
Last Update: Jan 03, 2023
This is a question our experts keep getting from time to time. Now, we have got the complete detailed explanation and answer for everyone, who is interested!
Asked by: Marcia White
Score: 4.3/5
(70 votes)
Microsoft Excel includes FFT as part of its Data Analysis ToolPak, which is disabled by default. To produce a graph displaying the frequencies in a signal, you must first enable the ToolPak since the process involves the use of numerous algorithms for the complex mathematics.
How do I use FFT in Excel?
Select Cell E2 and access Fourier Analysis by click Data/Data Analysis and select Fourier Analysis. number of samples. Output Range: select the range where the complex FFT will be stored. In our example, select the corresponding range in column E.
Where is FFT in Excel?
MS-Excel provides the FFT tools. One can access it from the tools menu as by opening Data analysis. If in case data Analysis does not appear in the tools menu, so it can be access from Add-Ins menu by adding Analysis Toolpak as Fourier Transform is a part of it.
How do you spectral analysis in Excel?
Setting up a spectral analysis
After opening XLSTAT, select the XLSTAT / Time / Spectral analysis command. Once you’ve clicked on the button, the Spectral analysis dialog box will appear. Select the data on the Excel sheet. The Variable to analyze corresponds to the series of interest, the sunspot data.
What is spectral analysis used for?
Spectral analysis provides a means of measuring the strength of periodic (sinusoidal) components of a signal at different frequencies. The Fourier transform takes an input function in time or space and transforms it into a complex function in frequency that gives the amplitude and phase of the input function.
21 related questions found
Who invented the fast Fourier transform?
What we accomplished: James Cooley (pictured) co-invented with John Tukey (and possibly repeating Gauss in the 1800s) the Fast Fourier Transform (FFT) to convert time-domain signals to frequency domain. Another fast alternative was invented by Shmuel Winograd.
How do you perform a FFT?
The FFT operates by decomposing an N point time domain signal into N time domain signals each composed of a single point. The second step is to calculate the N frequency spectra corresponding to these N time domain signals. Lastly, the N spectra are synthesized into a single frequency spectrum.
How do I add data analysis to Excel?
Load the Analysis ToolPak in Excel
- Click the File tab, click Options, and then click the Add-Ins category. …
- In the Manage box, select Excel Add-ins and then click Go. …
- In the Add-Ins box, check the Analysis ToolPak check box, and then click OK.
What is Fourier analysis Excel?
Fourier Analysis Excel: Overview.
The Analysis converts a single set of data points into a second, equal size set of data points. The Fourier analysis Excel tool has a couple of limitations: The maximum number of points is 4,096. The data points must be in powers of two.
How do you get FFT in Matlab?
Y = fft( X ) computes the discrete Fourier transform (DFT) of X using a fast Fourier transform (FFT) algorithm.
- If X is a vector, then fft(X) returns the Fourier transform of the vector.
- If X is a matrix, then fft(X) treats the columns of X as vectors and returns the Fourier transform of each column.
How do you do imaginary numbers in Excel?
Excel IMAGINARY Function
- Summary. …
- Get imaginary coefficient of complex number.
- Imaginary coefficient as number.
- =IMAGINARY (inumber)
- inumber — A complex number.
- The Excel IMAGINARY function returns the imaginary coefficient of a complex number in the form x + yi or x + yj.
How do you make a Fourier transform in Python?
Example:
- # Python example — Fourier transform using numpy.fft method. import numpy as np.
- import matplotlib.pyplot as plotter. # How many time points are needed i,e., Sampling Frequency.
- samplingFrequency = 100; …
- samplingInterval = 1 / samplingFrequency; …
- beginTime = 0; …
- endTime = 10; …
- signal1Frequency = 4; …
- # Time points.
Can Excel work with complex numbers?
The Microsoft Excel COMPLEX function converts coefficients (real and imaginary) into a complex number. The complex number can be in either form, x + yi or x + yj. The COMPLEX function is a built-in function in Excel that is categorized as an Engineering Function. It can be used as a worksheet function (WS) in Excel.
How do I add data analysis in Excel 2020?
Click the File tab, click Options, and then click the Add-Ins category. In the Manage box, select Excel Add-ins and then click Go. In the Add-Ins available box, select the Analysis ToolPak check box, and then click OK.
Is Excel a data analysis tool?
The Analysis ToolPak is an Excel add-in program that provides data analysis tools for financial, statistical and engineering data analysis. To load the Analysis ToolPak add-in, execute the following steps. 1.
How do I calculate a mean in Excel?
To find the mean in Excel, you start by typing the syntax =AVERAGE or select AVERAGE from the formula dropdown menu. Then, you select which cells will be included in the calculation. For example: Say you will be calculating the mean for column A, rows two through 20. Your formula will look like this: =AVERAGE(A2:A20).
How accurate is FFT?
Discrete Fourier transforms computed through the FFT are far more accurate than slow transforms, and convolutions computed via FFT are far more accurate than the direct results. … Even in higher dimensions, the FFT is remarkably stable.
What is the purpose of FFT?
The FFT algorithm is used to convert a digital signal (x) with length (N) from the time domain into a signal in the frequency domain (X), since the amplitude of vibration is recorded on the basis of its evolution versus the frequency at that the signal appears [40].
What does an FFT tell you?
The «Fast Fourier Transform» (FFT) is an important measurement method in the science of audio and acoustics measurement. It converts a signal into individual spectral components and thereby provides frequency information about the signal.
What is the formula for Fourier transform?
The function F(ω) is called the Fourier transform of the function f(t). Symbolically we can write F(ω) = F{f(t)}.
Why is FFT faster than DFT?
The number of calculations to implement the DFT equation directly is proportional to N*N, where N is the number of data points. The FFT algorithm reduces this a number proportional to NlogN where the log is to base 2. Since logN increasea at a much lower rate than N, the time saved in using the FFT can be considerable.
What can spectral analysis reveal?
A stellar spectrum can reveal many properties of stars, such as their chemical composition, temperature, density, mass, distance and luminosity. … Spectroscopy is also used to study the physical properties of many other types of celestial objects such as planets, nebulae, galaxies, and active galactic nuclei.
What is the method of spectral analysis?
Spectral analysis or Spectrum analysis is analysis in terms of a spectrum of frequencies or related quantities such as energies, eigenvalues, etc. In specific areas it may refer to: Spectroscopy in chemistry and physics, a method of analyzing the properties of matter from their electromagnetic interactions.
Excel for Microsoft 365 Excel for Microsoft 365 for Mac Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 for Mac Excel 2016 Excel 2016 for Mac Excel 2013 Excel 2010 Excel 2007 More…Less
If you need to develop complex statistical or engineering analyses, you can save steps and time by using the Analysis ToolPak. You provide the data and parameters for each analysis, and the tool uses the appropriate statistical or engineering macro functions to calculate and display the results in an output table. Some tools generate charts in addition to output tables.
The data analysis functions can be used on only one worksheet at a time. When you perform data analysis on grouped worksheets, results will appear on the first worksheet and empty formatted tables will appear on the remaining worksheets. To perform data analysis on the remainder of the worksheets, recalculate the analysis tool for each worksheet.
The Analysis ToolPak includes the tools described in the following sections. To access these tools, click Data Analysis in the Analysis group on the Data tab. If the Data Analysis command is not available, you need to load the Analysis ToolPak add-in program.
-
Click the File tab, click Options, and then click the Add-Ins category.
-
In the Manage box, select Excel Add-ins and then click Go.
If you’re using Excel for Mac, in the file menu go to Tools > Excel Add-ins.
-
In the Add-Ins box, check the Analysis ToolPak check box, and then click OK.
-
If Analysis ToolPak is not listed in the Add-Ins available box, click Browse to locate it.
-
If you are prompted that the Analysis ToolPak is not currently installed on your computer, click Yes to install it.
-
Note: To include Visual Basic for Application (VBA) functions for the Analysis ToolPak, you can load the Analysis ToolPak — VBA Add-in the same way that you load the Analysis ToolPak. In the Add-ins available box, select the Analysis ToolPak — VBA check box.
The Anova analysis tools provide different types of variance analysis. The tool that you should use depends on the number of factors and the number of samples that you have from the populations that you want to test.
Anova: Single Factor
This tool performs a simple analysis of variance on data for two or more samples. The analysis provides a test of the hypothesis that each sample is drawn from the same underlying probability distribution against the alternative hypothesis that underlying probability distributions are not the same for all samples. If there are only two samples, you can use the worksheet function T.TEST. With more than two samples, there is no convenient generalization of T.TEST, and the Single Factor Anova model can be called upon instead.
Anova: Two-Factor with Replication
This analysis tool is useful when data can be classified along two different dimensions. For example, in an experiment to measure the height of plants, the plants may be given different brands of fertilizer (for example, A, B, C) and might also be kept at different temperatures (for example, low, high). For each of the six possible pairs of {fertilizer, temperature}, we have an equal number of observations of plant height. Using this Anova tool, we can test:
-
Whether the heights of plants for the different fertilizer brands are drawn from the same underlying population. Temperatures are ignored for this analysis.
-
Whether the heights of plants for the different temperature levels are drawn from the same underlying population. Fertilizer brands are ignored for this analysis.
Whether having accounted for the effects of differences between fertilizer brands found in the first bulleted point and differences in temperatures found in the second bulleted point, the six samples representing all pairs of {fertilizer, temperature} values are drawn from the same population. The alternative hypothesis is that there are effects due to specific {fertilizer, temperature} pairs over and above the differences that are based on fertilizer alone or on temperature alone.
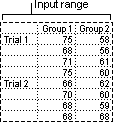
Anova: Two-Factor Without Replication
This analysis tool is useful when data is classified on two different dimensions as in the Two-Factor case With Replication. However, for this tool it is assumed that there is only a single observation for each pair (for example, each {fertilizer, temperature} pair in the preceding example).
The CORREL and PEARSON worksheet functions both calculate the correlation coefficient between two measurement variables when measurements on each variable are observed for each of N subjects. (Any missing observation for any subject causes that subject to be ignored in the analysis.) The Correlation analysis tool is particularly useful when there are more than two measurement variables for each of N subjects. It provides an output table, a correlation matrix, that shows the value of CORREL (or PEARSON) applied to each possible pair of measurement variables.
The correlation coefficient, like the covariance, is a measure of the extent to which two measurement variables «vary together.» Unlike the covariance, the correlation coefficient is scaled so that its value is independent of the units in which the two measurement variables are expressed. (For example, if the two measurement variables are weight and height, the value of the correlation coefficient is unchanged if weight is converted from pounds to kilograms.) The value of any correlation coefficient must be between -1 and +1 inclusive.
You can use the correlation analysis tool to examine each pair of measurement variables to determine whether the two measurement variables tend to move together — that is, whether large values of one variable tend to be associated with large values of the other (positive correlation), whether small values of one variable tend to be associated with large values of the other (negative correlation), or whether values of both variables tend to be unrelated (correlation near 0 (zero)).
The Correlation and Covariance tools can both be used in the same setting, when you have N different measurement variables observed on a set of individuals. The Correlation and Covariance tools each give an output table, a matrix, that shows the correlation coefficient or covariance, respectively, between each pair of measurement variables. The difference is that correlation coefficients are scaled to lie between -1 and +1 inclusive. Corresponding covariances are not scaled. Both the correlation coefficient and the covariance are measures of the extent to which two variables «vary together.»
The Covariance tool computes the value of the worksheet function COVARIANCE.P for each pair of measurement variables. (Direct use of COVARIANCE.P rather than the Covariance tool is a reasonable alternative when there are only two measurement variables, that is, N=2.) The entry on the diagonal of the Covariance tool’s output table in row i, column i is the covariance of the i-th measurement variable with itself. This is just the population variance for that variable, as calculated by the worksheet function VAR.P.
You can use the Covariance tool to examine each pair of measurement variables to determine whether the two measurement variables tend to move together — that is, whether large values of one variable tend to be associated with large values of the other (positive covariance), whether small values of one variable tend to be associated with large values of the other (negative covariance), or whether values of both variables tend to be unrelated (covariance near 0 (zero)).
The Descriptive Statistics analysis tool generates a report of univariate statistics for data in the input range, providing information about the central tendency and variability of your data.
The Exponential Smoothing analysis tool predicts a value that is based on the forecast for the prior period, adjusted for the error in that prior forecast. The tool uses the smoothing constant a, the magnitude of which determines how strongly the forecasts respond to errors in the prior forecast.
Note: Values of 0.2 to 0.3 are reasonable smoothing constants. These values indicate that the current forecast should be adjusted 20 percent to 30 percent for error in the prior forecast. Larger constants yield a faster response but can produce erratic projections. Smaller constants can result in long lags for forecast values.
The F-Test Two-Sample for Variances analysis tool performs a two-sample F-test to compare two population variances.
For example, you can use the F-Test tool on samples of times in a swim meet for each of two teams. The tool provides the result of a test of the null hypothesis that these two samples come from distributions with equal variances, against the alternative that the variances are not equal in the underlying distributions.
The tool calculates the value f of an F-statistic (or F-ratio). A value of f close to 1 provides evidence that the underlying population variances are equal. In the output table, if f < 1 «P(F <= f) one-tail» gives the probability of observing a value of the F-statistic less than f when population variances are equal, and «F Critical one-tail» gives the critical value less than 1 for the chosen significance level, Alpha. If f > 1, «P(F <= f) one-tail» gives the probability of observing a value of the F-statistic greater than f when population variances are equal, and «F Critical one-tail» gives the critical value greater than 1 for Alpha.
The Fourier Analysis tool solves problems in linear systems and analyzes periodic data by using the Fast Fourier Transform (FFT) method to transform data. This tool also supports inverse transformations, in which the inverse of transformed data returns the original data.
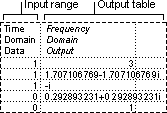
The Histogram analysis tool calculates individual and cumulative frequencies for a cell range of data and data bins. This tool generates data for the number of occurrences of a value in a data set.
For example, in a class of 20 students, you can determine the distribution of scores in letter-grade categories. A histogram table presents the letter-grade boundaries and the number of scores between the lowest bound and the current bound. The single most-frequent score is the mode of the data.
Tip: In Excel 2016, you can now create a histogram or Pareto chart.
The Moving Average analysis tool projects values in the forecast period, based on the average value of the variable over a specific number of preceding periods. A moving average provides trend information that a simple average of all historical data would mask. Use this tool to forecast sales, inventory, or other trends. Each forecast value is based on the following formula.
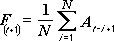
where:
-
N is the number of prior periods to include in the moving average
-
A
j is the actual value at time j -
F
j is the forecasted value at time j
The Random Number Generation analysis tool fills a range with independent random numbers that are drawn from one of several distributions. You can characterize the subjects in a population with a probability distribution. For example, you can use a normal distribution to characterize the population of individuals’ heights, or you can use a Bernoulli distribution of two possible outcomes to characterize the population of coin-flip results.
The Rank and Percentile analysis tool produces a table that contains the ordinal and percentage rank of each value in a data set. You can analyze the relative standing of values in a data set. This tool uses the worksheet functions RANK.EQ andPERCENTRANK.INC. If you want to account for tied values, use the RANK.EQ function, which treats tied values as having the same rank, or use the RANK.AVG function, which returns the average rank for the tied values.
The Regression analysis tool performs linear regression analysis by using the «least squares» method to fit a line through a set of observations. You can analyze how a single dependent variable is affected by the values of one or more independent variables. For example, you can analyze how an athlete’s performance is affected by such factors as age, height, and weight. You can apportion shares in the performance measure to each of these three factors, based on a set of performance data, and then use the results to predict the performance of a new, untested athlete.
The Regression tool uses the worksheet function LINEST.
The Sampling analysis tool creates a sample from a population by treating the input range as a population. When the population is too large to process or chart, you can use a representative sample. You can also create a sample that contains only the values from a particular part of a cycle if you believe that the input data is periodic. For example, if the input range contains quarterly sales figures, sampling with a periodic rate of four places the values from the same quarter in the output range.
The Two-Sample t-Test analysis tools test for equality of the population means that underlie each sample. The three tools employ different assumptions: that the population variances are equal, that the population variances are not equal, and that the two samples represent before-treatment and after-treatment observations on the same subjects.
For all three tools below, a t-Statistic value, t, is computed and shown as «t Stat» in the output tables. Depending on the data, this value, t, can be negative or nonnegative. Under the assumption of equal underlying population means, if t < 0, «P(T <= t) one-tail» gives the probability that a value of the t-Statistic would be observed that is more negative than t. If t >=0, «P(T <= t) one-tail» gives the probability that a value of the t-Statistic would be observed that is more positive than t. «t Critical one-tail» gives the cutoff value, so that the probability of observing a value of the t-Statistic greater than or equal to «t Critical one-tail» is Alpha.
«P(T <= t) two-tail» gives the probability that a value of the t-Statistic would be observed that is larger in absolute value than t. «P Critical two-tail» gives the cutoff value, so that the probability of an observed t-Statistic larger in absolute value than «P Critical two-tail» is Alpha.
t-Test: Paired Two Sample For Means
You can use a paired test when there is a natural pairing of observations in the samples, such as when a sample group is tested twice — before and after an experiment. This analysis tool and its formula perform a paired two-sample Student’s t-Test to determine whether observations that are taken before a treatment and observations taken after a treatment are likely to have come from distributions with equal population means. This t-Test form does not assume that the variances of both populations are equal.
Note: Among the results that are generated by this tool is pooled variance, an accumulated measure of the spread of data about the mean, which is derived from the following formula.
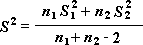
t-Test: Two-Sample Assuming Equal Variances
This analysis tool performs a two-sample student’s t-Test. This t-Test form assumes that the two data sets came from distributions with the same variances. It is referred to as a homoscedastic t-Test. You can use this t-Test to determine whether the two samples are likely to have come from distributions with equal population means.
t-Test: Two-Sample Assuming Unequal Variances
This analysis tool performs a two-sample student’s t-Test. This t-Test form assumes that the two data sets came from distributions with unequal variances. It is referred to as a heteroscedastic t-Test. As with the preceding Equal Variances case, you can use this t-Test to determine whether the two samples are likely to have come from distributions with equal population means. Use this test when there are distinct subjects in the two samples. Use the Paired test, described in the follow example, when there is a single set of subjects and the two samples represent measurements for each subject before and after a treatment.
The following formula is used to determine the statistic value t.
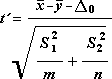
The following formula is used to calculate the degrees of freedom, df. Because the result of the calculation is usually not an integer, the value of df is rounded to the nearest integer to obtain a critical value from the t table. The Excel worksheet function T.TEST uses the calculated df value without rounding, because it is possible to compute a value for T.TEST with a noninteger df. Because of these different approaches to determining the degrees of freedom, the results of T.TEST and this t-Test tool will differ in the Unequal Variances case.
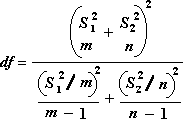
The z-Test: Two Sample for Means analysis tool performs a two sample z-Test for means with known variances. This tool is used to test the null hypothesis that there is no difference between two population means against either one-sided or two-sided alternative hypotheses. If variances are not known, the worksheet function Z.TEST should be used instead.
When you use the z-Test tool, be careful to understand the output. «P(Z <= z) one-tail» is really P(Z >= ABS(z)), the probability of a z-value further from 0 in the same direction as the observed z value when there is no difference between the population means. «P(Z <= z) two-tail» is really P(Z >= ABS(z) or Z <= -ABS(z)), the probability of a z-value further from 0 in either direction than the observed z-value when there is no difference between the population means. The two-tailed result is just the one-tailed result multiplied by 2. The z-Test tool can also be used for the case where the null hypothesis is that there is a specific nonzero value for the difference between the two population means. For example, you can use this test to determine differences between the performances of two car models.
Need more help?
You can always ask an expert in the Excel Tech Community or get support in the Answers community.
See Also
Create a histogram in Excel 2016
Create a Pareto chart in Excel 2016
Load the Analysis ToolPak in Excel
ENGINEERING functions (reference)
Overview of formulas in Excel
How to avoid broken formulas
Find and correct errors in formulas
Excel keyboard shortcuts and function keys
Excel functions (alphabetical)
Excel functions (by category)
Need more help?
Want more options?
Explore subscription benefits, browse training courses, learn how to secure your device, and more.
Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.
Table of Contents
- How do you create a Fourier analysis in Excel?
- What is Excel data analysis?
- What is difference between FFT and DFT?
- How accurate is FFT?
- What is the output of FFT?
- Does FFT have to be power of 2?
- What is radix 2 FFT algorithm?
- Why do we do zero padding?
- How do you zero a pad in Python?
- Why is padding needed in image processing?
- What is the difference between linear and circular convolution?
- What is the application of convolution?
- Why do we use convolution?
- Is linear convolution better or circular convolution Why?
- Why do we need circular convolution?
- Is a convolution linear?
- What are the applications of circular convolution?
- What is difference between correlation and convolution?
- How convolution is used in image processing?
- What is periodic convolution *?
- How do you define convolution Sanfoundry?
Click on the “Data” tab in “Excel” and then click “Data Analysis” in the “Analysis” section on the right. Choose “Fourier Analysis” from the list of options and click “OK.” A dialog box will appear with options for the analysis.
What is Excel data analysis?
Data Analysis with Excel is a comprehensive tutorial that provides a good insight into the latest and advanced features available in Microsoft Excel. It explains in detail how to perform various data analysis functions using the features available in MS-Excel.
What is difference between FFT and DFT?
DFT or Discrete Fourier Transform is an algorithm that computes the Fourier transform of a digitized (discrete) signal. FFT (Fast Fourier Transform) is an optimized implementation of this transform.
How accurate is FFT?
Everyone uses Fast Fourier Transform, which is fast at the detriment of precision. The input audio has sample accuracy and the FFT has 1/64 sample accuracy.
What is the output of FFT?
You can find more information on the FFT functions used in the reference here, but at a high level the FFT takes as input a number of samples from a signal (the time domain representation) and produces as output the intensity at corresponding frequencies (the frequency domain representation).
Does FFT have to be power of 2?
Modern FFT libraries, such as FFTW and Apple’s Accelerate framework can do non-power-of-2 FFTs very efficiently, as long as all the prime divisors of the composite length are fairly small (2,3,5,etc.)
What is radix 2 FFT algorithm?
Radix 2. means that the number of samples must be an integral power of two. The decimation. in time means that the algorithm performs a subdivision of the input sequence into its.
Why do we do zero padding?
Zero padding in the time domain is used extensively in practice to compute heavily interpolated spectra by taking the DFT of the zero–padded signal. Such spectral interpolation is ideal when the original signal is time limited (nonzero only over some finite duration spanned by the orignal samples).
How do you zero a pad in Python?
To pad zeros to a string, use the str. zfill() method. It takes one argument: the final length of the string you want and pads the string with zeros to the left. If you enter a value less than the length of the string, it returns the string unmodified.
Why is padding needed in image processing?
In order to assist the kernel with processing the image, padding is added to the frame of the image to allow for more space for the kernel to cover the image. Adding padding to an image processed by a CNN allows for more accurate analysis of images.
What is the difference between linear and circular convolution?
6 Answers. Linear convolution is the basic operation to calculate the output for any linear time invariant system given its input and its impulse response. Circular convolution is the same thing but considering that the support of the signal is periodic (as in a circle, hence the name).
What is the application of convolution?
Convolution has applications that include probability, statistics, acoustics, spectroscopy, signal processing and image processing, engineering, physics, computer vision and differential equations. The convolution can be defined for functions on Euclidean space and other groups.
Why do we use convolution?
Convolution is a mathematical way of combining two signals to form a third signal. It is the single most important technique in Digital Signal Processing. … Convolution is important because it relates the three signals of interest: the input signal, the output signal, and the impulse response.
Is linear convolution better or circular convolution Why?
It is applicable for both continuous and discrete-time signals. Circular convolution is also applicable for both continuous and discrete-time signals. Here, y(n) is the output (also known as convolution sum). … In linear convolution, both the sequences (input and impulse response) may or may not be of equal sizes.
Why do we need circular convolution?
Although DTFTs are usually continuous functions of frequency, the concepts of periodic and circular convolution are also directly applicable to discrete sequences of data. In that context, circular convolution plays an important role in maximizing the efficiency of a certain kind of common filtering operation.
Is a convolution linear?
, Convolution is a linear operator and, therefore, has a number of important properties including the commutative, associative, and distributive properties.
What are the applications of circular convolution?
Convolution is similar to cross-correlation. It has applications that include probability, statistics, computer vision, image and signal processing, electrical engineering, and differential equations.
What is difference between correlation and convolution?
Theoretically, convolution are linear operations on the signal or signal modifiers, whereas correlation is a measure of similarity between two signals. As you rightly mentioned, the basic difference between convolution and correlation is that the convolution process rotates the matrix by 180 degrees.
How convolution is used in image processing?
Convolution is a simple mathematical operation which is fundamental to many common image processing operators. Convolution provides a way of `multiplying together’ two arrays of numbers, generally of different sizes, but of the same dimensionality, to produce a third array of numbers of the same dimensionality.
What is periodic convolution *?
Explanation: When a function g is periodic, with period T, then for functions, f, such that f∗g exists, the convolution is also periodic. This is called a periodic convolution.
How do you define convolution Sanfoundry?
Explanation: Convolution is defined as weighted superposition of time shifted responses where the whole of the signals is taken into account. But multiplication leads to loss of those signals which are after the limits.
Excel contains a data analysis add-in that allows to to perform a Fourier analysis of a series of numbers. Follow the steps below.
Installing Analysis Toolpak
Install the Excel Analysis ToolPak. Launch Excel and click on the «File». Select «Options» and then click on «Add-Ins». Click the drop-down menu next to «Manage» at the bottom of the window and then click «Go.» Click the check-box next to «Analysis ToolPak» and then click «OK.»

Enter number for your series
IMPORTANT: In the Fourier series the data must be in the multiples of 2 and cannot excel 4096
Evaluating Fourier series
Click on the «Data» tab then click «Data Analysis» in the «Analysis» group. Choose «Fourier Analysis» and click «OK.» A dialog box will appear with options for the analysis.


Click in the «Input Range» box in the dialog that appears. Click and drag on the spreadsheet to highlight the data you want to analyze.

Click in the «Output Range» box and then click and drag on the spreadsheet where you want the analysis to appear. Click OK.

Click and drag on the spreadsheet to select the column or row where your Fourier analysis appeared. Click on the «Insert» tab, click «Scatter» and choose «Scatter with Smooth Lines.» The Fourier series will be plotted as a curve on your graph.

Fourier analysis can be a complex mathematical technique, and the accuracy of the results will depend on factors such as the number of data points, the spacing of the data, and the quality of the signal. It’s important to have a solid understanding of Fourier analysis and the assumptions underlying the FFT algorithm before performing this analysis in Excel.
This is a basic tutorial about implementation of a standard Fourier transform model in Excel. It is not an introduction to Fourier analysis.
You could choose to familiarize yourself with the subject before proceeding with this tutorial. Solving a few Fourier transform excersises would be of help too.
Essentially, this part shows you how to adapt the general Fourier formula for a continuous real signal to a sampled signal having a limited number of samples.
A Fourier Transform Model in Excel #1
by George Lungu
-This is a tutorial about the implementation of a Fourier
transform in Excel. This first part goes over adjustments in
the general Fourier transform formula to be applicable on real
time sampled signals with a finite number of known samples.
– This is not an introduction to complex functions or Fourier
transform. In order to follow this it’s ideal to have minimal
knowledge of basic complex number theory.
If you learned Fourier analysis in school a couple of years or a couple of
decades back and you are vaguely aware of the Fourier
transform theory, it is enough.
You could stop and go back and read some theory at any time.
<excelunusual.com> by George Lungu
Introduction:
– “t” and “f” are time and
– The definition of the Fourier transform
G(f ) g(t)e dt frequency respectively,
of a temporal signal G(t) is:
they are real numbers.
– “j” is the imaginary
f
symbol, “i” is some times
– The definition of the inverse Fourier 2jf t
g(t) G(f )e df used to denote it.
transform of a frequency function G(f) is:
f
jz
– The Euler Formula is: ecos(z) jsin(z )
– Using Euler’s formula and assuming in our particular case that
g(t) is a real function we can rewrite the Fourier transform as:
G( f ) g(t) cos(2 f t)dt j g(t) sin( 2 f t)dt
<excelunusual.com> 2
Let’s see how we can apply the previous formula in practice to get a reasonable approximation of the Fourier transform:
– In practice we usually have a limited number of equally spaced time samples of a continuous function contained in a table.
gN-1 gN (N+1)
g(t)
We used the – In practice the samples usually start at an arbitrary “time zero”. Minus infinity or plus infinity are unfeasible so we will
do the integration on the available period of time [0, T].
– We can approximate the integral of a function in numerical
fashion by using a sum of its samples multiplied by the
length of the time interval between the sample “h”.
– Though very similar, the formula above is not the standard DFT (Discrete Fourier Transform) formula but
something improvised “ad hoc” based on the full formula of the transform and numerical approximations.
Since we sum from 0 to N not from -N/2 to N/2 the formula above is an approximation of the Fourier
transform of g(t+N/2) rather then g(t)
The first term is the real part of the transform and the second term (after “j”) the imaginary part
<excelunusual.com> 3
Real part – Re(G(f)) Imaginary part – Im(G(f))
A visualization:
3.5
– If we have a saw-tooth g(t) function and a cosine function of frequency f. Calculating the sampled Fourier transform for frequency f would mean multiplying all red and blue point values situated on the same vertical grid line and adding all the products together.
Detailed visualization for calculating the real part of the Fourier transform at frequency f:
3 h cos(2pi*f*t)
2.5 g(t)
RFT – Redneck Fourier Transform
<excelunusual.com> 4
3.5
cos(2pi*f*t)
– In order to calculate the real part of G(f) we need to do the operation demonstrated in the previous page for every frequency that we want to calculate G(f) for. This implies
multiplication of g(t) with a cosine of that g(t) frequency for N time samples.
– In order to calculate the imaginary part of G(f) we need to do the operation demonstrated in the previous page (with a sine instead of a cosine) for every frequency that we want to calculate G(f)
for. This implies multiplication of g(t) with a sine of that frequency for N time samples.
– The charts the right show the saw-tooth function g(t) and a cosine of four different g(t) frequencies used to calculate the real part of the Fourier transform for four different frequencies.
<excelunusual.com> 5
Overview of the Fourier transform components:
– If we write the Fourier transform of a real value time signal we can see that it has a real part and an
imaginary part:
Real part – Re(G(f)) Imaginary part – Im(G(f))
– Which can be written in short like this:
G( f ) Re G (f ) jIm G (f)
– Instead of writing as real and G( f ) Re G( f ) Im G (f ) imaginary, the Fourier transform is most of the times expressed as
Im G( f )
Amplitude and Phase:
Phase G( f ) atan
Re G( f )
by George Lungu <excelunusual.com> 6