
Creating sentences (writing)
Often the focus in classrooms is on producing whole texts; however, it is important to give students explicit opportunity to pay attention to writing at the text, sentence and word levels (Rose and Martin 2012).
Text level requires attention to patterns that are evident in different genres (e.g. passive voice in an explanation, abstract nouns in an argument) as well as to the ways in which the parts of the text are linked (e.g. through the use of connectives) (Derewianka, 2011).
Sentence level requires examination of the ways in which clauses are combined or how clauses relate to each other (e.g. relationships of time, place, causality) (Derewianka, 2011). Word level attends to the individual words or groups of words such as nouns/ noun groups. (Derewianka, 2011).
The following strategies support students to focus on the construction of sentences and to develop confidence in talking about their writing. Both also offer students the experience of exploring articulating both the language choices they have made and exploring the effect of their writing on others (VCELY395 and
VCELY396).
Quaker share
A Quaker Share (Dawson 2009) is used to support students to share their own writing in a group, to build confidence about reading aloud, and to provide them with opportunities to explore the impact of their writing on others.
A traditional Quaker Share is loosely structured in the following ways:
- Students read aloud a few of their sentences to the group.
- The reading moves around the group, but no comments are made about what is read.
- Students can be encouraged to record things they hear that they find enjoyable or particularly interesting.
- Once each member of the group has shared some of their writing, they discuss how it felt to read to a group who is quiet and listens.
This activity can be adapted and focused in in many ways, depending upon the context of the group and purpose of learning. Always consider the ways that you may employ this strategy so that your students feel comfortable to share their writing. The teacher may decide that on the first occasion students share with a small group but then progress to a larger group as confidence is developed.
In the context of narrative writing, the teacher might ask for students to share a paragraph that includes 2-3 sentences that use expanded noun groups well (for example, ‘a kind-hearted soul in the shape of a lonely old man leaning on the window’) or employs particular types of figurative language such as metaphor or simile (for example, ‘like a hungry lion grabbing free meat’).
Students can be led in a sharing time once the reading has completed, where they reflect on their experiences reading their work aloud, and experiences of listening to others. What did they learn about language and their own writing through this process?
Supports and scaffolds can be adjusted for differing student abilities and confidence, particularly for students for whom English is an additional language/dialect.
If the activity is done regularly through writing units, students can build up reflections on the writing process in a writing journal.

Celebrating sentences
Hattie and Timperley (2007) remind us of the vital role of
feedback on student learning.
Building on the Quaker Share strategies, Celebrating Sentences is designed to:
- support the sharing of writing at the level of sentences in the classroom
- to draw attention to the way language creates meaning and effect
- to encourage students to feel empowered as writers.
This strategy is used when students are peer conferencing a piece of writing, such as an argumentative text.
They are asked to highlight two to three sentences in the paragraph, or paragraphs they are reading that they find convincing. Both students (writer and reader) are then tasked with identifying what makes these sentences convincing, and then applying this learning to another part of the text.
For example, the following sentence from a Year 8 persuasive essay on compulsory sport might be highlighted by the student writer’s peer:
Secondly, compulsory sport is a negative experience for students who are not good at sport.
Some students feel embarrassed, degraded, and belittled about their skill levels and might be bullied by their team mates because they aren’t very good at sport.
16% of students in America are overweight, they need to do some activity but compulsory sport is not the solution. A school psychologist called Emma says that for some students, sport is an ‘uncomfortable experience’. If students
feel bad about themselves then they might quit sport as adults which
will be bad for their health. This means that compulsory sport can have a bad impact on students’ wellbeing.
The questions students might ask each other are:
- Which words have an impact on the reader? They might notice the sensing verb
‘feel’ and evaluative adjectives embarrassed, degraded, and belittled which present negative feelings. - What might this mean for other sentences that are not as persuasive? They might notice
will be bad and
might be bullied to consider more effective use of modal verbs and intensifying or modal adverbs (for example, possibly, probably, certainly, definitely) to suggest the degree of likelihood or probability of the occurrence of feelings. The table below assists student to build verb groups in this and other activities.
Experimenting with modal verbs and modal adverbs (intensifiers)
| ‘Everyday language’ | More precise language with modal adverbs (intensifiers) | |
|---|---|---|
| low modality | might feel bad | might possibly experience discomfort or embarrassment or might possibly have an impact on student confidence |
| medium modality | will feel bad | will probably experience discomfort and embarrassment or would probably have a significant impact on student confidence |
| high modality | will absolutely feel bad | will definitely experience discomfort and embarrassment or would certainly have a significant impact on student confidence |
Students can write the sentences they are celebrating on a shared digital space (such as a word document or padlet.com). The teacher can then lead a discussion of the characteristics of the celebratory sentences. This can provide opportunities for the class to see and understand what makes successful writing in the particular genre being studied, such as the examples detailed below that explore the use of modality in persuasive texts.
Discussion of the example sentences could include discussion points such as the following:
- Modal verbs of different strength such as might, will, must can modulate the writer’s stance or position.
- Modal adverbs or intensifiers of different strength such as possibly, probably, certainly can also modulate the writer’s stance or position.
- More precise language choices such as ‘experience’ instead of ‘feel’, ‘discomfort’ or ‘embarrassment’ instead of ‘bad’ suggest a stronger sense of negative attitudes or feelings.
- Including a noun group such as ‘a significant impact on student confidence’ is more ‘written like’ or academic language and provides a sense of the author’s authority or expertise on the topic.
Identifying key vocabulary (writing)
Helping students to identify key words about their topic before they commence the writing process is an important way to build vocabulary.
Word cline
A word cline is an effective strategy that helps students to reinforce their understanding of the meaning of words and to extend their vocabularies. The word cline comes from the Greek word clino – to slope.
A word cline, therefore, is a graded sequence of words whose meanings are arranged in a continuum that is usually shown on a sloping line. The purpose of the activity is to have students discuss and explore the subtle shifts in meaning that occur when language is arranged in a graduated manner. This strategy can be used in all forms of writing, including, narratives, imaginative and persuasive texts.
| Verb | walk | pace, tread, stroll, saunter, march, amble, hike, promenade |
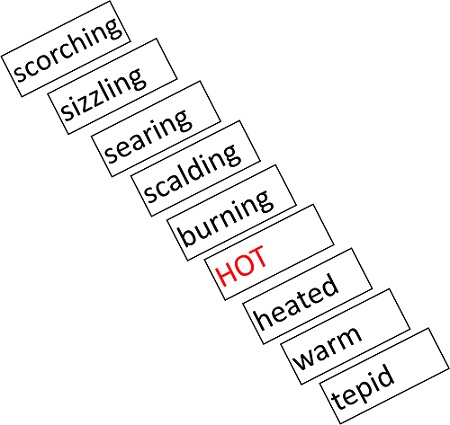
| Adjective | hot | burning, scorching, blistering, sizzling, searing, broiling, warm, tepid, scalding, heated |
| Adverb | slowly | gradually, leisurely, unhurriedly, sluggishly, gently |
Word cline for the adjective ‘hot’
Word cline for the verb ‘states’
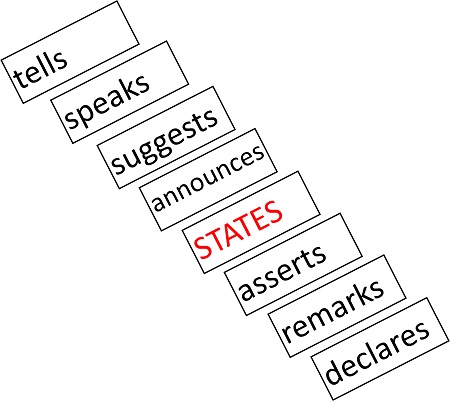
At the Year 7 level, word clines help students investigate how language works and prepare students for their own writing (VCELA371,
VCELY387).
Word clines for verbs are helpful scaffolds that assist students’ discussion of word choices and shades of meaning, setting them up well for textual analysis in the later secondary years (VCELA474).
Sentence starters (writing)
When students begin to write more sustained pieces of written work, one of the challenges they often face is being able to vary the language used to open new paragraphs.
Teachers can help students to experiment with their language, through the explicit teaching (HITS Strategy 3) of sentence starters. This strategy supports students to build their repertoire of text connectives so that they develop cohesion in their writing.
Using sentence starter lists
A useful way for students to learn to build sentence starters into their own work is to provide them with a list of words that relate specifically to the text type or genre they are creating.
The most appropriate text connectives to use are the ones that fit the purpose of the writing. For example, the text connectives in a narrative indication time are used to sequence events chronologically, often at the beginning of the sentence. For example, after that, after a while, then.
In an exposition, a range of text connectives might be used for different purposes. For example:
- additive, also, moreover; causative
- as a result, consequently, conditional/concessional
- otherwise, in that case, however, sequential
- to begin with, in conclusion; clarifying
- for instance, in fact, in addition.
For the purposes of this activity, focus on the text connectives that can be used at the beginning of sentences.
To clarify
- in other words
- in other words
- to put it another way
- for example
- for instance
- in particular
- in fact
- as a matter of fact
- namely
To show cause/result
- therefore
- then
- consequently
- as a consequence
- as a result
- accordingly
- in that case
- due to
- for that reason
To indicate time
- then
- next
- afterwards
- previously
- meanwhile
- later
- earlier
- finally
- in the end
To sequence ideas
- firstly
- to begin
- at this point
- then
- finally
- all in all
To add information
- furthermore
- also
- moreover
- likewise
- equally
- above all
- again
To concede
- in that case
- otherwise
- however
- besides
- despite
- still
- instead
(Adapted from Derewianka, Beverly. (2011) A New Grammar Companion for Teachers. NSW, PETA.)
In addition to highlighting text connectives, students can be taught about the ways in which dependent clauses and prepositional phrases are used at the beginning of sentences to create particular narrative effect.
For example, after a second of wondering, they ran through the door… In the enchanted forest on a magical land far, far away, three pixies were sleeping under a tree …In an exposition, passive voice might be used to foreground the object e.g. When the rainforests are burnt to make way for palm oil plantations, the orangutans’ habitat is destroyed.
Curriculum link for the above example:
VCELA414.
Supporting student spelling (reading and viewing, writing)
Developing spelling knowledge is best undertaken contextually, through the production of texts. The spelling strategies below, conducted in the context of meaningful interaction with texts, take a number of forms that increase in complexity, including strategies which develop knowledge at four levels:
- Phonological knowledge — knowledge of the sound structure of language.
- Visual knowledge — knowledge of the system of written symbols used to represent spoken language.
- Morphological knowledge — knowledge of the smallest parts of words that carry meaning.
- Etymological knowledge — knowledge of the origins of words (Oakley & Fellowes, 2016, p.6).
We might also translate this knowledge into simpler terms:
- Phonological strategies: how words sound.
- Visual strategies: how words look.
- Morphological strategies: how to find meaningful parts within words.
- Etymological strategies: how the origin of words determine spellings.
Teachers should consider how to incorporate these spelling strategies into the teaching of genre and text types, as a way of building and extending vocabulary.
While the Look, Say, Cover Write, Check (LSCWC) approach has dominated English classrooms for decades as the primary strategy for teaching spelling, research has found that this approach provides minimal transfer to later independent writing and that students lack the ability to use this strategy to generalise (Beckham-Hungler et al, 2003).
The memorisation of whole words from lists that are then assessed through weekly spelling tests does not represent best practice, and research has shown that successful spellers use a greater variety of strategies compared to poor spellers (Critten, Connelly, Dockrell & Walter, 2014).
Systematic instruction in spelling is important, however, it should take place in the context of general principles and sound policy towards writing.
In addition to
inquiry-based approaches to teach spelling, Winch et al. (2012) describe the following principles which should be kept in mind when supporting students to develop connections between spoken and written words:
- The language skills of reading, writing, listening and speaking are inextricably linked.
- The main responsibility of a teacher is to motivate students to write clearly over a wide range of text-types.
- Shared, guided and independent writing activities will help students to write more confidently.
- The teacher should assist where advice is most likely to be noticed and acted upon, namely at the individual student’s point of need.
- The teacher should encourage a habit of self-correcting when students write (p.329).
Segmenting
Phonological knowledge refers to knowledge about the sounds in language. It is an important part of learning to write (and read). As part of learning to spell, students need to develop phonological awareness, that is, the ability to hear, identify, and manipulate syllables, rhymes and individual sounds (phonemes) in increasingly complex words (VCELA475).
One way to improve spelling is through segmenting activities. Segmenting is the ability to split words into their separate speech sounds. Segmenting advances in complexity, from:
- sentence segmentation
- to syllable segmenting and blending
- to blending and segmenting individual sounds (phonemes).
It cannot be assumed that all students in the secondary years have successfully developed phonological knowledge, and secondary English teachers may find it useful to introduce sentence segmenting activities (below) before moving onto to more complex segmenting approaches.
Segmenting at the word level begins with an emphasis on syllables. Teachers should begin with one and two syllable words, asking students to sound-out aloud each syllable in a word (as in ‘to-pic’, ‘no-vel’, ‘po-em’). Students can be encouraged to clap as they complete this activity which will allow them to make stronger connections between individual sounds and syllables. Progression can be made by adding two-three syllable words, and so on.
For some students in secondary school, there might be a need to identify individual sounds (phonemes) in words and to provide support in blending sounds or using onset-rime activities to decode words.
Onset-rime activities involve breaking words into their onsets (consonants before the consonants), and the rime (everything left in the word).
For example, the rime «own» as in «down» could have different onsets to make words such as:
- fr-own
- t-own
- cl-own.
This use of segmenting, from the sentence to syllable to phoneme, will help develop phonological awareness and an understanding of the relationship between sounds and the alphabetic symbols that represent them in writing (phonics).
Visualisation
Visual, or orthographic, knowledge is the awareness of the symbols (letters or groups of letters) used to represent the individual sounds of spoken language in written form. To spell fluently, students also need to know about how written letters are arranged in English (VCELA384).
Two visual strategies which represent variations of Look, Say, Cover, Write, Check, have been devised by Westwood (1994) and develop visual knowledge. They are:
Variation 1:
- Look at the word.
- Say – make sure you know how to pronounce the word.
- Break the word into syllables.
- Write the word without copying.
- Check what you have written.
- Revise.
Variation 2:
- Select a difficult word.
- Pronounce the word slowly and clearly.
- Say each syllable of the word.
- Name the letters in the word.
- Write the word, naming each letter as you write.
These visual strategies can help students remember specific written words and word parts.
Grouping common morphemes
Morphemes represent the smallest meaningful units of language. Morphemes come in two forms.
Free morphemes that can stand alone with a specific meaning. For example, Catch, Cook, or Strong.
Bound morphemes cannot stand on their own and can only appear as part of another word. Prefixes and suffixes are examples of bound morphemes. Prefixes are bolted on to the front of a word to add specific meaning.
Prefixes can give a sense of order in time. For example, the prefix [fore-] in the words
- foresee
- foretell
- forewarn.
Fore- indicates a sense of something happening before the action described in the base word. To foresee is to see something before it happens.
Other English prefixes like [dis-] [de-] [mis-] and [un-] signal the opposite meaning to the word it is attached to (Hamawand, 2011).
We can see negative prefixes in words like:
- destabilise
- deconstruct
- dissimilar
- displease
- uncertain
- unrest
- misinterpret
- misshapen.
English spelling rule for adding prefixes
When you add a prefix to a base or root word, you can always just bolt it straight on. No need to change the spelling of the word it attaches to.
Dis + similar = dissimilar mis + shapen = misshapen un + necessary = unnecessary
Suffixes carry meaning and are bolted on to the end of a word where the combination of the base and the suffix forms a new word.
Suffixes also play an important role in the nominalisation of English words. Nominalisation refers to the process of turning a verb into a noun form.
Example, ‘Consideration of this issue is vital’ instead of ‘You should consider this issue’.
Nominal suffixes
Nominal suffixes are attached to the end of verbs or adjectives to form nouns.
For example, we can form nouns when we add the suffixes:
- [-al]
- [-ce]
- [-ion]
- [-ment].
We can see how verbs are nominalised by adding a nominal suffix in these word sums:
- celebrate + ion = celebration
- modulate + ion = modulation
- enjoy + ment = enjoyment.
We can see how adjectives are nominalised by adding a nominal suffix in these word sums:
- aware + ness = awareness
- appear + ance = appearance.
English spelling rule for adding suffixes
When you add a suffix to a word, you need to change the spelling if the word it attaches to ends in a vowel letter and the suffix also begins with a vowel letter.
For example, the verb ‘regulate’ can be nominalised by adding the suffix [-ion]. The spelling rule for adding suffixes determines that the final letter ‘e’ must be dropped before adding ‘ion’ as it begins with a vowel letter (a, e, I, o, u or y).
If the suffix begins with a consonant letter as in [-ment] or [-ness], you can always just bolt these suffixes onto the base word. For example, the verb ‘amaze’ can be nominalised by adding the suffix [-ment]. The spelling rule for adding suffixes determines it is bolted on to the base without dropping the final ‘e’, so we have ‘amazement’.
Working with morphemes teaches students to ‘look inside’ the word to find meaningful parts within the whole word (VCELA354). Working with students to group words that share common morphemes is an effective strategy for developing their morphological understandings (Herrington & Macken-Horarik, 2015).
Grouping common morphemes together provides an opportunity for students to make meaningful connections or links between words despite changes in sounds. For example, Herrington and Macken-Horarik explain how a grouping activity allowed the following words to be grouped:
- native
- nature
- natural
- nationwide
- nationality
- national
- naturalistic
- naturally.
All words shared the common root morpheme [nat-] (meaning source, birth or tribe) even though the [nat-] morpheme is spoken differently. For example, the morpheme [nat-] in ‘natural’ is spoken with a short vowel sound, and in the word ‘native’ it is spoken with a long /a/ sound.
This activity can also be conducted in reverse, with the teacher placing a target word on the whiteboard, for example, the word, remember, and asking students to identify the various morphemes.
Once the morpheme [-mem-] (meaning to call to mind) is identified, students are encouraged to brainstorm other words that share this morpheme, encouraging them to look inside words to find the meaningful parts. Word sums are an effective grouping activity to build understanding about how meaningful word structures (morphemes) combine to construct words and play a vital role in the English spelling system (Bowers & Cooke, 2012).
Here are some examples of word sums using the base word, construct:
- construct + s = constructs
- construct + ed = constructed
- construct + ing = constructing
- construct + ive = constructive
- construct + ion = construction
- de + construct = deconstruct
- de + construct + ion = deconstruction
- re + construct + ing = reconstructing
- re + construct + ed = reconstructed
- re + construct + ion = reconstruction.
Parts cards
Another strategy seeking to develop morphological knowledge is the parts card strategy.
Stants’s (2013) parts card strategy is one way for teachers to introduce students to new vocabulary. The parts card strategy requires students to:
- dissect new vocabulary
- generate a meaning
- and then draw a diagram to demonstrate their understanding.
Zoski et al. (2018) have modified Stants’s parts card strategy to emphasise the language modes (reading, writing, speaking and listening). An example is below.
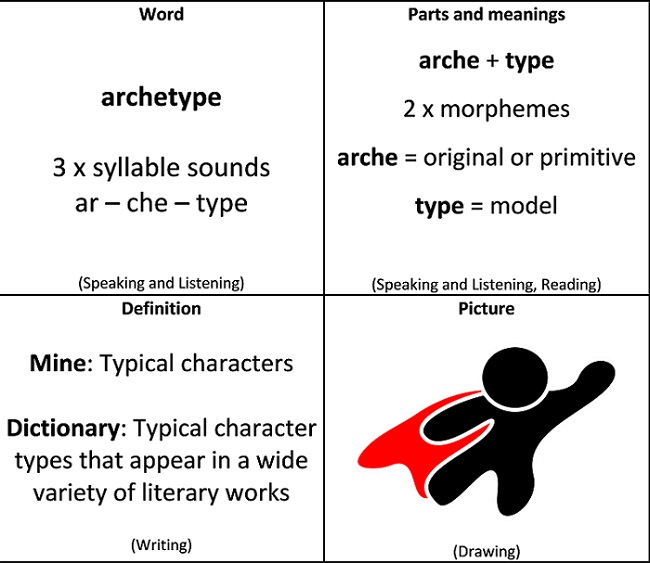
Image source: Pixabay.com
Word webs
Etymological knowledge refers to how the history and origins of words relate to their meaning and spelling. Knowing about the origin of these words is helpful to students when learning to spell them (VCELA384).
Devonshire, Morris, and Fluck (2013) describe a word web activity:
- begin with researching the historical origins of the target word
- place this at the top of the whiteboard
- Write the morpheme (smallest meaningful units of language) of the target word in the middle of the whiteboard
- students are encouraged to brainstorm other words that share the same morpheme.
For example:

Using and editing punctuation (writing, reading and viewing)
Punctuation is “the use of standard symbols, spaces, capitalisation and indentation to help the reader understand written text” (Wing Jan, 2009, p.37).
Punctuation “provides the conventional framework for sentence structure” to aid in meaning making.
Knowing how and when to use the most appropriate punctuation when writing is a skill that requires development over time. As students move through the secondary years of English, the explicit teaching (HITS Strategy 3) of punctuation continues to play a critical role in the way that students develop as writers.
Students can be shown examples of the ways that subtle changes to punctuation can drastically change the meaning of a sentence, such as the one below:
The teacher stood by the door and called the students’ names.
The teacher stood by the door and called the students names.
Discussions of punctuation are supported by an understanding of the impact that it has on meaning, and the potential for clarifying or confusing a reader. One of the most effective ways for students to improve their own punctuation use is through the drafting and editing of their own writing. One strategy to support this is through individual or peer reviews that target punctuation use.
Individual or peer reviews of punctuation use
Once the explicit teaching/revision of punctuation has been completed:
- teachers request students to make two copies of one piece of their own writing
- the other copy has its punctuation removed
- students read the version that has had the punctuation omitted and insert a new set of punctuation
- students compare the newly punctuated version to the original version
- in pairs, students discuss the two different versions of the same piece of writing. Through negotiation and discussion, students make decisions about the correct and most appropriate way to punctuate the piece.
Narrative: original version (with punctuation)
That morning Mark woke up early, the early morning sun was streaming through the open window. Mark did not groan, he did not struggle to get out of bed, for he knew exactly what he had to do, and his heart was thumping just thinking about it. He climbed out of bed and pulled on a tracksuit. The bitter outside air hit him like a brick wall, but he did not stumble. He put his hands in his pockets and stepped out onto the street. The day was just starting up, cars and trams drizzling down Flinders street. Mark joined the small group of people crossing the street, and while waiting there, thought carefully about the plans in his head. The crossing signal indicated go, and Mark walked slowly but purposefully across, and ducked into the coffee shop. He ordered his coffee, and then sat and waited. Mark checked the clock on the wall, he had exactly five minutes before Thaddeus’ train should arrive…
Narrative: clean version (no punctuation)
That morning Mark woke up early the early morning sun was streaming through the open window Mark did not groan he did not struggle to get out of bed for he knew exactly what he had to do and his heart was thumping just thinking about it He climbed out of bed and pulled on a tracksuit The bitter outside air hit him like a brick wall but he did not stumble he put his hands in his pockets and stepped out onto the street The day was just starting up cars and trams drizzling down Flinders street Mark joined the small group of people crossing the street and while waiting there thought carefully about the plans in his head The crossing signal indicated go and Mark walked slowly but purposefully across and ducked into the coffee shop he ordered his coffee and then sat and waited Mark checked the clock on the wall he had exactly five minutes before Thaddeus train should arrive
Curriculum links for the above example:
VCELA415,
VCELA445,
VCELY450,
VCELY480,
VCELA472.
Using feedback to increase the sophistication of student writing (writing, reading and viewing)
Writing demands in the secondary years increase significantly in complexity and sophistication (Shanahan & Shanahan, 2008). Students can be explicitly taught how to create more sophistication in their writing through a range of approaches.
The examples below demonstrate the kind of feedback that teachers can provide students, focusing on two aspects of language:
Nominalisation
Nominalisation refers to the process of turning a verb into a noun form.
Example:
‘Consideration of this issue is vital’ instead of ‘You should consider this issue’.
It is a linguistic tool frequently used in many disciplines particularly when describing abstract ideas or making theoretical arguments. Nominalisation is less evident in spoken language but is a critical feature in written academic texts.
Compare the two examples below, taken from Derewianka and Jones (2016, p. 308):
Spoken example:
‘When plastic bags are made, toxic gases and other dangerous substances are released into the air and these by-products pollute the atmosphere and ruin water supplies.
Written example:
The production of toxic gases during the manufacture of plastic bags causes air and water pollution.
There are four clauses in the spoken example; these have been collapsed into one in the written example. As a result, the text is more dense and information is compressed. There is also a causal relationship between the production of plastic bags and the impact.
The following table (also called an anchor chart) was created by a Year 8 class as they worked on persuasive essays regarding the topic ‘Climate Change’ (VCELA397,
VCELA401,
VCELA415).
The class (initially led by teacher, and increasingly independently):
- identifies everyday phrases that could increase in sophistication
- brainstorms ways to nominalise these terms
- lists these on the chart
The anchor chart should be visible for the class to pool their ideas about changing every day phrases into nominalised, sophisticated language choices.
| Everyday language | Nominalised word choices |
|---|---|
| The climate is getting hotter |
Climate change global warming |
| People can’t agree about climate change… |
Disagreement about climate change… |
| Solve the problem | Find a workable solution |
| Human’s actions are making the issue worse | Human impact Human involvement |
| Scientists have told us why | Scientific explanation |
| Cutting down trees | Deforestation of areas |
The presence of the anchor chart in the classroom creates an additional scaffold to support students in providing peer feedback to one another. They can refer to the chart to identify ways that their peers can improve their work by making nominalised word choices.
Creating reference chains
Reference chains refer ways in which links are made between items in a text to help the reader track meaning, for example, through the use of
pronouns or the definite article (the) or
demonstratives such as this, that, these.
To strengthen student understanding of reference chains and cohesive links, teachers can use a model text to demonstrate the interconnected ideas across a passage. This can begin at the paragraph level, in the case modelled below.
This example demonstrates how reference chains can be colour coded to show how they operate in a paragraph from Zana Fraillon’s The Bone Sparrow in a Year 8 class (VCELA414). It can also be modelled at the whole-of-text level to highlight how cohesive devices are employed in text, for example, when explicitly teaching the structure of websites in Year 7 (VCELA380).

In this example, sets of reference chains are highlighted in three different colours to show the three different sets of chains, and arrows show the linkage between the references.
Once students have had these features modelled to them, teachers can provide specific feedback to students on how to improve their writing by employing these language features, as seen in the student work sample below.

References
Beckham-Hungler, D., Williams, C., Smith, K., & Dudley-Marling, C. (2003). Teaching words that students misspell: Spelling instruction and young children’s writing. Language Arts, 80(4), 299–309.
Bowers, P. N., & Cooke, G. (2012). Morphology and the common core building students’ understanding of the written word. Perspectives on Language and Literacy, 38(4), 31–35.
Critten, S., Connelly, V., Dockrell, J. E., & Walter, K. (2014). Inflectional and derivational morphological spelling abilities of children with Specific Language Impairment. Frontiers in Psychology, 5, 1–10.
Dawson, C. (2009). Beyond checklists and rubrics: Engaging students in authentic conversations about their writing. The English Journal, 98(5), 66–71.
Derewianka, B. (2011). A new grammar companion for teachers. Newtown: Primary English Teaching Association of Australia.
Derewianka, B., & Jones, P. (2016). Teaching language in context. New York: Oxford University Press.
Devonshire, V., Morris, P., & Fluck, M. (2013). Spelling and reading development: The effect of teaching children multiple levels of representation in their orthography. Learning and Instruction, 25, 85–94.
Hamawand, Z. (2011). Morphology in English: Word formation in cognitive grammar. London: Bloomsbury Publishing.
Hattie, J., & Timperley, H. (2007). The power of feedback. Review of Educational Research, 77(1), 81–112.
Herrington, M. H., & Macken-Horarik, M. (2015). Linguistically informed teaching of spelling: Toward a relational approach. Australian Journal of Language and Literacy, 38(2), 61¬–71.
Oakley, G., & Fellowes, J. (2016). A closer look at spelling in the primary classroom. Newtown: Primary English Teaching Association of Australia.
Shanahan, T., & Shanahan, C. (2008). Teaching disciplinary literacy to adolescents: Rethinking content area literacy. Harvard Education Review, 78(1), 40–59.
Stants, N. (2013). Parts cards: Using morphemes to teach science vocabulary. Science Scope, 36(5), 58–63.
Westwood, P. (1994). Issues in spelling instruction. Special Education Perspectives, 3(1), 31–44.
Winch, G., Johnston, R., March, P., Ljungdahl, L., & Holliday, M. (2012). Literacy. South Melbourne: Oxford University Press.
Wing Jan, L. (2009). Write ways: Modelling writing forms (3rd Ed.). Melbourne: Oxford University Press.
Zoski, J.L., Nellenbach, K.M., & Erickson, K.A. (2018). Using morphological strategies to help adolescents decode, spell, and comprehend big words in science. Communication Disorders Quarterly, 40(1), 57–64.
The
1 level is Phonetic and Phonology (all
sounds, phonemes).
Phonetics is the study of individual speech sounds; phonology is the
study of phonemes, which are the speech sounds of an individual
language. These two heavily subfields cover all the sounds that
humans can make. The 2
level is morphological Morphology
is the study of words and other meaningful units of language like
suffixes and prefixes. The
3 level is syntactical Syntax
studies
phrases and sentences. The
next level is semantical.
Semantics is
the study of the
meaning of sentences.
The
basic units of language are the phoneme, the morpheme, the word and
the sentence. The
phoneme
is the smallest phonetic distinctive unit in a language which is
realized in speech as different segments in different positions. The
morpheme,
the basic unit of morphology, is the smallest meaningful linguistic
unit that has semantic meaning. It is expressed in some sequence of
the phonemes of a language. Un-fail-ing-ly,
for instance, contains four meaningful parts, that is four morphemes.
The
word is
the smallest naming unit. Sentences
consist of phrases, and phrases consist of words. Every word consists
of at least one morpheme, a minimal unit that contributes in some way
to the meaning of the word. The mentioned units (the phoneme, the
morpheme, the word and the sentence) are units of different levels of
language structure. The phoneme is a unit of the lowest level, the
sentence is a unit of the highest one. A unit of a higher level
usually contains one or more units of the preceding level. Thus,
the units of LANGUAGE from largest to smallest are:
TEXT→SENTENCE→PHRASE→WORD→MORPHEME→PHONEME
5. Style, norm context expressive means stylistic device. Types of context
Style
is a subsystem of the principles, extralinguistic circumstances, and
the effect of the usage of phonetic, morphological, lexical, and
syntactic language means of expressing human thoughts and
emotions; The most traditional styles are: the newspaper style,
the conversational style, the publicistic style, the style of
official communication. Norm
is a set of certain rules which in a certain epoch and in a certain
society is considered to be most correct and standard for a definite
functional style; It is almost impossible to work out language
norms because each functional style has its own regularities. For
example, such sentence as «I ain`t got no news from nobody» is not
grammatical from the point of literary grammar, but it is correct so
to say according colloquial grammar rules. Expressive
means
are phonetic, morphological, lexical, and syntactic units and forms
which are used to intensify the meaning of the utterance; for
instance stresses, pauses, melody, coloured suffix (–ie) girlie;
-иця,
-ичка
водичка
водиця,
epithets and слЭни
slangy words. Stylistic
devices
is phonetic, morphological, lexical and syntactic figure of speech
formed on the basis of language units and forms;
Context
is linguistic or situational encirclement of a language unit that
makes the meaning of the unit clear. There
are 4 types of context
a)
microcontext
is
a
context of a single utterance (sentence);
b)
macrocontext
is a context of a paragraph in a text.
c)
megacontext
is
a context of a chapter, a story, or the whole book;
d)
stylistic
context
is
a
context which contains unpredictable, untypical of a certain style
language unit(s);
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
Writing about Texts
Sometimes it can be helpful to examine the way sentences are used in a text. Ask the question, what is making the sentences work? Let’s consider a few ideas.
Begin by considering the sentence length. Is the text comprised of mostly short sentences, mostly long (or really long) sentences, or a mixture of both?
Short sentences are a perfectly fine addition to any essay work. But if overused, they can feel boring and monotonous.
I needed to be at work early. I set my alarm for 5:00 am. It went off on time, and I got up. I showered and dressed. I ate cereal for breakfast. I had orange juice, too. My drive to work went well. I only hit three lights. Traffic wasn’t bad. I found a good parking place at work. I walked into the office early.
![]()
Try reading these examples aloud. This will help you “hear” their flow in a way you cannot by simply reading silently with eyes alone. Reading aloud is really the only way to hear the sound of writing.
In the above example, every one of those sentences is correct and perfectly legal in terms of grammar and structure. But how does it sound? A little choppy? Repetitive? Flat?
Now let’s look at the same paragraph, adjusted to combine the short sentences into much longer ones—and again, read it aloud:
I needed to be at work early, so I set my alarm for 5:00 am. It went off on time, and I got up, showered, dressed, ate cereal for breakfast, and had orange juice, too. My drive to work went well because I only hit three lights, traffic wasn’t bad, I found a good parking place at work, and I walked into the office early.
Once again, each of the sentences in the above example is grammatically correct. But how does the sample sound now? It seems to go on and on for a bit, doesn’t it? Longer sentences—especially once after another—can be a little hard to follow.
Let’s see if we can find a happy medium, creating a paragraph that includes both long and short sentences (yes, read it aloud again, please):
I needed to be at work early, so I set my alarm for 5:00 am. It went off on time. I got up, showered, dressed, and had cereal and orange juice for breakfast. My drive to work went well. I only hit three lights, and traffic wasn’t bad. I found a good parking place at work and walked into the office early.
You’ll probably agree that the final sample has the best, most fluid sound. Why? When we humans speak, we tend to speak in a mixture of long sentences, short sentences, and incomplete sentences—not to mention single words and short phrases. Thus, when we use varying sentence lengths in our writing, it sounds more conversational to our ear. Reading text composed of mixed-length sentences is both easier to do and easier to understand.
That said, sentence length can be used to create specific effects, too. Long, complicated sentences are often used in description or to create a rhythmic, flowing feel. In contrast, short sentences may be used for emphasis or to ramp up a feeling of anxiety or suspense.
 Check Your Understanding: Sentence Length
Check Your Understanding: Sentence Length
 Check Your Understanding: Sentence Length
Check Your Understanding: Sentence LengthConsider this long sentence from the children’s book, Stuart Little, by E.B. White:
.
In the loveliest town of all, where the houses were white and high and the elm trees were green and higher than the houses, where the front yards were wide and pleasant and the back yards were bushy and worth finding out about, where the streets sloped down to the stream and the stream flowed quietly under the bridge, where the lawns ended in orchards and the orchards ended in fields and the fields ended in pastures and the pastures climbed the hill and disappeared over the top toward the wonderful wide sky, in this loveliest of all towns Stuart stopped to get a drink of sarsaparilla.
- The above passage is a single, long, complex sentence and is grammatically correct. How did you feel when you read it? What kind of mood or tone did it create? Could you imagine the place being described?
- Now, consider this excerpt from a piece by Ben Montgomery, written as he covered a state football championship:
“Complete pass. Again. Clock’s ticking. Again. Down the field they go. The kid can’t miss. The Panthers are nearing the end zone….The whole place is on its feet. Ball’s on the 5-yard line. Marve takes the snap. Drops back. Throws.” - Montgomery’s piece is built of short sentences, sentence fragments, and even single words. How did you feel when you read this? What kind of mood or tone did it create? Can you hear the difference from the Stuart Little passage?
- What have you discovered about the effect of sentence length?
- Try your hand at playing with sentence length. Imagine the most beautiful place you’ve ever been. Write a few lines that describe the place. Aim for writing long, flowing sentences that include lots of sensory description: sight, sound, texture, etc. Now imagine something you’ve done that made you anxious or frightened. Write a few sentences that recreate the scene and sensations. Use short, abrupt sentences to ramp up the tension.
See the Appendix, Results for the “Check Your Understanding” Activities, for answers.
Introduction
Reading fluently and comprehending text are essential skills in our literate society. Yet, what exactly entails fluent reading is still debated. Definitions of reading fluency show great variation; they range from rather narrow, only considering rate of word recognition (e.g., Ehri and Wilce, 1983), to very wide, encompassing all aspects of reading including comprehension (Samuels, 2006, 2007; see Breznitz, 2006, for an overview). This variation results from a strong divide between studies on underlying processes involved in fluent reading and processes related to comprehension of texts. Both types of studies come from largely separate domains with their own research traditions. Consequently, we have some knowledge about basic word-level processes underlying reading fluency of words (e.g., de Jong, 2011; Protopapas et al., 2013; van den Boer and de Jong, 2015; Zoccolotti et al., 2015; Altani et al., 2018) and about text-level processes involved in the reading fluency of texts (e.g., Fuchs et al., 2001; Jenkins et al., 2003). However, it is still unclear how demands on individual, basic word-level processes underlying reading fluency differ across relevant fluency measures. Moreover, we have limited knowledge about how word-level processes might interact with text-level processes when the complexity of fluency measures changes or context becomes available.
Here, we investigated to what extent basic word- and text-level processes contribute to a variety of reading fluency measures, aiming to better understand the mechanisms underlying fluent reading. We generally adhere to the widely accepted definition of the National Reading Panel [NRP], 2000 stating that reading fluency is “the ability to read a text quickly, accurately, and with proper expression (p. 3–5, see also Hudson et al., 2005; Kuhn et al., 2010). In our study, however, we wish to bring together word-list and text-based metrics of fluency. We therefore omit prosody, which is not relevant for word lists. Our working definition of reading fluency is thus the accurate and rapid reading of a series of words. Specifically, we assessed (a) word-list reading of simple familiar words (i.e., serial word reading rate; covering unrelated short high-frequency words of low difficulty), (b) word-list reading of increasingly difficult unfamiliar words (i.e., word-list reading fluency; as in common tests of “word reading efficiency,” e.g., Torgesen et al., 2012; covering unrelated longer and lower frequency words), and (c) reading fluency of sentences. These fluency measures represent a gradual increase in complexity regarding word length and familiarity as well as context availability. As such, these measures may tap underlying word- and text-level processes differentially, so that differences can be detected in the relations of the three measures to underlying word- and text-level processes.
Word recognition, or processing efficiency of individual words, is one of the main word-level processes related to reading fluency. After all, how rapidly and effortlessly a child can identify single words will largely determine the child’s potential reading speed of series of words. In the development of reading skill, word identification generally starts out as a slow and laborious process in which words are deciphered letter-by-letter using grapheme-phoneme correspondence rules. Repeated successful identification through phonological recoding helps the child to form an orthographic representation of the word (Share, 2008). This representation makes it easier to recognize the word, in larger chunks or as a whole, in future encounters. Eventually, a word is assumed to become part of the child’s sight word vocabulary. The child is then able to recognize the word at a glance, that is, retrieve its pronunciation from memory on seeing the written form (Ehri, 2005, 2014). This gradual change from letter-by-letter decoding to sight word reading has long been considered the key explanation for the development of word-level reading fluency as measured by word list formats. Hence, prediction of reading fluency of word lists by the recognition rate of individual words (as measured by a discrete reading task displaying only one word at a time) should be close to perfect, if individual word recognition were indeed the sole factor underlying the development of the fluent reading of lists of words. Likewise, outcomes on the two kinds of measures should be almost identical. However, multiple studies have shown that this is not the case (e.g., de Jong, 2011; Protopapas et al., 2013; Altani et al., 2020).
Recent research by Protopapas et al. (2013, 2018) suggests that the presence of multiple simultaneously available words in a sequence, as opposed to the display of one single word at a time, is a critical feature that distinguishes word-list fluency tasks from individual word recognition tasks. They hypothesize that sequential processing efficiency (i.e., the ability to process multiple items in a sequence) is an additional ability that is crucial for achieving reading fluency. Sequential processing efficiency is believed to depend on the ‘cascaded’ processing of words or other stimuli. Multiple items in a sequence are processed simultaneously, but at different stages: While the first word is articulated, the second word is processed, the third is viewed, and the fourth is previewed, all of which happens largely in parallel (e.g., Protopapas et al., 2013, 2018). Accordingly, sequential processing efficiency specifically taps into the coordination of these processes between multiple items in a sequence. This coordination can only be optimized once individual words are recognized instantly (by sight).
Studies into the nature and measurement of sequential processing efficiency have shown that this skill can be captured by serial rapid automatized naming (RAN) tasks (de Jong, 2011; Protopapas et al., 2013). Naming of digits seems to capture the sequential processing of adjacent items best in relation to reading fluency of word lists, even though other kinds of serial naming tasks target this process as well (e.g., including objects, number words or dice; Protopapas et al., 2018). This may be because the individual elements in serial digit naming tasks are automated to such an extent that they allow unmediated one-chunk processing, closely mimicking reading words by sight (de Jong, 2011; Protopapas et al., 2018, see also Altani et al., 2020). Consequently, the sequential processing of multiple familiar items is what dominates performance in the serial digit naming task.
Reading fluency will require more than individual word recognition and sequential processing efficiency when the words are connected, such as in sentences or texts. Words in sentences and texts are not combined randomly but are connected to each other by supra-lexical elements, structures, and operations. As such, fluent reading of connected text requires semantic and syntactic processing (e.g., Ouellette, 2006; van Silfhout et al., 2015). Previous research has shown that skilled and less skilled readers rely on their knowledge of words and syntactic relations to support word recognition during reading (e.g., West et al., 1983; Nation and Snowling, 1998; Mokhtari and Thompson, 2006). More specifically, identification of anaphoric referents, use of connectives, and semantic probability have been identified as factors that facilitate reading fluency of sentences and texts (Perfetti, 1995; Frisson et al., 2005; Crosson and Lesaux, 2013; van den Bosch et al., 2018). This indicates that basic word-level processes as well as comprehension processes play a role in fluent reading at higher levels of complexity (e.g., Jenkins et al., 2003; Kim et al., 2014). Therefore, in this study we assess the role of receptive vocabulary and syntactic skills as relevant text-level processes across reading fluency measures and investigate their contribution in addition to the individual word-level processes mentioned above.
Regarding the word-list reading of familiar words (i.e., short words of high frequency that are likely to be read by sight), multiple studies have shown that individual word recognition speed is only a moderate predictor of serial word reading rate (Protopapas et al., 2013; Altani et al., 2017, 2020). Additionally, several studies have shown that the relation between individual word recognition speed and serial word reading rate decreases over time (Protopapas et al., 2013, 2018; Altani et al., 2020). The predictive power of individual word recognition skill is weakened as children become more skilled readers and are able to read word lists more fluently (de Jong, 2011; Altani et al., 2020). This indicates that the reading processes underlying reading fluency of word lists change over time and skills other than individual word recognition speed become more important for fluent reading (see also van den Boer and de Jong, 2015).
Indeed, multiple studies have shown that serial digit naming is also a unique predictor of serial word reading rate (van den Boer et al., 2016; Altani et al., 2017, 2018) and explains additional variance beyond individual word recognition speed (de Jong, 2011; Protopapas et al., 2013; van den Boer and de Jong, 2015; Altani et al., 2020). Moreover, the correlation between serial digit naming and serial word reading rate is stable or even increasing over time (de Jong, 2011; Protopapas et al., 2013, 2018; Altani et al., 2018, 2020). This pattern of findings has been observed across orthographies varying in transparency (i.e., Greek, Italian, Dutch, English; Zoccolotti et al., 2013; van den Boer et al., 2016; Altani et al., 2017, 2020; see also Moll et al., 2014; Landerl et al., 2019, on the role of RAN in reading fluency of word lists across orthographies). The same pattern has also been found across different writing systems (i.e., Chinese, Korean; Altani et al., 2017; see also Araújo et al., 2015, for an overview of relevant aspects of the RAN-reading relationship).
For example, in a study on Grade 3 children, Altani et al. (2020) showed that both individual word recognition speed and sequential processing efficiency are important and unique predictors of serial word reading rate. Word recognition contributed slightly more in Greek (in which the word list was composed of simple two-syllable words), whereas sequential processing contributed more in English (using one-syllable words). Combined, both word-level processes explained about 50% of the variance in serial word reading rate. Altani et al. (2017; using the same data for Greek and English) showed that sequential processing efficiency was also the larger contributing factor in Korean and Chinese. This resulted in similar amounts of total explained variance in Korean (51.2%), but much less in Chinese (31.2%). Based on these findings, we consider individual word recognition speed and sequential processing efficiency to be the two main word-level reading processes underlying reading fluency. We know nothing about the role of text-level comprehension processes in relation to serial word reading rate. However, it is unlikely that they greatly influence reading fluency in simple tasks in which words are expected to be read by sight.
Word-lists of increasingly difficult words (i.e., longer words of low frequency that cannot all be read by sight) are frequently used in educational and diagnostic settings. Nonetheless, we know very little about how individual word- and text-level processes affect these fluency measures (e.g., TOWRE; Torgesen et al., 2012). Evidently, individual word recognition speed and sequential processing efficiency are expected to play an essential role. Yet, the fact that not all words can be read by sight in measures of increasing difficulty might make a crucial difference. de Jong (2011) was the first to suggest that sequential processing may capture serial processes both between words and within words that are not yet read by sight. Supporting evidence comes from correlations between discrete and serial RAN and word-reading tasks in beginning and more advanced readers. Specifically, in more advanced readers, the strong correlations that are found between serial RAN and serial word reading suggest that words are activated in an automated fashion, like single digits; that is, they are read by sight. In beginning readers, however, correlations are strongest between serial RAN and discrete word reading tasks. This pattern of correlations suggests that less-skilled readers identify words by processing a series of individual elements, that is, letter-by-letter or letter cluster-by-letter cluster, because they cannot yet read the words by sight (de Jong, 2011; van den Boer et al., 2016; Altani et al., 2018). Sequential processing might thus play a bigger role in word-list reading of increasingly difficult words than in word lists of familiar words. In the latter, sequential processing is restricted to between-word processing, because each single word is assumed to be read by sight. In the reading of a list of increasingly difficult words, however, sequential processing is related to both between- and within-word processing. Surprisingly, the only available data show that correlations of discrete word reading and serial digit naming with word-list reading of familiar and increasingly difficult words are comparable (de Jong, 2011). In addition, the influence of discrete word reading was found to decrease for both types of word lists as children become better readers (de Jong, 2011). That is, there is no evidence that word lists of increasingly difficult words pose increasing demands on sequential processing efficiency, compared to lists of familiar words. This suggests that other factors are more important for individual differences in word-list reading fluency, so that the relative contribution of sequential processing to the total variation is limited.
One potential factor explaining additional variance in word-list reading fluency may be vocabulary knowledge, even though word-list reading fluency cannot really be considered a complex fluency measure in terms of semantic relations between words. A larger vocabulary is reflected in a larger phonological lexicon. This larger phonological lexicon would facilitate the build-up of an orthographic lexicon, because the phonological representation of a word does not have to be acquired (as would be the case in the reading of non-words). This might thus increase the probability that words are read by sight. Alternatively, vocabulary might also play a role in the fast and accurate recognition of the more difficult words of lower frequency that cannot be (fully) read by sight. Multiple studies have shown that vocabulary is generally more strongly related to word reading of irregular words than regular words (Nation and Snowling, 2004; Ricketts et al., 2007; Krepel et al., 2021; but see Ricketts et al., 2016). Also, children with larger vocabularies tend to be better at word reading (see Taylor et al., 2015, for an overview). Ouellette (2006) has looked specifically into the role of vocabulary in word-list reading fluency of increasingly difficult words in French. The findings showed that vocabulary size was an independent predictor of word-list reading fluency and explained unique variance even after accounting for pseudoword decoding. In contrast, research in Dutch has shown that the relation between vocabulary and word-list reading fluency is rather weak (de Jong and van der Leij, 2002; de Jong, 2011). A recent study by Kim (2015) in Korean has looked at the combined influence of individual word- and text-level processes on word-list reading fluency. The results suggested that vocabulary may explain unique variance in word-list reading fluency after sequential processing speed has been taken into account.
Turning to reading fluency of connected text, there is quite some research on the role of comprehension processes, and specifically vocabulary. Fuchs et al. (2001) argued that reading fluency of connected text is a good indicator of reading competence, because it involves all skills necessary for reading, including word recognition and comprehension skills (see also Samuels, 2006, 2007). Others have suggested that there may be a reciprocal relation between fluency and comprehension (e.g., Klauda and Guthrie, 2008; see also Jenkins et al., 2003; Lai et al., 2014), but further research is necessary to support this (Kuhn et al., 2010). Other studies on the role of text-level processes at the sentence level have mainly focused on reading comprehension as an outcome, instead of fluency (e.g., Foorman et al., 2015). There is also research on the influence of word-level reading fluency on sentence and text reading fluency (e.g., Schwanenflugel et al., 2004; Miller and Schwanenflugel, 2008; Benjamin and Schwanenflugel, 2010) as well as on reading comprehension (e.g., van Viersen et al., 2018). Yet, it is still unclear how individual differences in word-level reading processes (specifically word recognition speed and sequential processing efficiency) contribute to reading fluency of connected text, and in particular to sentence reading fluency. Moreover, information about the combined contributions of basic word- and text-level processes is also lacking. Sentence reading fluency is an interesting starting point in this respect, because it lies at the intersection between word-list reading fluency and (oral) text reading fluency. It could be considered as the fluency measure where word- and text-level processes first meet and is therefore included as one of the relevant reading fluency outcomes in this study.
The findings of one particular study on text reading fluency are also relevant for our understanding of sentence reading fluency: Altani et al. (2020) investigated word-level reading processes in text reading fluency and compared their results to those on serial word reading rate. Their brief texts were syntactically very simple and consisted of familiar (short and high frequency) words matched to those in the serial word-reading task. Their findings indicated some differences in terms of the contributions of the separate word-level processes. In English, sequential processing efficiency was the larger contributor to text reading fluency. In Greek, however, individual word recognition and sequential processing were equally strong predictors and explained equal amounts of total variance (see Zoccolotti et al., 2014, for similar findings using slightly different tasks in Italian Grade 6 children).
In addition, there are a few studies that focused on the combination of word- and text-level processes in text reading fluency. The results of Kim (2015) suggested that both vocabulary and syntactic skills were independent predictors of text reading fluency after controlling for sequential processing speed. However, this study was conducted in Korean kindergartners, hence very much beginning readers. Moreover, the findings were inconsistent over time (i.e., Kindergarten year 1 and Kindergarten year 2). Kim et al. (2011) found that word-list reading fluency of increasingly difficult words and listening comprehension (i.e., oral comprehension) together explain about 94% of the variance in text reading fluency of United States first graders (again, beginning readers). This is likely to be much less though when word-level processes underlying word-list reading fluency and text-level processes underlying listening comprehension are taken into account independently.
In this study, we aim to extend research into the mechanisms underlying reading fluency. To this end, we investigated the combined contribution of basic word- and text-level processes to a range of reading fluency measures that are assumed to differ in their underlying skill demands. The study is conducted with Dutch third grade children. Dutch is a semi-transparent language with a complex syllable structure (Seymour et al., 2003). Typical readers generally reach high accuracy levels by the end of second grade, after which fluency starts to increase rapidly (van Viersen et al., 2018). The third graders in our study can, on average, be considered intermediate-level readers. They have developed sufficient automaticity to show relevant variability in between-word processes and are able to free up enough cognitive resources to attend to comprehension aspects of reading. Hence our choice for this grade level given our range of fluency measures.
Several hypotheses can be formulated to gain more insight into the unique and shared contributions of individual word- and text-level processes to our set of reading fluency measures. First, we hypothesize that individual word recognition speed plays a crucial role in all fluency measures, but its individual contribution decreases with increasing complexity of the fluency measure. Second, we hypothesize that sequential processing speed will also be an independent predictor of all three fluency measures. However, if sequential processing speed represents both between- and within-word serial processes, its contribution could be larger to fluency measures in which words cannot be (fully) read by sight (i.e., word-list reading of increasingly difficult words). Third, we hypothesize that receptive vocabulary contributes to word-list reading fluency of increasingly difficult words as well as to sentence reading fluency. Syntactic skills are expected to only contribute to sentence reading fluency. A remaining question concerns the total amount of variance that can be explained by word- and text-level processes combined. Word-level processes are expected to take up the largest portion of variance in serial word reading rate, but it is not entirely clear whether they are similarly involved in word-list and sentence reading fluency. One possibility is that the additional involvement of text-level processes in these fluency measures accounts for additional variance. Alternatively, involvement of text-level processes could also result in a reduction of variance explained by word-level processes. Overall, these hypotheses are posited to reveal (a) the role of sequential processing speed across different reading fluency outcomes and (b) the point at which complexity and context become relevant for reading fluency to an extent that text-level factors come into play.
Materials and Methods
Participants
A total of 73 Dutch Grade 3 children (50.7% girls) participated in the study. Children came from four different schools in the middle and west of the Netherlands, recruited through school boards. Parents were informed about the school’s participation in the study and provided consent for their child to participate. Data were collected as part of a larger longitudinal study into orthographic learning (van Viersen et al., 2021) approved by the Ethics Committee of the University of Amsterdam (case no. 2017-CDE-8332). Children of all reading levels and language backgrounds participated in the study, but children with a dyslexia diagnosis or those who did not list Dutch as their preferred language were excluded. Background characteristics are provided in Table 1.
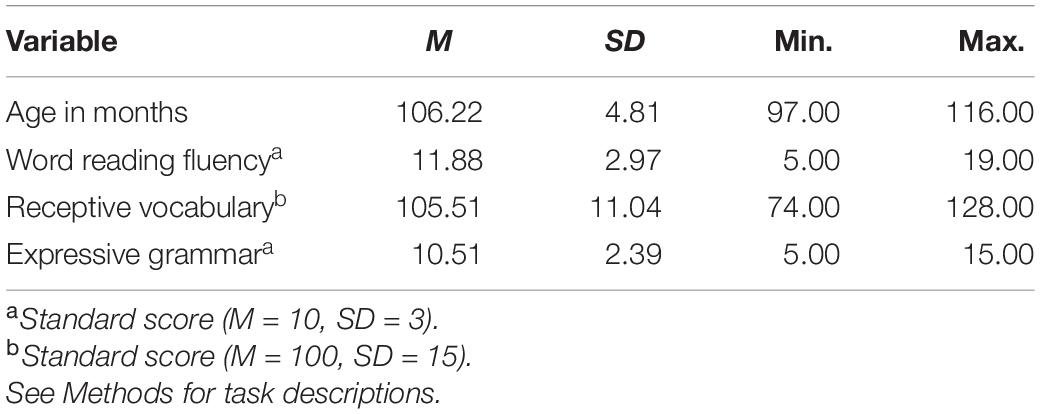
Table 1. Background characteristics.
Instruments
Individual Word Recognition
A discrete word-reading task was administered to measure individual word recognition speed. The task consisted of 36 high-frequency four-letter words previously used by van den Boer et al. (2016). Words were originally selected from the CELEX database (Baayen et al., 1993) and contained either vowel digraphs or consonant clusters (e.g., boer, vuur, stil, werk). The task was administered in DMDX (Forster and Forster, 2003) and was preceded by four practice items. Words were displayed one at a time in black 20-point Consolas on a white screen. Children had to read the word aloud when it appeared and their response was audio recorded. The experimenter controlled moving to the next item by pressing a key. Items were separated by an empty white screen. The raw score for discrete word reading was the mean reading time in seconds across correct items (including onset latency and articulation duration (see e.g., van den Boer and de Jong, 2015; Altani et al., 2018). Cronbach’s α was 0.96 on the current sample.
Sequential Processing
A serial digit-naming task was administered to measure sequential processing efficiency (Altani et al., 2018; Protopapas et al., 2018). A set of 36 digits, consisting of nine repetitions of four digits (i.e., 2, 3, 5, and 6), was displayed in four rows of nine items using DMDX. Children had to name the complete series of digits from the top left to bottom right as fast and accurately as possible. The task started with four practice items. The raw score for serial digit naming was the total naming time in seconds for the entire array, as is common for rapid automatized naming tasks (see also e.g., van den Boer and de Jong, 2015; Altani et al., 2018). Reliabilities of digit naming tasks lie between 0.79 and 0.87 in this age group (Evers et al., 2009–2012) and generally show high correlations with the same task in a somewhat different format (e.g., columns vs. rows; van den Bos et al., 2002).
Vocabulary
The Peabody Picture Vocabulary Test NL (PPVT-NL; Schlichting, 2005) was used to measure receptive vocabulary. Children had to choose the correct picture out of four alternatives to match a verbally presented target word. The test, consisting of 17 sets of 12 words, starts with the entry set that matches the child’s age. Correct answers are counted from the start set, which is the first set in which the child obtains at least four correct answers. The end set is the last set in which the child provides nine or more incorrect answers. The raw score is the number of correctly chosen pictures in the administered sets plus all non-administered items in preceding sets auto-scored as correct. Age-based standard scores are also available (M = 100, SD = 15). Reliability of the PPVT-NL has been evaluated as good (Egberink et al., 2017).
Syntactic Skills
The formulated sentences subtest of the Clinical Evaluation of Language Fundamentals-4 NL (CELF; Kort et al., 2010) was used to measure expressive grammar skills. Children had to make a sentence about a situation displayed in a picture using a verbally presented target word. For example, they had to use the word ‘eindelijk’ (finally) to formulate a grammatically correct sentence about a picture showing a boy handing in his homework (simpler item), or the words ‘in plaats van’ (instead) to describe a situation in which a boy chooses a book from a shelf (more difficult item). Quality of the formulated sentences was scored using the manual, which provided rules for the number of points awarded per sentence (ranging from 2 to 0). There were 20 items in total and testing was terminated after five consecutive sentences with zero points. Raw scores were used in the analyses. Age-based standard scores were also available. Internal consistency of the subtest is 0.78 (Evers et al., 2009–2012).
Serial Word Reading Rate
A serial word-reading task was administered to measure serial word reading rate (e.g., Protopapas et al., 2018). A set of 36 high-frequency four-letter words was displayed in four rows of nine words using DMDX. Words in this set were matched to those in the discrete word-reading task on onset phoneme, length, consonant-vowel structure, and frequency (van den Boer et al., 2016). Children had to read the words aloud from the top left to bottom right as fast and accurately as possible, starting with four practice items. The raw serial word-reading score for each child was the total reading time in seconds for the complete series of words (e.g., Altani et al., 2018).
Word-List Reading Fluency
The Dutch Eén Minuut Test (EMT; Brus and Voeten, 1999) was used to measure word-list reading fluency. Children had to read as many items as possible within 1 min. The test consisted of 116 items that increased in difficulty from one to four syllables. Raw score is the number of correctly read words within the time limit. Grade-level standard scores are available per semester (M = 10, SD = 3). Test–retest reliability is 0.90 (Evers et al., 2009–2012).
Sentence Reading Fluency
A measure of sentence reading fluency was obtained through a sentence-reading task in which children had to read aloud sentences displayed on a computer screen under eye tracking (see van Viersen et al., 2021). Eye movements were recorded in “remote” mode, without any form of head stabilization, allowing children to move freely within reasonable boundaries. The task contained 16 context-neutral sentences with similar structure (e.g., ‘De groene rups at zijn buikje vol met blaadjes’ [The green caterpillar filled his belly with leafs], ‘Het gevlekte kalf sprong vrolijk door de wei’ [The spotted calf jumped happily through the meadow]). The sentences were followed by a yes/no comprehension question (e.g., Was het kalf buiten? [Was the calf outside?]) to ensure that children were reading and not scanning. The sentences were part of a larger experiment containing an additional 64 sentences in which a target word was experimentally manipulated. Those sentences are not taken into account in the current study to avoid confounding effects of the manipulations. Children’s responses were recorded to determine reading times in seconds and number of errors per sentence (see below). This information was used to compute the mean number of correctly read words per second across all sentences.
Procedure
Children were tested at school during two individual sessions in February and March 2019. The first session took about 20 min and contained the sentence-reading task. The second session contained the reading and related tasks used for the word- and text-level factors. This session was scheduled several days after the first session and lasted about 40 min. Testing was conducted by trained and supervised research assistants.
Data Preparation
The voice recordings of the sentence-reading task were processed using CheckFiles 2.3.1 (distributed with CheckVocal; Protopapas, 2007). Vocal responses were displayed audiovisually (waveform and spectrogram) to allow marking offsets to determine the total reading time per sentence (including onset latency and articulation). Decoding errors were manually marked in a separate Excel file. Sentences with incomplete or missing vocal responses were discarded. The recorded responses from the discrete and serial reading and serial naming tasks were processed using CheckVocal 2.3.1 and 3.0a (Protopapas, 2007). Response times (RTs) were determined following the same procedure as described above. Errors were marked using the same software. RTs were converted to reading rates (i.e., number of items per second; see also Altani et al., 2017). For the discrete word-reading task, reading rates were averaged for each participant across correctly read words. For the serial naming and serial word-reading tasks, two different scores were calculated: Rate scores were computed through including correct and incorrect responses (i.e., 36 divided by the total RT), to match common practice in scoring serial naming tasks. In addition, fluency scores were computed through only including correct responses (i.e., number of correct items divided by total RT), thus penalizing decoding errors to match common practice in oral reading fluency measures (e.g., Altani et al., 2018; Protopapas et al., 2018).
Analyses
The extent to which word- and text-level predictors explain variance in serial word reading rate, word-list reading fluency, and sentence reading fluency was assessed with a path model using lavaan (Rosseel, 2012) in R version 4.1.1 (R Core Team, 2021). This path model contains only observed variables and combines three multiple regressions that would otherwise have been conducted separately. Doing so allows us to take correlations between predictors as well as among outcomes into account. It also allow us to test for equality of regression coefficients among fluency outcomes. Rate variables (i.e., number of items per second) were preferred over fluency variables (i.e., number of correct items per second) for serial digit-naming and serial word-reading tasks. This approach matches previous studies using serial naming measures (see also Altani et al., 2020). Moreover, a direct comparison between models with reading/naming rate vs. reading/naming fluency scores for serial naming and word reading showed that they produced the same results. For word-list and sentence reading fluency, the number of correctly read words per second was used to match the scale of the serial and discrete tasks. The initial path model contained all three reading outcomes and their correlations, all four predictors and their correlations, and the intercepts of all predictors and outcomes. This comes down to a just-identified model (i.e., a model with zero degrees of freedom and perfect fit). Non-significant paths can be trimmed step-by-step to arrive at a more parsimonious solution and to allow for the evaluation of model fit. Exact model fit is evaluated using the χ2-value with associated p-value (non-significant p-value indicates good fit). Approximate model fit is evaluated using the root mean square error of approximation (RMSEA; good ≤ 0.05, acceptable ≤ 0.08) including 90% confidence interval (CI; not exceeding 0.10) and pclose (>0.05), comparative fit index (CFI; good ≥ 0.95, acceptable ≥ 0.90), and standardized root mean square residual (SRMR; good ≤ 0.05, acceptable ≤ 0.08; Kline, 2011; Little, 2013).
In addition, we performed a fixed-order regression analysis within SEM to examine the unique contributions of the word- and text-level predictors to the individual reading outcomes (see van den Boer et al., 2014; de Jong and van den Boer, 2021, for examples). In this analysis, the predictors were entered in the regression model in a pre-specified order, first word-level and then text-level predictors. Fixed-order regression with a SEM model requires the specification of so called phantom factors (de Jong, 1999; Macho and Ledermann, 2011). The phantom factors are uncorrelated latent variables with their variances fixed to one. The first phantom factor is identical to the predictor entered first in the regression model. The loading of the first predictor is set to one and its residual variance to zero. The second phantom factor captures the variance of the second predictor after the variance that this predictor has in common with the first has been removed. To this end, the loading of the second predictor on the first factor is allowed to vary freely, but its loading on the second phantom factor is fixed to one. As with the first predictor, the residual variance of the second predictor is specified to be zero. The same logic applies to the subsequent predictors that are included in the model. Thus, fixed-order regression in SEM requires an alternative specification of the relations among the predictors (see Figure 2). Subsequently, the proportion of variance explained by the first predictor in the first outcome variable is computed by squaring the correlation between the first phantom factor and this outcome variable. Squaring the, now partial, correlation between the second phantom factor and this outcome gives the additional variance explained by the second predictor controlling for the first predictor. The same logic applies to the third predictor. The square of the partial correlation between the fourth (and last) phantom factor and the outcome indicates the unique variance explained by the predictor entered in the fourth step while controlling for all other predictors in the model. This alternative model specification using phantom factors does not affect model fit (de Jong and van den Boer, 2021).
Results
All variables were approximately normally distributed, based on examination of quantile-quantile plots and skewness and kurtosis indices. Three univariate outliers (i.e., based on z-score <−3.30 or >3.30 and scatterplots; one on word-list reading fluency, one on serial digit naming, and one on vocabulary) were winsorized (i.e., replaced with percentile-adjusted values) to decrease their influence. The proportion of missing data points across variables ranged from zero to 2.7%. Missing data were neither imputed nor excluded, as models were fit using full-information maximum likelihood estimation. This approach permits the inclusion of cases with missing data. The scores for vocabulary and syntactic skills were rescaled to ease the estimation procedure. Descriptive statistics of the variables used in the analyses are reported in Table 2.
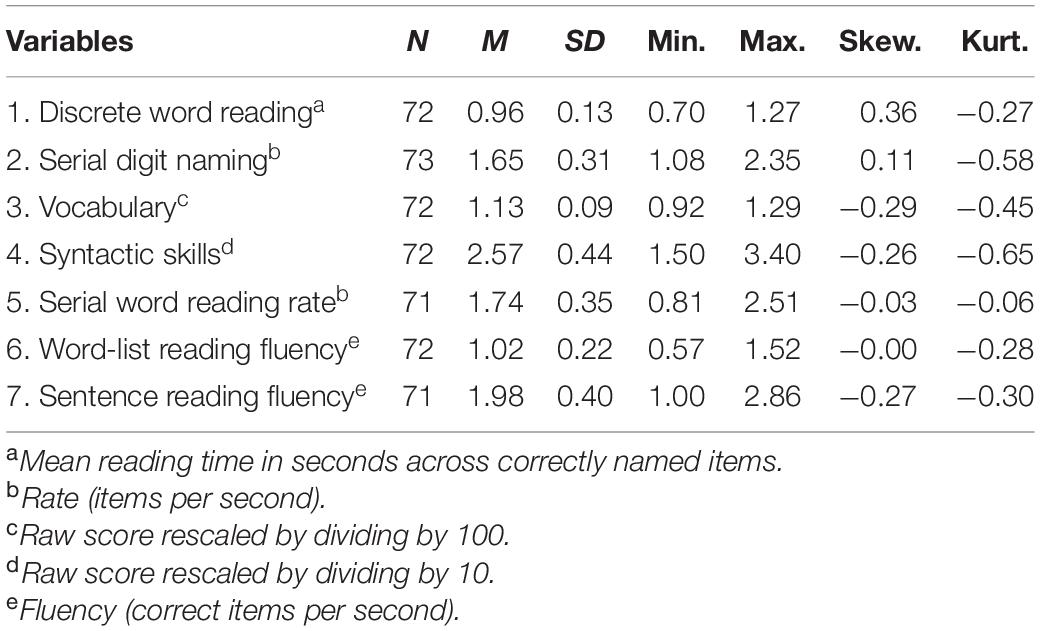
Table 2. Descriptives for predictors and outcomes.
Table 3 shows the correlations between all variables. Both discrete word reading and serial digit naming correlate moderately with all reading outcomes. Correlations between the text-level predictors and reading outcomes are not significant, except for the relation between vocabulary and sentence reading fluency and between syntactic skills and word-list reading fluency. In addition, correlations between serial word reading rate, word-list reading fluency, and sentence reading fluency are strong.
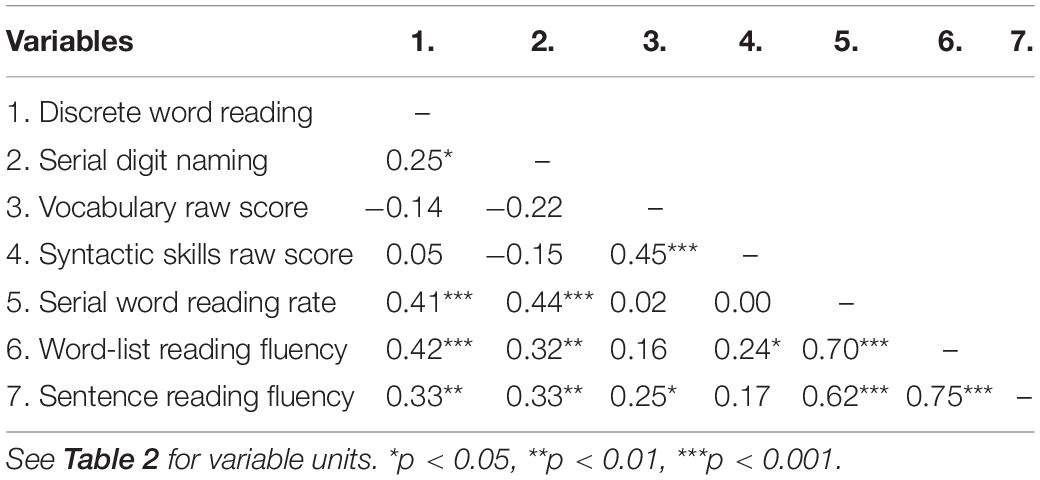
Table 3. Pearson’s correlations between predictors and outcomes.
The initial just-identified path model was trimmed by fixing non-significant correlations between word-level and text-level predictors at zero (four correlations in total). Correlations were fixed one at a time and the changes did not result in a significant deterioration in model fit. The final model, including the standardized path weights (i.e., β), is displayed in Figure 1. The fit of the final model was acceptable, χ2(4, N = 73) = 6.25, p = 0.18, RMSEA = 0.09, 90% CI = [0.00–0.21], pclose = 0.26, CFI = 0.99, SRMR = 0.07. Discrete word reading and serial digit naming both moderately predict all three reading outcomes and are weakly correlated with each other. Vocabulary only moderately predicts sentence reading fluency. Syntactic skills are not a significant predictor of any outcome, but do contribute to sentence reading fluency through their moderate correlation with vocabulary (specific indirect effect: β = 0.16, p = 0.02). Parameter estimates are listed in Supplementary Table 1. Combined, the word- and text-level processes account for 34.8% of the variance in serial word reading rate, 36.2% of the variance in word-list reading fluency, and 35.9% of the variance in sentence reading fluency.
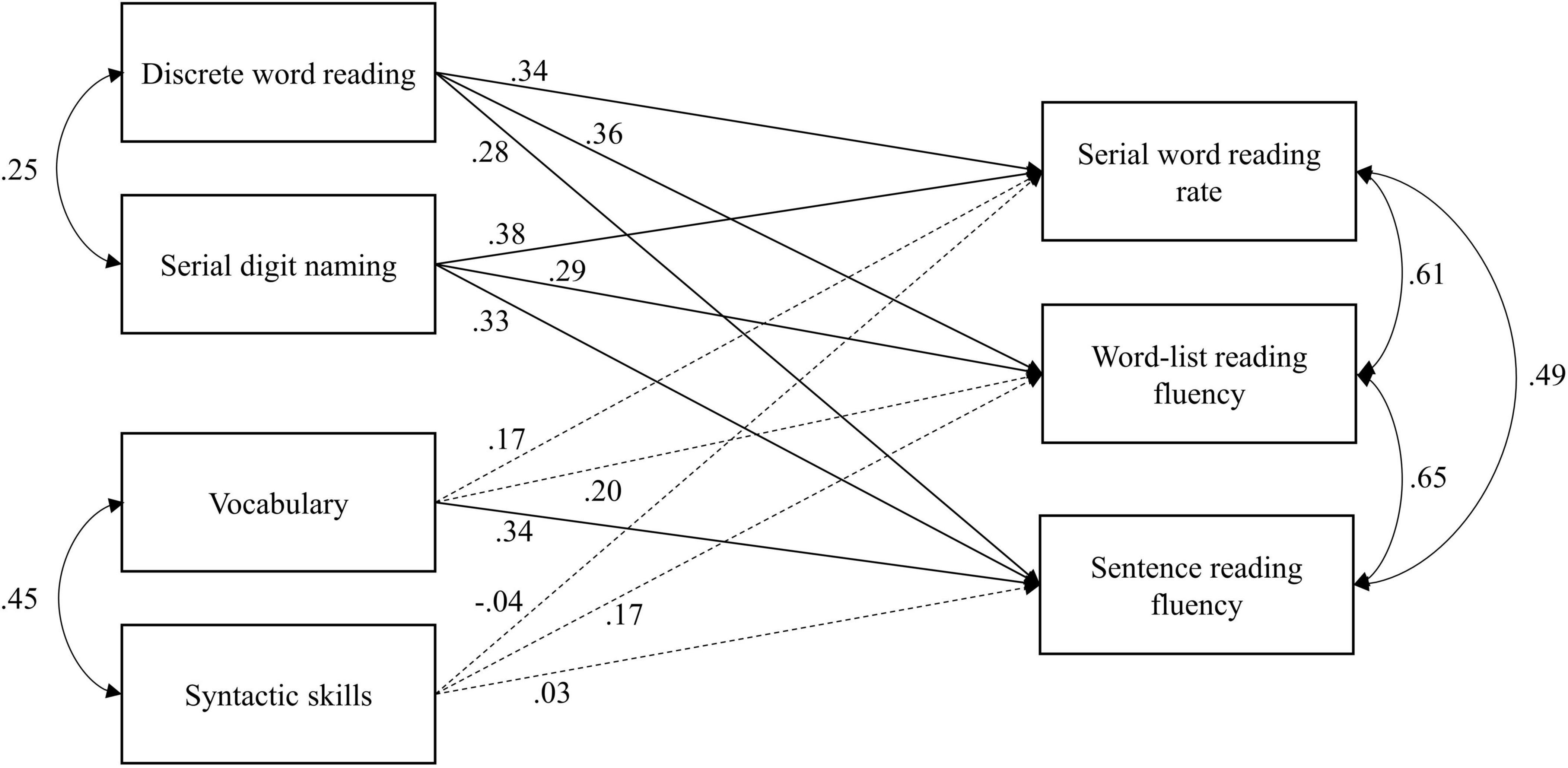
Figure 1. Path model of word- and text-level processes predicting reading fluency outcomes. Values on single-headed arrows are standardized regression coefficients. Double-headed arrows indicate correlations (standardized covariances). Solid lines indicate significant effects (p < 0.05) and dashed lines indicate non-significant effects. Error terms and correlations between predictors that are fixed at zero are not displayed to aid visibility.
Testing for possible differences between regression coefficients (as formulated in the hypotheses about the word-level processes) was done by constraining these coefficients to be equal across fluency outcomes for each individual word-level predictor. For the effect of discrete word reading, regression coefficients were found to be approximately equal across fluency measures. There was no significant deterioration in fit after posing equality constraints [i.e., Δχ2(2) = 2.87, p = 0.24]. For the effect of serial digit naming, regression coefficients were not found to be approximately equal, as constraining them resulted in a significant deterioration in model fit [i.e., Δχ2(2) = 8.97, p = 0.01]. Further examination revealed that the regression coefficient of serial digit naming on word-list reading fluency had to be estimated freely because it is significantly lower than the regression coefficients for serial word reading rate and sentence reading fluency. Further testing of differences between regression coefficients revealed that discrete word reading is a stronger predictor of word-list reading fluency than serial digit naming (p = 0.04).
The variance contributed by each word- or text-level predictor separately was assessed through fixed-order regression in SEM using phantom factors for both the predictors and outcomes (de Jong, 1999; see Analyses for more details). The model with the phantom factors is presented in Figure 2. Factor loadings between predictors and predictor phantom factors were structured to correspond to sequential steps taken in a traditional hierarchical regression to determine the additional variance explained by each predictor, beyond variance accounted for by “previous” predictors. The order of the steps was determined by ranking the processes underlying reading fluency from most basic (i.e., individual word recognition speed) to more advanced (i.e., syntactic skills) based on theory (see also our hypotheses). Accordingly, discrete word reading was evaluated first. As can be deduced from Figure 2, PH-DWR contains all variance explained by discrete word reading. Serial digit naming was evaluated second. PH-SDN is the factor that remains after the variance that serial digit naming has in common with discrete word reading is accounted for. The same logic applies to vocabulary, which was evaluated third. Syntactic skills were evaluated last. As such, PH-SYS is the factor that remains after the all the other predictors have been controlled, that is, the unique variance explained by syntactic skills. The unique variance of the other predictors was determined by changing the order of the predictors through adaptation of the factor loadings to the phantom factors. Several factor loadings between observed predictors and predictor phantom factors were fixed at zero to mirror the correlations between the predictors in the initial path model (e.g., as vocabulary and discrete word reading did not correlate in the initial path model, the factor loading from vocabulary on the discrete word reading phantom factor is fixed at zero; see the dotted lines on the left in Figure 2).
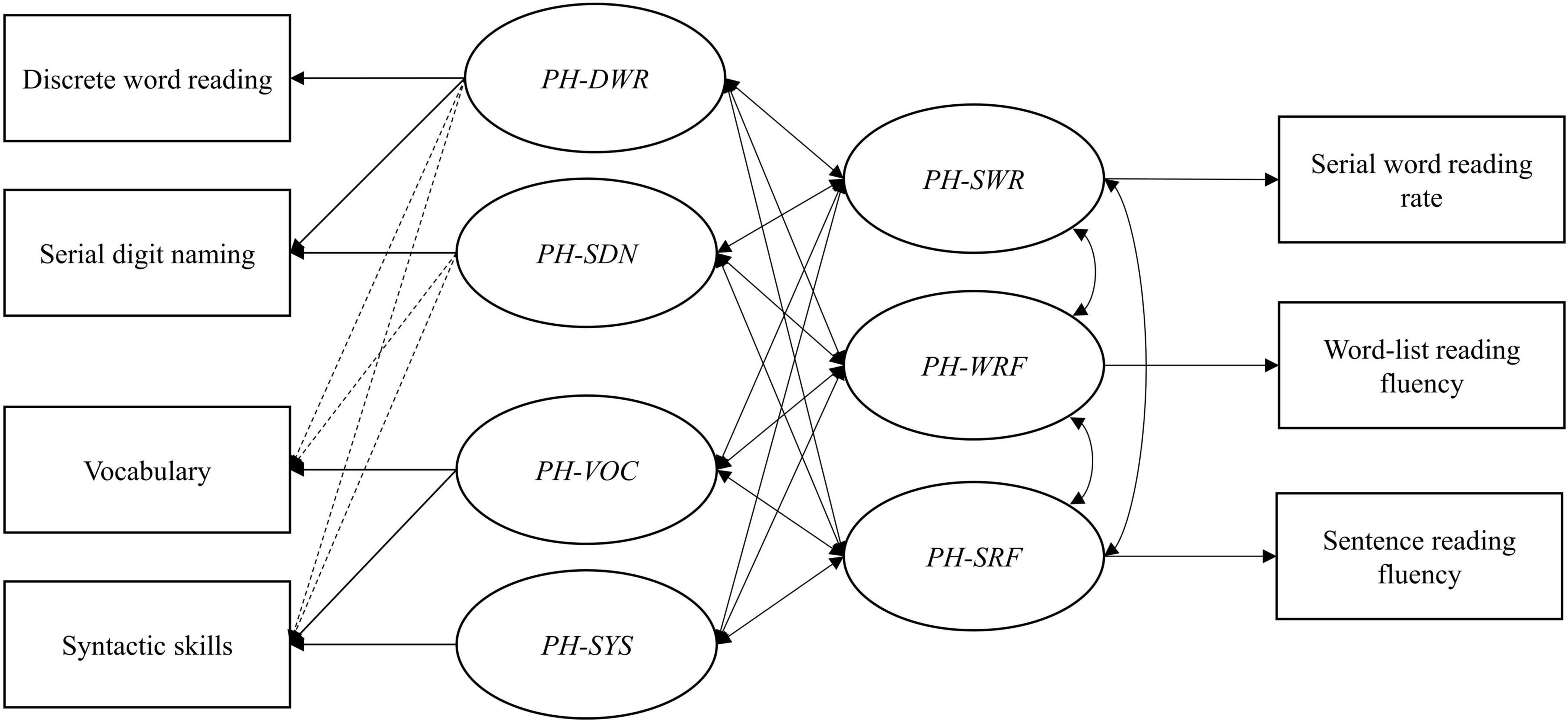
Figure 2. Fixed-order regression model predicting reading fluency outcomes from word- and text-level processes. PH, phantom factor; DWR, discrete word reading; SDN, serial digit naming; VOC, vocabulary; SYS, syntactic skills; SWR, serial word reading rate; WRF, word-list reading fluency; SFR, sentence reading fluency. Solid lines indicate freely estimated paths and dotted lines indicate paths that were fixed at zero. Error terms of observed variables and correlations between phantom factors that are fixed at zero are not displayed to aid visibility.
The results of the fixed-order regression analyses are reported in Table 4. Discrete word reading accounts for a similar amount of (shared and unique) variance in all three fluency outcomes. The somewhat lower amount for sentence reading fluency is not likely to be significantly different based on the comparisons of regression coefficients in the original path model. Serial digit naming explains additional variance in all reading outcomes after discrete word reading is controlled and also contributes uniquely to all reading outcomes after controlling for all other predictors in the model. In line with the original path model, its contribution to word-list reading fluency seems lower than for the other fluency measures. Vocabulary explains additional variance in both word-list and sentence reading fluency, but only contributes uniquely to the latter. Syntactic skills do not explain any additional variance while controlling for the other predictors and do not contribute uniquely to any of the reading outcomes.
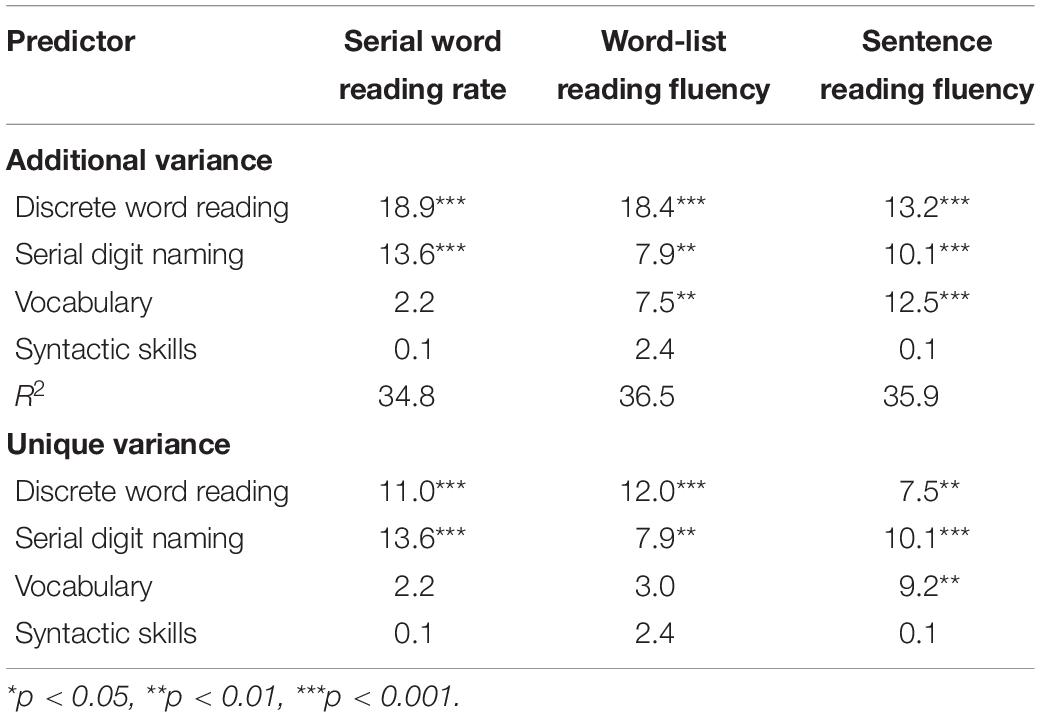
Table 4. Additional and unique variance (percent) per predictor for all reading outcomes.
Discussion
In this study, we investigated to what extent basic word- and text-level processes contribute to different measures of reading fluency to better understand the mechanisms underlying fluent reading. Individual word recognition speed and sequential processing efficiency were included as word-level processes, and vocabulary and syntactic skills were included as text-level processes. Reading rate of a list of unrelated familiar words (i.e., serial word reading rate), reading fluency of a list of increasingly difficult words (i.e., word-list reading fluency), and reading fluency of sentences were assessed as reading fluency measures. These measures represent a relevant variation in task complexity and availability of context. The main findings indicate that sequential processing efficiency plays an essential role in reading fluency across reading fluency measures besides individual word recognition speed. In addition, text-level processes come into play when complexity of fluency measures increases and context becomes available. However, the exact timing of these effects requires further investigation. The total variance that the word- and text-level factors accounted for did not increase appreciably with increasing complexity of fluency tasks or availability of context (all R2 within 0.015 of one another).
Word-Level Processes
The first hypothesis regarded the crucial role of individual word recognition speed as a basic word-level process underlying reading fluency across measures varying in complexity and availability of context. This was largely confirmed, as individual word recognition speed indeed contributed uniquely to every fluency measure. This finding confirms previous research on the role of individual word recognition in serial word reading rate (Protopapas et al., 2013; Altani et al., 2017) and word-list reading fluency (de Jong, 2011). However, its individual contribution did not decrease with increasing complexity of the fluency measures. Additionally, individual word recognition speed was found to account for a similar amount of variance in serial word reading rate and sentence reading fluency as sequential processing efficiency, which was hypothesized as another essential word-level process. This latter finding provides further evidence that individual word recognition speed is not the sole factor necessary and sufficient for fluent reading of unrelated words in lists. This can now be extended to words in connected text as well (see also Altani et al., 2020).
The second hypothesis positing sequential processing efficiency as an additional independent word-level predictor of reading fluency was confirmed. Sequential processing efficiency was indeed found to be a unique predictor of all three fluency measures. However, the size of its individual contribution differed across fluency measures. The amount of variance sequential processing efficiency explained in word-list reading of familiar words was similar to findings of previous studies covering serial word reading rate (e.g., van den Boer et al., 2016; Altani et al., 2017, 2018; see also de Jong, 2011; van den Boer and de Jong, 2015; Altani et al., 2020). However, in contrast to our hypothesis, its predictive value was found to decrease when moving from serial word reading to word-list reading fluency. This was also reflected in a lower amount of unique and shared variance in word-list reading fluency accounted for by sequential processing efficiency. In other words, sequential processing efficiency seems to become less important when words are less likely to be read by sight. This does not align with the suggestion that sequential processing efficiency might account for both between- and within-word serial processes, and would thus contribute more variance when words cannot be (fully) read by sight in more complex fluency measures (de Jong, 2011; van den Boer et al., 2016). The correlations reported by de Jong (2011) suggest that sequential processing efficiency should at least explain comparable amounts of unique variance in both word-list reading measures. As our study is the first to compare the individual contributions of word-level processes to reading fluency of word lists of familiar and increasingly difficult words, replication is warranted. Yet, our findings add to the ongoing debate about the role of sequential processing efficiency in reading fluency. They also highlight the need to determine whether within- and between-word serial processes are partly overlapping constructs or completely separate skills (see also de Jong and van den Boer, 2021).
Regarding sentence reading fluency, the role of sequential processing efficiency seems to increase again (to a level comparable with that in serial word reading rate) when words are no longer unrelated but interconnected through supra-lexical elements. The contribution of sequential processing efficiency is similar to that of individual word recognition speed. This aligns with the findings of Altani et al. (2020) on Greek third graders. The specific amount of variance explained by sequential processing efficiency in that study was comparable with our finding and about equal to the amount explained by individual word recognition speed. In contrast, sequential processing efficiency was the dominant word-level process predicting reading fluency of texts containing simple short words in English-speaking third graders. As stated before, Dutch is a semi-transparent language that is somewhere in between the more transparent Greek and more opaque English. These findings are consistent with the idea that languages differ in the relative importance of word-level processes for reading fluency (Altani et al., 2017, 2020). Overall, our findings for sequential processing efficiency support the suggestion that reading fluency is further developed by the coordination of processing across multiple items in a sequence once sight word reading has been established (Protopapas et al., 2013, 2018).
Text-Level Processes
The third hypothesis, regarding the contribution of vocabulary to both word-list reading fluency and sentence reading fluency, and the contribution of syntactic skills solely to sentence reading fluency, was partly confirmed. As expected, vocabulary accounted for unique variance in sentence reading fluency. In contrast, syntactic skills did not contribute to sentence reading fluency, despite a small indirect effect through vocabulary. This is the first study assessing this specific set of word- and text-level factors in reading fluency of sentences. Therefore, it is reassuring that the findings align with previous studies on the interaction between word reading and semantics in the presence of context (e.g., Nation and Snowling, 1998; Jenkins et al., 2003; Kim et al., 2014). However, the absence of an influence of syntactic skills stands in contrast to studies illustrating the essential role of syntax as a supra-lexical influence on reading fluency of connected text (e.g., Mokhtari and Thompson, 2006; van den Bosch et al., 2018).
An explanation might be that the sentences used in the sentence-reading task of this study were relatively simple. All sentences followed a similar structure and were of limited length (M = 8.4 words, range 7–14). As a comparison: the study by van den Bosch et al. (2018) included sentences with strong manipulations in syntactic complexity through presence and absence of connectives (i.e., ‘because’) as well as linear order of clauses (cause-effect vs. effect-cause). Their study also focused on second language learners with limited syntactic skills. Our measure of expressive grammar specifically targeted aspects deemed relevant for sentence reading fluency, challenging children to formulate sentences using increasingly complex connectives in specific contexts. An expressive measure was preferred over a receptive measure, such as sentence repetition from the CELF test battery (Kort et al., 2010), to ensure sufficient variability in scores across our sample of typically developing readers. However, the syntactic complexity of the sentences in our experiment may not have been high enough to require such substantial syntactic processing. Accordingly, sentence complexity did not reach the basic threshold to elicit effects of syntax on sentence reading fluency.
In that respect, the findings for the role of vocabulary in word-list reading fluency of increasingly difficult words might be explained through a similar argument. In this fluency measure, vocabulary accounted for additional variance after controlling for word-level processes, but did not account for any unique variance. The nature of the items in this task is quite difficult to capture and not as straightforward as in the word-list reading measure with short and familiar words. Words in the word-list reading fluency task increase in length (number of letters and syllables) and difficulty (complexity of syllables). At the same time, they also decrease in frequency. Although the least familiar, most complex items may not have been read by sight, children may not have reached this point during the time limit of the task. Consequently, they may not have needed their vocabulary knowledge yet to support their word identification skills.
Taken together, these findings imply that systematic manipulation of complexity, in terms of demands on both word-level processes and text-level processes, is necessary to acquire more knowledge about interactions between these processes during fluent reading. It then becomes important to determine when text-level processes come into play once meaning plays a role or words are connected through supra-lexical elements. Likewise, the type of text-level factors might also be important. For example, morphological skills may influence reading fluency more at the within-sentence level or when increasing difficulty of words also reflects higher morphological complexity (see e.g., Berninger et al., 2001). Syntactic skills may account for more variance at the between-sentence level. Further systematic manipulation and comparison of reading fluency measures and relevant factors is thus warranted.
Reading Fluency Measures
The remaining question regards the total amount of explained variance and the relative importance of each word- and text-level process in the individual fluency measures. This question was partly answered: Individual word recognition speed and sequential processing efficiency both have an important role in all three reading fluency measures. But their combined impact slightly decreases with increasing complexity of fluency measures. Yet, the additional influence of text-level processes in more complex reading fluency measures does not lead to a higher total amount of explained variance. Our specific set of word- and text-level processes accounts for about the same amount of variance in all reading fluency measures included in the study. It seems that the addition of text-level processes, that is, mainly vocabulary, leads to a redistribution of variance across the different predictors. This then results in a reduction of variance accounted for by word-level processes. This might also partly explain why sequential processing efficiency seems to play a smaller role in word-list and sentence reading fluency than in serial word reading, to which vocabulary did not contribute in any way. Still, the underlying mechanisms might be different for word-list and sentence reading fluency (see above). Although text-level processes may be expected to account for additional variance on top of basic word-level processes, they only appear to fill the resulting gap when word-level processes become somewhat less important. This leads to similar amounts of total explained variance across fluency measures of varying complexity.
Turning to each separate reading fluency measure, our findings for serial word reading rate in Dutch children are again somewhere in between those for Greek and English children of the same age (third graders) reported by Altani et al. (2020). Individual word recognition speed and sequential processing efficiency seem to be the two main reading processes underlying word-list reading of familiar words. Sequential processing efficiency accounts for a similar amount of unique variance as individual word recognition, in alignment with the pattern for Greek children. It is surprising that the dominance of sequential processing efficiency as a word-level process is not yet more visible in the Greek children in the Altani et al. (2020) study and the Dutch children in our study. Fluency-related processes generally develop earlier in more transparent languages. The amounts of unique variance accounted for by the individual word-level factors in our study are also more in line with the findings in Greek children. What further stands out is that the total amount of variance that is explained by the word-level processes is considerably lower in our study (32.5%) than the 49–50% in both Greek and English children reported by Altani et al. (2020). This is unexpected because the lower correlation between word-level predictors in Dutch compared to Greek and English (i.e., 0.25 vs. 0.44 and 0.36) suggest lower shared variance between the two word-level predictors in Dutch. This would normally result in higher total amounts of explained variance, as the two processes account for different sources of variance. The amounts of explained variance may be higher for both other languages due to the use of bisyllabic words in Greek (which may be processed in larger chunks instead of letter-by-letter) and whole-word reading in English. As Dutch is more transparent than English, but used shorter words than Greek (i.e., monosyllabic words), this results in lower overall shared variance. It is not clear why both processes are then not better able to predict different components of variance in reading fluency. More cross-language comparisons, such as done by van den Boer et al. (2016) and Altani et al. (2017, 2020), are needed to gain more insight into how orthography influences the role of word-level processes. Such studies can also shed more light on the weight of word-level processes across different types of fluency measures, as well as the timing of developmental shifts in dominance of specific processes.
Word-level processes (especially sequential processing efficiency) seem to contribute less to word-list reading fluency than to the simpler measure of serial word reading. The influence of sequential processing efficiency would be expected to increase as fluency tasks become more complex and entail both between- and within-word serial processes (de Jong, 2011; van den Boer et al., 2016); this pattern is not borne out in our data. Instead, it seems that the role of retrieval processes (as captured by the discrete word-reading task aiming to measure sight word reading) is more or less similar across all three fluency measures. Consequently, sequential processing efficiency may only account for the between-word processing and not for within-word processes. Additional factors related to task difficulty may be relevant here: The mean number of words processed per second is much higher for serial word reading (1.74) than for word-list reading fluency (1.02). This makes between-word serial processing much more prominent in the former task.
No previous studies have examined the prediction of sentence reading fluency by word- and text-level processes. There is thus no baseline against which we can compare the proportion of variance in sentence reading fluency that was accounted for in our study. Studies including listening comprehension or word-list reading fluency as predictors of text reading fluency (e.g., Kim et al., 2011) are not directly relevant for this comparison. These more encompassing tasks do not provide the level of detail in terms of underlying mechanisms associated with fluent reading that we aimed to identify in our study. As such, including a wider but also more controlled range of fluency measures is essential for unraveling the underlying processes that are involved in reading fluency development and that may be deficient in struggling readers. Systematic manipulations should entail both word- and text-level demands.
Implications
Our findings confirm that reading fluency is more than just fast recognition of individual words. Reading fluency of word lists, as so often used in clinical and educational contexts, also requires the coordination of processes across consecutive words. Moreover, reading fluency of connected text, which would be a more ecologically valid measure of reading fluency, also requires the integration of text-level comprehension processes. Even though we are only beginning to understand how these individual processes interact and contribute to reading fluency, this study provides important clues for future research. We were able to illustrate that there are meaningful differences between fluency measures concerning the underlying processes that play a role in them. If we want to understand where these differences come from and how they can be explained (and perhaps eventually supported), we need to start mapping underlying processes more systematically to identify potential bottlenecks during development. Aspects to take into account pertain to (1) creating relevant and systematic variation in demands on word- and text-level processes within fluency measures, (2) ascertain variation in complexity and length of materials that match reading fluency across development (e.g., adding pseudoword-list reading, syntactically complex sentences, and short and longer texts), (3) inclusion of a broader range of word- and text-level processes (e.g., adding decoding and morphological skills), (4) more detailed tracking of the timing of developmental shifts in underlying processes, and (5) possible effects of orthography (e.g., van den Boer et al., 2016; Altani et al., 2017, 2020).
Regarding the relevance for diagnostic practice, our findings confirm that typical word reading efficiency tests (such as TOWRE; Torgesen et al., 2012) are very suitable as a screening and diagnostic tool for word-level reading difficulties: they seem to capture the main mechanisms underlying word reading fluency (Protopapas et al., 2018). Our study further shows that this measure captures both individual word recognition speed and sequential processing efficiency, as well as some overall word knowledge. These tests provide a good indication of a child’s word-level reading fluency skills when combined with a pseudoword-list reading fluency test, filtering out the role of vocabulary. However, we contend that it is important to increase both the breadth and depth of reading fluency assessment, especially in developing readers, if we want to understand what part of reading fluency may be particularly weak or underdeveloped. By depth we mean specific assessment of underlying word- and/or text-level processes (e.g., individual word recognition and sequential processing; see e.g., Nomvete and Easterbrooks, 2020, for text-level suggestions) with the aim to identify specific deficiencies. By increasing breadth we mean mapping reading fluency through measures that have educational and societal relevance (i.e., covering connected text) and fit literacy progress as reading becomes more advanced, with the aim to make instructional decisions (see Washburn, 2022, for an overview). Combined, the resulting information can provide input for further improvement of literacy instruction throughout education and foster tailored assessment and interventions for struggling readers.
Data Availability Statement
The original contributions presented in the study are publicly available. These data can be found here: https://osf.io/mkurw/?view_only=51d0227d5df74e229f1e0c14b8cb3047.
Ethics Statement
The studies involving human participants were reviewed and approved by The ethics committee of the University of Amsterdam (case number 2017-CDE-8332). Written informed consent to participate in this study was provided by the participants’ legal guardian/next of kin.
Author Contributions
SV acquired funding, conceptualized and managed the study, developed the measures, collected the data, conducted the analyses, interpreted the findings, and wrote and revised the manuscript as lead author. AP contributed to the conception and design of the study, the data processing, analyses and interpretation of the findings, and reviewed and edited the manuscript. PJ contributed to acquiring funding and conceptualizing the study, analyses and interpretation of findings, and reviewed and edited the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by a Rubicon grant from the Netherlands Organization for Scientific Research (NWO) to SV (Grant Number 019.181SG.013) and partly supported by a grant from the Social Sciences and Humanities Research Council of Canada (Grant Number RES0029061) to George K. Georgiou. Open access publication of this manuscript has been funded by the LiNCon research group of the Department of Special Needs Education of the University of Oslo.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We are grateful to the schools, children, and parents for participating in the study. We also thank Frederike, Amber, Anne-Mieke, and Romany for collecting and processing the eye-tracking data, Lois, Iris, Myrna, Dora, and Lotte for administering the reading and related tasks, and Angeliki Altani for her assistance during data processing.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2021.789313/full#supplementary-material
References
Altani, A., Georgiou, G. K., Deng, C., Cho, J.-R., Katopodi, K., Wei, W., et al. (2017). Is processing of symbols and words influenced by writing system? Evidence from Chinese, Korean, English, and Greek. J. Exp. Child Psychol. 164, 117–135. doi: 10.1016/j.jecp.2017.07.006
PubMed Abstract | CrossRef Full Text | Google Scholar
Altani, A., Protopapas, A., and Georgiou, G. K. (2018). Using serial and discrete digit naming to unravel word reading processes. Front. Psychol. 9:524.
Google Scholar
Altani, A., Protopapas, A., Katopodi, K., and Georgiou, G. K. (2020). Tracking the serial advantage in the naming rate of multiple over isolated stimulus displays. Read. Writ. 33, 349–375. doi: 10.1007/s11145-019-09962-7
CrossRef Full Text | Google Scholar
Araújo, S., Reis, A., Petersson, K. M., and Faísca, L. (2015). Rapid automatized naming and reading performance: a meta-analysis. J. Educ. Psychol. 107, 868–883. doi: 10.1037/edu0000006
CrossRef Full Text | Google Scholar
Baayen, R. H., Piepenbrock, R., and van Rijn, H. (1993). The CELEX Lexical Database (CD-ROM). Philadelphia: Linguistic Data Consortium.
Google Scholar
Benjamin, R. G., and Schwanenflugel, P. J. (2010). Text complexity and oral reading prosody in young readers. Read. Res. Q. 45, 388–404. doi: 10.1598/RRQ.45.4.2
CrossRef Full Text | Google Scholar
Berninger, V. W., Abbott, R. D., Billingsley, F., and Nagy, W. (2001). “Processes underlying timing and fluency of reading: efficiency, automaticity, coordination, and morphological awareness,” in Dyslexia, fluency, and the brain, ed. M. Wolf (Timonium: York Press), 383–414.
Google Scholar
Breznitz, Z. (2006). Fluency in reading: synchronization of processes. Mahwah, NJ: Erlbaum.
Google Scholar
Brus, B. T., and Voeten, M. J. M. (1999). Eén minuut test [One minute test]. San Diego, California: Hartcourt Test Publishers.
Google Scholar
Crosson, A. C., and Lesaux, N. K. (2013). Does knowledge of connectives play a unique role in the reading comprehension of English learners and English-only students? J. Res. Read. 36, 241–260. doi: 10.1111/j.1467-9817.2011.01501.x
CrossRef Full Text | Google Scholar
de Jong, P. F. (1999). Hierarchical regression analysis in structural equation modeling. Struct. Equ. Modeling 6, 198–211. doi: 10.1080/10705519909540128
CrossRef Full Text | Google Scholar
de Jong, P. F. (2011). What discrete and serial rapid automatized naming can reveal about reading. Sci. Stud. Read. 15, 314–337. doi: 10.1080/10888438.2010.485624
CrossRef Full Text | Google Scholar
de Jong, P. F., and van den Boer, M. (2021). The relation of visual attention span with serial and discrete rapid automatized naming and reading. J. Exp. Child Psychol. 207:105093. doi: 10.1016/j.jecp.2021.105093
PubMed Abstract | CrossRef Full Text | Google Scholar
de Jong, P. F., and van der Leij, A. (2002). Effects of phonological abilities and linguistic comprehension on the development of reading. Sci. Stud. Read. 6, 51–77. doi: 10.1207/S1532799XSSR0601_03
PubMed Abstract | CrossRef Full Text | Google Scholar
Egberink, I. J. L., Holly-Middelkamp, F. R., and Vermeulen, C. S. M. (2017). COTAN beoordeling 2010, Peabody Picture Vobaculary Test-III-NL (PPVT-III-NL) [COTAN review 2010, PPVT-III-NL]. Available Online at: www.cotandocumentatie.nl (accessed 2017, August 9)
Google Scholar
Ehri, L. C. (2005). Learning to read words: theory, findings, and issues. Sci. Stud. Read. 9, 167–188. doi: 10.1207/s1532799xssr0902_4
CrossRef Full Text | Google Scholar
Ehri, L. C. (2014). Orthographic mapping in the acquisition of sight word reading, spelling memory, and vocabulary learning. Sci. Stud. Read. 18, 5–21. doi: 10.1080/10888438.2013.819356
CrossRef Full Text | Google Scholar
Ehri, L. C., and Wilce, L. S. (1983). Development of word identification speed in skilled and less skilled beginning readers. J. Educ. Psychol. 75, 3–18. doi: 10.1037/0022-0663.75.1.3
CrossRef Full Text | Google Scholar
Evers, A., Egberink, I. J. L., Braak, M. S. L., Frima, R. M., Vermeulen, C. S. M., and van Vliet-Mulder, J. C. (2009–2012). COTAN documentatie [COTAN documentation]. Amsterdam, The Netherlands: Boom testuitgevers.
Google Scholar
Foorman, B. R., Koon, S., Petscher, Y., Mitchell, A., and Truckenmiller, A. (2015). Examining general and specific factors in the dimensionality of oral language and reading in 4th–10th grades. J. Educ. Psychol. 107, 884–899. doi: 10.1037/edu0000026
PubMed Abstract | CrossRef Full Text | Google Scholar
Frisson, S., Rayner, K., and Pickering, M. J. (2005). Effects of contextual predictability and transitional probability on eye movements during reading. J. Exp. Psychol. Learn. Mem. Cogn. 31, 862–877. doi: 10.1037/0278-7393.31.5.862
PubMed Abstract | CrossRef Full Text | Google Scholar
Fuchs, L. S., Fuchs, D., Hosp, M. K., and Jenkins, J. R. (2001). Oral reading fluency as an indicator of reading competence: a theoretical, empirical, and historical analysis. Sci. Stud. Read. 5, 239–256. doi: 10.1207/S1532799XSSR0503_3
CrossRef Full Text | Google Scholar
Hudson, R. F., Lane, H. B., and Pullen, P. C. (2005). Reading fluency assessment and instruction: what, why, and how? Read. Teach. 58, 702–714. doi: 10.1598/RT.58.8.1
CrossRef Full Text | Google Scholar
Jenkins, J. R., Fuchs, L. S., van den Broek, P., Espin, C., and Deno, S. L. (2003). Sources of individual differences in reading comprehension and reading fluency. J. Educ. Psychol. 95, 719–729. doi: 10.1037/0022-0663.95.4.719
CrossRef Full Text | Google Scholar
Kim, Y. S., Wagner, R. K., and Foster, E. (2011). Relations among oral reading fluency, silent reading fluency, and reading comprehension: a latent variable study of first-grade readers. Sci. Stud. Read. 15, 338–362. doi: 10.1080/10888438.2010.493964
PubMed Abstract | CrossRef Full Text | Google Scholar
Kim, Y. S. G. (2015). Developmental, component-based model of reading fluency: an investigation of predictors of word-reading fluency, text-reading fluency, and reading comprehension. Read. Res. Q. 50, 459–481. doi: 10.1002/rrq.107
PubMed Abstract | CrossRef Full Text | Google Scholar
Klauda, S. L., and Guthrie, J. T. (2008). Relationships of three components of reading fluency to reading comprehension. J. Educ. Psychol. 100, 310–321. doi: 10.1037/0022-0663.100.2.310
CrossRef Full Text | Google Scholar
Kline, R. B. (2011). Principle and Practice of Structural Equation Modeling. New York: The Guildford Press.
Google Scholar
Kort, W., Schittekatte, M., and Compaan, E. L. (2010). Clinical Evaluation of Language Fundamentals-4 NL (CELF-4-NL). London: Pearson.
Google Scholar
Krepel, A., de Bree, E. H., Mulder, E., van de Ven, M., Segers, E., Verhoeven, L., et al. (2021). The unique contribution of vocabulary in the reading development of English as a foreign language. J. Res. Read. 44, 453–474. doi: 10.1111/1467-9817.12350
CrossRef Full Text | Google Scholar
Kuhn, M. R., Schwanenflugel, P. J., and Meisinger, E. B. (2010). Aligning theory and assessment of reading fluency: automaticity, prosody, and definitions of fluency. Read. Res. Q. 45, 230–251. doi: 10.1598/RRQ.45.2.4
CrossRef Full Text | Google Scholar
Lai, S. A., Benjamin, R. G., Schwanenflugel, P. J., and Kuhn, M. R. (2014). The longitudinal relationship between reading fluency and reading comprehension skills in second-grade children. Read. Writ. Q. 30, 116–138. doi: 10.1080/10573569.2013.789785
CrossRef Full Text | Google Scholar
Landerl, K., Freudenthaler, H. H., Heene, M., de Jong, P. F., Desrochers, A., Manolitsis, G., et al. (2019). Phonological awareness and rapid automatized naming as longitudinal predictors of reading in five alphabetic orthographies with varying degrees of consistency. Sci. Stud. Read. 23, 220–234. doi: 10.1080/10888438.2018.1510936
CrossRef Full Text | Google Scholar
Little, T. D. (2013). Longitudinal Structural Equation Modeling. New York: The Guildford Press.
Google Scholar
Macho, S., and Ledermann, T. (2011). Estimating, testing and comparing specific effects in structural equation models: the phantom model approach. Psychol. Methods 16, 34–43. doi: 10.1037/a0021763
PubMed Abstract | CrossRef Full Text | Google Scholar
Miller, J., and Schwanenflugel, P. J. (2008). A longitudinal study of the development of reading prosody as a dimension of oral reading fluency in early elementary school children. Read. Res. Q. 43, 336–354. doi: 10.1598/RRQ.43.4.2
PubMed Abstract | CrossRef Full Text | Google Scholar
Mokhtari, K., and Thompson, H. B. (2006). How problems of reading fluency and comprehension are related to difficulties in syntactic awareness skills among fifth graders. Lit. Res. Instr. 46, 73–94. doi: 10.1080/19388070609558461
CrossRef Full Text | Google Scholar
Moll, K., Ramus, F., Bartling, J., Bruder, J., Kunze, S., Neuhoff, N., et al. (2014). Cognitive mechanisms underlying reading and spelling development in five European orthographies. Learn. Instr. 29, 65–77. doi: 10.1016/j.learninstruc.2013.09.003
CrossRef Full Text | Google Scholar
Nation, K., and Snowling, M. J. (1998). Individual differences in contextual facilitation: evidence from dyslexia and poor reading comprehension. Child Dev. 69, 996–1011. doi: 10.1111/j.1467-8624.1998.tb06157.x
CrossRef Full Text | Google Scholar
Nation, K., and Snowling, M. J. (2004). Beyond phonological skills: broader language skills contribute to the development of reading. J. Res. Read. 27, 342–356. doi: 10.1111/j.1467-9817.2004.00238.x
CrossRef Full Text | Google Scholar
National Reading Panel [NRP] (2000). Report of the national reading panel: teaching children to read, reports of the subgroups (NIH Pub. No. 00-4754). Washington, DC: U.S. Department of Health and Human Services.
Google Scholar
Nomvete, P., and Easterbrooks, S. R. (2020). Phrase-reading mediates between words and syntax in struggling adolescent readers. Commun. Disord. Q. 41, 162–175. doi: 10.1177/1525740119825616
CrossRef Full Text | Google Scholar
Ouellette, G. P. (2006). What’s meaning got to do with it: the role of vocabulary in word reading and reading comprehension. J. Educ. Psychol. 98, 554–566. doi: 10.1037/0022-0663.98.3.554
CrossRef Full Text | Google Scholar
Perfetti, C. A. (1995). Cognitive research can inform reading education. J. Res. Read. 18, 106–115. doi: 10.1111/j.1467-9817.1995.tb00076.x
CrossRef Full Text | Google Scholar
Protopapas, A. (2007). CheckVocal: a program to facilitate checking the accuracy and response time of vocal responses from DMDX. Behav. Res. Methods 39, 859–862. doi: 10.3758/BF03192979
PubMed Abstract | CrossRef Full Text | Google Scholar
Protopapas, A., Altani, A., and Georgiou, G. K. (2013). Development of serial processing in reading and rapid naming. J. Exp. Child Psychol. 116, 914–929. doi: 10.1016/j.jecp.2013.08.004
PubMed Abstract | CrossRef Full Text | Google Scholar
Protopapas, A., Katopodi, K., Altani, A., and Georgiou, G. K. (2018). Word reading fluency as a serial naming task. Sci. Stud. Read. 22, 248–263. doi: 10.1080/10888438.2018.1430804
CrossRef Full Text | Google Scholar
R Core Team (2021). R: a language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing.
Google Scholar
Ricketts, J., Davies, R., Masterson, J., Stuart, M., and Duff, F. J. (2016). Evidence for semantic involvement in regular and exception word reading in emergent readers of English. J. Exp. Child Psychol. 150, 330–345. doi: 10.1016/j.jecp.2016.05.013
PubMed Abstract | CrossRef Full Text | Google Scholar
Ricketts, J., Nation, K., and Bishop, D. V. (2007). Vocabulary is important for some, but not all reading skills. Sci. Stud. Read. 11, 235–257. doi: 10.1080/10888430701344306
CrossRef Full Text | Google Scholar
Rosseel, Y. (2012). lavaan: an R Package for Structural Equation Modeling. J. Stat. Softw. 48, 1–36. doi: 10.18637/jss.v048.i02
CrossRef Full Text | Google Scholar
Samuels, S. J. (2006). “Toward a model of reading fluency,” in What research has to say about fluency instruction, eds S. J. Samuels and A. E. Farstrup (Newark, Delaware: International Reading Association), 24–46.
Google Scholar
Samuels, S. J. (2007). The DIBELS tests: is speed of barking at print what we mean by reading fluency? Read. Res. Q. 42, 563–566.
Google Scholar
Schlichting, L. (2005). Peabody picture vocabulary test-III-NL. Amsterdam: Hartcourt Assessment BV.
Google Scholar
Schwanenflugel, P. J., Hamilton, A. M., Kuhn, M. R., Wisenbaker, J. M., and Stahl, S. A. (2004). Becoming a fluent reader: reading skill and prosodic features in the oral reading of young readers. J. Educ. Psychol. 96, 119–129. doi: 10.1037/0022-0663.96.1.119
PubMed Abstract | CrossRef Full Text | Google Scholar
Seymour, P. H., Aro, M., Erskine, J. M., and Collaboration with Cost Action A8 Network (2003). Foundation literacy acquisition in European orthographies. Br. J. Psychol. 94, 143–174. doi: 10.1348/000712603321661859
PubMed Abstract | CrossRef Full Text | Google Scholar
Share, D. L. (2008). On the anglocentricities of current reading research and practice: the perils of overreliance on an “outlier” orthography. Psychol. Bull. 134, 584–615. doi: 10.1037/0033-2909.134.4.584
PubMed Abstract | CrossRef Full Text | Google Scholar
Taylor, J. S. H., Duff, F. J., Woollams, A. M., Monaghan, P., and Ricketts, J. (2015). How word meaning influences word reading. Curr. Dir. Psychol. Sci. 24, 322–328. doi: 10.1177/0963721415574980
CrossRef Full Text | Google Scholar
Torgesen, J. K., Wagner, R. K., and Rashotte, C. A. (2012). Test of Word Reading Efficiency Second Edition (TOWRE-2). Austin: Pro-Ed.
Google Scholar
van den Boer, M., and de Jong, P. F. (2015). Parallel and serial reading processes in children’s word and nonword reading. J. Educ. Psychol. 107, 141–151. doi: 10.1037/a0037101
CrossRef Full Text | Google Scholar
van den Boer, M., Georgiou, G. K., and de Jong, P. F. (2016). Naming of short words is (almost) the same as naming of alphanumeric symbols: evidence from two orthographies. J. Exp. Child Psychol. 144, 152–165. doi: 10.1016/j.jecp.2015.11.016
PubMed Abstract | CrossRef Full Text | Google Scholar
van den Bos, K. P., Zijlstra, B. J., and lutje Spelberg, H. C. (2002). Life-span data on continuous-naming speeds of numbers, letters, colors, and pictured objects, and word-reading speed. Sci. Stud. Read. 6, 25–49. doi: 10.1207/S1532799XSSR0601_02
CrossRef Full Text | Google Scholar
van den Bosch, L. J., Segers, E., and Verhoeven, L. (2018). Online processing of causal relations in beginning first and second language readers. Learn. Individ. Differ. 61, 59–67. doi: 10.1016/j.lindif.2017.11.007
CrossRef Full Text | Google Scholar
van Silfhout, G., Evers-Vermeul, J., and Sanders, T. (2015). Connectives as processing signals: how students benefit in processing narrative and expository texts. Discourse Process. 52, 47–76. doi: 10.1080/0163853X.2014.905237
CrossRef Full Text | Google Scholar
van Viersen, S., de Bree, E. H., Zee, M., Maassen, B., van der Leij, A., and de Jong, P. F. (2018). Pathways into literacy: the role of early oral language abilities and family risk for dyslexia. Psychol. Sci. 29, 418–428. doi: 10.1177/0956797617736886
PubMed Abstract | CrossRef Full Text | Google Scholar
van Viersen, S., Protopapas, A., Georgiou, G. K., Parrila, R., Ziaka, L., and de Jong, P. F. (2021). Lexicality effects on orthographic learning in beginning and advanced readers of Dutch: an eye-tracking study. Q. J. Exp. Psychol. doi: 10.1177/17470218211047420 [Epub Online ahead of print]
PubMed Abstract | Google Scholar
Washburn, J. (2022). Reviewing evidence on the relations between oral reading fluency and reading comprehension for adolescents. J. Learn. Disabil. 55, 22–42. doi: 10.1177/00222194211045122
PubMed Abstract | CrossRef Full Text | Google Scholar
West, R. F., Stanovich, K. E., Feeman, D. J., and Cunningham, A. E. (1983). The effect of sentence context on word recognition in second-and sixth-grade children. Read. Res. Q. 19, 6–15. doi: 10.2307/747333
CrossRef Full Text | Google Scholar
Zoccolotti, P., De Luca, M., Lami, L., Pizzoli, C., Pontillo, M., and Spinelli, D. (2013). Multiple stimulus presentation yields larger deficits in children with developmental dyslexia: a study with reading and RAN-type tasks. Child Neuropsychol. 19, 639–647. doi: 10.1080/09297049.2012.718325
PubMed Abstract | CrossRef Full Text | Google Scholar
Zoccolotti, P., De Luca, M., Marinelli, C. V., and Spinelli, D. (2014). Modeling individual differences in text reading fluency: a different pattern of predictors for typically developing and dyslexic readers. Front. Psychol. 5:1374. doi: 10.3389/fpsyg.2014.01374
PubMed Abstract | CrossRef Full Text | Google Scholar
Zoccolotti, P., De Luca, M., and Spinelli, D. (2015). Discrete versus multiple word displays: a re-analysis of studies comparing dyslexic and typically developing children. Front. Psychol. 6:1530. doi: 10.3389/fpsyg.2015.01530
PubMed Abstract | CrossRef Full Text | Google Scholar
1. Stylistics as a science. Branches of stylistics.
Stylistics is a branch of general linguistics. It has mainly with two tasks:
Stylistics – is regarded as a lang-ge science which deals with the results of the act of communication.
There are 2 basic objects of stylistics:
— stylistic devices and figures of speech
— functional styles
Branches of stylistics:
— Lexical stylistics – studies functions of direct and figurative meanings, also the way contextual meaning of a word is realized in the text. L.S. deals with various types of connotations – expressive, evaluative, emotive; neologisms, dialectal words and their behavior in the text.
— Grammatical stylistics – is subdivided into morphological and syntactical
Morphological s. views stylistic potential of grammatical categories of different parts of speech. Potential of the number, pronouns…
Syntactical s. studies syntactic, expressive means, word order and word combinations, different types of sentences and types of syntactic connections. Also deals with origin of the text, its division on the paragraphs, dialogs, direct and indirect speech, the connection of the sentences, types of sentences.
— Phonostylistics – phonetical organization of prose and poetic texts. Here are included rhythm, rhythmical structure, rhyme, alliteration, assonance and correlation of the sound form and meaning. Also studies deviation in normative pronunciation.
— Functional S (s. of decoding) – deals with all subdivisions of the language and its possible use (newspaper, colloquial style). Its object — correlation of the message and communicative situation.
— Individual style study –studies the style of the author. It looks for correlations between the creative concepts of the author and the language of his work.
— stylistics of encoding — The shape of the information (message) is coded and the addressee plays the part of decoder of the information which is contained in message. The problems which are connected with adequate reception of the message without any loses (deformation) are the problems of stylistics of encoding.
Stylistics is not equal to linguistics science, such as phonetics, linguistics disciplines – lexicology, morphology, syntax because they are level disciplines as they treat only one linguistic level and stylistics investigates the questions on all the levels and different aspects of the texts in general. The smallest unit of lang-ge is the phoneme. Several phonemes combined make a unit of a higher level – morpheme (morphemic level). One or more morphemes makes a word, a lexeme (lexical level). One or more than one words make an utterance, a sentence (sentence level). Words combinations are treated either on the lexical or syntactical level:
Winter… смысл целого предл.
Never!
Each level consists of units of lower level.
Read – er [э] морфема
Stylistics must be subdivided into separate, independent branches – stylistic phonetics, Stylistic morphology, Stylistic lexicology, Stylistic syntax
Whatever level we take, stylistics is describes not what is in common use, but what is specific in this or that respect, what differentiates one sublanguage from others.
General (non-stylistic) phonetics investigates the whole articulatory — audial system of language. Stylistic ph-cs describes variants of pronunciation occuring in different types of speech. Special attention is also paid to prosodic features of prose and poetry.
General (non-stylistic) morphology treats morphemes and grammatical meanings expressed by them in language in general, without regard to their stylistic value. Stylistic mor-gy is interested in grammatical forms and grammatical meanings that are peculiar to particular sublanguages, explicity or implicity comparing them with the neutral ones common to all the sublanguages.
Lexicology deals with stylistic classification (differentiation) of the vocabulary that form a part of stylistics (stylistics lexicology). In stylistic lexicology each units are studied separately, instead of as a whole text (group of words, word classification).
General syntax treats word combinations and sentences, analyzing their structures and stating what is permissible and what is inadmissible in constructing correct utterances in the given language.
Stylistic syntax shows what particular constructions are met with in various types of speech, what syntactical structures are style forming (specific) in the sublanguages in question.
Semantic level – connected with meaning
2. Classifications of functional styles
Style is depth, deviations, choice, context style restricted linguistic variation, style is the man himself (Buffon). According to Galperin the term ‘style’ refers to the following spheres:
1) the aesthetic function of language
It may be seen in works of art- poetry, imaginative prose, fiction, but works of science, technical instruction or business correspondence have no aesthetic value.
2) synonymous ways of rendering one and the same idea
The possibility of choice of using different words in similar situations is connected with the question of style as if the form changes, the contents changes too and the style may be different.
3) expressive means in language
— are employed mainly in the following spheres – poetry, fiction, colloquial speech, speeches but not in scientific articles, business letters and others.
4) emotional coloring in language
Very many types of texts are highly emotional – declaration of love, funeral oration, poems(verses), but a great number of texts is unemotional or non-emphatic (rules in textbooks).
5) a system of special devices called stylistic devices
The style is formed with the help of characteristic features peculiar to it. Many texts demonstrate various stylistic features:
She wears ‘fashion’ = what she wears is fashionable or is just the fashion methonimy.
6) the individual manner of an author in making use
the individual style of speaking, writing must be investigated with the help of common rules and generalization.
Galperin distinguishes five styles in present-day English:
I. Belles Lettres ( беллетристика)
1. Poetry
2. Emotive prose
3. The Drama
III. Publicistic Style
1. Oratory and Speeches
2. The Essay
3. Articles
IV. Newspapers
1. brief News Items (короткие новости)
2. Headlines
3. Advertisements and Announcements (объявления)
4. The Editorial ( редакторская статья)
V. Scientific Prose
VI. Official Documents
He didn’t single out a colloquial style. Its created by the work of the author –the result of creative activity.
Arnold classification consists of four styles:
1. Poetic style
2. Scientific style
3. Newspaper style
4. Colloquial style
Singling out a poetic and a scientific style seems valid. But Arnold insists on the validity of the ‘newspaper style’ theory. She says that the specificity of mass media make acknowledgement of newspaper style, as one of functional style.
In the handbook by Morokhovsky, Vorobyova, Likhosherst give following classification of style:
1. official business style
2. scientific – professional style
3. publicistic style
4. literary colloquial style
5. familiar colloquial style
Kozhina lists type — forming and socially significant spheres of communication as follows:
1) official 2)scientific 3) artistic 4) publicistic 5) of daily intercourse (=colloquial).
Just as in some of the above classification we can doubt the validity of treating separately (and thus opposing) the artistic (belles-lettres) and the publicistic spheres. Not only writers of poetry or fiction, but publicists and orators as well make abundant use of ornament and expressive means of language — tropes and figures first and foremost
Problematic aspects:
Newspaper style as a part of publicist style. That why it can’t be individual. It has no situation of communication. Newspaper style to give information, to influence, to represent social, political idea, means of pursuage. Its important to concentrate. That is why the text of newspaper style should be organized in the certain style. It must contain elements of stylistic colored words and have certain graphic organization. The articles contain questions, the sentence interrogative, elliptical construction and direct speech is included. The use of political words and expressions, cliches, colloquial words, slang, professionalisms, large amount of stylistic devises, various graphical means. The text of NP style is read by people od different social status.
Belles – Lettres style is so many colored. It includes features of all the styles if it necessary. The author uses proffessional words of all levels. The basic function – informative and aesthetic.
Poetic style in the past many scholars distinguished this style. Nowadays it included in Belles – Lettres style.
S. of official Documents here are included the language of business documents, the language of legal documents, diplomacy, military, the function – to achieve the agreement between contrastive parts; has very strict organization. All the words are used in the dictionary meanings, a large number of abbreviation, terms, cliches.
Publicistic style in the past it named oratoric style. The aim of the style also influence of public opinion. Bravity of expression, strong logic, strict organization of syntactical structure and a wide system of syntactical connection; the use of colloquial words, neutral, direct address to the audience.
Scientific style is the style of reporting and conveying serious scientific idea. It is connected with oral and written forms. Here are included seminars, sc. Articles, discussions, written form – monograph, brochures, all kinds of academic publications. The aim is to prove a hypothesis. The use of large number of terms. Clarity of expression. The use of references, logical connection with the previous one, interdependance the speeches is usually produced in the second person – we.
3. Classification of english words. Groups of english words.
Basic subdivision; formal, informal, neautral.
Formal words:
Poetic words-constitute the highest level of the scale; every poetic word pertains to the uppermost part of the scheme; it demonstrates the maximum of aesthetic value.
Arhaic words, are also stylistically heterogeneous. They are usually thought to pertain to the upper strata of vocabulary. This words practically unknown to the public at large.
e. g. Thou, thee, knight.
Bookishwords –the words thus called are used as their name shows, in cultivated spheres of speech: in books or in such types of oral communication as public speeches, official negotiations, and so on. Bookish words are either formal synonyms of ordinary neutral words.
e. g. Commence and begin, respond and answer, individual and man.
Barbarism, or foreign words. Words originally borrowed from a foreign language are usually assimilated into the native vocabulary, so as not to differ from its units in appearance or in sound.
e. g. From french (bouquet, garage). Italian (dolce-far-niente) or latin (alter ego).
Neologisms, or new creations. A neologisms seems, to the majority of language users, a stranger, a new comer and hence a word of low stylistic value, although the intention of the speaker may be quite opposite.
Special terms. This word-class constitute the actual majority of the lexical units of every modern language serving the needs of a highly developed science and technology. In special (professional) spheres the term performs no expressive or aesthetic function whatever. In non professional spheres (imaginative prose, newspaper texts, everyday speech) popular terms are of the first (minimal) or the second (medial) degree of elevation. The use of special non-popular terms, unknown to average speaker, shows a pretentious manner of speech, luck of taste or tact.
Informal words:
Colloquial words demonstrate the minimal degree of stylistic degradation. They are words with a tinge of informality or familiarity about them. There is nothing ethically improper in their stylistic colouring, except that they cannot be used in formal speech.
i.g. drifter (a person without steady job), gaffer (grand father) and so on.
Jargon words. These appear in professional or social groups as informal.
Jargon can be subdivided into two groups. One of them consists of names of objects, phenomena, and processes characteristic of the given profession – not the real denominations , bat rather nicknames as opposed to the official terms used in this professional sphere.
i.g. in soldiers jargon, the expression picture show is current, which has nothig to do with the cinema, but denotes a purely military concept for which there is an official word – the word battle.
The other group is made up of terms of the profession used to denote non-professional objects, phenomena, and processes.
i.g. big gun – important person.
Every professional group has its own jargon. We distinguish students’ , musicians’, lowers’, soldiers jargon and so on.
Slang. Slang is part of the vocabulary consisting of commonly understood and widely used words and expression of humorous or derogatory character – intentional substitutes for neutral or elevated words and expressions.
i.g. food: chuck, chow, hash;
money: jack, tin, brass, oof, and so on.
Vulgar words. This stylistically lowest group consists of words which are considered too offensive for polite usage.
Objectionable words may be divided into two groups: lexical stylistic vulgarisms.
To the first group belong words expressing ideas concidered unmentionable in civilized society. Quite unmentionable are so- called “four- letters words”.
The second group – stylistic vulgarisms- are words and phrases the lexical meanings of which have nothing indecent or on the whole , improper about them. Their impropriety in civilized life is due solely to their stylistic value – to stylistic connotation expressing a derogatory attitude of the speaker towards the objects of speech.
i.g. old bean (old man ), smeller (nose), pay dirt (money) and the like.
4.Stylistics devises. Trope and figures of speech.
In the European philological tradition there have always existed phenomena regarded as linguostylistic concepts proper.
They are:
Tropes which are based on the “transfer” of meaning, when a word (or combination of words) is used to denote (указывать) an object which is not normally correlated with this word. And
Figures of speech whose stylistic effect is achieved due to the unusual arrangement (классификация) of linguistic units, unusual construction or extension (добавление) of utterance (произношение).
Tropes and figures are organized into levels:
1, Phonetic devices —
alliteration, assonance – f. repetition of the same sound — a university should be a place of light, of liberty, and of learning – they produce effect of euphony
2. Graphical – graphon
3. Lexical – interrelation of different meaning of one word of connotative meanings of different words.
Metathor – t. use of words (word combinations) in transferred meanings by way of similarity or analogy — art is a jealous mistress
t — Metonymy, antonomasia, hyperbole, f — zeugma, pan, oxymoron
4. Syntactical – is based on the arrangement of the members of the sentence, on the completence-incompletence of sentence structure.
Inversion, detachment, ellipsis, f. polysindeton, syndeton, rhetorical question
5. Lexico-syntactic – f. simile, litotes
Alliteration – a figure of speech which consists in the repetition of the same sound in words in close succession (usually in the stressed syllables): *(the , the , the)
Anaphora — a figure of beginning successive sentences, syntagms, lines, etc. with the same sounds, morphemes, words, or word-combinations:
*(you, sir, are an unnatural, ungrateful, unloveable boy)
Antonomasia – (a variant of METAPHOR) a trope which consists in the use of a proper name to denote a different person who possesses some qualities of the primary owner of the name: *(Every Caesar has his Brutus (O’Henry)) II. (a variant of PEROPHRASIS) – a figure of speech which names a familiar person in a indirect way: *(the Maid of Orleans (for Jean of Arc), the day that comes between a Saturday and monday)
Apostrophe — a figure of speech which consists in addressing an absent, dead or invented person, as well as animals and things.
Personification – (a variant of METAPHOR) – a trope in which an “animate” or human feature is ascribed to an inanimate object or to an abstract concept: *(a cold, unseen stranger)
Polysyndeton — a figure of speech which consists in the combination of Homogeneous (однородных) parts of sentence by mean of the same conjunction: * (and of the golden lyre,
And of the golden hair…)
Parallel construction – a figure based on the use of the similar syntactic pattern (структура) in two or more sentences or syntagms:
*(When the lamp is shattered….
When the cloud is scattered )
Litotes – (a variant of PERIPHRASIS) a figure of speech which consists in the affirmation of the contrary by negation : *(the wedding was no distant event)
Metaphor – a trope which consists in the use of words in transferred meanings by way of similarity or analogy: *(merry larks are ploughmen’s clooks (Shake speare))
Hyperbole – a trope which consists in a deliberate exaggeration (умышленное преувеличение) of a feature essential to an object or phenomenon. * (Her family is one aunt about a thousand years old
5. Different levels of language units.
Generally speaking, the word level became very popular in twentieth century science and even in political phraseology:
Prime Minister level
on the highest level
in linguistic, the word level is used in collocations like language level, speech level, observation level (уровень наблюдения), construct leve l(уровень конструктов), prosodic level (просодический), phraseological level, the level of the principal parts of the sentence, and even stylistic level (proposed by Galperin).
The term level as applied to language is more appropriate when used in the sense implied by the French linguists Benveniste, who used it to characterize the hierarchical structure of language itself, not the arbitrary aspects of research. Our compatriot Maslov employs the term tier – ярус- instead.
The smallest or shortest unit of language is the phoneme. The sequence of phonemes making units of higher ranks represents the phonemic level. One or several phonemes combined constitute a unit of a higher level, the second level – that of morphemes, or the morphemic level. One or usually more than one morpheme make a word, a ‘lexeme’ – hence, the lexical level. One or usually more than one word make an utterance, or, in traditional terminology, a sentence. Hence, the sentence level. Word combinations are best treated as not forming an independent level for two reasons – 1)functionally, they do not differ from words, because they name without communicating
2) one word does not make a word combination, whereas one word can make an utterance: OUT! WHY? WINTER.
We could go on singling out paragraph level and even text level paying hamage to the now fashionable text linguistics but for the fact that not every text is divided into paragraphs, although every paragraph or every text is divisible into sentences.
Each level consists of units of the neighbouring lower level with nothing besides – a sentence consists only of words; a word is divided into morphemes or sometimes coincides with one; a morpheme containes nothing but phonemes or is represented by one of them, as in make-s, read –er, pen –s.
Summing up, we must say that the first meaning of the word level suggests the idea of horizontal layers (subdivisions) of some structure. And, indeed, when we come to inspect language, we discover that language presents a hierarchy of level, from the lowest up to the highest.
And each level is described by what we named above a ‘level discipline’ – phonetics, morphology, lexicology, syntax. To these the modern text linguistics may be added. Of course, stylistics does not fit in here.
6. The concept of sublanguages.
L-ge is heterogeneous.
Sublanguage is a language subsistem which satisfy the needs and purpose of communication in certain sphere, Functional styles can represent by sublanguage style. There are 2 spheres odf communication: official and inofficial – they represent different sublanguages.
The classification of style by Ilya Golperin.
1. bellesletters – poetry, emotive words, drama
2. pablicistic style- speeches, essay, articles
3. newspaper- briefnews, headlines, advertisements, editorial
4. .scientific prose.
5, official doc-s.
Very important features of this clas-n; he didn’t single out colloqual style, as he considered it spontaneous unprepared and perfunctory (поверхностный).
Irina Arnold singles out 4 styles:
Poetic style, scientific style, newspaper style, colloqual style.
Sublanguages in different spheres:
1. sphere of busines. — Business correspondence, Diplomatic corr., International treaties, Private corr.
2. sphere of law (legal documents) — civil law, criminal law, settlements
3. personal doc-s. (sertificates, diplomes).
— Diplomatic sphere. — As usual this language is international. As usual this sphere concerns with the written texts.i.g. public speeches in the government etc. The form and contense are equally significant here. Every person must give his ideas in a concrete and thoughtfull way, but at the same time these speeches should be artistic & emotive. i.g. mr. President! It is natural to mean to enduldge in the illusion of hope.
— Legal sphere (lang. Of law). Legal terminology is used. i.g. the prosecutor represents the people of the state (прокурор представляет народ штата). There are some specific phrases: i.g. his honour to court! Everybody, please rises. Суд идет! Прошу всех встать.
— The colloqual sphere. By coll. We mean what is slightly lower than neutral. People use them when they don’t to be rude, sarcastic or witty. And the speech becomes calloqual & with a tinge of familiarity. Talking with our friends we don’t notice the forms of the sublanguage we employ. But not in the company of strangers it may not be done. Coll. Sphere may contain words belonging to jargonisms, professionalisms, & slang. This speech may be careless, unconventional. i.g. if I was you, I would… (were).
The number of sublanguages is not clear at all.
Each sublanguage characterize:
1. Non-specific units – neutral
2. relatively specific – may be unknown to people without education, children. Can be used for different sublanguages. Meaning is narrower.
3. absolutely specific
НА ГЛАВНУЮ
