
[This article was first published on One R Tip A Day, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
A word cloud (or tag cloud) can be an handy tool when you need to highlight the most commonly cited words in a text using a quick visualization. Of course, you can use one of the several on-line services, such as wordle or tagxedo , very feature rich and with a nice GUI. Being an R enthusiast, I always wanted to produce this kind of images within R and now, thanks to the recently released Ian Fellows’ wordcloud package, finally I can!
In order to test the package I retrieved the titles of the XKCD web comics included in my RXKCD package and produced a word cloud based on the titles’ word frequencies calculated using the powerful tm package for text mining (I know, it is like killing a fly with a bazooka!).
library(RXKCD)
library(tm)
library(wordcloud)
library(RColorBrewer)
path <- system.file("xkcd", package = "RXKCD")
datafiles <- list.files(path)
xkcd.df <- read.csv(file.path(path, datafiles))
xkcd.corpus <- Corpus(DataframeSource(data.frame(xkcd.df[, 3])))
xkcd.corpus <- tm_map(xkcd.corpus, removePunctuation)
xkcd.corpus <- tm_map(xkcd.corpus, tolower)
xkcd.corpus <- tm_map(xkcd.corpus, function(x) removeWords(x, stopwords("english")))
tdm <- TermDocumentMatrix(xkcd.corpus)
m <- as.matrix(tdm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
pal <- brewer.pal(9, "BuGn")
pal <- pal[-(1:2)]
png("wordcloud.png", width=1280,height=800)
wordcloud(d$word,d$freq, scale=c(8,.3),min.freq=2,max.words=100, random.order=T, rot.per=.15, colors=pal, vfont=c("sans serif","plain"))
dev.off()

As a second example, inspired by this post from the eKonometrics blog, I created a word cloud from the description of 3177 available R packages listed at http://cran.r-project.org/web/packages.
require(XML)
require(tm)
require(wordcloud)
require(RColorBrewer)
u = "http://cran.r-project.org/web/packages/available_packages_by_date.html"
t = readHTMLTable(u)[[1]]
ap.corpus <- Corpus(DataframeSource(data.frame(as.character(t[,3]))))
ap.corpus <- tm_map(ap.corpus, removePunctuation)
ap.corpus <- tm_map(ap.corpus, tolower)
ap.corpus <- tm_map(ap.corpus, function(x) removeWords(x, stopwords("english")))
ap.tdm <- TermDocumentMatrix(ap.corpus)
ap.m <- as.matrix(ap.tdm)
ap.v <- sort(rowSums(ap.m),decreasing=TRUE)
ap.d <- data.frame(word = names(ap.v),freq=ap.v)
table(ap.d$freq)
pal2 <- brewer.pal(8,"Dark2")
png("wordcloud_packages.png", width=1280,height=800)
wordcloud(ap.d$word,ap.d$freq, scale=c(8,.2),min.freq=3,
max.words=Inf, random.order=FALSE, rot.per=.15, colors=pal2)
dev.off()

As a third example, thanks to Jim’s comment, I take advantage of Duncan Temple Lang’s RNYTimes package to access user-generate content on the NY Times and produce a wordcloud of ‘today’ comments on articles.
Caveat: in order to use the RNYTimes package you need a API key from The New York Times which you can get by registering to the The New York Times Developer Network (free of charge) from here.
require(XML)
require(tm)
require(wordcloud)
require(RColorBrewer)
install.packages(packageName, repos = "http://www.omegahat.org/R", type = "source")
require(RNYTimes)
my.key <- "your API key here"
what= paste("by-date", format(Sys.time(), "%Y-%m-%d"),sep="/")
# what="recent"
recent.news <- community(what=what, key=my.key)
pagetree <- htmlTreeParse(recent.news, error=function(...){}, useInternalNodes = TRUE)
x <- xpathSApply(pagetree, "//*/body", xmlValue)
# do some clean up with regular expressions
x <- unlist(strsplit(x, "n"))
x <- gsub("t","",x)
x <- sub("^[[:space:]]*(.*?)[[:space:]]*$", "\1", x, perl=TRUE)
x <- x[!(x %in% c("", "|"))]
ap.corpus <- Corpus(DataframeSource(data.frame(as.character(x))))
ap.corpus <- tm_map(ap.corpus, removePunctuation)
ap.corpus <- tm_map(ap.corpus, tolower)
ap.corpus <- tm_map(ap.corpus, function(x) removeWords(x, stopwords("english")))
ap.tdm <- TermDocumentMatrix(ap.corpus)
ap.m <- as.matrix(ap.tdm)
ap.v <- sort(rowSums(ap.m),decreasing=TRUE)
ap.d <- data.frame(word = names(ap.v),freq=ap.v)
table(ap.d$freq)
pal2 <- brewer.pal(8,"Dark2")
png("wordcloud_NewYorkTimes_Community.png", width=1280,height=800)
wordcloud(ap.d$word,ap.d$freq, scale=c(8,.2),min.freq=2,
max.words=Inf, random.order=FALSE, rot.per=.15, colors=pal2)
dev.off()

![]()
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Word Cloud is a data visualization technique used for representing text data in which the size of each word indicates its frequency or importance. Significant textual data points can be highlighted using a word cloud. Word clouds are widely used for analyzing data from social network websites.
Why Word Cloud?
The reasons one should use word clouds to present the text data are:
- Word clouds add simplicity and clarity. The most used keywords stand out better in a word cloud
- Word clouds are a potent communication tool. They are easy to understand, to be shared, and are impactful.
- Word clouds are visually engaging than a table data.
Implementation in R
Here are steps to create a word cloud in R Programming.
Step 1: Create a Text File
Copy and paste the text in a plain text file (e.g:file.txt) and save the file.
Step 2: Install and Load the Required Packages
Python3
install.packages("tm")
install.packages("SnowballC")
install.packages("wordcloud")
install.packages("RColorBrewer")
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
Step 3: Text Mining
- Load the Text:
The text is loaded using Corpus() function from text mining(tm) package. Corpus is a list of a document.- Start by importing text file created in step 1:
To import the file saved locally in your computer, type the following R code. You will be asked to choose the text file interactively.Python3
text=readLines(file.choose()) - Load the data as a corpus:
Python3
docs=Corpus(VectorSource(text)) - Text transformation:
Transformation is performed using tm_map() function to replace, for example, special characters from the text like “@”, “#”, “/”.Python3
toSpace=content_transformer(function (x, pattern)gsub(pattern," ", x))docs1=tm_map(docs, toSpace,"/")docs1=tm_map(docs, toSpace,"@")docs1=tm_map(docs, toSpace,"#")
- Start by importing text file created in step 1:
- Cleaning the Text:
The tm_map() function is used to remove unnecessary white space, to convert the text to lower case, to remove common stopwords. Numbers can be removed using removeNumbers.
Python3
docs1=tm_map(docs1,content_transformer(tolower))docs1=tm_map(docs1, removeNumbers)docs1=tm_map(docs1, stripWhitespace)
Step 4: Build a term-document Matrix
Document matrix is a table containing the frequency of the words. Column names are words and row names are documents. The function TermDocumentMatrix() from text mining package can be used as follows.
Python3
dtm = TermDocumentMatrix(docs)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d = data.frame(word = names(v), freq = v)
head(d, 10)
Step 5: Generate the Word Cloud
The importance of words can be illustrated as a word cloud as follows.
Python3
wordcloud(words = d$word,
freq = d$freq,
min.freq = 1,
max.words = 200,
random.order = FALSE,
rot.per = 0.35,
colors = brewer.pal(8, "Dark2"))
The complete code for the word cloud in R is given below.
Python3
install.packages("tm")
install.packages("SnowballC")
install.packages("wordcloud")
install.packages("RColorBrewer")
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
text = readLines(file.choose())
docs = Corpus(VectorSource(text))
toSpace = content_transformer(
function (x, pattern)
gsub(pattern, " ", x))
docs1 = tm_map(docs, toSpace, "/")
docs1 = tm_map(docs, toSpace, "@")
docs1 = tm_map(docs, toSpace, "#")
strwrap(docs1)
docs1 = tm_map(docs1, content_transformer(tolower))
docs1 = tm_map(docs1, removeNumbers)
docs1 = tm_map(docs1, stripWhitespace)
dtm = TermDocumentMatrix(docs)
m = as.matrix(dtm)
v = sort(rowSums(m),
decreasing = TRUE)
d = data.frame(word = names(v),
freq = v)
head(d, 10)
wordcloud(words = d$word,
freq = d$freq,
min.freq = 1,
max.words = 200,
random.order = FALSE,
rot.per = 0.35,
colors = brewer.pal(8, "Dark2"))
Output:


Advantages of Word Clouds
- Analyzing customer and employee feedback.
- Identifying new SEO keywords to target.
- Word clouds are killer visualisation tools. They present text data in a simple and clear format
- Word clouds are great communication tools. They are incredibly handy for anyone wishing to communicate a basic insight
Drawbacks of Word Clouds
- Word Clouds are not perfect for every situation.
- Data should be optimized for context.
- Word clouds typically fail to give the actionable insights that needs to improve and grow the business.
Like Article
Save Article
So you’ve heard that Word Cloud is a great way to spark excitement in your presentations, lessons and team meetings. You’re really onto something here…
Still, knowing this and knowing how to use a live word cloud for free to the best of its abilities are two very different things.
Below are 101 live word cloud examples that will show you the path to mega engagement at work, school or any event you’re looking to make memorable.
- How Does a Live Word Cloud Generator Work?
- 40 Ice Breaker Word Cloud Examples
- 40 School Word Cloud Examples
- 21 Pointless Word Cloud Examples
- Best Practices for Word Clouds
More Tips with AhaSlides
- Discover the best collaborative word cloud tools that can earn you total engagement, wherever you need it
- Check out how to add Word Cloud to Powerpoint Slides by Powerpoint Word Cloud.
- Make your own word cloud with AhaSlides Live Word Cloud Generator!
How Does a Live Word Cloud Work?
A live word cloud is a tool that lets a group of people contribute to a one-word cloud. The more popular a response is, the larger it will appear on the screen. The most popular answer will sit as the largest answer in the middle of the cloud
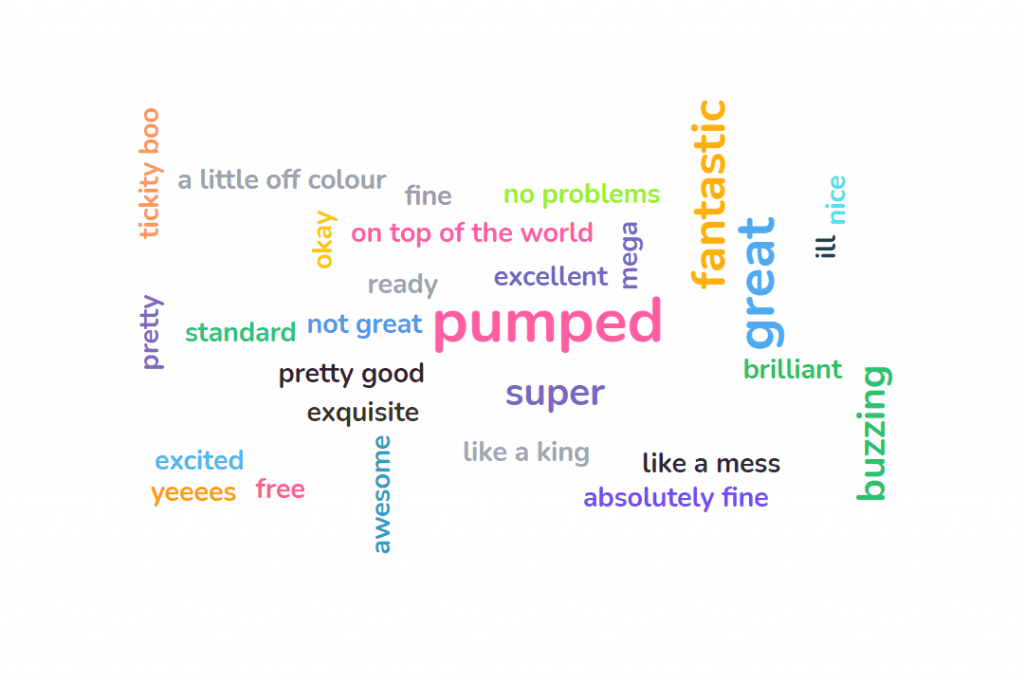
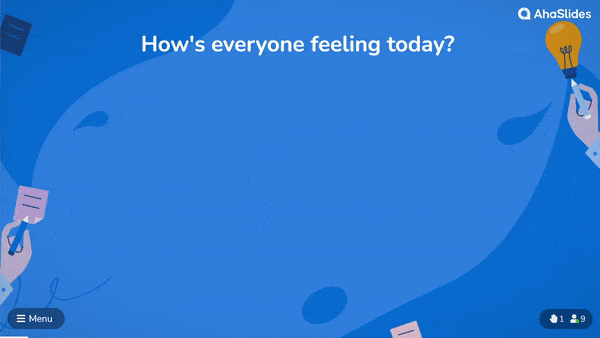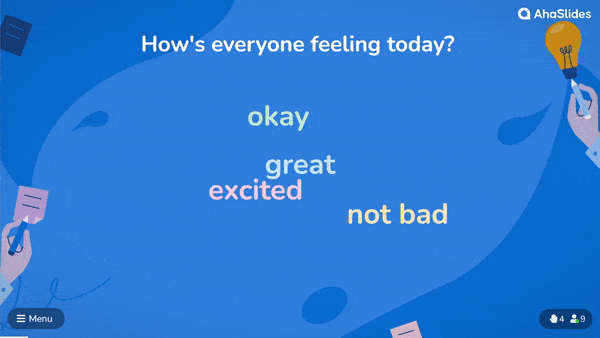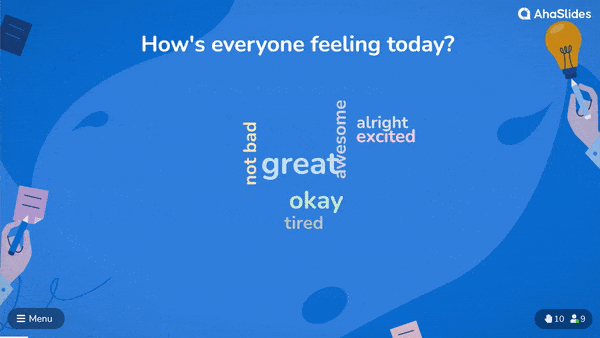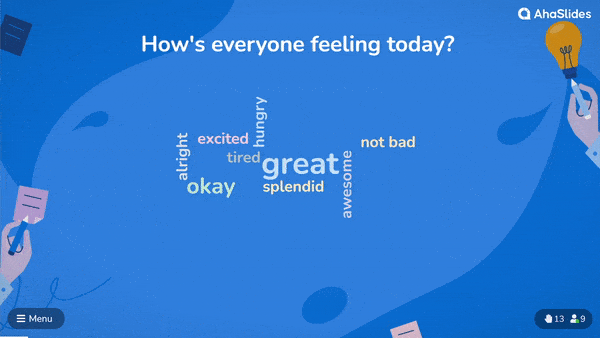
With most live word cloud software, all you have to do is write the question and choose the settings for your cloud. Then, share the unique URL code of the word cloud with your audience, who type it into their phone’s browser.
After this, they can read your question and input their own word to the cloud 👇
40 Ice Breaker Word Cloud Examples
Need a Word Cloud Sample? Climbers break the ice with pickaxes, facilitators break the ice with word clouds.
The following word cloud examples and ideas offer different ways for employees and students to connect, catch up remotely, motivate each other and solve teambuilding riddles together.
10 Hilariously Controversial Questions
- What TV series is disgustingly overrated?
- What’s your favourite swear word?
- What is the worst pizza topping?
- What’s the most useless Marvel superhero?
- What’s the sexiest accent?
- What’s the best cutlery to use for eating rice?
- What’s the largest acceptable age gap when dating?
- What’s the cleanest pet to own?
- What’s the worst singing competition series?
- What’s the most annoying emoji?

10 remote team catch-up questions
- How are you feeling?
- What is your biggest hurdle with working remotely?
- What communication channels do you prefer?
- What Netflix series have you been watching?
- If you weren’t at home, where would you be?
- What’s your favourite work-from-home item of clothing?
- How many minutes before work starts do you get out of bed?
- What’s a must-have item in your remote office (not your laptop)?
- How do you relax during lunch?
- What have you omitted from your morning routine since going remote?

10 motivating questions for students/employees
- Who nailed their work this week?
- Who’s been your main motivator this week?
- Who made you laugh the most this week?
- Who have you spoken with the most outside of work/school?
- Who’s got your vote for employee/student of the month?
- If you had a super tight deadline, who would you turn to for help?
- Who do you think is next in line for my job?
- Who’s the best at dealing with difficult customers/problems?
- Who’s the best at dealing with tech issues?
- Who’s your unsung hero?

10 team riddles
- What has to be broken before you can use it? Egg
- What has branches but no trunk, roots or leaves? Bank
- What becomes bigger the more you remove from it? Hole
- Where does today come before yesterday? Dictionary
- What kind of band never plays music? Rubber
- What building has the most stories? Library
- If two’s a company, and three’s a crowd, what are four and five? Nine
- What begins with an “e” and only contains one letter? Envelope
- What five-letter word has one left when two are removed? Stone
- What can fill a room but takes up no space? Light (or air)

🧊 Want more icebreaker games to play with your team? Check them out!
40 School Word Cloud Examples
Whether you’re getting to know a new class or letting your students have their say, these word cloud activities for your classroom can illustrate opinions and ignite discussion whenever it’s needed.
10 questions to learn about your students
- What’s your favourite food?
- What’s your favourite genre of movie?
- What’s your favourite subject?
- What’s your least favourite subject?
- What attributes make the perfect teacher?
- What software do you use the most in your learning?
- Give me 3 words to describe yourself.
- What’s your main hobby outside of school?
- Where’s your dream field trip?
- Which friend do you rely on the most in class?

10 end-of-lesson review questions
- What did we learn about today?
- What’s the most interesting topic from today?
- What topic did you find difficult today?
- What would you like to review next lesson?
- Give me one of the keywords from this lesson.
- How did you find the pace of this lesson?
- Which activity did you like the most today?
- How much did you enjoy today’s lesson? Give me a number from 1 – 10.
- What would you like to learn about the next lesson?
- How included did you feel in class today?

10 virtual learning review questions
- How do you find learning online?
- What’s the best thing about learning online?
- What’s the worst thing about learning online?
- In which room is your computer?
- Do you like your at-home learning environment?
- In your opinion, the perfect online lesson is how many minutes long?
- How do you relax in between your online lessons?
- What’s your favourite software that we use in online lessons?
- How many times do you go outside your house in a day?
- How much do you miss sitting with your classmates?

10 book club questions
Note: Questions 77 – 80 are for asking about a specific book in a book club.
- What’s your favourite genre of book?
- What’s your favourite book or series?
- Who’s your favourite author?
- Who’s your favourite book character of all time?
- Which book would you love to see made into a movie?
- Who would be the actor to play your favourite character in a movie?
- What word would you use to describe the main villain of this book?
- If you were in this book, which character would you be?
- Give me a keyword from this book.
- What word would you use to describe the main villain of this book?

21 Pointless Word Cloud Examples
Explainer: In Pointless, the aim is to get the most obscure correct answer possible. Ask a word cloud question then delete the most popular answers one by one. The winner(s) is whoever submitted a correct answer that no one else submitted 👇

Give me the name of the most obscure…
- … country beginning with ‘B’.
- … Harry Potter character.
- … manager of the England national football team.
- … Roman emperor.
- … war in the 20th century.
- … album by The Beatles.
- … city with a population of over 15 million.
- … fruit with 5 letters in it.
- … a bird that can’t fly.
- … type of nut.
- … impressionist painter.
- … method for cooking an egg.
- … state in America.
- … noble gas.
- … animal beginning with ‘M’.
- … character on Friends.
- … English word with 7 syllables or more.
- … generation 1 Pokémon.
- … Pope in the 21st century.
- … member of the English royal family.
- … luxury car company.
Try it Out!
Put these word cloud examples into action. Try a demo to see how our free interactive word cloud works 👇
Best Practices for Word Clouds
If the word cloud examples and ideas above have inspired you to create your own, here are a few quick guidelines to get the most out of your word cloud session.
- Avoid yes/no – Make sure your questions are open-ended. A word cloud with just ‘yes’ and ‘no’ responses is missing the point of a word cloud (it’s better to use a multiple choice slide for yes / no questions.
- More word cloud – discover the best collaborative word cloud tools that can earn you total engagement, wherever you need it. Let’s dive in!
- Keep it short – Phrase your question in a way that encourages just one or two-word responses. Not only do short answers look better in a word cloud, they also lessen the chance that someone will write the same thing in a different way. Learn how to create a word cloud with images to keep it short easily! Or, check out the Powerpoint Word Cloud
- Ask for opinions, not answers – Unless you’re running something like this live word cloud example, it’s always best to use this tool for gathering opinions, rather than assessing knowledge of a certain topic. If you’re looking to assess knowledge then a live quiz is the way to go!
Introduction: What is a Word Cloud?
Word Clouds have become quite a popular way for marketing campaigns. As more and more information is shown to the viewer, these Word Cloud present a modern graphic way to represent an idea or focus around which the whole concept is born.
Let us start with simple Word Cloud examples with the topic web 2.0. We can see the main topic in the center (web 2.0) and multiple related topics around that. Here, size and words after the main topic define the importance or relation to the overall topic.
![]()
A Word Cloud for terms related to Web 2.0 Source
A larger font size depicts the higher weight of the particular subject in a given Word Cloud topic. So the topic of Usability, Design, Convergence, Standardization, Economy, and Participation has more influence than Web Standards, Mobility, Data-Driven, CSS, Simplicity, and Microformats.
On a general note, these are also known as a tag cloud, or wordle, or a weighted list. Many online platforms use the tag cloud to represent specific items or tags that are found on that website. Suppose a website has hundreds of posts or content on a website. A tag cloud can separate the use of words on these posts to define the number of views on a specific analysis.
Word Clouds have three main types as frequency, Significance, and Categorization based on meaning rather than their visual appearances. In this post, we will learn step by step process for how to make a Word Cloud in R language.
- Who is using Word Clouds?
- Reason to use Word Clouds to present your text data
- Main steps to create Word Cloud in R
- Word Cloud examples
- When you should use Word Clouds
1. Who is using Word Clouds?
With data analysis gaining focus in almost every industry, these Word Clouds are gaining a lot of importance in getting facts and discovering patterns. Word Clouds are now used across multiple domains as in topics of:
- Research to conclude qualitative information from large amount and multiple forms of data
- Social Media Sites to collect and analyze data in discovering potential current trends, separate miscreant or offenders, and upcoming changes in user behaviors.
- Marketing to uncover present trends, user behavior, and trending products.
- Education to bring more focus on the essential issues that need more attention.
- Politicians and Journalists to get more attention from users.
2. Reason to use Word Clouds to present your text data
Here are the main reasons to use Word Clouds in presenting text data.
- Keeps the Focus: Word Cloud represents a sophisticated communication tool for modern viewers to focus on the main factors or reasons rather than going through the whole document.
- Simple and precise information: A Word Cloud will bring the exact information to the viewers instantly.
- Highly engaging: Word Clouds are more visually engaging in the viewer’s eye.
- Enhance user experience: Overall Word Cloud is a great way to improvise user experience.
3. Main steps to create Word Cloud in R
Here is your guide for creating the first Word Cloud in R.
Step 1: Starting by creating a text file
The first step is choosing the topic or selecting the data and creating a text file for easy processing. You can take any speech from a Politician leader or thousands of social media posts. You can use any editor from your system or online to copy-paste the data and create a specific text file for building a Word Cloud.
Step 2: Install and loading the WordCloud package in R
Then open the RStudio. And for generating Word Cloud in R, you must have the WordCloud package in R and RcolorBrewer package for representing colors, respectively. Here are the commands to use these packages in the RStudio:
#Installalation and loading of packages
install.packages(“wordcloud”)
library(wordcloud)
install.packages(“RColorBrewer”)
library(RColorBrewer)
Users also have the option to use the WordCloud2 package that offers extra designs and funny applications for developing a more engaging Word Cloud in R. Here is the command for that:
install.packages(“wordcloud2)
library(wordcloud2)
Now data or texts take center stage for the whole analysis. Now you need to load your text data as a corpus. Here tm package can help you in this process.
library(tm)
#Command for creating a vector containing only the text
text <- data$text
#Command to Create a corpus
docs <- Corpus(VectorSource(text))
And in case you are using Twitter data, then there is a separate rtweet package that can ease your process too.
Step 3: Text Mining in R: Cleaning the data
Once the text is available with Corpus() function via the text mining ™, then cleaning the data is the next stage. Now you must remove the special characters, punctuation, or any numbers from the complete text for separating words. This will help the WordCloud to focus on words only and be more productive in delivering insights precisely.
There are multiple packages to help you clean data when using the corpus. For the tm package, you can use the following list of commands.
docs <- docs %>%
tm_map(removeNumbers) %>%
tm_map(removePunctuation) %>%
tm_map(stripWhitespace)
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeWords, stopwords(“english”))
Text mining in R can have numerous key points in the process.
- Removes all the number present in the data or text (removeNumbers argument)
- Removes all the punctuation marks from the sentences (remove punctuation argument)
- Strips the text for any white space (stripWhitespace argument)
- Transforms all the words into lower case (content_transformer(tolower))
- Removing common stop words such as “we”, “I”, or “the” in the whole document. (removeWords, stopwords )
And in case you are working with Twitter data. Here is a code for refining data for a sample of tweets to clean your texts.
gsub(“https\S*”, “”, tweets$text)
gsub(“@\S*”, “”, tweets$text)
gsub(“amp”, “”, tweets$text)
gsub(“[rn]”, “”, tweets$text)
gsub(“[[:punct:]]”, “”, data$text)
Here is a complete list of R Codes to help you in the text mining process.
# Transforming the text to lower case docs <- tm_map(docs, content_transformer(tolower))
# Removing the numbers docs <- tm_map(docs, removeNumbers)
# Remove english common stopwords docs <- tm_map(docs, removeWords, stopwords(“english”))
# Remove own stop word for any specific document# specify stopwords as a character vector docs <- tm_map(docs, removeWords, c(“example1”, “example2”))
# Removing punctuations docs <- tm_map(docs, removePunctuation)
# Eliminating all the rest of the extra white spaces docs <- tm_map(docs, stripWhitespace)
# Text stemming from the document docs <- tm_map(docs, stemDocument)
Step 4: Creating a document-term-matrix
In the next step, we create a document-term-matrix that defines a mathematical matrix with the frequency of words in a given document.
Once executed, this creates a data frame with two columns, one as a word and the second as their frequency in the document. Here is the code for building a document term matrix for the tm package using the TermDocumentMatrix function.
dtm <- TermDocumentMatrix(docs)
matrix <- as.matrix(dtm)
words <- sort(rowSums(matrix),decreasing=TRUE)
df <- data.frame(word = names(words),freq=words)
There is a tidytext package you can use for creating a document term-matrix more specifically for working with tweets.
tweets_words <- tweets %>%
select(text) %>%
unnest_tokens(word, text)
words <- tweets_words %>% count(word, sort=TRUE)
Step 5: Generating the Word Cloud
Now you can simply use the wordcloud function to generate a Word Cloud from the text. You can set limits for a number of words, frequency, and more to get a final presentation for the Word Cloud.
set.seed(1234) # for reproducibility
wordcloud(words = df$word, freq = df$freq, min.freq = 1,max.words=100, random.order=FALSE, rot.per=0.35, colors=brewer.pal(8, “Dark2”))
![]()
Here are parameters to help you build a more specific Word Cloud.
- words: To define words that you want to see in the cloud
- freq: To define word frequencies
- min.freq: To define the minimum frequency of words to be listed in the Cloud
- max.words: To defines the maximum number of words in the cloud (otherwise you might see every word in the graphic)
- random.order: To represent words in the cloud in random order. (For selecting false you will get them in decreasing order)
- rot.per: To define the vertical text percentage in the given data
- colors: To defines a wide variety of choice for colors in representing data
- Scale: to manage the font size between the smallest and largest words
You may also find some words that are often cropped or don’t show up in the Word Cloud. You can adjust them as per your preference and get more productive by enhancing the quality of results. Another common mistake that one sees in Word Cloud is the use of many words with little frequency. Here you can use min.freq function to further limit the use of words respectively.
4. Word Cloud examples
Here is a collective result for a document term matrix from Martin Luther King’s speech titled ‘I have a dream speech.
word freqwill will 17freedom freedom 13ring ring 12day day 11dream dream 11let let 11every every 9able able 8one one 8together together 7
A matrix showing the words and their corresponding frequency in the data And the result for that Word Cloud will be as below:
![]()
On analysis, you can visualize that the top words that came in his speech were will, freedom, let, dream, ringday, every, able, one, together, and then decreasing thereafter.
The WordCloud2 package has more added visualizations and features for users. This package allows you to give custom shapes to the Word Cloud, such as Pentagon or a particular letter ‘L’. Here are your code and visual presentation of UN speeches given by presidents.
wordcloud2(data=df, size=1.6, color=’random-dark’)
![]()
wordcloud2(data=df, size = 0.7, shape = ‘pentagon’)
![]()
5. When you should use Word Clouds
Communication: With the right use of Word Clouds, writers can know the focus points of content and build their content around that. Especially for fiction writing, writers can use Word Clouds to know the importance of any particular character, scene, or emotion to collaborate into a final product.
Business Insights: Here, Word Clouds can help in discovering customers’ strong or weak points from their feedback analysis to be more close to their emotions. Things such as getting the main topic in Word Cloud as long delays showing an essential weaker point in their procedure can be done easily.
While for Business to Consumer analysis, Word Clouds can also pinpoint the specific technical information or Jargon in creating a balance of different words in a single piece of content.
Conclusion
In this age of data analysis, Word Cloud presents a unique and engaging way to simplify data into graphical presentations. Today, organizations and businesses around the world are making sure to build more engaging content. This guide is a comprehensive guide to build Word Cloud examples in R from scratch and get more user attention for their data analysis.
You start by selecting the text file and then learn how to install Wordcloud and other packages. Text mining in R is quite a sophisticated technique to draw Word Cloud and get more user engagement for their platforms. Then create a document-term-matrix and enjoy your first Word Cloud output.
Though Word Cloud in R has gained a lot of popularity with the prominence of Data analysis and provides an engaging way for qualitative insight, still, Word Cloud can’t be used to represent the whole research or any statistical analysis. While many researchers, online platforms, and marketing professionals enjoy showcasing Word Cloud in their field to get more user focus towards their focus, products, or services.
If you are interested in making a career in the Data Science domain, our 11-month in-person Postgraduate Certificate Diploma in Data Science course can help you immensely in becoming a successful Data Science professional.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| library(wordcloud) | |
| library(RColorBrewer) | |
| conventions <- read.table(«conventions.csv«, | |
| header = TRUE, | |
| sep = «,«) | |
| png(«dnc.png«) | |
| wordcloud(conventions$wordper25k, # words | |
| conventions$democrats, # frequencies | |
| scale = c(4,1), # size of largest and smallest words | |
| colors = brewer.pal(9,«Blues«), # number of colors, palette | |
| rot.per = 0) # proportion of words to rotate 90 degrees | |
| dev.off() | |
| png(«rnc.png«) | |
| wordcloud(conventions$wordper25k, | |
| conventions$republicans, | |
| scale = c(4,1), | |
| colors = brewer.pal(9,«Reds«), | |
| rot.per = 0) | |
| dev.off() |
- R tag cloud generator function : rquery.wordcloud
- Usage
- Required R packages
- Create a word cloud from a plain text file
- Change the color of the word cloud
- Operations on the result of rquery.wordcloud() function
- Frequency table of words
- Operations on term-document matrix
- Create a word cloud of a web page
- R code of rquery.wordcloud function
- Infos
As you may know, a word cloud (or tag cloud) is a text mining method to find the most frequently used words in a text. The procedure to generate a word cloud using R software has been described in my previous post available here : Text mining and word cloud fundamentals in R : 5 simple steps you should know.
The goal of this tutorial is to provide a simple word cloud generator function in R programming language. This function can be used to create a word cloud from different sources including :
- an R object containing plain text
- a txt file containing plain text. It works with local and online hosted txt files
- A URL of a web page
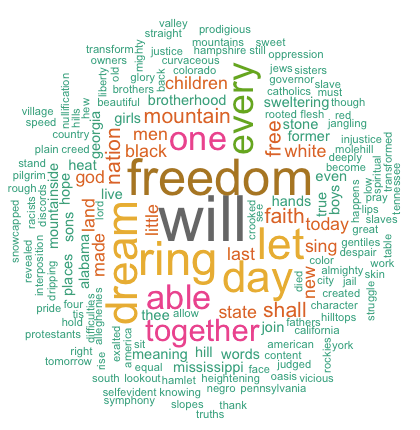
Creating word clouds requires at least five main text-mining steps (described in my previous post). All theses steps can be performed with one line R code using rquery.wordcloud() function described in the next section.
R tag cloud generator function : rquery.wordcloud
The source code of the function is provided at the end of this page.
Usage
The format of rquery.wordcloud() function is shown below :
rquery.wordcloud(x, type=c("text", "url", "file"),
lang="english", excludeWords = NULL,
textStemming = FALSE, colorPalette="Dark2",
max.words=200)- x : character string (plain text, web URL, txt file path)
- type : specify whether x is a plain text, a web page URL or a .txt file path
- lang : the language of the text. This is important to be specified in order to remove the common stopwords (like ‘the’, ‘we’, ‘is’, ‘are’) from the text before further analysis. Supported languages are danish, dutch, english, finnish, french, german, hungarian, italian, norwegian, portuguese, russian, spanish and swedish.
- excludeWords : a vector containing your own stopwords to be eliminated from the text. e.g : c(“word1”, “word2”)
- textStemming : reduces words to their root form. Default value is FALSE. A stemming process reduces the words “moving” and “movement” to the root word, “move”.
- colorPalette : Possible values are :
- a name of color palette taken from RColorBrewer package (e.g.: colorPalette = “Dark2”)
- color name (e.g. : colorPalette = “red”)
- a color code (e.g. : colorPalette = “#FF1245”)
- min.freq : words with frequency below min.freq will not be plotted
- max.words : maximum number of words to be plotted. least frequent terms dropped
Note that, rquery.wordcloud() function returns a list, containing two objects :
— tdm : term-document matrix which can be explored as illustrated in the next sections. — freqTable : Frequency table of words
Required R packages
The following packages are required for the rquery.wordcloud() function :
- tm for text mining
- SnowballC for text stemming
- wordcloud for generating word cloud images
- RCurl and XML packages to download and parse web pages
- RColorBrewer for color palettes
Install these packages, before using the function rquery.wordcloud, as follow :
install.packages(c("tm", "SnowballC", "wordcloud", "RColorBrewer", "RCurl", "XML")Create a word cloud from a plain text file
Plain text file can be easily created using your favorite text editor (e.g : Word). “I have a dream speech” (from Martin Luther King) is processed in the following example but you can use any text you want :
- Copy and paste your text in a plain text file
- Save the file (e.g : ml.txt)
Generate the word cloud using the R code below :
source('http://www.sthda.com/upload/rquery_wordcloud.r')
filePath <- "http://www.sthda.com/sthda/RDoc/example-files/martin-luther-king-i-have-a-dream-speech.txt"
res<-rquery.wordcloud(filePath, type ="file", lang = "english")
Change the arguments max.words and min.freq to plot more words :
- max.words : maximum number of words to be plotted.
- min.freq : words with frequency below min.freq will not be plotted
res<-rquery.wordcloud(filePath, type ="file", lang = "english",
min.freq = 1, max.words = 200)
The above image clearly shows that “Will”, “freedom”, “dream”, “day” and “together” are the five most frequent words in Martin Luther King “I have a dream speech”.
Change the color of the word cloud
The color of the word cloud can be changed using the argument colorPalette.
Allowed values for colorPalete :
- a color name (e.g.: colorPalette = “blue”)
- a color code (e.g.: colorPalette = “#FF1425”)
- a name of a color palette taken from RColorBrewer package (e.g.: colorPalette = “Dark2”)
The color palettes associated to RColorBrewer package are shown below :

Color palette can be changed as follow :
# Reds color palette
res<-rquery.wordcloud(filePath, type ="file", lang = "english",
colorPalette = "Reds")
# RdBu color palette
res<-rquery.wordcloud(filePath, type ="file", lang = "english",
colorPalette = "RdBu")
# use unique color
res<-rquery.wordcloud(filePath, type ="file", lang = "english",
colorPalette = "black")


Operations on the result of rquery.wordcloud() function
As mentioned above, the result of rquery.wordcloud() is a list containing two objects :
- tdm : term-document matrix
- freqTable : frequency table
tdm <- res$tdm
freqTable <- res$freqTableFrequency table of words
The frequency of the first top10 words can be displayed and plotted as follow :
# Show the top10 words and their frequency
head(freqTable, 10) word freq
will will 17
freedom freedom 13
ring ring 12
day day 11
dream dream 11
let let 11
every every 9
able able 8
one one 8
together together 7# Bar plot of the frequency for the top10
barplot(freqTable[1:10,]$freq, las = 2,
names.arg = freqTable[1:10,]$word,
col ="lightblue", main ="Most frequent words",
ylab = "Word frequencies")
Operations on term-document matrix
You can explore the frequent terms and their associations. In the following example, we want to identify words that occur at least four times :
findFreqTerms(tdm, lowfreq = 4) [1] "able" "day" "dream" "every" "faith" "free" "freedom" "let" "mountain" "nation"
[11] "one" "ring" "shall" "together" "will" You could also analyze the correlation (or association) between frequent terms. The R code below identifies which words are associated with “freedom” in I have a dream speech :
findAssocs(tdm, terms = "freedom", corlimit = 0.3) freedom
let 0.89
ring 0.86
mississippi 0.34
mountainside 0.34
stone 0.34
every 0.32
mountain 0.32
state 0.32Create a word cloud of a web page
In this section we’ll make a tag cloud of the following web page :
http://www.sthda.com/english/wiki/create-and-format-powerpoint-documents-from-r-software
url = "http://www.sthda.com/english/wiki/create-and-format-powerpoint-documents-from-r-software"
rquery.wordcloud(x=url, type="url")
The above word cloud shows that “powerpoint”, “doc”, “slide”, “reporters” are among the most important words on the analyzed web page. This confirms the fact that the article is about creating PowerPoint document using ReporteRs package in R
R code of rquery.wordcloud function
#++++++++++++++++++++++++++++++++++
# rquery.wordcloud() : Word cloud generator
# - http://www.sthda.com
#+++++++++++++++++++++++++++++++++++
# x : character string (plain text, web url, txt file path)
# type : specify whether x is a plain text, a web page url or a file path
# lang : the language of the text
# excludeWords : a vector of words to exclude from the text
# textStemming : reduces words to their root form
# colorPalette : the name of color palette taken from RColorBrewer package,
# or a color name, or a color code
# min.freq : words with frequency below min.freq will not be plotted
# max.words : Maximum number of words to be plotted. least frequent terms dropped
# value returned by the function : a list(tdm, freqTable)
rquery.wordcloud <- function(x, type=c("text", "url", "file"),
lang="english", excludeWords=NULL,
textStemming=FALSE, colorPalette="Dark2",
min.freq=3, max.words=200)
{
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
if(type[1]=="file") text <- readLines(x)
else if(type[1]=="url") text <- html_to_text(x)
else if(type[1]=="text") text <- x
# Load the text as a corpus
docs <- Corpus(VectorSource(text))
# Convert the text to lower case
docs <- tm_map(docs, content_transformer(tolower))
# Remove numbers
docs <- tm_map(docs, removeNumbers)
# Remove stopwords for the language
docs <- tm_map(docs, removeWords, stopwords(lang))
# Remove punctuations
docs <- tm_map(docs, removePunctuation)
# Eliminate extra white spaces
docs <- tm_map(docs, stripWhitespace)
# Remove your own stopwords
if(!is.null(excludeWords))
docs <- tm_map(docs, removeWords, excludeWords)
# Text stemming
if(textStemming) docs <- tm_map(docs, stemDocument)
# Create term-document matrix
tdm <- TermDocumentMatrix(docs)
m <- as.matrix(tdm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
# check the color palette name
if(!colorPalette %in% rownames(brewer.pal.info)) colors = colorPalette
else colors = brewer.pal(8, colorPalette)
# Plot the word cloud
set.seed(1234)
wordcloud(d$word,d$freq, min.freq=min.freq, max.words=max.words,
random.order=FALSE, rot.per=0.35,
use.r.layout=FALSE, colors=colors)
invisible(list(tdm=tdm, freqTable = d))
}
#++++++++++++++++++++++
# Helper function
#++++++++++++++++++++++
# Download and parse webpage
html_to_text<-function(url){
library(RCurl)
library(XML)
# download html
html.doc <- getURL(url)
#convert to plain text
doc = htmlParse(html.doc, asText=TRUE)
# "//text()" returns all text outside of HTML tags.
# We also don’t want text such as style and script codes
text <- xpathSApply(doc, "//text()[not(ancestor::script)][not(ancestor::style)][not(ancestor::noscript)][not(ancestor::form)]", xmlValue)
# Format text vector into one character string
return(paste(text, collapse = " "))
}Infos
This analysis has been performed using R (ver. 3.1.0).
Enjoyed this article? I’d be very grateful if you’d help it spread by emailing it to a friend, or sharing it on Twitter, Facebook or Linked In.
Show me some love with the like buttons below… Thank you and please don’t forget to share and comment below!!
Avez vous aimé cet article? Je vous serais très reconnaissant si vous aidiez à sa diffusion en l’envoyant par courriel à un ami ou en le partageant sur Twitter, Facebook ou Linked In.
Montrez-moi un peu d’amour avec les like ci-dessous … Merci et n’oubliez pas, s’il vous plaît, de partager et de commenter ci-dessous!
Post on:
Google+
Or copy & paste this link into an email or IM:
Время на прочтение
4 мин
Количество просмотров 3.4K

Всем привет! Хочу продемонстрировать вам, как я использовал библиотеку WordCloud для создания подарка для друга/подруги. Я решил составить облако слов по переписке с человеком, чтобы выделить основные темы, которые мы обсуждаем.
Выгружаем переписку
Для начала нам нужно будет выгрузить переписку из ВК. Как это сделать? Очень просто! Я пользовался расширением для браузера «VkOpt». Скачиваем его и устанавливаем. Теперь заходим в диалог с человеком, переписку с которым хотим скачать.

Наводим на три точки и выбираем «сохранить переписку». Далее будет окно с выбором типа файла. Я предпочитаю json.
Обработка переписки
Импортируем json и открываем наш файл с перепиской.
import json
vk = open('vk2.json', 'r', encoding='utf8')
vk = json.load(vk)Теперь давайте выведем его и посмотрим как он выглядит.

Ну в общем всё ясно, массив таких вот сообщений. Каждый элемент соответствует одному облако-сообщению.
Давайте теперь вытащим из каждого сообщения его текст и разделим этот текст на слова.
mas = []
for i in range(len(vk)):
mas.append(vk[i]['body'].split())
data = []
for i in mas:
for j in range(len(i)):
data.append(i[j].lower())
Теперь у нас есть массив data, в котором каждый элемент — это одно слово. Далее создадим большую строку, в которую просто запишем через пробел все наши слова.
big_string=''
for i in range(len(data)):
big_string+=(data[i]+' ')WordCloud
Почти всё готово, теперь давайте воспользуемся библиотекой WordCloud и построим наше облако слов.
pip install wordcloud
import matplotlib.pyplot as plt
%matplotlib inline
from wordcloud import WordCloud, STOPWORDS
wordCloud = WordCloud(width = 10000, height = 10000, random_state=1, background_color='black', colormap='Set2', collocations=False).generate(big_string)
plt.figure(figsize=(5,5))
plt.imshow(wordCloud)
Убираем стоп-слова
Так, и что же это? Не очень похоже на оригинальный подарок. Естественно всё не так просто. Дело в том, что в нашей речи и сообщениях встречается куча стоп-слов. Собственно, эти слова вы и видите на картинке. Они встречались в диалоге чаще всего, поэтому алгоритм выделил их крупным шрифтом.
Теперь наша задача: почистить строку от ненужный слов. Для этого скачаем словарик стоп-слов русского языка(https://snipp.ru/seo/stop-ru-words). Он представлен как обычный txt-шник, а значит прочитаем его и разделим по переносу строки.
stop_words = open('stop-ru.txt', 'r', encoding='utf8')
stop_words = stop_words.read()
stop_words = stop_words.split('n')Далее создадим массив clear_data, куда будем заносить слова из массива data, которые не содержатся в списке стоп-слов(т. е. нормальные слова).
clear_data=[]
for i in data:
if(i not in stop_words):
clear_data.append(i)А теперь формируем нашу большую строку, только теперь из нового массива и заново строим WordCloud.
big_string=''
for i in range(len(clear_data)):
big_string+=(clear_data[i]+' ')
wordCloud = WordCloud(width = 10000, height = 10000, random_state=1, background_color='black', colormap='Set2', collocations=False).generate(big_string)
plt.figure(figsize=(5,5))
plt.imshow(wordCloud)
Результат на лицо. Начинает проявляться оттенок переписки с тем или иным человеком. Ну и, естественно, куда же мы русского могучего, он тоже начинает проявляться на изображении, приходится его замазывать 
Переходим на ручное управление
Так, вроде стоп-слова убрали, но картинка всё равно не выглядит привлекательной. В выборке остались различные выражения, которые мы часто используем в переписке. Например, мои слова паразиты: «ок», «ща», «крч». Что делать? Все просто. Открываем наш текстовик с русскими стоп-слова и просто вписываем туда слова, которые не должны присутствовать в новом облаке слов(не забудьте сохранить текстовик, перед повторным чтением).
P.S. На самом деле есть и второй вариант удалить слова паразиты. Создадим массив, который заполним словами паразитами, и подадим его как параметр в WordCloud. Тоже хороший вариант, но мне больше нравится с текстовиком.
stopw = ['а', 'ок', 'крч'] #массив слов, которые хотим удалить
#подадим массив stopw в WordCloud как параметр stopwords
wordCloud = WordCloud(width = 1000, height = 1000, random_state=1,
background_color='black', colormap='Set2',
collocations=False, stopwords=stopw).generate(big_string)Таким образом, мы всё глубже и глубже погружаемся в чертоги нашей переписки. Обычно появляются слова, соответствующие темам, которые вы и ваш друг часто обсуждаете.
Форма облака слов
Теперь давайте воспользуемся одной фишкой WordCloud. Оформим наше облако слов в виде какой-то картинки. Я выберу банальное сердечко)
from PIL import Image
original_image = Image.open('путь до картинки')
image = original_image.resize([2000,2000], Image.ANTIALIAS)
image = np.array(image)Подадим в функцию нашу картинку как параметр mask.
wordCloud = WordCloud(width = 1000, height = 1000, random_state=1,
background_color='black', colormap='Set2',
collocations=False, stopwords=stopw, mask=image).generate(big_string)
Вот такая штука у меня получилась.
По-хорошему, нужно удалить ещё около десятка слов, для более-менее приятной картины, но я уверен ту вы справитесь сами)
P.S. Выбирайте черно-белые изображения предметов. Лучше всего, если они выглядят как силуэты. С .png у меня не прошло, поэтому я сохранял в .jpg, может быть у вас получится.
Итог
Я нарисовал облако слов, которое отражает тональность переписки с тем или иным человеком. Дополнительно, в облаке содержатся слова, которые соответствуют тем темам, которые вы часто обсуждали в диалоге. Как вариант, можно сохранить эту картинку, распечатать, поставить в рамочку и вручить как подарок вашему собеседнику. Ему будет очень приятно, ведь всегда интересно посмотреть на то, как оценивает вашу переписку алгоритм)