
In finance and banking, it’s important to measure and understand credit risk. Let’s learn how to do vintage analysis in Microsoft Excel.
In finance and banking, it’s important to measure and understand credit risk. This helps track performance, manage downside, and make better decisions. Fortunately, Excel is an excellent way to perform this type of study. One method is vintage analysis. Let’s learn how to do vintage analysis in Microsoft Excel.
How to Do Vintage Analysis in Excel
Vintage analysis, in essence, is a table-format risk matrix. It helps you determine how many clients or customers are past-due on balances for varying periods of time. This layout is easy to structure with Excel, and it can provide plenty of meaningful information at a glance.
To use vintage analysis, you’ll first need to construct the matrix. One great way is to list account opening dates in a single column, like column A. In the next column, list how many accounts were opened in each of the date ranges. For example, if 36 accounts opened in January, type 36 in cell B2 beside January.

In subsequent columns, list time frames since accounts were opened. For example, you can use 6 months, 12 months, 18 months, and so on.
Once you have the matrix built, you can begin building formulas. You’ll need to pull information from your records regarding how many accounts have past-due balances.
For example, considering the January example again, imagine that 2 accounts are past-due after 6 months. In cell C2, input the following formula:
=2/B2

On the Home tab, format the cell to Percent Style. Now, think of what this is telling you. After 6 months, 5.56% of accounts opened in January are past-due. From here, you can repeat the same vintage analysis steps, calculating the percentage of past-due accounts by referencing formulas back to the total number of accounts.

As you can see, it’s easy to perform vintage analysis in Microsoft Excel.
Винтажный анализ портфеля: методика применения для кредитов мсб
«Банковское кредитование», 2018, N 6
Как измерить риски уже выданного портфеля ссуд МСБ, однородных по размеру? Есть несколько альтернатив: подход с использованием внутренних рейтингов, которые необходимо обновить на дату мониторинга; параметрический подход, связанный с моделированием убытков согласно известному аналитику виду распределения (на практике частоту дефолтов прогнозируют распределением Пуассона, а их размер — логнормальным распределением); моделирование непараметрическими методами. Как использование винтажного анализа может дать наиболее реалистичную оценку дефолтности портфеля и связанных с ним потерь?
При накоплении достаточного количества данных закономерности, связанные с поведением ссуд МСБ во времени по отношению к вероятности дефолта, становятся очевидными: в первый год кредиты гасят практически все заемщики, а период от полутора до двух с половиной лет является наиболее рискованным. Игнорирование этого факта может привести к серьезным ошибкам, как будет показано далее.
Методология
Пусть P(t) — портфель выданных поручительств на начало первого квартала года t. В первом квартале портфель состоит из поручительств разных возрастов (число кварталов, прошедших от даты заключения договора поручительства до текущего квартала года t):
,
где Si(t) — сумма выданных поручительств возраста i на начало первого квартала года t;
Tmax — максимальный возраст поручительств.
Считая, что pi — вероятность дефолта по договору, имеющему возраст i, на протяжении квартала зависит только от его возраста и не зависит ни от момента времени t, ни от суммы контракта, найдем вероятность того, что по договору возраста i произойдет дефолт в течение года t. Дефолт может произойти в любой из четырех кварталов с вероятностями:
pi — в первом квартале;
(1 — pi)pi+1 — во втором квартале;
(1 — pi)(1 — pi+1)pi+2 — в третьем квартале;
(1 — pi)(1 — pi+1)(1 — pi+2)pi+3 — в четвертом квартале;
(1 — pi)(1 — pi+1)(1 — pi+2)(1 — pi+3) — ни в одном из кварталов.
Таким образом, вероятность qi того, что дефолт по контракту, имеющему на начало года t возраст i, произойдет в течение года t, равна:
qi = 1 — (1 — pi)(1 — pi+1)(1 — pi+2)(1 — pi+3).
Сумма дефолтов по портфелю будет равна .
Для расчета прогнозного значения суммы дефолтных контрактов SD(t) необходимо знать вероятности p1, …, pTmax дефолта контрактов каждого возраста 1.., Tmax. Для оценки этих вероятностей предлагается использовать исторические данные. Пусть на начало некоторого квартала q имеется Nq открытых договоров. Обозначим Nqi сумму в рублях всех открытых договоров возраста i:
.
Пусть в течение квартала q дефолт случился для nq договоров. Обозначим nqi сумму в рублях дефолтных договоров возраста i:
.
Оценкой вероятности того, что дефолт в течение квартала q случится для договора возраста i, является показатель:
.
Используя 104 случайных подстановок сумм открытых договоров прогнозного периода согласно их текущему возрасту в исторические данные hqi, получим 104 сценариев убытка портфеля прогнозного периода. Штраф за низкую гранулированность портфеля предлагается рассчитывать так, чтобы убыток в каждом сценарии был не менее минимальной суммы кредита соответствующего периода, скорректированного на долю потерь при дефолте. SD(t) будет равна значению статистического обоснованного доверительного уровня совокупности значений полученных сценариев модели. Усложнением модели будут являться:
- Подстановка недискретных данных винтажной дефолтности, подобранных по типу распределения (наиболее близкий вид распределения винтажной дефолтности в большинстве случаев — экспоненциальное распределение).
- Создание гибридной модели путем расчета винтажной дефолтности, основанной на давности наблюдения через функцию где а k — количество наблюдений.
При наличии значительного количества данных, распределенных во времени, данную функцию экспоненциального сглаживания целесообразно заменить линейно рассчитываемым весом давности наблюдения относительно размаха дат наблюдений, установив минимальный уровень веса по принципу: , где , и, соответственно, един для всех наблюдений.
Такой подход позволит не удалять из расчетов старые данные, которые при экспоненциальном сглаживании получают вес, близкий к 0, и одновременно не игнорировать нулевые значения дефолтности последних наблюдений путем отражения в знаменателе веса даты не последнего дефолта, а последнего кредитного договора. В качестве порогового значения можно установить величину 0,5, если мы уверены, что качество риск-менеджмента последних периодов значительно отличается от прежних показателей.
- Создание гибридной модели путем расчета винтажной дефолтности, основанной на функции волатильности дефолтности рассчитываемых поколений относительно последних наблюдений («штраф» за волатильность) .
- Создание гибридной модели путем расчета винтажной дефолтности, основанной на функции корреляции дефолтности соответствующих поколений, получаемой путем перемножения дефолтности поколения на вариационно-ковариационную матрицу:
.
Итоговые распределения результатов модели лишь в некоторых случаях представляют собой логнормальные распределения — вид распределения, обычно используемый «по умолчанию» аналитиками. В ситуации, представленной на рис. 1, лишь два распределения являются логнормальными, одно — распределение Вейбулла, а остальные представляют собой гамма-распределения согласно информационному критерию Акаике.
Распределение результатов моделирования Рисунок 1
Выбор доверительного уровня моделирования может являться предметом отдельной статьи. Однако необходимо упомянуть, что выбор может быть осуществлен путем подбора моделей на исторических портфелях по правилам, сходным с известным коэффициентом логарифмического правдоподобия LRcc <1> с пороговым значением 5,99, широко использующимся для бэктестирования моделей. В этом отношении следует также упомянуть о возможности применения критерия Expected Shortfall (усредненного значения функции распределения, лежащей за пределами определенной отметки кредитного VaR), спектральных моделей (применения весов к значениям функции вероятности распределения, зависящих от квантиля распределения), однако полагаем, что простая методика определения минимального доверительного уровня, который ни разу не был превышен, представляется наиболее предпочтительной при наличии достаточной статистики.
<1> http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.41.8009&rep=rep1&type=pdf.
Методология на примере
Рассмотрим крупный банк, который развивает свою деятельность. Заложим параметры в модель, упростив некоторые из них (табл. 1 — 3).
Таблица 1
Исходные данные
|
Исторический портфель, руб. |
4 400 000 000 |
|
Доля дефолтов, % |
3,63 |
|
Новый портфель, руб. |
7 500 000 000 |
|
Действующий портфель на начало периода, руб. |
1 000 000 000 |
Таблица 2
Распределение выдач и дефолтов по кварталам исторического портфеля (1-й и 2-й годы) (руб.)
|
История |
Выдачи |
Дефолты |
|
I квартал |
1 000 000 000 |
0 |
|
II квартал |
1 000 000 000 |
0 |
|
III квартал |
1 000 000 000 |
10 000 000 |
|
IV квартал |
1 000 000 000 |
30 000 000 |
|
V квартал |
100 000 000 |
40 000 000 |
|
VI квартал |
100 000 000 |
40 000 000 |
|
VII квартал |
100 000 000 |
20 000 000 |
|
VIII квартал |
100 000 000 |
15 000 000 |
|
Итого |
4 400 000 000 |
155 000 000 |
Таблица 3
Новый портфель (3-й год) (руб.)
|
Период |
Выдачи |
|
IX квартал |
500 000 000 |
|
X квартал |
1 000 000 000 |
|
XI квартал |
2 000 000 000 |
|
XII квартал |
4 000 000 000 |
|
Итого |
7 500 000 000 |
Так как 1 млрд руб. из исторического портфеля согласно табл. 1 все еще действует, а новый портфель составляет 7,5 млрд руб., для прогноза убытков используется сумма 8,5 млрд руб., распределенная по договорам.
Убыточность (процент дефолтов к портфелю) на конец первого года составила 1%. На второй год деятельности, за оба года деятельности убыточность, рассчитанная на основании доли дефолтов в рублях по формуле:
,
составила 3,52% (измерять дефолтность в рублях убытка, а не в штуках представляется идеей довольно очевидной, обратное годится лишь для гомогенных (однородных) портфелей как по динамике, так и по суммам кредитов, что на практике встречается крайне редко). Часто умножают 3,52% на 8,5 млрд руб., получая некорректный результат в 299,4 млн руб. (ошибка усреднения), в то время как портфель может сгенерировать крайне низкий убыток, например в 28 млн руб.
Из табл. 4 видно, за счет чего может произойти прогнозная ошибка, — рассматривается фактор времени.
Таблица 4
Распределение дефолтов по кварталам каждого поколения с учетом новых выдач (винтажный анализ)
Данная таблица детализирует значения табл. 2. Она развертывает во времени информацию о том, по какому кварталу выдачи произошел дефолт. Например, в IV квартале (столбец IV кв.’) произошел дефолт в размере 30 млн руб., и он случился по выдачам I квартала (строка I кв.). Чтобы получить сумму дефолтов за какой-либо квартал, нужно сложить вертикальные значения, то есть просуммировать столбец с соответствующим кварталом. В VI квартале общая сумма дефолтов составила 10 млн руб. + 30 млн руб. — итого 40 млн руб., что соответствует табл. 2. Однако, в отличие от табл. 2, в данной таблице мы можем увидеть, что эта сумма дефолтов сложилась из выдач I кв. и III кв.
Из таблицы видно, что дефолты по всему портфелю на 3-й год жизни портфеля составили всего лишь 28 млн руб. (сумма столбцов IX — XII кв.). Чтобы понять, почему так произошло, можем перестроить таблицу в относительные значения как по убыточности, так и по времени (табл. 5).
Таблица 5
Убыточность (%) и срок жизни поколений
Ячейка XII кв.-1′ соответствует ячейке XII кв.-XII кв.’ табл. 4. XII квартал — это последний квартал выданных нами кредитов, поэтому возраст его равен 1. Срок жизни, то есть количество кварталов, прошедших к текущему моменту с даты завершения данного квартала, также равен 1.
Ячейка XI кв.-2′ соответствует ячейке XI кв. — XII кв.’ табл. 4. XI квартал — это предпоследний квартал выданных нами кредитов, поэтому возраст его равен 2. Срок жизни, то есть количество кварталов, прошедших к текущему моменту с даты завершения данного квартала, также равен 2, однако из таблицы мы можем посмотреть, как он показывал свою дефолтность и в сроке жизни 1.
Ячейка VII кв.-5′ соответствует ячейке VII кв. — XI кв.’ табл. 4. Это значит, что в XI квартале кредиты, выданные в VII квартале, имеют возраст 5, что также подтверждается нехитрым вычислением: 7 + 5 — 1 = 11.
Для простоты возьмем год, а не квартал, и создадим шаблон винтажной таблицы: например, первым поколением будет 2016 г. (табл. 6).
Таблица 6
Шаблон винтажной таблицы
|
Возраст поколения |
Срок жизни поколения к настоящему моменту |
||||||||
|
2009 |
8 |
Дефолты 2009 по портфелю 2009 |
Дефолты 2010 по портфелю 2009 |
Дефолты 2011 по портфелю 2009 |
Дефолты 2012 по портфелю 2009 |
Дефолты 2013 по портфелю 2009 |
Дефолты 2014 по портфелю 2009 |
Дефолты 2015 по портфелю 2009 |
Дефолты 2016 по портфелю 2009 |
|
2010 |
7 |
Дефолты 2010 по портфелю 2010 |
Дефолты 2011 по портфелю 2010 |
Дефолты 2012 по портфелю 2010 |
Дефолты 2013 по портфелю 2010 |
Дефолты 2014 по портфелю 2010 |
Дефолты 2015 по портфелю 2010 |
Дефолты 2016 по портфелю 2010 |
— |
|
2011 |
6 |
Дефолты 2011 по портфелю 2011 |
Дефолты 2012 по портфелю 2011 |
Дефолты 2013 по портфелю 2011 |
Дефолты 2014 по портфелю 2011 |
Дефолты 2015 по портфелю 2011 |
Дефолты 2016 по портфелю 2011 |
— |
— |
|
2012 |
5 |
Дефолты 2012 по портфелю 2012 |
Дефолты 2013 по портфелю 2012 |
Дефолты 2014 по портфелю 2012 |
Дефолты 2015 по портфелю 2012 |
Дефолты 2016 по портфелю 2012 |
— |
— |
— |
|
2013 |
4 |
Дефолты 2013 по портфелю 2013 |
Дефолты 2014 по портфелю 2013 |
Дефолты 2015 по портфелю 2013 |
Дефолты 2016 по портфелю 2013 |
— |
— |
— |
— |
|
2014 |
3 |
Дефолты 2014 по портфелю 2014 |
Дефолты 2015 по портфелю 2014 |
Дефолты 2016 по портфелю 2014 |
— |
— |
— |
— |
— |
|
2015 |
2 |
Дефолты 2015 по портфелю 2015 |
Дефолты 2016 по портфелю 2015 |
— |
— |
— |
— |
— |
— |
|
2016 |
1 |
Дефолты 2016 по портфелю 2016 |
— |
— |
— |
— |
— |
— |
— |
В данной таблице особенно простым становится преобразование года выдачи в возраст соответствующего поколения. Его можно использовать как шаблон для собственной аналитики, а также трансформировать в более короткие винтажные периоды, увеличивающие размер таблицы: кварталы, месяцы, 10-дневные периоды.
На основании табл. 5 построим график убыточности поколений (рис. 2).
Ненакопительный график убыточности поколений Рисунок 2
Седьмое поколение показывало убыток 3% два раза подряд и является самым «плохим» поколением портфеля. Девятое поколение показывало всего один раз убыток, составивший 0,5%, и является «хорошим» поколением портфеля.
Что касается ошибки усреднения, то, делая прогноз на основе дефолтов в портфеле на базе нескольких прошедших лет, нельзя понять, из каких поколений состоит текущий портфель и какого он возраста. Игнорирование винтажей портфеля при моделировании может привести к существенным ошибкам: смоделированные убытки могут отличаться от фактических приблизительно так, как кривая средних значений отличается от убыточности поколения 5 или 7 на графике.
Практическое применение данного графика заключается в визуальной оценке максимальной убыточности поколений и общем представлении о распределении убытков в зависимости от того, когда был выдан тот или иной блок кредитов. Также мы точно можем понять, что после девяти кварталов убытков по портфелю больше нет: портфель «отжил» свой срок. Больше информации мы сможем получить, перестроив график в накопительный (рис. 3), который получается путем сложения массива предыдущих значений в каждой строке табл. 5.
Накопительный график убыточности поколений (горизонтальный анализ) Рисунок 3
Данный график можно назвать горизонтальным анализом винтажной таблицы, так как исследуются закономерности одного поколения во времени.
Предположения оказались верными: риск-менеджеры 7-го поколения отработали хуже всех. Кажется, что лучше всех отработали риск-менеджеры 9-го поколения. Разберемся, так ли это.
«Невидимая» часть графика, совпадающая с абсциссой, — четыре поколения с нулевыми значениями дефолтности — это 1-е — 4-е поколения, то есть кредиты, выданные в XII, XI, X и IX кварталах соответственно. Вероятно, 1-е, только что выданное (в XII квартале), поколение оценить сложно — не прошло достаточного количества времени. Попробуем применить массив имеющихся значений к оценке того, насколько поведение 1-го — 4-го поколений типично для данных возрастов. Используем статистику нашего портфеля и выстроим гипотезы созревания портфеля поручительств во времени. Для этого исследуем массив значений столбцов винтажной таблицы (вертикальный анализ) — то есть поведение всех поколений портфеля во времени (рис. 4).
Созревание убыточности портфеля во времени (вертикальный анализ) Рисунок 4
Данный график созревания портфеля показывает, как убыточность зависит от возраста поколения.
Получается, что результат 2-го — 4-го поколений лучше медианных значений статистического массива, и тем лучше значения 85-го персентиля и максимума убытков. Таким образом, мы можем сделать вывод, что риск-менеджеры 2-го — 4-го поколений отработали лучше, чем обычно.
Также мы видим ценную информацию: пик убытков приходится на VI и VII кварталы жизни кредита, при этом в течение V и VI кварталов он сохраняется высоким. Это значит, что подводить итоги нужно только после того, как этот пик будет пройден.
После VIII квартала за портфелем можно уже не наблюдать: он в большинстве случаев новых убытков не принесет.
Эта таблица, а вернее массив значений, ее составляющих, важнейшая в винтажном анализе, так как данный массив значений может быть экстраполирован на дальнейшие выдачи и позволяет в том числе прогнозировать поведение новых поколений кредитов.
Таким образом, пример с убытком в 28 млн руб. в наблюдаемом портфеле может быть объяснен крайне просто: большой портфель 1-го года из примера уже созрел и не дает убытков, малый портфель 2-го года находится на пике своей убыточности, но слишком мал, чтобы привести к большим потерям в денежном выражении, а существенный рост выдач 3-го года еще не показал свою убыточность.
Для получения прогноза необходимо последовательно «продвинуть» портфель во времени, взяв случайные величины из винтажной дефолтности возраста соответствующего поколения и принимая во внимание тот факт, что новых выдач по данному поколению уже не будет. Соответственно, на винтажную дефолтность умножается сумма выдачи поколения с поправкой на фактор экспирации (кредитные договоры, которые на предыдущем шаге прогноза уже закрыты, не учитываются). В случае если винтажи рассчитывались на квартальных данных, а прогноз делается на год, искусственно «состарить» портфель необходимо последовательно на один квартал, далее еще на один и далее на то число кварталов, которое содержится в прогнозном периоде (в примере с годовым прогнозом мы последовательно «продвигаем» портфель во времени четыре раза).
Полученные значения являются результатом одной модели. Для прогноза берется 104 моделей, в каждой из которых действия по «состариванию» портфеля повторяются. Сохраненные результаты представляют собой многомерное дискретное распределение, для упрощения интерпретации которого можно выбрать доверительный уровень и рассчитать соответствующий квантиль значений каждого шага прогноза. Для более продвинутой работы с портфелем можно подобрать наиболее подходящий тип распределения и рассчитать его характеристики.
Работая с функцией уже известного распределения, можно перестраивать результаты моделирования без необходимости повторных расчетов и экспериментировать с вопросами оптимальных характеристик нового бизнеса, включая требования к суммам и длительности новых договоров (что позволяет создать некий «идеальный» по убыточности портфель на данных конкретного финансового учреждения), а также значительно расширять горизонты планирования.
Изложенный подход в своей основе довольно известен, однако раз за разом демонстрирует свою применимость на практике, позволяя избежать избыточных оценок CVaR на 99,9%-ном доверительном уровне и далекого от практики (на взгляд автора) подхода к расчету вероятности потерь через дискретное распределение Пуассона. Дополнительным плюсом является отсутствие необходимости формирования каких-либо экспертных оценок или макроэкономических моделей, а также необходимости получения внешних данных по пулу заемщиков.
Кроме того, хотелось бы отметить довольно большое количество опций расчетов, что, с одной стороны, представляет определенный научный интерес, а с другой — обусловливает необходимость единообразного и последовательного применения параметров моделей в случае, если их результаты используются бизнесом на постоянной основе.
Хочется пожелать всем специалистам взвешенных оценок при принятии решений!
В. Козлов
Член экспертного совета журнала
Время на прочтение
18 мин
Количество просмотров 18K

Привет!
В предыдущей статье цикла о моделировании в задачах управления кредитным риском (здесь) мы провели обзор трех задач кредитного риск-менеджмента, нашли возможные точки приложения ML и DS к этим задачам и попутно ввели набор терминов для дальнейшей работы.
Сейчас мы расскажем о трех компонентах (PD, LGD, EAD), которые участвуют при расчете ожидаемых потерь: рассмотрим основные драйверы и методологию построения моделей. В конце статьи приведем сводную таблицу с особенностями работы с компонентами на различных этапах разработки, сформированную на основе нашего проектного опыта.
За подробностями добро пожаловать под кат.
PD или как ковер задает стиль всей комнате

Определение дефолта
Начнем с главной компоненты, которую необходимо оценивать (например, в случае базового или продвинутого ПВР) PD (a. k. a. probability of default) – вероятность дефолта клиента. В качестве свидетельства о дефолте клиента могут выступать разные события в кредитной истории. Часто – это просрочка платежа по кредитному договору 90 и более дней.
Для подсчета количества дней просрочки существует два метода: LIFO (last in first out) и FIFO (first in first out) [1]:
- По методу LIFO, подсчет количества дней просрочки долга начинается с даты возникновения ненулевой суммы на счете просрочки и до момента обнуления суммы на этом счете.
- По методу FIFO, счётчик количества дней просрочки основного долга также начинает работать с даты возникновения ненулевой суммы на счете просрочки, но может уменьшаться при погашении одного из просроченных платежей.
Мы работаем с расчетом количества дней просрочки по методу FIFO. С FIFO проще определять просрочку и учитывать динамику ее уменьшения. В случае LIFO величина просрочки резко уменьшается до 0 при полном погашении. В такой ситуации сложнее управлять одним из параметров дефолта: датой его окончания. Здесь необходимо пояснить, какие атрибуты являются ключевыми для описания события дефолта.
Для определения дефолта необходимо задать следующие три атрибута:
- Тип события дефолта. Таким событием может являться как уже упомянутая выше просрочка 90+, так и реструктуризация долга, банкротство заемщика, ухудшение категории качества кредитного договора и др.;
- Дата начала дефолта — обычно напрямую зависит от причины и определяется как дата ее возникновения;
- Дата окончания дефолта — дата события, при наступлении которого мы можем считать, что клиент «выздоровел» (например, для просрочки 90+ это может быть снижение просрочки до 30-/0 или даже дата получения нескольких подряд своевременных платежей после полного погашения задолженности). Все зависит от политики банка.
В связи с наличием вариативности в определении дефолта, хорошая практика – составление так называемой витрины дефолтов, в которой хранится информация об атрибутах дефолта.
Но этого недостаточно для формирования целевого события. У целевого события есть еще один важный атрибут: горизонт сбора информации о дефолте, или горизонт моделирования.
Определение длины горизонта
Информация о дефолте используется для оценки ожидаемых потерь, под которые банк осуществляет резервирование. В этом случае возникает вопрос, а на каком периоде смотреть выходы в дефолт? Важно ли это? С точки зрения бизнеса, важно понимать период планирования, с точки зрения моделей мы хотим выбрать такой период, в котором будет охвачено не менее 80%-90% всех возможных выходов в дефолт для всех открытых и не находящихся в дефолте договоров на текущий момент времени.
Для целей выбора длины горизонта может быть использован винтажный анализ [2]. Он заключается в построении графической аналитики и последующего вывода о данных по ней. График может быть построен так:
- Рассматриваются несколько временных срезов (поколений/когорт) на исторической выборке;
- Для каждого из поколений учитываются все наблюдения из выборки для моделирования, не находящиеся в дефолте;
- Для таких наблюдений строится кумулятивный график выхода в дефолт. Обычно временной шаг – месяц. График может быть построен как в штуках, так и в деньгах;
- Горизонт может быть определен, например, как временной интервал, на котором выходят в дефолт 80% всех тех клиентов, которые вообще окажутся дефолте за весь доступный исторический период.
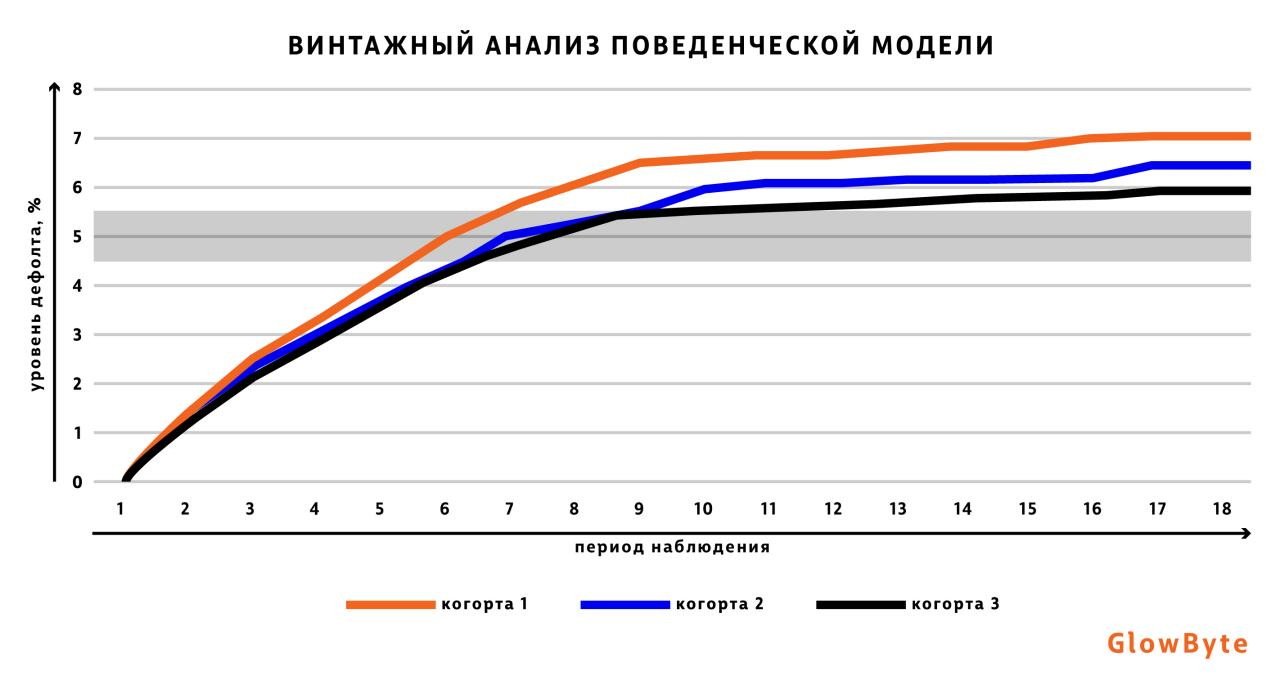
При построении графика выше для каждой когорты было рассчитано значение, составляющее 80% от максимального числа наблюдений, вышедших в дефолт, а диапазон полученных значений обозначен серой полосой. По графику можно сделать вывод о том, что оптимальная длина горизонта лежит в интервале 6-8 месяцев.
Сегментирование выборки
Некоторые атрибуты настолько сильно коррелируют с целевой переменной, что вклад остальных практически нивелируется. Это приводит к моделям с плохим ранжированием внутри группы с одинаковым значением «главного» атрибута. Во избежание такой ситуации используют подход сегментации, в рамках которого выборку делят на два или несколько сегментов — по одному на каждое значение «главного» атрибута (драйвера), и для каждого из них строят отдельную модель. В кредитном риске один из таких драйверов – наличие или длительность просрочки по платежу.
Если выборка была разделена на два сегмента по длительности просрочки: сегмент с малой просрочкой и сегмент с большой просрочкой, и второй сегмент достаточно мал, то для него можно сделать простую модель на двух атрибутах: на скоринговом балле модели с малой просрочкой и длительности текущей просрочки. Если результат удовлетворяет всем требованиям валидации, то на нем можно остановиться.
Альтернативно можно разделить выборки на сегменты с просрочками за историю (I) и без просрочек за историю (II).
- Сегмент I – это наблюдения (клиент – дата наблюдения), для которых за всю историю или на каком-то горизонте ранее не наблюдалось просрочки.
- Сегмент II содержит наблюдения у которых в истории или на каком-то горизонте ранее наблюдались просрочки по платежу.
В этом случае разделение на классы, как правило, более сбалансировано.
Необходимое условие для сегментации – достаточное количество дефолтных наблюдений в каждом из сегментов. А для того, чтобы выяснить целесообразность и границы новых сегментов используется roll-rate анализ [3]. Он заключается в разделении выборки на подсегменты на основании значений величины текущей просрочки и сравнении между ними среднего уровня дефолта. Те группы, уровень дефолта которых значимо различается, имеет смысл моделировать по отдельности.
Рассмотрим, например, сегментацию наблюдений по величине просрочки. На картинке ниже в качестве примера выделены следующие 5 сегментов, соответствующих интервалам (бакетам) значений просрочки: 0-4 дня, 5-14 дней, 15-29 дней, 30-59 дней, 60-89 дней. Эти сегменты рассматриваются в нескольких моментах времени: HY1_2015, HY2_2015 — соответственно, первое и второе полугодия 2015 года, HY1_2016, HY2_2016 — соответственно, первое и второе полугодия 2016 года. В процессе анализа нас интересует динамика выхода наблюдений в просрочку более 89 дней, поэтому для каждого из этих сегментов подсчитан процент клиентов, просрочка которых на горизонте наблюдения составила более 89 дней.
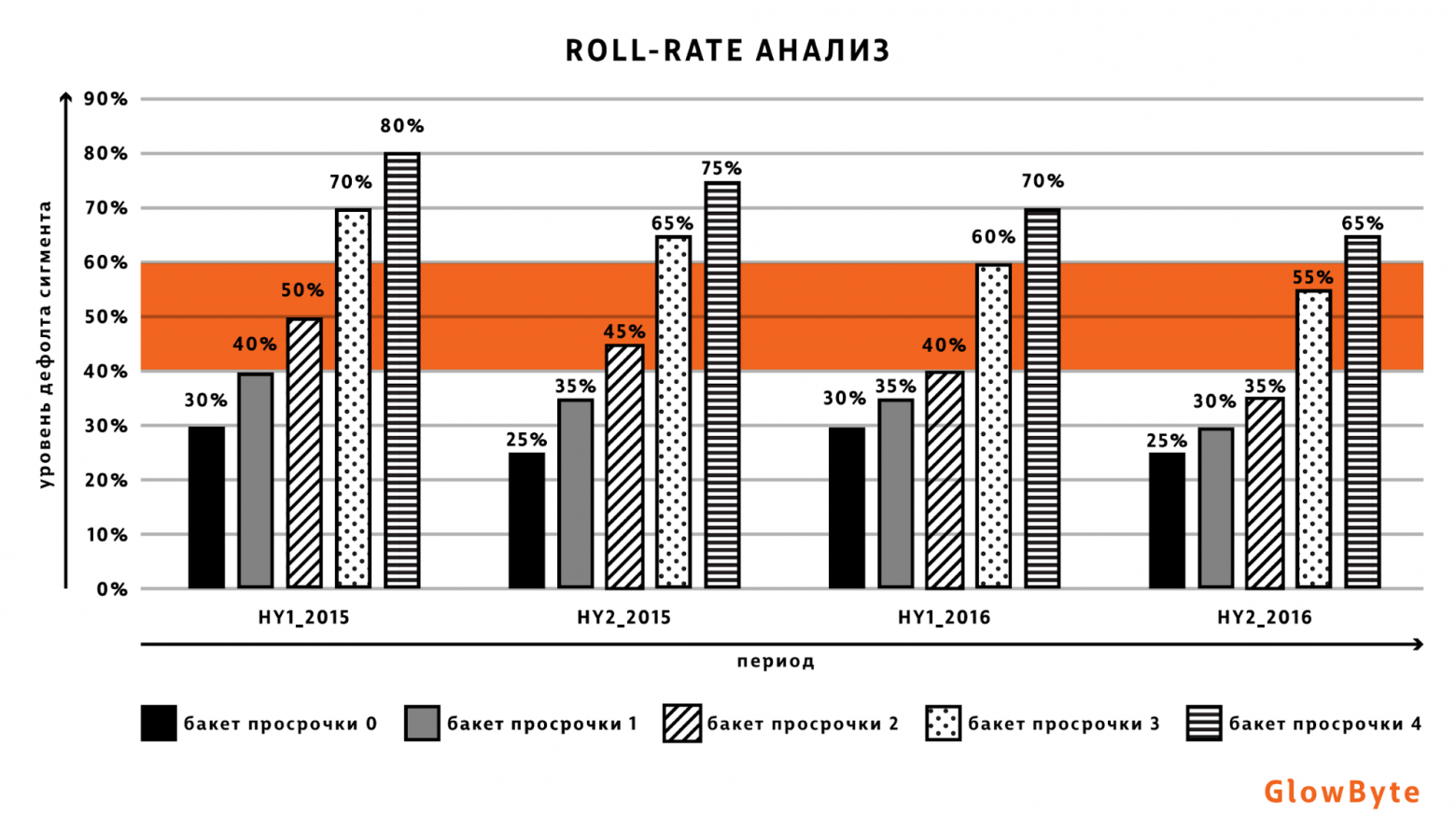
По графику можно сделать следующие выводы:
- В 0-1 сегментах низкая вероятность выхода наблюдений в просрочку 90+ дней, наблюдения из данных сегментов можно отнести к «good»/недефолтному сегменту. Можем воспользоваться данной информацией для определения границы при сегментировании клиентов по уровню текущей просрочки.
- В 3-4 сегментах высокая вероятность выхода наблюдений в просрочку более 90+, наблюдения из данных сегментов можно отнести к «bad»/дефолтному сегменту. Это может быть полезно, если мы хотим сместить границу и увеличить число дефолтов в good сегменте.
- Сегмент номер 2 является промежуточным, наблюдения из данного сегмента нельзя отнести ни к дефолтному сегменту, ни к не-дефолтному. Такие наблюдения могут исключаться из разработки для увеличения ранжирующей способности модели.
После дефолта вероятность дефолта становится равной 100%. А что еще происходит в момент дефолта? Смотрим дальше.
EAD (Деньги в дефолте)
После того, как оценена вероятность дефолта заемщика, ставится вопрос – с какой суммой задолженности заемщик уйдет в дефолт? Эта сумма линейно влияет на размер ожидаемых потерь и, соответственно, объем резервов, и называется exposure at default – требования в дефолте. Итак, EAD – exposure at default – кредитные обязательства по договору на момент дефолта.
Напрямую, как правило, EAD не моделируют. Так как эта величина – денежная, её распределение не носит нормальный характер: в выборке могут присутствовать наблюдения очень большие и очень маленькие, не являющиеся при этом аномалиями. В зависимости от специфики портфеля можно выбрать разные целевые переменные – об этом подробнее будет сказано в последующих статьях цикла, но наиболее широко используемая – CCF – credit conversion factor – коэффициент кредитной конверсии – вычисляется следующим образом:

где:
Balance – сумма средств, которые клиент должен банку в момент наблюдения,
Limit – доступный клиенту лимит,
EAD – сумма средств, который клиент должен банку в момент дефолта.
Получается, что CCF – это та часть доступных на момент наблюдения средств, которая будет использована клиентом к моменту дефолта.
Как и вероятность дефолта, эту величину необходимо прогнозировать заранее. Обычно горизонт прогноза такой же, что и у PD.
Все описанное выше касалось денег до дефолта и во время него. А что происходит сразу после? Об этом компонента LGD.
LGD («Где деньги, Лебовски?»)

Даже в случае дефолта заемщика, часть средств возвращается в банк:
- Заемщик осуществляет платежи;
- Банк реализует залог;
- Осуществляется списание или продажа долга;
- …
Та часть EAD, которую банку всё-таки не удалось вернуть, называется LGD – loss given default.
Поскольку временной интервал, на котором происходит т.н. «восстановление» (возвращение долга), может варьироваться поклиентно, возникает необходимость определить длину горизонта восстановления, на котором будет рассчитываться целевая переменная. На длину горизонта влияет в первую очередь доступность достаточного временного периода в данных для моделирования. Обычно длина горизонта лежит в диапазоне 3-5 лет после дефолта.
В общем случае LGD рассчитывается формуле:
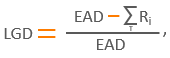
где:
Ri – денежный поток от клиента (выплаты, реализация залога и др.), полученный на горизонте восстановления после дефолта,
T – временной период от момента учета возмещения после момента дефолта (в годах).
При расчете денежного потока, который идет на восстановление, обычно используется дисконтирование – механизм учета текущей стоимости денежных средств, полученных на горизонте восстановления. Особенно это актуально на больших горизонтах, когда стоимость денег может существенно изменяться.
Суммы возмещения, затрат и продажи долга при дисконтировании умножаются на «фактор дисконтирования» [4] P(T):
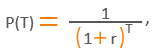
где:
T – временной период от момента учета возмещения после момента дефолта (в годах),
r – ставка дисконтирования.
В качестве r может быть использована, например, процентная ставка по договору.
С компонентами, в первом приближении, понятно: все разные, а моделировать их нужно вместе! Есть ли какой-то подход, который позволит более-менее единообразно отобрать переменные для моделей и выбрать наиболее оптимальную комбинацию? Можно попробовать. О возможном варианте далее.
«Великолепный план, Уолтер … надёжный как … швейцарские часы» или pipeline разработки

Этапы моделирования компонент риска схематично изображены на следующей диаграмме (стрелки – дополнительные итерации, возникающие в процессе разработки):
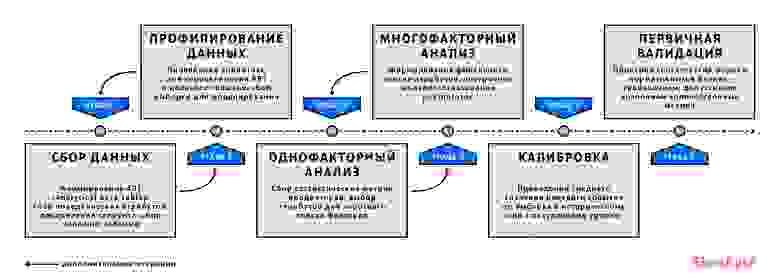
Подготовка данных
Подготовка данных включает в себя формирование трёх сущностей: наблюдения (сегмент), витрина дефолтов, витрина атрибутов,- с единым внешним ключом — ID заемщика или договора и временная метка.
Такая декомпозиция обеспечивает гибкий подход к формированию выборки – легко изменять горизонт, гранулярность наблюдений, определение дефолта и не беспокоиться о корректности сбора атрибутов для итоговой витрины.
Каждое наблюдение – ID заемщика или договора и временная метка; другими словами, нас интересует состояние заемщика или договора на конкретную дату. Обычно используются наблюдения, соответствующие временным срезам, отстоящим друг от друга на равные промежутки времени (например, квартальным).
В случае задачи резервирования объем данных должен включать в себя полный экономический цикл, что составляет примерно 5-7 лет.
Для формирования выборки необходимо учитывать горизонт.
Пояснение схематично изображено на картинке под катом

В выборки для разработки и тестирования включаются наблюдения, для которых есть данные о выходе в дефолт на всем горизонте, поскольку включение наблюдений, для которых не прошел полный этап сбора (на картинке изображен красным цветом) приведёт к смещению величины уровня дефолта.
Из-за необходимости учитывать период сбора, оптимальная глубина данных составляет 2-3 горизонта наблюдения.
Также, если в модели планируется учесть какого-то рода сезонность — необходимо соответствующим образом выбирать глубину данных и периодичность срезов.
В таблице под катом перечислены основные группы и примеры атрибутов широкого списка переменных.
Атрибуты широкого списка переменных
Один из способов увеличения интерпретируемости и стабильности модели – это использование в качестве атрибутов не абсолютных значений признаков, а относительных: нормированных, например, на доход (выручку) или отражающих тренд/динамику показателя на временном интервале.
Однофакторный анализ
Целью проведения однофакторного анализа является уточнение широкого списка факторов таким образом, чтобы исключить неподходящие переменные.
Для проведения однофакторного анализа необходимо разбить выборку на выборки для разработки (train) и тестирования (test). Выборка для тестирования может быть сформирована одним из следующих способов:
- Out-of-time – разделение происходит по временной метке наблюдений; при данном разбиении нас интересует стабильность модели во времени. Самый распространенный способ разбиения;
- Out-of-time X Out-of-id – разделение происходит как по временной метке, так и по id клиента; множество id клиентов и множество временных меток в выборке для разработки и тестирования не пересекаются, при данном разбиении нас интересует стабильность модели как во времени, так и по клиентам. Данный способ используется при достаточном количестве наблюдений в выборке.
Отбор факторов происходит на основании экспертных правил. Пример такого отбора:

По результатам однофакторного анализа формируется таблица с матрицей взаимных корреляций факторов и таблица, содержащая исходный ранжированный список переменных, а также следующие поля: значение показателя оценки предсказательной способности (коэффициент Джини) на выборке для разработки и тестирования, значение статистики PSI для определения стабильности фактора, комментарий по поводу отбора фактора для дальнейшего исследования.
Стоит отметить, что в идеальном мире (где достаточное число клиентов и дефолтов) корректнее разбивать исходную выборку на три части (разработка, валидация и тестирование). В рамках такого разбиения проведение однофакторного анализа ведется на выборках для разработки и валидации, а итоговое качество отбора оценивается на выборке для тестирования. Для упрощения мы здесь и далее рассматриваем разбиение на train/test.
Многофакторный анализ и финальная модель
Цель многофакторного анализа – построение оптимальной комбинации факторов из списка, образованного на предыдущем шаге, для максимизации предсказательной силы модели при сохранении стабильности.
Процесс многофакторного анализа заключается в построении множества моделей и выборе наилучшей из них. Модели строятся на различных наборах атрибутов из списка, сформированного на этапе однофакторного анализа,
Две самые распространенные модели для прогноза вероятности дефолта – это:
- Логистическая регрессия с последующим построением скоринговой карты – интерпретируемый результат;
- Различные реализации градиентного бустинга – неинтерпретируемый результат.
Рассмотрим построение интерпретируемой модели – модель логистической регрессии. Для увеличения стабильности и интерпретируемости перед построением модели над атрибутами проводятся следующие действия:
- Категоризация атрибута – разбиение атрибута по значениям на группы/бины;
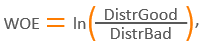
- Вычисление значения WOE – значение, вычисляемое для каждого бина атрибута, образованного при категоризации по следующей формуле: [5]

где:
DistrGood – отношение числа недефолтных наблюдений, имевших значение атрибута из данного бина, к общему числу недефолтных наблюдений;
DistrBad – отношение числа дефолтных наблюдений, имевших значение атрибута из данного бина, к общему числу дефолтных наблюдений.
Общие правила для выполнения категоризации атрибутов складываются из экспертных правил (принципы заполнения пропусков, условие монотонности WOE, соответствие логике атрибута) и статистических критериев (достаточность наблюдений в категории).
Одним из недостатков подхода с использованием значений WOE вместо реальных значений атрибута являются потенциально возможные скачки значений вероятности дефолта (PD). Для решения указанной проблемы может использоваться сглаживание порогов функции WOE с целью создания непрерывных «плавных» переходов между соседними значениями WOE. Чаще всего сглаживание может производиться с помощью сигмоиды или гиперболического тангенса.
После описанных выше преобразований над атрибутами модель логистической регрессии строится над преобразованными атрибутами. Для выбора оптимальной комбинации факторов может быть использовано несколько подходов: [6]:
- Forward – подход с последовательным добавлением факторов;
- Backward – подход с последовательным удалением факторов;
- Stepwise – комбинация подходов Forward и Backward.
При этом все выбранные атрибуты должны быть не коррелирующими (порог определяется экспертно) друг с другом, и p-value (уровень значимости) каждого атрибута не должен превышать порога, например, в 5%. Дополнительная проверка на мультиколлинеарность может быть произведена с помощью метрики VIF [7].
При построении модели в качестве оптимизируемой метрики могут быть использованы информационные критерии (например, SBC [8], AIC [9]). Разбиение атрибутов на группы и расчет значений WOE производится на выборке для разработки, а затем сформированный биннинг и соответствующие ему значения WOE транслируются в выборку для тестирования.
В случае, когда нет требования интерпретируемости, может быть использована модель градиентного бустинга, наиболее часто используется реализация библиотеки Xgboost. В данном случае отсутствует требование к слабой корреляции атрибутов модели. В случае необходимости ограничить набор признаков модели, используется значимость атрибута – его вклад в итоговое качество, оцениваемое коэффициентом Джини, дает не менее 1% или уменьшает функцию потерь на величину, превышающую пороговое значение.
Итоговое качество модели определяется на тестовой выборке. Выборка для тестирования может формироваться тем же способом, что и при проведении однофакторного анализа.
Сводная таблица по компонентам
В заключение – таблица с указанием особенностей моделирования в разрезе компонент ожидаемых потерь.
Выводы
Итак, в статье мы провели детализацию особенностей моделирования компонент ожидаемых потерь: PD, LGD и EAD.
Главный вывод можно сформулировать следующим образом: прежде чем мы дойдем до
import xgboost as xgb
ML необходимо существенную часть времени потратить на аналитику и учитывать особенности бизнес-процессов при разработке и тестировании модели. Формулу для DS, применительно к нашим компонентам, можно записать в следующем виде:

Однако здесь стоит иметь ввиду два момента. Во-первых, для сегмента физических лиц характерна большая доля ML и автоматизации решений, по сравнению с сегментом юридических лиц. Во-вторых, доля ML вырастает за счет привлечения продвинутых алгоритмов для анализа, например текстовых и геоданных, а также для поиска сложных паттернов поведения клиентов по разнородным источникам.
Авторы статьи: Александр Бородин (abv_gbc), Алиса Пугачёва (alisaalisa),
Артём Савинов (artysav), Илья Могильников (eienkotowaru).
Список использованных терминов и сокращений
- ABT — analytical base table – витрина данных для моделирования [10].
- CCF – credit conversion factor — часть доступных на момент наблюдения средств, которая будет использована клиентом к моменту дефолта.
- DS — data science.
- DTF – downturn factor – фактор, учитывающий вероятность экономического спада.
- EAD – exposure at default – кредитные обязательства по договору на момент дефолта. По сути, баланс на дату дефолта, где баланс = Тело долга + Просрочка.
- FIFO просрочка – метод расчета просрочки, при котором счётчик количества дней просрочки основного долга начинает работать с даты возникновения ненулевой суммы на счете просрочки, но может уменьшаться при погашении одного из просроченных платежей.
- GLM – generalized linear model.
- LGD – loss given default – доля EAD, которую клиент не возвращает на горизонте восстановления.
- LIFO просрочка – метод расчета просрочки, при котором подсчет количества дней просрочки долга начинается с даты возникновения ненулевой суммы на счете просрочки и до момента обнуления суммы на этом счете.
- Loss-shortfall – коэффициент, отражающий насколько общие фактические потери превышают общие смоделированные потери.
- ML – machine learning.
- MLP – multilayer perceptron.
- PD – probability of default – вероятность дефолта.
- PSI – population stability index – метрика, которая оценивает, насколько «изменилось» распределение переменной/целевой переменной относительно референсной группы (например, выборка для разработки) [11].
- RR – Recovery Rate – сумма, которая будет возмещена клиентом в процентах от суммы задолженности (EAD).
- Валидация – процедура проверки соответствия модели и используемых данных требованиям бизнес-задачи, допустимым границам значений количественных статистических метрик и внутренним нормативным документам и техническим процессам организации.
- Дисконтирование – механизм учета текущей стоимости денежных средств, полученных на горизонте восстановления.
- Калибровка – мета-модель, предназначенная для корректировки прогноза основной модели в соответствии с актуальным уровнем дефолта (PIT – Point In Time) или уровнем дефолта за экономический цикл (TTC – Through The Cycle).
Ссылки
[1] https://www.dvbi.ru/articles/reading/SSAS-as-tool-for-analysis-of-overdue-debts
[2] https://www.listendata.com/2019/09/credit-risk-vintage-analysis.html
[3] https://www.listendata.com/2019/09/roll-rate-analysis.html
[4]https://en.wikipedia.org/wiki/Discounting#Discount_factor
[5] https://towardsdatascience.com/model-or-do-you-mean-weight-of-evidence-woe-and-information-value-iv-331499f6fc2
[6] Kuhn, Max, and Kjell Johnson. Feature engineering and selection: A practical approach for predictive models. CRC Press, 2019.
[7] https://en.wikipedia.org/wiki/Variance_inflation_factor
[8] https://en.wikipedia.org/wiki/Bayesian_information_criterion
[9] https://en.wikipedia.org/wiki/Akaike_information_criterion
[10] https://en.wikipedia.org/wiki/Analytical_base_table
[11] Baesens Bart, Daniel Roesch, Harald Scheule. Credit risk analytics: Measurement techniques, applications, and examples in SAS. John Wiley & Sons, 2016. p. 395.
Пояснительный материал для наших клиентов
У инвесторов нашей платформы возникают вопросы относительно того, что из себя представляет винтажный анализ, предоставленный в личном кабинете каждого клиента. В этом посте разберем данный элемент.
Прежде всего, обратимся к понятию винтажного анализа.
Винтажный анализ представляет собой разновидность группового анализа, когда исследование поведенческих особенностей клиентов (заемщиков) на протяжении их жизненного цикла подразумевает формирование групп на основе времени их появления (период выдачи кредита). При этом сами группы называют винтажами.
Основное применение винтажного анализа — управление рисками в кредитно-финансовых учреждениях. В частности, он позволяет оценивать степень риска кредитного портфеля за определённые промежутки времени. Сам термин «винтаж» может относиться к месяцу или кварталу, в котором был открыт счёт, выдан кредит или кредитная карта. В нашем случае выдан займ.
Давайте обратимся к общему виду графика, который подлежит разбору.
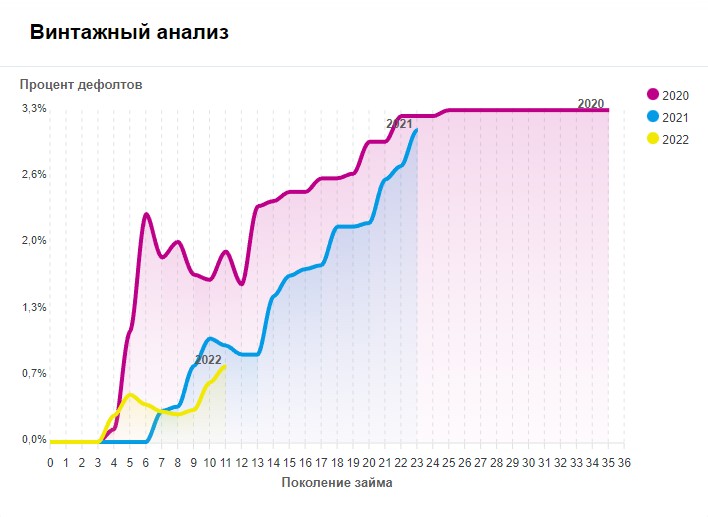
Разберем на данном графике шкалу X и Y.
Шкала X — данный показатель отвечает за отображение возраста займа в месяцах. Его наименование «Поколение займа».
Шкала Y — данный показатель отвечает за отображение объема дефолтов в процентах от общей суммы выдач. Его наименование «Процент дефолтов».
На графике изображены три линии за 2020, 2021 и 2022 год соответственно.
С помощью них мы можем наблюдать отношение суммы, ушедшей в дефолт, к общей сумме выданных займов в процентах в зависимости от срока займа.
Например, по займам, с момента выдачи которых прошло 3 месяца и менее, на платформе отсутствовали дефолты. Обратите внимание на то, что линии до 3-х месяцев прямые по всем годам.
По займам, с выдачи которых прошло 4 месяца, в 2020 году в дефолт ушло 0,1% от всей суммы выданных займов, в 2021 таких дефолтов не было, а в 2022 в дефолт ушли займы в объеме 0,3% от всех выданных.
23 / 11 / 22
Продолжаем наш цикл статей о рынке коллекторов. В третьей, заключительной части, расскажем о том, как проанализировать портфель ссудной задолженности. Статья может быть полезна не только тем, кто интересуется в финансировании выкупов долгов, но и тем, кто инвестирует в МФО и розничные банки.

Иллюстрация: unsplash.com
Отчасти, основных параметров оценки мы уже коснулись в первой и второй наших статьях. В этой статье рассмотрим показатели комплексно.
Основные параметры для оценки портфеля (его стоимости):
1. Тип кредита:
— автокредитование,
— ипотечное,
— потребительское,
— кредитные карты, экспресс-кредиты, кредит на неотложные нужды, пр.
2. Срок просрочки:
— 0-180 дней,
— 180-360 дней,
— 360-720 дней,
— свыше 720 дней.
3. Количество дел, средний объем займа.
Далее уже анализируются некие качественные параметры:
4. Регион проживания, возраст, пол, семейное положение, профессия, образование.
Часто у коллекторов есть свои наработанные базы должников по действующим отрабатываемым портфелям и при приобретении нового портфеля могут быть показаны контактные данные его должников и можно провести сверку на пересечение.
Все в совокупности позволяет оценить потенциальную стоимость портфеля и возможности взыскания.
Винтажный анализ
Это ключевой подход к измерению эффективности кредитования и прогнозирования уровня кредитных рисков.
Часто, банки и МФО предоставляют доступ к винтажному анализу приобретаемых портфелей и, безусловно, у каждого эффективного банка и МФО должен быть внедрен подобный инструмент.
В 2019 году Национальное бюро кредитных историй (НБКИ) сообщило о подобной аутсорсинговой услуге — аналитический сервис «Винтажный анализ кредитного портфеля».
Винтажный анализ представляет собой разновидность когортного анализа, когда исследование поведенческих особенностей клиентов (абонентов, заёмщиков) на протяжении их жизненного цикла подразумевает формирование групп (когорт) на основе времени их появления (период выдачи к
редита, регистрации абонента и т.д.). При этом сами когорты называют винтажами или поколениями.
Для примера приведем винтажный анализ по возврату модельного LPD портфеля (краткосрочные займы до зарплаты) по параметру возврата процентов и тела долга:

Что показывает данная таблица?
Из выданного портфеля займов в июле 2019 года компании вернулось 46,8%, всего за три месяца компании из выданных средств собрала вместе с процентами уже 112,1%, однако затем выплаты практически прекратились и за следующие 11 месяцев собрала лишь 125,6% от выданного портфеля, т.е. доходность за 14 месяцев составила 25,6%.
Он же без учета процентов:

Таким образом, по портфелю, выданному в июле 2019 года за 13 месяцев удалось собрать около 82% от тела долга, еще 42% составили проценты по возвращенным займам.
Если коллектор покупает в августе 2020 года просроченный портфель ссуд, который был выдан в июле 2019 года (объемом около 15%), то ожидаемый объем сбора составит не более 0,1% в месяц (или 1% в год).
Как видно из статистики, уже через 4-5 месяцев сборы по LPD портфелям обычно падают до уровня ниже 0,5%, но кредиторы, с учетом изъятых процентов, уже через три месяца снова выдают привлеченный ранее объем средств, однако в моменте без постоянной «подпитки» ликвидностью, бизнес по выдаче LPD ссуд будет каждый месяц испытывать существенное «сжатие».
Примерно на основе этих показателей и рассчитывается базовая стоимость портфеля.

В качестве якорей можно выбрать два параметра: возраст и регион проживания

Для более точного анализа в каждой группе дополнительно включается разбивка на сумму займа, пол, семейное положение, профессию и образование.
Каждая группа получает свой весовой коэффициент и получается полная многомерная матрица кредитного портфеля — задача векторной оптимизации.
Срок просрочки — это, фактически, винтажный анализ, который задает (вместе с типом кредита) максимальный потолок стоимости.
На основе этих данных можно точно оценить возможную стоимость портфеля, факторный анализ влияния различных параметров и другую аналитику.
Например:

Алексей Перехожев, генеральный директор ООО «Форвард», рассказал, что на практике теоретические модели не всегда работают: «На хорошем растущем рынке идет конкуренция за портфели, в результате цена может отличаться от теоретической. Как в опционах: при теоретической цене 100 рублей, сделки могут проходить и по 60 и по 140, все зависит от текущей конъюнктуры и ожиданий на рынке».
В настоящее время по данным бюро кредитных историй «Эквифакс» объемы просроченной задолженности по долгам физлиц в мае-июне выросли более, чем на 100%.
В том числе по автокредитам «просрочка» увеличилась на 129%, до 517 млн рублей, объем ипотечных займов, которые не обслуживаются 30-60 дней, вырос на 125%, до 601,5 млн рублей. Просроченных кредитов наличными за два месяца стало больше на 115%: к началу их общая сумма достигла 3,474 млрд рублей.
По кредитным картам, POS-кредитам и займам МФО люди не платят еще дольше: двухзначными темпами растет просрочка 60-90 дней: по микрозаймам объем просроченной задолженности за май-июнь взлетел на 63,8%, до 3,392 млрд рублей, по кредитам на покупку товаров — на 56% (до 351,7 млн. руб.); по кредитным картам — на 51,7%, до 1,922 млрд рублей.
Речь идет о ранней просрочке, которая сигнализирует о будущих проблемах: по методике ЦБ, просроченными считаются долги, которые не обслуживают от 90 дней.
«В ближайшие месяцы просроченная задолженность будет увеличиваться как в объеме, так и в длительности, достигнув пика к концу третьего квартала. В четвертом квартале стоит ожидать традиционного списания объема неработающей задолженности банками или её продажи коллекторским агентствам», — предупреждают эксперты «Эквифакса».
На таком негативном внешнем фоне возможно ожидать снижение стоимости портфелей относительно их теоретической цены, что может положительно отразиться на бизнесе коллекторских агентств в среднесрочной перспективе.