
MapReduce is simple. Some MapReduce algorithms can definitely be more difficult to write than others, but MapReduce as a programming approach is easy. However, people usually struggle the first time they are exposed to it. In our opinion, this comes from the fact that most MapReduce tutorials focus on explaining how to build MapReduce algorithms. Unfortunately, the way MapReduce algorithms are built (i.e., by building a mapper and a reducer) is not necessarily the best way to explain how MapReduce works because it tends to overlook the ‘shuffle’ step, which occurs between the ‘map’ step and the ‘reduce’ step and is usually made transparent by MapReduce frameworks such as Hadoop.
This post is an attempt to present MapReduce the way we would have liked to be introduced to it from the start.
Before you start
This tutorial assumes a basic knowledge of the Python language.
You can download the code presented in the examples below from here. In order to run it, you need:
- A Unix-like shell (e.g., bash, tcsh) as provided on Linux, Mac OS X, or Windows + Cygwin;
- Python (e.g., anaconda), note that the examples presented here can be ported into any other language that permits to read data from the standard input and write it to the standard output.
In addition, if you want to run your code on Hadoop, you will need to install Hadoop 2.6, which requires java to run.
Counting Word Occurrences
Counting the number of occurrences of words in a text is sometimes considered as the “Hello world!” equivalent of MapReduce. A classical way to write such a program is presented in the python script below. The script is very simple. It parses the standard input from which it extracts and counts words and stores the result in a dictionary that uses words as keys and the number of occurrences as values.
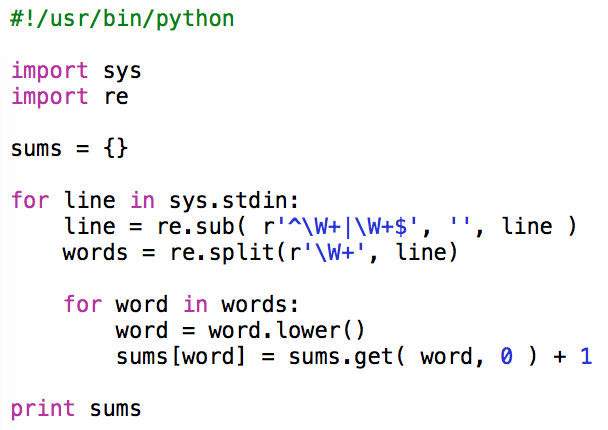
Let’s look at this script in more details. It uses 2 packages: ‘sys’, which allows for reading data from the standard input, and ‘re’, that provides support for regular expression.
import sys
import re
Before the parsing starts, a dictionary, named ‘sums’, which will be used to store the word counts, is created and initialized.
sums = {}
The standard input is read line by line and put in a variable named ‘line’
for line in sys.stdin:
For each line, a regular expression is used to remove all the leading and trailing non-word characters (e.g., blanks, tabs, punctuation)
line = re.sub( r'^W+|W+$', '', line )
Then a second regular expression is used to split the line (on non-word characters) into words. Note that removing the leading and trailing non-word characters before splitting the line on these non-word characters lets you avoid the creation of empty words. The words obtained this way are put in a list named ‘words’.
words = re.split( r'W+', line )
Then, for each word in the list
for word in words:
The lower-case version of the word is taken.
word = word.lower()
Before the word is used as key to access the ‘sums’ dictionary and increment its value (i.e., the word occurrence count) by one. Note that taking the lower-case version of each word avoids counting the same word as different words when it appears with different combinations of upper- and lower-case characters in the parsed text.
sums[word] = sums.get( word, 0 ) + 1
Finally, once the whole text has been parsed, the content of the dictionary is sent to the standard output.
print sums
Now that the script is ready, let’s test it by counting the number of word occurrences in Moby Dick, the novel by Herman Melville. The text can be obtained here.
wget https://www.gutenberg.org/cache/epub/2701/pg2701.txt
mv pg2701.txt input.txt
Its content can be displayed using the cat command. As seen on the screenshot below, it finishes by a notice describing the Project Gutenberg.
cat input.txt

Assuming that the python script was saved in a file named counter.py, which was made executable (chmod +x counter.py), and that the text containing the words to count was saved in a file named input.txt, the script can be launched using the following command line:
./counter.py < input.txt
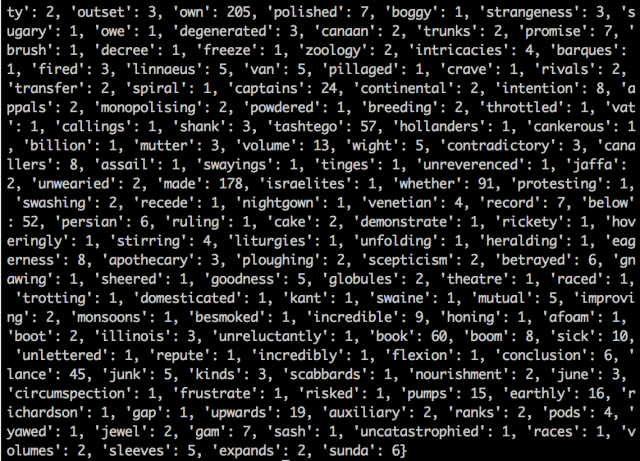
The result of this is partly displayed in the screenshot below where we can see that the word ‘own’ appears 205 times in the text, the word ‘polished’ appears 7 times, etc.
Limitations of the Dictionary Approach
The main problem with this approach comes from the fact that it requires the use of a dictionary, i.e., a central data structure used to progressively build and store all the intermediate results until the final result is reached.
Since the code we use can only run on a single processor, the best we can expect is that the time necessary to process a given text will be proportional to the size of the text (i.e., the number of words processed per second is constant). Actually, the performance degrades as the size of the dictionary grows. As shown on the diagram below, the number of words processed per second diminishes when the size of the dictionary reaches the size of the processor data cache (note that if the cache is structured in several layers of different speeds, the processing speed will decrease each time the dictionary reaches the size of a layer). A new diminution of the processing speed will be reached when the dictionary reaches the size of the Random Access Memory. Eventually, if the dictionary continues to grow, it will exceed the capacity of the swap and an exception will be raised.

The MapReduce Approach
The MapReduce approach does not require a central data structure. It consists of 3 steps:
- A mapping step that produces intermediate results and associates them with an output key;
- A shuffling step that groups intermediate results associated with the same output key; and
- A Reducing step that processes groups of intermediate results with the same output key.
This might seem a little abstract so let’s look at what these three steps look like in practice when applied to our example.
Mapping
The mapping step is very simple. It consists of parsing the input text, extracting the words it contains, and, for each word found, producing an intermediate result that says: “this word occurs one time”. Translated into an output key / intermediate result format, this is expressed by using the word itself as output key and the number of occurrences of the word (in this specific case ‘1’) as intermediate result.
The code of the mapper is provided below:

The beginning of the script is identical to the initial script. The standard input is read line by line and split into words.
Then, for each word in the list
for word in words:
The lower-case version of the word is sent to the standard output followed by a tabulation and the number 1.
print( word.lower() + "t1" )
The word is used as output key and “1” (i.e., the number of occurrences of this word) is the intermediate value. Following a Hadoop convention, the tabulation character (“t”) is used to separate the key from the value.
As in the initial script, taking the lower-case version of each word avoids counting the same word as different words when it appears with different combination of upper- and lower-case characters in the parsed text.
Assuming that the mapping script is saved in a file named mapper.py, the script can be launched using the following command line:
./mapper.py < input.txt
The result of this is partly displayed in the screenshot below where we can see that the words are sent in the order they appear in text, each of them followed by a tabulation and the number 1.

Shuffling
The shuffling step consists of grouping all the intermediate values that have the same output key. As in our example, the mapping script is running on a single machine using a single processor and the shuffling simply consists of sorting the output of the mapping. This can easily be achieved using the standard “sort” command provided by the operating system:
./mapper.py < input.txt | sort
The result of this is partly displayed in the screenshot below. It differs from the output of mapper.py by the fact that the keys (i.e., the words) are now sorted in alphabetic order.

Reducing
Now that the different values are ordered by keys (i.e., the different words are listed in alphabetic order), it becomes easy to count the number of times they occur by summing values as long as they have the same key and publish the result once the key changes.

Let’s look at the reducing script in more details. Like the other scripts, it uses the package ‘sys’, which allows for reading data from the standard input.
import sys
Before the parsing of the standard input starts, two variables are created: ‘sum’, which will be used to store the count of the current word and is initialized to 0 and ‘previous’ that will be used to store the previous key and is initialized to None.
previous = None
sum = 0
Then the standard input is read line by line and put in a variable named ‘line’
for line in sys.stdin:
Then, the key and value are extracted of each line by splitting the line on the tab character.
key, value = line.split( 't' )
The current key (key) is compared to the previous one (previous).
if key != previous:
If the current and previous key are different, it means that a new word has be found and, unless the previous key is empty, this is not the first word (i.e., the script is not handling the very first line of the standard input)
if previous is not None:
The variable ‘count’ contains the total number of occurrences of the previous word and this result can be displayed (note that this result is also produced using the key-tabulation-value format).
print str( sum ) + 't' + previous
As a new word is found, it is necessary to reinitiate the working variables
previous = key
sum = 0
And, in all cases, the loop ends with adding the current ‘value’ to the ‘sum’
sum = sum + int( value )
Finally, after having exited the loop, the last result can be displayed
print str( sum ) + 't' + previous
Assuming that the reducing script is saved in a file named reducer.py, the full MapReduce job can be launched using the following command line:
./mapper.py < input.txt | sort | ./reducer.py
The result of this is partly displayed in the screenshot below where we can see one word per line with each word preceded by the number of times it occurs in the text.

MapReduce Frameworks
In the example above, which runs on a single processing unit, Unix pipes and the sort command are used to group the mapper’s output by key so that it can be consumed by the reducer.
./mapper.py < input.txt | sort | ./reducer.py
Similarly, when using a cluster of computers, a MapReduce framework such as Hadoop is responsible for redistributing data (produced in parallel by mappers running on the different cluster nodes using local data) so that all data with the same output key ends up on the same node to be consumed by a reducer.
As shown by the bash code below, the mapper.py and reducer.py scripts presented above do not need to be changed in order to run on Hadoop.

Note that:
- The output will appear in a file automatically created in directory ‘./output’ (Hadoop will fail if this directory is not empty);
- Environment variable HADOOP_HOME must point to the directory in which Hadoop has been uncompressed.
Hopefully, as you see, this tutorial simplifies your introduction to MapReduce by making explicit the shuffle step. If you know other ways to learn MapReduce we will be interested to hear about it.
Hadoop Streaming is a feature that comes with Hadoop and allows users or developers to use various different languages for writing MapReduce programs like Python, C++, Ruby, etc. It supports all the languages that can read from standard input and write to standard output. We will be implementing Python with Hadoop Streaming and will observe how it works. We will implement the word count problem in python to understand Hadoop Streaming. We will be creating mapper.py and reducer.py to perform map and reduce tasks.
Let’s create one file which contains multiple words that we can count.
Step 1: Create a file with the name word_count_data.txt and add some data to it.
cd Documents/ # to change the directory to /Documents touch word_count_data.txt # touch is used to create an empty file nano word_count_data.txt # nano is a command line editor to edit the file cat word_count_data.txt # cat is used to see the content of the file

Step 2: Create a mapper.py file that implements the mapper logic. It will read the data from STDIN and will split the lines into words, and will generate an output of each word with its individual count.
cd Documents/ # to change the directory to /Documents touch mapper.py # touch is used to create an empty file cat mapper.py # cat is used to see the content of the file
Copy the below code to the mapper.py file.
Python3
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%st%s' % (word, 1)
Here in the above program #! is known as shebang and used for interpreting the script. The file will be run using the command we are specifying.

Let’s test our mapper.py locally that it is working fine or not.
Syntax:
cat <text_data_file> | python <mapper_code_python_file>
Command(in my case)
cat word_count_data.txt | python mapper.py
The output of the mapper is shown below.

Step 3: Create a reducer.py file that implements the reducer logic. It will read the output of mapper.py from STDIN(standard input) and will aggregate the occurrence of each word and will write the final output to STDOUT.
cd Documents/ # to change the directory to /Documents touch reducer.py # touch is used to create an empty file
Python3
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%st%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%st%s' % (current_word, current_count)
Now let’s check our reducer code reducer.py with mapper.py is it working properly or not with the help of the below command.
cat word_count_data.txt | python mapper.py | sort -k1,1 | python reducer.py

We can see that our reducer is also working fine in our local system.
Step 4: Now let’s start all our Hadoop daemons with the below command.
start-dfs.sh start-yarn.sh
Now make a directory word_count_in_python in our HDFS in the root directory that will store our word_count_data.txt file with the below command.
hdfs dfs -mkdir /word_count_in_python
Copy word_count_data.txt to this folder in our HDFS with help of copyFromLocal command.
Syntax to copy a file from your local file system to the HDFS is given below:
hdfs dfs -copyFromLocal /path 1 /path 2 .... /path n /destination
Actual command(in my case)
hdfs dfs -copyFromLocal /home/dikshant/Documents/word_count_data.txt /word_count_in_python

Now our data file has been sent to HDFS successfully. we can check whether it sends or not by using the below command or by manually visiting our HDFS.
hdfs dfs -ls / # list down content of the root directory hdfs dfs -ls /word_count_in_python # list down content of /word_count_in_python directory

Let’s give executable permission to our mapper.py and reducer.py with the help of below command.
cd Documents/ chmod 777 mapper.py reducer.py # changing the permission to read, write, execute for user, group and others
In below image,Then we can observe that we have changed the file permission.

Step 5: Now download the latest hadoop-streaming jar file from this Link. Then place, this Hadoop,-streaming jar file to a place from you can easily access it. In my case, I am placing it to /Documents folder where mapper.py and reducer.py file is present.
Now let’s run our python files with the help of the Hadoop streaming utility as shown below.
hadoop jar /home/dikshant/Documents/hadoop-streaming-2.7.3.jar > -input /word_count_in_python/word_count_data.txt > -output /word_count_in_python/output > -mapper /home/dikshant/Documents/mapper.py > -reducer /home/dikshant/Documents/reducer.py

In the above command in -output, we will specify the location in HDFS where we want our output to be stored. So let’s check our output in output file at location /word_count_in_python/output/part-00000 in my case. We can check results by manually vising the location in HDFS or with the help of cat command as shown below.
hdfs dfs -cat /word_count_in_python/output/part-00000

Basic options that we can use with Hadoop Streaming
|
Option |
Description |
|---|---|
| -mapper | The command to be run as the mapper |
| -reducer | The command to be run as the reducer |
| -input | The DFS input path for the Map step |
| -output | The DFS output directory for the Reduce step |
Articles Catalogue
- introduce
- Hadoop Stream
- The Role of Streaming
- Limitations of Streaming
- Relevant parameters of Streaming command
- Python implements MapReduce’s WordCount
introduce
- Hadoop is the foundation project of Apache, which solves the problem of long data processing time. MapReduce parallel processing framework is an important member of Hadoop. Because the architecture of Hadoop is implemented by JAVA, JAVA program is used more in large data processing. However, if you want to use deep learning algorithm in MapReduce, Python is an easy language for deep learning and data mining, so based on the above considerations, this paper introduces Python implementation. WordCount experiment in MapReduce, the content of the article (code part) comes from a blogger’s CSDN blog, the reference link is at the end.
Hadoop Stream
Hadoop Streaming, which is provided by Hadoop, is mainly used. First, let’s introduce Hadoop Stream.
The Role of Streaming
- Hadoop Streaming framework, the greatest advantage is that any language written map, reduce program can run on the hadoop cluster; map/reduce program as long as it follows from the standard input stdin read, write out to the standard output stdout;
- Secondly, it is easy to debug on a single machine, and streaming can be simulated by connecting pipes before and after, so that the map/reduce program can be debugged locally.
#cat inputfile | mapper | sort | reducer > output - Finally, streaming framework also provides a rich parameter control for job submission, which can be done directly through streaming parameters without using java language modification; many higher-level functions of mapreduce can be accomplished by adjusting steaming parameters.
Limitations of Streaming
Streaming can only deal with text data by default. For binary data, a better method is to encode the key and value of binary system into text by base64.
Mapper and reducer need to convert standard input and standard output before and after, involving data copy and analysis, which brings a certain amount of overhead.
Relevant parameters of Streaming command
# hadoop jar hadoop-streaming-2.6.5.jar [common option] [Streaming option]
Ordinary options and Stream options can be consulted from the following websites:
https://www.cnblogs.com/shay-zhangjin/p/7714868.html
Python implements MapReduce’s WordCount
- First, write the mapper.py script:
import sys for line in sys.stdin: line = line.strip() words = line.split() for word in words: print '%st%s' % (word, 1)
In this script, instead of calculating the total number of words that appear, it will output «1» quickly, although it may occur multiple times in the input, and the calculation is left to the subsequent Reduce step (or program) to implement. Remember to grant executable permissions to mapper.py: chmod 777 mapper.py
- Reducr.py script
from operator import itemgetter import sys current_word = None current_count = 0 word = None for line in sys.stdin: line = line.strip() word, count = line.split('t', 1) try: count = int(count) except ValueError: continue if current_word == word: current_count += count else: if current_word: print '%st%s' % (current_word, current_count) current_count = count current_word = word if current_word == word: print '%st%s' % (current_word, current_count)
Store the code in / usr/local/hadoop/reducer.py. The script works from mapper.py. STDIN reads the results, calculates the total number of occurrences of each word, and outputs the results to STDOUT.
Also, note the script permissions: chmod 777 reducer.py
- It is recommended that the script run correctly when running MapReduce tasks:
root@localhost:/root/pythonHadoop$ echo "foo foo quux labs foo bar quux" | ./mapper.py foo 1 foo 1 quux 1 labs 1 foo 1 bar 1 quux 1 root@localhost:/root/pythonHadoop$ echo "foo foo quux labs foo bar quux" |./mapper.py | sort |./reducer.py bar 1 foo 3 labs 1 quux 2
If the execution effect is as above, it proves feasible. You can run MapReduce.
- Run python scripts on the Hadoop platform:
[root@node01 pythonHadoop] hadoop jar contrib/hadoop-streaming-2.6.5.jar -mapper mapper.py -file mapper.py -reducer reducer.py -file reducer.py -input /ooxx/* -output /ooxx/output/
- Finally, HDFS dfs-cat/ooxx/output/part-00000 is executed to view the output results.
The results do not show that the hello.txt file can be produced by echo or downloaded from the Internet. For the test results, the results of different data sets are different.
Reference article: https://blog.csdn.net/crazyhacking/article/details/43304499
On day 4, we saw how to process text data using the Enron email dataset. In reality, we only processed a small fraction of the entire dataset: about 15 megabytes of Kenneth Lay’s emails. The entire dataset containing many Enron employees’ mailboxes is 1.3 gigabytes, about 87 times than what we worked with. And what if we worked on GMail, Yahoo! Mail, or Hotmail? We’d have several petabytes worth of emails, at least 71 million times the size of the data we dealt with.
All that data would take a while to process, and it certainly couldn’t fit on or be crunched by a single laptop. We’d have to store the data on many machines, and we’d have to process it (tokenize it, calculate tf-idf) using multiple machines. There are many ways to do this, but one of the more popular recent methods of parallelizing data computation is based on a programming framework called MapReduce, an idea that Google presented to the world in 2004. Luckily, you do not have to work at Google to benefit from MapReduce: an open-source implementation called Hadoop is available for your use!
You might worry that we don’t have hundreds of machines sitting around for us to use them. Actually, we do! Amazon Web Services offers a service called Elastic MapReduce (EMR) that gives us access to as many machines as we would like for about 10 cents per hour of machine we use. Use 100 machines for 2 hours? Pay Amazon aroud $2.00. If you’ve ever heard the buzzword cloud computing, this elastic service is part of the hype.
Let’s start with a simple word count example, then rewrite it in MapReduce, then run MapReduce on 20 machines using Amazon’s EMR, and finally write a big-person MapReduce workflow to calculate TF-IDF!
Setup
We’re going to be using two files, dataiap/day5/term_tools.py and dataiap/day5/package.tar.gz. Either write your code in the dataiap/day5 directory, or copy these files to the directory where your work lives.
Counting Words
We’re going to start with a simple example that should be familiar to you from day 4’s lecture. First, unzip the JSON-encoded Kenneth Lay email file:
unzip dataiap/datasets/emails/kenneth_json.zip
This will result in a new file called lay-k.json, which is JSON-encoded. What is JSON? You can think of it like a text representation of python dictionaries and lists. If you open up the file, you will see on each line something that looks like this:
{"sender": "rosalee.fleming@enron.com", "recipients": ["lizard_ar@yahoo.com"], "cc": [], "text": "Liz, I don't know how the address shows up when sent, but they tell us it's nkenneth.lay@enron.com.nnTalk to you soon, I hope.nnRosie", "mid": "32285792.1075840285818.JavaMail.evans@thyme", "fpath": "enron_mail_20110402/maildir/lay-k/_sent/108.", "bcc": [], "to": ["lizard_ar@yahoo.com"], "replyto": null, "ctype": "text/plain; charset=us-ascii", "fname": "108.", "date": "2000-08-10 03:27:00-07:00", "folder": "_sent", "subject": "KLL's e-mail address"}
It’s a dictionary representing an email found in Kenneth Lay’s mailbox. It contains the same content that we dealt with on day 4, but encoded into JSON, and rather than one file per email, we have a single file with one email per line.
Why did we do this? Big data crunching systems like Hadoop don’t deal well with lots of small files: they want to be able to send a large chunk of data to a machine and have to crunch on it for a while. So we’ve processed the data to be in this format: one big file, a bunch of emails line-by-line. If you’re curious how we did this, check out dataiap/day5/emails_to_json.py.
Aside from that, processing the emails is pretty similar to what we did on day 4. Let’s look at a script that counts the words in the text of each email (Remember: it would help if you wrote and ran your code in dataiap/day5/... today, since several modules like term_tools.py are available in that directory).
import sys from collections import defaultdict from mrjob.protocol import JSONValueProtocol from term_tools import get_terms input = open(sys.argv[1]) words = defaultdict(lambda: 0) for line in input: email = JSONValueProtocol.read(line)[1] for term in get_terms(email['text']): words[term] += 1 for word, count in words.items(): print word, count
You can save this script to exercise1.py and then run python exercise1.py dataiap/datasets/emails/lay-k.json. It will print the word count in due time. get_terms is similar to the word tokenizer we saw on day 4. words keeps track of the number of times we’ve seen each word. email = JSONValueProtocol.read(line)[1] uses a JSON decoder to convert each line into a dictionary called email, that we can then tokenize into individual terms.
As we said before, running this process on several petabytes of data is infeasible because a single machine might not have petabytes of storage, and we would want to enlist multiple computers in the counting process to save time.
We need a way to tell the system how to divide the input data amongst
multiple machines, and then combine all of their work into a single
count per term. That’s where MapReduce comes in!
Motivating MapReduce
You may have noticed that the various programs we have written in previous exercises look somewhat repetitive.
Remember when we processed the campaign donations dataset to create a
histogram? We basically:
- extracted the candidate name and donation amount from each line and
computed the histogram bucket for the amount - grouped the donations by candidate name and donation amount.
- summarized each (candidate, donation) bucket by counting the number
of donations.
Now consider computing term frequency in the previous class. We:
- cleaned and extracted terms from each email file
- grouped the terms by which folder they were from
- summarized each folder’s group by counting the number of times
each term was seen.
This three-step pattern of 1) extracting and processing from each
line or file, 2) grouping by some attribute(s), and 3)
summarizing the contents of each group is common in data processing tasks. We implemented step 2 by
adding elements to a global dictionary (e.g.,
folder_tf[e['folder']].update in day 4’s
code). We implemented step 3 by counting or summing the values in
the dictionary.
Using a dictionary like this works because the dictionary fits in
memory. However if we had processed a lot more data, the dictionary
may not fit into memory, and it’ll take forever to run. Then what do
we do?
The researchers at Google also noticed this problem, and developed a
framework called MapReduce to run these kinds
of patterns on huge amounts of data. When you use this framework, you just need to write
functions to perform each of the three steps, and the framework takes
care of running the whole pattern on one machine or a thousand machines! They use a
different terminology for the three steps:
- Map (from each)
- Shuffle (grouping by)
- Reduce (summarize)
OK, now that you’ve seen the motivation behind the MapReduce
technique, let’s actually try it out.
MapReduce
Say we have a JSON-encoded file with emails (3,000,000 emails on
3,000,000 lines), and we have 3 computers to compute the number of
times each word appears.
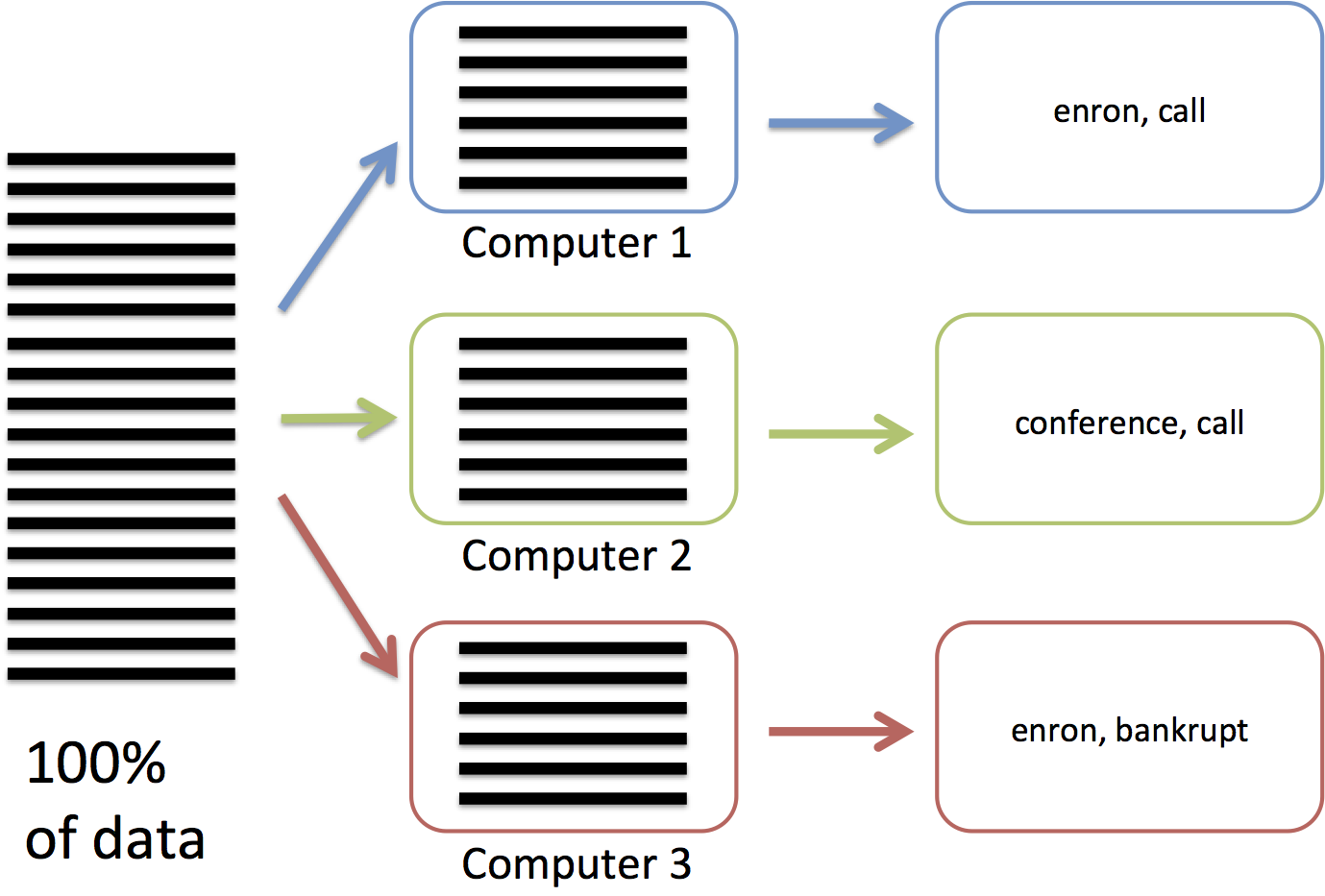
In the map phase (figure below), we are going to send each computer
1/3 of the lines. Each computer will process their 1,000,000 lines by
reading each of the lines and tokenizing their words.
For example, the first machine may extract «enron, call,…», while
the second machine extracts «conference, call,…».
From the words, we will create (key, value) pairs (or (word, 1) pairs
in this example). The shuffle phase will
assigned each key to one of the 3 computer, and all the values associated with
the same key are sent to the key’s computer. This is necessary because the whole
dictionary doesn’t fit in the memory of a single computer! Think of
this as creating the (key, value) pairs of a huge dictionary that
spans all of the 3,000,000 emails. Because the whole dictionary
doesn’t fit into a single machine, the keys are distributed across our
3 machines. In this example, «enron» is assigned to computer 1, while
«call» and «conference» are assigned to computer 2, and «bankrupt» is
assigned to computer 3.
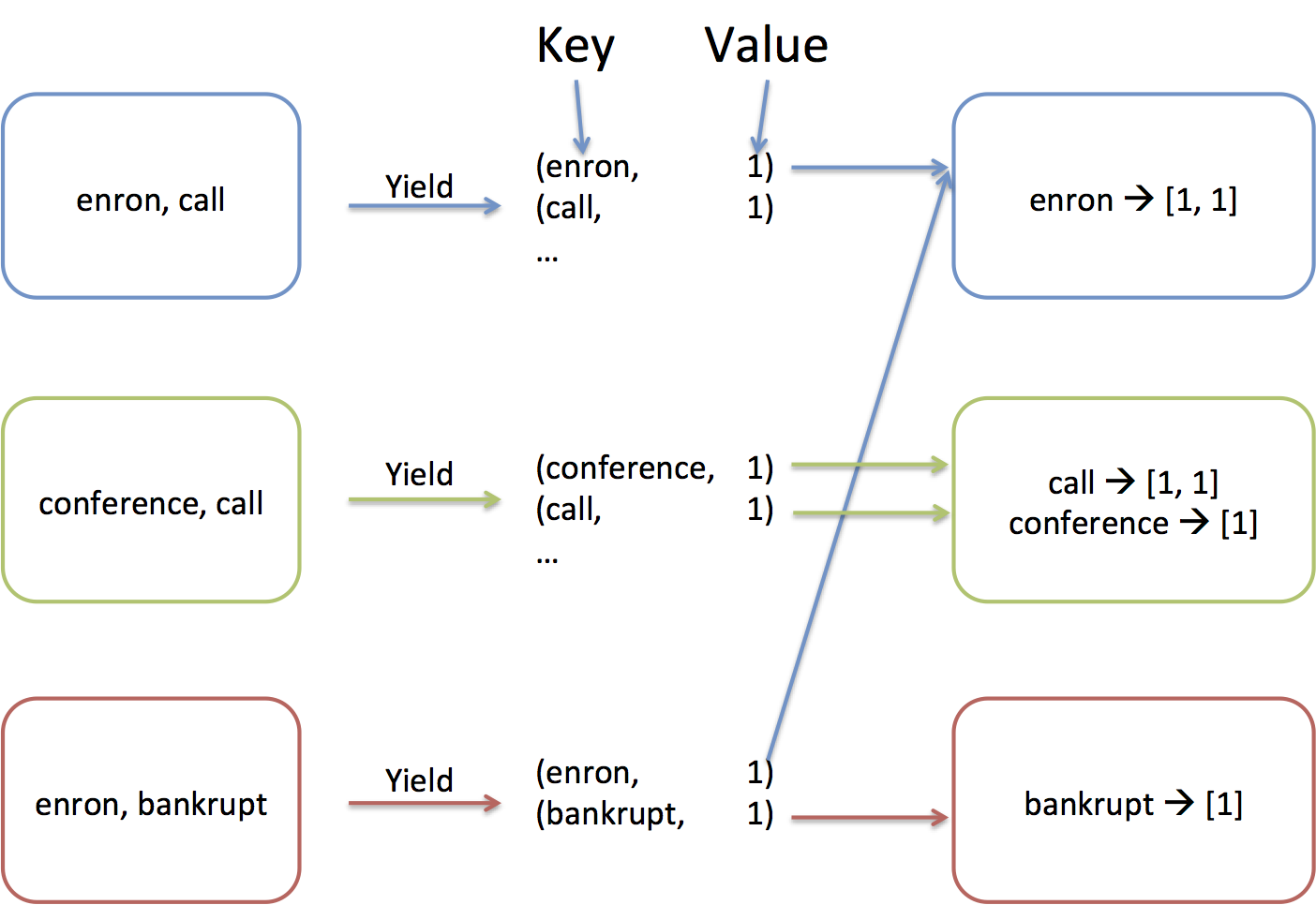
Finally, once each machine has received the values of the keys it’s
responsible for, the reduce phase will process each key’s value. It does this by
going through each key that is assigned to the machine and executing
a reducer function on the values associated with the key. For example,
«enron» was associated with a list of three 1’s, and the reducer step
simply adds them up.
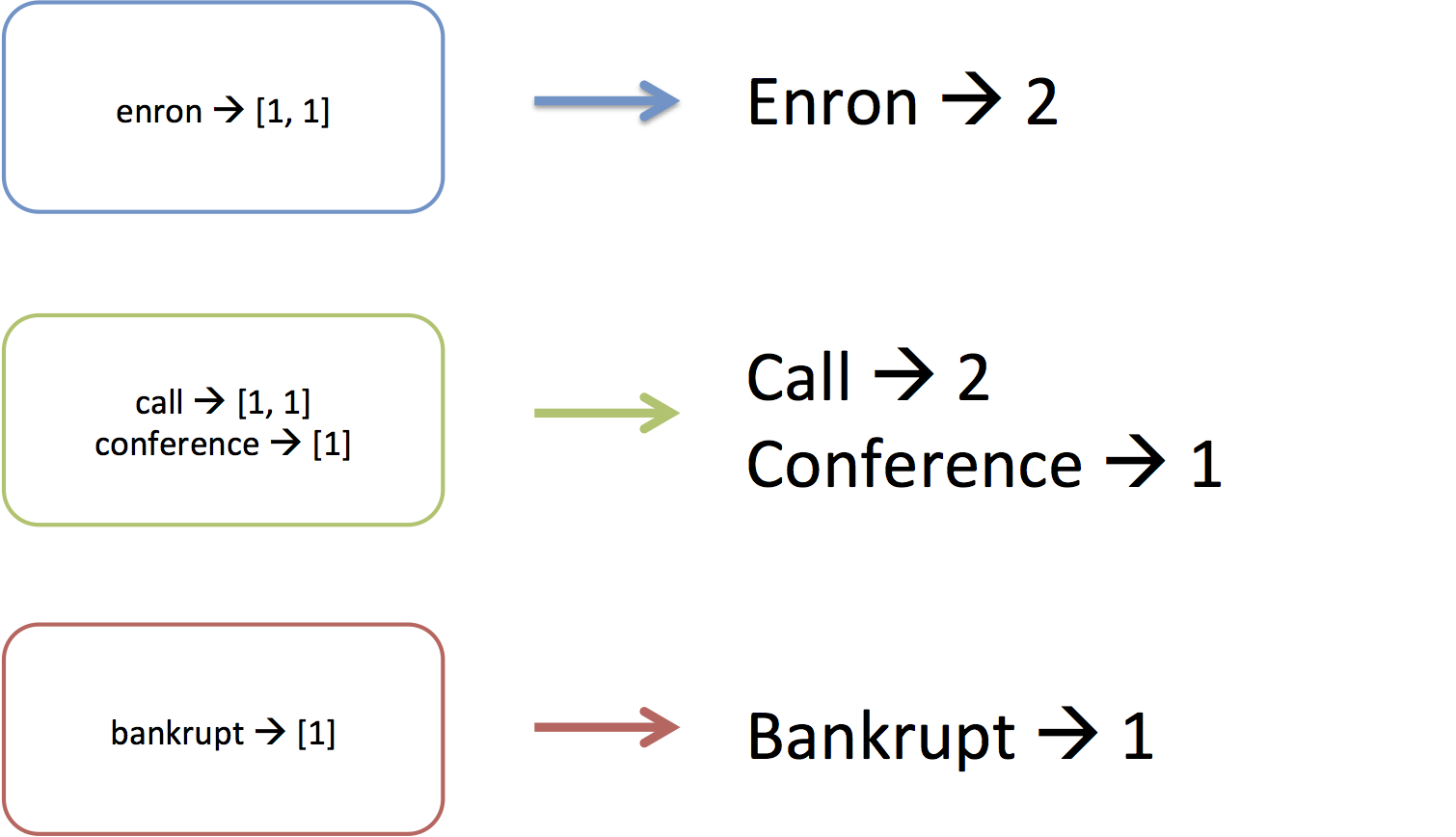
MapReduce is more general-purpose than just serving to count words.
Some people have used it to do exotic things like process millions of
songs,
but we want you to work through an entire end-to-end example.
Without further ado, here’s the wordcount example, but written as a
MapReduce application:
import sys from mrjob.protocol import JSONValueProtocol from mrjob.job import MRJob from term_tools import get_terms class MRWordCount(MRJob): INPUT_PROTOCOL = JSONValueProtocol OUTPUT_PROTOCOL = JSONValueProtocol def mapper(self, key, email): for term in get_terms(email['text']): yield term, 1 def reducer(self, term, occurrences): yield None, {'term': term, 'count': sum(occurrences)} if __name__ == '__main__': MRWordCount.run()
Let’s break this thing down. You’ll notice the term MRJob in a bunch
of places. MRJob is a python package
that makes writing MapReduce programs easy. The developers at Yelp (they wrote the mrjob module)
wrote a convenience class called MRJob that you will extend. When it’s run, it automatically hooks into the MapReduce
framework, reads and parses the input files, and does a bunch of other
things for you.
What we do is create a class MRWordCount that extends MRJob, and
implement the mapper and reducer functions. If the program is run from the
command line (the if __name__ == '__main__': part), it will execute
the MRWordCount MapRedce program.
Looking inside MRWordCount, we see INPUT_PROTOCOL being set to
JSONValueProtocol. By default, map functions expect a line of text
as input, but we’ve encoded our emails as JSON, so we let MRJob know
that. Similarly, we explain that our reduce tasks will emit
dictionaries by setting OUTPUT_PROTOCOL appropriately.
The mapper function handles the functionality described in the first
image of the last section. It takes each email, tokenizes it into
terms, and yields each term. You can yield a key and a value
(term and 1) in a mapper (notice «yield» arrows in the second
figure above). We yield the term with the value 1,
meaning one instance of the word term was found. yield is a
python keyword that turns functions into iterators (stack
overflow explanation). In the context of writing mapper and
reducer functions, you can think of it as return.
The reducer function implements the third image of the last section.
We are given a word (the key emitted from mappers), and a list
occurrences of all of the values emitted for each instance of
term. Since we are counting occurrences of words, we yield a
dictionary containing the term and a sum of the occurrences we’ve seen.
Note that we sum instead of len the occurrences. This allows us to change the mapper implementation to emit the number of times each word occurs in a document, rather than 1 for each word.
Both the mapper and reducer offer us the parallelism we wanted. There is no loop through our entire set of emails, so MapReduce is free to distribute the emails to multiple machines, each of which will run mapper on an email-by-email basis. We don’t have a single dictionary with the count of every word, but instead have a reduce function that has to sum up the occurrences of a single word, meaning we can again distribute the work to several reducing machines.
Run It!
Enough talk! Let’s run this thing.
python mr_wordcount.py -o 'wordcount_test' --no-output '../datasets/emails/lay-k.json'
The -o flag tells MRJob to output all reducer output to the wordcount_test directory. The --no-output flag says not to print the output of the reducers to the screen. The last argument ('../datasets/emails/lay-k.json') specifies which file (or files) to read into the mappers as input.
Take a look at the newly created wordcount_test directory. There should be at least one file (part-00000), and perhaps more. There is one file per reducer that counted words. Reducers don’t talk to one-another as they do their work, and so we end up with multiple output files. While the count of a specific word will only appear in one file, we have no idea which reducer file will contain a given word.
The output files (open one up in a text editor) list each word as a dictionary on a single line (OUTPUT_PROTOCOL = JSONValueProtocol in mr_wordcount.py is what caused this).
You will notice we have not yet run tasks on large datasets (we’re still using lay-k.json) and we are still running them locally on our computers. We will soon learn to movet his work to Amazon’s cloud infrastructure, but running MRJob tasks locally to test them on a small file is forever important. MapReduce tasks will take a long time to run and hold up several tens to several hundreds of machines. They also cost money to run, whether they contain a bug or not. Test them locally like we just did to make sure you don’t have bugs before going to the full dataset.
Show off What you Learned
Exercise Create a second version of the MapReduce wordcounter that counts the number of each word emitted by each sender. You will need this for later, since we’re going to be calculating TF-IDF implementing terms per sender. You can accomplish this with a sneaky change to the term emitted by the mapper. You can either turn that term into a dictionary, or into a more complicated string, but either way you will have to encode both sender and term information in that term. If you get stuck, take a peak at dataiap/day5/mr_wc_by_sender.py.
(Optional) Exercise The grep command on UNIX-like systems allows you to search text files for some term or terms. Typing grep hotdogs file1 will return all instances of the word hotdogs in the file file1. Implement a grep for emails. When a user uses your mapreduce program to find a word in the email collection, they will be given a list of the subjects and senders of all emails that contain the word. You might find you do not need a particularly smart reducer in this case: that’s fine. If you’re pressed for time, you can skip this exercise.
We now know how to write some pretty gnarly MapReduce programs, but they all run on our laptops. Sort of boring. It’s time to move to the world of distributed computing, Amazon-style!
Amazon Web Services
Amazon Web Services (AWS) is Amazon’s gift to people who don’t own datacenters. It allows you to elastically request computation and storage resources at varied scales using different services. As a testiment to the flexibility of the services, companies like NetFlix are moving their entire operation into AWS.
In order to work with AWS, you will need to set up an account. If you’re in the class, we will have given you a username, password, access key, and access secret. To use these accounts, you will have to login through a special class-only webpage. The same instructions work for people who are trying this at home, only you need to log in at the main AWS website.
The username and password log you into the AWS console so that you can click around its interface. In order to let your computer identify itself with AWS, you have to tell your computer your access key and secret. On UNIX-like platforms (GNU/Linux, BSD, MacOS), type the following:
export AWS_ACCESS_KEY_ID='your_key_id' export AWS_SECRET_ACCESS_KEY='your_access_id'
On windows machines, type the following at the command line:
set AWS_ACCESS_KEY_ID=your_key_id set AWS_SECRET_ACCESS_KEY=your_access_id
Replace your_key_id and your_access_id with the ones you were assigned.
That’s it! There are more than a day’s worth of AWS services to discuss, so let’s stick with two of them: Simple Storage Service (S3) and Elastic MapReduce (EMR).
AWS S3
S3 allows you to store gigabytes, terabytes, and, if you’d like, petabytes of data in Amazon’s datacenters. This is useful, because laptops often don’t crunch and store more than a few hundred gigabytes worth of data, and storing it in the datacenter allows you to securely have access to the data in case of hardware failures. It’s also nice because Amazon tries harder than you to have the data be always accessible.
In exchange for nice guarantees about scale and accessibility of data, Amazon charges you rent on the order of 14 cents per gigabyte stored per month.
Services that work on AWS, like EMR, read data from and store data to S3. When we run our MapReduce programs on EMR, we’re going to read the email data from S3, and write word count data to S3.
S3 data is stored in buckets . Within a bucket you create, you can store as many files or folders as you’d like. The name of your bucket has to be unique across all of the people that store their stuff in S3. Want to make your own bucket? Let’s do this!
- Log in to the AWS console (the website), and click on the S3 tab. This will show you a file explorer-like interface, with buckets listed on the left and files per bucket listed on the right.
- Click «Create Bucket» near the top left.
- Enter a bucket name. This has to be unique across all users of S3. Pick something like
dataiap-YOURUSERNAME-testbucket. Do not use underscores in the name of the bucket . - Click «Create»
This gives you a bucket, but the bucket has nothing in it! Poor bucket. Let’s upload Kenneth Lay’s emails.
- Select the bucket from the list on the left.
- Click «Upload.»
- Click «Add Files.»
- Select the
lay-k.jsonfile on your computer. - Click «Start Upload.»
- Right click on the uploaded file, and click «Make Public.»
- Verify the file is public by going to
http://dataiap-YOURUSERNAME-testbucket.s3.amazonaws.com/lay-k.json.
Awesome! We just uploaded our first file to S3. Amazon is now hosting the file. We can access it over the web, which means we can share it with other researchers or process it in Elastic MapReduce. To save time, we’ve uploaded the entire enron dataset to https://dataiap-enron-json.s3.amazonaws.com/. Head over there to see all of the different Enron employee’s files listed (the first three should be allen-p.json, arnold-j.json, and arora-h.json).
Two notes from here. First, uploading the file to S3 was just an exercise—we’ll use the dataiap-enron-json bucket for our future exercises. That’s because the total file upload is around 1.3 gigs, and we didn’t want to put everyone through the pain of uploading it themselves. Second, most programmers don’t use the web interface to upload their files. They instead opt to upload the files from the command line. If you have some free time, feel free to check out dataiap/resources/s3_util.py for a script that copies directories to and downloads buckets from S3.
Let’s crunch through these files!
AWS EMR
We’re about to process the entire enron dataset. Let’s do a quick sanity check that our mapreduce wordcount script still works. We’re about to get into the territory of spending money on the order of 10 cents per machine-hour, so we want to make sure we don’t run into preventable problems that waste money.
python mr_wordcount.py -o 'wordcount_test2' --no-output '../datasets/emails/lay-k.json'
Did that finish running and output the word counts to wordcount_test2? If so, let’s run it on 20 machines (costing us $2, rounded to the nearest hour). Before running the script, we’ll talk about the parameters:
python mr_wordcount.py --num-ec2-instances=20 --python-archive package.tar.gz -r emr -o 's3://dataiap-YOURUSERNAME-testbucket/output' --no-output 's3://dataiap-enron-json/*.json'
The parameters are:
num-ec2-instances: we want to run on 20 machines in the cloud. Snap!python-archive: when the script runs on remote machines, it will need term_tools.py in order to tokenize the email text. We have packaged this file into package.tar.gz.-r emr: don’t run the script locally—run it on AWS EMR.-o 's3://dataiap-YOURUSERNAME-testbucket/output': write script output to the bucket you made when playing around with S3. Put all files in a directory calledoutputin that bucket. Make sure you changedataiap-YOURUSERNAME-testbucketto whatever bucket name you picked on S3.--no-output: don’t print the reducer output to the screen.'s3://dataiap-enron-json/*.json': perform the mapreduce with input from thedataiap-enron-jsonbucket that the instructors created, and use as input any file that ends in.json. You could have named a specific file, likelay-k.jsonhere, but the point is that we can run on much larger datasets.
Check back on the script. Is it still running? It should be. You may as well keep reading, since you’ll be here a while. In total, our run took three minutes for Amazon to requisition the machines, four minutes to install the necessary software on them, and between 15 adn 25 minutes to run the actual MapReduce tasks on Hadoop. That might strike some of you as weird, and we’ll talk about it now.
Understanding MapReduce is about understanding scale . We’re used to thinking of our programs as being about performance , but that’s not the role of MapReduce. Running a script on a single file on a single machine will be faster than running a script on multiple files split amongst multiple machines that shuffle data around to one-another and emit the data to a service (like EMR and S3) over the internet is not going to be fast. We write MapReduce programs because they let us easily ask for 10 times more machines when the data we’re processing grows by a factor of 10, not so that we can achieve sub-second processing times on large datasets. It’s a mental model switch that will take a while to appreciate, so let it brew in your mind for a bit.
What it does mean is that MapReduce as a programming model is not a magic bullet. The Enron dataset is not actually so large that it shouldn’t be processed on your laptop. We used the dataset because it was large enough to give you an appreciation for order-of-magnitue file size differences, but not large enough that a modern laptop can’t process the data. In practice, don’t look into MapReduce until you have several tens or hundreds of gigabytes of data to analyze. In the world that exists inside most companies, this size dataset is easy to stumble upon. So don’t be disheartened if you don’t need the MapReduce skills just yet: you will likely need them one day.
Analyzing the output
Hopefully your first mapreduce is done by now. There are two bits of output we should check out. First, when the MapReduce job finishes, you will see something like the following message in your terminal window:
Counters from step 1: FileSystemCounters: FILE_BYTES_READ: 499365431 FILE_BYTES_WRITTEN: 61336628 S3_BYTES_READ: 1405888038 S3_BYTES_WRITTEN: 8354556 Job Counters : Launched map tasks: 189 Launched reduce tasks: 85 Rack-local map tasks: 189 Map-Reduce Framework: Combine input records: 0 Combine output records: 0 Map input bytes: 1405888038 Map input records: 516893 Map output bytes: 585440070 Map output records: 49931418 Reduce input groups: 232743 Reduce input records: 49931418 Reduce output records: 232743 Reduce shuffle bytes: 27939562 Spilled Records: 134445547
That’s a summary of, on your 20 machines, how many Mappers and Reducers ran. You can run more than one of each on a physical machine, which explains why more than 20 of each ran in our tasks. Notice how many reducers ran your task. Each reducer is going to receive a set of words and their number of occurrences, and emit word counts. Reducers don’t talk to one-another, so they end up writing their own files.
With this in mind, go to the S3 console, and look at the output directory of the S3 bucket to which you output your words. Notice that there are several files in the output directory named part-00000, part-00001. There should be as many files as there were reducers, since each wrote the file out. Download some of these files and open them up. You will see the various word counts for words across the entire Enron email corpus. Life is good!
(Optional) Exercise : Make a directory called copied. Copy the output from your script to copied using dataiap/resources/s3_util.py with a command like python ../resources/s3_util get s3://dataiap-YOURUSERNAME-testbucket/output copied. Once you’ve got all the files downloaded, load them up and sort the lines by their count. Do the popular terms across the entire dataset make sense?
TF-IDF
This section is going to further exercise our MapReduce-fu.
On day 4, we learned that counting words is not enough to summarize text: common words like the and and are too popular. In order to discount those words, we multiplied by the term frequency of wordX by log(total # documents/# documents with wordX). Let’s do that with MapReduce!
We’re going to emit a per-sender TF-IDF. To do this, we need three MapReduce tasks:
-
The first will calculate the number of documents, for the numerator in IDF.
-
The second will calculate the number of documents each term appears in, for the denominator of IDF, and emits the IDF (
log(total # documents/# documents with wordX)). -
The third calculates a per-sender IDF for each term after taking both the second MapReduce’s term IDF and the email corpus as input.
HINT Do not run these MapReduce tasks on Amazon. You saw how slow it was to run, so make sure the entire TF-IDF workflow works on your local machine with lay-k.json before moving to Amazon.
MapReduce 1: Total Number of Documents
Eugene and I are the laziest of instructors. We don’t like doing work where we don’t have to. If you’d like a mental exercise as to how to write this MapReduce, you can do so yourself, but it’s simpler than the wordcount example. Our dataset is small enough that we can just use the wc UNIX command to count the number of lines in our corpus:
Kenneth Lay has 5929 emails in his dataset. We ran wc -l on the entire Enron email dataset, and got 516893. This took a few seconds. Sometimes, it’s not worth overengineering a simple task!:)
MapReduce 2: Per-Term IDF
We recommend you stick to 516893 as your total number of documents, since eventually we’re going to be crunching the entire dataset!
What we want to do here is emit log(516893.0 / # documents with wordX) for each wordX in our dataset. Notice the decimal on 516893.0: that’s so we do floating point division rather than integer division. The output should be a file where each line contains {'term': 'wordX', 'idf': 35.92} for actual values of wordX and 35.92.
We’ve put our answer in dataiap/day5/mr_per_term_idf.py, but try your hand at writing it yourself before you look at ours. It can be implemented with a three-line change to the original wordcount MapReduce we wrote (one line just includes math.log!).
MapReduce 3: Per-Sender TF-IDFs
The third MapReduce multiplies per-sender term frequencies by per-term IDFs. This means it needs to take as input the IDFs calculated in the last step and calculate the per-sender TFs. That requires something we haven’t seen yet: initialization logic. Let’s show you the code, then tell you how it’s done.
import os from mrjob.protocol import JSONValueProtocol from mrjob.job import MRJob from term_tools import get_terms DIRECTORY = "/path/to/idf_parts/" class MRTFIDFBySender(MRJob): INPUT_PROTOCOL = JSONValueProtocol OUTPUT_PROTOCOL = JSONValueProtocol def mapper(self, key, email): for term in get_terms(email['text']): yield {'term': term, 'sender': email['sender']}, 1 def reducer_init(self): self.idfs = {} for fname in os.listdir(DIRECTORY): # look through file names in the directory file = open(os.path.join(DIRECTORY, fname)) # open a file for line in file: # read each line in json file term_idf = JSONValueProtocol.read(line)[1] # parse the line as a JSON object self.idfs[term_idf['term']] = term_idf['idf'] def reducer(self, term_sender, howmany): tfidf = sum(howmany) * self.idfs[term_sender['term']] yield None, {'term_sender': term_sender, 'tfidf': tfidf}
If you did the first exercise , the mapper and reducer functions should look a lot like the per-sender word count mapper and reducer functions you wrote for that. The only difference is that reducer takes the term frequencies and multiplies them by self.idfs[term], to normalize by each word’s IDF. The other difference is the addition of reducer_init, which we will describe next.
self.idfs is a dictionary containing term-IDF mappings from the second MapReduce. Say you ran the IDF-calculating MapReduce like so:
python mr_per_term_idf.py -o 'idf_parts' --no-output '../datasets/emails/lay-k.json'
The individual terms and IDFs would be emitted to the directory idf_parts/. We would want to load all of these term-idf mappings into self.idfs. Set DIRECTORY to the filesystem path that points to the idf_parts/ directory.
Sometimes, we want to load some data before running the mapper or the reducer. In our example, we want to load the IDF values into memory before executing the reducer, so that the values are available when we compute the tf-idf. The function reducer_init is designed to perform this setup. It is called before the first reducer is called to calculate TF-IDF. It opens all of the output files in DIRECTORY, and reads them into self.idfs. This way, when reducer is called on a term, the idf for that term has already been calculated.
To verify you’ve done this correctly, compare your output to ours. There were some pottymouths that emailed Kenneth Lay:
{«tfidf»: 13.155591168821202, «term_sender»: {«term»: «a-hole», «sender»: «justinsitzman@hotmail.com»}}
Why is it OK to Load IDFs Into Memory?
You might be alarmed at the moment. Here we are, working with BIG DATA, and now we’re expecting the TF-IDF calculation to load the entirety of the IDF data into memory on EVERY SINGLE reducer. That’s crazytown.
It’s actually not. While the corpus we’re analyzing is large, the number of words in the English language (roughly the amount of terms we calculate IDF for) is not. In fact, the output of the per-term IDF calculation was around 8 megabytes, which is far smaller than the 1.3 gigabytes we processed. Keep this in mind: even if calculating something over a large amount of data is hard and takes a while, the result might end up small.
Optional: Run The TF-IDF Workflow
We recommend running the TF-IDF workflow on Amazon once class is over. The first MapReduce script (per-term IDF) should run just fine on Amazon. The second will not. The reducer_init logic expects a file to live on your local directory. You will have to modify it to read the output of the IDF calculations from S3 using boto. Take a look at the code to implement get in dataiap/resources/s3_util.py for a programmatic view of accessing files in S3.
Where to go from here
We hope that MapReduce serves you well with large datasets. If this kind of work excites you, here are some things to read up on.
- As you can see, writing more complex workflows for things like TF-IDF can get annoying. In practice, folks use higher-level languages than
mapandreduceto build MapReduce workflows. Some examples are Pig, Hive, and Cascading. - If you care about making your MapReduce tasks run faster, there are lots of tricks you can play. One of the easiest things to do is to add a combiners between your
mapperandreducer. A combiner has similar logic to a reducer, but runs on a mapper before the shuffle stage. This allows you to, for example, pre-sum the words emitted by the map stage in a wordcount so that you don’t have to shuffle as many words around. - MapReduce is one model for parallel programming called data parallelism . Feel free to read about others.
- When MapReduce runs on multiple computers, it’s an example of distributed computing, which has a lot of interesting applications and problems to be solved.
- S3 is a distributed storage system and is one of many. It is built upon Amazon’s Dynamo technology. It’s one of many distributed file systems and distributed data stores.
Mapreduce with Hadoop via Python with Examples
Table of content
- Table of content
- Introduction
- Word count problem
- Implement the mapreduce function for word count
- Implement
mapperfunction - shuffle procedure
- Implement
reducerfunction
- Implement
- Submit the mapreduce program to Hadoop cluster
- Start local Hadoop server
- Copy data files to HDFS
- Submit job to Hadoop
- Implement
mapper.py - Implement
reducer.py
- Implement the mapreduce function for word count
Introduction
In this article I will try to set up two examples of running mapreduce functions on Hadoop by Python. Aparche Hadoop framework is originally meant for Java. However, with Hadoop streaming API we can implement mapreduce functions in Python. In particular, the input and output of mapreduce functions are handled by standard input/output stream STDIN and STDOUT. We use Python module sys.stdin to do the trick.
Word count problem
- Word count is a canonical problem which is to count the occurrences of words in a document.
- The mapper function will take in the raw text file and convert it into a collection of key-value pairs. Each key is a word, and all keys (words) will have a value of 1.
- The reducer function will summary all key-value pairs in which the values of the same key are combined. The result is a list of unique key with the count of appearance.
Implement the mapreduce function for word count
- With Hadoop streaming API, we aim to write a Python script acting as a mapper and a Python script acting as reducer.
-
In addition the scripts should work with data stream similar as the following
cat document | ./mapper.py | sort -k1,1 | ./reducer.py > output - Hadoop is implemented in Java and is meant for Java. However, with Hadoop streaming package we can write our own mapreduce function based on Python. There are a few good blog about using Hadoop streaming package with Python, for example,
- Writing a Hadoop mapreduce program in Python
- Performance analysis for scaling up R computation using Hadoop
- Python mapreduce on Hadoop — a beginners tutorial
- Here we provide a step-by-step tutorial on running a python mapreduce program on Hadoop on a Macos.
- The magic is to use Hadoop stream API which allows data pass Hadoop through
STDINandSTDOUT. - We will be using Python
sys.stdinandsys.stdoutto read and write data. Hadoop will take care of other matters.
Implement mapper function
- The first thing we need to do is to write a mapper function.
- Let us call the mapper function
mapper.py. - The function will read in a partition of data (probably a section of a file) from the standard input stream
STDINand output key and value pairs. - An example
mapper.pyis given as the following
#!/usr/bin/env python
import sys
def main():
for line in sys.stdin:
words = line.strip().split()
for word in words:
print "%st1" % word
if __name__ == "__main__":
main()
- It is worth noting that the first line is important which make the script executable by Hadoop.
- Make sure
mapper.pyare accessible by executing the commandchmod a+X mapper.py
shuffle procedure
- The operation between mapper reducer is sometimes called shuffle
- All key-value pairs are sorted according to the key before send to reducer.
- All pairs with the same key are send to the same reducer.
- The shuffle process is important because
- As the reducer are reading data stream, if it comes across a key that is different from the previous one, it knows that the previous key will never appear again.
- If all key-value pair share the same key, it ends up with only one reducer. There is no parallelization in this case.
Implement reducer function
- Now we are going to implement
reducer.py. - The function will get input from standard output stream
STDOUTwhich is the output of the mapper function, process the data and write toSTDOUT. - An example
reducer.pyis shown as the following
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#!/usr/bin/env python
import sys
def main():
curword = None
curcount = 0
for line in sys.stdin:
word,count=line.strip().split('t')
if curword == None:
curword = word
curcount = 1
continue
if curword == word:
curword = word
curcount += 1
else:
print "%st%d" %(curword,curcount)
curword = word
curcount = eval(count)
print "%st%d" %(curword,curcount)
if __name__=='__main__':
main()
- Make sure
reducer.pyare accessible by executing the commandchmod a+X reducer.py.
Submit the mapreduce program to Hadoop cluster
Start local Hadoop server
- If you have followed my instruction to set hadoop on MacOS, you can start Hadoop server with command
hstart -
Use command
jpsto check if everything is fine with your Hadoop. In particular, you should have the following servers up and running8257 Jps 6214 NameNode 6550 ResourceManager 6424 SecondaryNameNode 6651 NodeManager 8172 DataNode - You might come across the problem that the datanode is missing which means you did not manage to start the datanode. To start the datanode, you can
- Stop all Hadoop services with
hstop. - Format the HDFS filesystem with
hdfs datanote -format. - Restart all Hadoop services with
hstart.
- Stop all Hadoop services with
- If the above does not work or you don’t care about the data on the HSDF, you can
- Stop all Hadoop services with
hstop. - delete all file in
<name>hadoop.tmp.dir</name>which is specified in the configuration file located (in my case)/usr/local/Cellar/hadoop/2.7.1/libexec/etc/hadoop/Core-site.xml. - Format the HDFS filesystem with
hdfs datanote -format. - Restart all Hadoop services with
hstart.
- Stop all Hadoop services with
- The latter alternative works at least for me.
Copy data files to HDFS
-
First, let’s download a big text file with the following command
curl -O http://www.gutenberg.org/files/5000/5000-8.txtAs command
curlis for Macos, you might want to use other alternatives, e.g.wgetin other Linux machine -
Move the data file to the Hadoop file system with the following command
hadoop fs -put 5000-8.txt / -
Make sure that you have the file in the HDFS with the command
hadoop fs -ls /
Submit job to Hadoop
- Now, we should submit the job to Hadoop by calling its streaming function with the following command
1
2
3
4
5
hadoop jar
/usr/local/Cellar/hadoop/2.7.1/libexec/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar
-files ./mapper.py,./reducer.py
-mapper mapper.py -reducer reducer.py
-input /5000-8.txt -output /tmp
-
In case there are something wrong with codes, you should delete the result file from HDFS and run the above command again. Remove the previous result file with command
hadoop fs -rm -r /tmp -
Check the result with command
hadoop fs -cat /user/su/wc_out/part-00000
#Line count problem
Line count problem is to count the number of lines in a documents which can be accomplished by a mapreduce heuristics. Basically, the mapper function reads data one line by another and returns 1 after each line, and the reducer function sums up the returned valued.
Implement mapper.py
The mapper function is given as the following
Implement
reducer.pyThe
reducerfunction is given as the following
15 August 2015