
In computing, a word is the natural unit of data used by a particular processor design.The number of bits in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
Contents
- 1 What is word in memory?
- 2 What is computer easy word?
- 3 What is a word in binary?
- 4 How many bits make a word?
- 5 What is word in PLC?
- 6 How are words stored in a computer?
- 7 What are the 4 types of computer?
- 8 What are the 7 types of computers?
- 9 What is a computer for kids?
- 10 Why is a word 2 bytes?
- 11 What is word length in computer?
- 12 What is opposite word?
- 13 What is a bit word?
- 14 What is the name of 4 bit data?
- 15 What are 4 bits called?
- 16 Is a word 16 or 32 bits?
- 17 What is difference between word and integer?
- 18 How many words are in a PLC?
- 19 Which is word addressable RAM?
- 20 What is digital word?
What is word in memory?
A group of memory bits in a RAM or ROM block.In Verilog HDL, a memory word is a register in a memory (that is, RAM or ROM) block that contains the same range of bits as the other registers in the memory. For example, the memory reg [5:0] EXAMPLE [0:2] defines 3 memory words, each containing a bit range of 5 to 0 .
A computer is an electronic device that manipulates information, or data. It has the ability to store, retrieve, and process data. You may already know that you can use a computer to type documents, send email, play games, and browse the Web.
What is a word in binary?
Quick Reference. A binary word of length n is a string of n binary digits, or bits. For example, there are 8 binary words of length 3, namely, 000, 100, 010, 001, 110, 101, 011 and 111.
How many bits make a word?
16 bits
Fundamental Data Types
A byte is eight bits, a word is 2 bytes (16 bits), a doubleword is 4 bytes (32 bits), and a quadword is 8 bytes (64 bits).
What is word in PLC?
A word refers to the size of data the processor handles. This will vary by PLC model. If the PLC uses a 16 bit processor a word refers to 16 contiguous bits (2bytes). A 32 bit processor uses a 32 bit word. Older PLCs used 8 bit words, there are still alot of these out there.
How are words stored in a computer?
Text is stored on a computer by first converting each character to an integer and then storing the integer. For example, to store the letter `A’, we will actually store the number 65; `B’ is 66, `C’ is 67, and so on. The conversion of letters to numbers is called an encoding.
What are the 4 types of computer?
The four basic types of computers are as under: Supercomputer. Mainframe Computer. Minicomputer.
- Analog Computer.
- Digital Computer.
- Hybrid Computer.
What are the 7 types of computers?
Types of computers
- Supercomputer.
- Mainframe.
- Server Computer.
- Workstation Computer.
- Personal Computer or PC.
- Microcontroller.
- Smartphone. 8 References.
What is a computer for kids?
A computer is a. device for working with information. The information can be numbers, words, pictures, movies, or sounds. Computer information is also called data. Computers can process huge amounts of data very quickly.
Why is a word 2 bytes?
If a character is 8 bits, or 1 byte, then a WORD must be at least 2 characters, so 16 bits or 2 bytes.
What is word length in computer?
The word length of the processor in a computer refers to the maximum number of bits it can take as input. It is the number of bits processed by a computer CPU in a single pass. The computer further takes this input for process and gives the output.
What is opposite word?
The word which is a pronoun that means what one? It may also be used to introduce restrictive and nonrestrictive clauses. There are no categorical antonyms for this word.
What is a bit word?
A bit (short for binary digit) is the smallest unit of data in a computer. A bit has a single binary value, either 0 or 1.In many systems, four eight-bit bytes or octets form a 32-bit word. In such systems, instruction lengths are sometimes expressed as full-word (32 bits in length) or half-word (16 bits in length).
What is the name of 4 bit data?
From there, a group of 4 bits is called a nibble, and 8-bits makes a byte. Bytes are a pretty common buzzword when working in binary.
What are 4 bits called?
nibble
In computing, a nibble (occasionally nybble or nyble to match the spelling of byte) is a four-bit aggregation, or half an octet. It is also known as half-byte or tetrade. In a networking or telecommunication context, the nibble is often called a semi-octet, quadbit, or quartet.
Is a word 16 or 32 bits?
In x86 assembly language WORD , DOUBLEWORD ( DWORD ) and QUADWORD ( QWORD ) are used for 2, 4 and 8 byte sizes, regardless of the machine word size. A word is typically the “native” data size of the CPU. That is, on a 16-bit CPU, a word is 16 bits, on a 32-bit CPU, it’s 32 and so on.
What is difference between word and integer?
Integer is a signed value 16-bit (+32767 to -32768 range), WORD is an unsigned 16-bit value (0 to +65535 range).
How many words are in a PLC?
Most PLCs use 16-bit words. a 16-bit unsigned integer (0 to 65,535). a 16-bit signed integer (-32,768 to 32,767). 16 individual bits (such as a group of boolean values).
Which is word addressable RAM?
A memory word is certain bytes that bidirectional data bus can carry at a time.And such memory are called word addressable memory. In a 32 bit machine, size of the data bus is 32 bits or 4 bytes. So, a 32 bit machine has word size of 4 bytes.
What is digital word?
1 : relating to or using calculation directly with digits rather than through measurable physical quantities. 2 : of or relating to data in the form of numerical digits digital images digital broadcasting. 3 : providing displayed or recorded information in numerical digits from an automatic device a digital watch.
Updated: 01/18/2023 by
Word may refer to any of the following:
1. When referring to a word processor, Word is short for Microsoft Word.
2. In general, a word is a single element of verbal communication with a unique meaning or use. For example, this sentence contains seven words. The English language contains several hundred thousand different words and Computer Hope lists over 15,000 computer-related words in its computer dictionary.
What are word classes?
Word classes or parts of speech are categories of English words that help you construct good sentences. These categories are noun, verb, adjective, adverb, determiner, pronoun, preposition, conjunction, and interjection.
3. In computing, a word is a single unit of measurement that is assumed to be a 16-bits in length value. However, it can be any set value, common word size values included: 16, 18, 24, 32, 36, 40, 48, and 64.
Bit, Buzzword, Character, Computer abbreviations, Desktop publishing, Double Word, Editor, Google Docs, Software terms, Synonym, Typography terms, Word count, WordPad, Word processor, Word processor terms, WOTD
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of wordsEdit
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choiceEdit
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architecturesEdit
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressingEdit
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of twoEdit
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size familiesEdit
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizesEdit
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See alsoEdit
- Integer (computer science)
NotesEdit
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is . This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign
ReferencesEdit
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
What is a word in computing?
In computer architecture, a word is a unit of data of a defined bit length that can be addressed and moved between storage and the computer processor. Usually, the defined bit length of a word is equivalent to the width of the computer’s data bus so that a word can be moved in a single operation from storage to a processor register. For any computer architecture with an 8-bit byte, the word size is some multiple of 8 bits. In IBM’s System/360 mainframe architecture, a word is 32 bits, or four contiguous 8-bit bytes. In Intel’s PC processor architecture, a word is 16 bits, or two contiguous 8-bit bytes.
In general, the longer the architected word length, the more the computer system processor can do in a single operation.
Word sizes in computer architectures
Some computer processor architectures support a half word, which is half the number of bits in a word, and a double word, which is two contiguous words. Intel’s processor architecture also supports a quad word, or two contiguous double words, and a double quad word, or two contiguous quad words. Figure 1 depicts examples of an 8-bit byte, 8-bit word and 16-bit double word.
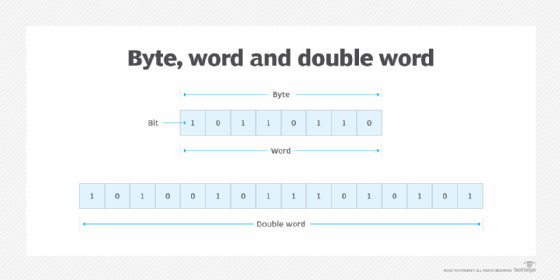
Functions of a computer word
A word can contain a computer instruction, a storage address or application data that is manipulated — for example, added to the data in another word space. In some architectures, a double word or larger unit is required to contain an instruction, address or application data. Typically, an instruction is a word in length, but some architectures support half word- and double word-length instructions.
A computer’s word size is typically a function of the computer’s design and how it moves data bits within the various system elements. For example, registers are important holders for various system functions, such as addressing, and the word size is likely to be the size accepted by the computer.
Here’s how words are used in a system:
- Fixed-point numbers. These are numerical values that typically include a standard word and can have different bit counts for various activities.
- Floating-point numbers. These are numerical values that have a minimum size of one word and can also have multiple word sizes using the basic word.
- Addresses. Used for memory, addresses can be a single word or multiples/fractions of that word.
- Registers. These are used to hold data in preparation for processing and can support data sizes ranging from standard words to fixed- and floating-point numbers, as well as other combinations.
- Memory-processor transfer. The movement of data from memory to central processing units (CPUs) typically uses registers that support the word size used by memory, usually a single word. However, depending on the system, variable word sizes may also be used.
- Instructions. Computing functions are executed using a variety of instructions that are typically formatted in the same size as the word used in the computer’s architecture.
Importance of word size
The word size is an important design decision that is made during the design phase of a computing system. It becomes the foundation upon which the computer’s capabilities are based. Once the word size has been decided, the architecture can be designed to accommodate multiple word sizes, such as double words, as part of the overall processing environment.
For example, Microsoft’s Windows operating system uses a 16-bit word as its foundation. Multiples of the 16-bit word size can be accommodated based on the type of Intel processor being used. An Intel x86 processor can support 32-bit or 64-bit words, which are then used to support Microsoft (and other vendor) applications (e.g., Word), various programming languages and application programming interfaces.
By contrast, traditional IBM mainframe platforms, such as System/360, System/370 and System/390, use 8-bit bytes, 16-bit half words, 32-bit words and 64-bit double words.
While they both execute some of the same computer tasks, their functions differ slightly. Learn how CPUs and microprocessors differ.
This was last updated in April 2023
Continue Reading About word (in computing)
- Server hardware guide to architecture, products and management
- Learn the difference between SMP vs. MPP
- Improvements in CPU features help shape selection
- NVMe key-value storage vs. block and object storage
What is a word? This question is one of the most deceptively simple ones I know. Everyone will say they know the answer, or at least say they know one when they see one, but even native speakers of a language can and do disagree. The dictionary isn’t much help since many dictionaries have multi-sentence, ad hoc definitions which basically boil down to «a word is a unit of language that means something, sort of.»
Let’s jump ahead and assume we know what a word is, or that we can get native speakers to identify most words most of the time. Furthermore, let’s say that our goal is to get a computer to understand a given language. Since humans learn languages initially by learning words and basic grammar it seems like a good choice to try and get computers to recognize words. So, our goal: given a string of English letters insert spaces between the words.
What is a word?
To show that the above exercise isn’t totally contrived let’s look at some of the subtleties in the idea of the word. This is only for people interested in the «linguistics» part of «computaitonal linguistics,» but if you want to read it then click here.
Assumptions
Obviously we can’t integrate all of the subtleties above as that would be tantamount to writing a computer program which actually processed text in the same way humans do. Rather, we will work under the following assumptions: first, we already have a database (called the «lexicon») of words; second, this database is complete. The first assumption isn’t totally off-the-wall since it’s a general working assumption among linguists that humans have just such a database. The second, however, is much harder to swallow since the lexicon is typically understood to contain root morphemes plus general information about the morphology, phonology, phonotactics, etc. of the language.
If I said «koop» were a verb, you’d know right away that «kooped,» «koops,» «kooper,» etc. were all also valid words. Likewise, even though «cromulent» is not actually an English word an English speaker knows that it could be (and that, furthermore, it would probably be an adjective), but that «plkdjfhg» could never be an English word. Our database, however, is very dumb and very uncompressed: every permutation of every word should be present, otherwise that permutation won’t be counted as a word. We’re only making this assumption to simplify the problem. I may be a pretty good programmer, but I’m not good enough to write a computer program which automatically learns a language’s syntax, morphology, and phonology.
Enough chit chat, let’s get to the code.
The Algorithm
The algorithm I’m going to use is a simple probabalistic dynamic programming algorithm. Let’s say we have a string like «therentisdue» and want to parse it as «the-rent-is-due.» Assuming our training data is representative of the language as a whole (a big assumption, for sure) then we know the probability of each word is #occurances of the word in the data over the total number of words in the data. The idea is that the best parse of a string, given our training data, is the parse which has the highest probability of occuring.
For the CS students out there this should scream «dynamic programming.» For everyone else, I’ll explain. The most obvious way to find the parse with the highest probability is to find every possible parse and then find that parse which has the highest probability. Implementing the algorithm this way is intractable since there are 2n-1 parses (why?). Instead we’ll do the following. The pseudo code:
BestParse[0] := "" FOR i in [1..length of StringToParse] DO FOR j in [0..i) DO parse := BestParse[j] + StringToParse[j,i] IF COST(parse) < COST(BestParse[i]) THEN BestParse[i] = parse ENDIF ENDFOR ENDFOR DEFINE COST(parse) return -LOG2(PROBABILITY(parse)) END DEFINE PROBABILITY(parse) return product of the frequencies of each word in parse END
Let the input string be s. At each point i, that is, for the initial i-length substring of s, determine what the best parse up to i is. Now, let’s say we know what the best parse at i is for some fixed i. To find the best parse at i+1 we try to insert a break after each initial j substring, for j < i+1. Since we’ve been keeping track of the best parse (and cost) at each such j the whole time, we just see which break insertion is the cheapest.
Here is an illustration, again with «therentisdue.» Let’s say we have «therenti» parsed so far. This means we know the best parse for each initial substring of this string, e.g., «t», «th», «the», etc. The best parse will probably be «the-rent-i» since each of these is a word and every other parse contains at least one non-word. Now let’s see how the algorithm determines the best parse of «therentis» from this.
After each character in the string we need to decide whether or not to insert a break. Should we insert a space after the first character? Well, yes, since the best parse of a single character is definitely that character. So at the first step we get «t-|herentis.» If we’re favoring single letters over non-words (it’s our choice to make) then the best parse after the second character would be «t-h-|erentis.» After the third, however, the parse is «the-|rentis» since «the» is a word and therefore the best parse of the first three letters is «the» (we know this because, by assumption, we have already computed the best parse for «the»). Next we get «the-r-|entis,» followed by «the-re-|ntis,» and so on, until we get to «the-ren-|tis.» After this step we try «the-rent-|is.» This is a very good parse since we have three words. Finally, we try «the-rent-i-|s,» which has a lower probability than the previous parse because «s» is not a word. Therefore «the-rent-is» is the parse which we save as the best parse of «therentis.»
I implemented this algorithm using C++, which you can download here. By default it uses the KJV Bible as training data, which means what it considers words can be a little funny. For example, «sin» is considered a very common word.