
Generate a Word Cloud from any pdf
To generate a word cloud from a pdf, add the name of the pdf in main.py. Also,
provide the starting page number & the ending page which the word cloud generator should consider.
Here are some examples
Indian Constitution

The pdf of Indian Constitution was downloaded from the website of Ministry of Law and Justice (Legislative Department).
Animal Farm by George Orwell

Pride and Prejudice by Jane Austen

Animal farm and Pride & Prejudice were downloaded from the website of Project Gutenberg
Requirements
Python
PyPDF2(https://github.com/mstamy2/PyPDF2)
word_cloud(https://github.com/amueller/word_cloud)
Word cloud (Tag cloud) has become a very popular visualization method for text data, despite it is almost useless in drawing statistically-relevent conclusions. Word clouds can, however, be a quick way to present research interests on personal webpages.
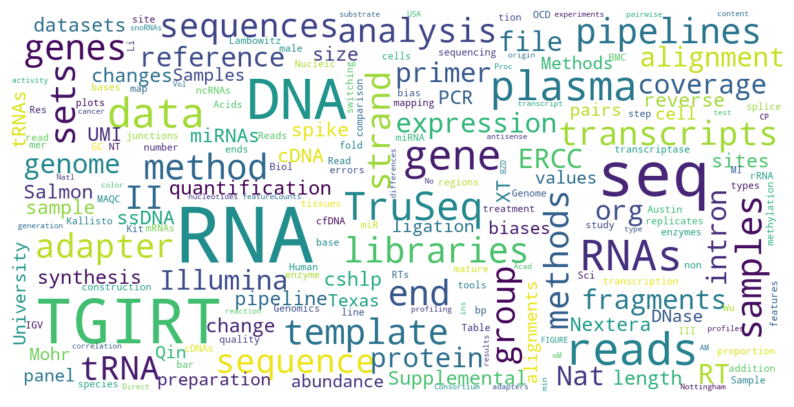
In this blog post, I will show how to use python to generate word cloud from a list of pdf files (a common file format for scientific publications).
We will need several python packages; wordcloud, PyPDF2, nltk and matplotlib, which can all be install from the conda-forge channel from conda.
- setting up the environment
conda create -n pdf_wordcloud python3 wordcloud
pypdf2 matplotlib nltk nltk_data
- activating the environment
source activate pdf_wordcloud
- here goes the scipt
TL;DR The script is deposited on github.
First import all the things that are needed:
import string
import re
import glob
import matplotlib.pyplot as plt
import wordcloud
import PyPDF2
import nltk
from calendar import month_name
from nltk.corpus import stopwords
In English, there are some general words (e.g. “you”, “me”, “is”) that are not necessarily helpful in natural language processings. We call these stop words and we want to exclude these words from our text database. Each of the NLTK and wordcloud package provides a list of stop words. So we will curate a list of stop words for filtering out the stop words in later steps.
ENGLISH_STOP = set(stopwords.words('english'))
I implemented the wordcloud as a python object, and only the required initializing input is the directory of the PDF files, and I also curated some extra words (self.paper_stop) that maybe publication-specific stop words (e.g. “Figure”, “Supplementary” and dates, in this case).
class research_wordcloud():
'''
Make word cloud from all PDF under a folder
Usage:
rs = research(paper_path)
rs.extract_text()
rs.filter_text()
rs.generate_wordcloud(figurename)
'''
def __init__(self, paper_path):
'''
find all pdf under paper_path
'''
self.paper_path = paper_path
self.PDFs = glob.glob(paper_path + '/*pdf') #any PDF can be found?
self.texts = '' # store all texts
self.tokens = None
self.words = None
self.paper_stop = ['fig','figure','supplementary', 'author','press',
'PubMed', 'manuscript','nt','et','al', 'laboratory',
'article','cold','spring','habor','harbor',
'additional', 'additionalfile','additiona file']
months = [month_name[i].lower() for i in range(1,13)]
self.paper_stop.extend(months)
self.paper_stop.extend(list(map(lambda x: x.capitalize(), self.paper_stop)))
self.paper_stop = set(self.paper_stop)
And then, I implemented a function to retrieve texts from the PDF files using PyPDF2:
def extract_text(self):
'''
read pdf text
'''
for pdf in self.PDFs:
with open(pdf, 'rb') as paper:
pdf = PyPDF2.PdfFileReader(paper)
for page_num in range(pdf.getNumPages()-1): #skip reference
page = pdf.getPage(page_num)
self.texts += page.extractText()
And a also function for filtering out stop words, as well as verbs. NLTK offers implementations to 1. tokenizing words (nltk.word_tokenize) from the full text, and 2. identifying if a word is a noun or verb, etc (nltk.pos_tag).
def filter_text(self):
'''
remove stop words and punctuations
'''
self.tokens = nltk.word_tokenize(self.texts)
self.tokens = nltk.pos_tag(self.tokens) #(tag the nature of each word, verb? noun?)
self.words = []
num_regex = re.compile('[0-9]+')
for word, tag in self.tokens:
IS_VERB = tag.startswith('V')
IS_STOP = word in set(string.punctuation)
IS_ENGLISH_STOP = word in set(ENGLISH_STOP)
IS_WORDCLOUD_STOP = word in wordcloud.STOPWORDS
IS_NUMBER = num_regex.search(word)
IS_PAPER_STOP = word in self.paper_stop
condition = [IS_VERB, IS_STOP, IS_ENGLISH_STOP,
IS_WORDCLOUD_STOP, IS_NUMBER, IS_PAPER_STOP]
if not any(condition):
if word == "coli":
self.words.append('E. coli') #unfortunate break down of E. coli
else:
self.words.append(word)
self.words = ' '.join(self.words)
Now, we can generate a wordcloud from the words we have curated.
def generate_wordcloud(self, figurename):
'''
plot
'''
wc = wordcloud.WordCloud(
collocations=False,
background_color='white',
max_words=200,
max_font_size=40,
scale=3
)
try:
wc.generate(self.words)
plt.imshow(wc, interpolation="bilinear")
plt.axis('off')
plt.savefig(figurename, bbox_inches='tight', transparent=True)
print('Written %s' %figurename)
except ValueError:
print(self.words)
So to run the whole thing:
PDF_path = '/home/wckdouglas/all_my_papers/'
wordcloud_image = '/home/wckdouglas/research_wordcloud.png'
wc = research_wordcloud(PDF_path)
wc.extract_text()
wc.filter_text()
wc.generate_wordcloud(wordcloud_image)

This work is licensed under a Creative Commons Attribution 4.0 International License.
If you liked this post, you can
share it with your followers
or
follow me on Twitter!
Project description
pdf_to_wordcloud
Generates a word cloud from a given PDF
Installation
$ pip install pdf_to_wordcloud
Arguments
Positional:
PDF: Name of PDF file from which to geneate the wordcloud
Optional:
—remove (-r): Removes word from wordcloud. Accepts multiple arguments (one per flag)
—save (-s): Saves wordcloud as PDF to current directory (no additional argument needed)
—saveto (-st): Saves wordcloud to specified directory
—mask (-m): PNG file to use as shape of wordcloud
—exportdata (-x): Save CSV of word frequency data
—filename (-n): Optional name of data and wordcloud files (omit .pdf/.csv)
Usage
Display wordcloud of file.pdf:
$ pdf file.pdf
Save image of wordcloud as PDF:
$ pdf file.pdf -s
Remove «this» and «that» from wordcloud and save:
$ pdf file.pdf -r this -r that -s
Remove «this» and «that» from wordcloud, export word frequency data and save both files with «my_output» filename:
$ pdf file.pdf -r this -r that -x -n my_output -s
Download files
Download the file for your platform. If you’re not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
PDF Converter
PDF is a document file format that contains text, images, data etc. This document type is Operating System independent. It is an open standard that compresses a document and vector graphics. It can be viewed in web browsers if the PDF plug-in is installed on the browser.
DOC Converter
DOC
DOC is a word processing file created by Microsoft. This files format turns a plain-text format into a formatted document. It supports almost all the Operating Systems. It can contain large amount of text, data, charts, table, image etc. It can contain rich text format (RTF) and HTML texts also.
+200 Formats Supported
CloudConvert is your universal app for file conversions. We support nearly all audio, video,
document, ebook, archive, image, spreadsheet, and presentation formats. Plus, you can use our online
tool without downloading any software.
Data Security
CloudConvert has been trusted by our users and customers since its founding in 2012. No one except you
will ever have access to your files. We earn money by selling access to our API, not by selling your
data. Read more about that in our Privacy Policy.
High-Quality Conversions
Besides using open source software under the hood, we’ve partnered with various software vendors to
provide the best possible results. Most conversion types can be adjusted to your needs such as setting
the quality and many other options.
Powerful API
Our API allows custom integrations with your app. You pay only for what you actually use, and there are
huge discounts for high-volume customers. We provide a lot of handy features such as full Amazon S3
integration. Check out the CloudConvert API.
On my professional website, I use wordclouds from the text of my publications as the featured images for the posts where I share the publications. I have used a website to generate those wordclouds for quite a while, but I’m trying to learn how to use the R statistical environment and knew that R can generate wordclouds. So, I thought I’d give it a try.
Here are the steps to generating a wordcloud from the text of a PDF using R.
First, in R, install the following four packages: “tm”, “SnowballC”, “wordcloud”, and “readtext”. This is done by typing the following into the R terminal:
install.packages("tm")
install.packages("SnowballC")
install.packages("wordcloud")
install.packages("readtext")
(NOTE: You may need to install the following packages on your Linux system using synaptic or bash before you can install the above packages: r-cran-slam, r-cran-rcurl, r-cran-xml, r-cran-curl, r-cran-rcpp, r-cran-xml2, r-cran-littler, r-cran-rcpp, python-pdftools, python-sip, python-qt4, libpoppler-dev, libpoppler-cpp-dev, libapparmor-dev.)
Next, you need to load those packages into the R environment. This is done by typing the following in the R terminal:
library(tm)
library(SnowballC)
library(wordcloud)
library(readtext)
Before we begin creating the wordcloud, we have to get the text out of the PDF file. To do this, first find out where your “working directory” is. The working directory is where the R environment will be looking for and storing files as it runs. To determine your “working directory,” use the following function:
getwd()
There are no arguments for this function. It will simply return where the R environment is currently looking for and storing files.
You’ll need to put the PDF from which you want to extract data into your working directory or change your working directory to the location of your PDF (technically, you could just include the path, but putting it in your working directory is easier). To change the working directory, use the “setwd()” function. Like this:
setwd("/home/ryan/RWD")
Once you have your PDF in your working directory, you can use the readtext package to extract the text and put it into a variable. You can do that using the following command:
wordbase <- readtext("paper.pdf")
“wordbase” is a variable I’m creating to hold the text from the PDF. The variable is actually a data frame (data.frame) with two columns and one row. The first column is the document ID (e.g., “paper.pdf”); the second column is the extracted text. You can see what kind of variable it is using the command:
print(wordbase)
This gives you the following information:
readtext object consisting of 1 document and 0 docvars.
# data.frame [1 × 2]
doc_id text
<chr> <chr>
1 career.pdf "" "..."
R won’t show you all of the text in the text column as it is likely quite a bit of text. If you want to display all the text (WARNING: It may be a lot of text), you can do so by telling R to display the contents of that cell of the data frame, which is row 1, column 2:
wordbase[1, 2]
“readtext” is the package that extracts the text from the PDF. The readtext package is robust enough to be able to extract text from numerous documents (see here) and is even able to determine what kind of document it is from the file extension; in this case, it recognize that it’s a PDF.
The list can now be converted into a corpus, which is a vector (see here for the different data types in R). To do this, we use the following function:
corp <- Corpus(VectorSource(wordbase))
In essence, we’re creating a new variable, “corp,” by using the Corpus function that calls the VectorSource function and applies it to the list of words in the variable “wordbase.”
We’re close to having the words ready to create the wordcloud, but it’s a good idea to clean up the corpus with several commands from the “tm” package. First, we want to make sure the corpus is a plain text:
corp <- tm_map(corp, PlainTextDocument)
Next, since we don’t want any of the punctuation included in the wordcloud, we remove the punctuation with this function from “tm”:
corp <- tm_map(corp, removePunctuation)
For my wordclouds, I don’t want numbers included. So, use this function to remove the numbers from the corpus:
corp <- tm_map(corp, removeNumbers)
I also want all of my words in lowercase. There is a function for that as well:
corp <- tm_map(corp, tolower)
Finally, I’m not interested in words like “the” or “a”, so I removed all of those words using this function:
corp <- tm_map(corp, removeWords, stopwords(kind = "en"))
At this point, you’re ready to generate the wordcloud. What follows is a wordcloud command, but it will generate the wordcloud in a window and you’ll then have to do a screen capture to turn the wordcloud into an image. Even so, here is the basic command:
wordcloud(corp, max.words = 100, random.order = FALSE)

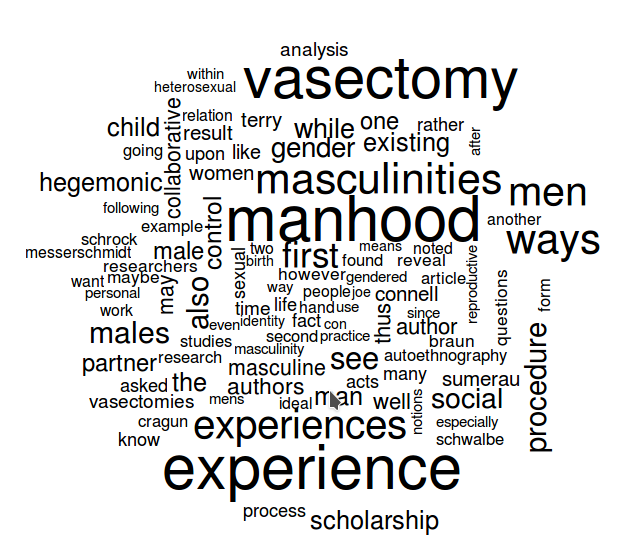
To explain the command, “wordcloud” is the package and function. “corp” is the corpus containing all the words. The other components of the command are parameters that can, of course, be adjusted. “max.words” can be increased or decreased to reflect the number of words you want to include in your wordcloud. “random.order” should be set to FALSE if you want the more frequently occurring words to be in the center with the less frequently occurring words surrounding them. If you set that parameter to TRUE, the words will be in random order, like this:
There are additional parameters that can be added to the wordcloud command, including a scale parameter (scale) that adjusts the relative sizes of the more and less frequently occurring words, a minimum frequency parameter (min.freq) that will limit the plotted words to only those that occur a certain number of times, a parameter for what proportion of words should be rotated 90 degrees (rot.per). Other parameters are detailed in the wordcloud documentation here.
One of the more important parameters that can be added is color (colors). By default, wordclouds are black letters on a white background. If you want the word color to vary with the frequency, you need to create a variable that details to the wordcloud function how many colors you want and from what color palette. A number of color palettes are pre-defined in R (see here). Here’s a sample command to create a color variable that can be used with the wordcloud package:
color <- brewer.pal(8,"Spectral")
The parameters in the parentheses indicate first, the number of colors desired (8 in the example above), and second, the palette title from the list noted above. Generating the wordcloud with the color palette applied involves adding one more variable to the command:
wordcloud(corp, max.words = 100, min.freq=15, random.order = FALSE, colors = color, scale=c(8, .3))
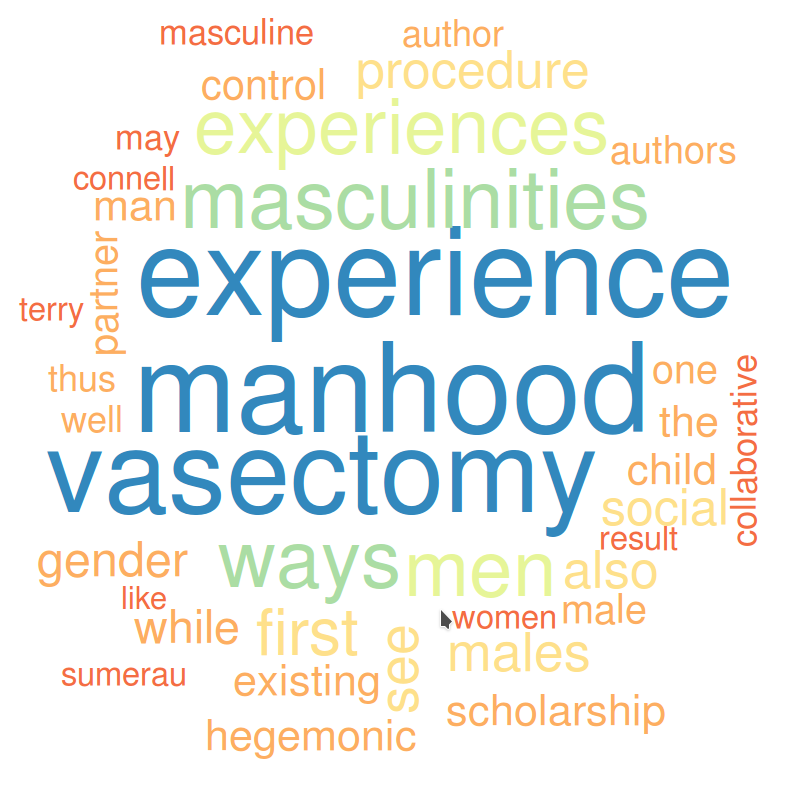
Finally, if you want to output the wordcloud as an image file, you can adjust the command to generate the wordcloud as, for instance, a PNG file. First, tell R to create the PNG file:
png("wordcloud.png", width=1280,height=800)
The text in quotes is the name of the PNG file to be created. The other two commands indicate the size of the PNG. Then create the wordcloud with the parameters you want:
wordcloud(corp, max.words = 100, random.order = FALSE, colors = color, scale=c(8, .3))
And, finally, pass the wordcloud just created on to the PNG file with this function:
dev.off()
If all goes according to plan, you will have created a PNG file with a wordcloud of your cleaned up corpus of text:
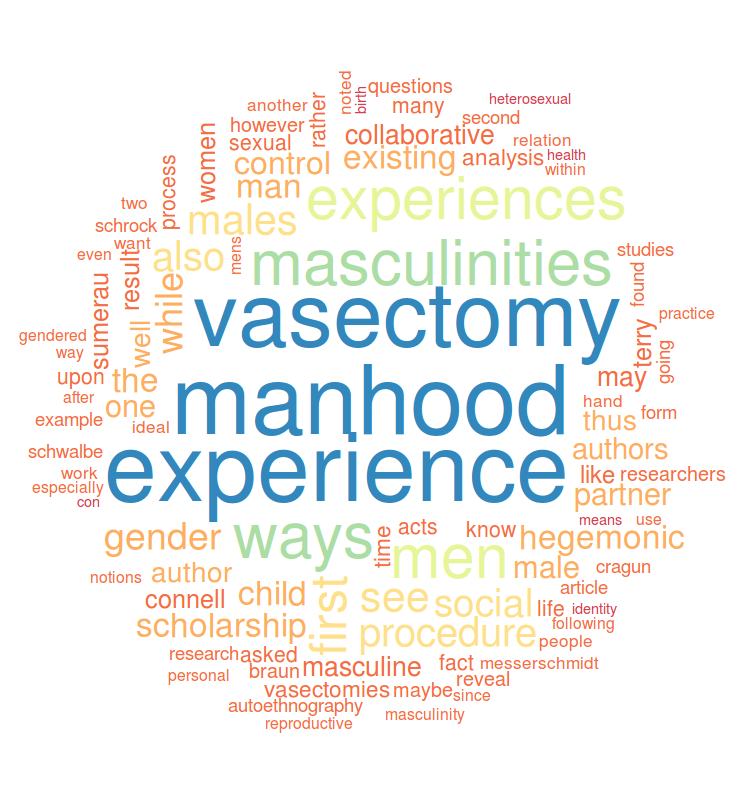
NOTE:
To remove specific words, use the following command (though make sure you have converted all your text to lower case before doing this):
corp <- tm_map(corp, removeWords, c("hello","is","it"))
Or use this series of functions, which is particularly helpful for removing any leftover punctation (e.g., “, /, ‘s, etc.):
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
corp <- tm_map(corp, toSpace, "/")
corp <- tm_map(corp, toSpace, "@")
corp <- tm_map(corp, toSpace, "\|")Source Information:
Reading PDF files into R for text mining
Building Wordclouds in R
Word cloud in R
Removing specific words
Text Mining and Word Cloud Fundamentals in R
Basics of Text Mining in R
For Advanced Wordcloud Creation:
There is another package that allows for some more advanced wordcloud creations called “wordcloud2.” It allows for the creation of wordclouds that use images as masks. Currently, the package is having problems if you install from the cran servers, but if you install directly from the github source, it works. Here’s how to do that:
install.packages("devtools")
library(devtools)
devtools::install_github("lchiffon/wordcloud2")
letterCloud(demoFreq,"R")
You can then use the “wordcloud2” package to create all sorts of nifty wordclouds, like this:

Before you can use wordcloud2 to create advanced wordclouds, you need to convert your data (after doing everything above) into a data matrix. Here’s how you do that:
dtm <- TermDocumentMatrix(corp)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)The data matrix is now contained in the variable “d”. To see the words in your frequency list ordered from most frequently used to least frequently used, you can use the following command. The number after “d” is how many words you want to see (e.g., you can see the top 10, 20, 50, 100, etc.)
head(d,100)To create a wordcloud using wordcloud2, you use the following command:
wordcloud2(d, color = "random-light", backgroundColor = "grey")And if you want to create a wordcloud using an image mask (the image has to be a PNG file with a transparent background, you use the following command:
wordcloud2(d, figPath = "figure.png", backgroundColor = "black," color = "random-light")Note: Source for directions on wordcloud2 are here and here; though see here for converting your corpus into a data matrix, which is what you have to use to create these fancy wordclouds.
NOTE: Color options for wordcloud2 are any CSS colors. See here for a complete list.
5,732 total views, 7 views today
Warning: This is not the hardest way to create a word cloud from pdf-documents, but it’s up there.
Say you have directory containing pdf documents:
$ ls
a.pdf
b.pdf
c.pdf
...
Say you want a word cloud of the words contained in the pdf documents, and you want to use the Linux command line. Say that you are only interested in words occuring between ABSTRACT and INTRODUCTION.
A word cloud is something that looks like this:

Step 1: Extract all content from pdf documents as HTML using find and pdftohtml (I got a suggestion to use pdftotext instead. In that case, it might be possible to skip the next step, i.e. using lynx to strip the tags):
find . -name "*.pdf" | xargs -n1 pdftohtml -stdout >> all.html
This produces a single file containing multiple HTML documents.
Step 2: Strip HTML tags using lynx:
lynx -dump all.html >> all.txt
This produces a rather noisy text file.
Step 3: Remove non-printable characters using perl:
perl -lpe s/[^[:print:]]+//g all.txt >> clean.txt
This produces a noisy text file but sans non-printable characters.
Step 4: Keep only the sections of text between ABSTRACT and INTRODUCTION (each occuring multiple times in an alternating fashion):
sed -n '/ABSTRACT/,/INTRODUCTION/p' < clean.txt | grep -v -w INTRODUCTION > abstracts.txt
Step 5: Download an stopwords file:
curl -o stopwords.txt http://skipperkongen.dk/files/english-stopwords-short.txt
Step 6: Keep only characters, make them lower case, put each word on a line, remove stopwords and some garbage. Sort them for good measure:
grep -v -w ABSTRACT < abstracts.txt | sed 's/[^a-zA-Z]/ /g' | tr '[:upper:]' '[:lower:]' | tr ' ' ' ' | sed '/^$/d' | sed '/^[a-z]$/d' | grep -v -w -f stopwords.txt | sort > words.txt
Step 7: At this point the file words.txt could be plugged into a piece of word cloud software like www.wordle.net.
If you want, you can also create a frequency file now with the following command:
uniq -c < words.txt | sort -r -n > frequencies.txt
Step 8: Only create a word cloud for the 500 most common terms. Create a «go-file» from the frequencies file.
head -n500 < frequencies.txt | cut -f3 -d' ' > go-file.txt
Step 9: Filter words.txt by 500 most common terms:
cat words.txt | grep -w -f go-file.txt > commonwords.txt
If you don’t like what you see, you can revisit your stopwords file and enter more terms.
I came across word cloud in various occasions, and today, I thought “maybe I should get one for myself as a summary of my research”.
A friend of mine, Google, has pointed me to a very good blog article CREATING A WORD CLOUD FROM PDF DOCUMENTS by kostas
I followed his instructions step by step to create my very own word cloud successfully. I don’t intend to copy everything from kostas’ blog, but here are some notes for using his guide.
In Step 4:
sed -n '/ABSTRACT/,/INTRODUCTION/p' < clean.txt | grep -v -w INTRODUCTION > abstracts.txt
“ABSTRACT” and “INTRODUCTION” are case sensitive, if you’re unable to produce clean.txt, you will have to do some manual work in all.text for sed to find these two keywords correctly.
You can also join all steps together as a handy script to make your life easier.