
Данные – числа и закодированные символы, используемые в качестве операндов команд.
Основные типы данных в ассемблере
| Тип | Директива | Количество байт |
| Байт | DB | 1 |
| Слово | DW | 2 |
| Двойное слово | DD | 4 |
| 8 байт | DQ | 8 |
| 10 байт | DT | 10 |
Данные, обрабатываемые вычислительной машиной, можно разделить на 4 группы:
- целочисленные;
- вещественные.
- символьные;
- логические;
Целочисленные данные
Целые числа в ассемблере могут быть представлены в 1-байтной, 2-байтной, 4-байтной или 8-байтной форме. Целочисленные данные могут представляться в знаковой и беззнаковой форме.
Беззнаковые целые числа представляются в виде последовательности битов в диапазоне от 0 до 2n-1, где n- количество занимаемых битов.

Знаковые целые числа представляются в диапазоне -2n-1 … +2n-1-1. При этом старший бит данного отводится под знак числа (0 соответствует положительному числу, 1 – отрицательному).

Вещественные данные
Вещественные данные могут быть 4, 8 или 10-байтными и обрабатываются математическим сопроцессором.
Логические данные
Логические данные представляют собой бит информации и могут записываться в виде последовательности битов. Каждый бит может принимать значение 0 (ЛОЖЬ) или 1 (ИСТИНА). Логические данные могут начинаться с любой позиции в байте.
Символьные данные
Символьные данные задаются в кодах и имеют длину, как правило, 1 байт (для кодировки ASCII) или 2 байта (для кодировки Unicode) .
Числа в двоично-десятичном формате
В двоично-десятичном коде представляются беззнаковые целые числа, кодирующие цифры от 0 до 9. Числа в двоично-десятичном формате могут использоваться в одном из двух видов:
- упакованном;
- неупакованном.
В неупакованном виде в каждом байте хранится одна цифра, размещенная в младшей половине байта (биты 3…0).

Упакованный вид допускает хранение двух десятичных цифр в одном байте, причем старшая половина байта отводится под старший разряд.

Числовые константы
Числовые константы используются для обозначения арифметических операндов и адресов памяти. Для числовых констант в Ассемблере могут использоваться следующие числовые форматы.
Десятичный формат – допускает использование десятичных цифр от 0 до 9 и обозначается последней буквой d, которую можно не указывать, например, 125 или 125d. Ассемблер сам преобразует значения в десятичном формате в объектный шестнадцатеричный код и записывает байты в обратной последовательности для реализации прямой адресации.
a DB 12
Шестнадцатеричный формат – допускает использование шестнадцатеричных цифр от 0 до F и обозначается последней буквой h, например 7Dh. Так как ассемблер полагает, что с буквы начинаются идентификаторы, то первым символом шестнадцатеричной константы должна быть цифра от 0 до 9. Например, 0Eh.
a DB 0Ch
Двоичный формат – допускает использование цифр 0 и 1 и обозначается последней буквой b. Двоичный формат обычно используется для более четкого представления битовых значений в логических командах (AND, OR, XOR).
a DB 00001100b
Восьмеричный формат – допускает использование цифр от 0 до 7 и обозначается последней буквой q или o, например, 253q.
a DB 14q
Массивы и цепочки
Массивом называется последовательный набор однотипных данных, именованный одним идентификатором.
Цепочка — массив, имеющий фиксированный набор начальных значений.
Примеры инициализации цепочек
M1 DD 0,1,2,3,4,5,6,7,8,9
M2 DD 0,1,2,3
DD 4,5,6,7
DD 8,9
Каждая из записей выделяет десять последовательных 4-байтных ячеек памяти и записывает в них значения 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
Идентификатор M1 определяет смещение начала этой области в сегменте данных .DATA.
Для инициализации всех элементов массива одинаковыми значениями используется оператор DUP:
Идентификатор Тип Размер DUP (Значение)
Идентификатор — имя массива;
Тип — определяет количество байт, занимаемое одним элементом;
Размер — константа, характеризующая количество элементов в массиве
Значение — начальное значение элементов.
Например
a DD 20 DUP (0)
описывает массив a из 20 элементов, начальные значения которых равны 0.
Если необходимо выделить память, но не инициализировать ее, в качестве поля Значение используется знак ?. Например,
b DD 20 DUP(?)
Символьные строки
Символьные строки представляют собой набор символов для вывода на экран. Содержимое строки отмечается
- одиночными кавычками », например, ‘строка’
- двойными кавычками «», например «строка»
Символьная строка определяется только директивой DB, в которой указывается более одного символа в последовательности слева направо.
Символьная строка, предназначенная для корректного вывода, должна заканчиваться нуль-символом ‘’ с кодом, равным 0.
Str DB ‘Привет всем!’, 0
Для перевода строки могут использоваться символы
- возврат каретки с кодом 13 (0Dh)
- перевод строки с кодом 10 (0Ah).
Stroka DB «Привет», 13, 10, 0
Назад
Назад: Язык ассемблера

Данные в ассемблере.
Данные в ассемблере — понятие широкое. Программу в целом можно воспринимать как одну большую совокупность данных, однако мы уже знаем и помним, что она состоит из данных и кода — набора команд, необходимых для обработки данных.
Данные в ассемблере в узком понимании (буква, строка, символ, текстовый файл, звуковой файл, видеофайл, документ Word и т.п), а также сам код представляют собой определённую строго регламентированную последовательность чисел. Эта последовательность формируется при преобразовании программного текста в исполняемый файл, то есть написанный программистом код транслируется в машинный язык цифр.
Машина манипулирует минимальным блоком памяти размером в 1 байт. Байт состоит из 8 бит и может содержать 256 значений (2 в степени 8). Байтовый мир машин транслируется отладчиками, дизассемблерами и HEX-редакторами в 16-тиричном виде для более удобного восприятия человеком.
Для дальнейшего изучения вопроса нам понадобиться редактор HIEW. Он есть среди прочего необходимого в архиве DOS-1.rar, который необходимо скачать.
Байты, слова, двойные слова …
Фактически все программы — от простых до самых сложным представляют собой набор команд процессора, манипулирующих с данными.
Команды процессора представляют собой цифровые значения, имеющие свою структуру.
Открываем с помощью Hiew нашу программу PRG.COM (выбор файлов — F9). При помощи F4 выбираем режим отображения информации HEX (как вы уже знаете, шестнадцатиричный режим):
|
00000000: B4 09 BA 08—01 CD 21 C3—48 65 6C 6C—6F 20 57 6F + ¦ =!+Hello Wo 00000010: 72 6C 64 21—0D 0A 24 — — rld! $ |
Мы видим набор байт: B4 09 BA 08 01 CD 21 и т.д. Байты разделены дефисами на группы — по четыре в каждой.
Группы байт имеют названия:
- Группа из 2 байт называется Word («Слово»).
- Группа из 4 байт называется Double Word («Двойное слово»).
- Группа из 8 байт называется Quatro Bytes («Восемь байт»).
- Группа из 10 байт называется Tetro Bytes («Десять байт»).
В ассемблере имеются специальные директивы для резервирования памяти:
- DB — Define Bite.
- DW — Define Word.
- DD — Define Double Word.
- DQ — Define Quatro Bites
- DT — Define Tetro Bites.
Код и данные — это упорядоченная последовательность чисел.
Одну из этих директив мы использовали в нашем коде для резервирования памяти и заполнения её текстом:
|
message db «Hello World!»,0Dh,0Ah,‘$’ ; строка для вывода |
Переходим в режим декодирования (F4->Decode):
|
00000000: B409 mov ah,009 ;» « 00000002: BA0801 mov dx,00108 ;» « 00000005: CD21 int 021 00000007: C3 retn 00000008: 48 dec ax 00000009: 65 gs: 0000000A: 6C insb 0000000B: 6C insb 0000000C: 6F outsw 0000000D: 20576F and [bx][0006F],dl 00000010: 726C jb 00000007E 00000012: 64210D and fs:[di],cx 00000015: 0A24 or ah,[si] |
Для машины и код и данные — это строго упорядоченная последовательность цифр. Мы видим, что дизассемблер попытался перевести в код и нашу строку «Hello World!»,0Dh,0Ah,’$’, но мы можем различить её по набору байт от 48h до 24h.
Ассемблерный код также представлен в виде цифр. Шестнадцатеричное число B409 декодируется в инструкцию mov ah,009. При этом, очевидно, что B4 — это «mov ah», а 09 — это число «09» (ещё один ноль добавлен HIEW перед числом, чтобы показать его принадлежность именно к числовому значению и мы его не будем учитывать).
Во второй строке кода обратите внимание на последовательность байт: BA 08 01, которая декодируется в инструкцию:
|
00000002: BA0801 mov dx,00108 |
Понятно, что BA — это «mov dx», а 0801 — это число «0108 » (первый ноль добавил HIEW). Однако отображена оно в коде побайтно наоборот — зеркально.
Младший байт — меньший адрес.
Продолжаем изучать данные в ассемблере и переходим к очень важному моменту, который необходимо запомнить: Младший байт числа в памяти компьютера имеет меньший адрес, поэтому читается «попарно и задом на перёд». В дизассемблированном коде (как часть ассемблерной команды, либо в как часть стека) число будет выглядеть «обычно».
Ещё раз:
команда ассемблера обозначает: «поместить в регистр dx шестнадцатеричное число 108 (0108h). Число 108 побайтно выглядит как слово 01 08. 08 — это младший байт, 01 — старший. Слово 01 08 расположено в памяти по адресам 00000003: и 00000004:, значит 08 должно находится по младшему адресу — 00000003:, а 01 — по старшему — 00000004, как оно и есть.
Итак, 16-ти битное число 1234h в памяти будет храниться как последовательность байт 34 12. Windows программирование оперирует с 32 и 64 битными числами: 32 битное число 12345678h будет храниться как последовательность байт 78 56 34 12, а 64 битное число 123456789ABCDEF0h будет храниться как
последовательность байт F0 DE BC 9A 78 56 34 12.
Ассемблер распознает набор основных внутренних типов данных (внутренние типы данных) и описывает их типы в соответствии с размером данных (байты, слова, двойные слова и т. Д.), Подписаны ли они, являются ли они целым или действительным числом. Эти типы в значительной степени перекрываются: например, тип DWORD (32-битное целое число без знака) может быть заменен типом SDWORD (32-битное целое число со знаком).
Некоторые люди могут сказать, что программист использует SDWORD, чтобы сообщить читателю, что это значение подписано, но это не обязательно для ассемблера. Ассемблер оценивает только размер операнда. Поэтому, например, программисты могут указывать только 32-разрядные целые числа как типы DWORD, SDWORD или REAL4.
В следующей таблице приведен список всех внутренних типов данных.Символы IEEE в некоторых записях относятся к стандартному формату вещественных чисел, опубликованному IEEE Computer Society.
| Типы | Применение |
|---|---|
| BYTE | 8-битное целое число без знака, B представляет байт |
| SBYTE | 8-битовое целое число со знаком, S означает знак |
| WORD | 16-битное целое число без знака |
| SWORD | 16-битное целое число со знаком |
| DWORD | 32-битное целое число без знака, D означает двойное (слово) |
| SDWORD | 32-битное целое число со знаком, SD означает двойное со знаком (слово) |
| FWORD | 48-битное целое число (дальний указатель в защищенном режиме) |
| QWORD | 64-битное целое число, Q представляет четыре (слово) |
| TBYTE | 80-битное (10-байтовое) целое число, T представляет 10 байтов |
| REAL4 | 32-битное (4 байта) короткое действительное число IEEE |
| REAL8 | 64-битное (8-байтовое) длинное действительное число IEEE |
| REAL10 | 80 бит (10 байт) Расширенное действительное число IEEE |
Заявление об определении данных
Оператор определения данных (оператор определения данных) резервирует место для хранения переменных в памяти и присваивает дополнительное имя. Оператор определения данных определяет переменную в соответствии с внутренним типом данных (таблица выше).
Синтаксис определения данных следующий:
[name] directive initializer [,initializer]…
Ниже приводится пример оператора определения данных:
count DWORD 12345
из их:
- Имя: необязательное имя, присвоенное переменной, должно соответствовать спецификации идентификатора.
- Псевдо-инструкция: псевдо-инструкция в операторе определения данных может быть BYTE, WORD, DWORD, SBTYE, SWORD или другими типами, перечисленными в приведенной выше таблице. Кроме того, это также может быть традиционная директива определения данных, как показано в следующей таблице.
| Псевдо-инструкция | Применение | Псевдо-инструкция | Применение |
|---|---|---|---|
| DB | 8-битное целое число | DQ | 64-битное целое или действительное число |
| DW | 16-битное целое число | DT | Определяет 80-битное (10-байтовое) целое число |
| DD | 32-битное целое или действительное число |
В определении данных должно быть хотя бы одно начальное значение, даже если значение равно 0. Остальные начальные значения, если есть, разделяются запятыми. Для целочисленных типов данных начальное значение (инициализатор) представляет собой целочисленную константу или целочисленное выражение, которое соответствует типу переменной, например BYTE или WORD.
Если программист не хочет инициализировать переменную (присвоить значение случайным образом), символ? Можно использовать в качестве начального значения. Все начальные значения, независимо от их формата, ассемблер преобразует в двоичные данные. Начальные значения 0011, 0010b, 32h и 50d имеют одинаковое двоичное значение.
Добавьте переменную в программу AddTwo
Программа AddTwo была представлена в предыдущем разделе «Сложение и вычитание целых чисел», а теперь создана ее новая версия, которая называется AddTwoSum. Эта версия вводит переменную сумму, которая появляется в полном листинге программы:
;AddTowSum.asm .386 .model flat,stdcall .stack 4096 ExitProcess PROTO, dwExitCode:DWORD .data sum DWORD 0 .code main PROC mov eax,5 add eax,6 mov sum,eax INVOKE ExitProcess,0 main ENDP END main
Вы можете установить точку останова в строке 13, выполнять по одной строке за раз и пошагово выполнять программу в отладчике. После выполнения строки 15 наведите указатель мыши на сумму переменной, чтобы просмотреть ее значение. Или откройте окно Watch.Процесс открытия выглядит следующим образом: выберите Windows в меню Debug (в сеансе отладки), выберите Watch и выберите один из четырех доступных вариантов (Watch1, Watch2, Watch3 или Watch4). Затем с помощью мыши выделите переменную суммы и перетащите ее в окно Watch. На следующем рисунке показан пример, где большая стрелка указывает текущее значение суммы после выполнения строки 15.

Определите данные BYTE и SBYTE
BYTE (определенный байт) и SBYTE (определенный байт со знаком) выделяют пространство для хранения для одного или нескольких значений без знака или со знаком. При сохранении каждого начального значения оно должно быть 8-битным. Например:
value1 BYTE'A '; значение символьной константы 2 BYTE 0; минимальное значение байта без знака 3 BYTE 255; максимальное значение байта без знака 4 SBYTE -128; минимальное значение байта со знаком 5 SBYTE +127; максимальное значение байта со знаком
Начальное значение вопросительного знака (?) Делает переменную неинициализированной, что означает присвоение значения переменной во время выполнения:
value6 BYTE ?
Необязательное имя — это метка, которая определяет смещение от начала переменной, содержащей раздел, до переменной. Например, если value1 находится по смещению 0000 сегмента данных и занимает один байт в памяти, то value2 автоматически находится по смещению 0001:
value1 BYTE 10h
value2 BYTE 20h
Директивы DB также могут определять 8-битные переменные со знаком или без знака:
val1 DB 255; беззнаковый байт
val2 DB -128; Байт со знаком
1) Несколько начальных значений
Если в одном определении данных используется несколько начальных значений, его метка указывает только смещение первого начального значения. В следующем примере предположим, что смещение списка равно 0000. Тогда смещение 10 равно 0000, смещение 20 равно 0001, смещение 30 равно 0002, а смещение 40 равно 0003:
list BYTE 10,20,30,40
На следующем рисунке показан список последовательности байтов, показывающий каждый байт и его смещение.

Не все определения данных должны использовать метки. Например, если вы продолжите добавлять массивы байтов после списка, вы можете определить их в следующей строке:
list BYTE 10,20,30,40 BYTE 50,60,70,80 BYTE 81,82,83,84
В одном определении данных для его начального значения могут использоваться разные базы. Также можно произвольно комбинировать символы и строковые константы. В следующем примере list1 и list2 имеют одинаковое содержимое:
list1 BYTE 10, 32, 41h, 00100010b list2 BYTE 0Ah, 20h, 'A', 22h
2) Определить строку
Чтобы определить строку, заключите ее в одинарные или двойные кавычки. Наиболее распространенный тип строки — использование нулевого байта (значение 0) в качестве конечного тега, который называется строкой с завершающим нулем. Этот тип строки используется во многих языках программирования:
greeting1 BYTE "Good afternoon",0 greeting2 BYTE 'Good night',0
Каждый символ занимает один байт памяти. Строки являются исключением из правила, согласно которому значения байтов должны разделяться запятыми. Если бы таких исключений не было, приветствие1 было бы определено как:
greeting1 BYTE ‘G’, ‘o’, ‘o’, ‘d’….etc.
Это очень долго. Строку можно разделить на несколько строк, и нет необходимости добавлять метку к каждой строке:
greeting1 BYTE "Welcome to the Encryption Demo program " BYTE "created by Kip Irvine.",0dh, 0ah BYTE "If you wish to modify this program, please " BYTE "send me a copy.",0dh,0ah,0
Шестнадцатеричные коды 0Dh и 0Ah также называются CR / LF (возврат каретки и перевод строки) или символы конца строки. При записи стандартного вывода они перемещают курсор в левую часть строки рядом с текущей строкой.
Символ продолжения строки () соединяет две строки исходного кода в оператор, и он должен быть последним символом строки. Следующие утверждения эквивалентны:
greeting1 BYTE «Welcome to the Encryption Demo program «
и
greeting1
BYTE «Welcome to the Encryption Demo program «
3) оператор DUP
Оператор DUP использует целочисленное выражение в качестве счетчика для выделения пространства хранения для нескольких элементов данных. Этот оператор очень полезен при выделении места для хранения строк или массивов. Он может использовать инициализированные или неинициализированные данные:
BYTE 20 DUP (0); 20 байтов, все значения: 0 BYTE 20 DUP (?); 20 байтов, неинициализированный BYTE 4 DUP ("СТЕК"); 20 байтов:
Определите данные WORD и SWORD
Директивы WORD (слово определения) и SWORD (слово со знаком определения) выделяют место для хранения одного или нескольких 16-битных целых чисел:
word1 WORD 65535; максимальное число без знака word2 SWORD -32768; минимальное число со знаком word3 WORD ?; неинициализированное, беззнаковое
Вы также можете использовать традиционную псевдо-инструкцию DW:
val1 DW 65535; беззнаковый val2 DW -32768; подписанный
Массив 16-битных слов создается путем перечисления элементов или с помощью оператора DUP. Следующий массив содержит набор значений:
myList WORD 1,2,3,4,5
На рисунке ниже представлена схематическая диаграмма массива в памяти при условии, что смещение начальной позиции myList равно 0000. Поскольку каждое значение занимает два байта, приращение его адреса равно 2.

Оператор DUP предоставляет удобный способ объявления массивов:
массив WORD 5 DUP (?); 5 значений, не инициализировано
Определите данные DWORD и SDWORD
Псевдоинструкции DWORD (определение двойного слова) и SDWORD (определение двойного слова со знаком) выделяют место для хранения одного или нескольких 32-битных целых чисел:
val1 DWORD 12345678h; unsigned val2 SDWORD -2147483648; подписанный val3 DWORD 20 DUP (?); массив без знака
Традиционная псевдо-инструкция DD также может использоваться для определения данных двойного слова:
val1 DD 12345678h; беззнаковый val2 DD -2147483648; подписанный
DWORD также можно использовать для объявления переменной, содержащей 32-битное смещение другой переменной. Как показано ниже, pVal содержит смещение val3:
pVal DWORD val3
32-битный массив двойных слов
Теперь определите массив двойных слов и явно инициализируйте каждое его значение:
myList DWORD 1,2,3,4,5
На следующем рисунке показана схематическая диаграмма этого массива в памяти.Предположим, что смещение начальной позиции myList равно 0000, а приращение смещения равно 4.

Определить данные QWORD
Псевдо-инструкция QWORD (определить четыре слова) выделяет место для хранения 64-битных (8 байтов) значений:
quad1 QWORD 1234567812345678h
Традиционная псевдо-инструкция DQ также может использоваться для определения данных из четырех слов:
quad1 DQ 1234567812345678h
Определить сжатые данные BCD (TBYTE)
Intel хранит сжатое двоично-десятичное (BCD, двоично-десятичное) целое число в 10-байтовом пакете. Каждый байт (кроме самого старшего) содержит две десятичные цифры. В младших 9 байтах памяти каждый полубайт хранит десятичное число. В старшем байте самый старший бит представляет бит знака числа. Если старший байт равен 80h, число отрицательное; если старший байт равен 00h, число положительное. Диапазон целых чисел: от -999 999 999 999 999 999 до +999 999 999 999 999 999.
Пример В следующей таблице перечислены шестнадцатеричные байты хранения положительных и отрицательных десятичных чисел 1234, в порядке от младшего до самого старшего байта:
| Десятичное значение | Байты памяти |
|---|---|
| +1234 | 34 12 00 00 00 00 00 00 00 00 |
| -1234 | 34 12 00 00 00 00 00 00 00 80 |
MASM использует псевдо-инструкцию TBYTE для определения сжатых переменных BCD. Начальное значение константы должно быть в шестнадцатеричном формате, поскольку ассемблер не будет автоматически преобразовывать начальное десятичное значение в код BCD. В следующих двух примерах показаны допустимые и недопустимые выражения десятичного числа -1234:
intVal TBYTE 800000000000001234h; допустимый intVal TBYTE -1234; недопустимый
Второй пример недействителен, поскольку MASM кодирует константы как двоичные целые числа вместо сжатия целых чисел BCD.
Если вы хотите закодировать действительное число в сжатый код BCD, вы можете использовать инструкцию FLD для загрузки действительного числа в стек регистров с плавающей запятой, а затем использовать инструкцию FBSTP для преобразования его в сжатый код BCD. Эта инструкция округляет значение до ближайшего Целое число:
.data posVal REAL8 1,5 bcdVal TBYTE? .code fid posVal; загружается в стек с плавающей запятой fbstp bcdVal; округляется до 2, значение сжатого кода BCD
Если posVal равно 1,5, результирующее значение BCD равно 2.
Определить тип с плавающей запятой
REAL4 определяет 4-байтовую переменную с плавающей запятой одинарной точности. REAL8 определяет 8-байтовое значение с двойной точностью, а REAL10 определяет 10-байтовое значение с расширенной точностью. Каждая псевдо-инструкция требует одного или нескольких реальных постоянных начальных значений:
rVal1 REAL4 -1.2 rVal2 REAL8 3.2E-260 rVal3 REAL10 4.6E+4096 ShortArray REAL4 20 DUP(0.0)
В следующей таблице описано минимальное количество значащих цифр и приблизительные диапазоны стандартных вещественных типов:
| тип данных | эффективное число | Приблизительный диапазон |
|---|---|---|
| Короткий реальный номер | 6 | 1.18x 10-38 to 3.40 x 1038 |
| Длинное действительное число | 15 | 2.23 x 10-308 to 1.79 x 10308 |
| Действительное число повышенной точности | 19 | 3.37 x 10-4932 to 1.18 x 104932 |
Псевдо-инструкции DD, DQ и DT также могут определять действительные числа:
rVal1 DD -1.2; короткое действительное число rVal2 DQ 3.2E-260; длинное действительное число rVal3 DT 4.6E + 4096; действительное число повышенной точности
Ассемблер MASM включает такие типы данных, как wal4 и real8, которые указывают на то, что значение является действительным числом. Чтобы быть более точным, эти значения представляют собой числа с плавающей запятой с ограниченной точностью и диапазоном. С математической точки зрения точность и размер действительных чисел неограниченны.
Программа сложения переменных
До сих пор в примерах программ в этом разделе реализовано целочисленное сложение, хранящееся в регистрах. Теперь, когда у вас есть некоторое представление о том, как определять данные, вы можете изменить ту же программу, чтобы добавить три целочисленные переменные и сохранить сумму в четвертой переменной.
;AddTowSum.asm .386 .model flat,stdcall .stack 4096 ExitProcess PROTO, dwExitCode:DWORD .data firstval DWORD 20002000h secondval DWORD 11111111h thirdval DWORD 22222222h sum DWORD 0 .code main PROC mov eax,firstval add eax,secondval add eax,thirdval mov sum,eax INVOKE ExitProcess,0 main ENDP END main
Обратите внимание, что три переменные инициализированы ненулевыми значениями (строки с 9 по 11). Добавьте переменные в строки 16-18. Набор инструкций x86 не позволяет напрямую добавлять одну переменную к другой переменной, но позволяет добавлять одну переменную в регистр. Вот почему EAX используется как аккумулятор в строках 16-17:
mov eax,firstval
add eax,secondval
После строки 17 EAX содержит сумму firstval и secondval. Затем в строке 18 добавьте третье значение к сумме в EAX:
add eax,thirdval
Наконец, в строке 19 сумма копируется в переменную с именем sum:
mov sum,eax
В качестве упражнения всем рекомендуется запускать эту программу в сеансе отладки и проверять каждый регистр после выполнения каждой инструкции. Окончательная сумма должна быть 53335333 в шестнадцатеричной системе.
Если во время сеанса отладки вы хотите, чтобы переменная отображалась в шестнадцатеричном формате, выполните следующие действия: наведите указатель мыши на переменную или зарегистрируйтесь в течение 1 секунды, пока под курсором мыши не появится серый прямоугольник. Щелкните прямоугольник правой кнопкой мыши и выберите во всплывающем меню «Шестнадцатеричный формат».
Little endian
Процессор x86 хранит и извлекает данные в памяти в обратном порядке (от младшего к большему). Младший байт сохраняется в первом адресе памяти, присвоенном данным, а остальные байты сохраняются в последующих последовательных ячейках памяти. Рассмотрим двойное слово 12345678h. Если он сохраняется по смещению 0000, 78h сохраняется в первом байте, 56h сохраняется во втором байте, а оставшиеся байты сохраняются по смещениям адресов 0002 и 0003, как показано на следующем рисунке. .

Некоторые другие компьютерные системы используют прямой порядок байтов (от старшего к младшему). На следующем рисунке показано, что 12345678h хранится в обратном порядке, начиная со смещения 0000.

Объявить неинициализированные данные
.DATA? Директива объявляет неинициализированные данные. При определении большого количества неинициализированных данных директива .DATA? Уменьшает размер компилятора. Например, следующий код является допустимым утверждением:
.data smallArray DWORD 10 DUP (0); 40 байт .data? bigArray DWORD 5000 DUP (?); 20000 байт, неинициализировано
С другой стороны, скомпилированная программа, сгенерированная следующим кодом, будет иметь дополнительные 20 000 байтов:
.data smallArray DWORD 10 DUP (0); 40 байт bigArray DWORD 5000 DUP (?); 20000 байт
Гибридный ассемблер кода и данных позволяет переключать код и данные в программе туда и обратно. Например, вы хотите объявить переменную, чтобы ее можно было использовать только в локальной области программы. В следующем примере между двумя операторами кода вставляется переменная с именем temp:
.code mov eax,ebx .data temp DWORD ? .code mov temp,eax
Хотя присутствие оператора temp прерывает поток исполняемых инструкций, MASM поместит temp в раздел данных и отделит его от раздела кода, который остается скомпилированным. Однако в то же время смешивание директив .code и .data может затруднить чтение программы.
Следующий:Директива знака равенства
Настоятельно рекомендую прочитать статьи
[Учебник] по разработке больших данных с годовой зарплатой 40 + Вт, все здесь!
Работа с данными и памятью
Типы данных
Последнее обновление: 28.12.2022
Перед загрузкой данных в/из памяти сначала надо определить память, с которой будет идти работа. Ассемблер GNU предоставляет ряд директив для выделения памяти для использования в программе.
-
.ascii: строка в двойных кавычках
-
.asciz: строка ascii, которая заканчивается 0-вым байтом
-
.byte: целое число размером в 1 байт
-
.octa: целое число размером в 16 байт
-
.quad: целое число размером в 8 байт
-
.short: целое число размером в 2 байта
-
.word: целое число размером в 4 байта
-
.float: число с плавающей точкой одинарной точности
-
.double: число с плавающей точкой двойной точности
Мы можем определить числа в одном из следующих форматов:
-
Число в десятичной системе, которое может содержать цифры от 0 до 9 и должно начинаться с любой цифры кроме 0
-
Число в восьмеричной системе, которое может содержать цифры от 0 до 7 и должно начинаться с нуля
-
Число в двоичной системе, которое может содержать цифры 0 и 1 и должно начинаться с символов 0b или 0B
-
Число в шестнадцатеричной системе, которое может содержать шестнадцатеричные цифры от 0 до F и должно начинаться с символов 0x или 0X
-
Число с плавающей точкой, которое начинается с символов 0f или 0e, за которым идет число с плавающей точкой
Для определения памяти в программе предназначена секция
.data. Например:
.global _start
_start:
// выход из программы
MOV X0, 0 // код возврата - 0
MOV X8, #93 // устанавливаем функцию Linux для выхода из программы
SVC 0 // Вызываем функцию Linux
.data
mybyte: .byte 15 // определяем один байт, который равен 15
myword: .word 18 // определяем одно слово (4 байта), которое равно 18
myshort: .short 3 // определяем двухбайтное число, которое равно 3
myquad: .quad 1248 // определяем двойное слово (8 байт), которое равно 1248
myocta: .octa 12 // определяем четверное слово (16 байт), которое равно 12
hello: .ascii "Hellon" // определяем строку
message: .asciz "Hi Wordl" // определяем строку, которая заканчивается нулевым байтом
В данном случае для каждого отдельного кусочка данных определена метка. Например, на метку mybyte проецируется байт, который имеет значение 15. Пока эти данные никак не используются.
Можно определять сразу набор значений через запятую:
.data
mybytes: .byte 74, 0112, 0b00101010, 0x4A, 0X4a
Здесь определяется 5 байт, каждый из которых имеет одно и то же значение. Мы можем определить значения в десятичной, восьмеричной, двоичной, шестнадцатеричной системах. При этом значения могут представлять результат выражений, которые вычисляет ассемблер, когда компилирует программу.
Перед целыми числами можно использовать два знака:
-
— (отрицательное значение) определяет дополнение числа до двух
-
~ определяет дополнение числа до единицы
Например
.byte -0x45, -33, ~0b00111001
Определение наборов данных
Для определения наборов данных большего размера можно использовать инструкцию .fill:
.fill repeat, size, value
Эта инструкция повторяет значение определенного размера определенное количество раз:
.data
zeros: .fill 10, 4, 0
Эта инструкция создает блок памяти из 10-ти 4-байтовых чисел (слов), каждое из которых равно нулю.
Еще одна конструкция — .rept:
.rept count ... .endr
Повторяет выражения между .rept и .endr столько раз, сколько указано в параметре count. Например:
rpn: .rept 3
.byte 0, 1, 2
.endr
Здесь создается 3 раза по 3 байта — 0, 1, 2. То есть этот код будет эквивалентен следующему:
.byte 0, 1, 2 .byte 0, 1, 2 .byte 0, 1, 2
Выравнивание данных
Данные располагаются в памяти непрерывно байт за байтом. Однако ARM-процессор часто требует, что данные были выравнены тем или иным образом, например, по границе слова (4-байтного числа или значения word)
С помощью директивы .align указать ассемблеру, что надо выравнить следующий кусочек данных. Например
.data
.byte 0x3F
.align 4
.word 0x12345678
Здесь инструкция .align 4 указывает, что предыдущий байт в реальности будет занимать 4 байта и будет выровнен по границе слова, хотя в реальности его данные занимают только 1 байт.
Инструкции ассемблера ARM должны быть выровнены по границам слова. И при вставке данных в некоторые инструкции, может потребоваться директива .align,
иначе программа не будет работать. Обычно ассемблер генерирует ошибку, если требуется выравнивание, тем самым подсказывая, что надо применить инструкцию .align 4
Часть команд процессор может обработать только со значениями одной разрядности. Процессор без колебаний перемножит байт на байт и слово на слово. Но никак не байт на слово, или двойное слово на слово. Чтобы складывать, перемножать и выполнять другие операции со значениями разных размеров, программист должен озаботиться преобразованием типов в своей программе.
Под преобразованием типов я подразумеваю изменение разрядности операнда от большего к меньшему (например, двойное слово в слово), или от меньшего к большему (например, байт в слово). Для преобразования больших типов в меньшие отбрасывается старшая часть значения. Операция может быть не безопасной, если утрачивается часть значения, хранимого в старшей части (например, беззнаковое слово хранит число 500, а его преобразование в байт отсекает всё выше 255). В таком случае преобразование приводит к ошибочному результату.
Преобразование типов без знака
Беззнаковое преобразовании с увеличением разряда происходит через добавление к исходному значению старшей части, биты которой заполняется нулями. На картинке показан пример расширения из байта в слово:
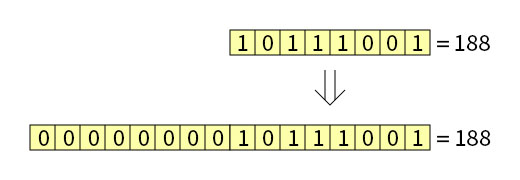
Преобразование беззнакового значения происходит просто. В программе на ассемблере для преобразования такого типа используется команда MOV:
|
mov dl,[a] mov dh,0 ;Другой вариант: mov dl,[a] xor dh,dh ;Вот еще один: mov dl,[a] sub dh,dh ;… a db 118 |
Также для беззнаковых преобразований в ассемблере есть специальная команда MOVZX (move with Zero-Extend, т.е. переместить с нулевым расширением). Она копирует содержимое операнда источника (регистр или значение в памяти) в операнд назначения (регистр). Старшая часть расширения заполняется нулями. Операнд назначения определяет размер расширения.
Преобразование командой MOVZX происходит так:
|
movzx cx,[b] ;CX = b ;… b db 193 |
Преобразование типов со знаком
Существует нюанс, касающийся старшего бита, который, как мы помним из Урока 8. Числа со знаком и без, является знаковым битом, то есть битом, определяющим, стоит перед числом знак «минус» или нет. Поэтому преобразования знакового числа происходит через прибавление старшей части и её заполнением знаковым битом. Говоря проще, если число было отрицательным, то старшая часть заполняется единицами, а если положительным – то нулями:
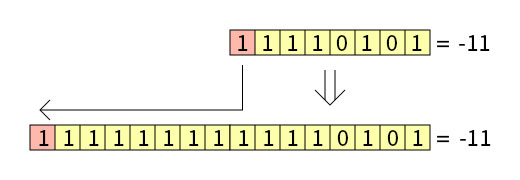
В ассемблере за преобразование типов знаковых значений отвечает команда MOVSX (Move with Sign-Extension, т.е. переместить со знаковым расширением). Она копирует содержание операнда источника (регистр или значение в памяти) в операнд назначения (регистр), расширяя значение знаковым битом:
Дополнительно в ассемблере есть еще команды для преобразования знаковых операндов: CBW – преобразует байт в слово (Convert Byte to Word) и CWD – преобразует слово в двойное слово (Convert Word to Double word). Они не получают явных операндов. Вместо этого CBW расширяет значение-байт в регистре AL в слово в регистре AX. В свою очередь CWD преобразует значение-слово в AX в двойное слово DX:AX. На практике обе команды часто сопутствуют операциями на умножении и деление.
Пример программы
Найдем решение формулы m = (a + 1) / (b – c). Все операнды со знаком. Размер m – слово, размер a – двойное слово, размер b – слово, размер c – байт.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
use16 ;Генерировать 16—битный код org 100h ;Программа начинается с адреса 100h mov ax,[b] ;AX = b movsx cx,[c] ;CX = c sub ax,cx ;AX = (b — c) mov cx,ax ;Запоминаем результат в CX mov ax,word[a] ;AX = младшая часть a mov dx,word[a+2] ;DX = старшая часть a add ax,1 ; adc dx,0 ;/DX:AX = (a + 1) idiv cx ;AX = (a + 1) / (b — c), в DX остаток mov [m],ax ;m = AX, в DX остаток int 20h ;Завершение программы a dd 12299 b dw 128 c db —16 m dw ? |
Упражнение
Теперь упражнение для самостоятельной работы. Закрепите пройденный урок написанием программы для решения формулы m = a^2 / (a + b). Все операнды со знаком. Размер a – слово, размеры b – байт, размер m – двойное слово. После компиляции откройте программу в Turbo Debugger, выполните все строки и проверьте, какое значение записалось по адресу переменной m. Результат отправьте в комментарии к уроку.
Практически любая программа содержит в себе перечень данных, с которыми она работает. Это могут быть символьные строки, предназначенные для вывода на экран; числа, определяющие ход выполнения программы или участвующие в вычислениях; адреса подпрограмм, обработчиков прерываний или просто тех или иных полей программы; специальные коды, например, коды цвета выводимых на экран символов и т.д. Кроме данных, определяемых в тексте программы, в программу часто входят зарезервированные поля, предназначенные для заполнения по ходу выполнения программы, например, результатами вычислений или путем чтения из файла. Все эти данные и зарезервированные поля должны быть определены в составе сегмента данных программы (в принципе они могут быть определены, и часто определяются, не в сегменте данных, а в сегменте команд, но здесь мы не будем касаться этого вопроса).
Формат описания данных:
[имя] Dn выражение
Имя элемента данных не обязательно (это указывается квадратными скобками), но если в программе имеются ссылки (обращения) на некоторый элемент, то это делается посредством имени.
Имена данных могут включать латинские буквы, цифры (не в качестве первого знака имени) и некоторые специальные знаки, например, знаки подчеркивания (_), доллара ($) и коммерческого at (@). Длину имени некоторые ассемблеры ограничивают (например, ассемблер MASM — 31 символом), другие — нет, но в любом случае слишком длинные имена затрудняют чтение программы. С другой стороны, имена данных следует выбирать таким образом, чтобы они отражали назначение конкретного данного, например counter для счетчика или filename для имени файла:
counter dw 10000
filename db ‘a:myfile.001’
Для определения данных используются, главным образом, три директивы ассемблера: db (define byte, определить байт) для записи байтов, dw (define word, определить слово) для записи слов и dd (define double, определить двойное слово) для записи двойных слов. Кроме перечисленных, имеются и другие директивы, например df (define fanvord, определить поле из 6 байт), dq (define quadword, определить четверное слово) или dt (define tcraword, определить 10-байтовую переменную), но они используются значительно реже.
Выражение может содержать числовое данное, например:
FLD1 DB 25
или знак вопроса для неопределенного значения, например
FLDB DB ?
Выражение может содержать несколько числовых данных, разделенных запятыми и ограниченными только длиной строки:
FLD3 DB 11, 12, 13, 14, 15, 16, …
Ассемблер определяет эти данные в виде последовательности смежных байт. Ссылка по имени FLD3 указывает на первое число, 11, по FLD3+1 — на второе, 12. (FLD3 можно представить как FLD3+0). Например команда
MOV AL,FLD3+3
загружает в регистр AL значение 14 (шест. 0E).
Выражение допускает также повторение константы в следующем формате:
[имя] Dn число-повторений DUP (выражение)
Следующие три примера иллюстрируют повторение:
DW 10 DUP(?) ;Десять неопределенных слов
DB 5 DUP(14) ;Пять байт, содержащих шест.14
DB 3 DUP(4 DUP(8));Двенадцать восьмерок
В третьем примере сначала генерируется четыре копии десятичной 8 (8888), и затем это значение повторяется три раза, давая в результате двенадцать восьмерок.
Выражение может содержать символьную строку или числовое данное.
Символьная строка используется для описания данных, таких как, например, имена людей или заголовки страниц. Содержимое строки отмечается одиночными кавычками, например, ‘PC’ или двойными кавычками — «PC». Ассемблер переводит символьные строки в объектный код в обычном формате ASCII. Символьная строка определяется только директивой DB, в которой указывается более два или более символов в нормальной последовательности слева направо. Следовательно, директива DB представляет единственно возможный формат для определения символьных данных.
Числовое данное используются для арифметических величин, для адресов памяти и т.п. Ассемблер преобразует все числовые данные в шестнадцатеричные и записывает байты в объектном коде в обратной последовательности — справа налево.
Значения числовых данных можно записывать в формате различных систем счисления; чаще других используются десятичная и шестнадцатеричная запись:
size dw 256 ;В ячейку size записывается
;десятичное число 256
setb7 db 80h ;В ячейку setb7 записывается
;16-ричное число 80h
Необходимо отметить неточность приведенных выше комментариев. В памяти компьютера могут храниться только двоичные коды. Если мы говорим, что в какой-то ячейке записано десятичное число 128, мы имеем в виду не физическое содержимое ячейки, а лишь форму представления этого числа в исходном тексте программы. В слове с именем size фактически будет записан двоичный код 0000000100000000, являющийся двоичным эквивалентом десятичного числа 256. Во втором случае в байте с именем setb7 будет записан двоичный эквивалент шестнадцатеричного числа 80h, который составляет 10000000 (т.е. байт с установленным битом 7, откуда и получила имя эта ячейка).
Форматы записи числовых данных
Десятичный формат допускает десятичные цифры от 0 до 9 и обозначается последней буквой D, которую можно не указывать, например, 125 или 125D. Несмотря на то, что ассемблер позволяет кодирование в десятичном формате, он преобразует эти значения в шестнадцатеричный объектный код. Например, десятичное число 125 преобразуется в 7Dh.
Шестнадцатеричный формат допускает шестнадцатеричные цифры от 0 до F и бозначается последней буквой H. Так как ассемблер полагает, что с буквы начинаются идентификаторы, то первой цифрой шестнадцатеричного данного должна быть цифра от 0 до 9. Например, 2EH или 0FFFH, которые ассемблер преобразует соответственно в 2E и FF0F (байты во втором примере записываются в объектный код в обратной последовательности).
Двоичный формат допускает двоичные цифры 0 и 1 и обозначается последней буквой B. Двоичный формат обычно используется для более четкого представления битовых значений в логических командах AND, OR, XOR и TEST.
Восьмеричный формат допускает восьмеричные цифры от 0 до 7 и обозначается последней буквой Q или O, например, 253Q. На сегодня восьмеричный формат используется весьма редко.
При записи символьных и числовых данных следует помнить, что, например, символьная строка, определенная как DB ’12’, представляет символы ASCII и генерирует шестнадцатеричное значение 3132h, а числовое данное, определенное как DB 12, представляет десятичное число и генерирует шестнадцатеричное 0Ch.
Присвоение данным символических имен позволяет обращаться к ним в программных предложениях, не заботясь о фактических адресах этих данных. Например, команда
mov AX,size
занесет в регистр АХ содержимое ячейки size (число 256), независимо от того, в каком месте сегмента данных эта ячейка определена, и в какое место физической памяти она попала. Однако программист, использующий язык ассемблера, должен иметь отчетливое представление о том, каким образом назначаются адреса ячейкам программы, и уметь работать не только с символическими обозначениями, но и со значениями адресов. Для обсуждения этого вопроса рассмотрим пример сегмента данных, в котором определяются данные различных типов. В левой колонке укажем смещения данных (в шестнадцатеричной форме), вычисляемые относительно начала сегмента.
data segment
0000h counter dw 10000
0002h pages db «Страница 1»
000Ch numbers db 0, 1, 2, 3, 4
0011h page_addr dw pages
data ends
Сегмент данных начинается с данного по имени counter, которое описано, как слово (2 байт) и содержит число 10000. Очевидно, что его смещение равно 0. Поскольку это данное занимает 2 байт, следующее за ним данное pages получило смещение 2. Данное pages описывает строку текста длиной 10 символов и занимает в памяти столько же байтов, поэтому следующее данное numbers получило относительный адрес 2 + 10 = 12 = Ch. В поле numbers записаны 5 байтовых чисел, поэтому последнее данное сегмента с именем page_addr размещается по адресу Ch + 5 = 11h.
Ассемблер, начиная трансляцию сегмента (в данном случае сегмента данных) начинает отсчет его относительных адресов. Этот отсчет ведется в специальной переменной транслятора (не программы!), которая называется счетчиком текущего адреса и имеет символическое обозначение знака доллара ($). По мере обработки полей данных, их символические имена сохраняются в создаваемой ассемблером таблице имен вместе с соответствующими им значениями счетчика текущего адреса. Другими словами, введенные нами символические имена получают значения, равные их смещениям. Таким образом, с точки зрения транслятора counter равно 0, pages — 2, numbers — Ch и т.д. Поэтому предложение
page_addr dw pages
трактуется ассемблером, как
page_addr dw 2
и приводит к записи в слово с относительным адресом 11h числа 2 (смещения строки pages).
 Приведенные рассуждения приходится использовать при обращении к «внутренностям» объявленных данных. Пусть, например, мы хотим выводить на экран строки «Страница 2», «Страница 3», «Страница 4» и т.д. Можно, конечно, все эти строки описать в сегменте данных по отдельности, но это приведет к напрасному расходу памяти. Экономнее поступить по-другому: выводить на экран одну и ту же строку pages, но модифицировать в ней номер страницы. Модификацию номера можно выполнить с помощью, например, такой команды:
Приведенные рассуждения приходится использовать при обращении к «внутренностям» объявленных данных. Пусть, например, мы хотим выводить на экран строки «Страница 2», «Страница 3», «Страница 4» и т.д. Можно, конечно, все эти строки описать в сегменте данных по отдельности, но это приведет к напрасному расходу памяти. Экономнее поступить по-другому: выводить на экран одну и ту же строку pages, но модифицировать в ней номер страницы. Модификацию номера можно выполнить с помощью, например, такой команды:
mov pages + 9,’2′
Здесь мы «вручную» определили смещение интересующего нас символа в строке, зная, что все данные размещаются ассемблером друг за другом в порядке их объявления в программе. При этом, какое бы значение не получило имя pages, выражение pages + 9 всегда будет соответствовать байту с номером страницы.
Таким же приемом можно воспользоваться при обращении к данному numbers, которое в сущности представляет собой небольшой массив из 5 чисел. Адрес первого числа в этом массиве равен просто numbers, адрес второго числа — numbers + 1, адрес третьего — numbers + 2 и т.д. Следующая команда прочитает последний элемент этого массива в регистр DL:
mov DL,numbers+4
Какой смысл имело объединение ряда чисел в массив numbers? Да никакого, если к этим числам мы все равно обращаемся по отдельности. Удобнее было объявить этот массив таким образом:
nmb0 db 0
nmbl db 1
nmb2 db 2
nmb3 db 3
nmb4 db 4
В этом случае для обращения к последнему элементу не надо вычислять его адрес, а можно воспользоваться именем nmb4. Если, с другой стороны, мы хотим работать с числами, как с массивом, используя индексы отдельных элементов (о чем речь будет идти позже), то присвоение массиву общего имени представляется естественным. Получение последнего элемента массива по его индексу выполняется с помощью такой последовательности команд:
mov SI,4 ;Индекс элемента в массиве
mov DL,numbers[SI] ;Обращение по адресу
;numbers + содержимое SI
Иногда желательно обращаться к элементам массива (обычно небольшого размера) то с помощью индексов, то по их именам. Для этого надо к описанию массива, как последовательности отдельных данных, добавить дополнительное символическое описание адреса начала массива с помощью директивы ассемблера label (метка):
numbers label byte
nmb0 db 0
nmbl db 1
nmb2 db 2
nmb3 db 3
nmb4 db 4
Метка numbers должна быть объявлена в данном случае с описателем byte, так как данные, следующие за этой меткой, описаны как байты и мы планируем работать с ними именно как с байтами. Если нам нужно иметь массив слов, то отдельные элементы массива следует объявить с помощью директивы dw, а метке numbers придать описатель word:
numbers label word
nmb0 dw 0
nmbl dw 1
nmb2 dw 2
nmb3 dw 3
nmb4 dw 4
В чем состоит различие двух последних описаний данных? Различие есть, и весьма существенное. Хотя в обоих случаях в память записывается натуральный ряд чисел от 0 до 4, однако в первом варианте под каждое число в памяти отводится один байт, а во втором — слово. Если мы в дальнейшем будем изменять значения элементов нашего массива, то в первом варианте каждому числу можно будет задавать значения от 0 до 255, а во втором — от 0 до 65535.
Выбирая для данных способ их описания, необходимо иметь в виду, что ассемблер выполняет проверку размеров используемых данных и не пропускает команды, в которых делается попытка обратиться к байтам, как к словам, или к словам — как к байтам. Рассмотрим последний вариант описания массива numbers. Хотя под каждый элемент выделено целое слово, однако реальные числа невелики и вполне поместятся в байт. Может возникнуть искушение поработать с ними, как с байтами, перенеся предварительно в байтовые регистры:
mov AL,nmb0 ;Переносим nmb0 в AL
mov DL,nmbl ;Переносим nmb1 в AL
mov CL,nmb2 ;Переносим nmb2 в AL
Так делать нельзя. Транслятор сообщит о грубой ошибке — несоответствии типов, и не будет создавать объектный файл. Однако довольно часто возникает реальная потребность в операциях такого рода. Для таких случаев предусмотрен специальный атрибутивный оператор byte ptr (byte pointer, байтовый указатель), с помощью которого можно на время выполнения одной Команды изменить размер операнда:
mov AL,byte ptr nmb0
mov DL,byte ptr nmbl
mov CL,byte ptr nmb2
Эти команды транслятор рассматривает, как правильные. Но следует заметить, что эта команда будет указывать на младший байт в слове (nmb0, nmb1 и т.д.).
Часто возникает необходимость выполнить обратную операцию — к паре байтов обратиться, как к слову. Для этого надо использовать оператор word ptr:
okey db ‘OK’
…
mov AX,word ptr okey
Здесь оба байта из байтовой переменной okey переносятся в регистр АХ. При этом первый по порядку байт, т.е. байт с меньшим адресом, содержащий букву «О», отправится в младшую половину АХ — регистр AL, а второй по порядку байт, с буквой «К», займет регистр АН.
До сих пор речь шла о данных, которые, в сущности, являлись переменными, в том смысле, что под них выделялась память и их можно было модифицировать. Язык ассемблера позволяет также использовать константы, которые являются символическими обозначениями чисел и могут использоваться всюду в тексте программы, как наглядные эквиваленты этих чисел:
maxsize = 0FFFFh
……
mov CX,maxsize
mov CX,0FFFFh
Последние две команды полностью эквивалентны.
При определении констант допустимо выполнение арифметических операций. Пусть нам надо задать позицию символа (или строки символов) на экране. Учитывая, что каждый символ записывается в видеопамяти в двух байтах (в первом — код ASCII символа, а во втором — его атрибут), строка экрана имеет длину 80 символов, а высота экрана составляет 25 строк, то для вывода некоторого символа в середину экрана его смещение в видеопамяти от начала видеостраницы можно определить следующим образом:
position=80*2*12+40*2
Такая запись достаточно наглядна, и ее легко модифицировать, если мы решим вывести символ в какую-то другую область экрана.
Константами удобно пользоваться для определения длины текстовых строк:
mes db ‘Ждите’
mes_len = $-mes
В этом примере константа mes_len получает значение длины строки mes (в данном случае 5 байт), которая вычисляется как разность значения счетчика текущего адреса после определения строки и ее начального адреса mes. Такой способ удобен тем, что при изменении содержимого строки достаточно перетранслировать программу, и та же константа mes_len автоматически получит новое значение.
ДИРЕКТИВА ОПРЕДЕЛЕНИЯ БАЙТА (DB)
Из различных директив, определяющих элементы данных, наиболее полезной является DB (определить байт). Символьное выражение в директиве DB может содержать строку символов любой длины. Числовое выражение в директиве DB может содержать одну или более однобайтовых констант. Один байт выражается двумя шестнадцатеричными цифрами. Если интерпретировать числовые значения, описанные директивой DB, как содержащие знак, то наибольшее положительное шестнадцатеричное число в одном байте это 7F, все «большие» числа от 80 до FF представляют отрицательные значения. В десятичном исчислении эти пределы выражаются числами +127 и -128.
ДИРЕКТИВА ОПРЕДЕЛЕНИЯ СЛОВА (DW)
Директива DW определяет элементы, которые имеют длину в одно слово (два байта). Символьное выражение в DW ограничено двумя символами, которые ассемблер представляет в объектном коде так, что, например, ‘PC’ становится ‘CP’. Для определения символьных строк директива DW имеет ограниченное применение.
Два байта представляются четырьмя шестнадцатеричными цифрами. Если интерпретировать числовые значения, описанные директивой DW, как содержащие знак, то наибольшее положительное шестнадцатеричное число в двух байтах это 7FFF; все «большие» числа от 8000 до FFFF представляют отрицательные значения. В десятичном исчислении эти пределы выражаются числами +32767 и -32768.
Для форматов директив DW, DD и DQ ассемблер преобразует константы в шестнадцатеричный объектный код, но записывает его в обратной последовательности.
Таким образом десятичное значение 12345 преобразуется в шестнадцатеричное 3039, но
записывается в объектном коде как 3930.
ДИРЕКТИВА ОПРЕДЕЛЕНИЯ ДВОЙНОГО СЛОВА (DD)
Директива DD определяет элементы, которые имеют длину в два слова (четыре байта). Если интерпретировать числовые значения, описанные директивой DD , как содержащие знак, то, наибольшее положительное шестнадцатеричное число в четырех байтах это 7FFFFFFF. Все «большие» числа от 80000000 до FFFFFFFF представляют отрицательные
значения. В десятичном исчислении эти пределы выражаются числами +2147483647 и -2147483648.
Ассемблер преобразует все числовые константы в директиве DD в шестнадцатеричное представление, но записывает объектный код в обратной последовательности. Таким образом десятичное значение 12345 преобразуется в шестнадцатеричное 00003039, но
записывается в объектном коде как 39300000.
Символьное выражение директивы DD ограничено двумя символами.
ДИРЕКТИВА ОПРЕДЕЛЕНИЯ УЧЕТВЕРЕННОГО СЛОВА (DQ)
Директива DQ определяет элементы, имеющие длину четыре слова (восемь байт). Наибольшее без знаковое значение может быть FFFFFFFFFFFFFFFF, что равно десятичному 18446744073709551615. Отрицательные и положительные значения считайте сами :).
Двоично-десятичный
ДИРЕКТИВА ОПРЕДЕЛЕНИЯ ДЕСЯТИ БАЙТ (DT)
Директива DT определяет элементы данных, имеющие длину в десять байт.
Назначение этой директивы связано с упакованным двоично-десятичным форматом данных.
Ну и на последок, кусок кода с моими экспериментами:

Для описания типов
данных используются директивы
резервирования и инициализации памяти:
-
DB – 1
байт – 8 бит, -
DW – 2
байта – 16 бит, -
DD – 4
байта – 32 бита, -
DQ – 8
байт – 64 бита, -
DT – 10
байт – 80 бит.
Примечание.
Дополнительными директивами являются
директивы, описывающие данные длиной
6 байт (для дальнего указателя – 2 байта
селектор и 4 байта смещение):
-
DF – 6
байт – 48 бит, -
DP – 6
байт – 48 бит,
Примеры:
The_byte DB 5 ;
0 … 255 (28-1)
The_word DW 3000 ;
0 … 65 535 (216-1)
The_dword DD 12345678 ;
0 … 4 294 967 295 (232-1)
The_qword DQ 1122334455667788 ;
0 … (264-1)
The_ptr DP 112233445566 ;
0 … (248-1)
При резервировании
памяти можно задавать различное
количество элементов данных, инициализируя
их значения или не инициализируя,
присваивая имя или не присваивая.
Для описания символов в коде ASCII
Ассемблер допускает записывать значения
байт в кавычках.
Примеры:
DB ? ;
один байт
без инициализации и
имени
DB 5,
0Fh ; два
байта без
имени с инициализацией
DB 5,?,7 ;
три байта,
два с инициализацией,
один – без
Five_bytes DB 0,0,0,0,0 ;
область 5 байт, значения всех нулевые
The_ptr DB 1122334455 ;
0 … (248-1)
Str DB ‘Строка
текста’ ;
13 байт
DB ‘5’ ;
один байт, равный 53 или 35h
или ‘5’
DB 5 ;
один байт, равный 5
При заполнении
памяти повторяющимися значениями
используется оператор dup:
Примеры:
Buffer DB 200h
dup
(0) ; буфер 512 байт
инициализирован нулями.
String_buf DB 78
dup
(‘ ‘) ; буфер приема
строки заполнен пробелами.
К одним и тем же
ячейкам памяти можно обращаться как к
данным различных типов. Один из способов
описания таких ячеек памяти предполагает
использование директивы LABEL.
Примеры:
Bytes label byte
Words label word
DB 0,1,2,3,4,5 ;
определены шесть байт или три слова
;
слова равны: 0100h,
0302h, 0504h
Обращение к ячейкам
как к данным нужного типа можно выполнять
и без описания их в директиве LABEL,
если явно указать тип данных в
команде, используя оператор PTR.
Примеры:
b_or_w db 1,2,3,4 ;
данные
…
mov al,
byte ptr b_or_w ; al := 01
mov ax,
word ptr b_or_w ; ax := 0201h
mov al,
byte ptr b_or_w+3 ; al := 04
mov ax,
word ptr b_or_w+2 ; ax := 0403h
w_or_b dw 0201h,0403h ;
те же данные
…
mov al,byte
ptr w_or_b+3 ; al := 04
mov ax,w_or_b+2 ;
ax := 0403h
Пример программы
Ниже приведен
пример программы на языке Ассемблер с
различными типами данных, описанными
в сегменте данных. Сегмент данных выделен
полужирным шрифтом.

На первой странице
листинга программы, приведенной ниже,
можно увидеть результаты трансляции
рассматриваемой программы. Описанные
в исходном модуле данные выделены.
Turbo Assembler Version 2.51 03/07/00 12:25:41 Page 1
prog.ASM
1 name prog
2
3 0000 .model small
4
5 0000 .data
6 ;———————
7 0000 42 65 67 69 6E 20 6F+ db ‘Begin of DATAseg’
8 66 20 44 41 54 41 73+
9 65 67
10
11 0010 12 x1 db 12h
12 0011 1234 x2 dw 1234h
13 0013 12345678 x3 dd 12345678h
14 0017 0123456789ABCDEF x4 dq 0123456789ABCDEFh
15 001F 112233445566778899AA x5 dt 112233445566778899AAh
16 0029 112233445566 x6 dp 112233445566h
17 002F AABBCCDDEEFF x7 df 0AABBCCDDEEFFh
18
19 0035 53 74 72 69 6E 67 20+ s1 db ‘String 1’
20 31
21 003D 2A db ‘*’
22 003E ?? db ?
23 003F ?? db ?
24
25 0040 10*(02 03) b1 db 10h dup (2,3)
26
27 0060 .code
28 ;———————
29 0000 main proc far
30 0000 start:
31 0000 B8 0000s mov ax,@data
32 0003 8E D8 mov ds,ax
33
34 0005 exit:
35 0005 B8 4C00 mov ax,4C00h ; exit
36 0008 CD 21 int 21h
37
38 000A main endp
39 ;———————
40 end start
На второй странице
листинга приведена таблица символических
имен с указанием их адресов. Так, адрес
переменной x4
равен 0017h,
т. е. находится в 23-ей
ячейке относительно начала сегмента
данных, который находится в группе
DGROUP.
Turbo Assembler Version 2.51 03/07/00 12:25:41 Page 2
Symbol Table
Symbol Name Type Value
??DATE Text «03/07/00»
??FILENAME Text «prog «
??TIME Text «12:25:41»
??VERSION Number 0205
@CODE Text _TEXT
@CODESIZE Text 0
@CPU Text 0101H
@CURSEG Text _TEXT
@DATA Text DGROUP
@DATASIZE Text 0
@FILENAME Text PROG
@MODEL Text 2
@WORDSIZE Text 2
B1 Byte DGROUP:0040
EXIT Near _TEXT:0005
MAIN Far _TEXT:0000
S1 Byte DGROUP:0035
START Near _TEXT:0000
X1 Byte DGROUP:0010
X2 Word DGROUP:0011
X3 Dword DGROUP:0013
X4 Qword DGROUP:0017
X5 Tbyte DGROUP:001F
X6 Pword DGROUP:0029
X7 Pword DGROUP:002F
Groups & Segments Bit Size Align Combine Class
DGROUP Group
_DATA 16 0060 Word Public DATA
_TEXT 16 000A Word Public CODE
Вид модуля в
отладчике AFD
показан на рис.1.
В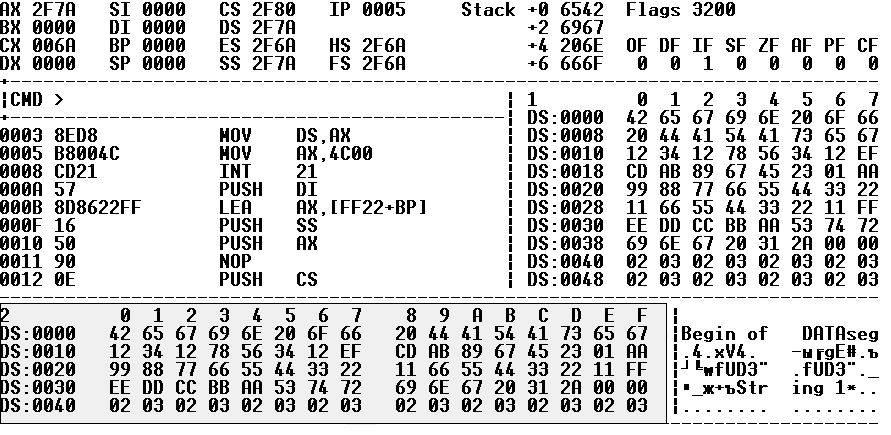
ыделенная
внизу область – это сегмент данных
программы. Адреса данных складываются
из двух шестнадцатеричных чисел: в левом
столбце и верхней строке над данными.
Так, начальный байт имеет адрес 0000h,
а его значение равно 42h,
или ‘B’ лат.,
первый символ строки String1
имеет адрес 0030h
+ 5h = 0035h,
а его значение равно 53h
или ‘S’
лат. Справа от шестнадцатеричного
дампа памяти расположено ASCII-представление
этих данных (символьное представление,
удобное для чтения текстовых констант).
Рисунок 1
С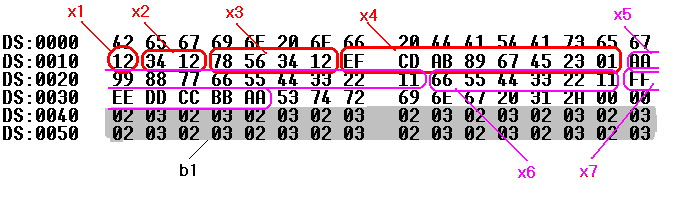
егмент
данных в модуле приведен на рис.2. Показаны
зарезервированные в исходном модуле
области данных. Обратное по отношению
с записью в исходном модуле расположение
байтов – характерный эффект, связанный
с представлением ячеек памяти в окне
отладчика слева направо (от младших к
старшим). Так, двойное слово x3,
значение которого инициализировано
шестнадцатеричной константой 12345678h,
занимает байты с адресами 13, 14, 15, 16. При
этом две младшие цифры числа (7 и 
занимают младший байт с адресом 13,
следующие две цифры (5 и 6) занимают
следующий байт с адресом 14 и т.д. Строка
текста в окне отладчика читается так
же, как и в исходном модуле, т.к. расположение
текста в памяти – от начала текста в
младших адресах к концу текста в старших
адресах – совпадает с естественным
расположением читаемого текста слева
направо (см. рис.1). Байты с адресами 3E,
3F,
значения которых равны нулю, не
инициализируются программой. Байты с
адресами 40-5F
занимают область, зарезервированную
с использованием оператора dup.
Рисунок 2
Вид модуля в
отладчике TurboDebuger
5.0 показан на рис.3.
Рисунок 3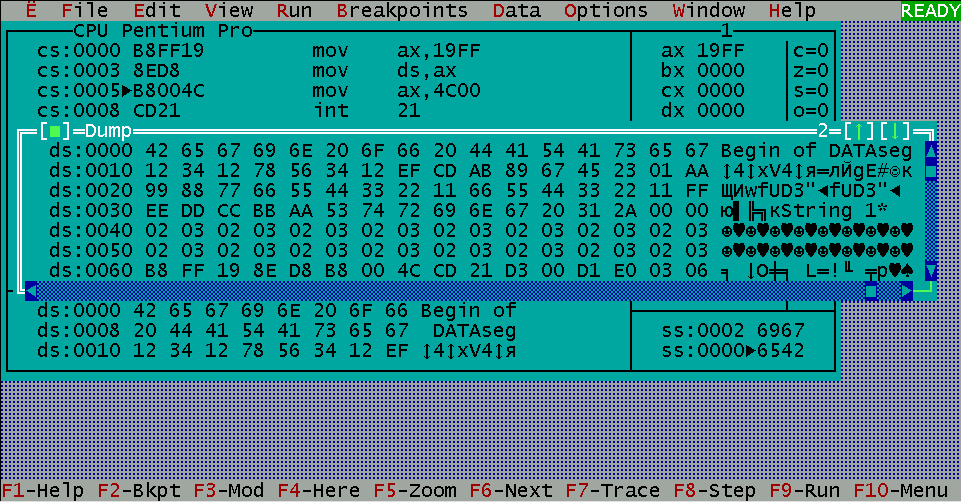
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #