
Вопрос
Ответ
Верно
1 Что является предметом изучения эконометрики?
факторы, формирующие развитие экономических явлений и процессов
да
2 Для чего составляются эконометрические модели?
3для выявления качественного и количественного влияния разных факторов на объект
да
3 Эконометрика занимается изучением
качественного и количественного влияния разных факторов на экономические объекты
да
4 Для решения эконометрических задач необходимо
построение математической модели
предварительное решение нескольких задач математического анализа
наличие специализированных программных средств
построение графиков
да
5 Что такое математическая модель экономического объекта?
записанное в математической форме абстрактное отображение экономического объекта
да
6 Математическая модель экономического объекта предназначена для
экспериментального изучения поведения объекта в различных обстоятельствах
да
7 Что может быть выполнено с помощью эконометрической модели?
прогнозирование поведения изучаемого экономического объекта
да
8 Математической моделью в эконометрических задачах является
уравнение регрессии или система уравнений регрессии
да
9 В эконометрических задачах математическая модель
это уравнение регрессии или система уравнений регрессии
да
10 Что означает наличие прямой связи между переменными х и у?
3что при увеличении значений х увеличиваются и значения у
да
11 Что означает наличие обратной связи между переменными х и у?
что при уменьшении значений х значения у увеличиваются
да
12 В каком случае связь между двумя факторами является тесной?
3если их коэффициент корреляции по модулю больше или равен 0,7
да
13 Для определения тесноты линейной связи между двумя факторами необходимо
рассчитать коэффициент корреляции
да
14 Взаимозависимости экономических переменных часто описываются
линейным уравнением
да
15 Линейная связь между переменными означает, что
2график зависимости представляется прямой линией
да
16 Регрессионный анализ оценивает
формулу связи двух или нескольких переменных
да
17 Оценка вида связи между переменными возможна
с помощью регрессионного анализа
да
18 Функция, описывающая корреляционную зависимость между х и у, называется
регрессией у на х
да
19 Регрессия у на х — это
формула связи между переменными у и х
да
20 Какой метод позволяет определить оценки параметров регрессии?
метод наименьших квадратов
да
21 Метод наименьших квадратов позволяет
найти оценки параметров регрессии
да
22 Метод наименьших квадратов состоит
2в минимизации суммы квадратов отклонений реальных значений у от расчетных
да
23 Решение по МНК в пакете Excel можно получить при помощи
опций Анализ данных — Регрессия
да
24 Что такое МНК?
3метод наименьших квадратов
да
25 Для чего применяется МНК?
для оценки параметров регрессии
да
26 Для оценки формы связи между переменными служит
уравнение регрессии
да
27 В каком случае регрессия является парной?
4если в уравнение регрессии входит одна зависимая и одна независимая переменная
да
28 В каком случае регрессия является множественной?
3если в ур-е регрессии входит одна зависимая и множество независимых переменных
да
29 Какие виды регрессионных зависимостей существуют?
парная, множественная, линейная, нелинейная
да
30 Какого вида регрессионная зависимость между переменными не может существовать?
прямая, линейная, нелинейная
да
31 Что является математической моделью эконометрической задачи?
одно уравнение или система уравнений регрессии
да
32 Можно ли на основании решения Excel прогнозировать изменение Y в зависимости от изменения X?
2можно, только если построенная регрессионная модель является качественной
да
33 После записи уравнения регрессии необходимо
оценить качество полученного уравнения
да
34 Регрессионная модель считается качественной при обязательном выполнении следующих условий:
1связь в модели тесная, объясняющие переменные значимы, наблюдений достаточно
да
35 При решении эконометрических задач уравнение регрессии является
математической моделью зависимости переменных
да
36 Уравнение регрессии оценивает
форму зависимости исследуемых переменных
да
37 Для оценки формы связи между переменными служит
уравнение регрессии
да
38 Для чего составляется уравнение регрессии?
2для определения формы зависимости исследуемых переменных
да
39 Значения х и у для поиска уравнения регрессионной зависимости берутся
из статистических данных
да
40 Значения a и b для поиска уравнения регрессионной зависимости берутся
из расчетов по методу наименьших квадратов
да
41 Уравнение регрессии записывается на основании
1величин коэффициентов регрессии
да
42 Какие величины служат для записи уравнения регрессии?
коэффициенты регрессии
да
43 В уравнении регрессии зависимая переменная обычно обозначается как
у
да
44 В уравнении регрессии независимая переменная обычно обозначается как
х
да
45 В уравнении регрессии факторы обычно обозначаются как
х и у
да
46. В уравнении регрессии параметры обычно обозначаются как
а и b
да
47. В уравнение регрессии входят
зависимая переменная, независимые переменные и коэффициенты при них
да
48 В уравнении регрессионной зависимости может быть только
3одна зависимая и одна или несколько независимых переменных
да
49. Сколько объясняющих переменных может быть в уравнении регрессии?
произвольное количество (желательно, не более трети от числа наблюдений)
да
50 Сколько зависимых переменных может быть в уравнении регрессии?
только одна
да
51 В уравнении y = a + bx коэффициенты а и b — это:
параметры регрессии
да
52 В уравнении y = a + bx коэффициент а является
параметром регрессии
да
53 В уравнении y = a + bx коэффициент b является
параметром регрессии
да
54 В уравнении регрессии параметры регрессии обычно обозначаются как
а и b
да
55 В результатах решения задачи коэффициент регрессии а отображается как:
Y-пересечение
да
56 В уравнении y = a + bx величина коэффициента а отражает
значение у при нулевых значениях х
да
56. В уравнении y = a + bx величина коэффициента а отражает
значение у при единичном увеличении х
значимость или незначимость переменной у
значимость или незначимость коэффициента а
нет
57 В результатах регрессионного анализа Y-пересечение — это
коэффициент регрессии а
да
58. Чему будет равен Y в парной линейной регрессии, если Y-пересечение = 5, b = 7, х = 10?
75
да
59 Чему будет равен Y в парной линейной регрессии, если Y-пересечение = 2, b = 6, х = 4?
26
да
60 Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 2, b1 = 5, b2 = 2, х1 = 4, x2 = 1?
24
да
61 Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4?
21
да
62 Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 6, b1 = 2, b2 = 5, х1 = 8, x2 = 4?
42
да
63 В уравнении регрессии у = a + bx коэффициент а показывает
прогнозируемую величину у при х = 0
да
64 В уравнении регрессии у = a + bx коэффициент а показывает
величину у при равенстве х нулю
да
65 Как в уравнении регрессии интерпретируется коэффициент перед переменной х?
показывает величину изменения у при единичном изменении х
да
66 В уравнении регрессии у = a + bx коэффициент b показывает
2величину изменения у при единичном изменении х
да
67 Вероятность выполнения нуль-гипотезы для коэффициента регрессии оценивается с помощью
Р-значения этого коэффициента регрессии
да
68 В уравнении y = a + bx незначимость коэффициента регрессии b означает, что
влияние переменной х на коэффициент b отсутствует
влияние переменной у на коэффициент b отсутствует
влияние коэффициента b на переменную х отсутствует
нет
69 В уравнении y = a + bx незначимость коэффициента регрессии а означает, что
3влияние коэффициента а на переменную у отсутствует
да
70 В уравнении y = a + bx незначимость Y-пересечения означает, что
в уравнении регрессии отсутствует константа
да
71 Что означает не значимость коэффициента регрессии?
что соответствующая ему независимая переменная не влияет на зависимую
да
72 Значимость коэффициентов регрессии определяется с помощью:
Р-значений
да
73 Что означает статистическая незначимость параметра (коэффициента) регрессии?
высокую вероятность равенства данного параметра нулю
да
74. Когда коэффициент регрессии считается значимым?
если его Р-значение меньше 5%
да
75 Какая величина «Р-значения» подтверждает влияние х на у?
Р-значение для него меньше 0,05
да
76 При одновременной незначимости нескольких объясняющих переменных модели нужно
4удалить их последовательно, начиная с той, чье Р-значение больше
да
77 Что следует делать, если коэффициент регрессии не значим?
удалять из модели переменную, которой он соответствует
да
78 Теснота связи в уравнении регрессии определяется с помощью
коэффициента корреляции
да
79 Какой показатель характеризует тесноту связи в уравнении регрессии?
коэффициент корреляции
да
80 С помощью какой величины определяется теснота связи в уравнении регрессии?
с помощью коэффициента корреляции
да
81 Что проверяется с помощью коэффициента корреляции?
теснота связи между факторами в уравнении регрессии
да
82 Коэффициент корреляции оценивает
тесноту связи в уравнении регрессии
да
83 Для констатации наличия тесной связи в регрессионной модели необходимо
чтобы модуль коэффициента корреляции был не меньше 0,7
да
84 Тесная связь между перменными модели констатируется в том случае, если
коэффициент корреляции по модулю не меньше 0,7
да
85 Коэффициент корреляции при решении в пакете Excel выдается как величина
«Множественный R»
да
86 В результатах решения задачи в Excel коэффициент корреляции отображается как:
Множественный R
да
87 Какие действия приводят к увеличению тесноты связи в регрессионной модели?
удаление выбросов, добавление ранее неучтенных факторов, видоизменение модели
да
88 Величина «Значимость F» показывает
1вероятность недостоверности коэффициента детерминации
да
89 Для чего служит величина «Значимость F»?
2для определения достоверности коэффициента детерминации
да
90 Нулевая гипотеза для коэфициента детерминации отвергается при
Значимости F, меньшей или равной 5%
да
91 Что означает незначимость коэффициента детерминации?
что рассчитанный коэффициент детерминации не достоверен
да
92 В каком случае коэффициент детерминации может быть не достоверен?
4в случае, если для анализа взято слишком мало наблюдений
да
93 Что необходимо сделать в случае незначимости коэффициента детерминации?
увеличить количество наблюдений в исследуемой выборке
да
94 Причиной недостоверности коэффициента детерминации может служить
недостаточное количество наблюдений
да
95 В каком случае коэффициент детерминации считается незначимым?
если величина «Значимость F» больше 0,05
да
96 В каком случае коэффициент детерминации признается не достоверным?
если Значимость F больше или равна 5%
да
97 Что показывает коэффициент детерминации?
объясненную регрессией долю дисперсии зависимой переменной у
да
98 Как рассчитывается коэффициент детерминации?
как доля объясненной регрессией дисперсии в общей дисперсии зависимой переменной
да
99 О чем свидетельствует близкое кзначение коэффициента детерминации?
о наличии тесной связи между изучаемыми показателями
да
100 Величина RSS показывает
3величину дисперсии зависимой переменной, объясненной регрессией
да
101. Величина ТSS показывает
общий разброс зависимой переменной вокруг ее среднего значения
да
102 Величина ЕSS показывает
4величину дисперсии зависимой переменной, не объясненной регрессией
да
103 Как рассчитывается коэффициент детерминации?
1RSS / TSS
да
104 Что такое остаток?
3разность между реальным и расчетным значением у
да
105 Какое количество остатков выводится при проведении регрессии?
2равное количеству наблюдений
да
106 Какое количество стандартных остатков выводится при проведении регрессии?
3равное количеству наблюдений
да
107 Что такое статистический выброс?
наблюдение, которое резко отклоняется от линии регрессии
да
108 Что такое статистический выброс?
нетипичное наблюдение, подлежащее удалению
да
109. Какое наблюдение считается статистическим выбросом?
наблюдение, не вошедшее в выборку, по которой производится регрессионный анализ
нет
110 Каким образом при решении регрессионной задачи в пакете Excel обнаруживаются статистические выбросы?
2по величинам стандартных остатков наблюдений
да
111 В каких случаях не обязательно удаление статистических выбросов?
2в случае сильной связи в регрессионной модели
да
112 В каких случаях необходимо удаление статистических выбросов?
в случае низкого значения коэффициента корреляции
да
113 Каковы последствия удаления статистических выбросов в регрессионном анализе?
увеличение тесноты связи в модели
да
114. Для проверки качества построенной регрессионной модели необходимо проанализировать:
коэффициент корреляции, Значимость F, Р-значения
да
115 Для чего в регрессионную модель вводятся бинарные переменные?
для учета качественных признаков
да
115. Для признания регрессионной модели качественной должны выполняться условия:
связь тесная, наблюдений достаточно, все объясняющие переменные значимы
да
116 Что такое бинарная переменная?
переменная, принимающая значения «0» или «1» при наличии или отсутствии признака
да
116. Зачем в регрессионном анализе используются бинарные переменные?
чтобы учесть в модели факторы, выражающиеся не количественными значениями
да
117 Фиктивная переменная — это
другое название бинарной переменной
да
118 Бинарная переменная является
равноправной переменной регрессионной модели
да
119 Уравнение регрессии, содержащее бинарные переменные, является
регрессионной моделью
да
120 Какие значения может принимать фиктивная переменная?
0 и
да
121 Можно ли использовать бинарные переменные в множественной регрессии?
да
да
122 Можно ли использовать бинарные переменные в парной регрессии?
да
да
123 Можно ли вводить в модель больше одной бинарной переменной?
нет
да
123. Можно ли вводить в модель больше одной бинарной переменной?
Нет
да, только при условии высокого коэффициента корреляции
нет
124 Может ли бинарная переменная быть независимой переменной регрессионной модели?
да, конечно
да
125 Может ли коэффициент при бинарной переменной быть отрицательным?
да
да
126 Что означает отрицательный коэффициент при бинарной переменной?
уменьшение зависимой переменной при наличии признака, описываемого бинарной
да
127 Что означает положительный коэффициент при бинарной переменной?
увеличение зависимой переменной при наличии признака, описываемого бинарной
да
128 Незначимость коэффициента при бинарной переменной означает
4отсутствие влияния данного качественного признака на зависимую переменную
да
129 Статистическая значимость бинарной переменной означает
подтвержденное влияние данного качественного признака на зависимую переменную
да
130 В каких случаях производится исключение бинарных переменных из модели?
2в случае высокого Р-значения для них
да
Содержание:
- Что такое выбросы и почему их важно найти?
- Найдите выбросы путем сортировки данных
- Поиск выбросов с помощью квартильных функций
- Поиск выбросов с помощью функций НАИБОЛЬШИЙ / МАЛЕНЬКИЙ
- Как правильно обращаться с выбросами
- Удалить выбросы
- Нормализовать выбросы (отрегулировать значение)
При работе с данными в Excel у вас часто возникают проблемы с обработкой выбросов в наборе данных.
Выбросы довольно часто встречаются во всех видах данных, и важно идентифицировать и обрабатывать эти выбросы, чтобы убедиться, что ваш анализ правильный и значимый.
В этом уроке я покажу вам как найти выбросы в Excel, а также некоторые методы, которые я использовал в своей работе для обработки этих выбросов.
Что такое выбросы и почему их важно найти?
Выброс — это точка данных, которая выходит за рамки других точек данных в наборе данных. Если у вас есть выброс в данных, это может исказить ваши данные, что может привести к неверным выводам.
Приведу простой пример.
Допустим, 30 человек едут на автобусе из пункта назначения A в пункт назначения B. Все люди относятся к одной весовой группе и группе доходов. Для целей этого руководства давайте предположим, что средний вес составляет 220 фунтов, а средний годовой доход — 70 000 долларов.
Сейчас где-то посередине нашего маршрута автобус останавливается, и в него садится Билл Гейтс.
Как вы думаете, как это повлияет на средний вес и средний доход людей в автобусе?
Хотя средний вес вряд ли сильно изменится, средний доход пассажиров автобуса резко вырастет.
Это связано с тем, что доход Билла Гейтса является исключением в нашей группе, и это дает нам неправильную интерпретацию данных. Средний доход каждого пассажира автобуса составит несколько миллиардов долларов, что намного превышает реальную стоимость.
При работе с фактическими наборами данных в Excel вы можете иметь выбросы в любом направлении (например, положительный выброс или отрицательный выброс).
И чтобы убедиться, что ваш анализ верен, вам нужно каким-то образом идентифицировать эти выбросы, а затем решить, как лучше всего их лечить.
Теперь давайте рассмотрим несколько способов найти выбросы в Excel.
Найдите выбросы путем сортировки данных
С небольшими наборами данных быстрый способ определить выбросы — просто отсортировать данные и вручную просмотреть некоторые значения в верхней части отсортированных данных.
А так как выбросы могут быть в обоих направлениях, убедитесь, что вы сначала отсортировали данные в порядке возрастания, а затем в порядке убывания, а затем перебрали самые верхние значения.
Позвольте мне показать вам пример.
Ниже у меня есть набор данных, в котором у меня есть продолжительность звонков (в секундах) для 15 звонков в службу поддержки.

Ниже приведены шаги по сортировке этих данных, чтобы мы могли идентифицировать выбросы в наборе данных:
- Выберите заголовок столбца, который вы хотите отсортировать (в этом примере ячейка B1).
- Перейдите на вкладку «Главная«

- В группе «Редактирование» щелкните значок «Сортировка и фильтр».
- Щелкните Custom Sort (Пользовательская сортировка).
- В диалоговом окне «Сортировка» выберите «Продолжительность» в раскрывающемся списке «Сортировка по» и «От наибольшего к наименьшему» в раскрывающемся списке «Порядок».
- Нажмите ОК




Вышеупомянутые шаги сортируют столбец продолжительности звонка с наивысшими значениями вверху. Теперь вы можете вручную просмотреть данные и посмотреть, есть ли выбросы.

В нашем примере я вижу, что первые два значения намного выше остальных значений (а два нижних намного ниже).
Примечание. Этот метод работает с небольшими наборами данных, где вы можете вручную сканировать данные. Это не научный метод, но он хорошо работает
Поиск выбросов с помощью квартильных функций
Теперь давайте поговорим о более научном решении, которое поможет вам определить, есть ли какие-то выбросы.
В статистике квартиль составляет четверть набора данных. Например, если у вас есть 12 точек данных, то первый квартиль будет тремя нижними точками данных, второй квартиль будет следующими тремя точками данных и так далее.
Ниже приведен набор данных, по которому я хочу найти выбросы. Для этого мне нужно будет вычислить 1-й и 3-й квартили, а затем с его помощью вычислить верхний и нижний предел.

Ниже приведена формула для вычисления первого квартиля в ячейке E2:
= QUARTILE.INC ($ B $ 2: $ B $ 15,1)

и вот тот, который вычисляет третий квартиль в ячейке E3:
= QUARTILE.INC ($ B $ 2: $ B $ 15,3)

Теперь я могу использовать два вышеупомянутых вычисления, чтобы получить межквартильный размах (который составляет 50% наших данных в пределах 1-го и 3-го квартилей).
= F3-F2

Теперь мы будем использовать межквартильный диапазон, чтобы найти нижний и верхний предел, который будет содержать большую часть наших данных.
Все, что выходит за эти нижние и верхние пределы, будет считаться выбросом.
Ниже приведена формула для расчета нижнего предела:
= Квартиль1 - 1,5 * (Межквартильный диапазон)
который в нашем примере становится:
= F2-1,5 * F4

И формула для расчета верхнего предела:
= Квартиль3 + 1,5 * (Межквартильный диапазон)
который в нашем примере становится:
= F3 + 1,5 * F4

Теперь, когда у нас есть верхний и нижний предел в нашем наборе данных, мы можем вернуться к исходным данным и быстро определить те значения, которые не лежат в этом диапазоне.
Быстрый способ сделать это — проверить каждое значение и вернуть ИСТИНА или ЛОЖЬ в новом столбце.
Я использовал приведенную ниже формулу ИЛИ, чтобы получить ИСТИНА для тех значений, которые являются выбросами.
= ИЛИ (B2 $ F $ 6)

Теперь вы можете фильтровать столбец Outlier и отображать только те записи, для которых значение TRUE.
Кроме того, вы также можете использовать условное форматирование, чтобы выделить все ячейки, в которых значение TRUE.
Примечание: Хотя это более распространенный метод поиска выбросов в статистике. Я считаю, что этот метод немного непригоден для использования в реальных сценариях. В приведенном выше примере нижний предел, рассчитанный по формуле, равен -103, в то время как набор данных, который у нас есть, может быть только положительным. Таким образом, этот метод может помочь нам найти выбросы в одном направлении (высокие значения), он бесполезен при выявлении выбросов в другом направлении.
Поиск выбросов с помощью функций НАИБОЛЬШИЙ / МАЛЕНЬКИЙ
Если вы работаете с большим количеством данных (значения в нескольких столбцах), вы можете извлечь 5 или 7 наибольших и наименьших значений и посмотреть, есть ли в них выбросы.
Если есть какие-либо выбросы, вы сможете их идентифицировать, не просматривая все данные в обоих направлениях.
Предположим, у нас есть приведенный ниже набор данных, и мы хотим знать, есть ли какие-либо выбросы.
Ниже приведена формула, которая даст вам наибольшее значение в наборе данных:
= БОЛЬШОЙ ($ B $ 2: $ B $ 16,1)
Точно так же второе по величине значение будет равно
= БОЛЬШОЙ ($ B $ 2: $ B $ 16,1)
Если вы не используете Microsoft 365, в которой есть динамические массивы, вы можете использовать приведенную ниже формулу, и она даст вам пять наибольших значений из набора данных с помощью одной формулы:
= БОЛЬШОЙ ($ B $ 2: $ B $ 16; СТРОКА ($ 1: 5))

Точно так же, если вам нужны 5 наименьших значений, используйте следующую формулу:
= МАЛЕНЬКИЙ ($ B $ 2: $ B $ 16; СТРОКА ($ 1: 5))
или следующее, если у вас нет динамических массивов:
= МАЛЕНЬКИЙ ($ B $ 2: $ B $ 16,1)
Когда у вас есть эти значения, очень легко обнаружить любые выбросы в наборе данных.
Хотя я решил извлечь 5 наибольших и наименьших значений, вы можете выбрать 7 или 10 в зависимости от размера вашего набора данных.
Я не уверен, является ли это приемлемым методом для поиска выбросов в Excel или нет, но это метод, который я использовал, когда мне приходилось работать с большим количеством финансовых данных на моей работе несколько лет назад. По сравнению со всеми другими методами, описанными в этом руководстве, я считаю этот наиболее эффективным.
Как правильно обращаться с выбросами
До сих пор мы видели методы, которые помогут нам найти выбросы в нашем наборе данных. Но что делать, если вы знаете, что есть выбросы.
Вот несколько методов, которые вы можете использовать для обработки выбросов, чтобы ваш анализ данных был правильным.
Удалить выбросы
Самый простой способ удалить выбросы из набора данных — просто удалить их. Таким образом, это не исказит ваш анализ.
Это более жизнеспособное решение, когда у вас большие наборы данных и удаление пары выбросов не повлияет на общий анализ. И, конечно же, перед удалением данных обязательно создайте копию и выясните, что вызывает эти выбросы.
Нормализовать выбросы (отрегулировать значение)
Нормализация выбросов — это то, что я делал, когда работал полный рабочий день. Для всех значений выбросов я бы просто изменил их на значение, немного превышающее максимальное значение в наборе данных.
Это гарантирует, что я не удаляю данные, но в то же время не позволяю им искажать мои данные.
Чтобы дать вам реальный пример, если вы анализируете маржу чистой прибыли компаний, где большинство компаний находится в пределах от -10% до 30%, а есть несколько значений, превышающих 100%, я просто изменит эти выбросы на 30% или 35%.
Итак, вот некоторые из методов, которые вы можете использовать в Excel, чтобы найти выбросы.
После того, как вы определили выбросы, вы можете углубиться в данные и посмотреть, что их вызывает, и в то же время выбрать один из методов обработки этих выбросов (который может удалить их или нормализовать, изменив значение)
Надеюсь, вы нашли этот урок полезным.
17 авг. 2022 г.
читать 3 мин
Выброс — это наблюдение, которое лежит аномально далеко от других значений в наборе данных. Выбросы могут быть проблематичными, поскольку они могут повлиять на результаты анализа.
Мы будем использовать следующий набор данных в Excel, чтобы проиллюстрировать два метода поиска выбросов:
Связанный: Как рассчитать среднее значение, исключая выбросы в Excel
Метод 1: используйте межквартильный диапазон
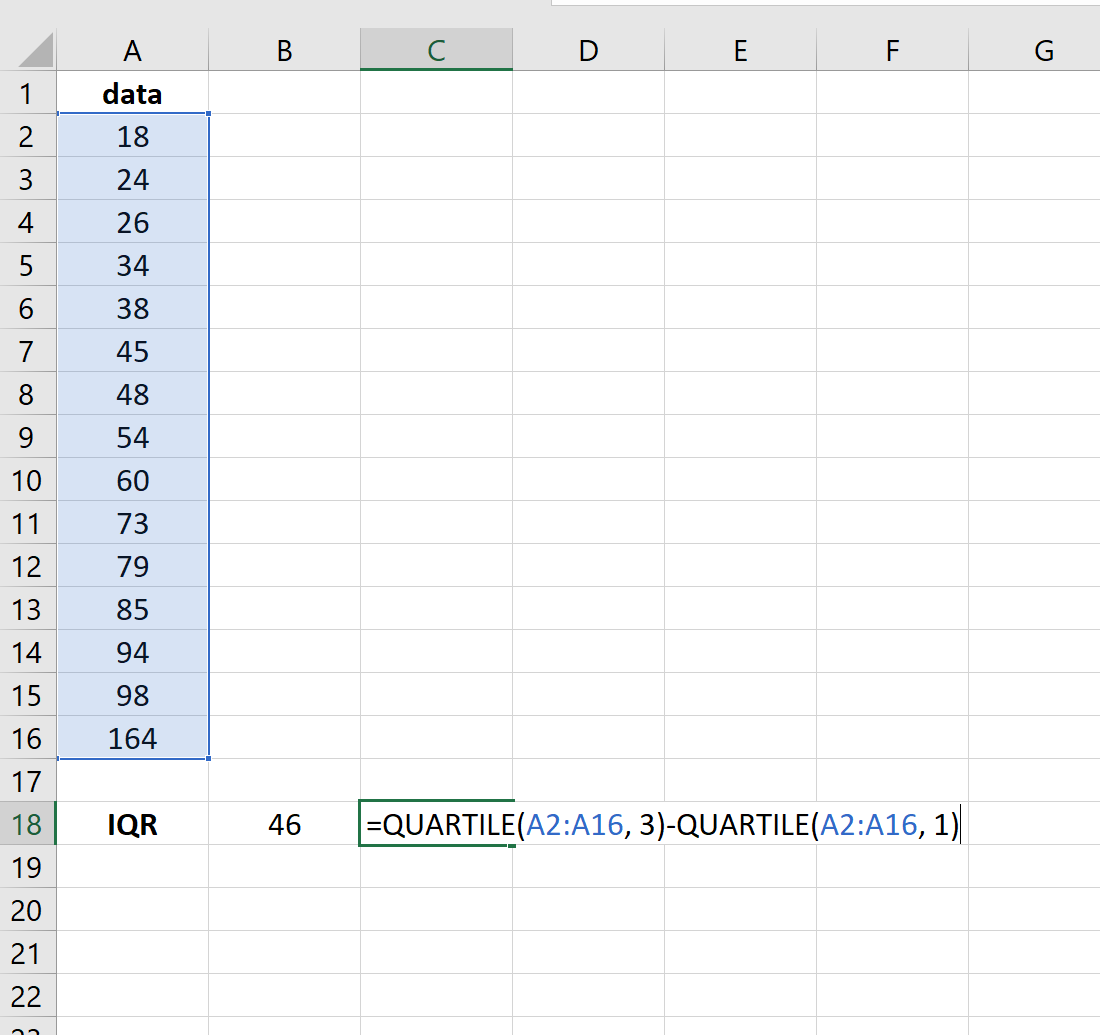
Межквартильный размах (IQR) — это разница между 75-м процентилем (Q3) и 25-м процентилем (Q1) в наборе данных. Он измеряет разброс средних 50% значений.
Мы можем определить наблюдение как выброс, если оно в 1,5 раза превышает межквартильный размах, превышающий третий квартиль (Q3), или в 1,5 раза превышает межквартильный размах меньше, чем первый квартиль (Q1).
На следующем изображении показано, как рассчитать межквартильный диапазон в Excel:
Затем мы можем использовать формулу, упомянутую выше, чтобы присвоить «1» любому значению, которое является выбросом в наборе данных:
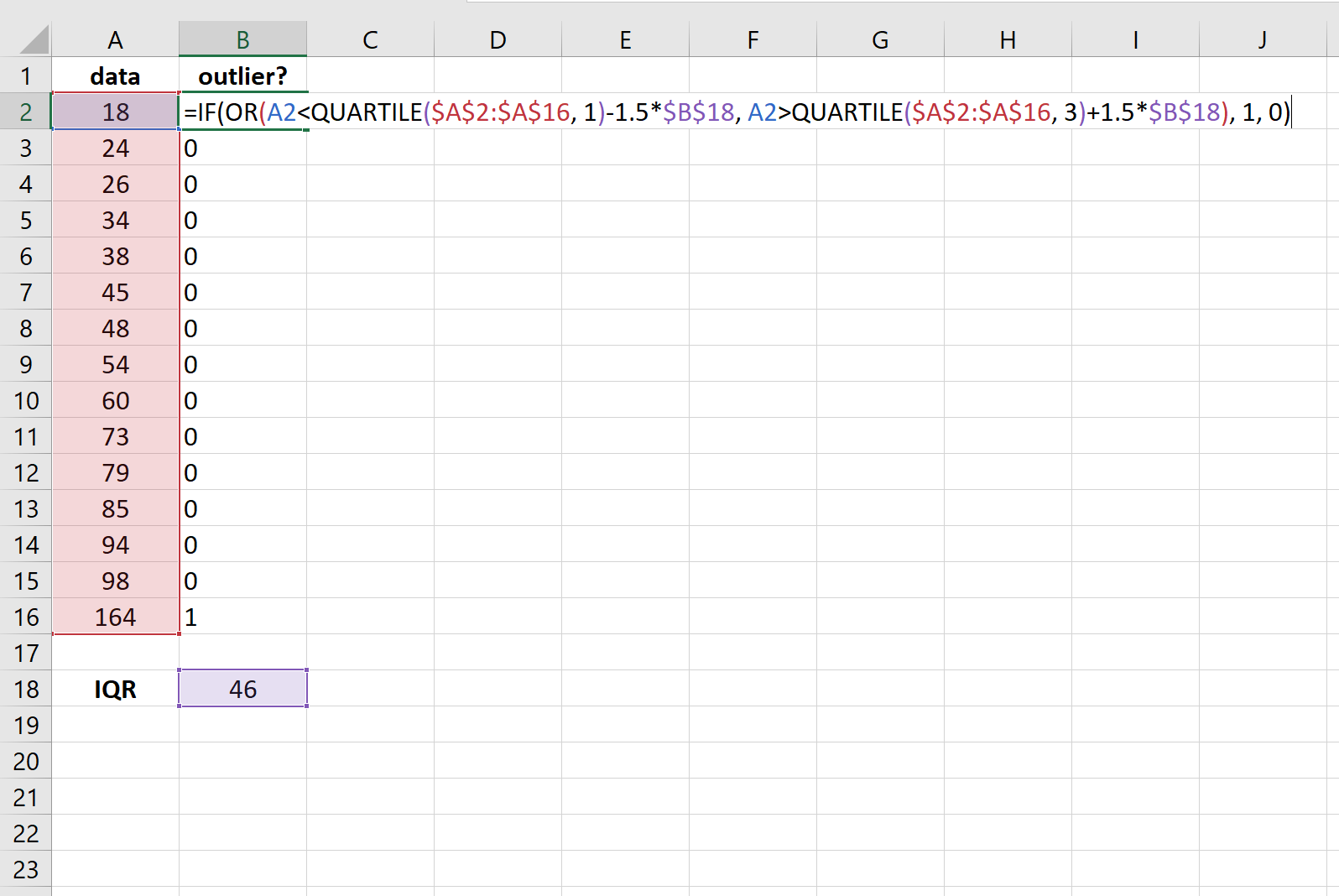
Мы видим, что только одно значение — 164 — оказывается выбросом в этом наборе данных.
Способ 2: использовать z-показатели
Z-оценка показывает, сколько стандартных отклонений данного значения от среднего. Мы используем следующую формулу для расчета z-показателя:
z = (X — μ) / σ
куда:
- X — это одно необработанное значение данных.
- μ — среднее значение населения
- σ — стандартное отклонение населения
Мы можем определить наблюдение как выброс, если его z-оценка меньше -3 или больше 3.
На следующем изображении показано, как рассчитать среднее значение и стандартное отклонение для набора данных в Excel:
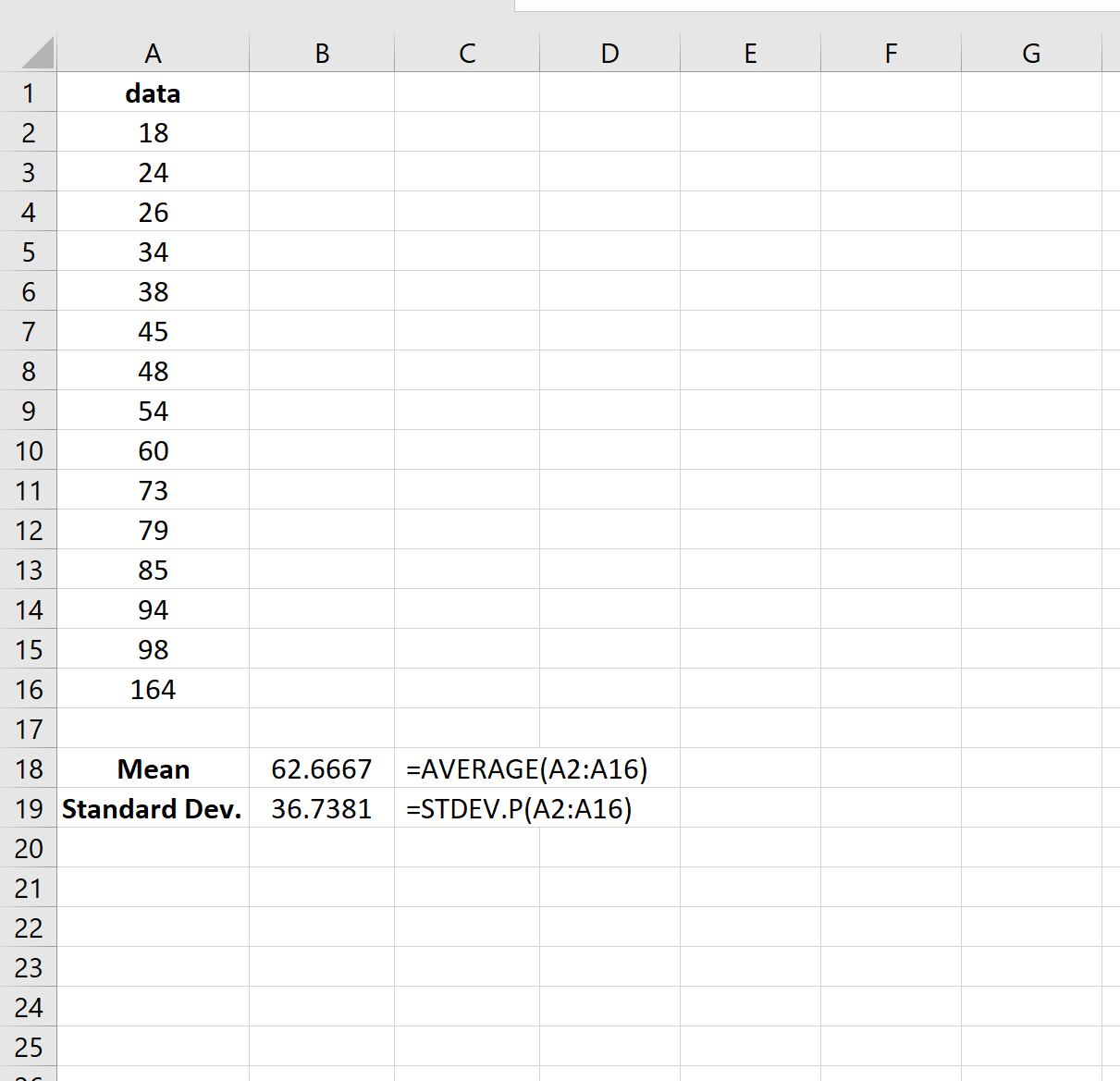
Затем мы можем использовать среднее значение и стандартное отклонение, чтобы найти z-оценку для каждого отдельного значения в наборе данных:
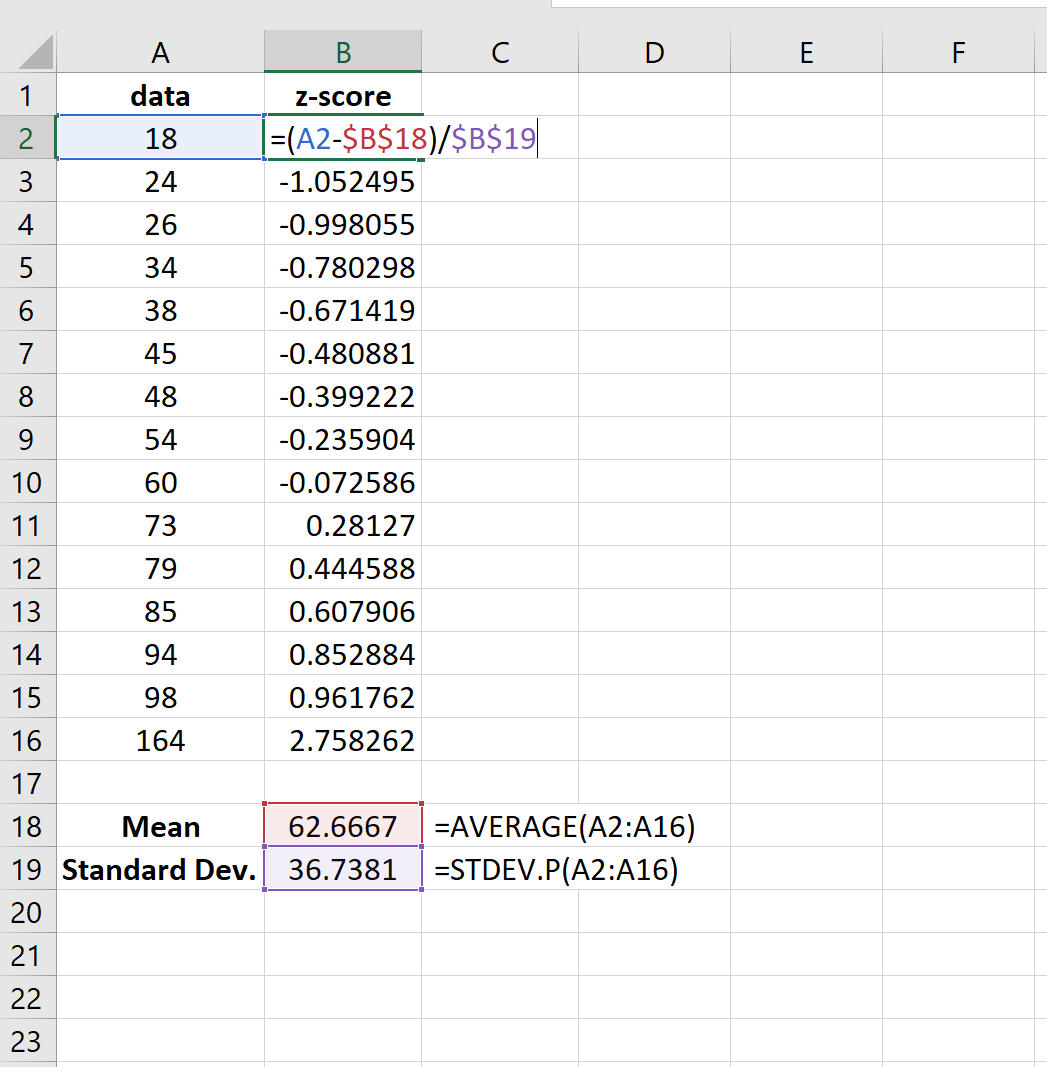
Затем мы можем присвоить «1» любому значению, которое имеет z-оценку меньше -3 или больше 3:
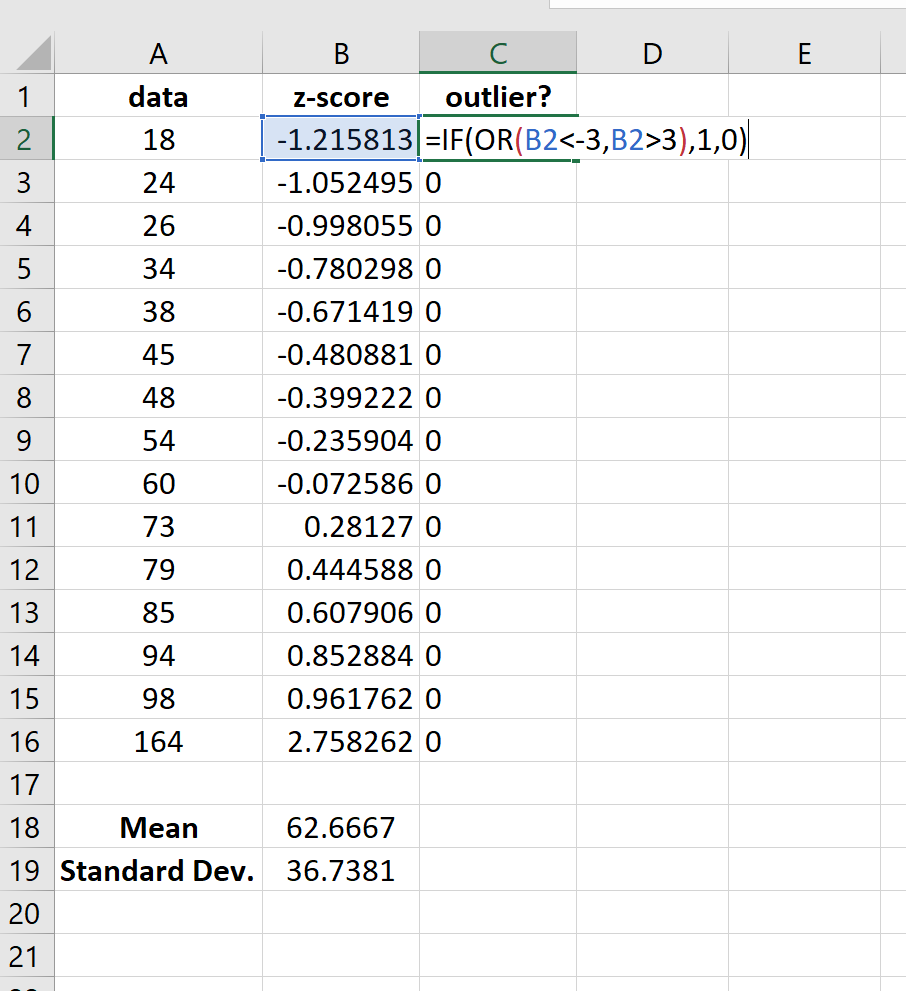
Используя этот метод, мы видим, что в наборе данных нет выбросов.
Примечание. Иногда вместо 3 используется z-показатель 2,5. В этом случае отдельное значение 164 будет считаться выбросом, поскольку его z-показатель больше 2,5. При использовании метода z-показателя руководствуйтесь своим здравым смыслом, какое значение z-показателя вы считаете выбросом.
Как обращаться с выбросами
Если в ваших данных присутствует выброс, у вас есть несколько вариантов:
1. Убедитесь, что выброс не является результатом ошибки ввода данных.
Иногда человек просто вводит неправильное значение данных при записи данных. Если присутствует выброс, сначала убедитесь, что значение было введено правильно и что это не ошибка.
2. Удалите выброс.
Если значение является истинным выбросом, вы можете удалить его, если оно окажет значительное влияние на общий анализ. Просто не забудьте упомянуть в своем окончательном отчете или анализе, что вы удалили выброс.
3. Присвойте новое значение выбросу .
Если выброс является результатом ошибки ввода данных, вы можете решить присвоить ему новое значение, такое как среднее или медиана набора данных.
|
Вопрос |
Ответ |
Верно |
|
1. |
факторы, |
да |
|
103. |
ESS |
нет |
|
110. |
по |
нет |
|
111. |
статистические |
нет |
|
126. |
наличие |
нет |
|
19. |
сумма |
нет |
|
20. |
метод |
нет |
|
25. |
для |
нет |
|
4. |
наличие |
нет |
|
41. |
величины |
нет |
|
46. |
R |
нет |
|
47. |
зависимая |
да |
|
5. |
совокупность |
нет |
|
51. |
доверительные |
нет |
|
56. |
значение |
нет |
|
61. |
10 |
нет |
|
7. |
приведение |
нет |
|
71. |
что |
да |
|
73. |
недостаточность |
нет |
|
75. |
Р-значение |
нет |
|
88. |
вероятность |
нет |
|
9. |
это |
да |
|
90. |
Р-значении, |
нет |
|
91. |
что |
да |
|
92. |
в |
нет |
|
Вопрос |
Ответ |
Верно |
|
107. |
наблюдение, |
нет |
|
108. |
процесс |
нет |
|
11. |
что |
нет |
|
111. |
в |
да |
|
116. |
переменная, |
да |
|
117. |
переменная, |
нет |
|
118. |
показателем |
нет |
|
121. |
да, |
нет |
|
17. |
с |
нет |
|
27. |
если |
нет |
|
32. |
можно, |
да |
|
40. |
из |
да |
|
44. |
у |
нет |
|
50. |
в |
нет |
|
55. |
Множественный |
нет |
|
56. |
значимость |
нет |
|
58. |
75 |
да |
|
61. |
14 |
нет |
|
68. |
влияние |
нет |
|
73. |
слабую |
нет |
|
75. |
Р-значение |
нет |
|
90. |
Значимости |
нет |
|
91. |
что |
да |
|
98. |
как |
да |
|
99. |
о |
да |
|
Вопрос |
Ответ |
Верно |
|
10. |
что |
нет |
|
100. |
величину |
нет |
|
104. |
разность |
нет |
|
111. |
в |
да |
|
112. |
в |
да |
|
115. |
для |
нет |
|
117. |
показатель |
нет |
|
119. |
регрессионной |
да |
|
122. |
да, |
нет |
|
124. висимой |
может |
нет |
|
128. |
отсутствие |
нет |
|
13. |
рассчитать |
нет |
|
16. |
формулу |
да |
|
23. |
опций |
да |
|
25. |
для |
нет |
|
30. |
тесная, |
нет |
|
33. |
рассчитать |
нет |
|
42. |
Множественный |
нет |
|
46. |
х |
нет |
|
48. |
несколько |
нет |
|
52. |
коэффициентом |
нет |
|
54. |
а |
да |
|
77. |
увеличить |
нет |
|
81. |
теснота |
да |
|
93. |
удалить |
нет |
|
Вопрос |
Ответ |
Верно |
|
100. |
величину |
нет |
|
101. |
величину |
нет |
|
108. |
незначимый |
нет |
|
11. |
что |
нет |
|
111. |
в |
да |
|
116. |
переменная, |
да |
|
119. |
регрессионной |
да |
|
120. |
0 |
да |
|
124. |
да, |
да |
|
14. |
линейным |
да |
|
19. |
коэффициент |
нет |
|
20. |
метод |
да |
|
25. |
для |
да |
|
28. |
если |
да |
|
42. |
коэффициенты |
да |
|
44. |
a |
нет |
|
45. |
х |
да |
|
48. |
одна |
нет |
|
55. |
Значимость |
нет |
|
57. |
величина |
нет |
|
62. |
42 |
да |
|
65. |
показывает |
нет |
|
9. |
это |
да |
|
90. |
Значимости |
да |
|
99. |
о |
да |
|
101. |
величину |
нет |
|
116. |
для |
нет |
|
121. |
да |
да |
|
130. |
в |
нет |
|
27. |
если |
нет |
|
28. |
если |
да |
|
29. |
парная, |
да |
|
3. |
статистических |
нет |
|
30. |
прямая, |
нет |
|
31. |
совокупность |
нет |
|
33. |
определить |
нет |
|
34. |
связь |
да |
|
44. |
b |
нет |
|
49. |
только |
нет |
|
53. |
коэффициентом |
нет |
|
61. |
24 |
нет |
|
64. |
является |
нет |
|
65. |
показывает |
да |
|
7. |
управление |
нет |
|
75. |
Р-значение |
да |
|
81. |
теснота |
да |
|
84. |
коэффициент |
да |
|
86. |
переменная |
нет |
|
89. |
является |
нет |
|
92. |
в |
нет |
|
Вопрос |
Ответ |
Верно |
|
102. |
величину |
нет |
|
111. |
в |
да |
|
113. |
увеличение |
да |
|
124. |
да, |
да |
|
128. |
отсутствие |
нет |
|
129. |
подтвержденное |
да |
|
26. |
коэффициент |
нет |
|
27. |
если |
нет |
|
29. |
парная, |
да |
|
32. |
можно, |
да |
|
33. |
оценить |
да |
|
34. |
связь |
да |
|
43. |
у |
да |
|
45. |
х |
да |
|
51. |
RSS |
нет |
|
53. |
параметром |
да |
|
6. |
накапливания |
нет |
|
61. |
21 |
да |
|
64. |
величину |
нет |
|
66. |
является |
нет |
|
7. |
прогнозирование |
да |
|
79. |
коэффициент |
да |
|
86. |
Множественный |
да |
|
94. |
недостаточное |
да |
|
97. |
объясненную |
нет |
|
Вопрос |
Ответ |
Верно |
|
1. |
факторы, |
да |
|
100. |
общий |
нет |
|
102. |
величину |
нет |
|
107. |
наблюдение, |
нет |
|
109. |
наблюдение, |
да |
|
118. |
показателем |
нет |
|
122. |
да, |
нет |
|
126. |
что |
нет |
|
128. |
отсутствие |
да |
|
18. |
регрессией |
да |
|
34. |
связь |
да |
|
36. |
сумму |
нет |
|
4. |
наличие |
нет |
|
43. |
у |
да |
|
48. |
одна |
да |
|
53. |
коэффициентом |
нет |
|
6. |
накапливания |
нет |
|
61. |
21 |
да |
|
72. |
величины |
нет |
|
8. |
уравнение |
да |
|
80. |
с |
нет |
|
81. |
теснота |
да |
|
84. |
все |
нет |
|
86. |
переменная |
нет |
|
95. |
если |
нет |
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Основные функции для решения регрессионной задачи в пакете Excel где обнаруживаются статистические выбросы.
Назначение функций табличного процессора
 Примеры функции ЧАСТНОЕ для деления без остатка в Excel.
Примеры функции ЧАСТНОЕ для деления без остатка в Excel.
Примеры работы функции ЧАСТНОЕ в формулах для создания калькулятора расчета давления воды в трубах разного диаметра. А также при статистическом анализе погрешностей в результативных показателях.
 Примеры функции ABS в Excel для пересчета значения по модулю.
Примеры функции ABS в Excel для пересчета значения по модулю.
Функция модуль ABS для арифметических операций с отрицательными числами со знаком минус. Вычисление абсолютного значения для отрицательных чисел.
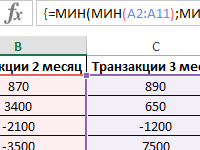 Примеры формул с использованием функций МИН и МИНА в Excel.
Примеры формул с использованием функций МИН и МИНА в Excel.
Работа с функциями МИН и МИНА для определения минимальных значений в таблице при нескольких условиях. Поиск суммы минимальных неотрицательных чисел в диапазоне ячеек.
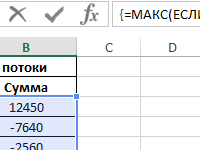 Функции МАКС и МАКСА в Excel для анализа максимальных значений.
Функции МАКС и МАКСА в Excel для анализа максимальных значений.
Примеры использования функций МАКС и МАКСА в анализах максимальных значений в диапазонах данных разного типа: числовой, логический, текстовый, при нескольких условиях.
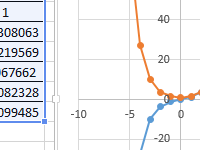 Тригонометрические функции SIN COS в Excel для синуса и косинуса.
Тригонометрические функции SIN COS в Excel для синуса и косинуса.
Примеры работы с тригонометрическими функциями SIN, SINH, COS и COSH: построение таблиц углов синусов и косинусов, построение графика функций, расчет траектории с учетом времени.
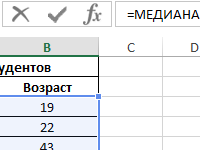 Функция МЕДИАНА в Excel для выполнения статистического анализа.
Функция МЕДИАНА в Excel для выполнения статистического анализа.
Примеры работы функции МЕДИАНА в статистическом анализе. Формулы с комбинациями функций МЕДИАНА, СРЗНАЧ, МОДА для выполнения статистических анализов.
 Примеры функций И ИЛИ в Excel для записи логических выражений.
Примеры функций И ИЛИ в Excel для записи логических выражений.
Примеры логических выражений в формулах выполненных с помощью функций ИЛИ, И. Как обрабатывать массивы логических значений с помощью выражений?
 Примеры формул с логическими функциями ИСТИНА ЛОЖЬ и НЕ в Excel.
Примеры формул с логическими функциями ИСТИНА ЛОЖЬ и НЕ в Excel.
Как работать с логическими функциями ИСТИНА ЛОЖЬ и НЕ в формулах? Примеры использования функций, которые возвращают истинные и ложные логические значения.
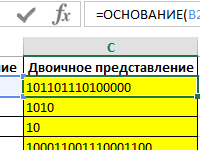 Функция ОСНОВАНИЕ в Excel переводит число в систему счисления.
Функция ОСНОВАНИЕ в Excel переводит число в систему счисления.
Как преобразовать число из одной системы счисления в другую? Примеры выполнения перевода и арифметических операций с числами разных систем счисления.
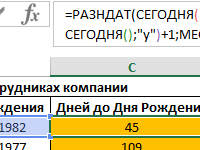 Примеры работы функции СЕГОДНЯ в Excel для вставки текущей даты.
Примеры работы функции СЕГОДНЯ в Excel для вставки текущей даты.
Примеры применения функции СЕГОДНЯ для получения актуальной текущей даты на сегодняшний день: график дней рождений сотрудников, анализ дебиторской задолженности.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Outliers as the name suggest are something that doesn’t fall in the required/given range. Outliers in statistics need to be removed because they affect the decision that is to be made after performing the required calculations. Outliers generally make the decision skewed i.e they move the decision in a positive or negative direction. Sometimes it is easy to find an outlier by looking at the data but it is difficult to find an outlier when the data is large. We’ll see this with the help of an example, given a dataset and you need to perform the average of the dataset 1, 89, 57, 100, 150, 139, 49, 87, 200, 250. So, the average of the given data set is 112.2. But, it is clearly visible that 1, 200, and 250 are ranges that are too small or too large to be a part of the dataset. These ranges are known as outliers in data. After removing the outliers, the average becomes 95.85. It is evidently seen from the above example that an outlier will make decisions based.
Finding Outliers using Sorting in Excel
This is one of the easiest ways to find outliers in MS excel when your data is not huge because by having a look at the data you’ll get to know about the values that are far away from the originally recorded values.
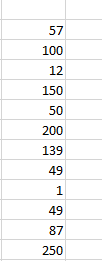
From the above image, we can clearly tell that the data is not sorted and hence it would take some time for us to identify outliers.
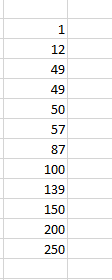
While looking at Img. 2, we can clearly say that the numbers 1, 200, and 250 are outliers.
Finding Outliers using LARGE/SMALL Excel Function
Another way to find outlier is by using built-in MS Excel functions known as LARGE and SMALL. The LARGE function will return the largest value from the array of data and the SMALL function will return the smallest value. Here, we will be using a LARGE and SMALL function which is an in-built function in Microsoft excel. Consider the example used above:
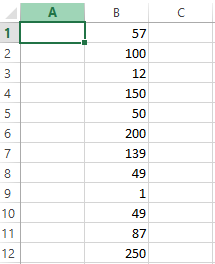
LARGE Function Syntax:
LARGE($B$1:$B$12, 1)
Here, we are passing an array and a number. The array has the dataset for which we have to find the outlier and the number, 1, represents the first largest number from the array. If we use 2, it will return the second largest value from the array. Now when we use this function in the above example, we will get the following output:
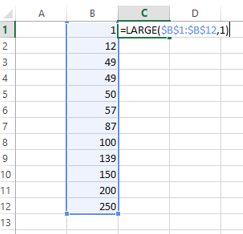
SMALL Function Syntax:
SMALL($B$1:$B$12, 1)
The syntax and pass-on value are the same. Now when we use this function in the above example, we will get the following output:
Note: If there are multiple outliers in the data then you have to use the function again and again.
Finding Outliers using Inter Quartile Range(IQR)
The data presented in the above example has a small sample size but when it comes to a real-life situation, the data can be huge, and that’s where the original problem arrives. As per IQR, An outlier is any point of data that lies over 1.5 times IQRs below the first quartile (Q1) and 1.5 times IQR above the third quartile (Q3)in a data set.
Formula is
High = Q3 + 1.5 * IQR
Low = Q1 – 1.5 * IQR
Finding Outliers using the following steps:
Step 1: Open the worksheet where the data to find outlier is stored.
Step 2: Add the function QUARTILE(array, quart), where an array is the data set for which the quartile is being calculated and a quart is the quartile number. In our case, the quart is 1 because we wish to calculate the 1st quartile to calculate the lowest outlier.
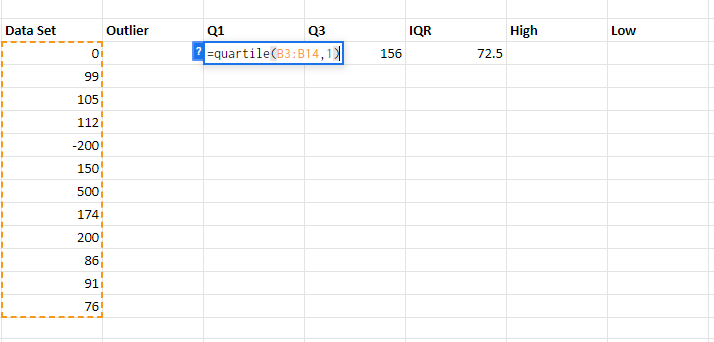
| Quart Number | Quartile Returns |
| 0 | Minimum Value |
| 1 | First quartile(25th percentile) |
| 2 | Median Value(50th percentile) |
| 3 | Third Quartile(75th percentile) |
| 4 | Maximum Value |
Step 3: Similar to step 2 add the quartile formula under Q3 and write 3 as quart number because we wish to calculate the 3rd quartile i.e 75th percentile to calculate the highest quartile value.
Step 4: Inter Quartile Range or IQR is Q3-Q1, put the formula to get the IQR value.
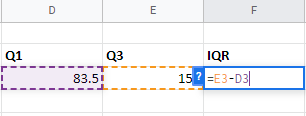
Step 5: To find the High value, the formula is Q3+(1.5*IQR). Similarly, for Low value, the formula is Q1-(1.5*IQR)
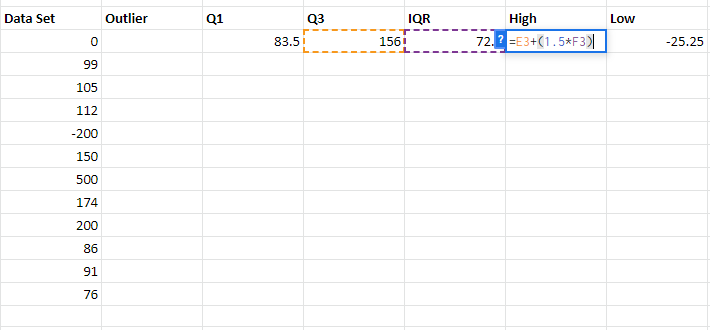
Step 6: To find whether the number in the data set is an outlier or not, we need to check whether the data entry is higher than the High value or lower than the Low value. To perform this we will use the OR function. The formula will be OR(B3>$G$3, B3<$H$3). Put the formula in the required cell and drag down the cell adjacent to the last data set, if the value returns TRUE, then the data is an outlier otherwise not.
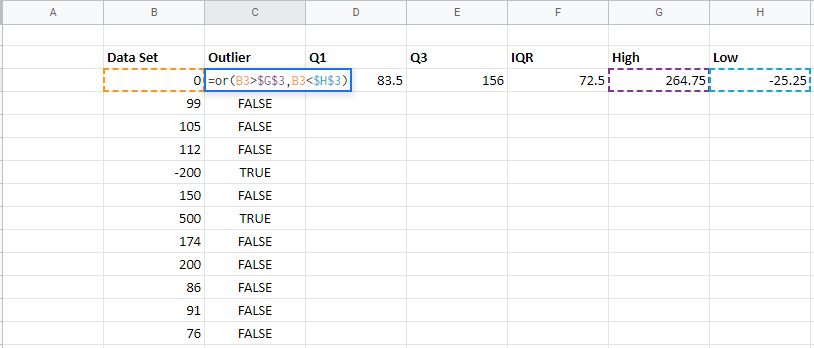
Since you’ve checked for the outlier data. Now you can remove the outliers and use the rest data for calculations and get unbiased results.
Корреляция и регрессия
Линейное уравнение регрессии имеет вид y=bx+a+ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид:
10a + 356b = 49
356a + 2135b = 9485
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 68.16, a = 11.17
Уравнение регрессии:
y = 68.16 x — 11.17
1. Параметры уравнения регрессии.
Выборочные средние.
1.1. Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 Y фактором X весьма высокая и прямая.
1.2. Уравнение регрессии (оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 68.16 x -11.17
Коэффициентам уравнения линейной регрессии можно придать экономический смысл. Коэффициент уравнения регрессии показывает, на сколько ед. изменится результат при изменении фактора на 1 ед.
Коэффициент b = 68.16 показывает среднее изменение результативного показателя (в единицах измерения у ) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 68.16.
Коэффициент a = -11.17 формально показывает прогнозируемый уровень у , но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений x , то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения x , можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и x определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
В нашем примере коэффициент эластичности больше 1. Следовательно, при изменении Х на 1%, Y изменится более чем на 1%. Другими словами — Х существенно влияет на Y.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего Y на 0.9796 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве регрессии.
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.98 2 = 0.9596, т.е. в 95.96 % случаев изменения x приводят к изменению у . Другими словами — точность подбора уравнения регрессии — высокая. Остальные 4.04 % изменения Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (xi— x ) 2 | |y — yx|:y |
| 0.371 | 15.6 | 0.1376 | 243.36 | 5.79 | 14.11 | 780.89 | 2.21 | 0.1864 | 0.0953 |
| 0.399 | 19.9 | 0.1592 | 396.01 | 7.94 | 16.02 | 559.06 | 15.04 | 0.163 | 0.1949 |
| 0.502 | 22.7 | 0.252 | 515.29 | 11.4 | 23.04 | 434.49 | 0.1176 | 0.0905 | 0.0151 |
| 0.572 | 34.2 | 0.3272 | 1169.64 | 19.56 | 27.81 | 87.32 | 40.78 | 0.0533 | 0.1867 |
| 0.607 | 44.5 | .3684 | 1980.25 | 27.01 | 30.2 | 0.9131 | 204.49 | 0.0383 | 0.3214 |
| 0.655 | 26.8 | 0.429 | 718.24 | 17.55 | 33.47 | 280.38 | 44.51 | 0.0218 | 0.2489 |
| 0.763 | 35.7 | 0.5822 | 1274.49 | 27.24 | 40.83 | 61.54 | 26.35 | 0.0016 | 0.1438 |
| 0.873 | 30.6 | 0.7621 | 936.36 | 26.71 | 48.33 | 167.56 | 314.39 | 0.0049 | 0.5794 |
| 2.48 | 161.9 | 6.17 | 26211.61 | 402 | 158.07 | 14008.04 | 14.66 | 2.82 | 0.0236 |
| 7.23 | 391.9 | 9.18 | 33445.25 | 545.2 | 391.9 | 16380.18 | 662.54 | 3.38 | 1.81 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=7 находим tкрит:
tкрит = (7;0.05) = 1.895
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 94.6484 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Sy = 9.7287 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя. (a + bxp ± ε) где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 1 (-11.17 + 68.16*1 ± 6.4554)
(50.53;63.44)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bx i ± ε)
где
| xi | y = -11.17 + 68.16xi | εi | ymin | ymax |
| 0.371 | 14.11 | 19.91 | -5.8 | 34.02 |
| 0.399 | 16.02 | 19.85 | -3.83 | 35.87 |
| 0.502 | 23.04 | 19.67 | 3.38 | 42.71 |
| 0.572 | 27.81 | 19.57 | 8.24 | 47.38 |
| 0.607 | 30.2 | 19.53 | 10.67 | 49.73 |
| 0.655 | 33.47 | 19.49 | 13.98 | 52.96 |
| 0.763 | 40.83 | 19.44 | 21.4 | 60.27 |
| 0.873 | 48.33 | 19.45 | 28.88 | 67.78 |
| 2.48 | 158.07 | 25.72 | 132.36 | 183.79 |
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (7;0.05) = 1.895
Поскольку 12.8866 > 1.895, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 2.0914 > 1.895, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(68.1618 — 1.895 • 5.2894; 68.1618 + 1.895 • 5.2894)
(58.1385;78.1852)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a — ta)
(-11.1744 — 1.895 • 5.3429; -11.1744 + 1.895 • 5.3429)
(-21.2992;-1.0496)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с lang=EN-US>n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=7, Fkp = 5.59
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция, нежели отрицательная автокорреляция. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения ei с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения ei (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скоре всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости ei от ei-1.
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Тест по «Эконометрике»
Автор: lopo15 • Февраль 20, 2018 • Тест • 1,628 Слов (7 Страниц) • 11,945 Просмотры
1 Что является предметом изучения эконометрики?
факторы, формирующие развитие экономических явлений и процессов
2 Для чего составляются эконометрические модели?
3для выявления качественного и количественного влияния разных факторов на объект
3 Эконометрика занимается изучением
качественного и количественного влияния разных факторов на экономические объекты
4 Для решения эконометрических задач необходимо
построение математической модели
предварительное решение нескольких задач математического анализа
наличие специализированных программных средств
5 Что такое математическая модель экономического объекта?
записанное в математической форме абстрактное отображение экономического объекта
6 Математическая модель экономического объекта предназначена для
экспериментального изучения поведения объекта в различных обстоятельствах
7 Что может быть выполнено с помощью эконометрической модели?
прогнозирование поведения изучаемого экономического объекта
8 Математической моделью в эконометрических задачах является
уравнение регрессии или система уравнений регрессии
9 В эконометрических задачах математическая модель
это уравнение регрессии или система уравнений регрессии
10 Что означает наличие прямой связи между переменными х и у?
3что при увеличении значений х увеличиваются и значения у
11 Что означает наличие обратной связи между переменными х и у?
что при уменьшении значений х значения у увеличиваются
12 В каком случае связь между двумя факторами является тесной?
3если их коэффициент корреляции по модулю больше или равен 0,7
13 Для определения тесноты линейной связи между двумя факторами необходимо
рассчитать коэффициент корреляции
14 Взаимозависимости экономических переменных часто описываются
15 Линейная связь между переменными означает, что
2график зависимости представляется прямой линией
16 Регрессионный анализ оценивает
формулу связи двух или нескольких переменных
17 Оценка вида связи между переменными возможна
с помощью регрессионного анализа
18 Функция, описывающая корреляционную зависимость между х и у, называется
регрессией у на х
19 Регрессия у на х — это
формула связи между переменными у и х
20 Какой метод позволяет определить оценки параметров регрессии?
метод наименьших квадратов
21 Метод наименьших квадратов позволяет
найти оценки параметров регрессии
22 Метод наименьших квадратов состоит
2в минимизации суммы квадратов отклонений реальных значений у от расчетных
23 Решение по МНК в пакете Excel можно получить при помощи
опций Анализ данных — Регрессия
24 Что такое МНК?
3метод наименьших квадратов
25 Для чего применяется МНК?
для оценки параметров регрессии
26 Для оценки формы связи между переменными служит
27 В каком случае регрессия является парной?
4если в уравнение регрессии входит одна зависимая и одна независимая переменная
28 В каком случае регрессия является множественной?
3если в ур-е регрессии входит одна зависимая и множество независимых переменных
29 Какие виды регрессионных зависимостей существуют?
парная, множественная, линейная, нелинейная
30 Какого вида регрессионная зависимость между переменными не может существовать?
прямая, линейная, нелинейная
31 Что является математической моделью эконометрической задачи?
одно уравнение или система уравнений регрессии
32 Можно ли на основании решения Excel прогнозировать изменение Y в зависимости от изменения X?
2можно, только если построенная регрессионная модель является качественной
33 После записи уравнения регрессии необходимо
оценить качество полученного уравнения
34 Регрессионная модель считается качественной при обязательном выполнении следующих условий:
1связь в модели тесная, объясняющие переменные значимы, наблюдений достаточно
35 При решении эконометрических задач уравнение регрессии является
математической моделью зависимости переменных
36 Уравнение регрессии оценивает
форму зависимости исследуемых переменных
37 Для оценки формы связи между переменными служит
38 Для чего составляется уравнение регрессии?
2для определения формы зависимости исследуемых переменных
39 Значения х и у для поиска уравнения регрессионной зависимости берутся
из статистических данных
40 Значения a и b для поиска уравнения регрессионной зависимости берутся
из расчетов по методу наименьших квадратов
41 Уравнение регрессии записывается на основании
1величин коэффициентов регрессии
42 Какие величины служат для записи уравнения регрессии?
43 В уравнении регрессии зависимая переменная обычно обозначается как
44 В уравнении регрессии независимая переменная обычно обозначается как
45 В уравнении регрессии факторы обычно обозначаются как
46. В уравнении регрессии параметры обычно обозначаются как
47. В уравнение регрессии входят
зависимая переменная, независимые переменные и коэффициенты при них
48 В уравнении регрессионной зависимости может быть только
3одна зависимая и одна или несколько независимых переменных
49. Сколько объясняющих переменных может быть в уравнении регрессии?
произвольное количество (желательно, не более трети от числа наблюдений)
50 Сколько зависимых переменных может быть в уравнении регрессии?
51 В уравнении y = a + bx коэффициенты а и b — это:
52 В уравнении y = a + bx коэффициент а является
53 В уравнении y = a + bx коэффициент b является
54 В уравнении регрессии параметры регрессии обычно обозначаются как
55 В результатах решения задачи коэффициент регрессии а отображается как:
56 В уравнении y = a + bx величина коэффициента а отражает
значение у при нулевых значениях х
56. В уравнении y = a + bx величина коэффициента а отражает
значение у при единичном увеличении х
значимость или незначимость переменной у
значимость или незначимость коэффициента а
57 В результатах регрессионного анализа Y-пересечение — это
коэффициент регрессии а
58. Чему будет равен Y в парной линейной регрессии, если Y-пересечение = 5, b = 7, х = 10?
59 Чему будет равен Y в парной линейной регрессии, если Y-пересечение = 2, b = 6, х = 4?
60 Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 2, b1 = 5, b2 = 2, х1 = 4, x2 = 1?
61 Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 10, b1 = 1, b2 = 2, х1 = 3, x2 = 4?
62 Чему будет равен Y в множественной линейной регрессии, если Y-пересечение = 6, b1 = 2, b2 = 5, х1 = 8, x2 = 4?
63 В уравнении регрессии у = a + bx коэффициент а показывает
прогнозируемую величину у при х = 0
64 В уравнении регрессии у = a + bx коэффициент а показывает
величину у при равенстве х нулю
65 Как в уравнении регрессии интерпретируется коэффициент перед переменной х?
показывает величину изменения у при единичном изменении х
66 В уравнении регрессии у = a + bx коэффициент b показывает
2величину изменения у при единичном изменении х
67 Вероятность выполнения нуль-гипотезы для коэффициента регрессии оценивается с помощью
Р-значения этого коэффициента регрессии
68 В уравнении y = a + bx незначимость коэффициента регрессии b означает, что
влияние переменной х на коэффициент b отсутствует
влияние переменной у на коэффициент b отсутствует
влияние коэффициента b на переменную х отсутствует
69 В уравнении y = a + bx незначимость коэффициента регрессии а означает, что
3влияние коэффициента а на переменную у отсутствует
70 В уравнении y = a + bx незначимость Y-пересечения означает, что
в уравнении регрессии отсутствует константа
71 Что означает не значимость коэффициента регрессии?
что соответствующая ему независимая переменная не влияет на зависимую
72 Значимость коэффициентов регрессии определяется с помощью:
73 Что означает статистическая незначимость параметра (коэффициента) регрессии?
высокую вероятность равенства данного параметра нулю
74. Когда коэффициент регрессии считается значимым?
если его Р-значение меньше 5%
75 Какая величина «Р-значения» подтверждает влияние х на у?
Р-значение для него меньше 0,05
76 При одновременной незначимости нескольких объясняющих переменных модели нужно
4удалить их последовательно, начиная с той, чье Р-значение больше
77 Что следует делать, если коэффициент регрессии не значим?
удалять из модели переменную, которой он соответствует
78 Теснота связи в уравнении регрессии определяется с помощью
79 Какой показатель характеризует тесноту связи в уравнении регрессии?
80 С помощью какой величины определяется теснота связи в уравнении регрессии?
с помощью коэффициента корреляции
81 Что проверяется с помощью коэффициента корреляции?
теснота связи между факторами в уравнении регрессии
82 Коэффициент корреляции оценивает
тесноту связи в уравнении регрессии
83 Для констатации наличия тесной связи в регрессионной модели необходимо
чтобы модуль коэффициента корреляции был не меньше 0,7
84 Тесная связь между перменными модели констатируется в том случае, если
коэффициент корреляции по модулю не меньше 0,7
85 Коэффициент корреляции при решении в пакете Excel выдается как величина
86 В результатах решения задачи в Excel коэффициент корреляции отображается как:
87 Какие действия приводят к увеличению тесноты связи в регрессионной модели?
удаление выбросов, добавление ранее неучтенных факторов, видоизменение модели
88 Величина «Значимость F» показывает
1вероятность недостоверности коэффициента детерминации
89 Для чего служит величина «Значимость F»?
2для определения достоверности коэффициента детерминации
90 Нулевая гипотеза для коэфициента детерминации отвергается при
Значимости F, меньшей или равной 5%
91 Что означает незначимость коэффициента детерминации?
что рассчитанный коэффициент детерминации не достоверен
92 В каком случае коэффициент детерминации может быть не достоверен?
4в случае, если для анализа взято слишком мало наблюдений
93 Что необходимо сделать в случае незначимости коэффициента детерминации?
увеличить количество наблюдений в исследуемой выборке
94 Причиной недостоверности коэффициента детерминации может служить
недостаточное количество наблюдений
95 В каком случае коэффициент детерминации считается незначимым?
если величина «Значимость F» больше 0,05
96 В каком случае коэффициент детерминации признается не достоверным?
если Значимость F больше или равна 5%
97 Что показывает коэффициент детерминации?
объясненную регрессией долю дисперсии зависимой переменной у
98 Как рассчитывается коэффициент детерминации?
как доля объясненной регрессией дисперсии в общей дисперсии зависимой переменной
99 О чем свидетельствует близкое кзначение коэффициента детерминации?
о наличии тесной связи между изучаемыми показателями
100 Величина RSS показывает
3величину дисперсии зависимой переменной, объясненной регрессией
101. Величина ТSS показывает
общий разброс зависимой переменной вокруг ее среднего значения
102 Величина ЕSS показывает
4величину дисперсии зависимой переменной, не объясненной регрессией
103 Как рассчитывается коэффициент детерминации?
104 Что такое остаток?
3разность между реальным и расчетным значением у
105 Какое количество остатков выводится при проведении регрессии?
2равное количеству наблюдений
106 Какое количество стандартных остатков выводится при проведении регрессии?
3равное количеству наблюдений
107 Что такое статистический выброс?
наблюдение, которое резко отклоняется от линии регрессии
108 Что такое статистический выброс?
нетипичное наблюдение, подлежащее удалению
109. Какое наблюдение считается статистическим выбросом?
наблюдение, не вошедшее в выборку, по которой производится регрессионный анализ
110 Каким образом при решении регрессионной задачи в пакете Excel обнаруживаются статистические выбросы?
2по величинам стандартных остатков наблюдений
111 В каких случаях не обязательно удаление статистических выбросов?
2в случае сильной связи в регрессионной модели
112 В каких случаях необходимо удаление статистических выбросов?
в случае низкого значения коэффициента корреляции
113 Каковы последствия удаления статистических выбросов в регрессионном анализе?
увеличение тесноты связи в модели
114. Для проверки качества построенной регрессионной модели необходимо проанализировать:
коэффициент корреляции, Значимость F, Р-значения
115 Для чего в регрессионную модель вводятся бинарные переменные?
для учета качественных признаков
115. Для признания регрессионной модели качественной должны выполняться условия:
связь тесная, наблюдений достаточно, все объясняющие переменные значимы
116 Что такое бинарная переменная?
переменная, принимающая значения «0» или «1» при наличии или отсутствии признака
116. Зачем в регрессионном анализе используются бинарные переменные?
чтобы учесть в модели факторы, выражающиеся не количественными значениями
117 Фиктивная переменная — это
другое название бинарной переменной
118 Бинарная переменная является
равноправной переменной регрессионной модели
119 Уравнение регрессии, содержащее бинарные переменные, является
120 Какие значения может принимать фиктивная переменная?
121 Можно ли использовать бинарные переменные в множественной регрессии?
122 Можно ли использовать бинарные переменные в парной регрессии?
123 Можно ли вводить в модель больше одной бинарной переменной?
123. Можно ли вводить в модель больше одной бинарной переменной?
да, только при условии высокого коэффициента корреляции
124 Может ли бинарная переменная быть независимой переменной регрессионной модели?
125 Может ли коэффициент при бинарной переменной быть отрицательным?
126 Что означает отрицательный коэффициент при бинарной переменной?
уменьшение зависимой переменной при наличии признака, описываемого бинарной
127 Что означает положительный коэффициент при бинарной переменной?
увеличение зависимой переменной при наличии признака, описываемого бинарной
128 Незначимость коэффициента при бинарной переменной означает
4отсутствие влияния данного качественного признака на зависимую переменную
129 Статистическая значимость бинарной переменной означает
подтвержденное влияние данного качественного признака на зависимую переменную
130 В каких случаях производится исключение бинарных переменных из модели?
источники:
http://statistica.ru/theory/osnovy-lineynoy-regressii/
http://ru.essays.club/%D0%AD%D0%BA%D0%BE%D0%BD%D0%BE%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5-%D0%B4%D0%B8%D1%81%D1%86%D0%B8%D0%BF%D0%BB%D0%B8%D0%BD%D1%8B/%D0%AD%D0%BA%D0%BE%D0%BD%D0%BE%D0%BC%D0%B8%D0%BA%D0%B0/%D0%A2%D0%B5%D1%81%D1%82-%D0%BF%D0%BE-%D0%AD%D0%BA%D0%BE%D0%BD%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B5-14909.html
На чтение 5 мин. Просмотров 4k. Опубликовано 21.06.2019
Содержание
- Быстрый пример
- Как найти выбросы в ваших данных
- Шаг первый: вычислите квартили
- Шаг второй: оценка межквартильного диапазона
- Шаг третий: вернуть нижнюю и верхнюю границы
- Шаг четвертый: выявить выбросы
- Игнорирование выбросов при расчете среднего значения

Выброс – это значение, которое значительно выше или ниже, чем большинство значений в ваших данных. При использовании Excel для анализа данных выбросы могут искажать результаты. Например, среднее значение набора данных может действительно отражать ваши значения. Excel предоставляет несколько полезных функций, которые помогут вам управлять своими выбросами, поэтому давайте взглянем.
Быстрый пример
На изображении ниже достаточно легко определить выбросы – значение двух, присвоенное Эрику, и значение 173, присвоенное Райану. В таком наборе данных достаточно легко определить и устранить эти выбросы вручную.

В большем наборе данных это не будет иметь место. Очень важно уметь определять выбросы и исключать их из статистических расчетов, и именно это мы и рассмотрим, как это сделать в этой статье.
Как найти выбросы в ваших данных
Чтобы найти выбросы в наборе данных, мы используем следующие шаги:
- Вычислите 1-й и 3-й квартили (мы немного поговорим о том, что это такое).
- Оцените межквартильный диапазон (мы также объясним это чуть ниже).
- Вернуть верхнюю и нижнюю границы нашего диапазона данных.
- Используйте эти границы для определения удаленных точек данных.
Диапазон ячеек справа от набора данных, показанного на рисунке ниже, будет использоваться для хранения этих значений.

Давайте начнем.
Шаг первый: вычислите квартили
Если вы разделите свои данные на кварталы, каждый из этих наборов называется квартилем. Самые низкие 25% чисел в диапазоне составляют 1-й квартиль, следующие 25% – 2-й квартиль и так далее. Сначала мы сделаем этот шаг, потому что наиболее широко используемое определение выброса – это точка данных, которая находится на расстоянии более 1,5 межквартильных диапазонов (IQR) ниже 1-го квартиля и 1,5 межквартильных диапазонов выше 3-го квартиля. Чтобы определить эти значения, мы сначала должны выяснить, что такое квартили.
Excel предоставляет функцию QUARTILE для расчета квартилей. Требуется две части информации: массив и кварт.
= QUARTILE (массив, кварт)
массив – это диапазон значений, которые вы оцениваете. И кварта – это число, представляющее квартиль, который вы хотите вернуть (например, 1 для 1-го квартиля, 2 для 2-го квартиля и т. Д.).
Примечание. В Excel 2010 Microsoft выпустила функции QUARTILE.INC и QUARTILE.EXC в качестве улучшений функции QUARTILE. QUARTILE более обратно совместим при работе с несколькими версиями Excel.
Давайте вернемся к нашему примеру таблицы.

Для вычисления 1-го квартиля мы можем использовать следующую формулу в ячейке F2.
= КВАРТИЛЬ (В2: B14,1)
При вводе формулы Excel предоставляет список параметров для аргумента кварта.

Чтобы вычислить третий квартиль, мы можем ввести формулу, аналогичную предыдущей, в ячейку F3, но используя три вместо одного.
= КВАРТИЛЬ (В2: B14,3)
Теперь у нас есть квартильные точки данных, отображаемые в ячейках.

Шаг второй: оценка межквартильного диапазона
Межквартильный диапазон (или IQR) – это средние 50% значений в ваших данных. Он рассчитывается как разница между значением 1-го квартиля и 3-го квартиля.
Мы собираемся использовать простую формулу в ячейке F4, которая вычитает 1-й квартиль из 3-го квартиля:
= F3-F2
Теперь мы можем видеть наш межквартильный диапазон.

Шаг третий: вернуть нижнюю и верхнюю границы
Нижние и верхние границы – это самые маленькие и самые большие значения диапазона данных, которые мы хотим использовать. Любые значения, меньшие или большие, чем эти связанные значения, являются выбросами.
Мы рассчитаем нижний предел границы в ячейке F5, умножив значение IQR на 1,5, а затем вычтя его из точки данных Q1:
= F2- (1,5 * F4)

Примечание . В этой формуле скобки не обязательны, так как часть умножения будет рассчитываться до части вычитания, но она облегчает чтение формулы.
Чтобы вычислить верхнюю границу в ячейке F6, мы снова умножим IQR на 1,5, но на этот раз добавим его в точку данных Q3:
= F3 + (1,5 * F4)

Шаг четвертый: выявить выбросы
Теперь, когда мы настроили все наши базовые данные, пришло время идентифицировать наши отдаленные точки данных – те, которые ниже, чем нижнее граничное значение, или выше, чем верхнее граничное значение.
Мы будем использовать функцию ИЛИ, чтобы выполнить этот логический тест и показать значения, которые соответствуют этим критериям, введя следующую формулу в ячейку C2:
= ИЛИ (В2 $ F $ 6)

Затем мы скопируем это значение в наши ячейки C3-C14. Значение TRUE указывает на выброс, и, как вы можете видеть, у нас есть два в наших данных.

Игнорирование выбросов при расчете среднего значения
Используя функцию QUARTILE, мы рассчитаем IQR и работаем с наиболее широко используемым определением выброса. Однако при расчете среднего значения для диапазона значений и игнорировании выбросов существует более быстрая и простая функция для использования. Этот метод не будет идентифицировать выброс как прежде, но он позволит нам быть гибкими с тем, что мы могли бы считать нашей частью выброса.
Функция, которая нам нужна, называется TRIMMEAN, и вы можете увидеть ее синтаксис ниже:
= TRIMMEAN (массив, проценты)
массив – это диапазон значений, которые вы хотите усреднить. процент – это процент точек данных, которые нужно исключить из верхней и нижней частей набора данных (вы можете ввести его в процентах или десятичном значении).
Мы ввели формулу ниже в ячейку D3 в нашем примере, чтобы вычислить среднее значение и исключить 20% выбросов.
= TRIMMEAN (B2: B14, 20%)

Там у вас есть две разные функции для обработки выбросов. Независимо от того, хотите ли вы определить их для каких-либо потребностей в отчетности или исключить их из вычислений, таких как средние значения, в Excel есть функция, отвечающая вашим потребностям.
Быстрый пример
На изображении ниже выбросы довольно легко обнаружить — значение два присвоено Эрику, а значение 173 — Райану. В таком наборе данных достаточно легко обнаружить и обработать эти выбросы вручную.
В большем наборе данных этого не будет. Возможность идентифицировать выбросы и удалять их из статистических расчетов важна — и это то, что мы рассмотрим, как это сделать в этой статье.
Как найти выбросы в ваших данных
Чтобы найти выбросы в наборе данных, мы используем следующие шаги:
Вычислите 1-й и 3-й квартили (мы немного поговорим о том, что это такое).
Оцените межквартильный размах (мы также объясним это немного ниже).
Верните верхнюю и нижнюю границы нашего диапазона данных.
Используйте эти границы для определения отдаленных точек данных.
Диапазон ячеек справа от набора данных, показанного на изображении ниже, будет использоваться для хранения этих значений.
Давайте начнем.
Шаг 1. Рассчитайте квартили
Если вы разделите данные на кварталы, каждый из этих наборов называется квартилем. Самые низкие 25% чисел в диапазоне составляют 1-й квартиль, следующие 25% — 2-й квартиль и т. Д. Мы делаем этот шаг в первую очередь, потому что наиболее широко используемое определение выброса — это точка данных, которая более чем на 1,5 интерквартильных диапазонов (IQR) ниже 1-го квартиля и на 1,5 межквартильных диапазонов выше 3-го квартиля. Чтобы определить эти значения, мы сначала должны выяснить, каковы квартили.
Excel предоставляет функцию КВАРТИЛЬ для расчета квартилей. Для этого требуются две части информации: массив и кварта.
=QUARTILE(array, quart)
Массив — это диапазон значений, которые вы оцениваете. Кварта — это число, которое представляет квартиль, который вы хотите вернуть (например, 1 для 1-го квартиля, 2 для 2-го квартиля и т. Д.).
Примечание. В Excel 2010 Microsoft выпустила функции QUARTILE.INC и QUARTILE.EXC как усовершенствования функции QUARTILE. QUARTILE более обратно совместима при работе с несколькими версиями Excel.
Вернемся к нашему примеру таблицы.
Для вычисления 1-го квартиля мы можем использовать следующую формулу в ячейке F2.
=QUARTILE(B2:B14,1)
Когда вы вводите формулу, Excel предоставляет список параметров для аргумента кварты.
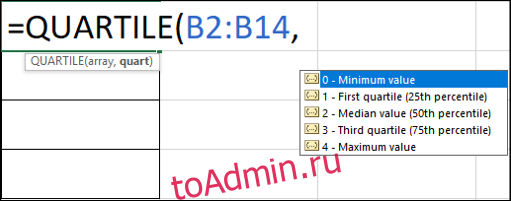
Чтобы вычислить 3-й квартиль, мы можем ввести формулу, аналогичную предыдущей, в ячейку F3, но используя тройку вместо единицы.
=QUARTILE(B2:B14,3)
Теперь у нас есть точки данных квартилей, отображаемые в ячейках.
Шаг второй: оцените межквартильный размах
Межквартильный диапазон (или IQR) — это средние 50% значений в ваших данных. Он рассчитывается как разница между значением 1-го квартиля и значением 3-го квартиля.
Мы собираемся использовать простую формулу в ячейке F4, которая вычитает 1-й квартиль из 3-го квартиля:
=F3-F2
Теперь мы можем видеть наш межквартильный размах.

Шаг третий: верните нижнюю и верхнюю границы
Нижняя и верхняя границы — это наименьшее и наибольшее значение диапазона данных, который мы хотим использовать. Любые значения, меньшие или большие, чем эти связанные значения, являются выбросами.
Мы рассчитаем нижний предел в ячейке F5, умножив значение IQR на 1,5, а затем вычтя его из точки данных Q1:
=F2-(1.5*F4)

Примечание. Скобки в этой формуле не нужны, потому что часть умножения будет вычисляться перед частью вычитания, но они облегчают чтение формулы.
Чтобы вычислить верхнюю границу в ячейке F6, мы снова умножим IQR на 1,5, но на этот раз добавим его к точке данных Q3:
=F3+(1.5*F4)
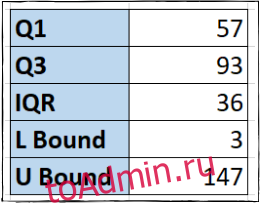
Шаг четвертый: выявление выбросов
Теперь, когда мы настроили все наши базовые данные, пришло время определить наши отдаленные точки данных — те, которые ниже значения нижней границы или выше значения верхней границы.
Мы будем использовать Функция ИЛИ для выполнения этого логического теста и отображения значений, соответствующих этим критериям, введите следующую формулу в ячейку C2:
=OR(B2$F$6)
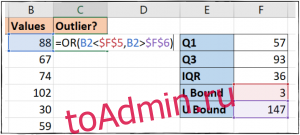
Затем мы скопируем это значение в наши ячейки C3-C14. Значение ИСТИНА указывает на выброс, и, как видите, в наших данных их два.
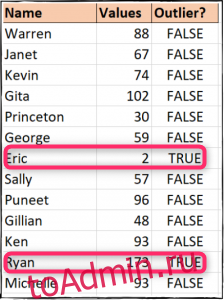
Игнорирование выбросов при вычислении среднего среднего
Использование функции КВАРТИЛЬ позволяет нам рассчитать IQR и работать с наиболее широко используемым определением выброса. Однако при вычислении среднего среднего для диапазона значений и игнорировании выбросов существует более быстрая и простая функция. Этот метод не будет определять выбросы, как раньше, но он позволит нам быть гибкими в выборе того, что мы можем считать своей частью выбросов.
Нужная нам функция называется TRIMMEAN, синтаксис для нее вы можете увидеть ниже:
=TRIMMEAN(array, percent)
Массив — это диапазон значений, которые вы хотите усреднить. Процент — это процент точек данных, которые необходимо исключить из верхней и нижней части набора данных (вы можете ввести его как процентное или десятичное значение).
В нашем примере мы ввели приведенную ниже формулу в ячейку D3, чтобы вычислить среднее значение и исключить 20% выбросов.
=TRIMMEAN(B2:B14, 20%)
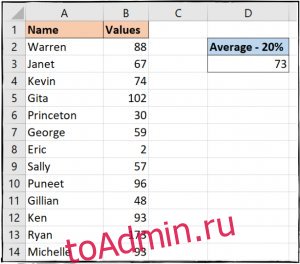
Здесь у вас есть две разные функции для обработки выбросов. Независимо от того, хотите ли вы идентифицировать их для каких-либо потребностей в отчетности или исключить их из вычислений, таких как средние значения, в Excel есть функция, соответствующая вашим потребностям.