
Дадим определение терминам уровень надежности и уровень значимости. Покажем, как и где они используется в
MS
EXCEL
.
Уровень значимости
(Level of significance) используется в
процедуре проверки гипотез
и при
построении доверительных интервалов
.
СОВЕТ
: Для понимания терминов
Уровень значимости и
Уровень надежности
потребуется знание следующих понятий:
-
выборочное распределение среднего
;
-
стандартное отклонение
;
-
проверка гипотез
;
-
нормальное распределение
.
Уровень значимости
статистического теста – это вероятность отклонить
нулевую гипотезу
, когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность
ошибки первого рода
(type I error).
Уровень значимости
обычно обозначают греческой буквой α (
альфа
). Чаще всего для
уровня значимости
используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении
доверительного интервала для оценки среднего значения распределения
, его ширину рассчитывают таким образом, чтобы вероятность события «
выборочное среднее (Х
ср
) находится за пределами доверительного интервала
» было равно
уровню значимости
. Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о
равенстве среднего заданному значению
.
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение
уровня значимости α
(т.е. вероятности
ошибки первого рода
) может привести к увеличению вероятности
ошибки второго рода
, то есть вероятности принять
нулевую гипотезу
, когда на самом деле она не верна. Подробнее об
ошибке второго рода
см. статью
Ошибка второго рода и Кривая оперативной характеристики
.
Уровень значимости
обычно указывается в аргументах
обратных функций MS EXCEL
для вычисления
квантилей
соответствующего распределения:
НОРМ.СТ.ОБР()
,
ХИ2.ОБР()
,
СТЬЮДЕНТ.ОБР()
и др. Примеры использования этих функций приведены в статьях про
проверку гипотез
и про построение
доверительных интервалов
.
Уровень надежности
Уровень
доверия
(этот термин более распространен в отечественной литературе, чем
Уровень надежности
) — означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Уровень
доверия
равен
1-α,
где α –
уровень значимости
.
Термин
Уровень надежности
имеет синонимы:
уровень доверия, коэффициент доверия, доверительный уровень
и
доверительная вероятность (англ.
Confidence
Level
,
Confidence
Coefficient
).
В математической статистике обычно используют значения
уровня доверия
90%; 95%; 99%, реже 99,9% и т.д.
Например,
Уровень
доверия
95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор
уровня доверия
полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание
: Стоит отметить, что математически не корректно говорить, что
Уровень
доверия
является вероятностью, того что оцениваемый параметр распределения принадлежит
доверительному интервалу
, вычисленному на основе
выборки
. Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что
доверительный интервал
, с вероятностью равной
Уровню
доверия,
накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL
Уровень надежности
упоминается в
надстройке Пакет анализа
. После вызова надстройки, в диалоговом окне необходимо выбрать инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно.
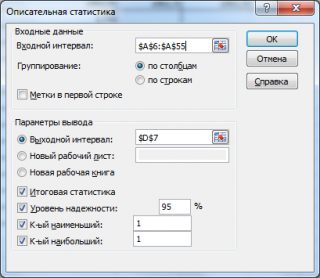
В этом окне задается
Уровень надежности,
т.е.значениевероятности в процентах. После нажатия кнопки
ОК
в
выходном интервале
выводится значение равное
половине ширины
доверительного интервала
. Этот
доверительный интервал
используется для оценки
среднего значения распределения, когда дисперсия не известна
(подробнее см.
статью про доверительный интервал
).
Необходимо учитывать, что данный
доверительный интервал
рассчитывается при условии, что
выборка
берется из
нормального распределения
. Но, на практике обычно принимается, что при достаточно большой
выборке
(n>30),
доверительный интервал
будет построен приблизительно правильно и для распределения, не являющегося
нормальным
(если при этом это распределение не будет иметь
сильной асимметрии
).
Примечание
: Понять, что в диалоговом окне речь идет именно об оценке
среднего значения распределения
, достаточно сложно. Хотя в английской версии диалогового окна это указано прямо:
Confidence
Level
for
Mean
.
Если
Уровень надежности
задан 95%, то
надстройка Пакет анализа
использует следующую формулу (выводится не сама формула, а лишь ее результат):
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) *СТЬЮДЕНТ.ОБР.2Х(1-0,95;СЧЁТ(Выборка)-1)
или эквивалентную ей
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) *СТЬЮДЕНТ.ОБР((1+0,95)/2;СЧЁТ(Выборка)-1)
где
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка))
– является
стандартной ошибкой среднего
(формулы приведены в
файле примера
).
или
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Подробнее см. в
статьях про доверительный интервал
.
Содержание
- Определение термина
- Расчет показателя в Excel
- Способ 1: Мастер функций
- Способ 2: работа со вкладкой «Формулы»
- Способ 3: ручной ввод
- Вопросы и ответы

Одним из наиболее известных статистических инструментов является критерий Стьюдента. Он используется для измерения статистической значимости различных парных величин. Microsoft Excel обладает специальной функцией для расчета данного показателя. Давайте узнаем, как рассчитать критерий Стьюдента в Экселе.
Определение термина
Но, для начала давайте все-таки выясним, что представляет собой критерий Стьюдента в общем. Данный показатель применяется для проверки равенства средних значений двух выборок. То есть, он определяет достоверность различий между двумя группами данных. При этом, для определения этого критерия используется целый набор методов. Показатель можно рассчитывать с учетом одностороннего или двухстороннего распределения.
Теперь перейдем непосредственно к вопросу, как рассчитать данный показатель в Экселе. Его можно произвести через функцию СТЬЮДЕНТ.ТЕСТ. В версиях Excel 2007 года и ранее она называлась ТТЕСТ. Впрочем, она была оставлена и в позднейших версиях в целях совместимости, но в них все-таки рекомендуется использовать более современную — СТЬЮДЕНТ.ТЕСТ. Данную функцию можно использовать тремя способами, о которых подробно пойдет речь ниже.
Способ 1: Мастер функций
Проще всего производить вычисления данного показателя через Мастер функций.
- Строим таблицу с двумя рядами переменных.
- Кликаем по любой пустой ячейке. Жмем на кнопку «Вставить функцию» для вызова Мастера функций.
- После того, как Мастер функций открылся. Ищем в списке значение ТТЕСТ или СТЬЮДЕНТ.ТЕСТ. Выделяем его и жмем на кнопку «OK».
- Открывается окно аргументов. В полях «Массив1» и «Массив2» вводим координаты соответствующих двух рядов переменных. Это можно сделать, просто выделив курсором нужные ячейки.
В поле «Хвосты» вписываем значение «1», если будет производиться расчет методом одностороннего распределения, и «2» в случае двухстороннего распределения.
В поле «Тип» вводятся следующие значения:
- 1 – выборка состоит из зависимых величин;
- 2 – выборка состоит из независимых величин;
- 3 – выборка состоит из независимых величин с неравным отклонением.
Когда все данные заполнены, жмем на кнопку «OK».



Выполняется расчет, а результат выводится на экран в заранее выделенную ячейку.

Способ 2: работа со вкладкой «Формулы»
Функцию СТЬЮДЕНТ.ТЕСТ можно вызвать также путем перехода во вкладку «Формулы» с помощью специальной кнопки на ленте.
- Выделяем ячейку для вывода результата на лист. Выполняем переход во вкладку «Формулы».
- Делаем клик по кнопке «Другие функции», расположенной на ленте в блоке инструментов «Библиотека функций». В раскрывшемся списке переходим в раздел «Статистические». Из представленных вариантов выбираем «СТЬЮДЕНТ.ТЕСТ».
- Открывается окно аргументов, которые мы подробно изучили при описании предыдущего способа. Все дальнейшие действия точно такие же, как и в нём.


Способ 3: ручной ввод
Формулу СТЬЮДЕНТ.ТЕСТ также можно ввести вручную в любую ячейку на листе или в строку функций. Её синтаксический вид выглядит следующим образом:
= СТЬЮДЕНТ.ТЕСТ(Массив1;Массив2;Хвосты;Тип)
Что означает каждый из аргументов, было рассмотрено при разборе первого способа. Эти значения и следует подставлять в данную функцию.
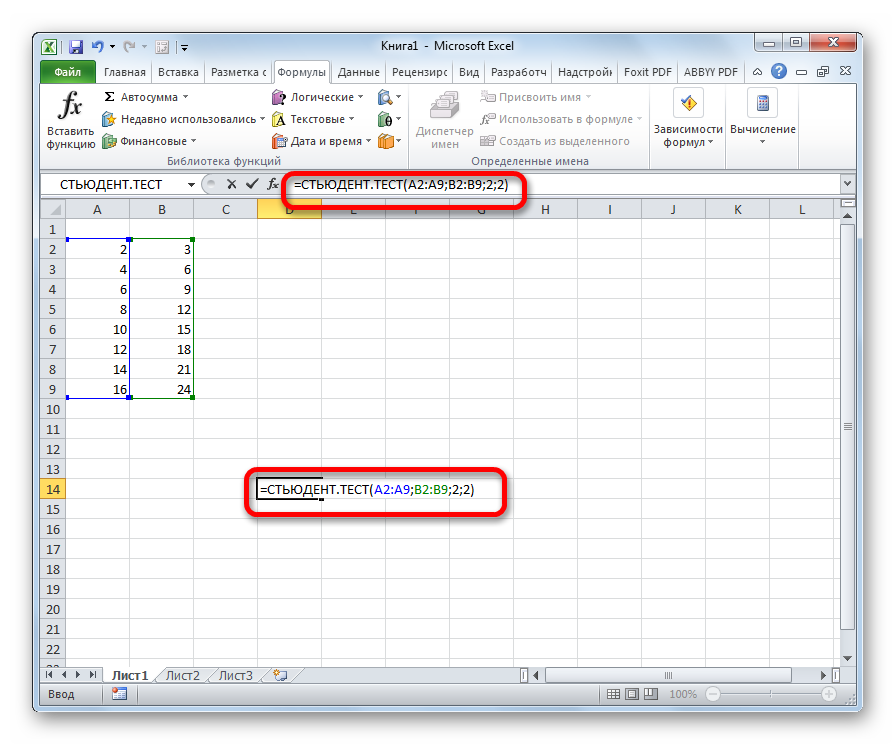
После того, как данные введены, жмем кнопку Enter для вывода результата на экран.
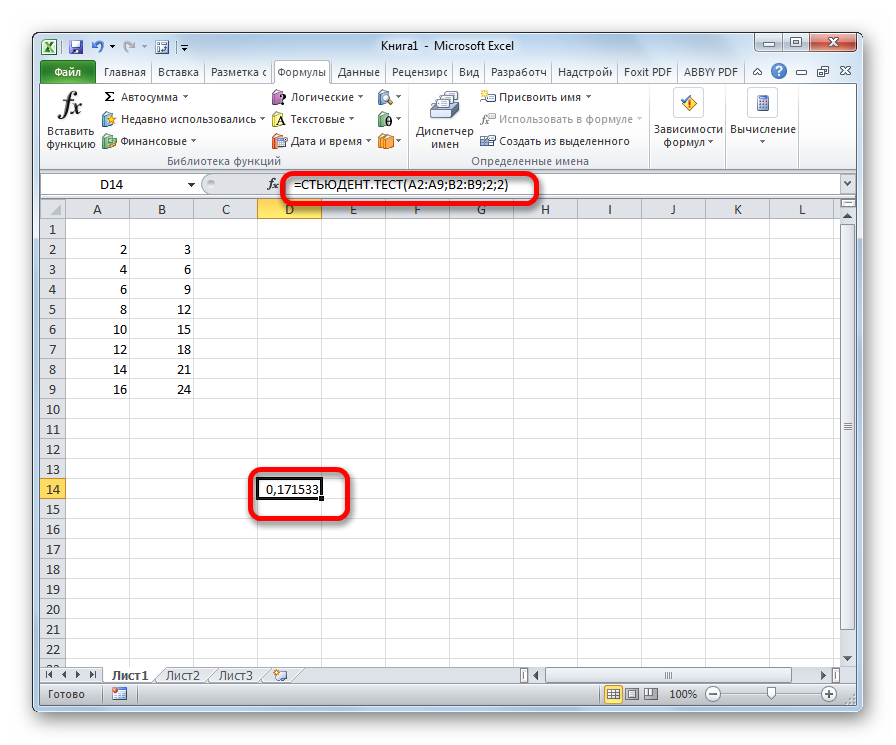
Как видим, вычисляется критерий Стьюдента в Excel очень просто и быстро. Главное, пользователь, который проводит вычисления, должен понимать, что он собой представляет и какие вводимые данные за что отвечают. Непосредственный расчет программа выполняет сама.
Еще статьи по данной теме:
Помогла ли Вам статья?
A T-test is a way of deciding if there are statistically significant differences between datasets, using a Student’s t-distribution. The T-Test in Excel is a two-sample T-test comparing the means of two samples. This article explains what statistical significance means and shows how to do a T-Test in Excel.
Instructions in this article apply to Excel 2019, 2016, 2013, 2010, 2007; Excel for Microsoft 365 and Excel Online.
What is Statistical Significance?
Imagine you want to know which of two dice will give a better score. You roll the first die and get a 2; you roll the second die and get a 6. Does this tell you the second die usually gives higher scores? If you answered, “Of course not,” then you already have some understanding of statistical significance. You understand the difference was due to the random change in the score, each time a die is rolled. Because the sample was very small (only one roll) it didn’t show anything significant.
Now imagine you roll each die 6 times:
- The first die rolls 3, 6, 6, 4, 3, 3; Mean = 4.17
- The second die rolls 5, 6, 2, 5, 2, 4; Mean = 4.00
Does this now prove the first die gives higher scores than the second? Probably not. A small sample with a relatively small difference between the means makes it likely the difference is still due to random variations. As we increase the number of dice rolls it becomes difficult to give a common sense answer to the question — is the difference between the scores the result of random variation or is one actually more likely to give higher scores than the other?
Significance is the probability that an observed difference between samples is due to random variations. Significance is often called the alpha level or simply ‘α.’ The confidence level, or simply ‘c,’ is the probability that the difference between the samples is not due to random variation; in other words, that there’s a difference between the underlying populations. Therefore: c = 1 – α
We can set ‘α’ at whatever level we want, to feel confident we’ve proven significance. Very often α=5% is used (95% confidence), but if we want to be really sure that any differences are not caused by random variation, we might apply a higher confidence level, using α=1% or even α=0.1%.
Various statistical tests are used to calculate significance in different situations. T-tests are used to determine whether the means of two populations are different and F-tests are used to determine whether the variances are different.
Why Test for Statistical Significance?
When comparing different things, we need to use significance testing to determine if one is better than the other. This applies to many fields, for example:
- In business, people need to compare different products and marketing methods.
- In sports, people need to compare different equipment, techniques, and competitors.
- In engineering, people need to compare different designs and parameter settings.
If you want to test whether something performs better than something else, in any field, you need to test for statistical significance.
What is a Student’s T-Distribution?
A Student’s t-distribution is similar to a normal (or Gaussian) distribution. These are both bell-shaped distributions with most results close to the mean, but some rare events are quite far from the mean in both directions, referred to as the tails of the distribution.
The exact shape of the Student’s t-distribution depends on the sample size. For samples of more than 30 it’s very similar to the normal distribution. As the sample size is reduced, the tails get larger, representing the increased uncertainty that comes from making inferences based on a small sample.
How to Do a T-Test in Excel
Before you can apply a T-Test to determine whether there’s a statistically significant difference between the means of two samples, you must first perform an F-Test. This is because different calculations are performed for the T-Test depending on whether there’s a significant difference between the variances.
You will need the Analysis Toolpak add-in enabled to perform this analysis.
Checking and Loading the Analysis Toolpak Add-In
To check and activate the Analysis Toolpak follow these steps:
-
Select the FILE tab >select Options.
-
In the Options dialogue box, select Add-Ins from the tabs on the left-hand side.
-
At the bottom of the window, select the Manage drop-down menu, then select Excel Add-ins. Select Go.
-
Ensure the check-box next to Analysis Toolpak is checked, then select OK.
-
The Analysis Toolpak is now active and you are ready to apply F-Tests and T-Tests.
Performing an F-Test and a T-Test in Excel
-
Enter two datasets into a spreadsheet. In this case, we’re considering the sales of two products during a week. The mean daily sales value for each product is also calculated, together with its standard deviation.
-
Select the Data tab > Data Analysis
-
Select F-Test Two-Sample for Variances from the list, then select OK.
The F-Test is highly sensitive to non-normality. It may therefore be safer to use a Welch test, but this is more difficult in Excel.
-
Select the Variable 1 Range and Variable 2 Range; set the Alpha (0.05 gives 95% confidence); select a cell for the top left corner of the output, considering that this will fill 3 columns and 10 rows. Select OK.
For the for Variable 1 Range, the sample with the largest standard deviation (or variance) must be selected.
-
View the F-Test results to determine whether there is a significant difference between the variances. The results give three important values:
- F: The ratio between the variances.
- P(F<=f) one-tail: The probability that variable 1 doesn’t actually have a larger variance than variable 2. If this is larger than alpha, which is generally 0.05, then there’s no significant difference between the variances.
- F Critical one-tail: The value of F that would be required to give P(F<=f)=α. If this value is greater than F, this also indicates there’s no significant difference between the variances.
P(F<=f) can also be calculated using the FDIST function with F and the degrees of freedom for each sample as its inputs. Degrees of freedom is simply the number of observations in a sample minus one.
-
Now that you know whether there is a difference between the variances you can select the appropriate T-Test. Select the Data tab > Data Analysis, then select either t-Test: Two-Sample Assuming Equal Variances or t-Test: Two-Sample Assuming Unequal Variances.
-
Regardless of which option you chose in the previous step, you will be presented with the same dialogue box to enter the details of the analysis. To start, select the ranges containing the samples for Variable 1 Range and Variable 2 Range.
-
Assuming you want to test for no difference between the means, set the Hypothesized Mean Difference to zero.
-
Set the significance level Alpha (0.05 gives 95% confidence), and select a cell for the top left corner of the output, considering that this will fill 3 columns and 14 rows. Select OK.
-
Review the results to decide if there’s a significant difference between the means.
Just as with the F-Test, if the p-value, in this case P(T<=t), is greater than alpha, then there’s no significant difference. However, in this case there are two p-values given, one for a one-tail test and the other for a two-tail test. In this case, use the two-tail value since either variable having a greater mean would be a significant difference.
Thanks for letting us know!
Get the Latest Tech News Delivered Every Day
Subscribe
Программа Эксель используется для выполнения различных статистических задач, одной из которых является вычисление доверительного интервала, который применяется как наиболее подходящая замена точечной оценки при малом объеме выборки.
Хотим сразу заметить, что сама процедура вычисления доверительного интервала довольно непростая, однако, в Excel существует ряд инструментов, призванных облегчить выполнение данной задачи. Давайте рассмотрим их.
Содержание
- Вычисление доверительного интервала
- Метод 1: оператор ДОВЕРИТ.НОРМ
- Метод 2: оператор ДОВЕРИТ.СТЬЮДЕНТ
- Заключение
Вычисление доверительного интервала
Доверительный интервал нужен для того, чтобы дать интервальную оценку каким-либо статическим данным. Основная цель этой операции – убрать неопределенности точечной оценки.
В Microsoft Excel существует два метода выполнения данной задачи:
- Оператор ДОВЕРИТ.НОРМ – применяется в случаях, когда дисперсия известна;
- Оператор ДОВЕРИТ.СТЬЮДЕНТ– когда дисперсия неизвестна.
Ниже мы пошагово разберем оба метода на практике.
Метод 1: оператора ДОВЕРИТ.НОРМ
Данная функция впервые была внедрена в арсенал программы в редакции Эксель 2010 года (до этой версии ее заменял оператор “ДОВЕРИТ”). Оператор входит в категорию “статистические”.
Формула функции ДОВЕРИТ.НОРМ выглядит так:
=ДОВЕРИТ.НОРМ(Альфа;Станд_откл;Размер)
Как мы видим, у функции есть три аргумента:
- “Альфа” – это показатель уровня значимости, который берется за основу при расчете. Доверительный уровень считается так:
1-"Альфа". Это выражение применимо в случае, если значение “Альфа” представлено в виде коэффициента. Например, 1-0,7=0,3, где 0,7=70%/100%.(100-"Альфа")/100. Применятся это выражение, если мы считаем доверительным уровень со значением “Альфа” в процентах. Например, (100-70)/100=0,3.
- “Стандартное отклонение” — соответственно, стандартное отклонение анализируемой выборки данных.
- “Размер” – объем выборки данных.
Примечание: У данной функции наличие всех трех аргументов является обязательным условием.
Оператор “ДОВЕРИТ”, который применялся в более ранних редакциях программы, содержит такие же аргументы и выполняет те же самые функции.
Формула функции ДОВЕРИТ выглядит следующим образом:
=ДОВЕРИТ(Альфа;Станд_откл;Размер)
Отличий в самой формуле нет никаких, лишь название оператора иное. В редакциях приложения Эксель 2010 года и последующих этот оператор находится в категории “Совместимость”. В более же старых версиях программы он находится в разделе статических функций.
Граница доверительного интервала определяется следующей формулой:
X+(-)ДОВЕРИТ.НОРМ
где Х – это среднее значение по заданному диапазону.
Теперь давайте разберемся, как применять эти формулы на практике. Итак, у нас есть таблица с различными данными 10-ти проведенных замеров. При этом, стандартное отклонение совокупности данных равняется 8.

Перед нами стоит задача – получить значение доверительного интервала с 95%-ым уровнем доверия.
- Первым делом выбираем ячейку для вывода результата. Затем кликаем по кнопке “Вставить функцию” (слева от строки формул).

- Откроется окно Мастера функций. Кликнув по текущей категории функций, раскрываем список и щелкаем в нем по строке “Статистические”.

- В предложенном перечне кликаем по оператору “ДОВЕРИТ.НОРМ”, затем жмем OK.
- Перед нами появится окно с настройками аргументов функции, заполнив которые нажимаем кнопку OK.
- в поле “Альфа” указываем уровень значимости. В нашей задаче предполагается 95%-ый уровень доверия. Подставив данное значение в формулу расчета, которую мы рассматривали выше, получаем выражение:
(100-95)/100. Пишем его в поле аргумента (или можно сразу написать результат вычисления, равный 0,05). - в поле “Станд_откл” согласно нашим условия, пишем цифру 8.
- в поле “Размер” указываем количество исследуемых элементов. В нашем случае было проведено 10 замеров, значит пишем цифру 10.

- в поле “Альфа” указываем уровень значимости. В нашей задаче предполагается 95%-ый уровень доверия. Подставив данное значение в формулу расчета, которую мы рассматривали выше, получаем выражение:
- Чтобы при изменении данных не пришлось заново настраивать функцию, можно автоматизировать ее. Для это применим функцию “СЧЁТ”. Ставим указатель в область ввода информации аргумента “Размер”, затем щелкаем по значку треугольника с левой стороны от строки формул и кликаем по пункту “Другие функции…”.

- В результате откроется еще одно окно Мастера функций. Выбрав категорию “Статистические”, кликаем по функции “СЧЕТ”, затем – OK.
- На экране отобразится еще одно окно с настройками аргументов функции, которая применяется для определения числа ячеек в заданном диапазоне, в которых находятся числовые данные.
Формула функции СЧЕТ пишется так:=СЧЁТ(Значение1;Значение2;...).
Количество доступных аргументов этой функции может достигать 255 штук. Здесь можно прописать, либо конкретные числа, либо адреса ячеек, либо диапазоны ячеек. Мы воспользуемся последним вариантом. Для этого кликаем по области ввода информации для первого аргумента, затем зажав левую кнопку мыши выделяем все ячейки одного из столбцов нашей таблицы (не считая шапки), после чего жмем кнопку OK.
- В результате проделанных действий в выбранной ячейке будет выведено результат расчетов по оператору ДОВЕРИТ.НОРМ. В нашей задаче его значение оказалось равным 4,9583603.
- Но это еще не конечный результат в нашей задаче. Далее требуется рассчитать среднее значение по заданному интервалу. Для этого потребуется применить функцию “СРЗНАЧ”, которая выполняет задачу по вычислению среднего значения в пределах указанного диапазона данных.
Формула оператора пишется так:=СРЗНАЧ(число1;число2;...).
Выделяем ячейку, куда планируем вставить функцию и жмем кнопку “Вставить функцию”. - В категории “Статистические” выбираем нудный оператор “СРЗНАЧ” и кликаем OK.
- В аргументах функции в значении аргумента “Число” указываем диапазон, в который входят все ячейки со значениями всех замеров. Затем кликаем OK.

- В результате проделанных действий среднее значение будет автоматически подсчитано и выведено в ячейку с только что вставленной функцией.
- Теперь нам нужно рассчитать границы ДИ (доверительного интервала). Начнем с расчета значения правой границы. Выбираем ячейку, куда хотим вывести результат, и выполняем в ней сложение результатов, полученных с помощью операторов “СРЗНАЧ” и “ДОВЕРИТ.НОРМ”. В нашем случае формула выглядит так:
A14+A16. После ее набора жмем Enter. - В результате будет произведен расчет и результат немедленно отобразится в ячейке с формулой.
- Затем аналогичным способом выполняем расчет для получения значения левой границы ДИ. Только в этом случае значение результата “ДОВЕРИТ.НОРМ” нужно не прибавлять, а вычитать из результата, полученного при помощи оператора “СРЗНАЧ”. В нашем случае формула выглядит так:
=A16-A14. - После нажатия Enter мы получим результат в заданной ячейке с формулой.
















Примечание: В пунктах выше мы постарались максимально подробно расписать все шаги и каждую применяемую функцию. Однако все прописанные формулы можно записать вместе, в составе одной большой:
- Для определения правой границы ДИ общая формула будет выглядеть так:
=СРЗНАЧ(B2:B11)+ДОВЕРИТ.НОРМ(0,05;8;СЧЁТ(B2:B11)). - Точно также и для левой границы, только вместо плюса нужно поставить минус:
=СРЗНАЧ(B2:B11)-ДОВЕРИТ.НОРМ(0,05;8;СЧЁТ(B2:B11)).
Метод 2: оператор ДОВЕРИТ.СТЬЮДЕНТ
Теперь давайте познакомимся со вторым оператором для определения доверительного интервала – ДОВЕРИТ.СТЬЮДЕНТ. Данная функция была внедрена в программу относительно недавно, начиная с версии Эксель 2010, и направлена на определение ДИ выбранной совокупности данных с применением распределения Стьюдента, при неизвестной дисперсии.
Формула функции ДОВЕРИТ.СТЬЮДЕНТ выглядит следующим образом:
=ДОВЕРИТ.СТЬЮДЕНТ(Альфа;Cтанд_откл;Размер)
Давайте разберем применение данного оператора на примере все той же таблицы. Только теперь стандартное отклонение по условиям задачи нам неизвестно.
- Сначала выбираем ячейку, куда планируем вывести результат. Затем кликаем по значку “Вставить функцию” (слева от строки формул).
- Откроется уже хорошо знакомое окно Мастера функций. Выбираем категорию “Статистические”, затем из предложенного списка функций щелкаем по оператору “ДОВЕРИТ.СТЬЮДЕНТ”, после чего – OK.
- В следующем окне нам нужно настроить аргументы функции:.
- В выбранной ячейке отобразится значение доверительного интервала согласно заданным нами параметрам.
- Далее нам нужно рассчитать значения границ ДИ. А для этого потребуется получить среднее значение по выбранному диапазону. Для этого снова применим функцию “СРЗНАЧ”. Алгоритм действий аналогичен тому, что был описан в первом методе.
- Получив значение “СРЗНАЧ”, можно приступать к расчетам границ ДИ. Сами формулы ничем не отличаются от тех, что использовались с оператором “ДОВЕРИТ.НОРМ”:
- Правая граница ДИ=СРЗНАЧ+ДОВЕРИТ.СТЬЮДЕНТ
- Левая граница ДИ=СРЗНАЧ-ДОВЕРИТ.СТЬЮДЕНТ





Заключение
Арсенал инструментов Excel невероятно большой, и наряду с распространенными функциями, программа предлагает большое разнообразие специальных функций, которые помогут существенно облегчить работу с данными. Возможно, описанные выше шаги некоторым пользователям, на первый взгляд, могут показаться сложными. Но после детального изучения вопроса и последовательности действий, все станет намного проще.
Теория “p-values” и нулевая гипотеза может показаться сложной на первый взгляд, но понимание концепций поможет вам ориентироваться в мире статистики. К сожалению, эти термины часто неправильно используются в популярной науке, поэтому всем необходимо понимать основы.
< p>Вычисление “p-значения” модели и доказательство/опровержение нулевой гипотезы на удивление просто с MS Excel. Есть два способа сделать это. Давайте углубимся.
Нулевая гипотеза — это утверждение, также называемое позицией по умолчанию, утверждающее, что взаимосвязь между наблюдаемыми явлениями не существует. Нулевая гипотеза может также применяться к ассоциациям между двумя экспериментальными группами. В ходе исследования вы проверяете эту гипотезу и пытаетесь ее опровергнуть.
Например, вы хотите посмотреть, дает ли конкретная причудливая диета значительные результаты. Нулевая гипотеза в данном случае состоит в том, что между испытуемыми нет существенной разницы». вес до и после диеты. Альтернативная гипотеза состоит в том, что диета действительно имела значение. Альтернатива — это то, что попытаются доказать исследователи.
“p-значение” представляет вероятность того, что статистическая сводка будет равна или больше наблюдаемого значения, когда нулевая гипотеза верна для конкретной статистической модели. Хотя “p-значение” часто выражается в виде десятичного числа, обычно лучше описывать его в процентах. Например, значение “p-value” 0,1 должно быть представлено как 10%.
Низкое значение “p-значение” означает, что доказательства против нулевой гипотезы сильны. Это также означает, что ваши данные важны. С другой стороны, высокое “значение p” означает, что нет убедительных доказательств против гипотезы. Чтобы доказать, что причудливая диета работает, исследователям необходимо найти низкое “p-значение”
Статистически значимый результат — это такой результат, который маловероятен, если нулевая гипотеза верна. Уровень значимости обозначается греческой буквой “альфа” и оно должно быть больше “p-value” чтобы результат был статистически значимым.
Многие исследователи используют “p-значение” для лучшего и более глубокого понимания данных эксперимента. Некоторые известные научные области, в которых используется значение “p-value” включают социологию, уголовное правосудие, психологию, финансы и экономику.
Поиск значения p в Excel 2010
Вы можете найти “р-значение” набора данных в MS Excel с помощью теста “T-Test” или с помощью функции “Анализ данных” инструмент. Во-первых, мы рассмотрим “T-Test” функция. Вы увидите пять студентов колледжа, которые соблюдали 30-дневную диету, и сопоставимые данные об их весе до и после диеты.
ПРИМЕЧАНИЕ. В этой статье рассматриваются функции p-value для MS Excel 2010 и 2016, но шаги должны применяться ко всем версиям. Однако макет графического пользовательского интерфейса (GUI) меню и многого другого будет отличаться.
Функция T-теста
Выполните следующие действия, чтобы вычислить “p-значение” с помощью функции T-Test.
- Создайте и заполните таблицу. Наша таблица выглядит следующим образом:

- Нажмите на любую ячейку за пределами таблицы.
< img src=»/wp-content/uploads/2022/06/1ef3347516be459ba15580224cbc478d.png» /> - Тип”=T.Test(“(включите открывающую скобку) в ячейку.
- После открывающей скобки введите в первом аргументе. В этом примере это “Перед диетой” столбец. Диапазон должен быть ”B2:B6.” Пока функция выглядит так: T.Test(B2:B6.
- Далее введите второй аргумент. Программа «После диеты» столбец вместе с его результатами является вторым аргументом, и вам нужен следующий диапазон: “C2:C6.” Давайте добавим его в формулу: T.Test(B2:B6,C2:C6.
- Введите запятую после второго аргумента. Параметры одностороннего распределения и двустороннего распределения автоматически появятся в раскрывающемся меню. Продолжайте и выберите “одностороннее распределение”, дважды щелкнув по нему.< бр>
- Введите еще одну запятую. Для простоты использования полный код приведен ниже.
- Дважды щелкните значок Параметр «Пара» в следующем раскрывающемся меню.
- Теперь, когда у вас есть все необходимые элементы, вам нужно вставить закрывающую скобку. Формула для этого примера выглядит следующим образом: =T.Test(B2:B6,C2:C6,1,1)
- Нажмите “Ввод”. Теперь в ячейке отображается значение “p-value” немедленно. В нашем случае значение равно “0,133905569” или “13.3905569%.”









Более 5%, это “p-значение” не дает убедительных доказательств против нулевой гипотезы. В нашем примере исследование не доказало, что диета помогла испытуемым значительно похудеть. Результаты не обязательно означают, что нулевая гипотеза верна, а только то, что она еще не была опровергнута.
Маршрут анализа данных
«Анализ данных»; позволяет делать много интересных вещей, в том числе “p-значение” расчеты. Мы будем использовать ту же таблицу, что и в предыдущем методе, чтобы упростить процесс.
Вот как использовать “Анализ данных” инструмент.
- Поскольку у нас уже есть “вес” различия в “D” столбец, мы пропустим вычисление разницы. Для будущих таблиц используйте следующую формулу: =”Ячейка 1”-“Ячейка 2”.
- Далее нажмите “Данные” в главном меню.
- Выберите инструмент “Анализ данных”.
- Прокрутите список вниз и выберите “t-Test: два образца в паре для средних значений”
< img src=»/wp-content/uploads/2022/06/b3c8545a8ccf465a320b19b78794cf5f.png» /> - Нажмите “ОК”< br>
- Появится всплывающее окно. Это выглядит так:
- Введите первый диапазон/аргумент. В нашем примере это “$B$2:$B$6“как “B2:B6.”
- Введите второй диапазон/аргумент. В данном случае это “$C$2:$C$6“как в “C2:C6”
- Оставьте значение по умолчанию в “Alpha” текстовое поле (0,05).
- Нажмите “Вывод Диапазон” и выберите желаемый результат. Если это “A8″ введите следующее:”$A$8.”
- Нажмите <эм>“ОК”
- Excel рассчитает “p-значение” и ряд других параметров. Итоговая таблица может выглядеть так:










Как видите, односторонний “p-значение” такое же, как и в первом случае (0,133905569). Поскольку оно выше 0,05, к этой таблице применима нулевая гипотеза, а доказательства против нее слабые.
Поиск значения p в Excel 2016
Как и в предыдущих шагах, давайте рассмотрим расчет “p-Value” в Excel 2016.
- Мы будем использовать тот же пример, что и выше, поэтому создайте таблицу, если хотите продолжить.
- Теперь в ячейке “A8&rdquo ; введите следующее: =T.Test(B2:B6, C2:C6.
- Затем в ячейке A8 введите “запятую” после “C6” и выберите “Одностороннее распределение”
- Затем введите еще одну “запятую” и выберите “В паре”
- Теперь уравнение должно выглядеть следующим образом: =T.Тест(B2:B6, C2:C6,1,1).
- Наконец нажмите “Enter”, чтобы показать результат.




Результаты могут отличаться на несколько знаков после запятой в зависимости от ваших настроек и доступного места на экране. .
Что нужно знать о значении p
Вот несколько ценных советов относительно “p-value” расчеты в Excel.
- Если значение “p-value” равно 0,05 (5%), данные в вашей таблице “значительны” Если он меньше 0,05 (5%), данные являются “высокозначимыми”
- В случае “p-значения” больше 0,1 (10%), данные в вашей таблице “несущественны” Если он находится в диапазоне 0,05–0,10, у вас есть “минимально значимый” данные.
- Вы можете изменить “альфа” значение, хотя наиболее распространенными вариантами являются 0,05 (5%) и 0,10 (10%).
- В зависимости от вашей гипотезы выбор “двухстороннего тестирования” может быть лучшим выбором. В приведенном выше примере “одностороннее тестирование” означает, что мы исследуем, потеряли ли испытуемые вес после диеты, что нам и нужно было выяснить точно. Но «двухвостый» тест также будет проверять, значительно ли они прибавили в весе.
- “p-значение” не может идентифицировать переменные. Другими словами, если он находит корреляцию, он не может распознать причины, лежащие в ее основе.
p– Демистификация ценности
Каждый статистик должен знать все тонкости проверки нулевой гипотезы и знать значение “p-value” означает. Эти знания также пригодятся исследователям во многих других областях.

history 23 ноября 2016 г.
- Группы статей
- Статистический вывод
Дадим определение терминам уровень надежности и уровень значимости. Покажем, как и где они используется в MS EXCEL .
СОВЕТ : Для понимания терминов Уровень значимости и Уровень надежности потребуется знание следующих понятий:
Уровень значимости статистического теста – это вероятность отклонить нулевую гипотезу , когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность ошибки первого рода (type I error).
Уровень значимости обычно обозначают греческой буквой α ( альфа ). Чаще всего для уровня значимости используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении доверительного интервала для оценки среднего значения распределения , его ширину рассчитывают таким образом, чтобы вероятность события « выборочное среднее (Х ср ) находится за пределами доверительного интервала » было равно уровню значимости . Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о равенстве среднего заданному значению .
Ошибка первого рода часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина ошибки первого рода задается перед проверкой гипотезы , таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение уровня значимости α (т.е. вероятности ошибки первого рода ) может привести к увеличению вероятности ошибки второго рода , то есть вероятности принять нулевую гипотезу , когда на самом деле она не верна. Подробнее об ошибке второго рода см. статью Ошибка второго рода и Кривая оперативной характеристики .
Уровень значимости обычно указывается в аргументах обратных функций MS EXCEL для вычисления квантилей соответствующего распределения: НОРМ.СТ.ОБР() , ХИ2.ОБР() , СТЬЮДЕНТ.ОБР() и др. Примеры использования этих функций приведены в статьях про проверку гипотез и про построение доверительных интервалов .
Уровень надежности
Уровень доверия (этот термин более распространен в отечественной литературе, чем Уровень надежности ) — означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Уровень доверия равен 1-α, где α – уровень значимости .
Термин Уровень надежности имеет синонимы: уровень доверия, коэффициент доверия, доверительный уровень и доверительная вероятность (англ. Confidence Level , Confidence Coefficient ).
В математической статистике обычно используют значения уровня доверия 90%; 95%; 99%, реже 99,9% и т.д.
Например, Уровень доверия 95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор уровня доверия полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание : Стоит отметить, что математически не корректно говорить, что Уровень доверия является вероятностью, того что оцениваемый параметр распределения принадлежит доверительному интервалу , вычисленному на основе выборки . Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что доверительный интервал , с вероятностью равной Уровню доверия, накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL Уровень надежности упоминается в надстройке Пакет анализа . После вызова надстройки, в диалоговом окне необходимо выбрать инструмент Описательная статистика . 
После нажатия кнопки ОК будет выведено другое диалоговое окно. 
В этом окне задается Уровень надежности, т.е.значениевероятности в процентах. После нажатия кнопки ОК в выходном интервале выводится значение равное половине ширины доверительного интервала . Этот доверительный интервал используется для оценки среднего значения распределения, когда дисперсия не известна (подробнее см. статью про доверительный интервал ).
Необходимо учитывать, что данный доверительный интервал рассчитывается при условии, что выборка берется из нормального распределения . Но, на практике обычно принимается, что при достаточно большой выборке (n>30), доверительный интервал будет построен приблизительно правильно и для распределения, не являющегося нормальным (если при этом это распределение не будет иметь сильной асимметрии ).
Примечание : Понять, что в диалоговом окне речь идет именно об оценке среднего значения распределения , достаточно сложно. Хотя в английской версии диалогового окна это указано прямо: Confidence Level for Mean .
Если Уровень надежности задан 95%, то надстройка Пакет анализа использует следующую формулу (выводится не сама формула, а лишь ее результат):
или эквивалентную ей
где =СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) – является стандартной ошибкой среднего (формулы приведены в файле примера ).
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Решение задач описательной статистики средствами пакета анализа Microsoft Excel Текст научной статьи по специальности « Компьютерные и информационные науки»
CC BY
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Трущелёв Сергей Андреевич
Представлено определение описательной статистики , изложены методика вычисления основных ее показателей, а также пошаговая процедура статистического анализа. Сообщение содержит обучающий компонент.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Трущелёв Сергей Андреевич
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics , and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with.
Текст научной работы на тему «Решение задач описательной статистики средствами пакета анализа Microsoft Excel»
МЕТОДОЛОГИЯ НАУЧНО-ИССЛЕДОВАТЕЛЬСКОЙ ДЕЯТЕЛЬНОСТИ
Уважаемые читатели, коллеги!
В связи с возрастающими требованиями к качеству публикаций результатов научно-исследовательских работ в «Российском психиатрическом журнале» открыта новая рубрика «Методология научно-исследовательской деятельности». Планируется публикация обучающих и информационно-разъяснительных материалов по разным разделам науковедения, организации научной работы, биоинформатике, биостатистике, биоэтике и т.д. Приглашаем ученых и исследователей поделиться опытом в этой области. Надеемся, что наша инициатива будет поддержана не только в научном сообществе, но и воспринята в среде практикующих специалистов.
© С.А. Трущелёв, 2013 Для корреспонденции
УДК 311:004 Трущелёв Сергей Андреевич — кандидат медицинских наук,
доцент, ведущий научный сотрудник ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Адрес: 107076, г. Москва, ул. Потешная, д. 3 Телефон: (495) 963-25-31 E-mail: sat-geo@mail.ru
Решение задач описательной статистики средствами пакета анализа Microsoft Excel
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics, and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with. Key words: science of science, biostatistics, descriptive statistics, data analysis toolpak, Excel
ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Moscow Research Institute of Psychiatry
Представлено определение описательной статистики, изложены методика вычисления основных ее показателей, а также пошаговая процедура статистического анализа. Сообщение содержит обучающий компонент.
Ключевые слова: науковедение, биостатистика, описательная статистика, пакет анализа, Excel
Каждое явление (предмет исследования) определяется многими факторами. В научном исследовании полностью учесть все факторы и обеспечить их стабильность удается редко. Следовательно, явление, определяемое этими факторами, не поддается точному предсказанию — оно приобретает вероятностные черты, т.е. ведет себя случайным образом. Этому подвержены многие явления, поэтому они определяются случайной величиной, которая принимает в результате опыта или наблюдения одно из множества значений. Случайные величины могут быть дискретными (прерывными) и непрерывными. Немаловажно их распределение — правило, которое устанавливает связь между значениями случайной величины и вероятностями (частотами) их появления.
Наглядное представление о распределении случайных величин дает разброс песчинок, образующих кучу при высыпании (рассеивании) из некоторого точечного источника. Его проекция является параметром положения и соответствует математическому ожиданию распределения, если куча симметрична. Разброс песчинок (параметр рассеяния) характеризуется радиусом кучи на высоте примерно 2/3. Такой параметр рассеяния соответствует так называемому стандартному (среднеквадратичному) отклонению случайных величин в распределении. Горизонтальные расстояния песчинок от проекции источника (математического ожидания) моделируют рассеяние случайной величины. Поверхность кучи (ее высоты) соответствует частоте случайных величин на разных расстояниях от центра. Вершина кучи, расположенная под источником, отвечает максимуму частоты. На периферии высота кучи уменьшается до нуля, что соответствует уменьшению частот больших отклонений от центра рассеяния. Статистическая обработка совокупности данных состоит в некоторых осредняющих вычислительных процедурах, погашающих сугубо индивидуальные особенности — отклонения от общей закономерности и подчеркивающих типичные (популяцион-ные) свойства явления в целом. Начальный раздел математической статистики — описательная статистика — занимается характеристикой (описанием) картины случайного рассеяния по совокупности данных. В соответствии с законом распределения данных решаются вопросы выбора и вычислений надлежащих показателей. Описательная статистика включает методы организации, суммирования и описания данных. Дескриптивные (от англ. descriptive — описательный) показатели позволяют быстро обобщать данные. К описательным методам относят частотные распределения, меры централь-
ной тенденции и меры относительного положения [4, с. 95].
К основным показателям описательной статистики относятся среднее значение (среднее арифметическое, медиана, мода), усредненное значение, разброс (диапазон разброса данных), дисперсия, стандартное среднеквадратное отклонение (СКО), квартили, доверительный интервал [2, с. 28].
Статистическая обработка результатов исследований и получение показателей описательной статистики в недалеком прошлом обычно занимали много времени, однако с внедрением средств компьютерной техники многое изменилось — вычислительные процессы стали происходить очень быстро. Для проведения статистических расчетов в электронной таблице Microsoft Excel имеется пакет анализа. Надстройка «Анализ данных» располагается во вкладке «Данные», в крайне правом блоке ленты (рис. 1).
Для демонстрации вычислений будем использовать гипотетический набор данных. Далее приведем пошаговую инструкцию по созданию описательной статистики признака (показателя систолического давления), измеренного до лечения и после него, в группе наблюдения (n=60).
Для проведения вычисления обратитесь к ленте: Данные ^ Анализ данных ^ Описательная статистика ^ ОК. Затем, перейдя в окно инструмента, выберите входной интервал, группирование (по столбцам), поставьте галочку, если в первой строке выделены метки; в параметрах вывода на поле электронной страницы выберите ячейку вывода результатов, установите галочку рядом с итоговой статистикой. Потом нажмите кнопку ОК. После этого вы получите результаты описательной статистики выбранных признаков (рис. 2 и 3).
[й1 A «ï- V m И^ЭгшИ Главная Ш I» 1 Описательная статистика — Microsoft Excel □ 0 й Вставка Разметка страницы Формулы Данные Рецензирование Вид Разработчик Надстройки MetaXL Л □ S3
П внец m 1олучение jних данныхт ч [^Подключения ^Свойства Обновить все т && Изменить связи Подключения A I AIЯ I Я + Я 1А1 Я| Сортировка Со pi ч Ш ^ Очистить ^ Повторить Фильтр ™ № Дополнительно ировка и фильтр S Ii ы» вш а в Текст по Удалить ,—, столбцам дубликаты » Работа сданными Ф Фор» орма Jbi ssprfa ф ^ ^Анализданных Поиск решения Стр^И^ра Анализ
А в с D Е F G У 1 J К 1 L _
1 Номер_исс Признак_1 Признак_2 у
3 2 178 143 Анализ данным lia
Инструменты анализа У _ 1 о, 1
4 3 320 188 Двухфакторный дисперсионный^нализ без повторений Корреляция Л* 3 J d Отмена |
6 5 159 161 Экспоненциальное сглаживание Двухвыборочный Р-тест для дисперсии Анализ Фурье Гистограмма Скользящее среднее 1 Генерация случайных чисел_| Справка
Рис. 1. Пошаговый выбор инструмента анализа данных
Рис. 2. Окно инструмента описательной статистики
Среднее (арифметическое; М; х ) — одна из наиболее распространенных мер центральной тенденции, представляющая собой сумму всех значений, деленную на их количество. Если значения интересующего нас признака у большинства объектов близки к их среднему и с равной вероятностью отклоняются от него в большую или меньшую сторону, лучшими характеристиками совокупности будут само среднее значение и стандартное отклонение. Напротив, когда значения признака распределены несимметрично относительно среднего, совокупность лучше описать с помощью медианы и процен-тилей [1, с. 27].
Стандартная ошибка (т) — показатель надежности расчетного параметра; стандартное отклонение оценок, которые будут получены при многократной случайной выборке данного размера из одной и той же совокупности. Стандартная ошибка — это убывающая функция объема выборки: чем меньше стандартная ошибка, тем более достоверной является оценка параметра. Весьма часто для описания непрерывных количественных данных используют стандартную ошибку, которая (в отличие от СКО) является не характеристикой, описывающей распределение наблюдений исследуемой выборки по области значений, а только мерой точности оценки популяционного среднего и, следовательно, не характеризует дисперсию (разброс) в анализируемой выборке. Однако часто именно стандартную ошибку среднего приводят в качестве параметра описательной статистики, пытаясь продемонстрировать тем самым малую вариабельность своих данных, так как всегда (по определению) т Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
60 Среднее 161,77 Среднее 134,03
61 Стандартная ошибка 12,46 Стандартная ошибка 6.59
62 Медиана 167 Медиана 121,5
63 Мода 72 Мода 141
64 Стандартное отклонение 96.54 Стандартное отклонение 51,03
65 Дисперсия выборки 9320.59 Дисперсия выборки 2604.34
66 Эксцесс 0.89 Эксцесс 2.75
67 Асимметричность 0.96 Асимметричность 1,43
68 Интервал 420 Интервал 254
69 Минимум 50 Минимум 55
70 Максимум 470 Максимум 309
71 Сумма 9706 Сумма 8042
72 Счет 60 Счет 60
73 74 Уровень надежности(95.0%) 24.94 Уровень надежности(95.0%) 13,18
Коэффициент вариации 60% Коэффициент вариации 38%
Рис. 3. Результаты описательной статистики двух признаков
Медиану и интерквартильный размах рекомендуется применять для описания распределения, не являющегося нормальным (а это большинство распределений медико-биологических параметров) [1, с. 34]. Интерквартильный размах указывают в виде процентилей. Рекомендуется указывать уровни 25 и 75%, которые соответствуют верхней границе 1-го и нижней границе 4-го квартилей. Пример описания: Me (25%; 75%) = 60 (23; 78).
Мода (Мо) — значение, которое встречается наиболее часто во множестве. Иногда в совокупности встречается более одной моды. Тогда говорят, что совокупность мультимодальна — свидетельство того, что набор данных не подчиняется нормальному распределению. Мода как средняя величина употребляется чаще для данных, имеющих нечисловую природу. Например, в группе пациентов наибольшая частота тяжести болезни будет равна моде. При экспертной оценке с помощью этого показателя определяют предпочтения участников исследования. Недостаток — показатель не учитывает поведение распределения в других точках.
Стандартное отклонение (синонимы: среднеквадратичное отклонение, квадратичное отклонение; стандартный разброс; СКО; в; о) — в теории вероятностей и статистике наиболее распространенный показатель рассеивания значений случайной величины относительно ее математического ожидания. Измеряется в единицах случайной величины. Равно корню квадратному из дисперсии случайной величины. Стандартное отклонение используют при расчете стандартной ошибки среднего арифметического, построении доверительных интервалов, статистической проверке гипотез, измерении линейной взаимосвязи между случайными величинами. Большое значение СО показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения во множестве сгруппированы вокруг среднего. Если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратичного отклонения), то полученные значения или метод их получения следует перепроверить.
Дисперсия (D; о2) — мера разброса случайной величины, т.е. ее отклонения от математического ожидания. Квадратный корень из дисперсии называется стандартным отклонением. Дисперсия измеряется в квадратах единицы измерения. Однако в самостоятельном виде (как, например, средняя арифметическая) дисперсия используется редко. Это скорее вспомогательный и промежуточный показатель, который применяют в других методах статистического анализа.
Эксцесс — скалярная характеристика островершинности графика плотности вероятности унимо-
дального распределения, которую используют в качестве некоторой меры отклонения рассматриваемого распределения от нормального. Если коэффициент эксцесса равен нулю или близок к нему, то плотность вероятности распределения имеет нормальный эксцесс. Если коэффициент эксцесса сильно больше нуля, то плотность вероятности имеет положительный эксцесс. Это, как правило, соответствует тому, что график плотности рассматриваемого распределения в окрестности моды имеет более острую и более высокую вершину, чем нормальная кривая. Когда коэффициент эксцесса сильно больше нуля, говорят об отрицательном эксцессе плотности, при этом плотность вероятности имеет в окрестности моды более низкую и плоскую вершину, чем плотность нормального закона. Для генеральных совокупностей больших объемов его малыми значениями можно пренебречь.
Асимметричность (коэффициент асимметрии или скоса) — величина, характеризующая асимметрию распределения данной случайной величины. Коэффициент асимметрии положителен, если правый хвост распределения длиннее левого, и отрицателен в альтернативном случае. Если распределение симметрично относительно математического ожидания, то его коэффициент асимметрии равен нулю.
Интервал — размах показателей, т.е. разность между максимумом и минимумом значений вариант.
Максимум — наибольшее значение вариант.
Минимум — наименьшее значение вариант.
Сумма — сумма значений вариант.
Счет — количество вариант.
Уровень надежности — свойство объекта сохранять в установленных пределах значения всех параметров. Показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%.
Коэффициент вариации случайной величины -мера относительного разброса случайной величины. Показывает, какую долю среднего значения этой величины составляет ее средний разброс. Исчисляется в процентах. Вычисляется только для количественных данных. В отличие от стандартного отклонения, он измеряет не абсолютную, а относительную меру разброса значений признака в статистической совокупности. В Excel нет готовой функции для расчета коэффициента вариации. Расчет можно провести простым делением стандартного отклонения на среднее значение. Эти значения имеются в таблице описательной статистики. Для вычисления этого важного показателя в ячейке ниже надписи Уровень надежности пишем Коэффициент вариации, затем в ячейке справа делаем запись: =G64/G60. То же необходимо по-
вторить для вычисления коэффициента вариации для другого измерения.
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на панели инструментов в закладке «Главная». Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что совокупность данных является однородной, если коэффициент вариации менее 33%, неоднородной — если более 33%. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений.
Анализ показателей описательной статистики
При сравнении значений среднего, медианы, моды в каждом измерении следует отметить, что эти показатели сильно отличаются друг от друга.
Коэффициенты эксцесса и асимметрии значимо отличаются от установленных границ, коэффициенты вариации больше критического (предельного) значения. Следовательно, распределение данных в обеих группах измерений отлично от нормального. В последующем необходимо применять непараметрические методы статистического анализа. Для быстрой сравнительной оценки можно использовать показатели доверительных интервалов.
Для представления результатов сравнения обычно используют формат в виде М (95% ДИ) — значение среднего и указание 95% доверительного интервала. В тексте публикации запись может выглядеть следующим образом: Средний уровень систолического давления в группе пациентов до лечения составил 161,77 мм рт. ст. (95% ДИ от 136,83 до 186,71 мм рт. ст.), после лечения -134,03 мм рт. ст. (95% ДИ от 120,85 до 147,21 мм рт. ст.). Указанные доверительные интервалы имеют зону совмещения, следовательно, существенного различия в изменении признака нет. Исходя из этого с большой долей вероятности можно утверждать, что для данной группы пациентов лекарственный препарат, примененный для снижения уровня систолического артериального давления, был не эффективен.
1. Гланц С. Медико-биологическая статистика / Пер. с англ. -М., Практика, 1998. — 459 с.
2. Ланг Т.А., Сесик М. Как описывать статистику в медицине. Аннотированное руководство для авторов, редакторов и рецензентов / Пер. с англ. под ред. В.П. Леонова. -М.: Практическая медицина, 2011. — 480 с.
3. Леонов В.П. Ошибки статистического анализа биомедицинских данных // Междунар. журн. мед. практики. — 2007. -№ 2. — С. 19-35.
4. Трущелев С.А. Медицинская диссертация: руководство: 3-е изд. / Под ред. проф. И.Н. Денисова. — М.: ГЭОТАР-Медиа, 2009. — 416 с.
Большинству из нас хорошо знакома колоколообразная кривая нормального распределения. Она отлично работает, когда выборки большие, но занижает значения на «хвостах», когда выборки малые. Для описания статистики малых выборок была разработана t-статистика Стьюдента. Она также симметрична и подчиняется колоколообразному распределению, но дает лучшую оценку для малых выборок. В отличие от нормального распределения t-статистика не одна, а представлена целым семейством распределений. Дополнительный параметр – размер выборки или число степеней свободы.
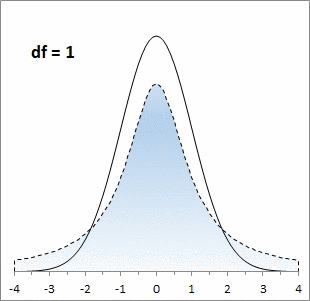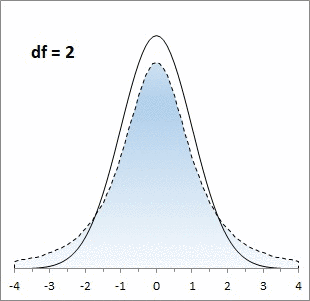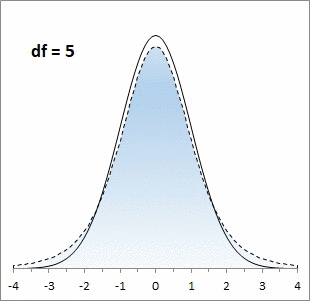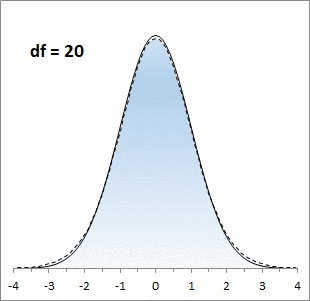
Рис. 1. Нормальная кривая и кривые t-распределения; df – число степеней свободы (от англ. degrees of freedom); gif-файл создан с помощью бесплатного сервиса ezgif.com, на который меня навела Евгения Крюкова
Скачать заметку в формате Word или pdf, примеры в формате Excel
Подход пивовара
В начале XX века Уильяму Сили Госсету, химику и статистику ирландской пивоваренной компании Guinness, потребовалось установить, какой из двух сортов ячменя дает лучшее пиво с большим выходом.[1] Ранее была разработана статистика нормального распределения, позволяющая находить доверительный интервал на основе случайной выборки, состоящей из не менее чем 30 объектов. К сожалению, у Госсета не было возможности протестировать большое число партий пива, изготовленных из каждого сорта ячменя. Однако он не отказался от своей затеи измерить то, что как будто не поддавалось оценке, и решил вывести новый вид распределения для крайне малых выборок. К 1908 г. Госсет разработал новый эффективный метод, который назвал t-статистикой, и захотел опубликовать результаты своей работы.
Однако у Guinness уже были проблемы с разглашением коммерческой тайны, и служащим компании было запрещено публиковать любую информацию о бизнес-процессах. Госсет понимал значение своей работы. Ему сильнее хотелось рассказать о своей идее, чем добиться немедленного признания. Поэтому он опубликовал статью под псевдонимом Стьюдент. И хотя истинный автор давно известен, практически во всех работах по статистике метод называется t-статистикой Стьюдента.
От физических значений к z-статистике
Колоколообразная кривая нормального распределения описывается формулой:
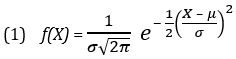
где f(X) – вероятность значения Х; f(X) откладывается по оси ординат; е — основание натурального логарифма; μ — математическое ожидание генеральной совокупности, σ — стандартное отклонение генеральной совокупности, X — произвольное значение непрерывной случайной величины; X откладывается по оси абсцисс; –∞ < X < +∞ (о вычислении μ и σ подробнее см. Определение среднего значения, вариации и формы распределения. Описательные статистики).
Формула (1) довольно сложная, и в докомпьютерную эру статистики использовали заранее рассчитанные таблицы. Поскольку составление таблиц для всего разнообразия Х, μ и σ дело неподъемное, была придумана стандартизация, которая состоит в приведении физических величин к z-единицам, путем простой арифметической подстановки
![]()
В этом случае всё многообразие нормальных кривых сводится к единому стандартизованному распределению:
![]()
где математическое ожидание (среднее) стандартизованного нормального распределения μ = 0, а стандартное отклонение σ = 1. Фактически, z – это десятичное число, для которого σ = 1, μ = 0.
Сейчас функция в Excel НОРМ.РАСП(x;среднее;стандартное_откл;интегральная) значительно упростила работу с формулой (1). Однако, заложенная традиция сохранилась, и статистики обсуждают особенности распределения, критические границы и т.п. в терминах стандартного нормального распределения (рис. 2). Для последнего в Excel используется функция НОРМ.СТ.РАСП(z;интегральная).
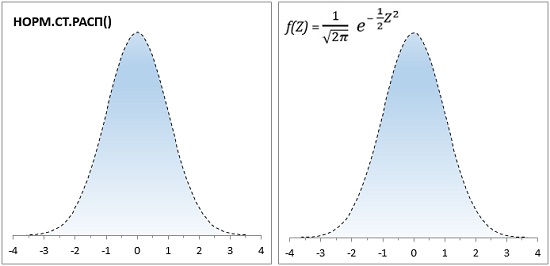
Рис. 2. Формула (3) реализована в Excel с помощью функции НОРМ.СТ.РАСП(); по оси абсцисс – z-единицы, по оси ординат – вероятность.
Для перехода от стандартного распределения к физическим величинам нужно применить обратное преобразование:
![]()
Допустим вы изучаете время загрузки некой Web-страницы, и выясняете, что оно распределено нормально, причем математическое ожидание равно μ = 7с, а стандартное отклонение σ = 2с. Как показывает рис. 3, каждому значению переменной X соответствует нормированное значение Z, полученное с помощью формулы преобразования (2). Следовательно, время загрузки, равное 9с, на одну стандартную единицу превышает математическое ожидание: Z = (9 – 7) / 2 = +1, а время загрузки равное 1с на три z-единицы (стандартных отклонения) меньше математического ожидания: Z = (1 – 7) / 2 = –3.
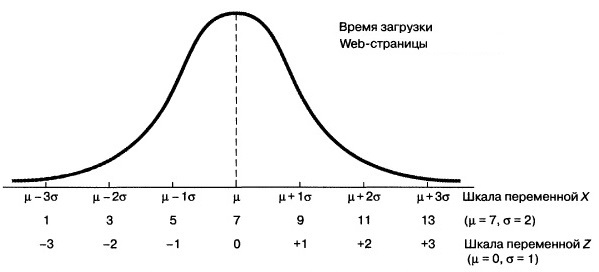
Рис. 3. Преобразование физических значений в z-значения для μ = 7, σ = 2
Описанные выше z-единицы используют для индивидуальных оценок, т.е. для измерений, приписываемых отдельным элементам выборки (например, рост каждого ученика школы). Если в качестве точек кривой нормального распределения берутся средние значения выборок (например, средний рост учеников различных классов), используют термин z-значение или z-статистика:[2]
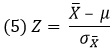
где X̅ – среднее значение выборки (средний рост учеников 5А класса), μ – среднее значение генеральной совокупности (средний рост всех учеников школы), ![]() – стандартная ошибка средних (стандартное отклонение среднего роста учеников отдельных классов от среднего роста всех учеников школы). Последняя рассчитывается по формуле:
– стандартная ошибка средних (стандартное отклонение среднего роста учеников отдельных классов от среднего роста всех учеников школы). Последняя рассчитывается по формуле:

где σ – стандартная ошибка индивидуальных значений, n – размер выборки (число учеников в классе).
t-значение
Допустим, вы предполагаете, что дизельные двигатели автомобилей определенной модели выбрасывают в атмосферу больше оксида азота, чем заявлено в рекламных объявлениях. Вы знаете, что стандарт устанавливает ограничение на выбросы – не более 0,4 грамма на милю пробега. Вы хотели бы сравнить эмпирически полученные результаты не со средним по генеральной совокупности, а с этим стандартом – 0,4 г/милю. Это целевое значение, а не параметр генеральной совокупности. Вы тестируете пять автомобилей данной модели и измеряете уровень выброса оксида азота в дорожных условиях. Далее вы вычисляете среднее количество выбросов оксида азота для пяти автомобилей и находите стандартное отклонение. Наконец, вы находите величину:
![]()
где X̅ – средний уровень выбросов диоксида азота для пяти автомобилей; μ = 0,4 – установленный стандартом граничный уровень выбросов оксида азота;[3] s — стандартное отклонение уровня выбросов оксида азота по результатам для пяти автомобилей.
Это отношение очень похоже на формулу (2) для z-значения, но в действительности это t-значение. z- и t-значения отличаются тем, что для нахождения t-значения используется стандартное отклонение, полученное на основе выборочных результатов s, а не известное значение параметра генеральной совокупности σ. Использование латинской буквы s вместо греческой буквы σ для обозначения стандартного отклонения напоминает о том, что в данном случае значение стандартного отклонения является выборочной оценкой (статистикой), а не известным параметром.
Плотность распределения t-значений рассчитывается не с помощью формулы (3), а существенно сложнее. Я не привожу её здесь, поскольку сейчас в лоб ее никто не считает. Все используют готовые функции в статистических пакетах.
В Excel есть ряд функций, работающих с t-статистикой (рис. 4). Функции, имена которых включают часть РАСП, принимают t-значение в качестве аргумента и возвращают вероятность. Функции, имена которых включают часть ОБР, принимают значение вероятности в качестве аргумента и возвращают t-значение. Две последние функции на рис. 4 устарели и оставлены для обратной совместимости с более ранними версиями Excel.
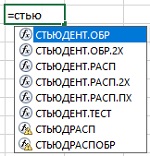
Рис. 4. Семейство функций в Excel, работающих с t-статистикой Стьюдента
Степени свободы
Кривая t-распределения аналогична стандартной нормальной кривой, но ее форма немного меняется в зависимости от количества наблюдений, использованных для ее построения. В общем случае количество степеней свободы df = n – k, где n — количество наблюдений в выборке, а k — количество статистик, фиксированных для выборки. Например, если мы просто изучаем выборку, то k = 1, так как мы зафиксировали только среднее значение выборки. Если мы изучаем регрессионную зависимость от одной переменной, то k = 2; зафиксированы две статистики: среднее по выборке и наклон регрессионной кривой. Каждая дополнительная независимая переменная в регрессионной зависимости уменьшает число степеней свободы на единицу.
Во все функции Excel, предназначенные для работы с t-распределением, вторым аргументом входит количество степеней свободы df. Этот параметр необходим Excel для того, чтобы правильно вычислить форму кривой плотности t-распределения и вернуть корректное значение вероятности t-значения, заданного с помощью первого аргумента. Так для одного и того же z-значения = t-значению = 2,5 вероятность встретить его зависит от размера выборки (числа степеней свободы; рис. 5).
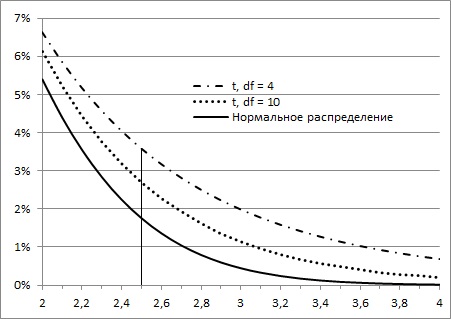
Рис. 5. Вероятность появления z- или t-значения зависит от того, какое распределение используется
То, насколько толстыми или тяжелыми являются хвосты t-распределения можно выразить количественно (рис. 6). Так, например, в пределах одного стандартного отклонение от среднего при нормальном распределении находится 68,27% значений. Для t-распределения с двумя степенями свободы такая вероятность существенно меньше – 57,74%.
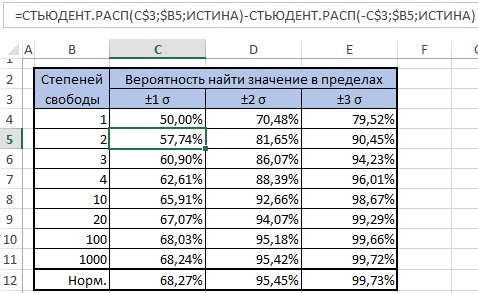
Рис. 6. Сравнение нормального и t-распределений
Функции Excel для работы с t-распределением
Рассмотрим работу функций Excel подробнее. Функция =СТЬЮДЕНТ.РАСП(t-значение;df;интегральная) возвращает левостороннее t-распределение Стьюдента (рис. 7). t-значение должно быть стандартизовано согласно формуле (7), т.е., выражено в долях стандартного отклонения σ при математическом ожидание генеральной совокупности µ = 0. Последний аргумент функции СТЬЮДЕНТ.РАСП() является логическим значением. Если он равен ЛОЖЬ, возвращается функция плотности распределения, т.е., вероятность для одного t-значения – Р(Х=t). Если он равен ИСТИНА, функция возвращает интегральное (накопленное) значение, т.е., вероятность попасть в интервал от минус бесконечности до t-значения – Р(Х≤t).
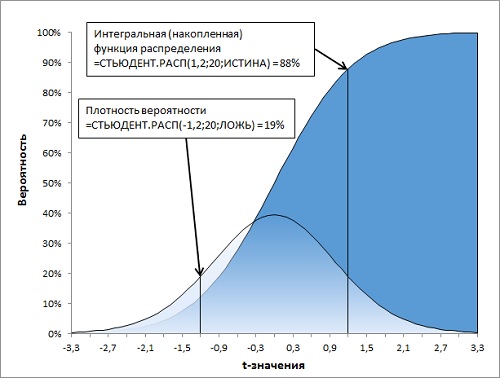
Рис. 7. Левостороннее t-распределение Стьюдента, функция Excel СТЬЮДЕНТ.РАСП()
Если функцию СТЬЮДЕНТ.РАСП() дополнить простыми арифметическими действиями, можно решить множество задач, связанных с t-распределением. Некоторые из них представлены ниже (рис. 8; во всех случаях df = 20):
- какова вероятность найти значение за пределами диапазона ±2,4σ от среднего значения Р(|Х|≥2,4)? =СТЬЮДЕНТ.РАСП(-2,4;20;ИСТИНА)*2
- какова вероятность найти значение внутри диапазона ±1,8σ от среднего значения Р(|Х|≤1,8)? =СТЬЮДЕНТ.РАСП(1,8;20;ИСТИНА)-СТЬЮДЕНТ.РАСП(-1,8;20;ИСТИНА) или, учитывая симметричность t-распределения, =(0,5-СТЬЮДЕНТ.РАСП(-1,8;20;ИСТИНА))*2
- какова вероятность найти значение справа от 2σ Р(Х≥2)?
=1-СТЬЮДЕНТ.РАСП(2;20;ИСТИНА) - какова вероятность среднего значения Р(Х=0)?
=СТЬЮДЕНТ.РАСП(0;20;ЛОЖЬ)
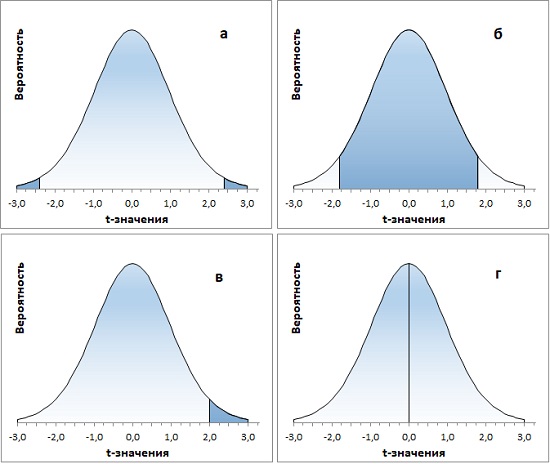
Рис. 8. Функция Excel СТЬЮДЕНТ.РАСП() позволяет решать основные задачи с t-распределением
Функция СТЬЮДЕНТ.РАСП.ПХ() возвращает правостороннее t-распределение, причем только интегральное. Т.е., она показывает накопленную вероятность, начиная с правой точки +∞ при движении влево – Р(X≥t).[4] У функции только два аргумента: t-значение и число степеней свободы. Она чуть более удобна, чем СТЬЮДЕНТ.РАСП() в задачах, где нас интересует вероятность обнаружить то или иное значение правого хвоста. Для примера (в) выше (см. также рис. 8в) формула будет такой: =СТЬЮДЕНТ.РАСП.ПХ(2;20).
Функция СТЬЮДЕНТ.РАСП.2Х() возвращает двустороннее t-распределение Стьюдента – P(|X|≥t) или P(X≥t или X≤-t). Как и функция СТЬЮДЕНТ.РАСП.ПХ(), она имеет два аргумента (t-значение и число степеней свободы), и возвращает только интегральное значение. Функция СТЬЮДЕНТ.РАСП.2Х() показывает накопленную вероятность для двух симметричных хвостов. Она чуть более удобна, чем СТЬЮДЕНТ.РАСП() в задачах, где нас интересует вероятность обнаружить два хвоста сразу. При этом задать нужно t-значение правого хвоста (отрицательные t-значения функция не принимает). Для примера (а) выше (см. также рис. 9а) формула будет такой: =СТЬЮДЕНТ.РАСП.2Х(2,4;20).
t-критерий
Одно из важных применений t-статистики связано с ответом на вопрос, насколько выборка характерна для генеральной совокупности? Например, если в генеральной совокупности среднее μ, а в выборке – х̅, какова вероятность, что выборка сделана из этой генеральной совокупности, а не из другой?
Рассмотрим пример (рис. 9). Исследуется зависимость веса от роста. Функция массива ЛИНЕЙН() (ячейки D2:E6), возвращает, в частности, наклон регрессионной кривой, он же коэффициент регрессии (ячейка D2) и стандартную ошибку коэффициента регрессии (ячейка D3). На рис. 9 данные роста и веса помещены на точечную диаграмму. На ней изображена регрессионная прямая (пунктирная линия; чтобы вывести ее, кликните в области диаграммы правой кнопкой мыши, и выберите опцию Добавить линию тренда…). Выведена также и формула регрессионной кривой y = 2,0922x – 3,5905 (естественно, коэффициент при х равен значению в ячейке D2).
t-критерий параметра = значение параметра, деленное на стандартную ошибку параметра
В нашем случае t-критерий коэффициента регрессии = коэффициент регрессии / стандартная ошибка коэффициента регрессии = 2,0922 / 0,8177 = 2,559 (ячейка Е8).
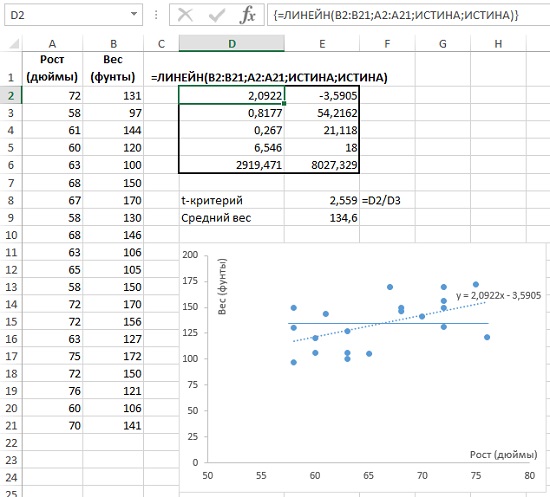
Рис. 9. Коэффициент регрессии = 2,0922 и t-критерий коэффициента регрессии = 2,559
Допустим, в генеральной совокупности вес не зависит от роста (нулевая гипотеза; на рис. 9 изображена сплошной прямой). Это значит, что коэффициент регрессии генеральной совокупности равен 0. В нашей выборке из 20 человек, мы обнаружили линейную зависимость веса от роста с коэффициентом регрессии (коэффициентом при х) = 2,0922. Если нормировать эту величину на стандартную ошибку, мы получим безразмерную величину = 2,559. Т.е., подсчитанный нами коэффициент регрессии в выборке на 2,559 сигм отстоит от нуля.
Насколько невероятно (или вероятно) получить такое отклонение в выборке, если в генеральной совокупности коэффициент регрессии = 0? Можно ли дать определение того, какое событие можно считать «невероятным». Считать ли его таковым, если оно происходит один раз в серии из 20 испытаний? Или в серии из 100 испытаний? А может быть, из 1000 испытаний? Как правило, событие считают «невероятным», если оно может произойти не чаще, чем в одном случае из двадцати.
Итак, в качестве нулевой гипотезы можно принять, что вес не зависит от роста. В качестве альтернативной гипотезы мы предположим, что вес положительно коррелирован с ростом (чем больше рост, тем больше вес). Мы отклоним нулевую гипотезу, только если t-значение коэффициента регрессии попадет в правый хвост распределения в область, соответствующую 5% всей площади под кривой (α = 0,05). Это, как раз, произойдет не чаше, чем один раз на двадцать выборок (рис. 10).
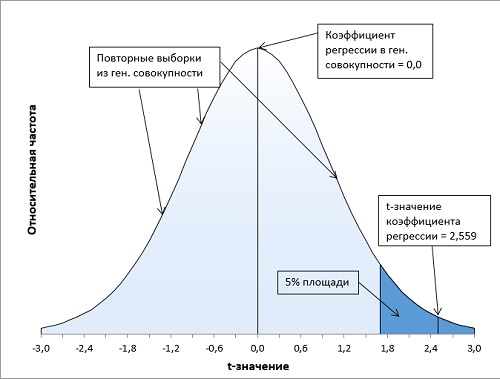
Рис. 10. Расположение t-значения коэффициента регрессии (2,559) на кривой t-распределения Стьюдента (df = 18) показывает, что его вероятность около 1% не превышает α-уровень = 5%. Нулевая гипотеза может быть отвергнута. Статистики выборки говорят о зависимости веса от роста.
Расчет t-значения, соответствующего заданному уровню значимости
Проблема выбора «уровня невероятности», т.е. уровня статистической значимости, или α-уровня, десятилетиями будоражила статистиков. Найти ответы на подобные вопросы зачастую очень трудно, и многие исследователи лишь пожимают плечами и выбирают для альфа-уровня одно из общепринятых значений: р < 0,05 или р < 0,01. Почему именно такие значения?
Главная причина — это то, что в течение многих лет исследователи должны были полагаться на справочные таблицы, позволяющие найти такое t-значение, которое можно было бы считать «статистически значимым» на уровне 0,05 или 0,01 (таблиц для других α-значений практически не было). В наше время определение критического значения t-статистики при любом заданном уровне значимости не составляет труда.
В Excel есть две функции для расчета t-критерия по уровню значимости (вероятности). СТЬЮДЕНТ.ОБР(вероятность;степени_свободы) возвращает левостороннее обратное t-распределение. В качестве первого аргумента функция принимает накопленную вероятность, начиная с –∞. Как правило, используется для односторонних тестов. В случае использования в двустороннем тесте α-значение следует разделить на 2. Например, t-значение для 5%-ного уровня значимости на рис. 10 можно найти с помощью формул =–СТЬЮДЕНТ.ОБР(0,05;18) или =СТЬЮДЕНТ.ОБР(1–0,05;18). В обоих случаях ответ 1,7341. В первом случае СТЬЮДЕНТ.ОБР(0,05;18) возвращает значение –1,7341, соответствующее 5%, накопленным от –∞ до –1,7341 (рис. 11а). Для получения окончательного ответа нужно воспользоваться свойством симметрии кривой распределения, и добавить знак минус перед функцией. Во втором случае СТЬЮДЕНТ.ОБР(1–0,05;18) возвращает значение 1,7341, соответствующее 95%, накопленным от –∞ до 1,7341 (рис. 11б).
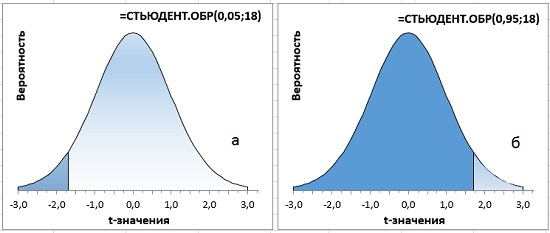
Рис. 11. Односторонний t-критерий с уровнем значимости α = 5%
Вторая функция =СТЬЮДЕНТ.ОБР.2Х() используется в двусторонних тестах, когда мы допускаем, что исследуемое значение может отклоняться в обе стороны от среднего. В формулу следует подставить α-уровень значимости, функция сама разобьет его на две части и вернет значение, соответствующее двум симметричным хвостам (рис. 12; сравните с рис. 11а).
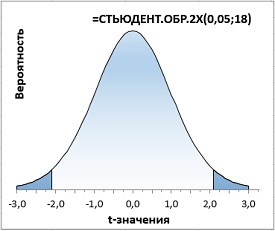
Рис. 12. Двусторонний t-критерий с уровнем значимости α = 5%
Ошибка первого рода
Предположим, перед вами стоит задача увеличить трафик нескольких веб-сайтов. Вы договариваетесь с владельцем популярного рекламного сайта о том, чтобы на его страницах отображались ссылки на 16 сайтов, случайным образом выбираемых из списка сайтов, контролируемых вашей компанией. Другие ваши 16 сайтов, также выбираемые случайным образом, не будут продвигаться в течение месяца.
Вы намереваетесь сравнить между собой средние показатели посещений сайтов, ссылки на которые специально продвигаются поставщиком рекламных услуг, и остальных сайтов. Вы останавливаете свой выбор на направленной гипотезе с альфа-уровнем 0,05: только если специально продвигаемые сайты характеризуются большим средним количеством посещений и только если различие между двумя группами сайтов настолько велико, что при многократном повторении данного испытания оно может случайно встретиться не чаще, чем в одном случае из 20, вы будете отбрасывать гипотезу о том, что специальное продвижение сайта не влияет на среднее количество его посещений.
Через месяц вы получаете свои данные и обнаруживаете, что средний показатель для вашей контрольной группы – сайтов, не получающих специального продвижения, – составляет 45 посещений в час, а для продвигаемых сайтов – 55 посещений в час. Стандартная ошибка среднего равна 5.
Итак, у нас имеется контрольная группа из 16 сайтов (df = 15), правосторонний однонаправленный тест с α-уровнем = 0,05. t-значение определяется по формуле =-СТЬЮДЕНТ.ОБР(0,05;15) и равно 1,7531. Критическое значение посещаемости определяется по формуле (4) и равно: t-значение * стандартное отклонение выборки + среднее по выборке = 1,7531 * 5 + 45 = 53,8. Среднее по экспериментальной группе (55) больше критического t-значения (55 > 53,8). Мы можем отвергнуть нулевую и принять альтернативную гипотезу – продвижение сайтов влияет на посещаемость (рис. 13).
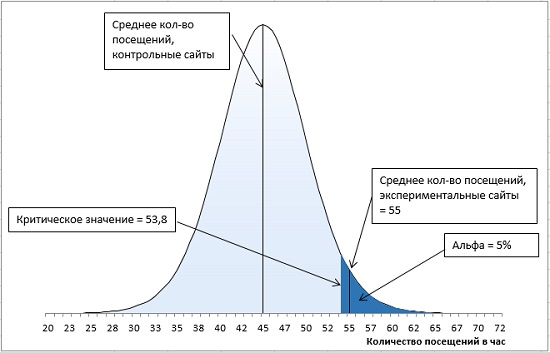
Рис. 13. Попадание среднего значения внутрь α-уровня позволяет отвергнуть нулевую гипотезу
Но, значение альфа-уровня полностью контролируется нами — это наше правило принятия решений. Если бы мы установили для альфа-уровня значение 0,01, мы бы не отвергли нулевую гипотезу (рис. 14). Мы могли бы сказать, что среднее экспериментальной группы происходит из той же генеральной совокупности, что и среднее контрольной группы. Итак, статистическая ошибка I рода: мы отвергаем нулевую гипотезу, когда она верна.
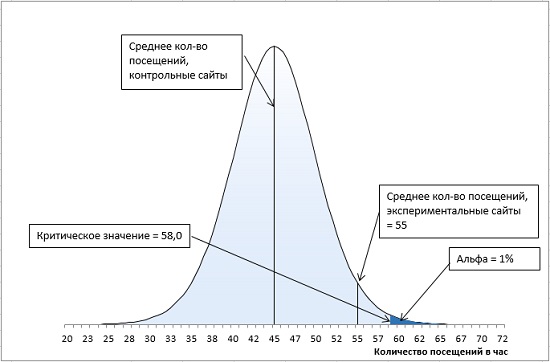
Рис. 14. Для α-уровня = 0,01 среднее экспериментальной группы не позволяет отвергнуть нулевую гипотезу
Что же мешает установить α-уровень достаточно маленьким, и не отвергать нулевую гипотезу, когда она верна? …Ошибка II рода, заключающаяся в том, что мы не принимаем альтернативную гипотезу, хотя она верна.
Ошибка второго рода
Представьте, что существуют две генеральные совокупности: одна из них состоит из сайтов, не получающих специального продвижения, вторая — из сайтов, получающих продвижение. Если вы повторите свое месячное исследование сотни или даже тысячи раз, то, возможно, получите две колоколообразные кривые (рис. 15).
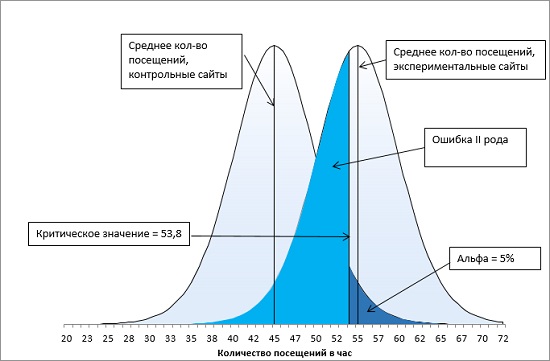
Рис. 15. Ошибка второго рода при α-уровне = 0,05
Иногда среднее значение экспериментальной группы будет происходить из правого хвоста левой кривой распределения исключительно из-за выборочной ошибки. Поскольку в данном случае среднее экспериментальной группы превышает среднее контрольной группы более чем на 1,75 стандартной ошибки (попадает в область α-уровня = 0,05), вы должны отвергнуть нулевую гипотезу, даже если обе генеральные совокупности в действительности имеют одно и то же среднее. Такое неверное отбрасывание нулевой гипотезы, когда в действительности она является истинной, мы назвали ошибкой I рода. В терминах рис. 15 ошибка I рода – приписывание среднего результата экспериментальной выборки, равное 55, правой кривой, а не хвосту левой кривой.
Кривая слева представляет генеральную совокупность веб-сайтов, не получающих специального продвижения. На протяжении месяца частота посещений для некоторых из этих сайтов (очень немногих) составит всего 25 посещений в час, тогда как для других, столь же немногочисленных, – 62 посещения в час. Но 90% всех средних показателей выборок лежат в диапазоне 36,2–53,8 посещений в час.
Кривая справа представляет специально продвигаемые сайты. Как правило, показатели для них примерно на 10 посещений в час выше, чем для сайтов, представленных кривой слева. Их общее среднее составляет 55 посещений в час. Однако большая часть этой информации скрыта от вас. У вас отсутствуют данные о генеральной совокупности, и вы располагаете только результатами двух извлеченных вами выборок, но и этого вам будет вполне достаточно.
Рассмотрим правую кривую на рис. 15. Площадь под этой кривой от минимальных до критического значения (равного 53,8) выделена ярко голубым. Она определяет вероятность ошибки II рода. Средние выборок, проистекающие из этой области, мы относим к левой кривой, а не к правой. Для количественной оценки вероятности ошибки II рода найдем t-значение границы для правой кривой по формуле (7):
Вероятность того, что значение относится к правой кривой и лежит в диапазоне t-значений от –∞ до –0,247 определяется формулой =СТЬЮДЕНТ.РАСП(-0,247;15;ИСТИНА) = 0,404. Т.е., при выбранном нами α-уровне = 0,05 с вероятностью 40,4% мы отклоним альтернативную гипотезу, хотя она верна!
Что произойдет, если мы выберем α-уровень = 0,01, как на рис. 14? Вероятность ошибки II рода увеличится до 72,2% (рис. 16).
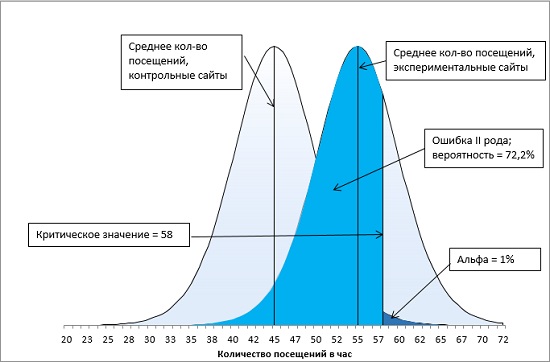
Рис. 16. Ошибка второго рода при α-уровне = 0,01
Статистическая мощность
Вероятность, количественно определяющую величину ошибки второго рода, называют β (на рис. 16 β = 72,2%). А вероятность р = (1 – β) – статистической мощностью (рис. 17).
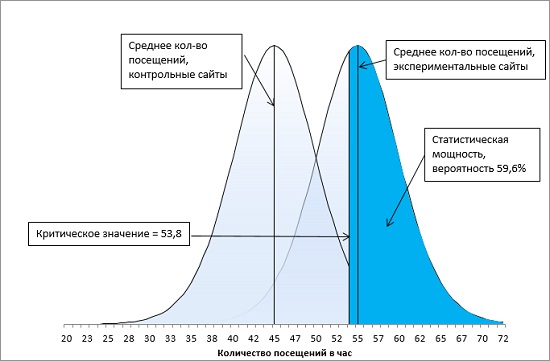
Рис. 17. Статистическая мощность исследования при α-уровне = 0,05
Чем выше статистическая мощность, тем больше вероятность того, что мы отклоним нулевую гипотезу и примем альтернативную гипотезу. На мощность влияют четыре основных фактора:
- Тип теста (переход от двунаправленного теста к однонаправленному увеличивает мощность).
- Уровень α, то есть вероятность ошибки I рода: более высокая α увеличивает мощность.
- Разница между средними значениями выборок (мощность выше при большей разнице).
- Стандартная ошибка среднего (чем ниже ошибка, тем мощность выше).
Давайте на нашем примере рассмотрим, как каждый из указанных факторов изменяет мощность, считая, что факторы меняться по одному (рис 18; расчеты и формулы можно найти в файле Excel).
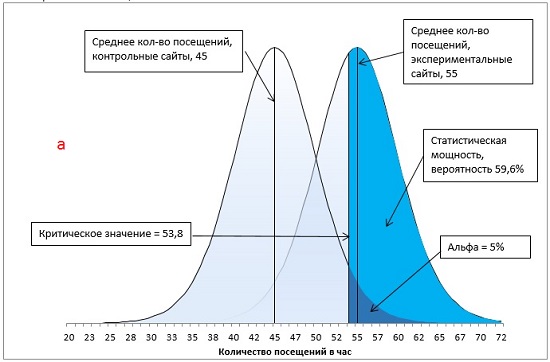
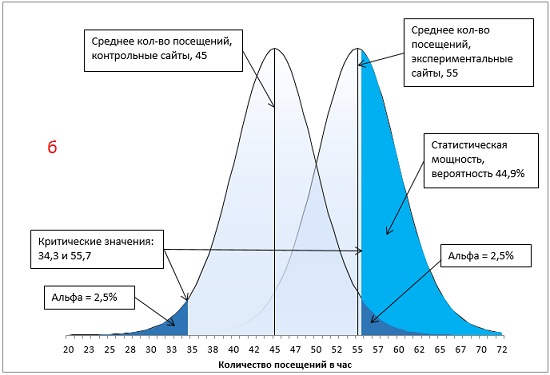

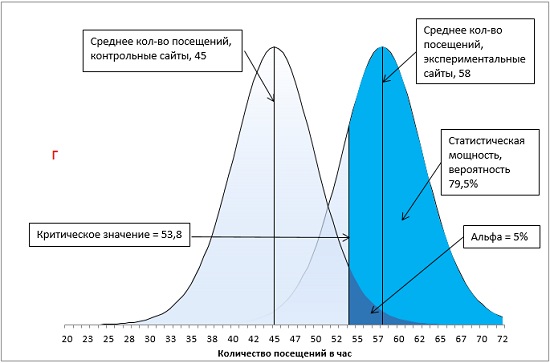
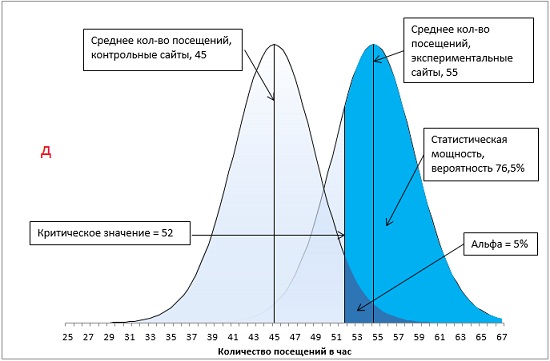
Рис. 18. Методы увеличения статистической мощности: а) базовый вариант; б) ненаправленная гипотеза; в) увеличение α с 0,05 до 0,1; г) увеличение разницы между средними экспериментальной и контрольной групп с 10 до 13 посещений в час; д) увеличение размера групп с 16 до 24 сайтов.
Первый метод повышения статистической мощности связан с подготовкой эксперимента. Если вместо ненаправленной гипотезы (двуххвостовой тест) использовать направленную (однохвостовой тест), вся величина α-уровня отнесется к одному хвосту распределения (сравните рис. 18а и 18б). В результате критическое значение сместится в сторону среднего значения распределения. Чем ближе критическое значение к среднему, тем более вероятно, что вы получите результат, превышающий критическое значение, что увеличивает статистическую мощность тестов. В нашем примере, мощность возрастет с 44,9% до 59,6%.
Второй метод повышения мощности теста предлагает ослабить α-уровень. Например, увеличивая α от 0,05 до 0,10, вы увеличиваете вероятность совершения ошибки I рода, но уменьшаете вероятность совершения ошибки II рода (сравните рис. 18а и 18в). В нашем примере, мощность возросла с 59,6% до 74%.
Оставшиеся два метода повышения статистической мощности основаны на формуле расчета t-статистики:

где t – t-значение для среднего выборки (а не для индивидуального значения), X̅ – среднее значение выборки, μ – среднее значение генеральной совокупности (или среднее значение контрольной выборки), ![]() – стандартная ошибка средних по выборкам (а не индивидуальных значений), равная:
– стандартная ошибка средних по выборкам (а не индивидуальных значений), равная:
![]()
где s – стандартная ошибка индивидуальных значений, n – размер выборки.
Для увеличения t-статистики (и, как следствие, статистической мощности) нужно, либо увеличить числитель, либо уменьшить знаменатель в формуле (8). Для увеличения разности X̅ – μ требуется внесение изменений в проведение эксперимента. Как это сделать, непростой вопрос, решаемый в каждом конкретном случае. В нашем примере, увеличение X̅ с 55 до 58 посещений в час при неизменном μ = 45, приведет к росту статистической мощности с 59,6% до 79,5% (рис. 18г).
И, наконец, уменьшение величины знаменателя тестовой статистики в формуле (8), есть не что иное, как уменьшение стандартной ошибки . Одним из способов уменьшения стандартной ошибки является увеличение размера выборки, n. В соответствии с формулой (9), чем больше n, тем меньше . В нашем примере, при неизменной стандартной ошибке индивидуальных значений s, увеличение контрольной и экспериментальной групп с 16 до 24 сайтов приведет к уменьшению с 5 до 4,1 и росту мощности с 59,6% до 76,5% (рис. 18д).
Один из хороших способов познакомиться с влиянием разных факторов на мощность – это поэкспериментировать с графическим калькулятором мощности, например, здесь.
Основные положения заметки
t-статистика Стьюдента используется вместо нормального распределения: а) для малых выборок; б) если стандартное отклонение генеральной совокупности σ не известно.
t-распределение представлено семейством распределений; дополнительный параметр – размер выборки или число степеней свободы.
Число степеней свободы равно размеру выборки минус число фиксированных статистик выборки (среднее, коэффициент регрессии, …)
Чем больше степеней свободы, тем ближе t-распределение к нормальному.
Функции в Excel, имена которых включают часть РАСП, принимают t-значение в качестве аргумента и возвращают вероятность. Функции, имена которых включают часть ОБР, принимают значение вероятности в качестве аргумента и возвращают t-значение.
Для подстановки в функции Excel значения предварительно должны быть стандартизованы.
Ошибка I рода: отбрасывание нулевой гипотезы, когда в действительности она является истинной. Ошибка II рода: не принятие альтернативной гипотезы, хотя она верна. Чем больше ошибка первого рода, тем меньше ошибка второго рода.
Критерий отнесения события к маловероятному является произвольным. Традиционно маловероятным считают событие, происходящее не чаще, чем 1 раз из 20 попыток.
Один из основных методов уменьшения ошибки второго рода – увеличение элементов в выборке.
[1] При написании замети использованы материалы книг: Дуглас Хаббард. Как измерить всё, что угодно, Левин и др. Статистика для менеджеров, Сара Бослаф. Статистика для всех, Конрад Карлберг. Регрессионный анализ в Microsoft Excel.
[2] На самом деле, можно встретить довольно много различных терминов в отношении нормированных значений z. Ориентируйтесь не на названия, а на суть понятий.
[3] Могут высказать справедливое замечание, что не следует обозначать граничный уровень так же, как и математическое ожидание генеральной совокупности µ. Соглашусь, но всё же использую обозначение, поскольку, в иных задачах здесь часто фигурирует именно математическое ожидание генеральной совокупности µ.
[4] Некоторые авторы указывают знак меньше или равно для левостороннего распределения Р(Х≤t), и больше для правостороннего Р(X>t). Однако, для t=0 значения СТЬЮДЕНТ.РАСП(0;df;ИСТИНА) = СТЬЮДЕНТ.РАСП.ПХ(0;df) = 0,5 для любого значения df. На мой взгляд, Excel при интегральном расчете трактует границу, как исчезающе малую. Поэтому, нет разницы, использовать знак ≥ или >.
Проверка статистической гипотезы позволяет сделать строгий вывод о характеристиках генеральной совокупности на основе выборочных данных. Гипотезы бывают разные. Одна из них – это гипотеза о средней (математическом ожидании). Суть ее в том, чтобы на основе только имеющейся выборки сделать корректное заключение о том, где может или не может находится генеральная средняя (точную правду мы никогда не узнаем, но можем сузить круг поиска).
Распределение Стьюдента
Общий подход в проверке гипотез описан здесь, поэтому сразу к делу. Предположим для начала, что выборка извлечена из нормальной совокупности случайных величин X с генеральной средней μ и дисперсией σ2. Средняя арифметическая из этой выборки, очевидно, сама является случайной величиной. Если извлечь много таких выборок и посчитать по ним средние, то они также будут иметь нормальное распределение с математическим ожиданием μ и дисперсией
![]()
Тогда случайная величина
![]()
имеет стандартное нормальное распределение со всеми вытекающими отсюда последствиями. Например, с вероятностью 95% ее значение не выйдет за пределы ±1,96.
Однако такой подход будет корректным, если известна генеральная дисперсия. В реальности, как правило, она не известна. Вместо нее берут оценку – несмещенную выборочную дисперсию:
![]()
где
![]()
Возникает вопрос: будет ли генеральная средняя c вероятностью 95% находиться в пределах ±1,96sx̅. Другими словами, являются ли распределения случайных величин
![]()
и
![]()
эквивалентными.
Впервые этот вопрос был поставлен (и решен) одним химиком, который трудился на пивной фабрике Гиннесса в г. Дублин (Ирландия). Химика звали Уильям Сили Госсет и он брал пробы пива для проведения химического анализа. В какой-то момент, видимо, Уильяма стали терзать смутные сомнения на счет распределения средних. Оно получалось немного более размазанным, чем должно быть у нормального распределения.
Собрав математическое обоснование и рассчитав значения функции обнаруженного им распределения, химик из Дублина Уильям Госсет написал заметку, которая была опубликована в мартовском выпуске 1908 года журнала «Биометрика» (главред – Карл Пирсон). Гиннесс строго-настрого запретил выдавать секреты пивоварения, и Госсет подписался псевдонимом Стьюдент.
Несмотря на то что, К. Пирсон уже изобрел распределение Хи-квадрат, все-таки всеобщее представление о нормальности еще доминировало. Никто не собирался думать, что распределение выборочных оценок может быть не нормальным. Поэтому статья У. Госсета осталась практически не замеченной и забытой. И только Рональд Фишер по достоинству оценил открытие Госсета. Фишер использовал новое распределение в своих работах и дал ему название t-распределение Стьюдента. Критерий для проверки гипотез, соответственно, стал t-критерием Стьюдента. Так произошла «революция» в статистике, которая шагнула в эру анализа выборочных данных. Это был краткий экскурс в историю.
Посмотрим, что же мог увидеть У. Госсет. Сгенерируем 20 тысяч нормальных выборок из 6-ти наблюдений со средней (X̅) 50 и среднеквадратичным отклонением (σ) 10. Затем нормируем выборочные средние, используя генеральную дисперсию:
![]()
Получившиеся 20 тысяч средних сгруппируем в интервалы длинной 0,1 и подсчитаем частоты. Изобразим на диаграмме фактическое (Norm) и теоретическое (ENorm) распределение частот выборочных средних.

Точки (наблюдаемые частоты) практически совпадают с линией (теоретическими частотами). Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Проведем новый эксперимент. Нормируем средние, используя выборочную дисперсию.
![]()
Снова подсчитаем частоты и нанесем их на диаграмму в виде точек, оставив для сравнения линию стандартного нормального распределения. Обозначим эмпирическое частоты средних, скажем, через букву t.

Видно, что распределения на этот раз не очень-то и совпадают. Близки, да, но не одинаковы. Хвосты стали более «тяжелыми».
У Госсета-Стьюдента не было последней версии MS Excel, но именно этот эффект он и заметил. Почему так получается? Объяснение заключается в том, что случайная величина
![]()
зависит не только от ошибки выборки (числителя), но и от стандартной ошибки средней (знаменателя), которая также является случайной величиной.
Давайте немного разберемся, какое распределение должно быть у такой случайной величины. Вначале придется кое-что вспомнить (или узнать) из математической статистики. Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
1. средняя X̅ и выборочная дисперсия s2 являются независимыми величинами;
2. соотношение выборочной и генеральной дисперсии, умноженное на количество степеней свободы, имеет распределение χ2(хи-квадрат) с таким же количеством степеней свободы, т.е.
![]()
где k – количество степеней свободы (на английском degrees of freedom (d.f.))
Вернемся к распределению средней. Разделим числитель и знаменатель выражения
![]()
на σX̅. Получим
![]()
Числитель – это стандартная нормальная случайная величина (обозначим ξ (кси)). Знаменатель выразим из теоремы Фишера.

Тогда исходное выражение примет вид

Это и есть t-критерий Стьюдента в общем виде (стьюдентово отношение). Вывести функцию его распределения можно уже непосредственно, т.к. распределения обеих случайных величин в данном выражении известны. Оставим это удовольствие математикам.
Функция t-распределения Стьюдента имеет довольно сложную для понимания формулу, поэтому не имеет смысла ее разбирать. Вероятности и квантили t-критерия приведены в специальных таблицах распределения Стьюдента и забиты в функции разных ПО вроде Excel.
Итак, вооружившись новыми знаниями, вы сможете понять официальное определение распределения Стьюдента.
Случайной величиной, подчиняющейся распределению Стьюдента с k степенями свободы, называется отношение независимых случайных величин
где ξ распределена по стандартному нормальному закону, а χ2k подчиняется распределению χ2 c k степенями свободы.
Таким образом, формула критерия Стьюдента для средней арифметической
![]()
есть частный случай стьюдентова отношения
Из формулы и определения следует, что распределение т-критерия Стьюдента зависит лишь от количества степеней свободы.

При k > 30 t-критерий практически не отличается от стандартного нормального распределения.
В отличие от хи-квадрат, t-критерий может быть одно- и двусторонним. Обычно пользуются двусторонним, предполагая, что отклонение может происходить в обе стороны от средней. Но если условие задачи допускает отклонение только в одну сторону, то разумно применять односторонний критерий. От этого немного увеличивается мощность критерия.
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.

Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.

Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.
Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.

Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП – «классическое» левостороннее t-распределение Стьюдента. На вход подается значение t-критерия, количество степеней свободы и опция (0 или 1), определяющая, что нужно рассчитать: плотность или значение функции. На выходе получаем, соответственно, плотность или вероятность того, что случайная величина окажется меньше указанного в аргументе t-критерия, т.е. левосторонний p-value.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия (по модулю), т.е. фактический уровень значимости (p-value).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ.РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-value.
СТЬЮДЕНТ.ОБР – используется для расчета левостороннего обратного значения t-распределения. В качестве аргумента подается вероятность и количество степеней свободы. На выходе получаем соответствующее этой вероятности значение t-критерия. Отсчет вероятности идет слева. Поэтому для левого хвоста нужен сам уровень значимости α, а для правого 1 — α.
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α. Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-value.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅) составила 50,3кг, среднеквадратичное отклонение (s) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
H0: μ = 50 кг
Ha: μ ≠ 50 кг
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двусторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
![]()
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей для критерия Стьюдента (есть в любом учебнике по статистике).

По столбцам идет вероятность правой части распределения, по строкам – число степеней свободы. Нас интересует двусторонний t-критерий с уровнем значимости 0,05, что равносильно t-значению для половины уровня значимости справа: 1 — 0,05/2 = 0,975. Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-value попробовать найти, но он будет приближенным. А, как правило, именно p-value используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.

Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двусторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.
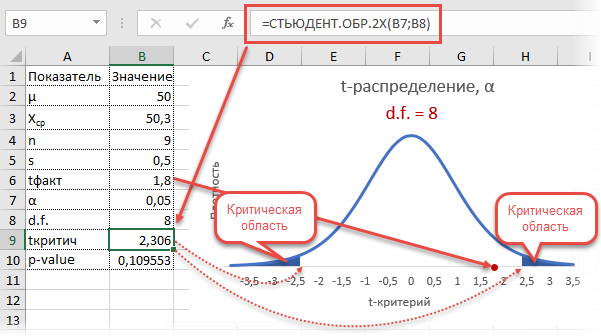
Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-value, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.

P-value равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-value оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
![]()
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.

Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-value (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Расчет доверительного интервала для математического ожидания с помощью t-распределения Стьюдента в Excel
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов. Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α, стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.

Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия
2. Более современным, рассчитав p-value, добавив степень уверенности при отклонении гипотезы.
3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия). Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю видеоролик о том, как рассчитать критерий Стьюдента и проверить гипотезу о генеральной средней в Excel.
Иногда просят объяснить, как делаются такие наглядные диаграммы с распределением. Ниже можно скачать файл, где проводились расчеты для этой статьи.
Скачать файл с примером.
Всего доброго, будьте здоровы.
Поделиться в социальных сетях:
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование
в Microsoft Excel.
Описание
Возвращает доверительный интервал для среднего генеральной совокупности с нормальным распределением.
Доверительный интервал — это диапазон значений. Выборка «x» находится в центре этого диапазона, а диапазон — x ± ДОВЕРИТ. Например, если x — это пример времени доставки продуктов, заказаных по почте, то x ± ДОВЕРИТ — это диапазон средств численности населения. Для любого средней численности населения (μ0) в этом диапазоне вероятность получения выборки от μ0 больше, чем x, больше, чем альфа; для любого средней численности населения (μ0, не в этом диапазоне), вероятность получения выборки от μ0 больше, чем x, меньше, чем альфа. Другими словами, предположим, что для построения двунамерного теста на уровне значимости альфа гипотезы о том, что это μ0, используются значения x, standard_dev и размер. Тогда мы не отклонить эту гипотезу, если μ0 находится через доверительный интервал, и отклонить эту гипотезу, если μ0 не находится в доверительный интервал. Доверительный интервал не позволяет нам сделать вывод о том, что вероятность 1 — альфа, что следующий пакет займет время доставки через доверительный интервал.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Чтобы узнать больше о новых функциях, см. в разделах Функция ДОВЕРИТ.НОРМ и Функция ДОВЕРИТ.СТЬЮДЕНТ.
Синтаксис
ДОВЕРИТ(альфа;стандартное_откл;размер)
Аргументы функции ДОВЕРИТ описаны ниже.
-
Альфа — обязательный аргумент. Уровень значимости, используемый для вычисления доверительного уровня. Доверительный уровень равен 100*(1 — альфа) процентам или, иными словами, значение аргумента «альфа», равное 0,05, означает 95-процентный доверительный уровень.
-
Стандартное_откл — обязательный аргумент. Стандартное отклонение генеральной совокупности для диапазона данных, предполагается известным.
-
Размер — обязательный аргумент. Размер выборки.
Замечания
-
Если какой-либо из аргументов не является числом, возвращается #VALUE! значение ошибки #ЗНАЧ!.
-
Если альфа ≤ 0 или ≥ 1, доверит возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если Standard_dev ≤ 0, возвращается #NUM! значение ошибки #ЗНАЧ!.
-
Если значение аргумента «размер» не является целым числом, оно усекается.
-
Если размер < 1, доверит возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если предположить, что альфа = 0,05, то нужно вычислить область под стандартной нормальной кривой, которая равна (1 — альфа), или 95 процентам. Это значение равно ± 1,96. Следовательно, доверительный интервал определяется по формуле:
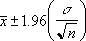
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
Описание |
|
|
0,05 |
Уровень значимости |
|
|
2,5 |
Стандартное отклонение для генеральной совокупности |
|
|
50 |
Размер выборки |
|
|
Формула |
Описание |
Результат |
|
=ДОВЕРИТ(A2;A3;A4) |
Доверительный интервал для математического ожидания генеральной совокупности. Иными словами, доверительный интервал средней продолжительности поездки на работу для генеральной совокупности составляет 30 ± 0,692952 минуты или от 29,3 до 30,7 минут. |
0,692951912 |