
Openpyxl is a Python library to manipulate xlsx/xlsm/xltx/xltm files. With Openpyxl you can create a new Excel file or a sheet and can also be used on an existing Excel file or sheet.
Installation
This module does not come built-in with Python. To install this type the below command in the terminal.
pip3 install openpyxl
In this article, we will discuss how to delete rows in an Excel sheet with openpyxl. You can find the Excel file used for this article here.
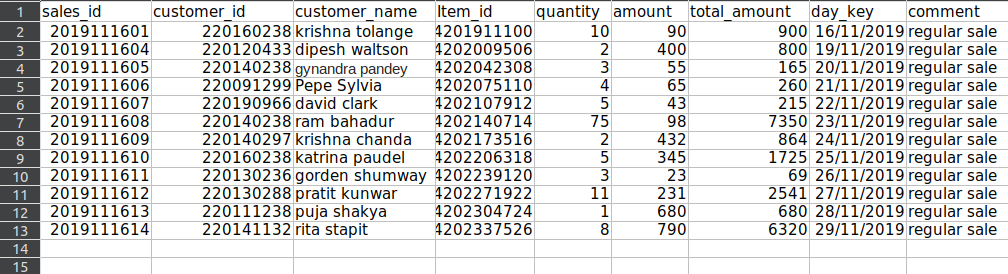
Deleting Empty rows (one or more)
Method 1:
This method removes empty rows but not continues empty rows, because when you delete the first empty row the next row gets its position. So it is not validated. Hence, this problem can be solved by recursive function calls.
Approach:
- Import openpyxl library.
- Load Excel file with openpyxl.
- Then load the sheet from the file.
- Iterate the rows from the sheet that is loaded.
- Pass the row to remove the function.
- Then check for each cell if it is empty if any of the cells non-empty return the function, so only empty rows will exit the for loop without returning.
- Only if all rows are empty, remove statement is executed.
- Finally, save the file to the path.
Python3
import openpyxl
def remove(sheet, row):
for cell in row:
if cell.value != None:
return
sheet.delete_rows(row[0].row, 1)
if __name__ == '__main__':
path = './delete_empty_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['daily sales']
print("Maximum rows before removing:", sheet.max_row)
for row in sheet:
remove(sheet,row)
print("Maximum rows after removing:",sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 14
File after deletion:
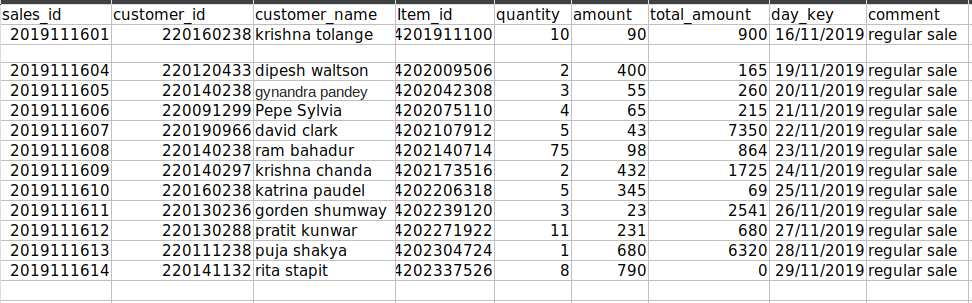
The first method deleted only the first empty row and the second continuous empty row is not deleted.
Method 2:
This method removes empty rows, including continuous empty rows by using the recursive approach. The key point is to pass the modified sheet object as an argument to the recursive function. If there is no empty row function is returned immediately.
Approach:
- Import openpyxl library.
- Load Excel file with openpyxl.
- Then load the sheet from the file.
- Pass the sheet that is loaded to the remove function.
- Iterate the rows with iter_rows().
- If any of the cells in a row is non-empty, any() return false, so it is returned immediately.
- If all cells in a row are empty, then remove the row with delete_rows().
- Then pass the modified sheet object to the remove function, this repeats until the end of the sheet is reached.
- Finally, save the file to the path.
Python3
import openpyxl
def remove(sheet):
for row in sheet.iter_rows():
if not all(cell.value for cell in row):
sheet.delete_rows(row[0].row, 1)
remove(sheet)
return
if __name__ == '__main__':
path = './delete_empty_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['daily sales']
print("Maximum rows before removing:", sheet.max_row)
for row in sheet:
remove(sheet)
print("Maximum rows after removing:",sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 13
File after deletion:
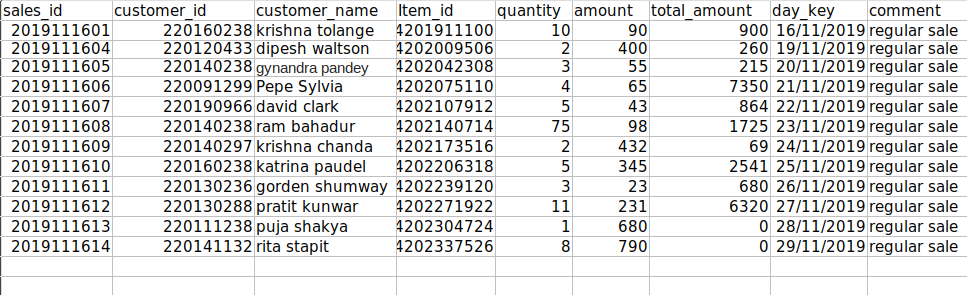
This method deleted both continuous empty rows as expected.
Deleting All rows
Method 1:
In this method, we delete the second row repeatedly until a single row is left(column names).
Approach:
- Import openpyxl library.
- Load the Excel file and the sheet to work with.
- Pass the sheet object to delete function.
- Delete the second row, until there is a single row left.
- Finally, return the function.
Python3
import openpyxl
def delete(sheet):
while(sheet.max_row > 1):
sheet.delete_rows(2)
return
if __name__ == '__main__':
path = './delete_every_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['sheet1']
print("Maximum rows before removing:", sheet.max_row)
delete(sheet)
print("Maximum rows after removing:", sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 1
File after deletion:
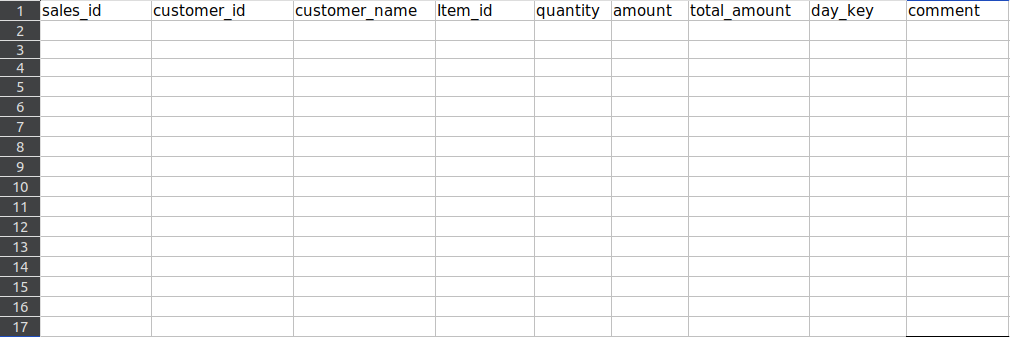
Method 2:
In this method, we use openpyxl sheet method to delete entire rows with a single command.
Approach:
- Import openpyxl library.
- Load the Excel file and the sheet to work with.
- Use delete_rows function to delete all rows except the column names.
- So a single empty row is left over.
Python3
import openpyxl
if __name__ == '__main__':
path = './delete_every_rows.xlsx'
book = openpyxl.load_workbook(path)
sheet = book['sheet1']
print("Maximum rows before removing:", sheet.max_row)
sheet.delete_rows(2, sheet.max_row-1)
print("Maximum rows after removing:", sheet.max_row)
path = './openpy.xlsx'
book.save(path)
Output:
Maximum rows before removing: 15 Maximum rows after removing: 1
File after deletion:
this works for both rows and cols:
import openpyxl
from openpyxl import *
import numpy as np
wb2 = openpyxl.load_workbook('/content/Drafts .xlsx')
for sheet in wb2.worksheets:
print ('Your currently in ', sheet)
max_row_in_sheet = sheet.max_row
max_col_in_sheet = sheet.max_column
print (max_row_in_sheet, max_col_in_sheet)
array_3 = np.array([])
array_4 = np.array([])
r = 1 # initially declaring row as 1
c = 1 # initially declaring column as 1
for r in range(1, max_row_in_sheet + 1): # 31 row
array_1 = np.array([])
array_2 = np.array([])
for c in range(1, max_col_in_sheet + 1): # 9 cols
if sheet.cell(row=r, column=c).value == None: # (9,1)
array_1 = np.append(array_2, c)
array_2 = array_1 # 1,2,3,4,5,6,7,8,9
if len(array_1) == max_col_in_sheet: # ( 9 == 9 )
array_3 = np.append(array_4, r) # 9
array_4 = array_3
array_3 = array_3.astype(int)
if len(array_3) != 0: # 11len
index_of_last_array_element = len(array_3) - 1
while index_of_last_array_element != -1:
sheet.delete_rows(array_3[index_of_last_array_element], 1)
index_of_last_array_element = index_of_last_array_element
- 1
max_row_in_sheet = sheet.max_row # maximum enterd row
max_col_in_sheet = sheet.max_column # maximum entered column
print 'Maximum Rows and Cols after Removing'
print (max_row_in_sheet, max_col_in_sheet)
print '======================================'
col_arr = []
for x in range(1, sheet.max_column + 1):
col_arr.append(0)
for r in range(1, max_row_in_sheet + 1):
array_1 = np.array([])
array_2 = np.array([])
for c in range(1, max_col_in_sheet + 1):
if sheet.cell(row=r, column=c).value == None:
array_1 = np.append(array_2, c)
array_2 = array_1
col_arr[c - 1] += 1
print col_arr
array_2 = [int(x) for x in array_2]
print len(array_2)
print array_2
if len(array_2) != 0:
index = len(array_2) - 1
print index
while index != -1:
temp = array_2[index]
# print(temp)
sheet.delete_cols(temp, 1)
index = index - 1
wb2.save('/content/outputs.xlsx')
How to remove the entire blank row from the existing Excel Sheet using Python?
I need a solution which DOES NOT :
Include reading the whole file and rewriting it without the deleted row.
IS THERE ANY DIRECT SOLUTION?
asked Jan 4, 2016 at 6:12
![]()
3
I achieved using Pandas package….
import pandas as pd
#Read from Excel
xl= pd.ExcelFile("test.xls")
#Parsing Excel Sheet to DataFrame
dfs = xl.parse(xl.sheet_names[0])
#Update DataFrame as per requirement
#(Here Removing the row from DataFrame having blank value in "Name" column)
dfs = dfs[dfs['Name'] != '']
#Updating the excel sheet with the updated DataFrame
dfs.to_excel("test.xls",sheet_name='Sheet1',index=False)
answered Jan 5, 2016 at 8:49
![]()
Jd16Jd16
3771 gold badge3 silver badges11 bronze badges
2
If using memory is not an issue you can achieve this using an extra dataframe.
import pandas as pd
#Read from Excel
xl= pd.ExcelFile("test.xls")
dfs = xl.parse(xl.sheet_names[0])
df1 = dfs[dfs['Sal'] == 1000]
df1 = df1[df1['Message']=="abc"]
ph_no = df1['Number']
print df1
answered Jan 6, 2016 at 5:48
![]()
Varsha Varsha
864 bronze badges
To delete an Excel row, say row 5, column does not matter so 1:
sh.Cells(5,1).EntireRow.Delete()
To delete a range of Excel rows, say row 5 to 20
sh.Range(sh.Cells(5,1),sh.Cells(20,1)).EntireRow.Delete()
![]()
user247702
23.5k15 gold badges111 silver badges157 bronze badges
answered Jan 27, 2017 at 15:17
![]()
Deleting rows and columns¶
To delete the columns F:H:
Note
Openpyxl does not manage dependencies, such as formulae, tables, charts,
etc., when rows or columns are inserted or deleted. This is considered to
be out of scope for a library that focuses on managing the file format.
As a result, client code must implement the functionality required in
any particular use case.
Moving ranges of cells¶
You can also move ranges of cells within a worksheet:
>>> ws.move_range("D4:F10", rows=-1, cols=2)
This will move the cells in the range D4:F10 up one row, and right two
columns. The cells will overwrite any existing cells.
If cells contain formulae you can let openpyxl translate these for you, but
as this is not always what you want it is disabled by default. Also only the
formulae in the cells themselves will be translated. References to the cells
from other cells or defined names will not be updated; you can use the
Parsing Formulas translator to do this:
>>> ws.move_range("G4:H10", rows=1, cols=1, translate=True)
This will move the relative references in formulae in the range by one row and one column.
Merge / Unmerge cells¶
When you merge cells all cells but the top-left one are removed from the
worksheet. To carry the border-information of the merged cell, the boundary cells of the
merged cell are created as MergeCells which always have the value None.
See Styling Merged Cells for information on formatting merged cells.
>>> from openpyxl.workbook import Workbook >>> >>> wb = Workbook() >>> ws = wb.active >>> >>> ws.merge_cells('A2:D2') >>> ws.unmerge_cells('A2:D2') >>> >>> # or equivalently >>> ws.merge_cells(start_row=2, start_column=1, end_row=4, end_column=4) >>> ws.unmerge_cells(start_row=2, start_column=1, end_row=4, end_column=4)
Last Updated on July 14, 2022 by
This tutorial will show you how to use the Python openpyxl library to delete rows or columns from existing Excel files.
Library
To install the openpyxl library, type the following in a command prompt window:
pip install openpyxlSample Dataset
Copy and run the following code to create a sample Excel file to follow the tutorial.
from openpyxl import load_workbook, Workbook
wb = Workbook()
ws = wb.create_sheet('eg')
data = [('id', 'name', 'country'),
(1, 'Trudeau','Canada'),
(2,'Zelenskyy', 'Ukraine'),
(3,'Putin', 'Russia'),
(4,),
(5,'Biden', 'US'),
(6, 'Xi', 'China'),
(7,'Johnson', 'UK'),
(8, 'Castex', 'France'),
(9,),
(10, 'Steinmeier', 'Germany'),
(11, 'Rutte', 'Netherlands'),
(12,'Loong', 'Singapore')]
for row in data:
ws.append(row)
wb.save('names.xlsx')
In openpyxl, we can use delete_rows() and delete_cols() methods from the Worksheet object to remove entire rows and columns. The syntax is straightforward:
- delete_rows(row_id, number_of_rows)
- delete_cols(col_id, number_of_cols)
Delete at Known Position
Since we need to delete from existing Excel files, let’s first read the file content into Python. Then we can use the delete_rows() or delete_cols() to remove rows and columns.
wb2 = load_workbook('names.xlsx')
ws2 = wb2['eg']
for i in ws2.values:
print(i)
('id', 'name', 'country')
(1, 'Trudeau', 'Canada')
(2, 'Zelenskyy', 'Ukraine')
(3, 'Putin', 'Russia')
(4, None, None)
(5, 'Biden', 'US')
(6, 'Xi', 'China')
(7, 'Johnson', 'UK')
(8, 'Castex', 'France')
(9, None, None)
(10, 'Steinmeier', 'Germany')
(11, 'Rutte', 'Netherlands')
(12, 'Loong', 'Singapore')
Delete 1 Row or Column
If we want to delete just 1 row, just call delete_rows(n), which will delete the nth row from the top. We can ignore the second argument, which equals 1 by default. Similarly, to delete just 1 column, use delete_cols(n) and skip the second argument.
Delete Multiple Rows or Columns
To delete multiple rows or columns, we’ll need to use both arguments. The following code will delete the 2nd row to the 5th row. It means to delete row 2, plus the 3 rows underneath it, for a total of 4 rows.
ws2.delete_rows(2,4)
for i in ws2.values:
print(i)
('id', 'name', 'country')
(5, 'Biden', 'US')
(6, 'Xi', 'China')
(7, 'Johnson', 'UK')
(8, 'Castex', 'France')
(9, None, None)
(10, 'Steinmeier', 'Germany')
(11, 'Rutte', 'Netherlands')
(12, 'Loong', 'Singapore')Similarly, to delete multiple columns we need to use both arguments. The below deletes from column 2 (B), and for a total of 2 columns (B and C).
ws2.delete_cols(2,2)
for i in ws2.values:
print(i)
('id',)
(1,)
(2,)
(3,)
(4,)
(5,)
(6,)
(7,)
(8,)
(9,)
(10,)
(11,)
(12,)Unfortunately, there’s no easy way to delete multiple non-consecutive rows or columns. We have to delete one by one and figure out the new position of the rows/cols after each delete.
Delete Based on Cell Values
Our dataset contains 2 empty rows at id 4 and 9. Let’s say if the empty rows can appear randomly anywhere in a file, then we don’t know the exact location of those rows (or columns) so we can’t use the delete methods directly.

We need to first find where those rows are. Basically, we need to know which rows have empty values.
In the below code, using ws.iter_rows() we can get tuples of Cell objects. Then from those Cell objects, we can access the cell values and row/column positions.
any() returns True if at least one of the elements is not None, and returns False if all elements are None. We can use this function to locate the empty rows.
Of course, don’t forget to save the changes back to the Excel file!
any([1,2,None])
True
any([None,None,None])
False
for row in ws2.iter_rows():
if not any([cell.value for cell in row[1:]]):
ws2.delete_rows(row[0].row)
for i in ws2.values:
print(i)
('id', 'name', 'country')
(1, 'Trudeau', 'Canada')
(2, 'Zelenskyy', 'Ukraine')
(3, 'Putin', 'Russia')
(5, 'Biden', 'US')
(6, 'Xi', 'China')
(7, 'Johnson', 'UK')
(8, 'Castex', 'France')
(10, 'Steinmeier', 'Germany')
(11, 'Rutte', 'Netherlands')
(12, 'Loong', 'Singapore')
wb.save('names.xlsx)Additional Resources
Python & Excel – Number Format
Python openpyxl – How to Insert Rows, Columns in Excel
Adjust Excel Fonts using Python openpyxl
Write Data to Excel using Python