
Deoxyribonucleic acid (;[1] DNA) is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.
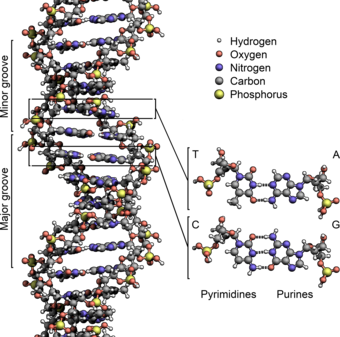
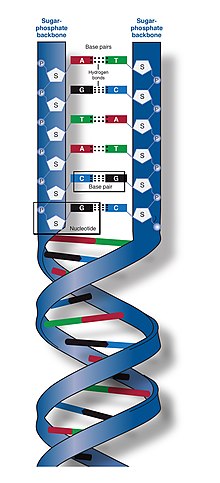
The two DNA strands are known as polynucleotides as they are composed of simpler monomeric units called nucleotides.[2][3] Each nucleotide is composed of one of four nitrogen-containing nucleobases (cytosine [C], guanine [G], adenine [A] or thymine [T]), a sugar called deoxyribose, and a phosphate group. The nucleotides are joined to one another in a chain by covalent bonds (known as the phosphodiester linkage) between the sugar of one nucleotide and the phosphate of the next, resulting in an alternating sugar-phosphate backbone. The nitrogenous bases of the two separate polynucleotide strands are bound together, according to base pairing rules (A with T and C with G), with hydrogen bonds to make double-stranded DNA. The complementary nitrogenous bases are divided into two groups, pyrimidines and purines. In DNA, the pyrimidines are thymine and cytosine; the purines are adenine and guanine.
Both strands of double-stranded DNA store the same biological information. This information is replicated when the two strands separate. A large part of DNA (more than 98% for humans) is non-coding, meaning that these sections do not serve as patterns for protein sequences. The two strands of DNA run in opposite directions to each other and are thus antiparallel. Attached to each sugar is one of four types of nucleobases (or bases). It is the sequence of these four nucleobases along the backbone that encodes genetic information. RNA strands are created using DNA strands as a template in a process called transcription, where DNA bases are exchanged for their corresponding bases except in the case of thymine (T), for which RNA substitutes uracil (U).[4] Under the genetic code, these RNA strands specify the sequence of amino acids within proteins in a process called translation.
Within eukaryotic cells, DNA is organized into long structures called chromosomes. Before typical cell division, these chromosomes are duplicated in the process of DNA replication, providing a complete set of chromosomes for each daughter cell. Eukaryotic organisms (animals, plants, fungi and protists) store most of their DNA inside the cell nucleus as nuclear DNA, and some in the mitochondria as mitochondrial DNA or in chloroplasts as chloroplast DNA.[5] In contrast, prokaryotes (bacteria and archaea) store their DNA only in the cytoplasm, in circular chromosomes. Within eukaryotic chromosomes, chromatin proteins, such as histones, compact and organize DNA. These compacting structures guide the interactions between DNA and other proteins, helping control which parts of the DNA are transcribed.
Properties
Chemical structure of DNA; hydrogen bonds shown as dotted lines. Each end of the double helix has an exposed 5′ phosphate on one strand and an exposed 3′ hydroxyl group (—OH) on the other.
DNA is a long polymer made from repeating units called nucleotides.[6][7] The structure of DNA is dynamic along its length, being capable of coiling into tight loops and other shapes.[8] In all species it is composed of two helical chains, bound to each other by hydrogen bonds. Both chains are coiled around the same axis, and have the same pitch of 34 ångströms (3.4 nm). The pair of chains have a radius of 10 Å (1.0 nm).[9] According to another study, when measured in a different solution, the DNA chain measured 22–26 Å (2.2–2.6 nm) wide, and one nucleotide unit measured 3.3 Å (0.33 nm) long.[10]
DNA does not usually exist as a single strand, but instead as a pair of strands that are held tightly together.[9][11] These two long strands coil around each other, in the shape of a double helix. The nucleotide contains both a segment of the backbone of the molecule (which holds the chain together) and a nucleobase (which interacts with the other DNA strand in the helix). A nucleobase linked to a sugar is called a nucleoside, and a base linked to a sugar and to one or more phosphate groups is called a nucleotide. A biopolymer comprising multiple linked nucleotides (as in DNA) is called a polynucleotide.[12]
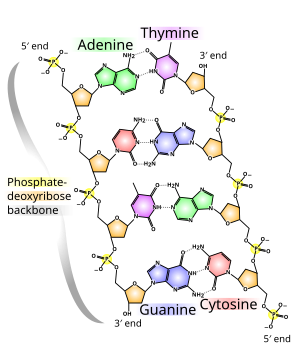
The backbone of the DNA strand is made from alternating phosphate and sugar groups.[13] The sugar in DNA is 2-deoxyribose, which is a pentose (five-carbon) sugar. The sugars are joined by phosphate groups that form phosphodiester bonds between the third and fifth carbon atoms of adjacent sugar rings. These are known as the 3′-end (three prime end), and 5′-end (five prime end) carbons, the prime symbol being used to distinguish these carbon atoms from those of the base to which the deoxyribose forms a glycosidic bond.[11]
Therefore, any DNA strand normally has one end at which there is a phosphate group attached to the 5′ carbon of a ribose (the 5′ phosphoryl) and another end at which there is a free hydroxyl group attached to the 3′ carbon of a ribose (the 3′ hydroxyl). The orientation of the 3′ and 5′ carbons along the sugar-phosphate backbone confers directionality (sometimes called polarity) to each DNA strand. In a nucleic acid double helix, the direction of the nucleotides in one strand is opposite to their direction in the other strand: the strands are antiparallel. The asymmetric ends of DNA strands are said to have a directionality of five prime end (5′ ), and three prime end (3′), with the 5′ end having a terminal phosphate group and the 3′ end a terminal hydroxyl group. One major difference between DNA and RNA is the sugar, with the 2-deoxyribose in DNA being replaced by the related pentose sugar ribose in RNA.[11]
A section of DNA. The bases lie horizontally between the two spiraling strands[14] (animated version).
The DNA double helix is stabilized primarily by two forces: hydrogen bonds between nucleotides and base-stacking interactions among aromatic nucleobases.[15] The four bases found in DNA are adenine (A), cytosine (C), guanine (G) and thymine (T). These four bases are attached to the sugar-phosphate to form the complete nucleotide, as shown for adenosine monophosphate. Adenine pairs with thymine and guanine pairs with cytosine, forming A-T and G-C base pairs.[16][17]
Nucleobase classification
The nucleobases are classified into two types: the purines, A and G, which are fused five- and six-membered heterocyclic compounds, and the pyrimidines, the six-membered rings C and T.[11] A fifth pyrimidine nucleobase, uracil (U), usually takes the place of thymine in RNA and differs from thymine by lacking a methyl group on its ring. In addition to RNA and DNA, many artificial nucleic acid analogues have been created to study the properties of nucleic acids, or for use in biotechnology.[18]
Non-canonical bases
Modified bases occur in DNA. The first of these recognized was 5-methylcytosine, which was found in the genome of Mycobacterium tuberculosis in 1925.[19] The reason for the presence of these noncanonical bases in bacterial viruses (bacteriophages) is to avoid the restriction enzymes present in bacteria. This enzyme system acts at least in part as a molecular immune system protecting bacteria from infection by viruses.[20] Modifications of the bases cytosine and adenine, the more common and modified DNA bases, play vital roles in the epigenetic control of gene expression in plants and animals.[21]
A number of noncanonical bases are known to occur in DNA.[22] Most of these are modifications of the canonical bases plus uracil.
- Modified Adenine
- N6-carbamoyl-methyladenine
- N6-methyadenine
- Modified Guanine
- 7-Deazaguanine
- 7-Methylguanine
- Modified Cytosine
- N4-Methylcytosine
- 5-Carboxylcytosine
- 5-Formylcytosine
- 5-Glycosylhydroxymethylcytosine
- 5-Hydroxycytosine
- 5-Methylcytosine
- Modified Thymidine
- α-Glutamythymidine
- α-Putrescinylthymine
- Uracil and modifications
- Base J
- Uracil
- 5-Dihydroxypentauracil
- 5-Hydroxymethyldeoxyuracil
- Others
- Deoxyarchaeosine
- 2,6-Diaminopurine (2-Aminoadenine)
Grooves
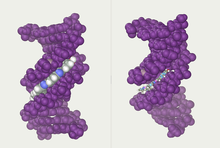
DNA major and minor grooves. The latter is a binding site for the Hoechst stain dye 33258.
Twin helical strands form the DNA backbone. Another double helix may be found tracing the spaces, or grooves, between the strands. These voids are adjacent to the base pairs and may provide a binding site. As the strands are not symmetrically located with respect to each other, the grooves are unequally sized. The major groove is 22 ångströms (2.2 nm) wide, while the minor groove is 12 Å (1.2 nm) in width.[23] Due to the larger width of the major groove, the edges of the bases are more accessible in the major groove than in the minor groove. As a result, proteins such as transcription factors that can bind to specific sequences in double-stranded DNA usually make contact with the sides of the bases exposed in the major groove.[24] This situation varies in unusual conformations of DNA within the cell (see below), but the major and minor grooves are always named to reflect the differences in width that would be seen if the DNA was twisted back into the ordinary B form.
Base pairing

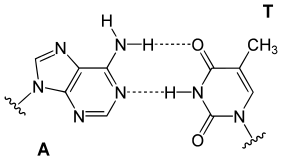
Top, a GC base pair with three hydrogen bonds. Bottom, an AT base pair with two hydrogen bonds. Non-covalent hydrogen bonds between the pairs are shown as dashed lines.
In a DNA double helix, each type of nucleobase on one strand bonds with just one type of nucleobase on the other strand. This is called complementary base pairing. Purines form hydrogen bonds to pyrimidines, with adenine bonding only to thymine in two hydrogen bonds, and cytosine bonding only to guanine in three hydrogen bonds. This arrangement of two nucleotides binding together across the double helix (from six-carbon ring to six-carbon ring) is called a Watson-Crick base pair. DNA with high GC-content is more stable than DNA with low GC-content. A Hoogsteen base pair (hydrogen bonding the 6-carbon ring to the 5-carbon ring) is a rare variation of base-pairing.[25] As hydrogen bonds are not covalent, they can be broken and rejoined relatively easily. The two strands of DNA in a double helix can thus be pulled apart like a zipper, either by a mechanical force or high temperature.[26] As a result of this base pair complementarity, all the information in the double-stranded sequence of a DNA helix is duplicated on each strand, which is vital in DNA replication. This reversible and specific interaction between complementary base pairs is critical for all the functions of DNA in organisms.[7]
ssDNA vs. dsDNA
As noted above, most DNA molecules are actually two polymer strands, bound together in a helical fashion by noncovalent bonds; this double-stranded (dsDNA) structure is maintained largely by the intrastrand base stacking interactions, which are strongest for G,C stacks. The two strands can come apart—a process known as melting—to form two single-stranded DNA (ssDNA) molecules. Melting occurs at high temperatures, low salt and high pH (low pH also melts DNA, but since DNA is unstable due to acid depurination, low pH is rarely used).
The stability of the dsDNA form depends not only on the GC-content (% G,C basepairs) but also on sequence (since stacking is sequence specific) and also length (longer molecules are more stable). The stability can be measured in various ways; a common way is the melting temperature (also called Tm value), which is the temperature at which 50% of the double-strand molecules are converted to single-strand molecules; melting temperature is dependent on ionic strength and the concentration of DNA. As a result, it is both the percentage of GC base pairs and the overall length of a DNA double helix that determines the strength of the association between the two strands of DNA. Long DNA helices with a high GC-content have more strongly interacting strands, while short helices with high AT content have more weakly interacting strands.[27] In biology, parts of the DNA double helix that need to separate easily, such as the TATAAT Pribnow box in some promoters, tend to have a high AT content, making the strands easier to pull apart.[28]
In the laboratory, the strength of this interaction can be measured by finding the melting temperature Tm necessary to break half of the hydrogen bonds. When all the base pairs in a DNA double helix melt, the strands separate and exist in solution as two entirely independent molecules. These single-stranded DNA molecules have no single common shape, but some conformations are more stable than others.[29]
Amount

In humans, the total female diploid nuclear genome per cell extends for 6.37 Gigabase pairs (Gbp), is 208.23 cm long and weighs 6.51 picograms (pg).[30] Male values are 6.27 Gbp, 205.00 cm, 6.41 pg.[30] Each DNA polymer can contain hundreds of millions of nucleotides, such as in chromosome 1. Chromosome 1 is the largest human chromosome with approximately 220 million base pairs, and would be 85 mm long if straightened.[31]
In eukaryotes, in addition to nuclear DNA, there is also mitochondrial DNA (mtDNA) which encodes certain proteins used by the mitochondria. The mtDNA is usually relatively small in comparison to the nuclear DNA. For example, the human mitochondrial DNA forms closed circular molecules, each of which contains 16,569[32][33] DNA base pairs,[34] with each such molecule normally containing a full set of the mitochondrial genes. Each human mitochondrion contains, on average, approximately 5 such mtDNA molecules.[34] Each human cell contains approximately 100 mitochondria, giving a total number of mtDNA molecules per human cell of approximately 500.[34] However, the amount of mitochondria per cell also varies by cell type, and an egg cell can contain 100,000 mitochondria, corresponding to up to 1,500,000 copies of the mitochondrial genome (constituting up to 90% of the DNA of the cell).[35]
Sense and antisense
A DNA sequence is called a «sense» sequence if it is the same as that of a messenger RNA copy that is translated into protein.[36] The sequence on the opposite strand is called the «antisense» sequence. Both sense and antisense sequences can exist on different parts of the same strand of DNA (i.e. both strands can contain both sense and antisense sequences). In both prokaryotes and eukaryotes, antisense RNA sequences are produced, but the functions of these RNAs are not entirely clear.[37] One proposal is that antisense RNAs are involved in regulating gene expression through RNA-RNA base pairing.[38]
A few DNA sequences in prokaryotes and eukaryotes, and more in plasmids and viruses, blur the distinction between sense and antisense strands by having overlapping genes.[39] In these cases, some DNA sequences do double duty, encoding one protein when read along one strand, and a second protein when read in the opposite direction along the other strand. In bacteria, this overlap may be involved in the regulation of gene transcription,[40] while in viruses, overlapping genes increase the amount of information that can be encoded within the small viral genome.[41]
Supercoiling
DNA can be twisted like a rope in a process called DNA supercoiling. With DNA in its «relaxed» state, a strand usually circles the axis of the double helix once every 10.4 base pairs, but if the DNA is twisted the strands become more tightly or more loosely wound.[42] If the DNA is twisted in the direction of the helix, this is positive supercoiling, and the bases are held more tightly together. If they are twisted in the opposite direction, this is negative supercoiling, and the bases come apart more easily. In nature, most DNA has slight negative supercoiling that is introduced by enzymes called topoisomerases.[43] These enzymes are also needed to relieve the twisting stresses introduced into DNA strands during processes such as transcription and DNA replication.[44]
Alternative DNA structures
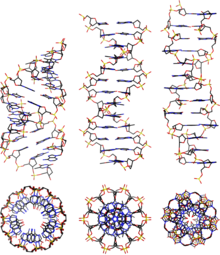
From left to right, the structures of A, B and Z-DNA
DNA exists in many possible conformations that include A-DNA, B-DNA, and Z-DNA forms, although only B-DNA and Z-DNA have been directly observed in functional organisms.[13] The conformation that DNA adopts depends on the hydration level, DNA sequence, the amount and direction of supercoiling, chemical modifications of the bases, the type and concentration of metal ions, and the presence of polyamines in solution.[45]
The first published reports of A-DNA X-ray diffraction patterns—and also B-DNA—used analyses based on Patterson functions that provided only a limited amount of structural information for oriented fibers of DNA.[46][47] An alternative analysis was proposed by Wilkins et al. in 1953 for the in vivo B-DNA X-ray diffraction-scattering patterns of highly hydrated DNA fibers in terms of squares of Bessel functions.[48] In the same journal, James Watson and Francis Crick presented their molecular modeling analysis of the DNA X-ray diffraction patterns to suggest that the structure was a double helix.[9]
Although the B-DNA form is most common under the conditions found in cells,[49] it is not a well-defined conformation but a family of related DNA conformations[50] that occur at the high hydration levels present in cells. Their corresponding X-ray diffraction and scattering patterns are characteristic of molecular paracrystals with a significant degree of disorder.[51][52]
Compared to B-DNA, the A-DNA form is a wider right-handed spiral, with a shallow, wide minor groove and a narrower, deeper major groove. The A form occurs under non-physiological conditions in partly dehydrated samples of DNA, while in the cell it may be produced in hybrid pairings of DNA and RNA strands, and in enzyme-DNA complexes.[53][54] Segments of DNA where the bases have been chemically modified by methylation may undergo a larger change in conformation and adopt the Z form. Here, the strands turn about the helical axis in a left-handed spiral, the opposite of the more common B form.[55] These unusual structures can be recognized by specific Z-DNA binding proteins and may be involved in the regulation of transcription.[56]
Alternative DNA chemistry
For many years, exobiologists have proposed the existence of a shadow biosphere, a postulated microbial biosphere of Earth that uses radically different biochemical and molecular processes than currently known life. One of the proposals was the existence of lifeforms that use arsenic instead of phosphorus in DNA. A report in 2010 of the possibility in the bacterium GFAJ-1 was announced,[57][58] though the research was disputed,[58][59] and evidence suggests the bacterium actively prevents the incorporation of arsenic into the DNA backbone and other biomolecules.[60]
Quadruplex structures
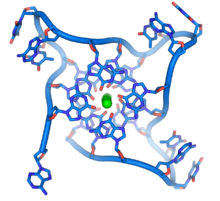
DNA quadruplex formed by telomere repeats. The looped conformation of the DNA backbone is very different from the typical DNA helix. The green spheres in the center represent potassium ions.[61]
At the ends of the linear chromosomes are specialized regions of DNA called telomeres. The main function of these regions is to allow the cell to replicate chromosome ends using the enzyme telomerase, as the enzymes that normally replicate DNA cannot copy the extreme 3′ ends of chromosomes.[62] These specialized chromosome caps also help protect the DNA ends, and stop the DNA repair systems in the cell from treating them as damage to be corrected.[63] In human cells, telomeres are usually lengths of single-stranded DNA containing several thousand repeats of a simple TTAGGG sequence.[64]
These guanine-rich sequences may stabilize chromosome ends by forming structures of stacked sets of four-base units, rather than the usual base pairs found in other DNA molecules. Here, four guanine bases, known as a guanine tetrad, form a flat plate. These flat four-base units then stack on top of each other to form a stable G-quadruplex structure.[65] These structures are stabilized by hydrogen bonding between the edges of the bases and chelation of a metal ion in the centre of each four-base unit.[66] Other structures can also be formed, with the central set of four bases coming from either a single strand folded around the bases, or several different parallel strands, each contributing one base to the central structure.
In addition to these stacked structures, telomeres also form large loop structures called telomere loops, or T-loops. Here, the single-stranded DNA curls around in a long circle stabilized by telomere-binding proteins.[67] At the very end of the T-loop, the single-stranded telomere DNA is held onto a region of double-stranded DNA by the telomere strand disrupting the double-helical DNA and base pairing to one of the two strands. This triple-stranded structure is called a displacement loop or D-loop.[65]
Branched DNA can form networks containing multiple branches.
Branched DNA
In DNA, fraying occurs when non-complementary regions exist at the end of an otherwise complementary double-strand of DNA. However, branched DNA can occur if a third strand of DNA is introduced and contains adjoining regions able to hybridize with the frayed regions of the pre-existing double-strand. Although the simplest example of branched DNA involves only three strands of DNA, complexes involving additional strands and multiple branches are also possible.[68] Branched DNA can be used in nanotechnology to construct geometric shapes, see the section on uses in technology below.
Artificial bases
Several artificial nucleobases have been synthesized, and successfully incorporated in the eight-base DNA analogue named Hachimoji DNA. Dubbed S, B, P, and Z, these artificial bases are capable of bonding with each other in a predictable way (S–B and P–Z), maintain the double helix structure of DNA, and be transcribed to RNA. Their existence could be seen as an indication that there is nothing special about the four natural nucleobases that evolved on Earth.[69][70] On the other hand, DNA is tightly related to RNA which does not only act as a transcript of DNA but also performs as molecular machines many tasks in cells. For this purpose it has to fold into a structure. It has been shown that to allow to create all possible structures at least four bases are required for the corresponding RNA,[71] while a higher number is also possible but this would be against the natural principle of least effort.
Acidity
The phosphate groups of DNA give it similar acidic properties to phosphoric acid and it can be considered as a strong acid. It will be fully ionized at a normal cellular pH, releasing protons which leave behind negative charges on the phosphate groups. These negative charges protect DNA from breakdown by hydrolysis by repelling nucleophiles which could hydrolyze it.[72]
Macroscopic appearance

Impure DNA extracted from an orange
Pure DNA extracted from cells forms white, stringy clumps.[73]
Chemical modifications and altered DNA packaging
Structure of cytosine with and without the 5-methyl group. Deamination converts 5-methylcytosine into thymine.
Base modifications and DNA packaging
The expression of genes is influenced by how the DNA is packaged in chromosomes, in a structure called chromatin. Base modifications can be involved in packaging, with regions that have low or no gene expression usually containing high levels of methylation of cytosine bases. DNA packaging and its influence on gene expression can also occur by covalent modifications of the histone protein core around which DNA is wrapped in the chromatin structure or else by remodeling carried out by chromatin remodeling complexes (see Chromatin remodeling). There is, further, crosstalk between DNA methylation and histone modification, so they can coordinately affect chromatin and gene expression.[74]
For one example, cytosine methylation produces 5-methylcytosine, which is important for X-inactivation of chromosomes.[75] The average level of methylation varies between organisms—the worm Caenorhabditis elegans lacks cytosine methylation, while vertebrates have higher levels, with up to 1% of their DNA containing 5-methylcytosine.[76] Despite the importance of 5-methylcytosine, it can deaminate to leave a thymine base, so methylated cytosines are particularly prone to mutations.[77] Other base modifications include adenine methylation in bacteria, the presence of 5-hydroxymethylcytosine in the brain,[78] and the glycosylation of uracil to produce the «J-base» in kinetoplastids.[79][80]
Damage
DNA can be damaged by many sorts of mutagens, which change the DNA sequence. Mutagens include oxidizing agents, alkylating agents and also high-energy electromagnetic radiation such as ultraviolet light and X-rays. The type of DNA damage produced depends on the type of mutagen. For example, UV light can damage DNA by producing thymine dimers, which are cross-links between pyrimidine bases.[82] On the other hand, oxidants such as free radicals or hydrogen peroxide produce multiple forms of damage, including base modifications, particularly of guanosine, and double-strand breaks.[83] A typical human cell contains about 150,000 bases that have suffered oxidative damage.[84] Of these oxidative lesions, the most dangerous are double-strand breaks, as these are difficult to repair and can produce point mutations, insertions, deletions from the DNA sequence, and chromosomal translocations.[85] These mutations can cause cancer. Because of inherent limits in the DNA repair mechanisms, if humans lived long enough, they would all eventually develop cancer.[86][87] DNA damages that are naturally occurring, due to normal cellular processes that produce reactive oxygen species, the hydrolytic activities of cellular water, etc., also occur frequently. Although most of these damages are repaired, in any cell some DNA damage may remain despite the action of repair processes. These remaining DNA damages accumulate with age in mammalian postmitotic tissues. This accumulation appears to be an important underlying cause of aging.[88][89][90]
Many mutagens fit into the space between two adjacent base pairs, this is called intercalation. Most intercalators are aromatic and planar molecules; examples include ethidium bromide, acridines, daunomycin, and doxorubicin. For an intercalator to fit between base pairs, the bases must separate, distorting the DNA strands by unwinding of the double helix. This inhibits both transcription and DNA replication, causing toxicity and mutations.[91] As a result, DNA intercalators may be carcinogens, and in the case of thalidomide, a teratogen.[92] Others such as benzo[a]pyrene diol epoxide and aflatoxin form DNA adducts that induce errors in replication.[93] Nevertheless, due to their ability to inhibit DNA transcription and replication, other similar toxins are also used in chemotherapy to inhibit rapidly growing cancer cells.[94]
Biological functions
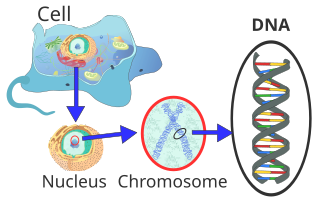
Location of eukaryote nuclear DNA within the chromosomes
DNA usually occurs as linear chromosomes in eukaryotes, and circular chromosomes in prokaryotes. The set of chromosomes in a cell makes up its genome; the human genome has approximately 3 billion base pairs of DNA arranged into 46 chromosomes.[95] The information carried by DNA is held in the sequence of pieces of DNA called genes. Transmission of genetic information in genes is achieved via complementary base pairing. For example, in transcription, when a cell uses the information in a gene, the DNA sequence is copied into a complementary RNA sequence through the attraction between the DNA and the correct RNA nucleotides. Usually, this RNA copy is then used to make a matching protein sequence in a process called translation, which depends on the same interaction between RNA nucleotides. In an alternative fashion, a cell may copy its genetic information in a process called DNA replication. The details of these functions are covered in other articles; here the focus is on the interactions between DNA and other molecules that mediate the function of the genome.
Genes and genomes
Genomic DNA is tightly and orderly packed in the process called DNA condensation, to fit the small available volumes of the cell. In eukaryotes, DNA is located in the cell nucleus, with small amounts in mitochondria and chloroplasts. In prokaryotes, the DNA is held within an irregularly shaped body in the cytoplasm called the nucleoid.[96] The genetic information in a genome is held within genes, and the complete set of this information in an organism is called its genotype. A gene is a unit of heredity and is a region of DNA that influences a particular characteristic in an organism. Genes contain an open reading frame that can be transcribed, and regulatory sequences such as promoters and enhancers, which control transcription of the open reading frame.
In many species, only a small fraction of the total sequence of the genome encodes protein. For example, only about 1.5% of the human genome consists of protein-coding exons, with over 50% of human DNA consisting of non-coding repetitive sequences.[97] The reasons for the presence of so much noncoding DNA in eukaryotic genomes and the extraordinary differences in genome size, or C-value, among species, represent a long-standing puzzle known as the «C-value enigma».[98] However, some DNA sequences that do not code protein may still encode functional non-coding RNA molecules, which are involved in the regulation of gene expression.[99]

Some noncoding DNA sequences play structural roles in chromosomes. Telomeres and centromeres typically contain few genes but are important for the function and stability of chromosomes.[63][101] An abundant form of noncoding DNA in humans are pseudogenes, which are copies of genes that have been disabled by mutation.[102] These sequences are usually just molecular fossils, although they can occasionally serve as raw genetic material for the creation of new genes through the process of gene duplication and divergence.[103]
Transcription and translation
A gene is a sequence of DNA that contains genetic information and can influence the phenotype of an organism. Within a gene, the sequence of bases along a DNA strand defines a messenger RNA sequence, which then defines one or more protein sequences. The relationship between the nucleotide sequences of genes and the amino-acid sequences of proteins is determined by the rules of translation, known collectively as the genetic code. The genetic code consists of three-letter ‘words’ called codons formed from a sequence of three nucleotides (e.g. ACT, CAG, TTT).
In transcription, the codons of a gene are copied into messenger RNA by RNA polymerase. This RNA copy is then decoded by a ribosome that reads the RNA sequence by base-pairing the messenger RNA to transfer RNA, which carries amino acids. Since there are 4 bases in 3-letter combinations, there are 64 possible codons (43 combinations). These encode the twenty standard amino acids, giving most amino acids more than one possible codon. There are also three ‘stop’ or ‘nonsense’ codons signifying the end of the coding region; these are the TAG, TAA, and TGA codons, (UAG, UAA, and UGA on the mRNA).
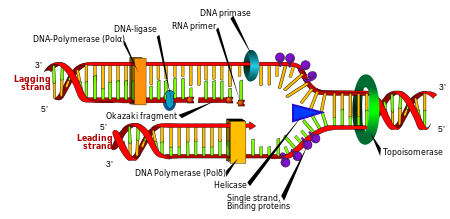
Replication
Cell division is essential for an organism to grow, but, when a cell divides, it must replicate the DNA in its genome so that the two daughter cells have the same genetic information as their parent. The double-stranded structure of DNA provides a simple mechanism for DNA replication. Here, the two strands are separated and then each strand’s complementary DNA sequence is recreated by an enzyme called DNA polymerase. This enzyme makes the complementary strand by finding the correct base through complementary base pairing and bonding it onto the original strand. As DNA polymerases can only extend a DNA strand in a 5′ to 3′ direction, different mechanisms are used to copy the antiparallel strands of the double helix.[104] In this way, the base on the old strand dictates which base appears on the new strand, and the cell ends up with a perfect copy of its DNA.
Naked extracellular DNA (eDNA), most of it released by cell death, is nearly ubiquitous in the environment. Its concentration in soil may be as high as 2 μg/L, and its concentration in natural aquatic environments may be as high at 88 μg/L.[105] Various possible functions have been proposed for eDNA: it may be involved in horizontal gene transfer;[106] it may provide nutrients;[107] and it may act as a buffer to recruit or titrate ions or antibiotics.[108] Extracellular DNA acts as a functional extracellular matrix component in the biofilms of several bacterial species. It may act as a recognition factor to regulate the attachment and dispersal of specific cell types in the biofilm;[109] it may contribute to biofilm formation;[110] and it may contribute to the biofilm’s physical strength and resistance to biological stress.[111]
Cell-free fetal DNA is found in the blood of the mother, and can be sequenced to determine a great deal of information about the developing fetus.[112]
Under the name of environmental DNA eDNA has seen increased use in the natural sciences as a survey tool for ecology, monitoring the movements and presence of species in water, air, or on land, and assessing an area’s biodiversity.[113][114]
Neutrophil extracellular traps (NETs) are networks of extracellular fibers, primarily composed of DNA, which allow neutrophils, a type of white blood cell, to kill extracellular pathogens while minimizing damage to the host cells.
Interactions with proteins
All the functions of DNA depend on interactions with proteins. These protein interactions can be non-specific, or the protein can bind specifically to a single DNA sequence. Enzymes can also bind to DNA and of these, the polymerases that copy the DNA base sequence in transcription and DNA replication are particularly important.
DNA-binding proteins

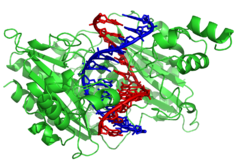
Interaction of DNA (in orange) with histones (in blue). These proteins’ basic amino acids bind to the acidic phosphate groups on DNA.
Structural proteins that bind DNA are well-understood examples of non-specific DNA-protein interactions. Within chromosomes, DNA is held in complexes with structural proteins. These proteins organize the DNA into a compact structure called chromatin. In eukaryotes, this structure involves DNA binding to a complex of small basic proteins called histones, while in prokaryotes multiple types of proteins are involved.[115][116] The histones form a disk-shaped complex called a nucleosome, which contains two complete turns of double-stranded DNA wrapped around its surface. These non-specific interactions are formed through basic residues in the histones, making ionic bonds to the acidic sugar-phosphate backbone of the DNA, and are thus largely independent of the base sequence.[117] Chemical modifications of these basic amino acid residues include methylation, phosphorylation, and acetylation.[118] These chemical changes alter the strength of the interaction between the DNA and the histones, making the DNA more or less accessible to transcription factors and changing the rate of transcription.[119] Other non-specific DNA-binding proteins in chromatin include the high-mobility group proteins, which bind to bent or distorted DNA.[120] These proteins are important in bending arrays of nucleosomes and arranging them into the larger structures that make up chromosomes.[121]
A distinct group of DNA-binding proteins is the DNA-binding proteins that specifically bind single-stranded DNA. In humans, replication protein A is the best-understood member of this family and is used in processes where the double helix is separated, including DNA replication, recombination, and DNA repair.[122] These binding proteins seem to stabilize single-stranded DNA and protect it from forming stem-loops or being degraded by nucleases.

In contrast, other proteins have evolved to bind to particular DNA sequences. The most intensively studied of these are the various transcription factors, which are proteins that regulate transcription. Each transcription factor binds to one particular set of DNA sequences and activates or inhibits the transcription of genes that have these sequences close to their promoters. The transcription factors do this in two ways. Firstly, they can bind the RNA polymerase responsible for transcription, either directly or through other mediator proteins; this locates the polymerase at the promoter and allows it to begin transcription.[124] Alternatively, transcription factors can bind enzymes that modify the histones at the promoter. This changes the accessibility of the DNA template to the polymerase.[125]
As these DNA targets can occur throughout an organism’s genome, changes in the activity of one type of transcription factor can affect thousands of genes.[126] Consequently, these proteins are often the targets of the signal transduction processes that control responses to environmental changes or cellular differentiation and development. The specificity of these transcription factors’ interactions with DNA come from the proteins making multiple contacts to the edges of the DNA bases, allowing them to «read» the DNA sequence. Most of these base-interactions are made in the major groove, where the bases are most accessible.[24]
DNA-modifying enzymes
Nucleases and ligases
Nucleases are enzymes that cut DNA strands by catalyzing the hydrolysis of the phosphodiester bonds. Nucleases that hydrolyse nucleotides from the ends of DNA strands are called exonucleases, while endonucleases cut within strands. The most frequently used nucleases in molecular biology are the restriction endonucleases, which cut DNA at specific sequences. For instance, the EcoRV enzyme shown to the left recognizes the 6-base sequence 5′-GATATC-3′ and makes a cut at the horizontal line. In nature, these enzymes protect bacteria against phage infection by digesting the phage DNA when it enters the bacterial cell, acting as part of the restriction modification system.[128] In technology, these sequence-specific nucleases are used in molecular cloning and DNA fingerprinting.
Enzymes called DNA ligases can rejoin cut or broken DNA strands.[129] Ligases are particularly important in lagging strand DNA replication, as they join the short segments of DNA produced at the replication fork into a complete copy of the DNA template. They are also used in DNA repair and genetic recombination.[129]
Topoisomerases and helicases
Topoisomerases are enzymes with both nuclease and ligase activity. These proteins change the amount of supercoiling in DNA. Some of these enzymes work by cutting the DNA helix and allowing one section to rotate, thereby reducing its level of supercoiling; the enzyme then seals the DNA break.[43] Other types of these enzymes are capable of cutting one DNA helix and then passing a second strand of DNA through this break, before rejoining the helix.[130] Topoisomerases are required for many processes involving DNA, such as DNA replication and transcription.[44]
Helicases are proteins that are a type of molecular motor. They use the chemical energy in nucleoside triphosphates, predominantly adenosine triphosphate (ATP), to break hydrogen bonds between bases and unwind the DNA double helix into single strands.[131] These enzymes are essential for most processes where enzymes need to access the DNA bases.
Polymerases
Polymerases are enzymes that synthesize polynucleotide chains from nucleoside triphosphates. The sequence of their products is created based on existing polynucleotide chains—which are called templates. These enzymes function by repeatedly adding a nucleotide to the 3′ hydroxyl group at the end of the growing polynucleotide chain. As a consequence, all polymerases work in a 5′ to 3′ direction.[132] In the active site of these enzymes, the incoming nucleoside triphosphate base-pairs to the template: this allows polymerases to accurately synthesize the complementary strand of their template. Polymerases are classified according to the type of template that they use.
In DNA replication, DNA-dependent DNA polymerases make copies of DNA polynucleotide chains. To preserve biological information, it is essential that the sequence of bases in each copy are precisely complementary to the sequence of bases in the template strand. Many DNA polymerases have a proofreading activity. Here, the polymerase recognizes the occasional mistakes in the synthesis reaction by the lack of base pairing between the mismatched nucleotides. If a mismatch is detected, a 3′ to 5′ exonuclease activity is activated and the incorrect base removed.[133] In most organisms, DNA polymerases function in a large complex called the replisome that contains multiple accessory subunits, such as the DNA clamp or helicases.[134]
RNA-dependent DNA polymerases are a specialized class of polymerases that copy the sequence of an RNA strand into DNA. They include reverse transcriptase, which is a viral enzyme involved in the infection of cells by retroviruses, and telomerase, which is required for the replication of telomeres.[62][135] For example, HIV reverse transcriptase is an enzyme for AIDS virus replication.[135] Telomerase is an unusual polymerase because it contains its own RNA template as part of its structure. It synthesizes telomeres at the ends of chromosomes. Telomeres prevent fusion of the ends of neighboring chromosomes and protect chromosome ends from damage.[63]
Transcription is carried out by a DNA-dependent RNA polymerase that copies the sequence of a DNA strand into RNA. To begin transcribing a gene, the RNA polymerase binds to a sequence of DNA called a promoter and separates the DNA strands. It then copies the gene sequence into a messenger RNA transcript until it reaches a region of DNA called the terminator, where it halts and detaches from the DNA. As with human DNA-dependent DNA polymerases, RNA polymerase II, the enzyme that transcribes most of the genes in the human genome, operates as part of a large protein complex with multiple regulatory and accessory subunits.[136]
Genetic recombination
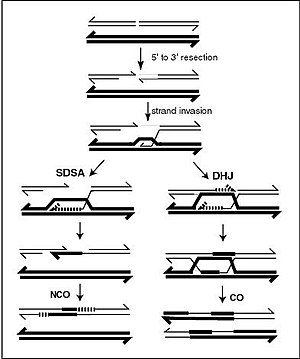
A current model of meiotic recombination, initiated by a double-strand break or gap, followed by pairing with an homologous chromosome and strand invasion to initiate the recombinational repair process. Repair of the gap can lead to crossover (CO) or non-crossover (NCO) of the flanking regions. CO recombination is thought to occur by the Double Holliday Junction (DHJ) model, illustrated on the right, above. NCO recombinants are thought to occur primarily by the Synthesis Dependent Strand Annealing (SDSA) model, illustrated on the left, above. Most recombination events appear to be the SDSA type.
A DNA helix usually does not interact with other segments of DNA, and in human cells, the different chromosomes even occupy separate areas in the nucleus called «chromosome territories».[138] This physical separation of different chromosomes is important for the ability of DNA to function as a stable repository for information, as one of the few times chromosomes interact is in chromosomal crossover which occurs during sexual reproduction, when genetic recombination occurs. Chromosomal crossover is when two DNA helices break, swap a section and then rejoin.
Recombination allows chromosomes to exchange genetic information and produces new combinations of genes, which increases the efficiency of natural selection and can be important in the rapid evolution of new proteins.[139] Genetic recombination can also be involved in DNA repair, particularly in the cell’s response to double-strand breaks.[140]
The most common form of chromosomal crossover is homologous recombination, where the two chromosomes involved share very similar sequences. Non-homologous recombination can be damaging to cells, as it can produce chromosomal translocations and genetic abnormalities. The recombination reaction is catalyzed by enzymes known as recombinases, such as RAD51.[141] The first step in recombination is a double-stranded break caused by either an endonuclease or damage to the DNA.[142] A series of steps catalyzed in part by the recombinase then leads to joining of the two helices by at least one Holliday junction, in which a segment of a single strand in each helix is annealed to the complementary strand in the other helix. The Holliday junction is a tetrahedral junction structure that can be moved along the pair of chromosomes, swapping one strand for another. The recombination reaction is then halted by cleavage of the junction and re-ligation of the released DNA.[143] Only strands of like polarity exchange DNA during recombination. There are two types of cleavage: east-west cleavage and north–south cleavage. The north–south cleavage nicks both strands of DNA, while the east–west cleavage has one strand of DNA intact. The formation of a Holliday junction during recombination makes it possible for genetic diversity, genes to exchange on chromosomes, and expression of wild-type viral genomes.
Evolution
DNA contains the genetic information that allows all forms of life to function, grow and reproduce. However, it is unclear how long in the 4-billion-year history of life DNA has performed this function, as it has been proposed that the earliest forms of life may have used RNA as their genetic material.[144][145] RNA may have acted as the central part of early cell metabolism as it can both transmit genetic information and carry out catalysis as part of ribozymes.[146] This ancient RNA world where nucleic acid would have been used for both catalysis and genetics may have influenced the evolution of the current genetic code based on four nucleotide bases. This would occur, since the number of different bases in such an organism is a trade-off between a small number of bases increasing replication accuracy and a large number of bases increasing the catalytic efficiency of ribozymes.[147] However, there is no direct evidence of ancient genetic systems, as recovery of DNA from most fossils is impossible because DNA survives in the environment for less than one million years, and slowly degrades into short fragments in solution.[148] Claims for older DNA have been made, most notably a report of the isolation of a viable bacterium from a salt crystal 250 million years old,[149] but these claims are controversial.[150][151]
Building blocks of DNA (adenine, guanine, and related organic molecules) may have been formed extraterrestrially in outer space.[152][153][154] Complex DNA and RNA organic compounds of life, including uracil, cytosine, and thymine, have also been formed in the laboratory under conditions mimicking those found in outer space, using starting chemicals, such as pyrimidine, found in meteorites. Pyrimidine, like polycyclic aromatic hydrocarbons (PAHs), the most carbon-rich chemical found in the universe, may have been formed in red giants or in interstellar cosmic dust and gas clouds.[155]
In February 2021, scientists reported, for the first time, the sequencing of DNA from animal remains, a mammoth in this instance over a million years old, the oldest DNA sequenced to date.[156][157]
Uses in technology
Genetic engineering
Methods have been developed to purify DNA from organisms, such as phenol-chloroform extraction, and to manipulate it in the laboratory, such as restriction digests and the polymerase chain reaction. Modern biology and biochemistry make intensive use of these techniques in recombinant DNA technology. Recombinant DNA is a man-made DNA sequence that has been assembled from other DNA sequences. They can be transformed into organisms in the form of plasmids or in the appropriate format, by using a viral vector.[158] The genetically modified organisms produced can be used to produce products such as recombinant proteins, used in medical research,[159] or be grown in agriculture.[160][161]
DNA profiling
Forensic scientists can use DNA in blood, semen, skin, saliva or hair found at a crime scene to identify a matching DNA of an individual, such as a perpetrator.[162] This process is formally termed DNA profiling, also called DNA fingerprinting. In DNA profiling, the lengths of variable sections of repetitive DNA, such as short tandem repeats and minisatellites, are compared between people. This method is usually an extremely reliable technique for identifying a matching DNA.[163] However, identification can be complicated if the scene is contaminated with DNA from several people.[164] DNA profiling was developed in 1984 by British geneticist Sir Alec Jeffreys,[165] and first used in forensic science to convict Colin Pitchfork in the 1988 Enderby murders case.[166]
The development of forensic science and the ability to now obtain genetic matching on minute samples of blood, skin, saliva, or hair has led to re-examining many cases. Evidence can now be uncovered that was scientifically impossible at the time of the original examination. Combined with the removal of the double jeopardy law in some places, this can allow cases to be reopened where prior trials have failed to produce sufficient evidence to convince a jury. People charged with serious crimes may be required to provide a sample of DNA for matching purposes. The most obvious defense to DNA matches obtained forensically is to claim that cross-contamination of evidence has occurred. This has resulted in meticulous strict handling procedures with new cases of serious crime.
DNA profiling is also used successfully to positively identify victims of mass casualty incidents,[167] bodies or body parts in serious accidents, and individual victims in mass war graves, via matching to family members.
DNA profiling is also used in DNA paternity testing to determine if someone is the biological parent or grandparent of a child with the probability of parentage is typically 99.99% when the alleged parent is biologically related to the child. Normal DNA sequencing methods happen after birth, but there are new methods to test paternity while a mother is still pregnant.[168]
DNA enzymes or catalytic DNA
Deoxyribozymes, also called DNAzymes or catalytic DNA, were first discovered in 1994.[169] They are mostly single stranded DNA sequences isolated from a large pool of random DNA sequences through a combinatorial approach called in vitro selection or systematic evolution of ligands by exponential enrichment (SELEX). DNAzymes catalyze variety of chemical reactions including RNA-DNA cleavage, RNA-DNA ligation, amino acids phosphorylation-dephosphorylation, carbon-carbon bond formation, etc. DNAzymes can enhance catalytic rate of chemical reactions up to 100,000,000,000-fold over the uncatalyzed reaction.[170] The most extensively studied class of DNAzymes is RNA-cleaving types which have been used to detect different metal ions and designing therapeutic agents. Several metal-specific DNAzymes have been reported including the GR-5 DNAzyme (lead-specific),[169] the CA1-3 DNAzymes (copper-specific),[171] the 39E DNAzyme (uranyl-specific) and the NaA43 DNAzyme (sodium-specific).[172] The NaA43 DNAzyme, which is reported to be more than 10,000-fold selective for sodium over other metal ions, was used to make a real-time sodium sensor in cells.
Bioinformatics
Bioinformatics involves the development of techniques to store, data mine, search and manipulate biological data, including DNA nucleic acid sequence data. These have led to widely applied advances in computer science, especially string searching algorithms, machine learning, and database theory.[173] String searching or matching algorithms, which find an occurrence of a sequence of letters inside a larger sequence of letters, were developed to search for specific sequences of nucleotides.[174] The DNA sequence may be aligned with other DNA sequences to identify homologous sequences and locate the specific mutations that make them distinct. These techniques, especially multiple sequence alignment, are used in studying phylogenetic relationships and protein function.[175] Data sets representing entire genomes’ worth of DNA sequences, such as those produced by the Human Genome Project, are difficult to use without the annotations that identify the locations of genes and regulatory elements on each chromosome. Regions of DNA sequence that have the characteristic patterns associated with protein- or RNA-coding genes can be identified by gene finding algorithms, which allow researchers to predict the presence of particular gene products and their possible functions in an organism even before they have been isolated experimentally.[176] Entire genomes may also be compared, which can shed light on the evolutionary history of particular organism and permit the examination of complex evolutionary events.
DNA nanotechnology

DNA nanotechnology uses the unique molecular recognition properties of DNA and other nucleic acids to create self-assembling branched DNA complexes with useful properties.[178] DNA is thus used as a structural material rather than as a carrier of biological information. This has led to the creation of two-dimensional periodic lattices (both tile-based and using the DNA origami method) and three-dimensional structures in the shapes of polyhedra.[179] Nanomechanical devices and algorithmic self-assembly have also been demonstrated,[180] and these DNA structures have been used to template the arrangement of other molecules such as gold nanoparticles and streptavidin proteins.[181] DNA and other nucleic acids are the basis of aptamers, synthetic oligonucleotide ligands for specific target molecules used in a range of biotechnology and biomedical applications.[182]
History and anthropology
Because DNA collects mutations over time, which are then inherited, it contains historical information, and, by comparing DNA sequences, geneticists can infer the evolutionary history of organisms, their phylogeny.[183] This field of phylogenetics is a powerful tool in evolutionary biology. If DNA sequences within a species are compared, population geneticists can learn the history of particular populations. This can be used in studies ranging from ecological genetics to anthropology.
Information storage
DNA as a storage device for information has enormous potential since it has much higher storage density compared to electronic devices. However, high costs, slow read and write times (memory latency), and insufficient reliability has prevented its practical use.[184][185]
History

Maclyn McCarty (left) shakes hands with Francis Crick and James Watson, co-originators of the double-helix model based on the X-ray diffraction data and insights of Rosalind Franklin and Raymond Gosling.
Pencil sketch of the DNA double helix by Francis Crick in 1953
DNA was first isolated by the Swiss physician Friedrich Miescher who, in 1869, discovered a microscopic substance in the pus of discarded surgical bandages. As it resided in the nuclei of cells, he called it «nuclein».[186][187] In 1878, Albrecht Kossel isolated the non-protein component of «nuclein», nucleic acid, and later isolated its five primary nucleobases.[188][189]
In 1909, Phoebus Levene identified the base, sugar, and phosphate nucleotide unit of RNA (then named «yeast nucleic acid»).[190][191][192] In 1929, Levene identified deoxyribose sugar in «thymus nucleic acid» (DNA).[193] Levene suggested that DNA consisted of a string of four nucleotide units linked together through the phosphate groups («tetranucleotide hypothesis»). Levene thought the chain was short and the bases repeated in a fixed order. In 1927, Nikolai Koltsov proposed that inherited traits would be inherited via a «giant hereditary molecule» made up of «two mirror strands that would replicate in a semi-conservative fashion using each strand as a template».[194][195] In 1928, Frederick Griffith in his experiment discovered that traits of the «smooth» form of Pneumococcus could be transferred to the «rough» form of the same bacteria by mixing killed «smooth» bacteria with the live «rough» form.[196][197] This system provided the first clear suggestion that DNA carries genetic information.
In 1933, while studying virgin sea urchin eggs, Jean Brachet suggested that DNA is found in the cell nucleus and that RNA is present exclusively in the cytoplasm. At the time, «yeast nucleic acid» (RNA) was thought to occur only in plants, while «thymus nucleic acid» (DNA) only in animals. The latter was thought to be a tetramer, with the function of buffering cellular pH.[198][199]
In 1937, William Astbury produced the first X-ray diffraction patterns that showed that DNA had a regular structure.[200]
In 1943, Oswald Avery, along with co-workers Colin MacLeod and Maclyn McCarty, identified DNA as the transforming principle, supporting Griffith’s suggestion (Avery–MacLeod–McCarty experiment).[201] Erwin Chargaff developed and published observations now known as Chargaff’s rules, stating that in DNA from any species of any organism, the amount of guanine should be equal to cytosine and the amount of adenine should be equal to thymine.[202][203] Late in 1951, Francis Crick started working with James Watson at the Cavendish Laboratory within the University of Cambridge. DNA’s role in heredity was confirmed in 1952 when Alfred Hershey and Martha Chase in the Hershey–Chase experiment showed that DNA is the genetic material of the enterobacteria phage T2.[204]

In May 1952, Raymond Gosling, a graduate student working under the supervision of Rosalind Franklin, took an X-ray diffraction image, labeled as «Photo 51»,[205] at high hydration levels of DNA. This photo was given to Watson and Crick by Maurice Wilkins and was critical to their obtaining the correct structure of DNA. Franklin told Crick and Watson that the backbones had to be on the outside. Before then, Linus Pauling, and Watson and Crick, had erroneous models with the chains inside and the bases pointing outwards. Franklin’s identification of the space group for DNA crystals revealed to Crick that the two DNA strands were antiparallel.[206] In February 1953, Linus Pauling and Robert Corey proposed a model for nucleic acids containing three intertwined chains, with the phosphates near the axis, and the bases on the outside.[207] Watson and Crick completed their model, which is now accepted as the first correct model of the double helix of DNA. On 28 February 1953 Crick interrupted patrons’ lunchtime at The Eagle pub in Cambridge to announce that he and Watson had «discovered the secret of life».[208]
The 25 April 1953 issue of the journal Nature published a series of five articles giving the Watson and Crick double-helix structure DNA and evidence supporting it.[209] The structure was reported in a letter titled «MOLECULAR STRUCTURE OF NUCLEIC ACIDS A Structure for Deoxyribose Nucleic Acid«, in which they said, «It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.»[9] This letter was followed by a letter from Franklin and Gosling, which was the first publication of their own X-ray diffraction data and of their original analysis method.[47][210] Then followed a letter by Wilkins and two of his colleagues, which contained an analysis of in vivo B-DNA X-ray patterns, and which supported the presence in vivo of the Watson and Crick structure.[48]
In 1962, after Franklin’s death, Watson, Crick, and Wilkins jointly received the Nobel Prize in Physiology or Medicine.[211] Nobel Prizes are awarded only to living recipients. A debate continues about who should receive credit for the discovery.[212]
In an influential presentation in 1957, Crick laid out the central dogma of molecular biology, which foretold the relationship between DNA, RNA, and proteins, and articulated the «adaptor hypothesis».[213] Final confirmation of the replication mechanism that was implied by the double-helical structure followed in 1958 through the Meselson–Stahl experiment.[214] Further work by Crick and co-workers showed that the genetic code was based on non-overlapping triplets of bases, called codons, allowing Har Gobind Khorana, Robert W. Holley, and Marshall Warren Nirenberg to decipher the genetic code.[215] These findings represent the birth of molecular biology.[216]
See also
- Autosome – Any chromosome other than a sex chromosome
- Crystallography – Scientific study of crystal structures
- DNA Day – Holiday celebrated on April 25
- DNA microarray – Collection of microscopic DNA spots attached to a solid surface
- DNA sequencing – Process of determining the nucleic acid sequence
- Genetic disorder – Health problem caused by one or more abnormalities in the genome
- Genetic genealogy – DNA testing to infer relationships
- Haplotype – Group of genes from one parent
- Meiosis – Cell division producing haploid gametes
- Nucleic acid notation – Universal notation using the Roman characters A, C, G, and T to call the four DNA nucleotides
- Nucleic acid sequence – Succession of nucleotides in a nucleic acid
- Ribosomal DNA – specific region of DNA that that codes for ribosomal RNA
- Southern blot – DNA analysis technique
- X-ray scattering techniques – family of non-destructive analytical techniques
- Xeno nucleic acid – group of compounds
References
- ^ «deoxyribonucleic acid». Merriam-Webster Dictionary.
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2014). Molecular Biology of the Cell (6th ed.). Garland. p. Chapter 4: DNA, Chromosomes and Genomes. ISBN 978-0-8153-4432-2. Archived from the original on 14 July 2014.
- ^ Purcell A. «DNA». Basic Biology. Archived from the original on 5 January 2017.
- ^ «Uracil». Genome.gov. Retrieved 21 November 2019.
- ^ Russell P (2001). iGenetics. New York: Benjamin Cummings. ISBN 0-8053-4553-1.
- ^ Saenger W (1984). Principles of Nucleic Acid Structure. New York: Springer-Verlag. ISBN 0-387-90762-9.
- ^ a b Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Peter W (2002). Molecular Biology of the Cell (Fourth ed.). New York and London: Garland Science. ISBN 0-8153-3218-1. OCLC 145080076. Archived from the original on 1 November 2016.
- ^ Irobalieva RN, Fogg JM, Catanese DJ, Catanese DJ, Sutthibutpong T, Chen M, Barker AK, Ludtke SJ, Harris SA, Schmid MF, Chiu W, Zechiedrich L (October 2015). «Structural diversity of supercoiled DNA». Nature Communications. 6: 8440. Bibcode:2015NatCo…6.8440I. doi:10.1038/ncomms9440. ISSN 2041-1723. PMC 4608029. PMID 26455586.
- ^ a b c d Watson JD, Crick FH (April 1953). «Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid» (PDF). Nature. 171 (4356): 737–38. Bibcode:1953Natur.171..737W. doi:10.1038/171737a0. ISSN 0028-0836. PMID 13054692. S2CID 4253007. Archived (PDF) from the original on 4 February 2007.
- ^ Mandelkern M, Elias JG, Eden D, Crothers DM (October 1981). «The dimensions of DNA in solution». Journal of Molecular Biology. 152 (1): 153–61. doi:10.1016/0022-2836(81)90099-1. ISSN 0022-2836. PMID 7338906.
- ^ a b c d Berg J, Tymoczko J, Stryer L (2002). Biochemistry. W.H. Freeman and Company. ISBN 0-7167-4955-6.
- ^ IUPAC-IUB Commission on Biochemical Nomenclature (CBN) (December 1970). «Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents. Recommendations 1970». The Biochemical Journal. 120 (3): 449–54. doi:10.1042/bj1200449. ISSN 0306-3283. PMC 1179624. PMID 5499957. Archived from the original on 5 February 2007.
- ^ a b Ghosh A, Bansal M (April 2003). «A glossary of DNA structures from A to Z». Acta Crystallographica Section D. 59 (Pt 4): 620–26. doi:10.1107/S0907444903003251. ISSN 0907-4449. PMID 12657780.
- ^ Bank, RCSB Protein Data. «RCSB PDB — 1D65: MOLECULAR STRUCTURE OF THE B-DNA DODECAMER D(CGCAAATTTGCG)2; AN EXAMINATION OF PROPELLER TWIST AND MINOR-GROOVE WATER STRUCTURE AT 2.2 ANGSTROMS RESOLUTION». www.rcsb.org. Retrieved 27 March 2023.
- ^ Yakovchuk P, Protozanova E, Frank-Kamenetskii MD (2006). «Base-stacking and base-pairing contributions into thermal stability of the DNA double helix». Nucleic Acids Research. 34 (2): 564–74. doi:10.1093/nar/gkj454. ISSN 0305-1048. PMC 1360284. PMID 16449200.
- ^ Tropp BE (2012). Molecular Biology (4th ed.). Sudbury, Mass.: Jones and Barlett Learning. ISBN 978-0-7637-8663-2.
- ^ Carr S (1953). «Watson-Crick Structure of DNA». Memorial University of Newfoundland. Archived from the original on 19 July 2016. Retrieved 13 July 2016.
- ^ Verma S, Eckstein F (1998). «Modified oligonucleotides: synthesis and strategy for users». Annual Review of Biochemistry. 67: 99–134. doi:10.1146/annurev.biochem.67.1.99. ISSN 0066-4154. PMID 9759484.
- ^ Johnson TB, Coghill RD (1925). «Pyrimidines. CIII. The discovery of 5-methylcytosine in tuberculinic acid, the nucleic acid of the tubercle bacillus». Journal of the American Chemical Society. 47: 2838–44. doi:10.1021/ja01688a030. ISSN 0002-7863.
- ^ Weigele P, Raleigh EA (October 2016). «Biosynthesis and Function of Modified Bases in Bacteria and Their Viruses». Chemical Reviews. 116 (20): 12655–12687. doi:10.1021/acs.chemrev.6b00114. ISSN 0009-2665. PMID 27319741.
- ^ Kumar S, Chinnusamy V, Mohapatra T (2018). «Epigenetics of Modified DNA Bases: 5-Methylcytosine and Beyond». Frontiers in Genetics. 9: 640. doi:10.3389/fgene.2018.00640. ISSN 1664-8021. PMC 6305559. PMID 30619465.
- ^ Carell T, Kurz MQ, Müller M, Rossa M, Spada F (April 2018). «Non-canonical Bases in the Genome: The Regulatory Information Layer in DNA». Angewandte Chemie. 57 (16): 4296–4312. doi:10.1002/anie.201708228. PMID 28941008.
- ^ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson RE (October 1980). «Crystal structure analysis of a complete turn of B-DNA». Nature. 287 (5784): 755–58. Bibcode:1980Natur.287..755W. doi:10.1038/287755a0. PMID 7432492. S2CID 4315465.
- ^ a b Pabo CO, Sauer RT (1984). «Protein-DNA recognition». Annual Review of Biochemistry. 53: 293–321. doi:10.1146/annurev.bi.53.070184.001453. PMID 6236744.
- ^ Nikolova EN, Zhou H, Gottardo FL, Alvey HS, Kimsey IJ, Al-Hashimi HM (2013). «A historical account of Hoogsteen base-pairs in duplex DNA». Biopolymers. 99 (12): 955–68. doi:10.1002/bip.22334. PMC 3844552. PMID 23818176.
- ^ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub HE (April 2000). «Mechanical stability of single DNA molecules». Biophysical Journal. 78 (4): 1997–2007. Bibcode:2000BpJ….78.1997C. doi:10.1016/S0006-3495(00)76747-6. PMC 1300792. PMID 10733978.
- ^ Chalikian TV, Völker J, Plum GE, Breslauer KJ (July 1999). «A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques». Proceedings of the National Academy of Sciences of the United States of America. 96 (14): 7853–58. Bibcode:1999PNAS…96.7853C. doi:10.1073/pnas.96.14.7853. PMC 22151. PMID 10393911.
- ^ deHaseth PL, Helmann JD (June 1995). «Open complex formation by Escherichia coli RNA polymerase: the mechanism of polymerase-induced strand separation of double helical DNA». Molecular Microbiology. 16 (5): 817–24. doi:10.1111/j.1365-2958.1995.tb02309.x. PMID 7476180. S2CID 24479358.
- ^ Isaksson J, Acharya S, Barman J, Cheruku P, Chattopadhyaya J (December 2004). «Single-stranded adenine-rich DNA and RNA retain structural characteristics of their respective double-stranded conformations and show directional differences in stacking pattern» (PDF). Biochemistry. 43 (51): 15996–6010. doi:10.1021/bi048221v. PMID 15609994. Archived (PDF) from the original on 10 June 2007.
- ^ a b Piovesan A, Pelleri MC, Antonaros F, Strippoli P, Caracausi M, Vitale L (2019). «On the length, weight and GC content of the human genome». BMC Res Notes. 12 (1): 106. doi:10.1186/s13104-019-4137-z. PMC 6391780. PMID 30813969.
- ^ Gregory SG, Barlow KF, McLay KE, Kaul R, Swarbreck D, Dunham A, et al. (May 2006). «The DNA sequence and biological annotation of human chromosome 1». Nature. 441 (7091): 315–21. Bibcode:2006Natur.441..315G. doi:10.1038/nature04727. PMID 16710414.
- ^ Anderson, S.; Bankier, A. T.; Barrell, B. G.; de Bruijn, M. H. L.; Coulson, A. R.; Drouin, J.; Eperon, I. C.; Nierlich, D. P.; Roe, B. A.; Sanger, F.; Schreier, P. H.; Smith, A. J. H.; Staden, R.; Young, I. G. (April 1981). «Sequence and organization of the human mitochondrial genome». Nature. 290 (5806): 457–465. Bibcode:1981Natur.290..457A. doi:10.1038/290457a0. PMID 7219534. S2CID 4355527.
- ^ «Untitled». Archived from the original on 13 August 2011. Retrieved 13 June 2012.
- ^ a b c Satoh, M; Kuroiwa, T (September 1991). «Organization of multiple nucleoids and DNA molecules in mitochondria of a human cell». Experimental Cell Research. 196 (1): 137–140. doi:10.1016/0014-4827(91)90467-9. PMID 1715276.
- ^ Zhang D, Keilty D, Zhang ZF, Chian RC (2017). «Mitochondria in oocyte aging: current understanding». Facts Views Vis Obgyn. 9 (1): 29–38. PMC 5506767. PMID 28721182.
- ^ «Chemistry — Queen Mary University of London». www.qmul.ac.uk. Retrieved 27 March 2023.
- ^ Hüttenhofer A, Schattner P, Polacek N (May 2005). «Non-coding RNAs: hope or hype?». Trends in Genetics. 21 (5): 289–97. doi:10.1016/j.tig.2005.03.007. PMID 15851066.
- ^ Munroe SH (November 2004). «Diversity of antisense regulation in eukaryotes: multiple mechanisms, emerging patterns». Journal of Cellular Biochemistry. 93 (4): 664–71. doi:10.1002/jcb.20252. PMID 15389973. S2CID 23748148.
- ^ Makalowska I, Lin CF, Makalowski W (February 2005). «Overlapping genes in vertebrate genomes». Computational Biology and Chemistry. 29 (1): 1–12. doi:10.1016/j.compbiolchem.2004.12.006. PMID 15680581.
- ^ Johnson ZI, Chisholm SW (November 2004). «Properties of overlapping genes are conserved across microbial genomes». Genome Research. 14 (11): 2268–72. doi:10.1101/gr.2433104. PMC 525685. PMID 15520290.
- ^ Lamb RA, Horvath CM (August 1991). «Diversity of coding strategies in influenza viruses». Trends in Genetics. 7 (8): 261–66. doi:10.1016/0168-9525(91)90326-L. PMC 7173306. PMID 1771674.
- ^ Benham CJ, Mielke SP (2005). «DNA mechanics» (PDF). Annual Review of Biomedical Engineering. 7: 21–53. doi:10.1146/annurev.bioeng.6.062403.132016. PMID 16004565. S2CID 1427671. Archived from the original (PDF) on 1 March 2019.
- ^ a b Champoux JJ (2001). «DNA topoisomerases: structure, function, and mechanism» (PDF). Annual Review of Biochemistry. 70: 369–413. doi:10.1146/annurev.biochem.70.1.369. PMID 11395412. S2CID 18144189.
- ^ a b Wang JC (June 2002). «Cellular roles of DNA topoisomerases: a molecular perspective». Nature Reviews Molecular Cell Biology. 3 (6): 430–40. doi:10.1038/nrm831. PMID 12042765. S2CID 205496065.
- ^ Basu HS, Feuerstein BG, Zarling DA, Shafer RH, Marton LJ (October 1988). «Recognition of Z-RNA and Z-DNA determinants by polyamines in solution: experimental and theoretical studies». Journal of Biomolecular Structure & Dynamics. 6 (2): 299–309. doi:10.1080/07391102.1988.10507714. PMID 2482766.
- ^
- Franklin RE, Gosling RG (6 March 1953). «The Structure of Sodium Thymonucleate Fibres I. The Influence of Water Content» (PDF). Acta Crystallogr. 6 (8–9): 673–77. doi:10.1107/S0365110X53001939. Archived (PDF) from the original on 9 January 2016.
- Franklin RE, Gosling RG (1953). «The structure of sodium thymonucleate fibres. II. The cylindrically symmetrical Patterson function» (PDF). Acta Crystallogr. 6 (8–9): 678–85. doi:10.1107/S0365110X53001940. Archived (PDF) from the original on 29 June 2017.
- ^ a b Franklin RE, Gosling RG (April 1953). «Molecular configuration in sodium thymonucleate» (PDF). Nature. 171 (4356): 740–41. Bibcode:1953Natur.171..740F. doi:10.1038/171740a0. PMID 13054694. S2CID 4268222. Archived (PDF) from the original on 3 January 2011.
- ^ a b Wilkins MH, Stokes AR, Wilson HR (April 1953). «Molecular structure of deoxypentose nucleic acids» (PDF). Nature. 171 (4356): 738–40. Bibcode:1953Natur.171..738W. doi:10.1038/171738a0. PMID 13054693. S2CID 4280080. Archived (PDF) from the original on 13 May 2011.
- ^ Leslie AG, Arnott S, Chandrasekaran R, Ratliff RL (October 1980). «Polymorphism of DNA double helices». Journal of Molecular Biology. 143 (1): 49–72. doi:10.1016/0022-2836(80)90124-2. PMID 7441761.
- ^ Baianu IC (1980). «Structural Order and Partial Disorder in Biological systems». Bull. Math. Biol. 42 (4): 137–41. doi:10.1007/BF02462372. S2CID 189888972.
- ^ Hosemann R, Bagchi RN (1962). Direct analysis of diffraction by matter. Amsterdam – New York: North-Holland Publishers.
- ^ Baianu IC (1978). «X-ray scattering by partially disordered membrane systems» (PDF). Acta Crystallogr A. 34 (5): 751–53. Bibcode:1978AcCrA..34..751B. doi:10.1107/S0567739478001540. Archived from the original (PDF) on 14 March 2020. Retrieved 29 August 2019.
- ^ Wahl MC, Sundaralingam M (1997). «Crystal structures of A-DNA duplexes». Biopolymers. 44 (1): 45–63. doi:10.1002/(SICI)1097-0282(1997)44:1<45::AID-BIP4>3.0.CO;2-#. PMID 9097733.
- ^ Lu XJ, Shakked Z, Olson WK (July 2000). «A-form conformational motifs in ligand-bound DNA structures». Journal of Molecular Biology. 300 (4): 819–40. doi:10.1006/jmbi.2000.3690. PMID 10891271.
- ^ Rothenburg S, Koch-Nolte F, Haag F (December 2001). «DNA methylation and Z-DNA formation as mediators of quantitative differences in the expression of alleles». Immunological Reviews. 184: 286–98. doi:10.1034/j.1600-065x.2001.1840125.x. PMID 12086319. S2CID 20589136.
- ^ Oh DB, Kim YG, Rich A (December 2002). «Z-DNA-binding proteins can act as potent effectors of gene expression in vivo». Proceedings of the National Academy of Sciences of the United States of America. 99 (26): 16666–71. Bibcode:2002PNAS…9916666O. doi:10.1073/pnas.262672699. PMC 139201. PMID 12486233.
- ^ Palmer J (2 December 2010). «Arsenic-loving bacteria may help in hunt for alien life». BBC News. Archived from the original on 3 December 2010. Retrieved 2 December 2010.
- ^ a b Bortman H (2 December 2010). «Arsenic-Eating Bacteria Opens New Possibilities for Alien Life». Space.com. Archived from the original on 4 December 2010. Retrieved 2 December 2010.
- ^ Katsnelson A (2 December 2010). «Arsenic-eating microbe may redefine chemistry of life». Nature News. doi:10.1038/news.2010.645. Archived from the original on 12 February 2012.
- ^ Cressey D (3 October 2012). «‘Arsenic-life’ Bacterium Prefers Phosphorus after all». Nature News. doi:10.1038/nature.2012.11520. S2CID 87341731.
- ^ «Structure Summary for 1KF1». ndbserver.rutgers.edu. Retrieved 27 March 2023.
- ^ a b Greider CW, Blackburn EH (December 1985). «Identification of a specific telomere terminal transferase activity in Tetrahymena extracts». Cell. 43 (2 Pt 1): 405–13. doi:10.1016/0092-8674(85)90170-9. PMID 3907856.
- ^ a b c Nugent CI, Lundblad V (April 1998). «The telomerase reverse transcriptase: components and regulation». Genes & Development. 12 (8): 1073–85. doi:10.1101/gad.12.8.1073. PMID 9553037.
- ^ Wright WE, Tesmer VM, Huffman KE, Levene SD, Shay JW (November 1997). «Normal human chromosomes have long G-rich telomeric overhangs at one end». Genes & Development. 11 (21): 2801–09. doi:10.1101/gad.11.21.2801. PMC 316649. PMID 9353250.
- ^ a b Burge S, Parkinson GN, Hazel P, Todd AK, Neidle S (2006). «Quadruplex DNA: sequence, topology and structure». Nucleic Acids Research. 34 (19): 5402–15. doi:10.1093/nar/gkl655. PMC 1636468. PMID 17012276.
- ^ Parkinson GN, Lee MP, Neidle S (June 2002). «Crystal structure of parallel quadruplexes from human telomeric DNA». Nature. 417 (6891): 876–80. Bibcode:2002Natur.417..876P. doi:10.1038/nature755. PMID 12050675. S2CID 4422211.
- ^ Griffith JD, Comeau L, Rosenfield S, Stansel RM, Bianchi A, Moss H, de Lange T (May 1999). «Mammalian telomeres end in a large duplex loop». Cell. 97 (4): 503–14. CiteSeerX 10.1.1.335.2649. doi:10.1016/S0092-8674(00)80760-6. PMID 10338214. S2CID 721901.
- ^ Seeman NC (November 2005). «DNA enables nanoscale control of the structure of matter». Quarterly Reviews of Biophysics. 38 (4): 363–71. doi:10.1017/S0033583505004087. PMC 3478329. PMID 16515737.
- ^ Warren M (21 February 2019). «Four new DNA letters double life’s alphabet». Nature. 566 (7745): 436. Bibcode:2019Natur.566..436W. doi:10.1038/d41586-019-00650-8. PMID 30809059.
- ^ Hoshika S, Leal NA, Kim MJ, Kim MS, Karalkar NB, Kim HJ, et al. (22 February 2019). «Hachimoji DNA and RNA: A genetic system with eight building blocks (paywall)». Science. 363 (6429): 884–887. Bibcode:2019Sci…363..884H. doi:10.1126/science.aat0971. PMC 6413494. PMID 30792304.
- ^ Burghardt B, Hartmann AK (February 2007). «RNA secondary structure design». Physical Review E. 75 (2): 021920. arXiv:physics/0609135. Bibcode:2007PhRvE..75b1920B. doi:10.1103/PhysRevE.75.021920. PMID 17358380. S2CID 17574854.
- ^ Reusch, William. «Nucleic Acids». Michigan State University. Retrieved 30 June 2022.
- ^ «How To Extract DNA From Anything Living». University of Utah. Retrieved 30 June 2022.
- ^ Hu Q, Rosenfeld MG (2012). «Epigenetic regulation of human embryonic stem cells». Frontiers in Genetics. 3: 238. doi:10.3389/fgene.2012.00238. PMC 3488762. PMID 23133442.
- ^ Klose RJ, Bird AP (February 2006). «Genomic DNA methylation: the mark and its mediators». Trends in Biochemical Sciences. 31 (2): 89–97. doi:10.1016/j.tibs.2005.12.008. PMID 16403636.
- ^ Bird A (January 2002). «DNA methylation patterns and epigenetic memory». Genes & Development. 16 (1): 6–21. doi:10.1101/gad.947102. PMID 11782440.
- ^ Walsh CP, Xu GL (2006). «Cytosine methylation and DNA repair». Current Topics in Microbiology and Immunology. 301: 283–315. doi:10.1007/3-540-31390-7_11. ISBN 3-540-29114-8. PMID 16570853.
- ^ Kriaucionis S, Heintz N (May 2009). «The nuclear DNA base 5-hydroxymethylcytosine is present in Purkinje neurons and the brain». Science. 324 (5929): 929–30. Bibcode:2009Sci…324..929K. doi:10.1126/science.1169786. PMC 3263819. PMID 19372393.
- ^ Ratel D, Ravanat JL, Berger F, Wion D (March 2006). «N6-methyladenine: the other methylated base of DNA». BioEssays. 28 (3): 309–15. doi:10.1002/bies.20342. PMC 2754416. PMID 16479578.
- ^ Gommers-Ampt JH, Van Leeuwen F, de Beer AL, Vliegenthart JF, Dizdaroglu M, Kowalak JA, Crain PF, Borst P (December 1993). «beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei». Cell. 75 (6): 1129–36. doi:10.1016/0092-8674(93)90322-H. hdl:1874/5219. PMID 8261512. S2CID 24801094.
- ^ Created from PDB 1JDG Archived 22 September 2008 at the Wayback Machine
- ^ Douki T, Reynaud-Angelin A, Cadet J, Sage E (August 2003). «Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation». Biochemistry. 42 (30): 9221–26. doi:10.1021/bi034593c. PMID 12885257.
- ^ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget JP, Ravanat JL, Sauvaigo S (March 1999). «Hydroxyl radicals and DNA base damage». Mutation Research. 424 (1–2): 9–21. doi:10.1016/S0027-5107(99)00004-4. PMID 10064846.
- ^ Beckman KB, Ames BN (August 1997). «Oxidative decay of DNA». The Journal of Biological Chemistry. 272 (32): 19633–36. doi:10.1074/jbc.272.32.19633. PMID 9289489.
- ^ Valerie K, Povirk LF (September 2003). «Regulation and mechanisms of mammalian double-strand break repair». Oncogene. 22 (37): 5792–812. doi:10.1038/sj.onc.1206679. PMID 12947387.
- ^ Johnson G (28 December 2010). «Unearthing Prehistoric Tumors, and Debate». The New York Times. Archived from the original on 24 June 2017.
If we lived long enough, sooner or later we all would get cancer.
- ^ Alberts B, Johnson A, Lewis J, et al. (2002). «The Preventable Causes of Cancer». Molecular biology of the cell (4th ed.). New York: Garland Science. ISBN 0-8153-4072-9. Archived from the original on 2 January 2016.
A certain irreducible background incidence of cancer is to be expected regardless of circumstances: mutations can never be absolutely avoided, because they are an inescapable consequence of fundamental limitations on the accuracy of DNA replication, as discussed in Chapter 5. If a human could live long enough, it is inevitable that at least one of his or her cells would eventually accumulate a set of mutations sufficient for cancer to develop.
- ^ Bernstein H, Payne CM, Bernstein C, Garewal H, Dvorak K (2008). «Cancer and aging as consequences of un-repaired DNA damage». In Kimura H, Suzuki A (eds.). New Research on DNA Damage. New York: Nova Science Publishers. pp. 1–47. ISBN 978-1-60456-581-2. Archived from the original on 25 October 2014.
- ^ Hoeijmakers JH (October 2009). «DNA damage, aging, and cancer». The New England Journal of Medicine. 361 (15): 1475–85. doi:10.1056/NEJMra0804615. PMID 19812404.
- ^ Freitas AA, de Magalhães JP (2011). «A review and appraisal of the DNA damage theory of ageing». Mutation Research. 728 (1–2): 12–22. doi:10.1016/j.mrrev.2011.05.001. PMID 21600302.
- ^ Ferguson LR, Denny WA (September 1991). «The genetic toxicology of acridines». Mutation Research. 258 (2): 123–60. doi:10.1016/0165-1110(91)90006-H. PMID 1881402.
- ^ Stephens TD, Bunde CJ, Fillmore BJ (June 2000). «Mechanism of action in thalidomide teratogenesis». Biochemical Pharmacology. 59 (12): 1489–99. doi:10.1016/S0006-2952(99)00388-3. PMID 10799645.
- ^ Jeffrey AM (1985). «DNA modification by chemical carcinogens». Pharmacology & Therapeutics. 28 (2): 237–72. doi:10.1016/0163-7258(85)90013-0. PMID 3936066.
- ^ Braña MF, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A (November 2001). «Intercalators as anticancer drugs». Current Pharmaceutical Design. 7 (17): 1745–80. doi:10.2174/1381612013397113. PMID 11562309.
- ^ Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, et al. (February 2001). «The sequence of the human genome». Science. 291 (5507): 1304–51. Bibcode:2001Sci…291.1304V. doi:10.1126/science.1058040. PMID 11181995.
- ^ Thanbichler M, Wang SC, Shapiro L (October 2005). «The bacterial nucleoid: a highly organized and dynamic structure». Journal of Cellular Biochemistry. 96 (3): 506–21. doi:10.1002/jcb.20519. PMID 15988757.
- ^ Wolfsberg TG, McEntyre J, Schuler GD (February 2001). «Guide to the draft human genome». Nature. 409 (6822): 824–26. Bibcode:2001Natur.409..824W. doi:10.1038/35057000. PMID 11236998.
- ^ Gregory TR (January 2005). «The C-value enigma in plants and animals: a review of parallels and an appeal for partnership». Annals of Botany. 95 (1): 133–46. doi:10.1093/aob/mci009. PMC 4246714. PMID 15596463.
- ^ Birney E, Stamatoyannopoulos JA, Dutta A, Guigó R, Gingeras TR, Margulies EH, et al. (June 2007). «Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project». Nature. 447 (7146): 799–816. Bibcode:2007Natur.447..799B. doi:10.1038/nature05874. PMC 2212820. PMID 17571346.
- ^ Bank, RCSB Protein Data. «RCSB PDB — 1MSW: Structural basis for the transition from initiation to elongation transcription in T7 RNA polymerase». www.rcsb.org. Retrieved 27 March 2023.
- ^ Pidoux AL, Allshire RC (March 2005). «The role of heterochromatin in centromere function». Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. 360 (1455): 569–79. doi:10.1098/rstb.2004.1611. PMC 1569473. PMID 15905142.
- ^ Harrison PM, Hegyi H, Balasubramanian S, Luscombe NM, Bertone P, Echols N, Johnson T, Gerstein M (February 2002). «Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22». Genome Research. 12 (2): 272–80. doi:10.1101/gr.207102. PMC 155275. PMID 11827946.
- ^ Harrison PM, Gerstein M (May 2002). «Studying genomes through the aeons: protein families, pseudogenes and proteome evolution». Journal of Molecular Biology. 318 (5): 1155–74. doi:10.1016/S0022-2836(02)00109-2. PMID 12083509.
- ^ Albà M (2001). «Replicative DNA polymerases». Genome Biology. 2 (1): REVIEWS3002. doi:10.1186/gb-2001-2-1-reviews3002. PMC 150442. PMID 11178285.
- ^ Tani K, Nasu M (2010). «Roles of Extracellular DNA in Bacterial Ecosystems». In Kikuchi Y, Rykova EY (eds.). Extracellular Nucleic Acids. Springer. pp. 25–38. ISBN 978-3-642-12616-1.
- ^ Vlassov VV, Laktionov PP, Rykova EY (July 2007). «Extracellular nucleic acids». BioEssays. 29 (7): 654–67. doi:10.1002/bies.20604. PMID 17563084. S2CID 32463239.
- ^ Finkel SE, Kolter R (November 2001). «DNA as a nutrient: novel role for bacterial competence gene homologs». Journal of Bacteriology. 183 (21): 6288–93. doi:10.1128/JB.183.21.6288-6293.2001. PMC 100116. PMID 11591672.
- ^ Mulcahy H, Charron-Mazenod L, Lewenza S (November 2008). «Extracellular DNA chelates cations and induces antibiotic resistance in Pseudomonas aeruginosa biofilms». PLOS Pathogens. 4 (11): e1000213. doi:10.1371/journal.ppat.1000213. PMC 2581603. PMID 19023416.
- ^ Berne C, Kysela DT, Brun YV (August 2010). «A bacterial extracellular DNA inhibits settling of motile progeny cells within a biofilm». Molecular Microbiology. 77 (4): 815–29. doi:10.1111/j.1365-2958.2010.07267.x. PMC 2962764. PMID 20598083.
- ^ Whitchurch CB, Tolker-Nielsen T, Ragas PC, Mattick JS (February 2002). «Extracellular DNA required for bacterial biofilm formation». Science. 295 (5559): 1487. doi:10.1126/science.295.5559.1487. PMID 11859186.
- ^ Hu W, Li L, Sharma S, Wang J, McHardy I, Lux R, Yang Z, He X, Gimzewski JK, Li Y, Shi W (2012). «DNA builds and strengthens the extracellular matrix in Myxococcus xanthus biofilms by interacting with exopolysaccharides». PLOS ONE. 7 (12): e51905. Bibcode:2012PLoSO…751905H. doi:10.1371/journal.pone.0051905. PMC 3530553. PMID 23300576.
- ^ Hui L, Bianchi DW (February 2013). «Recent advances in the prenatal interrogation of the human fetal genome». Trends in Genetics. 29 (2): 84–91. doi:10.1016/j.tig.2012.10.013. PMC 4378900. PMID 23158400.
- ^ Foote AD, Thomsen PF, Sveegaard S, Wahlberg M, Kielgast J, Kyhn LA, et al. (2012). «Investigating the potential use of environmental DNA (eDNA) for genetic monitoring of marine mammals». PLOS ONE. 7 (8): e41781. Bibcode:2012PLoSO…741781F. doi:10.1371/journal.pone.0041781. PMC 3430683. PMID 22952587.
- ^ «Researchers Detect Land Animals Using DNA in Nearby Water Bodies».
- ^ Sandman K, Pereira SL, Reeve JN (December 1998). «Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome». Cellular and Molecular Life Sciences. 54 (12): 1350–64. doi:10.1007/s000180050259. PMID 9893710. S2CID 21101836.
- ^ Dame RT (May 2005). «The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin». Molecular Microbiology. 56 (4): 858–70. doi:10.1111/j.1365-2958.2005.04598.x. PMID 15853876. S2CID 26965112.
- ^ Luger K, Mäder AW, Richmond RK, Sargent DF, Richmond TJ (September 1997). «Crystal structure of the nucleosome core particle at 2.8 A resolution». Nature. 389 (6648): 251–60. Bibcode:1997Natur.389..251L. doi:10.1038/38444. PMID 9305837. S2CID 4328827.
- ^ Jenuwein T, Allis CD (August 2001). «Translating the histone code» (PDF). Science. 293 (5532): 1074–80. doi:10.1126/science.1063127. PMID 11498575. S2CID 1883924. Archived (PDF) from the original on 8 August 2017.
- ^ Ito T (2003). «Nucleosome assembly and remodeling». Current Topics in Microbiology and Immunology. 274: 1–22. doi:10.1007/978-3-642-55747-7_1. ISBN 978-3-540-44208-0. PMID 12596902.
- ^ Thomas JO (August 2001). «HMG1 and 2: architectural DNA-binding proteins». Biochemical Society Transactions. 29 (Pt 4): 395–401. doi:10.1042/BST0290395. PMID 11497996.
- ^ Grosschedl R, Giese K, Pagel J (March 1994). «HMG domain proteins: architectural elements in the assembly of nucleoprotein structures». Trends in Genetics. 10 (3): 94–100. doi:10.1016/0168-9525(94)90232-1. PMID 8178371.
- ^ Iftode C, Daniely Y, Borowiec JA (1999). «Replication protein A (RPA): the eukaryotic SSB». Critical Reviews in Biochemistry and Molecular Biology. 34 (3): 141–80. doi:10.1080/10409239991209255. PMID 10473346.
- ^ Bank, RCSB Protein Data. «RCSB PDB — 1LMB: REFINED 1.8 ANGSTROM CRYSTAL STRUCTURE OF THE LAMBDA REPRESSOR-OPERATOR COMPLEX». www.rcsb.org. Retrieved 27 March 2023.
- ^ Myers LC, Kornberg RD (2000). «Mediator of transcriptional regulation». Annual Review of Biochemistry. 69: 729–49. doi:10.1146/annurev.biochem.69.1.729. PMID 10966474.
- ^ Spiegelman BM, Heinrich R (October 2004). «Biological control through regulated transcriptional coactivators». Cell. 119 (2): 157–67. doi:10.1016/j.cell.2004.09.037. PMID 15479634.
- ^ Li Z, Van Calcar S, Qu C, Cavenee WK, Zhang MQ, Ren B (July 2003). «A global transcriptional regulatory role for c-Myc in Burkitt’s lymphoma cells». Proceedings of the National Academy of Sciences of the United States of America. 100 (14): 8164–69. Bibcode:2003PNAS..100.8164L. doi:10.1073/pnas.1332764100. PMC 166200. PMID 12808131.
- ^ Bank, RCSB Protein Data. «RCSB PDB — 1RVA: MG2+ BINDING TO THE ACTIVE SITE OF ECO RV ENDONUCLEASE: A CRYSTALLOGRAPHIC STUDY OF COMPLEXES WITH SUBSTRATE AND PRODUCT DNA AT 2 ANGSTROMS RESOLUTION». www.rcsb.org. Retrieved 27 March 2023.
- ^ Bickle TA, Krüger DH (June 1993). «Biology of DNA restriction». Microbiological Reviews. 57 (2): 434–50. doi:10.1128/MMBR.57.2.434-450.1993. PMC 372918. PMID 8336674.
- ^ a b Doherty AJ, Suh SW (November 2000). «Structural and mechanistic conservation in DNA ligases». Nucleic Acids Research. 28 (21): 4051–58. doi:10.1093/nar/28.21.4051. PMC 113121. PMID 11058099.
- ^ Schoeffler AJ, Berger JM (December 2005). «Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism». Biochemical Society Transactions. 33 (Pt 6): 1465–70. doi:10.1042/BST20051465. PMID 16246147.
- ^ Tuteja N, Tuteja R (May 2004). «Unraveling DNA helicases. Motif, structure, mechanism and function» (PDF). European Journal of Biochemistry. 271 (10): 1849–63. doi:10.1111/j.1432-1033.2004.04094.x. PMID 15128295.
- ^ Joyce CM, Steitz TA (November 1995). «Polymerase structures and function: variations on a theme?». Journal of Bacteriology. 177 (22): 6321–29. doi:10.1128/jb.177.22.6321-6329.1995. PMC 177480. PMID 7592405.
- ^ Hubscher U, Maga G, Spadari S (2002). «Eukaryotic DNA polymerases» (PDF). Annual Review of Biochemistry. 71: 133–63. doi:10.1146/annurev.biochem.71.090501.150041. PMID 12045093. S2CID 26171993. Archived from the original (PDF) on 26 January 2021.
- ^ Johnson A, O’Donnell M (2005). «Cellular DNA replicases: components and dynamics at the replication fork». Annual Review of Biochemistry. 74: 283–315. doi:10.1146/annurev.biochem.73.011303.073859. PMID 15952889.
- ^ a b Tarrago-Litvak L, Andréola ML, Nevinsky GA, Sarih-Cottin L, Litvak S (May 1994). «The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention». FASEB Journal. 8 (8): 497–503. doi:10.1096/fasebj.8.8.7514143. PMID 7514143. S2CID 39614573.
- ^ Martinez E (December 2002). «Multi-protein complexes in eukaryotic gene transcription». Plant Molecular Biology. 50 (6): 925–47. doi:10.1023/A:1021258713850. PMID 12516863. S2CID 24946189.
- ^ Bank, RCSB Protein Data. «RCSB PDB — 1M6G: Structural Characterisation of the Holliday Junction TCGGTACCGA». www.rcsb.org. Retrieved 27 March 2023.
- ^ Cremer T, Cremer C (April 2001). «Chromosome territories, nuclear architecture and gene regulation in mammalian cells». Nature Reviews Genetics. 2 (4): 292–301. doi:10.1038/35066075. PMID 11283701. S2CID 8547149.
- ^ Pál C, Papp B, Lercher MJ (May 2006). «An integrated view of protein evolution». Nature Reviews Genetics. 7 (5): 337–48. doi:10.1038/nrg1838. PMID 16619049. S2CID 23225873.
- ^ O’Driscoll M, Jeggo PA (January 2006). «The role of double-strand break repair – insights from human genetics». Nature Reviews Genetics. 7 (1): 45–54. doi:10.1038/nrg1746. PMID 16369571. S2CID 7779574.
- ^ Vispé S, Defais M (October 1997). «Mammalian Rad51 protein: a RecA homologue with pleiotropic functions». Biochimie. 79 (9–10): 587–92. doi:10.1016/S0300-9084(97)82007-X. PMID 9466696.
- ^ Neale MJ, Keeney S (July 2006). «Clarifying the mechanics of DNA strand exchange in meiotic recombination». Nature. 442 (7099): 153–58. Bibcode:2006Natur.442..153N. doi:10.1038/nature04885. PMC 5607947. PMID 16838012.
- ^ Dickman MJ, Ingleston SM, Sedelnikova SE, Rafferty JB, Lloyd RG, Grasby JA, Hornby DP (November 2002). «The RuvABC resolvasome». European Journal of Biochemistry. 269 (22): 5492–501. doi:10.1046/j.1432-1033.2002.03250.x. PMID 12423347. S2CID 39505263.
- ^ Joyce GF (July 2002). «The antiquity of RNA-based evolution». Nature. 418 (6894): 214–21. Bibcode:2002Natur.418..214J. doi:10.1038/418214a. PMID 12110897. S2CID 4331004.
- ^ Orgel LE (2004). «Prebiotic chemistry and the origin of the RNA world». Critical Reviews in Biochemistry and Molecular Biology. 39 (2): 99–123. CiteSeerX 10.1.1.537.7679. doi:10.1080/10409230490460765. PMID 15217990.
- ^ Davenport RJ (May 2001). «Ribozymes. Making copies in the RNA world». Science. 292 (5520): 1278a–1278. doi:10.1126/science.292.5520.1278a. PMID 11360970. S2CID 85976762.
- ^ Szathmáry E (April 1992). «What is the optimum size for the genetic alphabet?». Proceedings of the National Academy of Sciences of the United States of America. 89 (7): 2614–18. Bibcode:1992PNAS…89.2614S. doi:10.1073/pnas.89.7.2614. PMC 48712. PMID 1372984.
- ^ Lindahl T (April 1993). «Instability and decay of the primary structure of DNA». Nature. 362 (6422): 709–15. Bibcode:1993Natur.362..709L. doi:10.1038/362709a0. PMID 8469282. S2CID 4283694.
- ^ Vreeland RH, Rosenzweig WD, Powers DW (October 2000). «Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal». Nature. 407 (6806): 897–900. Bibcode:2000Natur.407..897V. doi:10.1038/35038060. PMID 11057666. S2CID 9879073.
- ^ Hebsgaard MB, Phillips MJ, Willerslev E (May 2005). «Geologically ancient DNA: fact or artefact?». Trends in Microbiology. 13 (5): 212–20. doi:10.1016/j.tim.2005.03.010. PMID 15866038.
- ^ Nickle DC, Learn GH, Rain MW, Mullins JI, Mittler JE (January 2002). «Curiously modern DNA for a «250 million-year-old» bacterium». Journal of Molecular Evolution. 54 (1): 134–37. Bibcode:2002JMolE..54..134N. doi:10.1007/s00239-001-0025-x. PMID 11734907. S2CID 24740859.
- ^ Callahan MP, Smith KE, Cleaves HJ, Ruzicka J, Stern JC, Glavin DP, House CH, Dworkin JP (August 2011). «Carbonaceous meteorites contain a wide range of extraterrestrial nucleobases». Proceedings of the National Academy of Sciences of the United States of America. 108 (34): 13995–98. Bibcode:2011PNAS..10813995C. doi:10.1073/pnas.1106493108. PMC 3161613. PMID 21836052.
- ^ Steigerwald J (8 August 2011). «NASA Researchers: DNA Building Blocks Can Be Made in Space». NASA. Archived from the original on 23 June 2015. Retrieved 10 August 2011.
- ^ ScienceDaily Staff (9 August 2011). «DNA Building Blocks Can Be Made in Space, NASA Evidence Suggests». ScienceDaily. Archived from the original on 5 September 2011. Retrieved 9 August 2011.
- ^ Marlaire R (3 March 2015). «NASA Ames Reproduces the Building Blocks of Life in Laboratory». NASA. Archived from the original on 5 March 2015. Retrieved 5 March 2015.
- ^ Hunt, Katie (17 February 2021). «World’s oldest DNA sequenced from a mammoth that lived more than a million years ago». CNN News. Retrieved 17 February 2021.
- ^ Callaway, Ewen (17 February 2021). «Million-year-old mammoth genomes shatter record for oldest ancient DNA – Permafrost-preserved teeth, up to 1.6 million years old, identify a new kind of mammoth in Siberia». Nature. 590 (7847): 537–538. doi:10.1038/d41586-021-00436-x. ISSN 0028-0836. PMID 33597786.
- ^ Goff SP, Berg P (December 1976). «Construction of hybrid viruses containing SV40 and lambda phage DNA segments and their propagation in cultured monkey cells». Cell. 9 (4 PT 2): 695–705. doi:10.1016/0092-8674(76)90133-1. PMID 189942. S2CID 41788896.
- ^ Houdebine LM (2007). «Transgenic animal models in biomedical research». Target Discovery and Validation Reviews and Protocols. Methods in Molecular Biology. Vol. 360. pp. 163–202. doi:10.1385/1-59745-165-7:163. ISBN 978-1-59745-165-9. PMID 17172731.
- ^ Daniell H, Dhingra A (April 2002). «Multigene engineering: dawn of an exciting new era in biotechnology». Current Opinion in Biotechnology. 13 (2): 136–41. doi:10.1016/S0958-1669(02)00297-5. PMC 3481857. PMID 11950565.
- ^ Job D (November 2002). «Plant biotechnology in agriculture». Biochimie. 84 (11): 1105–10. doi:10.1016/S0300-9084(02)00013-5. PMID 12595138.
- ^ Curtis C, Hereward J (29 August 2017). «From the crime scene to the courtroom: the journey of a DNA sample». The Conversation. Archived from the original on 22 October 2017. Retrieved 22 October 2017.
- ^ Collins A, Morton NE (June 1994). «Likelihood ratios for DNA identification». Proceedings of the National Academy of Sciences of the United States of America. 91 (13): 6007–11. Bibcode:1994PNAS…91.6007C. doi:10.1073/pnas.91.13.6007. PMC 44126. PMID 8016106.
- ^ Weir BS, Triggs CM, Starling L, Stowell LI, Walsh KA, Buckleton J (March 1997). «Interpreting DNA mixtures» (PDF). Journal of Forensic Sciences. 42 (2): 213–22. doi:10.1520/JFS14100J. PMID 9068179. S2CID 14511630.
- ^ Jeffreys AJ, Wilson V, Thein SL (1985). «Individual-specific ‘fingerprints’ of human DNA». Nature. 316 (6023): 76–79. Bibcode:1985Natur.316…76J. doi:10.1038/316076a0. PMID 2989708. S2CID 4229883.
- ^ «Colin Pitchfork». 14 December 2006. Archived from the original on 14 December 2006. Retrieved 27 March 2023.
- ^ «DNA Identification in Mass Fatality Incidents». National Institute of Justice. September 2006. Archived from the original on 12 November 2006.
- ^ Pollack, Andrew (19 June 2012). «Before Birth, Dad’s ID». The New York Times. ISSN 0362-4331. Retrieved 27 March 2023.
- ^ a b Breaker RR, Joyce GF (December 1994). «A DNA enzyme that cleaves RNA». Chemistry & Biology. 1 (4): 223–29. doi:10.1016/1074-5521(94)90014-0. PMID 9383394.
- ^ Chandra M, Sachdeva A, Silverman SK (October 2009). «DNA-catalyzed sequence-specific hydrolysis of DNA». Nature Chemical Biology. 5 (10): 718–20. doi:10.1038/nchembio.201. PMC 2746877. PMID 19684594.
- ^ Carmi N, Shultz LA, Breaker RR (December 1996). «In vitro selection of self-cleaving DNAs». Chemistry & Biology. 3 (12): 1039–46. doi:10.1016/S1074-5521(96)90170-2. PMID 9000012.
- ^ Torabi SF, Wu P, McGhee CE, Chen L, Hwang K, Zheng N, Cheng J, Lu Y (May 2015). «In vitro selection of a sodium-specific DNAzyme and its application in intracellular sensing». Proceedings of the National Academy of Sciences of the United States of America. 112 (19): 5903–08. Bibcode:2015PNAS..112.5903T. doi:10.1073/pnas.1420361112. PMC 4434688. PMID 25918425.
- ^ Baldi P, Brunak S (2001). Bioinformatics: The Machine Learning Approach. MIT Press. ISBN 978-0-262-02506-5. OCLC 45951728.
- ^ Gusfield D (15 January 1997). Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Cambridge University Press. ISBN 978-0-521-58519-4.
- ^ Sjölander K (January 2004). «Phylogenomic inference of protein molecular function: advances and challenges». Bioinformatics. 20 (2): 170–79. CiteSeerX 10.1.1.412.943. doi:10.1093/bioinformatics/bth021. PMID 14734307.
- ^ Mount DM (2004). Bioinformatics: Sequence and Genome Analysis (2nd ed.). Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press. ISBN 0-87969-712-1. OCLC 55106399.
- ^ Strong, Michael (2004). «Protein Nanomachines». PLOS Biology. 2 (3): e73. doi:10.1371/journal.pbio.0020073. PMC 368168. PMID 15024422. S2CID 13222080.
- ^ Rothemund PW (March 2006). «Folding DNA to create nanoscale shapes and patterns» (PDF). Nature. 440 (7082): 297–302. Bibcode:2006Natur.440..297R. doi:10.1038/nature04586. PMID 16541064. S2CID 4316391.
- ^ Andersen ES, Dong M, Nielsen MM, Jahn K, Subramani R, Mamdouh W, Golas MM, Sander B, Stark H, Oliveira CL, Pedersen JS, Birkedal V, Besenbacher F, Gothelf KV, Kjems J (May 2009). «Self-assembly of a nanoscale DNA box with a controllable lid». Nature. 459 (7243): 73–76. Bibcode:2009Natur.459…73A. doi:10.1038/nature07971. hdl:11858/00-001M-0000-0010-9362-B. PMID 19424153. S2CID 4430815.
- ^ Ishitsuka Y, Ha T (May 2009). «DNA nanotechnology: a nanomachine goes live». Nature Nanotechnology. 4 (5): 281–82. Bibcode:2009NatNa…4..281I. doi:10.1038/nnano.2009.101. PMID 19421208.
- ^ Aldaye FA, Palmer AL, Sleiman HF (September 2008). «Assembling materials with DNA as the guide». Science. 321 (5897): 1795–99. Bibcode:2008Sci…321.1795A. doi:10.1126/science.1154533. PMID 18818351. S2CID 2755388.
- ^ Dunn, Matthew; Jimenez, Randi; Chaput, John (2017). «Analysis of aptamer discovery and technology». Nature Reviews Chemistry. 1 (10). doi:10.1038/s41570-017-0076. Retrieved 30 June 2022.
- ^ Wray GA (2002). «Dating branches on the tree of life using DNA». Genome Biology. 3 (1): REVIEWS0001. doi:10.1186/gb-2001-3-1-reviews0001. PMC 150454. PMID 11806830.
- ^ Panda D, Molla KA, Baig MJ, Swain A, Behera D, Dash M (May 2018). «DNA as a digital information storage device: hope or hype?». 3 Biotech. 8 (5): 239. doi:10.1007/s13205-018-1246-7. PMC 5935598. PMID 29744271.
- ^ Akram F, Haq IU, Ali H, Laghari AT (October 2018). «Trends to store digital data in DNA: an overview». Molecular Biology Reports. 45 (5): 1479–1490. doi:10.1007/s11033-018-4280-y. PMID 30073589. S2CID 51905843.
- ^ Miescher F (1871). «Ueber die chemische Zusammensetzung der Eiterzellen» [On the chemical composition of pus cells]. Medicinisch-chemische Untersuchungen (in German). 4: 441–60.
[p. 456] Ich habe mich daher später mit meinen Versuchen an die ganzen Kerne gehalten, die Trennung der Körper, die ich einstweilen ohne weiteres Präjudiz als lösliches und unlösliches Nuclein bezeichnen will, einem günstigeren Material überlassend. (Therefore, in my experiments I subsequently limited myself to the whole nucleus, leaving to a more favorable material the separation of the substances, that for the present, without further prejudice, I will designate as soluble and insoluble nuclear material («Nuclein»))
- ^ Dahm R (January 2008). «Discovering DNA: Friedrich Miescher and the early years of nucleic acid research». Human Genetics. 122 (6): 565–81. doi:10.1007/s00439-007-0433-0. PMID 17901982. S2CID 915930.
- ^ See:
- Kossel A (1879). «Ueber Nucleïn der Hefe» [On nuclein in yeast]. Zeitschrift für physiologische Chemie (in German). 3: 284–91.
- Kossel A (1880). «Ueber Nucleïn der Hefe II» [On nuclein in yeast, Part 2]. Zeitschrift für physiologische Chemie (in German). 4: 290–95.
- Kossel A (1881). «Ueber die Verbreitung des Hypoxanthins im Thier- und Pflanzenreich» [On the distribution of hypoxanthins in the animal and plant kingdoms]. Zeitschrift für physiologische Chemie (in German). 5: 267–71.
- Kossel A (1881). Trübne KJ (ed.). Untersuchungen über die Nucleine und ihre Spaltungsprodukte [Investigations into nuclein and its cleavage products] (in German). Strassburg, Germany. p. 19.
- Kossel A (1882). «Ueber Xanthin und Hypoxanthin» [On xanthin and hypoxanthin]. Zeitschrift für physiologische Chemie. 6: 422–31.
- Albrect Kossel (1883) «Zur Chemie des Zellkerns» Archived 17 November 2017 at the Wayback Machine (On the chemistry of the cell nucleus), Zeitschrift für physiologische Chemie, 7 : 7–22.
- Kossel A (1886). «Weitere Beiträge zur Chemie des Zellkerns» [Further contributions to the chemistry of the cell nucleus]. Zeitschrift für Physiologische Chemie (in German). 10: 248–64.
On p. 264, Kossel remarked presciently: Der Erforschung der quantitativen Verhältnisse der vier stickstoffreichen Basen, der Abhängigkeit ihrer Menge von den physiologischen Zuständen der Zelle, verspricht wichtige Aufschlüsse über die elementaren physiologisch-chemischen Vorgänge. (The study of the quantitative relations of the four nitrogenous bases—[and] of the dependence of their quantity on the physiological states of the cell—promises important insights into the fundamental physiological-chemical processes.)
- ^ Jones ME (September 1953). «Albrecht Kossel, a biographical sketch». The Yale Journal of Biology and Medicine. 26 (1): 80–97. PMC 2599350. PMID 13103145.
- ^ Levene PA, Jacobs WA (1909). «Über Inosinsäure». Berichte der Deutschen Chemischen Gesellschaft (in German). 42: 1198–203. doi:10.1002/cber.190904201196.
- ^ Levene PA, Jacobs WA (1909). «Über die Hefe-Nucleinsäure». Berichte der Deutschen Chemischen Gesellschaft (in German). 42 (2): 2474–78. doi:10.1002/cber.190904202148.
- ^ Levene P (1919). «The structure of yeast nucleic acid». J Biol Chem. 40 (2): 415–24. doi:10.1016/S0021-9258(18)87254-4.
- ^ Cohen JS, Portugal FH (1974). «The search for the chemical structure of DNA» (PDF). Connecticut Medicine. 38 (10): 551–52, 554–57. PMID 4609088.
- ^ Koltsov proposed that a cell’s genetic information was encoded in a long chain of amino acids. See:
- Кольцов, Н. К. (12 December 1927). Физико-химические основы морфологии [The physical-chemical basis of morphology] (Speech). 3rd All-Union Meeting of Zoologist, Anatomists, and Histologists (in Russian). Leningrad, U.S.S.R.
- Reprinted in: Кольцов, Н. К. (1928). «Физико-химические основы морфологии» [The physical-chemical basis of morphology]. Успехи экспериментальной биологии (Advances in Experimental Biology) series B (in Russian). 7 (1): ?.
- Reprinted in German as: Koltzoff NK (1928). «Physikalisch-chemische Grundlagen der Morphologie» [The physical-chemical basis of morphology]. Biologisches Zentralblatt (in German). 48 (6): 345–69.
- In 1934, Koltsov contended that the proteins that contain a cell’s genetic information replicate. See: Koltzoff N (October 1934). «The structure of the chromosomes in the salivary glands of Drosophila». Science. 80 (2075): 312–13. Bibcode:1934Sci….80..312K. doi:10.1126/science.80.2075.312. PMID 17769043.
From page 313: «I think that the size of the chromosomes in the salivary glands [of Drosophila] is determined through the multiplication of genonemes. By this term I designate the axial thread of the chromosome, in which the geneticists locate the linear combination of genes; … In the normal chromosome there is usually only one genoneme; before cell-division this genoneme has become divided into two strands.»
- ^ Soyfer VN (September 2001). «The consequences of political dictatorship for Russian science». Nature Reviews Genetics. 2 (9): 723–29. doi:10.1038/35088598. PMID 11533721. S2CID 46277758.
- ^ Griffith F (January 1928). «The Significance of Pneumococcal Types». The Journal of Hygiene. 27 (2): 113–59. doi:10.1017/S0022172400031879. PMC 2167760. PMID 20474956.
- ^ Lorenz MG, Wackernagel W (September 1994). «Bacterial gene transfer by natural genetic transformation in the environment». Microbiological Reviews. 58 (3): 563–602. doi:10.1128/MMBR.58.3.563-602.1994. PMC 372978. PMID 7968924.
- ^ Brachet J (1933). «Recherches sur la synthese de l’acide thymonucleique pendant le developpement de l’oeuf d’Oursin». Archives de Biologie (in Italian). 44: 519–76.
- ^ Burian R (1994). «Jean Brachet’s Cytochemical Embryology: Connections with the Renovation of Biology in France?» (PDF). In Debru C, Gayon J, Picard JF (eds.). Les sciences biologiques et médicales en France 1920–1950. Cahiers pour I’histoire de la recherche. Vol. 2. Paris: CNRS Editions. pp. 207–20.
- ^ See:
- Astbury WT, Bell FO (1938). «Some recent developments in the X-ray study of proteins and related structures» (PDF). Cold Spring Harbor Symposia on Quantitative Biology. 6: 109–21. doi:10.1101/sqb.1938.006.01.013. Archived from the original (PDF) on 14 July 2014.
- Astbury WT (1947). «X-ray studies of nucleic acids». Symposia of the Society for Experimental Biology (1): 66–76. PMID 20257017. Archived from the original on 5 July 2014.
- ^ Avery OT, Macleod CM, McCarty M (February 1944). «Studies on the Chemical Nature of the Substance Inducing Transformation of Pneumococcal Types: Induction of Transformation by a Desoxyribonucleic Acid Fraction Isolated from Pneumococcus Type III». The Journal of Experimental Medicine. 79 (2): 137–58. doi:10.1084/jem.79.2.137. PMC 2135445. PMID 19871359.
- ^ Chargaff, Erwin (June 1950). «Chemical specificity of nucleic acids and mechanism of their enzymatic degradation». Experientia. 6 (6): 201–209. doi:10.1007/BF02173653. PMID 15421335. S2CID 2522535.
- ^ Kresge, Nicole; Simoni, Robert D.; Hill, Robert L. (June 2005). «Chargaff’s Rules: the Work of Erwin Chargaff». Journal of Biological Chemistry. 280 (24): 172–174. doi:10.1016/S0021-9258(20)61522-8.
- ^ Hershey AD, Chase M (May 1952). «Independent functions of viral protein and nucleic acid in growth of bacteriophage». The Journal of General Physiology. 36 (1): 39–56. doi:10.1085/jgp.36.1.39. PMC 2147348. PMID 12981234.
- ^ «Linus Pauling and the Race for DNA: A Documentary History — Special Collections & Archives Research Center — Oregon State University». scarc.library.oregonstate.edu. Retrieved 27 March 2023.
- ^ Schwartz J (2008). In pursuit of the gene : from Darwin to DNA. Cambridge, Mass.: Harvard University Press. ISBN 978-0-674-02670-4.
- ^ Pauling L, Corey RB (February 1953). «A Proposed Structure For The Nucleic Acids». Proceedings of the National Academy of Sciences of the United States of America. 39 (2): 84–97. Bibcode:1953PNAS…39…84P. doi:10.1073/pnas.39.2.84. PMC 1063734. PMID 16578429.
- ^ Regis E (2009). What Is Life?: investigating the nature of life in the age of synthetic biology. Oxford: Oxford University Press. p. 52. ISBN 978-0-19-538341-6.
- ^ «Double Helix of DNA: 50 Years». Nature Archives. Archived from the original on 5 April 2015.
- ^ «Original X-ray diffraction image». Oregon State Library. Archived from the original on 30 January 2009. Retrieved 6 February 2011.
- ^ «The Nobel Prize in Physiology or Medicine 1962». Nobelprize.org.
- ^ Maddox B (January 2003). «The double helix and the ‘wronged heroine’» (PDF). Nature. 421 (6921): 407–08. Bibcode:2003Natur.421..407M. doi:10.1038/nature01399. PMID 12540909. S2CID 4428347. Archived (PDF) from the original on 17 October 2016.
- ^ Crick F (1955). A Note for the RNA Tie Club (PDF) (Speech). Cambridge, England. Archived from the original (PDF) on 1 October 2008.
- ^ Meselson M, Stahl FW (July 1958). «The Replication of DNA in Escherichia Coli». Proceedings of the National Academy of Sciences of the United States of America. 44 (7): 671–82. Bibcode:1958PNAS…44..671M. doi:10.1073/pnas.44.7.671. PMC 528642. PMID 16590258.
- ^ «The Nobel Prize in Physiology or Medicine 1968». Nobelprize.org.
- ^ Pray L (2008). «Discovery of DNA structure and function: Watson and Crick». Nature Education. 1 (1): 100.
Further reading
- Berry A, Watson J (2003). DNA: the secret of life. New York: Alfred A. Knopf. ISBN 0-375-41546-7.
- Calladine CR, Drew HR, Luisi BF, Travers AA (2003). Understanding DNA: the molecule & how it works. Amsterdam: Elsevier Academic Press. ISBN 0-12-155089-3.
- Carina D, Clayton J (2003). 50 years of DNA. Basingstoke: Palgrave Macmillan. ISBN 1-4039-1479-6.
- Judson HF (1979). The Eighth Day of Creation: Makers of the Revolution in Biology (2nd ed.). Cold Spring Harbor Laboratory Press. ISBN 0-671-22540-5.
- Olby RC (1994). The path to the double helix: the discovery of DNA. New York: Dover Publications. ISBN 0-486-68117-3. First published in October 1974 by MacMillan, with foreword by Francis Crick; the definitive DNA textbook, revised in 1994 with a nine-page postscript.
- Olby R (January 2003). «Quiet debut for the double helix». Nature. 421 (6921): 402–05. Bibcode:2003Natur.421..402O. doi:10.1038/nature01397. PMID 12540907.
- Olby RC (2009). Francis Crick: A Biography. Plainview, N.Y: Cold Spring Harbor Laboratory Press. ISBN 978-0-87969-798-3.
- Micklas D (2003). DNA Science: A First Course. Cold Spring Harbor Press. ISBN 978-0-87969-636-8.
- Ridley M (2006). Francis Crick: discoverer of the genetic code. Ashland, OH: Eminent Lives, Atlas Books. ISBN 0-06-082333-X.
- Rosenfeld I (2010). DNA: A Graphic Guide to the Molecule that Shook the World. Columbia University Press. ISBN 978-0-231-14271-7.
- Schultz M, Cannon Z (2009). The Stuff of Life: A Graphic Guide to Genetics and DNA. Hill and Wang. ISBN 978-0-8090-8947-5.
- Stent GS, Watson J (1980). The Double Helix: A Personal Account of the Discovery of the Structure of DNA. New York: Norton. ISBN 0-393-95075-1.
- Watson J (2004). DNA: The Secret of Life. Random House. ISBN 978-0-09-945184-6.
- Wilkins M (2003). The third man of the double helix the autobiography of Maurice Wilkins. Cambridge, England: University Press. ISBN 0-19-860665-6.
External links
![]()
This audio file was created from a revision of this article dated 12 February 2007, and does not reflect subsequent edits.
- DNA at Curlie
- DNA binding site prediction on protein
- DNA the Double Helix Game From the official Nobel Prize web site
- DNA under electron microscope
- Dolan DNA Learning Center
- Double Helix: 50 years of DNA, Nature
- Proteopedia DNA
- Proteopedia Forms_of_DNA
- ENCODE threads explorer ENCODE home page at Nature
- Double Helix 1953–2003 National Centre for Biotechnology Education
- Genetic Education Modules for Teachers – DNA from the Beginning Study Guide
- PDB Molecule of the Month DNA
- «Clue to chemistry of heredity found». The New York Times, June 1953. First American newspaper coverage of the discovery of the DNA structure
- DNA from the Beginning Another DNA Learning Center site on DNA, genes, and heredity from Mendel to the human genome project.
- The Register of Francis Crick Personal Papers 1938 – 2007 at Mandeville Special Collections Library, University of California, San Diego
- Seven-page, handwritten letter that Crick sent to his 12-year-old son Michael in 1953 describing the structure of DNA. See Crick’s medal goes under the hammer, Nature, 5 April 2013.
Table of contents
- What does DNA look like?
- What is DNA made of?
- DNA stands for deoxyribose and acid: The “backbone” of DNA
- DNA stands for nucleotides: The four bases of DNA
- Where is DNA found in a cell?
- Defining what DNA stands for: the Double helix
- Do all living things have DNA?
- What exactly does DNA do?
- It makes a copy of itself
- It sends blueprints to the cell to manufacture proteins
- The genetic code
- Interesting facts about DNA and what it stands for
- FAQ for What does DNA stand for?
- Get a reading of your DNA today!
DNA stands for “deoxyribonucleic acid,” and it is one of the most fascinating things you ever saw. Perhaps you remember it from school, but do you remember everything there is to it? This hard-to-pronounce name comes from its structure, a sugar (deoxyribose) and phosphate backbone (acid) with units called bases sticking out from it located in the cell’s nucleus.

DNA is the chemical molecule that carries genetic information in all living things. It is passed on from one generation to the next and holds the key to our survival on the planet. Almost every single one of the cells in the body contains an exact copy of DNA. This is due to a characteristic that sets it apart from any other molecule: the ability to copy itself.
In 1869, Friedrich Miescher was the first scientist to isolate nucleic acid. By 1952, it was confirmed that DNA is the molecule responsible for the passing of genetic information. Since then, scientists have engaged in an authentic race into knowing more about it. This has led to remarkable discoveries and so many practical uses, especially in the medical field. You have probably heard stuff about cloning or the production of insulin in a lab. All of that and so much more stem from our understanding of this structure.
What does DNA look like?
But what does it look like?
As you have seen in many images, including the one above, DNA looks like a twisted ladder. The “rungs” of a DNA molecule stand for small chemical bases: adenine (A), thymine (T), cytosine (C), and guanine (G). The “side rails” are composed of units called nucleotides, which are made of two substances: a phosphate group and a sugar.
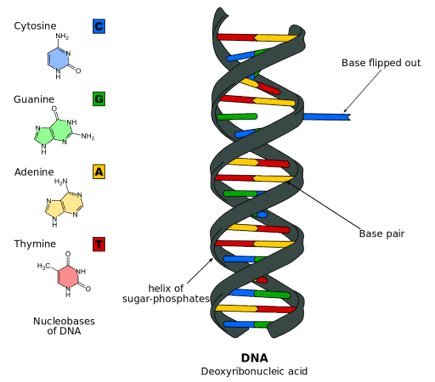
Erwin Chargoff discovered in 1949 that even though different organisms have different amounts of DNA, the amount of adenine was always the same as thymine, and the amount of cytosine was always the same as guanine. This led to the conclusion that the ladder is composed of only A-T and C-G runs, called complementary bases, positioned in specific sequences that codify for particular characteristics.
But let’s take a closer look at this fascinating and unique molecule to understand why it is so fundamental to the perpetuation of life.
What is DNA made of?
This molecule’s chemical composition can be split into three major structural parts: a phosphate group, a deoxyribose sugar, and a nitrogenous base.
DNA is a polymer made of units called nucleotides. These nucleotides are joined together in rows through the chemical bond between the phosphate group of one and the deoxyribose sugar of the next and so on.
The two “railways” or “backbones” are joined together through weak hydrogen bonds between the nitrogenous bases (adenine and thymine; cytosine and guanine).
DNA stands for deoxyribose and acid: The “backbone” of DNA
This is like the “boring” part of DNA since it is a repetitive sequence, one after the other. Here we find the acidic phosphate group of one nucleotide bonded to the deoxyribose sugar of the next to form a long line of nucleotides.
DNA stands for nucleotides: The four bases of DNA
You can think of these as the exciting part of DNA. The nitrogen or nitrogenous bases make up the “letters” of your genome. The adenine from one strand bonds with the thymine of the other and the cytosine with guanine, creating an A-T and C-G order particular to each organism. Together with a deoxyribose and phosphate of the backbone, a nitrogenous base pair forms a nucleotide – the monomer of the large nucleic acid polymer.
Changes in these bases are classified as genetic mutations, many of which are hallmarks to increased or decreased risks of certain diseases or conditions. Get your DNA sequenced today!
Now that you know that DNA stands for deoxyribonucleic acid, have you ever wondered why it is classified as an acid? That’s because it is!
Does the word phosphate remind you of phosphoric acid? The acidity of DNA comes from this phosphate group.
An acid is defined as a substance that releases protons. Phosphoric acid (H3PO4), for instance, releases three protons. The only difference between phosphoric acid and the phosphate group is the replacement of two protons with protons from the sugar molecule of the nucleotide. The remaining proton is what makes the entire molecule acidic.
Where is DNA found in a cell?
Typically, genetic material is found in the cell’s nucleus, where it never leaves. However, a small amount of DNA can also be found in the mitochondria (mitochondrial DNA).
This DNA is cut in segments tightly coiled in the nucleus into structures called chromosomes. In humans, DNA is stored in 23 pairs of chromosomes (46 in total). This means that all the cells in your body contain this number of chromosomes packed inside the nucleus. This number varies among organisms. Corn, for example, has 20 chromosomes total in each cell, while dogs have 78.
Your sex cells (sperms in males and ovules in females) contain only half that number of chromosomes, which, when combined with your couple’s sex cell, will create an entire being with the complete set of 46.
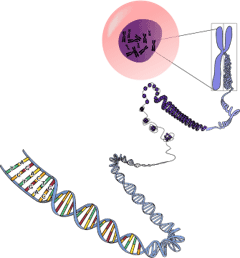
Defining what DNA stands for: the Double helix
In its physical composition, DNA has the shape of a ladder that naturally coils into the famous double helix shape due to its weight and structure.
The Merriam-Webster dictionary defines a double helix as “a helix or spiral consisting of two strands in the surface of a cylinder that coil around its axis.” This definition applies especially to the structural arrangement of DNA.
The term was popularized by the 1968 book by James Watson (one of the discoverers of the DNA structure) titled The Double Helix: A Personal Account of the Discovery of the Structure of DNA.
James Watson and Francis Crick discovered this model of DNA in 1953, upon the grounds of the work of Rosalind Franklin, an X-ray crystallographer who took an X-ray diffraction photo of a DNA molecule. Then, aided by the work of other remarkable scientists, Watson and Crick were able to construct what we now know as the nucleic acid double helix.
Do all living things have DNA?
Fortunately for us, all living things have DNA since they all need instructions on building their anatomies, configure their physiology, and pass on these instructions to their offspring. Even microscopic organisms such as some viruses have DNA.
All living organisms store their hereditary information in the form of DNA. This information includes all the instructions for every genetic trait, from skin color to blood type; it is stored in DNA segments. These segments are what we call genes.
So, what is the difference between your DNA and the DNA found in a carrot, for example? The difference is the sequence of DNA base pairs A, T, C, and G. Think of it as the English alphabet letters. You can create two different stories with the same 26 letters.
The order or sequence of base pairs (A-T and C-G) varies from one organism to another. This sequence determines the instructions to produce insulin in humans and chlorophyll in plants, for example. A human’s DNA does not have the sequence that instructs chlorophyll production, and a plant’s DNA lacks the instructions for insulin.
But, if all cells in the human body have an exact copy of DNA, what is the difference between a bone cell and a skin cell, for example? That has to do with gene expression. Both cells activate the genes required for basic living processes, but only skin cells express the genes for skin proteins. So bone (and other) genes are silenced in this case.
You just saw how DNA has the same letters for all organisms. What is even more impressive is that the language of DNA is the same for all forms of life. Thus, a gene from an organism can be copied, transferred, and translated by any other living organism to produce the same protein.
Insulin is now created by a microbe that has been engineered with instructions from human DNA to produce human insulin. In other words, a copy of human genes for insulin production is copied and transferred to these microbes. These organisms have no blood or blood sugar, but they will produce insulin as they read the recipe to do so, even if they have no use for it.
What exactly does DNA do?
Remember, DNA stands for deoxyribose nucleic acid and is the repository of all bacteria, plant, and animal hereditary information. In any organism, every cell has the same base sequence as every other cell in that living organism.
Three distinct processes encompass DNA’s job to all organisms. These are replication, transcription, and translation.
It makes a copy of itself
Every cell in your body will divide through a process called mitosis. During this cell division, DNA copies itself via the process of replication.
So, how does DNA make a copy of itself?
Through a complex process involving enzymes, DNA uncoils into two single strands. Free nucleotides in the nucleus are bonded to each strand, complementing them and creating two exact copies.
DNA is the only molecule known to do this.
It sends blueprints to the cell to manufacture proteins
We mentioned earlier that DNA never exits the nucleus. So, what tells your cells what to do? This is where the process of transcription comes in. Through this process, DNA will create a blueprint that does exit the cell. This copy is known as RNA.
Transcription is an essential process to life as it sends the information out for cells to carry out their operations and manufacture large molecules called proteins, the building blocks of organisms. The process involves the uncoiling of DNA through specialized enzymes. Free nucleotides complement one of the strands, creating a unique strand (RNA) that acts as a blueprint that will exit the nucleus.
Many transcribed genes contain instructions for manufacturing proteins. This RNA will be read through the process of translation.
The genetic code
If you put together the words r, e, a, and d, you will get a grapheme that is “translated” into a sound; in this case, the word read. Similarly, a set of three consecutive nitrogenous bases are translated into a particular unit called an amino acid. Many amino acids put together form a protein.
This set of rules that determines what a gene in a DNA section stands for what amino acid is known as the genetic code. Simply put, the genetic code is used by living cells to translate encoded genetic information into proteins.
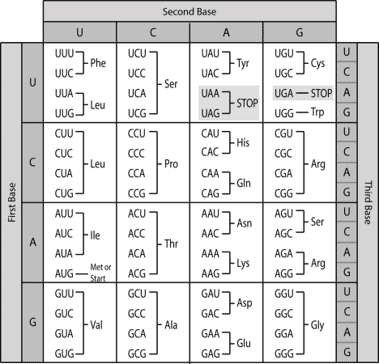
Just like in school you played games where you had to discover a secret message using a code, living cells will use this code to translate a “message” into actionable proteins.
Interesting facts about DNA and what it stands for
- The human genome has an approximate 3 billion base pairs. Out of all these, we share more than 99.9%. This means that less than 0.1% is what makes every one of us unique. Humans share the same anatomy and physiology; it is the slight variations that make us look different from the rest. Identical twins share 100% of their DNA.
- Genes are short sections of DNA that codify for proteins. The human genome contains about 20,000 genes. This comprises only 1.2% of the total genome. The rest of DNA used to be known as junk DNA until scientists continue to discover that it has some functions.
- Paternity DNA tests compare the DNA sequence between a child and a father.
- The genetic similarity between a human and a chimpanzee is more than 90%. Between humans and chickens, it is 60%.
- In 2012, Scientists at the University of Leicester printed the entire human genome into 130 book volumes that would take 95 years to read at a rate of one letter per second.
- Before 1943, it was believed that proteins stored genetic information.
How long is a DNA strand?
If you could uncoil the DNA in your chromosomes and stretch it out, it would be about 2 m (6 ft) long. Considering an estimated 37.2 trillion cells in your body, if you could put together every strand, the distance would be the equivalent of 96,000 round trips to the moon.
What are genes?
Genes are sections of DNA that codify for a protein. There are 20,000 of them in human DNA, which accounts for only 1.2%. The rest is noncoding DNA which scientists are only recently discovering has certain functions, like helping organize DNA in the nucleus and turning on and off gene expression.
Do all cells have the same DNA?
Yes, all living organisms have the same DNA but with different instructions among species.
What does DNA look like under a microscope?
You probably saw a project at a science fair called “DNA extraction.” In this case, DNA cells looked like strands of white noodles. But under a microscope, you can see the double-helix structure.
What is the difference between DNA and genes?
DNA is the molecule, and genes are sections of DNA. Take a look at the illustration below.
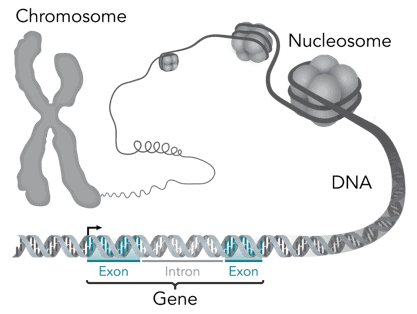
What is the difference between DNA and chromosome?
Chromosomes are packed bundles of DNA inside the nucleus. Every species has a distinct number of chromosomes in its cells.
What is the relationship between DNA bases and traits?
Traits in an organism are determined by the sequence of DNA bases.
Do all humans have the same DNA?
Yes, we do. In fact, we share about 99.8% of our DNA sequence.
Can a DNA test reveal if I have European ancestry?
Yes, a DNA test can reveal if you are more British than your brother, for example, by observing your DNA variations and comparing them to certain populations.
Get a reading of your DNA today!
DNA stands for deoxyribosenucleaic acid. There is a lot to DNA that we have been able to understand through the years. Your genome can reveal the genetic composition of your potential children or if your gene instructions make you more susceptible to a certain type of cancer. Through DNA, you can even find those ancestors you thought were lost.

In Nebula Genomics, we decrypt your entire DNA to provide you with the most comprehensive information of your genome. Imagine the whole new world that will unfold before your eyes! Our 30x Whole Genome Sequencing guarantees complete information on your genetic composition. Order your DNA test today!
Edited by Christina Swords, PhD
Want more information on DNA? Check out these other articles:
- The DNA Model: A History of the People and Science of the Double Helix
Last Update: Jan 03, 2023
This is a question our experts keep getting from time to time. Now, we have got the complete detailed explanation and answer for everyone, who is interested!
Asked by: Ms. Kasey Daniel
Score: 4.6/5
(55 votes)
Deoxyribonucleic acid is a molecule composed of two polynucleotide chains that coil around each other to form a double helix carrying genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid are nucleic acids.
What do the letters in DNA stand for?
Genetic Code
= The instructions in a gene that tell the cell how to make a specific protein. A, C, G, and T are the «letters» of the DNA code; they stand for the chemicals adenine (A), cytosine (C), guanine (G), and thymine (T), respectively, that make up the nucleotide bases of DNA.
What is DNA in full words?
= DNA is the chemical name for the molecule that carries genetic instructions in all living things. The DNA molecule consists of two strands that wind around one another to form a shape known as a double helix.
What does DNA stand for easy definition?
DNA, or deoxyribonucleic acid, is the hereditary material in humans and almost all other organisms. Nearly every cell in a person’s body has the same DNA.
What does DNA stand for and pronounce it?
English pronunciation of deoxyribonucleic acid.
31 related questions found
What is the most longest word?
Major dictionaries
The longest word in any of the major English language dictionaries is pneumonoultramicroscopicsilicovolcanoconiosis, a word that refers to a lung disease contracted from the inhalation of very fine silica particles, specifically from a volcano; medically, it is the same as silicosis.
What are the 3 types of DNA?
Three major forms of DNA are double stranded and connected by interactions between complementary base pairs. These are terms A-form, B-form,and Z-form DNA.
What does DNA look like?
What does DNA look like? The two strands of DNA form a 3-D structure called a double helix. When illustrated, it looks a little like a ladder that’s been twisted into a spiral in which the base pairs are the rungs and the sugar phosphate backbones are the legs. … In a prokaryotic cell, the DNA forms a circular structure.
Is DNA unique to each person?
Human DNA is 99.9% identical from person to person. … There are multiple ways our bodies ensure that we have a unique set of DNA that differs from our parents. For starters, you inherit two copies of each chromosome—one copy from your mom and one copy from your dad.
Where Is DNA Found?
Where is DNA found? In organisms called eukaryotes, DNA is found inside a special area of the cell called the nucleus. Because the cell is very small, and because organisms have many DNA molecules per cell, each DNA molecule must be tightly packaged. This packaged form of the DNA is called a chromosome.
What is difference between DNA and RNA?
Like DNA, RNA is made up of nucleotides. … There are two differences that distinguish DNA from RNA: (a) RNA contains the sugar ribose, while DNA contains the slightly different sugar deoxyribose (a type of ribose that lacks one oxygen atom), and (b) RNA has the nucleobase uracil while DNA contains thymine.
Who do you inherit your DNA from?
Your genome is inherited from your parents, half from your mother and half from your father. The gametes are formed during a process called meiosis. Like your genome, each gamete is unique, which explains why siblings from the same parents do not look the same.
What are DNA monomers called?
The monomers of DNA are called nucleotides. Nucleotides have three components: a base, a sugar (deoxyribose) and a phosphate residue. The four bases are adenine (A), cytosine (C), guanine (G) and thymine (T).
Why is DNA called a blueprint?
DNA is called the blueprint of life because it contains the instructions needed for an organism to grow, develop, survive and reproduce. DNA does this by controlling protein synthesis. Proteins do most of the work in cells, and are the basic unit of structure and function in the cells of organisms.
Is there DNA in a banana?
DNA contains a code for how to build a life-form and put together the features that make that organism unique. … Just like us, banana plants have genes and DNA in their cells, and just like us, their DNA determines their traits.
Does DNA determine your looks?
Did you know that your DNA determines things such as your eye color, hair color, height, a nd even the size of your nose? The DNA in your cells is respons ible for these physical attribute as well as many others that you will soon see.
What are the 3 functions of DNA?
DNA now has three distinct functions—genetics, immunological, and structural—that are widely disparate and variously dependent on the sugar phosphate backbone and the bases.
What DNA is present in humans?
There are two types of DNA in the cell – autosomal DNA and mitochondrial DNA. Autosomal DNA (also called nuclear DNA) is packaged into 22 paired chromosomes. In each pair of autosomes, one was inherited from the mother and one was inherited from the father.
Can DNA be washed away with water?
However, it is generally assumed that the water «erodes» a large part of the DNA depending especially on the exposure time. … All in all, the results demonstrate that DNA could still be recovered from clothes exposed to water for more than 1 week.
Where is DNA found in the human body?
Where Is DNA Contained in the Human Body? DNA is contained in blood, semen, skin cells, tissue, organs, muscle, brain cells, bone, teeth, hair, saliva, mucus, perspiration, fingernails, urine, feces, etc.
What is the shortest word?
Eunoia, at six letters long, is the shortest word in the English language that contains all five main vowels. Seven letter words with this property include adoulie, douleia, eucosia, eulogia, eunomia, eutopia, miaoued, moineau, sequoia, and suoidea.
What word takes 3 hours to say full word?
Pneumonoultramicroscopicsilicovolcanoconiosis (45 letters)
Which word takes 3 hours to say?
The word is 189,819 letters long. It’s actually the name of a giant protein called Titin. Proteins are usually named by mashing-up the names of the chemicals making them. And since Titin is the largest protein ever discovered, its name had to be equally as large.
What is DNA example?
Examples of extranuclear DNAs are mitochondrial DNA (mtDNA) and chloroplast DNA (cpDNA). … These organelles have their own genetic system that enables DNA replication and protein synthesis although certain proteins for replication and protein synthesis are still encoded by the nuclear DNA.

(Image credit: ImageFlow/Shutterstock)
DNA stands for deoxyribonucleic acid, and it’s a molecule that supplies the genetic instructions that tell living creatures how to develop, live and reproduce. DNA can be found inside every cell and is passed down from parents to their offspring.
What is DNA made of?
DNA is made up of molecules called nucleotides. Each nucleotide contains three components: a phosphate group, which is one phosphorus atom bonded to four oxygen atoms; a sugar molecule; and a nitrogen base. The four types of nitrogen bases are adenine (A), thymine (T), guanine (G) and cytosine (C), and together, these serve as the «letters» that make up the genetic code of our DNA.
DNA has a structure called a double helix. Nucleotides are attached together to form two long strands that spiral to create this structure. If you think of the double-helix as a ladder, the phosphate and sugar molecules would be the sides, while the base pairs would be the rungs. The bases on one strand pair with the bases on another strand: Adenine pairs with thymine (A-T), and guanine pairs with cytosine (G-C).
Human DNA is made up of around 3 billion base pairs, and more than 99% of those bases are the same in all people, according to the U.S. National Library of Medicine (opens in new tab) (NLM).
Related: How accurate are DNA tests?
Similar to the way that letters in the alphabet can be arranged to form words, the order of nitrogen bases in a DNA sequence forms genes, which, in the language of the cell, tell cells how to make proteins. The shorthand for this process is that genes «encode» proteins.
But DNA is not the direct template for protein production. To make a protein, the cell makes a copy of the gene, using not DNA but ribonucleic acid, or RNA. RNA shares a similar structure to DNA, except it contains only one strand, rather than two — so it looks like just one half of a ladder. In addition, while RNA has three of the four nitrogen bases in common with DNA, it uses a base called uracil rather than thymine to pair with adenine.
As a cell prepares to build a new protein, its DNA unzips to expose one strand of the gene with the instructions to build said protein. Then, an enzyme zooms in and constructs a new RNA molecule whose sequence mirrors that of the unzipped gene. This RNA copy, called messenger RNA (mRNA), tells the cell’s protein-making machinery which amino acids to string together into a protein, according to «Biochemistry (opens in new tab)» (W. H. Freeman and Company, 2002).
DNA molecules are long — so long, in fact, that they can’t fit into cells without the right packaging. To fit inside cells, DNA is coiled tightly to form structures called chromosomes. Each chromosome contains a single DNA molecule, wrapped tightly around spool-like proteins called histones, which provide chromosomes their structure. Humans have 23 pairs of chromosomes, which are found inside each cell’s nucleus, the control center of the cell.
Most chromosomes look like microscopic Xs; that said, humans and most other mammals carry a pair of sex chromosomes that can be either X or Y-shaped, according to the National Human Genome Research Institute (opens in new tab). In general, females carry two X sex chromosomes in each body cell and males carry one X and one Y. But there is some natural variation in the number of sex chromosomes people carry — sometimes, there may be extra sex chromosomes, or one might be missing, so other patterns, such as X, XXX, XXY and XXYY, can also occur, Discover reported (opens in new tab).
Who discovered DNA?

(opens in new tab)
DNA was first observed by Swiss biochemist Friedrich Miescher in 1869, according to a paper published in 2005 in the journal Developmental Biology (opens in new tab). Miescher used biochemical methods to isolate DNA — which he then called nuclein — from white blood cells and sperm, and determined that it was very different from protein. (The term «nucleic acid» derives from «nuclein.»)
But for many years, researchers did not realize the importance of this molecule.
In 1952, chemist Rosalind Franklin, who was working in the lab of biophysicist Maurice Wilkins, used X-ray diffraction — a way of determining the structure of a molecule by the way X-rays bounce off it — to learn that DNA had a helical structure. Franklin documented this structure in what became known as Photo 51.
In 1953, Wilkins showed the photo to biologists James Watson and Francis Crick — without Franklin’s knowledge. Armed with the information that DNA was a double helix and previous reports that the bases adenine and thymine occurred in equal amounts within DNA, as did guanine and cytosine, Watson and Crick published a landmark 1953 paper in the journal Nature (opens in new tab). In that paper, they proposed the iconic double-helix model of DNA as we now know it, with sugar-phosphate sides and rungs made up of A-T and G-C base pairs. They also suggested that, based on their proposed structure, DNA could be copied — and, therefore, passed on.
Watson, Crick and Wilkins were awarded the Nobel Prize in medicine in 1962 «for their discoveries concerning the molecular structure of nucleic acids and its significance for information transfer in living material.» Franklin was not included in the award, even though her work was integral to the research.
What is the function of DNA?
Genes encode proteins that perform all sorts of functions for humans (and other living beings).
The human gene HBA1, for example, contains instructions for building the protein alpha globin, which is a component of hemoglobin, the oxygen-carrying protein in red blood cells, according to the NLM (opens in new tab). To take another example, the gene OR6A2 encodes an olfactory receptor, a protein that detects odors in the nose, according to the National Center for Biotechnology Information’s Gene database (opens in new tab). Depending on which version of OR6A2 you have, you may love cilantro or think it tastes like soap, according to a study published in 2012 in the journal Flavour (opens in new tab).
Although each one of your 37.2 trillion cells carries a copy of your DNA, not all cells build the same proteins. One reason for this is that molecules called «transcription factors» latch onto DNA to control which genes get switched on and off, and therefore, which proteins get made when, where and in what quantities in each cell, Live Science previously reported. DNA also gets packaged slightly differently in different cell types, and this influences how and where transcription factors can grab onto the molecule.
In addition, epigenetics — which literally means «above» or «on top of» genetics — refers to external modifications to DNA that turn specific genes on or off.
For instance, small molecules called methyl groups can attach to a DNA strand and prevent specific genes from being expressed. Another example of epigenetics is called «histone modification,» where changes to the spool-like proteins inside chromosomes can make specific segments of DNA more or less accessible to the proteins that «read» genes. Such epigenetic changes to DNA can be passed onto future generations if the changes occur in sperm or egg cells, Live Science previously reported.
How is DNA sequenced?
DNA sequencing involves technology that allows researchers to determine the order of bases in a section of DNA. The technology can be used to determine the order of bases in genes, chromosomes or an entire genome. In 2000, researchers completed a «working draft» sequence of the human genome, according to the National Human Genome Research Institute (opens in new tab), and finished the project in 2003.
(opens in new tab)
DNA testing
A person’s DNA contains information about their heritage, and it can sometimes reveal whether they are at an elevated risk for certain diseases.
DNA tests, or genetic tests, are used for a variety of reasons, including to diagnose genetic disorders, to determine whether a person is a carrier of a genetic mutation that they could pass on to their children and to examine whether a person is at risk for a genetic disease. For instance, certain mutations in the BRCA1 and BRCA2 genes are known to increase the risk of breast and ovarian cancers, and a genetic test can reveal whether a person has these mutations.
Genetic test results can have implications for a person’s health, and the tests are often provided along with genetic counseling to help individuals understand the results and consequences.
People also use the results of genetic testing to find relatives and learn about their family trees through companies such as Ancestry and MyHeritage.
Additional resources and reading
- Learn about how much of your DNA is just «junk» with SciShow on Youtube (opens in new tab).
- Read more about how DNA testing works with Science News for Students (opens in new tab).
- Check out renowned science writer Carl Zimmer’s 2018 book, «She Has Her Mother’s Laugh: The Powers, Perversions, and Potential of Heredity (opens in new tab).»
Bibliography
Berg, J. M., Tymoczko, J. L., & Stryer, L. (2002). DNA, RNA, and the Flow of Genetic Information. In Biochemistry (5th ed.). chapter, W H Freeman & Co.
Dahm, R. (2005). Friedrich Miescher and the discovery of DNA. Developmental Biology, 278(2), 274–288. https://doi.org/10.1016/j.ydbio.2004.11.028 (opens in new tab)
Eriksson, N., Wu, S., Do, C. B., Kiefer, A. K., Tung, J. Y., Mountain, J. L., Hinds, D. A., & Francke, U. (2012). A genetic variant near olfactory receptor genes influences cilantro preference. Flavour, 1(1). https://doi.org/10.1186/2044-7248-1-22 (opens in new tab)
Incorvaia, D. (2021, September 28). Sex is more complex than a simple binary suggests. Discover Magazine. Retrieved January 14, 2022, from https://www.discovermagazine.com/the-sciences/sex-is-more-complex-than-a-simple-binary-suggests (opens in new tab)
NIH National Human Genome Research Institute. (2021, February 12). Human genome project timeline of events. Genome.gov. Retrieved January 14, 2022, from https://www.genome.gov/human-genome-project/Timeline-of-Events (opens in new tab)
NIH National Human Genome Research Institute. (n.d.). Sex chromosome. Genome.gov. Retrieved January 14, 2022, from https://www.genome.gov/genetics-glossary/Sex-Chromosome (opens in new tab)
U.S. National Library of Medicine. (2020, September 28). HBA1 gene. MedlinePlus. Retrieved January 14, 2022, from https://medlineplus.gov/genetics/gene/hba1/ (opens in new tab)
U.S. National Library of Medicine. (2022, January 5). OR6A2 olfactory receptor family 6 subfamily a member 2 [homo sapiens (human)] — gene — NCBI. National Center for Biotechnology Information. Retrieved January 14, 2022, from https://www.ncbi.nlm.nih.gov/gene/8590 (opens in new tab)
U.S. National Library of Medicine. (2021, January 19). What is DNA?: Medlineplus Genetics. MedlinePlus. Retrieved January 14, 2022, from https://medlineplus.gov/genetics/understanding/basics/dna/ (opens in new tab)
Watson, J. D., & Crick, F. H. (1953). Molecular structure of Nucleic Acids: A structure for deoxyribose nucleic acid. Nature, 171(4356), 737–738. https://doi.org/10.1038/171737a0 (opens in new tab)
Additional reporting by Alina Bradford and Ashley P. Taylor, Live Science contributors, as well as Live Science staff writer Nicoletta Lanese. This page was last updated on Jan. 26, 2022.
Originally published on Live Science.
Rachael is a Live Science contributor, and was a former channel editor and senior writer for Live Science between 2010 and 2022. She has a master’s degree in journalism from New York University’s Science, Health and Environmental Reporting Program. She also holds a B.S. in molecular biology and an M.S. in biology from the University of California, San Diego. Her work has appeared in Scienceline, The Washington Post and Scientific American.
Most Popular
Deoxyribonucleic acid—or DNA— is a molecule that serves as the hereditary material containing biological instructions that make every human and other organism unique. During reproduction, adult organisms pass their DNA and its set of instructions along to their offspring.
Verywell / Jessica Olah
The Structure and Makeup of DNA
DNA is made up of nucleotides, which are essentially chemical building blocks. Nucleotides join together in chains to form a strand of DNA, and contain three parts: a phosphate group, a sugar group, and one of four types of chemical bases:
- Adenine (A)
- Guanine (G)
- Cytosine (C)
- Thymine (T)
These chemical bases come together to create the information found in DNA, and stores it in a code, based on their sequence. A human genome—or the full set of instructions from DNA—contains about 3 billion bases and about 20,000 genes on 23 pairs of chromosomes.
Where DNA Is Found
DNA is found in nearly every cell of the human body. It is primarily located in the nucleus (where it is also referred to as «nuclear DNA»), though there is also a small amount in the mitochondria as well. Mitochondria are another part of human cells and are in charge of converting energy from food into a form that can power the cells. Collectively, all the nuclear DNA in an organism is known as its «genome.»
How DNA Works
The purpose of DNA is to instruct organisms—including humans—on how to develop, survive, and reproduce. In order for this to happen, DNA sequences—known as «genes»—are converted into proteins, which are complex molecules responsible for carrying out most of the work in human bodies. While genes vary in size—ranging from about 1,000 bases to 1 million bases in humans—they only make up approximately 1% of the DNA sequence. The rest of the DNA sequences regulate when, how, and how much of a protein is made.
It takes two separate steps to make proteins using instructions from DNA. The first is when enzymes read the information delivered in a DNA molecule and then transcribe it to a separate molecule called messenger ribonucleic acid, or mRNA. Once that happens, the information sent by the mRNA molecule is then translated into a language that amino acids—also known as the building blocks of proteins—can understand. The cell applies those instructions in order to link the correct amino acids together to create a specific type of protein. Given that there are 20 types of amino acids that can be put together in many possible orders and combinations, it gives DNA the opportunity to form a wide range of proteins.
The Double Helix
To understand how DNA works, it’s important to go back to the four chemical bases mentioned earlier: A, G, C, and T. They each pair up with another base in order to create units called «base pairs.» Then, each base also attaches to a sugar molecule and a phosphate molecule, forming a nucleotide. When arranged in two long strands, nucleotides form what looks like a twisted ladder or spiral staircase known as a «double helix.» Using the example of a ladder, the base pairs are the rungs, while the sugar and phosphate molecules form the vertical sides of the ladder, holding it all together.
The shape of the double helix is what gives DNA the capability to pass along biological instructions with great accuracy. This is the case because the spiral shape is the reason DNA is able to replicate itself during cell division. When it comes time for a cell to divide, the double helix separates down the middle to become two single strands. From there, the single strands function as templates to form new double helix DNA molecules, which—once the bases are partnered and added to the structure—turns out as a replica of the original DNA molecule.
Click Play to Learn All About DNA
The History and Discovery of DNA
In 1869, Swiss physician and biochemist Friedrich Miescher discovered a chemical substance in human leucocytes. His research focused on the chemical contents of a cell’s nucleus, and in order to get a better look at them, he examined pus on surgical bandages from the local hospital. Pus was known to contain large amounts of leucocytes, so Miescher purified their nuclei to better understand their makeup. In doing so, he was able to isolate a new chemical substance in the nucleus, which he named «nuclein»—but is known today as DNA. While there was a significant amount of research done on nucleic acids during and shortly after Miescher’s lifetime, it would take several more decades before scientists understood their significance.
There was a renewed interest in DNA starting in the 1930s, with many major discoveries soon following, including the understanding that DNA was responsible for passing along hereditary characteristics. The structure of DNA was also the subject of research in the 1930s, including that of English physicist and molecular biologist William T. Astbury, who suggested that DNA was a long and helical linear molecule.
The best-known DNA breakthrough came in 1953, when Rosalind Franklin, James Watson, Francis Crick, and Maurice Wilkins conducted research that would result in the discovery of the double helix model of DNA. Using X-ray diffraction patterns and building models, the scientists determined that the double helix structure of DNA enabled it to carry biological information from one generation to the next.
In 1962, Watson, Crick, and Wilkins were awarded the Nobel Prize in medicine for their discovery. Though Franklin would have been eligible to receive the prize, she died in 1958 from ovarian cancer at the age of 37, and the Nobel Prize rules stipulate that the award can’t be split among more than three people, or given out after someone has died.
A Word From Verywell
Like many scientists who researched genetics in the field’s early days, Watson was known to hold damaging—and scientifically inaccurate—beliefs on race, ethnicity, gender, and sexual identity, among other demographics. While the discoveries he made alongside his colleagues were significant, it’s also important to acknowledge aspects of his work that don’t hold up today.
Verywell Health uses only high-quality sources, including peer-reviewed studies, to support the facts within our articles. Read our editorial process to learn more about how we fact-check and keep our content accurate, reliable, and trustworthy.
:max_bytes(150000):strip_icc()/Yukophoto1-22fb13a563204bd5b63bd9f965095b8f.JPG)
By Elizabeth Yuko, PhD
Elizabeth Yuko, PhD, is a bioethicist and journalist, as well as an adjunct professor of ethics at Dublin City University. She has written for publications including The New York Times, The Washington Post, The Atlantic, Rolling Stone, and more.
Thanks for your feedback!
DNA Definition
Deoxyribonucleic acid, or DNA, is a biological macromolecule that carries hereditary information in many organisms. DNA is necessary for the production of proteins, the regulation, metabolism, and reproduction of the cell. Large compressed DNA molecules with associated proteins, called chromatin, are mostly present inside the nucleus. Some cytoplasmic organelles like the mitochondria also contain DNA molecules.
DNA is usually a double-stranded polymer of nucleotides, although single-stranded DNA is also known. Nucleotides in DNA are molecules made of deoxyribose sugar, a phosphate and a nitrogenous base. The nitrogenous bases in DNA are of four types – adenine, guanine, thymine and cytosine. The phosphate and the deoxyribose sugars form a backbone-like structure, with the nitrogenous bases extending out like rungs of a ladder. Each sugar molecule is linked through its third and fifth carbon atoms to one phosphate molecule each.
Functions of DNA
DNA was isolated and discovered chemically before its functions became clear. DNA and its related molecule, ribonucleic acid (RNA), were initially identified simply as acidic molecules that were present in the nucleus. When Mendel’s experiments on genetics were rediscovered, it became clear that heredity was probably transmitted through discrete particles, and that there was a biochemical basis for inheritance. A series of experiments demonstrated that among the four types of macromolecules within the cell (carbohydrates, lipids, proteins and nucleic acids), the only chemicals that were consistently transmitted from one generation to the next were nucleic acids.
As it became clear that DNA was the material that was transferred from one generation to the next, its functions began to be investigated.
Replication and Heredity
Every DNA molecule is distinguished by its sequence of nucleotides. That is, the order in which nitrogenous bases appear within the macromolecule identify a DNA molecule. For instance, when the human genome was sequenced, the nucleotides constituting each of the 23 pairs of chromosomes were laid out, like a string of words on a page. There are individual differences in these nucleotide sequences, but overall, for every organism, large stretches are conserved. The sugar phosphate backbone, on the other hand, is common to all DNA molecules, across species, whether in bacteria, plants, invertebrates or humans.
When a double-stranded DNA molecule needs to be replicated, the first thing that happens is that the two strands separate along a short stretch, creating a bubble-like structure. In this transient single-stranded region, a number of enzymes and other proteins, including DNA polymerase work to create the complementary strand, with the correct nucleotide being chosen through hydrogen bond formation. These enzymes continue along each strand creating a new polynucleotide molecule until the entire DNA is replicated.
Life begins from a single cell. For humans, this is the zygote formed by the fertilization of an egg by a sperm. After this, the entire dazzling array of cells and tissue types are produced by cell division. Even the maintenance of normal functions in an adult requires constant mitosis. Each time a cell divides, nuclear genetic material is duplicated. This implies that nearly 3 billion nucleotides are accurately read and copied. High-fidelity DNA polymerases and a host of error repair mechanisms ensure that there is only one incorrectly incorporated nucleotide for every 10 billion base pairs.
Transcription
The second important function of genetic material is to direct the physiological activities of the cell. Most catalytic and functional roles in the body are carried out by peptides, proteins and RNA. The structure and function of these molecules is determined by nucleotide sequences in DNA.
When a protein or RNA molecule needs to be produced, the first step is transcription. Like DNA replication, this begins with the transient formation of a single-stranded region. The single-stranded region then acts as the template for the polymerization of a complementary polynucleotide RNA molecule. Only one of the two strands of DNA is involved in transcription. This is called the template strand and the other strand is called the coding strand. Since transcription is also dependent on complementary base pairing, the RNA sequence is nearly the same as the coding strand.
In the image, the coding strands and the template strands are depicted in orange and purple respectively. RNA is transcribed in the 5’ to 3’ direction.
Mutation and Evolution
One of the main functions of any hereditary material is to be replicated and inherited. In order to create a new generation, genetic information needs to be accurately duplicated and then transmitted. The structure of DNA ensures that the information coded within every polynucleotide strand is replicated with astonishing accuracy.
Even though it is important for DNA to be duplicated with a very high degree of accuracy, the overall process of evolution requires the presence of genetic variability within every species. One of the ways in which this happens is through mutations in DNA molecules.
Changes to the nucleotide sequence in genetic material allows for the formation of new allele. Alleles are different, mostly functional, varieties of every gene. For instance, people who have B blood group have a certain gene resulting in a particular surface protein on red blood cells. This protein is distinct from the surface antigens in those who have blood group A. Similarly, people with sickle cell anemia have a different hemoglobin allele compared to those who do not suffer from the illness.
The presence of this variability allows at least some populations to survive when there is a sudden and drastic change to the environment. For instance, individuals carrying a mutated allele for hemoglobin are at risk for sickle cell anemia. However, they also have a higher chance of survival in regions where malaria is endemic.
These mutations and the presence of variability allow populations to evolve and adapt to changing circumstances.
Genetic Engineering
On another level, DNA’s role as genetic material and an understanding of its chemistry allows us to manipulate it and use it to enhance quality of life. For example, genetically modified crops that are pest or drought resistant have been generated from wild type varieties through genetic engineering. A lot of molecular biology is dependent on the isolation and manipulation of DNA, for the study of living processes.
Structure of DNA
When its definitive role in heredity was established, understanding DNA’s structure became important. Previous work on protein crystals guided the interpretation of crystallization and X-Ray differaction of DNA. The correct interpretation of diffraction data started a new era in understanding and manipulating genetic material. While initially, scientists like Linus Pauling suggested that DNA was perhaps made of three strands, Rosalind Franklin’s data supported the presence of a double helix.
The structure of DNA therefore, was elucidated in a step-wise manner through a series of experiments, starting from the chemical isolation of deoxyribonucleic acid by Frederich Miescher to the X-ray crystallography of this macromolecule by Rosalind Franklin.
Double Helix and Antiparallel Strands
The image is a simplified representation of a short DNA molecule, with deoxyribose sugar molecules in orange, linked to phosphate molecules through a special type of covalent linkage called the phosphodiester bond. Each nitrogenous base is represented by a different color – thymine in purple, adenine in green, cytosine in red and guanine in blue. The bases from each strand form hydrogen bonds with one another, stabilizing the double-stranded structure.
The structure of the sugar phosphate backbone in a DNA molecule results in a chemical polarity. Each deoxyribose sugar has five carbon atoms. Of these, the third and the fifth carbon atoms can form covalent bonds with phosphate moieties through phosphodiester bonds. A phosphodiester linkage essentially has a phosphate molecule forming two covalent bonds and a series of these bonds creates the two spines of a double-stranded DNA molecule.
Alternating sugar and phosphate residues results in one end of every DNA strand having a free phosphate group attached to the fifth carbon of a deoxyribose sugar. This is called the 5’ end. The other end has a reactive hydroxyl group attached to the third carbon atom of the sugar molecule and makes the 3’ end.
The two strands of every DNA molecule have opposing chemical polarities. That is, at the end of every double-stranded DNA molecule, one strand will have a reactive 3’ hydroxyl group and the other strand will have the reactive phosphate group attached to the fifth carbon of deoxyribose. This is why a DNA molecule is said to be made of antiparallel strands.
A DNA molecule can look like a ladder, with a sugar phosphate backbone and nucleotide rungs. However, a DNA molecule forms a three-dimensional helical structure, with the bases tucked inside the double helix. Hydrogen bonding between nucleotides allows the intermolecular distance between two strands to remain fairly constant, with ten base pairs in every turn of the double helix.
Complementarity and Replication
Nucleotide bases on one strand interact with those on the other strand through two or three hydrogen bonds. This pattern is predictable (though exceptions exist), with every thymine base pairing with an adenine base, and the guanine and cytosine nucleotides forming hydrogen bonds with each other. Due to this, when the sequence of a single strand is known, the nucleotides present in the complementary strand of DNA are automatically revealed. For instance, if one strand of a DNA molecule has the sequence 5’ CAGCAGCAG 3’, the bases on the other antiparallel strand that pair with this stretch will be 5’ CTGCTGCTG 3’. This property of DNA double strands is called complementarity.
Initially, there was debate about the manner in which DNA molecules are duplicated. There were three major hypotheses about the mechanism of DNA replication. The two complementary strands of DNA could unwind at short stretches and provide the template for the formation of a new DNA molecule, formed completely from free nucleotides. This method was named the conservative hypothesis.
Alternatively, each template strand could catalyze the formation of its complementary strand through nucleotide polymerization. In this semi-conservative mode of replication, all duplicated DNA molecules would carry one strand from the parent and one newly synthesized strand. In effect, all duplicated DNA molecules would be hybrids. The third hypothesis stated that every large DNA molecule was probably broken into small segments before it was replicated. This was called the dispersive hypothesis and would result in mosaic molecules.
A series of elegant experiments by Matthew Meselson, and Franklin Stahl, with help from Mason MacDonald and Amandeep Sehmbi, supported the idea that DNA replication was, in fact, semi-conservative. At the end of every duplication event, all DNA molecules carry one parental strand and one strand newly created from nucleotide polymerization.
Discovery of DNA
As microscopes started to become more sophisticated and provide greater magnification, the role of the nucleus in cell division became fairly clear. On the other hand, there was the common understanding of heredity as the ‘mixing’ of maternal and paternal characteristics, since the fusion of two nuclei during fertilization had been observed.
However, the discovery of DNA as the genetic material probably began with the work of Gregor Mendel. When his experiments were rediscovered, an important implication came to light. His results could only be explained through the inheritance of discrete particles, rather than through the diffuse mixing of traits. While Mendel called them factors, with the advent of chemistry into biological sciences, a hunt for the molecular basis of heredity began.
Chemical Isolation of DNA
DNA was first chemically isolated and purified by Johann Friedrich Miescher who was studying immunology. Specifically, he was trying to understand the biochemistry of white blood cells. After isolating the nuclei from the cytoplasm, he discovered that when acid was added to these extracts, stringy white clumps that looked like a tufts of wool, separated from the solution. Unlike proteins, these precipitates went back into solution upon the addition of an alkali. This led Miescher to conclude that the macromolecule was acidic in nature. When further experiments showed that the molecule was neither a lipid nor a protein, he realized that he had isolated a new class of molecules. Since it was derived from the nucleus, he named this substance nuclein.
The work of Albrecht Kossel shed more light on the chemical nature of this substance when he showed that nuclein (or nucleic acid as it was beginning to be called) was made of carbohydrates, phosphates, and nitrogenous bases. Kossel also made the important discovery connecting the biochemical study of nucleic acids with the microscopic analysis of dividing cells. He linked this acidic substance with chromosomes that could be observed visually and confirmed that this class of molecules was nearly completely present only in the nucleus. The other important discovery of Kossel’s was to link nucleic acids with an increase in protoplasm, and cell division, thereby strengthening its connection with heredity and reproduction.
Genes and DNA
By the turn of the twentieth century, molecular biology experienced a number of seminal discoveries that brought about an enhanced understanding of the chemical basis of life and cell division. In 1944, experiments by three scientists, (Avery, McCarty and McLeod) provided strong evidence that nucleic acids, specifically DNA, was probably the genetic material. A few years later, Chargaff’s experiments showed that the number of purine bases in every DNA molecule equaled the number of pyrimidine bases. In 1952, an elegant experiment by Alfred Hershey and Martha Chase confirmed DNA as the genetic material.
By this time, advances in X-Ray crystallography had allowed the crystallization of DNA and study of its diffraction patterns. Finally, these molecules could be visualized with greater granularity. The data generated by Rosalind Franklin allowed James Watson and Francis Crick to then propose the double-stranded helical model for DNA, with a sugar-phosphate backbone. They incorporated Chargaff’s rules for purine and pyrimidine quantities by showing that every purine base formed specific hydrogen bond linkages with another pyrimidine base. They understood even as they proposed this structure that they had provided a mechanism for DNA duplication.
In order to visualize this molecule, they built a three-dimensional model of a double helical DNA, using aluminum templates. The image above shows the template of the base Thymine, with accurate bond angles and lengths.
The final model built by Watson and Crick (as seen above) is now on display at the National Science Museum in London.
Quiz
1. Which of these statements about DNA is NOT true?
A. In eukaryotes, DNA is present exclusively in the nucleus
B. DNA is the genetic material for some viruses
C. DNA replication is semi-conservative
D. None of the above
Answer to Question #1
A is correct. Even in eukaryotes, DNA does exist outside the nucleus. Organelles such as mitochondria and chloroplasts carry some DNA molecules.
2. Which of these scientists designed an experiment to show that DNA replication was semi-conservative?
A. Meselson
B. James Watson
C. Linus Pauling
D. All of the above
Answer to Question #2
A is correct. Among these three scientists, only Meselson was involved in the design of the experiment that showed how DNA was replicated. Linus Pauling was involved in developing X-Ray crystallography as a method for understanding the structure of biological macromolecules. James Watson used the X-Ray diffraction data generated by Rosalind Franklin to propose the double helical model for the three-dimensional structure of DNA.
3. Why was the rediscovery of Mendel’s experiments important for the development of molecular biology?
A. Mendel’s experiments suggested that DNA was the hereditary material
B. Mendel’s laws of inheritance suggested that there were discrete biochemical particles involved in heredity
C. Mendel’s experiments with pea plants gave molecular biologists a useful model organism
D. All of the above
Answer to Question #3
B is correct. Until Mendel experimented with pea plants, it was never clear how heredity was achieved. Though the gross mechanisms involved were always known, the details were never clear. Common knowledge seemed to suggest that traits reached an ‘average’ between parents. For instance, with one tall parent and a short parent, the offspring was usually of intermediate height. Similarly for skin coloring and so on. However, once Mendel had done his experiments using true breeding specimens, it was fairly clear that discrete particles were being inherited. This, along with advancements in chemistry, allowed the development of molecular biology and biochemistry as fields of study. There was nothing in Mendel’s experiments to suggest that DNA was the genetic material. In addition, Mendel’s pea plants are not really preferred as model organisms because of the vast areas needs to cultivate the specimens and their long generation time.
References
- Alberts, Bruce, et al. (2002). Molecular Biology of the Cell, 4th. ed. Ch. 4. Garland Science: New York. ISBN: 978-0815316206.
- Lodish H, et al., (2000) Molecular Cell Biology. 4th ed. W. H. Freeman: New York. ISBN-10: 0-7167-3136-3.
- Nobel Media AB (2014) “The Nobel Prize in Physiology or Medicine 1910” Nobelprize.org. Retrieved 10 May 2017 from http://www.nobelprize.org/nobel_prizes/medicine/laureates/1910/

DNA stands for DeoxyriboNucleic Acid
Contents
- 1 DNA stands for DeoxyriboNucleic Acid
- 2 DNA and what exactly does it stand for?
- 3 Modern biology
- 4 DNA technology
DNA, the acronym for Deoxyribonucleic Acid, stands for the key foundation on which the structure of life is built.
DNA and what exactly does it stand for?
Deoxyribose – This is sugar, known chemically as a pentose, a five-carbon sugar.
Nucleic – Refers to the location of DNA inside the nucleus. The molecule was originally called ‘nuclein’ by Frederick Miescher, the man who discovered DNA in 1869.
Acid – It is phosphoric acid.
It is the set of instructions contained within the DNA and the difference in these instructions from one DNA to the other that results in one human being different from the other.
 The difference that we are talking about here is not only regarding different hair color and facial features but that these human beings even differ in the way they react to the same situation and same environment.
The difference that we are talking about here is not only regarding different hair color and facial features but that these human beings even differ in the way they react to the same situation and same environment.
It is very interesting to note that although each cell of the human body holds the same DNA, the structures of different parts of the body even though based on this same DNA are very different.
Modern biology
Modern biology has found out that this is due to the fact that different areas of DNA are active in different parts of the body. That’s why DNA in blood cells produces what is required for the blood and DNA in muscle cells build proteins that are needed by muscles.
DNA stands for the progression and advancement in modern-day biotechnology. Nowadays the biotechnology industry has become a lucrative business. There are many firms studying and synthesizing DNA all around the world from Washington D.C. to Tehran and Hong Kong for example.
Developments in biology and especially genetic studies have pretty much answered the question of “What does DNA stand for?”.
Thanks to James Watson and Francis Crick, it’s already more than 50 years that the structure of DNA was explained in precise detail.

DNA technology
However, not all that DNA stands for is good. DNA has changed the concept of security and defense for a country because of the dangers it faces from the development of biological weapons.
These biological weapons, based on DNA technology, can be exploited to not only paralyze but also demoralize a nation by causing a devastating breakout of viral, infectious, and untreatable diseases.
Many terms of the known and curable diseases have been improvised to become more dangerous and incurable. Dirty bombs are easy to be manufactured with this knowledge, as they do not require high technology or heavy investment.
If these bombs ever fall in the wrong hands they can cause a high-security risk globally. So all is not fine about DNA’s discovery, we have to be very careful about the ill uses of this technology.
What is DNA?
Simply put, DNA (Deoxyribonucleic Acid) is a string of nitrogenous bases (Adenine, Thymine, Guanine, and Cytosine) repeated over and over, and arranged in a seemingly random fashion. Here the genetic code is contained. These bases are connected to each other through chemical bonds. Two complementary strands of DNA are bonded to each other, and are twisted in a helical structure. This extremely long double-stranded twisted string has parts that code for everything in all organisms. Different parts are under different selection pressures.
Below we will outline the history, structure of DNA, the differences and similarities between DNA and RNA. After this, we will then dive into why DNA is so important. Given how important this structure is, we will also talk about how it is replicated (DNA replication), packaged, and how these can be exploited or used for DNA fingerprinting.
History of DNA
The discovery of the structure of DNA opened many avenues in the field of biology. In 1962, Watson, Crick, and Wilkins obtained a Nobel Peace Prize for describing it. However, its existence was known of before that. In 1866, Gregor Mendel first hypothesized the existence of inherited entities, now known as genes. Later on (1869), Friedrich Miescher noted an acidic substance in the cell’s nuclei; this substance was referred to as nuclein (we now know this as DNA). Rosalind Franklin captured the famous X-Ray imagery clearly showing its double helical nature. It is her work together with that of the above-mentioned Nobel Laureates that gave us the gold mine (DNA) that has led to advances in all fields of biology; most notably, medicine.
This part of the DNA story is a lot more complex than this, but we will end here for the purpose of this lesson.
DNA Structure
DNA is a nucleic acid, hinted at in the name. Nucleic acids are the building blocks of all living organisms. Nucleotides simply refer to nitrogenous bases, pentose sugar together with the phosphate backbone. Nucleotides are adjacently strung together through a phosphate backbone and are held together with their complements through hydrogen bonds. The number of bonds holding nucleotides from the complementary strands depends on the type of nitrogenous base the nucleotide contains.

A nitrogenous base is a molecule with nitrogen that possesses the chemical properties of a base. These are crucial to the DNA as they define the genetic code (they are the code!). The pentose sugar connects the nitrogenous base to the phosphate backbone. There are four kinds of nitrogenous bases; namely, thymine (T), cytosine (C), adenine (A) and guanine (G). Guanine and adenine are purines while thymine and cytosine are pyrimidines. Purines have two rings (see adenine on figure 2) while pyrimidines have one ring. For the structure of the DNA to be able to twist and be packaged accordingly without bulging and the opposite bases to be able to pair up, a purine has to fit in a pyrimidine. To this end, the purine guanine pairs with the pyrimidine cytosine and the purine adenine pairs with the pyrimidine thymine.

Differences and Similarities between DNA and RNA
Both molecules are nucleic acids made up of nucleotides, supported by a phosphate backbone. They are both major players in the central dogma. RNA is transcribed from the DNA to make proteins. DNA carries all the information needed for DNA replication and transfer new information to new cells.
They are involved in the maintenance, replication, and expression of hereditary information. DNA holds the key to heredity. RNA helps DNA unlock this code and show us what this code is capable of achieving. Together these molecules ensure that the DNA is replicated, the code is translated, expressed and that things go where they should go.
DNA and RNA work hand in hand in biology. It is rare that one can speak of the one without bringing up the other. Simply put, they are connected by the central dogma. The central dogma is the process of DNA transcription and translation for the purpose of protein synthesis which then perform a multitude of tasks in organisms. Different types of proteins guide the gene expression. Therefore, even though the DNA is the same throughout- different things happen at different part of the body. In addition to this, it also tells stem cells what to differentiate to. This is due to strict regulatory mechanisms in place to control gene expression.
Both DNA and RNA have a negative backbone (because of the phosphate group). They both have four nucleotides each, three of which they share (Guanine, Cytosine, and Adenine); with one significant difference, DNA has Thymine while RNA has Uracil. DNA is double-stranded while RNA is single-stranded. Last but not least, DNA is found in the nucleus while RNA resides both in the nucleus and the cytoplasm. DNA is long-lived while RNA is regenerated with each reaction.
They are both central to cell function.
DNA Packaging
How does DNA fit into the cell? Consider this; each and every one of your cells contains approximately 6 billion base pairs of DNA, with each base pair being 0.34 nanometers long. This works out to about 2 meters of DNA per diploid cell! If the DNA sequence is so long how does the nucleus manage to house the DNA and many other components necessary for the functioning of the cell? The answer is very simple, through condensing and packaging.
DNA is packaged with the help of histone proteins. Histones are small proteins with basic, positively charged amino acids; namely, arginine and lysine. They bind and neutralize the negatively charged DNA (because of the negatively charged phosphate backbone). It takes five types of histones to package DNA; H1, H2A, H2B, H3, and H4. Core histones (H2A, H2B, H3, and H4) with DNA coiled around them are referred to as nucleosomes. It takes two of each of the core histones to make up a nucleosome. Per nucleosome an H1 histone sits outside the coil holding the nucleosome intact. The nucleosome together with histone H1 are collectively referred to as chromatosome. The nucleosomes are condensed to fibers called chromatin. Bigger loops of tightly packed chromatin then make chromosomes.

Keeping DNA in a coiled and inaccessible state ensures DNA safety. As you can imagine, with this much coiling, twisting and packing the DNA is not accessible for transcription and/ or replication. This becomes redundant if the DNA cannot perform its functions. For DNA to perform its functions it needs to be unpacked and made accessible again. It is in this state that DNA can be replicated in order to, amongst other things; accommodate organism’s growth and maturity through cell division facilitated by DNA replication to ensure there is sufficient DNA in every cell.
DNA Replication
To understand DNA replication you will need to keep the following in mind:
– Replication duplicates the genetic information; this means you end up with a collection of identical DNA strands.
– The rules of DNA replication (A to T; G to C) govern replication.
– Each of the two strands DNA serves as a template of the new strand.
-DNA replication is essential for cell division.

DNA replication takes place in 5’®3’ direction. This means that bases will be added from left to right direction. The template strand will guide this process by telling the new strand which base comes next, this will go on until the new strand is complete and the DNA will once again be double-stranded. Both strands of the old DNA will serve as templates of two new strands. This means that at the end there will be two double-stranded DNAs, identical to each other. This way once cell division occurs, the new cells will contain identical information as the rest of the body. A slew of proteins oversee the whole process make sure things happen at the right time and in the right way.

Due to the complementary nature of DNA, one strand is in the 5’®3’ direction while the other is in the 3’®5’ direction. The fore is referred to as the lagging strand while the latter is called the leading strand.
In preparation for DNA replication, the double-strand unwinds and separate to form replication forks. Each template strand attracts the complements to the now exposed bases; this happens in a stepwise fashion. The back-bone solidifies and the DNA rewinds. This is a very simplified version of the process. What follows is the detailed version with the enzymes involved to guide the process.
An enzyme called helicase unwinds the template strands. The single strand binding proteins then stabilize the template strands in preparation for the replication, it holds it open until the end of the replication process. DNA polymerase III synthesizes nucleotides onto the leading end in the 5’®3′ direction.
The replication directed by the lagging strand, however, is a little more complicated. Helicase can only synthesize in the 5’®3′ direction, this poses a problem where the only available direction is 3’®5’. To get around this, Okazaki fragments are synthesized. Primase, as the name suggests, primes the synthesis of the new strand through synthesizing RNA primers to direct the addition of Okazaki fragments. Okazaki fragments are added onto the lagging strand by DNA ligase bonding the 3’ end to the 5’ of the previous fragment. The primers that prime the addition of the Okazaki fragments are then removed by DNA polymerase I and replaced by DNA bases. At the end of the process after the removal of the last primer there is an exposed 3’ end. DNA polymerase III completes the synthesis of the new strand, by adding DNA nucleotides at the end of the new strand. Nuclease provides proofreading services, correcting mistakes made during replication. As you can imagine, there will be a very tight coil at the end of the replication fork. Topoisomerase fixes this problem by making a small nick that releases the tension build up.
DNA Comparison and DNA Fingerprinting
DNA information has been used in comparative studies in order to understand not just where we stand as a species in the animal kingdom but where other species fit and how their genetic make-up influences their way of living. DNA fingerprinting, also called DNA profiling, refers to a technique of using a collection of individual specific regions of their genome. This is based on the idea that different combinations of various regions of the genome are very unlikely to be shared across individual. So, for example even though some of these sections can be shared between family members it is highly unlikely that they would all be identical between family members.
Different parts of the DNA code are under stricter selection pressures. This fact is one of the most exploited properties of the genome when studying organisms at different levels (e.g. population level, species level, genus level, etc.). Gene regions such as those coding for the internal transcriber region of the ribosome are under somewhat strict controls, and these evolve relatively slow. These, can, therefore, be used to study variations at the species level (species level marker). Other markers are under very little to no selection (neutral selection) and therefore evolve more freely, for example, simple sequence repeats such as micro satellites. These are more informative and can be used to study population dynamics. Some areas evolve so fast that they can be used to identify and different between individuals in a population to differentiating between individuals born of the same parents.

Using regions in the nuclear DNA to identify individuals, species or higher taxa is what we refer to as DNA bar coding. To study population dynamics markers such micro-satellites prove useful as their polymorphic profile can tell us a lot about how often intra and inter-breeding occur within and across populations. It can also give clues to infer modes of dispersal. To study evolutionary processes and phylogenetic relationships slow evolving markers such as mitochondrial DNA can be used. These can tell us where species sit in the bigger picture.
There are a large variety of fields in biology that exist because of the ability to study and manipulate the DNA code. These include fields such as genetic engineering; this is how you can enjoy summer fruits in winter. Other fields include gene therapy; here biologists use the knowledge of the genome to manipulate specific parts of the genome to remove lethal variants of some genes. The availability of techniques such as DNA fingerprinting also helps to better understand genetic diseases, and with the help of research such as that into CRISPR-CAS9, hopefully, enable us to cure diseases such as cancer.
Is DNA Important?
The simple answer is, yes, very much so. We hope at this point you agree with this answer. Just think of all the things DNA code for (pretty much everything). Now imagine life without them. What is left? Is any of it biotic?
DNA is what makes you special, alive and functional. Without DNA you would not exist. Everything you have, the thing you consider your best feature would not exist without DNA. DNA directs cell function. If there was no DNA, cell division would not happen—therefore no differentiation, this means you would not exist neither would your pet. Even though DNA is not solely responsible for life as we know it is still arguably the most important factor. Other factors include the environment and experience.
DNA is important for many reasons—so many in fact that we cannot list them all. To name a few it is important in the fields of genealogy, forensic science, agriculture, and virology.
Conclusion
In conclusion, DNA forms the basis for life. The discovery of the DNA structure has led to major strides in research, medicine, agriculture and many other fields. Given how important this structure is to our existence, it only makes sense that its description has affected so many areas of our lives. We hope at this point you have as much appreciation as we do for what DNA is and can do, how is differs from RNA, how many lives it has revolutionized and DNA fingerprinting. At this point, you should also have an appreciation for what DNA is in biology and what it means for this field.
Featured Image Source
Let’s put everything into practice. Try this Biology practice question:
Looking for Looking for more Biology practice?
Check out our other articles on Biology.
You can also find thousands of practice questions on Albert.io. Albert.io lets you customize your learning experience to target practice where you need the most help. We’ll give you challenging practice questions to help you achieve mastery in Biology.
Start practicing here.
Are you a teacher or administrator interested in boosting Biology student outcomes?
Learn more about our school licenses here.
- Your genome is made of a chemical called deoxyribonucleic acid, or DNA for short.
- DNA contains four basic building blocks or ‘bases’: adenine (A), cytosine (C), guanine (G) and thymine (T).
- The order, or sequence, of these bases form the instructions in the genome.
- DNA is a two-stranded molecule.
- DNA has a unique ‘double helix’ shape, like a twisted ladder.

An illustration to show the double helix structure of DNA.
Image credit: Genome Research Limited
- Each strand is composed of long sequences of the four bases, A, C, G and T.
- The bases on one strand of the DNA molecule pair together with complementary bases on the opposite strand of DNA to form the ‘rungs’ of the DNA ‘ladder’.
- The bases always pair together in the same way, A with T, C with G.
- Each base pair is joined together by hydrogen bonds.
- Each strand of DNA has a beginning and an end, called 5’ (five prime) and 3’ (three prime) respectively.
- The two strands run in the opposite direction (antiparallel) to each other so that one runs 5’ to 3’ and one runs 3’ to 5’, they are called the sense strand and the antisense strand, respectively.
- The strands are separated during DNA replication.
- This double helix structure was first discovered by Francis Crick and James Watson with the help of Rosalind Franklin and Maurice Wilkins.
- The human genome is made of 3.2 billion bases of DNA but other organisms have different genome sizes.
This page was last updated on 2022-02-18