
From Wikipedia, the free encyclopedia
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of words[edit]
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choice[edit]
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architectures[edit]
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressing[edit]
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of two[edit]
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size families[edit]
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizes[edit]
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See also[edit]
- Integer (computer science)
Notes[edit]
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is
 . This gives an equivalent of about 9.51 bits for 6 trits.
. This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign

References[edit]
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
Difference between Bit, Byte and Words
This article will help you to learn about the difference between bit, byte and words.
Difference between Bit, Byte and Words
Bit
The computer does not have a large number of symbols for representing data. It has only two, 0 and 1 (called binary digits or bits). These correspond to the two electronic ox magnetic states used in computer circuits and storage.
The smallest unit used for feeding data and program into computer is bit. Information is handled in the computer by electrical components such as transistors, integrated circuits, semiconductors and wires, all of which can only indicate two states or conditions.
Transistors are either conducting or non-conducting; magnetic materials are either magnetized or non-magnetized in one direction or in the opposite direction; a pulse or voltage is present or not present.
These two possible states can be expressed with the help of bits -0 and 1. For example, the presence of current pulse in a circuit in computer may be represented by the bit 1 and the absence of current pulse in a circuit may be represented by the bit 0.
Byte
A collection of some bits is called a byte. Byte is a group of adjacent bits (binary digits) operated upon as a unit. An 8 bit unit is commonly called a byte and has become the standard unit for storing a single character.
In many computers, it is 8-bit set encoding one alphanumeric character or two decimal digits. Alphanumeric is a contraction for alphabetic (A, B, C, etc.) and numeric, (0, 1, 2, etc.). A set of alphanumeric characters will usually include special characters too such as dollar sign, comma etc.
Words
Some memory units are not made up of bytes but of words. A computer word consists of the data which is stored or retrieved when a memory location is specified Word is a collection of bits treated as a single unit. Word is an ordered set of characters handled as a unit by the computer. The word may be fixed or variable in length. The word length depends upon the number of bits or characters in a word.
The number of bits varies from 4, 8, 12, 16, 32 etc., up to 64 i.e., the word may be as long as 64 bits or as short as 8 bits. In a fixed word-length computer, the number of characters in a word does not vary, and an address will typically refer to one set of characters. In a variable word-length computer, each character or byte has an address and the word utilized by the computer can include a variable number of characters.
The length of the variable word is specified either by the instruction which calls for it or by a word- mark in storage. A byte is usually shorter than a word, typically consisting of 8 bits. In some computers the grouping of bits, bytes or words is flexible in design to meet the different storage requirements of numbers, alphanumeric characters and instructions.
Page load link
Go to Top
I’ve done some research.
A byte is 8 bits and a word is the smallest unit that can be addressed on memory. The exact length of a word varies. What I don’t understand is what’s the point of having a byte? Why not say 8 bits?
I asked a prof this question and he said most machines these days are byte-addressable, but what would that make a word?
![]()
Peter Cordes
317k45 gold badges583 silver badges818 bronze badges
asked Oct 13, 2011 at 6:17
5
Byte: Today, a byte is almost always 8 bit. However, that wasn’t always the case and there’s no «standard» or something that dictates this. Since 8 bits is a convenient number to work with it became the de facto standard.
Word: The natural size with which a processor is handling data (the register size). The most common word sizes encountered today are 8, 16, 32 and 64 bits, but other sizes are possible. For examples, there were a few 36 bit machines, or even 12 bit machines.
The byte is the smallest addressable unit for a CPU. If you want to set/clear single bits, you first need to fetch the corresponding byte from memory, mess with the bits and then write the byte back to memory.
By contrast, one definition for word is the biggest chunk of bits with which a processor can do processing (like addition and subtraction) at a time – typically the width of an integer register. That definition is a bit fuzzy, as some processors might have different register sizes for different tasks (integer vs. floating point processing for example) or are able to access fractions of a register. The word size is the maximum register size that the majority of operations work with.
There are also a few processors which have a different pointer size: for example, the 8086 is a 16-bit processor which means its registers are 16 bit wide. But its pointers (addresses) are 20 bit wide and were calculated by combining two 16 bit registers in a certain way.
In some manuals and APIs, the term «word» may be «stuck» on a former legacy size and might differ from what’s the actual, current word size of a processor when the platform evolved to support larger register sizes. For example, the Intel and AMD x86 manuals still use «word» to mean 16 bits with DWORD (double-word, 32 bit) and QWORD (quad-word, 64 bit) as larger sizes. This is then reflected in some APIs, like Microsoft’s WinAPI.
answered Oct 13, 2011 at 6:51
![]()
DarkDustDarkDust
90.4k19 gold badges188 silver badges223 bronze badges
21
What I don’t understand is what’s the point of having a byte? Why not say 8 bits?
Apart from the technical point that a byte isn’t necessarily 8 bits, the reasons for having a term is simple human nature:
-
economy of effort (aka laziness) — it is easier to say «byte» rather than «eight bits»
-
tribalism — groups of people like to use jargon / a private language to set them apart from others.
Just go with the flow. You are not going to change 50+ years of accumulated IT terminology and cultural baggage by complaining about it.
FWIW — the correct term to use when you mean «8 bits independent of the hardware architecture» is «octet».
answered Oct 13, 2011 at 6:47
![]()
Stephen CStephen C
692k94 gold badges792 silver badges1205 bronze badges
2
BYTE
I am trying to answer this question from C++ perspective.
The C++ standard defines ‘byte’ as “Addressable unit of data large enough to hold any member of the basic character set of the execution environment.”
What this means is that the byte consists of at least enough adjacent bits to accommodate the basic character set for the implementation. That is, the number of possible values must equal or exceed the number of distinct characters.
In the United States, the basic character sets are usually the ASCII and EBCDIC sets, each of which can be accommodated by 8 bits.
Hence it is guaranteed that a byte will have at least 8 bits.
In other words, a byte is the amount of memory required to store a single character.
If you want to verify ‘number of bits’ in your C++ implementation, check the file ‘limits.h’. It should have an entry like below.
#define CHAR_BIT 8 /* number of bits in a char */
WORD
A Word is defined as specific number of bits which can be processed together (i.e. in one attempt) by the machine/system.
Alternatively, we can say that Word defines the amount of data that can be transferred between CPU and RAM in a single operation.
The hardware registers in a computer machine are word sized.
The Word size also defines the largest possible memory address (each memory address points to a byte sized memory).
Note – In C++ programs, the memory addresses points to a byte of memory and not to a word.
answered May 29, 2012 at 18:12
![]()
It seems all the answers assume high level languages and mainly C/C++.
But the question is tagged «assembly» and in all assemblers I know (for 8bit, 16bit, 32bit and 64bit CPUs), the definitions are much more clear:
byte = 8 bits
word = 2 bytes
dword = 4 bytes = 2Words (dword means "double word")
qword = 8 bytes = 2Dwords = 4Words ("quadruple word")
answered Feb 3, 2013 at 18:38
![]()
johnfoundjohnfound
6,8014 gold badges30 silver badges58 bronze badges
5
Why not say 8 bits?
Because not all machines have 8-bit bytes. Since you tagged this C, look up CHAR_BIT in limits.h.
answered Oct 13, 2011 at 6:19
![]()
cnicutarcnicutar
177k25 gold badges361 silver badges391 bronze badges
A word is the size of the registers in the processor. This means processor instructions like, add, mul, etc are on word-sized inputs.
But most modern architectures have memory that is addressable in 8-bit chunks, so it is convenient to use the word «byte».
answered Oct 13, 2011 at 6:21
![]()
VoidStarVoidStar
5,1611 gold badge30 silver badges44 bronze badges
5
In this context, a word is the unit that a machine uses when working with memory. For example, on a 32 bit machine, the word is 32 bits long and on a 64 bit is 64 bits long. The word size determines the address space.
In programming (C/C++), the word is typically represented by the int_ptr type, which has the same length as a pointer, this way abstracting these details.
Some APIs might confuse you though, such as Win32 API, because it has types such as WORD (16 bits) and DWORD (32 bits). The reason is that the API was initially targeting 16 bit machines, then was ported to 32 bit machines, then to 64 bit machines. To store a pointer, you can use INT_PTR. More details here and here.
![]()
answered Oct 13, 2011 at 6:39
![]()
npclaudiunpclaudiu
2,3911 gold badge16 silver badges18 bronze badges
The exact length of a word varies. What I don’t understand is what’s the point of having a byte? Why not say 8 bits?
Even though the length of a word varies, on all modern machines and even all older architectures that I’m familiar with, the word size is still a multiple of the byte size. So there is no particular downside to using «byte» over «8 bits» in relation to the variable word size.
Beyond that, here are some reasons to use byte (or octet1) over «8 bits»:
- Larger units are just convenient to avoid very large or very small numbers: you might as well ask «why say 3 nanoseconds when you could say 0.000000003 seconds» or «why say 1 kilogram when you could say 1,000 grams», etc.
- Beyond the convenience, the unit of a byte is somehow as fundamental as 1 bit since many operations typically work not at the byte level, but at the byte level: addressing memory, allocating dynamic storage, reading from a file or socket, etc.
- Even if you were to adopt «8 bit» as a type of unit, so you could say «two 8-bits» instead of «two bytes», it would be often be very confusing to have your new unit start with a number. For example, if someone said «one-hundred 8-bits» it could easily be interpreted as 108 bits, rather than 100 bits.
1 Although I’ll consider a byte to be 8 bits for this answer, this isn’t universally true: on older machines a byte may have a different size (such as 6 bits. Octet always means 8 bits, regardless of the machine (so this term is often used in defining network protocols). In modern usage, byte is overwhelmingly used as synonymous with 8 bits.
answered Feb 10, 2018 at 22:17
![]()
BeeOnRopeBeeOnRope
59k15 gold badges200 silver badges371 bronze badges
Whatever the terminology present in datasheets and compilers, a ‘Byte’ is eight bits. Let’s not try to confuse enquirers and generalities with the more obscure exceptions, particularly as the word ‘Byte’ comes from the expression «By Eight». I’ve worked in the semiconductor/electronics industry for over thirty years and not once known ‘Byte’ used to express anything more than eight bits.
answered Feb 3, 2013 at 18:04
![]()
3
A group of 8 bits is called a byte ( with the exception where it is not  for certain architectures )
for certain architectures )
A word is a fixed sized group of bits that are handled as a unit by the instruction set and/or hardware of the processor. That means the size of a general purpose register ( which is generally more than a byte ) is a word
In the C, a word is most often called an integer => int
answered Oct 13, 2011 at 6:23
![]()
tolitiustolitius
22k6 gold badges69 silver badges81 bronze badges
3
Reference:https://www.os-book.com/OS9/slide-dir/PPT-dir/ch1.ppt
The basic unit of computer storage is the bit. A bit can contain one of two
values, 0 and 1. All other storage in a computer is based on collections of bits.
Given enough bits, it is amazing how many things a computer can represent:
numbers, letters, images, movies, sounds, documents, and programs, to name
a few. A byte is 8 bits, and on most computers it is the smallest convenient
chunk of storage. For example, most computers don’t have an instruction to
move a bit but do have one to move a byte. A less common term is word,
which is a given computer architecture’s native unit of data. A word is made up
of one or more bytes. For example, a computer that has 64-bit registers and 64-
bit memory addressing typically has 64-bit (8-byte) words. A computer executes
many operations in its native word size rather than a byte at a time.
Computer storage, along with most computer throughput, is generally measured
and manipulated in bytes and collections of bytes.
A kilobyte, or KB, is 1,024 bytes
a megabyte, or MB, is 1,024 2 bytes
a gigabyte, or GB, is 1,024 3 bytes
a terabyte, or TB, is 1,024 4 bytes
a petabyte, or PB, is 1,024 5 bytes
Computer manufacturers often round off these numbers and say that a
megabyte is 1 million bytes and a gigabyte is 1 billion bytes. Networking
measurements are an exception to this general rule; they are given in bits
(because networks move data a bit at a time)
answered Apr 13, 2020 at 9:00
![]()
LiLiLiLi
3833 silver badges11 bronze badges
If a machine is byte-addressable and a word is the smallest unit that can be addressed on memory then I guess a word would be a byte!
answered Oct 13, 2011 at 6:19
![]()
K-balloK-ballo
80k20 gold badges159 silver badges169 bronze badges
2
The terms of BYTE and WORD are relative to the size of the processor that is being referred to. The most common processors are/were 8 bit, 16 bit, 32 bit or 64 bit. These are the WORD lengths of the processor. Actually half of a WORD is a BYTE, whatever the numerical length is. Ready for this, half of a BYTE is a NIBBLE.
answered Feb 9, 2018 at 17:59
![]()
1
In fact, in common usage, word has become synonymous with 16 bits, much like byte has with 8 bits. Can get a little confusing since the «word size» on a 32-bit CPU is 32-bits, but when talking about a word of data, one would mean 16-bits. Microcontrollers with a 32-bit word size have taken to calling their instructions «longs» (supposedly to try and avoid the word/doubleword confusion).
answered Oct 13, 2011 at 12:52
![]()
Brian KnoblauchBrian Knoblauch
20.5k15 gold badges61 silver badges92 bronze badges
3
«tribit» redirects here. Not to be confused with tibit or trit.
In computing and telecommunications, a unit of information is the capacity of some standard data storage system or communication channel, used to measure the capacities of other systems and channels. In information theory, units of information are also used to measure information contained in messages and the entropy of random variables.
The most commonly used units of data storage capacity are the bit, the capacity of a system that has only two states, and the byte (or octet), which is equivalent to eight bits. Multiples of these units can be formed from these with the SI prefixes (power-of-ten prefixes) or the newer IEC binary prefixes (power-of-two prefixes).
Primary unitsEdit
Comparison of units of information: bit, trit, nat, ban. Quantity of information is the height of bars. Dark green level is the «nat» unit.
In 1928, Ralph Hartley observed a fundamental storage principle,[1] which was further formalized by Claude Shannon in 1945: the information that can be stored in a system is proportional to the logarithm of N possible states of that system, denoted logb N. Changing the base of the logarithm from b to a different number c has the effect of multiplying the value of the logarithm by a fixed constant, namely logc N = (logc b) logb N.
Therefore, the choice of the base b determines the unit used to measure information. In particular, if b is a positive integer, then the unit is the amount of information that can be stored in a system with b possible states.
When b is 2, the unit is the shannon, equal to the information content of one «bit» (a portmanteau of binary digit[2]). A system with 8 possible states, for example, can store up to log2 8 = 3 bits of information. Other units that have been named include:
- Base b = 3
- the unit is called «trit», and is equal to log2 3 (≈ 1.585) bits.[3]
- Base b = 10
- the unit is called decimal digit, hartley, ban, decit, or dit, and is equal to log2 10 (≈ 3.322) bits.[1][4][5][6]
- Base b = e, the base of natural logarithms
- the unit is called a nat, nit, or nepit (from Neperian), and is worth log2 e (≈ 1.443) bits.[1]
The trit, ban, and nat are rarely used to measure storage capacity; but the nat, in particular, is often used in information theory, because natural logarithms are mathematically more convenient than logarithms in other bases.
Units derived from bitEdit
Several conventional names are used for collections or groups of bits.
ByteEdit
Historically, a byte was the number of bits used to encode a character of text in the computer, which depended on computer hardware architecture; but today it almost always means eight bits – that is, an octet. A byte can represent 256 (28) distinct values, such as non-negative integers from 0 to 255, or signed integers from −128 to 127. The IEEE 1541-2002 standard specifies «B» (upper case) as the symbol for byte (IEC 80000-13 uses «o» for octet in French,[nb 1] but also allows «B» in English, which is what is actually being used). Bytes, or multiples thereof, are almost always used to specify the sizes of computer files and the capacity of storage units. Most modern computers and peripheral devices are designed to manipulate data in whole bytes or groups of bytes, rather than individual bits.
NibbleEdit
A group of four bits, or half a byte, is sometimes called a nibble, nybble or nyble. This unit is most often used in the context of hexadecimal number representations, since a nibble has the same amount of information as one hexadecimal digit.[7]
CrumbEdit
A group of two bits or a quarter byte was called a crumb,[8] often used in early 8-bit computing (see Atari 2600, ZX Spectrum).[citation needed] It is now largely defunct.
Word, block, and pageEdit
Computers usually manipulate bits in groups of a fixed size, conventionally called words. The number of bits in a word is usually defined by the size of the registers in the computer’s CPU, or by the number of data bits that are fetched from its main memory in a single operation. In the IA-32 architecture more commonly known as x86-32, a word is 16 bits, but other past and current architectures use words with 4, 8, 9, 12, 13, 16, 18, 20, 21, 22, 24, 25, 29, 30, 31, 32, 33, 35, 36, 38, 39, 40, 42, 44, 48, 50, 52, 54, 56, 60, 64, 72[9] bits or others.
Some machine instructions and computer number formats use two words (a «double word» or «dword»), or four words (a «quad word» or «quad»).
Computer memory caches usually operate on blocks of memory that consist of several consecutive words. These units are customarily called cache blocks, or, in CPU caches, cache lines.
Virtual memory systems partition the computer’s main storage into even larger units, traditionally called pages.
Systematic multiplesEdit
Terms for large quantities of bits can be formed using the standard range of SI prefixes for powers of 10, e.g., kilo = 103 = 1000 (as in kilobit or kbit), mega = 106 = 1000000 (as in megabit or Mbit) and giga = 109 = 1000000000 (as in gigabit or Gbit). These prefixes are more often used for multiples of bytes, as in kilobyte (1 kB = 8000 bit), megabyte (1 MB = 8000000bit), and gigabyte (1 GB = 8000000000bit).
However, for technical reasons, the capacities of computer memories and some storage units are often multiples of some large power of two, such as 228 = 268435456 bytes. To avoid such unwieldy numbers, people have often repurposed the SI prefixes to mean the nearest power of two, e.g., using the prefix kilo for 210 = 1024, mega for 220 = 1048576, and giga for 230 = 1073741824, and so on. For example, a random access memory chip with a capacity of 228 bytes would be referred to as a 256-megabyte chip. The table below illustrates these differences.
| Symbol | Prefix | SI Meaning | Binary meaning | Size difference |
|---|---|---|---|---|
| k | kilo | 103 = 10001 | 210 = 10241 | 2.40% |
| M | mega | 106 = 10002 | 220 = 10242 | 4.86% |
| G | giga | 109 = 10003 | 230 = 10243 | 7.37% |
| T | tera | 1012 = 10004 | 240 = 10244 | 9.95% |
| P | peta | 1015 = 10005 | 250 = 10245 | 12.59% |
| E | exa | 1018 = 10006 | 260 = 10246 | 15.29% |
| Z | zetta | 1021 = 10007 | 270 = 10247 | 18.06% |
| Y | yotta | 1024 = 10008 | 280 = 10248 | 20.89% |
| R | ronna | 1027 = 10009 | 290 = 10249 | 23.79% |
| Q | quetta | 1030 = 100010 | 2100 = 102410 | 26.77% |
In the past, uppercase K has been used instead of lowercase k to indicate 1024 instead of 1000. However, this usage was never consistently applied.
On the other hand, for external storage systems (such as optical discs), the SI prefixes are commonly used with their decimal values (powers of 10). There have been many attempts to resolve the confusion by providing alternative notations for power-of-two multiples. In 1998 the International Electrotechnical Commission (IEC) issued a standard for this purpose, namely a series of binary prefixes that use 1024 instead of 1000 as the main radix:[10]
| Symbol | Prefix | |||
|---|---|---|---|---|
| Ki | kibi, binary kilo | 1 kibibyte (KiB) | 210 bytes | 1024 B |
| Mi | mebi, binary mega | 1 mebibyte (MiB) | 220 bytes | 1024 KiB |
| Gi | gibi, binary giga | 1 gibibyte (GiB) | 230 bytes | 1024 MiB |
| Ti | tebi, binary tera | 1 tebibyte (TiB) | 240 bytes | 1024 GiB |
| Pi | pebi, binary peta | 1 pebibyte (PiB) | 250 bytes | 1024 TiB |
| Ei | exbi, binary exa | 1 exbibyte (EiB) | 260 bytes | 1024 PiB |
The JEDEC memory standard JESD88F notes that the definitions of kilo (K), giga (G), and mega (M) based on powers of two are included only to reflect common usage.[11]
Size examplesEdit
- 1 bit: Answer to a yes/no question
- 1 byte: A number from 0 to 255
- 90 bytes: Enough to store a typical line of text from a book
- 512 bytes = 0.5 KiB: The typical sector of a hard disk
- 1024 bytes = 1 KiB: The classical block size in UNIX filesystems
- 2048 bytes = 2 KiB: A CD-ROM sector
- 4096 bytes = 4 KiB: A memory page in x86 (since Intel 80386)
- 4 kB: About one page of text from a novel
- 120 kB: The text of a typical pocket book
- 1 MiB: A 1024×1024 pixel bitmap image with 256 colors (8 bpp color depth)
- 3 MB: A three-minute song (133 kbit/s)
- 650–900 MB – a CD-ROM
- 1 GB: 114 minutes of uncompressed CD-quality audio at 1.4 Mbit/s
- 32/64/128 GB: Three common sizes of USB flash drives
- 6 TB: The size of a $100 hard disk (as of early 2022)
- 20 TB: Largest hard disk drive (as of early 2022)
- 100 TB: Largest commercially available solid state drive (as of early 2022)
- 200 TB: Largest solid state drive constructed (prediction for mid 2022)
- 1.3 ZB: Prediction of the volume of the whole internet in 2016
Obsolete and unusual unitsEdit
Several other units of information storage have been named:
- 1 bit: unibit,[12][13] sniff[citation needed]
- 2 bits: dibit,[14][15][12][16] crumb,[8] quartic digit,[17] quad, quarter, taste, tayste, tidbit, tydbit, lick, lyck, semi-nibble, snort, nyp[18]
- 3 bits: tribit,[14][15][12] triad,[19] triade,[20][21] tribble
- 4 bits: character (on Intel 4004[22] – however, characters are typically 8 bits wide or larger on other processors), for others see nibble
- 5 bits: pentad, pentade,[23] nickel, nyckle[citation needed]
- 6 bits: byte (in early IBM machines using BCD alphamerics), hexad, hexade,[23][24] sextet[19]
- 7 bits: heptad, heptade[23]
- 8 bits: octet, commonly also called byte
- 9 bits: nonet,[25] rarely used
- 10 bits: declet,[26][27][28][29] decle,[30] deckle, dyme[citation needed]
- 12 bits: slab[31][32][33]
- 15 bits: parcel (on CDC 6600 and CDC 7600)
- 16 bits: doublet,[34] wyde,[3][35] parcel (on Cray-1), plate, playte, chomp, chawmp (on a 32-bit machine)[36]
- 18 bits: chomp, chawmp (on a 36-bit machine)[36]
- 32 bits: quadlet,[34][37][38] tetra,[35] dinner, dynner, gawble (on a 32-bit machine)[citation needed]
- 48 bits: gobble, gawble (under circumstances that remain obscure)[citation needed]
- 64 bits: octlet,[34] octa[35]
- 96 bits: bentobox (in ITRON OS)
- 128 bits: hexlet[34][39]
- 16 bytes: paragraph (on Intel x86 processors)[40][41]
- 256 bytes: page (on Intel 4004,[22] 8080 and 8086 processors,[40] also many other 8-bit processors – typically much larger on many 16-bit/32-bit processors)
- 6 trits: tryte[42]
- combit, comword[43][44][45]
Some of these names are jargon, obsolete, or used only in very restricted contexts.
See alsoEdit
- Metric prefix
- File size
NotesEdit
- ^ However, the IEC 80000-13 abbreviation «o» for octets can be confused with the postfix «o» to indicate octal numbers in Intel convention.
ReferencesEdit
- ^ a b c Abramson, Norman (1963). Information theory and coding. McGraw-Hill.
- ^ Mackenzie, Charles E. (1980). Coded Character Sets, History and Development. The Systems Programming Series (1 ed.). Addison-Wesley Publishing Company, Inc. p. xii. ISBN 0-201-14460-3. LCCN 77-90165. Retrieved 2016-05-22. [1]
- ^ a b Knuth, Donald Ervin. The Art of Computer Programming: Seminumerical algorithms. Vol. 2. Addison Wesley.
- ^ Shanmugam (2006). Digital and Analog Computer Systems.
- ^ Jaeger, Gregg (2007). Quantum information: an overview.
- ^ Kumar, I. Ravi (2001). Comprehensive Statistical Theory of Communication.
- ^ Nybble at dictionary reference.com; sourced from Jargon File 4.2.0, accessed 2007-08-12
- ^ a b Weisstein, Eric. W. «Crumb». MathWorld. Retrieved 2015-08-02.
- ^ Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ ISO/IEC standard is ISO/IEC 80000-13:2008. This standard cancels and replaces subclauses 3.8 and 3.9 of IEC 60027-2:2005. The only significant change is the addition of explicit definitions for some quantities. ISO Online Catalogue
- ^ JEDEC Solid State Technology Association (February 2018). «Dictionary of Terms for Solid State Technology – 7th Edition». JESD88F. Retrieved 2021-06-25.
- ^ a b c Horak, Ray (2007). Webster’s New World Telecom Dictionary. John Wiley & Sons. p. 402. ISBN 9-78047022571-4.
- ^ «Unibit».
- ^ a b Steinbuch, Karl W.; Wagner, Siegfried W., eds. (1967) [1962]. Written at Karlsruhe, Germany. Taschenbuch der Nachrichtenverarbeitung (in German) (2 ed.). Berlin / Heidelberg / New York: Springer-Verlag OHG. pp. 835–836. LCCN 67-21079. Title No. 1036.
- ^ a b Steinbuch, Karl W.; Weber, Wolfgang; Heinemann, Traute, eds. (1974) [1967]. Written at Karlsruhe / Bochum. Taschenbuch der Informatik — Band III — Anwendungen und spezielle Systeme der Nachrichtenverarbeitung. Taschenbuch der Nachrichtenverarbeitung (in German). Vol. 3 (3 ed.). Berlin / Heidelberg / New York: Springer Verlag. pp. 357–358. ISBN 3-540-06242-4. LCCN 73-80607.
- ^ Bertram, H. Neal (1994). Theory of magnetic recording (1 ed.). Cambridge University Press. ISBN 0-521-44973-1. 9-780521-449731.
[…] The writing of an impulse would involve writing a dibit or two transitions arbitrarily closely together. […]
- ^ Control Data 8092 TeleProgrammer: Programming Reference Manual (PDF). Minneapolis, Minnesota, USA: Control Data Corporation. 1964. IDP 107a. Archived (PDF) from the original on 2020-05-25. Retrieved 2020-07-27.
- ^ Knuth, Donald Ervin. The Art of Computer Programming: Cobinatorial Algorithms part 1. Vol. 4a. Addison Wesley.
- ^ a b Svoboda, Antonín; White, Donnamaie E. (2016) [2012, 1985, 1979-08-01]. Advanced Logical Circuit Design Techniques (PDF) (retyped electronic reissue ed.). Garland STPM Press (original issue) / WhitePubs Enterprises, Inc. (reissue). ISBN 0-8240-7014-3. LCCN 78-31384. Archived (PDF) from the original on 2017-04-14. Retrieved 2017-04-15. [2][3]
- ^ Paul, Reinhold (2013). Elektrotechnik und Elektronik für Informatiker — Grundgebiete der Elektronik. Leitfaden der Informatik (in German). Vol. 2. B.G. Teubner Stuttgart / Springer. ISBN 978-3-32296652-0. Retrieved 2015-08-03.
- ^ Böhme, Gert; Born, Werner; Wagner, B.; Schwarze, G. (2013-07-02) [1969]. Reichenbach, Jürgen (ed.). Programmierung von Prozeßrechnern. Reihe Automatisierungstechnik (in German). Vol. 79. VEB Verlag Technik [de] Berlin, reprint: Springer Verlag. doi:10.1007/978-3-663-02721-8. ISBN 978-3-663-00808-8. 9/3/4185.
- ^ a b «Terms And Abbreviations / 4.1 Crossing Page Boundaries». MCS-4 Assembly Language Programming Manual — The INTELLEC 4 Microcomputer System Programming Manual (PDF) (Preliminary ed.). Santa Clara, California, USA: Intel Corporation. December 1973. pp. v, 2-6, 4-1. MCS-030-1273-1. Archived (PDF) from the original on 2020-03-01. Retrieved 2020-03-02.
[…] Bit — The smallest unit of information which can be represented. (A bit may be in one of two states I 0 or 1). […] Byte — A group of 8 contiguous bits occupying a single memory location. […] Character — A group of 4 contiguous bits of data. […] programs are held in either ROM or program RAM, both of which are divided into pages. Each page consists of 256 8-bit locations. Addresses 0 through 255 comprise the first page, 256-511 comprise the second page, and so on. […]
(NB. This Intel 4004 manual uses the term character referring to 4-bit rather than 8-bit data entities. Intel switched to use the more common term nibble for 4-bit entities in their documentation for the succeeding processor 4040 in 1974 already.) - ^ a b c Speiser, Ambrosius Paul (1965) [1961]. Digitale Rechenanlagen — Grundlagen / Schaltungstechnik / Arbeitsweise / Betriebssicherheit [Digital computers — Basics / Circuits / Operation / Reliability] (in German) (2 ed.). ETH Zürich, Zürich, Switzerland: Springer-Verlag / IBM. pp. 6, 34, 165, 183, 208, 213, 215. LCCN 65-14624. 0978.
- ^ Steinbuch, Karl W., ed. (1962). Written at Karlsruhe, Germany. Taschenbuch der Nachrichtenverarbeitung (in German) (1 ed.). Berlin / Göttingen / New York: Springer-Verlag OHG. p. 1076. LCCN 62-14511.
- ^ Crispin, Mark R. (2005). RFC 4042: UTF-9 and UTF-18.
- ^ IEEE 754-2008 — IEEE Standard for Floating-Point Arithmetic. IEEE STD 754-2008. 2008-08-29. pp. 1–70. doi:10.1109/IEEESTD.2008.4610935. ISBN 978-0-7381-5752-8. Retrieved 2016-02-10.
- ^ Muller, Jean-Michel; Brisebarre, Nicolas; de Dinechin, Florent; Jeannerod, Claude-Pierre; Lefèvre, Vincent; Melquiond, Guillaume; Revol, Nathalie; Stehlé, Damien; Torres, Serge (2010). Handbook of Floating-Point Arithmetic (1 ed.). Birkhäuser. doi:10.1007/978-0-8176-4705-6. ISBN 978-0-8176-4704-9. LCCN 2009939668.
- ^ Erle, Mark A. (2008-11-21). Algorithms and Hardware Designs for Decimal Multiplication (Thesis). Lehigh University (published 2009). ISBN 978-1-10904228-3. 1109042280. Retrieved 2016-02-10.
- ^ Kneusel, Ronald T. (2015). Numbers and Computers. Springer Verlag. ISBN 9783319172606. 3319172603. Retrieved 2016-02-10.
- ^ Zbiciak, Joe. «AS1600 Quick-and-Dirty Documentation». Retrieved 2013-04-28.
- ^ «315 Electronic Data Processing System» (PDF). NCR. November 1965. NCR MPN ST-5008-15. Archived (PDF) from the original on 2016-05-24. Retrieved 2015-01-28.
- ^ Bardin, Hillel (1963). «NCR 315 Seminar» (PDF). Computer Usage Communique. 2 (3). Archived (PDF) from the original on 2016-05-24.
- ^ Schneider, Carl (2013) [1970]. Datenverarbeitungs-Lexikon [Lexicon of information technology] (in German) (softcover reprint of hardcover 1st ed.). Wiesbaden, Germany: Springer Fachmedien Wiesbaden GmbH / Betriebswirtschaftlicher Verlag Dr. Th. Gabler GmbH. pp. 201, 308. doi:10.1007/978-3-663-13618-7. ISBN 978-3-409-31831-0. Retrieved 2016-05-24.
[…] slab, Abk. aus syllable = Silbe, die kleinste adressierbare Informationseinheit für 12 bit zur Übertragung von zwei Alphazeichen oder drei numerischen Zeichen. (NCR) […] Hardware: Datenstruktur: NCR 315-100 / NCR 315-RMC; Wortlänge: Silbe; Bits: 12; Bytes: –; Dezimalziffern: 3; Zeichen: 2; Gleitkommadarstellung: fest verdrahtet; Mantisse: 4 Silben; Exponent: 1 Silbe (11 Stellen + 1 Vorzeichen) […] [slab, abbr. for syllable = syllable, smallest addressable information unit for 12 bits for the transfer of two alphabetical characters or three numerical characters. (NCR) […] Hardware: Data structure: NCR 315-100 / NCR 315-RMC; Word length: Syllable; Bits: 12; Bytes: –; Decimal digits: 3; Characters: 2; Floating point format: hard-wired; Significand: 4 syllables; Exponent: 1 syllable (11 digits + 1 prefix)]
- ^ a b c d IEEE Std 1754-1994 — IEEE Standard for a 32-bit Microcontroller Architecture. IEEE STD 1754-1994. The Institute of Electrical and Electronics Engineers, Inc. 1995. pp. 5–7. doi:10.1109/IEEESTD.1995.79519. ISBN 1-55937-428-4. Retrieved 2016-02-10. (NB. The standard defines doublets, quadlets, octlets and hexlets as 2, 4, 8 and 16 bytes, giving the numbers of bits (16, 32, 64 and 128) only as a secondary meaning. This might be important given that bytes were not always understood to mean 8 bits (octets) historically.)
- ^ a b c Knuth, Donald Ervin (2004-02-15) [1999]. Fascicle 1: MMIX (PDF). The Art of Computer Programming (0th printing, 15th ed.). Stanford University: Addison-Wesley. Archived (PDF) from the original on 2017-03-30. Retrieved 2017-03-30.
- ^ a b Raymond, Eric S. (1996). The New Hacker’s Dictionary (3 ed.). MIT Press. p. 333. ISBN 0262680920.
- ^ Böszörményi, László; Hölzl, Günther; Pirker, Emaneul (February 1999). Written at Salzburg, Austria. Zinterhof, Peter; Vajteršic, Marian; Uhl, Andreas (eds.). Parallel Cluster Computing with IEEE1394–1995. Parallel Computation: 4th International ACPC Conference including Special Tracks on Parallel Numerics (ParNum ’99) and Parallel Computing in Image Processing, Video Processing, and Multimedia. Proceedings: Lecture Notes in Computer Science 1557. Berlin, Germany: Springer Verlag.
- ^ Nicoud, Jean-Daniel (1986). Calculatrices. Traité d’électricité de l’École polytechnique fédérale de Lausanne (in French). Vol. 14 (2 ed.). Lausanne: Presses polytechniques romandes. ISBN 2-88074054-1.
- ^ Proceedings. Symposium on Experiences with Distributed and Multiprocessor Systems (SEDMS). Vol. 4. USENIX Association. 1993.
- ^ a b «1. Introduction: Segment Alignment». 8086 Family Utilities — User’s Guide for 8080/8085-Based Development Systems (PDF). Revision E (A620/5821 6K DD ed.). Santa Clara, California, USA: Intel Corporation. May 1982 [1980, 1978]. p. 1-6. Order Number: 9800639-04. Archived (PDF) from the original on 2020-02-29. Retrieved 2020-02-29.
- ^ Dewar, Robert Berriedale Keith; Smosna, Matthew (1990). Microprocessors — A Programmer’s View (1 ed.). Courant Institute, New York University, New York, USA: McGraw-Hill Publishing Company. p. 85. ISBN 0-07-016638-2. LCCN 89-77320. (xviii+462 pages)
- ^ Brousentsov, N. P.; Maslov, S. P.; Ramil Alvarez, J.; Zhogolev, E. A. «Development of ternary computers at Moscow State University». Retrieved 2010-01-20.
- ^ US 4319227, Malinowski, Christopher W.; Rinderle, Heinz & Siegle, Martin, «Three-state signaling system», issued 1982-03-09, assigned to AEG-Telefunken
- ^ «US4319227». Google.
- ^ «US4319227» (PDF). Patentimages.
External linksEdit
- Representation of numerical values and SI units in character strings for information interchanges
- Bit Calculator – Make conversions between bits, bytes, kilobits, kilobytes, megabits, megabytes, gigabits, gigabytes, terabits, terabytes, petabits, petabytes, exabits, exabytes, zettabits, zettabytes, yottabits, yottabytes.
- Paper on standardized units for use in information technology
- Data Byte Converter
- High Precision Data Unit Converters
You hear these terms when you talk about computers: Megabyte, Gigabyte, Terabyte, 32-bit, 64-bit. For a novice computer user, these can be quite confusing. So, here’s an explanation of a Bit and a Byte.

The terminology is familiar to almost everyone, but do you know what they are? To understand it, we have to go break it down to the primary 0’s and 1’s.
What is a Bit?
A Bit is the basic unit in computer information and has only two different values, generally defined as a 0 or 1. These values can be interpreted as on or off, yes or no, true or false, etc. It just depends on the binary code.
What is a Byte?
A Byte is just 8 Bits and is the smallest unit of memory that can be addressed in many computer systems. The following list shows the relationship between all of the different units of data.
| 0 (Off) or 1 (On) | = | 1 Bit |
| 8 Bits | = | 1 Byte |
| 1,024 Bytes | = | 1 Kilobyte |
| 1,024 Kilobytes | = | 1 Megabyte |
| 1,024 Megabytes | = | 1 Gigabyte |
| 1,024 Gigabytes | = | 1 Terabyte |
| 1,024 Terabytes | = | 1 Petabyte |
| 1,024 Petabytes | = | 1 Exabyte |
| 1,024 Exabytes | = | 1 Zettabyte |
Let’s take a look at a simple text file I created called sample.txt. It contains only eight (8) characters, four (4) upper case, and four (4) lower case letters. I created my text file using Notepad, so it is encoded using the American National Standards Institute (ANSI) standard binary code.
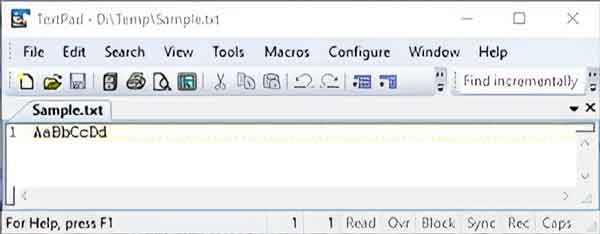
A sample text file with only eight characters opened in a text editor
The closest we can get to viewing raw binary code is to open my sample text file in a hexadecimal file editor. Hexadecimal digits allow for a more human-friendly representation of binary code.
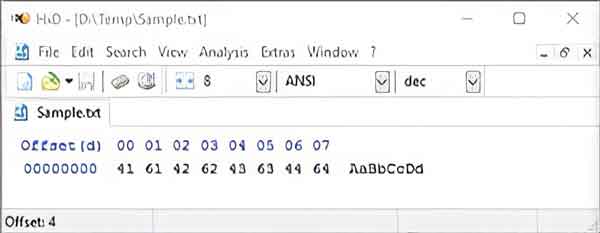
A sample text file with only eight characters opened in a hexadecimal editor
Since the ANSI code standard is a revision of the American Standard Code for Information Interchange (ASCII) code, we’ll need to use that standard for references to binary information. Using the table of ASCII printable characters on Wikipedia, we can find the binary code equivalent.
| Character | Hexadecimal | Binary |
|---|---|---|
| A | 41 | 01000001 |
| a | 61 | 01100001 |
| B | 42 | 01000010 |
| b | 62 | 01100010 |
| C | 43 | 01000011 |
| c | 63 | 01100011 |
| D | 44 | 01000100 |
| d | 64 | 01100100 |
So, as you can see, each character contains 8 bits or 1 byte, and the whole sample.txt file is 8 bytes in size. To put this in perspective, I created a Microsoft Word document (sample.docx) with the same characters as the sample text file.
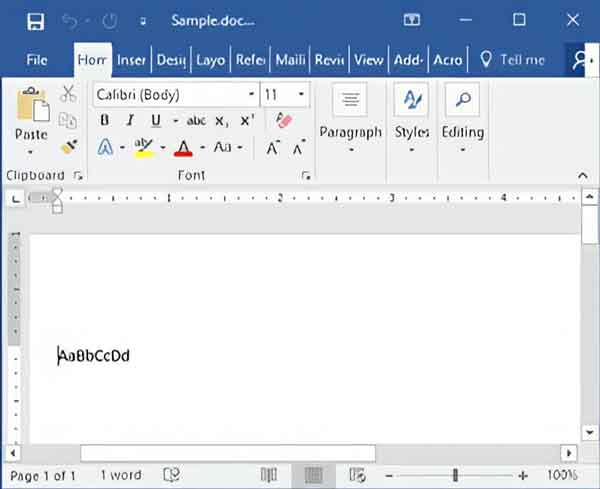
A sample Microsoft Word file with only eight characters opened in Microsoft Word
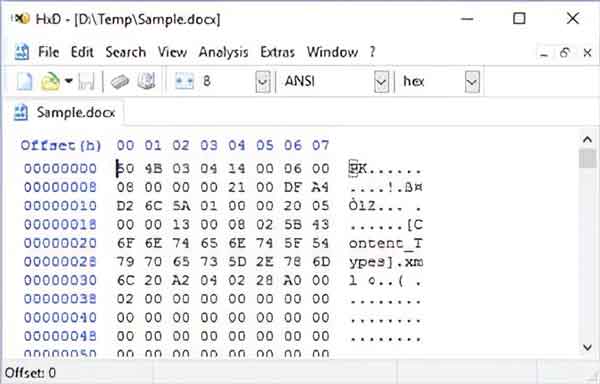
A sample Microsoft Word file with only eight characters opened in a hexadecimal editor
Here you can see all of the underlying formatting, and the size has increased significantly. The sample.docx file is almost 12 kilobytes (11,513 bytes) in size but contains only eight (8) characters.
What is 32-bit / 64-bit?
The terms 32-bit and 64-bit define the fixed-size piece of data a processor can transfer to and from memory. So, in theory, 64-bit computers can handle data twice as fast 32-bit systems.
The 32-bit computer architecture is most commonly known as x86 and was based on the Intel 8086 / 8088 processor. The Intel 8086 / 8088 processor was found in the original stand-alone Pac-Man video arcade console. The term for 64-bit computer architecture is x64, a little more straight forward.
The following Wikipedia articles were used for reference:
Bit — Wikipedia
Byte — Wikipedia
American National Standards Institute (ANSI) — Wikipedia
American Standard Code for Information Interchange (ASCII) — Wikipedia
Binary code — Wikipedia
Hexadecimal — Wikipedia
72fd31bc-af4c-4a2b-a757-8edac24beb17|0|.0|96d5b379-7e1d-4dac-a6ba-1e50db561b04