
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
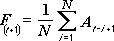
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
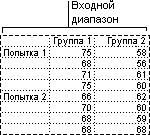
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
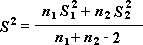
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
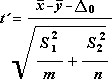
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
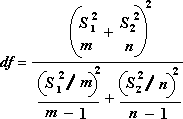
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
![]()
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Если вы ищете работу и она хоть как-то связана с математикой/экономикой/финансами, то вы очень часто будете встречать такие требования к кандидату:
— Отличное знание статистики;
— Знание и умение Python/R, чтобы эту статистику применять.
Но что делать, если никаких знаний по языкам программирования у вас нет, а встречаться со статистическими моделями так или иначе придется? А работу-то найти нужно срочно…
К счастью, в версии Microsoft Excel выше 2010 вшит целый статистический пакет. О нем мало кто знает, а его реально можно использовать, если нет навыков программирования или доступного компилятора под рукой.
Для начала поговорим, где все эти формулы найти. Как обычно, переходим на вкладку «Формулы» на главной панели, выбираем «Другие функции» и пакет «Статистические». Перед Вами полный перечень статистических возможностей Excel.
Как вы можете видеть, формул в этом разделе представлено довольно много, как «ходовых», так и «узкоспециализированных». К сожалению, разобрать все в одной статье не получится, поэтому рассмотрим здесь самые часто встречающиеся. Если вы хотите познакомиться с математическими функциями Excel, то рекомендуем скачать наш бесплатный гайд.
На первый взгляд они могут показаться очень простыми. Однако, мы постарались раскрыть те моменты, которые обычно остаются без внимания и могут быть полезными.
СРЗНАЧ() и СРЗНАЧА()
Редко кто задумывался, а ведь вычисление среднего значения – сугубо статистическая процедура: именно поэтому это операция и помещена в статистический пакет.
Наверно, особо не стоит останавливаться на правилах использования формулы: функция СРЗНАЧ() принимает на вход массив аргументов и дает на выходе среднее значение по всем ячейкам, содержащим числа(!). Это очень важный момент, который далеко не все знают. Поясним на примере.
Пусть дан диапазон А1:С2 и мы ищем среднее значение по всем 6 ячейкам диапазона:
Однако, результат функции СРЗНАЧ(А1:С2) будет не 8,7, а 13. Почему? (4+15+11+22)/6 = 8,7 ведь?
Да, это правильно, но функция СРЗНАЧ() берет в расчет только те ячейки, где «встречает» числа. Текстовая информация и пустые ячейки просто игнорируются. Поэтому в данном примере СРЗНАЧ() усредняет по 4 ячейкам и выдает правильный ответ – 13.
А вот если нужно произвести усреднение по всему диапазону, вне зависимости от типа данных, нужно использовать функцию СРЗНАЧА().
Принцип работы такой же, как и у СРЗНАЧ(), только на вход будут поступать абсолютно все ячейки. Результат в нашем примере будет уже ожидаемый – 8,7.
Замечание
Выбор той или иной функции происходит в зависимости от задачи. В реальной жизни они могут понадобится в одинаковой мере.
Например, менеджеру нужно узнать среднедневную выручку за месяц на основании продаж за каждый день. Допустим, за несколько дней ячейки оставлены пустыми. Есть два варианта, почему так произошло:
1. В эти дни не было ни одной продажи. Тогда эти дни должны принимать участие в расчете среднего значения и менеджеру нужно использовать СРЗНАЧА() – так он исключит игнорирование пустых ячеек.
2. Эти дни были выходными. Тогда пропуски сами по себе никакой информации не несут и их надо игнорировать: фактически, эти дни не принимают участие в статистической выборке и функция СРЗНАЧ() поможет их пропустить.
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
СРЗНАЧЕСЛИ()
Очевидно, что функция СРЗНАЧЕСЛИ() возвращает среднее тех значений, который удовлетворяют каким-то условиям. Помимо этого, условия можно накладывать не только на сами значения, но и на другие ячейки. Проиллюстрируем.
Например, вычислим среднее значение всех ячеек, которые больше нуля:
Мы выделили диапазон А1:С3 и наложили на него условие – «>0». А можно сделать по-другому.
Рассмотрим таблицу, в которую занесены продажи лекарств в городе. Посчитаем среднюю цену Анальгина по всему городу. Для этого наложим условие уже не на саму цену, а на название лекарства.
Формула записывается так:
=СРЗНАЧЕСЛИ(Диапазон_на_который_накладываем_условия; “Условие”; Диапазон_по_которому_считаем_среднее_значение)
В нашем случае это примет вид:
Кстати говоря, условия можно комбинировать с помощью функции СРЗНАЧЕСЛИМН().
Предположим, что в аптеке Зеленый Крест продается несколько видов Анальгина и в нашу таблицу они все занесены как Анальгин.
Тогда, чтобы усреднить цену всех Анальгинов в аптеке Зеленый Крест, нужно просто использовать формулу:
=СРЗНАЧЕСЛИМН(С2:С13; A2:A13; “зеленый крест”;B2:B13; “анальгин”)
Обратите внимание: диапазон усреднения указывается в конце только при использовании функции СРЗНАЧЕСЛИ() с дополнительным условием. В остальных случаях диапазон ячеек, по которым вычисляется среднее значение, стоит первым.
МИН()/МАКС() и НАИБОЛЬШИЙ()/НАИМЕНЬШИЙ()
На первый взгляд, разница между этими функциями не особо прослеживается, хотя зачем их используют – очевидно – найти самое большое или маленькое число. Однако, в работе этих функций есть небольшая, но очень полезная разница. Разберем подробней.
Функция МИН() просто принимает массив аргументов и находит самое маленькое число. МАКС() – самое большое. Все просто.
Функция НАИМЕНЬШИЙ() же находит n-ое наименьшее число в массиве. НАИБОЛЬШИЙ(), наоборот, находит n-ое наибольшее число.
Например, нужно найти пятое по величине число. Вводим:
=НАИБОЛЬШИЙ(диапазон; 5).
Фактически, получается, что результат работы НАИБОЛЬШИЙ(массив;1) и МАКС(массив) – одно и то же. Аналогичная ситуация с НАИМЕНЬШИЙ(массив;1) и МИН(массив).
Рекомендуем записаться на наш открытый онлайн-курс «Аналитика в Excel», если вы хотите научиться выполнять рутинную работу быстрее.
МЕДИАНА() и МОДА()
Общеизвестные и достаточно важные статистические характеристики моды и медианы вычисляются по одноименным формулам.
Напомним, что медианой называется «середина» числового множества.
Например, если есть массив чисел от одного до десяти, то медианой будет число 5,5 (хотя оно само в массив не входит). Это из-за того, что количество элементов в массиве – четно и выбрать «центральное» просто невозможно.
Вот если бы выборка начиналась не с единицы, а с двойки, то ответ был бы ровно 6.
Теперь перейдем к моде. Мода – самое часто встречающееся число в выборке.
У функции нахождения моды есть целых три модификации в Excel старшее версии 2010 года: МОДА(), МОДА.ОДН() и МОДА.НСК().
Функция МОДА() оставлена для совместимости – ей, в целом, можно пользоваться: она работает совершенно аналогично функции МОДА.ОДН().
«ОДН» в названии функции значит, что, если в выборке несколько самых часто встречающихся элементов, то возвращено в качестве ответа будет только первое.
Для подсчета всех мод в выборке нужно использовать функцию МОДА.НСК().
Работает МОДА.НСК() следующим образом: выделяем побольше ячеек (если заранее не знаем, сколько мод у нас получится), в строке формул прописываем =МОДА.НСК(диапазон) и нажимаем Ctrl+Shift+Enter. Получили все моды в столбик.
Значения #Н/Д появляются, просто потому что мод у нас всего 2. Такой метод поиска мод называется «слепым» – мы просто берем побольше ячеек, чтобы наверняка хватило.
Если Вы не любите подобный «мусор» и Вам нравится, когда все красиво, можно сначала оценить: а сколько же у нас вообще будет мод? А потом просто выделить нужное количество ячеек.
Делается это так: сначала применяем функцию СЧЁТ() к нашей МОДА.НСК() – получили количество мод. А теперь выделяем только две ячейки и делаем все также, как написано выше.
Заключение
Статистический пакет Microsoft Excel содержит в себе еще огромное количество формул: проверку гипотез, принадлежность распределениям, доверительные интервалы, корреляцию и прочие инструменты, которые могут пригодиться при работе со статистикой даже на серьезном уровне.
Как мы и писали ранее, обозреть все в одной статье невозможно. Поэтому, если вы хотите узнать про менее известные, но не менее полезные статистические возможности Excel – пишите в комментариях, что вам было бы интересно и мы подготовим для вас новую статью из этого цикла.
Автор: Андрон Алексанян, СОО “Аптека-Центр”, эксперт SF Education
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Блог SF Education
MS Office
5 примеров экономии времени в Excel
Содержание статьи Что для работодателя главное в сотруднике? Добросовестность, ответственность, профессионализм и, конечно же, умение пользоваться отведенным временем! Предлагаем познакомиться с очень нужными, на…
Как работать с датами в Excel?
Содержание статьи История о том, как я пропустил свидание с очаровательной блондинкой… Вы никогда не попадали впросак из-за того, что неправильно читали дату? «Да…
Содержание
- Статистические функции
- МАКС
- МИН
- СРЗНАЧ
- СРЗНАЧЕСЛИ
- МОДА.ОДН
- МЕДИАНА
- СТАНДОТКЛОН
- НАИБОЛЬШИЙ
- НАИМЕНЬШИЙ
- РАНГ.СР
- Вопросы и ответы

Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ информации с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть огромное количество инструментов, которые помогают проводить исследования в данной области. Последние версии этой программы в плане возможностей практически ничем не уступают специализированным приложениям в области статистики. Главными инструментами для выполнения расчетов и анализа являются функции. Давайте изучим общие особенности работы с ними, а также подробнее остановимся на отдельных наиболее полезных инструментах.
Статистические функции
Как и любые другие функции в Экселе, статистические функции оперируют аргументами, которые могут иметь вид постоянных чисел, ссылок на ячейки или массивы.
Выражения можно вводить вручную в определенную ячейку или в строку формул, если хорошо знать синтаксис конкретного из них. Но намного удобнее воспользоваться специальным окном аргументов, которое содержит подсказки и уже готовые поля для ввода данных. Перейти в окно аргумента статистических выражений можно через «Мастер функций» или с помощью кнопок «Библиотеки функций» на ленте.
Запустить Мастер функций можно тремя способами:
- Кликнуть по пиктограмме «Вставить функцию» слева от строки формул.
- Находясь во вкладке «Формулы», кликнуть на ленте по кнопке «Вставить функцию» в блоке инструментов «Библиотека функций».
- Набрать на клавиатуре сочетание клавиш Shift+F3.

При выполнении любого из вышеперечисленных вариантов откроется окно «Мастера функций».
Затем нужно кликнуть по полю «Категория» и выбрать значение «Статистические».

После этого откроется список статистических выражений. Всего их насчитывается более сотни. Чтобы перейти в окно аргументов любого из них, нужно просто выделить его и нажать на кнопку «OK».

Для того, чтобы перейти к нужным нам элементам через ленту, перемещаемся во вкладку «Формулы». В группе инструментов на ленте «Библиотека функций» кликаем по кнопке «Другие функции». В открывшемся списке выбираем категорию «Статистические». Откроется перечень доступных элементов нужной нам направленности. Для перехода в окно аргументов достаточно кликнуть по одному из них.


Урок: Мастер функций в Excel
МАКС
Оператор МАКС предназначен для определения максимального числа из выборки. Он имеет следующий синтаксис:
=МАКС(число1;число2;…)

В поля аргументов нужно ввести диапазоны ячеек, в которых находится числовой ряд. Наибольшее число из него эта формула выводит в ту ячейку, в которой находится сама.
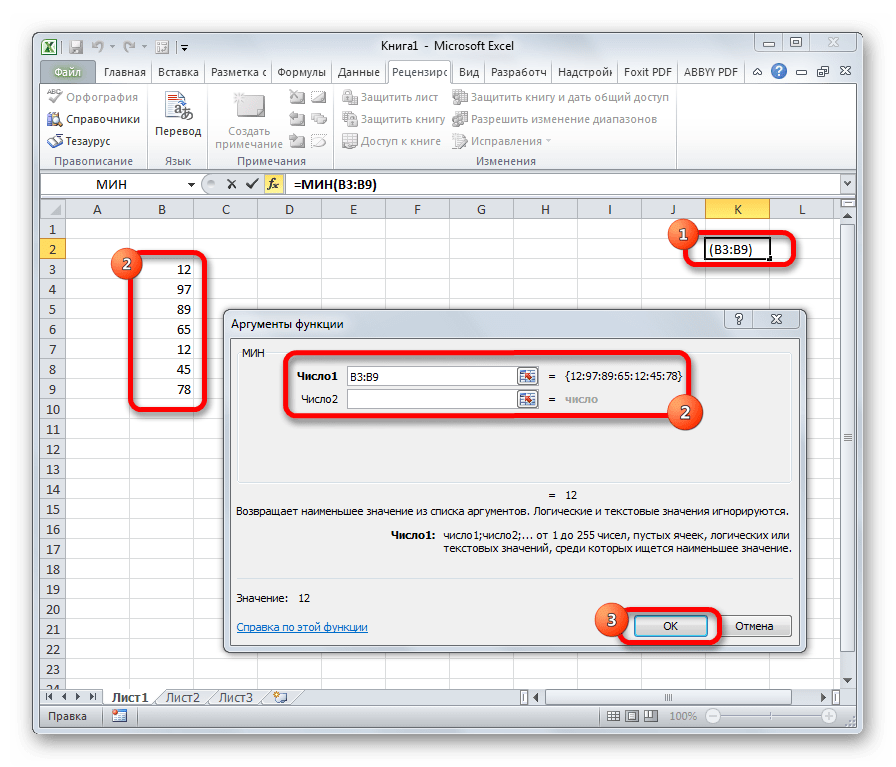
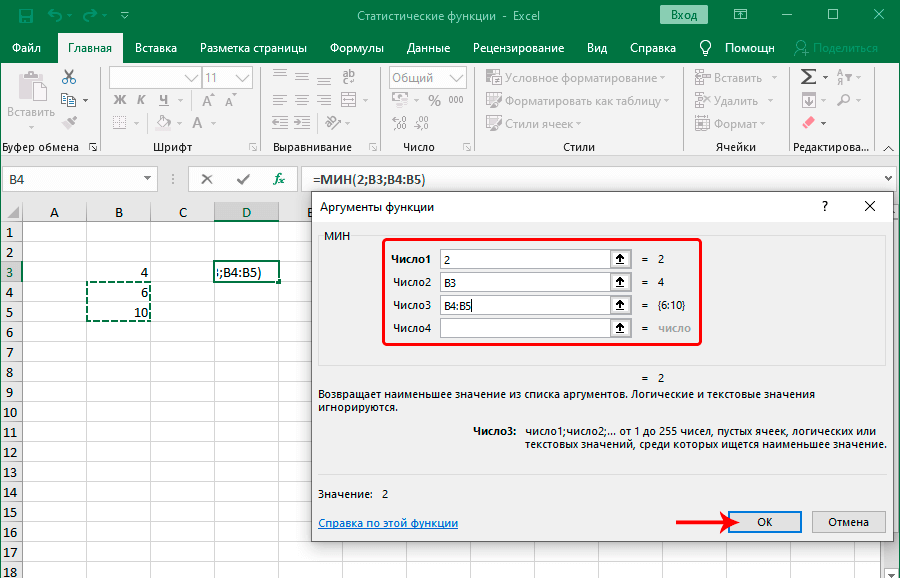
МИН
По названию функции МИН понятно, что её задачи прямо противоположны предыдущей формуле – она ищет из множества чисел наименьшее и выводит его в заданную ячейку. Имеет такой синтаксис:
=МИН(число1;число2;…)
СРЗНАЧ
Функция СРЗНАЧ ищет число в указанном диапазоне, которое ближе всего находится к среднему арифметическому значению. Результат этого расчета выводится в отдельную ячейку, в которой и содержится формула. Шаблон у неё следующий:
=СРЗНАЧ(число1;число2;…)
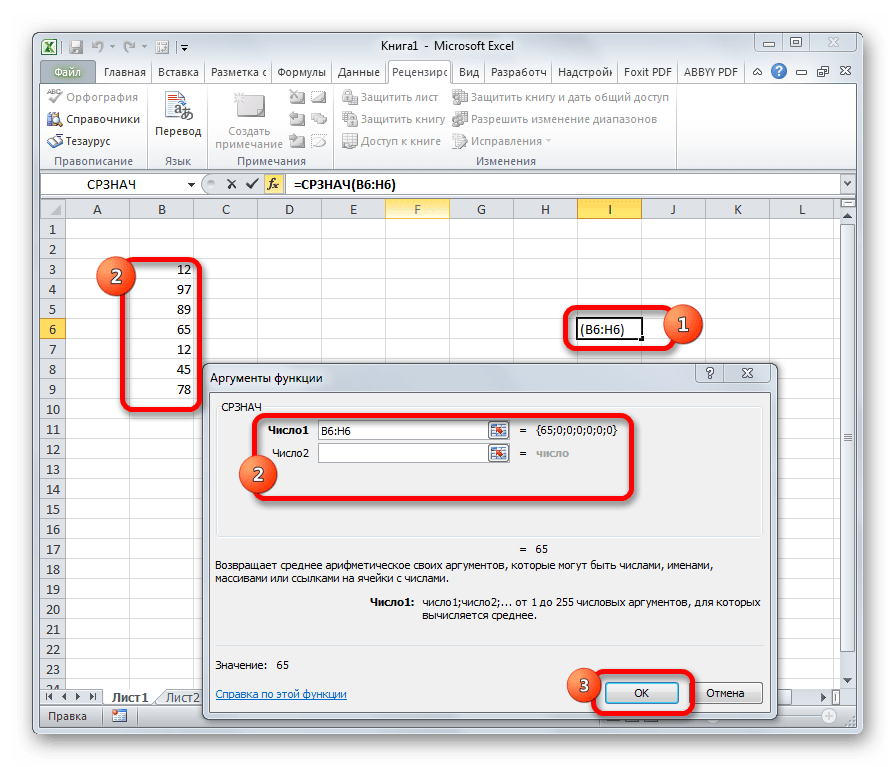
СРЗНАЧЕСЛИ
Функция СРЗНАЧЕСЛИ имеет те же задачи, что и предыдущая, но в ней существует возможность задать дополнительное условие. Например, больше, меньше, не равно определенному числу. Оно задается в отдельном поле для аргумента. Кроме того, в качестве необязательного аргумента может быть добавлен диапазон усреднения. Синтаксис следующий:
=СРЗНАЧЕСЛИ(число1;число2;…;условие;[диапазон_усреднения])
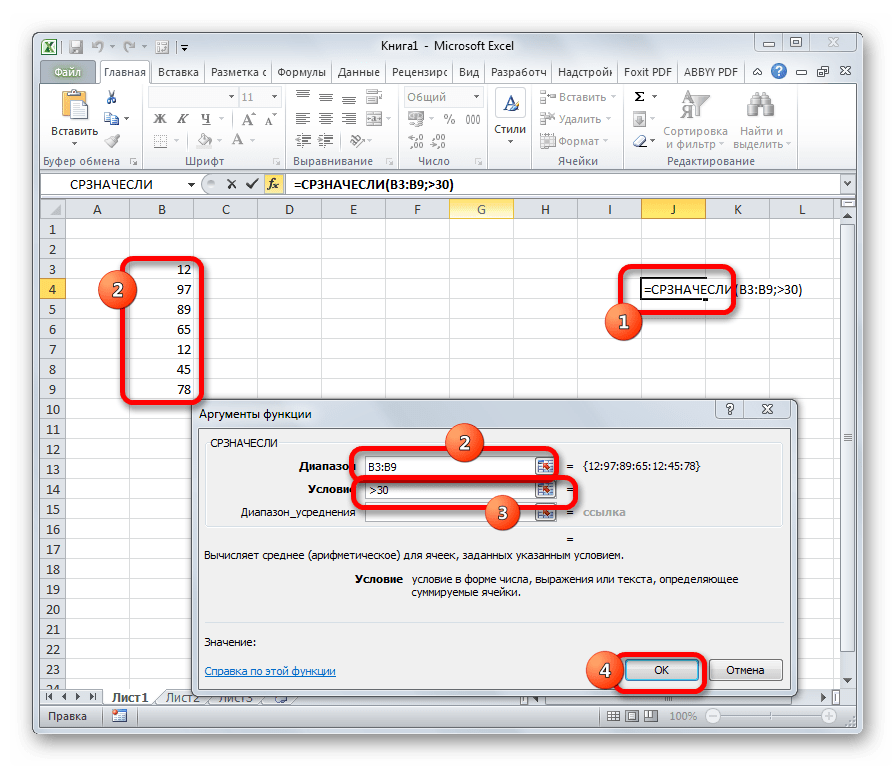
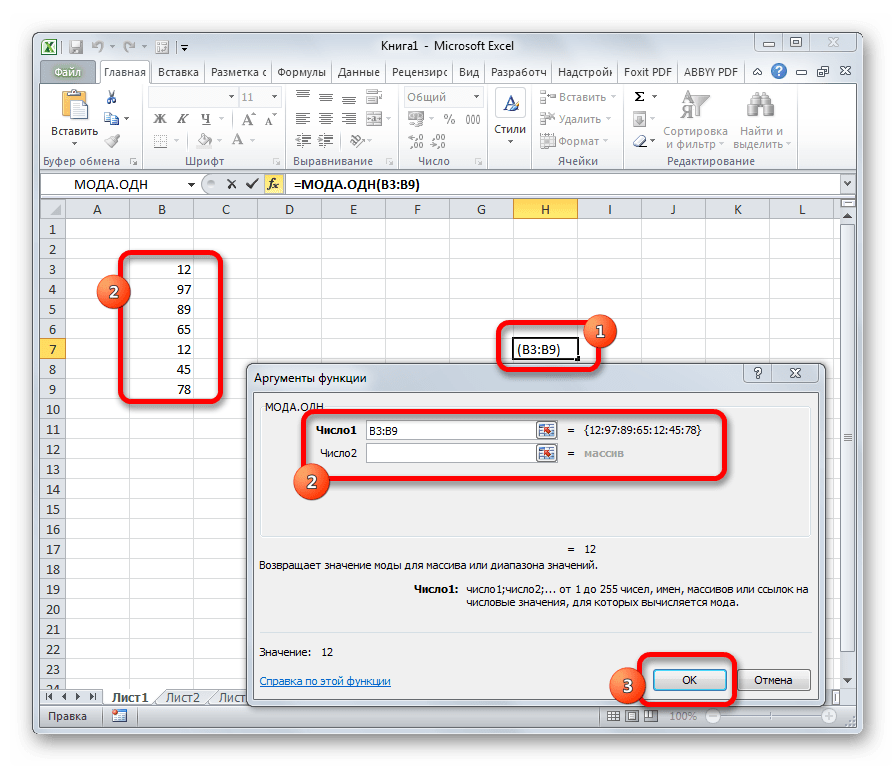
МОДА.ОДН
Формула МОДА.ОДН выводит в ячейку то число из набора, которое встречается чаще всего. В старых версиях Эксель существовала функция МОДА, но в более поздних она была разбита на две: МОДА.ОДН (для отдельных чисел) и МОДА.НСК(для массивов). Впрочем, старый вариант тоже остался в отдельной группе, в которой собраны элементы из прошлых версий программы для обеспечения совместимости документов.
=МОДА.ОДН(число1;число2;…)
=МОДА.НСК(число1;число2;…)
МЕДИАНА
Оператор МЕДИАНА определяет среднее значение в диапазоне чисел. То есть, устанавливает не среднее арифметическое, а просто среднюю величину между наибольшим и наименьшим числом области значений. Синтаксис выглядит так:
=МЕДИАНА(число1;число2;…)
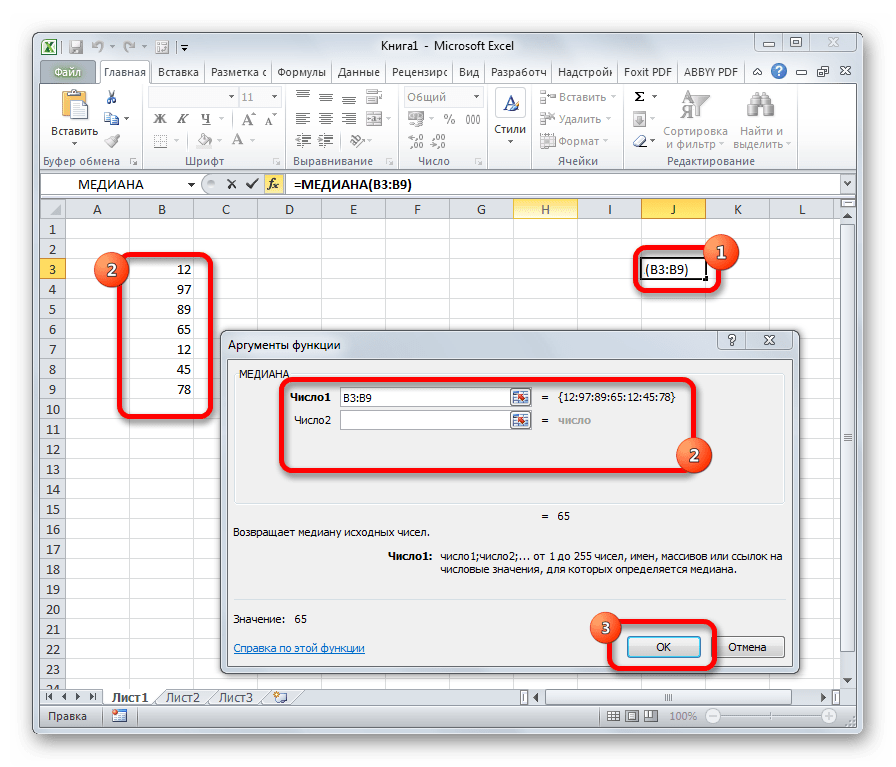
СТАНДОТКЛОН
Формула СТАНДОТКЛОН так же, как и МОДА является пережитком старых версий программы. Сейчас используются современные её подвиды – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Первая из них предназначена для вычисления стандартного отклонения выборки, а вторая – генеральной совокупности. Данные функции используются также для расчета среднего квадратичного отклонения. Синтаксис их следующий:
=СТАНДОТКЛОН.В(число1;число2;…)
=СТАНДОТКЛОН.Г(число1;число2;…)
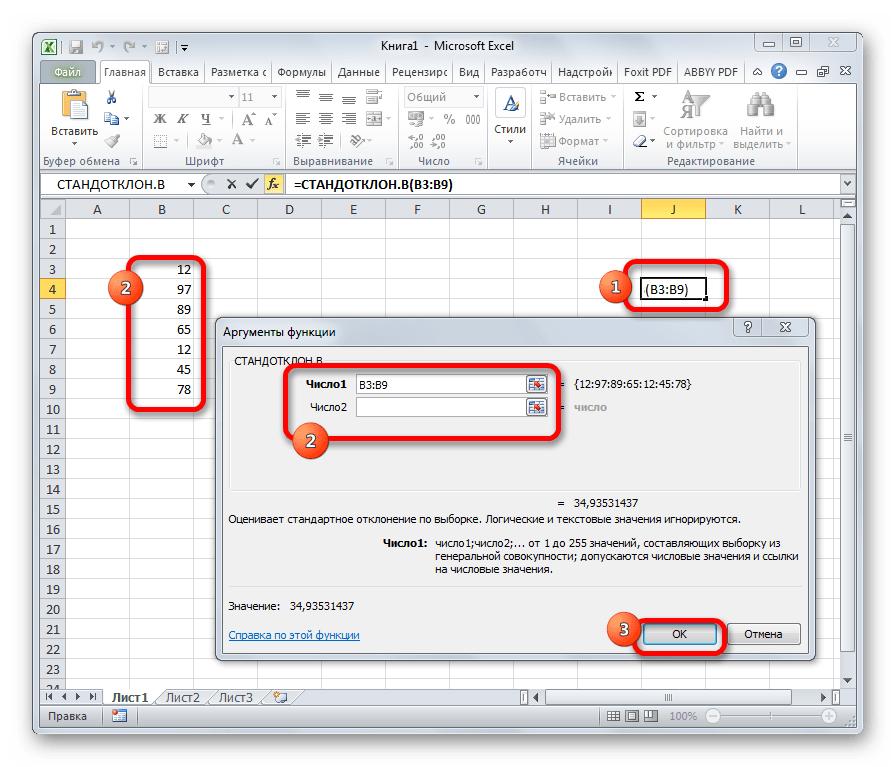
Урок: Формула среднего квадратичного отклонения в Excel
НАИБОЛЬШИЙ
Данный оператор показывает в выбранной ячейке указанное в порядке убывания число из совокупности. То есть, если мы имеем совокупность 12,97,89,65, а аргументом позиции укажем 3, то функция в ячейку вернет третье по величине число. В данном случае, это 65. Синтаксис оператора такой:
=НАИБОЛЬШИЙ(массив;k)
В данном случае, k — это порядковый номер величины.
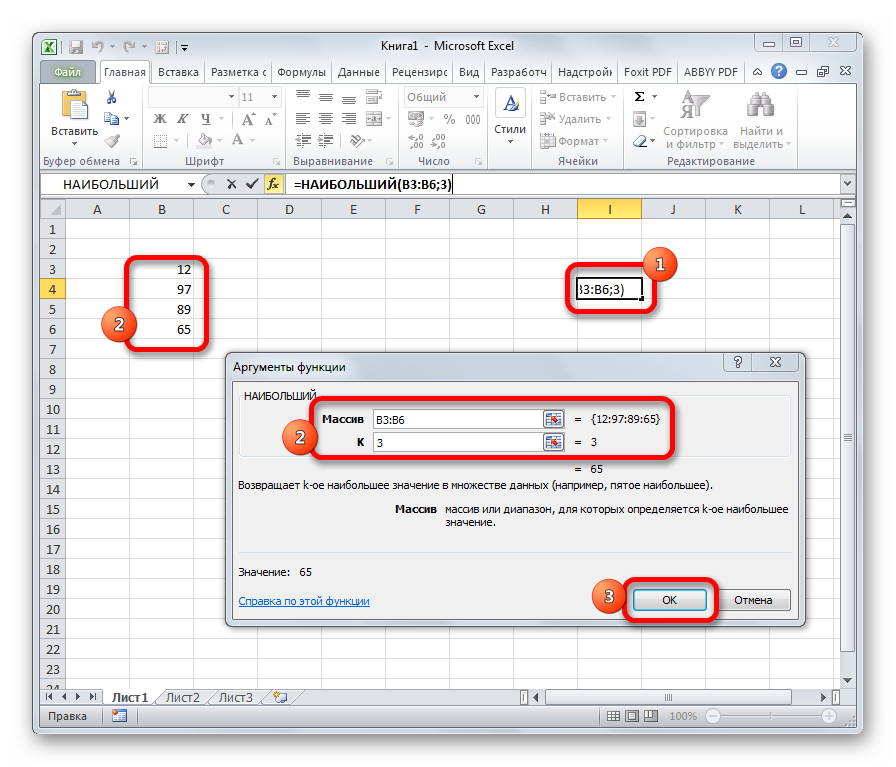
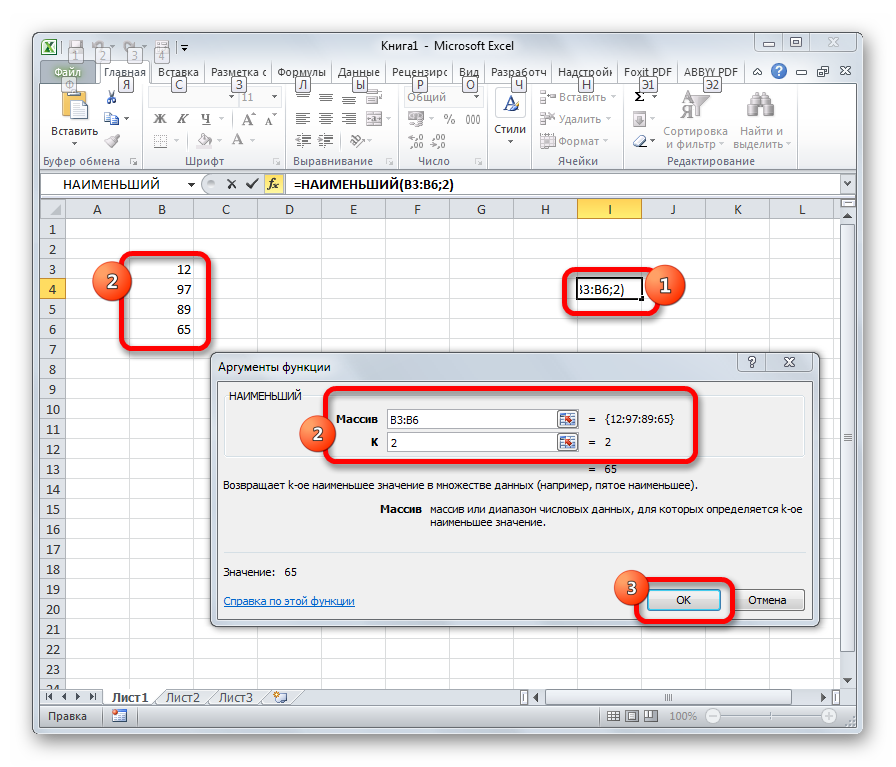
НАИМЕНЬШИЙ
Данная функция является зеркальным отражением предыдущего оператора. В ней также вторым аргументом является порядковый номер числа. Вот только в данном случае порядок считается от меньшего. Синтаксис такой:
=НАИМЕНЬШИЙ(массив;k)
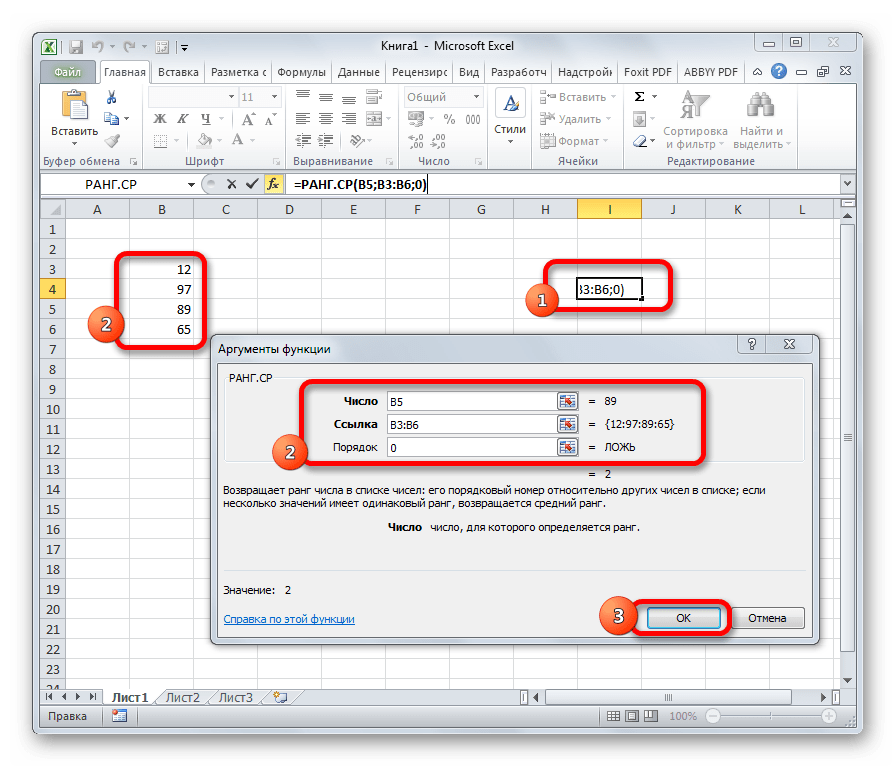
РАНГ.СР
Эта функция имеет действие, обратное предыдущим. В указанную ячейку она выдает порядковый номер конкретного числа в выборке по условию, которое указано в отдельном аргументе. Это может быть порядок по возрастанию или по убыванию. Последний установлен по умолчанию, если поле «Порядок» оставить пустым или поставить туда цифру 0. Синтаксис этого выражения выглядит следующим образом:
=РАНГ.СР(число;массив;порядок)
Выше были описаны только самые популярные и востребованные статистические функции в Экселе. На самом деле их в разы больше. Тем не менее, основной принцип действий у них похожий: обработка массива данных и возврат в указанную ячейку результата вычислительных действий.
-
Использование пакета анализа
Пакет
анализа представляет собой надстройку
Excel–
набор средств
и инструментов, расширяющих стандартные
возможности Excel,
связанные с анализом данных.
Возможности
надстройки Пакет
анализа данных:
1. Однофакторный
дисперсионный анализ.
2. Двухфакторный
дисперсионный анализ с повторениями.
3. Двухфакторный
дисперсионный анализ без повторений.
4. Корреляция.
5. Ковариация.
6. Описательная
статистика.
7. Экспоненциальное
сглаживание.
8.Двухвыборочный
F-тест для дисперсий.
9. Анализ Фурье.
10. Гистограмма.
11. Скользящее
среднее.
12. Генерация
случайных чисел.
13. Ранг и перцентиль.
14. Регрессия.
15. Выборка.
16. Парный
двухвыборочный t-тест для средних.
17.Двухвыборочный
t-тест с одинаковыми дисперсиями.
18.Двухвыборочный
t-тест с разными дисперсиями.
19.Двухвыборочный
z-тест для средних.
Для
того, чтобы воспользоваться одним из
инструментов Пакета
анализа
исследуемые данные следует представить
в виде таблицы, где столбцами являются
соответствующие показатели. При создании
таблицы Excel информация вводится в
отдельные ячейки. Совокупность ячеек,
содержащих анализируемые данные,
называется входным интервалом.
Для
того, чтобы воспользоваться набором
средств и инструментов Пакет
анализа
необходимо произвести его установку.
Необходимо выполнить следующие действия:
Открыть
панель быстрого доступа. И из меню
выбрать Другие
команды.

Рис.Вызов окна ПараметрыExcel
Появится диалоговое
окно Параметры
Excel,
в правом окне выбрать функцию Пакет
анализа VBA.

Рис.Настройка Пакета анализа.
Щелкнуть
по кнопке Перейти
и нажать на ОК.
Появиться диалоговое окно Надстройки.
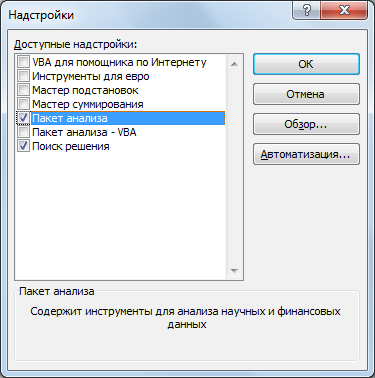
Рис.Диалоговое окно Настройки.
Ставим
флажок в поле Пакет
анализа и
подтверждаем свой выбор нажатием на
клавишу ОК.
Т.о. установили пакет анализа.
Для
дальнейшей работы на ленте выбираем
вкладку Данные.
И выбираем функцию Анализ
данных.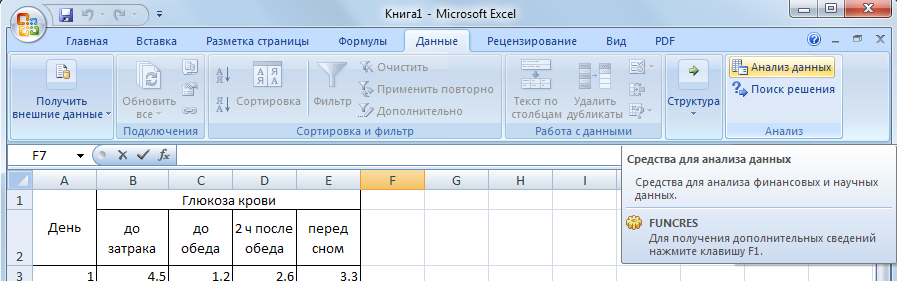
Рис.Вызов функции Анализ данных.
Далее
выбираем команду Данные
→ Анализ
→ Анализ
данных. В
списке Инструменты
анализа
открывшегося окна выберите пункт
Описательная
статистика
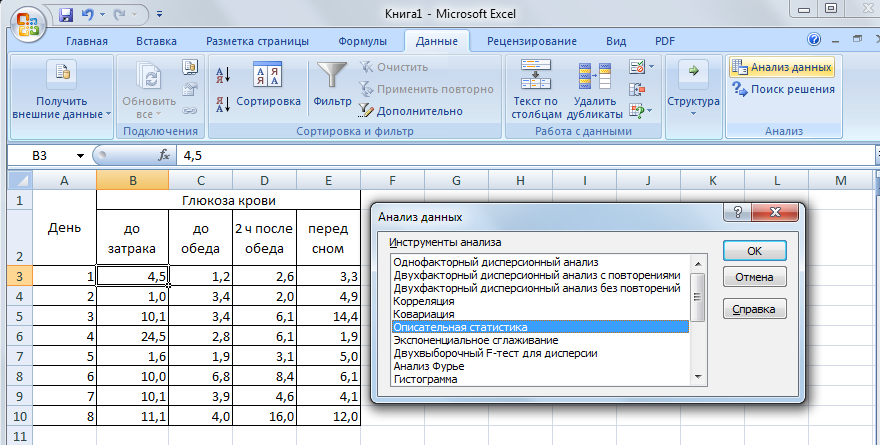 Рис.Работа с функцией Анализ данных
Рис.Работа с функцией Анализ данных
Появляется
диалоговое окно Описательная
статистика.
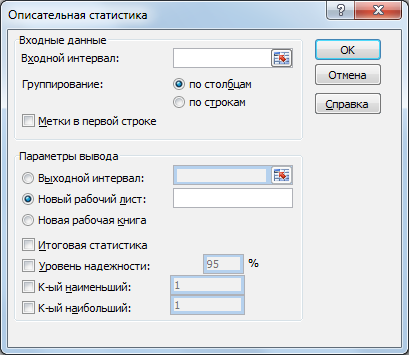
Рис.Диалоговое окно Описательная
статистика
Заполните
окно параметров статистики следующим
образом:
В
поле Входной
интервал –
диапазон ячеек с данными для статанализа,
в поле Выходной
интервал –
адрес ячейки, куда запишется результат
анализа.В параметрах вывода, устанавливаем
флажок в поле Итоговая
статистика
и нажимаем на ОК.

Рис.Ввод данных с диалоге Описательная
статистика
В результате
произведенных операций получим
рассчитанные показатели описательной
статистики.
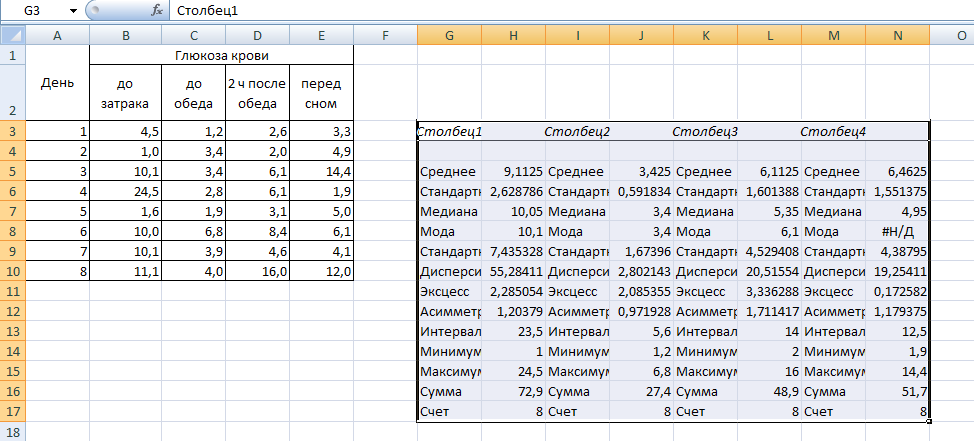
Рис. Результаты Описательной
статистики.
-
Диаграммы.
Диаграмма
– это способ наглядного представления
информации, заданной в виде таблицы
чисел. Демонстрация данных с помощью
диаграмм является более наглядной и
эффективной для восприятия.
Создание диаграммы
Диаграммы строятся
на основе данных, содержащихся на рабочем
листе, поэтому перед созданием диаграммы
они должны быть введены. Диаграммы в
Excel динамические, т. е. автоматически
обновляются после изменения данных, на
основе которых построены. Диаграмма
может быть размещена как на листе с
данными, так и на отдельном листе (занимая
весь лист).
По умолчанию
диаграмма состоит из следующих элементов:
• Ряды
данных –
представляют главную ценность, т.к.
визуализируют данные;
• Легенда
– содержит названия рядов и пример их
оформления;
• Оси
– шкала с определенной ценой промежуточных
делений;
• Область
построения
– является фоном для рядов данных;
• Линии
сетки.
Помимо упомянутых
выше объектов, могут быть добавлены
такие как:
• Названия
диаграммы;
• Линий
проекции –
нисходящие от рядов данных на горизонтальную
ось линии;
• Линия
тренда;
• Подписи
данных –
числовое значение для точки данных
ряда;
• И другие нечасто
используемые элементы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Статистические функции в Excel. Описание всех функций, как их использовать
- Как пользоваться статистическими функциями
- Перечень статистических функций
- Функция СРГЕОМ
- Функция СТАНДОТКЛОН
- Функция МОДА.ОДН
- Функция НАИМЕНЬШИЙ
- Функция НАИБОЛЬШИЙ
- Функция МЕДИАНА
- Функция СРЗНАЧЕСЛИ
- Функция МИН
- Функция МАКС
- Функции СРЗНАЧ и СРЗНАЧА
- Функция РАНГ.СР
- Лекция 2. Microsoft excel. Средства статистической обработки ms Excel
- Статистические функции в ms Excel
Статистические функции в Excel. Описание всех функций, как их использовать
Статистика – наука, которая используется для любых других исследований, а также обработки большого количества количественных и даже качественных данных. И что важно, это одно из главных применений электронных таблиц Excel, поэтому давайте более подробно рассмотрим, статистические формулы. Во-первых, что они нам дают? Прежде всего, они позволяют структурировать информацию и осуществить ее анализ. Статистические функции в Excel относятся к совершенно отдельной категории.
Как пользоваться статистическими функциями
Есть несколько способов ввода любой функции, и статистические не являются исключением:
- Ввести непосредственно в ячейке, предварительно нажав клавишу =. Это касается самых простых функций, несложных для запоминания и содержащих один или два аргумента. Например, так можно делать для операции умножения, сложения, вычитания и деления. А вот если функция сложная, то можно воспользоваться помощником. Это уже второй способ.
- Помощник по использованию функций. Он не только подсказывает, какая формула что означает, а и помогает ввести правильные аргументы применительно к конкретной функции.
Вызвать помощник можно несколькими способами:
- Воспользоваться кнопкой «Вставить функцию», расположенной слева от строки формул.

- Вызвать мастер ввода функций через кнопку «Вставить функцию», которая находится в левой части панели, которая открывается по клику на вкладку «Формулы».
- Воспользовавшись горячими клавишами Shift+F3.
Любой из этих методов приводит к одному результату – вызову мастера функций. Можно использовать тот, который больше всего подходит в конкретной ситуации. После того, как окно откроется, нам первым делом нужно выбрать категорию: статистические функции. 
После того, как тип функции будет выбран, нам нужно выбрать подходящую формулу из списка. Под перечнем видим, что есть описание, в котором рассказывается, что конкретная функция делает. 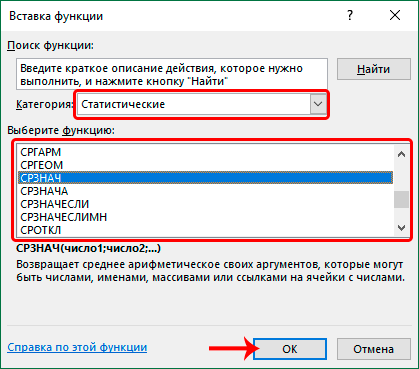
Чтобы подтвердить выбор функции, которая будет вводиться, нужно нажать клавишу ОК. После этого появится такое окно, в котором можно ввести параметры функции (или, как их еще называют, аргументы). 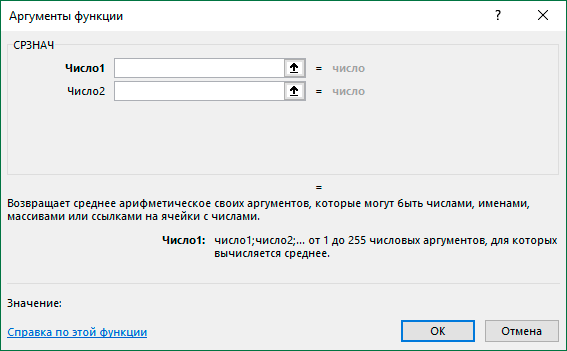
Интересный факт. Можно выбрать функцию еще одним способом. Для этого нужно перейти на вкладку «Формулы» и нажать на кнопку «Другие функции», расположенной на ленте.
Далее будет пункт «Другие функции» – «Статистические» и в появившемся списке ищем подходящую функцию и выбираем ее. Этот перечень может прокручиваться. 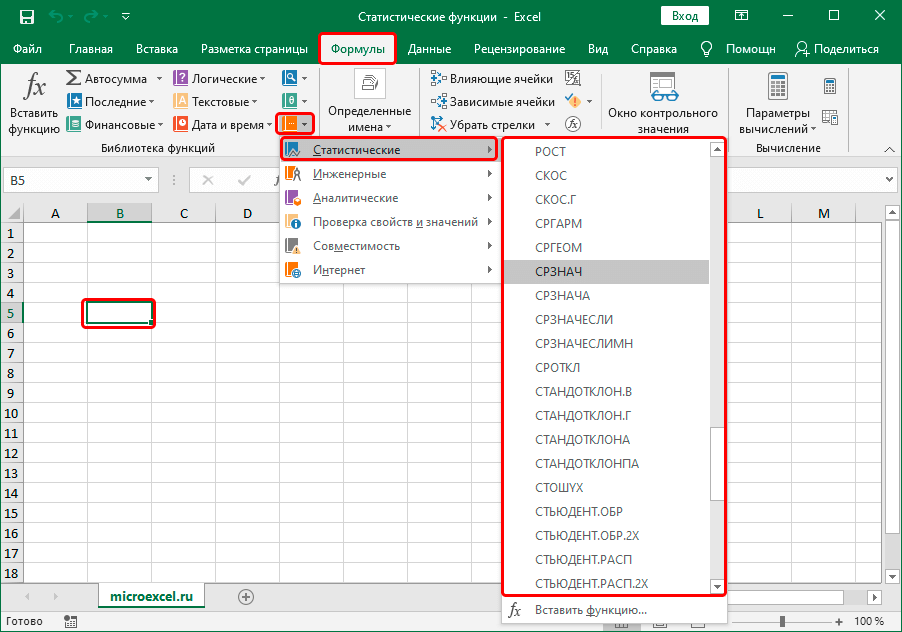
Перечень статистических функций
А теперь давайте перейдем непосредственно к рассмотрению статистических функций.
Функция СРГЕОМ
Много кто знает о таком параметре, как среднее арифметическое. Вычисляется оно с помощью функции, о которой мы еще сегодня обязательно поговорим. Но есть еще одна функция, которая определяет среднее геометрическое. 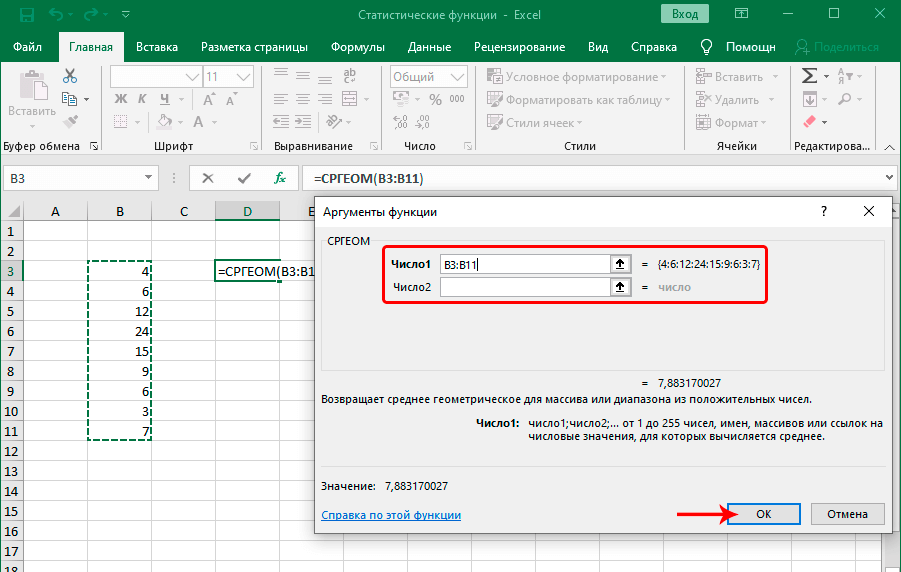
Формула очень простая: =СРГЕОМ(число1;число2;…). Кроме чисел также можно указать диапазон значений, которые учитываются этой функцией. Что же такое среднее геометрическое? Это число, которое может заменять любое из чисел в последовательности таким образом, чтобы не менялось произведение этих значений. Еще один часто используемый термин – среднее пропорциональное. Это синоним к среднему геометрическому. Такой второй термин используется, потому что среднее геометрическое пропорционально к первому и второму числам.
Функция СТАНДОТКЛОН
Один из главных статистических параметров, который должен рассчитываться вместо со средним арифметическим – стандартное отклонение. Это мера, демонстрирующая степень разброса значений. Выполняет ту же функцию, что и дисперсия, просто представлена в том же виде, что и среднее значение, в отличие от дисперсии.
Вообще, стандартное отклонение рассчитывается, как квадратный корень из дисперсии. Но в Эксель есть специальная формула, которая сразу вычисляет степень дисперсии, после чего на основе полученного значения получает стандартное (или среднеквадратическое) отклонение.
Сама эта формула довольно старая, но знать о ней надо, потому что время от времени ее можно найти в готовых таблицах. Сейчас уже есть более новые версии этой функции – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Последняя функция находит среднеквадратическое отклонение по генеральной совокупности, в то время как первая ориентируется исключительно на выборку.
В остальном, синтаксис обеих функций такой же, как и для вычисления среднего арифметического (об этом мы поговорим позже) – числа, которые перечислены через скобку.
Функция МОДА.ОДН
Мода выборки абсолютно не связана с одеждой или популярными машинами. Но при этом она связана со словом «популярный». Если говорить о статистике, то это значение в выборке, которое встречается наиболее часто. Соответственно, функция МОДА.ОДН дает возможность определить это значение.
Если говорить о синтаксисе, то он похож на многие другие статистические функции. Сначала пишется оператор, после чего в скобках записываются его аргументы, которые являют собой числа, разделенные запятой. В качестве значения аргумента может выступать не только число, но и отдельные ячейки, диапазоны значений. Это дает возможность более гибко управлять выборкой. На этом скриншоте отчетливо видно, как это работает на практике.
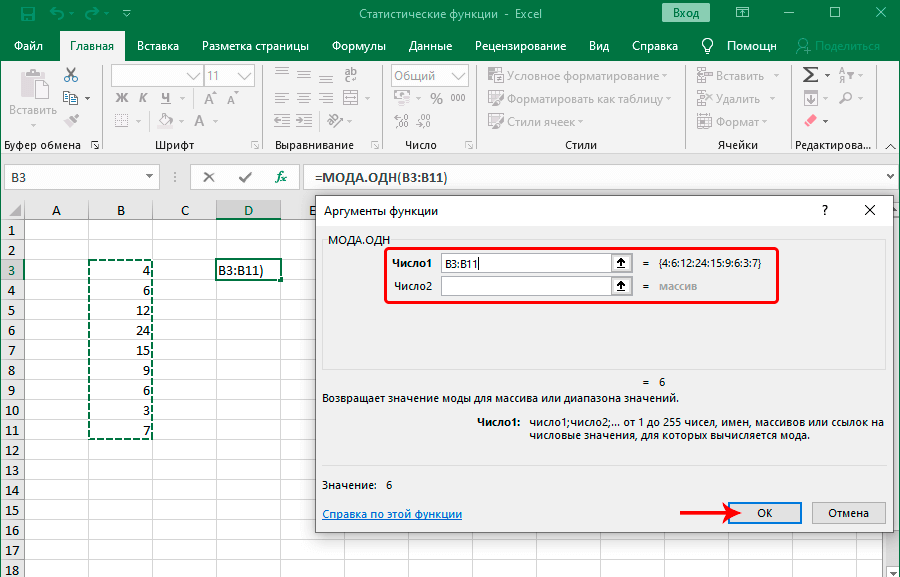
Эта функция подходит для горизонтальных массивов. Если же нужно определить моду выборки для вертикального массива, используется похожая функция МОДА.НСК. Общий внешний вид функции следующий: =МОДА.ОДН(аргумент 1, аргумент 2; аргумент …).
Функция НАИМЕНЬШИЙ
Задача этой функции – выполнение поиска из того набора значений, который был указан пользователем. Принцип ее работы такой же, как и следующий, только поиск осуществляется по направлению снизу вверх, от наименьшего числа к самому большому. Синтаксис этой функции предельно простой: =НАИМЕНЬШИЙ(массив;k).
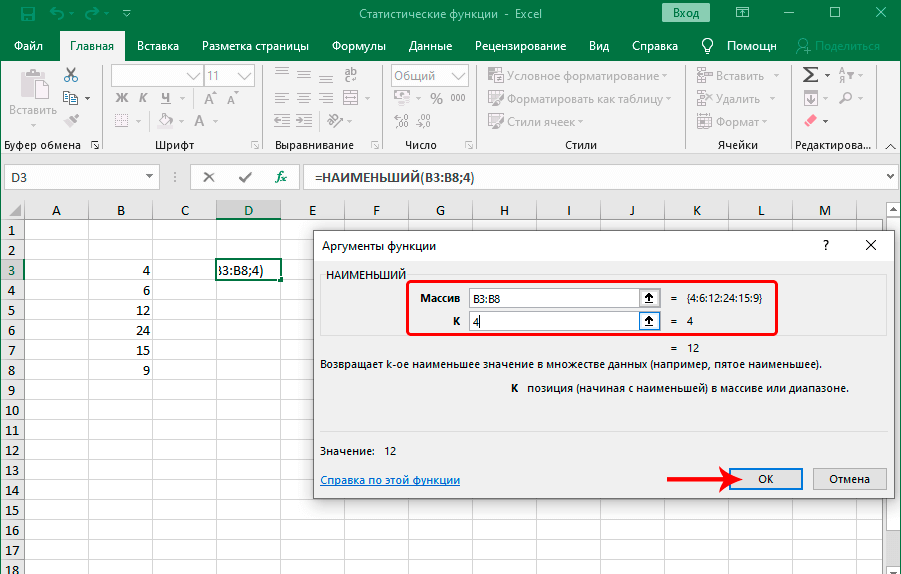
Функция имеет два основных аргумента: массив данных, по которым будет осуществляться поиск и порядковый номер элемента, который надо найти. Далее функция работает следующим образом: сначала она ищет самое маленькое значение, потом начинает перебирать цифры снизу вверх. Первое значение считается 1. То есть, если использовать число 1 во втором аргументе, то результат будет эквивалентным функции МИН, о которой мы поговорим немного позже.
Функция НАИБОЛЬШИЙ
Функция НАИБОЛЬШИЙ является аналогичной, только отсчет выполняет, начиная с самого большого значения. После того, как передать ей коэффициент, она ищет в порядковом ряду с большего в меньший число, занимающее соответствующее место и возвращает его. Работают обе функции аналогичным образом. Предположим, у нас есть числовой ряд. Если в нем в качестве числа k указать 2, то в результате получится число 15, поскольку оно является вторым по величине в диапазоне, который прописан в первом аргументе.
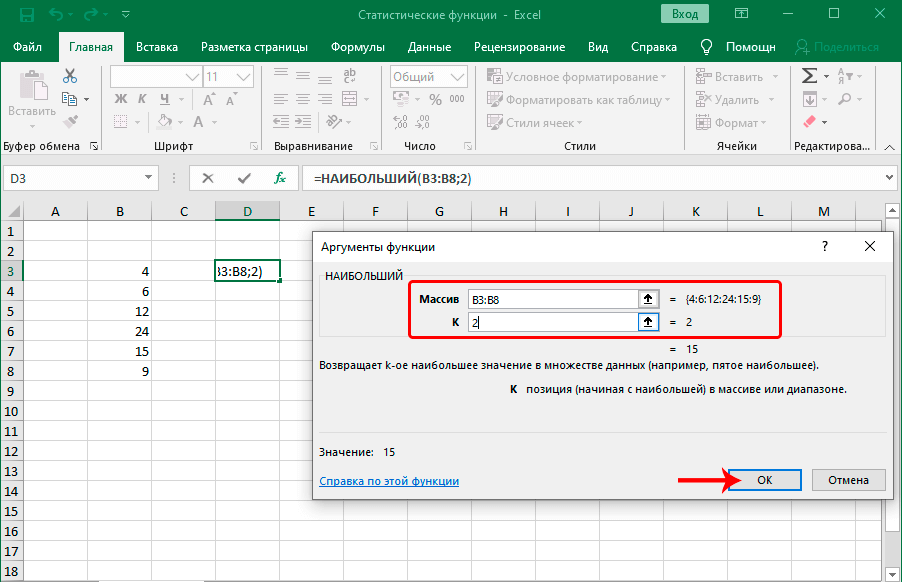
Эта функция может быть полезной в ситуациях, например, когда товар поступал в определенной последовательности, и нужно определить, сколько стоила, например, шубка, которая пришла второй по счету.
Функция МЕДИАНА
В статистике медиана – это разновидность среднего числа, которое находится ровно посередине числового ряда. Очень часто медиана является лучшим решением, чем стандартное среднее арифметическое, потому что позволяет определить действительно среднестатистическое значение. Синтаксис этой функции аналогичен тому, который имеет любой другой оператор, определяющий среднее значение – перечень цифр, ячеек или диапазонов, из которых данные будут получаться.
На этом примере видно, как на практике осуществляется работа с функцией. В диалоговом окне «Аргументы функции» можно вводить большое количество чисел, ячеек и диапазонов. На картинке мы попробовали ввести число в первую строку, ячейку во вторую и диапазон значений в третью. Получили в результате число 12. Максимальное количество аргументов этой функции – 255, что более, чем достаточно для полноценного использования этой функции. 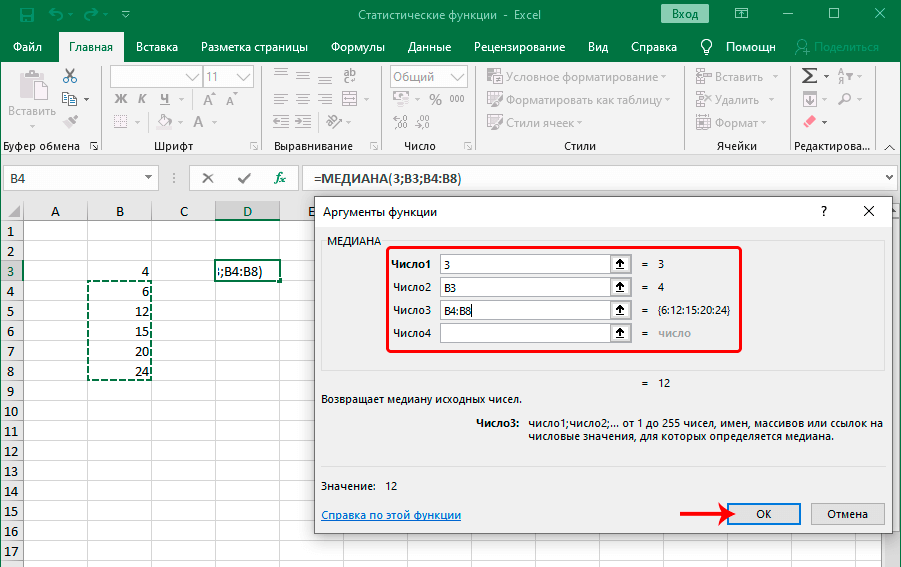
Функция СРЗНАЧЕСЛИ
Это улучшенная версия функции СРЗНАЧ, задача которой – находить среднее арифметическое, но лишь при условии, что определенное условие выполняется. Эта функция уже несколько сложнее тех, которые приводились выше: =СРЗНАЧЕСЛИ(диапазон;условие;диапазон_усреднения). Давайте рассмотрим каждый аргумент более подробно:
- Диапазон. Это ячейки, которые проверяются на предмет соответствия определенному условию.
- Условие. Это критерий, на предмет соответствия которому проверяется диапазон.
- Диапазон усреднения. Это тот диапазон, из которого будет доставаться среднее арифметическое. Этот аргумент вводить необязательно, поскольку диапазон ячеек и диапазон усреднения могут совпадать.
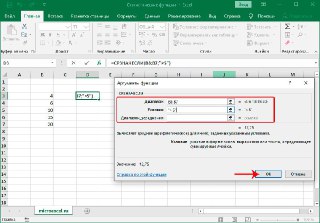
Функция МИН
В статистических подсчетах нередко нужно не только определить среднее значение, среднеквадратическое отклонение и вычислить другие показатели. Также важно значение наименьшего и наибольшего числа, в том числе, для получения указанных показателей. Практическое применение этой функции довольно обширное:
- На рынке акций для определения времени, когда цела была наиболее низкой.
- Для определения слабых мест в годовом бюджете (например, в каком месяце доходы компании были минимальными) с целью их дальнейшего исправления. Например, можно определить наименее доходный месяц и проанализировать факторы, которые этому способствовали.
Существует огромное количество других ситуаций, когда можно использовать функцию МИН. В самом общем виде она выглядит следующим образом: =МИН(число1;число2;…). Принцип заполнения аргументов этой функции аналогичен функции МАКС.
Функция МАКС
Как становится понятно из названия, эта функция ищет максимальное значение в определенной числовой выборке. Ситуации, в которых она может использоваться, в принципе, те же за тем лишь исключением, что все в противоположную сторону. Например, компания может с помощью функции МАКС определить самый доходный месяц и понять, каковы причины этого успеха.
Функции СРЗНАЧ и СРЗНАЧА
Стандартная функция СРЗНАЧ определяет среднее арифметическое в числовой выборке. Общий вид формулы такой же, как и для любой другой выборки значений. Сначала пишется название функции, после чего в скобках приводятся числа и диапазоны, которые необходимо обработать с помощью этой функции. То есть, общий вид формулы следующий: =СРЗНАЧ(число1;число2;…).
Как мы поняли, можно использовать как обычные числа (очень полезно для использования значений, которые не будут меняться в течение ближайшего времени), ссылки на ячейку (они применяются для тех значений, которые в будущем изменятся) и на диапазон (в этом случае будет использоваться целый набор чисел за один раз). Чтобы после ввода одного аргумента начать записывать другой, достаточно нажать на соответствующее поле в мастере функций или просто нажать на клавишу Tab.
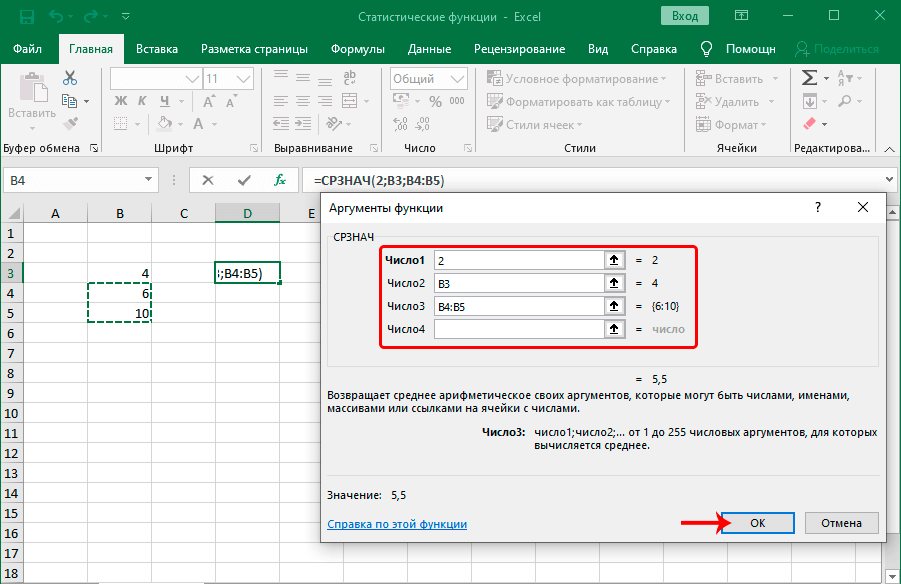
Максимальное количество аргументов, которые можно использовать в этой функции – 255. При этом обязательным аргументом является только первое число. В качестве аргументов не могут использоваться текстовые и логические значения. Они просто не учитываются формулой, в которой используется указанный оператор. Основное отличие функции СРЗНАЧА от СРЗНАЧ заключается в том, что текстовые значения и «ЛОЖЬ» считаются нулевыми, а значение «Истина» приравнивается к единице.
Функция РАНГ.СР
С помощью функции РАНГ.СР пользователь может вернуть ранг числа. Если несколько чисел в одном диапазоне относятся к одному рангу, то возвращается среднее. Имеет три аргумента, два из которых – обязательные:
- Число. Это то число, для которого осуществляется определение ранга.
- Ссылка. Это массив чисел, или ссылка на этот массив.
- Порядок. Это число, которое влияет на способ, в который значения будут упорядочиваться.
Таким образом, статистические функции Excel – это превосходный инструмент для обработки больших массивов информации.
Источник
Лекция 2. Microsoft excel. Средства статистической обработки ms Excel
1. Систематизировать знания о статистических функциях в Excel, получить представление о способах обработки статистические данных в табличном процессоре.
2. Ознакомиться с возможностями Пакета анализа в Excel.
3. Привести примеры работы со списками в Excel.
Статистические функции в ms Excel
Пусть представлены следующие статистические данные (см. таб. 1), по которым надо вычислить:
количество опрошенных женщин;
процент женщин среди опрошенных;
процент мужчин среди опрошенных;
средний возраст опрошенных (среднеарифметическое);
средний возраст (медиана);
минимальный и максимальный возраст опрошенных;
количество женщин с высшим образованием;
средний возраст женщин с высшим образованием;
Данные социологического опроса
Для такого рода вычислений будем пользоваться встроенными функциями. Рассмотрим некоторые из них.
1) СЧЕТ(значение1; значение2;…), которая подсчитывает количество чисел в списке аргументов. Функция СЧЁТ используется для получения количества числовых ячеек в интервалах или массивах ячеек.
Аргументы: значение1; значение2; …— это от 1 до 30 аргументов, которые могут содержать или ссылаться на данные различных типов, но в подсчете участвуют только числа.
2) СЧЕТЕСЛИ(диапазон;критерий), где диапазон – диапазон, в котором нужно подсчитать ячейки. Критерий – критерий в форме числа, выражения или текста, который определяет, какие ячейки надо подсчитывать.
3) СРЗНАЧ, которая возвращает среднее (арифметическое) своих аргументов. СРЗНАЧ(число1; число2; . )
Число1, число2, . – это от 1 до 30 аргументов, для которых вычисляется среднее.
4) МЕДИАНА(число1;число2;. ). Число1, число2. – от 1 до 30 чисел, для которых определяется медиана. Медиана – это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана.
5) МОДА(число1;число2;. ). Число1, число2. – от 1 до 30 чисел, для которых определяется мода. МОДА определяет значение, которое чаще других встречается во множестве чисел.
6) МАКС(число1;число2; . ). Число1, число2. – от 1 до 30 чисел, среди которых требуется найти наибольшее.
7) МИН(число1;число2; . ). Число1, число2. – от 1 до 30 чисел, среди которых требуется найти наименьшее.
 если числовые значения образуют полную генеральную совокупность, то для вычисления дисперсии и стандартного отклонения (среднего квадратического отклонения) используются функции ДИСПР и СТАНДОТКЛОНП.
если числовые значения образуют полную генеральную совокупность, то для вычисления дисперсии и стандартного отклонения (среднего квадратического отклонения) используются функции ДИСПР и СТАНДОТКЛОНП.
9) функции ДИСП и СТАНДОТКЛОН используются, если необходимо произвести вычисления дисперсии и стандартного отклонения по выборке.
Источник