
Property to prevent or allow words to be broken over multiple lines between letters.
Chrome
- 4 — 43: Partial support
- 44 — 111: Supported
- 112: Supported
- 113 — 115: Supported
Edge
- 12 — 110: Supported
- 111: Supported
Safari
- 3.1 — 8: Partial support
- 9 — 16.3: Supported
- 16.4: Supported
- 16.5 — TP: Supported
Firefox
- 2 — 14: Not supported
- 15 — 110: Supported
- 111: Supported
- 112 — 113: Supported
Opera
- 9 — 12.1: Not supported
- 15 — 30: Partial support
- 31 — 94: Supported
- 95: Supported
IE
- 5.5 — 10: Supported
- 11: Supported
Chrome for Android
- 111: Supported
Safari on iOS
- 3.2 — 8.4: Partial support
- 9 — 16.3: Supported
- 16.4: Supported
- 16.5: Supported
Samsung Internet
- 4 — 19.0: Supported
- 20: Supported
Opera Mini
- all: Not supported
Opera Mobile
- 10 — 12.1: Not supported
- 73: Supported
UC Browser for Android
- 13.4: Supported
Android Browser
- 2.1 — 4.4.4: Partial support
- 111: Supported
Firefox for Android
- 110: Supported
QQ Browser
- 13.1: Supported
Baidu Browser
- 13.18: Supported
KaiOS Browser
- 2.5: Supported
- 3: Supported
Partial support refers to supporting the break-all value, but not the keep-all value.
Chrome, Safari and other WebKit/Blink browsers also support the unofficial break-word value which is treated like word-wrap: break-word.
- Resources:
- MDN Web Docs — CSS word-break
- WebPlatform Docs
Свойство CSS word-break определяет, где будет установлен перевод на новую строку в случае превышения текстом границ блока.
Интерактивный пример
Синтаксис
/* Значения ключевых слов */
word-break: normal;
word-break: break-all;
word-break: keep-all;
word-break: break-word; /* не включено в стандарт */
/* Глобальные значения */
word-break: inherit;
word-break: initial;
word-break: unset;
Свойство word-break определяется одним из описанных ниже ключевых слов.
Значения
normal-
Поведение по умолчанию для расстановки перевода строк.
break-all-
При превышении границ блока, перевод строки будет вставлен между любыми двумя символами (за исключением текста на китайском/японском/корейском языке).
keep-all-
Перевод строки не будет использован в тексте на китайском/японском/корейском языке. Для текста на других языках будет применено поведение по умолчанию (
normal). break-word
Non-standard
-
При превышении границ блока, обычно остающиеся целыми слова, могут быть разбиты в произвольном месте, если не будет найдено более подходящее для переноса строки место.
Примечание: В отличие от word-break: break-word и overflow-wrap: break-word (смотри overflow-wrap), word-break: break-all вставит перевод строки в том месте, где текст будет превышать занимаемый им блок (даже в том случае, когда текст можно перенести по словам).
Формальный синтаксис
word-break =
normal | (en-US)
keep-all | (en-US)
break-all | (en-US)
break-word
Примеры
HTML
<p>1. <code>word-break: normal</code></p>
<p class="normal narrow">This is a long and
Honorificabilitudinitatibus califragilisticexpialidocious Taumatawhakatangihangakoauauotamateaturipukakapikimaungahoronukupokaiwhenuakitanatahu
グレートブリテンおよび北アイルランド連合王国という言葉は本当に長い言葉</p>
<p>2. <code>word-break: break-all</code></p>
<p class="breakAll narrow">This is a long and
Honorificabilitudinitatibus califragilisticexpialidocious Taumatawhakatangihangakoauauotamateaturipukakapikimaungahoronukupokaiwhenuakitanatahu
グレートブリテンおよび北アイルランド連合王国という言葉は本当に長い言葉</p>
<p>3. <code>word-break: keep-all</code></p>
<p class="keepAll narrow">This is a long and
Honorificabilitudinitatibus califragilisticexpialidocious Taumatawhakatangihangakoauauotamateaturipukakapikimaungahoronukupokaiwhenuakitanatahu
グレートブリテンおよび北アイルランド連合王国という言葉は本当に長い言葉</p>
<p>4. <code>word-break: break-word</code></p>
<p class="breakWord narrow">This is a long and
Honorificabilitudinitatibus califragilisticexpialidocious Taumatawhakatangihangakoauauotamateaturipukakapikimaungahoronukupokaiwhenuakitanatahu
グレートブリテンおよび北アイルランド連合王国という言葉は本当に長い言葉</p>
CSS
.narrow {
padding: 5px;
border: 1px solid;
display: table;
max-width: 100%;
}
.normal {
word-break: normal;
}
.breakAll {
word-break: break-all;
}
.keepAll {
word-break: keep-all;
}
.breakWord {
word-break: break-word;
}
Спецификации
| Specification | Status | Comment |
|---|---|---|
| CSS Text Module Level 3 Определение ‘word-break’ в этой спецификации. |
Кандидат в рекомендации | Initial definition |
| Начальное значение | normal |
|---|---|
| Применяется к | все элементы |
| Наследуется | да |
| Обработка значения | как указано |
| Animation type | discrete |
Браузерная совместимость
BCD tables only load in the browser
See also
Let’s talk about the various ways we can control how text wraps (or doesn’t wrap) on a web page. CSS gives us a lot of tools to make sure our text flows the way we want it to, but we’ll also cover some tricks using HTML and special characters.

Protecting Layout
Normally, text flows to the next line at “soft wrap opportunities”, which is a fancy name for spots you’d expect text to break naturally, like between words or after a hyphen. But sometimes you may find yourself with long spans of text that don’t have soft wrap opportunities, such as really long words or URLs. This can cause all sorts of layout issues. For example, the text may overflow its container, or it might force the container to become too wide and push things out of place.
It’s good defensive coding to anticipate issues from text not breaking. Fortunately, CSS gives us some tools for this.
Getting Overflowing Text to Wrap
Putting overflow-wrap: break-word on an element will allow text to break mid-word if needed. It’ll first try to keep a word unbroken by moving it to the next line, but will then break the word if there’s still not enough room.
See the Pen overflow-wrap: break-word by Will Boyd (@lonekorean) on CodePen.
There’s also overflow-wrap: anywhere, which breaks words in the same manner. The difference is in how it affects the min-content size calculation of the element it’s on. It’s pretty easy to see when width is set to min-content.
.top {
width: min-content;
overflow-wrap: break-word;
}.bottom {
width: min-content;
overflow-wrap: anywhere;
}
See the Pen overflow-wrap + min-content by Will Boyd (@lonekorean) on CodePen.
The top element with overflow-wrap: break-word calculates min-content as if no words are broken, so its width becomes the width of the longest word. The bottom element with overflow-wrap: anywhere calculates min-content with all the breaks it can create. Since a break can happen, well, anywhere, min-content ends up being the width of a single character.
Remember, this behavior only comes into play when min-content is involved. If we had set width to some rigid value, we’d see the same word-breaking result for both.
Breaking Words without Mercy
Another option for breaking words is word-break: break-all. This one won’t even try to keep words whole — it’ll just break them immediately. Take a look.
See the Pen word-break: break-all by Will Boyd (@lonekorean) on CodePen.
Notice how the long word isn’t moved to the next line, like it would have been when using overflow. Also notice how “words” is broken, even though it would have fit just fine on the next line.
word-break: break-all has no problem breaking words, but it’s still cautious around punctuation. For example, it’ll avoid starting a line with the period from the end of a sentence. If you want truly merciless breaking, even with punctuation, use line-break: anywhere.
See the Pen word-break: break-all vs line-break: anywhere by Will Boyd (@lonekorean) on CodePen.
See how word-break: break-all moves the “k” down to avoid starting the second line with “.”? Meanwhile, line-break: anywhere doesn’t care.
Excessive Punctuation
Let’s see how the CSS properties we’ve covered so far handle excessively long spans of punctuation.
See the Pen Excessive Punctuation by Will Boyd (@lonekorean) on CodePen.
overflow-wrap: break-word and line-break: anywhere are able to keep things contained, but then there’s word-break: break-all being weird with punctuation again — this time resulting in overflowing text.
It’s something to keep in mind. If you absolutely do not want text to overflow, be aware that word-break: break-all won’t stop runaway punctuation.
Specifying Where Words Can Break
For more control, you can manually insert word break opportunities into your text with <wbr>. You can also use a “zero-width space”, provided by the ​ HTML entity (yes, it must be capitalized just as you see it!).
Let’s see these in action by wrapping a long URL that normally wouldn’t wrap, but only between segments.
<!-- normal -->
<p>https://subdomain.somewhere.co.uk</p> <!-- <wbr> -->
<p>https://subdomain<wbr>.somewhere<wbr>.co<wbr>.uk</p>
<!-- ​ -->
<p>https://subdomain​.somewhere​.co​.uk</p>
See the Pen Manual Word Break Opportunities by Will Boyd (@lonekorean) on CodePen.
Automatic Hyphenation
You can tell the browser to break and hyphenate words where appropriate by using hyphens: auto. Hyphenation rules are determined by language, so you’ll need to tell the browser what language to use. This is done by specifying the lang attribute in HTML, possibly on the relevant element directly, or on <html>.
<p lang="en">This is just a bit of arbitrary text to show hyphenation in action.</p> p {
-webkit-hyphens: auto; /* for Safari */
hyphens: auto;
}See the Pen hyphens: auto by Will Boyd (@lonekorean) on CodePen.
Manual Hyphenation
You can also take matters into your own hands and insert a “soft hyphen” manually with the ­ HTML entity. It won’t be visible unless the browser decides to wrap there, in which case a hyphen will appear. Notice in the following demo how we’re using ­ twice, but we only see it once where the text wraps.
<p lang="en">Magic? Abraca­dabra? Abraca­dabra!</p>See the Pen Soft Hyphen by Will Boyd (@lonekorean) on CodePen.
hyphens must be set to either auto or manual for ­ to display properly. Conveniently, the default is hyphens: manual, so you should be good without any additional CSS (unless something has declared hyphens: none for some reason).
Preventing Text from Wrapping
Let’s switch things up. There may be times when you don’t want text to wrap freely, so that you have better control over how your content is presented. There are a couple of tools to help you with this.
First up is white-space: nowrap. Put it on an element to prevent its text from wrapping naturally.
See the Pen white-space: nowrap by Will Boyd (@lonekorean) on CodePen.
Preformatting Text
There’s also white-space: pre, which will wrap text just as you have it typed in your HTML. Be careful though, as it will also preserve spaces from your HTML, so be mindful of your formatting. You can also use a <pre> tag to get the same results (it has white-space: pre on it by default).
<!-- the formatting of this HTML results in extra whitespace! -->
<p>
What's worse, ignorance or apathy?
I don't know and I don't care.
</p><!-- tighter formatting that "hugs" the text -->
<p>What's worse, ignorance or apathy?
I don't know and I don't care.</p>
<!-- same as above, but using <pre> -->
<pre>What's worse, ignorance or apathy?
I don't know and I don't care.</pre>
p {
white-space: pre;
}pre {
/* <pre> sets font-family: monospace, but we can undo that */
font-family: inherit;
}
See the Pen Preformatted Text by Will Boyd (@lonekorean) on CodePen.
A Break, Where Words Can’t Break?
For line breaks, you can use <br> inside of an element with white-space: nowrap or white-space: pre just fine. The text will wrap.
But what happens if you use <wbr> in such an element? Kind of a trick question… because browsers don’t agree. Chrome/Edge will recognize the <wbr> and potentially wrap, while Firefox/Safari won’t.
When it comes to the zero-width space (​) though, browsers are consistent. None will wrap it with white-space: nowrap or white-space: pre.
<p>Darth Vader: Nooooooooooooo<br>oooo!</p><p>Darth Vader: Nooooooooooooo<wbr>oooo!</p>
<p>Darth Vader: Nooooooooooooo​oooo!</p>
See the Pen white-space: nowrap + breaking lines by Will Boyd (@lonekorean) on CodePen.
Non-Breaking Spaces
Sometimes you may want text to wrap freely, except in very specific places. Good news! There are a few specialized HTML entities that let you do exactly this.
A “non-breaking space” ( ) is often used to keep space between words, but disallow a line break between them.
<p>Something I've noticed is designers don't seem to like orphans.</p><p>Something I've noticed is designers don't seem to like orphans.</p>
See the Pen Non-Breaking Space by Will Boyd (@lonekorean) on CodePen.
Word Joiners and Non-Breaking Hyphens
It’s possible for text to naturally wrap even without spaces, such as after a hyphen. To prevent wrapping without adding a space, you can use ⁠ (case-sensitive!) to get a “word joiner”. For hyphens specifically, you can get a “non-breaking hyphen” with ‑ (it doesn’t have a nice HTML entity name).
<p>Turn right here to get on I-85.</p> <p>Turn right here to get on I-⁠85.</p>
<p>Turn right here to get on I‑85.</p>
See the Pen Word Joiners and Non-Breaking Hyphens by Will Boyd (@lonekorean) on CodePen.
CJK Text and Breaking Words
CJK (Chinese/Japanese/Korean) text behaves differently than non-CJK text in some ways. Certain CSS properties and values can be used for additional control over the wrapping of CJK text specifically.
Default browser behavior allows words to be broken in CJK text. This means that word-break: normal (the default) and word-break: break-all will give you the same results. However, you can use word-break: keep-all to prevent CJK text from wrapping within words (non-CJK text will be unaffected).
Here’s an example in Korean. Note how the word “자랑스럽게” does or doesn’t break.
See the Pen CJK Text + word-break by Will Boyd (@lonekorean) on CodePen.
Be careful though, Chinese and Japanese don’t use spaces between words like Korean does, so word-break: keep-all can easily cause long overflowing text if not otherwise handled.
CJK Text and Line Break Rules
We talked about line-break: anywhere earlier with non-CJK text and how it has no problem breaking at punctuation. The same is true with CJK text.
Here’s an example in Japanese. Note how “。” is or isn’t allowed to start a line.
See the Pen CJK Text + line-break by Will Boyd (@lonekorean) on CodePen.
There are other values for line-break that affect how CJK text wraps: loose, normal, and strict. These values instruct the browser on which rules to use when deciding where to insert line breaks. The W3C describes several rules and it’s possible for browsers to add their own rules as well.
Worth Mentioning: Element Overflow
The overflow CSS property isn’t specific to text, but is often used to ensure text doesn’t render outside of an element that has its width or height constrained.
.top {
white-space: nowrap;
overflow: auto;
}.bottom {
white-space: nowrap;
overflow: hidden;
}
See the Pen Element Overflow by Will Boyd (@lonekorean) on CodePen.
As you can see, a value of auto allows the content to be scrolled (auto only shows scrollbars when needed, scroll shows them always). A value of hidden simply cuts off the content and leaves it at that.
overflow is actually shorthand to set both overflow-x and overflow-y, for horizontal and vertical overflow respectively. Feel free to use what suits you best.
We can build upon overflow: hidden by adding text-overflow: ellipsis. Text will still be cut off, but we’ll get some nice ellipsis as an indication.
p {
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}See the Pen text-overflow: ellipsis by Will Boyd (@lonekorean) on CodePen.
Bonus Trick: Pseudo-Element Line Break
You can force a line break before and/or after an inline element, while keeping it as an inline element, with a little bit of pseudo-element trickery.
First, set the content of a ::before or ::after pseudo-element to 'A', which will give you the new line character. Then set white-space: pre to ensure the new line character is respected.
<p>Things that go <span>bump</span> in the night.</p>span {
background-color: #000;
}span::before, span::after {
content: 'A';
white-space: pre;
}
See the Pen Pseudo-Element Line Breaks by Will Boyd (@lonekorean) on CodePen.
We could have just put display: block on the <span> to get the same breaks, but then it would no longer be inline. The background-color makes it easy to see that with this method, we still have an inline element.
Bonus Notes
- There’s an older CSS property named
word-wrap. It’s non-standard and browsers now treat it as an alias foroverflow-wrap. - The
white-spaceCSS property has some other values we didn’t cover:pre-wrap,pre-line, andbreak-spaces. Unlike the ones we did cover, these don’t prevent text wrapping. - The CSS Text Module Level 4 spec describes a
text-wrapCSS property that looks interesting, but at the time of writing, no browser implements it.
Time to “Wrap” Things Up
There’s so much that goes into flowing text on a web page. Most of the time you don’t really need to think about it, since browsers handle it for you. For the times when you do need more control, it’s nice to know that you have a lot of options.
Writing this was definitely a rabbit hole for me as I kept finding more and more things to talk about. I hope I’ve shown you enough to get your text to break and flow just the way you want it.
Thanks for reading!
Свойство word-break позволяет перенести
буквы длинного слова на новую строку, если
это слово не влазит в ширину контейнера.
Синтаксис
селектор {
word-break: break-all | keep-all | normal;
}
Значения
| Значение | Описание |
|---|---|
break-all |
Заставляет длинные слова переносится на новую строку, если это слово не помещается в контейнер. |
keep-all |
Для переноса иероглифов. |
normal |
Стандартное поведение: если длинное слово не влазит по ширине в контейнер — оно просто вылезет за его границу (при этом начнется с новой строчки). |
Значение по умолчанию: normal.
Пример . Значение normal
В данном примере очень длинное слово не поместится
в контейнер и вылезет за его границы (при
этом начнется с новой строки):
<div id="elem">
Lorem ipsum dolor sit amet
оооооооооооооооооооооооооооооченьдлинноеслово,
consectetur adipiscing elit.
</div>
#elem {
width: 200px;
word-break: normal;
border: 1px solid red;
}
:
Пример . Значение break-all
А теперь те буквы, которые не помещались,
просто перенесутся на следующую строку:
<div id="elem">
Lorem ipsum dolor sit amet
оооооооооооооооооооооооооооооченьдлинноеслово,
consectetur adipiscing elit.
</div>
#elem {
width: 200px;
word-break: break-all;
border: 1px solid red;
}
:
Смотрите также
-
свойство
overflow-wrap,
которое также позволяет перенести буквы длинного слова на новую строку -
свойство
hyphens,
которое включает переносы слов по слогам -
свойство
overflow,
которое обрезает вылезающие за границу блока части -
тег
wbr,
который реализует мягкие переносы средствами HTML -
тег
br,
с помощью которого можно принудительно заставить перенести текст на новую строку
The definitions alone of word-break and word-wrap can easily make your head spin, but when comparing these two, specifically, it’s much easier to think of them like this:
First of all, you would probably like to use overflow: auto; as well, and you might want to try what using that alone looks like: if you can tolerate needing to scroll the text in the container rather than having arbitrary wrap positions, it might be just what you need.
Then keep in mind that in this context, a «word» is a string with no whitespaces in it.
word-break: break-all;
Prioritizes minimizing the space wasted while avoiding overflow, before keeping any words unbroken, so it never wraps anywhere but at the right margin. It even replaces line breaks with spaces in the contained text. This is useful if you want to avoid scrolling as much as possible and use a container that is enough wide for readability: however if your container is too narrow the result is in general not very satisfying, as Drkawashima noted.
word-wrap/overflow-wrap: break-word;
Prioritizes keeping any and all words unbroken while avoiding overflow, so if a word is too long to fit on the rest of the line, it wraps first and tries to fit the rest of the text on the next line even if it means leaving the line above as short as only one single character. This is useful if you want maximum readability while avoiding scrolling as much as possible and use a container that is enough wide: otherwise you might want to use only overflow: auto instead.
Regarding word-wrap, it isn’t really replaced (and maybe also more universally recognized than overflow-wrap by the browsers in use worldwide): it became an alias for overflow-wrap because all the big browsers and many many webpages had already adopted word-wrap although originally not being defined in the standards.
However, because of the widespread use, it wasn’t discarded when overflow-wrap was defined, but rather defined as the alias it is today, and for legacy reasons, UAs (User-Agents, e.g., web browsers) must treat word-wrap as a legacy name alias of the overflow-wrap property. So it has become a de facto standard of W3C and it isn’t going away any day soon (perhaps when the W3C standard becomes extinct or the entire web is universally updated by bots with AI).
5.5. Overflow Wrapping: the overflow-wrap/word-wrap property
overflow-wrap (MDN)
Свойство word-break указывает, как делать перенос строк внутри слов, которые не помещаются по ширине в заданную область.
Демо¶
Текст
- hanging-punctuation
- hyphens
- letter-spacing
- line-break
- overflow-wrap
- paint-order
- tab-size
- text-align
- text-align-last
- text-indent
- text-justify
- text-size-adjust
- text-transform
- white-space
- word-break
- word-spacing
- letter-spacing
- text-decoration
- text-decoration-color
- text-decoration-line
- text-decoration-style
- text-decoration-thickness
- text-decoration-skip
- text-decoration-skip-ink
- text-emphasis
- text-emphasis-color
- text-emphasis-position
- text-emphasis-style
- text-indent
- text-rendering
- text-shadow
- text-underline-position
- text-transform
- white-space
- word-spacing
Синтаксис¶
word-break: normal;
word-break: break-all;
word-break: keep-all;
/* Global values */
word-break: inherit;
word-break: initial;
word-break: unset;
Значения¶
normal- Используются правила переноса строк по умолчанию. Как правило, в этом случае строки не переносятся или переносятся в тех местах, где явно задан перенос (например, с помощью
<br>). break-all- Перенос строк добавляется автоматически, чтобы слово поместилось в заданную ширину блока. Значение не работает для текста на китайском, корейском или японском языке.
keep-all- Не разрешает перенос строк в словах на китайском, корейском или японском языке. Для остальных языков действует как
normal.
Значение по-умолчанию: normal
Применяется ко всем элементам
Спецификации¶
- CSS Text Level 3
Поддержка браузерами¶
Can I Use word-break? Data on support for the word-break feature across the major browsers from caniuse.com.
Описание и примеры¶
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>word-break</title>
<style>
.col {
background: #f0f0f0; /* Цвет фона */
width: 180px; /* Ширина блока */
padding: 10px; /* Поля */
word-break: break-all; /* Перенос слов */
}
</style>
</head>
<body>
<div class="col">
<p>Cуществительное</p>
<p>высокопревосходительство</p>
<p>Одушевленное существительное</p>
<p>одиннадцатиклассница</p>
<p>Химическое вещество</p>
<p>метоксихлордиэтиламинометилбутиламиноакридин</p>
</div>
</body>
</html>
Word Break Problem: Given a string and a dictionary of words, determine if the string can be segmented into a space-separated sequence of one or more dictionary words.
For example,
Input:
dict[] = { this, th, is, famous, Word, break, b, r, e, a, k, br, bre, brea, ak, problem };
word = Wordbreakproblem
Output:
Word b r e a k problem
Word b r e ak problem
Word br e a k problem
Word br e ak problem
Word bre a k problem
Word bre ak problem
Word brea k problem
Word break problem
Practice this problem
The idea is to use recursion to solve this problem. We consider all prefixes of the current string one by one and check if the current prefix is present in the dictionary or not. If the prefix is a valid word, add it to the output string and recur for the remaining string. The recursion’word base case is when the string becomes empty, and we print the output string.
Following is the C++, Java, and Python implementation of the idea:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
#include <iostream> #include <vector> #include <algorithm> using namespace std; // Function to segment a given string into a space-separated // sequence of one or more dictionary words void wordBreak(vector<string> const &dict, string word, string out) { // if the end of the string is reached, // print the output string if (word.size() == 0) { cout << out << endl; return; } for (int i = 1; i <= word.size(); i++) { // consider all prefixes of the current string string prefix = word.substr(0, i); // if the prefix is present in the dictionary, add it to the // output string and recur for the remaining string if (find(dict.begin(), dict.end(), prefix) != dict.end()) { wordBreak(dict, word.substr(i), out + » « + prefix); } } } // Word Break Problem Implementation in C++ int main() { // vector of strings to represent a dictionary // we can also use a Trie or a set to store a dictionary vector<string> dict = { «this», «th», «is», «famous», «Word», «break», «b», «r», «e», «a», «k», «br», «bre», «brea», «ak», «problem» }; // input string string word = «Wordbreakproblem»; wordBreak(dict, word, «»); return 0; } |
Download Run Code
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import java.util.Arrays; import java.util.List; class Main { // Function to segment given string into a space-separated // sequence of one or more dictionary words public static void wordBreak(List<String> dict, String word, String out) { // if the end of the string is reached, // print the output string if (word.length() == 0) { System.out.println(out); return; } for (int i = 1; i <= word.length(); i++) { // consider all prefixes of the current string String prefix = word.substring(0, i); // if the prefix is present in the dictionary, add it to the // output string and recur for the remaining string if (dict.contains(prefix)) { wordBreak(dict, word.substring(i), out + » « + prefix); } } } // Word Break Problem Implementation in Java public static void main(String[] args) { // List of strings to represent a dictionary List<String> dict = Arrays.asList(«this», «th», «is», «famous», «Word», «break», «b», «r», «e», «a», «k», «br», «bre», «brea», «ak», «problem»); // input string String word = «Wordbreakproblem»; wordBreak(dict, word, «»); } } |
Download Run Code
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# Function to segment given string into a space-separated # sequence of one or more dictionary words def wordBreak(words, word, out=»): # if the end of the string is reached, # print the output string if not word: print(out) return for i in range(1, len(word) + 1): # consider all prefixes of the current string prefix = word[:i] # if the prefix is present in the dictionary, add it to the # output string and recur for the remaining string if prefix in words: wordBreak(words, word[i:], out + ‘ ‘ + prefix) # Word Break Problem Implementation in Python if __name__ == ‘__main__’: # List of strings to represent a dictionary words = [ ‘self’, ‘th’, ‘is’, ‘famous’, ‘Word’, ‘break’, ‘b’, ‘r’, ‘e’, ‘a’, ‘k’, ‘br’, ‘bre’, ‘brea’, ‘ak’, ‘problem’ ] # input string word = ‘Wordbreakproblem’ wordBreak(words, word) |
Download Run Code
Output:
Word b r e a k problem
Word b r e ak problem
Word br e a k problem
Word br e ak problem
Word bre a k problem
Word bre ak problem
Word brea k problem
Word break problem
There is a very famous alternate version of the above problem in which we only have to determine if a string can be segmented into a space-separated sequence of one or more dictionary words or not, and not actually print all sequences. This version is demonstrated below in C++, Java, and Python:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
#include <iostream> #include <vector> #include <algorithm> using namespace std; // Function to determine if a string can be segmented into space-separated // sequence of one or more dictionary words bool wordBreak(vector<string> const &dict, string word) { // return true if the end of the string is reached if (word.size() == 0) { return true; } for (int i = 1; i <= word.size(); i++) { // consider all prefixes of the current string string prefix = word.substr(0, i); // return true if the prefix is present in the dictionary and the remaining // string also forms a space-separated sequence of one or more // dictionary words if (find(dict.begin(), dict.end(), prefix) != dict.end() && wordBreak(dict, word.substr(i))) { return true; } } // return false if the string can’t be segmented return false; } // Word Break Problem Implementation in C++ int main() { // vector of strings to represent a dictionary // we can also use a Trie or a set to store a dictionary vector<string> dict = { «this», «th», «is», «famous», «Word», «break», «b», «r», «e», «a», «k», «br», «bre», «brea», «ak», «problem» }; // input string string word = «Wordbreakproblem»; if (wordBreak(dict, word)) { cout << «The string can be segmented»; } else { cout << «The string can’t be segmented»; } return 0; } |
Download Run Code
Output:
The string can be segmented
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import java.util.Arrays; import java.util.List; class Main { // Function to determine if a string can be segmented into a // space-separated sequence of one or more dictionary words public static boolean wordBreak(List<String> dict, String word) { // return true if the end of the string is reached, if (word.length() == 0) { return true; } for (int i = 1; i <= word.length(); i++) { // consider all prefixes of the current string String prefix = word.substring(0, i); // return true if the prefix is present in the dictionary and the // remaining string also forms a space-separated sequence of // one or more dictionary words if (dict.contains(prefix) && wordBreak(dict, word.substring(i))) { return true; } } // return false if the string can’t be segmented return false; } // Word Break Problem Implementation in Java public static void main(String[] args) { // List of strings to represent a dictionary List<String> dict = Arrays.asList(«this», «th», «is», «famous», «Word», «break», «b», «r», «e», «a», «k», «br», «bre», «brea», «ak», «problem»); // input string String word = «Wordbreakproblem»; if (wordBreak(dict, word)) { System.out.println(«The string can be segmented»); } else { System.out.println(«The string can’t be segmented»); } } } |
Download Run Code
Output:
The string can be segmented
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# Function to determine if a string can be segmented into space-separated # sequence of one or more dictionary words def wordBreak(words, word): # return true if the end of the string is reached, if not word: return True for i in range(1, len(word) + 1): # consider all prefixes of the current string prefix = word[:i] # return true if the prefix is present in the dictionary and the remaining # string also forms a space-separated sequence of one or more # dictionary words if prefix in words and wordBreak(words, word[i:]): return True # return false if the string can’t be segmented return False # Word Break Problem Implementation in Python if __name__ == ‘__main__’: # List of strings to represent a dictionary words = [ ‘self’, ‘th’, ‘is’, ‘famous’, ‘Word’, ‘break’, ‘b’, ‘r’, ‘e’, ‘a’, ‘k’, ‘br’, ‘bre’, ‘brea’, ‘ak’, ‘problem’ ] # input string word = ‘Wordbreakproblem’ if wordBreak(words, word): print(‘The string can be segmented’) else: print(‘The string can’t be segmented’) |
Download Run Code
Output:
The string can be segmented
The time complexity of the above solution is exponential and occupies space in the call stack.
The word-break problem has optimal substructure. We have seen that the problem can be broken down into smaller subproblem, which can further be broken down into yet smaller subproblem, and so on. The word-break problem also exhibits overlapping subproblems, so we will end up solving the same subproblem over and over again. If we draw the recursion tree, we can see that the same subproblems are getting computed repeatedly.
The problems having optimal substructure and overlapping subproblem can be solved by dynamic programming, in which subproblem solutions are memoized rather than computed repeatedly. This method is demonstrated below in C++, Java, and Python:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
#include <iostream> #include <string> #include <unordered_set> #include <algorithm> using namespace std; // Function to determine if a string can be segmented into space-separated // sequence of one or more dictionary words bool wordBreak(unordered_set<string> const &dict, string word, vector<int> &lookup) { // `n` stores length of the current substring int n = word.size(); // return true if the end of the string is reached if (n == 0) { return true; } // if the subproblem is seen for the first time if (lookup[n] == —1) { // mark subproblem as seen (0 initially assuming string // can’t be segmented) lookup[n] = 0; for (int i = 1; i <= n; i++) { // consider all prefixes of the current string string prefix = word.substr(0, i); // if the prefix is found in the dictionary, then recur for the suffix if (find(dict.begin(), dict.end(), prefix) != dict.end() && wordBreak(dict, word.substr(i), lookup)) { // return true if the string can be segmented return lookup[n] = 1; } } } // return solution to the current subproblem return lookup[n]; } // Word Break Problem Implementation in C++ int main() { // set of strings to represent a dictionary // we can also use a Trie or a vector to store a dictionary unordered_set<string> dict = { «this», «th», «is», «famous», «Word», «break», «b», «r», «e», «a», «k», «br», «bre», «brea», «ak», «problem» }; // input string string word = «Wordbreakproblem»; // lookup array to store solutions to subproblems // lookup[i] stores if substring word[n-i…n) can be segmented or not vector<int> lookup(word.length() + 1, —1); if (wordBreak(dict, word, lookup)) { cout << «The string can be segmented»; } else { cout << «The string can’t be segmented»; } return 0; } |
Download Run Code
Output:
The string can be segmented
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
import java.util.Arrays; import java.util.Set; import java.util.stream.Collectors; import java.util.stream.Stream; class Main { // Function to determine if a string can be segmented into // space-separated sequence of one or more dictionary words public static boolean wordBreak(Set<String> dict, String word, int[] lookup) { // `n` stores length of the current substring int n = word.length(); // return true if the end of the string is reached if (n == 0) { return true; } // if the subproblem is seen for the first time if (lookup[n] == —1) { // mark subproblem as seen (0 initially assuming string // can’t be segmented) lookup[n] = 0; for (int i = 1; i <= n; i++) { // consider all prefixes of the current string String prefix = word.substring(0, i); // if the prefix is found in the dictionary, then recur for the suffix if (dict.contains(prefix) && wordBreak(dict, word.substring(i), lookup)) { // return true if the string can be segmented lookup[n] = 1; return true; } } } // return solution to the current subproblem return lookup[n] == 1; } // Word Break Problem Implementation in Java public static void main(String[] args) { // Set of strings to represent a dictionary // we can also use a Trie or a List to store a dictionary Set<String> dict = Stream.of(«this», «th», «is», «famous», «Word», «break», «b», «r», «e», «a», «k», «br», «bre», «brea», «ak», «problem») .collect(Collectors.toSet()); // input string String word = «Wordbreakproblem»; // lookup array to store solutions to subproblems // lookup[i] stores if substring word[n-i…n) can be segmented or not int[] lookup = new int[word.length() + 1]; Arrays.fill(lookup, —1); if (wordBreak(dict, word, lookup)) { System.out.println(«The string can be segmented»); } else { System.out.println(«The string can’t be segmented»); } } } |
Download Run Code
Output:
The string can be segmented
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# Function to determine if a string can be segmented into space-separated # sequence of one or more dictionary words def wordBreak(words, word, lookup): # `n` stores length of the current substring n = len(word) # return true if the end of the string is reached if n == 0: return True # if the subproblem is seen for the first time if lookup[n] == —1: # mark subproblem as seen (0 initially assuming string # can’t be segmented) lookup[n] = 0 for i in range(1, n + 1): # consider all prefixes of the current string prefix = word[:i] # if the prefix is found in the dictionary, then recur for the suffix if prefix in words and wordBreak(words, word[i:], lookup): # return true if the string can be segmented lookup[n] = 1 return True # return solution to the current subproblem return lookup[n] == 1 # Word Break Problem Implementation in Python if __name__ == ‘__main__’: # Set of strings to represent a dictionary # we can also use a Trie or a List to store a dictionary words = { ‘self’, ‘th’, ‘is’, ‘famous’, ‘Word’, ‘break’, ‘b’, ‘r’, ‘e’, ‘a’, ‘k’, ‘br’, ‘bre’, ‘brea’, ‘ak’, ‘problem’ } # input string word = ‘Wordbreakproblem’ # lookup table to store solutions to subproblems # lookup[i] stores if substring word[n-i…n) can be segmented or not lookup = [—1] * (len(word) + 1) if wordBreak(words, word, lookup): print(‘The string can be segmented’) else: print(‘The string can’t be segmented’) |
Download Run Code
Output:
The string can be segmented
The time complexity of the above solution is O(n2) and requires O(n) extra space, where n is the length of the input string.
Exercise: Implement a bottom-up version of the above solution.
DigitalOcean provides cloud products for every stage of your journey. Get started with $200 in free credit!
The word-break property in CSS can be used to change when line breaks ought to occur. Normally, line breaks in text can only occur in certain spaces, like when there is a space or a hyphen.
In the example below we can make the word-break between letters instead:
.element {
word-break: break-all;
}If we then set the width of the text to one em, the word will break by each letter:
See the Pen Setting text vertically with word-break by CSS-Tricks (@css-tricks) on CodePen.
This value is often used in places with user generated content so that long strings don’t risk breaking the layout. One very common example is a long copy and pasted URL. If that URL has no hyphens, it can extend beyond the parent box and look bad or worse, cause layout problems.
See the Pen Fixing links with word-break by CSS-Tricks (@css-tricks) on CodePen.
Values
normal: use the default rules for word breaking.break-all: any word/letter can break onto the next line.keep-all: for Chinese, Japanese and Korean text words are not broken. Otherwise this is the same asnormal.
This property is also often used in conjunction with the hyphens property so that when breaks occur a hypen is inserted, as per the standard in books.
The full usage, with needed vendor prefixes, is:
-ms-word-break: break-all;
word-break: break-all;
/* Non standard for WebKit */
word-break: break-word;
-webkit-hyphens: auto;
-moz-hyphens: auto;
hyphens: auto;Using these properties on the universal selector can be useful if you have a site with a lot of user-generated content. Although fair warning, it can look weird on titles and pre-formatted text (
- overflow-wrap
- hyphens
- white-space
- Handling Long Words and URLs
Browser Support
Desktop
| Chrome | Firefox | IE | Edge | Safari |
|---|---|---|---|---|
| 23 | 49 | 11 | 18 | 6.1 |
Mobile / Tablet
| Android Chrome | Android Firefox | Android | iOS Safari |
|---|---|---|---|
| 111 | 110 | 4.4 | 7.0-7.1 |
Safari and iOS support the break-all value but not keep-all
Editor’s note: This complete guide to word-wrap, overflow-wrap, and word-break in CSS was last updated 24 February 2023 to reflect the reflect the most recent version of CSS, include interactive code examples, and include a section on how to wrap text using CSS. To learn more about the overflow property, check out our guide to CSS overflow.
Making a site responsive so that it displays correctly on all devices is very important in this day and age. Unfortunately, despite your best efforts to do so, you may still end up with broken layouts. Broken layouts can happen when certain words are too long to fit in their container. Content overflow can occur when you are dealing with user-generated content you have no control over, such as the comments section of a post. Therefore, you need to apply styling to prevent content from overflowing their container.
Content overflow is a common problem for frontend developers. On the web, overflow occurs when your content doesn’t fit entirely within its containing element. As a result, it spills outside. In CSS, you can manage content overflow mainly using the overflow, word-wrap, overflow-wrap, and word-break CSS properties. However, our focus in this article will be on the word-wrap, overflow-wrap, and word-break CSS properties.
Jump ahead:
- Using
word-wrap,overflow-wrap, andword-breakCSS properties- How does content wrapping occur in browsers?
- What is the difference between a soft wrap break and a forced line break?
- Understanding the
Word-wrapandoverflow-wrapCSS propertiesNormalAnywhereBreak-word
- Implementing the
Word-breakCSS property- Setting
word-breaktoNormal - The
Break-allvalue - Using the
Keep-allvalue
- Setting
- What is the difference between
overflow-wrapandword-break? - How to wrap text using CSS
- Troubleshooting CSS content overflow with Chrome DevTools
Using word-wrap, overflow-wrap, and word-break CSS properties
You can use the word-wrap, overflow-wrap, or word-break CSS properties to wrap or break words that would otherwise overflow their container. This article is an in-depth tutorial on the word-wrap, overflow-wrap, and word-break CSS properties and how you can use them to prevent content overflow from ruining your nicely styled layout. Before we get started, let us understand how browsers wrap content in the next section.
How does content wrapping occur in browsers?
Browsers and other user agents perform content wrapping at allowed breakpoints, referred to as soft wrap opportunities. A browser will wrap content at a soft wrap opportunity, if one exists, to minimize content overflow. In English and other similar writing systems, soft wrap opportunities occur by default at word boundaries in the absence of hyphenation. Because words are bound by spaces and punctuation, that is where soft wraps occur.
Although soft wraps occur in space characters in English texts, the situation might be different for non-English writing systems. Some languages do not use spaces to separate words, meaning that content wrapping depends on the language or writing system. The value of the lang attribute you specify on the HTML element is mostly used to determine which language system is used.
This article will focus mainly on the English language writing system. The default wrapping at soft wrap opportunities may not be sufficient if you are dealing with long, continuous text, such as URLs or user-generated content, which you have very little or no control over. Before we go into a detailed explanation of these CSS properties, let’s look at the differences between soft wrap break and forced line break in the section below.
What is the difference between a soft wrap break and a forced line break?
Any text wrap that occurs at a soft wrap opportunity is referred to as a soft wrap break. For wrapping to occur at a soft wrap opportunity, you need to make sure you’ve enabled wrapping. For example, setting the value of white-space CSS property to nowrap will disable wrapping. Forced line breaks are caused by explicit line-breaking controls or line breaks marking the end or start of blocks of text.
Understanding the Word-wrap and overflow-wrap CSS properties
The name word-wrap is the legacy name for the overflow-wrap CSS property. Word-wrap was originally a non-prefixed Microsoft extension and was not part of the CSS standard, though most browsers implemented it with the name word-wrap. According to the draft CSS3 specification, browsers should treat word-wrap as a legacy name alias of the overflow-wrap property for compatibility.
Most recent versions of popular web browsers have implemented the overflow-wrap property. The draft CSS3 specification refers to the overflow-wrap property as:
This property specifies whether the browser may break at otherwise disallowed points within a line to prevent overflow when an otherwise-unbreakable string is too long to fit within the line box.
If you have a white-space property on an element, you need to set its value to allow wrapping for overflow-wrap to have an effect. Below are the values of the overflow-wrap property:
overflow-wrap: normal; overflow-wrap: anywhere; overflow-wrap: break-word;
You can also use the global values inherit, initial, revert, and unset with overflow-wrap, but we won’t cover them here. In the subsections below, we will look at the values of the overflow-wrap CSS property outlined above to understand the behavior of this property.
Normal
Applying the value normal will make the browser use the default line-breaking behavior of the system. For English and other related writing systems, line breaks will therefore occur at whitespaces and hyphens, as shown below:
.my-element{
overflow-wrap: normal;
}
In the example below, there is a word in the text that is longer than its container. Because there is no soft wrap opportunity and the value of the overflow-wrap property is normal, the word overflows its container. It describes the default line-breaking behavior of the system:
See the Pen
overflow-wrap-normal by Joseph Mawa (@nibble0101)
on CodePen.
Anywhere
Using the value anywhere will break an otherwise unbreakable string at arbitrary points between two characters. It will not insert a hyphen character even if you apply the hyphens property on the same element.
The browser will break the word only if displaying the word on its line will cause an overflow. If the word still overflows when placed on its line, it will break the word at the point where an overflow would otherwise occur. When you use anywhere, the browser will consider the soft wrap opportunities introduced by the word break when calculating min-content intrinsic sizes:
.my-element{
overflow-wrap: anywhere;
}
Unlike in the previous section, where we used overflow-wrap: normal, in the example below, we are using overflow-wrap: anywhere. The overflowing word that is otherwise unbreakable is broken into chunks of text using overflow-wrap: anywhere so that it fits in its container:
See the Pen
overlow-wrap-anywhere by Joseph Mawa (@nibble0101)
on CodePen.
Most recent versions of desktop browsers support overflow-wrap: anywhere. However, support for some mobile browsers is either lacking or unknown. The image below shows the browser support:
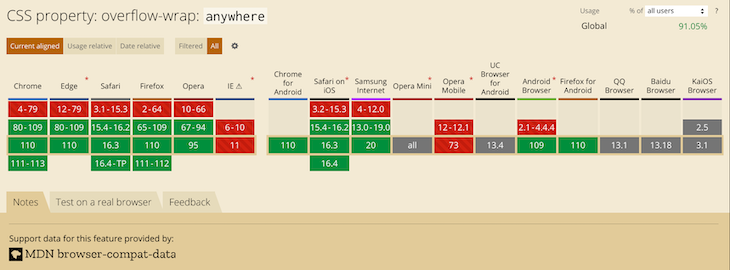
Break-word
The value break-word is like anywhere in terms of functionality. If the browser can wrap the overflowing word to its line without overflowing, that is what it will do. However, if the word still overflows its container even when it is on its line, the browser will break it at the point where the overflow would otherwise occur:
.my-element{
overflow-wrap: break-word;
}
The example below shows how the browser breaks the overflowing text when you apply overflow-wrap: break-word:
See the Pen
overflow-wrap-break-word by Joseph Mawa (@nibble0101)
on CodePen.
Notice that the text appears the same as in the last subsection. The difference between overflow-wrap: anywhere and overflow-wrap: break-word is in the min-content intrinsic sizes.
The difference between anywhere and break-word is apparent when calculating the min-content intrinsic sizes. With break-word, the browser doesn’t consider the soft wrap opportunities introduced by the word break when calculating min-content intrinsic sizes, but it does with anywhere. For more about min-content intrinsic sizes, check out our guide here.
The value break-word has decent coverage among the most recent versions of desktop browsers. Unfortunately, you cannot say the same about their mobile counterpart. It is, therefore, safer to use the legacy word-wrap: break-word instead of the more recent overflow-wrap: break-word.
The image below shows browser support for overflow-wrap: break-word:
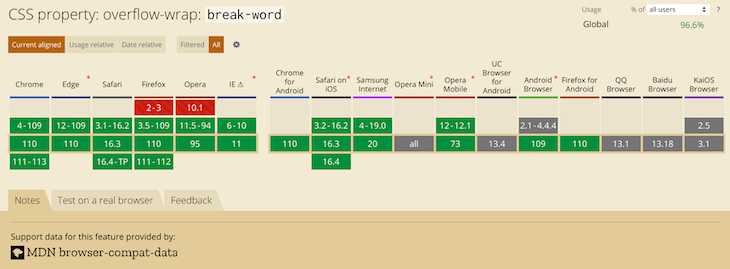
The most recent versions of desktop browsers have support, while support for some mobile browsers is unknown.
Implementing the Word-break CSS property
Word-break is another CSS property you can use to specify soft wrap opportunities between characters. You can use this property to break a word at the exact spot where an overflow would occur and wrap it onto the following line.
The draft CSS3 specification refers to the word-break CSS property as:
This property specifies soft wrap opportunities between letters, i.e., where it is “normal” and permissible to break lines of text. It controls what types of letters the browser can glom together to form unbreakable “words” — causing CJK characters to behave like non-CJK text or vice versa.
Below are the possible values of the word-break CSS property. Like overflow-wrap, you can use the global values inherit, initial, revert, and unset with word-break, but we won’t cover them here:
word-break: normal; word-break: break-all; word-break: keep-all;
Break-word is also a value of the word-break CSS property, though it was removed. However, browsers still support it for legacy reasons. Specifying this property has the same effect as word-break: normal and overflow-wrap: anywhere.
Now that we know the break-word CSS property and its corresponding values, let us look at them in the subsections below.
Setting word-break to Normal
Setting the value of the word-break property to normal will apply the default word breaking rules:
.my-element{
word-break: normal;
}
The example below illustrates what happens when you apply the styling word-break: normal to a block of text that contains a word longer than its container:
See the Pen
word-break-normal by Joseph Mawa (@nibble0101)
on CodePen.
What you see is the browser’s usual word-breaking rules in effect.
The Break-all value
The value break-all will insert a line break at the exact point where the text would otherwise overflow for non-Chinese, non-Japanese, and non-Korean writing systems. It will not put the word on its own line, even if doing so will prevent the need to insert a line break:
.my-element{
word-break: break-all;
}
In the example below, I am applying word-break: break-all styling to a p element of width 240px containing an overflowing text. The browser will insert a line break at the point where an overflow would occur and wrap the remaining text to the following line:
See the Pen
word-break-break-all by Joseph Mawa (@nibble0101)
on CodePen.
Using break-all will break a word between two characters at the exact point where an overflow would occur in English and other related language systems. However, it won’t apply the same behavior to Chinese, Japanese, and Korean (CJK) texts.
It doesn’t apply the same behavior for CJK texts because CJK writing systems have their own rules for applying breakpoints. Creating a line break between two characters arbitrarily just for the sake of avoiding overflow might significantly change the overall meaning of the text. For CJK systems, the browser will apply line breaks at the point where such breaks are allowed.
Using the Keep-all value
If you use the value keep-all, the browser will not apply word breaks to CJK texts, even if there is content overflow. The effect of applying keep-all value is the same as that of normal for non-CJK writing systems:
.my-element{
word-break: keep-all;
}
In the example below, applying word-break: keep-all will have the same effect as word-break: normal for a non-CJK writing system such as English:
See the Pen
word-break-keep-all by Joseph Mawa (@nibble0101)
on CodePen.
The image below shows the browser support for word-break: keep-all:

This value has support in most popular desktop browsers. Unfortunately, it is not the case for mobile browsers. Now that we have looked at the overflow-wrap and word-break CSS properties, what is the difference between the two? The section below will shed light on that.
What is the difference between overflow-wrap and word-break?
You can use the CSS properties overflow-wrap and word-break to manage content overflow. However, there are differences in the way the two properties handle it.
Using overflow-wrap will wrap the entire overflowing word to its line if it can fit in a single line without overflowing its container. The browser will break the word only if it cannot place it on a new line without overflowing. In most cases, the overflow-wrap property or its legacy name word-wrap might manage content overflow. Using word-wrap: break-word will wrap the overflowing word onto a new line and goes ahead to break it between two characters if it still overflows its container.
Word-break will ruthlessly break the overflowing word between two characters even if placing it on its line will negate the need for word break. Some writing systems, like the CJK writing systems, have strict word breaking rules the browser takes into consideration when creating line breaks using word-break.
How to wrap text using CSS
As hinted above, if you want to wrap text or break a word overflowing the confines of its box, your best bet is the overflow-wrap CSS property. You can also use its legacy name, word-wrap. Try the word-break CSS property if the overflow-wrap property doesn’t work for you. However, be aware of the differences between overflow-wrap and word-break highlighted above.
Below is an illustration of the overflow-wrap and word-wrap CSS properties. You can play with the CodePen to understand their effects:
See the Pen
how-to-wrap-text by Joseph Mawa (@nibble0101)
on CodePen.
Troubleshooting CSS content overflow with Chrome DevTools
More often than not, you might need to fix broken layouts caused by content overflow, as complex user interfaces are now commonplace in frontend development. Modern web browsers come with tools for troubleshooting such layout issues, such as Chrome DevTools.
It provides the capability to select an element in the DOM tree so that you can view, add, and remove CSS declarations and much more. It will help you track down the offending CSS style in your layout and fix it with ease.
To open the Chrome DevTools, you can use the F12 key. When open, it looks like in the image below. Selecting an element in the DOM tree will display its corresponding CSS styles. You can modify the styles and see the effect on your layout as you track down the source of the bug:
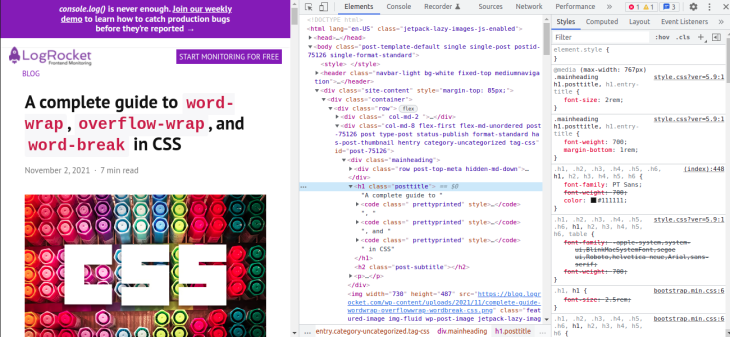
As already mentioned, if you have white-space property on an element, set its value to allow wrapping for overflow-wrap: anywhere or overflow-wrap: break-word to work.
Setting the value of overflow-wrap property to anywhere or break-word on a table content won’t break an overflowing word like in the examples above. The table will overflow its container and create a horizontal scroll if necessary. To get the table to fit within its container and overflow-wrap to work, set the value of the table-layout property to fixed and set the table width to 100% or to some fixed value.
Conclusion
As pointed out in the above sections, overflow-wrap and word-break are similar in so many ways, and you can use both of them for line-breaking controls. The name overflow-wrap is an alias of the legacy word-wrap property. Therefore, you can use the two interchangeably. However, it is worth mentioning that the browser support for the newer overflow-wrap property is still low. You are better off using word-wrap instead of overflow-wrap if you want near-universal browser support.
According to the draft CSS3 specification, browsers and user agents should continue supporting word-wrap for legacy reasons. If you are looking to manage content overflow, overflow-wrap or its legacy name word-wrap might be sufficient. You can also use word-break to break a word between two characters if the word overflows its container. Just like overflow-wrap, you need to tread with caution when using word-break because of limitations in the browser support.
Now that you know the behavior associated with the two properties, you can decide where and when to use them. Did I miss anything? Leave a comment in the comments section. I will be happy to update this article.
Is your frontend hogging your users’ CPU?
As web frontends get increasingly complex, resource-greedy features demand more and more from the browser. If you’re interested in monitoring and tracking client-side CPU usage, memory usage, and more for all of your users in production, try LogRocket.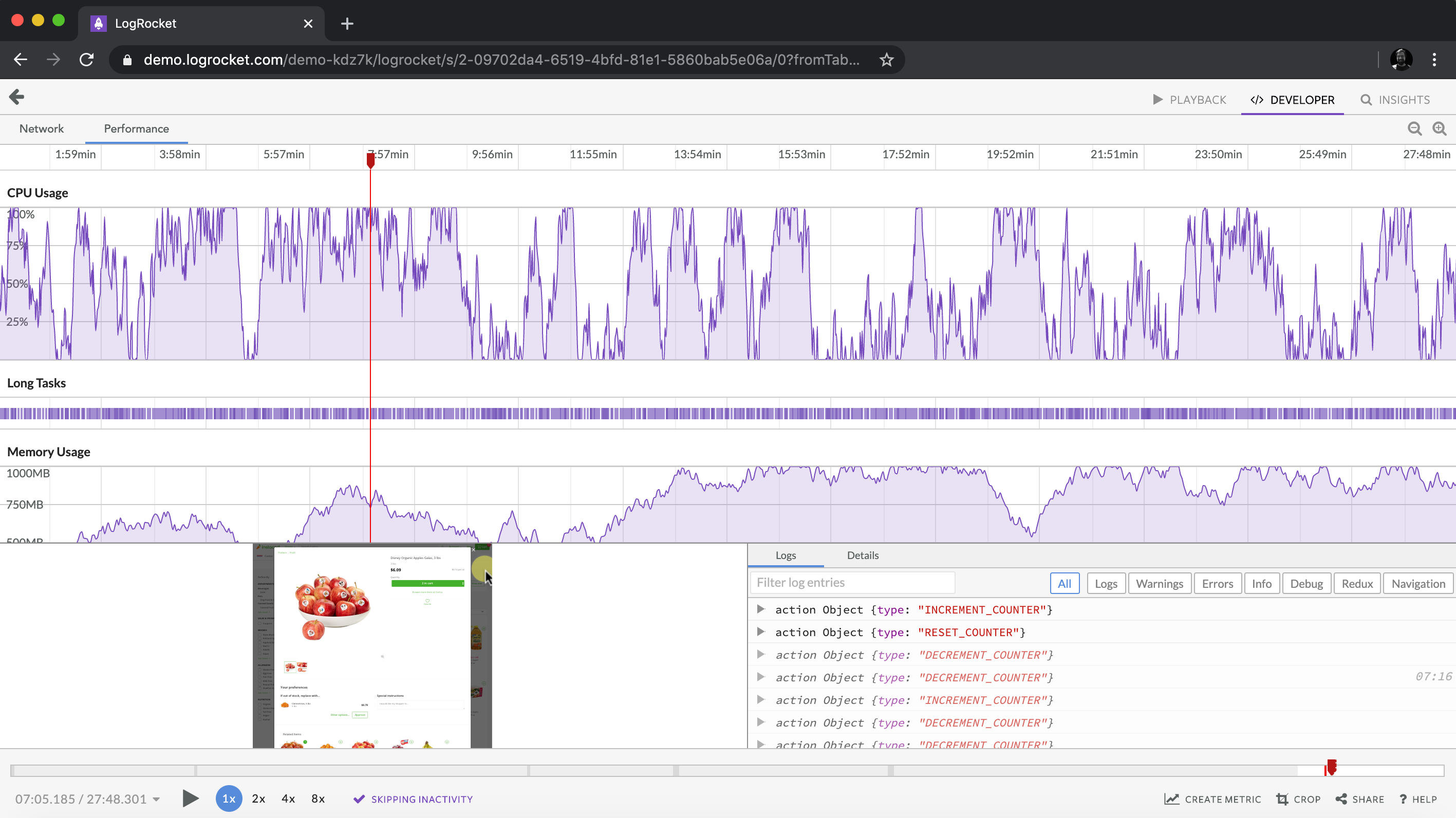 https://logrocket.com/signup/
https://logrocket.com/signup/
LogRocket is like a DVR for web and mobile apps, recording everything that happens in your web app, mobile app, or website. Instead of guessing why problems happen, you can aggregate and report on key frontend performance metrics, replay user sessions along with application state, log network requests, and automatically surface all errors.
Modernize how you debug web and mobile apps — Start monitoring for free.