
I am trying to create a substitute() that will convert greek characters to latin.
The problem is that after declaring
Dim Source As String
Source = "αβγδεζηικλμνξοπρστθφω"
Source is interpreted as «áâãäåæçéêëìíîïðñóôõöù»
is there any way use unicode at declaration level?
![]()
asked Sep 1, 2011 at 11:04
![]()
5
You can try StrConv:
StrConv("αβγδεζηικλμνξοπρστθφω", vbUnicode)
Source : http://www.techonthenet.com/excel/formulas/strconv.php
[EDIT] Another solution:
You can get every greek character (lower and upper case) thanks to this procedure:
Sub x()
Dim i As Long
For i = 913 To 969
With Cells(i - 912, 1)
.Formula = "=dec2hex(" & i & ")"
.Offset(, 1).Value = ChrW$(i)
End With
Next i
End Sub
You can create an array to find the char for instance.
Source: http://www.excelforum.com/excel-programming/636544-adding-greek-letters.html
[EDIT 2] Here is a sub to build the string you wanted:
Sub greekAlpha()
Dim sAlpha As String
Dim lLetter As Long
For lLetter = &H3B1 To &H3C9
sAlpha = sAlpha & ChrW(lLetter)
Next
End Sub
![]()
Jon Peltier
5,8151 gold badge27 silver badges26 bronze badges
answered Sep 1, 2011 at 12:43
![]()
JMaxJMax
25.9k12 gold badges69 silver badges88 bronze badges
8
As previously mentioned, VBA does support unicode strings, however you cannot write unicode strings inside your code, because the VBA editor only allows VBA files to be encoded in the 8-bit codepage Windows-1252.
You can however convert a binary equivalent of the unicode string you wish to have:
str = StrConv("±²³´µ¶·¹º»¼½¾¿ÀÁÃĸÆÉ", vbFromUnicode)
'str value is now "αβγδεζηικλμνξοπρστθφω"
Use notepad to convert the string: copy-paste the unicode string, save the file as unicode (not utf-8) and open it as ASCII (which is in fact Windows-1252), then copy-paste it into the VBA editor without the first two characters (ÿþ), which is the BOM marker
answered Apr 14, 2014 at 11:52
![]()
z̫͋z̫͋
1,53110 silver badges15 bronze badges
2
You say that your source is interpreted as «áâãäåæçéêëìíîïðñóôõöù».
Note that the Visual Basic Editor doesn’t display Unicode, but it does support manipulating Unicode strings:
Dim strValue As String
strValue = Range("A1").Value
Range("B1").Value = Mid(strValue, 3)
Range("C1").Value = StrReverse(strValue)
If A1 contains Greek characters, B1 and C1 will contain Greek characters too after running this code.
You just can’t view the values properly in the Immediate window, or in a MsgBox.
answered Dec 24, 2013 at 0:38
![]()
tricassetricasse
1,29113 silver badges18 bronze badges
- Remove From My Forums
-
Question
-
Is there any way to get the unicode value of a cell in Excel’s Visual Basic?
I have a column with cyrillic unicode characters that I need to be able to read, but when I attempt to read in the value in VB all of the cyrillic characters are replaced with a question mark (‘?’, &H3F). This happens if I use the Range properties «Text»,
«Value», or «Value2».Is there any way in VB that I can access the cell’s real unicode values before they get converted to ANSI? Or is this just a limitation of VBA for Excel?
~chris
Содержание
- Character set (0 — 127)
- See also
- Support and feedback
- Daily Dose of Excel
- Haphazardly Posted Excel Information and Other Stuff
- Unicode and VBA’s ChrW() and AscW() functions
- 8 thoughts on “ Unicode and VBA’s ChrW() and AscW() functions ”
Character set (0 — 127)
—>
| Code | Character | Code | Character | Code | Character | Code | Character |
|---|---|---|---|---|---|---|---|
| 0 | | 32 | [space] | 64 | @ | 96 | ` |
| 1 | | 33 | ! | 65 | A | 97 | a |
| 2 | | 34 | « | 66 | B | 98 | b |
| 3 | | 35 | # | 67 | C | 99 | c |
| 4 | | 36 | $ | 68 | D | 100 | d |
| 5 | | 37 | % | 69 | E | 101 | e |
| 6 | | 38 | & | 70 | F | 102 | f |
| 7 | | 39 | ‘ | 71 | G | 103 | g |
| 8 | * * | 40 | ( | 72 | H | 104 | h |
| 9 | * * | 41 | ) | 73 | I | 105 | i |
| 10 | * * | 42 | * | 74 | J | 106 | j |
| 11 | | 43 | + | 75 | K | 107 | k |
| 12 | | 44 | , | 76 | L | 108 | l |
| 13 | * * | 45 | — | 77 | M | 109 | m |
| 14 | | 46 | . | 78 | N | 110 | n |
| 15 | | 47 | / | 79 | O | 111 | o |
| 16 | | 48 | 0 | 80 | P | 112 | p |
| 17 | | 49 | 1 | 81 | Q | 113 | q |
| 18 | | 50 | 2 | 82 | R | 114 | r |
| 19 | | 51 | 3 | 83 | S | 115 | s |
| 20 | | 52 | 4 | 84 | T | 116 | t |
| 21 | | 53 | 5 | 85 | U | 117 | u |
| 22 | | 54 | 6 | 86 | V | 118 | v |
| 23 | | 55 | 7 | 87 | W | 119 | w |
| 24 | | 56 | 8 | 88 | X | 120 | x |
| 25 | | 57 | 9 | 89 | Y | 121 | y |
| 26 | | 58 | : | 90 | Z | 122 | z |
| 27 | | 59 | ; | 91 | [ | 123 | < |
| 28 | | 60 | 94 | ^ | 126 | ||
| 31 | | 63 | ? | 95 | _ | 127 | |
The values with blanks are control characters, not characters displayed or printed by Windows.
Values 8, 9, 10, and 13 convert to backspace, tab, linefeed, and carriage return characters, respectively. They have no graphical representation but, depending on the application, can affect the visual display of text.
See also
Support and feedback
Have questions or feedback about Office VBA or this documentation? Please see Office VBA support and feedback for guidance about the ways you can receive support and provide feedback.
Источник
Daily Dose of Excel
Haphazardly Posted Excel Information and Other Stuff
Unicode and VBA’s ChrW() and AscW() functions
Spreadsheets have their CHAR() function, and VBA has its Chr() function. Both return the text character for the specified numerical input, 0 to 255. And spreadsheets have their CODE() function, and VBA has its Asc() function. Both of those return the ASCII code for the leading character of a text string. All well-worn stuff.
But what if you want or need to work with Unicode values? All four functions fail you. As an example, assume you want the true prime character (‘, Unicode 2032) in a string. The prime character, technically, is not an italicized apostrophe (‘), a right single curly quote (‘), or an acute accent (‘).
VBA provides the ChrW() function that does that. ChrW() expects a long as input, but also accepts hexadecimal. Unicode is in hex numbering, so there are two choices: Change U2032 to decimal, or tell ChrW() that the input is in Hex. Since HEX2DEC(2032) is 8242, these two are equivalent:
Both will put ‘ into a string. If ChrW() repeated the same functionality of Chr() below 256, things would be simple. However, the Windows character set deviates from the Unicode character set for ASCII(128) to ASCII(159). In that range, Chr(CharCode) and ChrW(CharCode) produce different results. As WikiPedia says, Windows “coincides with ISO-8859-1 for all codes except the range 128 to 159 (hex 80 to 9F), where the little-used C1 controls are replaced with additional characters.” Not sure what C1 controls (probably a printer), but if we want to get Unicode to the spreadsheet, do we want it to give the functionality of CHAR()/Chr(), or that of ChrW() which is ISO-8859-1 compliant? Or, optionally both. The function CHARW() takes the optional route. If you set Exact_functionality to TRUE, you can put those C1 controls in your spreadsheet. The default is to do otherwise.
If CharCode Then
If Exact_functionality Then
CHARW = ChrW(CharCode)
Else
CHARW = Chr(CharCode)
End If
Else
CHARW = ChrW(CharCode)
End If
End Function
One very nice thing is that you can feed Clng() a hex value, and it will do the HEX2DEC conversion for you.
The VBA function AscW() goes the other way, and has the same ISO problems. It will tell you the decimal code of the first character in a Unicode string, with no regard to the Windows character set. We can make another UDF CODEW() that can optionally specify either the decimal or hex value for the first character is returned, and whether or not to be ISO compliant. The default is to return the HEX unicode (as Uxxxx) and not to comply.
If Exact_functionality Then
CODEW = AscW(Character)
If Unicode_value Then CODEW = “U” & Hex(CODEW)
Exit Function
End If
For i = 128 To 159 ‘where non-compliant
Characters = Characters & Chr(i)
Next i
If InStr(1, Characters, Left$(Character, 1), vbBinaryCompare) Then
CODEW = Asc(Character)
Else
CODEW = AscW(Character)
End If
If Unicode_value Then CODEW = “U” & Hex(CODEW)
End Function
The default will return U2032 when the first character is ‘, and 8242 when Unicode_value is set FALSE. For another example, is CHAR(128), Chr(128), ChrW(8354), CHARW(128), CHARW(“U80”), CHARW(“U20AC”,TRUE) and CHARW(8364,TRUE).
CODEW(“”) is “U80”, CODEW(“”,FALSE) is 128, CODEW(“”,,TRUE) is “U20AC”, and CODEW(“”,FALSE,TRUE) is 8354.
To see Unicode characters, the cell’s font has to be set to a Unicode font.
8 thoughts on “ Unicode and VBA’s ChrW() and AscW() functions ”
AscW returns negative numbers sometimes. This is documented in the MS Excel help files. Does the macro above also work in those cases?
There is nothing in the UDF to protect for bad AscW behavior.
This would be the modified code:
Function CODEW(Character As String , Optional Unicode_value As Boolean = True , _
Optional Exact_functionality As Boolean = False ) As Variant
‘ Exact Functionality returns exact Unicode for characters as AscW() does
‘ correcting for http://support.microsoft.com/kb/272138 behavior
‘ rather than Windows characters as Asc() does
Dim Characters As String
Dim i As Long
If Exact_functionality Then
CODEW = AscW(Character)
If CODEW If Unicode_value Then CODEW = “U” & Hex(CODEW)
Exit Function
End If
For i = 128 To 159 ‘where non-compliant
Characters = Characters & Chr(i)
Next i
If InStr(1, Characters, Left$(Character, 1), vbBinaryCompare) Then
CODEW = Asc(Character)
Else
CODEW = AscW(Character)
If CODEW End If
If Unicode_value Then CODEW = “U” & Hex(CODEW)
End Function
Can’t really call it “Exact Functionality” any more 🙄
…mrt
Related problem is a get inserted symbol’s code. Solution is to use dialog capabilities in context of selected symbol:
With Dialogs(wdDialogInsertSymbol)
Debug.Print “Font: ” & .Font
Debug.Print “Char number ” & .CharNum
End With
Thanks for this even though it’s an old post it helped with using ChrW(&H20AC) instead of chr(128). I believe this helps alleviate the issue of U.S. and non-U.S. character sets.
Do you have any thoughts on using the Unichar function for Chinese characters? It works in Excel, but doesn’t seem to be available in MS Access.
Not to derail the thread, but…I’m trying to build a db of Chinese characters and can’t find a char set that supports all 8,105 characters pubished by the PRC. Excel works fine with Unichar / Unicode functions, but I need similar functionality in MySQL, MS Access. So, in addition to the comments above, I need a character set that supports these outliers so they can be stored…
UTF8 works on some DB’s (not MySQL)
UTF8MB4 still doesn’t support all characters
GB18030 is supposed to support all officially listed characters, but still doesn’t quite work
Источник
In VBA, there are two types of string: Unicode string and ANSI string.
Definition
Unicode string
Unicode string (type String) contains a sequence of UTF-16 code points, and can represent any Unicode characters.
Characters not in the BMP (Basic Multilingual Plane) is represented by a pair of surrogate.
Functions such as ChrW, AscW handles
ANSI string
ANSI string (type Byte()) contains a sequence of bytes, which is interpreted as a sequence of characters in the current locale.
The locale ID for English (United States) is 1033.
It’s not possible to represent all Unicode characters in an ANSI string. Characters that cannot be represented is converted to ?.
Function to convert between the types
There’s a function StrConv. As mentioned in the documentation:
bytearray = StrConv(string, vbFromUnicode[, locale])converts from a Unicode string to an ANSI string.string = StrConv(bytearray, vbUnicode[, locale])converts from an ANSI string to a Unicode string.
Note that even though the input and output type of StrConv is always String, they must be taken to be String or Byte()
depends on the conversion type.
In VBA, String and Byte() are interchangeable (but not the same type).
It’s also possible to assign string to bytearray, in which case the content of the byte array
is assigned the internal representation of the string (UTF-16-LE).
Each UTF-16 code unit (not necessary a character) is represented by 2 bytes.
Function to manipulate
Functions such as LeftW manipulates Unicode string.
Functions such as LeftB manipulates ANSI string; however their declared return type is String instead of the actual Byte().
«Double Unicode» string
TODO write something
In some situations it seems to generate the correct result
- vba — Split string into array of characters? — Stack Overflow
- vba — How can I create text files with special characters in their filenames — Stack Overflow
but it’s not very «correct».
External API
TODO write something
Use LongPtr for example. See blog post for more details.
See also
- vb6 — What does vbFromUnicode mean? — Stack Overflow
- excel — How to convert a simple string to Byte Array in VBA? — Stack Overflow
strikethrough text are not verified.
Understanding Unicode variants like UTF8 and UTF16 and how they impact your Office VBA development is not so straightforward. This post will guide thru the experience of reading a text file with VBA, explain some of the pitfalls you may encounter on this path when dealing with different text encodings and file formats. We’ll shed some light on essential Unicode concepts you’ve preferred to leave aside until now, because – let’s face it – who wants to spend hours reading wikipedia or MSDN just to read a text file or understand the many rules and APIs for converting between encodings ?
No bulky and verbose .NET or undecipherable C++ code complications here.
Just immediately actionable, simple and humble, VBA code with one function to rule them all, and a 10 to 15 minutes read to understand it all.
Let’s start the experience right now. Try something:
- Open Windows notepad and copy/paste (or type) this text:
Fancy a café ? Or a piña colada ? – Oh, that’s so cliché!
I have a strong impression of Déjà vu.
You hide your true motive behind a friendly façade.
(Just my lame try to compose words with diacritics, in english. Inspiration found here and here)
- Save the file; let’s say in c:temptextfilesnotepad_text.txt
Now we’ll try to read it and display it in Visual Basic, line by line, as usual:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Private Const TEST_FILE1 As String = «c:temptextfilesnotepad_text.txt« Public Sub ReadTextFileByLine(ByVal psFileName As String) Dim hFile As Integer Dim sLine As String ‘Current line read from the file Dim iLineCt As Integer ‘Line counter Debug.Print «—- ReadTextFileByLine()« hFile = FreeFile Open psFileName For Input Access Read As #hFile Debug.Print «[File: « & psFileName & «]« While Not EOF(hFile) iLineCt = iLineCt + 1 Line Input #hFile, sLine Debug.Print iLineCt & «:« & sLine Wend Close hFile Debug.Print «[EOF]« End Sub Public Sub Test_ReadTextFileByLine() ReadTextFileByLine TEST_FILE1 End Sub |
Executing the “Test_ReadTextFileByLine” Sub (in the debug window) from this simple code snippet should do it…

…or not (!). The accented characters don’t display correctly.
Let’s state some facts before banging our heads on that:
- Two forms of Unicode will be of interest here: UTF8 and UTF16.
- “Windows is Unicode“, UTF16 Unicode. So is VBA. Unicode is a big character set which is meant to be able to represent the character glyphs of different languages.
- Unicode (UTF16) encodes a character with two bytes (a “wide” character, in extension “wide” strings).
(Note: UCS2 is history, assume UCS2 (or UCS-2) is UTF16) - The representation of a character in Unicode is also called a code point.
- UTF8: not all the characters in the Unicode character set really need two bytes of encoding. UTF8 is sort of a packed representation of a series of Unicode characters, where one or two bytes can be used to represent a wide character.
Back to reading our file
At this point, we can guess that our Notepad old friend (on Windows 10 en_US version in my setup), probably stored our text file using a UTF8 encoding, which VBA is not aware of. Let’s take a look at the bytes in the file:

We see at lines 0 and 30 that our accented “é” are encoded as the two bytes C3 and A9, so this is a UTF8 file.
Then, at some point, we’ll have to convert an UTF8 representation of string to a UTF16 VBA friendly one.
Unfortunately, VBA cannot help here, so let’s take a detour to our trustworthy Win32 API.
Converting from UTF8 to UTF16 with the Win32 API
You’ll find all the code in the demo database of my reading_text_files github repository.
The function we’ll need is MultiByteToWideChar(), which we can declare as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Public Const CP_UTF8 As Long = 65001 ‘UTF-8 Code Page Private Const ERROR_NO_UNICODE_TRANSLATION As Long = 1113& ‘No mapping for the Unicode character exists in the target multi-byte code page. Private Const MB_ERR_INVALID_CHARS As Long = &H8& #If Win64 Then Private Declare PtrSafe Function MultiByteToWideChar Lib «kernel32« ( _ ByVal CodePage As Long, _ ByVal dwFlags As Long, _ ByVal lpMultiByteStr As LongPtr, _ ByVal cchMultiByte As Long, _ ByVal lpWideCharStr As LongPtr, _ ByVal cchWideChar As Long) As Long Private Declare PtrSafe Function GetLastError Lib «kernel32« () As Long #Else ‘Sys call to convert multiple byte chars to a char Private Declare Function MultiByteToWideChar Lib «kernel32« ( _ ByVal lCodePage As Long, _ ByVal dwFlags As Long, _ ByVal lpMultiByteStr As Long, _ ByVal cchMultiByte As Long, _ ByVal lpWideCharStr As Long, _ ByVal cchWideChar As Long) As Long Private Declare Function GetLastError Lib «kernel32« () As Long #End If |
We’re going to have two variable sources, byte arrays and strings, to convert to UTF16, this is the VBA API functions signatures we’ll use:
|
Public Function UTF8DecodeByteArrayToString( _ ByRef pabBytes() As Byte, _ Optional ByVal plStart As Long = 0&) As String End Function Public Function UTF8DecodeString(ByVal psSource As String) As String End Function |
Unicode normalization
There’s more than one way to represent a combination of characters in Unicode (MSDN). Extract:
Capital A with dieresis (umlaut) can be represented either as a single Unicode code point “Ä” (U+00C4) or the combination of Capital A and the combining Dieresis character (“A” + “¨”, that is, U+0041 U+0308). Similar considerations apply for many other characters with diacritic marks.
Simply put, a problem rises if we compare two Unicode strings that conceptually are the same, but use different code points (as the example above).
There are two more Win32 API functions that can help with that. One, NormalizeString(), transforms a Unicode string to a standard form, so it can be compared with another, even if the representations are different. The other, IsNormalizedString(), tests if a Unicode string is in the expected form.
There are a number of standard forms, but mainly, the one that “compresses” the code points into one character (I mean we get the attached form of “ae” instead of the “a” and “e”) is “NormalizationC”, value 1, from the following (C++) enumeration:
|
typedef enum _NORM_FORM { NormalizationOther = 0, // Not supported NormalizationC = 0x1, // Each base + combining characters to canonical precomposed equivalent. NormalizationD = 0x2, // Each precomposed character to its canonical decomposed equivalent. NormalizationKC = 0x5, // Each base plus combining characters to the canonical precomposed // equivalents and all compatibility characters to their equivalents. NormalizationKD = 0x6 // Each precomposed character to its canonical decomposed equivalent // and all compatibility characters to their equivalents. } NORM_FORM; |
Normalization is an optional step, but for security considerations, should be used.
I wrapped the API (and followed MSDN guidance) in these two VBA API functions, and two others to get any error information:
|
Public Function UcIsNormalizedString(ByVal psText As String) As Boolean End Function Public Function UcNormalizeString(ByVal psText As String) As String End Function Public Function UcGetLastError() As Long End Function Public Function UcGetLastErrorText() As String End Function |
Note:
I’m not following my coding guidelines for keeping error information inside a module, because we get an error either when calling Win32 API functions or a “logical” error when using the VBA API.
Then to test if something went wrong when calling UcNormalizeString() we have to test like that:
|
If (UcGetLastError() <> 0) Or (Len(UcGetLastErrorText()) > 0) Then TryNormalization = «FAILED: « & UcGetLastErrorText() End If |
You can see a test scenario, that I sort of translated from the ones in MSDN, in the Test_Normalization() Sub, which calls:
|
Private Function TryNormalization(ByVal psText As String) As String If UcIsNormalizedString(psText) Then TryNormalization = «Already normalized in this form« Exit Function End If TryNormalization = UcNormalizeString(psText) If (UcGetLastError() <> 0) Or (Len(UcGetLastErrorText()) > 0) Then TryNormalization = «FAILED: « & UcGetLastErrorText() End If End Function |
Back to reading our file – again
Ok, now we know for sure that our file is in UTF8.
And we know that we have a nice UTF8DecodeString() at our disposal.
Are we not tempted to make this slight adaptation to our ReadTextFileByLine() function ? (see the UTF8DecodeString call in this code):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Public Sub ReadTextFileByLine_BadIdea(ByVal psFileName As String) Dim hFile As Integer Dim sLine As String ‘Current line read from the file Dim iLineCt As Integer ‘Line counter Debug.Print «—- ReadTextFileByLine()« hFile = FreeFile Open psFileName For Input Access Read As #hFile Debug.Print «[File: « & psFileName & «]« While Not EOF(hFile) iLineCt = iLineCt + 1 Line Input #hFile, sLine Debug.Print iLineCt & «:« & UTF8DecodeString(sLine) Wend Close hFile Debug.Print «[EOF]« End Sub Public Sub Test_ReadTextFileByLine_BadIdea() ReadTextFileByLine TEST_FILE1 End Sub |
The result:

Whaaaat ? – Let’s debug that using the provided DumpStringBytes() function:

Which brings us to that output:

As we can see (and compare with the previous file’s hex dump), we do not have an UTF8 string in the variable sLine that is read by VBA from the file.
VBA converts the line it read from the file to a double byte (UTF16) string.
We cannot use VBA to read an UTF8 encoded text file using string variables.
Solution for reading and converting an UTF8 text file
We have to open the file in binary mode and read the contents in a byte array. This way VBA doesn’t do any conversion. We then just convert the byte array to an UTF8 string with the UTF8DecodeByteArrayToString().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Public Sub ReadNotepadTextFile(ByVal psFileName As String) Dim abString() As Byte Dim sDecoded As String Dim hFile As Integer Debug.Print «—- ReadNotepadTextFile() in a byte array and convert to UTF8:« Debug.Print «[File: « & psFileName & «]« hFile = FreeFile Open psFileName For Binary Access Read As #hFile ReDim abString(1 To LOF(hFile)) As Byte Get #hFile, 1, abString Close hFile sDecoded = UTF8DecodeByteArrayToString(abString) Debug.Print sDecoded & vbCrLf & «[UTF8] (len=» & Len(sDecoded) & «)« Debug.Print «[EOF]« End Sub |
And finally, we get it right:

Other text file encodings and BOMs
If Notepad saves files in UTF8 encoding, there are other encodings of text and file formats.
UTF8 and UTF16 text files may have, or not, a special series of bytes at the start of the file called the BOM (Byte Order Mark). The BOM is a magic number that we can use to infer the file encoding and byte endianness (order of bytes) of the file contents.
Without the BOM, guessing the file encoding can be tough.
But when there’s one, we can use it to make the necessary conversions, like in the following GetFileText() function, that can handle the following file encodings:
- UTF16 BE / LE (Big Endian / Little Endian) with or without BOM,
- UTF8 with or without BOM
- ANSI (8 bits characters text, different character sets or code pages possible)
This is the signature of the function (code in the MTextFiles module of the Reading_Text_Files.accdb project), with a bit of documentation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
‘GetFileText() ‘ ‘Synopsis ‘——— ‘ Reads a text file as a binary file in memory, and converts the bytes into a VB string. ‘ Detects BOM (Byte Order Mark) if there’s one and handles BE/LE (Big/Little Endian). ‘ ‘Parameters ‘———- ‘ psFilename ‘ Full or relative path of file to read ‘ ‘ psInFileFormat ‘ can be either «», «utf8» or «utf16». Any other value plays ‘ as «», and «» is assumed to be UTF16 LE with no BOM (as when we ‘ write a text file with VB/A). ‘ Rules applied for psInFileFormat: ‘ 1. «» (empty), UTF16 LE nom BOM is assumed; ‘ 2. «utf8», if there’s a BOM, its not included in the returned ‘ text, and the text is UTF8decoded to a VB/A string (UTF16) ‘ 3. «utf16», it there’s a BOM, it is used to determine LE/BE. If ‘ there’s no BOM, LE is assumed. ‘ ‘Returns ‘——- ‘ The decoded file text. ‘ ‘Notes: ‘—— ‘1. Can handle files which size fits into a long, and in memory. ‘2. Use error trapping in your calling code to catch unexpected errors. ‘3. You can use Notepad++ to produce test files (See the «Encoding» menu) ‘ Notepad++ encoding | Translates to ‘ —————————+————— ‘ «Encode in ANSI» | «» ‘ «Encode in UTF-8» | «utf8» ‘ «Encode in UTF-8-BOM» | «utf8» ‘ «Encode in UCS-2 BE BOM» | «utf16» ‘ «Encode in UCS-2 LE BOM» | «utf16» ‘ (Remember UCS-2 = UTF16) ‘4. Tools like Typora (https://typora.io/) save files in utf8 with no BOM, ‘ Use «GetFileText(YourFilename,»utf8») to load them. ‘ Public Function GetFileText( _ ByVal psFileName As String, _ ByVal psInFileFormat As String) As String End Function |
There’s a “text_files_samples” directory, in the github repository, with one file for each possible text file encoding.
Note that there are no UTF16 files with no BOM, as I used Notepad++ to generate the files and there’s no option in Notepad++ to generate UTF16 files with no BOM.
The Test_ReadSampleEncodings() procedure will read and check the contents of each file with this GetFileText() function:

Conclusion
We’ve seen different representation of text and encodings like UTF8, UTF16. We’re now able to convert between those encodings. And we now know how to read text from files with some of the most common file formats we may encounter, with VBA.
From here, it should be quite easy to also write any of these formats (using files open in binary mode helps).
Downloads
Head to the Reading_Text_Files github repository to get the source code, the example files and the Access demo database.
(MIT Licence)
-
07-11-2018, 01:33 AM
#1

Forum Contributor
VBA functions with respect to Unicode characters
Which VBA function is the most congruent with the Unicode set of characters.
Unicode character link: https://unicode-table.com/en/
Unicode identification is by U+**** where * is an alpha-numeric character.
By congruent, I mean that the last 4 alpha-numeric characters from Unicode must equal the last 4 alpha-numeric characters of the VBA function.
So far I am using ChrW(&H****).
Is ChrW() the most suitable with all the variations in computing, most of which I don’t really know, but one is the operating system which could be Windows/Mac/Linux.As an example, the symbol «@» has Unicode identification of «U+0040» and VBA equivalent is «ChrW(&H0040)». The leading 2 zeros actually drop off.
-
07-11-2018, 04:49 PM
#2
Re: VBA functions with respect to Unicode characters
Hello Excel_&_Help,
VBA by its nature is ANSI based. However, strings in Windows are all Unicode. The Windows operating system makes the conversion from Unicode to ANSI automatically for strings.
So, to include Unicode characters in a VBA string, you can use the Character Wide (ChrW) function. Another way is to use the Windows API. This method is very low level coding and not as straightforward. Also, the API calls are only available on Windows.
Sincerely,
Leith RossRemember To Do the Following….
1. Use code tags. Place [CODE] before the first line of code and [/CODE] after the last line of code.
2. Thank those who have helped you by clicking the Star
below the post.3. Please mark your post [SOLVED] if it has been answered satisfactorily.
Old Scottish Proverb…
Luathaid gu deanamh maille! (Rushing causes delays!)
-
07-12-2018, 12:07 AM
#3
Forum Contributor
Re: VBA functions with respect to Unicode characters
Thanks for providing this input.


 below the post.
below the post.Cement mixer, anyone?
I’ve never worried too much about text file encodings or Unicode handling in my VBA code. And why should I? I’m an American, dammit!
I’ve modified an old joke to make my point for me:
Q: What do you call someone who speaks 3 languages?
A: Tri-lingual.Q: What do you call someone who speaks 2 languages?
A: Bilingual.Q: What do you call someone who speaks 1 language (and doesn’t care about code pages and file encodings)?
A: American.
The past few days I’ve written a series of articles detailing a variety of file handling functions that I’ve used *with no problems* for over a decade. Sounds great, right? The problem is that most of them are pretty useless outside the good old U.S. of A.
I mean, maybe my British brothers and sisters across the pond can use them without trouble. Perhaps even the Aussies down under. Those functions also probably work fine for Canadians. (Which makes sense, since they’re basically just Americans who like snow and don’t know how to pronounce «about» correctly, eh? No, wait, there is that weird province where the people can’t decide if they’re French or not.)
I was making a point before I went off on my ignorant-American digression. For my international audience who’ve managed to read this far without closing their browser tab in disgust, I’d like to atone for my previous disregard for the plight of the world outside my small ANSI box.
I was going to write a full article about ANSI, Unicode, file encodings, code points, etc., but I realized that I don’t really know very much about that world. Instead, I’ll do something I haven’t done very often around here. Put together a whole big pile of links to some better Unicode sources than anything I could provide myself.
Background
My fellow Americans, if you’ve read this far and been thinking, «What in the world is this guy even talking about?» then this first set of links are for you. My international readers can just skip over most of these because, well, you’ve been living with this pain for years now and know all about it.
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
«It does not make sense to have a string without knowing what encoding it uses.»
— Joel Spolsky
This article from Joel Spolsky is the perfect starting point for learning about Unicode. It’s getting a bit long in the tooth, particularly with some of the website examples, but all the concepts are still solid. Plus, Joel’s articles are just fun to read.
On the Goodness of Unicode
«Thus, while there are officially two standards you should care about, Unicode and ISO 10646, through some political/organizational magic they are exactly the same, and if you’re using one you’re also using the other.»
— Tim Bray
This article provides background on the world’s writing systems; the interplay of characters, encodings, and fonts; the history and politics of Unicode; and some technical information on the Unicode standard itself.
Character code tutorial
«This document in itself does not contain solutions to practical problems with character codes (but see section Further reading). Rather, it gives background information needed for understanding what solutions there might be, what the different solutions do — and what’s really the problem in the first place.»
— Jukka «Yucca» Korpela
This is more thorough technical reference than Joel’s. It’s from 2001, but the information seems to have aged pretty well.
Unicode and VBA
AKA, the stuff you actually care about.
Working with Unicode file names in VBA (using Dir, FileSystemObject, etc.)
«It sounds like you are being misled by the fact that while VBA itself supports Unicode characters, the VBA development environment does not. The VBA editor still uses the old «code page» character encodings based on the locale setting in Windows.»
— Gord Thompson
The above stackoverflow answer from Gord Thompson shows how to use the FileSystemObject to iterate through a folder of Unicode file names, where the Dir() function would otherwise choke.
VBA Read Unicode file contents in various encodings
«To read a text file, you need to be able to handle more character sets than just ANSI. Not just in the contents but also in the file and folder names.»
— Patrick O’Beirne
The above article includes two functions, ReadFileContentsAndCharset() (which tries to guess the character encoding), and ReadADOStreamText(). These are good alternatives to my FileRead() function. (Note that they are not drop-in replacements, as they return file contents via a ByRef function argument, rather than as the return value of the function.)
Thanks to @ExcelAnalytics for pointing me to Patrick’s article (and serving as the inspiration for this post).
Solving the Unicode, UTF8, UTF16 and Text Files conundrum in VBA
«No bulky and verbose .NET or undecipherable C++ code complications here. Just immediately actionable, simple and humble, VBA code with one function to rule them all, and a 10 to 15 minutes read to understand it all.»
— @francescofoti
Francesco recommends reading text files as binary using legacy statements like Open and Get. By reading the files in as binary, VBA won’t assume the contents are ANSI; it won’t assume anything at all. He then offers some code to convert the imported binary into UTF8 text.
VBA: Unicode Strings and the Windows API
«1. Do not use the
Aversion of API calls, always use theWversion instead.»
«7. Remember that the VBE IDE cannot process and display Unicode, so don’t expect yourdebug.printto display anything other than?for high code point characters.»
— Renaud Bompuis
The above article has some great information about Unicode considerations when making Windows API calls. He also talks about the built-in VBA message box’s lack of Unicode support and how to work around that. It’s a great, practical read.
How To Display Foreign Characters In Excel VBE
«In this article, you will be walked through the process of showing foreign characters in Visual Basic Editor.»
This article steps you through the process of changing the Windows Region settings so that the Visual Basic Editor will display Unicode characters correctly. Unfortunately, this only supports one character set at a time. Switching between character sets is clunky and appears to require a computer restart.
Note: In version 2004 of Windows 10, there is a regional setting to enable UTF-8 support system-wide. The feature is still in Beta…and they’re not kidding about that.
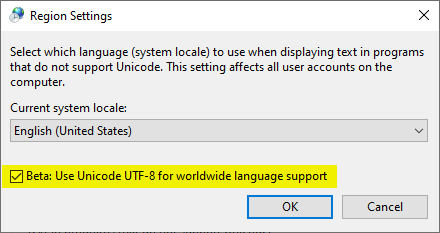
I tried enabling it and then using Alt codes to create Unicode characters in the VBE. It did not work. The Visual Basic Editor seems impervious to the Beta UTF-8 Windows setting, at least for now. Also, after enabling the feature, I was no longer able to use Alt codes to create Unicode characters in a UTF-8 encoded file in Notepad++. Instead, each time I tried, the Notepad++ window displayed a square box. I was able to copy and paste Unicode characters from other text files and they displayed fine; the problem seemed to be with the Alt code handling. I reverted to the non-UTF-8 Region Settings. Your mileage may vary. Mine sucked.
Assortment of stackoverflow VBA unicode questions
How to handle filenames with unicode characters in VBA using Dir?
I am selecting a list of files based on a criteria using Dir, and then storing these in an array of strings. I then iterate through the array and process the files. How can i handle filenames with
![]() Stack OverflowAtti
Stack OverflowAtti

VBA — Convert string to UNICODE
I need to convert the string HTML from a mix of Cyrillic and Latin symbols to UNICODE. I tried the following: Public HTML As String Sub HTMLsearch() GetHTML (“http://nfs.mobile.bg/pcgi/m…
![]() Stack OverflowTrenera
Stack OverflowTrenera
Using multiple language (english, chinese, japanese) in VBA
I need to be able to use strings of multiple languages (english, chinese and japanese) in VBA. Changing the region/locale setting of the computer only works if there is one language. Could someone …
![]() Stack OverflowNikhil Joseph
Stack OverflowNikhil Joseph
Getting the unicode value of a char in VB
How can I get the unicode value of a char? For example, I know that I can do this with ascii: i = Asc(“a”) // i == 97 (correct) What if I have a unicode char though? i = Asc(”•”) // i == 149 (
![]() Stack OverflowSenseful
Stack OverflowSenseful
References
Now, for the hard-core material.
Unicode Character Code Charts
This page from unicode.org has links to every currently recognized character set, from Basic Latin (ASCII) to Arabic, Ethiopic, Hebrew, Nandinagari, Tagalog, and Wancho. There are also links to symbols and punctuation, including Braille Patterns, Mathematical Operators, Currency Symbols, Chess Symbols, Dingbats, and Emoticons.
Character Sets And Code Pages At The Push Of A Button
This is an old page with lots of links. Unfortunately, most of those are now broken links, especially the ones linking to Microsoft and IBM reference pages toward the bottom of the site. That said, if you’re working on some esoteric issue and your Google-fu is failing you, this might be worth a shot.
Additional References
Dear readers in the future: leave additional references to good VBA Unicode articles in the comments below. Dear realtime readers who have no option to leave comments, email me suggested articles at mike {at} nolongerset.com. Or send them to me on Twitter @nolongerset, if you’re into that sort of thing.
Image by LEEROY Agency from Pixabay