
Write a sentence for each word/phrase.
1. (at the moment)
2. (on Sundays)
3. (in the summer)
4. (always)
5. (right now)
6. (in the winter)
7. (never)
![]()
reshalka.com
Английский язык 5 класс (рабочая тетрадь) Ваулина. 7 Grammar Practice. Номер №3
Решение
Перевод задания
Напишите предложение для каждого слова / фразы.
1. (на данный момент)
2. (по воскресеньям)
3. (летом)
4. (всегда)
5. (прямо сейчас)
6. (зимой)
7. (никогда)
ОТВЕТ
1. (at the moment) I am doing my homework at the moment.
2. (on Sundays) We go swimming in the swimming pool on Sundays.
3. (in the summer) We go camping in the summer.
4. (always) I always help my mother in the kitchen.
5. (right now) My sister is having a picnic right now.
6. (in the winter) My dad goes skiing in the winter.
7. (never) My sister never walks our dog.
Перевод ответа
1. (в данный момент) Я сейчас делаю домашнее задание.
2. (по воскресеньям) По воскресеньям купаемся в бассейне.
3. (летом) Летом ходим в походы.
4. (всегда) Я всегда помогаю маме на кухне.
5. (прямо сейчас) Моя сестра сейчас на пикнике.
6. (зимой) Папа зимой катается на лыжах.
7. (никогда) Моя сестра никогда не выгуливает нашу собаку.
Assignment #3
A primer on named entity recognition
In this section, we will build several different models to implement named entity recognition (NER). NER is a sub-task of information extraction, which aims to locate and classify named entities in text into predefined categories, such as names, organizations, locations, time expressions, quantities, currency values, percentages, etc. For a given word in the context, it is predicted whether it represents one of the following four categories:
- Personal Name (PER): For example, «Martha Stewart», «Obama», «Tim Wagner» and so on, pronouns «he» or «she» are not considered as named entities.
- ORG: For example, «American Airlines», «Goldman Sachs», «Department of Defense».
- Location (LOC): For example, «Germany», «Panama Strait», «Brussels», excluding unnamed locations such as «the bar» or «the farm».
- Other (MISC): such as «Japanese», «USD», «1000», «Englishmen».
We define this as a five-category problem, using the above four classes and an empty class (O) to represent words that do not represent named entities (most words belong to this category). For entities spanning more than one word («Department of Defense»), each word is marked separately, and each successive sequence of non-empty tags is treated as an entity.
Here is an example sentence(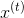 Each word is marked with a named entity(
Each word is marked with a named entity(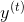 ) and hypothesis prediction generated by the system(
) and hypothesis prediction generated by the system(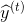 ):
):

In the above example, the system mistakenly predicts that «American» is a MISC class, and ignores «Airlines» and «Corp». Overall, it predicts three entities, «American», «AMR», «Tim Wagner». In order to evaluate the quality of NER system output, we focus on accuracy, recall rate and F1 value. In particular, we report accuracy, recall and F1 values at both token and named entity levels. In the previous example:
-
Accuracy is calculated as the ratio of the correct non-empty labels predicted to the total number of non-empty labels predicted (p=3/4 in the example above).
-
The recall rate is calculated as the ratio of the predicted total number of correct non-empty labels to the correct total number of non-empty labels (r=3/6 in the example above).
-
F1 is the harmonic average of accuracy and recall (in the example above, F1=6/10).
For entity level F1:
- The accuracy rate is the score of predicting the span of entity names, which is completely consistent with the span in the gold standard evaluation data. In our example, «AMR» will be mismarked because it does not include the entity as a whole, that is, «AMR Corp.», and «American» will also get a 1/3 accuracy score.
- The recall rate is also the number of names in the gold standard that appear at exactly the same location in the forecast. Here, we get a recall score of 1/3.
- Finally, the F1 value is still the harmonic average of the two, with 1/3 in the example.
Our model also outputs a word-level obfuscation matrix. Obfuscation matrix is a specific table layout that allows visual classification performance. Each column of the matrix represents an instance in the predicted category, and each row represents an instance in the actual category. The name derives from the fact that it can easily see whether the system confuses two classes (i.e., one class is usually mismarked as another).
1.A window into NER
Let’s look at a simple baseline model that uses features from surrounding windows to predict the labels of each word separately.

Figure 1 shows an example of an input sequence and the first window of the sequence. order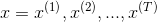 For an input sequence of length T,
For an input sequence of length T,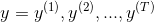 It is an output sequence of length T. Each elementandThey are one-hot vectors representing the words indexed to t in the sequence. In a window-based classifier, each input sequence is divided into T new data points, each point represents a window and its label. ByThe w words on the left and right sides are joined together.The surrounding window constructs a new input:
It is an output sequence of length T. Each elementandThey are one-hot vectors representing the words indexed to t in the sequence. In a window-based classifier, each input sequence is divided into T new data points, each point represents a window and its label. ByThe w words on the left and right sides are joined together.The surrounding window constructs a new input: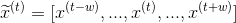 We continue to useAs its label. For the tag-centered window at the beginning of the sentence, we add a special start tag (< start >) at the beginning of the window, and for the tag-centered window at the end of the sentence, we add a special end tag (< end >). For example, consider building a window around «Jim» in the sentence above. If the window size is 1, we add a start word to the window (producing a window with [<START>, Jim, buy]). If the window size is 2, we add two start words to the window (producing a window with [<START>, <START>, Jim, buy, 300]).
We continue to useAs its label. For the tag-centered window at the beginning of the sentence, we add a special start tag (< start >) at the beginning of the window, and for the tag-centered window at the end of the sentence, we add a special end tag (< end >). For example, consider building a window around «Jim» in the sentence above. If the window size is 1, we add a start word to the window (producing a window with [<START>, Jim, buy]). If the window size is 2, we add two start words to the window (producing a window with [<START>, <START>, Jim, buy, 300]).
With these, each input and output has a uniform length (w and 1, respectively), and we can use a simple feedforward neural network from the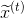 Forecast:
Forecast:
As a simple but effective model for predicting labels from each window, we will use a single hidden layer with ReLU activation, combined with the soft max output layer, and cross-entropy loss:
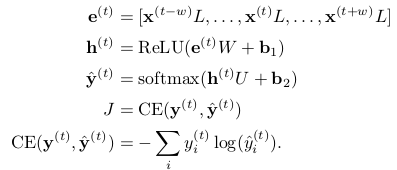
among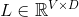 It’s a word vector.
It’s a word vector.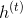 It’s H-dimensional.It is C-dimensional, where V is the size of the vocabulary, D is the size of the word vector, H is the size of the hidden layer, and C is the number of predicted categories (5 here).
It’s H-dimensional.It is C-dimensional, where V is the size of the vocabulary, D is the size of the word vector, H is the size of the hidden layer, and C is the number of predicted categories (5 here).
(a)
i. Provide two examples of sentences containing named entities with ambiguous types (e.g., entities can be individuals or organizations, or organizations or non-entities).
1)»Spokesperson for Levis, Bill Murray, said…», where Levis may be a person’s name or an organization.
2) Heartbreak is a new virus, in which Heartbreak may be another named entity (actually the name of virus) or simply a noun.
ii. Why is it important to use features other than words themselves to predict named entity labels?
Normally named entities are rare words, such as person names or «heartbreak», and the use of such features as case makes the system generalized.
iii. Describe at least two features that help to predict whether a word belongs to a named entity (excluding words).
Word capitalization and part of speech.
(b)
i. If the window size is w, then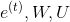 What is the dimension?
What is the dimension?
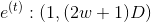
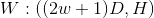
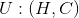
ii. What is the computational complexity of tags whose predicted sequence length is T?
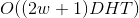
(c) Implementing a window-based classifier model:
i. In make_windowed_data function, batch of an input sequence is converted to batch of a windowed input-output pair.
def make_windowed_data(data, start, end, window_size = 1):
"""Uses the input sequences in @data to construct new windowed data points.
TODO: In the code below, construct a window from each word in the
input sentence by concatenating the words @window_size to the left
and @window_size to the right to the word. Finally, add this new
window data point and its label. to windowed_data.
Args:
data: is a list of (sentence, labels) tuples. @sentence is a list
containing the words in the sentence and @label is a list of
output labels. Each word is itself a list of
@n_features features. For example, the sentence "Chris
Manning is amazing" and labels "PER PER O O" would become
([[1,9], [2,9], [3,8], [4,8]], [1, 1, 4, 4]). Here "Chris"
the word has been featurized as "[1, 9]", and "[1, 1, 4, 4]"
is the list of labels.
start: the featurized `start' token to be used for windows at the very
beginning of the sentence.
end: the featurized `end' token to be used for windows at the very
end of the sentence.
window_size: the length of the window to construct.
Returns:
a new list of data points, corresponding to each window in the
sentence. Each data point consists of a list of
@n_window_features features (corresponding to words from the
window) to be used in the sentence and its NER label.
If start=[5,8] and end=[6,8], the above example should return
the list
[([5, 8, 1, 9, 2, 9], 1),
([1, 9, 2, 9, 3, 8], 1),
...
]
"""
windowed_data = []
for sentence, labels in data:
# YOUR CODE HERE (5-20 lines)
T = len(labels) # Sequence Length T
for t in range(T): # Traversing through each word in a single sequence
sen2fea = []
for l in range(window_size, 0, -1): # w Words in the Left Window
if t-l < 0:
sen2fea.extend(start)
else:
sen2fea.extend(sentence[t-l])
sen2fea.extend(sentence[t])
for r in range(1, window_size+1): # w words in the right window
if t+r >= T:
sen2fea.extend(end)
else:
sen2fea.extend(sentence[t+r])
windowed_data.append((sen2fea, labels[t]))
# END YOUR CODE
return windowed_data
ii. Implement the feed-forward model described above in the Windows Model class.
class WindowModel(NERModel):
"""
Implements a feedforward neural network with an embedding layer and
single hidden layer.
This network will predict what label (e.g. PER) should be given to a
given token (e.g. Manning) by using a featurized window around the token.
"""
def add_placeholders(self):
"""Generates placeholder variables to represent the input tensors
These placeholders are used as inputs by the rest of the model building and will be fed
data during training. Note that when "None" is in a placeholder's shape, it's flexible
(so we can use different batch sizes without rebuilding the model).
Adds following nodes to the computational graph
input_placeholder: Input placeholder tensor of shape (None, n_window_features), type tf.int32
labels_placeholder: Labels placeholder tensor of shape (None,), type tf.int32
dropout_placeholder: Dropout value placeholder (scalar), type tf.float32
Add these placeholders to self as the instance variables
self.input_placeholder
self.labels_placeholder
self.dropout_placeholder
(Don't change the variable names)
"""
# YOUR CODE HERE (~3-5 lines)
self.input_placeholder = tf.placeholder(shape=[None, Config.n_window_features], dtype=tf.int32)
self.labels_placeholder = tf.placeholder(shape=[None, ], dtype=tf.int32)
self.dropout_placeholder = tf.placeholder(dtype=tf.float32)
# END YOUR CODE
def create_feed_dict(self, inputs_batch, labels_batch=None, dropout=1):
"""Creates the feed_dict for the model.
A feed_dict takes the form of:
feed_dict = {
<placeholder>: <tensor of values to be passed for placeholder>,
....
}
Hint: The keys for the feed_dict should be a subset of the placeholder
tensors created in add_placeholders.
Hint: When an argument is None, don't add it to the feed_dict.
Args:
inputs_batch: A batch of input data.
labels_batch: A batch of label data.
dropout: The dropout rate.
Returns:
feed_dict: The feed dictionary mapping from placeholders to values.
"""
# YOUR CODE HERE (~5-10 lines)
if labels_batch is None:
feed_dict = {self.input_placeholder: inputs_batch,
self.dropout_placeholder: dropout}
else:
feed_dict = {self.input_placeholder: inputs_batch,
self.labels_placeholder: labels_batch,
self.dropout_placeholder: dropout}
# END YOUR CODE
return feed_dict
def add_embedding(self):
"""Adds an embedding layer that maps from input tokens (integers) to vectors and then
concatenates those vectors:
- Creates an embedding tensor and initializes it with self.pretrained_embeddings.
- Uses the input_placeholder to index into the embeddings tensor, resulting in a
tensor of shape (None, n_window_features, embedding_size).
- Concatenates the embeddings by reshaping the embeddings tensor to shape
(None, n_window_features * embedding_size).
Hint: You might find tf.nn.embedding_lookup useful.
Hint: You can use tf.reshape to concatenate the vectors. See following link to understand
what -1 in a shape means.
https://www.tensorflow.org/api_docs/python/array_ops/shapes_and_shaping#reshape.
Returns:
embeddings: tf.Tensor of shape (None, n_window_features*embed_size)
"""
# YOUR CODE HERE (!3-5 lines)
embedding = tf.Variable(self.pretrained_embeddings, name='embedding')
embeddings_3d = tf.nn.embedding_lookup(embedding, self.input_placeholder)
embeddings = tf.reshape(embeddings_3d, shape=[-1, Config.n_window_features*Config.embed_size])
# END YOUR CODE
return embeddings
def add_prediction_op(self):
"""Adds the 1-hidden-layer NN:
h = Relu(xW + b1)
h_drop = Dropout(h, dropout_rate)
pred = h_dropU + b2
Recall that we are not applying a softmax to pred. The softmax will instead be done in
the add_loss_op function, which improves efficiency because we can use
tf.nn.softmax_cross_entropy_with_logits
When creating a new variable, use the tf.get_variable function
because it lets us specify an initializer.
Use tf.contrib.layers.xavier_initializer to initialize matrices.
This is TensorFlow's implementation of the Xavier initialization
trick we used in last assignment.
Note: tf.nn.dropout takes the keep probability (1 - p_drop) as an argument.
The keep probability should be set to the value of dropout_rate.
Returns:
pred: tf.Tensor of shape (batch_size, n_classes)
"""
x = self.add_embedding()
dropout_rate = self.dropout_placeholder
# YOUR CODE HERE (~10-20 lines)
W = tf.get_variable(initializer=tf.contrib.layers.xavier_initializer(),
shape=[Config.n_window_features*Config.embed_size, Config.hidden_size],
name='W')
b1 = tf.get_variable(initializer=tf.zeros(Config.hidden_size), name='b1')
h = tf.nn.relu(tf.matmul(x, W) + b1)
h_drop = tf.nn.dropout(h, keep_prob=dropout_rate)
U = tf.get_variable(initializer=tf.contrib.layers.xavier_initializer(),
shape=[Config.hidden_size, Config.n_classes],
name='U')
b2 = tf.get_variable(initializer=tf.zeros(Config.n_classes), name='b2')
pred = tf.matmul(h_drop, U) + b2
# END YOUR CODE
return pred
def add_loss_op(self, pred):
"""Adds Ops for the loss function to the computational graph.
In this case we are using cross entropy loss.
The loss should be averaged over all examples in the current minibatch.
Remember that you can use tf.nn.sparse_softmax_cross_entropy_with_logits to simplify your
implementation. You might find tf.reduce_mean useful.
Args:
pred: A tensor of shape (batch_size, n_classes) containing the output of the neural
network before the softmax layer.
Returns:
loss: A 0-d tensor (scalar)
"""
# YOUR CODE HERE (~2-5 lines)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=pred,
labels=self.labels_placeholder))
# END YOUR CODE
return loss
def add_training_op(self, loss):
"""Sets up the training Ops.
Creates an optimizer and applies the gradients to all trainable variables.
The Op returned by this function is what must be passed to the
`sess.run()` call to cause the model to train. See
https://www.tensorflow.org/versions/r0.7/api_docs/python/train.html#Optimizer
for more information.
Use tf.train.AdamOptimizer for this model.
Calling optimizer.minimize() will return a train_op object.
Args:
loss: Loss tensor, from cross_entropy_loss.
Returns:
train_op: The Op for training.
"""
# YOUR CODE HERE (~1-2 lines)
train_op = tf.train.AdamOptimizer(learning_rate=Config.lr).minimize(loss)
# END YOUR CODE
return train_op
def preprocess_sequence_data(self, examples):
return make_windowed_data(examples, start=self.helper.START, end=self.helper.END, window_size=self.config.window_size)
def consolidate_predictions(self, examples_raw, examples, preds):
"""Batch the predictions into groups of sentence length.
"""
ret = []
#pdb.set_trace()
i = 0
for sentence, labels in examples_raw:
labels_ = preds[i:i+len(sentence)]
i += len(sentence)
ret.append([sentence, labels, labels_])
return ret
def predict_on_batch(self, sess, inputs_batch):
"""Make predictions for the provided batch of data
Args:
sess: tf.Session()
input_batch: np.ndarray of shape (n_samples, n_features)
Returns:
predictions: np.ndarray of shape (n_samples, n_classes)
"""
feed = self.create_feed_dict(inputs_batch)
predictions = sess.run(tf.argmax(self.pred, axis=1), feed_dict=feed)
return predictions
def train_on_batch(self, sess, inputs_batch, labels_batch):
feed = self.create_feed_dict(inputs_batch, labels_batch=labels_batch,
dropout=self.config.dropout)
_, loss = sess.run([self.train_op, self.loss], feed_dict=feed)
return loss
def __init__(self, helper, config, pretrained_embeddings, report=None):
super(WindowModel, self).__init__(helper, config, report)
self.pretrained_embeddings = pretrained_embeddings
# Defining placeholders.
self.input_placeholder = None
self.labels_placeholder = None
self.dropout_placeholder = None
self.build()
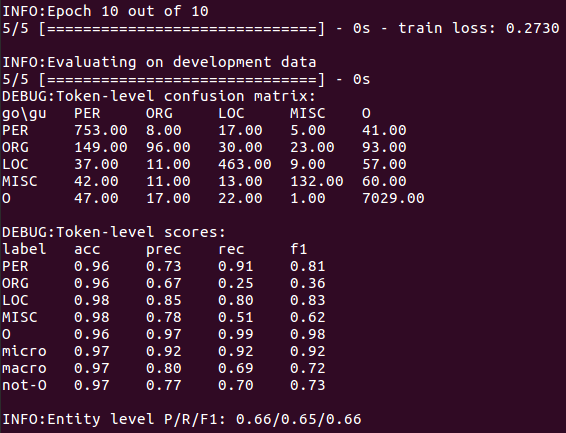
iii. Training models, models and outputs will be stored in results/window/<timestamp>/results.txt contains the formatted output of the model’s prediction on the verification set, and log files contain the printed output, i.e., the confusion matrix and F1 value calculated in training.
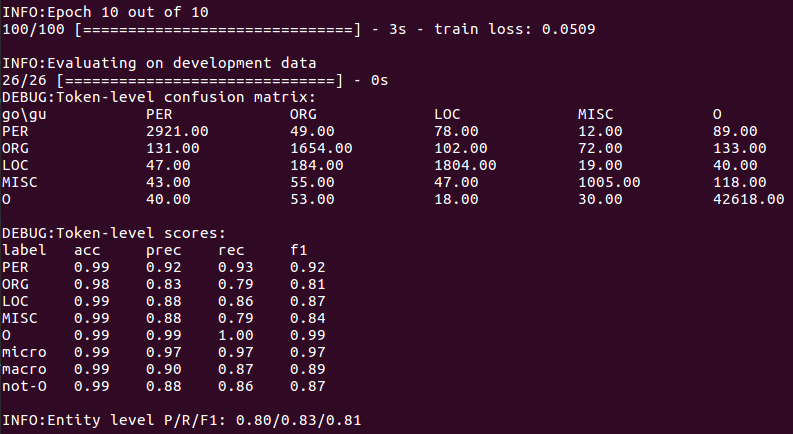
(d) Prediction using the file analysis model generated above.
i. Briefly describe the information about model prediction errors displayed by the obfuscation matrix.
The confusion matrix shows that the biggest source of confusion in the model comes from organization labels, many of which are mistaken for names or ignored directly. On the other hand, names seem to be well recognized.
ii. Describe at least two modeling constraints for window-based models.
The window-based model can not use the information from adjacent prediction to eliminate ambiguity in label decision-making, which leads to discontinuous entity prediction.
On the difference between tf.Variable and tf.get_variable:
https://blog.csdn.net/MrR1ght/article/details/81228087
On tf.nn.embedding_lookup:
https://blog.csdn.net/yinruiyang94/article/details/77600453
https://tensorflow.google.cn/api_docs/python/tf/nn/embedding_lookup
On tf.contrib.layers.xavier_initializer:
https://blog.csdn.net/yinruiyang94/article/details/78354257
https://tensorflow.google.cn/api_docs/python/tf/contrib/layers/xavier_initializer
поделиться знаниями или
запомнить страничку
- Все категории
-
экономические
43,633 -
гуманитарные
33,652 -
юридические
17,917 -
школьный раздел
611,709 -
разное
16,898
Популярное на сайте:
Как быстро выучить стихотворение наизусть? Запоминание стихов является стандартным заданием во многих школах.
Как научится читать по диагонали? Скорость чтения зависит от скорости восприятия каждого отдельного слова в тексте.
Как быстро и эффективно исправить почерк? Люди часто предполагают, что каллиграфия и почерк являются синонимами, но это не так.
Как научится говорить грамотно и правильно? Общение на хорошем, уверенном и естественном русском языке является достижимой целью.
I am trying to run word2vec (skip-gram model implemented in gensim with a default window size of 5) on a corpus of .txt files. The iterator that I use looks something like this:
class Corpus(object):
"""Iterator for feeding sentences to word2vec"""
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
word_tokenizer = TreebankWordTokenizer()
sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
text = ''
for root, dirs, files in os.walk(self.dirname):
for file in files:
if file.endswith(".txt"):
file_path = os.path.join(root, file)
with open(file_path, 'r') as f:
text = f.read().decode('utf-8')
sentences = sent_tokenizer.tokenize(text)
for sent in sentences:
yield word_tokenizer.tokenize(sent)
Here I use the punkt tokenizer (which uses an unsupervised algorithm for detecting sentence boundaries) in the nltk package for splitting the text into sentences. However, when I replace this with just a simple line.split() i.e just considering each sentence as one line and splitting the words, I get a time efficiency that is 1.5 times faster than using the nltk parser. The code inside the ‘with open’ looks something like this:
with open(file_path, 'r') as f:
for line in f:
line.decode('utf-8')
yield line.split()
My question is how important is it for the word2vec algorithm to be fed sentences that are actual sentences (something that I attempt to do with punkt tokenizer)? Is it sufficient for each word in the algorithm to receive a context of the surrounding words that lie on one line (these words may not necessarily be an actual sentence in the case of a sentence spanning several lines) as opposed to the context of words that the word may have in a sentence spanning several lines. Also, what sort of a part does window size play in this. When a window size is set to 5 for example, does the size of sentences yielded by the Sentences iterator ceases to play a part? Will only window size decide the context words then? In that case should I just use line.split() instead of trying to detect actual sentence boundaries using the punkt tokenizer?
I hope I have been able to describe the issue sufficiently, I would really appreciate any opinions or pointers or help regarding this.
word2vec is not a singular algorithm, rather, it is a family of model architectures and optimizations that can be used to learn word embeddings from large datasets. Embeddings learned through word2vec have proven to be successful on a variety of downstream natural language processing tasks.
These papers proposed two methods for learning representations of words:
- Continuous bag-of-words model: predicts the middle word based on surrounding context words. The context consists of a few words before and after the current (middle) word. This architecture is called a bag-of-words model as the order of words in the context is not important.
- Continuous skip-gram model: predicts words within a certain range before and after the current word in the same sentence. A worked example of this is given below.
You’ll use the skip-gram approach in this tutorial. First, you’ll explore skip-grams and other concepts using a single sentence for illustration. Next, you’ll train your own word2vec model on a small dataset. This tutorial also contains code to export the trained embeddings and visualize them in the TensorFlow Embedding Projector.
Skip-gram and negative sampling
While a bag-of-words model predicts a word given the neighboring context, a skip-gram model predicts the context (or neighbors) of a word, given the word itself. The model is trained on skip-grams, which are n-grams that allow tokens to be skipped (see the diagram below for an example). The context of a word can be represented through a set of skip-gram pairs of (target_word, context_word) where context_word appears in the neighboring context of target_word.
Consider the following sentence of eight words:
The wide road shimmered in the hot sun.
The context words for each of the 8 words of this sentence are defined by a window size. The window size determines the span of words on either side of a target_word that can be considered a context word. Below is a table of skip-grams for target words based on different window sizes.

The training objective of the skip-gram model is to maximize the probability of predicting context words given the target word. For a sequence of words w1, w2, … wT, the objective can be written as the average log probability

where c is the size of the training context. The basic skip-gram formulation defines this probability using the softmax function.

where v and v‘ are target and context vector representations of words and W is vocabulary size.
Computing the denominator of this formulation involves performing a full softmax over the entire vocabulary words, which are often large (105-107) terms.
The noise contrastive estimation (NCE) loss function is an efficient approximation for a full softmax. With an objective to learn word embeddings instead of modeling the word distribution, the NCE loss can be simplified to use negative sampling.
The simplified negative sampling objective for a target word is to distinguish the context word from num_ns negative samples drawn from noise distribution Pn(w) of words. More precisely, an efficient approximation of full softmax over the vocabulary is, for a skip-gram pair, to pose the loss for a target word as a classification problem between the context word and num_ns negative samples.
A negative sample is defined as a (target_word, context_word) pair such that the context_word does not appear in the window_size neighborhood of the target_word. For the example sentence, these are a few potential negative samples (when window_size is 2).
(hot, shimmered)
(wide, hot)
(wide, sun)
In the next section, you’ll generate skip-grams and negative samples for a single sentence. You’ll also learn about subsampling techniques and train a classification model for positive and negative training examples later in the tutorial.
Setup
import io
import re
import string
import tqdm
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
2022-12-14 06:16:44.816296: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 06:16:44.816401: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 06:16:44.816412: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
# Load the TensorBoard notebook extension
%load_ext tensorboard
SEED = 42
AUTOTUNE = tf.data.AUTOTUNE
Vectorize an example sentence
Consider the following sentence:
The wide road shimmered in the hot sun.
Tokenize the sentence:
sentence = "The wide road shimmered in the hot sun"
tokens = list(sentence.lower().split())
print(len(tokens))
8
Create a vocabulary to save mappings from tokens to integer indices:
vocab, index = {}, 1 # start indexing from 1
vocab['<pad>'] = 0 # add a padding token
for token in tokens:
if token not in vocab:
vocab[token] = index
index += 1
vocab_size = len(vocab)
print(vocab)
{'<pad>': 0, 'the': 1, 'wide': 2, 'road': 3, 'shimmered': 4, 'in': 5, 'hot': 6, 'sun': 7}
Create an inverse vocabulary to save mappings from integer indices to tokens:
inverse_vocab = {index: token for token, index in vocab.items()}
print(inverse_vocab)
{0: '<pad>', 1: 'the', 2: 'wide', 3: 'road', 4: 'shimmered', 5: 'in', 6: 'hot', 7: 'sun'}
Vectorize your sentence:
example_sequence = [vocab[word] for word in tokens]
print(example_sequence)
[1, 2, 3, 4, 5, 1, 6, 7]
Generate skip-grams from one sentence
The tf.keras.preprocessing.sequence module provides useful functions that simplify data preparation for word2vec. You can use the tf.keras.preprocessing.sequence.skipgrams to generate skip-gram pairs from the example_sequence with a given window_size from tokens in the range [0, vocab_size).
window_size = 2
positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams(
example_sequence,
vocabulary_size=vocab_size,
window_size=window_size,
negative_samples=0)
print(len(positive_skip_grams))
26
Print a few positive skip-grams:
for target, context in positive_skip_grams[:5]:
print(f"({target}, {context}): ({inverse_vocab[target]}, {inverse_vocab[context]})")
(3, 4): (road, shimmered) (5, 1): (in, the) (2, 1): (wide, the) (5, 3): (in, road) (4, 2): (shimmered, wide)
Negative sampling for one skip-gram
The skipgrams function returns all positive skip-gram pairs by sliding over a given window span. To produce additional skip-gram pairs that would serve as negative samples for training, you need to sample random words from the vocabulary. Use the tf.random.log_uniform_candidate_sampler function to sample num_ns number of negative samples for a given target word in a window. You can call the function on one skip-grams’s target word and pass the context word as true class to exclude it from being sampled.
# Get target and context words for one positive skip-gram.
target_word, context_word = positive_skip_grams[0]
# Set the number of negative samples per positive context.
num_ns = 4
context_class = tf.reshape(tf.constant(context_word, dtype="int64"), (1, 1))
negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(
true_classes=context_class, # class that should be sampled as 'positive'
num_true=1, # each positive skip-gram has 1 positive context class
num_sampled=num_ns, # number of negative context words to sample
unique=True, # all the negative samples should be unique
range_max=vocab_size, # pick index of the samples from [0, vocab_size]
seed=SEED, # seed for reproducibility
name="negative_sampling" # name of this operation
)
print(negative_sampling_candidates)
print([inverse_vocab[index.numpy()] for index in negative_sampling_candidates])
tf.Tensor([2 1 4 3], shape=(4,), dtype=int64) ['wide', 'the', 'shimmered', 'road']
Construct one training example
For a given positive (target_word, context_word) skip-gram, you now also have num_ns negative sampled context words that do not appear in the window size neighborhood of target_word. Batch the 1 positive context_word and num_ns negative context words into one tensor. This produces a set of positive skip-grams (labeled as 1) and negative samples (labeled as 0) for each target word.
# Reduce a dimension so you can use concatenation (in the next step).
squeezed_context_class = tf.squeeze(context_class, 1)
# Concatenate a positive context word with negative sampled words.
context = tf.concat([squeezed_context_class, negative_sampling_candidates], 0)
# Label the first context word as `1` (positive) followed by `num_ns` `0`s (negative).
label = tf.constant([1] + [0]*num_ns, dtype="int64")
target = target_word
Check out the context and the corresponding labels for the target word from the skip-gram example above:
print(f"target_index : {target}")
print(f"target_word : {inverse_vocab[target_word]}")
print(f"context_indices : {context}")
print(f"context_words : {[inverse_vocab[c.numpy()] for c in context]}")
print(f"label : {label}")
target_index : 3 target_word : road context_indices : [4 2 1 4 3] context_words : ['shimmered', 'wide', 'the', 'shimmered', 'road'] label : [1 0 0 0 0]
A tuple of (target, context, label) tensors constitutes one training example for training your skip-gram negative sampling word2vec model. Notice that the target is of shape (1,) while the context and label are of shape (1+num_ns,)
print("target :", target)
print("context :", context)
print("label :", label)
target : 3 context : tf.Tensor([4 2 1 4 3], shape=(5,), dtype=int64) label : tf.Tensor([1 0 0 0 0], shape=(5,), dtype=int64)
Summary
This diagram summarizes the procedure of generating a training example from a sentence:

Notice that the words temperature and code are not part of the input sentence. They belong to the vocabulary like certain other indices used in the diagram above.
Compile all steps into one function
Skip-gram sampling table
A large dataset means larger vocabulary with higher number of more frequent words such as stopwords. Training examples obtained from sampling commonly occurring words (such as the, is, on) don’t add much useful information for the model to learn from. Mikolov et al. suggest subsampling of frequent words as a helpful practice to improve embedding quality.
The tf.keras.preprocessing.sequence.skipgrams function accepts a sampling table argument to encode probabilities of sampling any token. You can use the tf.keras.preprocessing.sequence.make_sampling_table to generate a word-frequency rank based probabilistic sampling table and pass it to the skipgrams function. Inspect the sampling probabilities for a vocab_size of 10.
sampling_table = tf.keras.preprocessing.sequence.make_sampling_table(size=10)
print(sampling_table)
[0.00315225 0.00315225 0.00547597 0.00741556 0.00912817 0.01068435 0.01212381 0.01347162 0.01474487 0.0159558 ]
sampling_table[i] denotes the probability of sampling the i-th most common word in a dataset. The function assumes a Zipf’s distribution of the word frequencies for sampling.
Generate training data
Compile all the steps described above into a function that can be called on a list of vectorized sentences obtained from any text dataset. Notice that the sampling table is built before sampling skip-gram word pairs. You will use this function in the later sections.
# Generates skip-gram pairs with negative sampling for a list of sequences
# (int-encoded sentences) based on window size, number of negative samples
# and vocabulary size.
def generate_training_data(sequences, window_size, num_ns, vocab_size, seed):
# Elements of each training example are appended to these lists.
targets, contexts, labels = [], [], []
# Build the sampling table for `vocab_size` tokens.
sampling_table = tf.keras.preprocessing.sequence.make_sampling_table(vocab_size)
# Iterate over all sequences (sentences) in the dataset.
for sequence in tqdm.tqdm(sequences):
# Generate positive skip-gram pairs for a sequence (sentence).
positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams(
sequence,
vocabulary_size=vocab_size,
sampling_table=sampling_table,
window_size=window_size,
negative_samples=0)
# Iterate over each positive skip-gram pair to produce training examples
# with a positive context word and negative samples.
for target_word, context_word in positive_skip_grams:
context_class = tf.expand_dims(
tf.constant([context_word], dtype="int64"), 1)
negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(
true_classes=context_class,
num_true=1,
num_sampled=num_ns,
unique=True,
range_max=vocab_size,
seed=seed,
name="negative_sampling")
# Build context and label vectors (for one target word)
context = tf.concat([tf.squeeze(context_class,1), negative_sampling_candidates], 0)
label = tf.constant([1] + [0]*num_ns, dtype="int64")
# Append each element from the training example to global lists.
targets.append(target_word)
contexts.append(context)
labels.append(label)
return targets, contexts, labels
Prepare training data for word2vec
With an understanding of how to work with one sentence for a skip-gram negative sampling based word2vec model, you can proceed to generate training examples from a larger list of sentences!
Download text corpus
You will use a text file of Shakespeare’s writing for this tutorial. Change the following line to run this code on your own data.
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt 1115394/1115394 [==============================] - 0s 0us/step
Read the text from the file and print the first few lines:
with open(path_to_file) as f:
lines = f.read().splitlines()
for line in lines[:20]:
print(line)
First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You are all resolved rather to die than to famish? All: Resolved. resolved. First Citizen: First, you know Caius Marcius is chief enemy to the people. All: We know't, we know't. First Citizen: Let us kill him, and we'll have corn at our own price.
Use the non empty lines to construct a tf.data.TextLineDataset object for the next steps:
text_ds = tf.data.TextLineDataset(path_to_file).filter(lambda x: tf.cast(tf.strings.length(x), bool))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
Vectorize sentences from the corpus
You can use the TextVectorization layer to vectorize sentences from the corpus. Learn more about using this layer in this Text classification tutorial. Notice from the first few sentences above that the text needs to be in one case and punctuation needs to be removed. To do this, define a custom_standardization function that can be used in the TextVectorization layer.
# Now, create a custom standardization function to lowercase the text and
# remove punctuation.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
return tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation), '')
# Define the vocabulary size and the number of words in a sequence.
vocab_size = 4096
sequence_length = 10
# Use the `TextVectorization` layer to normalize, split, and map strings to
# integers. Set the `output_sequence_length` length to pad all samples to the
# same length.
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
Call TextVectorization.adapt on the text dataset to create vocabulary.
vectorize_layer.adapt(text_ds.batch(1024))
Once the state of the layer has been adapted to represent the text corpus, the vocabulary can be accessed with TextVectorization.get_vocabulary. This function returns a list of all vocabulary tokens sorted (descending) by their frequency.
# Save the created vocabulary for reference.
inverse_vocab = vectorize_layer.get_vocabulary()
print(inverse_vocab[:20])
['', '[UNK]', 'the', 'and', 'to', 'i', 'of', 'you', 'my', 'a', 'that', 'in', 'is', 'not', 'for', 'with', 'me', 'it', 'be', 'your']
The vectorize_layer can now be used to generate vectors for each element in the text_ds (a tf.data.Dataset). Apply Dataset.batch, Dataset.prefetch, Dataset.map, and Dataset.unbatch.
# Vectorize the data in text_ds.
text_vector_ds = text_ds.batch(1024).prefetch(AUTOTUNE).map(vectorize_layer).unbatch()
Obtain sequences from the dataset
You now have a tf.data.Dataset of integer encoded sentences. To prepare the dataset for training a word2vec model, flatten the dataset into a list of sentence vector sequences. This step is required as you would iterate over each sentence in the dataset to produce positive and negative examples.
sequences = list(text_vector_ds.as_numpy_iterator())
print(len(sequences))
32777
Inspect a few examples from sequences:
for seq in sequences[:5]:
print(f"{seq} => {[inverse_vocab[i] for i in seq]}")
[ 89 270 0 0 0 0 0 0 0 0] => ['first', 'citizen', '', '', '', '', '', '', '', ''] [138 36 982 144 673 125 16 106 0 0] => ['before', 'we', 'proceed', 'any', 'further', 'hear', 'me', 'speak', '', ''] [34 0 0 0 0 0 0 0 0 0] => ['all', '', '', '', '', '', '', '', '', ''] [106 106 0 0 0 0 0 0 0 0] => ['speak', 'speak', '', '', '', '', '', '', '', ''] [ 89 270 0 0 0 0 0 0 0 0] => ['first', 'citizen', '', '', '', '', '', '', '', '']
Generate training examples from sequences
sequences is now a list of int encoded sentences. Just call the generate_training_data function defined earlier to generate training examples for the word2vec model. To recap, the function iterates over each word from each sequence to collect positive and negative context words. Length of target, contexts and labels should be the same, representing the total number of training examples.
targets, contexts, labels = generate_training_data(
sequences=sequences,
window_size=2,
num_ns=4,
vocab_size=vocab_size,
seed=SEED)
targets = np.array(targets)
contexts = np.array(contexts)
labels = np.array(labels)
print('n')
print(f"targets.shape: {targets.shape}")
print(f"contexts.shape: {contexts.shape}")
print(f"labels.shape: {labels.shape}")
100%|██████████| 32777/32777 [00:47<00:00, 696.80it/s] targets.shape: (64953,) contexts.shape: (64953, 5) labels.shape: (64953, 5)
Configure the dataset for performance
To perform efficient batching for the potentially large number of training examples, use the tf.data.Dataset API. After this step, you would have a tf.data.Dataset object of (target_word, context_word), (label) elements to train your word2vec model!
BATCH_SIZE = 1024
BUFFER_SIZE = 10000
dataset = tf.data.Dataset.from_tensor_slices(((targets, contexts), labels))
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
print(dataset)
<BatchDataset element_spec=((TensorSpec(shape=(1024,), dtype=tf.int64, name=None), TensorSpec(shape=(1024, 5), dtype=tf.int64, name=None)), TensorSpec(shape=(1024, 5), dtype=tf.int64, name=None))>
Apply Dataset.cache and Dataset.prefetch to improve performance:
dataset = dataset.cache().prefetch(buffer_size=AUTOTUNE)
print(dataset)
<PrefetchDataset element_spec=((TensorSpec(shape=(1024,), dtype=tf.int64, name=None), TensorSpec(shape=(1024, 5), dtype=tf.int64, name=None)), TensorSpec(shape=(1024, 5), dtype=tf.int64, name=None))>
Model and training
The word2vec model can be implemented as a classifier to distinguish between true context words from skip-grams and false context words obtained through negative sampling. You can perform a dot product multiplication between the embeddings of target and context words to obtain predictions for labels and compute the loss function against true labels in the dataset.
Subclassed word2vec model
Use the Keras Subclassing API to define your word2vec model with the following layers:
target_embedding: Atf.keras.layers.Embeddinglayer, which looks up the embedding of a word when it appears as a target word. The number of parameters in this layer are(vocab_size * embedding_dim).context_embedding: Anothertf.keras.layers.Embeddinglayer, which looks up the embedding of a word when it appears as a context word. The number of parameters in this layer are the same as those intarget_embedding, i.e.(vocab_size * embedding_dim).dots: Atf.keras.layers.Dotlayer that computes the dot product of target and context embeddings from a training pair.flatten: Atf.keras.layers.Flattenlayer to flatten the results ofdotslayer into logits.
With the subclassed model, you can define the call() function that accepts (target, context) pairs which can then be passed into their corresponding embedding layer. Reshape the context_embedding to perform a dot product with target_embedding and return the flattened result.
class Word2Vec(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim):
super(Word2Vec, self).__init__()
self.target_embedding = layers.Embedding(vocab_size,
embedding_dim,
input_length=1,
name="w2v_embedding")
self.context_embedding = layers.Embedding(vocab_size,
embedding_dim,
input_length=num_ns+1)
def call(self, pair):
target, context = pair
# target: (batch, dummy?) # The dummy axis doesn't exist in TF2.7+
# context: (batch, context)
if len(target.shape) == 2:
target = tf.squeeze(target, axis=1)
# target: (batch,)
word_emb = self.target_embedding(target)
# word_emb: (batch, embed)
context_emb = self.context_embedding(context)
# context_emb: (batch, context, embed)
dots = tf.einsum('be,bce->bc', word_emb, context_emb)
# dots: (batch, context)
return dots
Define loss function and compile model
For simplicity, you can use tf.keras.losses.CategoricalCrossEntropy as an alternative to the negative sampling loss. If you would like to write your own custom loss function, you can also do so as follows:
def custom_loss(x_logit, y_true):
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=y_true)
It’s time to build your model! Instantiate your word2vec class with an embedding dimension of 128 (you could experiment with different values). Compile the model with the tf.keras.optimizers.Adam optimizer.
embedding_dim = 128
word2vec = Word2Vec(vocab_size, embedding_dim)
word2vec.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Also define a callback to log training statistics for TensorBoard:
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Train the model on the dataset for some number of epochs:
word2vec.fit(dataset, epochs=20, callbacks=[tensorboard_callback])
Epoch 1/20 63/63 [==============================] - 8s 112ms/step - loss: 1.6082 - accuracy: 0.2314 Epoch 2/20 63/63 [==============================] - 0s 3ms/step - loss: 1.5886 - accuracy: 0.5562 Epoch 3/20 63/63 [==============================] - 0s 3ms/step - loss: 1.5403 - accuracy: 0.5982 Epoch 4/20 63/63 [==============================] - 0s 3ms/step - loss: 1.4573 - accuracy: 0.5730 Epoch 5/20 63/63 [==============================] - 0s 3ms/step - loss: 1.3589 - accuracy: 0.5810 Epoch 6/20 63/63 [==============================] - 0s 3ms/step - loss: 1.2615 - accuracy: 0.6101 Epoch 7/20 63/63 [==============================] - 0s 3ms/step - loss: 1.1704 - accuracy: 0.6450 Epoch 8/20 63/63 [==============================] - 0s 3ms/step - loss: 1.0858 - accuracy: 0.6794 Epoch 9/20 63/63 [==============================] - 0s 3ms/step - loss: 1.0075 - accuracy: 0.7106 Epoch 10/20 63/63 [==============================] - 0s 3ms/step - loss: 0.9348 - accuracy: 0.7413 Epoch 11/20 63/63 [==============================] - 0s 3ms/step - loss: 0.8676 - accuracy: 0.7657 Epoch 12/20 63/63 [==============================] - 0s 3ms/step - loss: 0.8056 - accuracy: 0.7871 Epoch 13/20 63/63 [==============================] - 0s 3ms/step - loss: 0.7485 - accuracy: 0.8069 Epoch 14/20 63/63 [==============================] - 0s 3ms/step - loss: 0.6962 - accuracy: 0.8258 Epoch 15/20 63/63 [==============================] - 0s 3ms/step - loss: 0.6484 - accuracy: 0.8415 Epoch 16/20 63/63 [==============================] - 0s 3ms/step - loss: 0.6048 - accuracy: 0.8549 Epoch 17/20 63/63 [==============================] - 0s 3ms/step - loss: 0.5650 - accuracy: 0.8671 Epoch 18/20 63/63 [==============================] - 0s 3ms/step - loss: 0.5288 - accuracy: 0.8775 Epoch 19/20 63/63 [==============================] - 0s 3ms/step - loss: 0.4959 - accuracy: 0.8864 Epoch 20/20 63/63 [==============================] - 0s 3ms/step - loss: 0.4659 - accuracy: 0.8959 <keras.callbacks.History at 0x7f6bd0344f70>
TensorBoard now shows the word2vec model’s accuracy and loss:
#docs_infra: no_execute
%tensorboard --logdir logs

Embedding lookup and analysis
Obtain the weights from the model using Model.get_layer and Layer.get_weights. The TextVectorization.get_vocabulary function provides the vocabulary to build a metadata file with one token per line.
weights = word2vec.get_layer('w2v_embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Create and save the vectors and metadata files:
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('t'.join([str(x) for x in vec]) + "n")
out_m.write(word + "n")
out_v.close()
out_m.close()
Download the vectors.tsv and metadata.tsv to analyze the obtained embeddings in the Embedding Projector:
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Next steps
This tutorial has shown you how to implement a skip-gram word2vec model with negative sampling from scratch and visualize the obtained word embeddings.
-
To learn more about word vectors and their mathematical representations, refer to these notes.
-
To learn more about advanced text processing, read the Transformer model for language understanding tutorial.
-
If you’re interested in pre-trained embedding models, you may also be interested in Exploring the TF-Hub CORD-19 Swivel Embeddings, or the Multilingual Universal Sentence Encoder.
-
You may also like to train the model on a new dataset (there are many available in TensorFlow Datasets).
Write a sentence for each word / phrase.
1 (at the moment) 2(on Sundays) 3(in the summer) 4(always) 5(right now) 6(in the winter) 7(never).
Если вам необходимо получить ответ на вопрос Write a sentence for each word / phrase?, относящийся
к уровню подготовки учащихся 5 — 9 классов, вы открыли нужную страницу.
В категории Английский язык вы также найдете ответы на похожие вопросы по
интересующей теме, с помощью автоматического «умного» поиска. Если после
ознакомления со всеми вариантами ответа у вас остались сомнения, или
полученная информация не полностью освещает тематику, создайте свой вопрос с
помощью кнопки, которая находится вверху страницы, или обсудите вопрос с
посетителями этой страницы.
 pos + model.window + 1 — reduced_window)], start): pos + model.window + 1 — reduced_window)], start) pos + model.window + 1)], start)
pos + model.window + 1 — reduced_window)], start): pos + model.window + 1 — reduced_window)], start) pos + model.window + 1)], start) 3. Write a sentence for each word/phrase. 1) (at the moment) 2) (on Sundays) 3) (in the summer) 4) (always) 5) (right now) 6) (in the winter) 7) (never) 5. White the questions and then answer them. 1) where/you/go/now Where are you going now? To the park. 2) what / you/wear/right/now 3) what/be/the/weather/like/today 4) what/your/parents/do/at/the moment 5) what/time/you/get/up/every/day 6) which/season/you/like/most
Найди верный ответ на вопрос ✅ «3. Write a sentence for each word/phrase. 1) (at the moment) 2) (on Sundays) 3) (in the summer) 4) (always) 5) (right now) 6) (in the …» по предмету 📙 Английский язык, а если ответа нет или никто не дал верного ответа, то воспользуйся поиском и попробуй найти ответ среди похожих вопросов.
Искать другие ответы
Главная » Английский язык » 3. Write a sentence for each word/phrase. 1) (at the moment) 2) (on Sundays) 3) (in the summer) 4) (always) 5) (right now) 6) (in the winter) 7) (never) 5. White the questions and then answer them.