
This article is about the unit of speech and writing. For the computer software, see Microsoft Word. For other uses, see Word (disambiguation).

Codex Claromontanus in Latin. The practice of separating words with spaces was not universal when this manuscript was written.
A word is a basic element of language that carries an objective or practical meaning, can be used on its own, and is uninterruptible.[1] Despite the fact that language speakers often have an intuitive grasp of what a word is, there is no consensus among linguists on its definition and numerous attempts to find specific criteria of the concept remain controversial.[2] Different standards have been proposed, depending on the theoretical background and descriptive context; these do not converge on a single definition.[3]: 13:618 Some specific definitions of the term «word» are employed to convey its different meanings at different levels of description, for example based on phonological, grammatical or orthographic basis. Others suggest that the concept is simply a convention used in everyday situations.[4]: 6
The concept of «word» is distinguished from that of a morpheme, which is the smallest unit of language that has a meaning, even if it cannot stand on its own.[1] Words are made out of at least one morpheme. Morphemes can also be joined to create other words in a process of morphological derivation.[2]: 768 In English and many other languages, the morphemes that make up a word generally include at least one root (such as «rock», «god», «type», «writ», «can», «not») and possibly some affixes («-s», «un-«, «-ly», «-ness»). Words with more than one root («[type][writ]er», «[cow][boy]s», «[tele][graph]ically») are called compound words. In turn, words are combined to form other elements of language, such as phrases («a red rock», «put up with»), clauses («I threw a rock»), and sentences («I threw a rock, but missed»).
In many languages, the notion of what constitutes a «word» may be learned as part of learning the writing system.[5] This is the case for the English language, and for most languages that are written with alphabets derived from the ancient Latin or Greek alphabets. In English orthography, the letter sequences «rock», «god», «write», «with», «the», and «not» are considered to be single-morpheme words, whereas «rocks», «ungodliness», «typewriter», and «cannot» are words composed of two or more morphemes («rock»+»s», «un»+»god»+»li»+»ness», «type»+»writ»+»er», and «can»+»not»).
Definitions and meanings
Since the beginning of the study of linguistics, numerous attempts at defining what a word is have been made, with many different criteria.[5] However, no satisfying definition has yet been found to apply to all languages and at all levels of linguistic analysis. It is, however, possible to find consistent definitions of «word» at different levels of description.[4]: 6 These include definitions on the phonetic and phonological level, that it is the smallest segment of sound that can be theoretically isolated by word accent and boundary markers; on the orthographic level as a segment indicated by blank spaces in writing or print; on the basis of morphology as the basic element of grammatical paradigms like inflection, different from word-forms; within semantics as the smallest and relatively independent carrier of meaning in a lexicon; and syntactically, as the smallest permutable and substitutable unit of a sentence.[2]: 1285
In some languages, these different types of words coincide and one can analyze, for example, a «phonological word» as essentially the same as «grammatical word». However, in other languages they may correspond to elements of different size.[4]: 1 Much of the difficulty stems from the eurocentric bias, as languages from outside of Europe may not follow the intuitions of European scholars. Some of the criteria for «word» developed can only be applicable to languages of broadly European synthetic structure.[4]: 1-3 Because of this unclear status, some linguists propose avoiding the term «word» altogether, instead focusing on better defined terms such as morphemes.[6]
Dictionaries categorize a language’s lexicon into individually listed forms called lemmas. These can be taken as an indication of what constitutes a «word» in the opinion of the writers of that language. This written form of a word constitutes a lexeme.[2]: 670-671 The most appropriate means of measuring the length of a word is by counting its syllables or morphemes.[7] When a word has multiple definitions or multiple senses, it may result in confusion in a debate or discussion.[8]
Phonology
One distinguishable meaning of the term «word» can be defined on phonological grounds. It is a unit larger or equal to a syllable, which can be distinguished based on segmental or prosodic features, or through its interactions with phonological rules. In Walmatjari, an Australian language, roots or suffixes may have only one syllable but a phonologic word must have at least two syllables. A disyllabic verb root may take a zero suffix, e.g. luwa-ø ‘hit!’, but a monosyllabic root must take a suffix, e.g. ya-nta ‘go!’, thus conforming to a segmental pattern of Walmatjari words. In the Pitjantjatjara dialect of the Wati language, another language form Australia, a word-medial syllable can end with a consonant but a word-final syllable must end with a vowel.[4]: 14
In most languages, stress may serve a criterion for a phonological word. In languages with a fixed stress, it is possible to ascertain word boundaries from its location. Although it is impossible to predict word boundaries from stress alone in languages with phonemic stress, there will be just one syllable with primary stress per word, which allows for determining the total number of words in an utterance.[4]: 16
Many phonological rules operate only within a phonological word or specifically across word boundaries. In Hungarian, dental consonants /d/, /t/, /l/ or /n/ assimilate to a following semi-vowel /j/, yielding the corresponding palatal sound, but only within one word. Conversely, external sandhi rules act across word boundaries. The prototypical example of this rule comes from Sanskrit; however, initial consonant mutation in contemporary Celtic languages or the linking r phenomenon in some non-rhotic English dialects can also be used to illustrate word boundaries.[4]: 17
It is often the case that a phonological word does not correspond to our intuitive conception of a word. The Finnish compound word pääkaupunki ‘capital’ is phonologically two words (pää ‘head’ and kaupunki ‘city’) because it does not conform to Finnish patterns of vowel harmony within words. Conversely, a single phonological word may be made up of more than one syntactical elements, such as in the English phrase I’ll come, where I’ll forms one phonological word.[3]: 13:618
Lexemes
A word can be thought of as an item in a speaker’s internal lexicon; this is called a lexeme. Nevertheless, it is considered different from a word used in everyday speech, since it is assumed to also include inflected forms. Therefore, the lexeme teapot refers to the singular teapot as well as the plural, teapots. There is also the question to what extent should inflected or compounded words be included in a lexeme, especially in agglutinative languages. For example, there is little doubt that in Turkish the lexeme for house should include nominative singular ev or plural evler. However, it is not clear if it should also encompass the word evlerinizden ‘from your houses’, formed through regular suffixation. There are also lexemes such as «black and white» or «do-it-yourself», which, although consist of multiple words, still form a single collocation with a set meaning.[3]: 13:618
Grammar
Grammatical words are proposed to consist of a number of grammatical elements which occur together (not in separate places within a clause) in a fixed order and have a set meaning. However, there are exceptions to all of these criteria.[4]: 19
Single grammatical words have a fixed internal structure; when the structure is changed, the meaning of the word also changes. In Dyirbal, which can use many derivational affixes with its nouns, there are the dual suffix -jarran and the suffix -gabun meaning «another». With the noun yibi they can be arranged into yibi-jarran-gabun («another two women») or yibi-gabun-jarran («two other women») but changing the suffix order also changes their meaning. Speakers of a language also usually associate a specific meaning with a word and not a single morpheme. For example, when asked to talk about untruthfulness they rarely focus on the meaning of morphemes such as -th or -ness.[4]: 19-20
Semantics
Leonard Bloomfield introduced the concept of «Minimal Free Forms» in 1928. Words are thought of as the smallest meaningful unit of speech that can stand by themselves.[9]: 11 This correlates phonemes (units of sound) to lexemes (units of meaning). However, some written words are not minimal free forms as they make no sense by themselves (for example, the and of).[10]: 77 Some semanticists have put forward a theory of so-called semantic primitives or semantic primes, indefinable words representing fundamental concepts that are intuitively meaningful. According to this theory, semantic primes serve as the basis for describing the meaning, without circularity, of other words and their associated conceptual denotations.[11][12]
Features
In the Minimalist school of theoretical syntax, words (also called lexical items in the literature) are construed as «bundles» of linguistic features that are united into a structure with form and meaning.[13]: 36–37 For example, the word «koalas» has semantic features (it denotes real-world objects, koalas), category features (it is a noun), number features (it is plural and must agree with verbs, pronouns, and demonstratives in its domain), phonological features (it is pronounced a certain way), etc.
Orthography

Words made out of letters, divided by spaces
In languages with a literary tradition, the question of what is considered a single word is influenced by orthography. Word separators, typically spaces and punctuation marks are common in modern orthography of languages using alphabetic scripts, but these are a relatively modern development in the history of writing. In character encoding, word segmentation depends on which characters are defined as word dividers. In English orthography, compound expressions may contain spaces. For example, ice cream, air raid shelter and get up each are generally considered to consist of more than one word (as each of the components are free forms, with the possible exception of get), and so is no one, but the similarly compounded someone and nobody are considered single words.
Sometimes, languages which are close grammatically will consider the same order of words in different ways. For example, reflexive verbs in the French infinitive are separate from their respective particle, e.g. se laver («to wash oneself»), whereas in Portuguese they are hyphenated, e.g. lavar-se, and in Spanish they are joined, e.g. lavarse.[a]
Not all languages delimit words expressly. Mandarin Chinese is a highly analytic language with few inflectional affixes, making it unnecessary to delimit words orthographically. However, there are many multiple-morpheme compounds in Mandarin, as well as a variety of bound morphemes that make it difficult to clearly determine what constitutes a word.[14]: 56 Japanese uses orthographic cues to delimit words, such as switching between kanji (characters borrowed from Chinese writing) and the two kana syllabaries. This is a fairly soft rule, because content words can also be written in hiragana for effect, though if done extensively spaces are typically added to maintain legibility. Vietnamese orthography, although using the Latin alphabet, delimits monosyllabic morphemes rather than words.
Word boundaries
The task of defining what constitutes a «word» involves determining where one word ends and another word begins, that is identifying word boundaries. There are several ways to determine where the word boundaries of spoken language should be placed:[5]
- Potential pause: A speaker is told to repeat a given sentence slowly, allowing for pauses. The speaker will tend to insert pauses at the word boundaries. However, this method is not foolproof: the speaker could easily break up polysyllabic words, or fail to separate two or more closely linked words (e.g. «to a» in «He went to a house»).
- Indivisibility: A speaker is told to say a sentence out loud, and then is told to say the sentence again with extra words added to it. Thus, I have lived in this village for ten years might become My family and I have lived in this little village for about ten or so years. These extra words will tend to be added in the word boundaries of the original sentence. However, some languages have infixes, which are put inside a word. Similarly, some have separable affixes: in the German sentence «Ich komme gut zu Hause an«, the verb ankommen is separated.
- Phonetic boundaries: Some languages have particular rules of pronunciation that make it easy to spot where a word boundary should be. For example, in a language that regularly stresses the last syllable of a word, a word boundary is likely to fall after each stressed syllable. Another example can be seen in a language that has vowel harmony (like Turkish):[15]: 9 the vowels within a given word share the same quality, so a word boundary is likely to occur whenever the vowel quality changes. Nevertheless, not all languages have such convenient phonetic rules, and even those that do present the occasional exceptions.
- Orthographic boundaries: Word separators, such as spaces and punctuation marks can be used to distinguish single words. However, this depends on a specific language. East-asian writing systems often do not separate their characters. This is the case with Chinese, Japanese writing, which use logographic characters, as well as Thai and Lao, which are abugidas.
Morphology
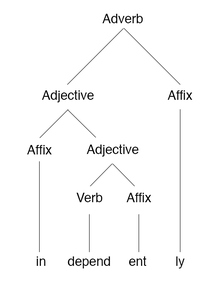
A morphology tree of the English word «independently»
Morphology is the study of word formation and structure. Words may undergo different morphological processes which are traditionally classified into two broad groups: derivation and inflection. Derivation is a process in which a new word is created from existing ones, often with a change of meaning. For example, in English the verb to convert may be modified into the noun a convert through stress shift and into the adjective convertible through affixation. Inflection adds grammatical information to a word, such as indicating case, tense, or gender.[14]: 73
In synthetic languages, a single word stem (for example, love) may inflect to have a number of different forms (for example, loves, loving, and loved). However, for some purposes these are not usually considered to be different words, but rather different forms of the same word. In these languages, words may be considered to be constructed from a number of morphemes.
In Indo-European languages in particular, the morphemes distinguished are:
- The root.
- Optional suffixes.
- A inflectional suffix.
Thus, the Proto-Indo-European *wr̥dhom would be analyzed as consisting of
- *wr̥-, the zero grade of the root *wer-.
- A root-extension *-dh- (diachronically a suffix), resulting in a complex root *wr̥dh-.
- The thematic suffix *-o-.
- The neuter gender nominative or accusative singular suffix *-m.
Philosophy
Philosophers have found words to be objects of fascination since at least the 5th century BC, with the foundation of the philosophy of language. Plato analyzed words in terms of their origins and the sounds making them up, concluding that there was some connection between sound and meaning, though words change a great deal over time. John Locke wrote that the use of words «is to be sensible marks of ideas», though they are chosen «not by any natural connexion that there is between particular articulate sounds and certain ideas, for then there would be but one language amongst all men; but by a voluntary imposition, whereby such a word is made arbitrarily the mark of such an idea».[16] Wittgenstein’s thought transitioned from a word as representation of meaning to «the meaning of a word is its use in the language.»[17]
Classes
Each word belongs to a category, based on shared grammatical properties. Typically, a language’s lexicon may be classified into several such groups of words. The total number of categories as well as their types are not universal and vary among languages. For example, English has a group of words called articles, such as the (the definite article) or a (the indefinite article), which mark definiteness or identifiability. This class is not present in Japanese, which depends on context to indicate this difference. On the other hand, Japanese has a class of words called particles which are used to mark noun phrases according to their grammatical function or thematic relation, which English marks using word order or prosody.[18]: 21–24
It is not clear if any categories other than interjection are universal parts of human language. The basic bipartite division that is ubiquitous in natural languages is that of nouns vs verbs. However, in some Wakashan and Salish languages, all content words may be understood as verbal in nature. In Lushootseed, a Salish language, all words with ‘noun-like’ meanings can be used predicatively, where they function like verb. For example, the word sbiaw can be understood as ‘(is a) coyote’ rather than simply ‘coyote’.[19][3]: 13:631 On the other hand, in Eskimo–Aleut languages all content words can be analyzed as nominal, with agentive nouns serving the role closest to verbs. Finally, in some Austronesian languages it is not clear whether the distinction is applicable and all words can be best described as interjections which can perform the roles of other categories.[3]: 13:631
The current classification of words into classes is based on the work of Dionysius Thrax, who, in the 1st century BC, distinguished eight categories of Ancient Greek words: noun, verb, participle, article, pronoun, preposition, adverb, and conjunction. Later Latin authors, Apollonius Dyscolus and Priscian, applied his framework to their own language; since Latin has no articles, they replaced this class with interjection. Adjectives (‘happy’), quantifiers (‘few’), and numerals (‘eleven’) were not made separate in those classifications due to their morphological similarity to nouns in Latin and Ancient Greek. They were recognized as distinct categories only when scholars started studying later European languages.[3]: 13:629
In Indian grammatical tradition, Pāṇini introduced a similar fundamental classification into a nominal (nāma, suP) and a verbal (ākhyāta, tiN) class, based on the set of suffixes taken by the word. Some words can be controversial, such as slang in formal contexts; misnomers, due to them not meaning what they would imply; or polysemous words, due to the potential confusion between their various senses.[20]
History
In ancient Greek and Roman grammatical tradition, the word was the basic unit of analysis. Different grammatical forms of a given lexeme were studied; however, there was no attempt to decompose them into morphemes. [21]: 70 This may have been the result of the synthetic nature of these languages, where the internal structure of words may be harder to decode than in analytic languages. There was also no concept of different kinds of words, such as grammatical or phonological – the word was considered a unitary construct.[4]: 269 The word (dictiō) was defined as the minimal unit of an utterance (ōrātiō), the expression of a complete thought.[21]: 70
See also
- Longest words
- Utterance
- Word (computer architecture)
- Word count, the number of words in a document or passage of text
- Wording
- Etymology
Notes
- ^ The convention also depends on the tense or mood—the examples given here are in the infinitive, whereas French imperatives, for example, are hyphenated, e.g. lavez-vous, whereas the Spanish present tense is completely separate, e.g. me lavo.
References
- ^ a b Brown, E. K. (2013). The Cambridge dictionary of linguistics. J. E. Miller. Cambridge: Cambridge University Press. p. 473. ISBN 978-0-521-76675-3. OCLC 801681536.
- ^ a b c d Bussmann, Hadumod (1998). Routledge dictionary of language and linguistics. Gregory Trauth, Kerstin Kazzazi. London: Routledge. p. 1285. ISBN 0-415-02225-8. OCLC 41252822.
- ^ a b c d e f Brown, Keith (2005). Encyclopedia of Language and Linguistics: V1-14. Keith Brown (2nd ed.). ISBN 1-322-06910-7. OCLC 1097103078.
- ^ a b c d e f g h i j Word: a cross-linguistic typology. Robert M. W. Dixon, A. Y. Aikhenvald. Cambridge: Cambridge University Press. 2002. ISBN 0-511-06149-8. OCLC 57123416.
{{cite book}}: CS1 maint: others (link) - ^ a b c Haspelmath, Martin (2011). «The indeterminacy of word segmentation and the nature of morphology and syntax». Folia Linguistica. 45 (1). doi:10.1515/flin.2011.002. ISSN 0165-4004. S2CID 62789916.
- ^ Harris, Zellig S. (1946). «From morpheme to utterance». Language. 22 (3): 161–183. doi:10.2307/410205. JSTOR 410205.
- ^ The Oxford handbook of the word. John R. Taylor (1st ed.). Oxford, United Kingdom. 2015. ISBN 978-0-19-175669-6. OCLC 945582776.
{{cite book}}: CS1 maint: others (link) - ^ Chodorow, Martin S.; Byrd, Roy J.; Heidorn, George E. (1985). «Extracting semantic hierarchies from a large on-line dictionary». Proceedings of the 23rd Annual Meeting on Association for Computational Linguistics. Chicago, Illinois: Association for Computational Linguistics: 299–304. doi:10.3115/981210.981247. S2CID 657749.
- ^ Katamba, Francis (2005). English words: structure, history, usage (2nd ed.). London: Routledge. ISBN 0-415-29892-X. OCLC 54001244.
- ^ Fleming, Michael; Hardman, Frank; Stevens, David; Williamson, John (2003-09-02). Meeting the Standards in Secondary English (1st ed.). Routledge. doi:10.4324/9780203165553. ISBN 978-1-134-56851-2.
- ^ Wierzbicka, Anna (1996). Semantics : primes and universals. Oxford [England]: Oxford University Press. ISBN 0-19-870002-4. OCLC 33012927.
- ^ «The search for the shared semantic core of all languages.». Meaning and universal grammar. Volume II: theory and empirical findings. Cliff Goddard, Anna Wierzbicka. Amsterdam: John Benjamins Pub. Co. 2002. ISBN 1-58811-264-0. OCLC 752499720.
{{cite book}}: CS1 maint: others (link) - ^ Adger, David (2003). Core syntax: a minimalist approach. Oxford: Oxford University Press. ISBN 0-19-924370-0. OCLC 50768042.
- ^ a b An introduction to language and linguistics. Ralph W. Fasold, Jeff Connor-Linton. Cambridge, UK: Cambridge University Press. 2006. ISBN 978-0-521-84768-1. OCLC 62532880.
{{cite book}}: CS1 maint: others (link) - ^ Bauer, Laurie (1983). English word-formation. Cambridge [Cambridgeshire]. ISBN 0-521-24167-7. OCLC 8728300.
- ^ Locke, John (1690). «Chapter II: Of the Signification of Words». An Essay Concerning Human Understanding. Vol. III (1st ed.). London: Thomas Basset.
- ^ Biletzki, Anar; Matar, Anat (2021). Ludwig Wittgenstein. The Stanford Encyclopedia of Philosophy (Winter 2021 ed.). Metaphysics Research Lab, Stanford University.
- ^ Linguistics: an introduction to language and communication. Adrian Akmajian (6th ed.). Cambridge, Mass.: MIT Press. 2010. ISBN 978-0-262-01375-8. OCLC 424454992.
{{cite book}}: CS1 maint: others (link) - ^ Beck, David (2013-08-29), Rijkhoff, Jan; van Lier, Eva (eds.), «Unidirectional flexibility and the noun–verb distinction in Lushootseed», Flexible Word Classes, Oxford University Press, pp. 185–220, doi:10.1093/acprof:oso/9780199668441.003.0007, ISBN 978-0-19-966844-1, retrieved 2022-08-25
- ^ De Soto, Clinton B.; Hamilton, Margaret M.; Taylor, Ralph B. (December 1985). «Words, People, and Implicit Personality Theory». Social Cognition. 3 (4): 369–382. doi:10.1521/soco.1985.3.4.369. ISSN 0278-016X.
- ^ a b Robins, R. H. (1997). A short history of linguistics (4th ed.). London. ISBN 0-582-24994-5. OCLC 35178602.
Bibliography
![]()
Wikimedia Commons has media related to Words.
![]()
Wikiquote has quotations related to Word.
![]()
Look up word in Wiktionary, the free dictionary.
- Barton, David (1994). Literacy: an introduction to the ecology of written language. Oxford, UK: Blackwell. p. 96. ISBN 0-631-19089-9. OCLC 28722223.
- The encyclopedia of language & linguistics. E. K. Brown, Anne Anderson (2nd ed.). Amsterdam: Elsevier. 2006. ISBN 978-0-08-044854-1. OCLC 771916896.
{{cite book}}: CS1 maint: others (link) - Crystal, David (1995). The Cambridge encyclopedia of the English language. Cambridge [England]: Cambridge University Press. ISBN 0-521-40179-8. OCLC 31518847.
- Plag, Ingo (2003). Word-formation in English. Cambridge: Cambridge University Press. ISBN 0-511-07843-9. OCLC 57545191.
- The Oxford English Dictionary. J. A. Simpson, E. S. C. Weiner, Oxford University Press (2nd ed.). Oxford: Clarendon Press. 1989. ISBN 0-19-861186-2. OCLC 17648714.
{{cite book}}: CS1 maint: others (link)
The word as a basic unit of language
The word is the subject matter of Lexicology. The
word may be described as a basic unit of language. The definition of
the word is one of the most difficult problems in Linguistics because
any word has many different aspects. It is simultaneously a semantic,
grammatical and phonological unit.
Accordingly the word may be defined as
the basic unit of a given language resulting from the association of
a particular meaning with a particular group of sounds capable of a
particular grammatical employment. This
definition based on the definition of a word given by the eminent
French linguist Arthur Meillet does
not permit us to distinguish words from phrases. We
can accept the given definition adding that a word is the smallest
significant unit of a given language capable of functioning alone and
characterized by positional mobility within a sentence, morphological
uninterruptability and semantic integrity.
In Russian Linguistics it is the word but not the morpheme as in
American descriptive linguistics that is the basic unit of language
and the basic unit of lexical articulation of the flow of the speech.
Thus, the word is a structural and
semantic entity within the language system. The word is the basic
unit of the language system, the largest on the morphological level
and the smallest on the syntactic level of linguistic analysis.
As any language unit the word is a two facet unit possessing both its
outer form (sound form) and content (meaning) which is not created in
speech but used ready-maid. As the basic unit of language the word is
characterized by independence or separateness (отдельность),
as a free standing item, and identity (тождество).
The word as an independent
free standing language unit is
distinguished in speech due to its ability to take on grammatical
inflections (грамматическая
оформленнасть) which makes it
different from the morpheme.
The structural
integrity (цельная
оформленнасть) of the word
combined with the semantic integrity and morphological
uninterruptability (морфологическая
непрерывность) makes the word
different from word combinations.
The identity of the
word manifests itself in the ability of
a word to exist as a system and unity of all its forms (grammatical
forms creating its paradigm) and variants: lexical-semantic,
morphological, phonetic and graphic.
The system showing a word in all its word forms is
called its paradigm. The lexical meaning of a word is the same
throughout the paradigm, i.e. all the word forms of one and the same
word are lexical identical while the grammatical meaning varies from
one form to another (give-gave-given-giving-gives;
worker-workers-worker’s-workers’).
Besides the grammatical forms of the words (or
word forms), words possess lexical varieties called variants of words
(a word – a polisemantic word in one of its meanings in which it is
used in speech is described as a lexical-semantic variants. The term
was introduced by A.I. Smernitskiy; e.g. “to learn at school” –
“to learn about smth”; man – мужчина/человек).
Words may have phonetic, graphic and morphological variants:
often – [Þfən]/[
Þftən] – phonetic
variants
birdy/birdie –
graphic variants
phonetic/phonetical – morphological
variants
Thus, within the language system the word exists as a system and
unity of all its forms and variants. The term lexeme may
serve to express the idea of the word as a system of its forms and
variants.
Every word names a given referent and another one and this
relationship creates the basis for establishing understanding in
verbal intercourse (общение). But because
words mirror concepts through our perception of the world there’s
no singleness in word-thing correlations.
As reality becomes more complicated, it calls for
more sophisticated means of nomination. In recent times Lexicology
has developed a more psycho-linguistic and ethno-cultural orientation
aimed at looking into the actual reality of how lexical items work.
Соседние файлы в папке Lecture1
- #
- #
- #
- #
What Is the Definition of Word?
«The trouble with words,» said British dramatist Dennis Potter, «is that you never know whose mouths they’ve been in.».
ZoneCreative S.r.l./Getty Images
A word is a speech sound or a combination of sounds, or its representation in writing, that symbolizes and communicates a meaning and may consist of a single morpheme or a combination of morphemes.
The branch of linguistics that studies word structures is called morphology. The branch of linguistics that studies word meanings is called lexical semantics.
Etymology
From Old English, «word»
Examples and Observations
- «[A word is the] smallest unit of grammar that can stand alone as a complete utterance, separated by spaces in written language and potentially by pauses in speech.»
-David Crystal, The Cambridge Encyclopedia of the English Language. Cambridge University Press, 2003 - «A grammar . . . is divided into two major components, syntax and morphology. This division follows from the special status of the word as a basic linguistic unit, with syntax dealing with the combination of words to make sentences, and morphology with the form of words themselves.» -R. Huddleston and G. Pullum, The Cambridge Grammar of the English Language. Cambridge University Press, 2002
- «We want words to do more than they can. We try to do with them what comes to very much like trying to mend a watch with a pickaxe or to paint a miniature with a mop; we expect them to help us to grip and dissect that which in ultimate essence is as ungrippable as shadow. Nevertheless there they are; we have got to live with them, and the wise course is to treat them as we do our neighbours, and make the best and not the worst of them.»
-Samuel Butler, The Note-Books of Samuel Butler, 1912 - Big Words
«A Czech study . . . looked at how using big words (a classic strategy for impressing others) affects perceived intelligence. Counter-intuitvely, grandiose vocabulary diminished participants’ impressions of authors’ cerebral capacity. Put another way: simpler writing seems smarter.»
-Julie Beck, «How to Look Smart.» The Atlantic, September 2014 - The Power of Words
«It is obvious that the fundamental means which man possesses of extending his orders of abstractions indefinitely is conditioned, and consists in general in symbolism and, in particular, in speech. Words, considered as symbols for humans, provide us with endlessly flexible conditional semantic stimuli, which are just as ‘real’ and effective for man as any other powerful stimulus. - Virginia Woolf on Words
«It is words that are to blame. They are the wildest, freest, most irresponsible, most un-teachable of all things. Of course, you can catch them and sort them and place them in alphabetical order in dictionaries. But words do not live in dictionaries; they live in the mind. If you want proof of this, consider how often in moments of emotion when we most need words we find none. Yet there is the dictionary; there at our disposal are some half-a-million words all in alphabetical order. But can we use them? No, because words do not live in dictionaries, they live in the mind. Look once more at the dictionary. There beyond a doubt lie plays more splendid than Antony and Cleopatra; poems lovelier than the ‘Ode to a Nightingale’; novels beside which Pride and Prejudice or David Copperfield are the crude bunglings of amateurs. It is only a question of finding the right words and putting them in the right order. But we cannot do it because they do not live in dictionaries; they live in the mind. And how do they live in the mind? Variously and strangely, much as human beings live, ranging hither and thither, falling in love, and mating together.»
-Virginia Woolf, «Craftsmanship.» The Death of the Moth and Other Essays, 1942 - Word Word
«Word Word [1983: coined by US writer Paul Dickson]. A non-technical, tongue-in-cheek term for a word repeated in contrastive statements and questions: ‘Are you talking about an American Indian or an Indian Indian?’; ‘It happens in Irish English as well as English English.'»
-Tom McArthur, The Oxford Companion to the English Language. Oxford University Press, 1992
Table of Contents
- What is the definition of abomination?
- What is the definition of abomination in the Bible?
- What is an example of an abomination?
- What is difference between word and morpheme?
- What is alphabet and numbers?
- What are the numbers for letters?
- What is the 26 letter alphabet called?
- Who had the first alphabet?
- What is the oldest letter in the alphabet?
- Why does the letter K exist?
- How old is the letter K?
- What language has a backwards K?
- What type of letter is M?
- How do you make the letter N?
In linguistics, a word of a spoken language can be defined as the smallest sequence of phonemes that can be uttered in isolation with objective or practical meaning. In many languages, the notion of what constitutes a “word” may be mostly learned as part of learning the writing system.
What is the definition of abomination?
1 : something regarded with disgust or hatred : something abominable considered war an abomination. 2 : extreme disgust and hatred : loathing a crime regarded with abomination.
What is the definition of abomination in the Bible?
Mrs Robinson believes that the term “abomination”, as used in the Bible, means that an action is wicked, vile, disgusting, and morally wrong.
What is an example of an abomination?
The noun abomination means a thing or action that is vile, vicious or terrible. For example, if you see a neighbor kick an old blind dog that’s done nothing wrong, you might remark, “That kind of cruelty is an abomination!”
What is difference between word and morpheme?
A morpheme is the smallest meaningful unit in a language. A morpheme is not necessarily the same as a word. The main difference between a morpheme and a word is that a morpheme sometimes does not stand alone, but a word, by definition, always stands alone. Every word is composed of one or more morphemes.
What is alphabet and numbers?
The English Alphabet consists of 26 letters: A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z. Letter. Number. Letter.
What are the numbers for letters?
The numbers are assigned to letters of the Latin alphabet as follows:
- 1 = a, j, s,
- 2 = b, k, t,
- 3 = c, l, u,
- 4 = d, m, v,
- 5 = e, n, w,
- 6 = f, o, x,
- 7 = g, p, y,
- 8 = h, q, z,
What is the 26 letter alphabet called?
modern English alphabet
Who had the first alphabet?
Phoenician alphabet
What is the oldest letter in the alphabet?
O
Why does the letter K exist?
The letter K comes from the Greek letter Κ (kappa), which was taken from the Semitic kaph, the symbol for an open hand. After Greek words were taken into Latin, the Kappa was transliterated as a C.
How old is the letter K?
The letter k may have started as a picture sign of the palm of the hand, as in Egyptian hieroglyphic writing (1) and in a very early Semitic writing used about 1500 bce on the Sinai Peninsula (2).
What language has a backwards K?
Faux Cyrillic, pseudo-Cyrillic, pseudo-Russian or faux Russian typography is the use of Cyrillic letters in Latin text, usually to evoke the Soviet Union or Russia, though it may be used in other contexts as well.
What type of letter is M?
M, or m, is the thirteenth letter of the modern English alphabet and the ISO basic Latin alphabet. Its name in English is em (pronounced /ˈɛm/), plural ems….
| M | |
|---|---|
| Writing system | Latin script |
| Type | Alphabetic and Logographic |
| Language of origin | Latin language |
| Phonetic usage | [m] [ɱ] [n] [n̼] /ɛm/ |
How do you make the letter N?
The lowercase ñ can be made in the Microsoft Windows operating system by doing Alt + 164 or Alt + 0241 on the numeric keypad (with Num Lock turned on); the uppercase Ñ can be made with Alt + 165 or Alt + 0209 . Character Map in Windows identifies the letter as “Latin Small/Capital Letter N With Tilde”.
What is a word? This question is one of the most deceptively simple ones I know. Everyone will say they know the answer, or at least say they know one when they see one, but even native speakers of a language can and do disagree. The dictionary isn’t much help since many dictionaries have multi-sentence, ad hoc definitions which basically boil down to «a word is a unit of language that means something, sort of.»
Let’s jump ahead and assume we know what a word is, or that we can get native speakers to identify most words most of the time. Furthermore, let’s say that our goal is to get a computer to understand a given language. Since humans learn languages initially by learning words and basic grammar it seems like a good choice to try and get computers to recognize words. So, our goal: given a string of English letters insert spaces between the words.
What is a word?
To show that the above exercise isn’t totally contrived let’s look at some of the subtleties in the idea of the word. This is only for people interested in the «linguistics» part of «computaitonal linguistics,» but if you want to read it then click here.
Assumptions
Obviously we can’t integrate all of the subtleties above as that would be tantamount to writing a computer program which actually processed text in the same way humans do. Rather, we will work under the following assumptions: first, we already have a database (called the «lexicon») of words; second, this database is complete. The first assumption isn’t totally off-the-wall since it’s a general working assumption among linguists that humans have just such a database. The second, however, is much harder to swallow since the lexicon is typically understood to contain root morphemes plus general information about the morphology, phonology, phonotactics, etc. of the language.
If I said «koop» were a verb, you’d know right away that «kooped,» «koops,» «kooper,» etc. were all also valid words. Likewise, even though «cromulent» is not actually an English word an English speaker knows that it could be (and that, furthermore, it would probably be an adjective), but that «plkdjfhg» could never be an English word. Our database, however, is very dumb and very uncompressed: every permutation of every word should be present, otherwise that permutation won’t be counted as a word. We’re only making this assumption to simplify the problem. I may be a pretty good programmer, but I’m not good enough to write a computer program which automatically learns a language’s syntax, morphology, and phonology.
Enough chit chat, let’s get to the code.
The Algorithm
The algorithm I’m going to use is a simple probabalistic dynamic programming algorithm. Let’s say we have a string like «therentisdue» and want to parse it as «the-rent-is-due.» Assuming our training data is representative of the language as a whole (a big assumption, for sure) then we know the probability of each word is #occurances of the word in the data over the total number of words in the data. The idea is that the best parse of a string, given our training data, is the parse which has the highest probability of occuring.
For the CS students out there this should scream «dynamic programming.» For everyone else, I’ll explain. The most obvious way to find the parse with the highest probability is to find every possible parse and then find that parse which has the highest probability. Implementing the algorithm this way is intractable since there are 2n-1 parses (why?). Instead we’ll do the following. The pseudo code:
BestParse[0] := "" FOR i in [1..length of StringToParse] DO FOR j in [0..i) DO parse := BestParse[j] + StringToParse[j,i] IF COST(parse) < COST(BestParse[i]) THEN BestParse[i] = parse ENDIF ENDFOR ENDFOR DEFINE COST(parse) return -LOG2(PROBABILITY(parse)) END DEFINE PROBABILITY(parse) return product of the frequencies of each word in parse END
Let the input string be s. At each point i, that is, for the initial i-length substring of s, determine what the best parse up to i is. Now, let’s say we know what the best parse at i is for some fixed i. To find the best parse at i+1 we try to insert a break after each initial j substring, for j < i+1. Since we’ve been keeping track of the best parse (and cost) at each such j the whole time, we just see which break insertion is the cheapest.
Here is an illustration, again with «therentisdue.» Let’s say we have «therenti» parsed so far. This means we know the best parse for each initial substring of this string, e.g., «t», «th», «the», etc. The best parse will probably be «the-rent-i» since each of these is a word and every other parse contains at least one non-word. Now let’s see how the algorithm determines the best parse of «therentis» from this.
After each character in the string we need to decide whether or not to insert a break. Should we insert a space after the first character? Well, yes, since the best parse of a single character is definitely that character. So at the first step we get «t-|herentis.» If we’re favoring single letters over non-words (it’s our choice to make) then the best parse after the second character would be «t-h-|erentis.» After the third, however, the parse is «the-|rentis» since «the» is a word and therefore the best parse of the first three letters is «the» (we know this because, by assumption, we have already computed the best parse for «the»). Next we get «the-r-|entis,» followed by «the-re-|ntis,» and so on, until we get to «the-ren-|tis.» After this step we try «the-rent-|is.» This is a very good parse since we have three words. Finally, we try «the-rent-i-|s,» which has a lower probability than the previous parse because «s» is not a word. Therefore «the-rent-is» is the parse which we save as the best parse of «therentis.»
I implemented this algorithm using C++, which you can download here. By default it uses the KJV Bible as training data, which means what it considers words can be a little funny. For example, «sin» is considered a very common word.