(),
[&count](std::string const& word){++count[word];});
}
Why this works:
operator>>
When you read a string from a stream with operator>> it read a space separated word. Try it.
int main()
{
std::string line;
std::cin >> line;
std::cout << line << "n";
}
If you run that and type a line of text. It will only print out the first space separated word.
std::istream_iterator
The standard provides an iterator for streams. std::istream_iterator<X> will read an object of type X from the stream using operator>>.
This allows you to use streams just like you would any other container when using standard algorithms. The standard algorithms take two iterators to represent a container (begin and end or potentially any two points in the container).
So by using std::istream_iterator<std::string> you can treat a stream like a container of space separated words and use it in an algorithm.
int main()
{
std::string line;
std::istream_iterator<std::string> iterator(std::cin);
line = *iterator; // de-reference the iterator.
// Which reads the stream with operator >>
std::cout << line << "n";
}
std::for_each
I use std::for_each above because it is trivial to use. But with a tiny bit of work you can use the range based for loop introduced in C++11 (as this just calls std::begin, std::end on the object to get the bounds of the loop.
But lets look at std::for_each first.
std::for_each(begin, end, action);
Basically it loops from begin to end and performs action on the result of de-referencing the iterator.
// In my case action was a lambda
[&count](std::string const& word){++count[word];}
It captures count from the current context to be used in the funtion. And de-referencing the std::istream_iterator<std::string> returns a reference to a std::string object. So we can not use that to increment the count for each word.
Note: count is std::unordered_map so be looking up a value it will automatically insert it if it does not already exist (using default value (for int that is zero). Then increment that value in the map.
Range based for
A quick search to use range based for with std::istream_iterator gives me this:
template <typename T>
struct irange
{
irange(std::istream& in): d_in(in) {}
std::istream& d_in;
};
template <typename T>
std::istream_iterator<T> begin(irange<T> r) {
return std::istream_iterator<T>(r.d_in);
}
template <typename T>
std::istream_iterator<T> end(irange<T>) {
return std::istream_iterator<T>();
}
int main()
{
std::ifstream inputFile("Bob");
std::unordered_map<std::string, int> count;
std::for(auto const& word : irange<std::string>(inputFle)) {
++count[word];
}
}
Issues with this technique.
We use space to separate words. So any punctuation is going to screw things up. Not to worry. C++ allows you to define what is a space in any given context. So we just need to tell the stream what is a space.
https://stackoverflow.com/a/6154217/14065
Review of code
Sure.
struct StringOccurrence //stores word and number of occurrences
{
std::string m_str;
unsigned int m_count;
StringOccurrence(const char* str, unsigned int count) : m_str(str), m_count(count) {};
};
But you can do this with a number of standard types.
typedef std::pair<std::string, unsigned int> StringOccurrence;
You are doing this to store the value in a vector. But a better way to store this is in a map. Because maps are ordered in some way internally lookup is a lot faster. std::map gives access in O(ln(n)) or std::unordered_map gives access in O(1).
I hate bad comments.
Bad comments are worse than no comments because they need to be maintained and the compiler will not help you maintain them.
if (!in) //check if file path is valid
Not quite, but close enough I suppose. But I don’t really need the comment to tell me that. The code seems pretty self explanatory.
Note sure if -1 is a good value. It will really depend on the OS you are running on. 0 is the only valid value. Anything else is considered an error. At your OS level this will probably be truncated to 255 on most systems (but not all).
return -1;
If you run this:
> cat xrt.cpp
int main()
{
return -1;
}
> g++ xrt.cpp
> ./a.out
> echo $? # Echos the error code of the last command.
255
I don’t think you need to copy the whole thing into memory.
std::vector<std::string>vec;
std::string lineBuff;
while (std::getline(in, lineBuff)) // write multiline text to vector of strings
{
vec.push_back(lineBuff);
}
Just read a line at a time and processes that.
Don’t use pointers in C++
std::vector<StringOccurrence*> strOc;
C++ has much better ways to handle dynamic memory allocation and pointers is never the way to go.
When you iterate from begin -> end of something. You can use the new range based for instead.
for (auto it = vec.begin(); it < vec.end(); it++)
// easier to write and read:
for(auto const& val : vec)
Going to comment on your comments again.
for (auto it = vec.begin(); it < vec.end(); it++) //itterate through each line
Not very useful. I can see that you are iterating over every line. From the code.
You should restrict your comments to WHY you are doing something.
Space ' ' is not the only white space character! What about tab or carrige return r or vertical tab v. You should test for space using standard library routines.
std::is_space(c)
I have use goto probably twice in the last ten years. One of those times was probably wrong.
goto end; //skip next step (need fix?)
Loops and conditions will always be better and easier to read.
We have a leak her:
strOc.push_back(new StringOccurrence(stringBuff.c_str(), 1));
I see a new (but no delete). See above about using pointers. There is no need to use a pointer here. Just use a normal object it will be moved into the vector.
We’re going to write our first nontrivial program.
Posted 15 January 2020 at 1:26 PM
This is the sixteenth article in the Making Sense of C series.
In this article, we’re going to write a basic word counter, our first goal in
programming in C.
I’ll be going through the code in excruciating detail to make sure that at no
point anything feels uncovered, meaning this is going to be a long article.
Everything We’ve Introduced
We had to set up a lot of features in C to get to this point, but we’re
finally here.
Up to this point, we’ve
- determined that we’re going to give the compiler a file with a bunch of
statements ending in semicolons, - established that we can use comments with
//for single line comments and/*
and*/for multiline comments, - reserved the symbols
+-*/%for arithmetic, - set up variables
[type] [variable] = [expression]which will allow us to store
values for later use, - come up with the integral types (
char,short,int, andlong long) and
the floating point types (floatanddouble), - figured out a way to represent characters using the
chartype and invented the
NULLcharacter, which indicates that we’re ending a string, - and decided to use single quotes around a character to represent the ASCII value
for thatchar. - explained how the program uses memory addresses to identify variables,
- came up with a way to access the memory address of a variable using the
address of operator (&), - came up with a way to access the value stored at a memory address using the
dereference operator (*), - created pointer variables to allow us to store memory addresses using the
syntaxtype * variable_name;, - came up with a way to tell the computer to get us a block of memory (a.k.a. an
array or buffer) using the syntaxtype,
array[num_elements]; - came up with a way to initialize an array with an initializer list,
- came up with a way to initialize a
chararray using double quotes,
("Hello!"), - came up with a way to access elements of an array using the syntax
variable_name[offset], - introduced a way to compare two values using the relational operators
(<,>,<=,>=,==,!=), - introduced ways to combine or invert Boolean statements using the logical
operators (&&,||, and!), - reserved the
ifandelsekeywords so that our program can act differently
if given different inputs (a.k.a. conditional branches), - added
whileanddo whileloops for unindexed looping, - added
forloops for indexed looping, - introduced functions to help break our code into more maintainable chunks and to
prevent us from typing the same thing repeatedly, - designated the
mainfunction as the entry point for our program and a way to
take in user input, - introduced the symbol table, which helps the compiler recognize valid code,
- set up function declarations, which allow us to add functions to the symbol
table, - introduced the preprocessor, which can generate code for us during compilation
without modifying the original source file, - added the
#includemacro and the concept of header files, which contain
function declarations and other stuff that we’ll learn about later that allow us
to automate some of the process of addings things to the symbol table, - introduced
stdio.h, which will allow us to do file I/O, - created the
FILEtype, which will allow us to interact with files, - created
fopen, which will allow us to create afileobject from a filename
and a mode, - reserved the keyword
const, which tells the compiler we will not modify
something and allows us to use certain things like string literals, - created
fclose, which will allow us to clean up afileobject, - set up our compiler and IDE so that we can modify and compile
Cprograms, - introduced
stdinfor user input,stdoutfor terminal output, andstderr
for error output, - created
fgetsto get a line from a file, - created
printfto print to the terminal, - created
fprintfto write to files, - and introduced format strings to make it easier for us to print things.
These tools are sufficient for us to write our first program: the word counter.
What is a Word?
Our definition of a word is any sequence of alphanumeric characters,
apostrophes, or dashes.
For example, «ji12fsadkl» would be a word but «f1.asd%as1» would be three words
because the period and the percent sign will break it apart.
You could define a word to mean something else (like anything separated by
spaces), but we’re going to use this definition.
Before We Begin
At certain points, I will discuss what our program needs to do and I would like
you to consider how you would solve the problem by breaking each problem into
smaller problems until you can use one of the tools we’ve introduced in this
series.
In fact, I would like you to record your ideas somewhere so you can compare them
to the approaches I’ll take, as it should be easier to tell which of your
approaches will work and which won’t.
Project Setup
This is a short step, but you’ll want to create two new directories: one for
all the C tutorials in this series and one inside that one for the word
counter specifically.
First, if you’re on Mac or Linux, open the terminal app.
If you’re on Windows, open the Ubuntu app, which you should have installed in
the Compilers and Ides for
C article.
If you’re on Mac or Linux, type in the command cd ~, which will put you in the
home folder (it’s exactly like clicking on folders in the Windows or Mac
file explorer until you get to Users/[your username]).
If you’re using the Windows Subsystem for Linux, type cd /mnt/c/Users/[your username], which
will bring you to your home directory (i.e. the directory that contains Desktop,
Documents, Downloads, etc.).
The /mnt/c/Users/[your username] directory is the Windows equivalent of ~ in Linux and Mac,
and you can replace every instance of ~ in the terminal with /mnt/c/Users/[your username]
and have it work.
Then, type mkdir -p dev/c-tutorial, which will then create a new directory in ~.
If you want to put your code in another
directory, you can use mkdir -p path/to/other/directory/c-tutorial.
You can see a list of all the directories in your current folder by typing ls.
From there, type cd c-tutorial to move into the c-tutorial directory.
If you put your code in another directory, you
can use cd path/to/other/directory/c-tutorial instead.
The entire process should look like this:
user@computer:~/some/random/dir$ cd ~ user@computer:~$ mkdir -p dev/c-tutorial user@computer:~$ ls dev Desktop Documents Downloads Music Pictures Public Videos user@computer:~$ cd dev/c-tutorial user@computer:~/dev/c-tutorial$
Now that you’re here, create a file called word-counter.c, which you can do
using your IDE, a text editor, or the command line.
If you’re using an IDE or a text editor, go to File > Open
> Folder, navigate to the c-tutorial folder, and click on it.
Then, right click on the c-tutorial folder and click New File.
If you’re using a command line text editor like vim or nano, then just type
vim word-counter.c or nano word-counter.c and the text editor should pop up
with a new file.
Command Line Text Editors
Although I personally use vim (I’m actually using it right now to write these
articles.) and would recommend it to an experienced programmer, I don’t
recommend that any novices use it because it’s made less for just putting text
on the screen like normal text editors (Google Docs, Microsoft Word, Notepad)
and more for coding.
It allows fast movement and operations throughout the code, but you have to put
in some effort.
The same reasoning also applies for emacs and nano.
Do not close the terminal, as we will use it later to compile and run our
code.
If you do close the terminal, you can just type cd on Linux or Mac or
~/dev/c-tutorial/cd.
/mnt/c/Users/[your username]/dev/c-tutorial/
From here, we can start typing our code into our new file.
The Top Level
We’re going to start with our goal: counting the number of times a word shows up
in a file and printing that number to the terminal.
From there, we’re going to go to the top level of our program, which will
correspond to our main function.
For us to count the number of times a word shows up in a file, we need to know
the word and the file to read from.
Then, we’ll also need to store the count somewhere and print it out.
Our algorithm currently looks like
- Get the user input.
- Count the number of times the word shows up in a file.
- Print the count of the word.
Boilerplate and Trivial Code
In this section, we’re going to handle getting the user input, printing the
count of the word, getting the file into our program, and reading the file line
by line.
Besides printing the count of the word, these tasks will show up commonly and
you can normally knock them out quite quickly since little changes from project
to project, which makes it Boilerplate Code.
Printing the count of the word, however, is trivial since we just have to call
printf with a simple format string.
Getting User Input
For now, let’s focus on getting the user input.
We can look through our list of tools we have in C (look above) and we find
that the main function will allow us
to get user input directly through its arguments, so we can just use it
directly.
int main(int argc, char ** argv) { char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; // TODO: Count the number of times the word shows up in a file. // TODO: Print the count of the word. return 0; } |
Now you might notice a problem.
What happens if the user doesn’t provide us with at least three arguments?
argv[0] always has to exist, but argv[1] and so on only exist if the user
provides other arguments on the command line.
We need to check that there are at least three arguments for the program to
continue running, so let’s add that check.
Furthermore, if the user types the command in without the proper arguments, the
general response is to print out a usage message showing the user how to use it,
which we’ll add too.
We want to print to stderr, so we’ll need to use fprintf or fputs and
we’ll need to include stdio.h.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; // TODO: Count the number of times the word shows up in a file. // TODO: Print the count of the word. return 0; } |
So now, we have the name of the file the user wants to run the program on in the
variable file_name and the word the user wants to find in word.
Printing the Count
You might think it’s a little weird that we skipped the part where we actually
count the word, but it’s easy enough that we can do it in a few lines.
To print a number out to the screen, we can use printf and be done with it.
Since we need to declare a variable before we can use it, we’re going to declare
unsigned int count = 0; before we calculate the count of the word.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; // TODO: Count the number of times the word shows up in a file. printf("%dn", count); return 0; } |
Count How Often the Word Shows up in the File
Now we’re going to get into some of the heavy lifting.
Here’s how I’m thinking we break down this part of the algorithm:
- Get the file into our
Cprogram in some way that we can interact with it. - Read the file line by line (since that’s how you normally read files).
- For each line, get the count of the word and add it to the total count.
Let’s work with this and see what happens.
Getting the File into C
As we went over in the article on files in
C, we can get files from our computer into our program using fopen,
which will return a FILE * object that we can use to interact with the file.
We’ll want to read the file, so we’re going to use "r" as the mode
(second argument to fopen).
Since we have to clean up after ourselves, we’ll also need a corresponding
fclose.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; FILE * reader = fopen(file_name, "r"); // TODO: Read the file line by line // TODO: For each line, get the count of the word and add it to // the total count fclose(reader); printf("%dn", count); return 0; } |
I decided to call the FILE * object reader since it’s reading the file.
If I had done something stupid and called it something like a, then I could
end up accidentally confusing it for something else or not recognizing that I’m
using it incorrectly.
Reading the File Line by Line
Now that we have a FILE *, we can read the file line by line.
We’re going to need somewhere to store the line, and since the line is made up
of characters, we’re going to use a char buffer.
We’ll need to allocate a safe amount to get decently long lines, so let’s
allocate room for 4096 (i.e. 212 or 4 KiB or about 4 kB)
characters.
If a user uses a line longer than 4096 characters, then fgets will
automatically break it into multiple lines every 4095 characters (remember
that the last character is the null terminator '').
We also want to keep reading until we reach the end of the file, which fgets
will allow us to do.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; FILE * reader = fopen(file_name, "r"); const int line_sz = 4096; // There are better ways to do this char line[line_sz]; // but we need features we haven't // gone over yet. while (fgets(line, line_sz, reader)) { // TODO: For each line, get the count of the word and add it to // the total count } fclose(reader); printf("%dn", count); return 0; } |
Making Another Function
Now, we need a function to count the number of times the word shows up in the
line.
We can then add it to the count.
For now, we’re going to create a function called count_word_in_line that takes
in a line and the word we want to count and return the number of times the word
shows up in the line.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; FILE * reader = fopen(file_name, "r"); const int line_sz = 4096; // There are better ways to do this char line[line_sz]; // but we need features we haven't // gone over yet. while (fgets(line, line_sz, reader)) { count += count_word_in_line(line, word); } fclose(reader); printf("%dn", count); return 0; } |
Now, we have to write count_word_in_line, but before we do that, we’re going
to take care of a few string operations first.
Setting Up count_word_in_line
Since count_word_in_line is going to be useful later in other programs, we
might as well put it in another file so we can reuse it.
Because we’re going to put it in another file, we’re going to have to also make
another header file.
I feel like we’re going to need to do other string operations for our programs,
so we’re going to create the files str-operations.h and str-operations.c.
You can make these files through the same process in which you created
the word-counter.c file.
Make sure to create these files in the same directory as word-counter.c.
For count_word_in_line, we’re going to need the line, the word we want to
find, and we’re going to return an int to get the proper count, which means
count_word_in_line has the syntax:
int count_word_in_line(char * line, const char * word);
We add the const because we won’t modify the word. We will need to modify
the line to remove punctuation, so it’s up to the user if they want to keep a
copy. Since we just need count_word_in_line in our main funciton, str-operations.h
will look like
int count_word_in_line(char * line, const char * word);
|
Furthermore, we’re going to want to #include "str-operations.h" in
word-counter.c so that we can use count_word_in_line in
word-counter.c.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include "str-operations.h" #include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; FILE * reader = fopen(file_name, "r"); const int line_sz = 4096; // There are better ways to do this char line[line_sz]; // but we need features we haven't // gone over yet. while (fgets(line, line_sz, reader)) { count += count_word_in_line(line, word); } fclose(reader); printf("%dn", count); return 0; } |
Now, we’re actually done with word-counter.c, so the rest of this article will
be working on str-operations.c and str-operations.h.
String Operations
Before we continue with count_word_in_line, we’re going to work on a few string
operations we need to implement: including check_if_strings_differ and to_upper.
check_if_strings_differ
We have already written check_if_strings_differ, so we can just put it
into str-operations.c near the top.
int check_if_strings_differ(const char * str1, const char * str2) { int i = 0; while (str1[i] && str2[i] && (str1[i] == str2[i])) { i += 1; } return str1[i] != str2[i]; } |
Converting Text to Uppercase
We also want to be able to convert things to the same case so that we match
«the» and «The», so we’ll need to write a function for it.
Since we’ll be converting from lowercase to uppercase, we’ll call this function
to_upper.
Since we haven’t covered dynamic memory allocation, we’ll have to convert the
characters to uppercase in place, meaning we’re going to modify the original
string and we won’t need to return anything.
Our function declaration will look like
void to_upper(char * string);
We’re going to want to go through all the characters in the string, so we’re
going to need a while loop like so:
void to_upper(char * string) { int i = 0; while (string[i]) { // TODO: convert string[i] to uppercase if necessary i += 1; } }
The code above will loop through each character of the string until it reaches
the end of the string since '' is 0 and 0 is false in C.
We can access the current character by using string[i].
Lowercase ASCII characters are between 'a' and 'z' inclusive, so we just
need to check if the current character is greater than or equal to 'a' and
less than or equal to 'z'.
void to_upper(char * string) { int i = 0; while (string[i]) { if ('a' <= string[i] && 'z' >= string[i]) { // TODO: convert string[i] to uppercase } i += 1; } }
We’ll want to subtact 32 from the character if it is a lowercase ASCII
character since the numerical value of a lowercase letter is 32 more than it’s
corresponding uppercase letter.
We haven’t covered bitwise operators, which would also work, but we’re going to
continue with this method.
void to_upper(char * string) { int i = 0; while (string[i]) { if ('a' <= string[i] && 'z' >= string[i]) { string[i] -= 32; } i += 1; } }
Now, we just need to add it to str-operations.c.
Since it’s declared in str-operations.h, we can just #include it and we
won’t need to worry about where it is in the file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#include "str-operations.h" void to_upper(char * string) { int i = 0; while (string[i]) { if ('a' <= string[i] && 'z' >= string[i]) { string[i] -= 32; } i += 1; } } int check_if_strings_differ(const char * str1, const char * str2) { int i = 0; while (str1[i] && str2[i] && (str1[i] == str2[i])) { i += 1; } return str1[i] != str2[i]; } |
count_word_in_line
Now, we’re going to come up with the algorithm to count the word in the line.
- Initialize an empty
intthat will serve as thecount. - While we haven’t reached the end of the line:
- find the next word,
- convert it to uppercase to account for differences in ASCII uppercase and
lowercase, - and add one to the count if it matches the input word.
- return the
count.
We’ll need to take care of the function input and output first, which we’ve done
below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
#include "str-operations.h" void to_upper(char * string) { int i = 0; while (string[i]) { if ('a' <= string[i] && 'z' >= string[i]) { string[i] -= 32; } i += 1; } } int check_if_strings_differ(const char * str1, const char * str2) { int i = 0; while (str1[i] && str2[i] && (str1[i] == str2[i])) { i += 1; } return str1[i] != str2[i]; } int count_word_in_line(char * line, const char * word) { int count = 0; // TODO: Copy word into a local buffer so we can convert it to // uppercase // Remove punctuation from line // Convert the local copy of word to uppercase // Create a local buffer to store the current word // Set up something to keep track of where we are in the // current line // TODO: For each word in line: // 1. Convert the word to uppercase // 2. Check if the current word matches the input word // 3. Add one to the count if it matches the input word return count; } |
Since we’re going to return the count and we’re going to increment it every time
we see the word, we need a variable to store the count.
Finding the Next Word
Now, we already have functions to convert each word to uppercase, check if
they’re the same word, and adding one to the count if it matches the input word
is trivial, so all we have to do is find the next word.
To make this easy on ourselves, we are going to sanitize our data, which
means removing characters we don’t care about.
Since the scanf functions will find words divided by whitespace, we’re going
to replace non-alphanumeric characters with spaces.
Replacing Characters with Spaces
We’re going to do a simple loop where we go through all the characters in the
line and make them into spaces if it’s not an uppercase letter, lowercase
letter, or number.
We’re going to create a new function called non_alphanumeric_to_spaces.
Reinventing the Wheel
An experienced programmer would likely see what we’re trying to do and think of
regular expressions because
replacing non-alphanumeric
characters with spaces is trivial using regular expressions.
In fact, we could replace a lot of the things we’re doing in this tutorial with
professional code, including functions in the standard library such as toupper and strcmp.
Given that experts have written highly optimized code that will beat anything
we’ll cover in this tutorial, why are we reinventing wheels left and right if
we’re not even going to be using them in practice?
Put simply, you have to have something round and roll it on the ground before
you can understand a wheel.
You might be expected to solve the integral 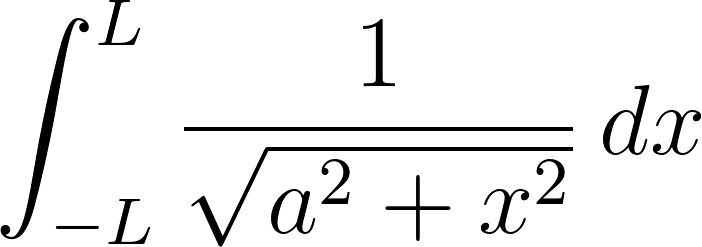 manually in a Calculus class,
manually in a Calculus class,
but in any other class or on a job, you would look it up.
At this part of the tutorial, we’re not concerned with writing industry-grade
code, we’re just applying what we’ve already covered about C into making a
non-trivial program.
Furthermore, I want to show you how to work on a project when you don’t have all
the functions written for you, I don’t want to teach anything new outside of
what we’ve learned so far, and I want to demostrate what you can do with the
tools that we have.
Once we have a thorough understanding of these topics, we’ll start using the
industry standards.
non_alphanumeric_to_spaces will be almost identical to to_upper but with a longer condition in
the if statement and the conversion from lower to upper being replaced.
Since the condition in the if statement is going to be longer, I’m going to
calculate it outside of the parentheses for the if statement. I’m also going
to call the function inside count_word_in_line.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#include "str-operations.h" void to_upper(char * string) { int i = 0; while (string[i]) { if ('a' <= string[i] && 'z' >= string[i]) { string[i] -= 32; } i += 1; } } void non_alphanumeric_to_spaces(char * string) { int i = 0; while (string[i]) { // calculating the condition outside the if statement int alphanumeric = // checking if it's a lowercase letter ('a' <= string[i] && 'z' >= string[i]) || // checking if it's an uppercase letter ('A' <= string[i] && 'Z' >= string[i]) || // checking if it's a digit ('0' <= string[i] && '9' >= string[i]) || (''' == string[i]) || ('-' == string[i]); if (!alphanumeric) { string[i] = ' '; } i += 1; } } int check_if_strings_differ(const char * str1, const char * str2) { int i = 0; while (str1[i] && str2[i] && (str1[i] == str2[i])) { i += 1; } return str1[i] != str2[i]; } int count_word_in_line(char * line, const char * word) { int count = 0; non_alphanumeric_to_spaces(line); // TODO: Copy word into a local buffer so we can convert it to // uppercase // Convert the local copy of word to uppercase // Create a local buffer to store the current word // Set up something to keep track of where we are in the // current line // TODO: For each word in line: // 1. Convert the word to uppercase // 2. Check if the current word matches the input word // 3. Add one to the count if it matches the input word return count; } |
You can read everything except the generic while loop stuff (anything involving
while or i) in non_alphanumeric_to_spaces as «if the current character is neither a lowercase
letter nor an uppercase letter nor a digit nor an apostrophe nor a dash, then
set it to a space».
Now that we have everything set up, we can finish count_word_in_line.
Finishing count_word_in_line
First, we have to create two local buffers: one for the current word and one for
the word we’re looking for.
Then, we need to convert the word we’re looking for to uppercase.
Since the file is getting kind of big, we’re going to just focus on
count_word_in_line.
We’re also going to introduce a new function called strncpy, which
copies up to n characters of a string.
To do so, we’ll have to include the header .
It has the syntax
char * strncpy(char * destination, const char * source, size_t num);
where destination is what you’re copying to, source is where you’re copying
from, and num is the maximum number of characters you can copy.
The char * it returns is just destination.
Don’t worry about the size_t, as it’s
just an alias for one of the unsigned integral types in C and C++.
It’s used mainly in the standard library to represent sizes and counts, and
we’ll be able to provide a positive integer argument without any problem.
int count_word_in_line(char * line, const char * word) { int count = 0; non_alphanumeric_to_spaces(line); const int buff_sz = 1024; char word_to_count[buff_sz]; char current_word[buff_sz]; strncpy(word_to_count, word, buff_sz - 1); word_to_count[buff_sz - 1] = ''; to_upper(current_word); // TODO: Set up something to keep track of where we are in the // current line // TODO: For each word in line: // 1. Convert the word to uppercase // 2. Check if the current word matches the input word // 3. Add one to the count if it matches the input word return count; }
We subtracted 1 from buff_sz and set the last character to '' to make
sure word_to_count always remains a valid C string.
Using sscanf
Now, generally you shouldn’t use any of the scanf family of functions because
if your input is even slightly different from what you’re expecting then it just
won’t work.
In fact, the only time you should use any scanf function is if you know that
the input will be in a simple format that scanf can parse, such as a bunch of
words separated by whitespace.
Since we have a bunch of words separated by whitespace, we’re going to use
sscanf (the scanf function to parse strings) to get the next word.
sscanf has the
syntax
int sscanf(const char * s, const char * format, ...);
where it reads from the string s according to the format specified by format
and all arguments after format are set in the order in which they appear in
the argument list using the format specifer to
determine how to set the argument.
For example
char str1[32]; char str2[32]; int num; sscanf("Hello World 7", "%s %s %d", str1, str2, &num);
will set str1 to "Hello", str2 to "World", and num to 7.
We had to provide the address of num to sscanf because it would otherwise
create a copy of num and modify the copy.
By providing the memory address instead, we can modify the variable directly.
sscanf also returns an int which indicates the number of arguments filled
with text from the string.
In our example, sscanf would return 3 since we filled str1, str2 and
num using text from the string.
Now, we can and should specify the width of each %s to prevent buffer
overflows, so we should have written
sscanf("Hello World 7", "%31s %31s %d", str1, str2, &num);
because we can copy at most 31 characters into str1 and str2 safely since
we have room for 32 characters and the last one needs to be '', so we only
have room for 31 characters.
Going Through Each Word
In our case, we have room for 1024 characters reserved for current_word, so
we’ll need to use "%1023s" to get the next word.
We’ll need to look for our next word starting at the end of the last
word, so we’ll need to know how many characters we read.
We can use the %n format specifier to get the number of characters sscanf
has read after calling it, leaving us with a format string of "%1023s%n".
We’ll need somewhere to store the number of characters we’ve read, so we’ll
create a variable called num_characters_read.
We need a variable to store our current position in the line, which we’ll call
cur_pos, and we’ll initialize it with line.
Inside our loop, we’ll add num_characters_read to cur_pos so that sscanf
can start reading from cur_pos instead of the beginning of the string.
Lastly, we’ll need to keep looping as long as all our arguments have been
filled.
I don’t use any of the scanf functions frequently enough to have known this
off the top of my head, but you only count the number of arguments filled using
characters in the text, meaning we should expect a return value of 1 since
%n isn’t filled with characters from the text.
int count_word_in_line(char * line, const char * word) { int count = 0; non_alphanumeric_to_spaces(line); const int buff_sz = 1024; char word_to_count[buff_sz]; char current_word[buff_sz]; strncpy(word_to_count, word, buff_sz - 1); word_to_count[buff_sz - 1] = ''; to_upper(word_to_count); const char * cur_pos = line; int num_characters_read = 0; while (sscanf(cur_pos, "%1023s%n", current_word, &num_characters_read) == 1) { cur_pos += num_characters_read; // TODO: 1. Convert the word to uppercase // 2. Check if the current word matches the input word // 3. Add one to the count if it matches the input word } return count; }
The Home Stretch
We have four lines of code left, and one of them is just a closing curly brace.
First, we convert current_word to uppercase, which we can do using to_upper.
Then, we check if current_word and word_to_count match, which we can do
using an if statement whose condition is
!check_if_strings_differ(word_to_count, current_word).
Lastly, we just have to put count += 1; inside the if statement, leaving us
with
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
#include "str-operations.h" #include <stdio.h> #include <string.h> void to_upper(char * string) { int i = 0; while (string[i]) { if ('a' <= string[i] && 'z' >= string[i]) { string[i] -= 32; } i += 1; } } void non_alphanumeric_to_spaces(char * string) { int i = 0; while (string[i]) { int alphanumeric = ('a' <= string[i] && 'z' >= string[i]) || ('A' <= string[i] && 'Z' >= string[i]) || ('0' <= string[i] && '9' >= string[i]) || (''' == string[i]) || ('-' == string[i]); if (!alphanumeric) { string[i] = ' '; } i += 1; } } int check_if_strings_differ(const char * str1, const char * str2) { int i = 0; while (str1[i] && str2[i] && (str1[i] == str2[i])) { i += 1; } return str1[i] != str2[i]; } int count_word_in_line(char * line, const char * word) { int count = 0; non_alphanumeric_to_spaces(line); const int buff_sz = 1024; char word_to_count[buff_sz]; char current_word[buff_sz]; strncpy(word_to_count, word, buff_sz - 1); word_to_count[buff_sz - 1] = ''; to_upper(word_to_count); const char * cur_pos = line; int num_characters_read = 0; while (sscanf(cur_pos, "%1023s%n", current_word, &num_characters_read) == 1) { cur_pos += num_characters_read; to_upper(current_word); if (!check_if_strings_differ(word_to_count, current_word)) { count += 1; } } return count; } |
And we’re done.
For your convenience, here is word-counter.c:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include "str-operations.h" #include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; FILE * reader = fopen(file_name, "r"); const int line_sz = 4096; // There are better ways to do this char line[line_sz]; // but we need features we haven't // gone over yet. while (fgets(line, line_sz, reader)) { count += count_word_in_line(line, word); } fclose(reader); printf("%dn", count); return 0; } |
and str-operations.h:
int count_word_in_line(char * line, const char * word); |
Compiling the Program
Assuming you followed all the steps up to this point, you should have all the
source code in the proper directory.
Remember that if you’re using the Windows Subsystem for Linux (the Ubuntu app)
that instead of ~, you should see /mnt/c/Users/[your username].
If you go to the terminal and type ls, you should see:
user@computer:~/dev/c-tutorial$ ls
str-operations.c
str-operations.h
word-counter.c
If you see these three files, then you can compile them into a program using
gcc:
user@computer:~/dev/c-tutorial$ gcc str-operations.c word-counter.c -o word-counter
You can then run the program using ./word-counter [file-to-read].
[word-to-count]
Running Tests
You can create your own test file or you can use this
sample text from this article.
user@computer:~/dev/c-tutorial$ mv ~/Downloads/test-file.txt . user@computer:~/dev/c-tutorial$ ls str-operations.c str-operations.h test-file.txt word-counter word-counter.c
The mv command is what you would get by opening up your file manager GUI,
moving to ~/Downloads (or /mnt/c/Users/[your username]/Downloads on Windows), right-clicking
on ~/Downloads/test-file.txt in your file manager GUI, selecting Cut,
moving to ~/dev/c-tutorial/ (or /mnt/c/Users/[your username]/dev/c-tutorial/ on Windows), then
right-clicking and hitting Paste.
Anyway, now that we’re here, we can run some tests.
If you’re using test-file.txt, then these are the results you should get:
user@computer:~/dev/c-tutorial$ ./word-counter ./word_counter file_name word_to_find user@computer:~/dev/c-tutorial$ ./word-counter test-file.txt the 21 user@computer:~/dev/c-tutorial$ ./word-counter test-file.txt THE 21 user@computer:~/dev/c-tutorial$ ./word-counter test-file.txt watermelon 0
The first test was with no input to make sure it printed out a usage message,
the second test was with some input with a known value since the word «the»
shows up twenty times in test-file.txt, the third test was to make sure that
searching was case insensitive, and the last test was to make sure that words
that do not show up in test-file.txt return a result of zero.
Note About Accuracy and a Challenge
If you have a line that has more characters than the buffer size (in this case,
hardcoded to be 4096), then there is a chance that a word is split between two
buffers. If that happens, the count for a word will be off. For example, if the
word «apple» is split into «app» and «le», the count for «apple» will be one
lower and the counts for «app» and «le» will be one higher.
For the following questions, try to think in terms of memory and algorithms like
a computer. Some of these questions may be quite easy for you and some might
sound weird, but I’m trying to make sure that people have as many chances for
it to click as possible. For example, the computer can only read data from
variables defined before the while loop and your answers should take that into
account.
- What data can you read? Name specific variables.
- Say you read a line from the file that was longer than
4095bytes (remember
fgetsadds a null terminator). What specific section of memory would you
be able to look at to know if you’ve read the entire line? How would you be able
to tell if you’ve read the entire line? - If you’ve read the entire line, do you have to worry about splitting a word?
- If you haven’t read the entire line, do you have to worry about splitting a
word? - Should you check if you split a word before or after running
count_word_in_line? - If you split a word, you will have two parts of the word. If you leave the
program as is, what happens to the first half of the word in the next iteration
of thewhileloop? How can you prevent that? Feel free to create another
variable or allocate a small array. - If you’re looking for the word «apple» and the word is split into «app» and
«le», how would you prevent the word «app» from being counted bycount_word_in_line? How
would you prevent the word «le» from being counted bycount_word_in_line? - Using your answers to the previous questions, how could you fix the problem of
the buffer splitting a word? Make sure you include how to recognize and fix the
problem. To test out your code, switch the buffer size to something smaller like
60and then write a file with long lines.
Hardcoding the array to be larger could lead to some weird performance problems,
could mess with systems with weird stack sizes, wastes memory for programs that
don’t need it, and only makes the problem less likely without solving it.
Mouse over the box below to see my answer.
I check the last character in the buffer and see if it’s set to '', which
means that fgets read line_sz - 1 number of characters and could split the
line. To prevent it from happening the first time, I set it to a space
character. If I see a '', I find where the word starts by moving from the
end of the buffer until I hit a space character. I then copy from that space
character until the end of the buffer into another local buffer while replacing
those characters in line with space characters. Lastly, I make sure to replace
the '' at the end with a space character again. At that point, I can pass it
into count_word_in_line and I don’t have to worry about the first part of the word being
counted as something else. I then copy the first part of the word to the front
of the line buffer and then read the next line, making sure to not read the
full line_sz number of characters since we’ve already added some characters to
the front of the buffer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#include "str-operations.h" #include <stdio.h> int main(int argc, char ** argv) { if (3 > argc) { fprintf(stderr, "./word_counter file_name word_to_countn"); return -1; } char * program_name = argv[0]; char * file_name = argv[1]; char * word = argv[2]; unsigned int count = 0; FILE * reader = fopen(file_name, "r"); const int line_sz = 4096; // There are better ways to do this char line[line_sz]; // but we need features we haven't // gone over yet. unsigned int offset; const int temp_word_sz = line_sz; char temp_word[temp_word_sz]; line[line_sz - 1] = ' '; while (fgets(line + offset, line_sz - offset, reader)) { offset = 0; if (line[line_sz - 1] == '') { while (line[(line_sz - 1) - (offset + 1)] != ' ') { offset += 1; } for (int i = 0; i < offset; i += 1) { int cur_char_index = (line_sz - 1) - (offset - i); temp_word[i] = line[cur_char_index]; line[cur_char_index] = ' '; } line[line_sz - 1] = ' '; } count += count_word_in_line(line, word); strncpy(line, temp_word, offset); } fclose(reader); printf("%dn", count); return 0; } |
Summary
In this article, we wrote and compiled a complete, functioning, nontrivial
program from scratch using the tools we’ve introduced.
What’s Next
In the next article, Printing Lines
Containing a Specific Word, we’re going to start discussing the next
program, which will print out every line from a file that contains a word the
user specifies. In doing so, we’re going to need to come up with what is known
as a build system.

Joseph Mellor is a Senior at TU majoring in Physics, Computer Science, and
Math.
He is also the chief editor of the website and the author of the tumd markdown
compiler.
If you want to see more of his work, check out his personal website.
Credit to Allison Pennybaker for the picture.