
From Wikipedia, the free encyclopedia
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of words[edit]
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choice[edit]
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architectures[edit]
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressing[edit]
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of two[edit]
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size families[edit]
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizes[edit]
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See also[edit]
- Integer (computer science)
Notes[edit]
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is
 . This gives an equivalent of about 9.51 bits for 6 trits.
. This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign

References[edit]
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
What is a word in computing?
In computer architecture, a word is a unit of data of a defined bit length that can be addressed and moved between storage and the computer processor. Usually, the defined bit length of a word is equivalent to the width of the computer’s data bus so that a word can be moved in a single operation from storage to a processor register. For any computer architecture with an 8-bit byte, the word size is some multiple of 8 bits. In IBM’s System/360 mainframe architecture, a word is 32 bits, or four contiguous 8-bit bytes. In Intel’s PC processor architecture, a word is 16 bits, or two contiguous 8-bit bytes.
In general, the longer the architected word length, the more the computer system processor can do in a single operation.
Word sizes in computer architectures
Some computer processor architectures support a half word, which is half the number of bits in a word, and a double word, which is two contiguous words. Intel’s processor architecture also supports a quad word, or two contiguous double words, and a double quad word, or two contiguous quad words. Figure 1 depicts examples of an 8-bit byte, 8-bit word and 16-bit double word.
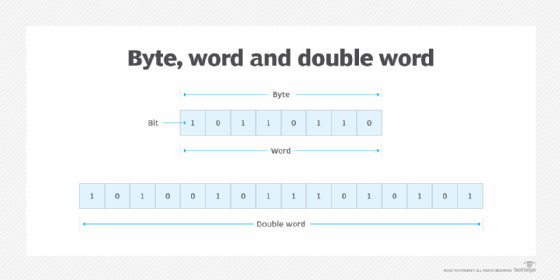
Functions of a computer word
A word can contain a computer instruction, a storage address or application data that is manipulated — for example, added to the data in another word space. In some architectures, a double word or larger unit is required to contain an instruction, address or application data. Typically, an instruction is a word in length, but some architectures support half word- and double word-length instructions.
A computer’s word size is typically a function of the computer’s design and how it moves data bits within the various system elements. For example, registers are important holders for various system functions, such as addressing, and the word size is likely to be the size accepted by the computer.
Here’s how words are used in a system:
- Fixed-point numbers. These are numerical values that typically include a standard word and can have different bit counts for various activities.
- Floating-point numbers. These are numerical values that have a minimum size of one word and can also have multiple word sizes using the basic word.
- Addresses. Used for memory, addresses can be a single word or multiples/fractions of that word.
- Registers. These are used to hold data in preparation for processing and can support data sizes ranging from standard words to fixed- and floating-point numbers, as well as other combinations.
- Memory-processor transfer. The movement of data from memory to central processing units (CPUs) typically uses registers that support the word size used by memory, usually a single word. However, depending on the system, variable word sizes may also be used.
- Instructions. Computing functions are executed using a variety of instructions that are typically formatted in the same size as the word used in the computer’s architecture.
Importance of word size
The word size is an important design decision that is made during the design phase of a computing system. It becomes the foundation upon which the computer’s capabilities are based. Once the word size has been decided, the architecture can be designed to accommodate multiple word sizes, such as double words, as part of the overall processing environment.
For example, Microsoft’s Windows operating system uses a 16-bit word as its foundation. Multiples of the 16-bit word size can be accommodated based on the type of Intel processor being used. An Intel x86 processor can support 32-bit or 64-bit words, which are then used to support Microsoft (and other vendor) applications (e.g., Word), various programming languages and application programming interfaces.
By contrast, traditional IBM mainframe platforms, such as System/360, System/370 and System/390, use 8-bit bytes, 16-bit half words, 32-bit words and 64-bit double words.
While they both execute some of the same computer tasks, their functions differ slightly. Learn how CPUs and microprocessors differ.
This was last updated in April 2023
Continue Reading About word (in computing)
- Server hardware guide to architecture, products and management
- Learn the difference between SMP vs. MPP
- Improvements in CPU features help shape selection
- NVMe key-value storage vs. block and object storage
Базовый блок памяти, обрабатываемый компьютером
В вычислениях, слово — это естественная единица данных, используемая конкретной конструкцией процессора . Слово — это фрагмент данных фиксированного размера, обрабатываемый как единица набором команд или аппаратными средствами процессора. Количество бит в слове (размер слова, ширина слова или длина слова) является важной характеристикой любой конкретной конструкции процессора или компьютерной архитектуры.
Размер слова отражается во многих аспектах устройства и работы компьютера; большинство регистров в процессоре обычно имеют размер слова, и самый большой фрагмент данных, который может быть передан в и из рабочей памяти за одну операцию, — это слово из многих ( не все) архитектуры. Наибольший возможный размер адреса, используемый для обозначения места в памяти, обычно является аппаратным словом (здесь «аппаратное слово» означает полноразмерное естественное слово процессора, в отличие от любого другого используемого определения).
Некоторые из самых ранних компьютеров (а также несколько современных) использовали двоично-десятичное, а не обычное двоичное, обычно с размером слова 10 или 12 десятичные цифры, а некоторые ранние десятичные компьютеры вообще не имели фиксированной длины слова. Ранние двоичные системы имели тенденцию использовать длину слова, несколько кратную 6-битному, причем 36-битное слово было особенно распространено на мэйнфреймах компьютерах. Введение ASCII привело к переходу к системам с длиной слова, кратной 8-битной, с 16-битными машинами, которые были популярны в 1970-х годах до перехода на современные процессоры с 32 или 64 битами. Конструкции специального назначения, такие как процессоры цифровых сигналов, могут иметь любую длину слова от 4 до 80 бит.
Размер слова иногда может отличаться от ожидаемого из-за обратной совместимости с более ранними компьютерами. Если несколько совместимых вариантов или семейство процессоров имеют общую архитектуру и набор инструкций, но различаются размером слов, их документация и программное обеспечение могут стать сложными в системе обозначений, чтобы учесть разницу (см. Семейства размеров ниже).
Содержание
- 1 Использование слов
- 2 Выбор размера слова
- 2.1 Архитектура переменных слов
- 2.2 Адресация слов и байтов
- 2.3 Степени двух
- 3 Семейство размеров
- 4 Таблица размеров слов
- 5 См. Также
- 6 Ссылки
Использование слов
В зависимости от того, как устроен компьютер, единицы размера слова могут использоваться для:
- Фиксированной точки числа
- Держатели для фиксированной точки, обычно целого числа, числовые значения могут быть доступны в одном или нескольких разных размерах, но один из доступных размеров почти всегда будет слово. Другие размеры, если таковые имеются, скорее всего, будут кратны или дроби размера слова. Меньшие размеры обычно используются только для эффективного использования памяти; при загрузке в процессор их значения обычно попадают в более крупный держатель размером с слово.
- Числа с плавающей запятой
- Держатели для числовых значений с плавающей запятой обычно либо слово или кратное слово.
- Адреса
- Держатели для адресов памяти должны иметь размер, способный выражать необходимый диапазон значений, но не быть чрезмерно большим, поэтому часто используемый размер слово, хотя оно также может быть кратным или дробной части размера слова.
- Регистры
- Регистры процессора имеют размер, соответствующий типу данных, которые они хранят, например целые числа, числа с плавающей запятой или адреса. Многие компьютерные архитектуры используют регистры общего назначения, которые могут хранить данные в нескольких представлениях.
- Передача памяти и процессора
- Когда процессор считывает данные из подсистемы памяти в зарегистрировать или записать значение регистра в память, объем передаваемых данных часто выражается словом. Исторически такое количество битов, которое могло быть передано за один цикл, в некоторых средах также называлось катеной (например, Bull GAMMA 60 [fr ]). В простых подсистемах памяти слово передается по шине данных памяти, которая обычно имеет ширину слова или полуслова. В подсистемах памяти, которые используют кеши, передача размером с слово — это передача между процессором и первым уровнем кеша; на более низких уровнях иерархии памяти обычно используются более крупные передачи (кратные размеру слова).
- Единица разрешения адреса
- В данной архитектуре, последовательные значения адреса обозначают последовательные единицы памяти; эта единица — единица разрешения адреса. На большинстве компьютеров единицей измерения является либо символ (например, байт), либо слово. (Некоторые компьютеры использовали битовое разрешение.) Если единицей измерения является слово, то можно получить доступ к большему объему памяти, используя адрес заданного размера за счет дополнительной сложности доступа к отдельным символам. С другой стороны, если единицей измерения является байт, то можно адресовать отдельные символы (т. Е. Выбирать во время операции с памятью).
- Инструкции
- Машинные команды обычно имеют размер слова архитектуры, например, в архитектурах RISC, или кратное размеру «char», составляющее его долю. Это естественный выбор, поскольку инструкции и данные обычно используют одну и ту же подсистему памяти. В гарвардской архитектуре размеры слов инструкций и данных не должны быть связаны, поскольку инструкции и данные хранятся в разных запоминающих устройствах; например, процессор в электронном телефонном коммутаторе 1ESS имел 37-битные инструкции и 23-битные слова данных.
Выбор размера слова
При проектировании компьютерной архитектуры выбор размер слова имеет существенное значение. Существуют конструктивные соображения, которые поощряют определенные размеры битовых групп для конкретных целей (например, для адресов), и эти соображения указывают на разные размеры для разных целей. Однако соображения экономии при проектировании настоятельно требуют использования одного размера или очень небольшого числа размеров, связанных кратными или дробными (частичными) размерами с основным размером. Этот предпочтительный размер становится размером слова архитектуры.
Размер символа был в прошлом (кодировка символов с предварительной переменной размером ) одно из влияний на единицу разрешения адреса и выбор размера слова. До середины 1960-х символы чаще всего хранились в шести битах; это позволяло использовать не более 64 символов, поэтому алфавит был ограничен прописными буквами. Поскольку во времени и пространстве эффективно иметь размер слова, кратный размеру символа, размеры слова в этот период обычно были кратны 6 битам (в двоичных машинах). Тогда обычным выбором было 36-битное слово, которое также является хорошим размером для числовых свойств формата с плавающей запятой.
После внедрения дизайна IBM System / 360, в котором использовались восьмибитные символы и поддерживались строчные буквы, стандартный размер символа (или более точно, байт ) стал восемью битами. После этого размер слов, естественно, был кратен восьми битам, причем обычно использовались 16, 32 и 64 бит.
Архитектуры с переменной длиной слова
Ранние разработки машин включали некоторые, в которых использовалось то, что часто называют переменной длиной слова. В этом типе организации числовой операнд не имеет фиксированной длины, а его конец обнаруживается при обнаружении символа со специальной маркировкой, часто называемой словесным знаком. Такие машины часто использовали десятичные дроби с двоичным кодом для чисел. К этому классу машин относились IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401 и IBM 1620.
Большинство этих машин работают с одной единицей памяти за раз, и поскольку каждая инструкция или данные имеют длину в несколько единиц, каждая инструкция занимает несколько циклов только для доступ к памяти. Из-за этого эти машины часто довольно медленные. Например, выборка инструкций в IBM 1620 Model I занимает 8 циклов только для чтения 12 цифр инструкции (Model II сократила это до 6 циклов или 4 циклов, если инструкция не нуждалась в обоих адресных полях). Выполнение инструкции занимало совершенно разное количество циклов в зависимости от размера операндов.
Адресация слов и байтов
Модель памяти в архитектуре сильно зависит от размера слова. В частности, в качестве слова часто выбирается разрешение адреса памяти, то есть наименьшая единица, которая может быть обозначена адресом. В этом подходе используется машина с адресацией по словам, значения адресов, которые отличаются на единицу, обозначают соседние слова памяти. Это естественно для машин, которые почти всегда работают с единицами слова (или нескольких слов), и имеет то преимущество, что позволяет командам использовать поля минимального размера для хранения адресов, что позволяет использовать меньший размер команды или большее разнообразие инструкций.
Когда обработка байтов должна составлять значительную часть рабочей нагрузки, обычно более выгодно использовать байт, а не слово в качестве единицы разрешения адреса. Значения адресов, которые отличаются на единицу, обозначают соседние байты в памяти. Это позволяет напрямую обращаться к произвольному символу в строке символов. Слово все еще может быть адресовано, но используемый адрес требует на несколько бит больше, чем альтернатива разрешения слова. Размер слова должен быть целым числом, кратным размеру символа в этой организации. Такой подход к адресации использовался в IBM 360 и с тех пор является наиболее распространенным подходом в машинах, разработанных.
В машине с побайтовой ориентацией (с байтовой адресацией ) перемещение одного байта из одного произвольного местоположения в другое обычно:
- ЗАГРУЗИТЬ исходный байт
- СОХРАНИТЕ результат обратно в целевой байт
. К отдельным байтам можно получить доступ на машине, ориентированной на слова, одним из двух способов. Байтами можно манипулировать с помощью комбинации операций сдвига и маски в регистрах. Для перемещения одного байта из одного произвольного места в другое может потребоваться эквивалент следующего:
- ЗАГРУЗИТЬ слово, содержащее исходный байт
- SHIFT исходное слово, чтобы выровнять желаемый байт с правильной позицией в целевом объекте слово
- И исходное слово с маской для обнуления всех битов, кроме желаемых
- ЗАГРУЗИТЬ слово, содержащее целевой байт
- И целевое слово с маской до нуля из целевого байта
- OR регистры, содержащие исходное и целевое слова, чтобы вставить исходный байт
- СОХРАНИТЬ результат обратно в целевое местоположение
В качестве альтернативы многие машины, ориентированные на слова, реализуют байтовые операции с инструкциями, используя специальные байтовые указатели в регистрах или в памяти. Например, указатель байта PDP-10 содержал размер байта в битах (позволяющий получить доступ к байтам разного размера), битовую позицию байта в слове и адрес слова данные. Инструкции могут автоматически настраивать указатель на следующий байт, например, при операциях загрузки и депонирования (сохранения).
Степени двух
Разные объемы памяти используются для хранения значений данных с разной степенью точности. Обычно используемые размеры — это степень двух, кратных единице разрешения адреса (байту или слову). Преобразование индекса элемента в массиве в адрес элемента требует только операции shift, а не умножения. В некоторых случаях эта связь позволяет избежать использования операций деления. В результате большинство современных компьютерных разработок имеют размеры слова (и другие размеры операндов), которые в два раза превышают размер байта.
Семейства размеров
По мере того, как компьютерные конструкции становились все более сложными, центральное значение размера одного слова для архитектуры уменьшалось. Хотя более мощное оборудование может использовать более широкий спектр размеров данных, рыночные силы оказывают давление на поддержание обратной совместимости при одновременном расширении возможностей процессора. В результате то, что могло быть центральным размером слова в новом дизайне, должно сосуществовать в качестве альтернативного размера к исходному размеру слова в обратно совместимом дизайне. Исходный размер слова остается доступным в будущих проектах, формируя основу семейства размеров.
В середине 1970-х годов DEC разработал VAX как 32-битный преемник 16-битного PDP-11. Они использовали слово для 16-битной величины, а длинное слово — для 32-битной величины. Это отличалось от более ранних машин, где естественная единица адресации памяти называлась словом, а величина, равная половине слова, называлась полусловом. В соответствии с этой схемой квадраслово VAX составляет 64 бита. Они продолжили эту терминологию слова / длинного слова / четверного слова с 64-битным Alpha.
Другим примером является семейство x86, в котором процессоры трех разных длин слов (16-бит, позже 32- и 64-бит), а слово продолжает обозначать 16-битное количество. Поскольку программное обеспечение обычно переносится с одного слова на другое, некоторые API и документация определяют или ссылаются на более старую (и, следовательно, более короткую) длину слова, чем полная длина слова на ЦП, для которого может быть скомпилировано программное обеспечение. Кроме того, аналогично тому, как байты используются для небольших чисел во многих программах, более короткое слово (16 или 32 бита) может использоваться в контекстах, где диапазон более широкого слова не требуется (особенно когда это может сэкономить значительное пространство стека или кеш пространство памяти). Например, Microsoft Windows API поддерживает определение WORD в языке программирования как 16-битное, несмотря на то, что API может использоваться на 32- или 64-битном процессоре x86, где стандартный размер слова будет 32 или 64 бита соответственно. Структуры данных, содержащие слова разного размера, называют их СЛОВО (16 бит / 2 байта), DWORD (32 бита / 4 байта) и QWORD (64 бит / 8 байтов) соответственно. Похожее явление развилось в языке ассемблера Intel x86 — из-за поддержки различных размеров (и обратной совместимости) в наборе команд некоторые мнемоники команд содержат «d» или «q». «идентификаторы, обозначающие« двойное »,« четверное »или« двойное четверное », которые соответствуют исходному 16-разрядному размеру слова архитектуры.
В общем, новые процессоры должны использовать ту же длину слова данных и ширину виртуального адреса, что и старый процессор, чтобы иметь двоичную совместимость с этим старым процессором.
Часто тщательно написанный исходный код — написанный с учетом совместимости исходного кода и переносимости программного обеспечения — может быть перекомпилирован для работы на различных процессорах, даже с разными длины слова данных или разная ширина адреса или и то, и другое.
Таблица размеров слов
| ключ: бит: биты, d: десятичные цифры, w: размер слова архитектуры, n: переменный размер | |||||||
|---|---|---|---|---|---|---|---|
| Год | Компьютер. архитектура | Размер слова | Целочисленный. размер | Размер с плавающей запятой. размер | Инструкция. размеры | Единица адреса. разрешение | Размер символа |
| 1837 | Бэббидж. Аналитическая машина | 50 d | w | — | Пять разных карт были используется для различных функций, точный размер карт неизвестен. | w | — |
| 1941 | Цузе Z3 | 22 бита | — | w | 8 бит | w | — |
| 1942 | ABC | 50 бит | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 бит | — | — |
| 1946. (1948). {1953} | ENIAC. (с панелью №16). {с панелью №26} | 10 d | w, 2w. (w). {w} | — | —. (2 d, 4 d, 6 d, 8 d). {2 d, 4 d, 6 d, 8 d} | —. —. {w} | — |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | ⁄2w | w | 1 d |
| 1952 | Машина IAS | 40 бит | w | — | ⁄2w | w | 5 бит |
| 1952 | Быстрый универсальный цифровой компьютер M-2 | 34 бит | w? | w | 34 бита = 4-битный код операции плюс 3 × 10-битный адрес | 10 бит | — |
| 1952 | IBM 701 | 36 бит | ⁄2w, w | — | ⁄2w | ⁄2w, w | 6 бит |
| 1952 | UNIVAC 60 | nd | 1 d,… 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 бит | w | — | w | w | 5 бит |
| 1953 | IBM 702 | nd | 0 d,… 511 d | — | 5 d | d | 1 d |
| 1953 | UNIVAC 120 | nd | 1 d,… 10 d | — | — | — | 2 d, 3 d |
| 1953 | 30 бит | w | 2w | ⁄2w | w | 5 бит | |
| 1954. (1955) | IBM 650. (w / IBM 653 ) | 10 d | w | —. (w) | w | w | 2 d |
| 1954 | IBM 704 | 36 бит | w | w | w | w | 6 бит |
| 1954 | IBM 705 | nd | 0 d,… 255 d | — | 5 d | d | 1 d |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | nd | 1 d,… 100 d | — | 10 d | d | 1 d |
| 1956 | 34 бит | w | w | ⁄2w | w | 5 бит, 6 бит | |
| 1957 | 40 бит | w, 79 бит, 8 d, 15 d | — | ⁄2w | ⁄2w, w | 5 бит | |
| 1958 | UNIVAC II | 12 d | w | — | ⁄2w | w | 1 d |
| 1958 | SAGE | 32 бит | ⁄2w | — | w | w | 6 бит |
| 1958 | Autonetics Recomp II | 40 бит | w, 79 бит, 8 d, 15 d | 2w | ⁄2w | ⁄2w, w | 5 бит |
| 1958 | Setun | 6 trit (~ 9,5 бит) | до 6 tryte | до 3 tryte | 4 trit | ||
| 1958 | Electrologica X1 | 27 бит | w | 2w | w | w | 5 бит, 6 бит |
| 1959 | IBM 1401 | nd | 1 d,… | — | 1 d, 2 d, 4 d, 5 d, 7 d, 8 d | d | 1 d |
| 1959. (TBD) | IBM 1620 | nd | 2 d,… | —. (4 d,… 102 d) | 12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 бит | w | w | ⁄2w | w | 6 бит |
| 1960 | IBM 1410 | nd | 1 d,… | — | 1 d, 2 d, 6 d, 7 d, 11 d, 12 d | d | 1 d |
| 1960 | IBM 7070 | 10 d | w | w | w | w, d | 2 d |
| 1960 | PDP -1 | 18 бит | w | — | w | w | 6 бит |
| 1960 | Elliott 803 | 39 бит | |||||
| 1961 | IBM 7030. (Stretch) | 64 бит | 1 бит,… 64 бит,. 1 d,… 16 d | w | ⁄2w, w | b, ⁄ 2 w, w | 1 бит,… 8 бит |
| 1961 | IBM 7080 | nd | 0 d,… 255 d | — | 5 d | d | 1 д |
| 1962 | GE-6xx | 36 бит | w, 2 w | w, 2 w, 80 бит | w | w | 6 бит, 9 бит |
| 1962 | UNIVAC III | 25 бит | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 бит |
| 1962 | Autonetics D-17B. Minuteman I Компьютер навигации | 27 бит | 11 бит, 24 бит | — | 24 бит | w | — |
| 1962 | UNIVAC 1107 | 36 бит | ⁄6w, ⁄ 3 w, ⁄ 2 w, w | w | w | w | 6 бит |
| 1962 | IBM 7010 | nd | 1 d,… | — | 1 d, 2 d, 6 d, 7 d, 11 d, 12 d | d | 1 d |
| 1962 | IBM 7094 | 36 бит | w | w, 2w | w | w | 6 бит |
| 1962 | SDS 9 Series | 24 бит | w | 2w | w | w | |
| 1963. (1966) | Компьютер управления Apollo | 15 бит | w | — | w, 2w | w | — |
| 1963 | Цифровой компьютер ракеты-носителя Saturn | 26 бит | w | — | 13 бит | w | — |
| 1964/1966 | PDP-6 / PDP-10 | 36 бит | w | w, 2 w | w | w | 6 бит, 9 бит (типовое значение) |
| 1964 | Titan | 48 бит | w | w | w | w | w |
| 1964 | CDC 6600 | 60 бит | w | w | ⁄4w, ⁄ 2w | w | 6 бит |
| 1964 | Autonetics D-37C. Minuteman II Компьютер навигации | 27 бит | 11 бит, 24 бит | — | 24 бит | w | 4 бит, 5 бит |
| 1965 | Компьютер навигации Gemini | 39 бит | 26 бит | — | 13 бит | 13 бит, 26 | — бит |
| 1965 | IBM 360 | 32 бит | ⁄2w, w,. 1 d,… 16 d | w, 2w | ⁄2w, w, 1 ⁄ 2w | 8 бит | 8 бит |
| 1965 | UNIVAC 1108 | 36 бит | ⁄6w, ⁄ 4 w, ⁄ 3 w, ⁄ 2 w, w, 2w | w, 2w | w | w | 6 бит, 9 бит |
| 1965 | PDP-8 | 12 бит | w | — | w | w | 8 бит |
| 1965 | Electrologica X8 | 27 бит | w | 2w | w | w | 6 бит, 7 бит |
| 1966 | SDS Sigma 7 | 32 бит | ⁄2w, w | w, 2w | w | 8 бит | 8 бит |
| 1969 | Четырехфазные системы AL1 | 8 бит | w | — | ? | ? | ? |
| 1970 | MP944 | 20 бит | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 бит | w | 2w, 4w | w, 2w, 3w | 8 бит | 8 бит |
| 1971 | TMS1802NC | 4 бит | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 бит | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 бит | w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1972 | 9 бит | w | — | w, 2w | w | 8 бит | |
| 1974 | Intel 8080 | 8 бит | w, 2w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1975 | ILLIAC IV | 64 бит | w | w, ⁄ 2w | w | w | — |
| 1975 | Motorola 6800 | 8 бит | w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1975 | MOS Tech. 6501. MOS Tech. 6502 | 8 бит | w, 2 d | — | w, 2w, 3w | w | 8 бит |
| 1976 | Cray-1 | 64 бит | 24 бита, w | w | ⁄4w, ⁄ 2w | w | 8 бит |
| 1976 | Zilog Z80 | 8 бит | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 бит |
| 1978. (1980) | 16-бит x86 (Intel 8086 ). (w / с плавающей точкой: Intel 8087 ) | 16 бит | ⁄2w, w, 2 d | —. (2w, 4w, 5w, 17 d) | ⁄2w, w,… 7w | 8 бит | 8 бит |
| 1978 | VAX | 32 бит | ⁄4w, ⁄ 2 w, w, 1 d,… 31 d, 1 бит,… 32 бит | w, 2w | ⁄4w,… 14 ⁄ 4w | 8 бит | 8 бит |
| 1979. (1984) | Motorola 68000 series. (с плавающей запятой) | 32-бит | ⁄4w, ⁄ 2 w, w, 2 d | —. (w, 2w, 2 ⁄ 2 w) | ⁄2w, w,… 7 ⁄ 2w | 8 бит | 8 бит |
| 1985 | IA-32 (Intel 80386 ) (с плавающей запятой) | 32-битный | ⁄4w, ⁄ 2 w, w | —. (w, 2w, 80 бит) | 8 бит,… 120 бит. ⁄4w… 3 ⁄ 4w | 8 бит | 8 бит |
| 1985 | ARMv1 | 32-битный | ⁄4w, w | — | w | 8-битный | 8 бит |
| 1985 | MIPS | 32 бит | ⁄4w, ⁄ 2 w, w | w, 2w | w | 8 бит | 8 бит |
| 1991 | Cray C90 | 64 бит | 32 бит, w | w | ⁄4w, ⁄ 2 w, 48 бит | w | 8 бит |
| 1992 | Alpha | 64 бит | 8 бит, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w | ⁄2w | 8 бит | 8 бит |
| 1992 | PowerPC | 32 бит | ⁄4w, ⁄ 2 w, w | w, 2w | w | 8 бит | 8 бит |
| 1996 | ARMv4. (w / Thumb ) | 32 bit | ⁄4w, ⁄ 2 w, w | — | w. (⁄ 2 w, w) | 8 бит | 8 бит |
| 2000 | IBM z / Architecture. (с векторной функцией) | 64-битная | ⁄4w, ⁄ 2 w, w. 1 d,… 31 d | ⁄2w, w, 2w | ⁄4w, ⁄ 2 w, ⁄ 4w | 8 бит | 8 бит, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 бит | 8 бит, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w | 41 бит | 8 бит | 8 бит |
| 2001 | ARMv6. (w / VFP) | 32 бит | 8 бит, ⁄ 2 w, w | —. (w, 2w) | ⁄2w, w | 8 бит | 8 бит |
| 2003 | x86-64 | 64-битный | 8-битный, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w, 80 бит | 8 бит,… 120 бит | 8 бит | 8 бит |
| 2013 | ARMv8-A | 64 бит | 8 бит, ⁄ 4 w, ⁄ 2 w, w | ⁄2w, w | ⁄2w | 8 бит | 8 бит |
| Год | Компьютер. архитектура | Размер слова | Целочисленный. размер | Размер с плавающей запятой. размер | Инструкция. размеры | Единица адреса. разрешение | Размер символа |
| ключ: бит: биты, d: десятичные цифры, w: размер слова архитектуры, n: переменный размер |
См. Также
- Целое число (информатика)
Ссылки
| Processors | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-bit | 4-bit | 8-bit | 12-bit | 16-bit | 18-bit | 24-bit | 31-bit | 32-bit | 36-bit | 48-bit | 60-bit | 64-bit | 128-bit |
| Applications | |||||||||||||
| 8-bit | 16-bit | 32-bit | 64-bit | ||||||||||
| Data Sizes | |||||||||||||
| bit nibble octet byte | |||||||||||||
| halfword word dword qword | |||||||||||||
| IEEE floating-point standard | |||||||||||||
| Single precision floating-point format (32-bit) Double precision floating-point format (64-bit) Quadruple precision floating-point format (128-bit) |
In computing, word is a term for the natural unit of data used by a particular processor design. A word is basically a fixed sized group of bits that are handled as a unit by the instruction set and/or hardware of the processor. The number of bits in a word (the word size, word width, or word length) is an important characteristic of a specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word sized and the largest piece of data that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (in other words, the full-sized natural word of the processor, as opposed to any other definition used).
Modern processors, including embedded systems, usually have a word size of 8, 16, 24, 32 or 64 bits, while modern general purpose computers usually use 32 or 64 bits. Special purpose digital processors, such as DSPs for instance, may use other sizes and many different sizes have been used historically, including 8, 9, 12, 18, 24, 36, 39, 40, 48 and 60 bits. The slab is an example of a system with an earlier word size. Several of the earliest computers (and a few modern as well) used BCD rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers had no fixed word length at all.
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Contents
- 1 Uses of words
- 2 Word size choice
- 2.1 Variable word architectures
- 2.2 Word and byte addressing
- 2.3 The power of two
- 3 Size families
- 4 Table of word sizes
- 5 See also
- 6 References
Uses of words
Depending on how a computer is organized, units of the word size may be used for:
- Integer numbers: Holders for integer numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating point numbers: Holders for floating point numerical values are typically either a word or a multiple of a word.
- Addresses: Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers: Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating point numbers or addresses. Many computer architectures use «general purpose» registers that can hold any of several types of data, these registers must be sized to hold the largest of the types, historically this is the word size of the architecture though increasingly special purpose, larger, registers have been added to deal with newer types.
- Memory-processor transfer: When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution: In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions: Machine instructions are normally fractions or multiples of the architecture’s word size. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related.
Word size choice
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size is one of the influences on a choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so alphabetics were limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design which used eight-bit characters and supported lower-case letters, the standard size of a character (or more accurately, a byte) became eight bits. Word sizes thereafter were naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable word architectures
Early machine designs included some that used what is often termed a variable word length. In this type of organization, a numeric operand had no fixed length but rather its end was detected when a character with a special marking was encountered. Such machines often used binary coded decimal for numbers. This class of machines included the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, and IBM 1620.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution took a completely variable number of cycles, depending on the size of the operands.
Word and byte addressing
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally-sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integral multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
The power of two
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the address of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size families
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a successor of the PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word in not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as WORD, DWORD and QWORD respectively. A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
Table of word sizes
| key: b: bits, d: decimal digits, w: word size of architecture, n: variable size | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer Architecture |
Word Size w |
Integer Sizes |
Floating Point Sizes |
Instruction Sizes |
Unit of Address Resolution |
Char Size |
| 1837 | Babbage Analytical engine |
50 d | w | — | 5 different cards were used for different functions, exact size of cards not known | w | — |
| 1941 | Zuse Z3 | 22 b | — | w | 8 b | w | — |
| 1942 | ABC | 50 b | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 b | — | — |
| 1946 (1948) {1953} |
ENIAC (w/ Panel #16[1]) {w/ Panel #26[2]} |
10 d | w, 2w (w) {w} |
— | — (2d, 4d, 6d, 8d) {2d, 4d, 6d, 8d} |
— — {w} |
— |
| 1951 | UNIVAC I | 12 d | w | — | ½w | w | 1 d |
| 1952 | IAS machine | 40 b | w | — | ½w | w | 5 b |
| 1952 | Fast Universal Digital Computer M-2 | 34 b | w? | w | 34 b = 4 b opcode plus 3× 10b address | 10 b | — |
| 1952 | IBM 701 | 36 b | ½w, w | — | ½w | ½w, w | 6 b |
| 1952 | UNIVAC 60 | n d | 1d, … 10d | — | — | — | 2d, 3d |
| 1953 | IBM 702 | n d | 0d, … 511d | — | 5d | d | 1 d |
| 1953 | UNIVAC 120 | n d | 1d, … 10d | — | — | — | 2d, 3d |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 b | w | w | w | w | 6 b |
| 1954 | IBM 705 | n d | 0d, … 255d | — | 5d | d | 1 d |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1d, … 100d | — | 10d | d | 1 d |
| 1957 | Autonetics Recomp I | 40 b | w, 79 b, 8d, 15d | — | ½w | ½w, w | 5 b |
| 1958 | UNIVAC II | 12 d | w | — | ½w | w | 1 d |
| 1958 | SAGE | 32 b | ½w | — | w | w | 6 b |
| 1958 | Autonetics Recomp II | 40 b | w, 79 b, 8d, 15d | 2w | ½w | ½w, w | 5 b |
| 1959 | IBM 1401 | n d | 1d, … | — | d, 2d, 4d, 5d, 7d, 8d | d | 1 d |
| 1959 (TBD) |
IBM 1620 | n d | 2d, … | — (4d, … 102d) |
12d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 b | w | w | ½w | w | 6 b |
| 1960 | IBM 1410 | n d | 1d, … | — | d, 2d, 6d, 7d, 11d, 12d | d | 1 d |
| 1960 | IBM 7070 | 10 d | w | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 b | w | — | w | w | 6 b |
| 1961 | IBM 7030 (Stretch) |
64 b | 1b, … 64b, 1d, … 16d |
w | ½w, w | b, ½w, w | 1 b, … 8 b |
| 1961 | IBM 7080 | n d | 0d, … 255d | — | 5d | d | 1 d |
| 1962 | UNIVAC III | 25 b, 6 d | w, 2w, 3w, 4w | — | w | w | 6 b |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 b | 11 b, 24 b | — | 24 b | w | — |
| 1962 | UNIVAC 1107 | 36 b | 1/6w, ⅓w, ½w, w | w | w | w | 6 b |
| 1962 | IBM 7010 | n d | 1d, … | — | d, 2d, 6d, 7d, 11d, 12d | d | 1 d |
| 1962 | IBM 7094 | 36 b | w | w, 2w | w | w | 6 b |
| 1963 | Gemini Guidance Computer | 39 b | 26 b | — | 13 b | 13 b, 26 b | — |
| 1963 (1966) |
Apollo Guidance Computer | 15 b | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 b | w | — | 13 b | w | — |
| 1964 | CDC 6600 | 60 b | w | w | ¼w, ½w | w | 6 b |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 b | 11 b, 24 b | — | 24 b | w | 4 b, 5 b |
| 1965 | IBM 360 | 32 b | ½w, w, 1d, … 16d |
w, 2w | ½w, w, 1½w | 8 b | 8 b |
| 1965 | UNIVAC 1108 | 36 b | 1/6w, ¼w, ⅓w, ½w, w, 2w | w, 2w | w | w | 6 b, 9 b |
| 1965 | PDP-8 | 12 b | w | — | w | w | 8 b |
| 1970 | PDP-11 | 16 b | w | 2w, 4w | w, 2w, 3w | 8 b | 8 b |
| 1971 | Intel 4004 | 4 b | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 b | w, 2d | — | w, 2w, 3w | w | 8 b |
| 1972 | Calcomp 900 | 9 b | w | — | w, 2w | w | 8 b |
| 1974 | Intel 8080 | 8 b | w, 2w, 2d | — | w, 2w, 3w | w | 8 b |
| 1975 | ILLIAC IV | 64 b | w | w, ½w | w | w | — |
| 1975 | Motorola 6800 | 8 b | w, 2d | — | w, 2w, 3w | w | 8 b |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 b | w, 2d | — | w, 2w, 3w | w | 8 b |
| 1976 | Cray-1 | 64 b | 24 b, w | w | ¼w, ½w | w | 8 b |
| 1976 | Zilog Z80 | 8 b | w, 2w, 2d | — | w, 2w, 3w, 4w, 5w | w | 8 b |
| 1978 (1980) |
Intel 8086 (w/Intel 8087) |
16 b | ½w, w, 2d (w, 2w, 4w) |
— (2w, 4w, 5w, 17d) |
½w, w, … 7w | 8 b | 8 b |
| 1978 | VAX-11/780 | 32 b | ¼w, ½w, w, 1d, … 31d, 1b, … 32b | w, 2w | ¼w, … 14¼w | 8 b | 8 b |
| 1979 | Motorola 68000 | 32 b | ¼w, ½w, w, 2d | — | ½w, w, … 7½w | 8 b | 8 b |
| 1982 (1983) |
Motorola 68020 (w/Motorola 68881) |
32 b | ¼w, ½w, w, 2d | — (w, 2w, 2½w) |
½w, w, … 7½w | 8 b | 8 b |
| 1985 | Intel 80386 | 32 b | ½w, w, 2d w, 2w, 4w |
2w, 4w, 5w, 17d | ½w, w, … 7w | 8 b | 8 b |
| 1985 | ARM1 | 32 b | w | — | w | 8 b | 8 b |
| 1985 | MIPS | 32 b | ¼w, ½w, w | w, 2w | w | 8 b | 8 b |
| 1989 | Motorola 68040 | 32 b | ¼w, ½w, w, 2d | w, 2w, 2½w | ½w, w, … 7½w | 8 b | 8 b |
| 1991 | Alpha | 64 b | ¼w, ½w, w | w, 2w | ½w | 8 b | 8 b |
| 1991 | Cray C90 | 64 b | 32 b, w | w | ¼w, ½w, 48b | w | 8 b |
| 1991 | PowerPC | 32–64 b | ¼w, ½w, w | w, 2w | w | 8 b | 8 b |
| 2000 | IA-64 | 64 b | 8 b, ¼w, ½w, w | ½w, w | 41 b | 8 b | 8 b |
| 2002 | XScale | 32 b | w | w, 2w | ½w, w | 8 b | 8 b |
| key: b: bits, d: decimal digits, w: word size of architecture, n: variable size |
[3][4]
See also
- 32-bit
- 32-bit applications
- 64-bit
- 128-bit
- Integer
- Short integer
- Long integer
References
- ^ Computer History, Eniac coding, US: ARL, http://ftp.arl.mil/~mike/comphist/48eniac-coding/
- ^ «8», Computer History, Eniac coding, US: ARL, http://ftp.arl.mil/~mike/comphist/48eniac-coding/sec8.html
- ^ Gerrit A. Blaauw & Frederick P. Brooks (1997). Computer Architecture: Concepts and Evolution. Addison-Wesley. ISBN 0-201-10557-8.
- ^ Anthony Ralston & Edwin D. Reilly (1993). Encyclopedia of Computer Science Third Edition. Van Nostrand Reinhold. ISBN 0-442-27679-6.
| v · d · eData types | |
|---|---|
| Uninterpreted |
|
| Numeric |
|
| Text |
|
| Pointer |
|
| Composite |
|
| Other |
|
| Related topics |
|
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits. Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of words
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers: Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
Word size choice
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architectures
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressing
See main article: word addressing and byte addressing. The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[1] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of two
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size families
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code — written with source-code compatibility and software portability in mind — can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizes
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| data-sort-type=»number» | Year | Computer architecture |
data-sort-type=»number» | Word size w | data-sort-type=»number» | Integer sizes |
data-sort-type=»number» | Floatingpoint sizes |
data-sort-type=»number» | Instruction sizes |
Unit of address resolution |
data-sort-type=»number» | Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — | ||||||
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — | ||||||
| 1942 | ABC | 50 bit | w | — | — | — | — | ||||||
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — | ||||||
| 1946 (1948) |
ENIAC (w/Panel #16) |
10 d | w, 2w (w) |
— | — (2 d, 4 d, 6 d, 8 d) |
— — |
— | ||||||
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — | ||||||
| 1951 | UNIVAC I | 12 d | w | — | w | w | 1 d | ||||||
| 1952 | IAS machine | 40 bit | w | — | w | w | 5 bit | ||||||
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — | ||||||
| 1952 | IBM 701 | 36 bit | w, w | — | w | w, w | 6 bit | ||||||
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d | ||||||
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit | ||||||
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit | ||||||
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d | ||||||
| 1953 | ARRA II | 30 bit | w | 2w | w | w | 5 bit | ||||||
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d | ||||||
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit | ||||||
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit | ||||||
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — | ||||||
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d | ||||||
| 1956 | ARMAC | 34 bit | w | w | w | w | 5 bit, 6 bit | ||||||
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit | ||||||
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | w | w, w | 5 bit | ||||||
| 1958 | UNIVAC II | 12 d | w | — | w | w | 1 d | ||||||
| 1958 | SAGE | 32 bit | w | — | w | w | 6 bit | ||||||
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | w | w, w | 5 bit | ||||||
| 1958 | Setun | 6 trit (~9.5 bits) | up to 6 tryte | up to 3 trytes | 4 trit? | ||||||||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit | ||||||
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm | ||||||
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d | ||||||
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d | ||||||
| 1960 | CDC 1604 | 48 bit | w | w | w | w | 6 bit | ||||||
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm | ||||||
| 1960 | IBM 7070 | 10 d | w, 1-9 d | w | w | w, d | 2 d | ||||||
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit | ||||||
| 1960 | Elliott 803 | 39 bit | |||||||||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | w, w | bit (integer), w (branch), w (float) |
1 bit, … 8 bit | ||||||
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit | ||||||
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit | ||||||
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit | ||||||
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — | ||||||
| 1962 | UNIVAC 1107 | 36 bit | w, w, w, w | w | w | w | 6 bit | ||||||
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm | ||||||
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit | ||||||
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |||||||
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — | ||||||
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — | ||||||
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
||||||
| 1964 | Titan | 48 bit | w | w | w | w | w | ||||||
| 1964 | CDC 6600 | 60 bit | w | w | w, w | w | 6 bit | ||||||
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit | ||||||
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit | ||||||
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit | ||||||
| 1965 | IBM System/360 | 32 bit | w, w, 1 d, … 16 d |
w, 2w | w, w, 1w | 8 bit | 8 bit | ||||||
| 1965 | UNIVAC 1108 | 36 bit | w, w, w, w, w, 2w | w, 2w | w | w | 6 bit, 9 bit | ||||||
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit | ||||||
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit | ||||||
| 1966 | SDS Sigma 7 | 32 bit | w, w | w, 2w | w | 8 bit | 8 bit | ||||||
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? | ||||||
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? | ||||||
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit | ||||||
| 1971 | CDC STAR-100 | 64 bit | w, w | w, w | w, w | bit | 8 bit | ||||||
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — | ||||||
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — | ||||||
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit | ||||||
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit | ||||||
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit | ||||||
| 1975 | ILLIAC IV | 64 bit | w | w, w | w | w | — | ||||||
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit | ||||||
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit | ||||||
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | w, w | w | 8 bit | ||||||
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit | ||||||
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | w, w, 2 d | — (2w, 4w, 5w, 17 d) |
w, w, … 7w | 8 bit | 8 bit | ||||||
| 1978 | VAX | 32 bit | w, w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | w, … 14w | 8 bit | 8 bit | ||||||
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | w, w, w, 2 d | — (w, 2w, 2w) |
w, w, … 7w | 8 bit | 8 bit | ||||||
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | w, w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit w … 3w |
8 bit | 8 bit | ||||||
| 1985 | ARMv1 | 32 bit | w, w | — | w | 8 bit | 8 bit | ||||||
| 1985 | MIPS I | 32 bit | w, w, w | w, 2w | w | 8 bit | 8 bit | ||||||
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | w, w, 48 bit | w | 8 bit | ||||||
| 1992 | Alpha | 64 bit | 8 bit, w, w, w | w, w | w | 8 bit | 8 bit | ||||||
| 1992 | PowerPC | 32 bit | w, w, w | w, 2w | w | 8 bit | 8 bit | ||||||
| 1996 | ARMv4 (w/Thumb) |
32 bit | w, w, w | — | w (w, w) |
8 bit | 8 bit | ||||||
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | w, w, w 1 d, … 31 d |
w, w, 2w | w, w, w | 8 bit | 8 bit, UTF-16, UTF-32 | ||||||
| 2001 | IA-64 | 64 bit | 8 bit, w, w, w | w, w | 41 bit (in 128-bit bundles)[2] | 8 bit | 8 bit | ||||||
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, w, w | — (w, 2w) |
w, w | 8 bit | 8 bit | ||||||
| 2003 | x86-64 | 64 bit | 8 bit, w, w, w | w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit | ||||||
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, w, w, w | w, w | w | 8 bit | 8 bit | ||||||
| data-sort-type=»number» | Year | Computer architecture |
data-sort-type=»number» | Word size w | data-sort-type=»number» | Integer sizes |
data-sort-type=»number» | Floatingpoint sizes |
data-sort-type=»number» | Instruction sizes |
Unit of address resolution |
data-sort-type=»number» | Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
See also
- Integer (computer science)
Notes and References
- Reference Manual 7030 Data Processing System . August 1961 . Format . http://bitsavers.org/pdf/ibm/7030/22-6530-2_7030RefMan.pdf#page=59 . 50-57 . December 15, 2021 . IBM .
- Intel Itanium Architecture Software Developer’s Manual . 3: Intel Itanium Instruction Set Reference . 4. Instruction Formats . https://www.intel.com/content/dam/www/public/us/en/documents/manuals/itanium-architecture-vol-3-manual.pdf#page=302 . 3:293 . Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field. . April 25, 2022 .